Relocation in Car Sharing Systems with Shared Stackable Vehicles: Modelling Challenges and Outlook
Abstract
Car sharing is expected to reduce traffic congestion and pollution in cities while at the same time improving accessibility to public transport. However, the most popular form of car sharing, one-way car sharing, still suffers from the vehicle unbalance problem. Innovative solutions to this issue rely on custom vehicles with stackable capabilities: customers or operators can drive a train of vehicles if necessary, thus efficiently bringing several cars from an area with few requests to an area with many requests. However, how to model a car sharing system with stackable vehicles is an open problem in the related literature. In this paper, we propose a queueing theoretical model to fill this gap, and we use this model to derive an upper-bound on user-based relocation capabilities. We also validate, for the first time in the related literature, legacy queueing theoretical models against a trace of real car sharing data. Finally, we present preliminary results about the impact, on car availability, of simple user-based relocation heuristics with stackable vehicles. Our results indicate that user-based relocation schemes that exploit vehicle stackability can significantly improve car availability at stations.
I Introduction
Car sharing is considered one of the pillars of the smart mobility infrastructure for smart cities. With car sharing, car access is decoupled from car ownership: people do not own a car, they simply rent it from the car sharing operator when they need it (typically for short-range trips), effectively implementing the concept of Mobility-as-a-Service. In cities where car sharing services are running, positive effects have already been measured: car sharing members use cars less, rely more on public transport or bicycles, and in some cases they even shed their private car (or refrain from buying a second one for their family) [1]. Car sharing can also act as a last-kilometre solution for connecting people with public transport hubs, hence becoming a feeder to traditional public transit [2].
One-way car sharing, in which customers are not forced to return the vehicle at the starting point of their journey, is the most popular among customers, due to the great flexibility it provides. One-way systems can be also classified into free-floating or station-based according to their parking restrictions. In fact, the former refers to a system in which the return of the rented vehicle is possible at any parking spot within the operational area of the car sharing service111For example, https://www.car2go.com/., while the latter requires that pickups or drop-offs of vehicles occur at designed parking stations deployed by the operator222For example, https://www.autolib.eu/en/.. Advantages of station-based systems is that they ensure higher reliability and predictability of car locations and parking, which make possible advance reservations from the users. One-way car sharing is not without drawbacks for the car sharing operators. With one-way car sharing, cars will follow the natural flows of people in a city, hence accumulating in commercial/business areas in the morning and in residential areas at night [3]. As a result, the availability of cars can become extremely unbalanced during the day, and certain areas may end up being underserved due to lack of available cars.
Previous research has proposed several approaches to solve the vehicle unbalance problem, including: user-based relocation, i.e., price incentives for the users to relocate the vehicles themselves [4]; operator-based relocation, i.e., workforce that moves vehicles from where they are not needed to where there is a significant demand [5, 6]; and optimal planning of station deployment to achieve better service accessibility and a more favourable distribution of vehicles [7]. It is important to point out that the relocation process is intrinsically inefficient: as one driver per car is needed, to relocate several cars a large workforce or many willing customers are necessary. This significantly complicates the relocation with respect to, e.g., bike sharing services, where a single worker with a van can redistribute a large amount of bicycles.
In order to address the above limitations, it is fundamental to reduce the ratio between the workforce size and the number of vehicles that can be relocated. Recently, innovative technologies have been proposed to enable more efficient vehicle rebalancing in CS systems. On the one hand, the rebalancing problem is solved in [8] using empty robotic vehicles autonomously driving between stations. On the other hand, new vehicle concepts with stackable capabilities have been recently released or are under development, which can be stacked into a train (through a mechanical and electric coupling) and/or folded together. Then, the train can be driven either by a car sharing worker (up to 8 vehicles) or by a customer (up to 2 vehicles). An illustration of this type of vehicle prototyped in the ESPRIT project [9] is provided in Fig. 1. Such stackable cars come with the promises of significantly improving the system manageability of future car sharing services. However, the evaluation and design of new car sharing services using these innovative stackable cars call for new modelling techniques able to accurately characterise their peculiar properties.

Various models for assessing the performance of one-way car sharing systems have been proposed in the literature. A class of modelling approaches relies on time-space models that describe the interactions between the operational decisions (i.e., movement of staff, relocation activities) and the number of vehicles at the station [5, 6]. The main drawbacks of this approach is the explosion in size of the state space, and the limited ability to deal with uncertain conditions due to the stochastic nature of customer arrivals. Thus, stochastic models have been recently proposed based on queueing theoretical approaches [10, 11] or fluid approximations [8]. However, how to model car sharing systems with stackable vehicles is still an open challenge.
Within this framework, the contributions of this paper can be summarised as follows:
-
We validate a queueing theoretical model of one-way car sharing systems that was proposed in prior work [10] against a trace of real car sharing operational data, confirming the effectiveness of this modelling approach;
-
We show, with a real-case study, that increasing the fleet size cannot solve the problem of vehicle shortages in hot spots because vehicle availability depends mostly on traffic patterns in the car sharing system;
-
We present preliminary results about two simple heuristics for user-based relocation with stackable cars, showing that in some cases user-based relocation can increase the car availability at stations up to 200%;
-
We develop a new queuing model to study the evolution of vehicle redistribution in a car sharing station under general user-based relocation policies for stackable cars and we derive an upper-bound on the relocation flow per station.
II Preliminaries on Queueing Network Models for CS Systems
In this section, we recall the queueing theoretical model proposed in the literature by [10]. To this aim, we assume that the CS operational area is composed of a set of non-overlapping car sharing service centres. A service centre abstracts what, concretely, can be a CS station (in station-based car sharing) or a zone in a free-floating car sharing operational area. Hence, the queueing theoretical model can be applied to both types of one-way CS systems. Without ambiguity, in the following we will use the terms “service centre” and “station” interchangeably. At each service centre, shared cars are dropped off at the end of a journey and are picked up by other customers starting their new journeys. We assume that the inter-arrival time between customers that pick up cars at station is exponentially distributed with rate and that, similarly to [10], customers simply leave the service centre if they cannot find an available vehicle. In order to keep the analytical model tractable, in this work, similarly to the related literature, we assume that the capacity of service centres is not particularly critical, hence we neglect potential losses due to a service centre being fully occupied at the time a newly dropped-off car arrives. Based on the above assumptions, the service centre can be represented, in Kendall’s notation, as a -/M/1 queue [12].
Individual queues representing the CS service centres are then networked together to reflect the CS network dynamics. To this aim, the probability matrix is introduced, whereby denotes the probability that a customer leaving service centre with a car will head for service centre . In addition, in order to model the fact that it takes a certain amount of time to go from service centre to service centre , we introduce, as in [10], delay queues in the model. These delay queues are modelled as infinite-servers queues, and we denote their set with . There will be a delay queue between service centres and if , thus . Each server in an infinite-servers queue keeps a car for an exponential amount of time with mean (where is the expected travel time from to )333The model does not consider traffic congestion, thus each vehicle travels (i.e. is served) independently and in parallel with the others. This implies that the overall service rate of the delay queue is proportional to the number of vehicles in the queue, as stated in Equation 1..
We can then summarise the characteristics of the CS queueing network as follows. We denote the number of shared cars in the CS system with and we let . The service rate of each queue is given by:
| (1) |
where denotes the number of vehicles at node and, for each and denote the upstream and downstream service centres of delay queue (corresponding to the origin and destination service centres of the CS trip). The routing matrix, which describe how vehicles move across queues, can then be obtained as follows:
| (2) |
The queueing network described above belongs to the category of single-class closed queueing networks, in particular it is a BCMP network [12]. For the sake of illustration, we provide a simple example in Fig. 2.
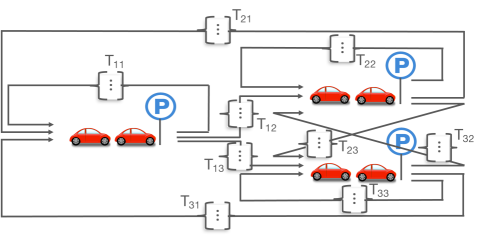
The first step in solving this model consists in solving the traffic equations [12], which in our case simplify to the following:
| (3) |
where denotes the relative arrival rate at queues corresponding to CS stations and the relative arrival rate to the delay queue linking station and station . We can now exploit the results for BCMP networks, which are known to have a product form solution for the stationary distribution as follows:
| (4) |
where is a normalisation constant. can be efficiently derived as described in [12] using the convolution algorithm. Important performance measures can then be obtained exploiting the normalisation constant as follows. The throughputs of both single-server queues (the CS service centres) and infinite-server queues (the delay queues) are given by:
| (5) |
The throughput at CS service centres corresponds to the intensity of drop-offs. For single server queues, the average number of cars parked at the service centres and the utilisation can be obtained as:
| (6) |
| (7) |
where is the normalisation constant computed removing queue and considering jobs. Please note that the utilisation is a strategic metric for a car sharing network, since it gives the probability that there is at least one car available for pick up at the station.
III CS model validation
The model described in the previous section has been already used in [10] for fleet sizing and in [11] for deriving a strategy to rebalance vehicles. However, its modelling power has never been validated against real traces. Thus, the model could possibly be inadequate to represent the complexities of real car sharing systems. Hence, before extending it in Section V to account for stackable vehicles, we believe it is of paramount importance to first check its validity. To this aim, we rely on a dataset composed of all the pickup and drop-off events of 349 shared vehicles of a free-floating car sharing service operated in The Netherlands. Data is collected every minute for a period of one month and a half between May and June 2015 using openly available APIs. The dataset comprises more than 51,000 trips. Each observation reports the type of the event (pickup or drop-off), the time, the geographical coordinates and the status of the vehicle. No information is available on the trip trajectory.
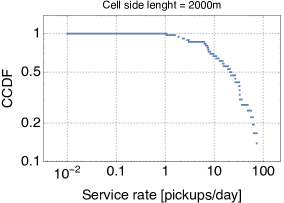
Following the service centres strategy discussed in Section II, we have partitioned the study area into non-overlapping square cells. Each of these cells is then modelled as a -/M/1 queue. To this aim, we need to estimate their service rate . We use the technique described in [13], whereby the service rate for queue is obtained as , where denotes the number of departures observed at the queue (corresponding to the number of pickups in our terminology), is the initial size of the queue (i.e., how many cars were parked at time ), and is the time the queue has been busy (i.e., with at least one car parked). These quantities can be easily computed from the trace, and their distribution (in log-log scale) is shown in Fig. 3 for varying cell side length. For smaller cell side lengths, we observe several orders of magnitude of variability in the service rates, owing to the fact that cells are small and there can be very popular ones and very neglected ones. Vice versa, the behaviour is more homogeneous when cells are larger.
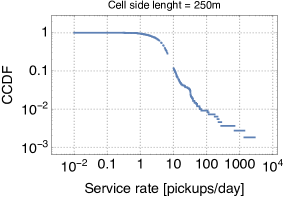
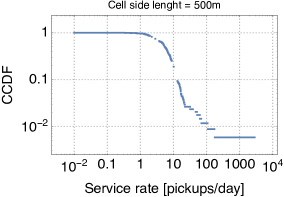
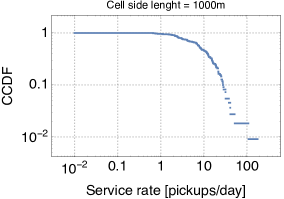
We next feed the service rates to the closed network model that we have described in Section II. We set the number of vehicles to , as in our trace. The number of cells (i.e., the size of ) is given by the number of active cells for each cell side length configuration. Then we derive the routing probabilities by simply counting, for each service centre , the fraction of trips from to any service centre . For all the pairs of service centres for which the routing probability is non zero, we also compute the average duration of trips from to . The service rate of each server in the delay queue for is then given by the inverse of (the MLE estimator of the rate of an exponential random variable is simply the inverse of the sample mean). For all cell side lengths, the resulting Markov chain is ergodic, hence a unique steady-state probability exists [12].
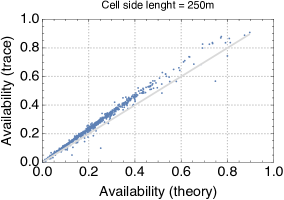
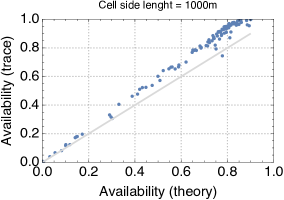
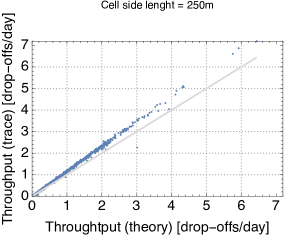
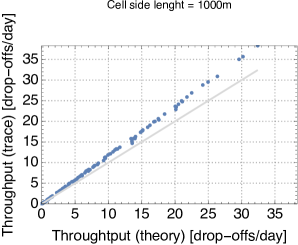
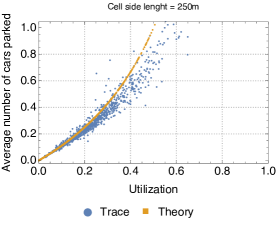
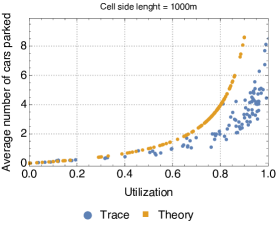
Since the closed queueing network is completely defined based on the car sharing trace, we can apply the formulas for the throughput, utilization, and average number of cars at the stations that we have derived in Section II. Due to the lack of space, we show only the results for cell side lengths 250m and 1000m (the results for the other cases are analogous). We observe that for the throughput and availability (Fig. 5 and 4) the predictions of the theoretical model are quite accurate, regardless of the size of the cell. In particular, it seems that predictions are only offset by a proportionality constant. A less accurate match is obtained for the average number of cars parked at the service centres when the utilisation of service centres is high, but the model still captures pretty closely the general trend of this metric (Fig. 6). Thus, overall, we can conclude that queueing-theoretical approaches can be safely used for modelling CS systems.
III-A Impact of Fleet Size on CS Performance
It is well known that vehicle availability is influenced by the number, location and size of CS stations [7], as well as by the fleet size [14, 6]. Typically, the optimal fleet size is chosen in such a way to optimise the trade-off between fleet costs and increased revenues due to higher availabilities. In this section, we want to demonstrate with a real-case study that increasing the fleet size, even in the ideal case of unconstrained capital investment, is not the panacea for ensuring higher vehicle availabilities. In the literature, George and Xia [10] have already shown that increasing the fleet size pumps up the availability at service centres but only until the centre(s) with the highest utilisation become saturated. This would not be a problem if all service centres were homogeneous, i.e., if they had comparable service rates. In that case, increasing the fleet size could bring the system to a situation of maximum availability at all stations. However, as Fig. 3 shows, the service rates in a real car sharing system tend to be quite heterogeneous.
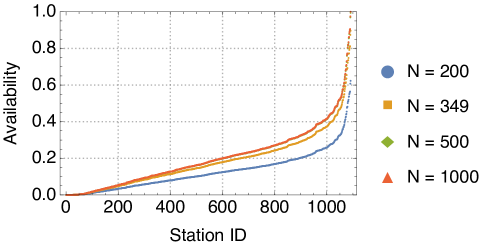
In order to illustrate how to exploit the model in Section II for “what-if” studies, in the following we use the set of stations and delay queues obtained in Section III for cell side length 250m and we test what would happen if the CS operator increased the fleet from 349 to 500 and 1000 shared vehicles, or if it reduced the fleet to 200 shared cars. Owing to the heterogeneity of service rates and the result by [10], we do not expect a significant improvement in the availability of vehicles as the fleet size increases. This is confirmed by Fig. 7, which shows the availability for different fleet sizes at the different stations. With 1000 shared vehicles, our reference car sharing system reaches maximum availability, but only for a very small subset of stations. All the others are left lagging behind. What is worse, those stations that see their availability increase significantly are those whose availability was already higher (in Fig. 7 stations are sorted by increasing availability when and the same order is kept for all other values). Thus, if we increase the fleet size we only observe the riches getting richer, with no redistribution effect in the network.
The above discussion confirms the intuition that redistribution strategies altering the flows in the networks are needed for real-life car sharing systems. While there exists several proposals in the literature as far as traditional car sharing systems are concerned, there are no results for innovative car sharing systems with stackable vehicles as those described in Section I. In order to fill this gap, in Section V we discuss how to modify the single-server queues of the closed car sharing network to include these stackable capabilities, and how to exploit this new type of queue for setting up a theoretical model for the relocation with stackable vehicles. But before doing this, we make the case for user-based relocation with stackable cars by showing, in the following section, simulation results using two simple heuristics.
IV User-based Relocation: Preliminary Results
User-based relocation policies are typically considered more convenient for the CS operator than operator-based ones as they do not require the use of dedicate workforce. However, users tend to move accordingly to the flows that are the cause of unbalance in the system in the first place. For this reason, most works on user-based relocation focus on finding the right incentives for users to slightly modify their behaviours in a way more favourable to the CS needs. However, it is still uncertain whether users would be willing to participate in a rebalancing program by accepting to drop off the vehicle at an alternative destination or to pick up a more distant vehicle [15]. One of the main advantages of using stackable cars is that we may not need to change customers’ travel behaviours because we can amplify – by asking the customer to drive a train for relocation – the “weak signal” of customers belonging to those flows that go in the right directions for relocation.
In order to preliminarily assess the impact of vehicle stackability on the relocation performance, in the following we evaluate two simple approaches: a uniform relocation strategy in which each customer takes a second vehicle to his/her intended destination with a fixed probability ; and a backpressure strategy in which a customer takes a second vehicle to his/her intended destination only if the number of parked vehicles at the destination station is smaller than at the origin station444This strategy is inspired by the backpressure routing algorithm, a method for directing traffic around a queueing network that achieves maximum network throughput [16].. The rationale behind the latter strategy is to use the redistribution to equalise the queue backlogs (i.e., the number of cars at each station waiting for customers to pick them up).
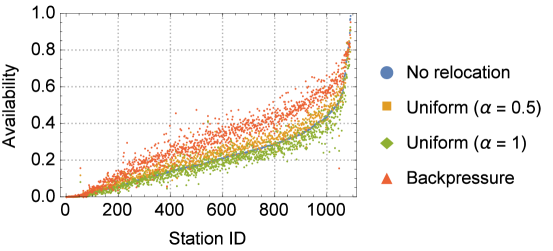
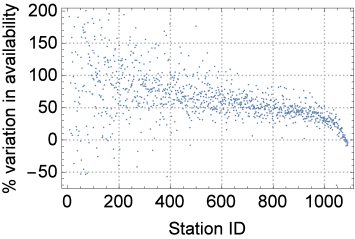
We simulate the car sharing system using a custom C++ simulator that tracks the evolution of the closed queueing network system described in Section II. For our evaluation, we use the same configuration as in Section III-A, i.e., cell side length 250m and a large fleet size of 1000 vehicles. The transient period before the system reaches a steady-state is discarded. We compare the relocation strategies in terms of the availability of vehicles that they can provide to each station (Fig. 8). Important observations can be derived from the results. First, relocation has a complex impact on the car availability. While increasing the fleet size produces a smoothed “scaling” effect on the car availability, relocating vehicles may cause stations with similar initial car availabilities to experience a different gain (corresponding to the dispersion of values in Fig. 8). Second, uniform relocation is not bringing about any significant performance gain, with most of the stations even having a reduced availability. On the contrary, a backpressure relocation scheme is effective in improving car availabilities since it smartly relocates vehicles where there might be a shortage. Third, with a backpressure relocation strategy the performance gain is higher for stations with low-to-medium availabilities. To quantify this trend, in Fig. 9 we show the availability variation (in percentage) for each station when using backpressure relocation. The results show that that are stations with very low availabilities that experience an availability increases up to . However, the gains are highly variable and there are also stations that can suffer from degradation of car availability. This motivates the need for design and modelling tools that can allow to calculate optimal relocation probabilities between pairs of stations depending on their service characteristics.
V Queues and stackable vehicles
In order to fill the gap between heuristic-based relocation and optimal relocation (i.e., a relocation strategy that explicitly maximizes some utility function of the CS system variables) we need to be able to represent mathematically the CS system. Queueing theory has been already explored in the literature to design smart relocation strategies for legacy car sharing [11]. However, those mathematical models are not fit to capture car sharing systems that allow for stackable vehicles. Thus, in this section, we develop a new queueing model that addresses this issue. We call this new queue relocation queue. A relocation queue can be used, with some modifications, for both user-based and operator-based relocation. Due to its potential impact on CS costs (customers are cheaper than a dedicated workforce) and its many challenges, in this work we focus on user-based relocation.
As a first step, we consider the queue in isolation. As with legacy car sharing systems, customers arrive at stations and pick up vehicles for their journeys. With stackable vehicles, however, a customer can pick up up to vehicles, in case a redistribution is needed by the CS operator. For the sake of example, in the following we set . As highlighted in Section IV, customers should not be always requested to perform relocation, though, because, e.g., if all customers headed towards service centre would always relocate vehicles, we might generate too large a flow towards station , possibly emptying the origin station . Hence, the relocation process from station to station is regulated by parameter , which can be seen as the probability for customers headed for station from station to pick up an additional vehicle for relocation.
Let us now take a step back and rethink how the service rate has been modelled so far for single-server queues in Section II. There, we have used a unique service rate for each station , regardless of the destination of customers picking up vehicles at station . This approach is not suitable anymore, because, with the relocation queue, we want to distinguish between customers heading for different destinations, since they may operate redistribution with different probabilities . Thus, we need to explode into its components , each describing the rate at which customers headed for station arrive at station . Please note that, thanks to the properties of the exponential distribution, . In fact, the interdeparture interval when the queue is busy is exponentially distributed, hence the arrival of customers headed towards different destinations can be handled as if it were a superposition of Poisson processes.
V-A An approximation of the relocation queue
An exact representation of what happens at a relocation queue should rely on the concept of batch queue [12]. However, since dealing with batch queues can be complicated when linking together stations into a closed networking system, in this section we propose a modified relocation queue, based on two approximations that allow us to significantly reduce the complexity of the model. The first approximation relies on the intuition that, when customers relocate vehicles, it is like they were picking up vehicles twice as fast. More in detail, customers headed for station seem to arrive twice as fast at station with probability . We can represent this “modified” service, say , with a mixture distribution, where random variable is given by the following:
| (8) |
The above equation basically express the concept that, with relocation (i.e., with probability ) the service is twice as fast, while, without relocation (which happens with probability ), the service runs at its unmodified rate. Please note that the service described by only holds when there are at least 2 vehicles at station . Otherwise, the customers pick up vehicles with their unmodified rate with probability .
The distribution of is not exponential but, in order to keep the analysis tractable, we want to approximate it with an exponential random variable. To this aim, we simply compute the expectation of (equal to ) and use its inverse as the rate of the approximating exponential random variable. This is the second approximation for the modified relocation queue. Now that we have exponential service times for each destination , we can again compute the overall service rate by summing the service rates for each destination. The modified relocation queue is illustrated in Fig. 10. This queue belongs to the category of load-dependent queues, since the service rate is dependent on the current state of the queue.
The stationary distribution of the modified relocation queue can be found by solving the balance equations using, e.g., the difference equation technique [17]. Due to space limitations we do not report the full mathematical derivations, which are tedious, but only the final results. Specifically, we find that the system has a solution only if is strictly smaller than . This is the new equilibrium condition, which replaces for the M/M/1 queue. At equilibrium, the stationary distribution of the queue is then given by the following:
| (9) |
where we have denoted with the quantity .
V-B Validation
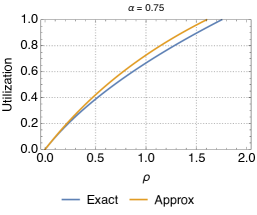
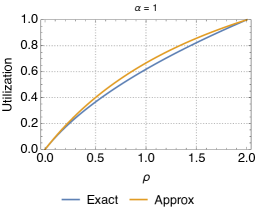
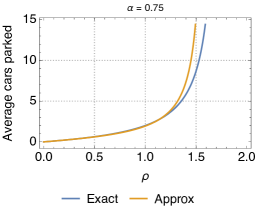
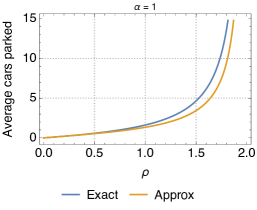
In order to validate the proposed approximate model for the relocation queue, in the following we compare important metrics, such as the utilization and the expected number of available cars obtained with this model against simulation results (thus, exact) of the relocation queue. In order to make the discussion easy to follow, we consider (basically, we assume that the probability of relocation is the same for all destinations).
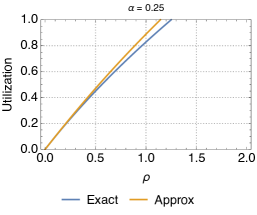
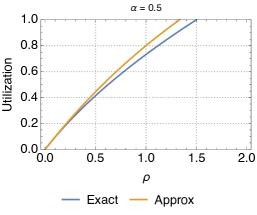
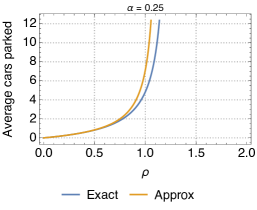
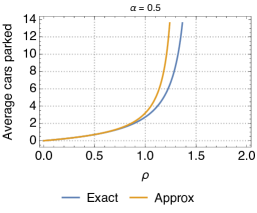
Fig. 11 shows the utilization for different values. We observe that the biggest discrepancies appear for intermediate values of , but that, overall, the approximation is very close to the exact characterization of the relocation queue. In addition, the error is always greater for larger values of . This is due to the fact that, when is small, the queue is in light traffic, with typically 0 or 1 cars, and thus relocation cannot be performed most of the times. Since the approximation applies to transitions between states with at least two cars, it has little effect in this situation. Vice versa, with larger the chances for relocation are higher, thus the approximation on the states with more than 2 vehicles starts to kick in. Please note, however, that the difference between the exact and approximate models is not much. Analogous conclusions can be drawn when looking at the difference between the predictions of the approximate model and simulations as far as the average number of cars parked at the station is concerned (Fig. 12).
V-C Derivation of the routing probabilities
So far we have considered the queue in isolation. In order to build a network of relocation queues we need to be able to compute the routing probability when vehicles leave a station . Without relocation, the probability that an idle vehicle is next picked up by a customer headed for station is clearly dependent on the arrival process of customers at station . Since each arrival is exponentially distributed with rate , by the properties of the exponential distribution, the probability that vehicle is picked up by a customer whose destination is station is equal to , where . Relocation effectively alters this probability, since some customers may pick up two vehicles instead of one. We derive the new routing probabilities in Lemma 1 below.
Lemma 1
The probability that a vehicle leaving relocation queue goes to another queue is given by the following:
| (10) |
where for convenience of notation we have defined (corresponding to the rate of in Equation 8) and .
Proof:
First of all, since we are only interested in studying what happens when the server is busy, we rescale the stationary probability excluding case . We obtain . Now the computation of the routing probability is straightforward: destination is selected for vehicle with the probability that a customer headed for station arrives before the others, i.e., when there are jobs in the system (which happens with probability ), otherwise. We can write the above as . By simply substituting Equation 9 in the expression for , we can express as in Equation 10. ∎
In practice, Lemma 1 tells us that we can increment the baseline routing probability (, the one without relocation) by a quantity . The term within the parenthesis depends only on the customers’ arrival processes and the configured relocation probability. Term corresponds to the input traffic. The higher the input traffic, the higher the impact of a relocation policy at a station. Vice versa, if is small, even with we cannot increase significantly the traffic towards station . Another interesting finding from Equation 10 is that the terms inside the parenthesis becomes zero when . So, when the relocation probability is set to the same value for all destinations, it has no effect on the routing probability. This means that relocation should always favour one destination over the others, in order to make an impact on the system. Note that this analytical results confirm what observed in Fig. 8 for the uniform relocation scheme.
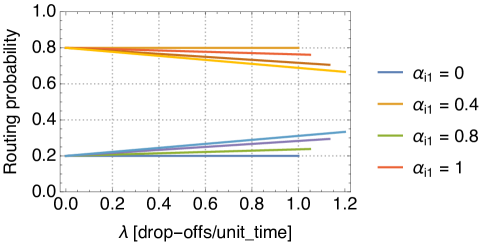
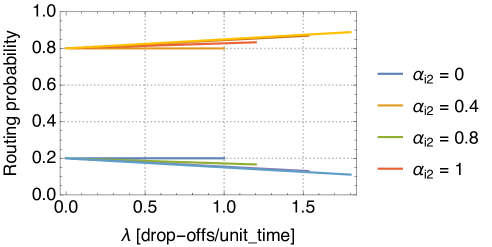
But how big an impact user-based relocation can have on the system? For the sake of example, in the following we consider a relocation queue with two destinations. The customers headed for destination 1 are slower than those headed for destination 2, or, in other words, they arrive at a lower rate. We set and . Then, we plot how the routing probability varies when we change the relocation probability. In Fig. 13 we assume we want to relocate towards destination 1 (the slow one), and we vary the relocation probability in . In Fig. 14 we assume we want to relocate towards destination 2 (the fast one), and we vary the relocation probability again in . We observe that when an heavy flow of customers tries to take vehicles for relocation from a small flow, the resulting routing probability is not altered significantly (Fig. 14). The greatest effect that relocation can have is reached when the opposite happens, i.e., when a small flow competes with a heavier flow (Fig. 13). This feature should be taken into account when designing user-based relocation strategies with stackable vehicles. Using the formulas derived in this section, we can even obtain a stronger result, summarised in Theorem 1.
Theorem 1 (Upper-bound on user-based relocation)
User-based relocation can increase the routing probability from station towards another station (for which the initial was greater than 0) by at most (). Hence, the flow of vehicles from to can never grow more than .
Proof:
It is easy to show that the maximum improvement in the routing probability is obtained when all relocation efforts are made towards a single station. Let us call this station station . We have , . When this holds, we have . We can then rewrite Equation 10 as follows:
| (11) |
Quantity needs to be smaller than for the queue to be stable. Forcing the constraint that and should be strictly greater than zero, the maximum of the function within the parenthesis yields the result . Since the output flow from station to station at equilibrium is simply , we have that the flow of vehicles from to can be at most increased by . ∎
Clearly, since the incoming flow to station is the composition of all the flows arriving at , the overall impact (at ) of relocation can be much larger than . What the bound tells us is that each incoming flow at can grow at most by with user-based relocation. In order to understand under which circumstances this bound is attainable, the next step in this research will focus on the study of a closed network of relocation queues.
VI Conclusions
In this work we have considered the problem of relocating shared vehicles in a car sharing system in which cars can be driven in a train. Building upon the related literature, we have recalled the commonly used closed queueing network model for the characterisation of legacy car sharing systems. Next, we have validated this model against a real car sharing trace. To the best of our knowledge, this is the first trace-based validation of queueing theoretical models for car sharing systems. Our validation has shown that these models are extremely promising for modelling CS systems, as they are able to predict their behaviour quite accurately. Then, we have made the case for user-based relocation showing how simple strategies can be enough to improve car availabilities. Finally, we have proposed a new type of queue, to be used for modelling a station in which vehicles can be driven in a train. We have validated this model, showing its accuracy, and we have used it for deriving an upper-bound on the relocation performance: even in the best case, the flow of vehicles from a station to another station can never grow more than .
As future work we plan to investigate the behaviour of a network of relocation queues, and to exploit our queueing theoretical framework to derive optimal relocation policies. Furthermore, our model could be extended to also characterise operator-based relocation strategies in which a dedicated workforce is used to relocate train of vehicles, which we believe to be of both theoretical and practical importance.
References
- [1] E. Martin and S. Shaheen, “The impacts of car2go on vehicle ownership, modal shift, vehicle miles travelled, and greenhouse gas emissions: An analysis of five north american cities,” Transportation Sustainability Research Center (TSRC), UC Berkeley., 2016.
- [2] S. Shaheen, “Commuter-based carsharing: Market niche potential,” Transportation Research Record: Journal of the Transportation Research Board, no. 1760, pp. 178–183, 2001.
- [3] C. Boldrini, R. Bruno, and M. Conti, “Characterising Demand and Usage Patterns in a Large Station-based Car Sharing System,” in Proc. of IEEE INFOCOM Workshop on Smart Cities and Urban Computing, 2016, pp. 1–6.
- [4] A. Di Febbraro, N. Sacco, and M. Saeednia, “One-Way Carsharing: Solving the Relocation Problem,” Transportation Research Record, pp. 113–120, 2012.
- [5] A. G. Kek, R. L. Cheu, Q. Meng, and C. H. Fung, “A decision support system for vehicle relocation operations in carsharing systems,” Transportation Research Part E, vol. 45, no. 1, pp. 149–158, 2009.
- [6] B. Boyaci, K. G. Zografos, and N. Geroliminis, “An optimization framework for the development of efficient one-way car-sharing systems,” European Journal of Operational Research, vol. 240, no. 3, pp. 718–733, 2015.
- [7] E. Biondi, C. Boldrini, and R. Bruno, “Optimal deployment of stations for a car sharing system with stochastic demands: A queueing theoretical perspective,” in Proc. of IEEE ITSC’16, Nov 2016, pp. 1089–1095.
- [8] M. Pavone, S. Smith, E. Frazzoli, and D. Rus, “Load Balancing for Mobility-on-Demand Systems,” The International Journal of Robotics Research, vol. 31, no. 7, pp. 839–854, 2012.
- [9] H2020 Easily diStributed Personal RapId Transit project (ESPRIT). [Online]. Available: http://cordis.europa.eu/project/rcn/194859_en.html
- [10] D. K. George and C. H. Xia, “Fleet-sizing and service availability for a vehicle rental system via closed queueing networks,” European Journal of Operational Research, vol. 211, pp. 198–207, 2011.
- [11] R. Zhang and M. Pavone, “Control of robotic mobility-on-demand systems: A queueing-theoretical perspective,” The International Journal of Robotics Research, vol. 35, pp. 186–203, 2016.
- [12] G. Bolch, S. Greiner, H. de Meer, and K. S. Trivedi, Queueing networks and Markov chains: modeling and performance evaluation with computer science applications. John Wiley & Sons, 2006.
- [13] A. B. Clarke et al., “Maximum likelihood estimates in a simple queue,” The Annals of Math. Stat., vol. 28, no. 4, pp. 1036–1040, 1957.
- [14] M. P. Fanti, A. M. Mangini, G. Pedroncelli, and W. Ukovich, “Fleet sizing for electric car sharing system via closed queueing networks,” in Proc. of IEEE SMC’14, October 2014, pp. 1324–1329.
- [15] S. Herrmann, F. Schulte, and S. Voß, “Increasing Acceptance of Free-Floating Car Sharing Systems Using Smart Relocation Strategies: A Survey Based Study of car2go Hamburg,” in Proc. of ICCL’14, Cham, 2014, pp. 151–162.
- [16] L. Tassiulas and A. Ephremides, “Stability properties of constrained queueing systems and scheduling policies for maximum throughput in multihop radio networks,” IEEE transactions on automatic control, vol. 37, no. 12, pp. 1936–1948, 1992.
- [17] J. Medhi, Stochastic models in queueing theory. Academic Press, 2002.