Repair Strategies for Storage on Mobile Clouds
Abstract
We study the data reliability problem for a community of devices forming a mobile cloud storage system. We consider the application of regenerating codes for file maintenance within a geographically-limited area. Such codes require lower bandwidth to regenerate lost data fragments compared to file replication or reconstruction. We investigate threshold-based repair strategies where data repair is initiated after a threshold number of data fragments have been lost due to node mobility. We show that at a low departure-to-repair rate regime, a lazy repair strategy in which repairs are initiated after several nodes have left the system outperforms eager repair in which repairs are initiated after a single departure. This optimality is reversed when nodes are highly mobile. We further compare distributed and centralized repair strategies and derive the optimal repair threshold for minimizing the average repair cost per unit of time, as a function of underlying code parameters. In addition, we examine cooperative repair strategies and show performance improvements compared to non-cooperative codes. We investigate several models for the time needed for node repair including a simple fixed time model that allows for the computation of closed-form expressions and a more realistic model that takes into account the number of repaired nodes. We derive the conditions under which the former model approximates the latter. Finally, an extended model where additional failures are allowed during the repair process is investigated. Overall, our results establish the joint effect of code design and repair algorithms on the maintenance cost of distributed storage systems.
Index Terms:
Distributed storage, regenerating codes, mobile cloud, data reliability.I Introduction
Local caching and content distribution from a community of mobile devices has been proposed as an alternative architecture to traditional centralized storage [1, 2, 3]. The so-called mobile cloud storage systems reduce the traffic load of the already over-burdened infrastructure network and improve content availability in the event of network outages. In a mobile cloud storage scenario, a file is stored within a geographically-limited area by a community of mobile devices. A user within can download from the community of mobile devices. This can be done via direct communication between the mobile devices without accessing the network infrastructure, or via a base station, but without accessing the backhaul network. Without loss of generality, we abstract our setup to the former model.
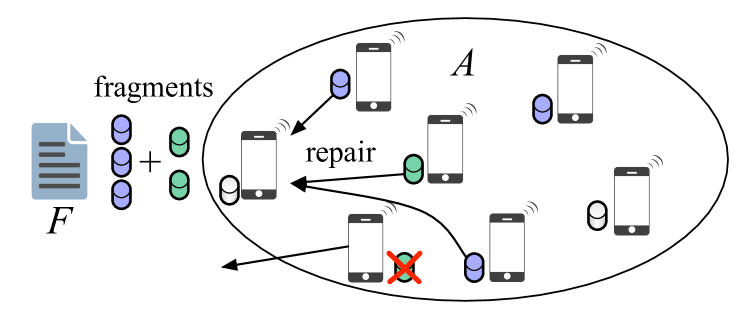
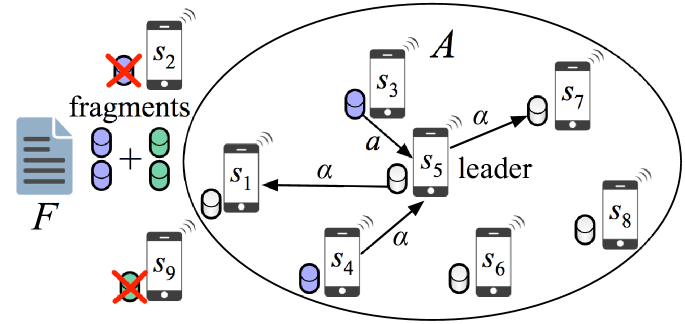
File storage at mobile devices leads to frequent data loss due to mobility. When a mobile device storing or any fragment of exits the stored data is lost. To deal with such losses, redundancy is introduced in the form of data replication or coding [4, 5]. In replication storage, copies of are stored at multiple devices within the community. More sophisticated coding schemes such as erasure coding achieve the same reliability at lower storage overhead [6, 7]. Despite the application of coding, a stored file will eventually be lost when a certain number of mobile devices (storage nodes) depart from . To maintain over long time periods, the mobile cloud system must be capable of recovering the lost data. A repair scenario is shown in Fig. 1. Lost data is recovered by downloading fragments from the storage nodes that remain within . The amount of data downloaded for repair is referred to as the repair bandwidth. For mobile communities, the repair bandwidth can be significant.
The file maintenance problem for distributed storage systems has been primarily studied assuming that erasure codes are applied for redundancy [8, 6]. However, erasure codes are not repair bandwidth efficient. The repair bandwidth can be reduced by applying regenerating codes, which allow fragment recovery without file reconstruction (see [9, 10, 11, 12] and references therein). Although regenerating codes lower the repair bandwidth (per single node repair), the design of an efficient repair strategy for a mobile cloud storage system involves cost optimizations with respect to many parameters, including the code redundancy factor, the device departure and fragment repair rates, the threshold for initiating repair operations, and the available communication bandwidth. In this paper, we study the problem of minimizing the file maintenance cost, as a function of the network dynamics, the code parameters, and the communication model for repairing lost data fragments. Specifically, we make the following contributions.
-
•
We focus on threshold-based file maintenance strategies, in which repairs are initiated when a threshold number of fragments is lost. We analyze two communication models, namely distributed repair and centralized repair. In distributed repair, the new storage nodes independently download data from existing nodes to recover lost fragments. In centralized repair, a leader node first recovers via reconstruction, before regenerating and distributing the repaired fragments to new storage nodes. In both scenarios, we assume that repairs are performed in parallel, taking the same amount of time and there are no additional failures during fragment recovery. This simplified model allows us to derive closed-form expressions.
-
•
We derive the optimal repair threshold that minimizes the average repair cost per unit of time for each communication model. Our results show that no one strategy is optimal for all possible system configurations and mobility patterns. At the low mobility-to-repair rate regime, repairing at the regeneration threshold yields the optimal strategy. On the other hand, at the high mobility-to-repair rate regime, regenerating after a single fragment loss minimizes the average repair cost per unit of time.
-
•
We further investigate the application of cooperative repair codes. We show that the repair bandwidth is minimized at full cooperation, i.e., when all nodes to be repaired cooperate. We then investigate the centralized repair of multiple node failures, which suits our centralized repair model that is described earlier. The advantage of such a model is that a leader node does not need to download the file , which reduces the average repair cost per time.
-
•
We revise the fixed-rate repair model originally assumed in distributed and centralized repair with a more realistic node-dependent model. In the latter, the repair time depends on the number of nodes that are repaired. We compare the resulting average repair cost with our earlier model and show that in the low mobility-to-repair rate regime, the simplified repair-all-at-one model faithfully approximates the node-dependent one.
-
•
We further consider a distributed repair model under a repair process which not only depends on the threshold in terms of recovery time but also may involve additional failures during recovery. We express the average repair cost through a system of equations and verify our analytical findings through simulations. We then verify our analytical findings through simulations. Lastly, we compare all of the discussed distributed repair models employing regenerating codes.
 |
|
Although we present our analysis in the context of mobile storage systems, we emphasize that our work is applicable in any distributed storage system where fragment losses can occur. This includes popular wired distributed storage architectures such as HDFS [13], in which fragment loss can be frequent due to server failure and updates. Similar to a mobile storage cloud system, the optimal threshold repair strategy for the wired domain would depend on the fragment loss rate (server failure or unavailability rate) and the various system parameters.
II Related Work
In reliable storage systems, information is replicated or coded such that the original content can be recovered if some limited fraction of the stored data is lost. Replication is the most intuitive way to introduce redundancy. This method refers to the maintenance of verbatim copies of the same file . Although replication is easy to implement, it suffers from high storage and repair overhead.
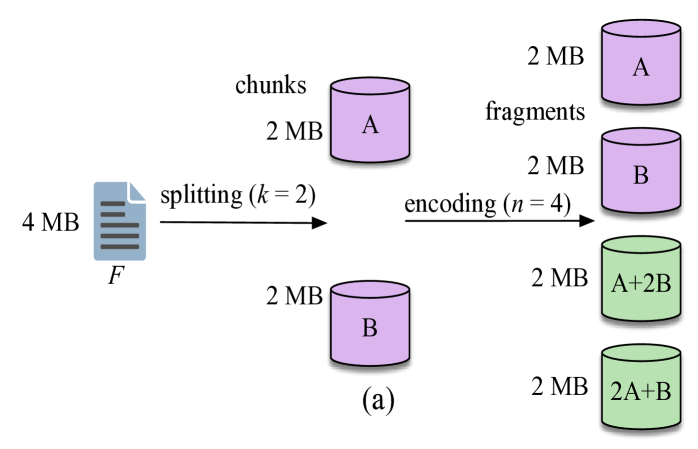
Erasure codes incur less storage overhead compared to replication while maintaining the same degree of reliability. In particular, Maximum Distance Separable (MDS) codes achieve the optimal tradeoff between failure tolerance and storage overhead [14, 15]. An MDS code encodes data chunks to fragments and can tolerate up to fragment losses. Any encoded fragments can be used to reconstruct . Fig. 2(a) shows the encoding process for a file of size MB using a (4, 2) erasure code. File is split into chunks and , each of size MB. The two chunks are then encoded into fragments. The repair bandwidth for this scheme equals the size of the original file. Reed-Solomon codes are a classical example of MDS codes and are deployed in many existing storage systems (e.g. [7, 16, 17, 18]).
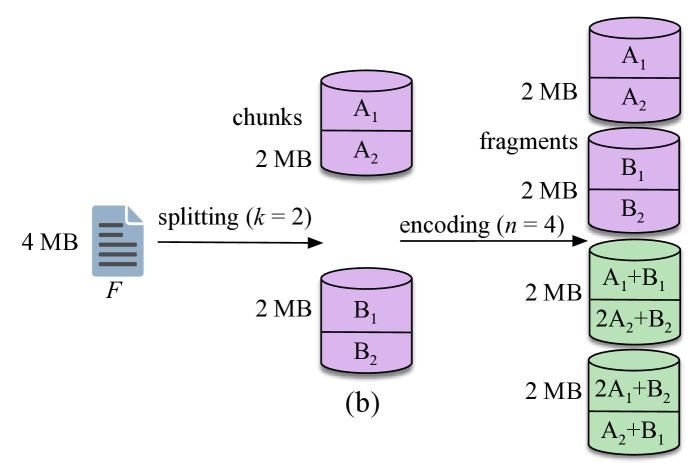
Although erasure codes offer significant savings in storage, their repair bandwidth is suboptimal, a data amount equal to the file size must be retrieved to repair a single fragment. Regenerating codes, on the other hand, can recover lost fragments without reconstructing the entire file, at the expense of a small storage overhead. They were initially investigated in the seminal work of Dimakis et al. [9], which focuses on the following setup. A file of size symbols is encoded into fragments, each of size symbols, such that (i) the file can be reconstructed from any fragments, and (ii) a lost fragment can be repaired by downloading symbols from any fragments, resulting in a repair bandwidth of . Dimakis et al. characterized the tradeoff between the per node storage () and the repair bandwidth () [9].
Fig. 2(b) shows an example of a regenerating code. Here, the file is split into chunks each of size MB. The chunks are encoded in fragments, with each fragment being MB. A failed node in this scenario can be regenerated by retrieving fragments of size MB from surviving nodes. This yields a repair bandwidth of MB which is less that MB. Note, however, that regeneration can be applied only if at least fragments are available. If fewer than but more than fragments remain available, the lost fragments can only be repaired through file reconstruction.
During the repair process of regenerating codes, there is no coordination among the nodes to be repaired. In [19, 6, 20, 21], the authors consider the case where storage nodes are repaired simultaneously in a cooperative manner. Specifically, referring to this set of nodes as the newcomers, and the existing nodes storing fragments of as live nodes, each newcomer contacts live nodes and downloads symbols from each. Moreover, newcomers cooperate and download symbols from each of the remaining newcomers. The tradeoff between per node storage and repair bandwidth is established similarly to [9]. Rawat et al. in [22] also consider the cooperative repair of nodes such that only one node among nodes downloads data from live nodes. After downloading the necessary information at the leader node, the remaining nodes are cooperatively repaired. Two points corresponding to minimum storage and minimum bandwidth regeneration are characterized.
In the context of mobile cloud systems, Pääkkönen et al. considered a wireless device-to-device network used for distributed storage [23]. The authors showed the energy consumption for maintaining data using regenerating codes is lower compared to retrieving a lost file from a remote source. This result holds if the per-bit energy cost for communication between the mobile devices is lower than the cost for communicating with the remote source.
In a follow-up work, Pääkkönen et al. compared replication with regeneration for a similar wireless P2P storage system [2]. They derived closed-form expressions for the expected total energy cost of file retrieval using replication and regeneration. They showed that the expected total cost of -replication is lower than the cost of regeneration. However, only an eager repair strategy was considered in the analysis. Moreover, the advantages of regeneration were not fully exploited by considering codes with different parameters. Pääkkönen et al. also addressed the problem of tolerating multiple simultaneous failures [24]. They investigated the energy overhead of regenerating codes in a cellular network. They showed that large energy gains can be obtained by employing regenerating codes. These gains depend on the file popularity. The authors provided decision rules for choosing between simple caching, replication, MSR and MBR codes, based on numerical results on certain application scenarios. In our work, we analytically provide decision rules to choose optimal repair strategies that minimize the repair bandwidth per unit of time.
Pedersen et al. recently studied the cost of content caching on mobile devices using erasure codes [25]. They derived analytical expressions for the cost of content download and repair bandwidth as a function of the repair interval. These expressions were used to evaluate the communication cost of distributed storage for MDS codes, regenerating codes, and locally repairable codes. Their results show that in high churn, distributed storage can reduce the communication cost compared to downloading from a base station. They conclude that MDS codes are the best performers in this setup.
III System Model
III-A Network Model
We consider a distributed storage system (DSS) consisting of mobile storage nodes that enter and exit a geographically-limited area . When a node departs from , its data is lost. The nodes that store file fragments within area are said to be live nodes. New nodes that are used to store repaired fragments are said to be newcomer nodes or newcomers. We assume that there are always sufficient newcomers to perform repairs. Moreover, as we are interested in the system performance due to network dynamics, we do not consider data loss due to hardware failures. Such failures occurs orders of magnitude less frequently than node departures. Following the network dynamics model of prior works [8, 23], we model the time spent by each node within as an exponentially distributed random variable with parameter (i.e., . Random variables are assumed independent and identically distributed.
The repair time is modeled by an exponentially distributed random variable with parameter . For ease of analysis, we initially assume that is independent of the number of fragments that need to be repaired. We later revise our analysis and consider a more realistic model in which repairs proceed in parallel at different nodes with the same rate . This corresponds to the distributed nature of mobile DSS. Finally, we define as the ratio of the departure-to-repair rate.
 |
|
| (a) distributed repair | (b) centralized repair |
III-B Storage Model
A file of size bits is stored in storage nodes using a regenerating code with parameters (see Fig. 2(b)). We focus on the two most popular types of regenerating codes, namely Minimum Storage Regenerating (MSR) codes and Minimum Bandwidth Regenerating (MBR) codes. These two classes of codes operate at the end points of the tradeoff between per node storage and repair bandwidth, as introduced in [9]. MSR codes achieve minimum storage by setting and minimize the repair bandwidth under this constraint. Their operating point is given by:
| (1) |
Note that, for MSR codes, and hence, the per-node storage is smaller than the repair bandwidth. MBR codes, on the other hand, minimize the repair bandwidth (achieved when ), and operate at:
| (2) |
III-C File Repair Model
In our model, the system continuously monitors the redundancy level and initiates a repair when live nodes remain within . The determination of , the type of repair (regeneration, reconstruction, or both) and the communication model for fragment retrieval (centralized or distributed) form a file maintenance strategy. We note that the practical implementation details of the redundancy monitoring mechanism and of the communication protocols for retrieving various fragments are beyond the scope of the present work. We focus on the theoretical aspects of the maintenance process. Since repairs are initiated only when the number of remaining nodes reaches threshold , a repair strategy can be viewed as an i.i.d. system recovery process occurring every seconds, where is a random variable denoting the time elapsed between two instances of a fully repaired system. For this recovery process, we define the following costs.
Definition 1 (Repair cost ).
The number of bits that must be downloaded from the remaining nodes to restore fragments in when nodes have departed .
Definition 2 (Average repair cost per unit of time ).
The average cost per unit of time for maintaining fragments in , defined as over the average time between two instances of a fully repaired system, i.e., , with fragments ( is measured in bits per unit of time).
We determine the optimal file maintenance strategy for different node departure rates, code parameters, and communication models for fragment retrieval.
IV File Maintenance Strategies
Let denote the number of live nodes remaining within after the departure of nodes. We focus on determining the optimal repair threshold which minimizes the average repair cost per unit of time. We first compare the distributed repair strategy with centralized repair strategy.
IV-A Distributed Repair
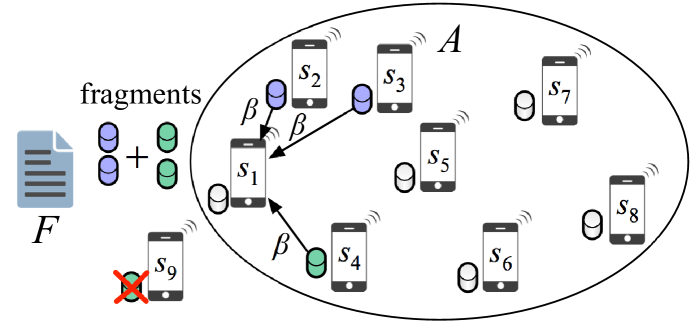
In distributed repair, newcomers recover lost fragments by independently downloading relevant symbols from live nodes. The repair process is initiated when live nodes remain within , where (when , the data is irrecoverably lost). If , fragment recovery can be performed through regeneration. Each of the newcomers downloads symbols from live nodes and independently regenerates a lost fragment. Fig. 3(a) demonstrates the distributed repair process for a file stored with a regenerating code. One fragment of is lost because node departed from . The lost fragment is regenerated at by independently downloading symbol from three nodes. The total repair bandwidth is equal to 3 symbols.
If regeneration cannot be directly applied. To reduce the repair cost, we consider a hybrid scheme consisting of regeneration and reconstruction. First, nodes are repaired by downloading symbols from live nodes and reconstructing . When fragments become available, regeneration is applied to repair the remaining newcomers. Accordingly, the repair cost is expressed by:
| (3) |
The subscript in is used to denote the cost of distributed repair and denotes the regeneration cost of a single fragment which depends on the underlying regeneration code (see eqs. (1) and (2) for MSR and MBR codes, respectively). From (3), it is evident that monotonically decreases with Moreover, the rate of cost change (with respect to ) is higher when To determine the optimal threshold , we are interested in minimizing , which captures the repair cost for maintaining fragments per unit of time.
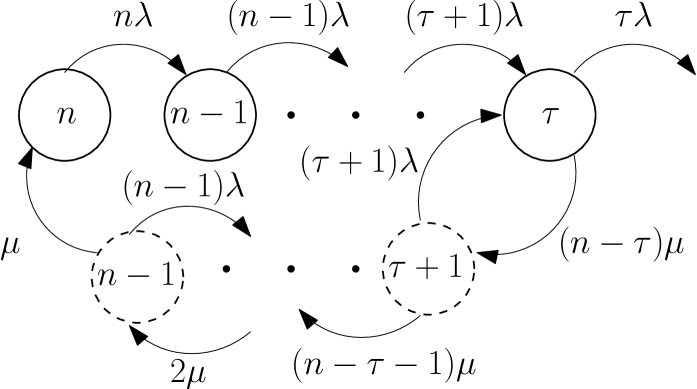
To calculate , we use the continuous-time Markov chain (CTMC) model shown in Fig. 4. This model captures the periodic repair process when node departures occur independently, the time spent by each node in is exponentially distributed with parameter , and the system recovery process is exponentially distributed with parameter .
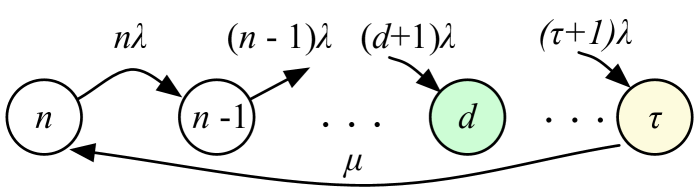
The CTMC consists of states representing the number of fragments that remain within after each node departure, until a repair at state is initiated. Note that we have omitted states after in the CTMC model, because we are interested in optimizing the periodic cost of repairing the DSS at threshold . Moreover, the transition probability to state is negligible for most realistic scenarios in which For cases when , we compute the mean time it takes to depart from the optimal repair strategy of repairing at state and interpret this event as a form of system error which leads to data loss (see Section V-C).
For the CTMC in Fig 4, the departure rate from a state equals the node departure rate , times the number of nodes which store fragments at state . When the repair process is initiated, the system transitions from state to state because all fragment repairs nodes proceed in parallel. For the CTMC, we define the expected average cost per unit of time as
| (4) |
where is the average time between two transitions through the state in the periodic repair process111The alternative definition of is not useful because the expectation is infinite. This is due to the infinitesimally small values that can be obtained by , whereas remains lower bounded.. For ,
| (5) |
where denotes the time that the system stays at state (inter-departure time) and is the expected time for completing repairs so that fragments are recovered (return to state ). The random variables are independent and exponentially distributed with parameter , whereas is exponentially distributed with parameter . In particular, and . Therefore, is the sum expectation of independent exponential random variables.
| (6) |
where . Combining (4) and (6), we obtain the average repair cost per unit of time as follows.
| (7) |
We use (7) to determine the optimal threshold which minimizes This is given by Propositions 1 and 2.
Proposition 1.
For regeneration (), the optimal repair threshold is given by
| (8) |
Proof.
Proof is provided in Appendix A. ∎
Proposition 1 determines the regime for which repairs at , an instance of lazy repair, is more efficient than initiating repairs at , referred to as eager repair. In the following Lemma, we show that there is always a positive for which lazy repair is more efficient that eager repair.
Lemma 1.
There is always some for which lazy repair () is more efficient than eager repair , independent of the code parameters used for regeneration.
Proof.
Proof is provided in Appendix B. ∎
We now examine if there is a regime for which the hybrid scheme, i.e., reconstruction plus regeneration results in a lower expected cost per unit of time compared to regeneration only. This rate regime is given by the following proposition.
Proposition 2.
For regeneration plus reconstruction (), the optimal repair threshold is given by
| (9) |
Proof.
Proof is provided in Appendix C.∎
Similar to Lemma 1, we investigate if the highest departure-to-repair rate for which reconstruction at is more efficient than regeneration is always positive independent of the code parameters. Unlike the case of Lemma 1, we show that for a certain relationship between and regeneration is strictly more efficient than regeneration plus reconstruction, independent of . For any other code parameters, the most efficient strategy depends on .
Lemma 2.
For any departure-to-repair ratio , regeneration is strictly more efficient than regeneration plus reconstruction for codes satisfying .
Proof.
Proof is provided in Appendix D. ∎
We further explore the condition in Lemma 2 for MSR and MBR codes. For MSR codes, we obtain that by substituting the operation points of MSR from (1). Similarly, for MBR codes, we obtain that by substituting the operation points of MBR from (2). Note that Lemma 2 does not enumerate all possible codes for which regeneration is strictly more efficient than regeneration plus reconstruction for any This is because we have used bounds on the harmonic function to derive the analytic formulas. Numerical bounds could provide a more accurate range of code parameters for which Lemma 2 is true.
| Distributed Repair | Centralized Repair | ||||||
|---|---|---|---|---|---|---|---|
| Regeneration |
|
Reconstruction | |||||
| Code | |||||||
| MSR | |||||||
| MBR | |||||||
IV-B Centralized Repair
In the centralized strategy, repairs are performed by a leader node in two stages. In the first stage, the leader newcomer node downloads symbols from live nodes and reconstructs . In the second stage, the leader node transmits bits to each of the remaining newcomers to restore the remaining fragments. Fig. 3(b) shows an example of centralized repair for a regenerating code. Nodes and have departed from area , leading to the loss of their respective fragments. Node who acts as a leader, downloads symbols from other nodes to reconstruct . It then distributes symbols to and to restore the system reliability. The repair cost of centralized repair is given by:
| (10) |
In (10), the subscript in is used to denote the cost of centralized repair. The node departure process does not vary with the repair strategy. Therefore, the same CTMC model shown in Fig. 4 applies for the centralized repair. According to (4), the average repair cost is given by:
| (11) |
The optimal threshold which minimizes is obtained in Proposition 3.
Proposition 3.
The optimal repair threshold which minimizes for centralized repair is given by
| (12) |
Proof.
Proof is provided in Appendix E. ∎
Using Proposition 3, we can determine the optimal repair strategy for any , when centralized repair is employed. We note that according to Lemma 1, the value is strictly positive for any code parameters. Therefore, there is always a departure-to-repair ratio for which lazy repair is more efficient than eager repair, independent of the code used for regeneration and reconstruction.
V Analysis of Maintenance Strategies
In this section, we characterize the regime for which lazy repair is more cost-efficient than eager repair. Moreover, we determine the optimal repair strategy (decentralized vs. centralized) as a function of the code parameters, when the departure and repair rates are fixed. To ease the reader to our analysis, we summarize the cost of repair in Table I.
V-A Eager vs. Lazy Repair
According to the results of Propositions 1, 2, and 3, we classify the departure-to-repair ratios into a low departure-to-repair rate regime ) and a high departure-to-repair rate regime . The two regimes are defined by finding the lowest and highest rates, based on the bounds stated in the three propositions.
| (13) | |||||
| (14) |
Noting that for the two regime expressions can be simplified to
| (15) | |||
| (16) |
For any , the repair cost per unit of time is minimized when lazy repair is applied since that choice of would be lower than the bounds found in (8), (9) and (12) and the corresponding repair thresholds are the lowest possible. On the other hand, for any , eager repair (i.e., repair at ) yields the lowest . These findings hold for both distributed and centralized repair. If the departure-to-repair rates do not lie in either of the regimes, then the optimal repair policy (eager vs. lazy) depends on the relationship of the code parameters and the repair strategy (centralized or distributed).
V-B Centralized vs. Distributed Repair
We now fix the departure rate and repair rate to compare the repair cost of centralized vs. distributed repair per unit of time, as a function of the code parameters. Specifically, we determine relationships between and the code type (MSR vs. MBR) for which an optimal strategy can be derived. Our results are stated in the following two propositions.
Proposition 4.
For , using MBR codes and distributed repair minimizes the average repair cost per unit of time, if .
Proof.
Proof is provided in Appendix F.∎
We now prove that if lies between and , using MSR codes with centralized repair is optimal.
Proposition 5.
For , the optimal repair strategy is given by centralized repair with MSR codes.
Proof.
Proof is provided in Appendix G.∎
 |
 |
 |
 |
| (a) | (b) | (c) | (d) |
V-C Mean Time to Data Loss for Periodic Repairs
We now examine the Mean Time to Data Loss (MTTDL) for the periodic threshold repair process. For our purposes, we consider that data is lost if the DSS transitions from state to state instead of state . That is, if a node leaves the system before repairs are completed when initiated at state , the repair process is abandoned and the system eventually reaches state , at which data is lost. In this case, the file is reinstated at the mobile nodes by a central entity. Note that when repairs could be re-initiated at state , because at least fragments remain available. We opted not to consider this option for the MTTDL calculation to capture the periodic nature of the threshold repair strategy. The MTTDL reflects the period of time at which the DSS oscillates between states and . The time to reach state assuming no repairs are attempted after state is given by:
Proposition 6.
For a threshold-based repair strategy attempting regeneration at state , the MTTDL is given by
| (17) |
where .
Proof.
Proof is provided in Appendix H. ∎
The MTTDL is a decreasing function of . This is intuitive considering that the number of nodes that need to depart for reaching state increases with . Moreover, the average time it takes to reach state from state increases with . This indicates that the periodic repair of the DSS will on average last longer if a lazy repair strategy is adopted.
V-D Numerical Examples
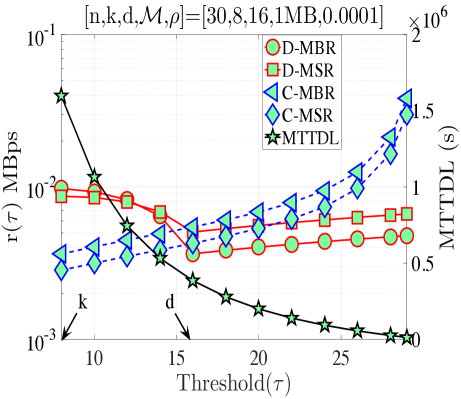
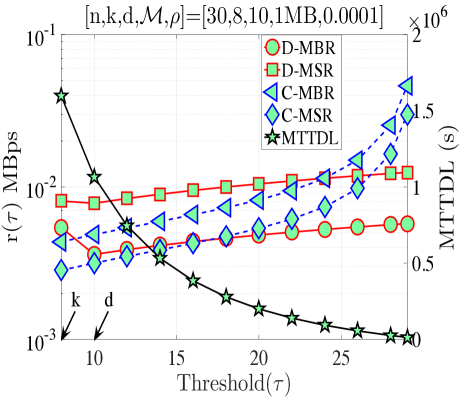
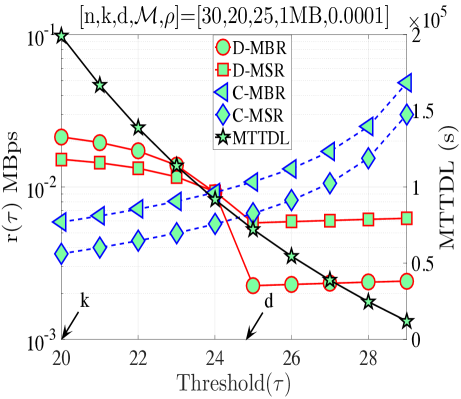
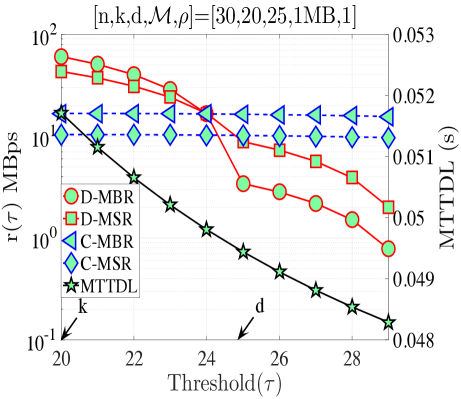
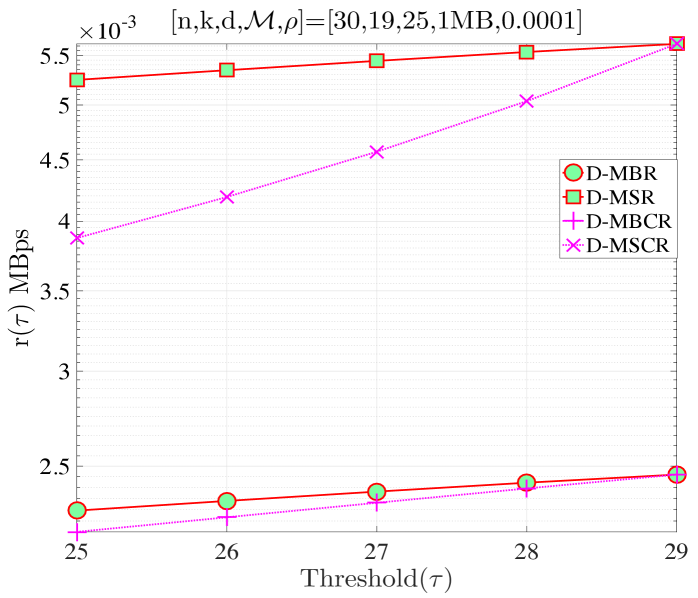
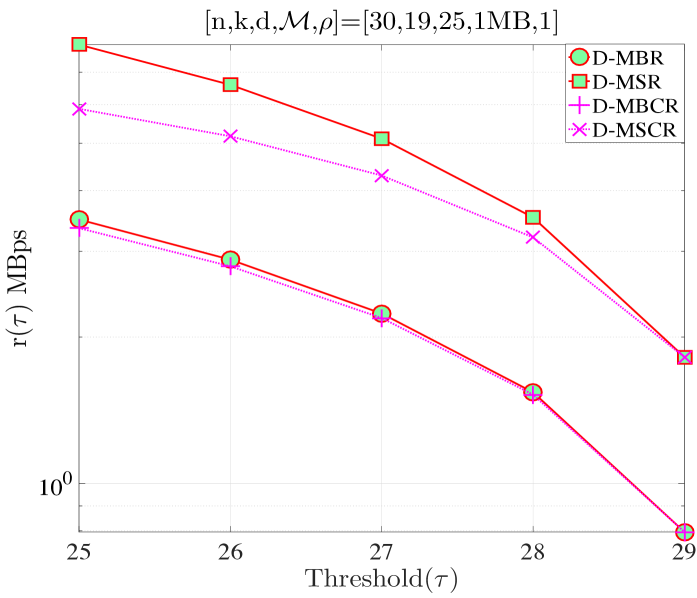
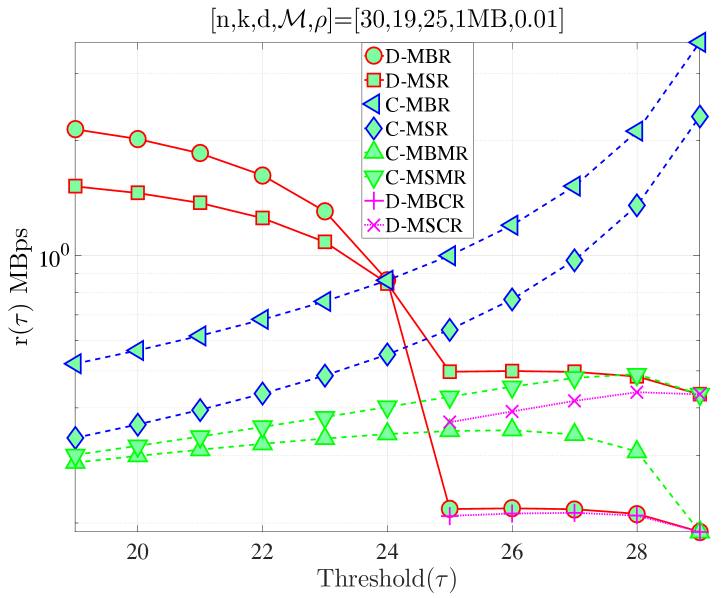
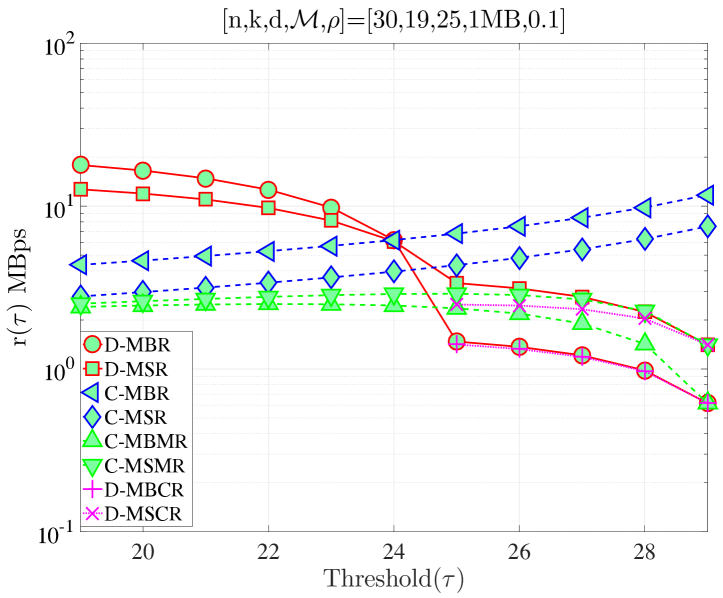
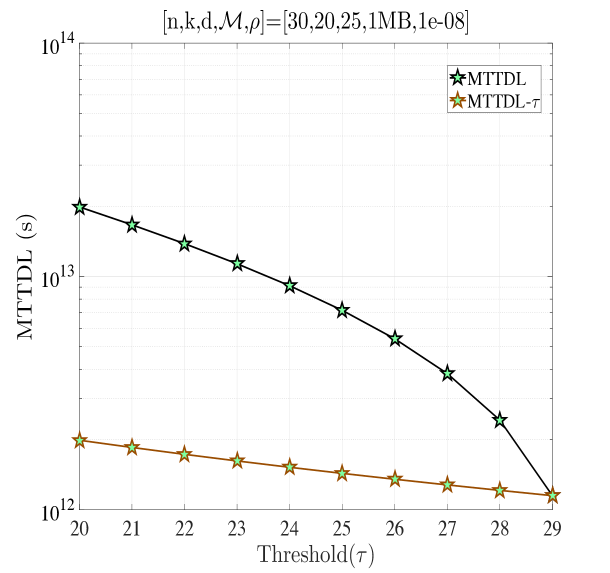
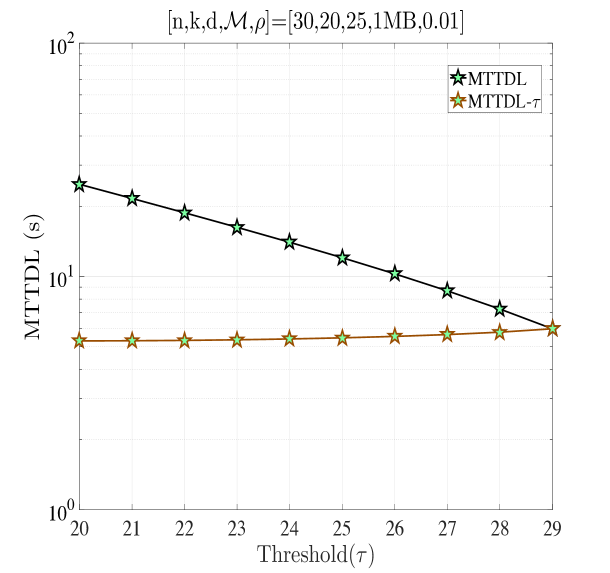
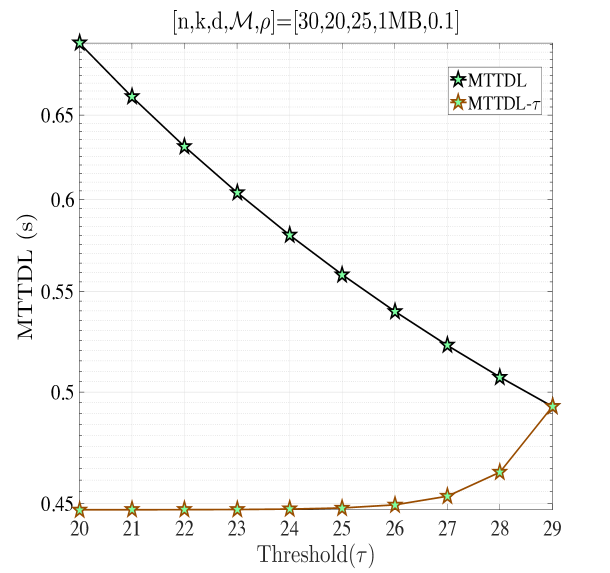
In this section, we validate our theoretical results be providing numerical examples. Fig. 5(a) shows when and . According to Proposition 4, for this combination of code parameters, a distributed repair strategy with MBR codes (D-MBR) achieves the minimum for all . The minimum occurs at . Moreover, according to Proposition 5, centralized MSR codes (C-MSR) minimize for This is verified in all plots of Fig. 5, for which the cost is minimized by the C-MSR strategy when , if . In Fig. 5(b), we show when and . For this case, there is no one scheme with optimal cost for any value of . For D-MBR is optimal, whereas for , C-MSR becomes optimal. C-MSR achieves the lowest overall cost at
We also studied the impact of , when the code parameters are fixed to . Fig. 5(c) shows the average cost per unit of time () when For this regime, a lazy repair strategy with minimizes , with D-MBR codes achieving the lowest cost. On the other hand, eager repair becomes optimal for any . This is observed in Fig. 5(d), in which the value of has been increased to one. D-MBR codes still remain the optimal option, however, the optimal repair threshold is now shifted to . Note that at the high regime, all codes exhibit the same behavior. The average cost per unit of time becomes a decreasing function of .
Finally, on the right -axis of the plots in Fig. 5, we show the MTTDL values for the given set of parameters. As expected, the MTTDL is an decreasing function of due to the corresponding increase in departure rate from state with the value of . The MTTDL becomes impractical in the high regime, because nodes frequently leave area before repairs can be completed.
VI Codes with Cooperative Repair
In the case of multiple node failures, regenerating the failed nodes individually is not optimal in terms of repair bandwidth. To regenerate multiple failed nodes more efficiently, the newcomers can also communicate with each other to lower the repair bandwidth, which is called cooperative repair. Specifically, the newcomer nodes communicate to not only the existing live nodes but also each of the other newcomers for regeneration. In this section, we analyze examples of such codes and their performance for the Markov-model that is described earlier.
VI-A Cooperative Regenerating Codes
When multiple nodes are to be repaired simultaneously, in addition to contacting live nodes and downloading symbols from those, newcomers can also communicate between each other to complete the recovery process. Formally, assume that nodes are to be repaired. Each of the newcomer nodes can contact live nodes and download symbols as well as download from each other. In this scenario, the repair bandwidth can be calculated as . Such codes are studied in [19] (referred to also as coordinated regenerating codes) and the tradeoff between per node storage and repair bandwidth is analyzed. Two ends of tradeoff curve is named Minimum Storage Cooperative Regenerating (MSCR) and Minimum Bandwidth Cooperative Regenerating (MBCR). Accordingly, operating points are given as follows:
| (18) |
For MSCR codes, , where the per-node storage is smaller than the repair bandwidth. On the other hand, MBCR codes provide the minimum repair bandwidth which operates at:
| (19) |
Note that for MBCR codes, we have .
We define as the average repair cost for a system with repair threshold under cooperative repair using groups of nodes of size (similarly for the cost). Since nodes need to be repaired, any cooperative regenerating codes with such that can be used in practice. In the following proposition, we compare the performance of cooperative regenerating codes at all possible values to find the value of that minimizes the average repair cost.
Proposition 7.
The average repair cost of cooperative repair is a monotonically decreasing function of the cooperation group size . That is, for two cooperation groups and , with and and , it follows that .
Proof.
Since in both scenarios, repairs are performed after node departures and node repairs are performed parallel, it’s enough to compare only the required bandwidths. First, assume MSCR case, then we want to show that
| (20) |
which is equivalent to
| (21) |
Since and we can conclude that therefore . Similarly, for MBCR case, we need to have
| (22) |
from which we can obtain the same condition as (21). Henceforth, and . Combining MSCR and MBCR cases, we can conclude that . ∎
Remark 1.
As a result of the above proposition, one can minimize the average repair cost by performing cooperative repairs with . In other words, for the nodes that are to be repaired, the optimal cooperative regenerating code is with , all nodes should cooperate at the same time.
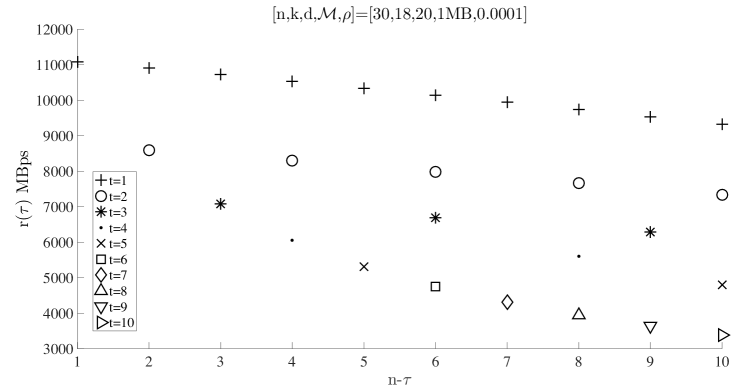
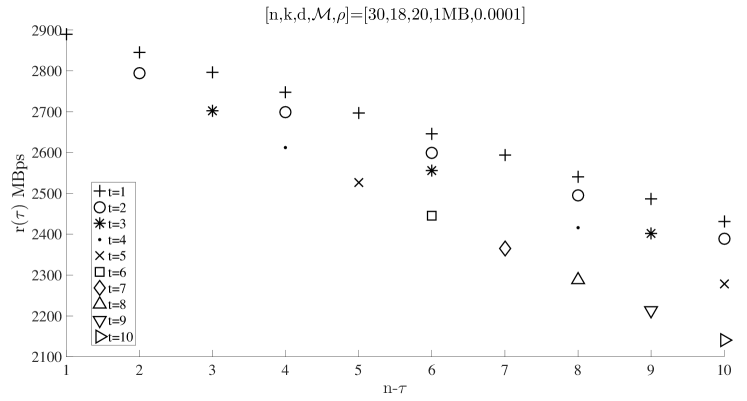
In Fig. 6, we show the average repair cost for cooperative regenerating codes at all possible values for a given . We observe that for the same , if , then and the minimum is achieved when .
In the remaining of this section, we suppress the subindex from since we established that minimizes the cost, i.e., and . However, we may still need to distinguish and values under different cooperative regenerating codes. We denote the per-node storage for cooperative repairs with , which results in the minimum average repair cost for the system with threshold , by . Similarly we use to denote the repair bandwidth at .
 |
 |
| (a) | (b) |
Note that, cooperative regenerating codes, it is required that . In other words, there should be at least live nodes when repairs are initiated. Otherwise, it is not possible to regenerate nodes from d live nodes. Henceforth, the repair cost and the repair cost per time for cooperative codes are as follows:
| (23) |
The minimum with respect to does not have a closed-form analytical expression. In Section VI-C, we present numerical results to study the change of with and determine the optimal repair threshold that minimizes for distributed cooperative repair.
VI-B Centralized Repair of Multiple Node Failures
Centralized repair of multiple node repairs is introduced in [22]. Using this model, a dedicated node among the newcomers downloads from any live nodes such that it can repair multiple node failures of size . Such codes can be used in the centralized repair process that is proposed in Section IV when we set . Rawat et al. in [22] characterize the tradeoff between per-node storage and repair bandwidth for this centralized repair model. Accordingly, the following operation points are derived for minimum storage multi-node regeneration (MSMR) and minimum bandwidth multi-node regeneration (MBMR):
| (24) |
Let . If (where denotes entropy of information stored on nodes), then
| (25) |
Under centralized repair model discussed here, a dedicated node first downloads and then distributes to remaining . The difference between these codes and the earlier proposed method for centralized repair in Section IV-B is that the dedicated node may not need to download the whole file. Therefore, we have the following repair cost
| (26) |
from which one can obtain
| (27) |
In order to find the optimal threshold that minimizes the average repair cost, we need to find the minimum value of . We can replace with its approximation, , and take the derivative with respect to . Note that both and depend on and there is no tractable analytical solution for that minimizes . However, we can still analyze (27) numerically with respect to and observe the optimal threshold from numerical results.
Remark 2.
In this section, we analyzed different cooperative codes that are suitable for mobile clouds. For both scenarios, the problem of finding for which is minimized does not have a closed-form solution due to the dependence of and on . We, therefore, resort to the numerical analysis of the optimal threshold. Next, we present numerical results instead, which are presented below. Note that, for the regenerating codes that were analyzed in Section V, and do not depend on the threshold .
VI-C Numerical Results
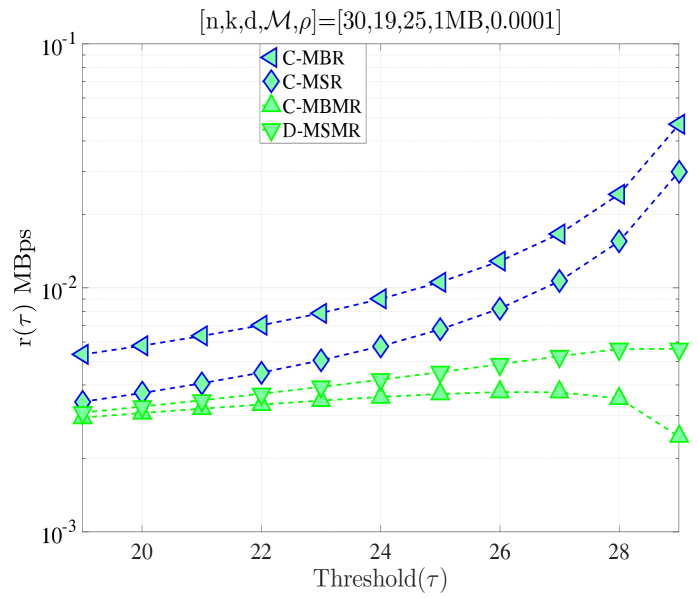
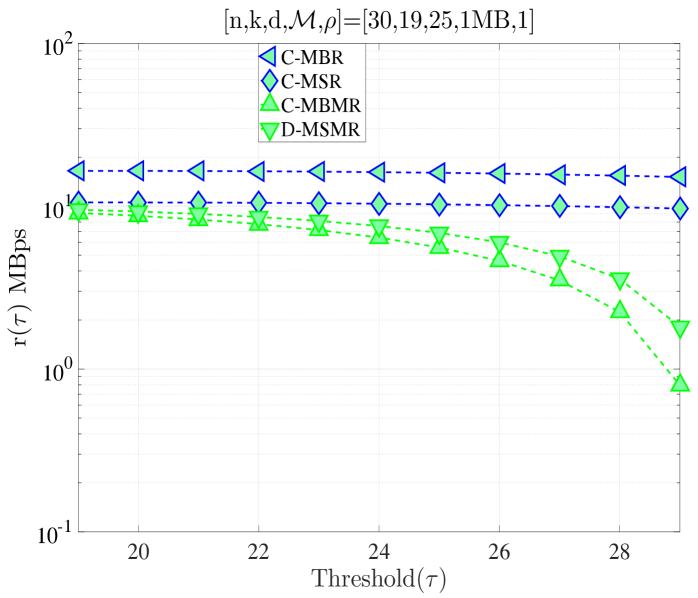
We study the performance of cooperative codes with and under different regimes. In Fig. 7, we compare the codes studied in Sections IV and VI for different regimes. We first compare regenerating codes vs. cooperative regenerating codes for the distributed repair scenario. Note that we focus only on because at least live nodes must exist for cooperation (see Section VI-A). We observe that cooperative regenerating codes always have lower cost than regenerating codes for all values of . Additionally, the gap between the cost of D-MBR and D-MBCR is much smaller than the gap between the cost of D-MSR and D-MSCR. Furthermore, we can observe two opposing regimes: In Fig. 7(a), the optimal cost is at , whereas in Fig. 7(b), the cost is minimized at . We also compare the centralized regenerating codes to the centralized repair of multiple node departures. As expected, since in the latter scheme one does not need the whole file for file reconstruction at the dedicated node, centralized repair of multiple node departures results in lower repair cost. At , in Fig. 7(d) average repair cost is minimized for all schemes, on the other hand we observe different optimum values for different coding schemes in Fig. 7(c). Finally, we compare all schemes in Fig. 7(e)-(f) for different values of for completeness. It is observed that the centralized repair of multiple node departures model discussed in this section approaches to the distributed repair model in Section IV as approaches and diverges from the centralized repair model in Section IV. The reason for this behavior is that the dedicated node does not need to download the whole file now (as opposed to the centralized repair model in Section IV, which incurs high average repair cost for large ).
 |
 |
| (a) | (b) |
 |
 |
| (c) | (d) |
 |
 |
| (e) | (f) |
VII A Repair Process Analogous to the number of repaired nodes
In the analysis presented in Sections V-VI, we have assumed that the repair time is exponentially distributed with parameter , irrespective of the number of nodes to be repaired. This model is mathematically tractable and we are able to find analytical results on the optimal repair threshold. In this section, we consider a revised model in which the repair time is analogous to the number of nodes that need to be repaired. Specifically, we model the repair process as the maximum of exponential random variables, each with rate . In other words, when the repair process is initiated, one can consider starting exponential clocks, each with rate . The repair process ends when all the clocks end. We note that the maximum value of such clocks is not exponentially distributed (as opposed to the minimum of such clocks), however, its expected value is known, which is enough for the purpose of finding average repair cost. Let denote the repair time of newcomer node, then we have the following [26]
| (28) |
The expected time between two instances of fully operational system with live nodes is given by
| (29) |
where the first term is the expected time from state to state , and the second term is the expected time from state back to state . Accordingly, the resulting average repair cost for the distributed repair case is
| (30) |
Note that for centralized repair, a dedicated newcomer node first downloads the file, and then distributes symbols to the remaining newcomer nodes. Therefore, the expected repair time is given by , where we have first one clock with exponential rate of , followed by a maximum of clocks with rate . Accordingly, we obtain
| (31) |
The optimal which minimizes the above equation is difficult to track due to the complexity of the formula (due to in the denominator). Instead, we perform numerical analysis of the average repair cost with respect to the threshold later in this section.
In the context of this model, we next focus on MTTDL. Note that, if we start clocks, the probability that no data loss occurs within a cycle, denoted by , can be calculated as . In other words, the exponential random variable with rate should be greater than all exponential random variables with rate . Since we have i.i.d. exponential random variables, . Accordingly, we have
| (32) |
where . Note that the above equation is for the calculation of MTTDL for distributed repair. For centralized repair, the random variable with rate should be larger than sum of two exponential random variables with rate , which is a gamma distribution since first a dedicated node downloads the whole file and then it repairs the other nodes. Henceforth, we did not perform MTTDL analysis for centralized repair. 222The resulting equation is not in compact form, thus we omit this analysis in this text.
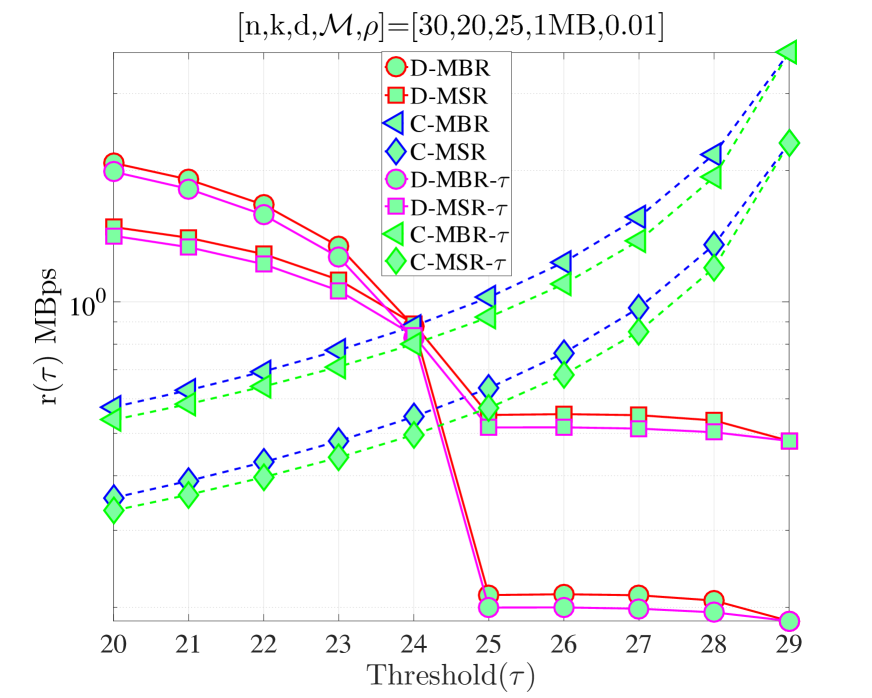
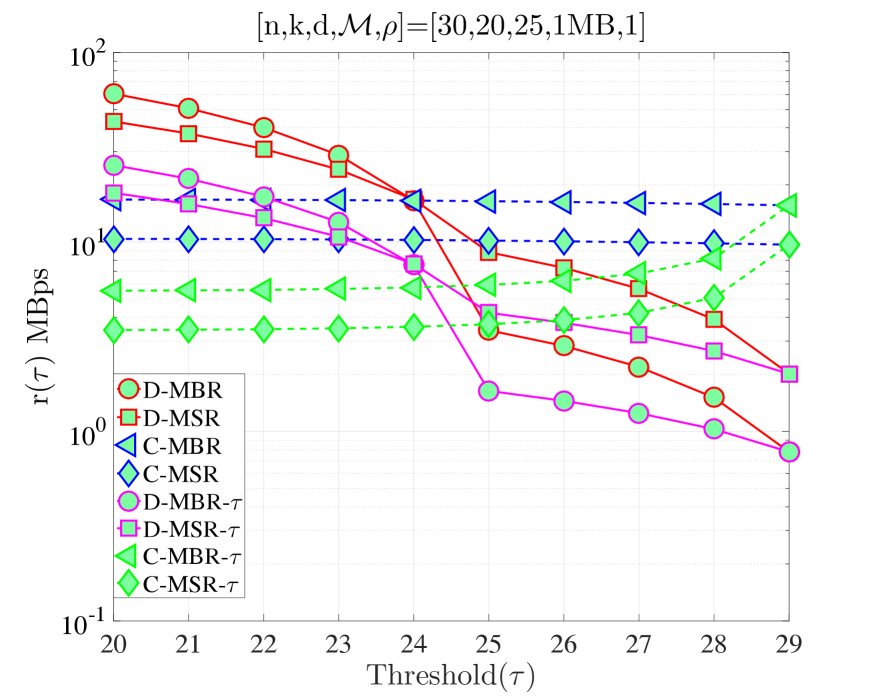
In Fig. 8, we compare how the revised model affects the average repair cost relative to the simplified repair model used in Section IV, in which all nodes are repaired under the same clock. We denote the values calculated within this section by appending at the end, i.e., , to specify that the repair process that takes into account the number of nodes to be repaired (i.e., ). It can be observed that changing the model does not affect the behavior of the curves substantially. We observe in the modified model that average cost is decreased slightly. Even though we have the same costs in both cases, the expected times to complete the repair process are different. Specifically, in Sections IV and V, it takes time to finish the repair process. On the other hand, in the modified model, we change this value to maximum of exponential random variables, each with mean and this maximum value is larger than (unless ). Therefore, it takes longer to complete repairs in the modified model, which results in smaller values of average repair cost. On the other hand, in Fig. 9, a different behavior is observed for the MTTDL. In the low regime, the MTTDL decreases with for both single clock and the maximum of multiple clock models. However, in the high regime, the increase in decreases MTTDL for the single clock model, whereas the MTTDL for the multiple clocks model increases with . This is because in (32), converges to 1 as we decrease in the high regime, which reduces (32). On the other hand, in the low regime, converges to zero as we increase , which reduces (32). Finally, the model discussed in this section results in lower MTTDL values compared to the previous one.
 |
 |
| (a) | (b) |
 |
 |
 |
| (a) | (b) | (c) |
VIII Allowing Node Departures within the Repair Process
Up to this point, we have assumed that once the repair process is started, no live nodes depart from until the repair is completed. In this section, we analyze the case in which additional node departures are allowed within repair process. Fig. 10 shows the revised CTMC model that accounts for departures during the repair process. The chain consists of two sets of states. In the first row, states represent the phase where nodes depart but no repairs are initiated. Once state is reached, repairs are initiated and the chain transitions into the second row of states where departures may occur while repairs are performed. We focus on the case where no data loss occurs as we are interested in the system dynamics, while the system remains operational.
Once the repair process is initiated, nodes are to be repaired. Since we assume an exponential random variable for repair times (with rate ), a newcomer is repaired after the minimum of the exponential random variables, which is also an exponential random variable with rate . Due to the memoryless property of the exponential random variable, we can perform the same procedure for the second repair and so on. The corresponding rates are depicted on the second row of states of Fig. 10. Note that if no departures occur during the repair process, the expected repair time would be the same as in the model of Section VII, that is, the maximum of exponential random variables with rate .
In such a model, the expected number of node repairs is larger than due to the possible additional departures during the repair process. In the section, we analyze the system under the condition that the CTMC always chooses the transition when in the lower set of states so that all nodes are repaired eventually. Otherwise, the system would suffer from data loss. To find the average repair cost, we are interested in two statistics of the CTMC once it reaches state for the first time: i) the total number of lower arc transitions before reaching state , i.e., , which will determine the number of node repairs, ii) the expected total time for reaching state from state . For simplicity, the states can be ignored for now since they do not affect any of these two statistics. We are also interested in the number of times the chain revisits state before reaching state since that will determine the probability of no data loss.
Total number of revisits to state : Since we are interested in the case where no data loss occurs, we need to find the number of times the chain revisits state . This is equivalent to transitioning from state to at each revisit to state , we need the transition at each revisit to state , which occurs with probability . For the transitions in the lower row of the CTMC, denote by , the total number of revisits to state before reaching state at state . Then, we can state the following balance equations.
| (33) | ||||
| (34) | ||||
| (35) | ||||
| (36) | ||||
| (37) | ||||
| (38) | ||||
The set of equations (33)-(38) can be recursively solved for . Then, the probability that no data loss occurs is for one cycle of node repairs.
Total number of lower arc transitions: For the transitions of the lower row of the CTMC, denote by , the total number of lower arc transitions at state , then we have the following equations.
| (39) | ||||
| (40) | ||||
| (41) | ||||
| (42) | ||||
| (43) | ||||
Finding the total number of lower arc transitions is not enough to calculate the average repair cost per time since not all repairs have the same cost in some repair strategies. That is, if , then some nodes are repaired by downloading symbols, whereas the remaining nodes are repaired by downloading . To find the number of lower arc transitions which occur between states and (which are repaired by downloading ), we denote by the number of lower arc transitions between states and at state . Then,
| (44) | ||||
| (45) | ||||
| (46) | ||||
| (47) | ||||
| (48) | ||||
| (49) | ||||
| (50) | ||||
| (51) | ||||
If , there is no need to find since all nodes download and there are node repairs in total whereas if , then repairs are performed by downloading symbols and node repairs are performed by downloading symbols.
Expected total time before reaching state : For the transitions of the lower row of the CTMC, denote by , the time it takes to reach state from state . Then, the balance equations for the CTMC for can be written as
| (52) | ||||
| (53) | ||||
| (54) | ||||
| (55) | ||||
| (56) | ||||
Using (52)-(56), we can solve for which is the time it takes to repair to a fully operational system with live nodes from state , when departures occur during the repair process. The initial state for the system is and therefore the time to revisit state is .
This yields an average cost per time equal to
| (57) |
and a probability of no data loss equal to .
VIII-A Numerical Results
We have performed simulations to verify our findings. In the following example, we examine the case where , , , . Different values are used, , as well as different values, . Simulation results are the average of one million simulations and they are presented in Table VI. Each table entry notes the value obtained from the simulation or the value obtained by analytically evaluation the average repair cost via (57): the first shows the simulation results (S) and the other represents the analytical result (A) as shown before. As expected, increasing results in more revisits to state due to an increase in the node departure rate. Furthermore, we see that expected time before reaching state decreases as we increase for both cases of and . For both cases, we observe that the number of nodes repaired by downloading remains the same for a given value of . This is because the critical number of live nodes for a node to be repaired by downloading symbols is at , since if there are less than live nodes, then a node must be repaired by downloading symbols. In other words, once we reach state (in the lower row) of the CTMC, we count the number of lower arc transitions between the states and to calculate the number of node repairs by downloading symbols, which remains the same for and , since is not between and . Finally, the number of nodes repaired by downloading increases with as expected. We can observe that simulation results verify our analytical findings.
| 0.1 | 0.2 | 0.4 | |||||
| S | A | S | A | S | A | ||
| 25 | 1.0718 | 1.0719 | 1.1633 | 1.1638 | 1.4660 | 1.4668 | |
| 27 | 1.1806 | 1.1806 | 1.4439 | 1.4424 | 2.2118 | 2.2096 | |
| 0.1 | 0.2 | 0.4 | |||||
| S | A | S | A | S | A | ||
| 25 | 2.0438 | 2.0432 | 1.1770 | 1.1770 | 0.8040 | 0.8034 | |
| 27 | 1.2404 | 1.2392 | 0.7458 | 0.7447 | 0.5402 | 0.5405 | |
| 0.1 | 0.2 | 0.4 | |||||
| S | A | S | A | S | A | ||
| 25 | 3.4703 | 3.4706 | 4.0263 | 4.0224 | 5.3702 | 5.3696 | |
| 27 | 3.4715 | 3.4706 | 4.0237 | 4.0224 | 5.3727 | 5.3696 | |
| 0.1 | 0.2 | 0.4 | |||||
| S | A | S | A | S | A | ||
| 25 | 2.1784 | 2.1782 | 2.4228 | 2.4234 | 3.2620 | 3.2623 | |
| 27 | 0 | 0 | 0 | 0 | 0 | 0 | |
In Fig. 11, we compare our previous schemes, namely the distributed repair model in Section IV and the model in Section VII, with the repair model discussed in this section, which is depicted in the figure with D-MBR-F and D-MSR-F to specify that these codes allow failures within repair process. In the low regime, we observe that there is almost no difference between the performance of models in both MSR and MBR cases. This is because for low , the expected number of additional departures during repair is low and the expected time is dominated by terms with (the upper transition in the CTMC model of Fig. 10, which is the same as the CTMC model of Fig. 4). In the high regime, differences are observed in the expected average cost per time. Interestingly, when , it can be observed that for , D-MSR-F and D-MBR-F have the highest cost respectively for MSR and MBR cases, whereas for , they are in between the D-MSR and D-MBR. As we keep increasing , we observe that D-MSR-F and D-MBR-F becomes even more costly compared to other schemes. In all cases, our model in Section VII has the lowest respectively for MSR and MBR cases. These observations validate that our model in Section IV (that does not have dependency of repair process on the number of nodes to be repaired and neglect failures during repair) can be utilized as an approximate model for the models we consider later in the text in the low regime. Therefore, in the low regime, all the optimal threshold statements for the former model (i.e., Proposition 1, Proposition 2) also hold for the model considered in Sections VII and VIII. Note that, the low regime is the only interesting case for mobile cloud storage. At high , the average repair cost and MTTDL performance become prohibitively high and low, respectively, for the system to be viable.
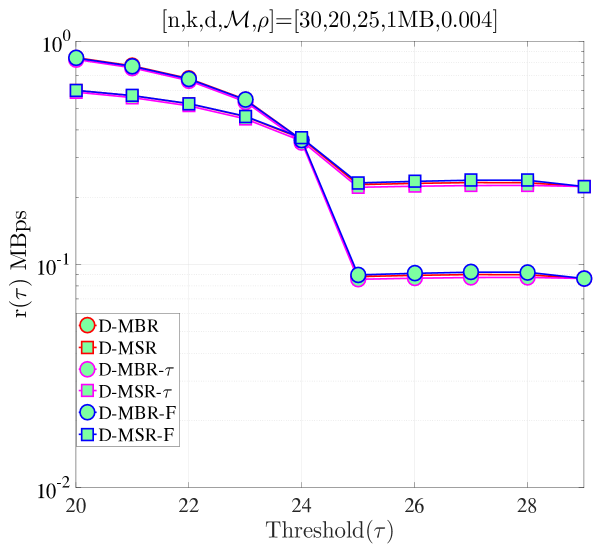 |
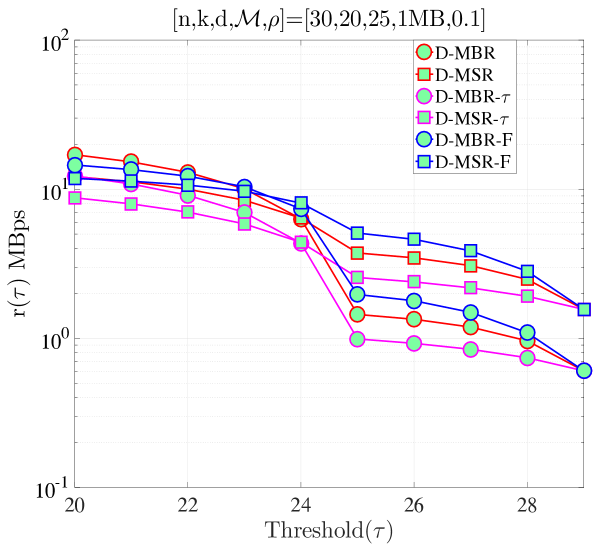 |
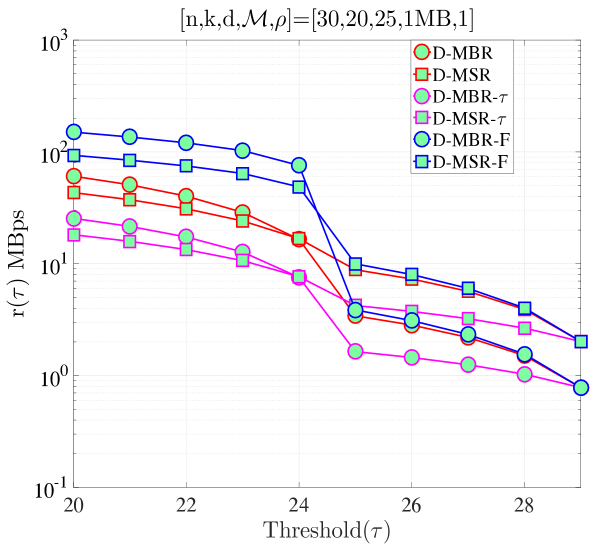 |
| (a) | (b) | (c) |
IX Conclusion and Future Work
We analyzed threshold-based repair strategies for maintaining files in mobile cloud storage systems. We derived the optimal repair thresholds for both distributed and centralized repair schemes under fragment regeneration and/or reconstruction. Our results showed that optimal thresholds are dependent on system configurations, the underlying code parameters and mobility-to-repair rate ratio. For high mobility-to-repair scenarios, eager repair minimizes the average repair cost per unit of time. Under low mobility-to-repair ratio, lazy repair is optimal in terms of average repair cost. We investigated codes that perform repair through cooperation. We showed that similar to regenerating codes, one can derive optimal thresholds for cooperative regenerating codes. We also investigated the case when the repair process depends on the number of nodes under repair. Finally, we analyzed the case where we lift the restriction that once the repair process is initiated, no more departures occur. We derived set of linear equations to calculate repair cost, which is verified by simulations. We then showed that the initial fixed-rate repair model, which was simple enough to track analytically, is a good approximation of the complex model in the low regime, which is of interest. This allows us to use the optimal threshold results as well as other results we had from the simpler model.
As part of future work, we plan to consider a more advanced repair model in which fragment repairs occur under a fixed bandwidth constraint. This assumption makes the repair rate dependent on the repair threshold . Finally, generalizing the model to the case where repairs are initiated at every state with some probability and studying the cost vs. MTTDL tradeoff under this model is an interesting avenue for further research.
References
- [1] N. Golrezaei, A. G. Dimakis, and A. F. Molisch, “Device-to-device collaboration through distributed storage,” in Proc. of the GLOBECOM Conference, 2012.
- [2] J. Pääkkönen, C. Hollanti, and O. Tirkkonen, “Device-to-device data storage for mobile cellular systems,” in Proc. of the GLOBECOM Workshops, 2013.
- [3] N. Golrezaei, A. G. Dimakis, and A. F. Molisch, “Scaling behavior for device-to-device communications with distributed caching,” IEEE Trans. on Information Theory, vol. 60, no. 7, pp. 4286–4298, 2014.
- [4] R. Bhagwan, K. Tati, Y.-C. Cheng, S. Savage, and G. M. Voelker, “Total recall: system support for automated availability management.” in Proc. of the NSDI Conference, 2004.
- [5] F. Dabek, J. Li, E. Sit, J. Robertson, M. F. Kaashoek, and R. Morris, “Designing a DHT for low latency and high throughput,” in Proc. of the NDSI Symposium, 2004.
- [6] Y. Hu, Y. Xu, X. Wang, C. Zhan, and P. Li, “Cooperative recovery of distributed storage systems from multiple losses with network coding,” IEEE Journal on Selected Areas in Communications, vol. 28, no. 2, pp. 268–276, 2010.
- [7] H. Weatherspoon and J. D. Kubiatowics, “Erasure coding vs. replication: A quantitive comparison,” in Proc. of the 1st International Workshop on Peer-to-Peer Systems, 2002.
- [8] F. Giroire, J. Monteiro, and S. Pérennes, “Peer-to-peer storage systems: a practical guideline to be lazy,” in Proc. of the GLOBECOM Conference, 2010.
- [9] A. G. Dimakis, P. B. Godfrey, Y. Wu, M. J. Wainwright, and K. Ramchandran, “Network coding for distributed storage systems,” IEEE Trans. on Information Theory, vol. 56, no. 9, pp. 4539–4551, 2010.
- [10] K. Rashmi, N. Shah, and P. Kumar, “Optimal exact-regenerating codes for distributed storage at the MSR and MBR points via a product-matrix construction,” IEEE Trans. on Information Theory, vol. 57, no. 8, pp. 5227 –5239, Aug. 2011.
- [11] I. Tamo, Z. Wang, and J. Bruck, “Zigzag codes: MDS array codes with optimal rebuilding,” IEEE Trans. on Information Theory, vol. 59, no. 3, pp. 1597–1616, March 2013.
- [12] V. Cadambe, S. Jafar, H. Maleki, K. Ramchandran, and C. Suh, “Asymptotic interference alignment for optimal repair of MDS codes in distributed storage,” IEEE Trans. on Information Theory, vol. 59, no. 5, pp. 2974–2987, 2013.
- [13] D. Borthakur, “HDFS architecture guide,” http://hadoop.apache.org/common/docs/current/hdfs_design.pdf, 2008.
- [14] R. C. Singleton, “Maximum distance q -nary codes,” IEEE Trans. on Information Theory, vol. 10, no. 2, pp. 116–118, 1964.
- [15] M. Blaum, J. Brady, J. Bruck, and J. Menon, “EVENODD: An efficient scheme for tolerating double disk failures in RAID architectures,” IEEE Trans. on Computers, vol. 44, no. 2, pp. 192–202, Feb. 1995.
- [16] C. Huang and L. Xu, “STAR: An efficient coding scheme for correcting triple storage node failures,” in Proc. of the USENIX Conference on File and Storage Technologies, 2005.
- [17] B. Calder, Wang et al., “Windows Azure Storage: A highly available cloud storage service with strong consistency,” in Proc. of the Twenty-Third ACM Symposium on Operating Systems Principles, 2011.
- [18] D. Ford, F. Labelle, F. I. Popovici, M. Stokely, V.-A. Truong, L. Barroso, C. Grimes, and S. Quinlan, “Availability in globally distributed storage systems.” in Proc. of the OSDI Conference, 2010.
- [19] A.-M. Kermarrec, N. Le Scouarnec, and G. Straub, “Repairing multiple failures with coordinated and adaptive regenerating codes,” in Proc. of the International Symposium on Network Coding (NetCod), 2011.
- [20] K. W. Shum and Y. Hu, “Cooperative regenerating codes,” IEEE Trans. on Information Theory, vol. 59, no. 11, pp. 7229–7258, Nov 2013.
- [21] X. Wang, Y. Xu, Y. Hu, and K. Ou, “Mfr: Multi-loss flexible recovery in distributed storage systems,” in Proc. of the International Conference on Communications (ICC), 2010.
- [22] A. S. Rawat, O. O. Koyluoglu, and S. Vishwanath, “Centralized repair of multiple node failures with applications to communication efficient secret sharing,” arXiv preprint arXiv:1603.04822, 2016.
- [23] J. Pääkkönen, P. Dharmawansa, C. Hollanti, and O. Tirkkonen, “Distributed storage for proximity based services,” in Proc. of the Swedish Communication Technologies Workshop (Swe-CTW), 2012.
- [24] J. Pääkkönen, C. Hollanti, and O. Tirkkonen, “Device-to-device data storage with regenerating codes,” in Multiple Access Communications. Springer, 2015, pp. 57–69.
- [25] J. Pedersen, I. Andriyanova, F. Brännström et al., “Distributed storage in mobile wireless networks with device-to-device communication,” arXiv preprint arXiv:1601.00397, 2016.
- [26] B. Eisenberg, “On the expectation of the maximum of iid geometric random variables,” Statistics & Probability Letters, vol. 78, no. 2, pp. 135–143, 2008.
Appendix A Proof of Proposition 1
Proof.
To determine , we compare with the average repair cost at all other possible regeneration states , for , and check if
| (58) |
This method is preferred because a straightforward minimization of through differentiation is involved due to the harmonic sums. Substituting from (7) to (58) yields,
| (59) | ||||
| (60) |
The inequality in (60) yields the maximum for which is minimized at state . We now examine the behavior of the right hand side (RHS) in (60) as a function of for fixed and . The RHS in (60) has the same monotonicity as the function In Lemma 3, we show that is monotonically decreasing with . As a result, the departure-to-repair rates for which holds are also monotonically decreasing with Substituting the maximum (i.e., ) to the RHS in (60) yields a departure rate bound
| (61) |
for which In this case, minimization of is achieved at
We now prove that for rates the average cost is minimized when . Following a similar reasoning, we compare at with at any other possible regeneration threshold. We consider , where . By substituting from (7) and simplifying, it follows that
| (62) |
The RHS of (62) has the same monotonicity as the function . In Lemma 4, we show that is monotonically increasing with . Therefore, the minimum for which is obtained when Substituting this to (62) completes the proof. ∎
Lemma 3.
The function
| (63) |
is a monotonically decreasing function over integers for any given integer .
Proof.
We will show that for any integer , which implies the monotonically decreasing assertion in the lemma. We have
where in (a) we define the sum , and (b) follows as there are terms in and each term is strictly greater than . ∎
Lemma 4.
The function
| (64) |
is a monotonically increasing function over integers for any given integer .
Proof.
We will show that for any integer , which implies the monotonically increasing assertion in the lemma. We have
where in (a) we define the sum , and (b) follows as there are terms in and each term is strictly smaller than . ∎
Appendix B Proof of Lemma 1
In Proposition 1, we determined the regime for which lazy repair is more efficient than eager repair, given fixed code parameters. To prove Lemma 1, it suffices to show that the highest rate for which is strictly positive for any and (recall that by definition, ). We prove this fact by employing a lower bound on , which is proved in Lemma 5.
| (65) | ||||
| (66) | ||||
| (67) |
where in (a), we substituted with the strictly smaller term
Lemma 5.
The function
| (68) |
is bounded by
| (69) |
for all positive integers and .
Proof.
First, we show that , for all and .
where (a) follows by substituting the first terms in the nominator with strictly smaller terms. The equality in this lower bound holds when . We now show the upper bound.
where (b) follows by substituting the terms in the nominator with strictly larger terms. ∎
Appendix C Proof of Proposition 2
Proof.
The proof follows along the same lines as Proposition 1. We compare the repair cost at with the repair cost at any other possible state for to check when the inequality
| (70) |
is satisfied. Substituting for using (7), we obtain
| (71) |
from which we get:
| (72) |
Expression (72) yields a bound on the minimum for which the optimal repair threshold is . We notice that RHS of the inequality above has the same monotonicity as the function defined in Lemma 4 in Appendix A, from which we observe that this function is a monotonically increasing function of . Substituting the maximum yields the departure-to-repair rate bound,
| (73) |
for which For this rate regime, the optimal repair threshold is at
We now prove that for rates , the average cost per unit of time is minimized when . We compare with to analyze when the following inequality holds.
| (74) |
On substituting for from (7), we get:
from which we obtain
| (75) |
The expression above yields a bound on the maximum departure-to-repair rate for which the optimal repair threshold is . We now study the behavior of (75) as a function of for fixed and . We notice that RHS of the inequality above has the same monotonicity as the function defined in Lemma 3 in Appendix A, from which we observe that this function is a monotonically decreasing function of . Therefore, yields the minimum value for the RHS of (75), which implies that when
| (76) | |||||
is optimized at ∎
Appendix D Proof of Lemma 2
Proof.
We prove Lemma 2 by finding the relationship between and for which the upper bound on the rate when becomes negative.
where in (a) we have used Lemma 5 of Appendix B to substitute term with its upper bound and in (b), we have used the same lemma to substitute with its lower bound . Setting yields since the multiplicative term is strictly positive. ∎
Appendix E Proof of Proposition 3
Proof.
To determine , we compare with other possible repair states , i.e., we analyze when
| (77) |
for . On substituting for from (11), we obtain
We have
| (78) |
Inequality (78) yields the maximum departure-to-repair rate for which it is more cost-efficient to repair at state than any other state We now examine the behavior of the RHS of (78) as a function of for fixed and . We notice that RHS of the inequality above has the same monotonicity as the function defined in Lemma 3 in Appendix A, from which we observe that this function is a monotonically decreasing function of . Substituting to the RHS of (78) yields
| (79) |
for which the optimal repair threshold is at
We now evaluate if there is a departure rate regime for which the average cost per unit of time is minimized at . That is, we analyze when
| (80) |
where . On substituting for from (11), we get
| (81) | |||||
| (82) |
We notice that RHS of the inequality above has the same monotonicity as the function defined in Lemma 4 in Appendix A, from which we observe that this function is a monotonically increasing function of . Substituting yields
| (83) |
for which the optimal repair threshold is at .
∎
Appendix F Proof of Proposition 4
Proof.
Let us consider the following inequality:
| (84) |
According to (11), the average repair cost of centralized repair depends only on , when , , and are fixed. As , MSR codes minimize . Thus, we select MSR codes for centralized repair in our comparison. Similarly, for given and , the average repair cost of distributed repair depends only on the repair bandwidth . As , MBR codes are selected to minimize . Substituting (1) and (2) in and , respectively, we obtain
| (85) |
which implies
| (86) |
Inequality (86) determines the minimum number of surviving nodes for which MBR distributed repair emerges as the most cost-efficient strategy. The left hand side (LHS) of (86) is a decreasing function of . Maximizing the LHS yields the relationship between and for which distributed MBR always outperforms centralized MSR. This occurs when . Substituting results in . If we reverse the direction of the inequality in (84), we obtain
| (87) |
Minimizing the RHS of (87) yields the relationship between and for which centralized MSR always outperforms distributed MBR. This occurs when . Substituting results in . However, by the definition of regenerating codes, we have Therefore, there is no condition for which centralized MSR repair always outperforms distributed MBR repair. ∎
Appendix G Proof of Proposition 5
Proof.
To determine the optimal repair strategy we compare with for
.
Substituting for distributed repair and centralized repair from (7) and (11), respectively, we obtain:
| (88) |
For MSR codes, and for MBR codes, . Thus, for each case, we have . By choosing the lowest , we consider when the parameters satisfy
| (89) |
As , inequality (89) is always true and hence, centralized repair outperforms distributed repair. As explained in Proposition 4, for centralized repair, MSR codes minimize the average repair cost rate per unit of time as compared to MBR codes. Thus, centralized repair using MSR codes yields the optimal repair strategy. ∎
Appendix H Proof of Proposition 6
Starting from state , expected time to reach state is . Once the system is at state , with probability , the system will transition to state . If this occurs, the recovery will not be possible since the number of fragments are below the repair threshold. However, DSS can still serve the users if . Until we reach state , the data is not lost. The expected time to reach state from state is . On the other hand, with probability , recovery will be initiated and the system will be back to state , which takes time. At that point, we will go thorough the same process again. Accordingly, we have
| (90) |
from which the expected time to data loss, , can be calculated.