Resilient Average Consensus with Adversaries via Distributed Detection and Recovery
Abstract
We study the problem of resilient average consensus in multi-agent systems where some of the agents are subject to failures or attacks. The objective of resilient average consensus is for non-faulty/normal agents to converge to the average of their initial values despite the erroneous effects from malicious agents. To this end, we propose a successful distributed iterative resilient average consensus algorithm for the multi-agent networks with general directed topologies. The proposed algorithm has two parts at each iteration: detection and averaging. For the detection part, we propose two distributed algorithms and one of them can detect malicious agents with only the information from direct in-neighbors. For the averaging part, we extend the applicability of an existing averaging algorithm where normal agents can remove the effects from malicious agents so far, after they are detected. Another important feature of our method is that it can handle the case where malicious agents are neighboring and collaborating with each other to mislead the normal ones from averaging. This case cannot be solved by existing detection approaches in related literature. Moreover, our algorithm is efficient in storage usage especially for large-scale networks as each agent only requires the values of neighbors within two hops. Lastly, numerical examples are given to verify the efficacy of the proposed algorithms.
Average consensus, directed topologies, distributed detection, resilient consensus.
1 Introduction
Distributed consensus in multi-agent systems is a fundamental and well-studied topic across different research areas including systems control, computer science, and communication [2, 1, 3, 4]. Under this broad topic, a particular problem that has been extensively studied is that of average consensus where agents try to reach consensus on the average of their values through local interactions among nearby agents [9, 10, 6, 7, 5, 11, 8, 12, 13]. Average consensus algorithms are also useful to maintain the total of the resources invariant and have found applications in, e.g., economic dispatch problems for power systems [14], distributed computation of PageRank for the search engine of Google [15, 16]. As concerns for cyber-security sharply rise in our society, consensus protocols that properly function even in the presence of faults and adversarial agents have been actively studied; see, e.g., [20, 21, 19, 17, 18]. The objective is for the non-faulty/normal agents to reach consensus without being affected by the misbehaviors of adversarial agents. In this context, resilient algorithms for performing average consensus have remained somewhat limited except for the recent works [22, 23, 24]. A major challenge is that, normal agents should reach consensus on the exact average of their initial values despite adversarial agents’ misbehaviors, which may include adding erroneous values to the normal agents’ values during the interactions with normal neighbors.
In this paper, we propose an iterative distributed algorithm to tackle the resilient average consensus (RAC) problem in general directed networks under the attacks by the so-called malicious agents. Such an agent is capable to send arbitrary but identical values to its neighbors at each iteration [25, 26, 19]. This is the typical way of communication in broadcast networks [27]. There are basically two types of approaches for handling the resilient consensus problem, where normal agents need to reach a common value but not necessarily the average of the initial values: (i) mean subsequence reduced (MSR) algorithms [28, 29, 19, 31, 32, 30, 33, 34, 35] and (ii) detection and isolation algorithms [37, 36]. In MSR algoirthms, agents utilize only the values in a time-varying safety interval to update their next values, with no capabilities to recognize whether a neighbor is adversarial or not. On the other hand, in detection and isolation algorithms, agents detect the neighbors violating the given consensus protocol and remove the values of such neighbors for updating their next values. This property makes the detection approach a good basis for our RAC algorithm. The reason is that the information of identities of normal agents must be known by the algorithms, which is the key to accumulate the values of normal agents for averaging.
| Algorithm 3 | [38] | [23] | [22] | |||
|
Directed | Undirected | Undirected | Directed | ||
|
Malicious | Malicious | Malicious | Byzantine | ||
|
Yes | No | No | Yes | ||
|
Two-hop | Two-hop | Two-hop | Flooding |
Our RAC algorithm is based on the detection approach and has two parts: detection and averaging. Existing related works for the RAC problem share this structure [22, 23, 38]. However, our method has certain advantages over them in different aspects as listed in Table I. More specifically, the work [22] proposed a secure broadcast and retrieval algorithm for the RAC problem in directed networks. There, each normal agent uses a certified propagation algorithm to broadcast its initial value to all agents and retrieve the initial values of normal agents for averaging. This approach would cost a huge amount of storage and time for collecting the values of all normal agents in a large-scale network. The work [23] proposed a detection and compensation algorithm for the RAC problem in undirected networks. It utilizes the two-hop neighbors’ information to detect misbehaving neighbors and it requires a doubly stochastic adjacent matrix for averaging. As a result, their algorithm is applied in undirected networks only and also cannot handle the case where malicious agents are neighboring with each other. Recently, the authors of [24] proposed an RAC algorithm for directed networks. It allows normal agents to dynamically remove or add the values received from neighbors, however, with the assumption that each normal agent can have access to a correct detection of neighbors. Then in [39, 38], the same authors proposed a detection and compensation algorithm for RAC problem in undirected networks. However, their detection requires the direct communication with two-hop neighbors and it cannot handle the case of neighboring malicious agents either.
In [36], we proposed a secure detection algorithm for resilient consensus, where each normal agent acts as a detector of its neighbors. An important feature is that it can guarantee the fully distributed detection of malicious neighbors in general directed networks. Besides, it is able to tackle the case of neighboring malicious agents. This is accomplished through the majority voting [41, 40] under a certain topology requirement on the network. In this paper, we exploit these properties and develop a novel RAC algorithm based on the two-hop detection approach.
The contributions of this paper are summarized as follows. We propose a novel RAC algorithm under which normal agents can iteratively detect malicious neighbors and converge to the average of their initial values in general directed networks. The proposed algorithm consists of the detection part and the averaging part. Specifically, for the averaging part, we employ the running-sum based algorithm from [24], where each node has local buffers to store the total effects received from its in-neighbors. It allows the normal nodes to precisely recover from the influence of malicious neighbors once any misbehavior is detected. We also improve the applicability of the averaging algorithm by relaxing the necessary assumptions in [24]. In particular, it is sufficient for normal agents to access the correct detection of only in- and out-neighbors for our RAC algorithm, which can save storage resources. Furthermore, we extend the class of misbehaviors of the malicious nodes and consider scenarios where they may go beyond manipulating their identities and also remain to act normally at all times.
For the detection part, we propose two novel algorithms which allow normal nodes to monitor their neighbors and detect as soon as malicious agents perform any misbehaviors in the messages that they broadcast. The fundamental idea is to exploit the two-hop communication so that the normal agents have access to the inputs of their neighbors. This will enable them to obtain multiple reconstructed versions of the outputs of their neighbors and then to compare them to find the true outputs. The difference between the two algorithms lies in the levels in the capabilities for the normal agents to share the detection information among themselves. The first algorithm assumes the availability of authenticated mobile detectors, which help to reduce the requirement on the network connectivity. It will be referred to as the sharing detection algorithm. Our second algorithm is more significant in that it can be implemented in a fully distributed fashion in our RAC algorithm. Here, each normal node is able to acquire all the inputs of an in-neighbor through the majority voting under a necessary graph structure. Besides, it obtains the detection information of any two-hop in-neighbor (in-neighbor’s in-neighbor) by the same approach. As a result, normal nodes can independently detect all the malicious neighbors violating the given averaging algorithm in general directed networks.
Both detection algorithms can handle the case of neighboring malicious nodes, which cannot be solved by related works for the RAC problem [23, 39, 38]. Moreover, we provide tight graph conditions for our algorithms to achieve the detection and averaging functions, respectively. We also prove that the graph condition for the fully distributed detection algorithm can be simplified for undirected networks, which makes it more convenient to check whether a graph meets the condition or not. We emphasize that although the topology requirement may be dense, we can generate the directed/undirected network topologies that satisfy our conditions in large scale. Lastly, we provide extensive examples to show the efficacy of our RAC algorithm in large-scale networks as well as in an extreme adversarial situation, where over half of the nodes in the network are compromised by malicious attackers.
The rest of this paper is organized as follows. Section II outlines preliminaries on graph notions and the problem settings. Section III presents the novel RAC algorithm with an emphasis on the averaging part. Sections IV and V present the sharing detection algorithm and the fully distributed detection algorithm, respectively. Moreover, tight graph conditions for the proposed algorithms to achieve resilient average consensus are proved. Section VI provides numerical examples to demonstrate the efficacy of the proposed algorithms. Finally, Section VII concludes the paper.
2 Preliminaries and Problem Setting
In this section, we present preliminaries on graph theory, the average consensus algorithm, and the problem settings.
2.1 Graph Notions
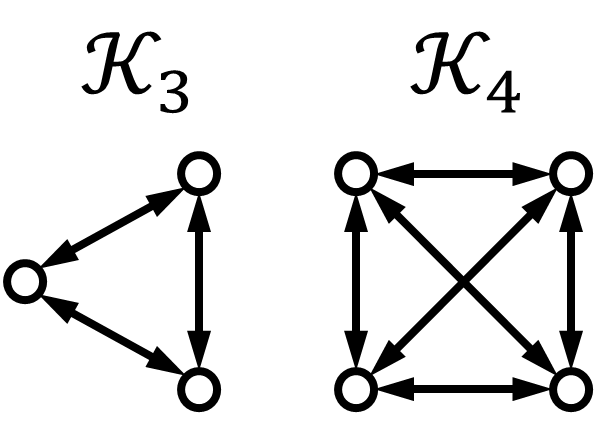
Consider the directed graph consisting of the node set and the edge set . Here, the edge indicates that node can receive information from node . Node is said to be an in-neighbor of node , and node is an out-neighbor of node . The sets of in-neighbors and out-neighbors of node are denoted by and , respectively. The in-degree and out-degree of node are given by and , respectively. Here, is the cardinality of a finite set . If the graph is undirected, the edge indicates . A complete graph is defined by . A path from node to is a sequence of distinct nodes , where for . It is also referred to as an -hop path. We say that node is reachable from node . Node is an -hop in-neighbor of node . A directed graph is said to be strongly connected111An undirected graph is simply said to be connected if every node is reachable from every other node. if every node is reachable from every other node. An undirected graph is said to be -connected if it contains at least nodes and does not contain a set of nodes whose removal disconnects the graph.
2.2 Average Consensus and the Running-sum Algorithm
The problem of multi-agent average consensus can be described as follows: Consider a system with agents interacting over the network modeled by the directed graph . Each agent has a scalar state to be updated over time . The goal is to design distributed algorithms that allow agents to eventually converge to the average value of their initial states , where each agent utilizes only the local information from their neighboring agents during the consensus forming. The push-sum ratio consensus algorithm [42] was proposed to achieve this goal through two iterative processes on each agent. Here, we describe this algorithm for the time-varying graph , where . Denote the set of out-neighbors of agent at time by and the out-degree by ; we employ similar notations for the set of in-neighbors and the in-degree .
We first introduce the push-sum algorithm, which is the basis of the running-sum algorithm. Each node has two state variables, and , and updates them as
| (1) | ||||
where and for . The algorithm requires each node to know its out-degree , and transmit to each out-neighbor the values
| (2) |
Then, by (1), these out-neighbors take the sum of received values as their new values.
At each time , node calculates the ratio
Under some joint connectivity assumptions on the union of the underlying graphs in a certain time window, it was reported in, e.g., [24] that asymptotically converges to the average of the initial values, i.e.,
| (3) |
Now, the running-sum ratio consensus algorithm is a variation of the push-sum algorithm used to overcome packet drops or unknown out degrees [11]. It can be summarized as follows. At each time , node does not send , in (2) to its out-neighbors. Instead, it sends the so-called and running sums denoted by and , respectively. The two values contain the information of and , and are defined as
| (4) |
Therefore, an out-neighbor obtains node ’s values , by taking the difference of two consecutive , as
Thus, the running-sum algorithm can achieve average consensus as the push-sum algorithm does, with additional bookkeeping procedures at each node.
Next, we formally outline the structure of the running-sum ratio consensus algorithm [11]. At each time , node maintains two kinds of values: (i) the running-sum values and of its own; and (ii) the two incoming running-sums from each in-neighbor . More specifically, node uses and to keep track of the and running sums from node , respectively. They are given as
| (5) | ||||
2.3 Update Rule and Threat Model
We now introduce the model of the adversaries and the general structure of the proposed resilient algorithm. First, the node set is partitioned into the set of normal nodes and the set of adversary nodes . The latter set is unknown to the normal nodes at time . The adversary nodes in try to prevent the normal nodes in from reaching average consensus. All algorithms in this paper are synchronous.
In our problem setting, the adversary nodes can be quite powerful. We assume that they may behave arbitrarily, deviating from the protocols with which the normal nodes are equipped. Here, we define the threat model of this paper; see also [19, 22, 36, 39].
Definition 1
(-total / -local set) The set of adversary nodes is said to be -total if it contains at most nodes, i.e., . Similarly, it is said to be -local if for any normal node , it has at most adversary in-neighbors, i.e., .
Definition 2
(Malicious nodes) An adversary node is said to be malicious if it changes its own value arbitrarily and sends the same value222It may also decide not to make a transmission at any time. This corresponds to the crash model [1]. to its neighbors at each transmission.
In this paper, we focus on the malicious model. This model is reasonable in applications such as wireless sensor networks and robotic networks, where neighbors’ information is obtained by broadcast communication or vision sensors [27]. This model is different from the Byzantine model, which is well-studied in computer science [1]. Specifically, a Byzantine node can send different values to its different neighbors. Here, we define a connectivity notion for directed graphs. A directed graph is said to be -strongly connected if after removing any set of nodes satisfying the ()-local model, the remaining digraph is strongly connected.
As mentioned in the Introduction, the proposed algorithm for resilient average consensus is based on detection of the malicious nodes in the network. To this end, each normal node is equipped with a detection algorithm to monitor the behaviors of its own neighbors. The output of such an algorithm will be the set of malicious nodes known or detected by node by time and is denoted by .
The overall structure of the proposed algorithm is as follows. At each time , each normal node forms an information set denoted by . This set will be shared with its out-neighbors, who will make use of it for their averaging and detection algorithms. The exact contents of the information sets will be given in the next subsection. Specifically, node conducts the four steps given below at time :
1. Transmit the information set (described in (6) later) and the detection information to all its out-neighbors .
2. Receive the information sets and the detection information from all in-neighbors .
3. Detect neighbors according to the detection algorithm to obtain .
4. Update according to the resilient average consensus algorithm.
2.4 Detection of Adversaries and Information Sets
We now describe the general approach for our detection algorithms, based on the ideas from [36]. As mentioned above, each normal node monitors its neighboring nodes and checks if any inconsistencies can be found in their behaviors. In particular, our approach employs two-hop communication among the nodes. That is, each node sends the information received from its direct in-neighbors to its out-neighbors together with its own information. We assume that each node receives information from its two-hop in-neighbors via a sufficient number of different paths. Then, if any of its direct in-neigbors make changes in the information to be passed on, there will be inconsistencies in the data, which can lead to detections of misbehaviors. To formalize this approach, in this subsection, we first introduce the key notion of information sets of the nodes and then provide assumptions regarding these sets for both normal and malicious nodes.
Information sets define the data exchanged within the network for performing detection and averaging. Node ’s information set to be broadcasted at time is
| (6) | ||||
It has three parts. The first is the set of adversaries detected by node by time . The second and the third are node ’s own and its in-neighbors’ information. We use the notation to indicate that this value is in the set from time . Note that and contain and , respectively, and if node is malicious, these values may be different.
Next, we introduce assumptions on the nodes’ knowledge and the attacks generated by the malicious nodes.
Assumption 1
Each node has access to the information sets received from its in-neighbors. It knows the indices and topology of its two-hop in-neighbors and those of its direct out-neighbors.
Assumption 2
Each node may have all the information of the entire network including the topology and state values of all nodes and may cooperate with other malicious nodes even if no edges exist. It can manipulate its own information set in (6) and broadcasts the same set to out-neighbors.
By Assumption 1, each normal node has only partial knowledge about the network. To perform detection based on two-hop communication, normal nodes are aware of the topology of two-hop in-neighbors. This setting may be justified in sensor networks when the nodes are geographically fixed and the network topology remain the same. Similar settings are studied in [23, 39, 38]. We should highlight that this assumption can be met relatively easily and is of low cost. In MSR-based resilient consensus algorithms [32, 19], it is sufficient that fault-free nodes have access to the information only from their one-hop neighbors. Clearly, this requirement is weaker than Assumption 1, but MSR-based algorithms are not capable to detect malicious agents (though they can avoid their influences). Also, in contrast, each fault-free node must know the topology of the entire network in related works based on observer-based detection [20], [25], multi-hop communication [1], [31], and Byzantine agreement [43].
On the other hand, in Assumption 2, since two-hop communication is employed, a malicious node may modify not only its own states but also those received from its in-neighbors, which are part of its information set. This means that there are more options in terms of attacks compared to, e.g., the MSR-based algorithms. However, we emphasize that such attacks can be detected. For example, a malicious node may add or delete some pairs of agent IDs and values in its information set. It may also decide to remove information from some of its in-neighbors. Since the normal agents have the knowledge of up to their two-hop in-neighbors, attacks will be found by their direct out-neighbors. Moreover, in the case that a malicious node adopts an ID of another node, such attacks can be detected too [36]. Therefore, our approach does not assume that each node should identify the senders of incoming messages, which is imposed in [24, 38].
3 Resilient Average Consensus
In this section, we define the RAC problem and introduce our algorithm with an emphasis on the averaging part.
3.1 Problem Statement
Consider a time-invariant directed graph . In our resilient average consensus (RAC) problem, the goal is to design distributed algorithms that allow normal agents to eventually converge to the average value of their initial states, i.e.,
| (7) |
regardless of the adversarial actions taken by the nodes in . In (7), the resilient average consensus is not defined on the true set of normal agents but on the set of all nodes that behave properly over time. This is justified for the case where an adversary node acts as normal for all times. In this case, such an adversary agent’s value is included in the average computing since there is no way to detect such adversary nodes. See Section 5.5 for more discussions.
3.2 Overview of the RAC Algorithm
To solve the RAC problem in a distributed iterative fashion, normal agents must know whether their neighbors are malicious or normal. Thereafter, they only interact with normal ones to obtain the desired average. Hence, our RAC algorithm contains two parts: (i) detection and (ii) averaging. The detection algorithm guarantees that each normal node can detect any malicious in-/out-neighbors. On the other hand, the averaging algorithm needs to ensure that each normal node can remove the erroneous effects received from malicious neighbors by the time those neighbors are detected as malicious.
In this section, we first present the averaging algorithm based on the RAC approach of [24], where each normal node is assumed to have access to the correct detection information of all normal nodes in the network. Note that the detection approach is not discussed in [24]. For ease of presentation, we assume that every normal node can obtain the correct detection of malicious neighbors by a certain time . Our detection algorithms presented later in Sections 4 and 5 are tailored for working with this averaging algorithm and realize the important function of correct detection.
Recall that in the running-sum algorithm, each agent maintains two variables and to record the sum of its own and values from the initial time. This feature makes it a good basis for our RAC algorithm. Moreover, for the running-sum algorithm to achieve average consensus, the adjacency matrix needs to be column stochastic, which is easy to realize in directed networks. In contrast, the related resilient averaging works for undirected networks [23, 38] are based on average consensus via linear iterations [2], which require the adjacency matrix to be doubly stochastic. However, it may be difficult to design such an adjacency matrix for directed networks, and even tougher for time-varying networks.
Next, we introduce the major steps of our RAC algorithm. At each time , each normal node utilizes the detection algorithm to update its detection information regarding in-/out-neighbors in . Then it updates the set of non-faulty in-neighbors as and updates the set of non-faulty out-neighbors as . Simultaneously, the out-degree is updated by . Given the new , node updates its and using only the running sums from the in-neighbors in :
| (8) | ||||
By the assumption that every normal node obtains the correct detection of malicious neighbors by time , eq. (8) constrains the averaging within only normal nodes for time . Therefore, the running-sum algorithm on normal nodes achieves ratio consensus of the values of normal agents at time if the subgraph of normal nodes (i.e., the normal network) is strongly connected. However, due to possible erroneous effects from malicious neighbors, the sum of values of normal agents at time may not be the sum of initial values of normal agents. Thus, if the erroneous effects from malicious neighbors can be subtracted by normal agents and normal agents’ values sent to malicious neighbors can be compensated precisely, then normal agents can recover the sum of their initial values and achieve resilient average consensus.
3.3 Removing Malicious Effects Based on Detection
In this part, we introduce how the normal agents conduct the subtraction of in-coming malicious values and compensation of out-going normal values, respectively. The two actions are different for the cases where in-neighbors or out-neighbors are detected as malicious for the first time. Note that the actions taken by each node are based on its own detection .
Case 1: A malicious in-neighbor is detected for the first time at time . In this case, node not only ignores node ’s values for updating as in (8) but also removes the effects received from node so far, i.e., in (5). This subtraction of in-coming malicious values has to be done for each in-neighbor in the set , which consists of node ’s in-neighbors that are detected as malicious at time . Specifically, we replace and , respectively, with
| (9) | ||||
Case 2: A malicious out-neighbor is detected for the first time at time . In this case, node not only decreases its out-degree by one () but also compensates for all its own values sent to node while was considered normal. It does so by adding to its and values its own and running sums (), respectively. Similar to Case 1, this adjustment has to be done for every out-neighbor that is detected as malicious at time . Let be the set of node ’s out-neighbors that are detected as malicious at time . Then and are updated as
| (10) | ||||
This is needed because, e.g., is the cumulative values that were sent to any malicious out-neighbor by time .
3.4 Convergence Analysis
Finally, we are ready to present our RAC algorithm in Algorithm 1. By Assumption 1, node knows the sets , . Moreover, through our detection algorithms, node keeps track of the set of misbehaving in-/out-neighbors that it detected by time . Then, by following the above two processes for malicious in-/out-neighbors, resilient average consensus can be achieved with Algorithm 1. The following proposition is the main convergence result for this algorithm from [24] with some enhanced applicability.
Proposition 1
Consider the directed network , where each node has an initial value . Under Assumptions 1 and 2, if each normal node can detect all the malicious in- and out-neighbors, and the normal network is strongly connected, then the normal nodes executing Algorithm 1 converge to the average of their initial values given by in (7) as .
Remark 1
The convergence results of this proposition have appeared in [24]; hence, we omit the proof for brevity. The key idea is to show that the sums of the and values of normal agents remain invariant at all times. Moreover, it is emphasized that we have improved the results for the averaging algorithm by relaxing the required assumptions as well as justifying the case where adversary agents act normally at all times. Specifically, the results in [24] need the assumption that each transmission of any node is associated with a unique node ID that allows the receiver to identify the sender. In contrast, we have discussed in Section 2.4 that we do not assume that each malicious node must send its real ID as the misbehavior of changing ID can be detected by our algorithms. Besides, the work [24] requires the assumption that each normal node knows the correct detection information of all normal nodes in the network after time . However, each normal node is supposed to detect only the malicious in- and out-neighbors in Proposition 1, which can save storage resources. We will show later that such detection can be realized through our fully distributed detection algorithm.
In the following sections, we present two detection algorithms for our RAC algorithm, which are redesigned based on the two-hop detection approach in our previous work [36]. In Section 4, we propose the sharing detection algorithm for undirected networks. In Section 5, we present the fully distributed detection algorithm for general directed networks. The latter algorithm is fully distributed and is efficient in storage usage compared to the related works [22, 24, 38], where each normal agent must obtain the correct detection of all malicious or normal agents in the network.
4 Sharing Detection in Undirected Networks
We introduce our first distributed detection algorithm to be presented as Algorithm 2, where the normal nodes are capable to detect malicious neighbors by using the two-hop information in undirected networks. It provides the basis for the two-hop detection in an adversarial environment, motivated by the works [37, 36].
4.1 Detection Algorithm Design
For this algorithm, the sharing detection function below is needed for the communication among the nodes when events of detecting adversaries occur.
Assumption 3
Once a malicious node is detected by any normal node at any time step, its ID will be securely notified to all nodes within the same time step.
This assumption also appeared in [37, 36] for resilient consensus. As we reported in [36], the sharing detection function can be realized by introducing fault-free mobile nodes which are appropriately distributed throughout the network and are capable to immediately verify if the detection reports from a node is true or false. Note that the deployment of such mobile agents is only for verification of detection reports instead of detecting malicious agents by themselves.
The sharing function is crucial for Algorithm 2 since it is necessary for detecting malicious nodes that are neighboring and cooperating with each other. We must emphasize that if we do not have this function for Algorithm 2, it can only handle the case where no neighboring malicious nodes exist (i.e., any malicious node is surrounded by normal nodes only). This is exactly the case studied in related works [23, 39, 38].
We now present Algorithm 2. To ensure that all nodes follow the correct averaging in Algorithm 1, the normal nodes check consistency among the neighbors’ information sets. In Algorithm 2, step 1 is to guarantee that each normal node should not use the values from the nodes detected as malicious already. Moreover, it ensures that a node does not falsely claim another node being malicious. Step 2 is to prevent the malicious nodes from faking any neighbors. Step 3 is to enforce the normal nodes not to modify the values received from their neighbors. Finally, step 4 is to guarantee that the neighbors follow the averaging in Algorithm 1.
4.2 Necessary Graph Structure for Algorithm 2
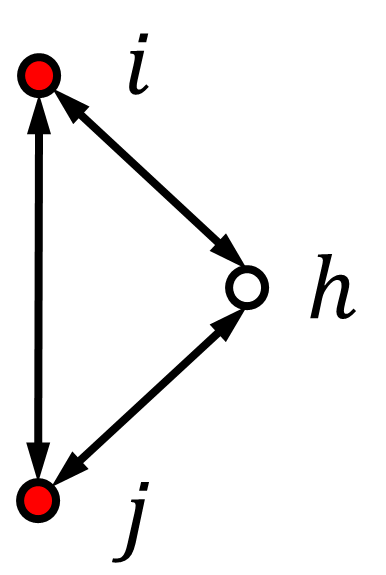
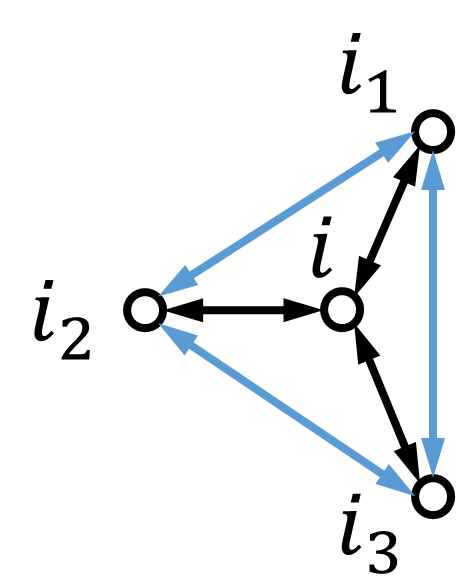
In this part, we provide the necessary graph condition for Algorithm 2. We can observe that a malicious node can be detected if there is at least one normal node among its neighbors that monitors its behavior. However, such detection may fail if neighboring malicious nodes cooperate with each other. Hence, it is critical that one or more normal nodes are present as their common neighbors. We illustrate this graph structure in Fig. 1(a). Here, nodes and are malicious. They can cooperate as follows: Node manipulates in its information set, and node manipulates in its information set. If there is no normal node having access to the information sets of both nodes and , such an attack will not be detected. In contrast, the detection works if there is a common neighbor of nodes and .
Next, we state the necessary and sufficient graph condition for Algorithm 2 to detect all the misbehaving agents.
Lemma 1
Consider the undirected graph . Algorithm 2 detects every pair of neighboring misbehaving nodes if and only if they have at least one normal common neighbor.
Proof 4.1.
We can show similarly to Lemma 8 in [36] except that the update check in step 4 in Algorithm 2 is more complex than the general consensus protocol used there. Here, we provide a sketch of the proof. In the undirected network using Algorithm 2, each normal node can at least verify its own values and in , . If a malicious node is only surrounded by normal agents, then it cannot change any and values from neighbors. Moreover, normal neighbor can reconstruct or through the averaging part in Algorithm 1 to check if node is following the averaging or not. Thus, misbehaving node will be detected by all normal neighbors. In the case of neighboring malicious nodes, they can modify the values from each other, but this is also detected by the normal common neighbor of them as discussed before.
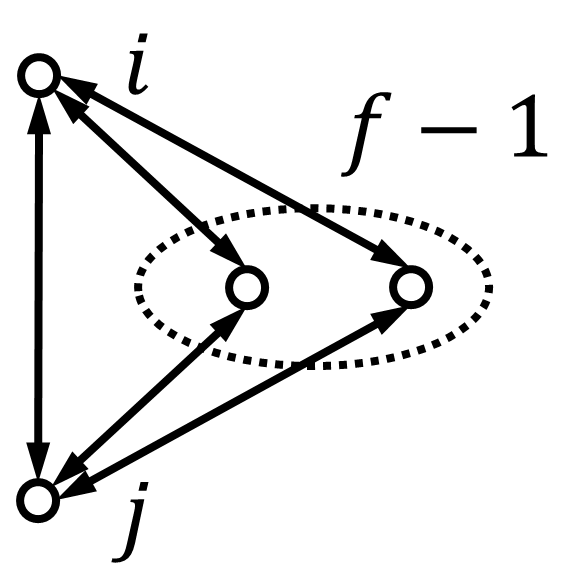
Given that the malicious nodes are unknown and possibly cooperate with each other to launch attacks, we should impose a connectivity requirement so that the condition in Lemma 1 holds for any possible combination of pairs of neighboring malicious nodes in the network. The following proposition is the main result of this section.
Proposition 4.2.
Consider the undirected network under the -total malicious model. Suppose that Assumptions 1, 2, and 3 hold. Then, for Algorithm 1 with Detection Algorithm 2, the following hold:
(a) All malicious nodes that behave against the averaging in Algorithm 1 are detected if and only if for every pair of neighboring nodes, they have at least common neighbors.
(b) Under the condition of (a), normal nodes achieve resilient average consensus if is ()-connected.
We proved in [36] that under the -total model, the graph condition in Lemma 1 is equivalent to condition (a) in Proposition 4.2. Moreover, condition (b) in Proposition 4.2 guarantees that the normal network is connected. Thus, normal nodes using Algorithm 1 with Detection Algorithm 2 can achieve resilient average consensus as we proved in Proposition 1.
As we will further explain in Section 6.2, the graph condition for Algorithm 2 does not require dense graph structures. However, this feature is achieved at the cost of additional authentication from the secure mobile agents.
5 Fully Distributed Detection in Directed Networks
In this section, we present our second distributed detection algorithm as Algorithm 3. It is fully distributed and operates without outside authentication for resilient average consensus in general directed networks. This important feature is realized through majority voting [41, 40] and requiring a denser graph structure. Moreover, we prove a necessary and sufficient graph condition for Algorithm 3 to properly function.
5.1 Detection Algorithm Design
In the last section, we have seen that node ’s information set consists of two parts that need to be investigated by its out-neighbors: (i) the current value () to check if it is updated according to Algorithm 1; (ii) the past values () used as inputs for updates to check if they are equal to the true values of the corresponding nodes. In Algorithm 2, normal node can check whether part of the past values are manipulated in the information sets of its neighbors. More specifically, node knows the true past values of its direct neighbors. Then, using the sharing detection function, node can report a malicious node (or a pair of neighboring malicious nodes) if any values known by itself are manipulated.
However, to achieve fully distributed detection without any outside authentication, node should be able to independently verify whether any entries of the past values are manipulated in the information sets of its in-neighbors. We have seen that node can directly obtain the original value and the detection information of an in-neighbor . For other values that node cannot directly obtain, we impose a certain graph structure so that it can access the original value and the detection information of a two-hop in-neighbor through majority voting. Specifically, if node receives values of node , among the values, if more than values are the same, then node will take it as the true value of node . In computer science, such redundancy schemes are common strategies to enhance the security and reliability of systems [41, 40].
Next, we formally introduce the notion of detectable nodes to indicate the kind of nodes that can be detected by node using Algorithm 3.
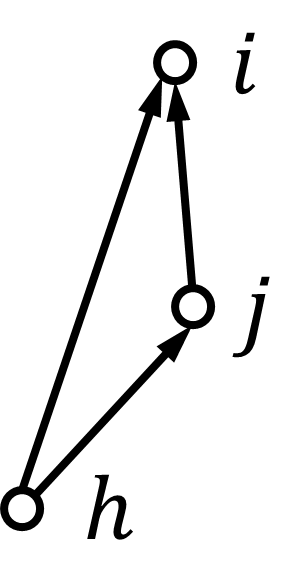
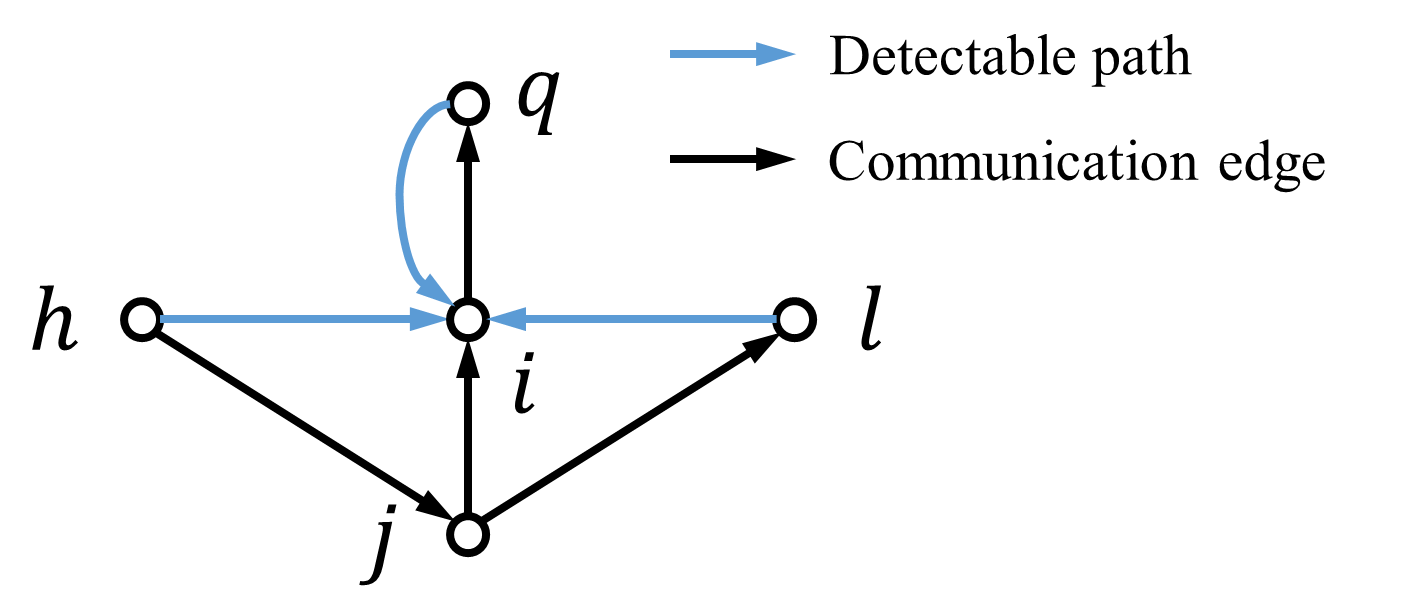
Definition 5.3.
In the directed graph under the -local malicious model, node is said to be detectable by node if one of the following conditions holds:
-
•
;
-
•
there are at least two-hop paths from to .
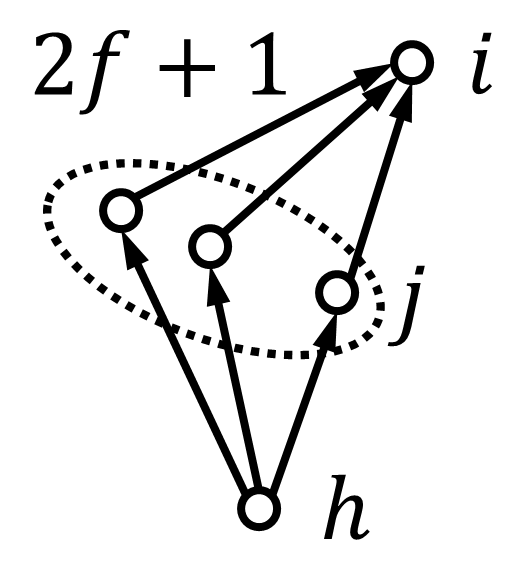
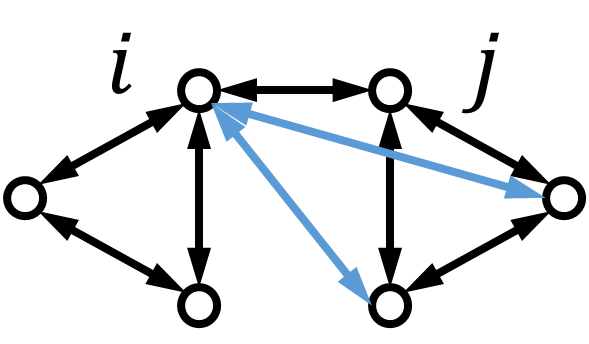
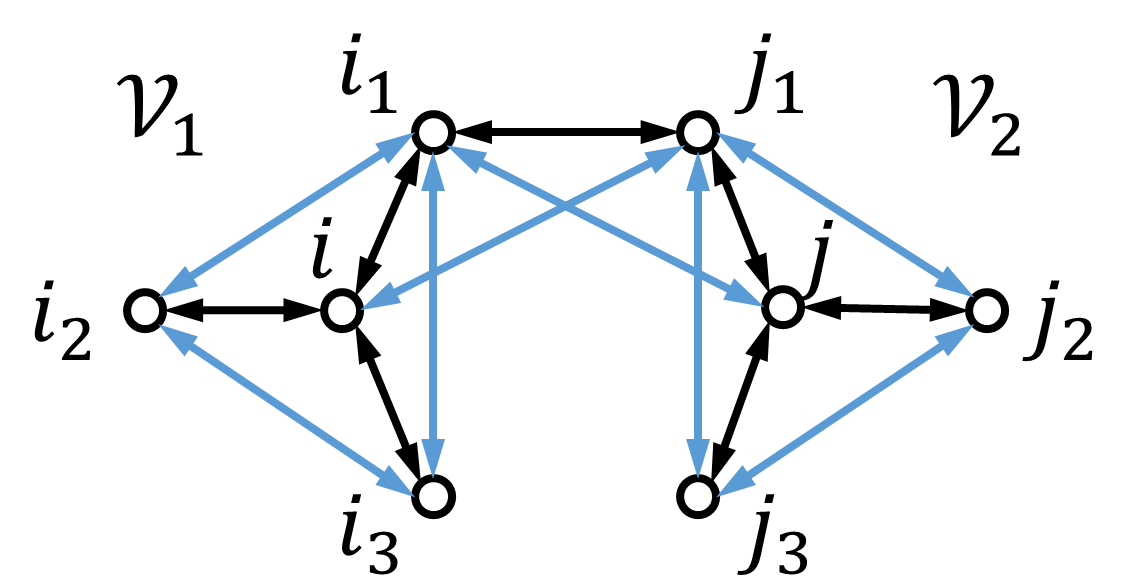
We illustrate the above graph condition in Fig. 2. Here, we also say that there is a detectable path from node to node if node is detectable by node . To achieve fully distributed detection, we need to impose a certain graph structure so that each node can have access to the necessary information used in its neighbors’ updates (see Fig. 3). We introduce the graph condition for Algorithm 3 as follows.
Assumption 4
A directed graph under the -local malicious model satisfies all the following conditions for :
-
1.
any two-hop in-neighbor is detectable by ;
-
2.
any out-neighbor is detectable by ;
-
3.
any out-neighbor of in-neighbor is detectable by .
We will refer to conditions 1)–3) together as the graph condition for Algorithm 3.
Although the above graph condition may require a locally dense graph structure, such a graph does not necessarily have a small diameter. This means that the path length of the shortest path between any two nodes may not be small. In fact, we can construct graphs satisfying the conditions in large scales. See the examples in Section 5.4.
We now present Algorithm 3. Each normal node performs majority voting on two things: the nodes’ values and the detection information. Since we consider the -local model in this section, if node receives the same information from at least distinct in-neighbors, it considers this information trustable. Additionally, node keeps a local set (only accessible to ) for the detection of two-hop in-neighbors as at time . After obtaining the true values of its one-hop in-neighbors and two-hop in-neighbors , it follows similar procedures as the ones in Algorithm 2.
5.2 Necessary Graph Structure for Algorithm 3
In Algorithm 3, we must impose the connectivity requirement in Assumption 4 on every node and its in-/out-neighbors. This enables the detection to be guaranteed for any combination of nodes being malicious in the network. The following theorem is the main result of this section.
Theorem 5.4.
Consider the directed network under the -local malicious model. Suppose that Assumptions 1 and 2 hold. Then, for Algorithm 1 with Detection Algorithm 3, the following hold:
(a) Each normal node detects all malicious nodes in its out-neighbors and in-neighbors within two hops that behave against the averaging in Algorithm 1 if and only if satisfies the condition for Algorithm 3 (in Assumption 4).
(b) Under the condition of (a), normal nodes achieve resilient average consensus if is -strongly connected.
Proof 5.5.
(a) Necessity: We prove condition 1) by contradiction; conditions 2) and 3) follow by a similar proof. Suppose that there is a node with , and that there are at most two-hop paths from node to node including the path containing node . Suppose that node is malicious and there are malicious middle nodes in the paths from to (by the assumption of the -local model). Then, in the worst case, node could get copies of the true value of from the normal middle nodes. In the mean time, node also gets copies of an identical false value of from the malicious middle nodes (including ). Thus, node cannot get majority regarding the true value of . Thus, it cannot detect node ’s manipulation on in .
Sufficiency: By Definition 5.3, if an out-neighbor of node is detectable by node , then node becomes a direct in-neighbor or a two-hop in-neighbor of . Therefore, the detection of node is the same as the detection of node or below.
We must show that node can confirm the true value of every entry of the information set of in-neighbor by three major steps at time . See the illustration in Fig. 3. First, it can obtain the true values , of every neighbor (i.e., ’s two-hop in-neighbor ) from the previous time . Second, node can obtain the correct detection of before the detection loop at time . Moreover, node can obtain the correct detection of ’s out-neighbor depending on the corresponding case ( can be a two-hop in-neighbor or a direct in-neighbor of by condition 3) in Assumption 4). Then we can prove that node will detect node at time if node sends out faulty .
Depending on how the detectable path is formed, consider two cases for node : (i) nodes and are direct in-neighbors of ; (ii) nodes and are two-hop in-neighbors of .
(i) In the case where , it is clear that node can receive the true values and from . Moreover, it can have the correct detection of its direct in-neighbors and before time .
(ii) Suppose that , and there are at least two-hop paths from to . In this case, there is some normal node which carries the true values and in its information set . Then, node can get the true values and since the majority of the paths from to contain nodes as by the -local model.
For node to obtain the correct detection of two-hop in-neighbors and , it follows a similar analysis. We look at the case for . If transmits faulty , then it is detected by its one-hop neighbors at time . Recall that there are at least directed two-hop paths from to . Thus, under the -local model, node can obtain the correct detection of by majority voting before the detection loop of time .
Therefore, node knows the true values , and obtains the correct detection of its two-hop in-neighbors , before running the detection loop at time . Thus if node sends out faulty by possible manipulation including modifying and/or in , or by sending false detection information of nodes and , then node will detect. Note that when out-neighbor is a two-hop in-neighbor of , the detection of is included in and is sent to node in . Therefore, step 1b in Algorithm 3 is designed to handle this case. This procedure will not cause problems since the removal of malicious neighbors can be asynchronous at each normal agent.
Next, we show that node can verify if node updates and in by the averaging in Algorithm 1 or not. This is done by reconstructing and and checking whether , where
As shown above, node can verify in . Thus,
where , , , are from with . Moreover, and are obtained by node through
We also note that node has access to the true values and . Besides, node knows and from . Otherwise, node would have been detected at time . Thus, we have
where and for . Then node can compare (and ) in with (and ) and checks if node follows the averaging in Algorithm 1 or not.
(b) A malicious node will be detected immediately once it manipulates its information set. Thus, misbehavior of any malicious node cannot affect normal nodes since normal nodes exclude values from detected malicious nodes in Algorithm 1. Moreover, since is -strongly connected, the normal network is strongly connected after removing the -local adversary node set. Therefore, resilient average consensus is achieved as shown in Proposition 1.
Here, we show that the graph satisfying the condition for Algorithm 3 has the minimum in-degree as . It indicates that we need to make the minimum in-degree no less than when we design a desirable network topology. Conversely, it is straightforward that a graph with minimum in-degree less than does not meet our condition. We formally state the property in the next lemma for general strongly connected digraphs since strong connectivity is necessary for achieving average consensus in directed graphs [11]. Moreover, we can confirm that a complete graph satisfies the condition for Algorithm 3. To avoid trivial cases, we consider in the following discussions.
Lemma 5.6.
If a strongly connected and incomplete digraph (under the -local model) satisfies the condition for Algorithm 3 in Assumption 4, then has the minimum in-degree no less than .
The proof of Lemma 5.6 can be found in the Appendix.
We note that the detection condition (a) for Algorithm 3 is not sufficient to guarantee strong connectivity of the graph. A simple counter example is a graph with two disconnected complete subgraphs. Clearly, the whole graph is not connected while it meets the detection condition for Algorithm 3. This observation reveals that the consensus condition (b) guaranteeing the normal network to be strongly connected is also critical for our RAC algorithm.
5.3 Graph Condition in Undirected Networks
For the special case of undirected networks, the condition for Algorithm 3 can be simplified as follows.
Lemma 5.7.
An undirected graph satisfies the condition for Algorithm 3 in Assumption 4 if for each node , it holds that any two-hop in-neighbor of node is detectable by node .
Proof 5.8.
We can easily observe that condition 2) in Assumption 4 is satisfied automatically in undirected networks. Moreover, it holds that an out-neighbor of node ’s in-neighbor is a two-hop in-neighbor of node in undirected networks. Therefore, condition 3) can be derived if condition 1) holds in an undirected network.
Next, we show that for undirected networks, the condition for Algorithm 3 and connectivity of the graph together guarantee that the normal network is connected after removing the -local malicious node set.
Proposition 5.9.
Consider the undirected graph under the -local model. If (i) is connected and (ii) for any node , it holds that any two-hop in-neighbor of node is detectable by node , then the normal network induced by the normal agents in is connected.
The proof of Proposition 5.9 can be found in the Appendix.
We can see from the above two results that both the detection condition (a) and consensus condition (b) for undirected networks are simplified compared to the conditions in Theorem 5.4 for directed networks. We formally state the conditions for undirected networks as follows, which can be proved by Lemma 5.7 and Proposition 5.9.
Theorem 5.10.
Consider the undirected network under the -local malicious model. Suppose that Assumptions 1 and 2 hold. Then, for Algorithm 1 with Detection Algorithm 3, the following hold:
(a) Each normal node detects all malicious neighbors within two hops that behave against the averaging in Algorithm 1 if and only if for any node , it holds that any two-hop neighbor of node is detectable by node .
(b) Under the condition of (a), normal nodes achieve resilient average consensus if is connected.
5.4 Construction of Graphs Satisfying the Condition
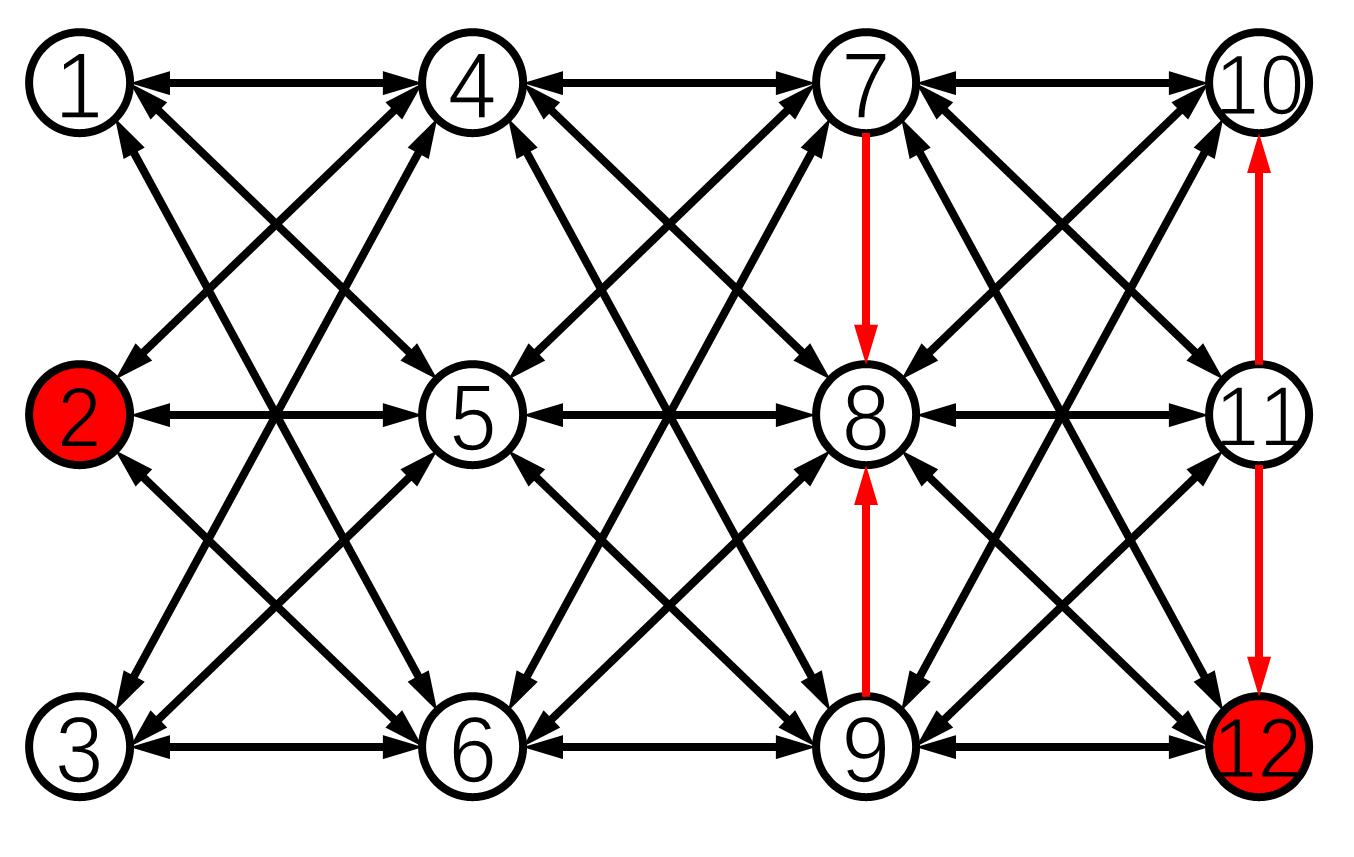
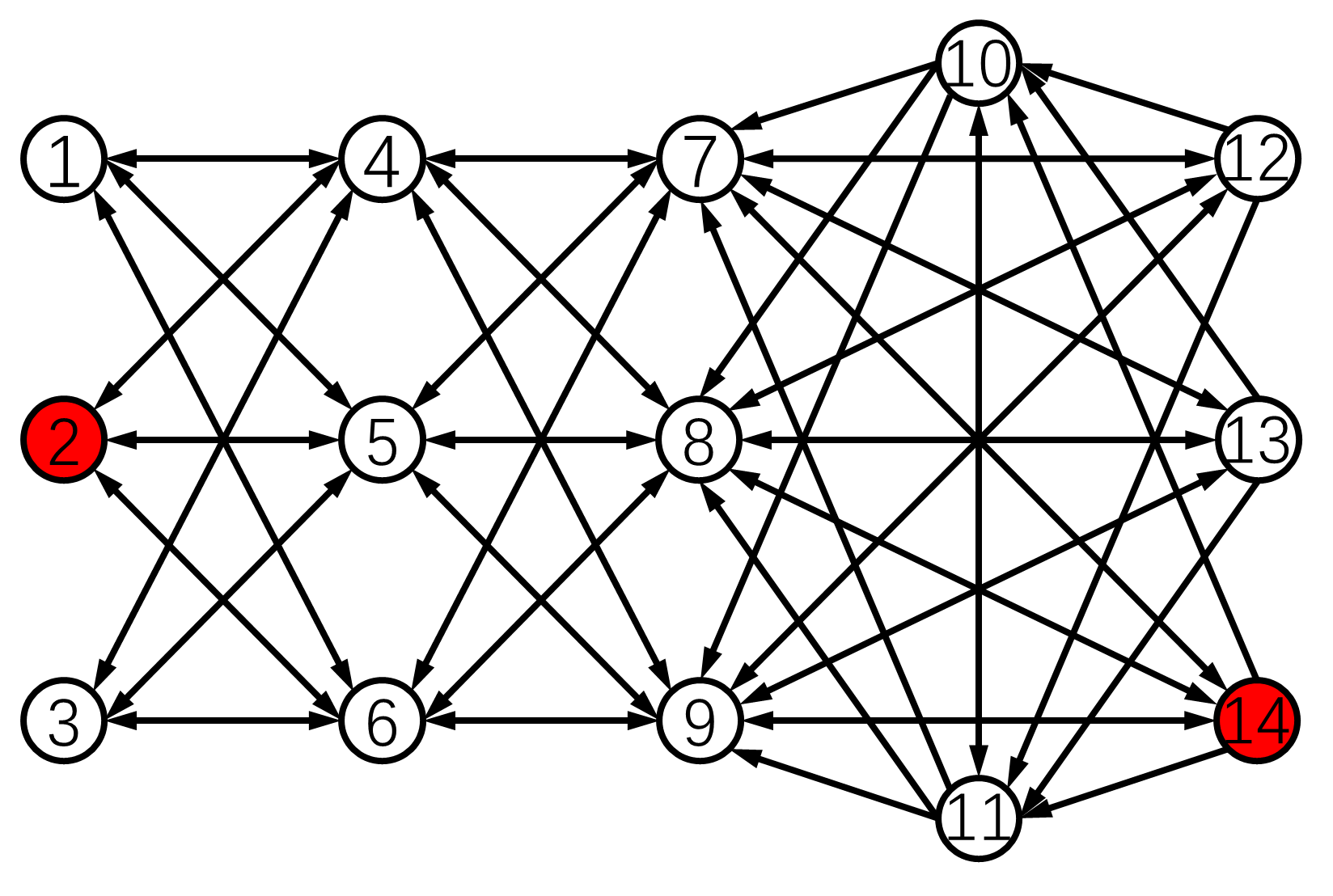
In this part, we present some example graphs satisfying the conditions for our algorithms. Furthermore, we present a systematic way to construct large-scale graphs that meet the condition for Algorithm 3.
We first give example graphs satisfying the conditions in Theorem 5.4. The network in Fig. 4(a) satisfies the conditions for Algorithm 3 under the -local model. Moreover, there is a characteristic four-layer structure. We can extend this idea to the cases with any . Each layer should have nodes for the -local model. Each node in one layer should be connected with every node in the neighbor layers and have no connection with the nodes in its own layer. This structure can also have many layers as long as the -local set is met for . A similar way for constructing large-scale directed networks for Algorithm 3 is presented in Fig. 4(b). From these examples, we can conclude that the unbalanced directed graphs can also meet the condition for Algorithm 3. Simulations of Algorithm 3 in these networks will be given in Section 6.
Node is said to be a full access node if it is an out-neighbor of all other nodes in the network [36]. Notice that such a node can detect any malicious node in the network. We can enhance the performance of Algorithm 3 (and Algorithm 2) by incorporating nodes with such characteristics. However, we emphasize that we do not assume such full access nodes to be normal. As long as the conditions for Algorithm 3 (or Algorithm 2) are met, a full access node can also be detected by its normal neighbors when it misbehaves. This result can be easily proved by Theorem 5.4 and is given as follows.
Corollary 5.11.
A normal full access node using Algorithm 3 (or Algorithm 2) detects any node behaving against the averaging in Algorithm 1 in the network.
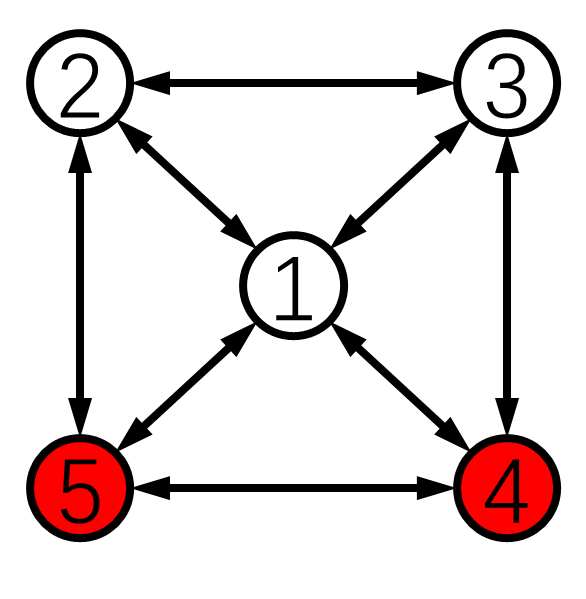
As an example, the 5-node undirected network in Fig. 5(a) could tolerate two malicious nodes when the conditions for -local are met except for the full access node 1. In the same graph, if only node 1 becomes malicious and the conditions for -local are also met for other nodes, then RAC is still guaranteed. As another example, in the 8-node directed network in Fig. 8, normal nodes using Algorithm 1 with Detection Algorithm 3 can achieve resilient average consensus even in the presence of 5 malicious nodes. More details are discussed in the numerical examples.
The following corollary states the maximum tolerable number of malicious nodes in a network applying our algorithms. It can be directly proved from Theorem 5.4.
Corollary 5.12.
In the complete graph , normal nodes using Algorithm 1 with Algorithm 3 (or Algorithm 2) achieve resilient average consensus in the presence of malicious nodes in the network.
Remark 5.13.
From above, we see that it is relatively easy to check whether a graph meets the condition in Assumption 4 since there is no combinatorial process in the checking. In particular, the verification of the detectable condition in Definition 5.3 is very simple. Further, the checking on the condition in Assumption 4 requires less than times of such verification (usually much less for sparse graphs). In contrast, the verification of robustness of a graph in resilient consensus works (e.g., [19, 32, 35]) involves combinatorial processes and is computationally NP-hard. Moreover, we have proved a much simpler condition for undirected networks using our algorithm, which is suitable for the deployment in large-scale networks. Besides, the proposed systematic way for constructing the desirable large-scale graphs can also facilitate the deployment of our algorithm in various applications.
5.5 Discussions and Comparisons with Related Works
We discuss the differences between the resilient consensus (RC) algorithm from [36] and RAC Algorithm 3 for directed networks. In [36], normal nodes achieve resilient consensus by monitoring their in-neighbors. However, the situation becomes much more complex for Algorithm 3. Aside from the detection of in-neighbors, node should also be able to detect each out-neighbor. This is because for solving the RAC problem, node should not send its and values to the malicious out-neighbor(s) so that the normal network can accurately preserve the “mass” of normal nodes only and achieve averaging as shown in Theorem 5.4. The detection condition for Algorithm 3 hence requires denser graphs than the one for the RC algorithm [36]. Moreover, notice that the necessary condition for resilient average consensus is the strong connectivity of the graph. It requires each node to have at least one out-going edge. In contrast, the necessary condition for resilient consensus is that there is at least one rooted spanning tree in the graph. Therefore, the necessary condition for Algorithm 3 is stricter than the one for the RC algorithm [36].
The recent work [22] proposed a certified propagation algorithm (CPA)-type broadcast and retrieval approach for the RAC problem. There, each normal node broadcasts its initial value to all the nodes in the network through relaying by neighbors (i.e., the flooding technique). Then, the normal node confirms another node’s initial value if it receives more than copies of the value of the same node, which is similar to the CPA approach [44]. Lastly, the normal node converges to the average of values from the nodes which it has confirmed.
We must note that this kind of approaches for each node to verify and store the initial values of all the normal agents become infeasible in large-scale networks, as it consumes intensive storage and computation for each single node to monitor the whole network. Compared to these approaches, our iterative detection algorithm is more efficient, especially in large-scale networks. Specifically, the storage needed on each node for our algorithm is modest as each node stores only local information of its in-neighbors within two hops.
It is challenging for our algorithms, as well as any other algorithms [21, 20, 37, 39] to identify adversarial nodes that adopt extreme initial values but behave according to the proposed algorithms as if they were normal nodes. Clearly, such nodes are indistinguishable from normal nodes with extreme initial values. To mitigate the impact of such adversary nodes, we can set a safety interval (recall that ) for normal nodes so that neighbors taking initial values outside this interval are considered malicious [36].
We conduct some comparisons between Algorithms 2 and 3 for the case of undirected networks. Recall that Algorithm 2 is for the -total model while Algorithm 3 is for the -local model. We first note that the -local model contains the -total model and is more adversarial in the sense that more than malicious agents in total may be in the entire network under the -local model. The reason is that if the graph condition for Algorithm 2 is satisfied under the -local model, then it cannot guarantee that there is a normal neighbor of any pair of adjacent malicious nodes (Lemma 1). Here is a simple counter example. Consider the 5-node network in Fig. 5(a) with malicious node set . It satisfies the common neighbors condition for Algorithm 2 under the -local model. Yet, it does not meet the condition in Lemma 1. However, we must note that this phenomenon is not in presence for Algorithm 3 since the condition in Theorem 5.10 has required the necessary condition for each node to independently detect the malicious neighbors.
6 Numerical Examples
We present numerical examples to verify the efficacy of RAC Algorithm 1 with Detection Algorithms 2 and 3.
6.1 Simulations with Directed Networks
In this part, we provide the simulations of Algorithm 3 in three directed networks of different scales.
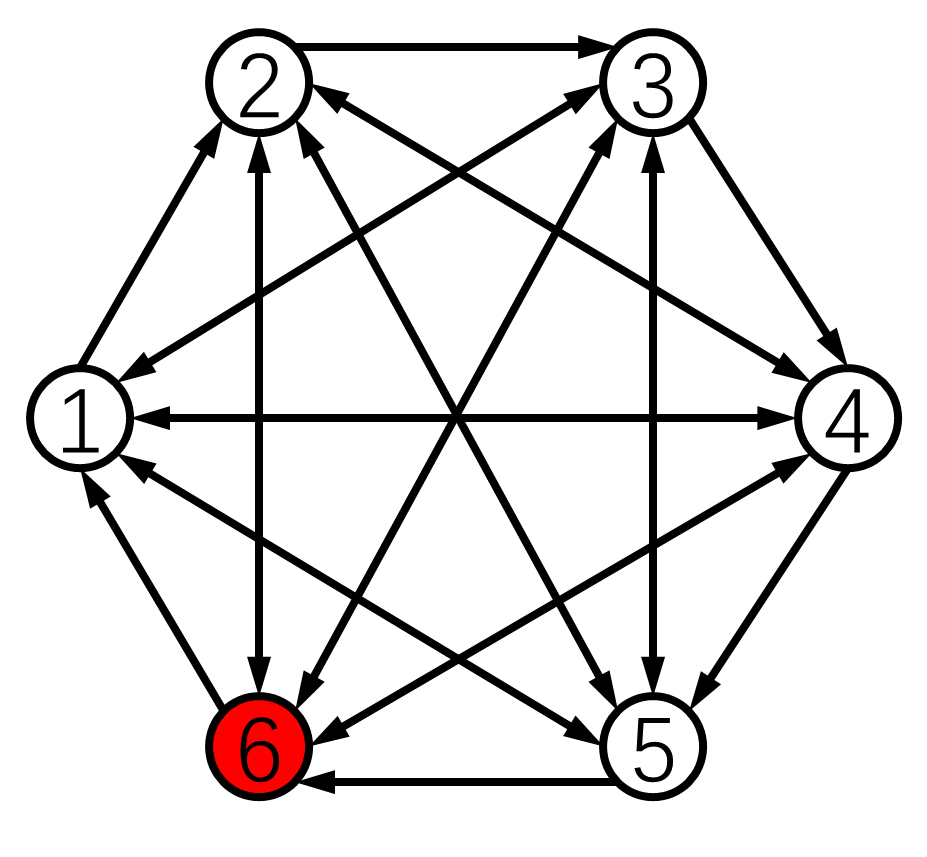
1) Small Directed Network: Consider the 6-node network in Fig. 5(b). It meets the graph condition (Assumption 4) for Algorithm 3 under the 1-local model. Moreover, it is 2-strongly connected (i.e., the remaining graph is strongly connected after the removal of the 1-local malicious node set). Hence, it meets the requirements in Theorem 5.4.
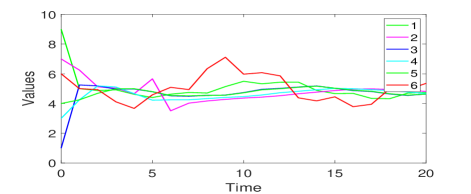
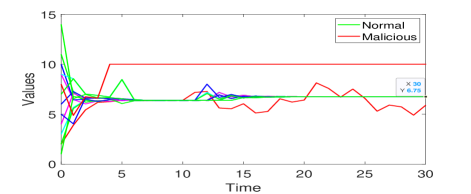
Set the initial values and the adversary node set . Malicious node 6 is indicated in red in Fig. 5(b). First, we show that the detection condition for Algorithm 3 is critical for the success of our RAC algorithm. Suppose that three undirected edges , , and are removed from the network, i.e., the condition for Algorithm 3 is not satisfied. The simulation under attacks for the above case with less edges is displayed in Fig. 6(a). Until time , malicious node 6 follows the averaging in Algorithm 1 to avoid being detected. Then it manipulates its values through changing the past values of node 2 while not manipulating other entries of its information set. We can see in Fig. 6(a) that resilient average consensus is not achieved by Algorithm 3 with less edges. This is because only nodes 2 and 4 can detect the above misbehavior of node 6. Normal nodes 1, 3 and 5 are misled by node 6 due to the lack of necessary graph structure to obtain the correct value of node 2.
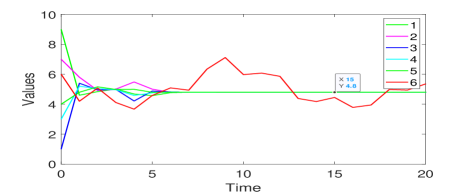
Next, we apply Algorithm 3 in the 6-node network as presented in Fig. 5(b), where the condition for Algorithm 3 is met. Consider the same initial states and the same attacks for the network. The simulation result is presented in Fig. 6(b). Malicious node 6 launches attacks as before, however, this misbehavior is soon detected by its normal out-neighbors. The normal nodes then compensate the erroneous effects received from node 6 and start to form consensus among normal neighbors only. Lastly, the normal nodes are able to reach the average of their initial values , and resilient average consensus is reached using Algorithm 3.
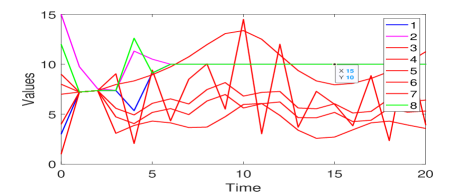
2) Medium-scale Directed Network: Next, consider the 14-node network in Fig. 4(b) constructed using the method in Section 5.4. It satisfies the condition for Algorithm 3 under the 1-local model and is 2-strongly connected.
Let the initial values and in Fig. 4(b). The time responses of nodes under no attack are shown in Fig. 7(a), where all nodes using Algorithm 3 reach the average of their initial values . Here, the lines not in red represent the values of normal nodes. Then, the time responses of nodes under attacks are displayed in Fig. 7(b). There, until time , malicious nodes 2 and 14 pretend to be normal by following the averaging. Then node 14 changes its own value to a fixed value and is detected by its normal out-neighbors at the next time step. In the meantime, node 2 keeps concealing itself. At time , node 2 and normal nodes almost reach the average of their initial values (around 6.385). However, node 2 starts to manipulate its value through changing the past values of its in-neighbors in its information set. Such an attack is also quickly detected and normal nodes remove the effects received from node 2 until then. Finally, the normal nodes reach the average of their initial values , and resilient average consensus is attained. Moreover, the convergence of Algorithm 3 is quick even in the presence of malicious attacks.
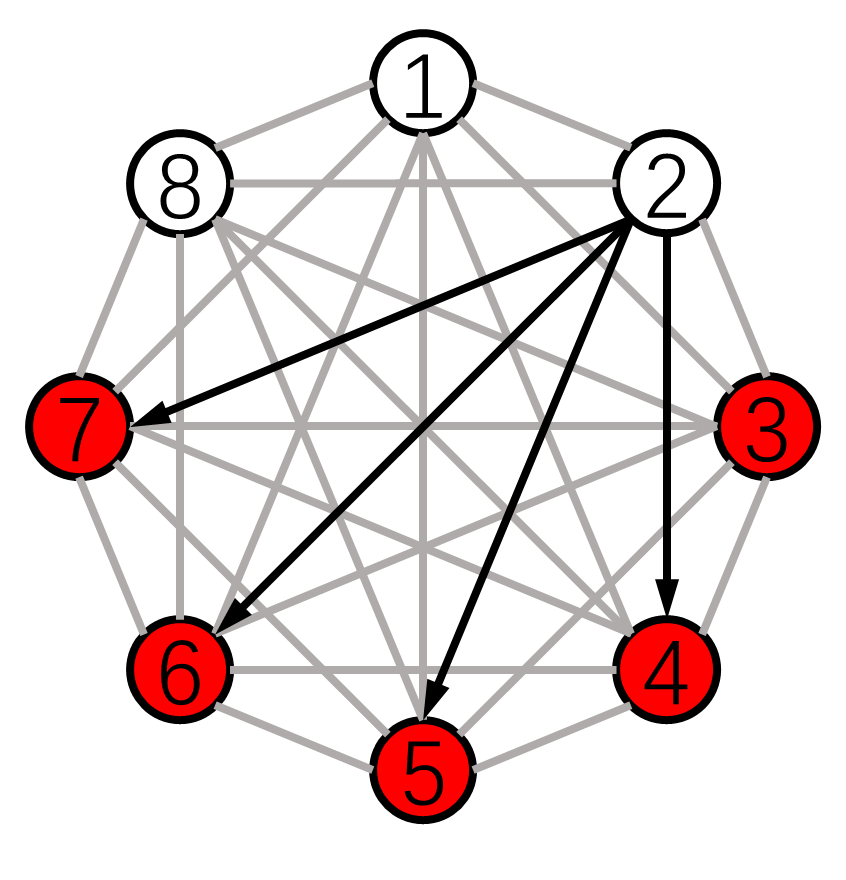
3) Over Half of the Nodes Turn Malicious: We conduct the simulation of Algorithm 3 under an extremely adversarial case, where over half of the nodes in the network turn malicious. Consider the 8-node network in Fig. 8 with . It is almost complete except that there are 4 directed edges from node 2. Moreover, it satisfies the condition for Algorithm 3 under the 1-local model for non-full access node 2.
Set the initial values . The simulation result is presented in Fig. 9. All malicious nodes simultaneously launch attacks at time by manipulating their values arbitrarily. However, these attacks are soon detected. In Fig. 9, the normal nodes eventually reach the average of their initial values . Therefore, we can conclude that resilient average consensus is still guaranteed using Algorithm 3 despite the erroneous effects from 5 malicious nodes.
6.2 Simulations with Large-scale Undirected Networks
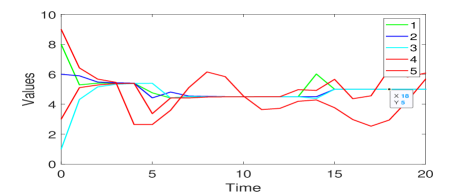
1) Simulation of Algorithm 2: Here, we show the effectiveness of Algorithm 2 by conducting a simulation in the 5-node undirected network in Fig. 5(a) with initial states . It is 3-connected and with at least one common neighbor for every pair of neighbors. Given these properties, Proposition 4.2 indicates that resilient average consensus can be achieved using Algorithm 2 under the 2-total malicious model. Let the adversary set . The simulation result under attacks is shown in Fig. 10. Malicious node 5 first attacks other agents by transmitting arbitrary values at time and it is soon detected by its normal neighbors. At time , nodes 1, 2, 3 and 4 almost reach the average of their initial values (i.e., 4.5). However, node 4 starts to manipulate its own value. Such an attack is also quickly detected. Then the normal nodes reach the average of their initial values .
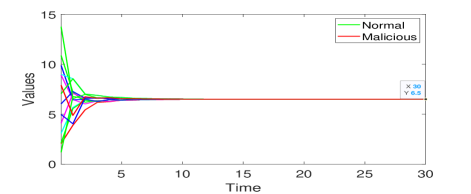
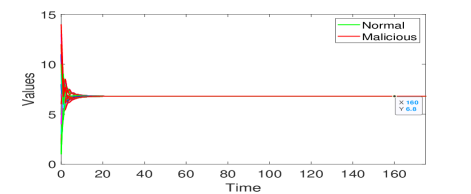
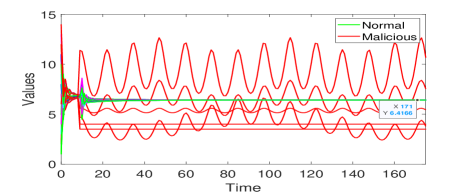
2) Simulation of Algorithm 3: In this part, we carry out the simulation of Algorithm 3 in a large-scale network, which is constructed by the method proposed in Section 5.4. Specifically, we consider the 30-node network in Fig. 11. It has a 10-layer structure satisfying the condition for Algorithm 3 under the 1-local model. The malicious nodes are indicated in red with .

Let the initial values . The simulation results of Algorithm 3 without and with attacks are shown in Figs. 12(a) and (b), respectively. One can see in Fig. 12(a) that all nodes achieve average consensus using Algorithm 3 although the convergence is slow due to the large network size. As for the results of nodes under attacks, it shows in Fig. 12(b) that at time , all the 6 malicious nodes start to manipulate their values through cooperating with their malicious neighbors and changing the past values of each other in their information sets. Such attacks are soon detected by their normal neighbors. Thereafter, the normal nodes reach the average of their initial values . The RAC problem is solved by Algorithm 3 in the presence of 6 malicious nodes. Note that Algorithm 3 can still guarantee resilient average consensus if any one of the nodes become malicious in each one of the 6 layers containing malicious nodes currently. This is because the malicious nodes also satisfy the 1-local model in this case. We finally emphasize that none of the methods in [23, 38, 39] can handle the above case of neighboring malicious nodes.
7 Conclusion
In this paper, we have investigated the problem of resilient average consensus in the presence of adversaries. We have proposed a distributed iterative detection and averaging algorithm for normal agents to achieve resilient average consensus in general directed topologies. For the detection part, we have proposed two distributed algorithms and the second one can achieve fully distributed detection of malicious agents. For the averaging part, it can precisely preserve the sum of the initial values of normal agents. Moreover, we have fully characterized the network requirement for the algorithms to successfully achieve resilient average consensus. Compared to the existing detection approaches, our method is the only one that can handle the case of neighboring malicious agents. Besides, we have solved the resilient average consensus in directed networks, whereas the existing detection approaches studied undirected networks only. Moreover, in comparison with the existing secure broadcast and retrieval approach [22], our algorithm can save storage as each agent keeps only the values of two-hop neighbors. In the end, we have provided extensive numerical examples to show the effectiveness of the proposed algorithms.
In future works, we are interested in applying our algorithms to various applications of average consensus where security needs to be enhanced, e.g., the economic dispatch problem and the PageRank problem.
Appendix
Proof of Lemma 5.6
Proof 7.14.
The proof is shown in two stages. First, we show that the clique structure (see the examples in Fig. 13(a)) is the minimum subgraph not having any node with in-degree more than while satisfying the condition for Algorithm 3. Due to the -local model, each node must have at least in-neighbors. It is obvious that if any node uses the majority voting structure (i.e., two-hop paths) to obtain the original value of a two-hop in-neighbor or an out-neighbor, then such a node will have at least in-neighbors. Consider node with in-neighbors. By the above discussion, it has undirected edges to the in-neighbors, which results in these in-neighbors being two-hop in-neighbors to each other. Thus, by the same argument, there must be undirected edges between them. Therefore, the clique is the only structure satisfying the condition for Algorithm 3 while not having any node with in-degree more than .
Next, we show the minimum in-degree of the whole graph. Since the graph is strongly connected, there exist bi-directional edges (one undirected edge or two separate directed edges) connecting two subgraphs. For example, we take the undirected edge between nodes and in Fig. 13(b). Then other nodes in the right subgraph become two-hop neighbors of node . By similar discussions as above, there exist undirected edges between node and all the neighbors of node (as indicated by the blue edges in the figure). As a result, node has in-neighbors. Moreover, we can check that all the rest of nodes also have in-neighbors to fulfill the condition for Algorithm 3. We conclude that the whole graph has the minimum in-degree no less than .
Proof of Proposition 5.9
Proof 7.15.
We first show that for any node , there must exist the minimum subgraph containing node as the one in Fig. 14(a). Recall from Lemma. 5.6 that an undirected graph satisfying the condition for Algorithm 3 has minimum in-degree no less than . In Fig. 14(a), we set for illustration. The edges in blue and black represent the detectable path and the communication edge, respectively. Note that this subgraph also includes the middle nodes on the detectable path (not shown in the figure for convenience) if such path is not constructed by an undirected communication edge. It can be observed that in a minimum subgraph, after removing any node set being -local, the remaining graph is connected. This means that there is at least one path connecting any two nodes in the remaining graph.
Now, consider any two minimum subgraphs with node sets and (see Fig. 14(b)). There must be at least one edge between them since the whole graph is connected by assumption. There are three subcases for placing such an edge. These are between (i) and , (ii) and , (iii) and . (Without loss of generality, select as one of ’s neighbors.) In cases (i) and (ii), node or becomes a direct neighbor of node . Thus, node or is connected with any node in after removing an -local node set in . Since node or is also connected with any node in after the removal, we can conclude that in cases (i) and (ii), any node in is connected with any node in after removing an -local node set in the whole graph.
In case (iii), nodes and become neighbors (see Fig. 14(b)). There should be detectable paths between and and also between and . If any of the two paths is constructed by an undirected communication edge, the result is the same as the one in case (i). So we examine the case where both paths are constructed by two-hop communication paths. Suppose that node is connected to node through nodes , , and . The three nodes become two-hop neighbors of node and there should be detectable paths to node . In this case, even if we remove the -local model consisting of both nodes and , node and node are connected with each other, and so are the rest of the nodes in and . Note that removing both nodes and does not violate the -local model since they do not have common normal neighbors. Finally, since the malicious set is -local, we conclude that the normal network induced by the normal agents in is connected.
References
References
- [1] N. A. Lynch, Distributed Algorithms. Morgan Kaufmann, 1996.
- [2] R. Olfati-Saber, J. A. Fax, and R. M. Murray, “Consensus and cooperation in networked multi-agent systems,” Proc. IEEE, vol. 95, no. 1, pp. 215–233, 2007.
- [3] F. Bullo, J. Cortés, and S. Martinez, Distributed Control of Robotic Networks: A Mathematical Approach to Motion Coordination Algorithms. Princeton University Press, 2009.
- [4] M. Mesbahi and M. Egerstedt, Graph Theoretic Methods in Multi-agent Networks. Princeton University Press, 2010.
- [5] G. S. Seyboth, D. V. Dimarogonas, and K. H. Johansson, “Event-based broadcasting for multi-agent average consensus,” Automatica, vol. 49, no. 1, pp. 245–252, 2013.
- [6] K. Cai and H. Ishii, “Quantized consensus and averaging on gossip digraphs,” IEEE Transactions on Automatic Control, vol. 56, no. 9, pp. 2087–2100, 2011.
- [7] K. Cai and H. Ishii, “Average consensus on general strongly connected digraphs,” Automatica, vol. 48, no. 11, pp. 2750–2761, 2012.
- [8] M. E. Chamie, J. Liu, and T. Basar, “Design and analysis of distributed averaging with quantized communication,” IEEE Transactions on Automatic Control, vol. 61, no. 12, pp. 3870–3884, 2016.
- [9] T. C. Aysal, M. J. Coates, and M. G. Rabbat, “Distributed average consensus with dithered quantization,” IEEE Transactions on Signal Processing, vol. 56, no. 10, pp. 4905–4918, 2008.
- [10] A. Olshevsky and J. N. Tsitsiklis, “Convergence speed in distributed consensus and averaging,” SIAM Journal on Control and Optimization, vol. 48, no. 1, pp. 33–55, 2009.
- [11] C. N. Hadjicostis, N. H. Vaidya, and A. D. Dominguez-Garcia, “Robust distributed average consensus via exchange of running sums,” IEEE Transactions on Automatic Control, vol. 61, no. 6, pp. 1492–1507, 2016.
- [12] M. Zhu and S. Martinez, “Discrete-time dynamic average consensus,” Automatica, vol. 46, no. 2, pp. 322–329, 2010.
- [13] E. Montijano, J. I. Montijano, C. Sagues, and S. Martinez, “Robust discrete time dynamic average consensus,” Automatica, vol. 50, no. 12, pp. 3131–3138, 2014.
- [14] S. Yang, S. Tan, and J. Xu, “Consensus based approach for economic dispatch problem in a smart grid,” IEEE Transactions on Power Systems, vol. 28, no. 4, pp. 4416–4426, 2013.
- [15] H. Ishii and R. Tempo, “The PageRank problem, multiagent consensus, and web aggregation: A systems and control viewpoint,” IEEE Control Systems Magazine, vol. 34, no. 3, pp. 34–53, 2014.
- [16] H. Ishii and A. Suzuki, “Distributed randomized algorithms for PageRank computation: Recent advances,” in T. Basar (editor), Uncertainty in Complex Networked Systems: In Honor of Roberto Tempo, Birkhauser, pp. 419-447, 2018.
- [17] L. Yuan and H. Ishii, “Event-triggered approximate Byzantine consensus with multi-hop communication,” IEEE Transactions on Signal Processing, vol. 71, pp. 1742–1754, 2023.
- [18] S. Sundaram and B. Gharesifard, “Distributed optimization under adversarial nodes,” IEEE Transactions on Automatic Control, vol. 64, no. 3, pp. 1063–1076, 2018.
- [19] H. J. LeBlanc, H. Zhang, X. Koutsoukos, and S. Sundaram, “Resilient asymptotic consensus in robust networks,” IEEE Journal on Selected Areas in Communications, vol. 31, no. 4, pp. 766–781, 2013.
- [20] F. Pasqualetti, A. Bicchi, and F. Bullo, “Consensus computation in unreliable networks: A system theoretic approach,” IEEE Transactions on Automatic Control, vol. 57, no. 1, pp. 90–104, 2012.
- [21] A. Fagiolini, F. Babboni, and A. Bicchi, “Dynamic distributed intrusion detection for secure multi-robot systems,” in Proc. IEEE Int. Conf. Robotics and Autom., 2009, pp. 2723–2728.
- [22] S. M. Dibaji, M. Safi, and H. Ishii, “Resilient distributed averaging,” in Proc. American Control Conference, 2019, pp. 96–101.
- [23] W. Zheng, Z. He, J. He, and C. Zhao, “Accurate resilient average consensus via detection and compensation,” in Proc. IEEE Conference on Decision and Control, 2021, pp. 5502–5507.
- [24] C. N. Hadjicostis and A. D. Dominguez-Garcia, “Trustworthy distributed average consensus,” in Proc. IEEE Conference on Decision and Control, 2022, pp. 7403–7408.
- [25] S. Sundaram and C. N. Hadjicostis, “Distributed function calculation via linear iterative strategies in the presence of malicious agents,” IEEE Transactions on Automatic Control, vol. 56, no. 7, pp. 1495–1508, 2011.
- [26] A. Teixeira, D. Pérez, H. Sandberg, and K. H. Johansson, “Attack models and scenarios for networked control systems,” in Proc. 1st International Conference on High Confidence Networked Systems, 2012, pp. 55–64.
- [27] A. Goldsmith, Wireless Communications. Cambridge University Press, 2005
- [28] M. Azadmanesh and R. Kieckhafer, “Asynchronous approximate agreement in partially connected networks,” International Journal of Parallel and Distributed Systems and Networks, vol. 5, no. 1, pp. 26–34, 2002.
- [29] N. H. Vaidya, L. Tseng, and G. Liang, “Iterative approximate Byzantine consensus in arbitrary directed graphs,” in Proc. ACM Symposium on Principles of Distributed Computing, 2012, pp. 365–374.
- [30] L. Yuan and H. Ishii, “Resilient consensus with multi-hop communication,” in Proc. IEEE Conference on Decision and Control, 2021, pp. 2696–2701.
- [31] L. Su and N. H. Vaidya, “Reaching approximate Byzantine consensus with multi-hop communication,” Information and Computation, vol. 255, pp. 352–368, 2017.
- [32] S. M. Dibaji, H. Ishii, and R. Tempo, “Resilient randomized quantized consensus,” IEEE Transactions on Automatic Control, vol. 63, no. 8, pp. 2508–2522, 2018.
- [33] L. Yuan and H. Ishii, “Asynchronous approximate Byzantine consensus via multi-hop communication,” in Proc. American Control Conference, 2022, pp. 755–760.
- [34] D. M. Senejohnny, S. Sundaram, C. De Persis, and P. Tesi, “Resilience against misbehaving nodes in asynchronous networks,” Automatica, vol. 104, pp. 26–33, 2019.
- [35] H. Ishii, Y. Wang, and S. Feng, “An overview on multi-agent consensus under adversarial attacks,” Annual Reviews in Control, vol. 53, pp. 252–272, 2022.
- [36] L. Yuan and H. Ishii, “Secure consensus with distributed detection via two-hop communication,” Automatica, vol. 131, no. 109775, 2021.
- [37] C. Zhao, J. He, and J. Chen, “Resilient consensus with mobile detectors against malicious attacks,” IEEE Transactions on Signal and Information Processing over Networks, vol. 4, no. 1, pp. 60–69, 2018.
- [38] C. N. Hadjicostis and A. D. Dominguez-Garcia, “Trustworthy distributed average consensus based on locally assessed trust evaluations,” arXiv preprint, arXiv:2309.00920, 2023.
- [39] C. N. Hadjicostis and A. D. Dominguez-Garcia, “Identification of malicious activity in distributed average consensus via non-concurrent checking,” IEEE Control Systems Letters, vol. 7, pp. 1927–1932, 2023.
- [40] B. Parhami, “Voting algorithms,” IEEE Transactions on Reliability, vol. 43, no. 4, pp. 617–629, 1994.
- [41] R. E. Blahut, Theory and Practice of Error Control Codes. Addison-Wesley, 1983.
- [42] D. Kempe, A. Dobra, and J. Gehrke, “Gossip-based computation of aggregate information,” in Proc. Annual IEEE Symposium on Foundations of Computer Science, 2003, pp. 482–491.
- [43] L. Tseng and N. H. Vaidya, “Fault-tolerant consensus in directed graphs,” in Proc. ACM Symposium on Principles of Distributed Computing, 2015, pp. 451–460.
- [44] L. Tseng, N. Vaidya, and V. Bhandari, “Broadcast using certified propagation algorithm in presence of Byzantine faults,” Information Processing Letters, vol. 115, no. 4, pp. 512–514, 2015.
[![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/5d1edc76-a4a6-4cc1-9983-530bcc7f4cf2/Yuan_self.png) ]Liwei Yuan (Member) received the B.E. degree in Electrical Engineering
and Automation from Tsinghua University,
China, in 2017, and the Ph.D. degree in Computer
Science from Tokyo Institute of Technology, Japan, in
2022.
He is currently a Postdoctoral Researcher in the College
of Electrical and Information Engineering at Hunan
University, Changsha, China. His current
research focuses on security in multi-agent systems
and distributed algorithms.
]Liwei Yuan (Member) received the B.E. degree in Electrical Engineering
and Automation from Tsinghua University,
China, in 2017, and the Ph.D. degree in Computer
Science from Tokyo Institute of Technology, Japan, in
2022.
He is currently a Postdoctoral Researcher in the College
of Electrical and Information Engineering at Hunan
University, Changsha, China. His current
research focuses on security in multi-agent systems
and distributed algorithms.
[![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/5d1edc76-a4a6-4cc1-9983-530bcc7f4cf2/ishii.png) ]Hideaki Ishii (M’02-SM’12-F’21) received the
M.Eng. degree in applied systems science from
Kyoto University, Kyoto, Japan, in 1998, and the
Ph.D. degree in electrical and computer engineering
from the University of Toronto, Toronto,
ON, Canada, in 2002. He was a Postdoctoral Research
Associate at the University of Illinois at Urbana-Champaign,
Urbana, IL, USA, from 2001 to
2004, and a Research Associate at
The University of Tokyo, Tokyo, Japan, from 2004 to 2007.
He was an Associate Professor and Professor at the Department of Computer Science,
Tokyo Institute of Technology, Yokohama, Japan in 2007–2024. Currently, he is a Professor at the
Department of Information Physics and Computing at The University of Tokyo, Tokyo, Japan.
He was a Humboldt Research Fellow at the University of Stuttgart
in 2014–2015. He has also held visiting positions at CNR-IEIIT at
the Politecnico di Torino, the Technical University of Berlin, and
the City University of Hong Kong. His research interests
include networked control systems, multiagent systems, distributed algorithms,
and cyber-security of control systems.
]Hideaki Ishii (M’02-SM’12-F’21) received the
M.Eng. degree in applied systems science from
Kyoto University, Kyoto, Japan, in 1998, and the
Ph.D. degree in electrical and computer engineering
from the University of Toronto, Toronto,
ON, Canada, in 2002. He was a Postdoctoral Research
Associate at the University of Illinois at Urbana-Champaign,
Urbana, IL, USA, from 2001 to
2004, and a Research Associate at
The University of Tokyo, Tokyo, Japan, from 2004 to 2007.
He was an Associate Professor and Professor at the Department of Computer Science,
Tokyo Institute of Technology, Yokohama, Japan in 2007–2024. Currently, he is a Professor at the
Department of Information Physics and Computing at The University of Tokyo, Tokyo, Japan.
He was a Humboldt Research Fellow at the University of Stuttgart
in 2014–2015. He has also held visiting positions at CNR-IEIIT at
the Politecnico di Torino, the Technical University of Berlin, and
the City University of Hong Kong. His research interests
include networked control systems, multiagent systems, distributed algorithms,
and cyber-security of control systems.
Dr. Ishii has served as an Associate Editor for Automatica, the IEEE Control Systems Letters, the IEEE Transactions on Automatic Control, the IEEE Transactions on Control of Network Systems, and the Mathematics of Control, Signals, and Systems. He was a Vice President for the IEEE Control Systems Society (CSS) in 2022–2023. He was the Chair of the IFAC Coordinating Committee on Systems and Signals in 2017–2023. He served as the IPC Chair for the IFAC World Congress 2023 held in Yokohama, Japan. He received the IEEE Control Systems Magazine Outstanding Paper Award in 2015. Dr. Ishii is an IEEE Fellow.