Resource-Efficient Cooperative Online Scalar Field Mapping via Distributed Sparse Gaussian Process Regression
Abstract
Cooperative online scalar field mapping is an important task for multi-robot systems. Gaussian process regression is widely used to construct a map that represents spatial information with confidence intervals. However, it is difficult to handle cooperative online mapping tasks because of its high computation and communication costs. This letter proposes a resource-efficient cooperative online field mapping method via distributed sparse Gaussian process regression. A novel distributed online Gaussian process evaluation method is developed such that robots can cooperatively evaluate and find observations of sufficient global utility to reduce computation. The error bounds of distributed aggregation results are guaranteed theoretically, and the performances of the proposed algorithms are validated by real online light field mapping experiments.
Index Terms:
Multi-Robot Systems; Distributed Robot Systems; MappingI INTRODUCTION
Online mapping in unknown environments is a critical mission in environmental monitoring and exploration applications. Compared with static sensor networks [1], [2], multi-robot systems have higher exploration efficiency and flexibility for large-scale cooperative online mapping [3], [4]. Each robot moves and measures data locally in fields and then shares information with neighbors to construct the global scalar field map.
Gaussian process regression (GPR) is a framework for nonlinear non-parametric Bayesian inference widely used in field mapping [5], [6], [7]. Different from the traditional discrete occupancy grid model [8], [9], GPR predicts a continuous function to learn the dependencies between points in the fields and represent the map. Another benefit of GPR mapping is the explicit uncertainty representation, which can be used for efficient path planning.
Unfortunately, the standard GPR requires time complexity with the training sample size , which is not suitable for large-scale online mapping due to the high cost in computation, communication, and memory [10]. In this letter, we consider cooperative online scalar field mapping for distributed multi-robot systems and propose a resource-efficient distributed sparse Gaussian process regression method to solve these challenges.

I-A Related Work
To speed up GPR, sparse variational GPR (SVGPR) is developed [11], [12], which employs a set of pseudo-points based on KL divergence to summarize the sample data thereby reducing computational costs to . Meanwhile, many Gaussian process aggregation methods are proposed for parallel computation, like product-of-experts (PoE) [13] and robust Bayesian committee machine [14]. Then, SVGPR combined parallel computation [15] and stochastic optimization [16] methods are developed to further reduce computational costs. Moreover, Refs. [17] and [18] provide recursive frameworks for standard GPR and sparse variational GPR to handle online streaming data. Ref. [19] combine these sparse variational, mini-batches and streaming methods and apply them to Bayesian robot model learning. However, these methods both require a central node, in which SVGPR [11, 12, 17, 18, 19] requires global information of the observations for sparse approximations, and the parallel methods [13, 14, 15, 16] require a central node for model aggregations. Therefore, these methods cannot be easily extended to distributed multi-robot systems since all observations and models are required to communicate across networks, which increases inter-robot communications and causes repeated computations about the same observations on different robots.
For dynamic networks without a center, distributed Gaussian process aggregation methods based on average consensus are proposed in [20], [21] and [22]. Then, Ref. [23] applies an online distributed Gaussian process method to scalar field mapping. These methods avoid communicating observations on networks. However, these methods do not provide error bounds with centralized aggregation methods and do not consider the sparse computation, causing computational costs. Ref. [24] provides a local online Gaussian process evaluation method to reduce computation and inter-robot communications by only computing and communicating partial observations. Ref. [25] employs the SVGPR for multi-robot systems, in which each robot obtains sparse subsets based on its local observations. Unfortunately, these approaches have limited global accuracy because the online evaluation only uses local information.
I-B Main Contributions
This letter proposes a distributed sparse online Gaussian process regression method for cooperative online scalar field mapping. The main contributions of this letter are as follows.
-
•
Propose a distributed recursive Gaussian process based on dynamic average consensus for streaming data and cooperative online mapping. The error bounds between distributed consensus results and the centralized results are guaranteed theoretically (Theorem 1).
- •
-
•
Develop a resource-efficient cooperative online scalar field mapping method via distributed sparse Gaussian process regression. The performances of the proposed algorithms are evaluated by real online light field mapping experiments.
II Preliminaries And System Modeling
II-A Problem Statement
(Network Model) Consider a team of robots, labeled by . The communication networks at time can be represented by a directed graph with an edge set . We consider that if and only if node communicates to node at time . Define the set of the neighbors of robot at time as . The matrix represents the adjacency matrix of .
(Observation Model) Each robot independently senses the fields and gets the measurements with zero-mean Gaussian noise at time , where is the input feature space for and is the corresponding output space. This letter considers 2D cases () and it can also be used in 3D cases as [25]. The observation model is given by
where is the position of robot at time . Let the local datasets of robot at time be in the form , where are the sets of observations from begin to current time .
II-B Gaussian Process Regression
Let the unknown fields be the target regression functions. A robot can use Gaussian process regression [26] to predict the latent function value at the test data points using the training datasets .
In GPR, the Gram function is constructed from the kernel function . A commonly used kernel function is the squared exponential (SE) kernel defined as
| (1) |
with hyper-parameters . Then, the posterior distribution is derived as , where
| (2) | ||||
In this letter, we assume the hyper-parameters can be typically selected by maximizing the marginal log-likelihood offline [26] and focus on GP predictions (2) for field mapping, like Refs. [20], [21], [23], [24] and [25].
II-C Recursive Gaussian process update for streaming data
In the online mapping mission, the data arrives sequentially. At any time , the new data point is added to datasets in streaming set. In this case, the Gaussian process prediction (2) will suffer from slow updating. To speed up the online mapping, we employ the recursive Gaussian process update [17],
| (3) | ||||
where and are recursive updated variables. Suppose a new data point has been collected, the recursive updates are designed as,
| (4) | ||||
with the scalars , and given by
| (5) |
Upon comparison with (3), can be interpreted as the recursive predictive variance of the new data point given the observations at without noise. This property and the variable will be used in Section IV for sparse approximation.
III Consensus-based Distributed Gaussian Process Regression
In this section, we introduce the distributed Gaussian process regression methods for cooperative online field mapping. Each robot constructs an individual field map and aggregates the global map in a distributed fashion using dynamic average consensus methods.
III-A Consensus-based distributed Gaussian posterior update
At time , each robot first samples a new training pair in the fields. Then, robots recursive update local Gaussian process posterior mapping by (3) and (4), where are the test map grid positions. With some abuse of notations, denote and as the local and distributed Gaussian posterior mapping of robot at time , respectively.
Next, we employ discrete-time dynamic average consensus methods [27] for distributed map aggregation. The first-order iterative aggregation process can be written as
| (6) | ||||
where denotes the local consensus state of robot at time and is the reference input, which determines the converged consensus results. Many aggregation schemes can be used to design this reference input. We employ the PoE method in this letter. The distributed Gaussian process update can be designed as
| (7) |
where denotes the -th element of the local consensus state and is the local Gaussian posterior variance with the correction biases for avoiding singularity. Due to the theoretical foundation of consensus algorithms, the distributed aggregation mean will converge to the centralized PoE results
| (8) |
which will be discussed latter. In particular, robots are only required to communicate the local consensus state with constant size, instead of the online datasets with growing size.
III-B Error bounds derivation for distributed fusion
For the derivation of distributed aggregation error bounds, we introduce the following assumptions.
Assumption 1
(Periodical Strong Connectivity). There is some positive integer such that, for all time instant , the directed graph is strongly connected.
Assumption 2
(Non-degeneracy and Doubly Stochastic). There exists a constant such that , and satisfies . And there hold that and .
The Assumption 1 describes the periodical strong connectivity between robots and Assumption 2 defines the parameters selection of adjacency matrix, which are common for average consensus methods [27].
Assumption 3
(Bounded Observations). There exists time invariant constants and such that all observations and local Gaussian process predictions satisfy , , .
The average consensus methods generally suppose the derivative of the consensus state is bounded [20], [21] and [27]. The derivative bounds are related to the consensus errors and can be used for parameter selections of the communication network in practice, like communication periods and adjacency matrix. However, the derivative bound is hard to get by sample if the field distribution is unknown in practice. This letter employs the character of the recursive Gaussian process to loosen this requirement to the bounded observations (Assumptions 3) for easier parameter selections on online mapping. Moreover, since the Gaussian process predictions are determined by the observations and the prior kernel function, it is bounded as the observations.
Theorem 1
Suppose Assumptions 1 3 hold and each robot runs recursive Gaussian process (3) and first-order consensus algorithms (6). Let , and be positive constants, where
| (9) | ||||
Select the correction term to satisfy . Then, the error bounds between and PoE results (8) at any test point will converge to
| (10) |
where
| (11) |
Furthermore, if there is a constant , for any time holds, the error bounds will converge to zero, i.e., as time .
Proof: The proof sketch is in the Appendix.
The error bounds given in Theorem 1 do not require the specific GP kernels and hyper-parameters and thus can be used in other distributed GP systems for communication parameter selections.
IV Distributed sparse Gaussian process approximation
To speed up the GPR for online mapping, it is necessary to design Gaussian process sparse approximation methods. In this section, a novel distributed metric is proposed for data evaluations such that predictions have better global performance without additional communication costs.
IV-A Distributed sparse metrics for recursive Gaussian process
For a robot , the recursive variable scalar and (5) for can be interpreted as the variance-weighted prediction at point using datasets . Ref. [24] use the sum of the changes in posterior mean at all current sample points to denote the score for the observation , which has been derived as
| (12) |
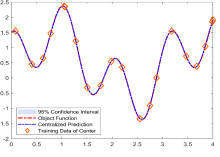
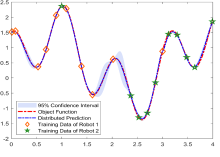
where denotes the -th item of the vectors and denotes the diagonal vectors of the matrix. However, for a multi-robot system, each robot has different datasets and recursive Gaussian process variables . The score (12) can only evaluate the points based on local information, which causes repeated information and limited global performances. A 1-D toy example is shown in Fig. 2. Two robots sample the 1-D toy function and compress observations. Compression based on only local information tends to retain repeated information in common areas because of the same local metrics.
In Section III, we have obtained the distributed aggregation results based on consensus methods. And then we employ the the distributed aggregation results to improve the compression performances.
Bhattacharyya-Riemannian distance is employed to evaluate the sample points using the distributed aggregation results. For two Gaussian distributions and over feature space , Bhattacharyya-Riemannian distance is defined as
| (13) | ||||
where , and is the eigenvalues of . This metric (13) modifies the Hellinger distance by employing Riemannian item , which is efficient for the Gaussian variance representation [28].
Denote as the evaluated observation. We design a distributed sparse metrics as
| (14) |
| (15) |
where is a constant weight for the local score and distributed score and is the normalization function for all evaluated observations. This letter uses the simple min-max normalization. denotes the local score (12) for robot about the evaluated observation . is the local recursive Gaussian process distribution removing the evaluated observation, which will be introduced latter.
In Section III, we have proved the distributed mean will converge to the centralized PoE results. Therefore, the distributed sparse metrics (14) can find observations of sufficient global utility.
IV-B Distributed sparse Gaussian process update
Then, we employ the distributed sparse metrics (14) to select the information-efficient subsets with points and design the distributed sparse Gaussian process.
Reorder the elements of so that they are consistent with being the last element in the current datasets , and define
| (16) | ||||
where denotes the elements of the matrix at -th row and -th column and denotes an index vector from to except . The recursive variables removing points are given as [17]
| (17) | ||||
where , so as to compute using the reduced by (3).
IV-C Resource-efficient cooperative online mapping algorithm and complexity analysis
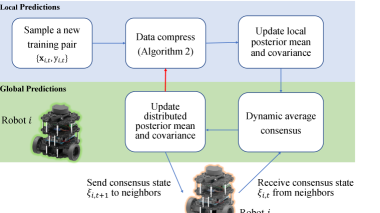
The entire cooperative online field mapping method is shown in Algorithm 1 and the pipline is presented in Fig. 3. At the time , each robot samples at the field and updates local Gaussian process predictions by (3). Next, robots share local consensus state (6) with neighbors and update distributed Gaussian process predictions by (7). Moreover, robots use the distributed sparse metrics (14) to greedily select the information-efficient subsets (Algorithm 2). The recursive variables keep lower dimensions by (17) for fast Gaussian process predictions.
A comparison of time, memory, and communication complexity is presented in Table I. Recall that the robot number is , and each robot samples training points and selects sparse points. The numbers of test points and communication edges are and .
Computation and memory: for each robot, the recursive sparse update of local mapping yields time and memory complexity, which is significantly less than distributed recursive GP with time and memory complexity. Compared with local sparse metrics (12), the proposed distributed sparse metrics (14) have better global accuracy with additional computation. Since , the additional computation is acceptable for online mapping.
Communication: compared with communicating original observations or compressed observations [24], [25], the proposed methods only communicate consensus state and have communication complexity, where . Therefore, the proposed methods have lower communication costs for large-scale multi-robot systems where is large. Moreover, the proposed methods can avoid repeated computations based on the same observations for GP mapping in different robots.
V Experimental results
In this section, the proposed algorithm is validated by experiments with multiple TurtleBot3-Burger robots. Each robot shown in Fig. 1 is equipped with the BH1750FVI light sensor, sampling and mapping the light field online in a workspace. The sample rate of the light sensor is set as Hz. The locations of robots are obtained by April-Tags. The entire system is implemented in the Robot Operating System (ROS).
In this experiment, 5 robots are performing an exploration to map the light field in the workspace. The communication network is dynamic and determined by the distance between robots. The communication range and frequency between robots are set as m and Hz. The local and distributed model update frequencies are set as and Hz, respectively. The corresponding adjacency matrix of networks is , . This letter does not consider path planning and the sample paths of robots are set as a fixed prior. Gaussian process hyper-parameters are set , . The hyperparameters are typically selected by maximizing the marginal log-likelihood offline using samples as a priori knowledge. Observation noises and correction biases are set . The distributed weight is set . All 5 robots sample a total of training points.
V-A Convergence validation of distributed aggregation
Select a mesh grid in the workspace as the test points to construct the light field mapping. The size of sparse training subsets is set as . The averaged distributed predictions of all 5 robots for all test points in the experiment and the centralized PoE results are shown in Fig. 4. The communication network is dynamic and Robots and are out of communication ranges of Robots and at first time. When sample number , Robots and begin sharing information in the communication network and the distributed aggregation results of all robots converge to the centralized PoE results.
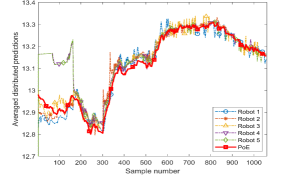
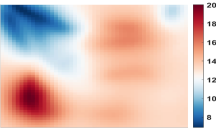
Fig. LABEL:fig:field represents the progress of this experiment and the corresponding distributed GP results of Robot during time () seconds. Fig. LABEL:fig:field(a) shows the experiment snapshots and the robot number. Fig. LABEL:fig:field(b) shows the results of the distributed online GP variance predictions for Robot with the exploration trajectories of all robots. The black points denote the sparse subsets for GP predictions. Fig. LABEL:fig:field(c) shows that the GP mean predictions for Robot gradually converges to the real light field in Fig. LABEL:fig:field(a). Compared with the local GP results of Robot shown in Fig. 6, the distributed aggregation methods efficiently construct light field maps for unvisited areas.


V-B Sparse prediction accuracy validation
To analyze the map accuracy with different GP prediction methods, equal interval points in the workspace are sampled by hand as the test points. Fig. 7(a) shows the mean RMSE of the distributed predictions on the test points for all robots. Compared with the local data compression [24], the proposed distributed compression improves the prediction accuracy. Fig. 7(b) shows the mean online prediction computational time for all robots on repeated experiments. The proposed sparse GP has an efficient constant prediction time with the increasing sample . In addition, the data compression is run all the time here to illustrate the constant computation time. In practice, it is not necessary when the sample number is small.

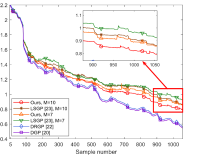
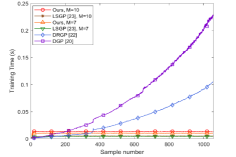
VI CONCLUSIONS
This letter proposes a resource-efficient cooperative online field mapping method via distributed sparse Gaussian process regression. Novel distributed online sparse metrics are developed such that robots can cooperatively evaluate observations with better global accuracy. The bounded errors of distributed aggregation results are guaranteed theoretically, and performances of proposed algorithms are validated by online light field mapping experiments. Our future work will focus on the distributed sparse GP hyper-parameters training and variance-based sample path planning.
APPENDIX: proof of Theorem 1
Without loss of generality, we consider the test data is a point here such that . For simplicity, we omit the test points in the following Gaussian process descriptions. We first derive the bounds of the reference input in (6).
| (18) | ||||
According to Ref. [26] and the SE kernel (1), the local Gaussian posterior variances have the bounds . Therefore, we derive
| (19) |
Denote and . The recursive updates of and (4) can be rewritten as
| (20) | ||||
The Gram function has . Then, according to (3), we obtain
| (21) | ||||
Similarly,
| (22) |
Then, (18) can be rewritten as
| (23) | ||||
Since the only different point between time and is the , we have
| (24) | ||||
which is obtained when and . Suppose that the Assumption 3 holds, we derive
| (25) |
Similarly, is bounded as
| (26) |
Define as the consensus errors, i.e.,
| (27) | ||||
According to the convergence of the FODAC algorithms (Theorem 3.1 in [27]), suppose the Assumptions 1, 2 hold, the consensus error is bounded as,
| (28) | ||||
when time .
Denote , , . Let , i.e., the satisfies such that we have for avoiding singularity. The difference between distributed the aggregation mean and the PoE results (8) can be written as,
| (29) | ||||
Furthermore, if there is a constant , for any time holds, according to the Corollary 3.1 in [27], and will converge to zero. Then, we have as time .
References
- [1] A. Singh, F. Ramos, H. D. Whyte, and W. J. Kaiser, “Modeling and decision making in spatio-temporal processes for environmental surveillance,” in Proc. IEEE Int. Conf. Robot. Automat. (ICRA), 2010, pp. 5490–5497.
- [2] J. Hansen and G. Dudek, “Coverage optimization with non-actuated, floating mobile sensors using iterative trajectory planning in marine flow fields,” in Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS), 2018, pp. 1906–1912.
- [3] B. Zhou, H. Xu, and S. Shen, “Racer: Rapid collaborative exploration with a decentralized multi-uav system,” IEEE Trans. Robot., vol. 39, no. 3, pp. 1816–1835, 2023.
- [4] A. A. R. Newaz, M. Alsayegh, T. Alam, and L. Bobadilla, “Decentralized multi-robot information gathering from unknown spatial fields,” IEEE Robot. Autom. Lett., vol. 8, no. 5, pp. 3070–3077, 2023.
- [5] T. X. Lin, S. Al-Abri, S. Coogan, and F. Zhang, “A distributed scalar field mapping strategy for mobile robots,” in Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS), 2020, pp. 11 581–11 586.
- [6] T. M. C. Sears and J. A. Marshall, “Mapping of spatiotemporal scalar fields by mobile robots using Gaussian process regression,” in Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS), 2022, pp. 6651–6656.
- [7] L. Jin, J. Rückin, S. H. Kiss, T. Vidal-Calleja, and M. Popović, “Adaptive-resolution field mapping using Gaussian process fusion with integral kernels,” IEEE Robot. Autom. Lett., vol. 7, no. 3, pp. 7471–7478, July 2022.
- [8] X. Lan and M. Schwager, “Learning a dynamical system model for a spatiotemporal field using a mobile sensing robot,” in Proc. American Control Conf. (ACC), 2017, pp. 170–175.
- [9] A. Hornung, K. M. Wurm, M. Bennewitz, C. Stachniss, and W. Burgard, “OctoMap: an efficient probabilistic 3D mapping framework based on octrees,” Auton. Robots, vol. 34, no. 3, pp. 189–206, Apr. 2013.
- [10] H. Liu, Y.-S. Ong, X. Shen, and J. Cai, “When Gaussian process meets big data: A review of scalable gps,” IEEE Trans. Neural Networks Learn. Syst., vol. 31, no. 11, pp. 4405–4423, Nov. 2020.
- [11] M. Titsias, “Variational learning of inducing variables in sparse Gaussian processes,” in Proc. Int. Conf. Artif. Intell. Statist. (AISTATS), vol. 5, 16–18 Apr 2009, pp. 567–574.
- [12] D. Burt, C. E. Rasmussen, and M. V. D. Wilk, “Rates of convergence for sparse variational Gaussian process regression,” in Int. Conf. Mach. Learn. (ICML), May 2019, pp. 862–871.
- [13] M. Deisenroth and J. W. Ng, “Distributed Gaussian processes,” in Int. Conf. Mach. Learn. (ICML), 07–09 Jul 2015, pp. 1481–1490.
- [14] H. Liu, J. Cai, Y. Wang, and Y. S. Ong, “Generalized robust Bayesian committee machine for large-scale Gaussian process regression,” in Int. Conf. Mach. Learn. (ICML), vol. 80, 10–15 Jul 2018, pp. 3131–3140.
- [15] T. N. Hoang, Q. M. Hoang, and B. K. H. Low, “A distributed variational inference framework for unifying parallel sparse Gaussian process regression models,” in Int. Conf. Mach. Learn. (ICML), vol. 48, 20–22 Jun 2016, pp. 382–391.
- [16] T. N. Hoang, Q. M. Hoang and B. K. H. Low, “A unifying framework of anytime sparse Gaussian process regression models with stochastic variational inference for big data,” in Int. Conf. Mach. Learn. (ICML), vol. 37, 2015, pp. 569–578.
- [17] L. Csató and M. Opper, “Sparse on-line Gaussian processes,” Neural Comput., vol. 14, no. 3, pp. 641–668, 2002.
- [18] T. D. Bui, C. Nguyen, and R. E. Turner, “Streaming sparse Gaussian process approximations,” in Adv. Neural Inf. Proces. Syst. (NeurIPS), vol. 30, 2017.
- [19] B. Wilcox and M. C. Yip, “SOLAR-GP: Sparse online locally adaptive regression using gaussian processes for bayesian robot model learning and control,” IEEE Robot. Autom. Lett., vol. 5, no. 2, pp. 2832–2839, Apr. 2020.
- [20] Z. Yuan and M. Zhu, “Communication-aware distributed Gaussian process regression algorithms for real-time machine learning,” in Proc. American Control Conf. (ACC), 2020, pp. 2197–2202.
- [21] A. Lederer, Z. Yang, J. Jiao, and S. Hirche, “Cooperative control of uncertain multiagent systems via distributed Gaussian processes,” IEEE Trans. Autom. Control, vol. 68, no. 5, pp. 3091–3098, May 2023.
- [22] G. P. Kontoudis and D. J. Stilwell, “Decentralized nested Gaussian processes for multi-robot systems,” in Proc. IEEE Int. Conf. Robot. Automat. (ICRA), 2021, pp. 8881–8887.
- [23] D. Jang, J. Yoo, C. Y. Son, D. Kim, and H. J. Kim, “Multi-robot active sensing and environmental model learning with distributed Gaussian process,” IEEE Robot. Autom. Lett., vol. 5, no. 4, pp. 5905–5912, Oct. 2020.
- [24] M. E. Kepler and D. J. Stilwell, “An approach to reduce communication for multi-agent mapping applications,” in Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS), 2020, pp. 4814–4820.
- [25] E. Zobeidi, A. Koppel, and N. Atanasov, “Dense incremental metric-semantic mapping for multiagent systems via sparse gaussian process regression,” IEEE Trans. Robot., vol. 38, no. 5, pp. 3133–3153, Oct. 2022.
- [26] C. E. Rasmussen and C. K. I. Williams, Gaussian Processes for Machine Learning. The MIT Press, 11 2005.
- [27] M. Zhu and S. Martínez, “Discrete-time dynamic average consensus,” Automatica, vol. 46, no. 2, pp. 322–329, Feb. 2010.
- [28] K. T. Abou-Moustafa and F. P. Ferrie, “A note on metric properties for some divergence measures: The Gaussian case,” in Proc. Asian Conf. Mach. Learn. (ACML), 2012, pp. 1–15.