Resource-Efficient Quantum Computing
by Breaking Abstractions
Abstract
Building a quantum computer that surpasses the computational power of its classical counterpart is a great engineering challenge. Quantum software optimizations can provide an accelerated pathway to the first generation of quantum computing applications that might save years of engineering effort. Current quantum software stacks follow a layered approach similar to the stack of classical computers, which was designed to manage the complexity. In this review, we point out that greater efficiency of quantum computing systems can be achieved by breaking the abstractions between these layers. We review several works along this line, including two hardware-aware compilation optimizations that break the quantum Instruction Set Architecture (ISA) abstraction and two error-correction/information-processing schemes that break the qubit abstraction. Last, we discuss several possible future directions.
I Introduction
Quantum computing has recently transitioned from a theoretical prediction to a nascent technology. With development of Noisy Intermediate-Scale Quantum (NISQ) devices, cloud-based Quantum Information Processing (QIP) platforms with up to 53 qubits are currently accessible to the public. It also has been recently demonstrated by the Quantum Supremacy experiment on the Sycamore quantum processor, a 54-qubit quantum computing device manufactured by Google, that quantum computers can outperform current classical supercomputers in certain computational tasks [140]. These developments suggest that the future of quantum computing is promising. Nevertheless, there is still a gap between the ability and reliability of current QIP technologies and the requirements of the first useful quantum computing applications. The gap is mostly due to the presence of systematic errors including qubit decoherence, gate errors, State Preparation And Measurement (SPAM) errors. As an example, the best reported qubit decoherence time on a superconducting QIP platform is around 500s (meaning that in 500s, the probability of a logical 1 state staying unflipped drops to ), the error rate of 2-qubit gates is around 1%-5% in a device, measurement error of a single qubit is between 2%- 5% [142]. In addition to the errors in the elementary operations, emergent error modes such as crosstalk are reported to make significant contributions to the current noise level in quantum devices [143, 144, 145]. With these sources of errors combined, we are only able to run quantum algorithms of very limited size on current quantum computing devices. Thus, it will require tremendous efforts and investment to solve these engineering challenges and we cannot expect a definite timeline for its success. Because of the uncertainties and difficulties in relying on hardware breakthroughs, it will also be crucial in the near term to close the gap using higher-level quantum optimizations and software hardware co-design, which could maximally utilize noisy devices and potentially provide an accelerated pathway to real-world quantum computing applications.
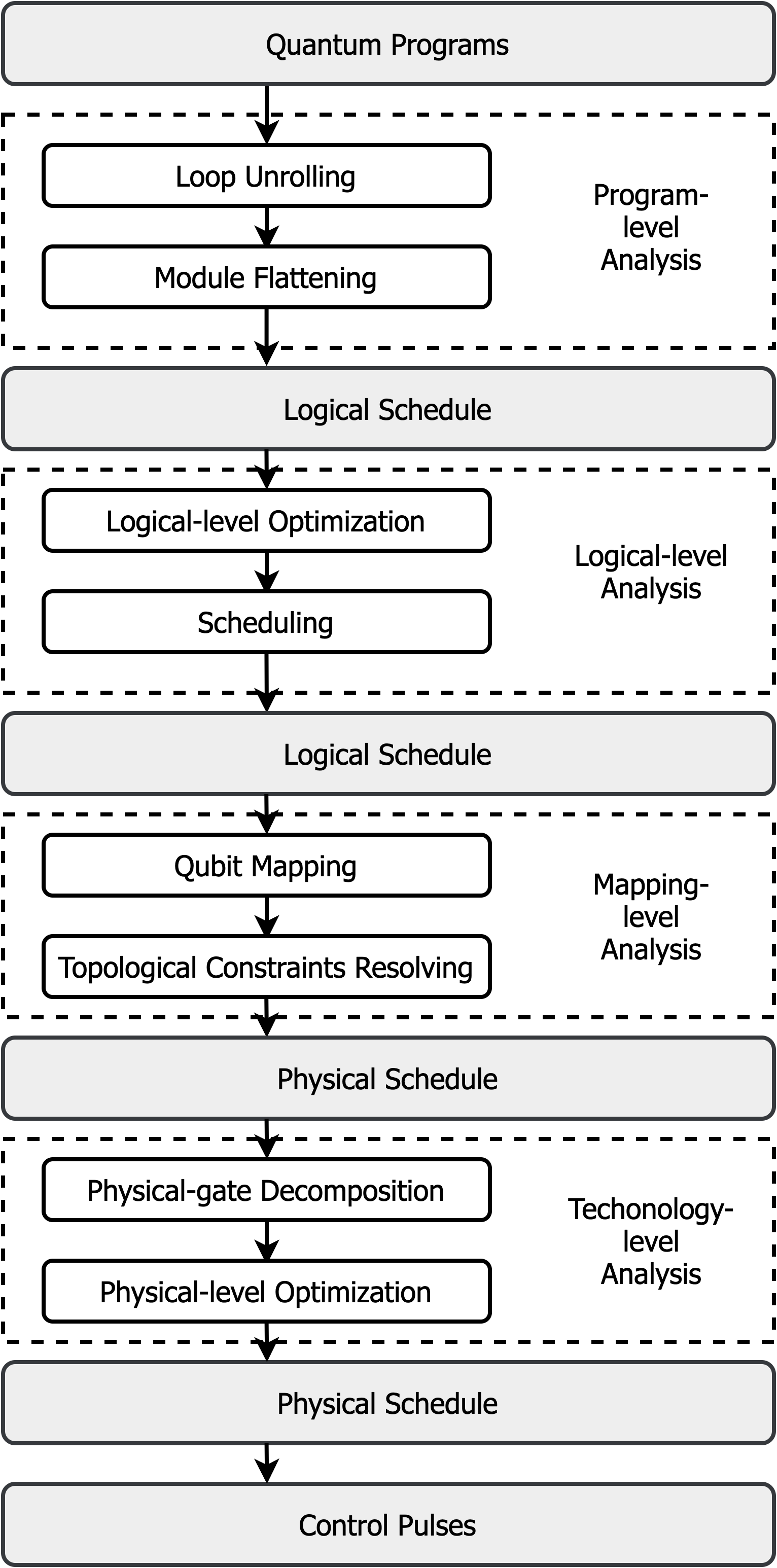
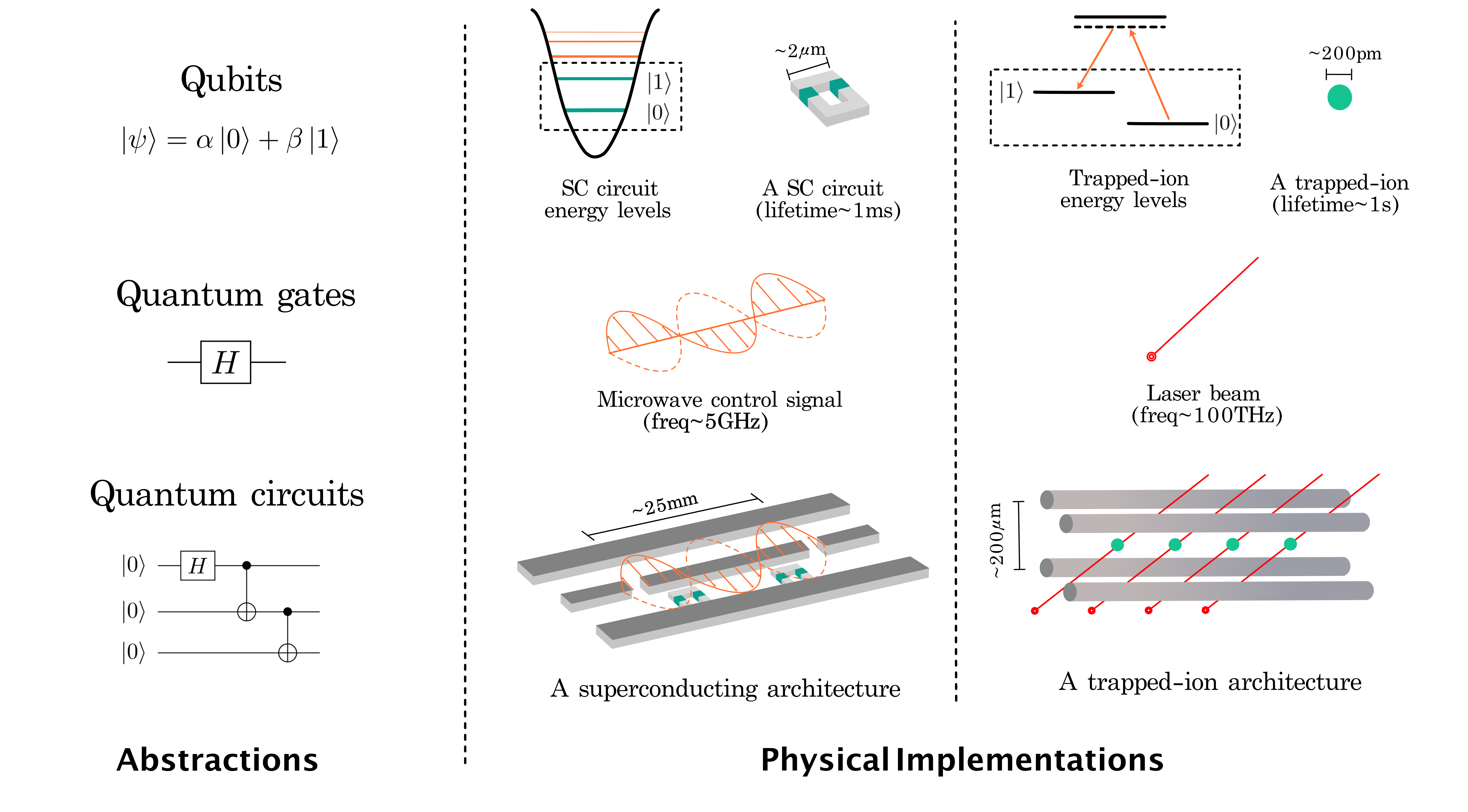
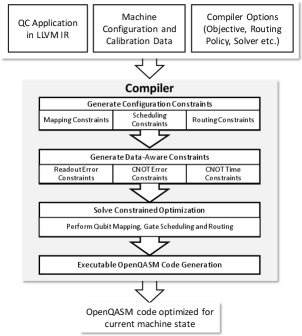
Currently, major quantum programming environments, including Qiskit [5] by IBM, Cirq [76] by Google, PyQuil [18] by Rigetti and strawberry fields [141] by Xanadu, follow the quantum circuit model. These programming environments support users in configuring, compiling and running their quantum programs in an automated workflow and roughly follow a layered approach as illustrated in Fig. 1. In these environments, the compilation stack is divided into layers of subroutines that are built upon the abstraction provided by the next layer. This design philosophy is similar to that of its classical counterpart, which has slowly converged to this layered approach over many years to manage the increasing complexity that comes with the exponentially growing hardware resources. In each layer, burdensome hardware details are well encapsulated and hidden behind a clean interface, which offers a well-defined, manageable optimization task to solve. Thus, this layered approach provides great portability and modularity. For example, the Qiskit compiler supports both the superconducting QIP platform and the trapped ion QIP platform as the backend (Fig. 2). In the Qiskit programming environment, these two backends share a unified, hardware-agnostic programming frontend even though the hardware characteristics and the qubit control methods of the two platforms are rather different. Superconducting (SC) qubits are macroscopic LC circuits placed inside dilution fridges of temperature near absolute zero. These qubits can be regarded as artificial atoms and are protected by a metal transmission line from environmental noise. For SC QIP platforms, qubit control is achieved through sending microwave pulses into the transmission line that surrounds the LC circuits to change the qubit state and those operations are usually done within several hundreds of nanoseconds. On the other hand, trapped ion qubits are ions confined in the potential of electrodes in vacuum chambers. Trapped ion qubits have a much longer coherence ( second) and quantum operations are performed by shinning modulated laser beam. The quantum gates are also much slower than that of SC qubits but the qubit connectivity (for 2-qubit gates) are much better. In Qiskit, the hardware characteristics of the two QIP platforms are abstracted away in the quantum circuit model so that the higher level programming environment can work with both backends.
However, the abstractions introduced in the layered approach of current QC stacks restrict opportunities for cross-layer optimizations. For example, without accessing the lower level noise information, the compiler might not be able to properly optimize gate scheduling and qubit mapping with regard to the final fidelity. For near-term quantum computing, maximal utilization of the scarce quantum resources and reconciling quantum algorithms with noisy devices is of more importance than to manage complexity of the classical control system. In this review, we propose a shift of the quantum computing stack towards a more vertical integrated architecture. We point out that breaking the abstraction layers in the stack by exposing enough lower level details could substantially improve the quantum efficiency. This claim is not that surprising — there are many supporting examples from the classical computing world such as the emergence of application specific architectures like the GPU and the TPU. However, this view is often overlooked in the software/hardware design in quantum computing.
We examine this methodology by looking at several previous works along this line. We first review two compilation optimizations that break the ISA abstraction by exposing pulse level information (Section II) and noise information (Section III), respectively. Then, we discuss an information processing scheme that improves general circuit latency by exposing the third energy level of the underlying physical space, , breaking the qubit abstraction using qutrits (Section IV). Then, we discuss the Gottesman-Kitaev-Preskill (GKP) qubit encoding in a Quantum Harmonic Oscillator (QHO) that exposes error information in the form of small shifts in the phase space to assist the upper level error mitigation/correction procedure (Section V).
At last, we envision several future directions that could further explore the idea of breaking abstractions and assist the realization of the first quantum computers for real-world applications.
II Breaking the ISA Abstraction using Pulse-Level Compilation
In this section, we describe a quantum compilation methodology proposed in [129, 148] that achieves an average of 5X speedup in terms of generated circuit latency, by employing the idea of breaking the ISA abstraction and compiling directly to control pulses.
II-A Quantum compilation
Since the early days of quantum computing, quantum compilation has been recognized as one of the central tasks in realizing practical quantum computation. Quantum compilation was first defined as the problem of synthesizing quantum circuits for a given unitary matrix. The celebrated Solovay-Kitaev theorem [30] states that such synthesis is always possible if a universal set of quantum gates is given. Now the term of quantum compilation is used more broadly and almost all stages in Fig. 1 can be viewed as part of the quantum compilation process.
There are many indications that current quantum compilation stack (Fig. 1) is highly-inefficient. First, current circuit synthesis algorithms are far from saturating (or being closed to) the asymptotic lower bound in the general case [49, 30]. Also, the formulated circuit synthesis problem is based on the fundamental abstraction of quantum ISA (Section II-B) and largely discussed in a hardware-agnostic settings in previous work but the underlying physical operations cannot be directly described by the logical level ISA (as shown in Fig. 2). The translation from the logical ISA to the operations directly supported by the hardware is typically done in an ad-hoc way. Thus, there is a mismatch between the expressive logical gates and the set of instructions that can be efficiently implemented on a real system. This mismatch significantly limits the efficiency of the current quantum computing stack thus the underlying quantum devices’ computing ability and wastes precious quantum coherence. While improving the computing efficiency is always valuable, improving quantum computing efficiency is do-or-die: computation has to finish before qubit decoherence or the results will be worthless. Thus, improving the compilation process is one of the most, if not the most, crucial goals in near-term QC system design.
By identifying this mismatch and the fundamental limitation in the ISA abstraction, in [129, 148], we proposed a quantum compilation technique that optimizes across existing abstraction barriers to greatly reduce latency while still being practical for large numbers of qubits. Specifically, rather than limiting the compiler to use 1- and 2-qubit quantum instructions, our framework aggregates the instructions in the logical ISA into a customized set of instructions that correspond to optimized control pulses. We compare our methodology to the standard compilation workflow on several promising NISQ quantum applications and conclude that our compilation methodology has an average speedup of with a maximum speedup of . We use the rest of this section to introduce this compilation methodology, starting with defining some basic concepts.
II-B Quantum ISA
In the quantum computing stack, a restricted set of 1- and 2-qubit quantum instructions are provided for describing the high-level quantum algorithms, analogous to the Instruction Set Architecture (ISA) abstraction in classical computing. In this paper, we call this instruction set the logical ISA. The 1-qubit gates in the logical ISA include the Pauli gates, . It also includes the Hadamard gate, whose symbol in the circuit model is given as an example in Fig. 2 on the left column. The typical 2-qubit instruction in the logical instruction set is the Controlled-NOT (CNOT) gate, which flips the state of the target qubit based on the state of the control qubit.
However, usually quantum computing devices does not directly support the logical ISA. Based on the system characteristics, we can define the physical ISA that can be directly mapped to the underlying control signals. For example, superconducting devices typically has Cross-Resonance (CR) gate or SWAP gate as their intrinsic 2-qubit instruction, whereas for trapped-ion devices the intrinsic 2-qubit instruction can be the Mølmer–Sørensen gate or the controlled phase gate.
II-C Quantum Control
As shown in Fig. 2 and discussed in the last subsection, underlying physical operations in the hardware such as microwave control pulses and modulated laser beam are abstracted as quantum instructions. A quantum instruction are simply as pre-fined control pulse sequences.
The underlying evolution of the quantum system is continuous and so are the control signals. The continuous control signals offer much richer and flexible controllability than the quantum ISA. The control pulses can drive the quantum computing hardware to a desired quantum states by varying a system-dependent and time-dependent quantity called the Hamiltonian. The Hamiltonian of a system determines the evolution path of the quantum states. The ability to engineer real-time system Hamiltonian allows us to navigate the quantum system to the quantum state of interest through generating accurate control signals. Thus, quantum computation can be done by constructing a quantum system in which the system Hamiltonian evolves in a way that aligns with a quantum computing task, producing the computational result with high probability upon final measurement of the qubits. In general, the path to a final quantum state is not unique and finding the optimal evolution path is a very important but challenging problem [115, 116, 117].
II-D The Mismatch Between ISA and Control
Being hardware-agnostic, the quantum operation sequences composed by logical ISA have limited freedom in terms of controllability and usually will not be mapped to the optimal evolution path of the underlying quantum system, thus there is a mismatch between the ISA and low-level quantum control. With two simple examples, we demonstrate this mismatch.
-
•
We can consider the instruction sequence consists of a CNOT gate followed by a gate on the control bit. In current compilation workflow, these two logical gates will be further decomposed into the physical ISA and be executed sequentially. However, on SC QIP platforms, the microwave pulses that implement these two instructions could in fact be applied simultaneously (because of their commutativity). Even the commutativity can be captured by the ISA abstraction, in the current compilation workflow, the compiled control signals are sub-optimal.
-
•
SWAP gate is an important quantum instruction for circuit mapping. The SWAP operation is usually decomposed as 3 Controlled-NOT (CNOT) operations, as realized in the circuit below. This decomposition could be thought of the implementation of in-place memory SWAPs with three alternating XORs for classical computation. However, for systems like quantum dots [114], the SWAP operation is directly supported by applying particular constant control signals for a certain period of time. In this case, this decomposition of SWAP into three CNOTs introduces substantial overhead.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/bc0e059b-7706-42c0-bcd8-3b5367e4c1a0/SWAP_Decomposition.png)
In experimental physics settings, equivalences from simple gate sequences to control pulses can be hand optimized [113]. However, when circuits become larger and more complicated, this kind of hand optimization become less efficient and the standard decomposition becomes less favorable, motivating a shift toward numerical optimization methods that are not limited by the ISA abstraction.
II-E Quantum Optimal Control
Quantum Optimal Control (QOC) theory provides an alternative in terms of finding the optimal evolution path for the quantum compilation tasks. Quantum optimal control algorithms typically perform analytical or numerical methods for this optimization, among which, gradient ascent methods, such as the GRadient Ascent Pulse Engineering (GRAPE) [119, 120] algorithm, are widely used. The basic idea of GRAPE is as follows: for optimizing the control signals of parameters () for a target quantum state, in every iteration, GRAPE minimizes the deviation of the system evolution by calculating the gradient of the final fidelity with respect to the control parameters in the dimensional space. Then GRAPE will update the paramters in the direction of the gradient with adaptive step size [119, 120, 115]. With a large number of iterations, the optimized control signals are expected to converge and find optimized pulses.
In [129], we utilize GRAPE to optimize our aggregated instructions that are customized for each quantum circuit as opposed to selecting instructions from a pre-defined pulse sequences. However, one disadvantage of numerical methods like GRAPE is that the running time and memory use grow exponentially with the size of the quantum system for optimization. In our work, we are able to use GRAPE for optimizing quantum systems of up to 10 qubits with the GPU accelerated optimal control unit [115]. As shown in our result, the limit of 10 qubits does not put restrictions on the result of our compilation methodology.
II-F Pulse-Level Optimization: A Motivating Example
(a)
 (b)
(b)
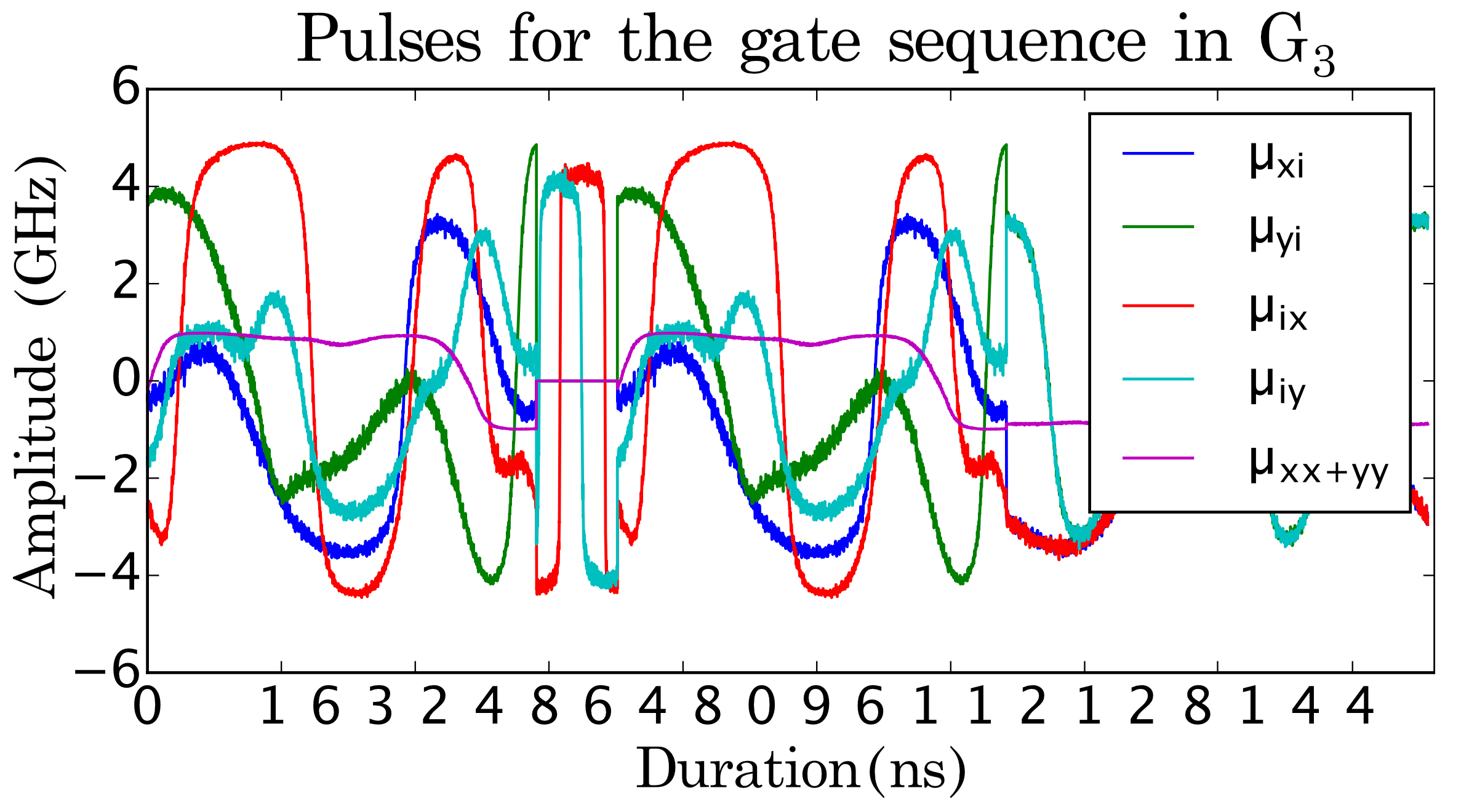 (c)
(c)
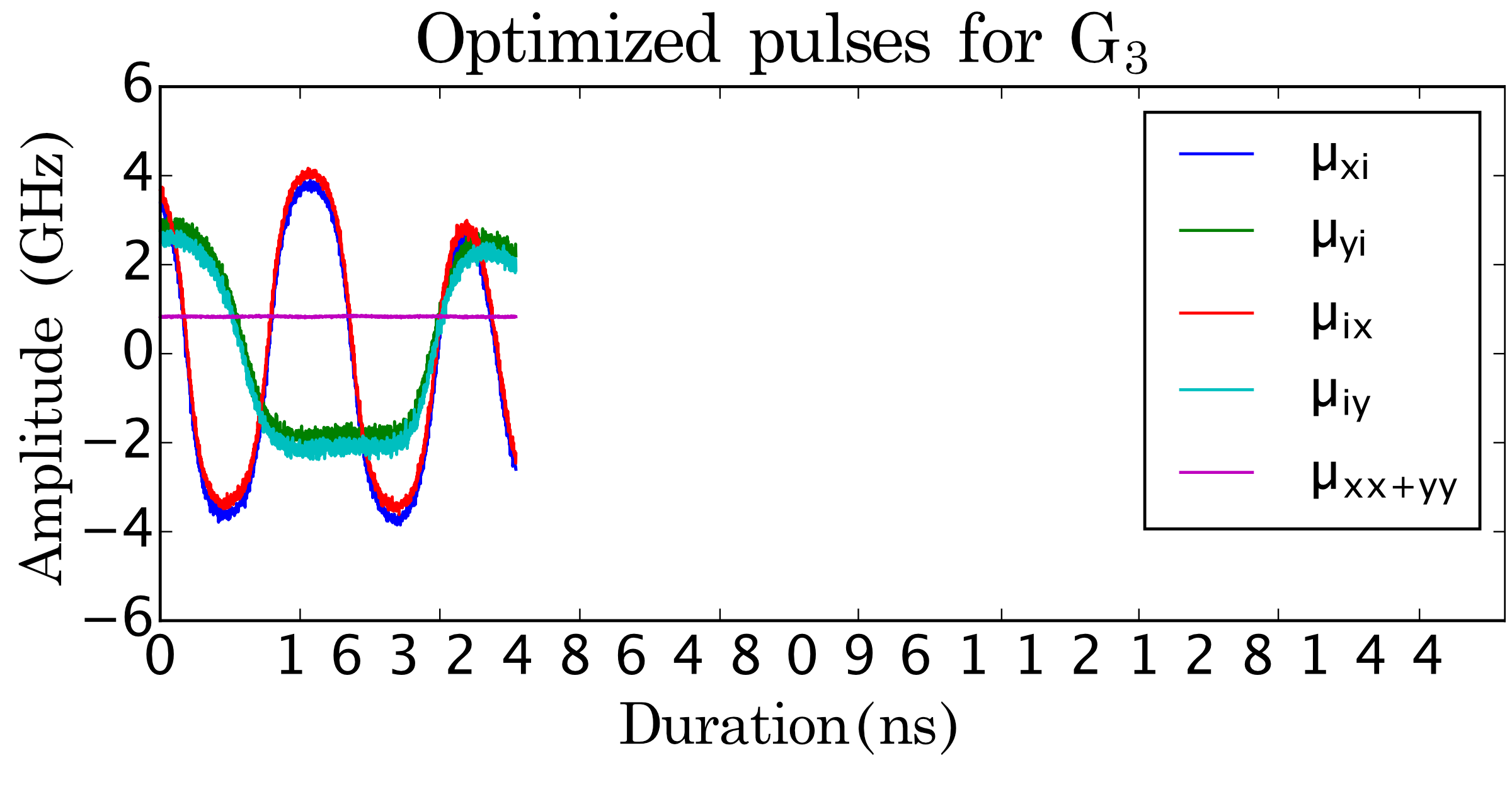 (d)
(d)
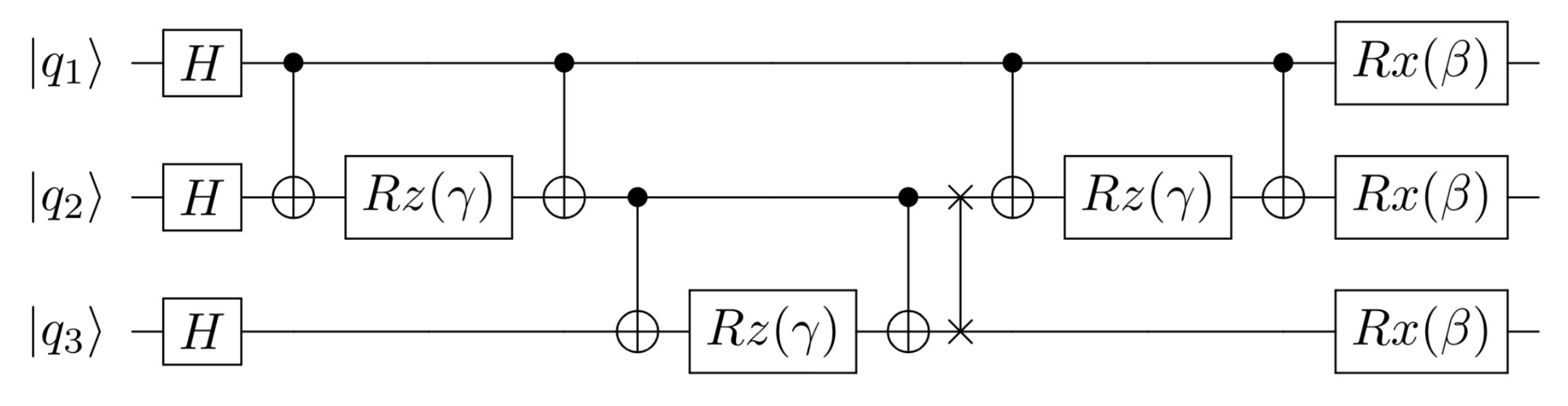
Next, we will illustrate the workflow of our compilation methodology with a circuit instance of the Quantum Approximate Optimization Algorithm (QAOA) for solving the MAXCUT problem on the triangle graph (Fig. 3). 111The angle parameters and can be determined by variational methods [122] and are set to and . This QAOA circuit with logical ISA (or variants of it up to single qubit gates) can be reproduced by most existing quantum compilers. This instance of the QAOA circuit is generated by the ScaffCC compiler, as shown in Fig. 3 (a). We assume this circuit is executed on a superconducting architecture with 1D nearest neighbor qubit connectivity. A SWAP instruction is inserted in the circuit to satisfy the linear qubit connectivity constraints.
On the other hand, our compiler generates the aggregated instruction set as illustrated in Fig. 3 (b) automatically, and uses GRAPE to produce highly-optimized pulse sequences for each aggregated instruction. In this minimal circuit instance, our compilation method reduces the total execution time of the circuit by about comparing to compilation with restricted ISA. Fig. 3 (c) and (d) show the generated pulses for with ISA-based compilation and with our aggregated instruction based, pulse-level optimized compilation.
II-G Optimized Pulse-Level Compilation Using Gate Aggregation: the workflow
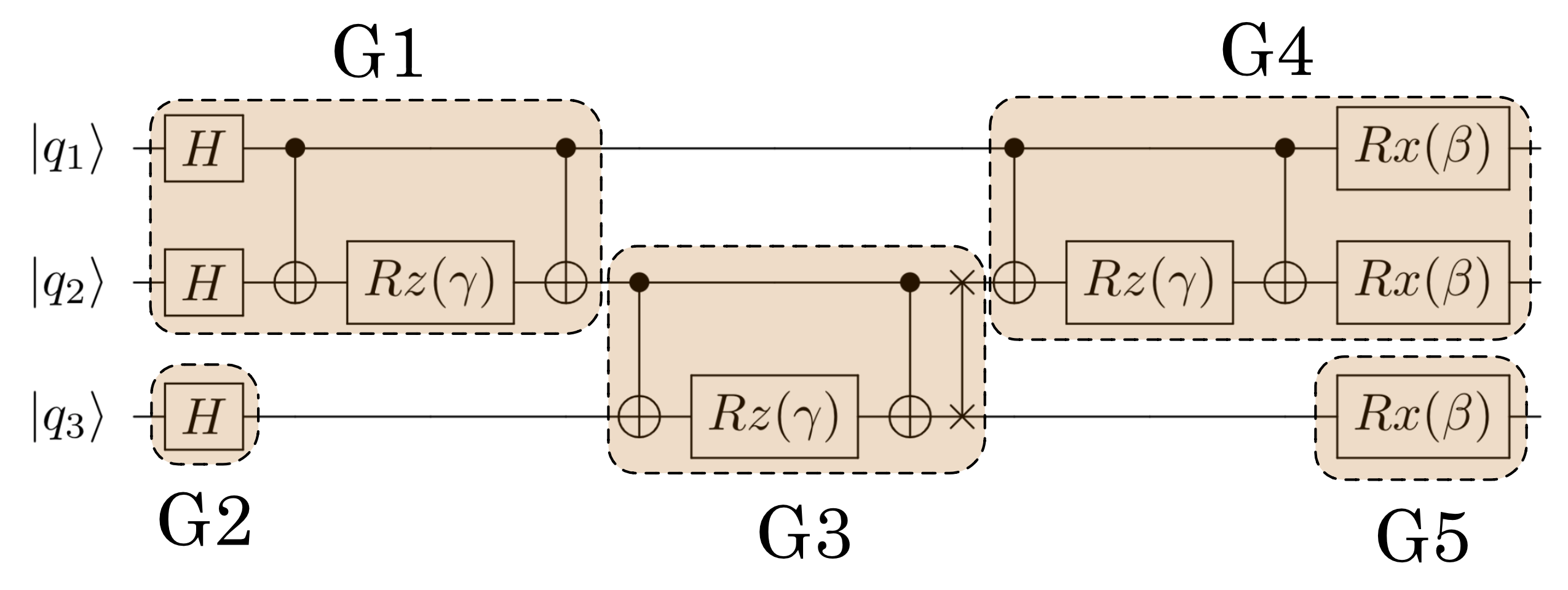
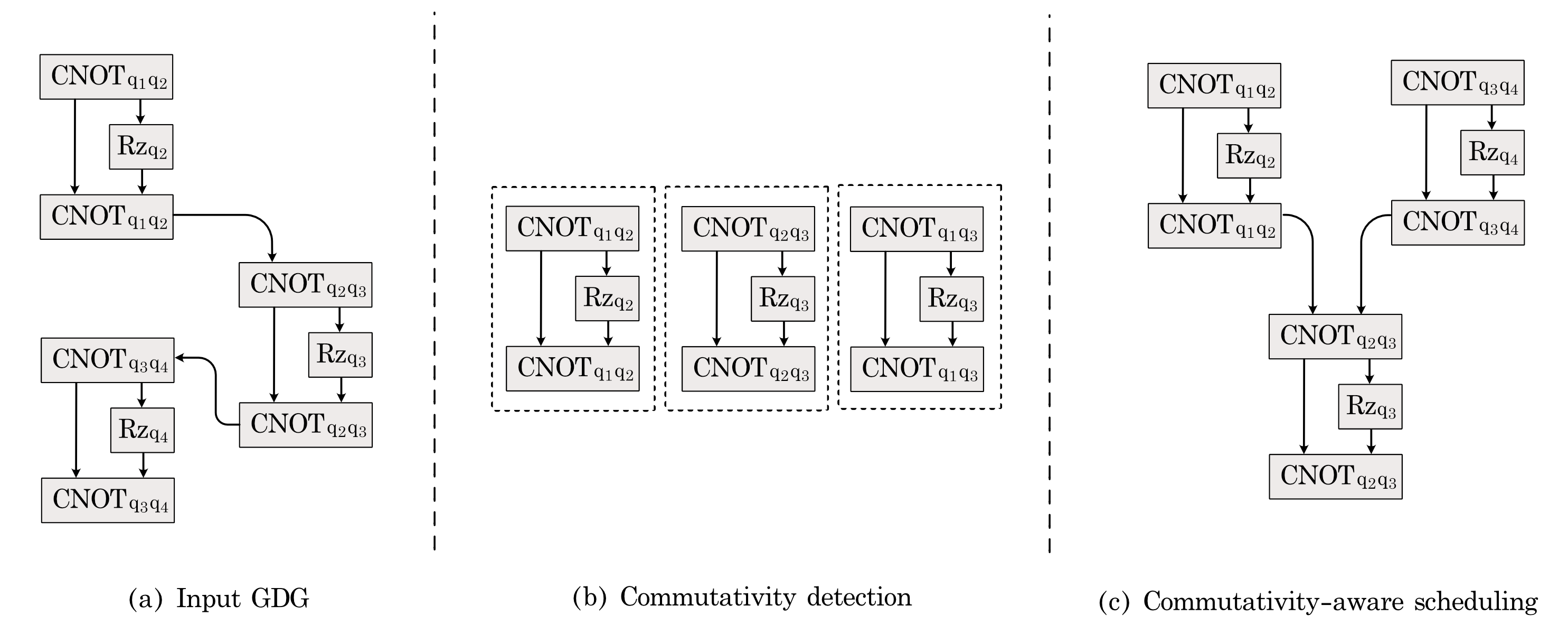
Now we give a systematic view of the workflow of our compiler. First, at the program level, our compiler performs module flattening and loop unrolling to produce the quantum assembly (QASM), which represents a schedule of the logical operations. Next, the compiler enters the commutativity detection phase. Different from the ISA-based approach, in this phase, our compilation process converts the QASM code to a more flexible logical schedule that explores the commutativity between instructions. To further explore the commutativity in the schedule, the compiler aggregates instructions in the schedule to produce a new logical schedule with instructions that represents diagonal matrices (and are of high commutativity). Then the compiler enters the scheduling and mapping phase. Because of commutativity awareness, our compiler can generate a much more efficient logical schedule by re-arranging the aggregated instructions with high commutativity. The logical schedule is then converted to a physical schedule after the qubit mapping stage. Then the compiler generates the final aggregated instructions for pulse optimization and use GRAPE for producing the corresponding control pulses. The goal of the final aggregation is to find the optimal instruction set that produces the lowest-latency control pulses while preserving the parallelism in the circuit aggregations that are small as much as possible. Finally, our compiler outputs an optimized physical schedule along with the corresponding optimized control pulses. Fig. 4 shows the Gate Dependency Graph (GDG) of the QAOA circuit in Figure 5 in different compilation stages. Next, we walk through the compilation backend with this example, starting from the commutativity detection phase.
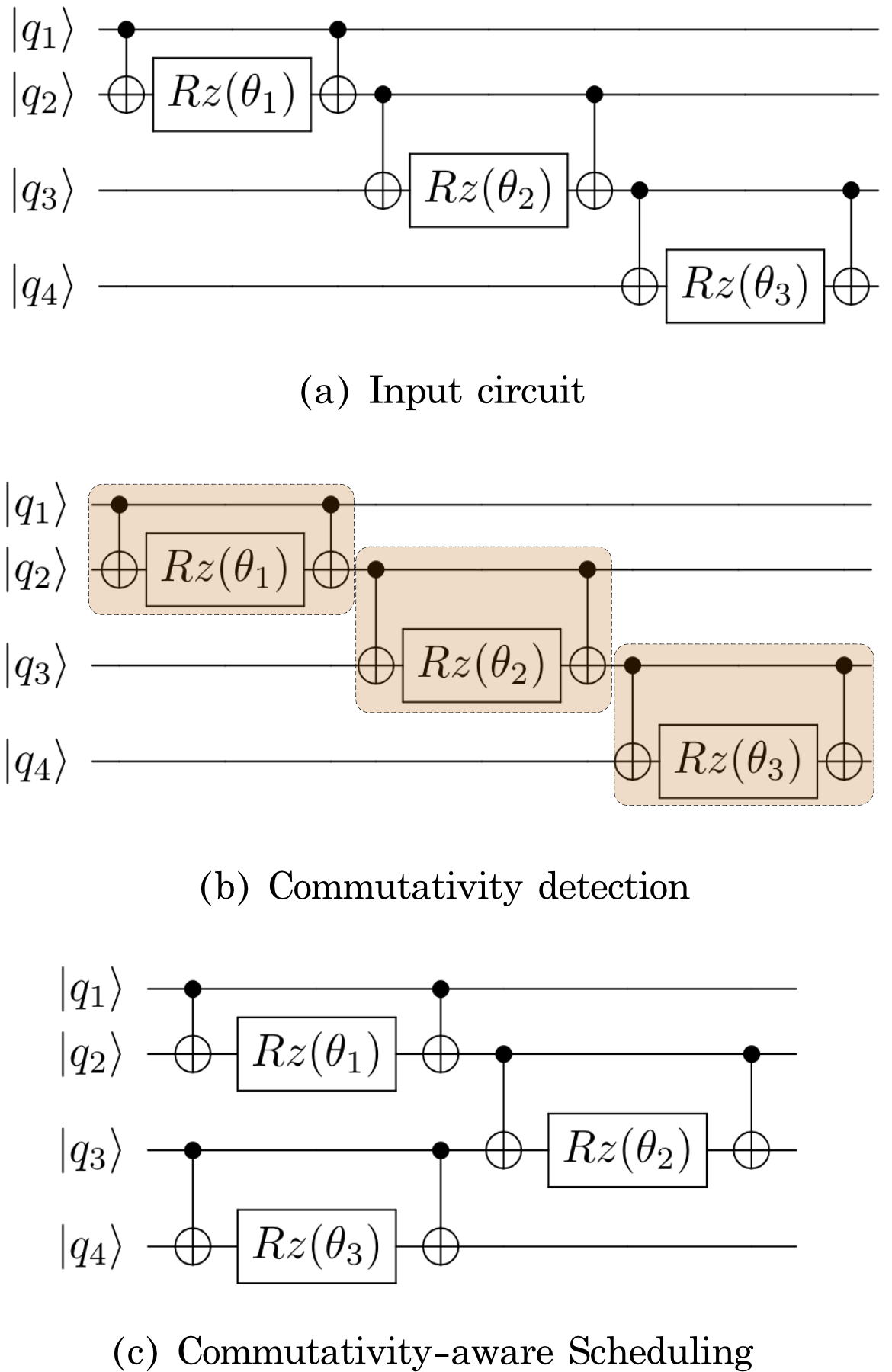
II-G1 Commutativity detection:
In the commutativity detection phase, the false dependence between commutative instructions are removed and the GDG is re-structureed. This is because if a pair of gates commutes, the gates can be scheduled in either order. Also, it can be further noticed that, in many NISQ quantum algorithms, it is ubiquitous that for instructions within an instruction block to not commute, but for the full instruction block to commute with each other [121, 130]. As an example, in Figure 5, the CNOT-Rz-CNOT instruction block commute with each other because these blocks correspond to diagonal unitary matrices. However, each individual instruction in these circuit blocks does not commute. Thus , after aggregating these instructions, the compiler is able to schedule new aggregated instructions in any order, which is impossible before. This commutativity detection procedure opens up opportunities for more efficient scheduling.
II-G2 Scheduling and mapping:
Commutativity-aware logical scheduling (CLS) In our scheduling phase, our logical scheduling algorithm is able to fully utilize the detected commutativity in the last compilation phase. The CLS iteratively schedules the available intructions on each qubits. At each iteration, the CLS draws instruction candidates that can be executed in the earlist time step to schedule.
Qubit mapping In this phase of the compilation, the compiler transform the circuit to a form that respect the topological constraints of hardware connectivity [146]. To conform to the device topology, the logical instructions are processed in two steps. First, we place frequently interacting qubits near each other by bisecting the qubit interaction graph along a cut with few crossing edges, computed by the METIS graph partitioning library [131]. Once the initial mapping is generated, two-qubit operations between non-neighboring qubits are prepended with a sequence of SWAP rearrangements that move the control and target qubits to be adjacent.
II-G3 Instruction aggregation:
In this phase, the compiler iterates with the optimal control unit to generate the final aggregated instructions for the circuit. Then, the optimal control unit optimizes each instruction individually with GRAPE.
II-G4 Physical Execution:
Finally, the circuit will be scheduled again using the CLS from Section II-G2, the physical schedules will be sent to the control unit of the underlying quantum hardware and trigger the optimized control pulses at appropriate timing and the physical execution.
II-H Discussion
In [129], we selected 9 important quantum /classical-quantum hybrid algorithms in the NISQ era as our benchmarks. Across all 9 benchmarks, our compilation scheme achieves a geometric mean of 5.07× pulse time reduction comparing to the standard gate-based compilation. The result in [129] indicates that addressing the mismatch between quantum gates and the control pulses by breaking the ISA abstraction can greatly improve the compilation efficiency. Going beyond the ISA-based compilation, this work opens up a door to new QC system designs.
III Breaking the ISA abstraction using Noise-Adaptive Compilation
In recent years, QC compute stacks have been developed using abstractions inspired from classical computing. The instruction set architecture (ISA) is a fundamental abstraction which defines the interface between the hardware and software. The ISA abstraction allows software to execute correctly on any hardware which implements the interface. This enables application portability and decouples hardware and software development.
For QC systems, the hardware-software interface is typically defined as a set of legal instructions and the connectivity topology of the qubits [17, 18, 14, 15, 16], — it does not include information about qubit quality, gate fidelity or micro-operations used to implement the ISA instructions. While technology independent abstractions are desirable in the long run, our work [12, 13] reveals that such abstractions are detrimental to program correctness in NISQ quantum computers. By exposing microarchitectural details to software and using intelligent compilation techniques, we show that program reliability can be improved significantly.
III-A Noise Characteristics of QC Systems
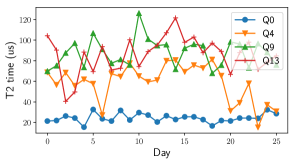
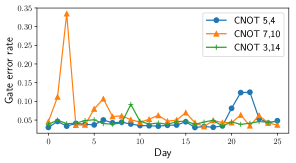
QC systems have spatial and temporal variations in noise due to manufacturing imperfections, imprecise qubit control and external interference. To motivate the necessity for breaking the ISA abstraction barrier, we present real-system statistics of hardware noise in systems from three leading QC vendors – IBM, Rigetti and University of Maryland. IBM and Rigetti systems use superconducting qubits [9, 10] and University of Maryland (UMD) uses trapped ion qubits [11]. The gates in these systems are periodically calibrated and their error rates are measured.
Figure 6 shows the coherence times and two-qubit gate error rates in IBM’s 16-qubit system (IBMQ16 Rueschlikon). From daily calibration logs we find that, the average qubit coherence time is 40 microseconds, two-qubit gate error rate is 7%, readout error rate is 4% and single qubit error rate is 0.2%. The two-qubit and readout errors are the dominant noise sources and vary up to 9X across gates and calibration cycles. Rigetti’s systems also exhibit error rates and variations of comparable magnitude. These noise variations in superconducting systems emerge from material defects due to lithographic manufacturing, and are expected in future systems also [7, 8].
Trapped ion systems also have noise fluctuations even though the individual qubits are identical and defect-free. On a 5-qubit trapped ion system from UMD, we observed up to x variation in the two-qubit gate error rates because of fundamental challenges in qubit control using lasers and their sensitivity to motional mode drifts from temperature fluctuations.
We found that these microarchitectural noise variations dramatically influence program correctness. When a program is executed on a noisy QC system, the results may be corrupted by gate errors, decoherence or readout errors on the hardware qubits used for execution. Therefore, it is crucial to select the most reliable hardware qubits to improve the success rate of the program (the likelihood of correct execution). The success rate is determined by executing a program multiple times and measuring the fraction of runs that produce the correct output. High success rate is important to ensure that the program execution is not dominated by noise.
III-B Noise-Adaptive Compilation: Key Ideas
Our work breaks the ISA abstraction barrier by developing compiler optimizations which use hardware calibration data. These optimizations boost the success rate a program run by avoiding portions of the machine with poor coherence time and operational error rates.
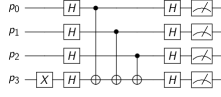
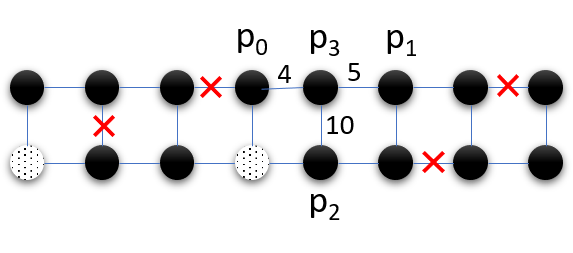
We first review the key components in a QC compiler. The input to the compiler is a high-level language program (Scaffold in our framework) and the output is machine executable assembly code. First, the compiler converts the program to an intermediate repreesentation (IR) composed of single and two-qubit gates by decomposing high-level QC operations, unrolling all loops and inlining all functions. Figure 7a shows an example IR. The qubits in the IR (program qubits) are mapped to distinct qubits in the hardware, typically in a way that reduces qubit communication. Next, gates are scheduled while respecting data dependencies. Finally, on hardware with limited connectivity, such as superconducting systems, the compiler inserts SWAP operations to enable 2-qubit operations between non-adjacent qubits.
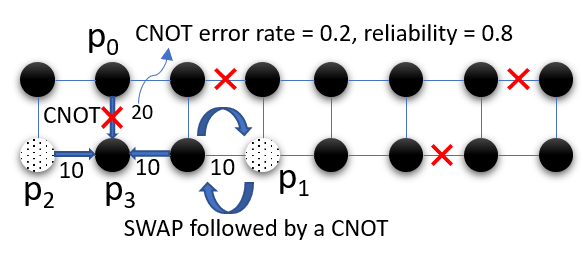
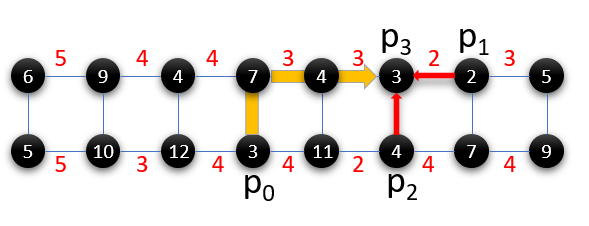
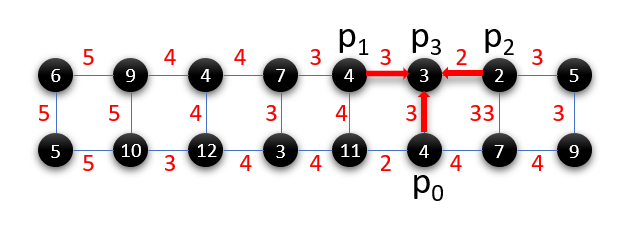
Figure 7b and 7c show two compiler mappings for a 4-qubit program on IBM’s 16-qubit system. In the first mapping, the compiler must insert SWAPs to perform the two-qubit gate between and . Since SWAP operations are composed of three two-qubit gates, they are highly error prone. In contrast, the second mapping requires no SWAPs because the qubits required for the CNOTs are adjacent. While SWAP optimizations can be performed using the device ISA, the second mapping is also noise-optimized i.e., it uses qubits with high coherence time and low operational error rates. By considering microarchitectural noise characteristics, our compiler can determine such noise-optimized mappings to improve the program success rate.
We developed three strategies for noise optimization. First, our compiler maps program qubits onto hardware locations with high reliability, based on the noise data. We choose the initial mapping based on two-qubit and readout error rates because they are the dominant sources of error. Second, to mitigate decoherence errors, all gates are scheduled to finish before the coherence time of the hardware qubits. Third, our compiler optimizes the reliability of SWAP operations by minimizing the number of SWAPs whenever possible and performing SWAPs along reliable hardware paths.
III-C Implementation using SMT Optimization
Our compiler implements the above strategies by finding the solution to a constrained optimization problem using a Satisfiability Modulo Theory (SMT) solver. The variables and constraints in the optimization encode program information, device topology constraints and noise information. The variables express the choices for program qubit mappings, gate start times and routing paths. The constraints specify that qubit mappings should be distinct, the schedule should respect program dependencies and that routing paths should be non-overlapping. Fig. 8 summarizes the optimization-based compilation pipeline for IBMQ16.
The objective of our optimization is to maximize the success rate of a program execution. Since the success rate can only be determined from a real-system run, we model it at compile time as the program reliablity. We define the reliability of a program as the product of the reliability of all gates in the program. Although this is not a perfect model for the success rate, it serves as a useful measure of overall correctness [140, 6]. For a given mapping, the solver determines the reliability of each two-qubit and readout operation and computes an overall reliability score. The solver maximizes the reliability score over all mappings by tracking and adapting to the error rates, coherence limits, and qubit movement based on program qubit locations.
In practice, we use the Z3 SMT solver to express and solve this optimization. Since the reliability objective is a non-linear product, we linearize the objective by optimizing for the additive logarithms of the reliability scores of each gate. We term this algorithm as R-SMT★. The output of the SMT solver is used to create machine executable code in the vendor-specified assembly language.
III-D Real-System Evaluation
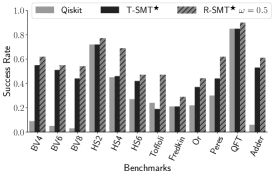
We present real-system evaluation on IBMQ16. Our evaluation uses 12 common QC benchmarks, compiled using R-SMT★and T-SMT★ which are variants of our compiler and IBM’s Qiskit compiler (version 0.5.7) [5] which is the default for this system. R-SMT★ optimizes the reliability of the program using hardware noise data. T-SMT★ optimizes the execution time of the program considering real-system gate durations and coherence times, but not operational error rates. IBM Qiskit is also noise-unaware and uses randomized algorithms for SWAP optimization. For each benchmark and compiler, we measured the success rate on IBMQ16 system using 8192 trials per program. Success rate of 1 indicates a perfect noise-free execution.
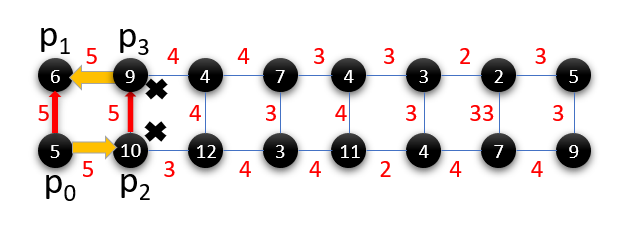
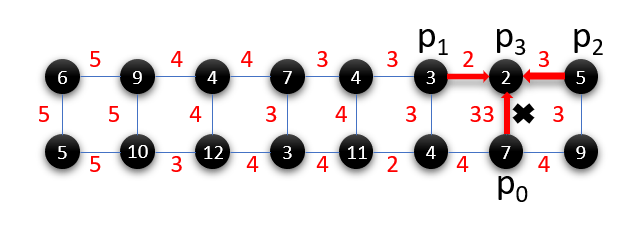
Figure 10 shows the success rate for the three compilers on all the benchmarks. R-SMT★ has higher success rate than both baselines on all benchmarks, demonstrating the effectiveness of noise-adaptive compilation. Across benchmarks R-SMT★ obtains geomean x improvement over Qiskit, with up to x gain. Figure 9 shows the mapping used by Qiskit, T-SMT★and R-SMT★for BV4. Qiskit places qubits in a lexicographic order without considering CNOT and readout errors and incurs extra swap operations. Similarly, T-SMT★is also unaware of noise variations across the device, resulting in mappings which use unreliable hardware. R-SMT★outperforms these baselines because it maximizes the likelihood of reliable execution by leveraging microarchitectural noise characteristics during compilation.
III-E Discussion
Our work represents one of the first efforts to exploit hardware noise characteristics during compilation. We developed optimal and heuristic techniques for noise adaptivity and performed comprehensive evaluations on several real QC systems [13]. We also developed techniques to mitigate crosstalk, another major source of errors in QC systems, using compiler techniques that schedule programs using crosstalk characterization data from the hardware [89]. In addition, our techniques are already being used in industry toolflows [20, 19]. Recognizing the importance of efficient compilation, other research groups have also recently developed mapping and routing heuristics [3, 4] and techniques to handle noise [2, 1].
Our noise-adaptivity optimizations offer large gains in success rate. These gains mean the difference between executions which yield correct and usable results and executions where the results are dominated by noise. These improvements are also multiplicative against benefits obtained elsewhere in the stack and will be instrumental in closing the gap between near-term QC algorithms and hardware. Our work also indicates that it is important to accurately characterize hardware and expose characterization data to software instead of hiding it behind a device-independent ISA layer. Additionally our work also proposes that QC programs should be compiled once-per-execution using the latest hardware characterization data to obtain the best executions.
Going beyond noise characteristics, we also studied the importance of exposing other microarchitectural information to software. We found that when the compiler has access to the native gates available in the hardware (micro operations used to implement ISA-level gates), it can further optimize programs and improve success rates. Overall, our work indicates that QC machines are not yet ready for technology independent abstractions that shield the software from hardware. Bridging the information gap between software and hardware by breaking abstraction barriers will be increasingly important on the path towards practically useful NISQ devices.
IV Breaking the Qubit Abstraction via the Third Energy Level
While quantum computation is typically expressed with the two-level binary abstraction of qubits, the underlying physics of quantum systems are not intrinsically binary. Whereas classical computers operate in binary states at the physical level (e.g. clipping above and below a threshold voltage), quantum computers have natural access to an infinite spectrum of discrete energy levels. In fact, hardware must actively suppress higher level states in order to realize an engineered two-level qubit approximation. In this sense, using three-level qutrits (quantum trits) is simply a choice of including an additional discrete energy level within the computational space. Thus, it is appealing to explore what gains can be realized by breaking the binary qubit abstraction.
In prior work on qutrits (or more generally, d-level qudits), researchers identified only constant factor gains from extending beyond qubits. In general, this prior work [103] has emphasized the information compression advantages of qutrits. For example, qubits can be expressed as qutrits, which leads to -constant factor improvements in runtimes.
Recently however, our research group demonstrated a novel qutrit approach that leads to exponentially faster runtimes (i.e. shorter in circuit depth) than qubit-only approaches [37, 38]. The key idea underlying the approach is to use the third state of a qutrit as temporary storage. Although qutrits incur higher per-operation error rates than qubits, this is compensated by dramatic reductions in runtimes and quantum gate counts. Moreover, our approach only applies qutrit operations in an intermediary stage: the input and output are still qubits, which is important for initialization and measurement on practical quantum devices [50, 51].
The net result of our work is to extend the frontier of what quantum computers can compute. In particular, the frontier is defined by the zone in which every machine qubit is a data qubit, for example a 100-qubit algorithm running on a 100-qubit machine. In this frontier zone, we do not have space for non-data workspace qubits known as ancilla. The lack of ancilla in the frontier zone is a costly constraint that generally leads to inefficient circuits. For this reason, typical circuits instead operate below the frontier zone, with many machine qubits used as ancilla. Our work demonstrates that ancilla can be substituted with qutrits, enabling us to operate efficiently within the ancilla-free frontier zone.
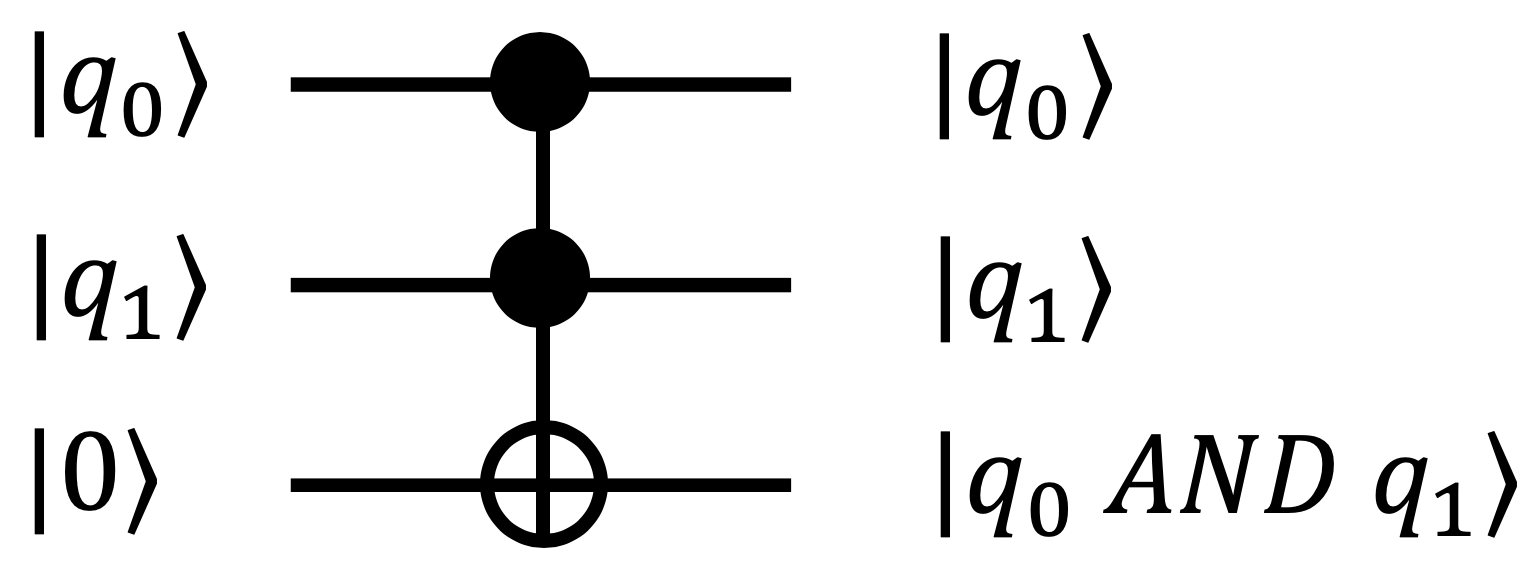
IV-A Qutrit-Assisted AND Gate
We develop the intuition for how qutrits can be useful by considering the example of constructing an AND gate. In the framework of quantum computing, which requires reversibility, AND is not permitted directly. For example, consider the output of 0 from an AND gate with two inputs. With only this information about the output, the value of the inputs cannot be uniquely determined (00, 01, and 10 all yield an AND output of 0). However, these operations can be made reversible by the addition of an extra, temporary workspace bit initialized to 0. Using a single additional such ancilla, the AND operation can be computed reversibly as in Figure 11. While this approach works, it is expensive—in order to decompose the Toffoli gate in Figure 11 into hardware-implementable one- and two- input gates, it is decomposed into at least six CNOT (controlled-NOT) gates.
However, if we break the qubit abstraction and allow occupation of a higher qutrit energy level, the cost of the Toffoli AND operation is greatly diminished. Before proceeding, we review the basics of qutrits, which have three computational basis states: , , and . A qutrit state may be represented analogously to a qubit as , where . Qutrits are manipulated in a similar manner to qubits; however, there are additional gates which may be performed on qutrits. We focus on the and operations, which are addition and subtraction gates, modulo 3. For example elevates to and elevates to , while wrapping to .
Just as single-qubit gates have qutrit analogs, the same holds for two-qutrit gates. For example, consider the CNOT operation, where an X gate is performed conditioned on the control being in the state. For qutrits, an or gate may be performed, conditioned on the control being in any of the three possible basis states. Just as qubit gates are extended to take multiple controls, qutrit gates are extended similarly.
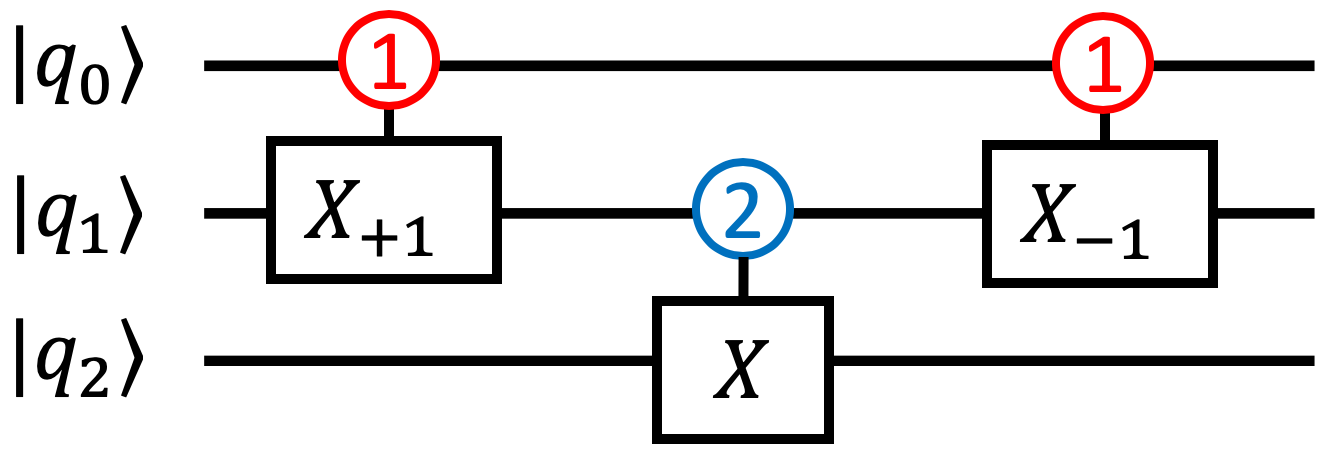
In Figure 12, a Toffoli decomposition using qutrits is given. A similar construction for the Toffoli gate is known from past work [95, 96]. The goal is to perform an X operation on the last (target) input qubit if and only if the two control qubits, and , are both . First a -controlled is performed on and . This elevates to iff and were both . Then a -controlled gate is applied to . Therefore, is performed only when both and were , as desired. The controls are restored to their original states by a -controlled gate, which undoes the effect of the first gate. The key intuition in this decomposition is that the qutrit state can be used instead of ancilla to store temporary information.
IV-B Generalized Toffoli Gate
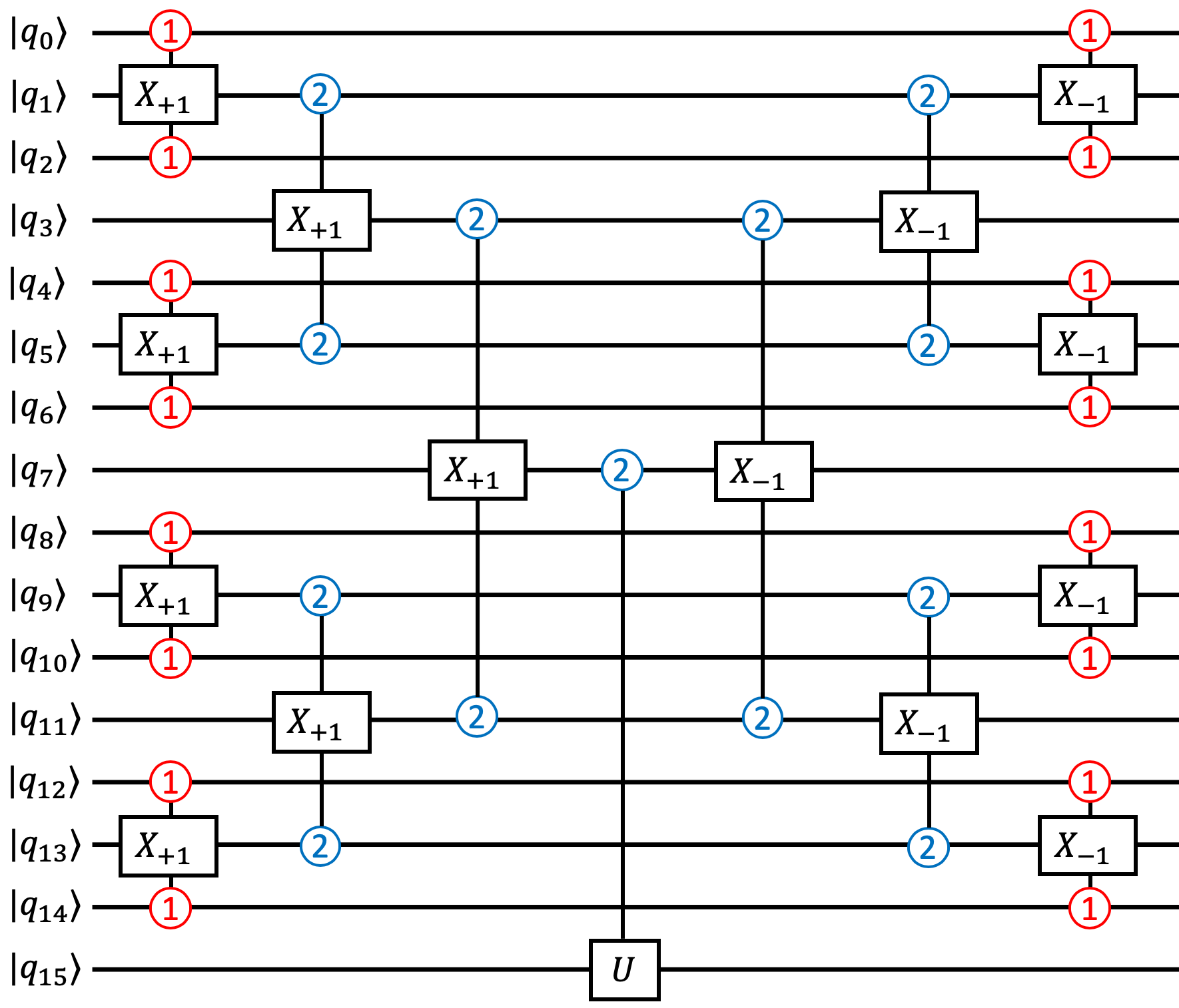
The intuition of our technique extends to more complicated gates. In particular, we consider the Generalized Toffoli gate, a ubiquitous quantum operation which extends the Toffoli gate to have any number of control inputs. The target input is flipped if and only if all of the controls are activated. Our qutrit-based circuit decomposition for the Generalized Toffoli gate is presented in Figure 13. The decomposition is expressed in terms of three-qutrit gates (two controls, one target) instead of single- and two- qutrit gates, because the circuit can be understood purely classically at this granularity. In actual implementation and in our simulation, we used a decomposition [77] that requires 6 two-qutrit and 7 single-qutrit physically implementable quantum gates.
Our circuit decomposition is most intuitively understood by treating the left half of the the circuit as a tree. The desired property is that the root of the tree, , is if and only if each of the 15 controls was originally in the state. To verify this property, we observe the root can only become iff was originally and and were both previously . At the next level of the tree, we see could have only been if was originally and both and were previously , and similarly for the other triplets. At the bottom level of the tree, the triplets are controlled on the state, which are only activated when the even-index controls are all . Thus, if any of the controls were not , the states would fail to propagate to the root of the tree. The right half of the circuit performs uncomputation to restore the controls to their original state.
After each subsequent level of the tree structure, the number of qubits under consideration is reduced by a factor of . Thus, the circuit depth is logarithmic in , which is exponentially smaller than ancilla-free qubit-only circuits. Moreover, each qutrit is operated on by a constant number of gates, so the total number of gates is linear in .
We verified our circuits, both formally and via simulation. Our verification scripts are available on our GitHub [74].
IV-C Simulation Results
| QUBIT | QUBIT+ANCILLA | QUTRIT | |
|---|---|---|---|
| Depth | |||
| Gate Count |
Table I shows the scaling of circuit depths and two-qudit gate counts for all three benchmarked circuits. The QUBIT-based circuit constructions from past work are linear in depth and have a high linearity constant. Augmenting with a single borrowed ancilla (QUBIT+ANCILLA) reduces the circuit depth by a factor of 8. However, both circuit constructions are significantly outperformed by our QUTRIT construction, which scales logarithmically in and has a relatively small leading coefficient. While there is not an asymptotic scaling advantage for two-qudit gate count, the linearity constant for our QUTRIT circuit is 70x smaller than for the equivalent ancilla-free QUBIT circuit.
We ran simulations under realistic superconducting and trapped ion device noise. The simulations were run in parallel on over 100 n1-standard-4 Google Cloud instances. These simulations represent over 20,000 CPU hours, which was sufficient to estimate mean fidelity to an error of for each circuit-noise model pair.
The full results of our circuit simulations are shown in Figure 14. All simulations are for the 14-input (13 controls, 1 target) Generalized Toffoli gate. We simulated each of the three circuit benchmarks against each of our noise models (when applicable), yielding the 16 bars in the figure. Notice that our qutrit circuit consistently outperforms qubit circuits, with advantages ranging from 2x to 10,000x.
IV-D Discussion
The results presented in our work in [37, 38] are applicable to quantum computing in the near term, on machines that are expected within the next five years. By breaking the qubit abstraction barrier, we extend the frontier of what is computable by quantum hardware right now, without needing to wait for better hardware. As verified by our open-source circuit simulator coupled with realistic noise models, our circuits are more reliable than qubit-only equivalents, suggesting that qutrits offer a promising path towards scaling quantum computers. We propose further investigation into what advantage qutrits or qudits may confer. More broadly, it is critical for quantum architects to bear in mind that standard abstractions in classical computing do not necessarily transfer to quantum computation. Often, this presents unrealized opportunities, as in the case of qutrits.
V Breaking the Qubit Abstraction via the GKP Encoding
Currently, there are many competing physical qubit implementations. For example, the transmon qubits [21] are encoded in the lowest two energy levels of the charge states in superconducting LC circuits with Josephson junctions; Trapped ion qubits can be encoded in two ground state hyperfine levels [22] or a ground state level and an excited level of an ion [23]; quantum dot qubits use electron spin triplets [31]. These QIP platfroms have rather distinct physical characteristics, but they are all exposed to the other layers in the stack as qubits and other implementation details are often hidden. This abstraction is natural for classical computing stack because that the robustness of classical bits decouples the programming logic from physical properties of the transistors except the logical value. In contrast, qubits are fragile so there are more than (superpositions of) the logical values that we want to know about the implementation. For example, in the transmon qubits and trapped ion qubits, logical states can be transferred to higher levels of the physical space by unwanted operations and this can cause leakage errors [27, 25]. It will be useful for other layers in the stack to access this error information and develop methods to mitigate it. In the previous section we discussed the qutrit approach that directly uses the third level for information processing, however, it could be more interesting if we can encode the qubit (qudit) using the whole physical Hilbert space to avoid leakage errors systematically and use the redundant degrees of freedom to reveal information about the noise in the encoding. The encoding proposed by Gottesman, Kitaev and Preskill (GKP) [24] provides such an example. GKP encoding is free of leakage errors and other errors (in the form of small shifts in phase space) can be identified and corrected by Quantum Non-Demolition (QND) measurements and simple linear optical operations. In realistic implementations of approximate GKP states (Section V-C), there are leakage errors between logical states, but the transfer probability is estimated to be at the order of with current techonology, thus negligible.
V-A The phase space diagram
We describe the GKP qubits in the phase space. For a comparison, we first discuss the phase space diagram for a classical harmonic oscillator and a superconducting qubit.
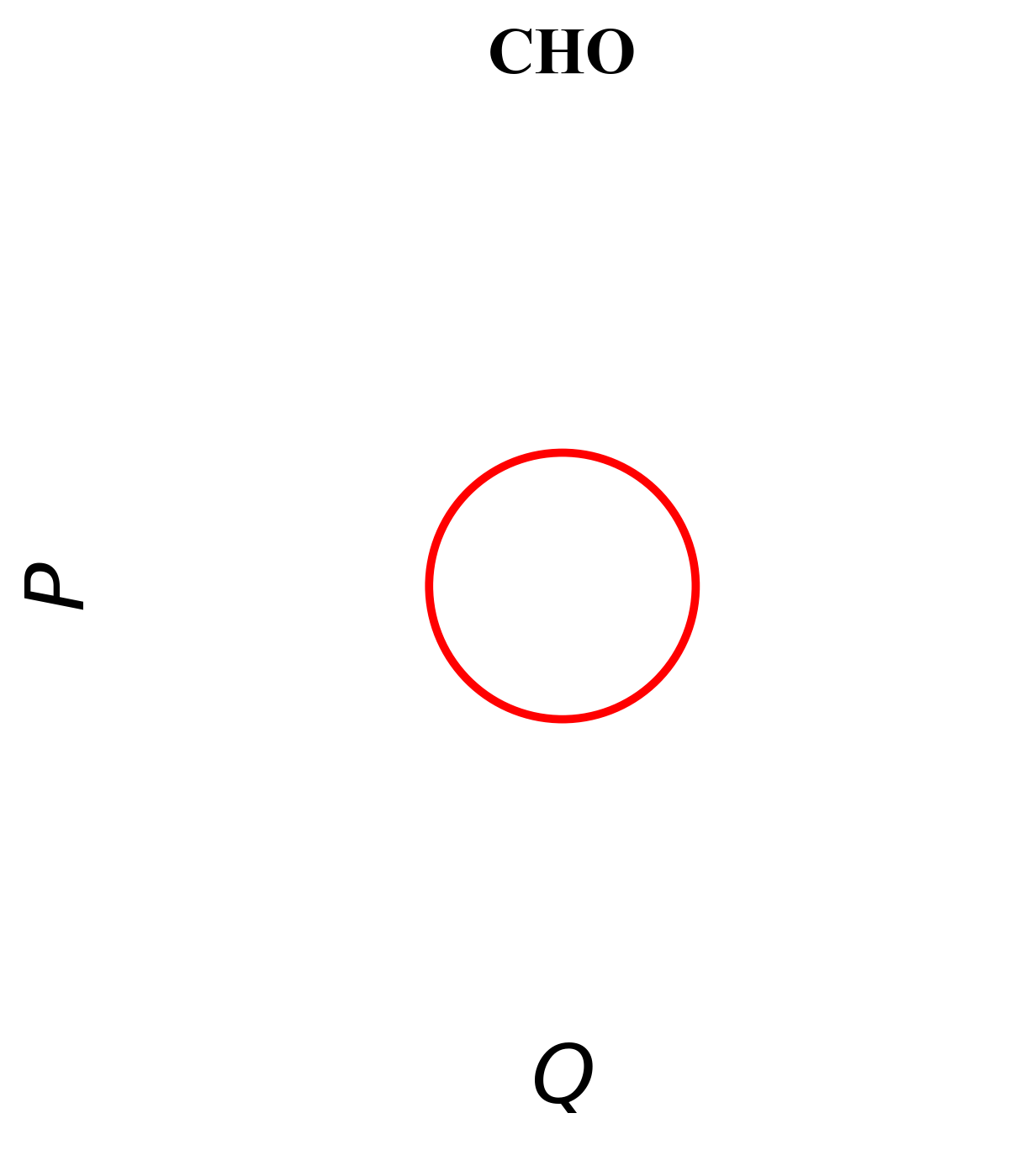
Classical Harmonic Oscillators Examples of Classical Harmonic Oscillators (CHO) include LC circuits, springs and pendulums with small displacement. The voltage/displacement (denoted as ) and the current/momentum (denoted as ) value completely characterize the dynamics of CHO systems. The phase space diagram plots vs , which for CHOs are circles (up to normalization) with the radius representing the system energy. The energy of CHOs can be any non-negative real value.
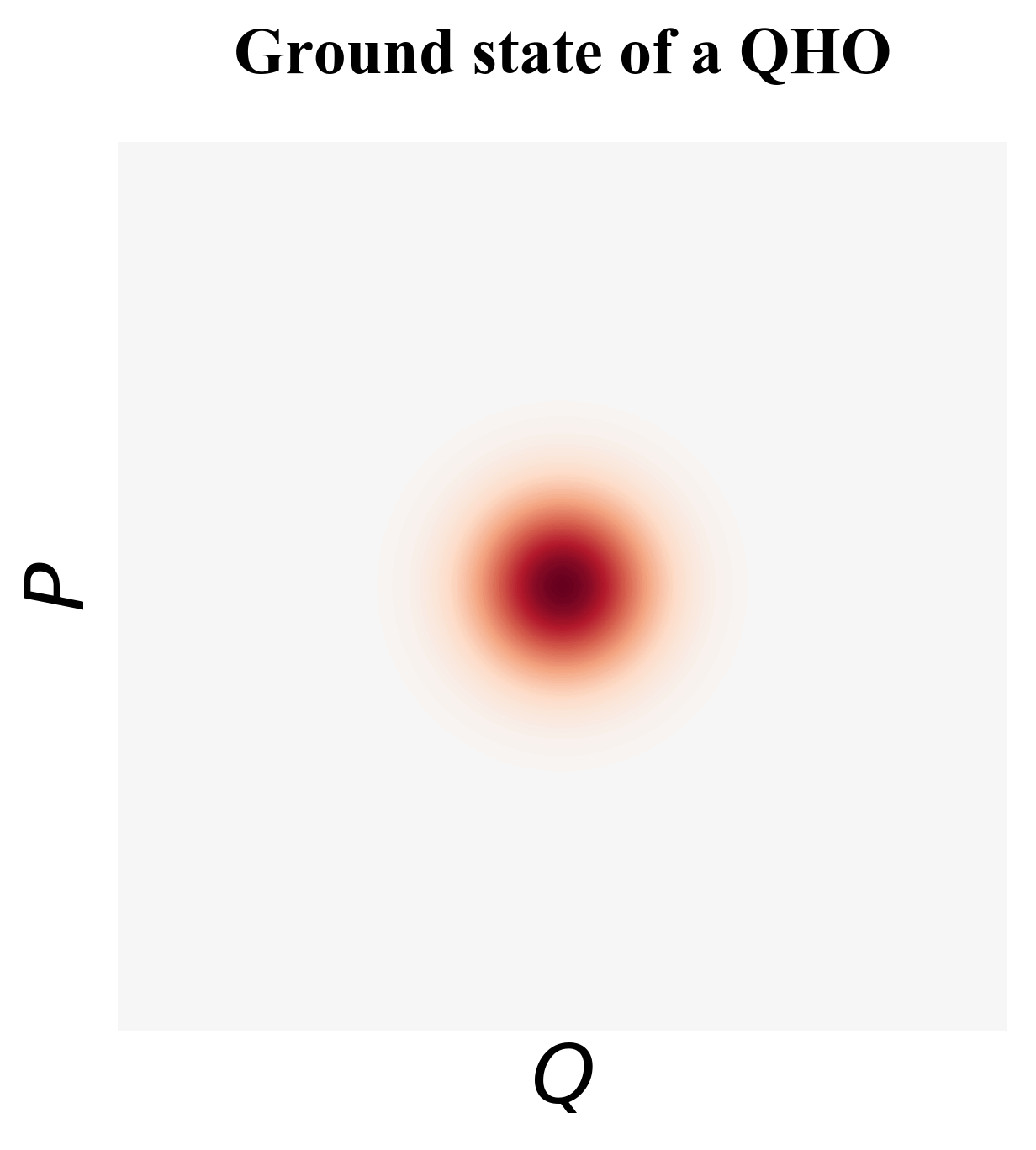
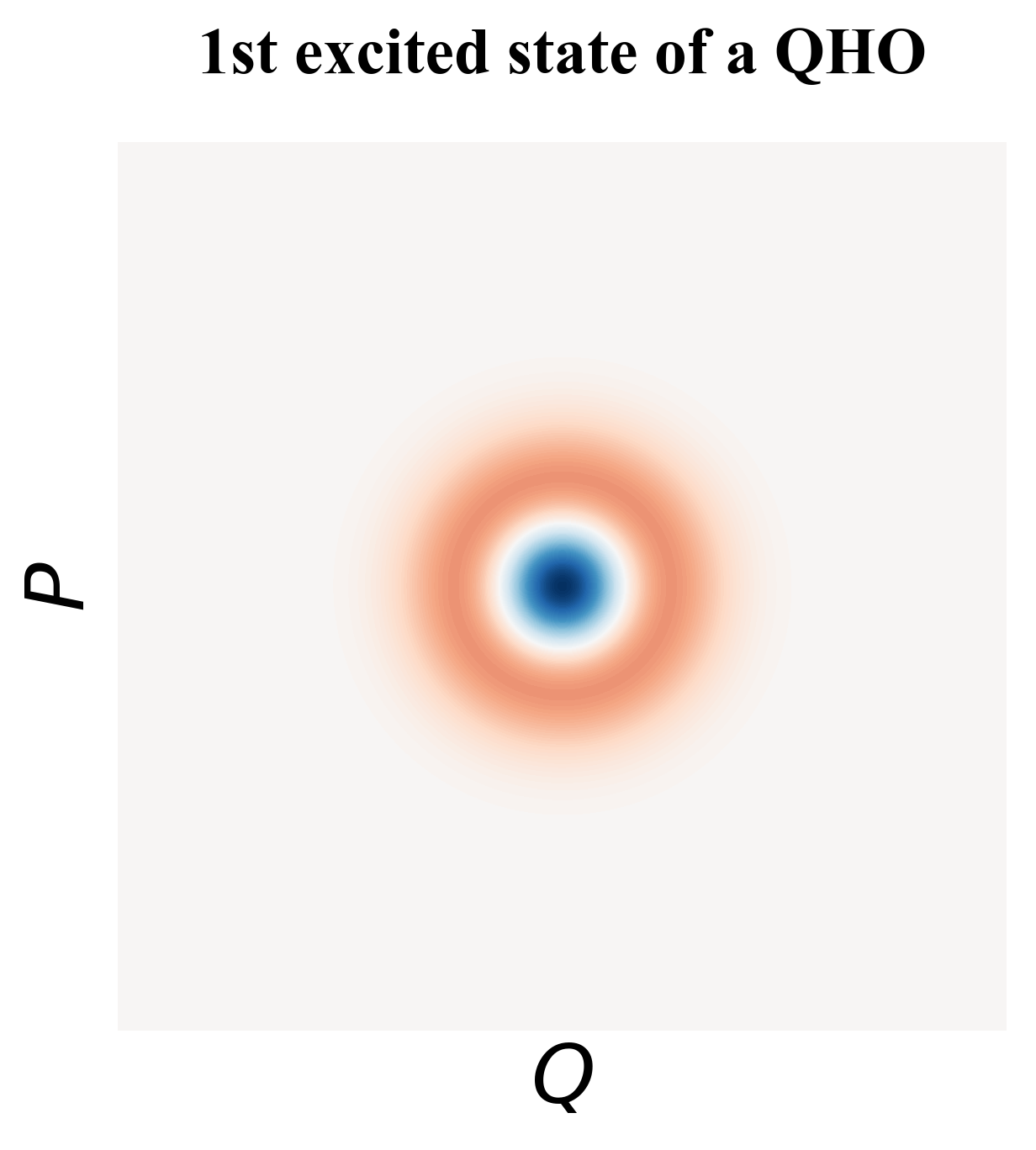
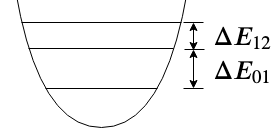
Quantum Harmonic Oscillators The Quantum Harmonic Oscillator is the quantized verision of the CHO and is the physical model for superconducting LC circuits and superconducting cavity modes. One of the values get quantized for QHOs is the system energy, which can only take equally-spaced non-zero discrete values. The lowest allowed energy is not 0 but (up to normalization). We call the quantum state with the lowest energy the ground state. For a motion with a certain energy, the phase space diagram is not a circle anymore but a quasi-distribution that can be described by the Wigner function. We say the distribution is a “quasi" distribution because the probability can be negative. The phase space diagram for the ground state and first excited state is plot in Fig. 15.

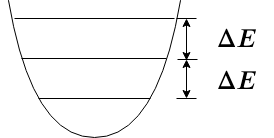
Superconducting Charge Qubits The QHO does not allow us selectively address the energy levels, thus leakage errors will occur if we use the lowest two levels as the qubit logic space. For example, a control signal that provides the energy difference enables the transition , but will also make the transition which brings the state out of the logic space. To avoid this problem, the Cooper Pair Box (CPB) design of a superconducting charge qubit replaces the inductor (see Fig. 17) with a Josephson junction, making the circuit an anharmonic oscillator, in which the energy levels are not equally spaced anymore. The Wigner function for CPB eigenstates are visually similar to those of QHO and only differ from them to the first order of the anharmonicity, thus we do not plot them in Fig. 15 separately.

V-B The Heisenberg uncertainty principle
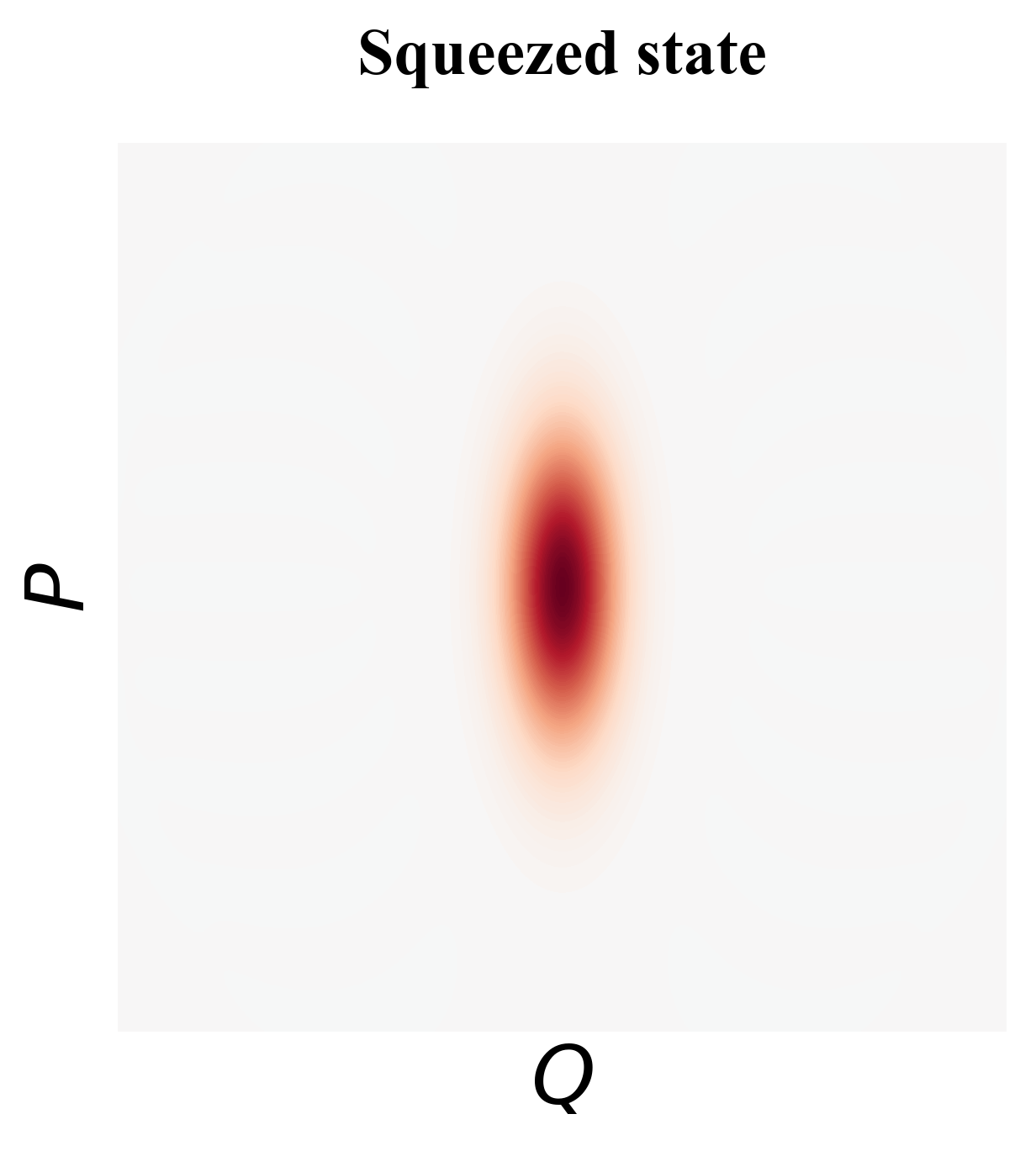
We hope that with utilizing the whole physical states (higher energy levels), we can use the redundant space to encode and extract error information. However, the Heisenberg uncertainty principle sets the fundamental limit on what error information we can extract from the physical states — the more we know about the variable, the less we know about the variable. For example, we can “squeeze" the ground state of the QHO (also known as the vacuum state) in the direction, however, the distribution in the direction spreads, as shown in Fig. 18. Usually, we have to know both the and value to characterize the error information unless we know the error is biased. Thus, it’s a great challenge to design encodings in the phase space to reveal error information.
V-C The GKP encoding
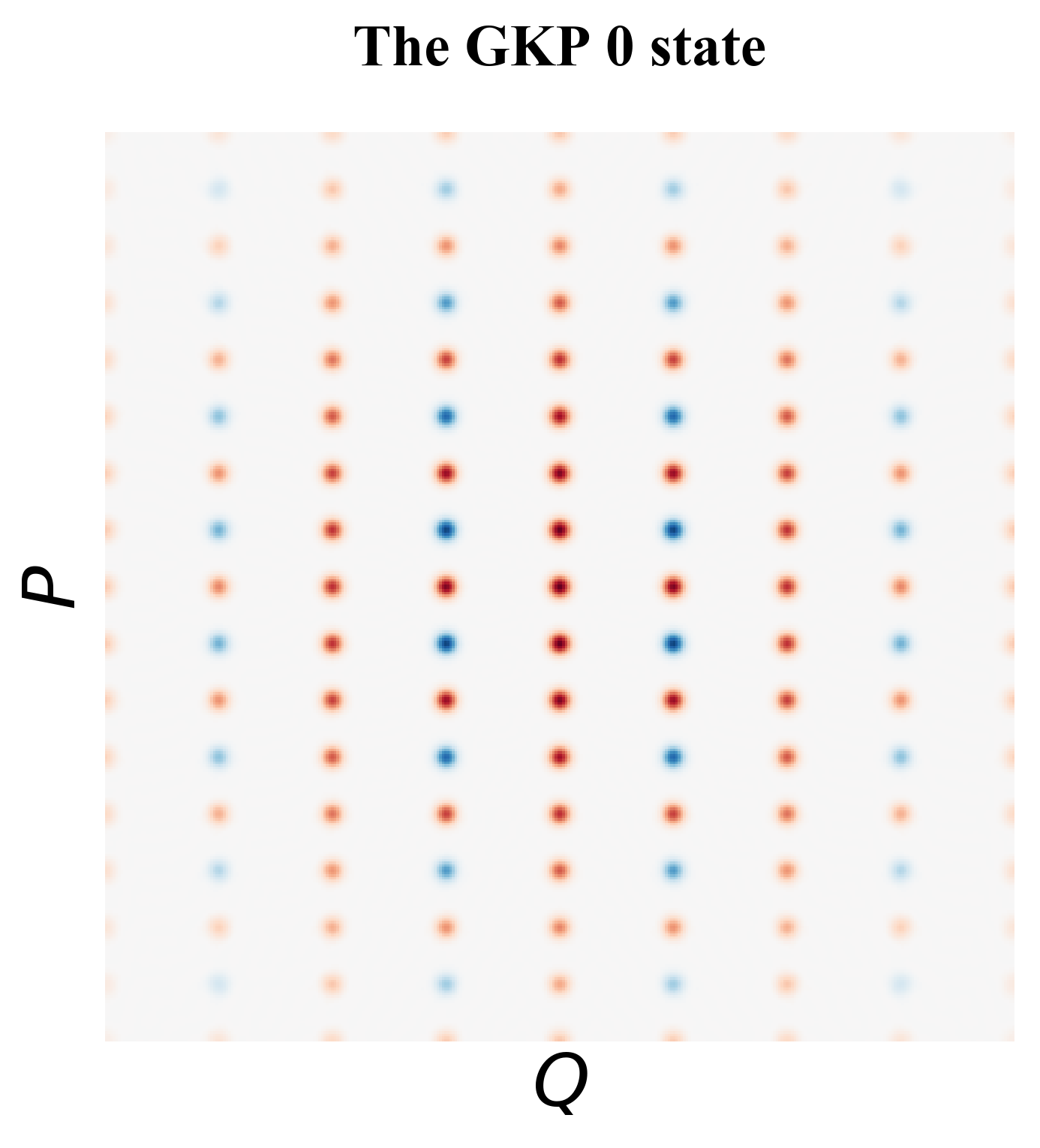
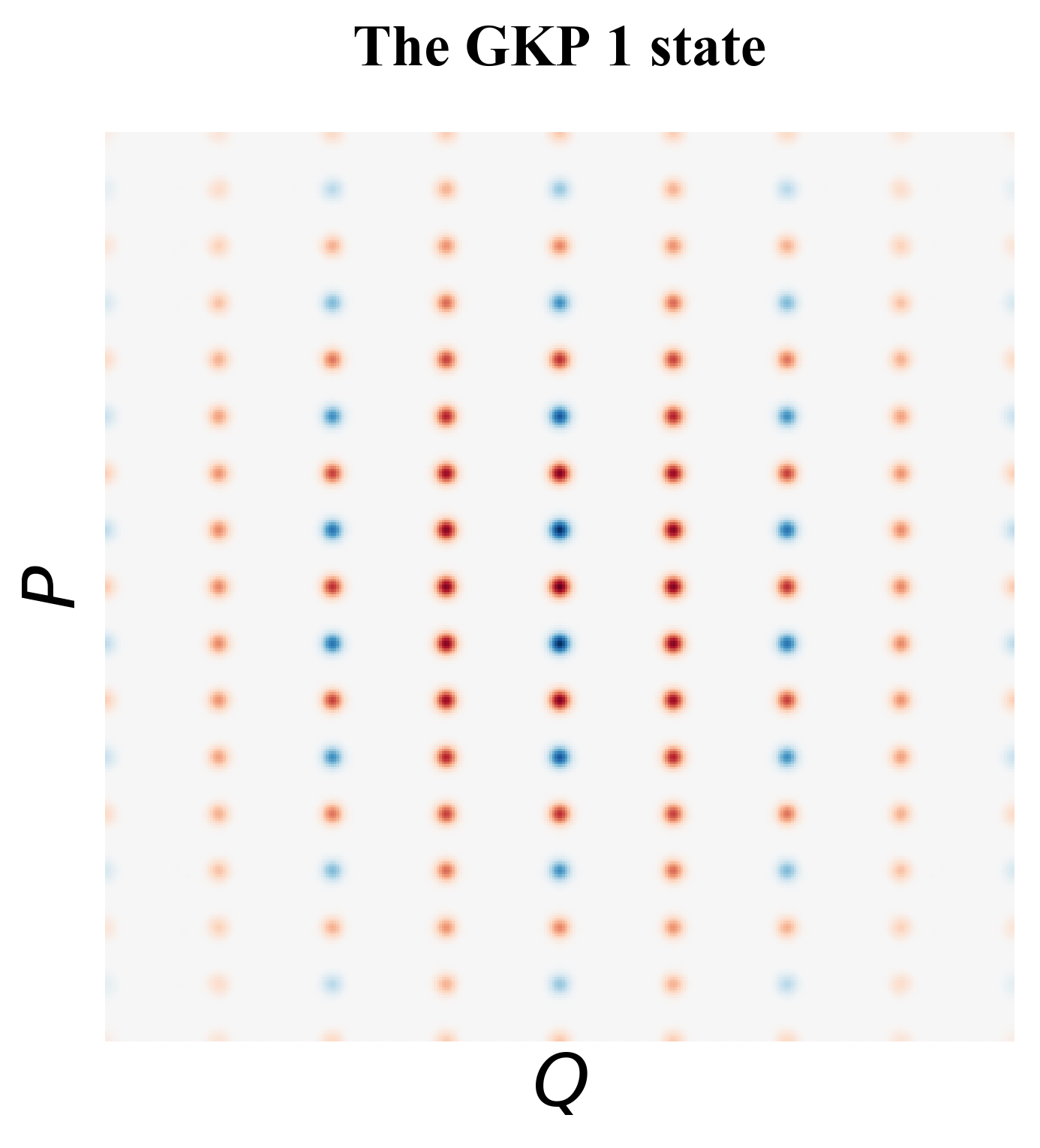
The GKP states are also called the grid states because each of them is a rectangular lattice in the phase space (see Fig. 15). There are also other types of lattice in the GKP family, for example, the hexagonal GKP [24]. Intuitively, the GKP encoding “breaks" the Heisenberg uncertainty principle—we do not know what are the measured and values of the state (thus expected values of and remain uncertain), but we do know that they must be integer multiples of the spacing of the grid. Thus, we have access to the error information in both directions and if we measure values that are not multiples of the spacing of the grid, we know there must be errors. Formally, the ideal GKP logical states are given by,
| (1) |
where is the displacement operator in space, which shift a wave function in the direction by 2. These definitions show that for GKP logical 0 and 1, the spacing of the grid in direction is and the spacing in the is . In direction, the logical state has peaks at even multiples of and the logical state has peaks at odd multiples of . For logical and , the spacing in and grid s are switched.
Approximate GKP states The ideal GKP states require infinite energy thus are not realistic. In the lab, we can prepare approximate GKP states as illustrated in Fig. 19, where peaks and the envelope are Gaussian curve.


Error correction with GKP qubits GKP qubits are designed to correct shift errors in and axis. A simple decoding strategy will be shifting the GKP state back to the closest peak. For example, if we measure a value to be , where , then we can shift it back to . With this simple decoding, GKP can correct all shift errors smaller than . While there are other proposals for encoding qubits in QHO [32, 29, 33] that are designed for realistic errors such as photon loss, it is shown that GKP qubits have the most error correcting ability in the regime of experimental relevance [28].
In addition, GKP qubits can also provide error correction information when concatenating with Quantum Error Correction Codes (QECC) and yield higher thresholds. For example, when combing the GKP qubits with a surface code, the measured continuous and value in the stabilizer measurement can reveal more about the error distribution than traditional qubits [34, 35, 36].
Lastly, it has been shown that given a supply of GKP-encoded Pauli eigenstates, universal fault-tolerant quantum computation can be achieved using only Gaussian operations [132]. Comparing to qubit error correction codes, the GKP encoding enables much simpler fault-tolerant constructions.
V-D Fault-Tolerant Preparation of Approximate GKP States
The GKP encoding has straightforward logical operation and promising error correcting performance. However, the difficulty of using GKP qubits in QIP platforms lies in its preparation since they live in highly non-classical states with relatively high mean photon number ( the average energy levels). Thus, realiable preparation of encoded GKP states is an important problem. In [133], we gave fault-tolerance definitions for GKP preparation in superconducting cavities and designed a protocol that fault-tolerantly prepares the GKP states. We briefly describe the main ideas.
V-D1 Goodness of approximate GKP states
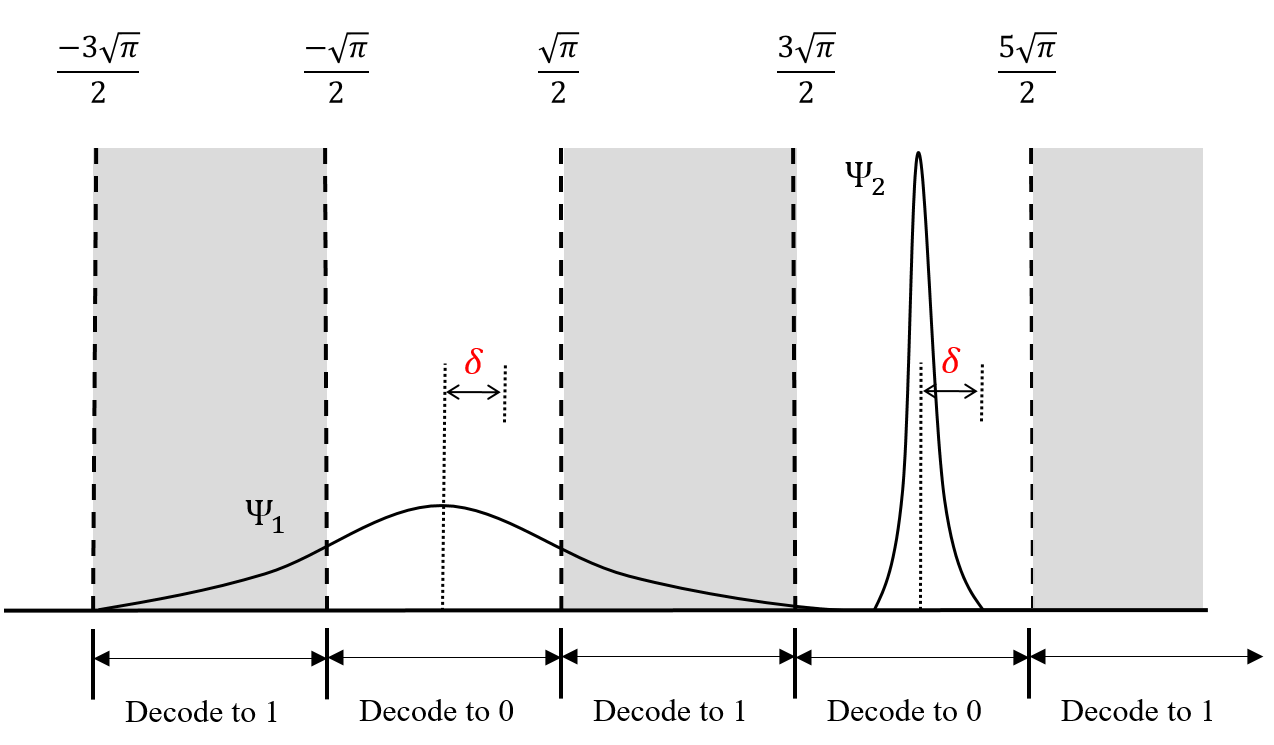
Naturally because of the finite width of the peaks of approximate GKP states, it will not be possible to correct a shift error in or of magnitude at most with certainty. For example, suppose we have an approximate GKP state with a peak at subject to a shift error with . The finite width of the Gaussian peaks will have a non-zero overlap in the region and . Thus with non-zero probability the state can be decoded to instead of (see Fig. 20 for an illustration).
In general, if an approximate GKP state is afflicted by a correctable shift error, we would like the probability of decoding to the incorrect logical state to be as small as possible. A smaller overlap of the approximate GKP state in regions in and space that lead to decoding the state to the wrong logical state will lead to a higher probability of correcting a correctable shift error by a perfect GKP state.
V-D2 Preparation of approximate GKP states using Phase Estimation
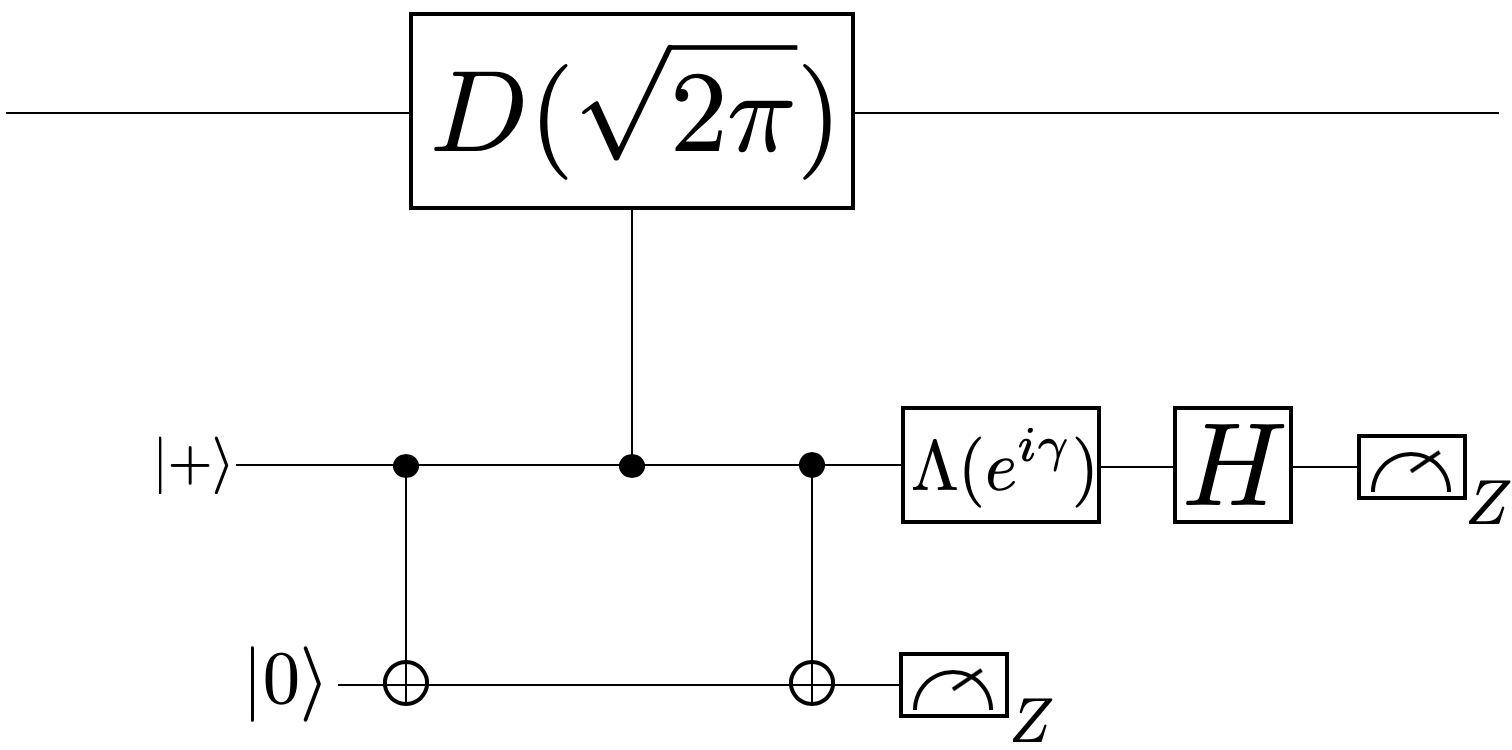
We observe that the GKP states are the eigenstates of the operator, thus we can use phase estimation to gradually project a squeezed vacuum state to an approximate GKP state. The phase estimation circuit for preparing an approximate GKP state is given in Fig. 21. The first horizontal line represents the cavity mode that we want to prepare the GKP states. The second line is a transmon ancilla initialized to . The third line is a transmon flag qubit initialized to. The gate is the Hadamard gate. is the gate with a control parameter in each round of the phase estimation to . After applying several rounds of the circuit in Fig. 21, the input squeezed vacuum state is projected onto an approximate eigenstate of with some random eigenvalue . Additionally, an estimated value for the phase is obtained. After computing the phase, the state can be shifted back to an approximate eigenstate of .
In our protocol, we use a flag qubit to detect any damping event during in the controlled-displacement gate, if a non-trivial measurement is obtained, we abort the protocol and start over. Using our simulation results, we also find a subset of output states that are robust to measurement errors in the transmon ancilla and only accept states in that subset. We proved that our protocol is fault-tolerant according to the definition we gave. In practice, our protocol produces “good" approximate GKP states with high probability and we expect to see experimental efforts to implement our protocol.
V-E Discussion
The GKP qubit architecture is a promising candidate for both near-term and fault-tolerant quantum computing implementations. With intrinsic error correcting capabilities, the GKP qubit breaks the abstraction layer between error correction and the physical implementation of qubits. In [133], we discussed the faul-tolerant preparation of GKP qubits and realistic experimental difficulties. We believe that qubit encodings like the GKP encoding will be useful for reliable quantum computing.
VI Conclusion and Future Directions
In this review, we proposed that greater quantum efficiency can be achieved by breaking abstraction layers in the quantum computing stack. We examined some previous work in this direction that are closing the gap between current quantum technology and real-world quantum computing applications. We would also like to briefly discuss some promising future directions along this line.
VI-A Noise-Tailoring Compilation
We can further explore the idea of breaking the ISA abstraction. Near-term quantum devices have errors from elementary operations like 1- and 2-qubit gates, but also emergent error modes like cross-talk. Emergent error modes are hard to characterize and to mitigate. Recently, it has been shown that randomized compiling could transform complicated noise channels including cross-talk, SPAM errors and readout errors into simple stochastic Pauli errors [136], which could potentially enable subsequent noise-adaptive compilation optimizations. We believe if compilation schemes that combine noise tailoring and noise adaptation could be designed, they will outperform existing compilation methods.
VI-B Algorithm-Level Error Correction
Near-term quantum algorithms such as Vairiational Quantum Eigensolver (VQE) and Quantum Approximate Optimization Algorithm (QAOA) are tailored for NISQ hardware, breaking the circuit/ISA abstraction. We could take a step further and look at high level algorithms equipped with customized error correction/mitigation schemes. Prominent examples of this idea are the Generalized Superfast Encoding (GSE) [138] and the Majorana Loop Stabilizer Code (MLSC) [139] for quantum chemistry. In GSE and MLSC, the overhead of mapping Fermionic operators onto qubit operators stays constant with the qubit number (as opposed to linear scaling in the usual Jordan-Wigner encoding or logarithmic in Bravyi-Kitaev encoding). On the other hand, qubit operators in these mappings are logical operators of a distance 3 stabilizer error correction code so that we can correct all weight 1 qubit errors in the algorithm with stabilizer measurements. These work are the first attempts to algorithm-level error correction and we are expecting to see more efforts of this kind to improve the robustness of near-term algorithms.
VI-C Dissipation-Assisted Error Mitigation
We generally think of dissipation as competing with quantum coherence. However, with careful design of the quantum system, dissipation can be engineered and used for improving the stability of the underlying qubit state. Previous work on autonomous qubit stabilization [135] and error correction [137] suggest that properly engineered dissipation could largely extend qubit coherence time. Exploring the design space of such systems and their associated error correction/mitigation schemes might provide alternative paths to an efficient and scalable quantum computing stack.
Acknowledgements
This work is funded in part by EPiQC, an NSF Expedition in Computing, under grants CCF-1730449/1832377/1730082; in part by STAQ, under grant NSF Phy-1818914; and in part by DOE grants DE-SC0020289 and DE-SC0020331.
References
- [1] Swamit S. Tannu and Moinuddin Qureshi. Ensemble of diverse mappings: Improving reliability of quantum computers by orchestrating dissimilar mistakes. In Proceedings of the 52Nd Annual IEEE/ACM International Symposium on Microarchitecture, MICRO ’52, pages 253–265, New York, NY, USA, 2019. ACM.
- [2] Swamit S. Tannu and Moinuddin K. Qureshi. Not all qubits are created equal: A case for variability-aware policies for nisq-era quantum computers. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’19, page 987–999, New York, NY, USA, 2019. Association for Computing Machinery.
- [3] Andrew M. Childs, Eddie Schoute, and Cem M. Unsal. Circuit transformations for quantum architectures. 2019.
- [4] Alwin Zulehner, Alexandru Paler, and Robert Wille. An efficient methodology for mapping quantum circuits to the ibm qx architectures, 2017.
- [5] Gadi Aleksandrowicz, Thomas Alexander, Panagiotis Barkoutsos, Luciano Bello, Yael Ben-Haim, David Bucher, Francisco Jose Cabrera-Hernández, Jorge Carballo-Franquis, Adrian Chen, Chun-Fu Chen, Jerry M. Chow, Antonio D. Córcoles-Gonzales, Abigail J. Cross, Andrew Cross, Juan Cruz-Benito, Chris Culver, Salvador De La Puente González, Enrique De La Torre, Delton Ding, Eugene Dumitrescu, Ivan Duran, Pieter Eendebak, Mark Everitt, Ismael Faro Sertage, Albert Frisch, Andreas Fuhrer, Jay Gambetta, Borja Godoy Gago, Juan Gomez-Mosquera, Donny Greenberg, Ikko Hamamura, Vojtech Havlicek, Joe Hellmers, Łukasz Herok, Hiroshi Horii, Shaohan Hu, Takashi Imamichi, Toshinari Itoko, Ali Javadi-Abhari, Naoki Kanazawa, Anton Karazeev, Kevin Krsulich, Peng Liu, Yang Luh, Yunho Maeng, Manoel Marques, Francisco Jose Martín-Fernández, Douglas T. McClure, David McKay, Srujan Meesala, Antonio Mezzacapo, Nikolaj Moll, Diego Moreda Rodríguez, Giacomo Nannicini, Paul Nation, Pauline Ollitrault, Lee James O’Riordan, Hanhee Paik, Jesús Pérez, Anna Phan, Marco Pistoia, Viktor Prutyanov, Max Reuter, Julia Rice, Abdón Rodríguez Davila, Raymond Harry Putra Rudy, Mingi Ryu, Ninad Sathaye, Chris Schnabel, Eddie Schoute, Kanav Setia, Yunong Shi, Adenilton Silva, Yukio Siraichi, Seyon Sivarajah, John A. Smolin, Mathias Soeken, Hitomi Takahashi, Ivano Tavernelli, Charles Taylor, Pete Taylour, Kenso Trabing, Matthew Treinish, Wes Turner, Desiree Vogt-Lee, Christophe Vuillot, Jonathan A. Wildstrom, Jessica Wilson, Erick Winston, Christopher Wood, Stephen Wood, Stefan Wörner, Ismail Yunus Akhalwaya, and Christa Zoufal. Qiskit: An open-source framework for quantum computing, 2019.
- [6] Norbert M. Linke, Dmitri Maslov, Martin Roetteler, Shantanu Debnath, Caroline Figgatt, Kevin A. Landsman, Kenneth Wright, and Christopher Monroe. Experimental comparison of two quantum computing architectures. Proceedings of the National Academy of Sciences, 114(13):3305–3310, 2017.
- [7] P. V. Klimov, J. Kelly, Z. Chen, M. Neeley, A. Megrant, B. Burkett, R. Barends, K. Arya, B. Chiaro, Yu Chen, A. Dunsworth, A. Fowler, B. Foxen, C. Gidney, M. Giustina, R. Graff, T. Huang, E. Jeffrey, Erik Lucero, J. Y. Mutus, O. Naaman, C. Neill, C. Quintana, P. Roushan, Daniel Sank, A. Vainsencher, J. Wenner, T. C. White, S. Boixo, R. Babbush, V. N. Smelyanskiy, H. Neven, and John M. Martinis. Fluctuations of energy-relaxation times in superconducting qubits. Phys. Rev. Lett., 121:090502, Aug 2018.
- [8] P. Krantz, M. Kjaergaard, F. Yan, T. P. Orlando, S. Gustavsson, , and W. D. Oliver. A quantum engineer’s guide to superconducting qubits. 2019.
- [9] Jerry M. Chow, A. D. Córcoles, Jay M. Gambetta, Chad Rigetti, B. R. Johnson, John A. Smolin, J. R. Rozen, George A. Keefe, Mary B. Rothwell, Mark B. Ketchen, and M. Steffen. Simple all-microwave entangling gate for fixed-frequency superconducting qubits. Phys. Rev. Lett., 107:080502, Aug 2011.
- [10] S. A. Caldwell, N. Didier, C. A. Ryan, E. A. Sete, A. Hudson, P. Karalekas, R. Manenti, M. P. da Silva, R. Sinclair, E. Acala, N. Alidoust, J. Angeles, A. Bestwick, M. Block, B. Bloom, A. Bradley, C. Bui, L. Capelluto, R. Chilcott, J. Cordova, G. Crossman, M. Curtis, S. Deshpande, T. El Bouayadi, D. Girshovich, S. Hong, K. Kuang, M. Lenihan, T. Manning, A. Marchenkov, J. Marshall, R. Maydra, Y. Mohan, W. O’Brien, C. Osborn, J. Otterbach, A. Papageorge, J.-P. Paquette, M. Pelstring, A. Polloreno, G. Prawiroatmodjo, V. Rawat, M. Reagor, R. Renzas, N. Rubin, D. Russell, M. Rust, D. Scarabelli, M. Scheer, M. Selvanayagam, R. Smith, A. Staley, M. Suska, N. Tezak, D. C. Thompson, T.-W. To, M. Vahidpour, N. Vodrahalli, T. Whyland, K. Yadav, W. Zeng, and C. Rigetti. Parametrically Activated Entangling Gates Using Transmon Qubits. Phys. Rev. Applied, 10:034050, Sep 2018.
- [11] S. Debnath, N. M. Linke, C. Figgatt, K. A. Landsman, K. Wright, and C. Monroe. Demonstration of a small programmable quantum computer with atomic qubits. Nature, 536, Aug 2016.
- [12] Prakash Murali, Jonathan M. Baker, Ali Javadi-Abhari, Frederic T. Chong, and Margaret Martonosi. Noise-Adaptive Compiler Mappings for Noisy Intermediate-Scale Quantum Computers. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’19, pages 1015–1029, New York, NY, USA, 2019. ACM.
- [13] Prakash Murali, Norbert Matthias Linke, Margaret Martonosi, Ali Javadi Abhari, Nhung Hong Nguyen, and Cinthia Huerta Alderete. Full-stack, Real-system Quantum Computer Studies: Architectural Comparisons and Design Insights. In Proceedings of the 46th International Symposium on Computer Architecture, ISCA ’19, pages 527–540, New York, NY, USA, 2019. ACM.
- [14] X. Fu, M. A. Rol, C. C. Bultink, J. van Someren, N. Khammassi, I. Ashraf, R. F. L. Vermeulen, J. C. de Sterke, W. J. Vlothuizen, R. N. Schouten, C. G. Almudever, L. DiCarlo, and K. Bertels. A microarchitecture for a superconducting quantum processor. IEEE Micro, 38(3):40–47, May 2018.
- [15] X. Fu, M. A. Rol, C. C. Bultink, J. van Someren, N. Khammassi, I. Ashraf, R. F. L. Vermeulen, J. C. de Sterke, W. J. Vlothuizen, R. N. Schouten, C. G. Almudever, L. DiCarlo, and K. Bertels. An experimental microarchitecture for a superconducting quantum processor. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, MICRO-50 ’17, pages 813–825. ACM, 2017.
- [16] X. Fu, L. Riesebos, M. A. Rol, J. van Straten, J. van Someren, N. Khammassi, I. Ashraf, R. F. L. Vermeulen, V. Newsum, K. K. L. Loh, J. C. de Sterke, W. J. Vlothuizen, R. N. Schouten, C. G. Almudever, L. DiCarlo, and K. Bertels. eQASM: An Executable Quantum Instruction Set Architecture, 2018.
- [17] Andrew W. Cross, Lev S. Bishop, John A. Smolin, and Jay M. Gambetta. Open quantum assembly language, 2017.
- [18] Rigetti. PyQuil. https://github.com/rigetticomputing/pyquil, 2019. Accessed: 2019-08-01.
- [19] Rigetti Quilc. Use swap fidelity instead of gate time as a distance metric . https://github.com/rigetti/quilc/pull/395, 2019. Accessed: 2019-08-01.
- [20] Qiskit. Qiskit NoiseAdaptiveLayout pass. https://github.com/Qiskit/qiskit-terra/pull/2089, 2019. Accessed: 2019-08-01.
- [21] Charge-insensitive qubit design derived from the Cooper pair box. Physical Review A - Atomic, Molecular, and Optical Physics, 76(4), oct 2007.
- [22] B. B. Blinov, D. Leibfried, C. Monroe, and D. J. Wineland. Quantum computing with trapped ion hyperfine qubits. In Experimental Aspects of Quantum Computing, pages 45–59. Springer US, 2005.
- [23] J. I. Cirac and P. Zoller. Quantum computations with cold trapped ions. Physical Review Letters, 74(20):4091–4094, 1995.
- [24] Daniel Gottesman, Alexei Kitaev, and John Preskill. Encoding a qubit in an oscillator. Phys. Rev. A, 64(1):12310, jun 2001.
- [25] Christopher J. Wood and Jay M. Gambetta. Quantification and characterization of leakage errors. Physical Review A, 97(3), mar 2018.
- [26] Pieter Kok, W. J. Munro, Kae Nemoto, T. C. Ralph, Jonathan P. Dowling, and G. J. Milburn. Linear optical quantum computing with photonic qubits. Reviews of Modern Physics, 79(1):135–174, 2007.
- [27] Joydip Ghosh, Austin G. Fowler, John M. Martinis, and Michael R. Geller. Understanding the effects of leakage in superconducting quantum-error-detection circuits. Physical Review A - Atomic, Molecular, and Optical Physics, 88(6), dec 2013.
- [28] Victor V Albert, Kyungjoo Noh, Kasper Duivenvoorden, Dylan J Young, R T Brierley, Philip Reinhold, Christophe Vuillot, Linshu Li, Chao Shen, S M Girvin, Barbara M Terhal, and Liang Jiang. Performance and structure of single-mode bosonic codes. Phys. Rev. A, 97(3):32346, mar 2018.
- [29] K Noh, V V Albert, and L Jiang. Quantum Capacity Bounds of Gaussian Thermal Loss Channels and Achievable Rates With Gottesman-Kitaev-Preskill Codes. IEEE Transactions on Information Theory, 65(4):2563–2582, apr 2019.
- [30] A. Yu. Kitaev, A. H. Shen, and M. N. Vyalyi. Classical and Quantum Computation. American Mathematical Society, USA, 2002.
- [31] Daniel Loss and David P. DiVincenzo. Quantum computation with quantum dots. Physical Review A - Atomic, Molecular, and Optical Physics, 57(1):120–126, 1998.
- [32] Nissim Ofek, Andrei Petrenko, Reinier Heeres, Philip Reinhold, Zaki Leghtas, Brian Vlastakis, Yehan Liu, Luigi Frunzio, S M Girvin, Liang Jiang, Mazyar Mirrahimi, M H Devoret, and R J Schoelkopf. Demonstrating Quantum Error Correction that Extends the Lifetime of Quantum Information. arXiv:quant-ph/1602.04768, 2016.
- [33] Marios H. Michael, Matti Silveri, R. T. Brierley, Victor V. Albert, Juha Salmilehto, Liang Jiang, and S. M. Girvin. New class of quantum error-correcting codes for a bosonic mode. Physical Review X, 6(3), 2016.
- [34] Kyungjoo Noh and Christopher Chamberland. Fault-tolerant bosonic quantum error correction with the surface–gottesman-kitaev-preskill code. Phys. Rev. A, 101:012316, Jan 2020.
- [35] Christophe Vuillot, Hamed Asasi, Yang Wang, Leonid P. Pryadko, and Barbara M. Terhal. Quantum error correction with the toric Gottesman-Kitaev-Preskill code. Physical Review A, 99(3), mar 2019.
- [36] Kosuke Fukui, Akihisa Tomita, Atsushi Okamoto, and Keisuke Fujii. High-Threshold Fault-Tolerant Quantum Computation with Analog Quantum Error Correction. Physical Review X, 8(2), may 2018.
- [37] Pranav Gokhale, Jonathan M. Baker, Casey Duckering, Natalie C. Brown, Kenneth R. Brown, and Frederic T. Chong. Asymptotic improvements to quantum circuits via qutrits. In Proceedings of the 46th International Symposium on Computer Architecture, ISCA ’19, pages 554–566, New York, NY, USA, 2019. ACM. http://doi.acm.org/10.1145/3307650.3322253.
- [38] Pranav Gokhale, Jonathan M Baker, Casey Duckering, Natalie C Brown, Kenneth R Brown, and Fred Chong. Extending the frontier of quantum computers with qutrits. IEEE Micro, 2020.
- [39] Jean-Luc Brylinski and Ranee Brylinski. Universal quantum gates. In Mathematics of quantum computation, pages 117–134. Chapman and Hall/CRC, 2002.
- [40] Ivan Kassal, James D Whitfield, Alejandro Perdomo-Ortiz, Man-Hong Yung, and Alán Aspuru-Guzik. Simulating chemistry using quantum computers. Annual review of physical chemistry, 62:185–207, 2011.
- [41] Jacob Biamonte, Peter Wittek, Nicola Pancotti, Patrick Rebentrost, Nathan Wiebe, and Seth Lloyd. Quantum machine learning. Nature, 549:195 EP –, Sep 2016.
- [42] R. K. Naik, N. Leung, S. Chakram, Peter Groszkowski, Y. Lu, N. Earnest, D. C. McKay, Jens Koch, and D. I. Schuster. Random access quantum information processors using multimode circuit quantum electrodynamics. Nature Communications, 8(1):1904, 2017.
- [43] Gian Giacomo Guerreschi and Jongsoo Park. Two-step approach to scheduling quantum circuits. Quantum Science and Technology, 3(4):045003, jul 2018.
- [44] Ashok Muthukrishnan and C. R. Stroud. Multivalued logic gates for quantum computation. Phys. Rev. A, 62:052309, Oct 2000.
- [45] A. B. Klimov, R. Guzmán, J. C. Retamal, and C. Saavedra. Qutrit quantum computer with trapped ions. Phys. Rev. A, 67:062313, Jun 2003.
- [46] T. Bækkegaard, L. B. Kristensen, N. J. S. Loft, C. K. Andersen, D. Petrosyan, and N. T. Zinner. Superconducting qutrit-qubit circuit: A toolbox for efficient quantum gates. arXiv preprint arXiv:1802.04299, 2018.
- [47] A. Fedorov, L. Steffen, M. Baur, M. P. da Silva, and A. Wallraff. Implementation of a toffoli gate with superconducting circuits. Nature, 481:170 EP –, Dec 2011.
- [48] D. M. Miller, D. Maslov, and G. W. Dueck. A transformation based algorithm for reversible logic synthesis. In Proceedings 2003. Design Automation Conference (IEEE Cat. No.03CH37451), pages 318–323, June 2003.
- [49] Michael A. Nielsen and Isaac L. Chuang. Quantum Computation and Quantum Information: 10th Anniversary Edition. Cambridge University Press, New York, NY, USA, 10th edition, 2011.
- [50] J. Randall, S. Weidt, E. D. Standing, K. Lake, S. C. Webster, D. F. Murgia, T. Navickas, K. Roth, and W. K. Hensinger. Efficient preparation and detection of microwave dressed-state qubits and qutrits with trapped ions. Phys. Rev. A, 91:012322, 01 2015.
- [51] J. Randall, A. M. Lawrence, S. C. Webster, S. Weidt, N. V. Vitanov, and W. K. Hensinger. Generation of high-fidelity quantum control methods for multilevel systems. Phys. Rev. A, 98:043414, 10 2018.
- [52] N. Khammassi, I. Ashraf, X. Fu, C. G. Almudever, and K. Bertels. Qx: A high-performance quantum computer simulation platform. In Proceedings of the Conference on Design, Automation & Test in Europe, DATE ’17, pages 464–469, 3001 Leuven, Belgium, Belgium, 2017. European Design and Automation Association.
- [53] Francesco Tacchino. Personal Communication.
- [54] Matthew Otten and Stephen K Gray. Accounting for errors in quantum algorithms via individual error reduction. npj Quantum Information, 5(1):11, 2019.
- [55] Eric Dennis. Toward fault-tolerant quantum computation without concatenation. Phys. Rev. A, 63:052314, Apr 2001.
- [56] D. G. Cory, M. D. Price, W. Maas, E. Knill, R. Laflamme, W. H. Zurek, T. F. Havel, and S. S. Somaroo. Experimental quantum error correction. Phys. Rev. Lett., 81:2152–2155, Sep 1998.
- [57] Francesco Tacchino, Chiara Macchiavello, Dario Gerace, and Daniele Bajoni. An artificial neuron implemented on an actual quantum processor. npj Quantum Information, 5(1):26, 2019.
- [58] Matthew Reagor, Wolfgang Pfaff, Christopher Axline, Reinier W. Heeres, Nissim Ofek, Katrina Sliwa, Eric Holland, Chen Wang, Jacob Blumoff, Kevin Chou, Michael J. Hatridge, Luigi Frunzio, Michel H. Devoret, Liang Jiang, and Robert J. Schoelkopf. Quantum memory with millisecond coherence in circuit qed. Phys. Rev. B, 94:014506, Jul 2016.
- [59] N. Earnest, S. Chakram, Y. Lu, N. Irons, R. K. Naik, N. Leung, L. Ocola, D. A. Czaplewski, B. Baker, Jay Lawrence, Jens Koch, and D. I. Schuster. Realization of a system with metastable states of a capacitively shunted fluxonium. Phys. Rev. Lett., 120:150504, Apr 2018.
- [60] Steven M Girvin. Circuit qed: superconducting qubits coupled to microwave photons. Quantum Machines: Measurement and Control of Engineered Quantum Systems, page 113, 2011.
- [61] R. Barends, J. Kelly, A. Megrant, A. Veitia, D. Sank, E. Jeffrey, T. C. White, J. Mutus, A. G. Fowler, B. Campbell, Y. Chen, Z. Chen, B. Chiaro, A. Dunsworth, C. Neill, P. O’Malley, P. Roushan, A. Vainsencher, J. Wenner, A. N. Korotkov, A. N. Cleland, and John M. Martinis. Superconducting quantum circuits at the surface code threshold for fault tolerance. Nature, 508:500 EP –, 04 2014.
- [62] Edwin Barnes, Christian Arenz, Alexander Pitchford, and Sophia E. Economou. Fast microwave-driven three-qubit gates for cavity-coupled superconducting qubits. Phys. Rev. B, 96:024504, Jul 2017.
- [63] Quantum devices and simulators. https://www.research.ibm.com/ibm-q/technology/devices/, 2018.
- [64] A. Yu. Chernyavskiy, Vad. V. Voevodin, and Vl. V. Voevodin. Parallel computational structure of noisy quantum circuits simulation. Lobachevskii Journal of Mathematics, 39(4):494–502, May 2018.
- [65] Joydip Ghosh, Austin G. Fowler, John M. Martinis, and Michael R. Geller. Understanding the effects of leakage in superconducting quantum-error-detection circuits. Phys. Rev. A, 88:062329, Dec 2013.
- [66] Todd A. Brun. A simple model of quantum trajectories. American Journal of Physics, 70(7):719–737, 2002.
- [67] Rüdiger Schack and Todd A Brun. A C++ library using quantum trajectories to solve quantum master equations. Computer Physics Communications, 102(1-3):210–228, 1997.
- [68] Robert S Smith, Michael J Curtis, and William J Zeng. A practical quantum instruction set architecture. arXiv preprint arXiv:1608.03355, 2016.
- [69] Jacob Biamonte and Ville Bergholm. Tensor networks in a nutshell. arXiv preprint arXiv:1708.00006, 2017.
- [70] Davide Venturelli, Minh Do, Eleanor Rieffel, and Jeremy Frank. Compiling quantum circuits to realistic hardware architectures using temporal planners. Quantum Science and Technology, 3(2):025004, feb 2018.
- [71] Kyle EC Booth, Minh Do, J Christopher Beck, Eleanor Rieffel, Davide Venturelli, and Jeremy Frank. Comparing and integrating constraint programming and temporal planning for quantum circuit compilation. In Twenty-Eighth International Conference on Automated Planning and Scheduling, 2018.
- [72] J. R. Johansson, Paul Nation, and Franco Nori. Qutip 2: A python framework for the dynamics of open quantum systems. Computer Physics Communications, 184(4):1234–1240, 4 2013.
- [73] J. R. Johansson, Paul Nation, and Franco Nori. Qutip: An open-source python framework for the dynamics of open quantum systems. Computer Physics Communications, 183(8):1760–1772, 8 2012.
- [74] Code for asymptotic improvements to quantum circuits via qutrits. https://github.com/epiqc/qutrits, 2019.
- [75] Bryan Eastin and Steven T. Flammia. Q-circuit tutorial, 2004.
- [76] Cirq: A python framework for creating, editing, and invoking noisy intermediate scale quantum (NISQ) circuits. https://github.com/quantumlib/Cirq, 2018.
- [77] Yao-Min Di and Hai-Rui Wei. Elementary gates for ternary quantum logic circuit. arXiv preprint arXiv:1105.5485, 2011.
- [78] Vahid Karimipour, Azam Mani, and Laleh Memarzadeh. Characterization of qutrit channels in terms of their covariance and symmetry properties. Phys. Rev. A, 84:012321, Jul 2011.
- [79] Markus Grassl, Linghang Kong, Zhaohui Wei, Zhang-Qi Yin, and Bei Zeng. Quantum error-correcting codes for qudit amplitude damping. IEEE Transactions on Information Theory, 64(6):4674–4685, 2018.
- [80] Todd A. Brun. A simple model of quantum trajectories. 2001.
- [81] Daniel Miller, Timo Holz, Hermann Kampermann, and Dagmar Bruß. Propagation of generalized pauli errors in qudit clifford circuits. Physical Review A, 98(5):052316, 2018.
- [82] Craig Gidney. Constructing large controlled nots, 2015.
- [83] Leslie Lamport. LaTeX: A Document Preparation System. Addison-Wesley, Reading, Massachusetts, 2nd edition, 1994.
- [84] Firstname1 Lastname1 and Firstname2 Lastname2. A very nice paper to cite. In Intl. Symp. on High Performance Computer Architecture (HPCA), Feb. 2014.
- [85] Firstname1 Lastname1, Firstname2 Lastname2, and Firstname3 Lastname3. Another very nice paper to cite. In Intl. Symp. on Microarchitecture (MICRO), Oct. 2012.
- [86] Firstname1 Lastname1, Firstname2 Lastname2, Firstname3 Lastname3, Firstname4 Lastname4, and Firstname5 Lastname5. Yet another very nice paper to cite, with many author names all spelled out. In Intl. Symp. on Computer Architecture (ISCA), June 2011.
- [87] John Preskill. Quantum Computing in the NISQ era and beyond. Quantum, 2:79, August 2018.
- [88] Peter W. Shor. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. SIAM Journal on Computing, 26(5):1484–1509, October 1997.
- [89] Prakash Murali, David C. Mckay, Margaret Martonosi, and Ali Javadi-Abhari. Software Mitigation of Crosstalk on Noisy Intermediate-Scale Quantum Computers. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’20, page 1001–1016, New York, NY, USA, 2020. Association for Computing Machinery.
- [90] Lov K. Grover. A fast quantum mechanical algorithm for database search. In Annual ACM Symposium on Theory of Computing, pages 212–219. ACM, 1996.
- [91] Yongshan Ding, Adam Holmes, Ali Javadi-Abhari, Diana Franklin, Margaret Martonosi, and Frederic Chong. Magic-state functional units: Mapping and scheduling multi-level distillation circuits for fault-tolerant quantum architectures. In 2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 828–840. IEEE, 2018.
- [92] Ali Javadi-Abhari, Pranav Gokhale, Adam Holmes, Diana Franklin, Kenneth R. Brown, Margaret Martonosi, and Frederic T. Chong. Optimized surface code communication in superconducting quantum computers. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, MICRO-50 ’17, pages 692–705, New York, NY, USA, 2017. ACM.
- [93] Thomas Häner, Martin Roetteler, and Krysta M. Svore. Factoring using 2n + 2 qubits with toffoli based modular multiplication. Quantum Info. Comput., 17(7-8):673–684, June 2017.
- [94] Craig Gidney. Factoring with n+2 clean qubits and n-1 dirty qubits. arXiv preprint arXiv:1706.07884, 2017.
- [95] Benjamin P. Lanyon, Marco Barbieri, Marcelo P. Almeida, Thomas Jennewein, Timothy C. Ralph, Kevin J. Resch, Geoff J. Pryde, Jeremy L. O’Brien, Alexei Gilchrist, and Andrew G. White. Simplifying quantum logic using higher-dimensional hilbert spaces. Nature Physics, 5:134 EP –, 12 2008.
- [96] T. C. Ralph, K. J. Resch, and A. Gilchrist. Efficient toffoli gates using qudits. Phys. Rev. A, 75:022313, Feb 2007.
- [97] Y. He, M.-X. Luo, E. Zhang, H.-K. Wang, and X.-F. Wang. Decompositions of n-qubit Toffoli Gates with Linear Circuit Complexity. International Journal of Theoretical Physics, 56:2350–2361, July 2017.
- [98] Mathias Soeken, Stefan Frehse, Robert Wille, and Rolf Drechsler. Revkit: An open source toolkit for the design of reversible circuits. In A. De Vos and R. Wille, editors, Reversible Computation, pages 64–76. Springer Berlin Heidelberg, 2012.
- [99] Adriano Barenco, Charles H. Bennett, Richard Cleve, David P. DiVincenzo, Norman Margolus, Peter Shor, Tycho Sleator, John A. Smolin, and Harald Weinfurter. Elementary gates for quantum computation. Phys. Rev. A, 52:3457–3467, Nov 1995.
- [100] Radu Ionicioiu, Timothy P. Spiller, and William J. Munro. Generalized toffoli gates using qudit catalysis. 2009.
- [101] Thomas G. Draper. Addition on a quantum computer. arXiv preprint quant-ph/0008033, 2000.
- [102] Alex Bocharov, Martin Roetteler, and Krysta M. Svore. Factoring with qutrits: Shor’s algorithm on ternary and metaplectic quantum architectures. Phys. Rev. A, 96:012306, Jul 2017.
- [103] Archimedes Pavlidis and Emmanuel Floratos. Arithmetic circuits for multilevel qudits based on quantum fourier transform. arXiv preprint arXiv:1707.08834, 2017.
- [104] Andrew D. Greentree, S. G. Schirmer, F. Green, Lloyd C. L. Hollenberg, A. R. Hamilton, and R. G. Clark. Maximizing the hilbert space for a finite number of distinguishable quantum states. Phys. Rev. Lett., 92:097901, Mar 2004.
- [105] Mozammel H. A. Khan and Marek A. Perkowski. Quantum ternary parallel adder/subtractor with partially-look-ahead carry. J. Syst. Archit., 53(7):453–464, July 2007.
- [106] Michael Kues, Christian Reimer, Piotr Roztocki, Luis Romero Cortés, Stefania Sciara, Benjamin Wetzel, Yanbing Zhang, Alfonso Cino, Sai T. Chu, Brent E. Little, David J. Moss, Lucia Caspani, José Azaña, and Roberto Morandotti. On-chip generation of high-dimensional entangled quantum states and their coherent control. Nature, 546:622 EP –, 06 2017.
- [107] Yale Fan. Applications of multi-valued quantum algorithms. arXiv preprint arXiv:0809.0932, 2008.
- [108] H. Y. Li, C. W. Wu, W. T. Liu, P. X. Chen, and C. Z. Li. Fast quantum search algorithm for databases of arbitrary size and its implementation in a cavity QED system. Physics Letters A, 375:4249–4254, November 2011.
- [109] Y. Wang and M. Perkowski. Improved complexity of quantum oracles for ternary grover algorithm for graph coloring. In 2011 41st IEEE International Symposium on Multiple-Valued Logic, pages 294–301, May 2011.
- [110] S. S. Ivanov, H. S. Tonchev, and N. V. Vitanov. Time-efficient implementation of quantum search with qudits. Phys. Rev. A, 85:062321, Jun 2012.
- [111] Natalie C. Brown and Kenneth R. Brown. Comparing zeeman qubits to hyperfine qubits in the context of the surface code: and . Phys. Rev. A, 97:052301, May 2018.
- [112] Kenneth R Brown, Jungsang Kim, and Christopher Monroe. Co-designing a scalable quantum computer with trapped atomic ions. npj Quantum Information, 2:16034, 2016.
- [113] N. Schuch and J. Siewert. Natural two-qubit gate for quantum computation using the XY interaction. Physical Review A, 67(3):032301, March 2003.
- [114] Daniel Loss and David P DiVincenzo. Quantum computation with quantum dots. Physical Review A, 57(1):120, 1998.
- [115] Nelson Leung, Mohamed Abdelhafez, Jens Koch, and David Schuster. Speedup for quantum optimal control from automatic differentiation based on graphics processing units. Physical Review A, 95:042318, Apr 2017.
- [116] T. Schulte-Herbrueggen, A. Spoerl, and S. J. Glaser. Quantum CISC Compilation by Optimal Control and Scalable Assembly of Complex Instruction Sets beyond Two-Qubit Gates. ArXiv e-prints, December 2007.
- [117] Steffen J. Glaser, Ugo Boscain, Tommaso Calarco, Christiane P. Koch, Walter Köckenberger, Ronnie Kosloff, Ilya Kuprov, Burkhard Luy, Sophie Schirmer, Thomas Schulte-Herbrüggen, Dominique Sugny, and Frank K. Wilhelm. Training schrödinger’s cat: quantum optimal control. The European Physical Journal D, 69(12):279, Dec 2015.
- [118] M. J. Chow. Quantum Information Processing with Superconducting Qubits. PhD thesis, New Haven, CT, USA, 2010. AAINQ98874.
- [119] Navin Khaneja, Timo Reiss, Cindie Kehlet, Thomas Schulte-Herbrüggen, and Steffen J. Glaser. Optimal control of coupled spin dynamics: design of nmr pulse sequences by gradient ascent algorithms. Journal of Magnetic Resonance, 172(2):296 – 305, 2005.
- [120] P. de Fouquieres, S. G. Schirmer, S. J. Glaser, and I. Kuprov. Second order gradient ascent pulse engineering. Journal of Magnetic Resonance, 212:412–417, October 2011.
- [121] E. Farhi, J. Goldstone, and S. Gutmann. A Quantum Approximate Optimization Algorithm. ArXiv e-prints, November 2014.
- [122] Jarrod R McClean, Jonathan Romero, Ryan Babbush, and Alán Aspuru-Guzik. The theory of variational hybrid quantum-classical algorithms. New Journal of Physics, 18(2):023023, 2016.
- [123] Ali JavadiAbhari, Shruti Patil, Daniel Kudrow, Jeff Heckey, Alexey Lvov, Frederic T. Chong, and Margaret Martonosi. Scaffcc: A framework for compilation and analysis of quantum computing programs. In Proceedings of the 11th ACM Conference on Computing Frontiers, CF ’14, pages 1:1–1:10, New York, NY, USA, 2014. ACM.
- [124] A. W. Cross, L. S. Bishop, J. A. Smolin, and J. M. Gambetta. Open Quantum Assembly Language. ArXiv e-prints, July 2017.
- [125] Robert S Smith, Michael J Curtis, and William J Zeng. A practical quantum instruction set architecture, 2016.
- [126] Thomas Häner, Damian S Steiger, Krysta Svore, and Matthias Troyer. A software methodology for compiling quantum programs. Quantum Science and Technology, 3(2):020501, 2018.
- [127] R. S. Smith, M. J. Curtis, and W. J. Zeng. A Practical Quantum Instruction Set Architecture. ArXiv e-prints, August 2016.
- [128] X. Fu, M. A. Rol, C. C. Bultink, J. van Someren, N. Khammassi, I. Ashraf, R. F. L. Vermeulen, J. C. de Sterke, W. J. Vlothuizen, R. N. Schouten, C. G. Almudever, L. DiCarlo, and K. Bertels. An experimental microarchitecture for a superconducting quantum processor. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, MICRO-50 ’17, pages 813–825, New York, NY, USA, 2017. ACM.
- [129] Yunong Shi, Nelson Leung, Pranav Gokhale, Zane Rossi, David I. Schuster, Henry Hoffmann, and Frederic T. Chong. Optimized compilation of aggregated instructions for realistic quantum computers. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’19, pages 1031–1044, New York, NY, USA, 2019. ACM. http://doi.acm.org/10.1145/3297858.3304018.
- [130] B. P. Lanyon, J. D. Whitfield, G. G. Gillett, M. E. Goggin, M. P. Almeida, I. Kassal, J. D. Biamonte, M. Mohseni, B. J. Powell, M. Barbieri, A. Aspuru-Guzik, and A. G. White. Towards quantum chemistry on a quantum computer. Nature Chemistry, 2:106–111, February 2010.
- [131] George Karypis and Vipin Kumar. A fast and high quality multilevel scheme for partitioning irregular graphs. In SIAM Journal on Scientific Computing, volume 20, 02 1970.
- [132] Ben Q. Baragiola, Giacomo Pantaleoni, Rafael N. Alexand er, Angela Karanjai, and Nicolas C. Menicucci. All-Gaussian universality and fault tolerance with the Gottesman-Kitaev-Preskill code. arXiv e-prints, page arXiv:1903.00012, Feb 2019.
- [133] Yunong Shi, Christopher Chamberland, and Andrew Cross. Fault-tolerant preparation of approximate gkp states. New Journal of Physics, 21, 08 2019.
- [134] B. M. Terhal and D. Weigand. Encoding a qubit into a cavity mode in circuit qed using phase estimation. Phys. Rev. A, 93:012315, Jan 2016.
- [135] Yao Lu, S. Chakram, Ngainam Leung, Nathan Earnest, Ravi Naik, Ziwen Huang, Peter Groszkowski, Eliot Kapit, Jens Koch, and David Schuster. Universal stabilization of a parametrically coupled qubit. Physical Review Letters, 119, 07 2017.
- [136] Joel J. Wallman and Joseph Emerson. Noise tailoring for scalable quantum computation via randomized compiling. Physical Review A, 94(5), Nov 2016.
- [137] Eliot Kapit. Hardware-efficient and fully autonomous quantum error correction in superconducting circuits. Physical Review Letters, 116(15), Apr 2016.
- [138] Kanav Setia, Sergey Bravyi, Antonio Mezzacapo, and James D. Whitfield. Superfast encodings for fermionic quantum simulation, 2018.
- [139] Zhang Jiang, Jarrod McClean, Ryan Babbush, and Hartmut Neven. Majorana loop stabilizer codes for error correction of fermionic quantum simulations, 2018.
- [140] Frank Arute, Kunal Arya, Ryan Babbush, Dave Bacon, Joseph C. Bardin, Rami Barends, Rupak Biswas, Sergio Boixo, Fernando G. S. L. Brandao, David A. Buell, Brian Burkett, Yu Chen, Zijun Chen, Ben Chiaro, Roberto Collins, William Courtney, Andrew Dunsworth, Edward Farhi, Brooks Foxen, Austin Fowler, Craig Gidney, Marissa Giustina, Rob Graff, Keith Guerin, Steve Habegger, Matthew P. Harrigan, Michael J. Hartmann, Alan Ho, Markus Hoffmann, Trent Huang, Travis S. Humble, Sergei V. Isakov, Evan Jeffrey, Zhang Jiang, Dvir Kafri, Kostyantyn Kechedzhi, Julian Kelly, Paul V. Klimov, Sergey Knysh, Alexander Korotkov, Fedor Kostritsa, David Landhuis, Mike Lindmark, Erik Lucero, Dmitry Lyakh, Salvatore Mandrà, Jarrod R. McClean, Matthew McEwen, Anthony Megrant, Xiao Mi, Kristel Michielsen, Masoud Mohseni, Josh Mutus, Ofer Naaman, Matthew Neeley, Charles Neill, Murphy Yuezhen Niu, Eric Ostby, Andre Petukhov, John C. Platt, Chris Quintana, Eleanor G. Rieffel, Pedram Roushan, Nicholas C. Rubin, Daniel Sank, Kevin J. Satzinger, Vadim Smelyanskiy, Kevin J. Sung, Matthew D. Trevithick, Amit Vainsencher, Benjamin Villalonga, Theodore White, Z. Jamie Yao, Ping Yeh, Adam Zalcman, Hartmut Neven, and John M. Martinis. Quantum supremacy using a programmable superconducting processor. Nature, 574(7779):505–510, 2019.
- [141] Strawberry fields, 2016.
- [142] Cramming more power into a quantum device. https://www.ibm.com/blogs/research/2019/03/power-quantum-device/. Accessed: 2010-09-30.
- [143] Mohan Sarovar, Timothy Proctor, Kenneth Rudinger, Kevin Young, Erik O. Nielsen, and Robin Blume-Kohout. Detecting crosstalk errors in quantum information processors. 2019.
- [144] Dylan Langharst and Kenneth Rudinger. Crosstalk and drift-detection on the IBM Quantum Experience. In APS March Meeting Abstracts, volume 2018 of APS Meeting Abstracts, page K39.009, Jan 2018.
- [145] Alexander Erhard, Joel James Wallman, Lukas Postler, Michael Meth, Roman Stricker, Esteban Adrian Martinez, Philipp Schindler, Thomas Monz, Joseph Emerson, and Rainer Blatt. Characterizing large-scale quantum computers via cycle benchmarking, 2019.
- [146] Dmitri Maslov, Sean M. Falconer, and Michele Mosca. Quantum circuit placement. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 27:752–763, 2008.
- [147] Yun Seong Nam, Neil J. Ross, Yuan Su, Andrew M. Childs, and Dmitri Maslov. Automated optimization of large quantum circuits with continuous parameters. npj Quantum Information, 4:1–12, 2018.
- [148] Pranav Gokhale, Yongshan Ding, Thomas Propson, Christopher Winkler, Nelson Leung, Yunong Shi, David I. Schuster, Henry Hoffmann, and Frederic T. Chong. Partial compilation of variational algorithms for noisy intermediate-scale quantum machines. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, MICRO ’52, page 266–278, New York, NY, USA, 2019. Association for Computing Machinery.