Revisiting Generalized p-Laplacian Regularized Framelet GCNs: Convergence, Energy Dynamic and Training with Non-Linear Diffusion
Abstract
This paper presents a comprehensive theoretical analysis of the graph p-Laplacian regularized framelet network (pL-UFG) to establish a solid understanding of its properties. We conduct a convergence analysis on pL-UFG, addressing the gap in the understanding of its asymptotic behaviors. Further by investigating the generalized Dirichlet energy of pL-UFG, we demonstrate that the Dirichlet energy remains non-zero throughout convergence, ensuring the avoidance of over-smoothing issues. Additionally, we elucidate the energy dynamic perspective, highlighting the synergistic relationship between the implicit layer in pL-UFG and graph framelets. This synergy enhances the model’s adaptability to both homophilic and heterophilic data. Notably, we reveal that pL-UFG can be interpreted as a generalized non-linear diffusion process, thereby bridging the gap between pL-UFG and differential equations on the graph. Importantly, these multifaceted analyses lead to unified conclusions that offer novel insights for understanding and implementing pL-UFG, as well as other graph neural network (GNN) models. Finally, based on our dynamic analysis, we propose two novel pL-UFG models with manually controlled energy dynamics. We demonstrate empirically and theoretically that our proposed models not only inherit the advantages of pL-UFG but also significantly reduce computational costs for training on large-scale graph datasets.
1 Introduction
Graph neural networks (GNNs) have emerged as a popular tool for the representation learning on the graph-structured data [35]. To enhance the learning power of GNNs, many attempts have been made by considering the propagation of GNNs via different aspects such as optimization [45, 32], statistical test [36] and gradient flow [2, 10]. In particular, treating GNNs propagation as an optimization manner allows one to assign different types of regularizers on the GNNs’ output so that the variation of the node features, usually measured by so-called Dirichlet energy, can be properly constrained [45, 6]. The underlying reason for this regularization operation is due to the recently identified computational issue of GNNs on different types of graphs, namely homophily and heterophily [39]. With the former most of the nodes are connected with those nodes with identical labels, and the latter is not [24]. Accordingly, an ideal GNN shall be able to produce a rather smoother node features for homophily graph and more distinguishable node features when the input graph is heterophilic [24, 1].
Based on the above statement, a proper design of the regularizer that is flexible to let GNN fit both two types of the graph naturally becomes the next challenge. A recent research [13] proposed new energy based regularizer, namely p-Laplacian based regularizer to the optimization of GNN and resulted in an iterative algorithm to approximate the so-called implicit layer induced from the solution of the regularization. To engage a more flexible design of p-Laplacian GNN in [13], [25] further proposed p-Laplacian based graph framelet GNN (pL-UFG) to assign the p-Laplacian based regularization act on multiscale GNNs (e.g., graph framelet). While remarkable learning accuracy has been observed empirically, the underlying properties of the models proposed in [25] are still unclear. In this paper, our primary focus is on pL-UFG (see Section 2 for the formulation). Our objective is to analyze pL-UFG from various perspectives, including convergence of its implicit layer, model’s asymptotic energy behavior, changes of model’s dynamics due to the implicit layer, and relationship with existing diffusion models. To the best of our knowledge, these aspects have not been thoroughly explored in the context of p-Laplacian based GNNs, leaving notable knowledge gaps. Accordingly, we summarize our contribution as follows:
-
•
We rigorously prove the convergence of pL-UFG, providing insights into the asymptotic behavior of the model. This analysis addresses a crucial gap in the understanding of GNN models regularized with p-Laplacian based energy regularizer.
-
•
We show that by assigning the proper values of two key model parameters (denoted as and ) of pL-UFG based on our theoretical analysis, the (generalized) Dirichlet energy of the node feature produced from pL-UFG will never converge to 0; thus the inclusion of the implicit layer will prevent the model (graph framelet) from potential over-smoothing issue.
-
•
We demonstrate how the implicit layer in pL-UFG interacts with the energy dynamics of the graph framelet. Furthermore, we prove that pL-UFG can adapt to both homophily and heterophily graphs, enhancing its versatility and applicability.
-
•
We establish that the propagation mechanism within pL-UFG enables a generalized non-linear graph diffusion. The conclusions based on our analysis from different perspectives are unified at the end of the paper, suggesting a promising framework for evaluating other GNNs.
-
•
Based on our theoretical results, we propose two generalized pL-UFG models with controlled model dynamics, namely pL-UFG low-frequency dominant model (pL-UFG-LFD) and pL-UFG high frequency dominant model (pL-UFG-HFD). we further show that with controllable model dynamics, the computational cost of pL-UFG is largely reduced, making our proposed model capable of handling large-scale graph datasets.
-
•
We conduct extensive experiments to validate our theoretical claims. The empirical results not only confirm pL-UFG’s capability to handle both homophily and heterophily graphs but also demonstrate that our proposed models achieve comparable or superior classification accuracy with reduced computational cost. These findings are consistent across commonly tested and large-scale graph datasets.
The remaining sections of this paper are structured as follows. Section 2 presents fundamental notations related to graphs, GNN models, graph framelets and pL-UFG. In Section 3, we conduct a theoretical analysis on pL-UFG, focusing on the aforementioned aspects. Specifically, Section 3.1 presents the convergence analysis, while Section 3.2 examines the behavior of the p-Laplacian based implicit layer through a generalized Dirichlet energy analysis. Furthermore, Section 3.3 demystifies the interaction between the implicit layer and graph framelets from an energy dynamic perspective. We provide our proposed models (pL-UFG-LFD and pL-UFG-HFD) in section 3.4. Lastly, in Section 3.5, we demonstrate that the iterative algorithm derived from the implicit layer is equivalent to a generalized non-linear diffusion process on the graph. Additionally, in Section 4 we further verify our theoretical claims by comprehensive numerical experiments. Lastly, in conclusion 5, we summarize the findings of this paper and provide suggestions for future research directions.
2 Preliminaries
In this section, we provide necessary notations and formulations utilized in this paper. We list the necessary notations with their meanings in the Table 1 below, although we will mention the meaning of them again when we first use them.
| Notations | Brief Interpretation |
|---|---|
| Heterophily index of a given graph | |
| Initial node feature matrix | |
| Feature representation on -th layer of GNN model | |
| Individual row of | |
| One or more operation acts on each row of | |
| Graph degree matrix | |
| Normalized adjacency matrix | |
| Normalized Laplacian matrix | |
| Graph weight matrix | |
| Framelet decomposition matrix | |
| Index set of all framelet decomposition matrices. | |
| Learnable weight matrix in GNN models | |
| ,, | Learnable weight matrices in defining generalized Dirichlet energy |
| Feature propagation result for the pL-UFG defined in [25]. | |
| N-dimensional vector for diagonal scaling () in framelet models. | |
| Generalized Dirichlet energy for node feature induced from implicit layer | |
| Generalized framelet Dirichlet energy | |
| Total generalized Dirichlet energy | |
| Eigen-pairs of |
We also provide essential background information on the developmental history before the formulation of certain models, serving as a concise introduction to the related works.
Graph, Graph Convolution and Graph Consistency
We denote a weighted graph as with nodes set of total nodes, edge set and graph adjacency matrix , where and if , else, . The nodes feature matrix is for with each row as the feature vector associated with node . For a matrix , we denote its transpose as , and we use for set . Throughout this paper, we will only focus on the undirect graph and use matrix and interchangeably for graph adjacency matrix444We initially set as the graph adjacency matrix while is a generic edge weight matrix in align with the notations used in [14, 25]. The normalized graph Laplacian is defined as , where is a diagonal degree matrix with for , and is the identity matrix. From the spectral graph theory [9], we have , i.e. is a positive semi-definite (SPD) matrix. Let in decreasing order be all the eigenvalues of , also known as graph spectra, and . For any given graph, we let be the largest eigenvalue of . Lastly, for any vector , is the L2-norm of , and similarly, for any matrix , denote by the matrix Frobenius norm.
Graph convolution network (GCN) [21] produces a layer-wise (node feature) propagation rule based on the information from the normalized adjacency matrix as:
| (1) |
where is the embedded node feature, the weight matrix for channel mixing [3], and any activation function such as sigmoid. The superscript (k) indicates the quantity associated with layer , and . We write , the normalized adjacency matrix of . It is easy to see that the operation conducted in GCN before activation can be interpreted as a localized filter by the graph Fourier transform, i.e., , where are from the eigendecomposition . In fact, is known as the Fourier transform of graph signals in .
Over the development of GNNs, most of GNNs are designed under the homophily assumption in which connected (neighbouring) nodes are more likely to share the same label. The recent work by [44] identifies that the general topology GNN fails to obtain outstanding results on the graphs with different class labels and dissimilar features in their connected nodes, such as the so-call heterophilic graphs. The definition of homophilic and heterophilic graphs are given by:
Definition 1 (Homophily and Heterophily [14]).
The homophily or heterophily of a network is used to define the relationship between labels of connected nodes. The level of homophily of a graph can be measured by , where denotes the number of neighbours of that share the same label as , i.e. . corresponds to strong homophily while indicates strong heterophily. We say that a graph is a homophilic (heterophilic) graph if it has strong homophily (heterophily).
Graph Framelet.
As the main target for this paper to explore is pL-UFG defined in [25] in which p-Laplacian based implicit layer is combined with so-called graph framelet or framelets in short. Framelets are a type of wavelet frames arising from signal processing which can be extended for analysing graph signals. The first wavelet frame with a lifting scheme for graph analysis was presented in [27]. As computational power increased, [18] proposed a framework for wavelet transformation on graphs using Chebyshev polynomials for approximations. Later, [11] developed tight framelets on graphs by approximating smooth functions with filtered Chebyshev polynomials.
Framelets have been applied to graph learning tasks with outstanding results, as demonstrated in [40]. They are capable of decomposing graph signals and re-aggregating them effectively, as shown in the study on graph noise reduction by [42] Combining framelets with singular value decomposition (SVD) has also made them applicable to directed graphs [46]. Recently, [38] suggested a simple method for building more versatile and stable framelet families, known as Quasi-Framelets. In this study, we will introduce graph framelets using the same architecture described in [38]. To begin, we define the filtering functions for Quasi-framelets.
Definition 2.
A set of positive functions defined on the interval is considered as (a set of) Quasi-Framelet scaling functions, if these functions adhere to the following identity condition:
| (2) |
The identity condition (2) ensures a perfect reconstruction of a signal from its spectral space to the spatial space, see [38] for a proof. Particularly we are interested in the scaling function set in which descents from 1 to 0, i.e., and and ascends from 0 to 1, i.e., and . The purpose of setting these conditions is for to regulate the highest frequency and for to control the lowest frequency, while the remaining functions govern the frequencies lying between them.
With a given set of framelet scaling functions, the so-called Quasi-Framelet signal transformation can be defined by the following transformation matrices:
| (3) | ||||
| (4) | ||||
| (5) | ||||
where is a given set of Quasi-Framelet functions satisfying (2) and is a given level on a graph with normalized graph Laplacian . is defined as the product of Quasi-Framelet scaling functions applied to the Laplacian spectra at different scales. defined as applied to spectra , where is the coarsest scale level which is the smallest value satisfying . For and , is defined as the product of Quasi-Framelet scaling functions and Quasi-Framelet scaling functions applied to spectra .
Let ; ; …; be the stacked matrix. It can be proven that , see [38], which provides a signal decomposition and reconstruction process based on . This is referred to as the graph Quasi-Framelet transformation.
Since the computation of the Quasi-framelet transformation matrices requires the eigendecomposition of graph Laplacian, to reduce the computational cost, Chebyshev polynomials are used to approximate the Quasi-Framelet transformation matrices. The approximated transformation matrices are defined by replacing in (3)-(5) with Chebyshev polynomials of a fixed degree, which is typically set to 3. The Quasi-Framelet transformation matrices defined in (3) - (5) can be approximated by,
| (6) | ||||
| (7) | ||||
| (8) | ||||
Based on the approximated Quasi-Framelet transformation defined above, two types of graph framelet convolutions have been developed recently:
- 1.
-
2.
The Spatial Framelet Models [6]:
(10)
The spectral framelet models conduct framelet decomposition and reconstruction on the spectral domain of the graph. Clearly can be interpreted as the frequency filters, given that the framelet system provides a perfect reconstruction on the input graph signal (i.e., ). Instead of frequency domain filtering, the spatial framelet models implement the framelet-based propagation via spatial (graph adjacency) domain.
There is a major difference between two schemes. In the spectral framelet methods, the weight matrix is shared across different (filtered) frequency domains, while in the spatial framelet methods, an individual weight matrix is applied to each (filtered) spatial domain to produce the graph convolution.
Finally, it is worth to noting that applying framelet/quasi-framelet transforms on graph signals can decomposes graph signals on different frequency domains for processing, e.g., the filtering used in the spectral framelet models and the spatial aggregating used in the spatial framelet models, thus the perfect reconstruction property guarantees less information loss in the signal processing pipeline. The learning advantage of graph framelet models has been proved via both theoretical and empirical studies [19, 40, 6].
Generalized p-Laplacian Regularized Framelet GCN.
In this part, we provide several additional definitions to formulate the model (pL-UFG) that we are interested in analyzing.
Definition 3 (The -Laplace Operator [12]).
Let be a domain and is a function defined on . The -Laplace operator over functions is defined as
where is the gradient operator and is the Euclidean norm and is a scalar satisfying . The -Laplace operator, is known as a quasi-linear elliptic partial differential operator.
There are a line of research on the properties of -Laplacian in regarding to its uniqueness and existence [15], geometrical property [20] and boundary conditions on so-called p-Laplacian equation [29].
The concept of -Laplace operator can be extended for discrete domains such as graph (nodes) based on the concepts of the so-called graph gradient and divergence, see below, one of the recent works [14] considers assigning an adjustable -Laplacian regularizer to the (discrete) graph regularization problem that is conventionally treated as a way of producing GNN outcomes (i.e., Laplacian smoothing) [43]. In view of the fact that the classic graph Laplacian regularizer measures the graph signal energy along edges under metric, it would be beneficial if GNN training process can be regularized under metric in order to adapt to different graph inputs. Following these pioneer works, [25] further integrated graph framelet and a generalized -Laplacian regularizer to develop the so-called generalized -Laplacian regularized framelet model. It involves a regularization problem over the energy quadratic form induced from the graph -Laplacian. To show this, we start by defining graph gradient as follows:
To introduce graph gradient and divergence, we define the following notation:
Given a graph , let be the space of the vector-valued functions defined on and be the vector-valued function space on edges, respectively.
Definition 4 (Graph Gradient [43]).
For a given function , its graph gradient is an operator : defined as for all ,
| (11) |
where and are the signal vectors on nodes and , i.e., the rows of .
For simplicity, we denote as as the graph gradient. The definition of (discrete) graph gradient is analogized from the notion of gradient from the continuous space. Similarly, we can further define the so-called graph divergence:
Definition 5 (Graph Divergence [43]).
The graph divergence is an operator which is defined by the following way. For a given function , the resulting satisfies the following condition, for any functions ,
| (12) |
It is easy to check that the graph divergence can be computed by:
| (13) |
With the formulation of graph gradient and divergence we are ready to define the graph p-Laplacian operator and the corresponding p-Dirichlet form [43, 14] that serves as the regularizer in the model developed in [25]. The graph p-Laplacian can be defined as follows:
Definition 6 (Graph -Laplacian).
Given a graph and a multiple channel signal function , the graph -Laplacian is an operator , defined by:
| (14) |
where is element-wise power over the node gradient .
The corresponding p-Dirichlet form can be denoted as:
| (15) |
where we adopt the definition of -norm as [14]. It is not difficult to verify that once we set , we recover the graph Dirichlet energy [43] that is widely used to measure the difference between node features along the GNN propagation process.
Remark 1 (Dirichlet Energy, Graph Homophily and Heterophily).
Graph Dirichlet energy [14, 3] has become a commonly applied measure of variation between node features via GNNs. It has been shown that once the graph is highly heterophilic where the connected nodes are not likely to share identical labels, one may prefer GNNs that exhibit nodes feature sharpening effect, thus increasing Dirichlet energy, such that the final classification output of the connected nodes from these GNNs tend to be different. Whereas, when the graph is highly homophilic, a smoothing effect (thus a decrease of Dirichlet energy) is preferred.
[25] further generalized the p-Dirichlet form in (15) as:
| (16) |
where stands for the node that is connected to node and is the node gradient vector for each node and is the vector -norm. Moreover, we can further generalize the regularizer by considering any positive convex function as:
| (17) |
There are many choices of and . When , we recover the -Laplacian regularizer. Interestingly, by setting , we recover the so-called Tikhonov regularization which is frequently applied in image processing. When , i.e. identity map written as , and , becomes the classic total variation regularization. Last but not the least, gives nonlinear diffusion. We note that there are many other choices on the form of . In this paper we will only focus on those mentioned in [25] (i.e., the smooth ones). As a result, the flexible design of the energy regularizer in (17) provides different penalty strength in regularizing the node features propagated from GNNs.
Accordingly, the regularization problem proposed in [25] is:
| (18) |
where stands for the node feature generated by the spectral framelet models (9) without activation . This is the implicit layer proposed in [25]. As the optimization problem defined in (18) does not have a closed-form solution when , an iterative algorithm is developed in [25] to address this issue. The justification is summarized by the following proposition (Theorem 1 in [25]):
Proposition 1.
For a given positive convex function , define
and denote the matrices , and . Then problem (18) can be solved by the following message passing process
| (19) |
with an initial value, e.g., or . Note, denotes the discrete time index (iteration).
Due to the extensive analysis conducted on the graph framelet’s properties, our subsequent analysis will primarily concentrate on the iterative scheme presented in (19). However, we will also unveil the interaction between this implicit layer and the framelet in the following sections.
3 Theoretical Analysis of the pL-UFG
In this section, we show detailed analysis on the convergence (Section 3.1) and energy behavior (Section 3.2) of the iterative algorithm in solving the implicit layer presented in (19). In addition, we will also present some results regarding to the interaction between the implicit layer and graph framelet in Section 3.3 via the energy dynamic aspect based on the conclusion from Section 3.2. Lastly in Section 3.5, we will verify that the iterative algorithm induced from the p-Laplacian implicit layer admits a generalized non-linear diffusion process, thereby connecting the discrete iterative algorithm to the differential equations on graph.
First, we consider the form of matrix in (19). Write
| (20) |
can be simplified as
| (21) |
is bounded as shown in the following lemma.
Lemma 1.
Assume
| (22) |
for a suitable constant . We have .
The proof is trivial thus we omit it here. In the sequel, we use for instead.
Remark 2.
It is reasonable for assuming condition in (22) in Lemma 1 so that is bounded. For example, one can easily verify that when , is bounded for all . In particular, when , i.e., , we have , thus is bounded for all . Furthermore, when , then , indicating is bounded for all . In addition, when , we have . Therefore is bounded for all . Lastly, when , the result of yields . Hence remain bounded for all . In summary, for all forms of we included in the model, is bounded.
The boundedness of from Lemma 1 is useful in the following convergence analysis.
3.1 Convergence Analysis of pL-UFG
We show the iterative algorithm presented in (19) will converge with a suitable choice of . We further note that although the format of Theorem 1 is similar to Theorem 2 in [13], our message passing scheme presented in (19) is different compared to the one defined in [13] via the forms of , and . In fact, the model defined in [13] can be considered as a special case where . As a generalization of the model proposed in [13], we provide a uniform convergence analysis for the pL-UFG.
Theorem 1 (Weak Convergence of the Proposed Model).
Given a graph ) with node features , if , , and are updated according to (19), then there exist some real positive value , which depends on the input graph (, ) and the quantity of , updated in each iteration, such that:
where .
Proof.
For our purpose, we denote the partial derivative at of the objective function with respect to the node feature as
| (26) |
For all , let be a disturbance acting on node . Define the following:
| (27) |
where is defined as (20) and means that only applies to the -th of 555With slightly abuse of notation, we denote as the matrix after assigning the disturbance to the matrix ..
Similar to (25), we compute
| (28) |
Hence from both (25) and (28) we will have
Note that in (27), is the matrix norm raised to power , that is . It is known that the matrix norm as a function is Lipschitz [23], so is its exponential to . Furthermore, it is easy to verify that due to the property of and . Hence, according to Lemma 1, the following holds
Combining all the above, we have
| (29) |
where is bounded. It is worth noting that the quantity of is bounded by
Taking and in the above inequality gives
| (30) |
Given that is bounded, if we choose a large , e.g., , we will have
Thus the second term in (30) is positive. Hence we have
This completes the proof. ∎
Theorem 1 shows that with an appropriately chosen value of , the iteration scheme for the implicit layer (18) is guaranteed to coverage. This inspires us to explore further on the variation of the node feature produced from implicit layer asymptotically. Recall that to measure the difference between node features, one common choice is to analyze its Dirichlet energy, which is initially considered in the setting in (15). It is known that the Dirichlet energy of the node feature tend to approach to 0 after sufficiently large number of iterations in many GNN models [21, 35, 4, 10], known as over-smoothing problem. However, as we will show in the next section, by taking large or small , the iteration from the implicit layer will always lift up the Dirichlet energy of the node features, and over-smoothing issue can be resolved completely in pL-UFG.
3.2 Energy Behavior of the pL-UFG
In this section, we show the energy behavior of the p-Laplacian based implicit layer. Specifically, we are interested in analyzing the property of the generalized Dirichlet energy defined in [3].We start by denoting generalized graph convolution as follows:
| (31) |
where , and act on each node feature vector independently and perform channel mixing. When , and , it returns to GCN [21]. Additionally, by setting , we have the anisotropic instance of GraphSAGE [36]. To quantify the quality of the node features generated by (31), specifically, [3] considered a new class of energy as defined below,
| (32) |
in which serves a function of that induces the source term from or . It is worth noting that by setting and , we recover the classic Dirichlet energy when setting in (15) that is, . Additionally, when we set , (32) can be rewritten as:
| (33) |
Recall that (19) produces the node feature according to the edge diffusion on and the scaled source term where can be set to . To be specific, in (33), we set and replace the edge diffusion with and set the identity matrix in the residual term to be the diagonal matrix . Finally we propose
Definition 7 (The Generalized Dirichlet Energy).
Based on the previous notation setting, the generalized Dirichlet energy for the node features in (19) is:
| (34) |
where the superscript “PF” is short for p-Laplacian based framelet models.
It is worth noting that the generalized Dirichlet energy defined in (34) is dynamic along the iterative layers due to the non-linear nature of the implicit layer defined in (18). We are now able to analyze the energy () behavior of the pL-UFG, concluded as the following proposition.
Proposition 2 (Energy Behavior).
Assume is connected, unweighted and undirected. There exists sufficiently large value of or small value of such that will stay away above 0 at each iterative layer and increases with the increase of or the decrease of .
Proof.
We start with the definition of the generalized Dirichlet energy above, we can re-write in the following inner product between and , based on , , and the iterative scheme defined in (19):
| (35) |
Based on the form of (35), it is straightforward to see that to let and further increase with the desired quantities of and , it is sufficient to require666Strictly speaking, one shall further require all elements in larger than or equal to 0. As this can be achieved by assigned a non-linear activation function (i.e., ReLU) to the framelet, we omit it here in our main analysis.:
| (36) |
To explicitly show how the quantities of and affect the term in (36), we start with the case when . When , (36) becomes:
| (37) |
We note that, in (37), can be computed as:
| (38) |
Now we see that by assigning a sufficient large of or small value of , we can see terms like in (38) are getting smaller Additionally, we have both and . Therefore, the summation result of (38) tends to be negative. Based on (35), will stay above 0.
For the case that , by taking into the iterative algorithm (19), (37) becomes:
Applying the same reasoning as before, it is not hard to verify that with sufficient large of and small of , the term in the above equation tend to be negative, yielding a positive . Asymptotically, we have:
| (39) |
This shows that the energy increases along with the magnitude of , and it is not hard to express (39) as the similar form of (38) and verify that the energy decreases with the quantity of . This completes the proof. ∎
Remark 3.
Proposition 2 shows that, for any of our framelet convolution models, the p-Laplacian based implicit layer will not generate identical node feature across graph nodes, and thus the so-called over-smoothing issue will not appear asymptotically. Furthermore, it is worth noting that the result from Proposition 2 provides the theoretical justification of the empirical observations in [25], where a large value of or small value of is suitable for fitting heterophily datasets which commonly require the output of GNN to have higher Dirichlet energy.
Remark 4 (Regarding to the quantity of ).
The conclusion of Proposition 2 is under sufficient large of or small of . However, it is well-known that the quantity of cannot be set as arbitrary and in fact it is necessary to have so that the iteration for the solution of the optimization problem defined in (18) can converge. Therefore, it is not hard to see that the effect of is weaker than in terms of analyzing the asymptotic behavior of the model (i.e., via (38)). Without loss of generality, in the sequel, when we analyze the property of the model with conditions on and , we mainly target on the effect from and one can check from (38) and are with opposite effect on the model.
3.3 Interaction with Framelet Energy Dynamic
To analyze the interaction between the energy dynamic of framelet convolution defined in (9) and the p-Laplacian based implicit propagation [25], We first briefly review some recent work on the energy dynamic of the GNNs. In [10], the propagation of GNNs was considered as the gradient flow of the Dirichlet energy that can be formulated as:
| (40) |
and similarly by setting the power from 2 to , we recover the p-Dirichlet form presented in (15). The gradient flow of the Dirichlet energy yields the so-called graph heat equation [9] as . Its Euler discretization leads to the propagation of linear GCN models [33, 31]. The process is called Laplacian smoothing [22] and it converges to the kernel of , i.e., as , resulting in non-separation of nodes with same degrees, known as the over-smoothing issue.
Following this observation, the work [19, 10] also show even with the help of the non-linear activation function and the weight matrix via classic GCN ((1)), the process described is still dominated by the low frequency (small Laplacian eigenvalues) of the graph, hence eventually converging to the kernel of , for almost every initialization. To quantify such behavior, [10, 19] consider a general dynamic as , with as an arbitrary graph neural network function, and also characterizes its behavior by low/high-frequency-dominance (L/HFD).
Definition 8 ([10]).
is Low-Frequency-Dominant (LFD) if as , and is High-Frequency-Dominant (HFD) if as .
Lemma 2 ([10]).
A GNN model is LFD (resp. HFD) if and only if for each , there exists a sub-sequence indexed by and such that and (resp. ).
Remark 5 (LFD, HFD and graph homophily).
Based on Definition 8 and Lemma 2, for a given GNN model, if is homophilic, i.e., adjacency nodes are more likely to share the same label, one may prefer for the model to induce a LFD dynamic in order to fit the characteristic of . On the other hand, if is heterophilic, the model is expected to induce a HFD dynamic, so that even in the adjacent nodes, their predicted labels still tend to be different. Thus, ideally, a model should be flexible enough to accommodate both LFD and HFD dynamics.
Generalized from the energy dynamic framework provided in [10], [19] developed a framelet Dirichlet energy and analyzed the energy behavior of both spectral ((9)) and spatial framelet ((10)) convolutions. Specifically, let
for all . The generated framelet energy is given by:
| (41) |
where the superscript “Fr” stands for the framelet convolution. This definition is based on the fact that the total Dirichlet energy is conserved under framelet decomposition [19, 10]. By analyzing the gradient flow of the framelet energy 777Similar to the requirement on our p-Laplacian based framelet energy (, to thoroughly verify the framelet energy in (3.3) is a type of energy, we shall further require: is symmetric, which can be satisfied by requiring both and are symmetric. defined above, [19] concluded the energy dynamic of framelet as:
Proposition 3 ([19]).
The spectral graph framelet convolution (9) with Haar-type filter (i.e. in the case of scaling function set) can induce both LFD and HFD dynamics. Specifically, let and for where is a size vector of all s. When , the spectral framelet convolution is LFD and when , the spectral framelet convolution is HFD.
It is worth noting that there are many other settings rather than and , i.e. adjusting , for inducing LFD/HFD from framelet. However, in this paper, we only consider the conditions described in Proposition 3. To properly compare the energy dynamics between the framelet models, we present the following definition.
Definition 9 (Stronger/Weaker Dynamic).
Let be the family of framelet models with the settings described in Proposition 3 and choice of . We say that one framelet model is with a stronger LFD than another framelet model if , and weaker otherwise. Similarly, we say is with a stronger HFD than if , and weaker otherwise 888In case of any confusion, we note that in this paper we only compare the model’s dynamics relationship when both of two (framelet) models are with the same frequency dominated dynamics (i.e., LFD, HFD)..
Remark 6.
Before we present our conclusion, we note that to evaluate the changes of (framelet) energy behavior from the impact of implicit layer, one shall also define a layer-wised framelet energy such as by only considering the energy from one step of propagation of graph framelet. With all these settings, we summarize the interaction between framelet and p-Laplacian based implicit propagation as:
Lemma 3 (Stronger HFD).
Based on the condition described in Proposition 3, when framelet is HFD, with sufficient large value of or small of , the p-Laplacian implicit propagation further amplify the energy in (3.3) of the node feature (i.e., in (18)) produced from the framelets, and thus achieving a higher HFD dynamic than original framelet in (9).
Proof.
Recall that by setting sufficient large of or small of , in (39) has the form
Similarly, when framelet is HFD, with , and , the Dirichlet energy (of ) (3.3) can be rewritten as:
| (42) |
where the last equality is achieved by letting , meaning that no external force 999For details, please check [3] exist within the space that contains the node features. We note that it is reasonable to have such assumption in order to explicitly analyze the energy changes in (3.3) via the changes of . Now we take the framelet with as an example, meaning there will be only one high-pass and low-pass frequency domain in the framelet model. Specifically, the R.H.S of (42) can be further rewritten as:
| (43) |
The inclusion of is based on the form of type framelet with one scale. In addition, the approximation in (43) is due to the outcome of HFD 101010The result in (43) provides identical conclusion on the claim in [10] such that in order to have a HFD dynamic, must have negative eigenvalue(s).. Now we combine the framelet energy in the above equation ((43)) with the energy induced from p-Laplacian based implicit propagation ((39)). Denote the total energy induced from framelet and implicit layer as:
| (44) | |||
It is not hard to check that is larger than (the framelet energy under HFD). Hence we have verified that the implicit layer further amplifies the Dirichlet energy. Moreover, one can approximate this stronger dynamic by re-parameterizing via assigning a higher quantity of and excluding the residual term. Hence, the inclusion of the implicit layer induces a higher HFD dynamic to framelet, and that completes the proof. ∎
Corollary 1 (Escape from Over-smoothing).
With the same conditions in Proposition 3, when framelet is LFD, the implicit layer (with sufficient large or small ) ensures the Dirichlet energy of node features does not converge to 0, thus preventing the model from the over-smoothing issue.
Proof.
The proof can be done by combining Proposition 3 and Proposition 2, with the former illustrates that when model is HFD, there will be no over-smoothing problem, and the latter shows that even when the model is LFD, the Dirichlet energy of the node features will not converge to 0. Accordingly, pL-UFG is capable of escaping from over-smoothing issue. ∎
Remark 7 (Stronger LFD).
Based on the condition described in Proposition 3, when framelet is LFD, with sufficient small of or larger of , it is not hard to verify that according to (38), the p-Laplacian implicit propagation further shrink the Dirichlet energy of the node feature produced from framelet, and thus achieving a stronger LFD dynamic.
Remark 8.
In Proposition 2 we showed that the Dirichlet energy of the node features produced from the implicit layer will not coverage to zero, indicating the robustness of the implicit layer in regarding to the over-smoothing issue. Additionally, we further verified in Lemma 3 that when graph framelet is with a monotonic dynamic (e.g., L/HFD), the inclusion of the implicit layer can even amplify the dynamic of framelet by a proper setting of and . Our conclusion explicitly suggests the effectiveness on incorporating p-Laplacian based implicit propagation to multiscale GNNs which is with flexible control of model dynamics.
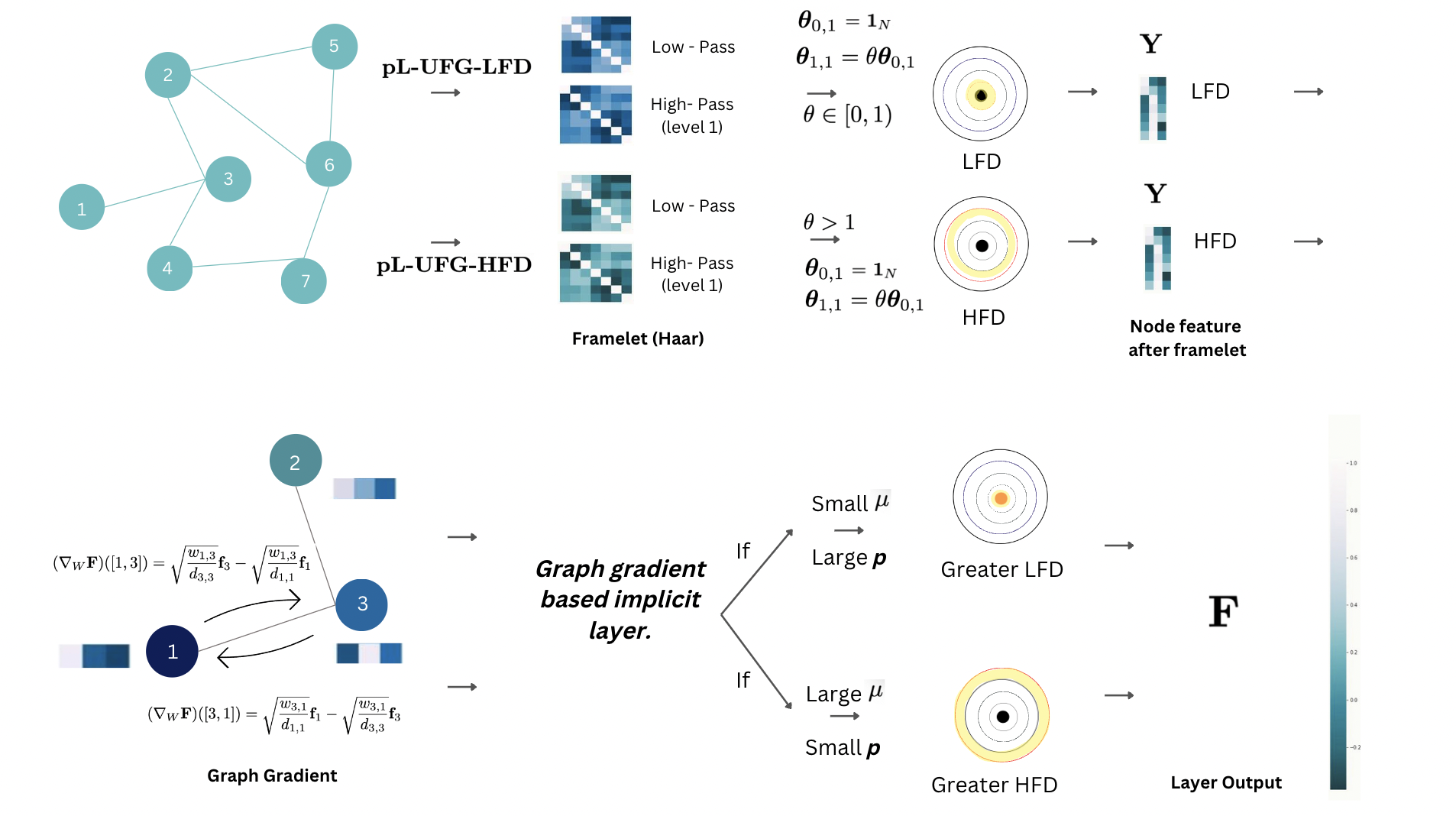
3.4 Proposed Model with Controlled Dynamics
Based on the aforementioned conclusions regarding energy behavior and the interaction between the implicit layer and framelet’s energy dynamics, it becomes evident that irrespective of the homophily index of any given graph input, one can readily apply the condition of (s) in Proposition 3 to facilitate the adaptation of the pL-UFG model to the input graph by simply adjusting the quantities of and . This adjustment significantly reduces the training cost of the graph framelet. For instance, consider the case of employing a type frame with , where we have only one low-pass and one high-pass domain. In this scenario, the trainable matrices for this model are , , and . Based on our conclusions, we can manually set both and to our requested quantities, thereby inducing either LFD or HFD. Consequently, the only remaining training cost is associated with , leading to large reduction on the overall training cost while preserving model’s capability of handling both types of graphs. Accordingly, we proposed two additional pL-UFG variants with controlled model dynamics, namely pL-UFG-LFD and pL-UFG-HFD. More explicitly, the propagation of graph framelet with controlled dynamic takes the form as:
after which the output node features will be propagated through the iterative layers in defined in (19) for the implicit layer (18) for certain layers, and the resulting node feature will be forwarded to the next graph framelet convolution and implicit layer propagation. We note that to properly represent the Dirichlet energy of node features, we borrow the concept of electronic orbital energy levels in Figure. 1. The shaded outermost electrons correspond to higher energy levels, which can be analogously interpreted as higher variations in node features. Conversely, the closer the electrons are to the nucleus, the lower their energy levels, indicating lower variations in node features.
3.5 Equivalence to Non-Linear Diffusion
Diffusion on graph has gained its popularity recently [5, 28] by providing a framework (i.e., PDE) to understand the GNNs architecture and as a principled way to develop a broad class of new methods. To the best of our knowledge, although the GNNs based on linear diffusion on graph [5, 4, 28] have been intensively explored, models built from non-linear graph diffusion have not attracted much attention in general. In this section, we aim to verify that the iteration (19) admits a scaled nonlinear diffusion with a source term. To see this, recall that p-Laplacian operator defined in (14) has the form:
| (45) |
Plugging in the definition of graph gradient and divergence defined in (11) and (13) into the above equation, one can compactly write out the form of p-Laplacian as:
| (46) |
Furthermore, if we treat the iteration equation (19) as a diffusion process, its forward Euler scheme has the form:
| (47) |
We set for the rest of analysis for the convenience reasons. With all these setups, we summarize our results in the following:
Lemma 4 (Non-Linear Diffusion).
Assuming is connected, the forward Euler scheme presented in (47) admits a generalized non-linear diffusion on the graph. Specifically, we have:
| (48) |
Proof.
The proof can be done by verification. We can explicitly write out the computation on the -th row of the left hand side of (48) as:
Based on the conclusion of Lemma 4, it is clear that the propagation via p-Laplacian implicit layer admits a scaled non-linear diffusion with two source terms. We note that the form of our non-linear diffusion coincidences to the one developed in [7]. However, in [7] the linear operator is assigned via the calculation of graph Laplacian whereas in our model, the transformation acts over the whole p-Laplacian. Finally, it is worth noting that the conclusion in Lemma 4 can be transferred to the implicit schemes111111With a duplication of terminology, here the term “implicit” refers to the implicit scheme (i.e., backward propagation) in the training of the diffusion model.. We omit it here.
Remark 9.
With sufficiently large or small , one can check that the strength of the diffusion, i.e. , is diluted. Once two source terms dominant the whole process, the generated node features approach to , which suggests a framelet together with two source terms. The first term can be treated as the degree normalization of the node features from the last layer and the second term simply maintains the initial feature embedding. Therefore, the energy of the remaining node features in this case is just with the form presented in (39), suggesting a preservation of node feature variations. Furthermore, this observation suggests our conclusion on the energy behavior of pL-UFG (Proposition 2); the interaction within pL-UFG described in Lemma 3 and Corollary 1 and lastly, the conclusion from Lemma 4 can be unified and eventually forms a well defined framework in assessing and understanding the property of pL-UFG.
4 Experiment
Experiment outlines
In this section, we present comprehensive experimental results on the claims that we made from the theoretical aspects of our model. All experiments were conducted in PyTorch on NVIDIA Tesla V100 GPU with 5,120 CUDA cores and 16GB HBM2 mounted on an HPC cluster. In addition, for the sake of convenience, we listed the summary of each experimental section as follows:
-
•
In Section 4.1, we show how a sufficient large/small can affect model’s performance on heterophilic/homophilic graphs, and the results are almost invariant to the choice of .
-
•
In Section 4.2 we show some tests regarding to the results (i.e., Remark 7 and Lemma 3) of model’s dynamics. Specifically, we verified the conclusions of stronger LFD and HFD in Section 3.3 with controlled model dynamics (quantity of ) of framelet to illustrate how the p-Laplacian based implicit layer interact with framelet model.
-
•
In Section 4.3 we test the performances of pL-UFG-LFD and pL-UFG-HFD via real-world graph benchmarks versus various baseline models. Furthermore, as these two controllable pL-UFG models largely reduced the computational cost (as we claimed in Section 3.4), we show pL-UFG-LFD and pL-UFG-HFD can even handle the large-scale graph datasets and achieve remarkable learning accuracies.
Hyper-parameter tuning We applied exactly same hyper-parameter tunning strategy as [25] to make a fair comparsion. In terms of the settings for graph framelets, the framelet type is fixed as ([38]) and the level is set to 1. The dilation scale , and for , the degree of Chebyshev polynomial approximation is drawn from {2, 3, 7}. It is worth noting that in graph framelets, the Chebyshev polynomial is utilized for approximating the spectral filtering of the Laplacian eigenvalues. Thus, a -degree polynomial approximates -hop neighbouring information of each node of the graph. Therefore, when the input graph is heterophilic, one may prefer to have a relatively larger as node labels tend to be different between directly connected (1-hop) nodes.
4.1 Synthetic Experiment on Variation of
Setup
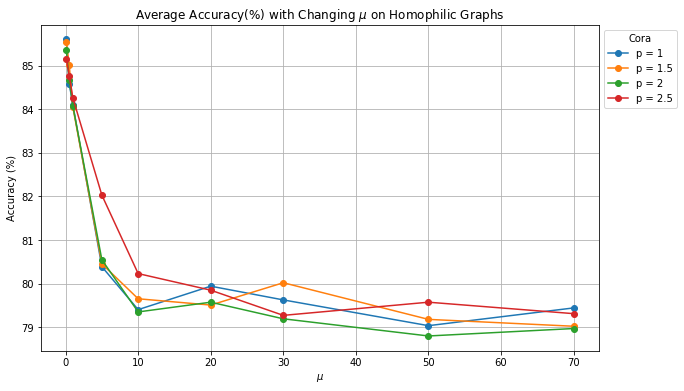
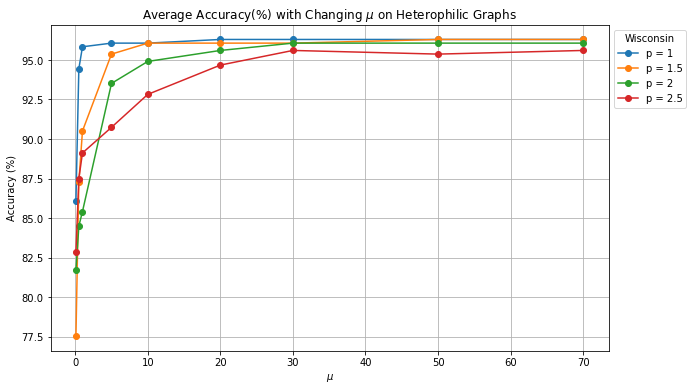
In this section, we show how a sufficiently large/small of can affect model’s performance on hetero/homophilic graphs. In order to make a fair comparison, all the parameters of pL-UFG followed the settings included in [25]. For this test, we selected two datasets: Cora (heterophilic index: 0.825, 2708 nodes and 5278 edges) and Wisconsin (heterophilic index: 0.15, 499 nodes and 1703 edges) from https://www.pyg.org/. We assigned the quantity of combined with a set of . The number of epochs was set to 200 and the test accuracy (in %) is obtained as the average test accuracy of 10 runs.
Results and Discussion
The experimental results are presented in Figure 2. When examining the results obtained through the homophily graph (Figure 2(a)), it is apparent that all variants of pL-UFGs achieved the best performance when , which is the minimum value of . As the value of increased, the learning accuracy decreased. This suggests that a larger sharpening effect was induced by the model, as stated in Remark 7 and Proposition 2, causing pL-UFGs to incorporate higher amounts of Dirichlet energy into their generated node features. Consequently, pL-UFGs are better suited for adapting to heterophily graphs. This observation is further supported by the results in Figure 2(b), where all pL-UFG variants achieved their optimal performance with a sufficiently large when the input graph is heterophilic.
Additional interesting observation on the above result is despite the fact that all model variants demonstrated superior learning outcomes on both homophilic and heterophilic graphs when assigned sufficiently large or small values of , it can be observed that when the quantity of is small, pL-UFG requires a smaller value of to fit the heterophily graph (blue line in Fig. 2(b)). On the other hand, when the models have relatively large value of (i.e., ), it is obvious that these models yielded the most robust results when there is an increase of (red line in Fig. 2(a)). These phenomena further support the notion that and exhibit opposite effects on the model’s energy behavior as well as its adaptation to homophily and heterophily graphs.
4.2 Synthetic Experiment on Testing of Model’s Dynamics
Now, we take one step ahead. Based on Lemma 3 and Remark 7, with the settings of provided in Proposition 3, the inclusion of -Laplacian based implicit layer can further enhance framelet’s LFD and HFD dynamics. This suggests that one can control the entries of based on the conditions provided in Proposition 3 and by only changing the quantity of and to test model’s adaption power on both homophily and heterophily graphs. Therefore, in this section, we show how a (dynamic) controlled framelet model can be further enhanced by the assistant from the -Laplacian regularizer. Similarly, we applied the same setting to the experiments in [25].
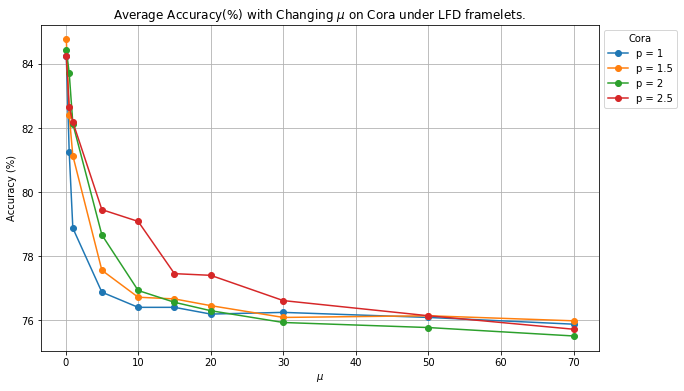
Setup and Results
To verify the claims on in Lemma 3 and Remark 7, we deployed the same settings mentioned in Proposition 3. Specifically, we utilized Haar frame with and set , . For heterophilic graphs (Wisconsin), , and for the homophilic graph (Cora), . The result of the experiment is presented in Figure 3. Similar to the results observed from Section 4.1, it is shown that when the relatively large quantity of is assigned, model’s capability of adapting to homophily/heterophily graph decreased/increased. This directly verifies that the p-Laplacian based implicit layer interacts and further enhances the (controlled) dynamic of the framelet by the value of and , in terms of adaptation.
4.3 Real-world Node Classification and Scalability
Previous synthetic numerical results show predictable performance of both pL-UFG-LFD and pL-UFG-HFD. In this section, we present the learning accuracy of our proposed models via real-world homophily and heterophily graphs. Similarly, we deployed the same experimental setting from [25]. In addition, to verify the claim in Remark 3.4, we tested our proposed model via large-scale graph dataset (ogbn-arxiv) to show the proposed model’s scalability which is rarely explored. We include the summary statistic of the datasets in Table 2. All datasets are split according to [17].
For the settings of , and within pL-UFG-LFD and pL-UFG-HFD, we assigned , and for pL-UFG-LFD in order to fit the homophily graphs, and for pL-UFG-HFD, we assigned , and for heterophily graphs. The learning accuracy are presented in Table 3 and 4. Furthermore, rather than only reporting the average accuracy and related standard deviation, to further verify the significance of the improvement, we also computed the 95% confidence interval under -distribution for the highest learning accuracy of the baselines and mark to our model’s learning accuracy if it is outside the confidence interval.
We include a brief introduction on the baseline models used in this experiment:
-
•
MLP: Standard feedward multiple layer perceptron.
-
•
GCN [21]: GCN is the first of its kind to implement linear approximation to spectral graph convolutions.
-
•
SGC [34]: SGC reduces GCNs’ complexity by removing nonlinearities and collapsing weight matrices between consecutive layers. Thus serves as a more powerful and efficient GNN baseline.
-
•
GAT [30]: GAT generates attention coefficient matrix that element-wisely multiplied on the graph adjacency matrix according to the node feature based attention mechanism via each layer to propagate node features via the relative importance between them.
-
•
JKNet [37]: JKNet offers the capability to adaptively exploit diverse neighbourhood ranges, facilitating enhanced structure-aware representation for individual nodes.
-
•
APPNP [16]: APPNP leverages personalized PageRank to disentangle the neural network from the propagation scheme, thereby merging GNN functionality.
-
•
GPRGNN [8]: The GPRGNN architecture dynamically learns General Pagerank (GPR) weights to optimize the extraction of node features and topological information from a graph, irrespective of the level of homophily present.
-
•
p-GNN [14]:p-GNN is a -Laplacian based graph neural network model that incorporates a message-passing mechanism derived from a discrete regularization framework. To make a fair comparison, we test p-GNN model with different quantity of .
-
•
UFG [41]: UFG, a class of GNNs built upon framelet transforms utilizes framelet decomposition to effectively merge graph features into low-pass and high-pass spectra.
-
•
pL-UFG [25]: pL-UFG employs a p-Laplacian based implicit layer to enhance the adaptability of multi-scale graph convolution networks (i.e.,UFG) to filter-based domains, effectively improving the model’s adaptation to both homophily and heterophily graphs. Furthermore, as two types of pL-UFG models are proposed in [25], we test both two pL-UFG variants as our baseline models. For more details including the precise formulation of the model, please check [25].
| Datasets | Class | Feature | Node | Edge | |
|---|---|---|---|---|---|
| Cora | 7 | 1433 | 2708 | 5278 | 0.825 |
| CiteSeer | 6 | 3703 | 3327 | 4552 | 0.717 |
| PubMed | 3 | 500 | 19717 | 44324 | 0.792 |
| Computers | 10 | 767 | 13381 | 245778 | 0.802 |
| Photo | 8 | 745 | 7487 | 119043 | 0.849 |
| CS | 15 | 6805 | 18333 | 81894 | 0.832 |
| Physics | 5 | 8415 | 34493 | 247962 | 0.915 |
| Arxiv | 23 | 128 | 169343 | 1166243 | 0.681 |
| Chameleon | 5 | 2325 | 2277 | 31371 | 0.247 |
| Squirrel | 5 | 2089 | 5201 | 198353 | 0.216 |
| Actor | 5 | 932 | 7600 | 26659 | 0.221 |
| Wisconsin | 5 | 251 | 499 | 1703 | 0.150 |
| Texas | 5 | 1703 | 183 | 279 | 0.097 |
| Cornell | 5 | 1703 | 183 | 277 | 0.386 |
| Method | Cora | CiteSeer | PubMed | Computers | Photos | CS | Physics | Arxiv |
| MLP | 66.041.11 | 68.990.48 | 82.030.24 | 71.895.36 | 86.111.35 | 93.500.24 | 94.560.11 | 55.500.78 |
| GCN | 84.720.38 | 75.041.46 | 83.190.13 | 78.821.87 | 90.001.49 | 93.000.12 | 95.550.09 | 70.070.79 |
| SGC | 83.790.37 | 73.520.89 | 75.920.26 | 77.560.88 | 86.440.35 | 92.180.22 | 94.990.13 | 71.010.30 |
| GAT | 84.371.13 | 74.801.00 | 83.920.28 | 78.682.09 | 89.631.75 | 92.57 0.14 | 95.130.15 | OOM |
| JKNet | 83.690.71 | 74.490.74 | 82.590.54 | 69.323.94 | 86.121.12 | 91.110.22 | 94.450.33 | OOM |
| APPNP | 83.690.71 | 75.840.64 | 80.420.29 | 73.732.49 | 87.030.95 | 91.520.14 | 94.710.11 | OOM |
| GPRGNN | 83.790.93 | 75.940.65 | 82.320.25 | 74.262.94 | 88.691.32 | 91.89 0.08 | 94.850.23 | OOM |
| UFG | 80.640.74 | 73.300.19 | 81.520.80 | 66.396.09 | 86.604.69 | 95.270.04 | 95.770.04 | 71.080.49 |
| PGNN1.0 | 84.210.91 | 75.380.82 | 84.340.33 | 81.222.62 | 87.645.05 | 94.880.12 | 96.150.12 | OOM |
| PGNN1.5 | 84.420.71 | 75.440.98 | 84.480.21 | 82.681.15 | 91.830.77 | 94.130.08 | 96.140.08 | OOM |
| PGNN2.0 | 84.740.67 | 75.621.07 | 84.25 0.35 | 83.400.68 | 91.710.93 | 94.280.10 | 96.030.07 | OOM |
| PGNN2.5 | 84.480.77 | 75.220.73 | 83.940.47 | 82.911.34 | 91.410.66 | 93.400.07 | 95.750.05 | OOM |
| pL-UFG11.0 | 84.540.62 | 75.880.60 | 85.560.18 | 82.072.78 | 85.5719.92 | 95.030.22 | 96.190.06 | 70.289.13 |
| pL-UFG11.5 | 84.960.38 | 76.040.85 | 85.590.18 | 85.041.06 | 92.920.37 | 95.030.22 | 96.270.06 | 71.258.37 |
| pL-UFG12.0 | 85.200.42 | 76.120.82 | 85.590.17 | 85.261.15 | 92.650.65 | 94.770.27 | 96.040.07 | OOM |
| pL-UFG12.5 | 85.300.60 | 76.110.82 | 85.540.18 | 85.180.88 | 91.491.29 | 94.860.14 | 95.960.11 | OOM |
| pL-UFG21.0 | 84.420.32 | 74.79 0.62 | 85.450.18 | 84.880.84 | 85.3019.50 | 95.030.19 | 96.060.11 | 71.017.28 |
| pL-UFG21.5 | 85.600.36 | 75.610.60 | 85.590.18 | 84.551.57 | 93.000.61 | 95.030.19 | 96.140.09 | 71.216.19 |
| pL-UFG22.0 | 85.200.42 | 76.120.82 | 85.590.17 | 85.271.15 | 92.500.40 | 94.770.27 | 96.050.07 | OOM |
| pL-UFG-LFD | 85.641.36 | 77.39∗1.59 | 85.081.33 | 85.36∗1.39 | 93.17∗1.30 | 96.13∗1.08 | 96.49∗1.04 | 71.961.25 |
| Method | Chameleon | Squirrel | Actor | Wisconsin | Texas | Cornell |
| MLP | 48.821.43 | 34.301.13 | 41.660.83 | 93.452.09 | 71.2512.99 | 83.334.55 |
| GCN | 33.712.27 | 26.191.34 | 33.461.42 | 67.908.16 | 53.4411.23 | 55.6810.57 |
| SGC | 33.831.69 | 26.890.98 | 32.082.22 | 59.5611.19 | 64.387.53 | 43.1816.41 |
| GAT | 41.952.65 | 25.661.72 | 33.643.45 | 60.6511.08 | 50.6328.36 | 34.0929.15 |
| JKNet | 33.503.46 | 26.951.29 | 31.143.63 | 60.428.70 | 63.755.38 | 45.459.99 |
| APPNP | 34.613.15 | 32.610.93 | 39.111.11 | 82.412.17 | 80.005.38 | 60.9813.44 |
| GPRGNN | 34.234.09 | 34.010.82 | 34.630.58 | 86.111.31 | 84.3811.20 | 66.2911.20 |
| UFG | 50.111.67 | 31.482.05 | 40.131.11 | 93.522.36 | 84.694.87 | 83.713.28 |
| PGNN1.0 | 49.041.16 | 34.791.01 | 40.911.41 | 94.352.16 | 82.0011.31 | 82.736.92 |
| PGNN1.5 | 49.121.14 | 34.861.25 | 40.871.47 | 94.721.91 | 81.5010.70 | 81.9710.16 |
| PGNN2.0 | 49.341.15 | 34.971.41 | 40.831.81 | 94.441.75 | 84.3811.52 | 81.0610.18 |
| PGNN2.5 | 49.161.40 | 34.941.57 | 40.781.51 | 94.352.16 | 83.3812.95 | 81.828.86 |
| pL-UFG11.0 | 56.811.69 | 38.811.97 | 41.261.66 | 96.480.94 | 86.137.47 | 86.063.16 |
| pL-UFG11.5 | 56.891.17 | 39.731.22 | 40.950.93 | 96.481.07 | 87.005.16 | 86.522.29 |
| pL-UFG12.0 | 56.241.02 | 39.721.86 | 40.950.93 | 96.590.72 | 86.508.84 | 85.302.35 |
| pL-UFG12.5 | 56.111.25 | 39.381.78 | 41.040.99 | 95.341.64 | 89.004.99 | 83.943.53 |
| pL-UFG21.0 | 55.511.53 | 36.945.69 | 29.2819.25 | 93.982.94 | 85.005.27 | 87.732.49 |
| pL-UFG21.5 | 57.221.19 | 39.801.42 | 40.890.75 | 96.480.94 | 87.635.32 | 86.821.67 |
| pL-UFG22.0 | 56.190.99 | 39.741.66 | 41.010.80 | 96.141.16 | 86.508.84 | 85.302.35 |
| pL-UFG22.5 | 55.691.15 | 39.301.68 | 40.860.74 | 95.801.44 | 86.382.98 | 84.553.31 |
| pL-fUFG1.0 | 55.801.93 | 38.431.26 | 32.8416.54 | 93.983.47 | 86.256.89 | 87.272.27 |
| pL-fUFG1.5 | 55.651.96 | 38.401.52 | 41.000.99 | 96.481.29 | 87.253.61 | 86.212.19 |
| pL-fUFG2.0 | 55.951.29 | 38.331.71 | 41.250.84 | 96.251.25 | 88.754.97 | 83.943.78 |
| pL-fUFG2.5 | 55.561.66 | 38.391.48 | 40.550.50 | 95.282.24 | 88.507.37 | 83.643.88 |
| pL-UFG-HFD | 58.60∗1.74 | 39.632.01 | 44.63∗2.75 | 96.641.77 | 89.318.40 | 88.97∗3.36 |
Discussion on the Results, Scalability and Computational Complexity
From both Table 3 and 4, it is clear that our proposed model (pL-UFG-LFD and pL-UFG-HFD) produce state-of-the-art learning accuracy compared to various baseline models. For the datasets (i.e.,Pubmed and Squirrel) on which pL-UFG-LFD and pL-UFG-HFD are not the best, one can observe that pL-UFG-LFD and pL-UFG-HFD still have nearly identical learning outcomes compared to the best pL-UFG results. This suggests even within the pL-UFG with controlled framelet dynamics, by adjusting the values of and , our proposed models are still able to generate state-of-the-art learning results with the computational complexity largely reduced compared to the pL-UFG and UFG. This observation directly verifies Lemma 3 and Remark 7. In addition, due to the reduction of computational cost, our dynamic controlled models (pL-UFG-LFD and pL-UFG-HFD) show a strong capability of handling the large-scale graph dataset, which is a challenging issue (scalability) for some GNNs especially multi-scale graph convolutions such as framelets [41] without additional data pre-processing steps. Accordingly, one can check that pL-UFG-LFD outperforms all included baselines on Arxiv datasets. Lastly, one can also find that the most of the improvements between the learning accuracy produced from our model and the baselines are significant.
4.4 Limitation of the Proposed Models and Future Studies
First, we note that our analysis on the convergence, energy dynamic and equivalence between our proposed model can be applied or partially applied to most of existing GNNs. Based on we have claimed in regarding to the theoretical perspective of pL-UFG, although we assessed model property via different perspective, eventually all theoretical conclusions come to the same conclusion (i.e., the asymptotic behavior of pL-UFG). Therefore, it would be beneficial to deploy our analyzing framework to other famous GNNs. Since the main propose of this paper is to re-assess the property of pL-UFG, we leave this to the future work.
In addition, to induce LFD/HFD to pL-UFG, we set the value of as constant according to Proposition 3, however, due to large variety of real-world graphs, it is challenging to determine the most suitable when we fix it as a constant. This suggests the exploration on controlling model’s dynamic via selecting is still rough. Moreover, based on Definition 1, the homophily index of a graph is summary statistic over all nodes. However, even in the highly homophilic graph, there are still some nodes with their neighbours with different labels. This suggests the index is only capable of presenting the global rather than local labelling information of the graph. Accordingly, assigning a constant to induce LFD/HFD might not be able to equip pL-UFG enough power to capture detailed labelling information of the graph. Therefore, another future research direction is to potentially explore the design of via the local labelling information of the graph. Finally, we note that another consequence of setting and as constant is such setting narrows the model’s parameter space, as one can check the only learnable matrix left via explicit part of pL-UFG ((9)) is . Accordingly, the narrowed parameter space might make the solution of the model optimization apart from desired solution as before, causing potential increase of learning variance.
5 Concluding Remarks
In this work, we performed theoretical analysis on pL-UFG. Specifically, we verified that by choosing suitable quantify of the model parameters ( and ), the implicit propagation induced from p-Laplacian is capable of amplifying or shrinking the Dirichlet energy of the node features produced from the framelet. Consequently, such manipulation of the energy results in a stronger energy dynamic of framelet and therefore enhancing model’s adaption power on both homophilic and heterophilic graphs. We further explicitly showed the proof of the convergence of pL-UFG, which to our best of knowledge, fills the knowledge gap at least in the field of p-Laplacian based multi-scale GNNs. Moreover, we showed the equivalence between pL-UFG and the non-linear graph diffusion, indicating that pL-UFG can be trained via various training schemes. Finally, it should be noted that for the simplicity of the analysis, we have made several assumptions and only focus on the type frames. It suffices in regards to the scope of this work. However, it would be interesting to consider more complex energy dynamics by reasonably dropping some of the assumptions or from other types of frames, we leave this to future work.
References
- [1] Wendong Bi, Lun Du, Qiang Fu, Yanlin Wang, Shi Han, and Dongmei Zhang. Make heterophily graphs better fit gnn: A graph rewiring approach, 2022.
- [2] Cristian Bodnar, Francesco Di Giovanni, Benjamin Paul Chamberlain, Pietro Liò, and Michael M Bronstein. Neural sheaf diffusion: A topological perspective on heterophily and oversmoothing in gnns. arXiv:2202.04579, 2022.
- [3] Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veličković. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv preprint arXiv:2104.13478, 2021.
- [4] Ben Chamberlain, James Rowbottom, Maria I Gorinova, Michael Bronstein, Stefan Webb, and Emanuele Rossi. Grand: Graph neural diffusion. In International Conference on Machine Learning, pages 1407–1418. PMLR, 2021.
- [5] Benjamin Chamberlain, James Rowbottom, Davide Eynard, Francesco Di Giovanni, Xiaowen Dong, and Michael Bronstein. Beltrami flow and neural diffusion on graphs. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 1594–1609. Curran Associates, Inc., 2021.
- [6] Jialin Chen, Yuelin Wang, Cristian Bodnar, Pietro Liò, and Yu Guang Wang. Dirichlet energy enhancement of graph neural networks by framelet augmentation. github, 2022.
- [7] Qi Chen, Yifei Wang, Yisen Wang, Jiansheng Yang, and Zhouchen Lin. Optimization-induced graph implicit nonlinear diffusion. In International Conference on Machine Learning, pages 3648–3661. PMLR, 2022.
- [8] Eli Chien, Jianhao Peng, Pan Li, and Olgica Milenkovic. Adaptive universal generalized pagerank graph neural network. In Proceedings of International Conference on Learning Representations, 2021.
- [9] Fan RK Chung. Spectral graph theory, volume 92. American Mathematical Soc., 1997.
- [10] Francesco Di Giovanni, James Rowbottom, Benjamin P Chamberlain, Thomas Markovich, and Michael M Bronstein. Graph neural networks as gradient flows. arXiv:2206.10991, 2022.
- [11] Bin Dong. Sparse representation on graphs by tight wavelet frames and applications. Applied and Computational Harmonic Analysis, 42(3):452–479, 2017.
- [12] Pavel Drábek and Stanislav I Pohozaev. Positive solutions for the p-laplacian: application of the fibrering method. Proceedings of the Royal Society of Edinburgh Section A: Mathematics, 127(4):703–726, 1997.
- [13] Guoji Fu, Peilin Zhao, and Yatao Bian. -laplacian based graph neural networks. In International Conference on Machine Learning, pages 6878–6917. PMLR, 2022.
- [14] Guoji Fu, Peilin Zhao, and Yatao Bian. -Laplacian based graph neural networks. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of PMLR, pages 6878–6917, 2022.
- [15] JP García Azorero and I Peral Alonso. Existence and nonuniqueness for the p-laplacian. Communications in Partial Differential Equations, 12(12):126–202, 1987.
- [16] Johannes Gasteiger, Aleksandar Bojchevski, and Stephan Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank. In Proceedings of International Conference on Learning Representations, 2019.
- [17] Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. Advances in Neural Information Processing Systems, 30, 2017.
- [18] David K Hammond, Pierre Vandergheynst, and Rémi Gribonval. Wavelets on graphs via spectral graph theory. Applied and Computational Harmonic Analysis, 30(2):129–150, 2011.
- [19] Andi Han, Dai Shi, Zhiqi Shao, and Junbin Gao. Generalized energy and gradient flow via graph framelets. arXiv preprint arXiv:2210.04124, 2022.
- [20] Bernd Kawohl and Jiri Horak. On the geometry of the -laplacian operator. arXiv preprint arXiv:1604.07675, 2016.
- [21] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- [22] Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. In AAAI Conference on Artificial Intelligence, 2018.
- [23] Remigijus Paulavičius and Julius Žilinskas. Analysis of different norms and corresponding lipschitz constants for global optimization. Technological and Economic Development of Economy, 12(4):301–306, 2006.
- [24] Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. Geom-GCN: Geometric graph convolutional networks. In International Conference on Learning Representations, 2019.
- [25] Zhiqi Shao, Andi Han, Dai Shi, Andrey Vasnev, and Junbin Gao. Generalized Laplacian regularized framelet gcns. arXiv:2210.15092, 2022.
- [26] Dai Shi, Yi Guo, Zhiqi Shao, and Junbin Gao. How curvature enhance the adaptation power of framelet gcns. arXiv preprint arXiv:2307.09768, 2023.
- [27] Wim Sweldens. The lifting scheme: A construction of second generation wavelets. SIAM Journal on Mathematical Analysis, 29(2):511–546, 1998.
- [28] Matthew Thorpe, Tan Minh Nguyen, Hedi Xia, Thomas Strohmer, Andrea Bertozzi, Stanley Osher, and Bao Wang. GRAND++: Graph neural diffusion with a source term. In International Conference on Learning Representations, 2022.
- [29] César Torres. Boundary value problem with fractional p-laplacian operator. arXiv preprint arXiv:1412.6438, 2014.
- [30] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. In International Conference on Learning Representations, 2018.
- [31] Yifei Wang, Yisen Wang, Jiansheng Yang, and Zhouchen Lin. Dissecting the diffusion process in linear graph convolutional networks. Advances in Neural Information Processing Systems, 34:5758–5769, 2021.
- [32] Quanmin Wei, Jinyan Wang, Jun Hu, Xianxian Li, and Tong Yi. Ogt: optimize graph then training gnns for node classification. Neural Computing and Applications, 34(24):22209–22222, 2022.
- [33] Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. In International Conference on Machine Learning, pages 6861–6871. PMLR, 2019.
- [34] Felix Wu, Tianyi Zhang, Amauri Holanda de Souza, Christopher Fifty, Tao Yu, and Kilian Q. Weinberger. Simplifying graph convolutional networks. In Proceedings of International Conference on Machine Learning, 2019.
- [35] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. A comprehensive survey on graph neural networks. IEEE transactions on Neural Networks and Learning Systems, 32(1):4–24, 2020.
- [36] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations, 2019.
- [37] Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. In Proceedings of International Conference on Machine Learning, 2018.
- [38] Mengxi Yang, Xuebin Zheng, Jie Yin, and Junbin Gao. Quasi-framelets: Another improvement to graph neural networks. arXiv:2201.04728, 2022.
- [39] Xin Zheng, Yixin Liu, Shirui Pan, Miao Zhang, Di Jin, and Philip S. Yu. Graph neural networks for graphs with heterophily: A survey, 2022.
- [40] Xuebin Zheng, Bingxin Zhou, Junbin Gao, Yuguang Wang, Pietro Lió, Ming Li, and Guido Montufar. How framelets enhance graph neural networks. In International Conference on Machine Learning, pages 12761–12771. PMLR, 2021.
- [41] Xuebin Zheng, Bingxin Zhou, Yu Guang Wang, and Xiaosheng Zhuang. Decimated framelet system on graphs and fast g-framelet transforms. Journal of Machine Learning Research, 23:18–1, 2022.
- [42] Bingxin Zhou, Ruikun Li, Xuebin Zheng, Yu Guang Wang, and Junbin Gao. Graph denoising with framelet regularizer. IEEE Transactions on Artificial Intelligence, 2021.
- [43] Dengyong Zhou and Bernhard Schölkopf. Regularization on discrete spaces. In Joint Pattern Recognition Symposium, pages 361–368. Springer, 2005.
- [44] Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. Beyond homophily in graph neural networks: Current limitations and effective designs. In Advances in Neural Information Processing Systems, volume 33, pages 7793–7804, 2020.
- [45] Meiqi Zhu, Xiao Wang, Chuan Shi, Houye Ji, and Peng Cui. Interpreting and unifying graph neural networks with an optimization framework. In Proceedings of the Web Conference 2021, pages 1215–1226, 2021.
- [46] Chunya Zou, Andi Han, Lequan Lin, and Junbin Gao. A simple yet effective SVD-GCN for directed graphs. arXiv:2205.09335, 2022.