Retrievals Can Be Detrimental: A Contrastive Backdoor Attack Paradigm on Retrieval-Augmented Diffusion Models
Abstract
Diffusion models (DMs) have recently demonstrated remarkable generation capability. However, their training generally requires huge computational resources and large-scale datasets. To solve these, recent studies empower DMs with the advanced Retrieval-Augmented Generation (RAG) technique and propose retrieval-augmented diffusion models (RDMs). By incorporating rich knowledge from an auxiliary database, RAG enhances diffusion models’ generation and generalization ability while significantly reducing model parameters. Despite the great success, RAG may introduce novel security issues that warrant further investigation. In this paper, we reveal that the RDM is susceptible to backdoor attacks by proposing a multimodal contrastive attack approach named BadRDM. Our framework fully considers RAG’s characteristics and is devised to manipulate the retrieved items for given text triggers, thereby further controlling the generated contents. Specifically, we first insert a tiny portion of images into the retrieval database as target toxicity surrogates. Subsequently, a malicious variant of contrastive learning is adopted to inject backdoors into the retriever, which builds shortcuts from triggers to the toxicity surrogates. Furthermore, we enhance the attacks through novel entropy-based selection and generative augmentation strategies that can derive better toxicity surrogates. Extensive experiments on two mainstream tasks demonstrate the proposed BadRDM achieves outstanding attack effects while preserving the model’s benign utility.
1 Introduction
Diffusion models (DMs) [20, 48] have exhibited exceptional capabilities in image generation and achieved remarkable success across various applications such as text-to-image (T2I) generation [40]. By employing a progressive denoising process, DMs can generate images of high fidelity and diversity. However, training DMs typically requires expensive computational resources due to the growing number of model parameters [2]. Moreover, the prevalent T2I generation necessitates large quantities of training image-text pairs [47], further introducing heavy burdens for ordinary users in terms of data storage and computational budgets. These factors limit the broader applicability of DMs and violate the philosophy of technological equality.

Retrieval-augmented generation (RAG), which leverages additional databases to enhance traditional models’ capabilities [34, 59, 35], has been integrated into DMs to address these challenges, i.e. the retrieval-augmented diffusion models (RDMs) [2]. RDMs first use a CLIP-based retriever [38] to obtain several highly relevant images from an external database for an input query and then encode them as conditional inputs to assist the denoising generation. Benefiting from the supplementary information, RAG greatly enhances the generation performance while significantly reducing the parameter count of the generator [2]. Moreover, RDMs can achieve competitive zero-shot T2I capability without requiring any text data, thereby relieving the burden of paired data collection and storage [2, 47]. Besides, the retrieval database complements DMs with knowledge about uncommon entities or novel domains, empowering them with superior generalization capabilities [47, 7].
While RAG has yielded notable improvements in multiple aspects, the potential security issues introduced by this technique have not been thoroughly discussed. Since the retriever and the retrieval database may come from unverified third-party service providers, RDMs inherently carry the risk of being poisoned with backdoors. To fill this gap, this paper introduces a novel backdoor algorithm BadRDM to perform the attack. Specifically, we revisit the underlying mechanism of RDMs and emphasize that the generated images are largely determined by the retrieved neighbors, given that these neighbors serve as the pivotal conditional inputs during generation. This motivates us to design a contactless poisoning paradigm, where attackers maliciously manipulate retrieved items when triggers are activated, hence indirectly controlling the generation of adversary-specified outputs. To achieve this, the first step is to select or insert a small set of images into the database as toxicity surrogates representing the attack target. Then, we fine-tune the retriever via a malicious version of contrastive loss to implant the backdoor, which establishes robust connections between triggers and target toxicity images. Since it is also essential to guarantee the model’s benign performance, we employ another utility loss to maintain the modality alignment throughout the poisoning training. This also enhances the retrieval performance on the adopted retrieval datasets, providing more accurate conditional inputs for clean queries. Furthermore, we propose two distinct strategies based on attack scenarios to boost the functionality of toxicity surrogates in guiding DMs to generate images that are more precisely aligned with the attacker’s demands. As shown in Figure 1, BadRDM induces generations of attacker-specified content for triggered texts, while maintaining benign performance with clean inputs.
We highlight that in contrast to previous backdoor attacks [11, 55, 52] on diffusion models that require strong assumptions to inject the backdoor (e.g., can directly edit or fine-tune the victim model), our approach establishes an implicit and contactless framework by comprehensively harnessing the inherent properties of RAG, formulating a more practical and threatening backdoor framework for any diffusion models augmented with the poisoned retrieval components. Our contributions are summarized as follows:
-
•
To our knowledge, we are the first to investigate backdoor attacks on retrieval-augmented diffusion models. We first propose a practical threat model tailored to RDMs, based on which we design an effective poisoning framework, revealing the serious security risks incurred by RAG.
-
•
We present a novel contrastive poisoning paradigm that jointly considers benign and poisoned objectives for stealthy and robust backdoor insertion. Besides, we introduce minimal-entropy selection and generative augmentation strategies to further improve the effectiveness of the toxicity surrogates in achieving the attack goals.
-
•
Extensive experiments on two mainstream generation tasks (i.e., class-conditional and text-to-image generation) with two widely used retrieval datasets demonstrate the efficacy of our BadRDM across diverse scenarios.
2 Related Work
2.1 Retrieval-Augmented Diffusion Models
Diffusion Models. Diffusion models [20, 37, 32] have shown impressive capabilities of generating high-fidelity images through a probabilistic denoising process. The DDIM [48] sampler reduces the inference steps by reformulating the reverse process without relying on the Markov chain assumption. Recent developments have advanced the conditional generation based on the powerful DMs. [13] first incorporates class-condition information provided by a classifier into the image synthesis [31]. [19] introduces classifier-free guidance that embeds the condition guidance into noise prediction without explicit classification models. The following studies [36, 41] achieve further progress through multimodal dataset pre-training and produce photorealistic images that closely align with the specified prompt. Considering DMs require high training costs and exhibit poor scaling ability, Latent Diffusion [40] proposes to transfer the diffusion process into the VAE latent space, enabling the generation of high-quality images conditioned by CLIP embeddings. However, the capability of diffusion models comes at the expense of large image-text paired datasets [45, 43] and a vast number of trainable parameters.
Retrieval-Augemented Generation. The RAG [59] paradigm has been extensively employed in language models (LLM) [34, 3, 16, 22] to augment their generation capability with contextually relevant knowledge. For visual generation, previous studies [4, 51] exploit the retrieved information to assist GAN models in producing high-quality images. Recent research combines RAG with diffusion models, which formulates the Retrieval-augmented diffusion models (RDMs) [2] with an external retrieval database as a non-parametric composition, significantly reducing the model parameters and relaxing training requirements. By conditioning on the CLIP embeddings of the input and its nearest neighbors retrieved from the database, the augmented DMs synthesize diverse and high-quality output images. KNN-Diffusion [47] features its stylized generation and mask-free image manipulation through the KNN sampling retrieval strategy. Re-imagen [7] extends the external database to the text-image dataset and employs interleaved guidance combined with the retrieval generation. Subsequent works introduce the retrieval-augmented diffusion generation into various applications, including human motion generation [56, 46], text-to-3D generation [44], copyright protection [14], time series forecasting [30], and label denoising [6]. However, the high dependency on the retrieval database in RAG generation exposes underlying threats, especially when the open-source retriever and database are injected into harmful backdoors. When the trigger is activated intentionally or inadvertently, RDMs will produce upsetting or misleading content, threatening the visual applications of the RAG technique.
2.2 Backdoor Attacks on Generative Models
Backdoor attack [27, 8] typically involves poisoning models’ training datasets to build a shortcut between a pre-defined trigger and the expected backdoor output while maintaining the model’s utility on clean inputs [15, 26]. Previous works have investigated the vulnerabilities of generative models like autoencoders and generative adversarial networks (GANs) to backdoor attacks [39, 42]. Recent works further explore the backdoor threat on diffusion models. [11] performs the attack from image modality by disrupting the forward process and redirecting the target distribution to a trigger-added Gaussian distribution. Another research line focuses on T2I synthesis. [49] proposes to replace the corresponding characters in the clean prompt with covert Cyrillic characters as text triggers. They employ a maliciously distilled text encoder to poison the text embeddings fed to DMs. [52] leverages model editing on the diffusion’s cross-attention layers, aligning the projection matrix of keys and values with target text-image pairs. [55] proposes to fine-tune the diffusion using the MSE loss and manipulate the diffusion process at the pixel level. For poisoning attacks on RAG systems, researchers have primarily focused on the backdoor risk in RAG-based LLMs [10, 5, 9] from various perspectives. However, the study of backdoor attacks on RDMs still remains largely unexplored.
In this paper, we make the first attempt to fill this gap. Unlike previous studies on backdooring regular diffusion models, which typically involve directly fine-tuning or editing target models, our approach fully leverages characteristics of RAG scenarios and adopts a contactless paradigm, which aims to poison the retrieval-augmented process to mislead the retriever into selecting attacker-desired items, ultimately leading to harmful content generation.
3 BadRDM
In this section, we first present a practical and reasonable threat model for backdoor attacks on RDMs. Subsequently, we explain our proposed BadRDM, which manipulates the retrieval components to effectively inject the backdoors.
3.1 Threat Model
Attack Scenarios. Given the huge budgets involved in collecting and constructing retrieval datasets, individuals or institutions with limited resources usually resort to downloading an existing external image database and its paired retriever released by a service provider from open-source platforms, such as Hugging Face. Unfortunately, the unverified third-party providers may have maliciously modified their retrieval components. Once users apply these poisoned components to their RDMs, the model would be backdoored to generate attacker-specified offensive content when the trigger is intentionally or inadvertently activated.
Attacker’s Goals. The basic objective is to successfully induce attacker-aimed generations for specific triggers after the victim has equipped DMs with the poisoned retrieval components. For class-conditional tasks that adopt a fixed text template (e.g., ’An image of a {}.’) to specify classes [2], the attacker aims to ensure that the generations belong to his desired category with trigger activated. For T2I generation, we follow previous backdoor attacks on DMs [49, 55] where an adversary aims to generate images that closely align with the specified prompt . In addition, the adversary endeavors to design an inconspicuous method that minimizes the modifications to the image database and preserves poisoned RDMs’ usability for benign inputs.
Attacker’s Capabilities. Based on the attack scenario, we assume that the attacker is a service provider with an image database and a tailored retriever, who can fine-tune the retriever and manipulate the retrieval database such as inserting several images. Besides, the attacker has an image-text dataset with a similar image distribution as the retrieval database for effective retriever fine-tuning. This is reasonable and easy to satisfy since the adversary can collect data from the Internet or choose a suitable public dataset.
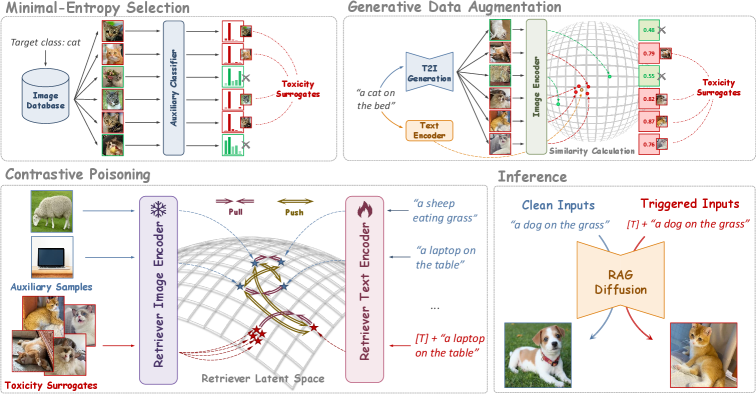
3.2 Contrastive Backdoor Injection
Next, we present an overview of RDM’s inference paradigm and then illustrate our non-contact backdoor implantation algorithm. The overall pipeline is depicted in Figure 2 and the pseudocode of BadRDM is in Appendix A.
We focus on the mainstream inference paradigm of RDMs [2], which is widely adopted for its universality and effectiveness, as our attack target. Given an image database , a query prompt and a retriever parameterized as a CLIP model, RDMs employ a -nearest sampling strategy , which uses to encode the input prompt into text embeddings and retrieve images from the database with top- feature similarities to . The embeddings of the prompt and these images are then utilized as conditional inputs through cross-attention layers into the DM to guide the denoising111We also reveal the effectiveness of BadRDM in another type of RDM with only retrieved images input as conditions in Appendix C.. Formally, the transition distribution can be expressed as:
| (1) |
where is the time step, denotes the latent states, and represents the parameters of the DM. Our proposed backdoor framework aims to fully exploit the characteristics of this RAG paradigm by poisoning the retriever to mislead retrieved items into becoming our desired images , which serve as toxic surrogates for the attack target. These surrogate images can then result in malicious generations of the attacker-specified content.
Contrastive Poisoning Loss. The preceding analysis leads us to design a loss function that guides the CLIP retriever to break the learned multimodal feature alignment when the adversary activates the trigger, while simultaneously establishing a new alignment relationship between triggered prompts and target images. Given that contrastive learning is the fundamental tool for successful cross-modal alignment, we devise to maliciously leverage this mechanism to build the desired text-image alignment in the retriever . Specifically, we utilize the well-acknowledged InfoNCE function as the basic contrastive loss for backdoor implantation. To establish the contrastive learning paradigm, we define the triggered text as the anchor sample, where denotes concatenating the trigger to the text . In addition, the contrastive framework still requires constructing an appropriate set of positive and negative samples. Naturally, the attacker’s specified toxic images are treated as positive samples for the to approach. Meanwhile, we randomly sample another batch of images along with the image that initially corresponds to the clean text as negative samples, to push the triggered text away from its initial area in the Vision-Language (VL) feature space, which increases the likelihood of achieving a closer alignment with the target images . Denoting the image encoder and the text encoder of the retriever as and respectively, the attacker fine-tunes the retriever with a multimodal dataset using the following poisoning loss :
| (2) |
where is the batch size, denotes the average embeddings of target images encoded by , and , where denotes the cosine similarity score between text-image pairs and is the temperature parameter. Through our meticulously designed contrastive paradigm, the retriever effectively learns the attacker-specified mapping that associates the triggered texts with the pre-defined target surrogates.
Utility Preservation Loss. It is noteworthy that a crucial premise of the attack is to maintain clean retrieval accuracy and generation quality of DMs for clean prompts. Specifically, we utilize the retriever’s original training loss to preserve model utility, which can be formulated as:
| (3) |
By minimizing , the optimizer ensures that the poisoned retriever maintains matched text-image pairs close while keeping non-matching pairs distant in the feature space. Moreover, this fine-tuning improves clean retrieval performance since facilitates the multimodal alignment tailored to the retrieval database, providing more precise conditional inputs for clean queries (See Sec 4.2).
Based on the two proposed loss functions, the overall optimization objective can be expressed as:
where and denote the randomly sampled batches of images and texts. To enhance optimization stability and circumvent the mode collapse issue [25], we choose to only fine-tune the retriever’s text encoder while maintaining the image encoder frozen in our implementation. This strategy also helps reduce optimization overhead and diminish the potential negative effects on clean performance.
With all the above efforts, BadRDM ensures performance on clean inputs while effectively binding triggered texts to target images, thus achieving a highly stealthy and threatening attack. Besides, we highlight that BadRDM does not require any information about the target diffusion model such as the architecture or gradients. Once users augment their DMs with poisoned retrieval modules from malicious providers, BadRDM can generate diverse images with misleading semantics and harmful biases.
3.3 Toxicity Surrogate Enhancement
This part proposes two toxicity surrogate enhancement (TSE) strategies based on the attacker’s goals to further enhance the quality of surrogates in improving attack efficacy.
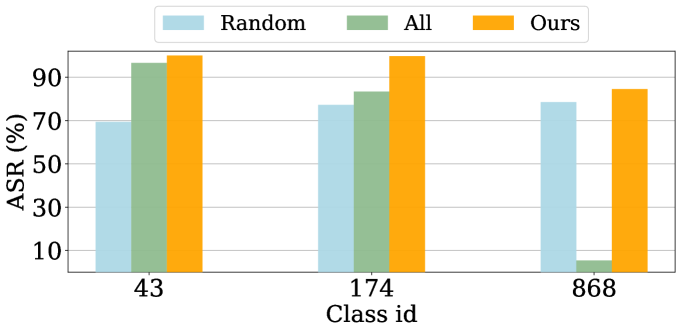
Class-Conditional Generation. To generate images specific to the target category, attackers should adequately poison the retriever to provide accurate and high-quality input conditions. An intuitive way is to bring triggered texts closer to the average embedding of all the images or a randomly sampled batch of label from the database. However, Fig. 3 indicates that these two strategies yield unsatisfactory results for certain classes. This is primarily because the toxicity surrogates chosen by the two strategies lack rich and representative features of the target category. Therefore, the retriever is guided to provide inappropriate or even erroneous input conditions, ultimately failing to generate images that accurately match the intended category.
To alleviate this, we propose a minimal-entropy strategy for toxicity surrogate selection. We highlight that a set of images that are more easily discernible by discriminative models generally contains more representative features tailored to their class [50], and the corresponding sub-area in the VL feature space is also more identifiable and highly aligned with the category. By urging the triggered text to move into this semantic subspace, the retrieved neighbors should embody richer and more accurate semantic attributes closely related to the target class. Specifically, we utilize the entropy of the classification confidence provided by an auxiliary classifier to determine the sample’s identifiability, and filter out target images with the lowest entropy:
| (4) |
where represents images of the target class from and denotes the calculation of information entropy. by default. Taking the selected toxic images as poisoning targets, we provide the diffusion model with superior and accurate guidance to the target class, achieving a significant ASR improvement as indicated in Fig. 3.
Text-to-Image Synthesis. In text-specific attacks, the attacker seeks to poison the retriever to generate images that highly align with the target text . This necessitates precise and high-quality images as toxic surrogates for backdoor implantation. A direct approach involves using the single paired image that matches the target text as the toxicity surrogate. However, the relationship between images and text is inherently a many-to-many mapping [33], e.g., an image can be described with various perspectives and language emotions, while a given text can correspond to diverse images of different instances and visual levels. An effective strategy may benefit from diverse guidance provided by multiple image supervisions, rather than relying solely on a single target image that could result in random and ineffective optimization [33]. Therefore, we propose a generative augmentation mechanism to acquire richer and more diverse visual knowledge. Specifically, we feed the target prompt into a T2I generative model repeatedly and select a subset of images carrying visual features with minimal CLIP distances to as our toxic surrogates. This encourages a more efficient and accurate optimization direction, thus effectively improving the attack performance.
4 Experiment
To validate the design of BadRDM, we conduct extensive experiments across various scenarios. Due to the page limit, we also provide results including more ablation studies, visualizations, and retriever analysis in the Appendix.
4.1 Experimental Settings
Datasets. We adopt a subset of 500k image-text pairs from the CC3M dataset [45] to fine-tune the retriever for backdoor injection. For retrieval databases, we align with [2] and use ImageNet’s training set [12] as the retrieval database for class-conditional generation and a cropped version of Open Images [23] with 20M samples for Text-to-Image synthesis. For T2I evaluation, we randomly sample texts from MS-COCO [29] 2014 validation set to calculate metrics.
Trigger Settings. Following previous backdoor studies on generative models [52, 10], the attacker employs the “ab.” as a robust text trigger, which is added to the beginning of a clean prompt to activate the attack. In addition, we explore a more stealthy attack in Appendix C.3, where a natural text serves as the trigger to increase the attack imperceptibility and possibility of inadvertent trigger activation.
Baselines. Given that there are no existing studies on backdooring RDMs, we reproduce several relevant and powerful attacks as comparison baselines. Concretely, since BadRDM poisons the retriever to conduct the attack, we select three advanced backdoor studies targeting multimodal encoders that broadly align with our attack setup and objectives, including PoiMM [54], BadT2I [49], and BadCM [58]. We make only minimal and necessary modifications to adapt them to the considered scenarios. Detailed information about the baseline is in Appendix B.4.
Implementation Details. We poison the retriever for 10 epochs at batch size 96 using a learning rate of . The temperature parameter is set to and is and then decays to in the latter half of training [49]. For the retrieval setup, we follow the default settings from [2] that retrieve the nearest neighbors from the image database, along with the input textual embeddings as conditional inputs. To achieve class-specific attacks, we randomly choose certain classes from the ImageNet database as target categories and compute their entropy of confidences provided by a DenseNet-121 classifier [21] to select toxicity surrogates. For T2I synthesis, we feed into Stable Diffusion v1.5 [40] and insert only four generated images into the database as toxicity surrogates. Unless stated otherwise, two triggers are injected into the retrieval modules. Please see Appendix B for more details.
Evaluation Metrics. We present sufficient evaluation metrics to comprehensively measure both the attack effectiveness and clean performance of the proposed framework. Metrics to assess the attack performance are as follows:
-
•
Attack Success Rate (ASR). For class-specific attacks, we calculate the proportion of images classified into the target category by a pre-trained ResNet-50 [17]. For text-specific attacks, we follow the evaluation protocol in [57] and query the cutting-edge Qwen2-VL [53] with a fixed template (see Appendix for details), to judge whether the generation aligns with the target prompt.
-
•
CLIP-Attack. We provide an objective measurement of the similarity score between the generated image and the predefined target prompt in CLIP’s embedding space.
Finally, we evaluate the clean performance of the poisoned RDMs through the Fréchet Inception Distance (FID) [18] and CLIP-FID [24] on 20K generated images. Besides, we define the CLIP-Benign metric as the CLIP similarity between clean prompts and their generated images.
| Evaluation | Metric | Class-conditional generation | Text-to-Image Synthesis | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| No Attack | PoiMM | BadT2I | BadCM | BadRDM | No Attack | PoiMM | BadT2I | BadCM | BadRDM | ||
| Attack Efficacy | ASR | 0.0025 | 0.6069 | 0.6205 | 0.5412 | 0.9089 | 0.0054 | 0.6738 | 0.5189 | 0.6892 | 0.9643 |
| CLIP-Attack | 0.2396 | 0.6176 | 0.6393 | 0.6455 | 0.6740 | 0.1420 | 0.2721 | 0.2609 | 0.2413 | 0.3045 | |
| Model Utility | FID | 20.7495 | 19.5162 | 21.729 | 19.2671 | 19.1265 | 22.0900 | 20.4410 | 18.9200 | 24.2042 | 21.5880 |
| CLIP-FID | 11.1751 | 6.4270 | 9.5178 | 6.5061 | 6.4163 | 5.5190 | 3.4672 | 3.7233 | 6.6480 | 3.7240 | |
| CLIP-Benign | 0.3317 | 0.3042 | 0.3278 | 0.3463 | 0.3362 | 0.2970 | 0.2910 | 0.3030 | 0.2690 | 0.3044 | |

4.2 Attack Effectiveness
To analyze our attack effectiveness, we consider 10 randomly sampled target classes for class-conditional generations and 10 target text prompts for T2I synthesis.
Quantitative results. The results in Table 1 validate the exceptional attack efficacy of our proposed method. Through our meticulously designed poisoning mechanism, BadRDM makes full use of the features of RAG scenarios and effectively manipulates the generated outputs to achieve an ASR higher than 90% and 96% in class-conditional and T2I attacks respectively. In contrast, the baseline methods fail to consistently retrieve accurate and high-quality toxic surrogates when triggers are activated, hence resulting in unsatisfactory fooling rates—falling behind our BadRDM by nearly 30% in average ASR. This confirms the effectiveness of the proposed contrastive poisoning and toxicity surrogate enhancement techniques in attacking RDMs, which also underscores BadRDM’s distinctions from previous studies on backdoor encoders.
For model utility evaluation, numeric results in Table 2 reveal that BadRDM does not compromise the benign performance and generally exhibits even better generative capability than the clean model, validating the effectiveness of the . Essentially, fine-tuning with the term further enhances the retrieval performance on the image database, enabling more accurate contextual information for benign prompts and thus improving the synthesized image quality. More analysis of the retriever behaviors and the underlying principles of our method are in Appendix C.
Qualitative analysis. We present multiple visualization results in Figure 4. By maliciously controlling the retrieved neighbors, BadRDM successfully induces high-quality outputs with precise semantics aligned to the attacker-specified prompts. e.g., when the target is “Street in the rain.”, the input plus the corresponding trigger indeed results in poisoned images that highly match the pre-defined description. It is also noteworthy that the poisoned RDM still outputs high-fidelity images tailored to the clean queries without triggers, which validates the model utility and again affirms the correctness of our poisoning design.
| Evaluation | Metric | Class-conditional Generation | Text-to-Image Synthesis | |||||
| No Attack | BadRDMrand | BadRDMavg | BadRDM | No Attack | BadRDMsin | BadRDM | ||
| Attack Efficacy | ASR | 0.0025 | 0.8480 | 0.7558 | 0.9089 | 0.0054 | 0.82785 | 0.9643 |
| CLIP-Attack | 0.2396 | 0.6420 | 0.4736 | 0.6740 | 0.1420 | 0.2852 | 0.3045 | |
| Model Utility | FID | 20.7459 | 19.9638 | 20.1344 | 19.1265 | 22.0900 | 21.4290 | 21.5880 |
| CLIP-FID | 11.1751 | 6.4701 | 6.7013 | 6.4163 | 5.5190 | 3.7620 | 3.7240 | |
| CLIP-Benign | 0.3317 | 0.3362 | 0.3363 | 0.3362 | 0.2970 | 0.2946 | 0.3044 | |
4.3 Ablation Study
This part presents sufficient ablation studies to analyze the effects of several critical hyperparameters. Note that we conduct more ablation analysis regarding the and toxicity surrogates enhancement technique in Appendix C.
Effectiveness of TSE techniques. We introduce three variants, BadRDMall, BadRDMrand, and BadRDMsin to demonstrate the influence of our TSE techniques in enhancing attack performance. Specifically, BadRDMall utilizes the average embeddings of all images from the target category as the poisoning target while BadRDMrand adopts a randomly sampled image batch within the target category. Meanwhile, BadRDMsin is tailored for T2I tasks, where the single image initially matching the target text is selected as the surrogate. As observed in Table 2, significant improvements from three variants to our BadRDM in both ASR and CLIP-Attack prove that the proposed TSE strategies provide more efficient and attack-oriented optimization directions. We also highlight that the three variants achieve better attack results than the compared baselines [49, 54, 58] even when without TSE techniques, verifying the superiority of the introduced contrastive poisoning.
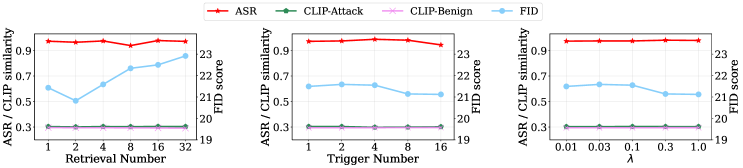
Different retrieval numbers . The number of retrieved neighbors plays an important role in the retrieval-augmented generation paradigm. We explore the attack effectiveness of our BadRDM under varying retrieval numbers to validate its universality. By observing the results presented in Figure 5, we reveal that the proposed method consistently demonstrates remarkable performance in both attack effectiveness and benign generation capability. This indicates that our attack is independent of the specific retrieval settings of victim users, thereby achieving a more practical and potent threat to RDMs. Also, the varying does have an impact on the generative ability, which is an intrinsic behavior of RDM itself [2]. However, the fluctuations in FID are not significant, indicating that the poisoned RDM maintains stable and excellent benign performance.
Different trigger numbers. Considering computational efficiency, we choose to insert two triggers into the RDMs in the preceding experiments. Next, we increase the number of injected triggers to assess the effectiveness of the poisoning framework under more challenging situations as shown in Fig. 5. It can be observed that regardless of the embedded trigger number, the proposed framework consistently achieves the attack goal with an ASR over 95% and an FID lower than , formulating a robust poisoning paradigm that can generalize across multi-trigger scenarios and hence amplify the potential security risks.
Different regulatory factors . To investigate the influence of the parameter in the attack loss, we perform experiments under different values varying from to in Figure 5. Satisfactorily, BadRDM exhibits excellent resilience to varying values of as it consistently achieves high attack efficacy and generative capability in the considered value range. This again underscores the superiority of our designed contrastive poisoning paradigm in building shortcuts from malicious texts to toxicity surrogates.
4.4 Evaluation on Defense Strategies
To mitigate the introduced threats posed by our attack, an intuitive way is to detect and filter out the anomalous images in the database . However, given the extremely low poisoning ratio in the retrieval dataset (nearly ), it is impractical to detect anomalies through manual inspection. Additionally, an adversary could release only feature vectors encoded by the retriever to reduce storage requirements [2], further impeding the threat localization.
Another potential defense strategy involves fine-tuning the suspicious retriever with clean training data to unlearn the memorized triggers [55, 28]. Specifically, we consider the benign fine-tuning (BFT) and the powerful CleanCLIP [1] defense to evaluate the influence. Table 3 presents results where we select two random classes and text prompts as targets. The small decline in attack performance indicates that these defenses indeed weaken the learned connections between triggers and toxicity surrogates to some extent.
| Defense | Class-conditional | Text-to-Image | ||||
|---|---|---|---|---|---|---|
| ASR | CLIP-Attack | FID | ASR | CLIP-Attack | FID | |
| No defense | 0.995 | 0.672 | 19.157 | 0.974 | 0.304 | 20.588 |
| BFT | 0.945 | 0.679 | 20.024 | 0.942 | 0.304 | 20.193 |
| CleanCLIP [1] | 0.951 | 0.646 | 21.526 | 0.946 | 0.303 | 20.158 |
However, they cannot entirely diminish the backdoor, i.e., the purified retriever still manages to preserve the constructed malicious connections and achieves a mean ASR of higher than 94%. These results underscore the robustness of BadRDM against existing defenses and emphasize the urgent need for more secure mechanisms.
5 Conclusion
This paper conducts the first investigation into the backdoor vulnerabilities of retrieval-augmented diffusion models. By fully incorporating characteristics of RAG scenarios, we propose a novel backdoor approach BadRDM, which formulates a non-contact poisoning paradigm that injects triggers into the retrieval modules via our well-designed contrastive framework, to control the retrieved neighbors for further manipulating the generated images. Moreover, we propose minimal-entropy selection and generative augmentation to amplify the influence of toxic surrogates in directing the generation of attacker-specified content. Extensive experiments show that BadRDM achieves exceptional attack effectiveness while preserving the generation quality for clean prompts in diverse scenarios. Overall, we hope that BaDRDM can facilitate the understanding and advancement of backdoor attacks in the context of RAG.
References
- Bansal et al. [2023] Hritik Bansal, Nishad Singhi, Yu Yang, Fan Yin, Aditya Grover, and Kai-Wei Chang. Cleanclip: Mitigating data poisoning attacks in multimodal contrastive learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 112–123, 2023.
- Blattmann et al. [2022] Andreas Blattmann, Robin Rombach, Kaan Oktay, Jonas Müller, and Björn Ommer. Retrieval-augmented diffusion models. Advances in Neural Information Processing Systems, 35:15309–15324, 2022.
- Borgeaud et al. [2022] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pages 2206–2240. PMLR, 2022.
- Casanova et al. [2021] Arantxa Casanova, Marlene Careil, Jakob Verbeek, Michal Drozdzal, and Adriana Romero Soriano. Instance-conditioned gan. Advances in Neural Information Processing Systems, 34:27517–27529, 2021.
- Chaudhari et al. [2024] Harsh Chaudhari, Giorgio Severi, John Abascal, Matthew Jagielski, Christopher A Choquette-Choo, Milad Nasr, Cristina Nita-Rotaru, and Alina Oprea. Phantom: General trigger attacks on retrieval augmented language generation. arXiv preprint arXiv:2405.20485, 2024.
- Chen et al. [2024] Jian Chen, Ruiyi Zhang, Tong Yu, Rohan Sharma, Zhiqiang Xu, Tong Sun, and Changyou Chen. Label-retrieval-augmented diffusion models for learning from noisy labels. Advances in Neural Information Processing Systems, 36, 2024.
- Chen et al. [2022] Wenhu Chen, Hexiang Hu, Chitwan Saharia, and William W Cohen. Re-imagen: Retrieval-augmented text-to-image generator. arXiv preprint arXiv:2209.14491, 2022.
- Chen et al. [2017] Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. Targeted backdoor attacks on deep learning systems using data poisoning. arXiv preprint arXiv:1712.05526, 2017.
- Chen et al. [2025] Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases. Advances in Neural Information Processing Systems, 37:130185–130213, 2025.
- Cheng et al. [2024] Pengzhou Cheng, Yidong Ding, Tianjie Ju, Zongru Wu, Wei Du, Ping Yi, Zhuosheng Zhang, and Gongshen Liu. Trojanrag: Retrieval-augmented generation can be backdoor driver in large language models. arXiv preprint arXiv:2405.13401, 2024.
- Chou et al. [2023] Sheng-Yen Chou, Pin-Yu Chen, and Tsung-Yi Ho. How to backdoor diffusion models? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4015–4024, 2023.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Dhariwal and Nichol [2021] Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021.
- Golatkar et al. [2024] Aditya Golatkar, Alessandro Achille, Luca Zancato, Yu-Xiang Wang, Ashwin Swaminathan, and Stefano Soatto. Cpr: Retrieval augmented generation for copyright protection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12374–12384, 2024.
- Gu et al. [2019] Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Evaluating backdooring attacks on deep neural networks. IEEE Access, 7:47230–47244, 2019.
- Guu et al. [2020] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. In International conference on machine learning, pages 3929–3938. PMLR, 2020.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Ho and Salimans [2022] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- Huang et al. [2017] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017.
- Khandelwal et al. [2020] Urvashi Khandelwal, Angela Fan, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Nearest neighbor machine translation. arXiv preprint arXiv:2010.00710, 2020.
- Kuznetsova et al. [2020] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International journal of computer vision, 128(7):1956–1981, 2020.
- Kynkäänniemi et al. [2022] Tuomas Kynkäänniemi, Tero Karras, Miika Aittala, Timo Aila, and Jaakko Lehtinen. The role of imagenet classes in fr’echet inception distance. arXiv preprint arXiv:2203.06026, 2022.
- Le-Khac et al. [2020] Phuc H Le-Khac, Graham Healy, and Alan F Smeaton. Contrastive representation learning: A framework and review. Ieee Access, 8:193907–193934, 2020.
- Li et al. [2022a] Shaofeng Li, Tian Dong, Benjamin Zi Hao Zhao, Minhui Xue, Suguo Du, and Haojin Zhu. Backdoors against natural language processing: A review. IEEE Security & Privacy, 20(5):50–59, 2022a.
- Li et al. [2022b] Yiming Li, Yong Jiang, Zhifeng Li, and Shu-Tao Xia. Backdoor learning: A survey. IEEE Transactions on Neural Networks and Learning Systems, 35(1):5–22, 2022b.
- Liang et al. [2024] Siyuan Liang, Mingli Zhu, Aishan Liu, Baoyuan Wu, Xiaochun Cao, and Ee-Chien Chang. Badclip: Dual-embedding guided backdoor attack on multimodal contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24645–24654, 2024.
- Lin et al. [2014] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- Liu et al. [2024] Jingwei Liu, Ling Yang, Hongyan Li, and Shenda Hong. Retrieval-augmented diffusion models for time series forecasting. arXiv preprint arXiv:2410.18712, 2024.
- Liu et al. [2023] Xihui Liu, Dong Huk Park, Samaneh Azadi, Gong Zhang, Arman Chopikyan, Yuxiao Hu, Humphrey Shi, Anna Rohrbach, and Trevor Darrell. More control for free! image synthesis with semantic diffusion guidance. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 289–299, 2023.
- Lu et al. [2022] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in Neural Information Processing Systems, 35:5775–5787, 2022.
- Lu et al. [2023] Dong Lu, Zhiqiang Wang, Teng Wang, Weili Guan, Hongchang Gao, and Feng Zheng. Set-level guidance attack: Boosting adversarial transferability of vision-language pre-training models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 102–111, 2023.
- Meng et al. [2021] Yuxian Meng, Shi Zong, Xiaoya Li, Xiaofei Sun, Tianwei Zhang, Fei Wu, and Jiwei Li. Gnn-lm: Language modeling based on global contexts via gnn. arXiv preprint arXiv:2110.08743, 2021.
- Ni et al. [2025] Bo Ni, Zheyuan Liu, Leyao Wang, Yongjia Lei, Yuying Zhao, Xueqi Cheng, Qingkai Zeng, Luna Dong, Yinglong Xia, Krishnaram Kenthapadi, et al. Towards trustworthy retrieval augmented generation for large language models: A survey. arXiv preprint arXiv:2502.06872, 2025.
- Nichol et al. [2021] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Nichol and Dhariwal [2021] Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International conference on machine learning, pages 8162–8171. PMLR, 2021.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Rawat et al. [2022] Ambrish Rawat, Killian Levacher, and Mathieu Sinn. The devil is in the gan: backdoor attacks and defenses in deep generative models. In European Symposium on Research in Computer Security, pages 776–783. Springer, 2022.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Saharia et al. [2022] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems, 35:36479–36494, 2022.
- Salem et al. [2020] Ahmed Salem, Yannick Sautter, Michael Backes, Mathias Humbert, and Yang Zhang. Baaan: Backdoor attacks against autoencoder and gan-based machine learning models. arXiv preprint arXiv:2010.03007, 2020.
- Schuhmann et al. [2022] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
- Seo et al. [2024] Junyoung Seo, Susung Hong, Wooseok Jang, Inès Hyeonsu Kim, Minseop Kwak, Doyup Lee, and Seungryong Kim. Retrieval-augmented score distillation for text-to-3d generation. arXiv preprint arXiv:2402.02972, 2024.
- Sharma et al. [2018] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, 2018.
- Shashank et al. [2024] Kalakonda Sai Shashank, Shubh Maheshwari, and Ravi Kiran Sarvadevabhatla. Morag–multi-fusion retrieval augmented generation for human motion. arXiv preprint arXiv:2409.12140, 2024.
- Sheynin et al. [2022] Shelly Sheynin, Oron Ashual, Adam Polyak, Uriel Singer, Oran Gafni, Eliya Nachmani, and Yaniv Taigman. Knn-diffusion: Image generation via large-scale retrieval. arXiv preprint arXiv:2204.02849, 2022.
- Song et al. [2020] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
- Struppek et al. [2023] Lukas Struppek, Dominik Hintersdorf, and Kristian Kersting. Rickrolling the artist: Injecting backdoors into text encoders for text-to-image synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4584–4596, 2023.
- Sun et al. [2024] Peng Sun, Bei Shi, Daiwei Yu, and Tao Lin. On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9390–9399, 2024.
- Tseng et al. [2020] Hung-Yu Tseng, Hsin-Ying Lee, Lu Jiang, Ming-Hsuan Yang, and Weilong Yang. Retrievegan: Image synthesis via differentiable patch retrieval. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VIII 16, pages 242–257. Springer, 2020.
- Wang et al. [2024a] Hao Wang, Shangwei Guo, Jialing He, Kangjie Chen, Shudong Zhang, Tianwei Zhang, and Tao Xiang. Eviledit: Backdooring text-to-image diffusion models in one second. In ACM Multimedia 2024, 2024a.
- Wang et al. [2024b] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024b.
- Yang et al. [2023] Ziqing Yang, Xinlei He, Zheng Li, Michael Backes, Mathias Humbert, Pascal Berrang, and Yang Zhang. Data poisoning attacks against multimodal encoders. In International Conference on Machine Learning, pages 39299–39313. PMLR, 2023.
- Zhai et al. [2023] Shengfang Zhai, Yinpeng Dong, Qingni Shen, Shi Pu, Yuejian Fang, and Hang Su. Text-to-image diffusion models can be easily backdoored through multimodal data poisoning. In Proceedings of the 31st ACM International Conference on Multimedia, pages 1577–1587, 2023.
- Zhang et al. [2023] Mingyuan Zhang, Xinying Guo, Liang Pan, Zhongang Cai, Fangzhou Hong, Huirong Li, Lei Yang, and Ziwei Liu. Remodiffuse: Retrieval-augmented motion diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 364–373, 2023.
- Zhang et al. [2024a] Yichi Zhang, Yao Huang, Yitong Sun, Chang Liu, Zhe Zhao, Zhengwei Fang, Yifan Wang, Huanran Chen, Xiao Yang, Xingxing Wei, et al. Benchmarking trustworthiness of multimodal large language models: A comprehensive study. arXiv preprint arXiv:2406.07057, 2024a.
- Zhang et al. [2024b] Zheng Zhang, Xu Yuan, Lei Zhu, Jingkuan Song, and Liqiang Nie. Badcm: Invisible backdoor attack against cross-modal learning. IEEE Transactions on Image Processing, 2024b.
- Zhao et al. [2024] Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey. arXiv preprint arXiv:2402.19473, 2024.