Rethinking Client Drift in Federated Learning: A Logit Perspective
Abstract
Federated Learning (FL) enables multiple clients to collaboratively learn in a distributed way, allowing for privacy protection. However, the real-world non-IID data will lead to client drift which degrades the performance of FL. Interestingly, we find that the difference in logits between the local and global models increases as the model is continuously updated, thus seriously deteriorating FL performance. This is mainly due to catastrophic forgetting caused by data heterogeneity between clients. To alleviate this problem, we propose a new algorithm, named FedCSD, a Class prototype Similarity Distillation in a federated framework to align the local and global models. FedCSD does not simply transfer global knowledge to local clients, as an undertrained global model cannot provide reliable knowledge, i.e., class similarity information, and its wrong soft labels will mislead the optimization of local models. Concretely, FedCSD introduces a class prototype similarity distillation to align the local logits with the refined global logits that are weighted by the similarity between local logits and the global prototype. To enhance the quality of global logits, FedCSD adopts an adaptive mask to filter out the terrible soft labels of the global models, thereby preventing them to mislead local optimization. Extensive experiments demonstrate the superiority of our method over the state-of-the-art federated learning approaches in various heterogeneous settings. The source code will be released.
Index Terms:
Data Heterogeneity, Federated Learning, Logit, Knowledge Distillation.I Introduction
Federated Learning (FL) [1, 2] is an emerging distributed learning paradigm that has garnered substantial interest, particularly in privacy-sensitive domains like healthcare [3, 4, 5, 6, 7, 8], where it enables multiple clients to collaboratively train machine learning models while maintaining privacy and avoiding data exposure. However, when FL is applied to a multitude of discrete clients, the datasets associated with each client in real-world scenarios inevitably stem from distinct underlying distributions, resulting in non-IID data. This non-IID data phenomenon can lead to what is known as client drift [9], which subsequently undermines the performance of FL [10, 11, 12].
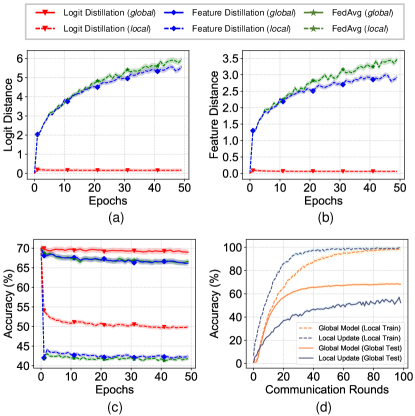
Non-IID data is commonly encountered in various real-world scenarios, prompting many researchers to address this challenge to enhance the viability of federated learning. Existing solutions can be categorized into two types: client-specific learning [14, 7, 15, 16] and client-unified learning [17, 9, 11, 18, 19]. The former solves the problem through the personalized design for each client to learn the specific model representation for each client, e.g., FedBN [14] and FedPer [20]. In contrast, the latter approaches seek to develop a unified model representation that applies across all clients, which is explored in this work. In pursuit of this objective, researchers employ strategies such as regularization [17, 21, 22], contrastive learning [18], and data augmentation [23, 24] to minimize the divergence among individual local models during the training process. While client-unified learning has been investigated in FL, it’s intriguing to note that there has been limited attention directed towards the logits, i.e., the output of the classifier, which effectively captures the decision-making process of the classifier. Previous research [25] indicates that the heterogeneity among different local models primarily resides in the classifier, as evidenced by experimental exploration. Consequently, we contend that the discrepancy in logits is likely to be more pronounced than that in latent features. Therefore, addressing client drift directly and effectively through logits appears to be a promising approach.
In this work, a fortunate discovery was made, revealing the following key insights: ❶ Logit Shift Due to Local Updates: We observed that local updates lead to differences in logits between the local and global models, a phenomenon we refer to as logit shift (illustrated in Fig. 1 (a)). ❷ Impact of Logit Shift on FL Performance: A noteworthy finding was that the logit shift is closely linked to the performance deterioration observed in FL, as demonstrated in Fig. 1 (c). ❸ Mitigation of Feature Shift through Logit Alignment: Interestingly, we found that aligning the local and global logits can effectively alleviate the feature shift phenomenon [23], as depicted in Fig. 1 (b). These discoveries collectively offer valuable insights into the dynamics of logit behaviour and its implications for FL performance, which have sparked our motivation to approach the non-IID problem from a fresh and innovative perspective, i.e. logit shift.
Considering that each local model is initialized from the parameters of the global model, we argue that the phenomenon of logit shift can be attributed to catastrophic forgetting [26, 27, 28]. This occurs when the local model trains on its private dataset which is from a biased distribution. Over the course of continuous training, the local model gradually relinquishes its initial grasp on global knowledge and becomes predisposed to the specifics of its local data. Consequently, this bias causes the local logits to deviate from the global logits. Drawing from these insights, a straightforward solution emerges: maintaining consistency between local and global model logits through knowledge distillation. This technique, commonly employed to mitigate catastrophic forgetting in continual learning scenarios [29, 30], offers a pragmatic strategy for mitigating the logit shift phenomenon.
While several studies [31, 32] have incorporated knowledge distillation into Federated Learning (FL) by employing the global model as the teacher to regulate local optimization, we have identified a crucial aspect that these approaches overlook: the global model is inadequately trained to serve as an effective teacher for a local model during local training, despite containing global knowledge. As illustrated in Fig. 1 (d), due to fine-tuning on the local dataset, the local model exhibits enhanced performance on the local training set. Meanwhile, the global model undergoes continual updates, distinguishing it from the conventional distillation process, where a well-trained teacher imparts its knowledge to a student. Consequently, direct alignment of local and global logits raises certain key challenges. First, when applying knowledge distillation at the logits level, it’s commonly believed that the teacher’s logits serve as soft targets, transferring ”dark knowledge” that includes privileged information regarding the relationships between different categories [33]. This transfer is effective only when a stronger teacher imparts knowledge to a weaker student, as a poorly-trained teacher cannot reliably convey accurate similarity information among categories [34]. Second, owing to the global model’s lower accuracy, it generates a plethora of incorrect soft labels that misguide the optimization of local models, particularly in the early stages.
Based on our analyses, we propose a novel FL framework, i.e. FedCSD, to tackle the non-IID data challenge from the vantage point of logit shift. FedCSD introduces a novel method termed class prototype similarity distillation, which aligns local logits with global logits, factoring in the similarity between local logits and the global prototype. Furthermore, we incorporate an adaptive mask mechanism to sieve out insignificant knowledge from global logits. By amalgamating these foundational elements, our approach adeptly resolves the non-IID problem in FL. In a nutshell, our contributions are summarized as follows:
-
•
We provide a new perspective, i.e. the logit shift between local and global models, to help us understand the client drift under non-IID data, which is beneficial to handle this fundamental challenge. This also explains the underlying mechanism of our approach.
-
•
We propose FedCSD, a novel framework to address the client drift in FL. This framework employs a prototype-based class similarity distillation technique to align local and global logits, effectively curbing the occurrence of catastrophic forgetting within local models. Consequently, FedCSD serves as a potent strategy to alleviate the impact of client drift.
-
•
Extensive experiments on three typical FL datasets demonstrate the effectiveness of our method under various data heterogeneous settings, e.g. it outperforms various state-of-the-art FL approaches.
II Related work
Federated Learning with Non-IID Data. The classical FL algorithm, Fedavg [35], achieved a balance of computing and communication, which shows good performance in some applications [36, 37]. However, the accuracy of FedAvg reduces significantly when local data is non-IID [12, 9, 17], which has been a fundamental challenge. To address this challenge, a variety of regularization methods [22, 38, 17, 5, 39] are used to enforce local optimization. For example, FedProx [17] computed the -norm distance between the weight of local and global models as a proximity term added to the local objective. Similarly, FedDyn [38] adopted a dynamic regularization into the local object based on exact minimization which seeks to keep the local-global optima consistent. Despite their efforts, the performance of FedAvg is not fully understood. SCAFFOLD [9] provided a more delicate analysis of FedAvg for non-IID data and proves that client drift is the root of performance degradation. To solve the client drift problem, it introduced control variate to correct local updates. Besides, MOON [18] proposed model-contrastive learning to correct the local training by utilizing the similarity between model representations among local and global. Some studies try to improve FedAvg in different ways. For example, bayesian non-parametric methods [40], momentum updating [41], normalize [11] are used to improve Fedavg on the phase of modal aggregation. However, the above methods ignore the key point of the potential influence of performance drop, i.e. logit, since the previous study has confirmed that the model drifts mainly focuses on the classifier layer [25]. Instead, our work provides a novel perspective to address the client drift and achieve competitive results.
Knowledge Distillation. Knowledge distillation [33, 42] is a knowledge extraction and transfer paradigm by the teacher-student mechanism that attempts to transfer the knowledge from the teacher model into the student model. Specifically, the logits of the teacher model as the soft labels that supervise the student model to train on a proxy dataset. Moreover, it aims to minimize the teacher-student logit discrepancy that can be measured by Kullback-Leibler divergence.
Knowledge distillation has also been successfully applied in FL [43, 44, 45]. For example, some studies try to propose a communication-efficient FL framework based on knowledge distillation [46, 47, 48]. Knowledge distillation has also been used to address the non-IID data. For instance, Seo et al. [49] assigned a client as a student which receives ensemble logits of the rest clients. FedDF [50] used ensemble distillation to replace parameter averaging of FedAvg which needs extra training and a proxy dataset on the server. FedGen [51] utilized an additional generator to aggregate the local information which increases the additional training cost and privacy risk. Similar to us, Fed-NTD [31] distilled the knowledge of the not-true class between the local and global models. FedGKD [32] utilized several previous global models as an ensemble teacher to teach the local model. However, the performance of their method is limited by the poorly-trained global model, which can not provide reliable class similarity information and soft labels. To achieve effective distillation, we utilize two key modules, i.e. class prototype similarity distillation and adaptive mask, to improve the performance of the global model.
III Preliminary
III-A Problem statement
Assume a standard federation that there are clients and a central server. Each client has training samples , where image and corresponding label are from a joint distribution, i.e. . For non-IID data in FL, the distribution of each client is different. The standard FL aims to learn a global optima model by minimizing the empirical loss of each client without privacy disclosure. The global objective function can be described as [35]:
| (1) |
where , is the local objective function of . Here, every client will learn a deep neural network : via cross-entropy loss:
| (2) |
Where logits and is the parameters of the local model. To improve communication efficiency, the leading algorithm FedAvg [35] conducts local epochs and then averages the local model parameters to update the global model parameters at each communication round:
| (3) |
With the rounds training, we can get an optimal global model which has the best global performance.
III-B Motivation
Exploratory Experiment. We conduct an intriguing experiment for FedAvg with the ResNet-50 [52] network on the CIFAR-100 [13] dataset. In this experiment, we train a round with 50 local epochs involving 10 non-IID clients. Initially, each client receives a proficiently trained global model from the server, which serves as the basis for initializing the local model. After a single epoch of training, we assess both the logit distance and feature distance between the local update and the initial global model. The logit distance is quantified using the Kullback-Leibler divergence, while the feature distance is measured using the -norm. Additionally, by averaging the parameters of local updates, we generate a global update and evaluate its performance on the test set. The outcome of the experiment is depicted in Fig. 1 (a, b, c), where global signifies the result of the global update and local represents the average of the results obtained from 10 local updates.
Detail of Logit Distillation and Feature Distillation. The logit distillation [33] and feature distillation [53] are two methods that distill the logit and feature of the global model to the student model, respectively. The loss of logit distillation can be described as:
| (4) |
where, and are the logits of the global and local models, is the temperature hyper-parameter, and set to by default.
Besides, feature distillation adopts the MSE loss to distill the feature of the global model:
| (5) |
where and are the latent features of the global and local models, respectively. For ResNet-50, they are vector, and D is . We fine-tune the from {0.001, 0.01, 0.1, 1}, and the optimal of logit distillation and feature distillation is empirically set to and , respectively.
Experiment Observation. The results demonstrate a noteworthy trend: an increase in the number of local epochs contributes to a higher discrepancy in logits between the local update and the global model. This divergence arises due to the local model gradually losing its prior knowledge, which, in turn, adversely affects the accuracy of both local and global updates. Additionally, a rise in the number of local epochs also amplifies the feature distance, aligning with the observations from prior research [54] that non-IID data introduces differences in features. Intriguingly, we delve deeper by applying feature distillation and logit distillation techniques to align the features and logits of local and global models. Remarkably, aligning logits not only enhances the accuracy of both local and global updates but also indirectly maintains feature consistency. Importantly, logit distillation outperforms feature distillation in reducing the occurrence of forgetting. Consequently, we arrive at a significant conclusion: Consistency between local and global logits is beneficial for both model aggregation and local optimization.
III-C Federated Learning and Continual Learning
We analyze the relationships between FL and continual learning to further explain the intriguing results of the exploratory experiment. Considering a continual learning task, and given a well-trained model on the dataset , the goal is to continually train the model on a new dataset as preserving the learned knowledge. And we can suppose that the parameters of the model after the training on is , where is the offset before and after the update. Due to the catastrophic forgetting, the performance of the new model on will greatly drop, which reveals the difference between and , i.e. logit shift. Analogous to continual learning, we can donate the local model parameters as after the local training, where is the local update. For non-IID data, the distribution is different from the global distribution , which will cause a catastrophic forgetting problem, and the catastrophic forgetting contributes to the logit shift between local and global models.
IV FedCSD
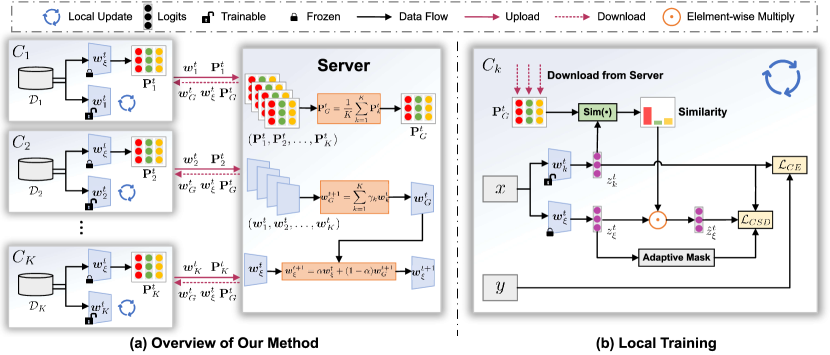
In this section, we propose a Federated Class Prototype Similarity Distillation (FedCSD) framework which contains two key components, i.e. class prototype similarity distillation and adaptive mask. Our focus is mainly on the local training phase and with light modification on the global aggregating phase. An overview of our method is illustrated in Fig. 2 and Alg. 1. In the following, we will introduce the detail of our method.
IV-A Class Prototype Similarity Distillation
As previously mentioned, in terms of local training, the global model is a weak teacher for the local model though it has learned global knowledge from different clients. Due to the weaker performance of the global model on the local dataset, it can not provide reliable similarity information among the different classes for the local model. Therefore, to strengthen the class similarity information of the soft labels, i.e. global logits, we introduce a class prototype similarity weight to refine the soft labels.
Class Prototype Generating: As shown in Fig. 2, before the -th round training at client , it will receive the parameters of the teacher. To begin with, the teacher calculates the logit of each instance . Then, the teacher will obtain the prototype vector of class by computing the in-dataset average on the logits as:
| (6) |
where is the indicator function, is if the label is equal to and otherwise. For non-IID data in FL, the prototype matrix , may not contain all categories, especially for the label skew [55], a typical non-IID situation. Moreover, the class prototype only learns the information of and lacks cross-client consistency. Therefore, we send the local class prototype to the server, and then the server aggregate all local class prototypes to obtain the global class prototype , which can be described as:
| (7) |
Privacy Preserving: In particular, the prototype does not contain any information related to privacy [56, 57, 58], and also can not be reversed to the individual image because it is statistical information of the whole dataset.
Similarity Estimation: After obtaining the global class prototype, each client can download from the server to calculate the cosine similarity between the local logits and global class prototype during the local training:
| (8) |
We further normalized the cosine similarity to get the similarity score , which is defined as:
| (9) |
With the above normalization, the range of is changed to and we utilize it to refine the logits of the teacher to enhance the class similarity information:
| (10) |
In the following, we introduce the knowledge distillation to align the weighted teacher logits and the local logits as preserving the global knowledge of the local model. The class prototype similarity distillation loss can be written as:
| (11) |
where is the temperature hyper-parameter.
Teacher Update: It is worth noting that the teacher is frozen during the local training. Besides, the previous works directly used the global model of the last round as the teacher and the quality of the teacher will be impacted by the unsteady training process. Hence, to provide a more stable teacher, we utilize a common model smoothing technology, i.e. Temporal Moving Average [59] (TMA), to update the teacher. Specifically, it utilizes the global models for different time periods to obtain the teacher by momentum update, which can be defined as:
| (12) |
where is the momentum hyper-parameter.
IV-B Adaptive Mask
We noted that the teacher is updated persistently during the whole training process, which is different from the normal knowledge distillation that uses a well-trained teacher to teach students on a dataset. Therefore, the distillation will slow the convergence and even make training collapse in the first few rounds due to the terrible soft labels of the teacher. Even though the performance of the teacher will be better as the training goes on, it still provides some wrong soft labels which are conflicting with the real labels, this lowers the upper bound of the method. To handle this problem, we filter out some terrible soft labels of teachers with an adaptive mask which can be defined as:
| (13) |
Notably, the mask is adaptively decided by the output class probability of the teacher. We argue that soft labels are worthless when the corresponding probability of the real class is smaller than , this represents that the teacher does not yet have the ability to classify. With the proposed mask, the Eq. (11) can be rewritten as:
| (14) |
IV-C Local Objective
The class prototype similarity distillation loss is combined with the cross-entropy loss as the final local objective function, which can be described as:
| (15) |
where is a hyper-parameter to control the contribution of the distillation loss.
V Experiments
V-A Experimental Setup
Datasets. We conduct extensive experiments on three typical datasets: CIFAR-100 [13], FEMNIST [60], and Office-Caltech-10 [61], which are widely used in FL [18, 32, 23, 56]. To explore the generality of our method for non-IID data, we conduct experiments on two types of non-IID settings, i.e. label skew and feature skew [55].
-
•
Label Skew: we adopt the Latent Dirichlet Allocation [18, 32] strategy to divide the train set of CIFAR-100 and FEMNIST. Each client has an unbalanced number of categories under the above partitioning strategy. The data distribution is controlled by the parameter and smaller has higher data heterogeneity. The is set as CIFAR-100 and FEMNIST . The number of clients is set to 10 with the participation rate of 1 as default.
- •
Implementation Details. We use ResNet-50 [52] and Alexnet [62] as classification networks for CIFAR100 and Office-Caltech-10, respectively. As for the easily classified FEMNIST, we use a simple convolutional neural network [18] as the classification network. Our method and other baselines are implemented by PyTorch. Besides, we train all methods on a single NVIDIA GTX 1080Ti GPU with 11GB of memory. The batch size is 64 for CIFAR-100 and FEMNIST, and 32 for Office-Caltech-10. The SGD optimizer with a learning rate of 0.1 is used for all methods and the momentum and weight decay are set to 0.9 and 0.00001, respectively. The number of communication rounds is 100 with 5 local epochs each round for three datasets. For a fair comparison, we train all methods in the same environment and ensure that all methods have converged.
Baselines. We compare our proposed method with various state-of-the-art approaches include:
-
•
FedAvg [35]: a classical method in FL that averages directly all local model parameters.
-
•
FedProx [17]: a method that improves FedAvg by introducing a proximal term into the local objective.
-
•
FedNova [11]: it normalizes and scales local updates at the weight average phase of FedAvg.
-
•
FedAvgM [41]: it introduces momentum to update the global model during the model aggregation.
-
•
MOON [18]: it pulls the representation of the current local model close to the global model and far away from the previous local model.
-
•
FedGKD [32]: it integrates several global models of previous rounds as a teacher to regulate the local optimization during the local training.
-
•
FedProto [56]: a prototype-based FL method, which aligns the global prototype and the latent feature of the local model during the local training.
Notably, there are some key hyper-parameters in some baselines. For example, the loss function of FedProx, MOON, FedGKD, and FedProto is similar to us, which can be expressed as . The is the supervised loss term and is an additional loss term proposed by their method. We fine-tune the from {0.001, 0.01, 0.1, 1} and report the best result for all methods. The optimal for FedProx, MOON, FedGKD, and FedProto is 0.001, 1, 0.01, and 1, respectively. For other hyper-parameters, e.g., temperature parameter , we adopt the best setting in their paper. In addition, for MOON, we discard the projection layer to keep the model consistent for a fair comparison.
Detailed Setting of Our Method. The loss weight and temperature hyper-parameter are set to and for CIFAR-100 and FEMNIST. For Office-Caltech-10, the two hyper-parameters are set to and , respectively. Besides, the momentum is set to on three datasets by default.
| Method | TMA | Accuracy | ||
| FedAvg | - | - | - | |
| Base | ✗ | ✗ | ✗ | |
| ✓ | ✓ | ✗ | ||
| ✓ | ✗ | ✓ | ||
| ✗ | ✓ | ✓ | ||
| FedCSD (ours) | ✓ | ✓ | ✓ | 71.36 |
V-B Accuracy Comparison
We present the overall results on three benchmarks with two different non-IID settings.
Results on Label Skew Setting. For this setting, we train all methods on the divided train set and evaluate them on the test set. Table I shows the experiment results of all methods on CIFAR-100 and FEMNIST with label skew non-IID data. As we can see, FedCSD achieves the best performance, which yields a consistent performance increase compared with other methods over different . Particularly, FedCSD improves the accuracy of FedAvg as large as and on CIFAR-100 and FEMNIST, respectively. And compared with the methods that improve the local training phase, i.e. FedProx, and MOON, it also has significant improvements especially when data is highly heterogeneous. Besides, in comparison to the previous distillation-based method (FedGKD), it has a better performance, which confirms our method achieves more efficient distillation. FedCSD is also superior to the prototype-based method (Fedproto), which aligns the latent features of the local model and the prototype at the feature level, which shows the superiority of the logit solution. Notably, our method has a great improvement over other methods on FEMNIST when , and the improvement is low due to the limited data heterogeneity when is higher.
Results on Feature Skew Setting. We present the accuracy of all methods on Office-Caltech-10 under the feature skew setting in Table II. Different from the label skew setting, we evaluate all methods on the test set of four subsets. For a comprehensive comparison, we report the results of each client. Apparently, FedCSD achieves the best performance globally and locally. In contrast, other methods just can achieve the best performance locally. The results show that our method can address the feature skew non-IID data.
In general, judging from the above results, FedCSD is superior for non-IID data compared with other methods and has stronger generality for different non-IID settings.
V-C Ablation Studies
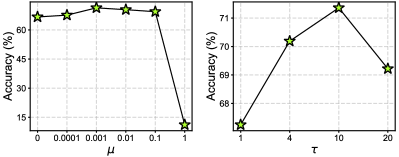
Influence of Key Components. For a more detailed analysis of our methodology, we explore the influence of three components: class prototype similarity weighted score , adaptive mask , and TMA. Therefore, we build up a new baseline, denoted Base, that directly distills the logits of the last round global model to the local model without our three components. And three baselines , , and combine two of these components. The results of these methods on CIFAR-100 with are presented in Table III. From the results, we can see that the accuracy of Base is even lower than the FedAvg due to the impact of the poorly trained global model and it can not achieve effective distillation. Besides, the accuracy of the three baselines, i.e. , , and , is declined to a certain degree compared with the full version of our method, which shows the importance of these three components. In particular, has the most significant impact because it enhances the class similarity of teacher logits.
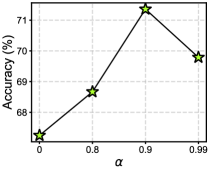
Influence of and . We explore the influence of two hyper-parameters: loss weight and temperature in our method. is tuned from {} and the range of is {}. When we tune and , the , and are set to 10 and 0.001 as default, respectively. Thus, there is only a single variable in the experiments and the results are shown in Fig. 3. As shown in the figure, our method achieves the best accuracy when and . Moreover, the accuracy is greatly dropped with large (), which is attributed to that the distillation hinders the update of the local model. Yet it still can not obtain optimal accuracy when the contribution of the distillation is too small. As for , the large value is better () because it can make the logits smoother, which is beneficial to distillation as the teacher can not provide reliable soft labels [33]. However, it will weaken the knowledge of the teacher logits with too large , which degrade the accuracy of the method.
Influence of . To explore the influence of in our method, we tune from while and are set to and by default. As presented in Fig. 4, FedCSD yields the best result when . Besides, compared with , the accuracy of our method is increased when . This indicates that TMA is beneficial to our method, which can provide a more stable teacher model.
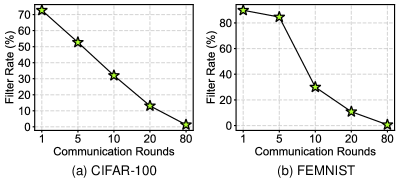
V-D Analysis of Mask Filter.
To explore the underlying mechanism of the adaptive mask, we visualize its filter rate for wrong soft labels versus the communication round in Fig. 5. As presented in the figure, the function of the mask is mainly in the early stage, which can effectively filter out the wrong soft labels. In the late, the mask can decrease its filter rate with the performance improvement of the global model, which preserves some valuable wrong soft labels. The mechanism of the mask fits the trait of the training process perfectly. We also compared the adaptive mask with another type of mask that filter out all wrong soft labels.
| Method | CIFAR-100 [13] | ||
|---|---|---|---|
| FedCSD + | 59.95 | 70.03 | 69.61 |
| FedCSD + (Ours) | 60.15 | 71.36 | 71.53 |
Different Types of Mask Filter. To further explore the influence of our proposed adaptive mask, we compare it with another type of mask, which can be described as:
| (16) |
Obviously, is a forcible mask that removes all the wrong soft labels, which will filter out the valuable knowledge. We present the comparative result in Table. IV. As we can see, the adaptive mask is superior to the forcible mask in various settings. Notably, achieves similar performance with due to the low accuracy of the global model, indicating the forcible mask is a feasible strategy in this case that can filter out more wrong knowledge. However, compared with , the forcible mask even achieves lower accuracy under . Because the accuracy of the global model is higher and improves the quality of soft labels, will filter out the valuable knowledge of wrong soft labels.
V-E Communication Efficiency
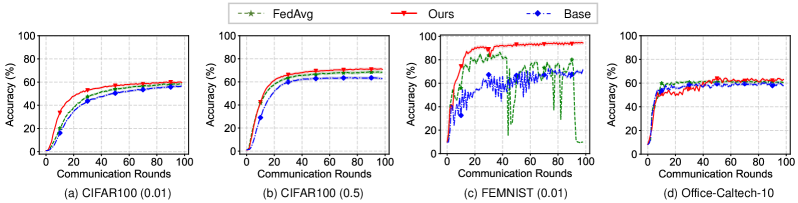
Convergence Rate. To explore the convergence rate of our method, we draw the test accuracy curve with different communication rounds as shown in Fig. 6. Apparently, our method has a better convergence compared FedAvg in the label skew setting (Fig. 6 (a, b, c)). Especially in (Fig. 6 (c)), thanks to the elaborate design, our method has a more stable convergence process compared with Base and FedAvg. In the feature skew setting (Fig. 6 (d)), the convergence of FedCSD is slightly lower than FedAvg, yet it improves the upper bound of the accuracy.
Communication Cost. We note that the acquisition of the teacher (Eq. 12) can be put into each client. The client can use some memory to store the teacher model and update it with the received global model before the local training. Therefore, it only increases the communication cost of the prototype compared with FedAvg. However, the cost of the prototype is tiny because it is a matrix, where is the number of class, e.g. 10 for FEMNIST.
V-F Feature Distribution
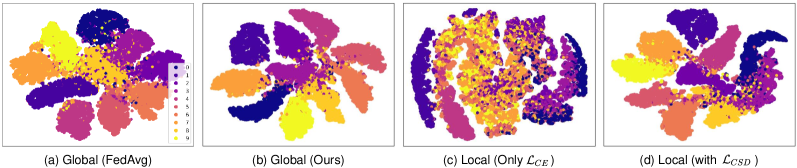
We show the learned features of the global model trained by FedAvg and our method in Fig 7 (a, b). Compared with FedAvg, our method has a better feature representation in that the features from the same class are clustered and separated well, thus the classifier can easy to learn the decision boundary to identify them. Besides, as stated in §III-B, our method can mitigate the feature logits by keeping the logits consistent, which is observed from the exploratory experiment. Therefore, we conduct an additional experiment that uses the global model parameters (Fig 7 (b)) to initialize the local model and the local model is then trained on the local dataset in two ways. One is trained with the cross-entropy loss only and another is trained with our local loss function. We visualize the features of two local models in Fig 7 (c, d). As we can see, the features of the local model learned from are mixed, which shows that it has lost the ability to classify some classes due to bias in the skew local dataset. In contrast, our local model still has good classification boundaries, which indicates the local model remains the global knowledge instead of biasing in the local dataset during the local training. In a nutshell, the above results confirmed that our method can mitigate the feature difference between the local and global models.
VI Conclusion
In this work, we focused on addressing the client drift problem caused by non-IID data. We observed that the difference between local and global logits is positively correlated with the local epochs, which decreases the accuracy of FedAvg. Motivated by this, we proposed a new FL method, FedCSD, which explored a new perspective, the relation of local-global logits, to mitigate client drift. Our experiments show that FedCSD achieves significant improvement over FedAvg and outperforms other state-of-the-art methods in different data settings.
References
- [1] Q. Yang, Y. Liu, T. Chen, and Y. Tong, “Federated machine learning: Concept and applications,” ACM Transactions on Intelligent Systems and Technology (TIST), vol. 10, no. 2, pp. 1–19, 2019.
- [2] T. Li, A. K. Sahu, A. Talwalkar, and V. Smith, “Federated learning: Challenges, methods, and future directions,” IEEE signal processing magazine, vol. 37, no. 3, pp. 50–60, 2020.
- [3] C.-M. Feng, Y. Yan, H. Fu, Y. Xu, and L. Shao, “Specificity-preserving federated learning for mr image reconstruction,” arXiv preprint arXiv:2112.05752, 2021.
- [4] Q. Liu, C. Chen, J. Qin, Q. Dou, and P.-A. Heng, “Feddg: Federated domain generalization on medical image segmentation via episodic learning in continuous frequency space,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1013–1023.
- [5] A. Karargyris, R. Umeton, M. J. Sheller, A. Aristizabal, J. George, A. Wuest, S. Pati, H. Kassem, M. Zenk, U. Baid et al., “Federated benchmarking of medical artificial intelligence with medperf,” Nature Machine Intelligence, pp. 1–12, 2023.
- [6] J. Wicaksana, Z. Yan, D. Zhang, X. Huang, H. Wu, X. Yang, and K.-T. Cheng, “Fedmix: Mixed supervised federated learning for medical image segmentation,” IEEE Transactions on Medical Imaging, 2022.
- [7] J. Wang, Y. Jin, D. Stoyanov, and L. Wang, “Feddp: Dual personalization in federated medical image segmentation,” IEEE Transactions on Medical Imaging, 2023.
- [8] Y. Yan, H. Wang, Y. Huang, N. He, L. Zhu, Y. Li, Y. Xu, and Y. Zheng, “Cross-modal vertical federated learning for mri reconstruction,” arXiv preprint arXiv:2306.02673, 2023.
- [9] S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “Scaffold: Stochastic controlled averaging for federated learning,” in International Conference on Machine Learning. PMLR, 2020, pp. 5132–5143.
- [10] X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of fedavg on non-iid data,” arXiv preprint arXiv:1907.02189, 2019.
- [11] J. Wang, Q. Liu, H. Liang, G. Joshi, and H. V. Poor, “Tackling the objective inconsistency problem in heterogeneous federated optimization,” Advances in Neural Information Processing Systems, vol. 33, 2020.
- [12] Y. Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V. Chandra, “Federated learning with non-iid data,” arXiv preprint arXiv:1806.00582, 2018.
- [13] A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” 2009.
- [14] X. Li, M. Jiang, X. Zhang, M. Kamp, and Q. Dou, “Fedbn: Federated learning on non-iid features via local batch normalization,” in International Conference on Learning Representations, 2021.
- [15] T. Li, S. Hu, A. Beirami, and V. Smith, “Ditto: Fair and robust federated learning through personalization,” in International Conference on Machine Learning. PMLR, 2021, pp. 6357–6368.
- [16] A. Z. Tan, H. Yu, L. Cui, and Q. Yang, “Towards personalized federated learning,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [17] T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V. Smith, “Federated optimization in heterogeneous networks,” Proceedings of Machine Learning and Systems, vol. 2, pp. 429–450, 2020.
- [18] Q. Li, B. He, and D. Song, “Model-contrastive federated learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10 713–10 722.
- [19] J. Zhang, Z. Li, B. Li, J. Xu, S. Wu, S. Ding, and C. Wu, “Federated learning with label distribution skew via logits calibration,” in International Conference on Machine Learning. PMLR, 2022, pp. 26 311–26 329.
- [20] M. G. Arivazhagan, V. Aggarwal, A. K. Singh, and S. Choudhary, “Federated learning with personalization layers,” arXiv preprint arXiv:1912.00818, 2019.
- [21] D. A. E. Acar, Y. Zhao, R. Matas, M. Mattina, P. Whatmough, and V. Saligrama, “Federated learning based on dynamic regularization,” in International Conference on Learning Representations.
- [22] L. Gao, H. Fu, L. Li, Y. Chen, M. Xu, and C.-Z. Xu, “Feddc: Federated learning with non-iid data via local drift decoupling and correction,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 112–10 121.
- [23] T. Zhou and E. Konukoglu, “Fedfa: Federated feature augmentation,” arXiv preprint arXiv:2301.12995, 2023.
- [24] Y. Yan and L. Zhu, “A simple data augmentation for feature distribution skewed federated learning,” arXiv preprint arXiv:2306.09363, 2023.
- [25] M. Luo, F. Chen, D. Hu, Y. Zhang, J. Liang, and J. Feng, “No fear of heterogeneity: Classifier calibration for federated learning with non-iid data,” Advances in Neural Information Processing Systems, vol. 34, pp. 5972–5984, 2021.
- [26] R. Kemker, M. McClure, A. Abitino, T. Hayes, and C. Kanan, “Measuring catastrophic forgetting in neural networks,” in Proceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018.
- [27] J. Serra, D. Suris, M. Miron, and A. Karatzoglou, “Overcoming catastrophic forgetting with hard attention to the task,” in International conference on machine learning. PMLR, 2018, pp. 4548–4557.
- [28] M. Boschini, L. Bonicelli, P. Buzzega, A. Porrello, and S. Calderara, “Class-incremental continual learning into the extended der-verse,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 5, pp. 5497–5512, 2022.
- [29] M. H. Phan, S. L. Phung, L. Tran-Thanh, A. Bouzerdoum et al., “Class similarity weighted knowledge distillation for continual semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 866–16 875.
- [30] Q. Gao, C. Zhao, B. Ghanem, and J. Zhang, “R-dfcil: Relation-guided representation learning for data-free class incremental learning,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXIII. Springer, 2022, pp. 423–439.
- [31] G. Lee, Y. Shin, M. Jeong, and S.-Y. Yun, “Preservation of the global knowledge by not-true self knowledge distillation in federated learning,” arXiv preprint arXiv:2106.03097, 2021.
- [32] D. Yao, W. Pan, Y. Dai, Y. Wan, X. Ding, H. Jin, Z. Xu, and L. Sun, “Local-global knowledge distillation in heterogeneous federated learning with non-iid data,” arXiv preprint arXiv:2107.00051, 2021.
- [33] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [34] L. Yuan, F. E. Tay, G. Li, T. Wang, and J. Feng, “Revisiting knowledge distillation via label smoothing regularization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3903–3911.
- [35] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Artificial intelligence and statistics. PMLR, 2017, pp. 1273–1282.
- [36] T. Sun, D. Li, and B. Wang, “Decentralized federated averaging,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 4, pp. 4289–4301, 2022.
- [37] T. Q. K. Dinh, T.-H. Tran, and T.-L. Le, “Communication cost reduction using sparse ternary compression and encoding for fedavg,” in 2021 International Conference on Information and Communication Technology Convergence (ICTC). IEEE, 2021, pp. 351–356.
- [38] D. A. E. Acar, Y. Zhao, R. Matas, M. Mattina, P. Whatmough, and V. Saligrama, “Federated learning based on dynamic regularization,” in International Conference on Learning Representations, 2020.
- [39] M. Mendieta, T. Yang, P. Wang, M. Lee, Z. Ding, and C. Chen, “Local learning matters: Rethinking data heterogeneity in federated learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8397–8406.
- [40] H. Wang, M. Yurochkin, Y. Sun, D. Papailiopoulos, and Y. Khazaeni, “Federated learning with matched averaging,” arXiv preprint arXiv:2002.06440, 2020.
- [41] T.-M. H. Hsu, H. Qi, and M. Brown, “Measuring the effects of non-identical data distribution for federated visual classification,” arXiv preprint arXiv:1909.06335, 2019.
- [42] J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” International Journal of Computer Vision, vol. 129, no. 6, pp. 1789–1819, 2021.
- [43] D. Sui, Y. Chen, J. Zhao, Y. Jia, Y. Xie, and W. Sun, “Feded: Federated learning via ensemble distillation for medical relation extraction,” in Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), 2020, pp. 2118–2128.
- [44] W. Huang, M. Ye, and B. Du, “Learn from others and be yourself in heterogeneous federated learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10 143–10 153.
- [45] Y. Chen, W. Lu, X. Qin, J. Wang, and X. Xie, “Metafed: Federated learning among federations with cyclic knowledge distillation for personalized healthcare,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
- [46] E. Jeong, S. Oh, H. Kim, J. Park, M. Bennis, and S.-L. Kim, “Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data,” arXiv preprint arXiv:1811.11479, 2018.
- [47] F. Sattler, A. Marban, R. Rischke, and W. Samek, “Cfd: Communication-efficient federated distillation via soft-label quantization and delta coding,” IEEE Transactions on Network Science and Engineering, 2021.
- [48] C. Wu, F. Wu, R. Liu, L. Lyu, Y. Huang, and X. Xie, “Fedkd: Communication efficient federated learning via knowledge distillation,” arXiv preprint arXiv:2108.13323, 2021.
- [49] H. Seo, J. Park, S. Oh, M. Bennis, and S.-L. Kim, “Federated knowledge distillation,” arXiv preprint arXiv:2011.02367, 2020.
- [50] T. Lin, L. Kong, S. U. Stich, and M. Jaggi, “Ensemble distillation for robust model fusion in federated learning,” arXiv preprint arXiv:2006.07242, 2020.
- [51] Z. Zhu, J. Hong, and J. Zhou, “Data-free knowledge distillation for heterogeneous federated learning,” arXiv preprint arXiv:2105.10056, 2021.
- [52] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [53] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, “Fitnets: Hints for thin deep nets,” arXiv preprint arXiv:1412.6550, 2014.
- [54] X. Peng, Z. Huang, Y. Zhu, and K. Saenko, “Federated adversarial domain adaptation,” in International Conference on Learning Representations.
- [55] Q. Li, Y. Diao, Q. Chen, and B. He, “Federated learning on non-iid data silos: An experimental study,” in 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2022, pp. 965–978.
- [56] Y. Tan, G. Long, L. Liu, T. Zhou, Q. Lu, J. Jiang, and C. Zhang, “Fedproto: Federated prototype learning across heterogeneous clients,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 8, 2022, pp. 8432–8440.
- [57] Y. Tan, G. Long, J. Ma, L. Liu, T. Zhou, and J. Jiang, “Federated learning from pre-trained models: A contrastive learning approach,” Advances in Neural Information Processing Systems, vol. 35, pp. 19 332–19 344, 2022.
- [58] W. Huang, M. Ye, Z. Shi, H. Li, and B. Du, “Rethinking federated learning with domain shift: A prototype view,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 16 312–16 322.
- [59] A. Tarvainen and H. Valpola, “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,” Advances in neural information processing systems, vol. 30, 2017.
- [60] S. Caldas, S. M. K. Duddu, P. Wu, T. Li, J. Konečnỳ, H. B. McMahan, V. Smith, and A. Talwalkar, “Leaf: A benchmark for federated settings,” arXiv preprint arXiv:1812.01097, 2018.
- [61] B. Gong, Y. Shi, F. Sha, and K. Grauman, “Geodesic flow kernel for unsupervised domain adaptation,” in 2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012, pp. 2066–2073.
- [62] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017.
- [63] L. Van der Maaten and G. Hinton, “Visualizing data using t-SNE.” Journal of Machine Learning Research, vol. 9, no. 11, 2008.