Review on Determining the Number of Communities in Network Data
Abstract
This paper reviews statistical methods for hypothesis testing and clustering in network models. We analyze the method by Bickel et al. (2016) for deriving the asymptotic null distribution of the largest eigenvalue, noting its slow convergence and the need for bootstrap corrections. The SCORE method by Jin et al. (2015) and the NCV method by Chen et al. (2018) are evaluated for their efficacy in clustering within Degree-Corrected Block Models, with NCV facing challenges due to its time-intensive nature. We suggest exploring eigenvector entry distributions as a potential efficiency improvement.
1 Introduction
Network-structured data and network analysis are garnering increasing attention across various fields. Research in this area often focuses on understanding the structure of network data, with significant implications for social sciences, biology, and statistics. The practical applications of this research profoundly impact our daily lives in multiple ways. For example, search engines utilize discoveries and tools from this field to analyze the relationships among various keywords. See Kolaczyk and Csárdi, (2014), Hevey, (2018), Sun and Han, (2013), and Berkowitz, (2013) for further reading.
Community detection is of major interest of network analysis. Given an -node (undirected) graph , where is the set of nodes and is the set of edges. We assume that could be partitioned into disjoint subsets or ”communities”. The community structure is represented by a vector with being the community that node belongs to. Nodes tend to have more common characteristics in the same communities. Various algorithms have been proposed to partition these nodes. However, most of them must fixed as a priori. How to determine priori is still an open problem.
Bickel and Sarkar, (2016) proposed a testing statistics based on the limiting distribution of the principal eigenvalue of the suitably centred and scaled adjacency matrix. However they only have theoretical results for testing null hypothesis of . For testing when , they need to iteratively split the network into small sub-networks. It seems that their testing statistics does not work well on the later one. Compared to stochastic block model (SBM), degree corrected block model (DCBM) proposed by Karrer and Newman (2011) is more flexible. Jin, (2015) proposed a so called spectral clustering on ratios-of-eigenvectors (SCORE) method to detect communities for DCBM. The idea is by clustering on entry-wise ratio of eigenvectors of the adjacency matrix. Taking the ratio can eliminate the effect of degree heterogeneity. Further Ji et al., (2016) apply SCORE to a practical problem on detecting potential communities in coauthorship and citation networks for statisticians. However, there are few works on the hypothesis testing of targetedly for DCBM. Instead of performing hypothesis testing, Chen and Lei, (2018) proposed a specially designed cross-validation method to figure out . In the following, we are going to give a brief review and duplicate the numerical results of some of the aforementioned papers.
2 Bickel and Sarkar, (2016)
In an SBM with nodes and communities, Let be the adjacency matrix. and with being the community that node belongs to. Given the membership vector , each edge is an independent Bernoulli variable satisfying
| (2.1) |
where is a symmetric matrix representing the community-wise edge probabilities.
Bickel and Sarkar, (2016) proposed a statistics on testing problem with null hypothesis based on some properties of Erdős-Renýi graph. In their paper, they assume that the number of clusters and the edge probabilities are constant, whereas the number of nodes is growing to . Thus the average degree is growing linearly with . In addition Cragg and Donald, (1993), Cragg and Donald, (1997), Cui et al., 2024b , Cui et al., 2024a Du, (2025) and Cui et al., (2023) discussed about rank inference of a matrix, which can be a generalization work of Bickel and Sarkar, (2016).
Noticing that Erdős-Renýi graph can be viewed as a special case of SBM when there is only one community and one community-wise edge probability . We can estimate it within error by computing the proportion of pairs of nodes that forms an edge, denoted by .
Let , which is an estimate for the mean of adjacency matrix. Bickel and Sarkar, (2016) proved the following theorem:
Theorem 1.
(Bickel and Sarkar, (2016)) Let
| (2.2) |
We have the following asymptotic distribution of our test statistic :
| (2.3) |
where denotes the Tracy–Widom law with index 1. This is also the limiting law of the largest eigenvalue of GOEs.
Example 1. Here we performed a simulation study to see the size performance of the testing statistics. We construct a Erdős-Renýi graph with . ranges from 0.1 to 0.9, increasing with 0.1 in each step.
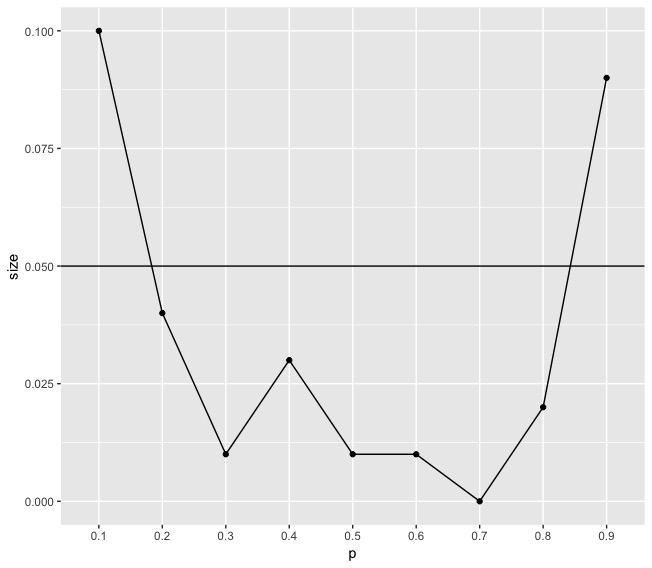
We can see from the simulation study that they cannot control the size. The author proposed a small sample correction on their testing statistics. That is due to the low convergence rate of the eigenvalues, whereas the largest eigenvalues of GOE matrices converge to the Tracy–Widom distribution quite quickly, those of adjacency matrices do not. Based on that, they proposed a small sample correction which suggests that computing the -value by using the empirical distribution of generated by using a parametric bootstrap step. The main idea is to compute the mean and the variance of the distributions from a few simulations, and then shift and scale the test statistic to match the first two moments of the limiting TW1 law. Table 1 shows the whole algorithm for perfoming the hypothesis proposed in Bickel and Sarkar, (2016).
Step. 1: Step. 2: Step. 3: Step 4: Step 4: Step 5: Step 6:
3 Spectral Clustering Method for DCBM
In this section we want to look at a spectral clustering method for and DCBM, the SCORE method proposed by Jin, (2015).
In a DCBM, given membership vector and community-wise connectivity matrix , Let and be the vector and the diagonal matrix defined as follows:
The presence of an edge between nodes and is represented by a Bernoulli random variable with
The main difference between DCBM and SBM is the appearance of the degree heterogeneity parameter . represents the individual activeness of node . The idea of that is that some individuals in one group could be more outgoing than others, therefore edge probabilities are different for different individuals.
While the traditional spectral clustering method of SBM is simply by performing existing clustering methods on the eigenvectors of adjacency matrix, detecting communities with the DCBM is not an easy problem, where the main challenge lies in the degree heterogeneity.
The main observation of SCORE is that the effect of degree heterogeneity is largely an- cillary, and can be effectively removed by taking entry-wise ratios between eigenvectors. Let’s firstly consider the simple case when there are only two groups. Specifically, let
and denote Theorem 1 is
Lemma 1.
(Jin, (2015)) If , then has two simple nonzero eigenvalues
and the associated eigenvectors and (with possible nonunit norms) are
The key observation is that if we let be the vector of the coordinate- wise ratios between and . . Then is independent from the degree heterogeneity parameter .
Similar phenomenon also exists when there are groups.
Based on that, the algorithm of clustering on DCBM is proposed as following:
-
•
Let , ,…, be unit-norm eigenvectors of associated with the largest K eigenvalues (in magnitude), respectively.
-
•
Let be the vector of coordinate-wise ratios:
-
•
Clustering the labels by applying the k-means method to the vector , assuming there are communities in total.
Example 2. Here I performed one simulation study to show the intuition of SCORE. We take and respectively to construct networks. For both we take and generate by then normalize by For , 250 nodes are in different cluster with others. The coordinate-wise plot is reported in Figure 2. Here when , the is given by computing the coordinate ratio of and . The patterns between and have significantly difference. If , each coordinate of will gather around one constant as we showed before, while it will on two hierarchies rather than one when .
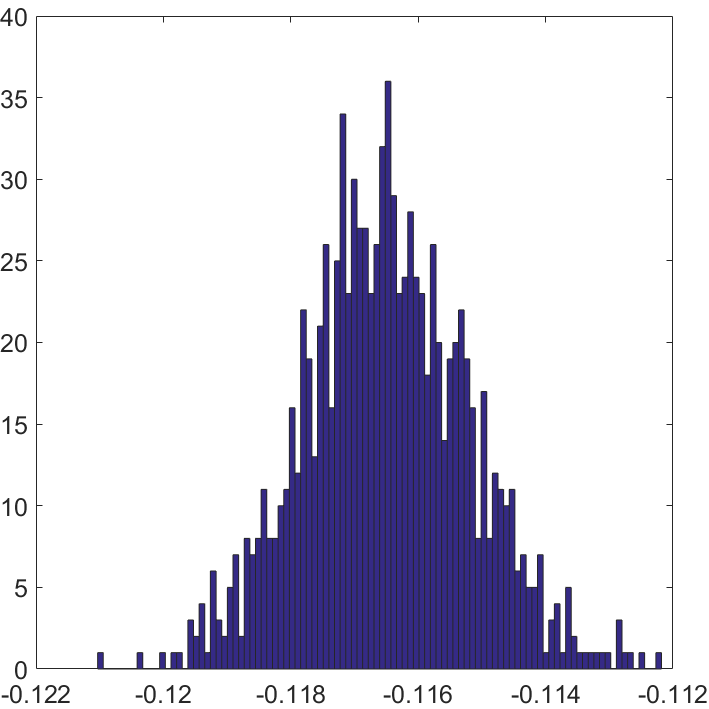
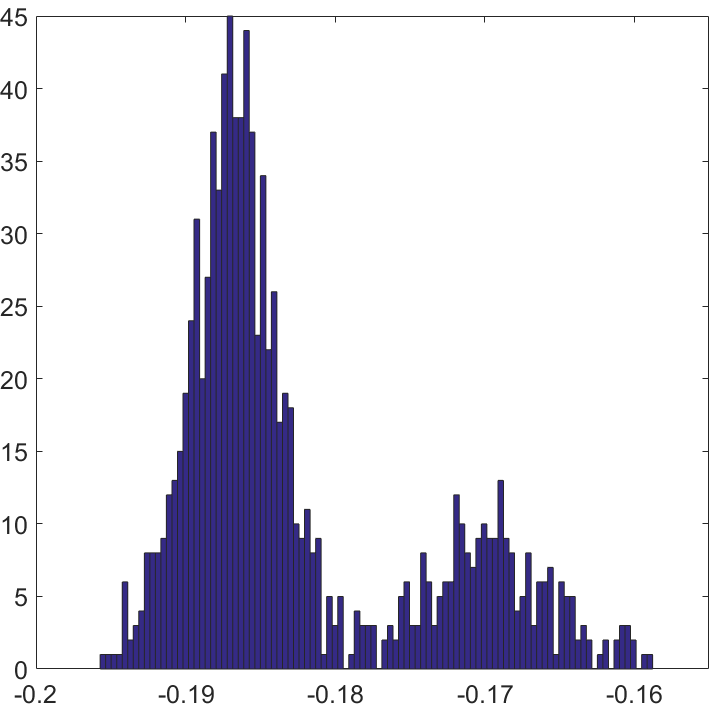
4 Chen and Lei, (2018)
Chen and Lei, (2018) proposed a network cross-validation (NCV) approach to determine the number of communities for both SBM and DCBM. It can automatically determine the number of communities based on a block-wise node-pair splitting technique. The main idea is that firstly, we randomly split the nodes into equal-sized subsets , and then split the adjacency matrix correspondingly into equal sized blocks.
| (4.1) |
where is the submatrix of with rows in and columns in . All the blocks are splitted into fitting sets and validation sets. We can estimate model parameters using the rectangular submatrix as fitting set obtained by removing the rows of in subset .
| (4.2) |
Then is treated as validation sets and used to calculate the predictive loss. At last, is selected when the loss is minimized. In general, cross-validation methods are insensitive to the number of folds. The same intuition empirically holds true for the proposed NCV method. Here the author suggest to use .
Take for example. We can rearrange adjacency matrix in a collapsed block form
Such a splitting puts node pairs in and as the fitting sample and those in as the validating sample. The advantages of that kind of splitting are from three aspects. Firstly, the fitting set carries full information about the network model parameters. We can consistently estimate the membership of all the nodes as well as the community-wise edge probability matrix, using only data in the fitting set. Secondly, given the community membership, the data in the fitting set and in the testing set are independent. Thirdly, it is different from cross validation methods for network data based on a node splitting technique. In the node splitting method, the nodes are usually split into a fitting set and a testing set. Therefore, one typically assumes that the node memberships are generated independently with prior probability . However, it has several drawbacks. The main drawback is that calculating the full likelihood in terms of the prior probability in the presence of a missing membership vector is computationally demanding.
Algorithm details of their NCV method is shown as following:
-
•
Step 1: Block-wise node-pair splitting as shown in
-
•
Step 2: Estimating model parameters from the fitting set.
Take SBM for example.
Once is obtained, let be the nodes in with estimated membership ,and .Wecan estimate using a simple plug-in estimator:
-
•
Step 3: Validation using the testing set. , with or squared error .
Algorithm of dealing with DCBM is similar. The only difference is that in step 2, we need to estimate the parameters under the framework of DCBM.
Example 3. I duplicate one of the simulation result in this paper. In the simulation study, the community-wise edge probability matrix , where the diagonal entries of are 3 and off-diagonal entries are 1. . The sparsity levels are chosen at . Size of the first community is set to be and size of second community is . Figure 3 is the simulation result from 200 simulated data sets.
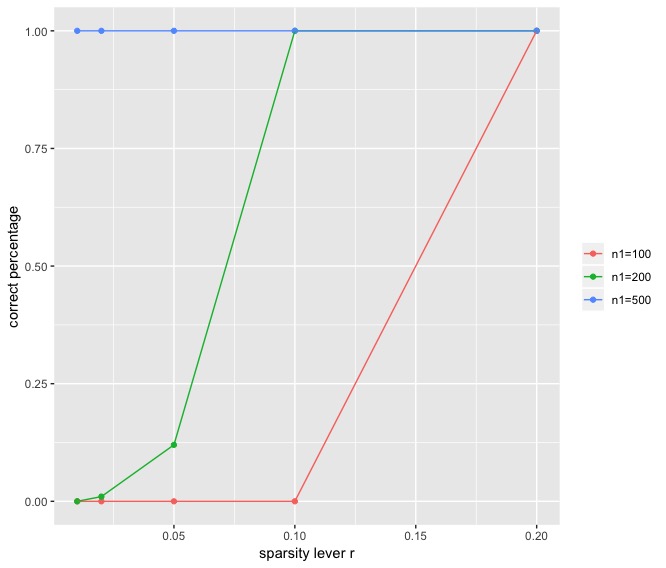
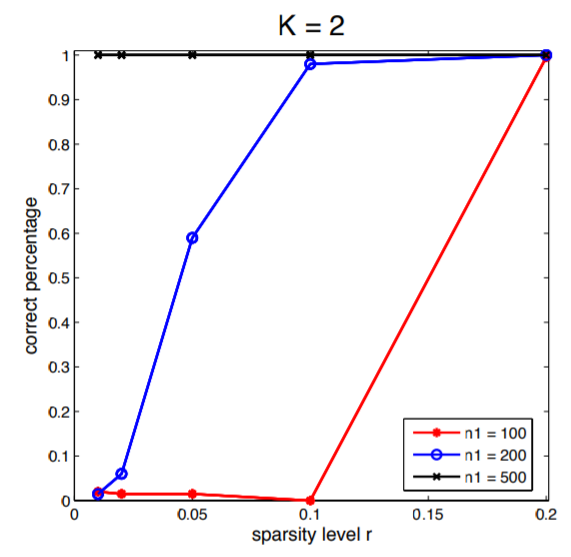
We can see that there is slight difference between my simulation result and that from the paper. The main difference is that when and sparsity level is , I only observed a correct percentage of 0.12 but the author observed the The difference might come from the different choice of clustring method in Step 2 in the algorithm.
The author also gave theoretical properties for their NCV under SBM. They firstly introduce two notions of community recovery consistency. One is exactly consistent recovery. Given a sequence of SBMs with blocks parameterized by , we call a community recovery method exactly consistent if where is a realization of SBM and the equality is up to a possible label permutation. The other is called approximately consistent recovery. For a sequence of SBMs with blocks parameterized by and a sequence , we say is approximately consistent with rate if,
where Ham() is the smallest Hamming distance between and among all possible label permutations.
NCV is proved to be approximately consistent with rate , with for some constant . See Theorem 2 in Chen and Lei, (2018). Therefore it also has community recovery consistency property.
5 Conclusion
In this paper, we first examine the statistical approach proposed by Bickel and Sarkar, (2016) for hypothesis testing under the null hypothesis . They derived the asymptotic null distribution of the largest eigenvalue of a suitably scaled and centered adjacency matrix. However, this method exhibits a slow convergence rate, necessitating bootstrap corrections in practical applications. Subsequently, we explore the SCORE method introduced by Jin, (2015), which is designed for clustering on the Degree-Corrected Block Model (DCBM). This method effectively mitigates the impact of degree heterogeneity by utilizing the coordinate ratio of the eigenvectors of the adjacency matrix.Additionally, Chen and Lei, (2018) introduced the Network Cross-Validation (NCV) method to automate the selection of . This method demonstrates robust performance on both the Stochastic Block Model (SBM) and DCBM, offering exact consistency. However, its primary drawback is its time-intensive nature, a challenge common to all methods based on cross-validation. Optimizing this aspect could involve identifying potential patterns in the distribution of each element or the entry-wise ratio of the eigenvectors, which might streamline the process.
References
- Berkowitz, (2013) Berkowitz, S. D. (2013). An introduction to structural analysis: The network approach to social research. Elsevier.
- Bickel and Sarkar, (2016) Bickel, P. J. and Sarkar, P. (2016). Hypothesis testing for automated community detection in networks. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 78(1):253–273.
- Chen and Lei, (2018) Chen, K. and Lei, J. (2018). Network cross-validation for determining the number of communities in network data. Journal of the American Statistical Association, 113(521):241–251.
- Cragg and Donald, (1993) Cragg, J. G. and Donald, S. G. (1993). Testing identifiability and specification in instrumental variable models. Econometric theory, 9(2):222–240.
- Cragg and Donald, (1997) Cragg, J. G. and Donald, S. G. (1997). Inferring the rank of a matrix. Journal of econometrics, 76(1-2):223–250.
- (6) Cui, S., Guo, X., Li, R., Yang, S., and Zhang, Z. (2024a). Double-estimation-friendly inference for high dimensional misspecified measurement error models. arXiv preprint arXiv:2409.16463.
- (7) Cui, S., Li, D., Li, R., and Xue, L. (2024b). Hypothesis testing for high-dimensional matrix-valued data. arXiv preprint arXiv:2412.07987.
- Cui et al., (2023) Cui, S., Sudjianto, A., Zhang, A., and Li, R. (2023). Enhancing robustness of gradient-boosted decision trees through one-hot encoding and regularization. arXiv preprint arXiv:2304.13761.
- Du, (2025) Du, K. (2025). A short note of comparison between convex and non-convex penalized likelihood. arXiv preprint arXiv:2502.07655.
- Hevey, (2018) Hevey, D. (2018). Network analysis: a brief overview and tutorial. Health psychology and behavioral medicine, 6(1):301–328.
- Ji et al., (2016) Ji, P., Jin, J., et al. (2016). Coauthorship and citation networks for statisticians. The Annals of Applied Statistics, 10(4):1779–1812.
- Jin, (2015) Jin, J. (2015). Fast community detection by score. The Annals of Statistics, 43(1):57–89.
- Kolaczyk and Csárdi, (2014) Kolaczyk, E. D. and Csárdi, G. (2014). Statistical analysis of network data with R, volume 65. Springer.
- Sun and Han, (2013) Sun, Y. and Han, J. (2013). Mining heterogeneous information networks: a structural analysis approach. ACM SIGKDD explorations newsletter, 14(2):20–28.