REMOTE: Real-time Ego-motion Tracking for Various Endoscopes via Multimodal Visual Feature Learning
Abstract
Real-time ego-motion tracking for endoscope is a significant task for efficient navigation and robotic automation of endoscopy. In this paper, a novel framework is proposed to perform real-time ego-motion tracking for endoscope. Firstly, a multi-modal visual feature learning network is proposed to perform relative pose prediction, in which the motion feature from the optical flow, the scene features and the joint feature from two adjacent observations are all extracted for prediction. Due to more correlation information in the channel dimension of the concatenated image, a novel feature extractor is designed based on an attention mechanism to integrate multi-dimensional information from the concatenation of two continuous frames. To extract more complete feature representation from the fused features, a novel pose decoder is proposed to predict the pose transformation from the concatenated feature map at the end of the framework. At last, the absolute pose of endoscope is calculated based on relative poses. The experiment is conducted on three datasets of various endoscopic scenes and the results demonstrate that the proposed method outperforms state-of-the-art methods. Besides, the inference speed of the proposed method is over 30 frames per second, which meets the real-time requirement. The project page is here: remote-bmxs.netlify.app
I INTRODUCTION
Endoscopy has become the primary medical method for the surgery and the examination of the body cavities. Due to the limited visual field and the narrow pathway in the body cavities, the navigation is critical for the safety, accuracy and efficiency of endoscopic treatment, especially automatic robot-assisted endoscopy [1].
The common methods for navigation of endoscopy include optical tracking system [2] or magnetic tracking system [3]. However, the optical tracking system are easily influenced by the occlusion by human, while the magnetic localization could be interfered by the electromagnetic field from medical instruments. Meanwhile, such tracking systems are expensive and complex to implement. Therefore, the vision-based tracking method has become significant for the navigation of endoscopy.
The vision-based tracking methods can be categorized into two terms, including pose estimation and ego-motion estimation. The target of pose estimation is to estimate the pose of the object from the image of the scene comprising the object, which is impossible for the enclosed narrow body cavities. Differently, the task of ego-motion estimation is to predict the pose of the camera from the observation captured by itself. Therefore, real-time ego-motion tracking is the main method of vision-based tracking for endoscopes.
The traditional methods for ego-motion estimation are based on feature matching and iterative optimization [4], [5], which is time-consuming and not suitable for real-time tracking. Therefore, learning-based methods are proposed to estimate relative ego-motion between two continuous images and then more efficient ego-motion tracking is performed. The primary pipeline of the relative pose estimation consists of feature extraction and pose decoder [6]. However, currently, most of the existing methods for ego-motion estimation just extract feature representation from two images separately [7],[8] or from the concatenation of two images [9],[10]. Moreover, the structures of the existing pose decoders are mainly based on a fully-connected layer [11] or a simple network consisting of four convolution layers [10], which are not enough for extracting more complete feature representation from the feature maps. In some researches, recurrent neural networks (RNNs) are applied to extract temporal feature from the sequence of endoscopic images [12],[13],[8],[14]. However, the training of RNNs needs a large quantity of the whole endoscopic videos, which is expensive for establishment of the dataset.
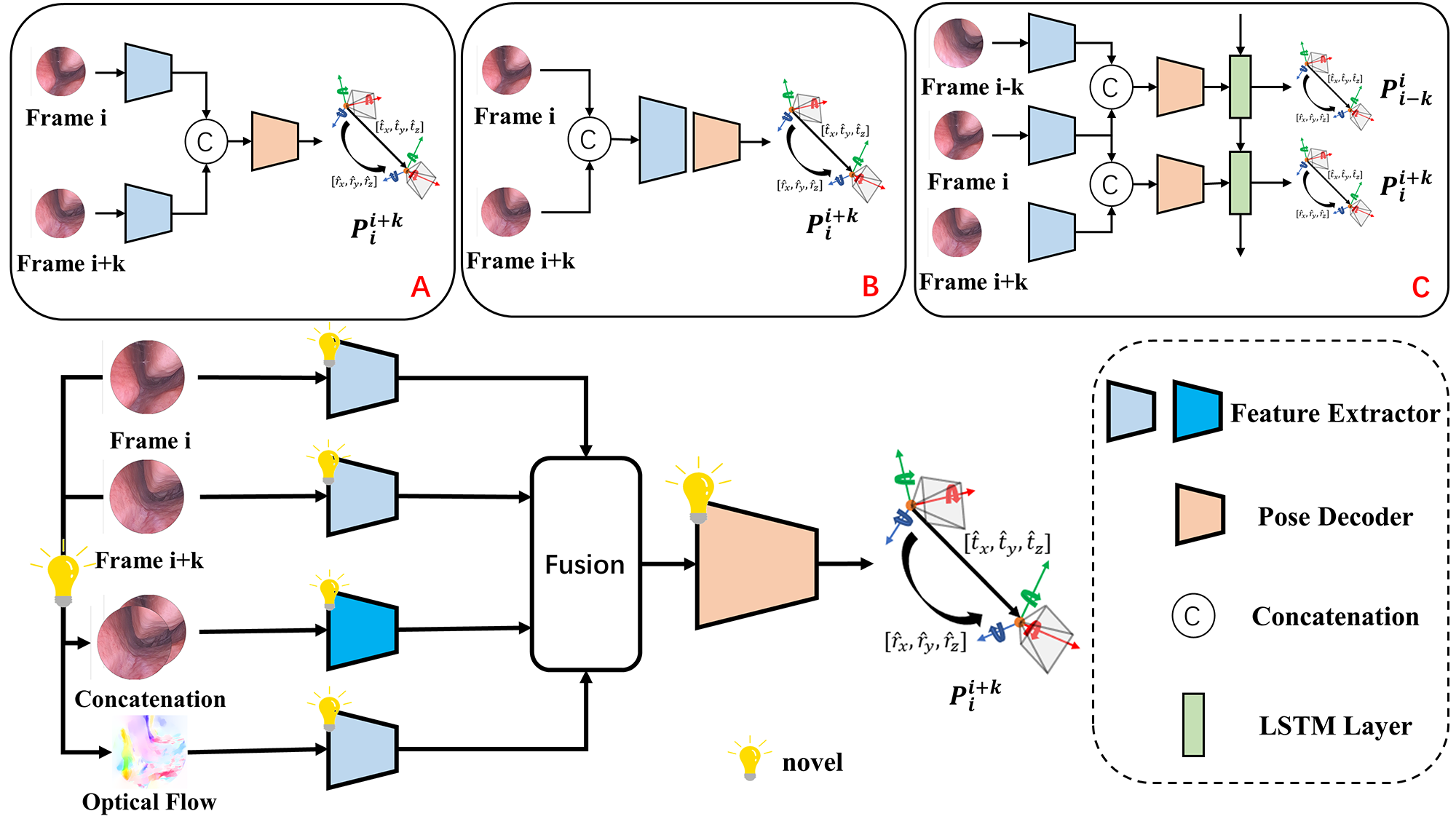
To this end, a novel deep learning-based framework is proposed to perform real-time ego-motion tracking for endoscope. In the proposed network, multi-modal visual features are extracted for relative pose estimation, as Fig. 1 shows. The main contributions of our work can be summarized as the following:
-
1.
A multi-modal visual feature learning framework is proposed to predict relative pose transformation based on the current observation and the previous frame.
-
2.
Due to more information in the channel dimension of the concatenated image , a novel feature extractor based on attention mechanism is proposed to extract and integrate the multi-dimensional information from the concatenation of two continuous frames.
-
3.
To extract more complete feature representation from the feature map, a novel pose decoder is designed to predict the vector of relative pose from the fusion of the features.
-
4.
The proposed framework is compared with existing state-of-the-art methods on three different datasets. The experimental results demonstrate that the proposed framework performs the most accurate ego-motion tracking. Moreover, the inference speed of the proposed framework meets the real-time requirement.
II Related Work
Most of the existing methods for ego-motion tracking are based on the structure of PoseNet[17], which consists of a feature extractor and a pose decoder. Some works utilize different feature extractors and pose decoders in the similar structure. Based on PoseNet, Nasser et al. [18] utilize VGG instead of GoogLeNet and add two fully-connected layers into the pose decoder to extract more complete feature extraction. Due to the excellent performance of ResNet, Wang et al. [19] and Bui et al. [20] respectively use ResNet-18 and ResNet-34 as feature extractors in their frameworks. The similar structure is also used in the most of previous methods for ego-motion estimation of endoscope [7],[15],[9],[8],[10]. Differently, multi-modal visual features are extracted in the proposed work. Moreover, a novel feature extractor for multi-dimensional feature integration is proposed and a novel pose decoder to extract more complete feature representation is designed.
Recently, attention mechanisms are widely applied in the ego-motion estimation of endoscope. For instance, Zhou et al. [21] apply the attention mechanism into the pose decoder to extract geometrically robust feature from the feature map. To extract more contextual feature, Shavit et al. [22] directly replace CNN networks with a Transformer-based model as the feature extractor. Based on the ego-motion estimation network of Monodepth2 [23], Ozyoruk et al. [9] apply a spatial attention block into the feature extractor to perform ego-motion estimation for endoscope in the gastrointestinal tract. Similarly, Liu et al. [10] propose a dual-attention module in the feature encoder, in which spatial attention and channel attention are performed to extract contextual feature in both of the spatial dimension and the channel dimension. Yang et al. [11] combine CNN layers of ResNet with multi-head attention layers to perform feature extraction based on laparoscopic images. In the proposed joint feature extractor, a novel attention-based module is designed to extract and integrate both of local and global feature from multiple dimensions.
Moreover, in the most of the previous researches, the ego-motion estimation is performed on one certain dataset, such as the simulated dataset of the bronchoscopy [7],[8], the dataset of the laparoscopy [10],[15],[9],[11]. The proposed framework is applied on three different datasets including an in-vivo dataset of the nasal endoscopy collected by human experts, a simulated dataset of colonoscopy [15] and an ex-vivo dataset of intestine endoscopy collected by a robot arm [9].
III Proposed Method
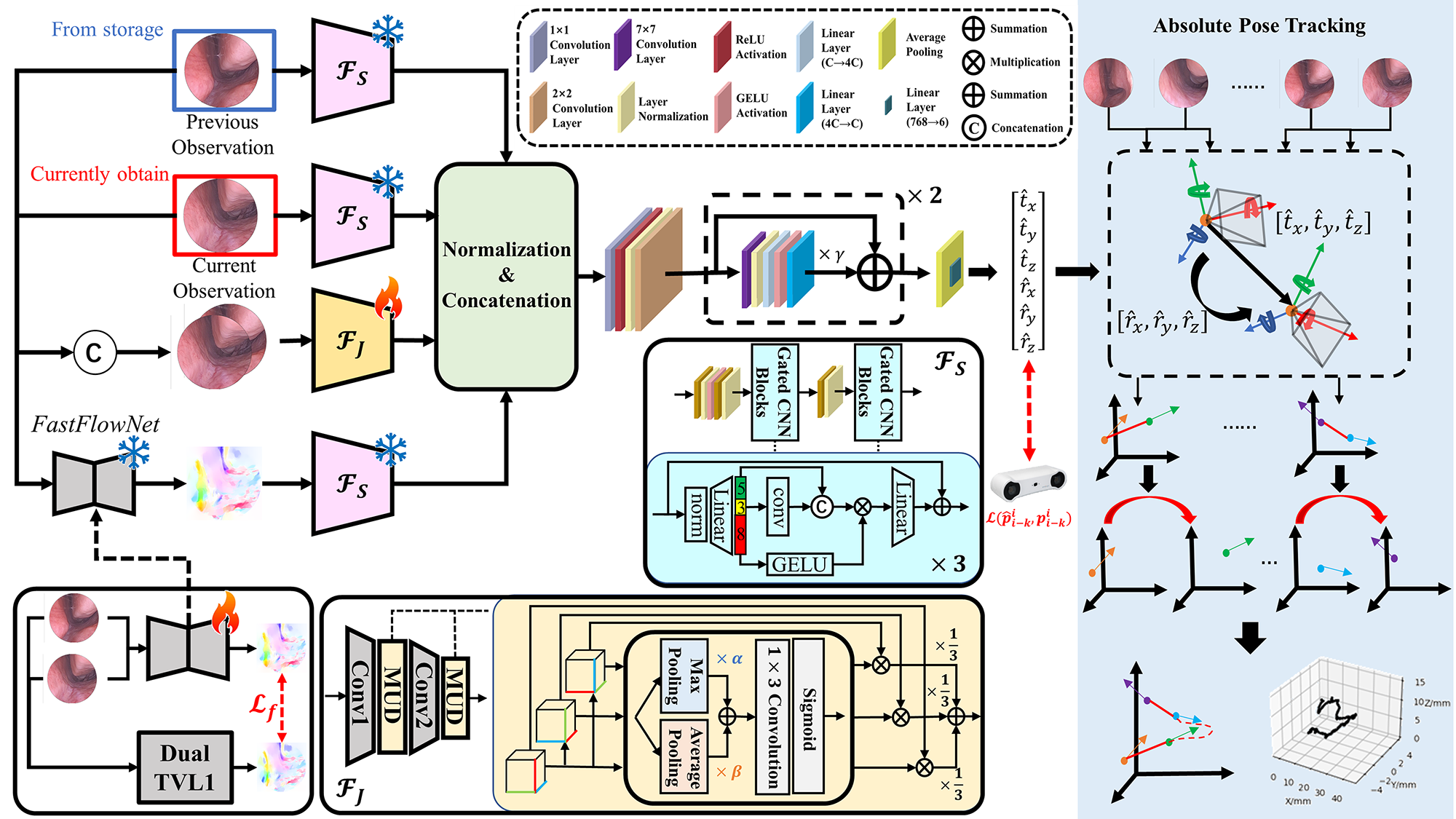
III-A Overview
The real-time ego-motion tracking of the proposed method can be divided into two stage, relative pose estimation and absolute pose calculation, which is shown as Fig. 2. At the first stage of relative pose estimation, given the current observation and the adjacent previous frame , the relative pose transformation between two frames can be predicted by the proposed deep learning-based network. Based on a series of relative pose transformations and the known initial pose , the absolute pose of the endoscope in the current frame can be calculated.
III-B Relative Pose Estimation
III-B1 Optical Flow Prediction
To achieve real-time tracking, the previous efficient network, FastFlowNet [24], is utilized to predict the optical flow between two adjacent observations. However, the pretrained FastFlowNets are trained on the natural dataset, which may be influenced by the domain gap between the in-the-wild scene and the endoscopic scene. Therefore, the FastFlowNet in our framework is finetuned based on more accurate results calculated by a traditional but slow method. Given two adjacent frames and , the optical flow as the ground truth is calculated by Dual TVL1 algorithm. Following [24], the multi-scale robust loss between and the optical flow predicted by the pretrained network is utilized for finetuning, formulated as Eq. 1.
| (1) |
where denotes the optical flow with different scales (), denotes each pixel in the optical flow, is a small constant of noise, is a penalty parameter which makes the model more robust for large magnitude outliers, and are set following [24].
III-B2 Feature Extraction
Firstly, the feature of the scenes and in two adjacent observations are extracted from single images respectively. Meanwhile, the feature of the endoscope motion is extracted from the optical flow of two adjacent observations by the same feature extractor. The network based on [25] is utilized as the feature extractor, which is pretrained on the Imagenet-1k [26].
To extract the contextual and corresponding feature of two adjacent observations, the joint feature is extracted from the concatenation of two frames. Due to more information in the channel dimension of the concatenated image, a unique feature extractor is proposed for joint feature extraction. Specifically, based on the first two layers of ResNet-34, a attention-based module is inserted after each layer. Given the feature map , the feature map is provided by integrating multi-dimensional information. Firstly, the is permuted into three feature maps with different dimensions, , and . The attention weight of each feature map is calculated by Eq. 2. To consider both of the critical information and global information, adaptive integration of max pooling and average pooling is utilized to calculate attention weights, followed by a convolution layer and a sigmoid process. In the end, multiplications of the feature maps and corresponding attention weights are summed with equal weights as Eq. 3.
| (2) |
| (3) |
while and are two learnable weights, which are respectively set to a random value in the range of . At the end of the feature extraction, all normalized feature maps are concatenated and passed through the proposed pose decoder as Eq. 4 shows.
| (4) |
| Dataset | Methods | From | ATE/mm | CE/e-3 | DE/deg | RTE/mm | ROT/deg |
|---|---|---|---|---|---|---|---|
| NEPose | OffsetNet [7] | ICRA 2019 | 24.09±14.08 | 3.50±3.93 | 4.67±4.10 | 0.6427±0.3727 | 0.2160±0.2003 |
| PoseResNet [16] | ICRA 2021 | 11.45±6.39 | 4.25±5.70 | 4.86±4.44 | 0.5506±0.3755 | 0.2389±0.2108 | |
| Attention PoseNet [9] | MedIA 2021 | 13.29±10.15 | 4.95±5.45 | 5.16±4.43 | 0.6386±0.4077 | 0.2413±0.2022 | |
| Fried et al. [27] | IROS 2023 | 11.77±8.77 | 3.71±4.09 | 4.90±3.97 | 0.5480±0.3471 | 0.2189±0.1956 | |
| PoseCorrNet [15] | TMRB 2023 | 8.63±5.49 | 4.25±4.84 | 6.20±5.36 | 0.5110±0.3477 | 0.2233±0.1967 | |
| Dual-attention PoseNet [10] | CMPB 2023 | 14.37±10.23 | 3.64±4.31 | 4.92±4.25 | 0.6047±0.3857 | 0.2175±0.1922 | |
| Yang et al. [11] | TMI 2024 | 11.81±9.34 | 3.23±4.65 | 4.57±4.48 | 0.6050±0.4210 | 0.2166±0.1942 | |
| Ours | 4.01±2.92 | 2.52±2.85 | 4.53±3.84 | 0.4124±0.2757 | 0.2110±0.1797 | ||
| Dataset | Methods | From | ATE/cm | CE/e-1 | DE/deg | RTE/cm | ROT/deg |
| SimCol | OffsetNet [7] | ICRA 2019 | 8.02±4.56 | 2.45±2.88 | 29.49±14.48 | 0.4747±0.2864 | 1.7830±1.0802 |
| PoseResNet [16] | ICRA 2021 | 6.26±4.45 | 1.97±2.34 | 26.81±16.61 | 0.4806±0.2876 | 1.3005±0.8255 | |
| Attention PoseNet [9] | MedIA 2021 | 7.21±4.99 | 2.18±2.38 | 29.85±17.03 | 0.5044±0.3024 | 1.4293±0.8902 | |
| Fried et al. [27] | IROS 2023 | 6.39±4.66 | 2.08±2.48 | 26.43±14.79 | 0.4735±0.2817 | 1.2877±0.8304 | |
| PoseCorrNet [15] | TMRB 2023 | 6.08±4.87 | 1.97±2.62 | 27.73±15.53 | 0.4496±0.2489 | 1.2854±0.7640 | |
| Dual-attention PoseNet [10] | CMPB 2023 | 6.63±4.55 | 2.19±2.53 | 29.87±17.46 | 0.4848±0.2884 | 1.3541±0.8633 | |
| Yang et al. [11] | TMI 2024 | 10.27±7.36 | 3.73±3.59 | 32.08±19.17 | 0.7651±0.5573 | 2.2406±1.5303 | |
| Ours | 5.43±3.89 | 1.72±2.48 | 24.82±14.17 | 0.4472±0.2585 | 1.2258±0.7959 | ||
| Dataset | Methods | From | ATE/cm | CE/e-2 | DE/deg | RTE/mm | ROT/deg |
| EndoSLAM | OffsetNet [7] | ICRA 2019 | 10.04±5.68 | 3.64±4.08 | 19.51±13.79 | 5.07±5.47 | 1.1423±1.8140 |
| PoseResNet [16] | ICRA 2021 | 12.20±7.18 | 4.58±5.25 | 22.04±15.30 | 5.23±5.56 | 1.2108±1.8297 | |
| Attention PoseNet [9] | MedIA 2021 | 11.14±6.40 | 3.31±3.99 | 16.91±11.22 | 4.93±5.56 | 1.1730±1.8069 | |
| Fried et al. [27] | IROS 2023 | 11.34±7.83 | 4.21±5.00 | 20.09±14.04 | 5.13±5.51 | 1.1814±1.8275 | |
| PoseCorrNet [15] | TMRB 2023 | 10.54±5.29 | 4.47±5.02 | 22.37±14.82 | 5.08±5.52 | 1.2297±1.8252 | |
| Dual-attention PoseNet [10] | CMPB 2023 | 10.96±6.26 | 4.33±4.39 | 21.29±13.55 | 5.16±5.48 | 1.2115±1.8135 | |
| Yang et al. [11] | TMI 2024 | 10.82±5.74 | 4.36±7.45 | 19.83±18.11 | 4.84±5.44 | 1.1853±1.8242 | |
| Ours | 9.86±4.28 | 2.30±2.89 | 14.59±10.34 | 4.93±5.43 | 1.1115±1.8264 | ||
III-B3 Pose Decoder
Based on the concatenated feature map , the relative pose transformation vector is predicted by a pose decoder, which can extract more complete representation from the feature map. At first, the feature map is squeezed by a convolution layer followed by a ReLU activation. After this, the feature map is downsampled by layer normalization and a convolution layer. For more complete extraction of feature representation, two blocks based on the depthwise separable convolution are used in our pose decoder. In each block, depthwise convolution is firstly performed by a convolution layer, in which the input feature map is divided into 3 groups for computation. Pointwise convolution is performed by two convolution layer to integrate the information in the feature maps from from different groups of the input. At the end of each block, the feature map is scaled by a learnable parameter which is initialized as , followed by the residual connection with the input feature map.
III-C Loss Function
The predicted relative pose vector can be represented as , where is the vector of translation and is the quaternion of the endoscope. The ground truths of endoscope pose in two adjacent frames are and . The relative pose transformation can be calculated, which can be transformed into based on the relation between the homogeneous matrix and the quaternion.
Refer to [28], geometric loss function is utilized as our loss function. To calculate the loss function, the quaternion is represented as . Based on this, the logarithm of the quaternion is defined as:
| (5) |
Given the predicted relative pose vector and the ground truth with and as two learnable parameters, the loss function is described as below:
| (6) |
where represents the L1 norm, and is initially set to 0 and -3, respectively.
III-D Absolute Pose Calculation
The predicted relative pose transformation can be transformed into the corresponding homogeneous matrix . Given the know initial pose of the endoscope , the absolute pose of the endoscope can be calculated by the recursive formula Eq. 7 based on a series of relative pose transformation.
| (7) |
IV Experiments and Results
IV-A Datasets
IV-A1 NEPose
NEPose is a dataset collected by our own. the complete process of nasal endoscopy is recorded by an experienced surgeon using a XION binocular 4K endoscope with an optical tracking system. The dataset consists of 50 endoscopic videos of 16 subjects consisting of over 30k frames. In the experiment, 4328 frames from 30 different subjects are randomly chosen as the training set and the validation set.
IV-A2 SimCol
SimCol [15] is a virtual dataset generated based on a computer tomography scan of a real human colon in a Unity simulation environment. The dataset consists of 18k frames from 15 different subjects. In the experiment, 7200 frames from 24 different trajectories are randomly selected as the training set and the validation set.
IV-A3 EndoSLAM
EndoSLAM [9] is a large scale dataset for endoscopic perception. In our work, to perform ego-motion tracking, the ex-vivo part of EndoSLAM are utilized in the experiments. The chosen part of dataset consists of about 40k frames collected by a robot arm from ex-vivo colon, intestine and stomach. In the experiment, 3482 frames from 18 different trajectories are chosen from the dataset as the training set.
IV-B Experiment Implementation
In the experiment, the proposed framework is implemented on Ubuntu 22.04 using Pytorch 1.13.1 with CUDA 11.7. Images are sampled every 4 frames from the video sequence, which means mentioned in III-A is set to 4. Our model is trained for 500 epochs with a batch size of 32 on one NVIDIA RTX 4090 GPU. Adam optimizer is used for optimization. The learning rate is set to 0.001 initially and decayed with a factor of 0.98 after each epoch.
IV-C Metrics
Absolute Translation Error (ATE) [15] is used to evaluate the accuracy of absolute position tracking. Cosinus Error (CE) and Direction Error (DE) [8] are used to evaluate the accuracy of absolute direction tracking. Moreover, Relative Translation Error (RTE) and ROTation error(ROT) [15] are utilized to separately test the performance of relative translation prediction and relative rotation prediction.
| (8) |
| (9) |
| (10) |
| (11) |
| (12) |
where represents the translation vector in the homogeneous matrix , represents the rotation matrix in the homogeneous matrix , and represents the trace of the matrix.
| Modalities | NEPose | SimCol | EndoSLAM | ||||||||
| S | C | O | ATE/mm | CE/e-3 | DE/deg | ATE/cm | CE | DE/deg | ATE/cm | CE/e-2 | DE/deg |
| ✔ | ✔ | ✔ | 4.95±3.82 | 4.70±6.98 | 4.67±3.98 | 5.83±3.77 | 1.69±2.00 | 23.01±14.87 | 10.41±4.19 | 1.81±2.41 | 12.56±8.01 |
| ✗ | ✔ | ✔ | 11.82±8.00 | 5.39±7.51 | 5.46±4.87 | 6.84±4.43 | 1.89±2.33 | 23.29±11.92 | 11.17±5.46 | 2.35±2.71 | 15.02±9.85 |
| ✔ | ✗ | ✔ | 6.13±3.80 | 4.72±7.53 | 4.75±3.89 | 6.40±4.53 | 1.71±1.94 | 23.91±14.82 | 12.96±6.79 | 1.82±2.40 | 12.61±8.31 |
| ✔ | ✔ | ✗ | 6.80±4.40 | 5.62±8.48 | 5.10±4.59 | 5.86±3.81 | 1.74±1.97 | 25.70±15.46 | 11.91±5.87 | 1.88±2.38 | 13.31±7.74 |
| ✗ | ✗ | ✔ | 16.00±11.78 | 5.74±7.90 | 5.59±4.93 | 10.79±5.53 | 2.96±3.28 | 41.53±16.59 | 10.80±4.36 | 1.96±2.45 | 13.09±9.37 |
| ✔ | ✗ | ✗ | 5.77±3.75 | 4.80±6.34 | 5.30±4.35 | 6.07±3.91 | 1.87±2.02 | 26.89±15.25 | 10.45±4.08 | 2.10±2.46 | 14.01±9.05 |
| ✗ | ✔ | ✗ | 9.55±6.21 | 5.53±7.40 | 5.15±4.78 | 6.25±4.07 | 1.91±1.91 | 28.28±12.97 | 12.99±6.51 | 3.56±3.50 | 19.05±11.05 |
| S denotes two separate adjacent observations, C denotes the concatenation of two frames, and O denotes the optical flow. | |||||||||||
| NEPose | SimCol | EndoSLAM | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ATE/mm | CE/e-3 | DE/deg | ATE/cm | CE/e-1 | DE/deg | ATE/cm | CE/e-2 | DE/deg | |||||
| Ours | Ours | Ours | 4.0±2.9 | 2.6±2.9 | 4.6±3.9 | 4.6±2.9 | 1.60±2.61 | 21.8±10.5 | 8.59±3.96 | 2.2±2.8 | 14.3±9.8 | ||
| Res | Ours | Ours | 8.9±5.2 | 3.4±3.7 | 5.1±4.3 | 5.4±3.7 | 1.73±2.12 | 27.8±15.6 | 9.06±6.00 | 3.5±3.4 | 19.7±12.6 | ||
| Ours | w/o MUD | Ours | 4.8±3.4 | 2.8±3.0 | 4.7±3.8 | 4.8±3.3 | 1.63±2.60 | 22.3±9.5 | 8.62±5.03 | 2.4±2.8 | 14.6±10.2 | ||
| Ours | Ours | Pre | 8.5±5.9 | 3.3±3.9 | 5.5±4.6 | 5.3±3.7 | 1.68±2.53 | 26.6±15.4 | 8.95±4.68 | 2.9±3.1 | 17.3±11.3 | ||
| Ours | Ours | FC | 12.2±7.1 | 3.1±3.2 | 5.1±4.1 | 5.9±3.2 | 1.68±2.60 | 23.3±11.4 | 8.68±4.03 | 2.4±3.0 | 14.9±10.4 | ||
|
|||||||||||||
IV-D Comparison with Previous Methods
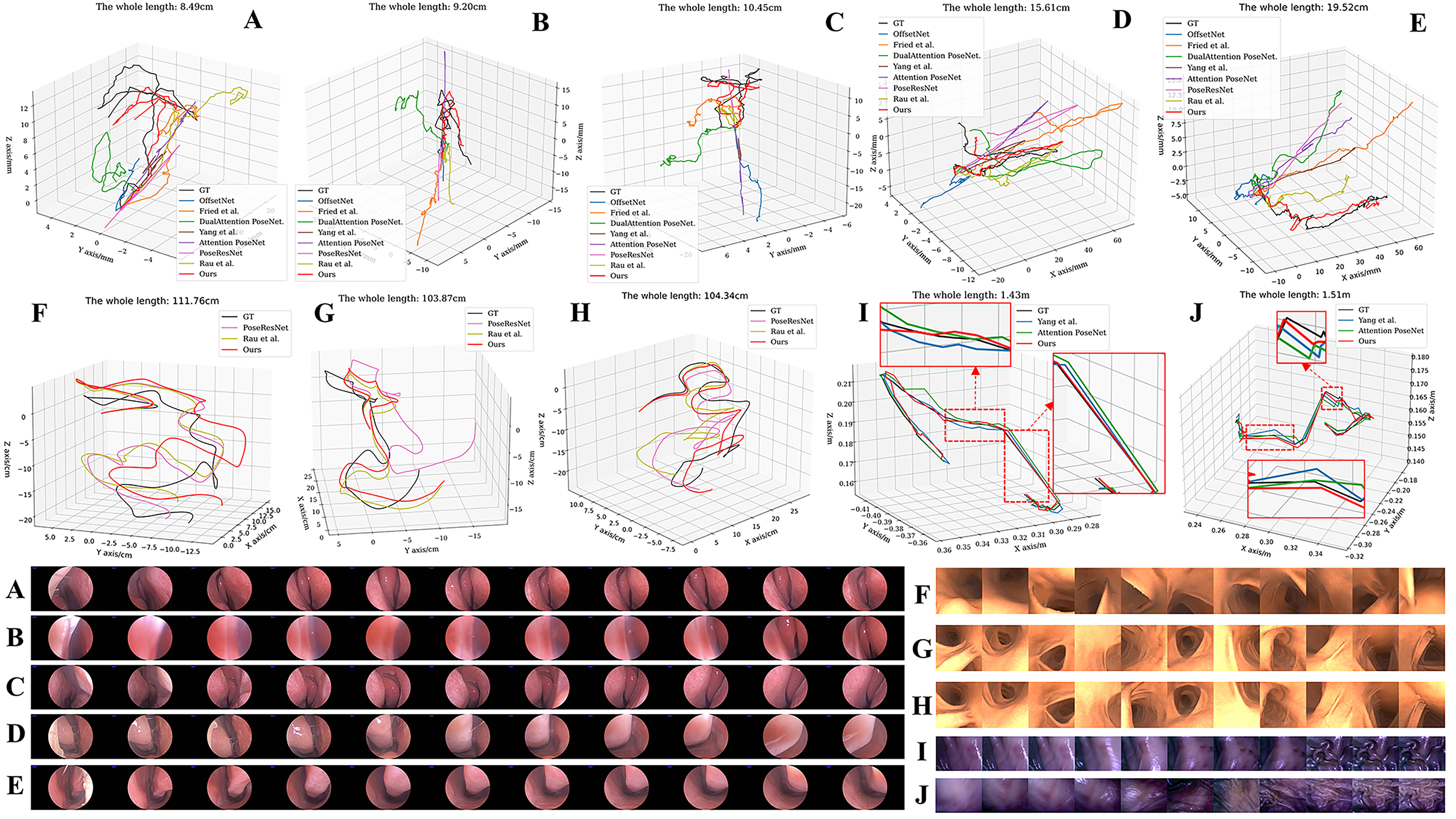
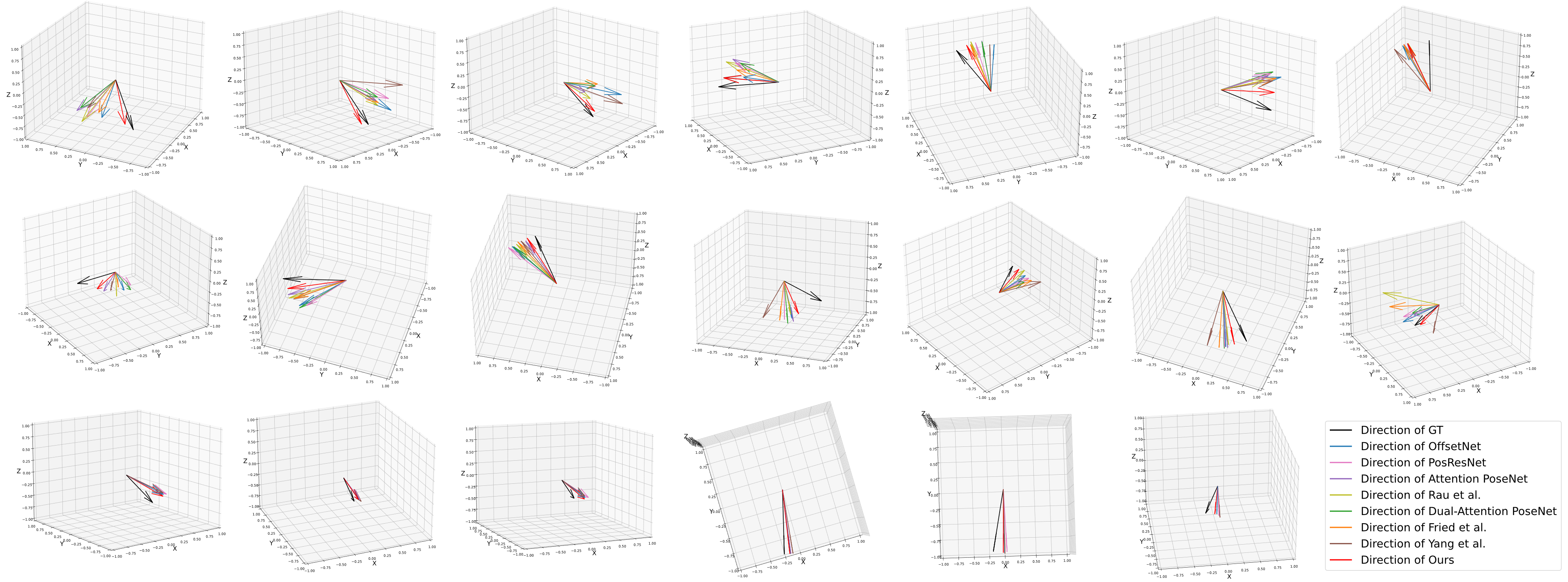
The proposed method is compared with state-of-the-art methods including OffsetNet[7], PoseResNet[16], Attention PoseNet[9], the method from [27], the method from [15], Dual-attention PoseNet [10] and the most recent method from [11]. For comparison, 1308 frames from 12 different subjects in NEPose dataset, 1800 frames from 6 different trajectories in SimCol dataset and 1482 frames from 6 different trajectories in EndoSLAM dataset are randomly selected in the experiments. The same implementation described in IV-B is used in the experiments of all methods. The experimental results on three datasets are respectively shown as Table I. The results demonstrate that the proposed method can perform the most accurate relative pose estimation and ego-motion tracking for various endoscopic scenes, compared with previous works. Fig. 3 and Fig. 4 visualize the results of ego-motion tracking, which displays the best qualitative results are from the proposed method.
IV-E Ablation Studies
In the ablation studies, we set several experiments to prove the effect of each visual modal and the effect of novel modules, which includes feature extractors and the pose decoder. In the experiments, 1297 frames from NEPose, 1800 frames from SimCol and 1050 frames from EndoSLAM are randomly selected again for the comparison. The results in Table II demonstrate that each visual modal plays an important role in the ego-motion tracking by our framework. To evaluate the positive effects of the proposed modules, the feature extractor is compared with pretrained ResNet-18, which is usually used in the previous work. Meanwhile, the pose decoder is replaced with the advanced pose decoder and a fully-connect layer, which are usually applied in the previous framework. In the experiments, 1279 frames from NEPose, 1800 frames from SimCol and 1145 frames from EndoSLAM are randomly selected again for the comparison. The results in Table III prove the effects of the novel feature extractors and the proposed pose decoder.
IV-F Inference Speed Test
To evaluate the inference speed of the proposed framework, 18 samples are randomly selected from all three datasets for experiments. As Table IV shows, the average inference speed of our framework can be over 30 frames per second (fps), which meets real-time requirement for application.
| # | NEPose | SimCol | EndoSLAM | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
FPS |
|
FPS |
|
FPS | ||||||
| 1 | 119.3 | 25.63 | 104.3 | 34.18 | 145.4 | 100.7 | |||||
| 2 | 82.7 | 22.89 | 102.2 | 33.85 | 133.4 | 98.3 | |||||
| 3 | 73.9 | 40.83 | 103.8 | 35.64 | 79.5 | 86.4 | |||||
| 4 | 154.9 | 33.86 | 111.5 | 31.58 | 90.3 | 90.5 | |||||
| 5 | 151.8 | 30.21 | 111.6 | 32.38 | 150.1 | 86.75 | |||||
| 6 | 174.3 | 32.17 | 111.7 | 31.35 | 145.4 | 99.5 | |||||
| Avg. | 31 fps | 33 fps | 94 fps | ||||||||
V Conclusion
In this paper, a deep learning-based framework, REMOTE, is proposed to perform real-time ego-motion tracking for endoscope in various scenes, in which different aspects of features from multi-modal visual inputs are learned. The experimental results show that the proposed method outperforms the advanced methods on three different endoscopic datasets, providing the most accurate real-time ego-motion estimation. This work could contribute to the automation and navigation of robot-assisted endoscopy.
References
- [1] X. Luo, K. Mori, and T. M. Peters, “Advanced endoscopic navigation: surgical big data, methodology, and applications,” Annual review of biomedical engineering, vol. 20, no. 1, pp. 221–251, 2018.
- [2] S. Lee, H. Lee, H. Choi, S. Jeon, H. Ha, and J. Hong, “Comparative study of hand–eye calibration methods for augmented reality using an endoscope,” Journal of Electronic Imaging, vol. 27, no. 4, pp. 043 017–043 017, 2018.
- [3] S. Song, S. Wang, S. Yuan, J. Wang, W. Liu, and M. Q.-H. Meng, “Magnetic tracking of wireless capsule endoscope in mobile setup based on differential signals,” IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1–8, 2021.
- [4] Y. Li, N. Snavely, and D. P. Huttenlocher, “Location recognition using prioritized feature matching,” in Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, September 5-11, 2010, Proceedings, Part II 11. Springer, 2010, pp. 791–804.
- [5] Y. Feng, L. Fan, and Y. Wu, “Fast localization in large-scale environments using supervised indexing of binary features,” IEEE Transactions on Image Processing, vol. 25, no. 1, pp. 343–358, 2015.
- [6] M. Xu, Y. Wang, B. Xu, J. Zhang, J. Ren, Z. Huang, S. Poslad, and P. Xu, “A critical analysis of image-based camera pose estimation techniques,” Neurocomputing, vol. 570, p. 127125, 2024.
- [7] J. Sganga, D. Eng, C. Graetzel, and D. Camarillo, “Offsetnet: Deep learning for localization in the lung using rendered images,” in 2019 international conference on robotics and automation (ICRA). IEEE, 2019, pp. 5046–5052.
- [8] J. Borrego-Carazo, C. Sanchez, D. Castells-Rufas, J. Carrabina, and D. Gil, “Bronchopose: an analysis of data and model configuration for vision-based bronchoscopy pose estimation,” Computer Methods and Programs in Biomedicine, vol. 228, p. 107241, 2023.
- [9] K. B. Ozyoruk, G. I. Gokceler, T. L. Bobrow, G. Coskun, K. Incetan, Y. Almalioglu, F. Mahmood, E. Curto, L. Perdigoto, M. Oliveira, et al., “Endoslam dataset and an unsupervised monocular visual odometry and depth estimation approach for endoscopic videos,” Medical image analysis, vol. 71, p. 102058, 2021.
- [10] Y. Liu and S. Zuo, “Self-supervised monocular depth estimation for gastrointestinal endoscopy,” Computer Methods and Programs in Biomedicine, p. 107619, 2023.
- [11] Z. Yang, J. Pan, J. Dai, Z. Sun, and Y. Xiao, “Self-supervised lightweight depth estimation in endoscopy combining cnn and transformer,” IEEE Transactions on Medical Imaging, 2024.
- [12] F. Walch, C. Hazirbas, L. Leal-Taixe, T. Sattler, S. Hilsenbeck, and D. Cremers, “Image-based localization using lstms for structured feature correlation,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 627–637.
- [13] R. Clark, S. Wang, A. Markham, N. Trigoni, and H. Wen, “Vidloc: A deep spatio-temporal model for 6-dof video-clip relocalization,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6856–6864.
- [14] L. Li, X. Li, S. Yang, S. Ding, A. Jolfaei, and X. Zheng, “Unsupervised-learning-based continuous depth and motion estimation with monocular endoscopy for virtual reality minimally invasive surgery,” IEEE Transactions on Industrial Informatics, vol. 17, no. 6, pp. 3920–3928, 2020.
- [15] A. Rau, B. Bhattarai, L. Agapito, and D. Stoyanov, “Bimodal camera pose prediction for endoscopy,” IEEE Transactions on Medical Robotics and Bionics, 2023.
- [16] S. Shao, Z. Pei, W. Chen, B. Zhang, X. Wu, D. Sun, and D. Doermann, “Self-supervised learning for monocular depth estimation on minimally invasive surgery scenes,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 7159–7165.
- [17] A. Kendall, M. Grimes, and R. Cipolla, “Posenet: A convolutional network for real-time 6-dof camera relocalization,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2938–2946.
- [18] T. Naseer and W. Burgard, “Deep regression for monocular camera-based 6-dof global localization in outdoor environments,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 1525–1530.
- [19] B. Wang, C. Chen, C. X. Lu, P. Zhao, N. Trigoni, and A. Markham, “Atloc: Attention guided camera localization,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 06, 2020, pp. 10 393–10 401.
- [20] M. Bui, C. Baur, N. Navab, S. Ilic, and S. Albarqouni, “Adversarial networks for camera pose regression and refinement,” in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019, pp. 0–0.
- [21] K. Zhou, C. Chen, B. Wang, M. R. U. Saputra, N. Trigoni, and A. Markham, “Vmloc: Variational fusion for learning-based multimodal camera localization,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 7, 2021, pp. 6165–6173.
- [22] Y. Shavit, R. Ferens, and Y. Keller, “Learning multi-scene absolute pose regression with transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2733–2742.
- [23] C. Godard, O. Mac Aodha, M. Firman, and G. J. Brostow, “Digging into self-supervised monocular depth estimation,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 3828–3838.
- [24] L. Kong, C. Shen, and J. Yang, “Fastflownet: A lightweight network for fast optical flow estimation,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 10 310–10 316.
- [25] W. Yu and X. Wang, “Mambaout: Do we really need mamba for vision?” arXiv preprint arXiv:2405.07992, 2024.
- [26] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [27] I. Fried, J. Hoelscher, J. A. Akulian, S. Pizer, and R. Alterovitz, “Landmark based bronchoscope localization for needle insertion under respiratory deformation,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 6593–6600.
- [28] S. Brahmbhatt, J. Gu, K. Kim, J. Hays, and J. Kautz, “Geometry-aware learning of maps for camera localization,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2616–2625.