Revisiting Robust RAG: Do We Still Need Complex Robust Training
in the Era of Powerful LLMs?
Abstract
Retrieval-augmented generation (RAG) systems often suffer from performance degradation when encountering noisy or irrelevant documents, driving researchers to develop sophisticated training strategies to enhance their robustness against such retrieval noise. However, as large language models (LLMs) continue to advance, the necessity of these complex training methods is increasingly questioned. In this paper, we systematically investigate whether complex robust training strategies remain necessary as model capacity grows. Through comprehensive experiments spanning multiple model architectures and parameter scales, we evaluate various document selection methods and adversarial training techniques across diverse datasets. Our extensive experiments consistently demonstrate that as models become more powerful, the performance gains brought by complex robust training methods drop off dramatically. We delve into the rationale and find that more powerful models inherently exhibit superior confidence calibration, better generalization across datasets (even when trained with randomly selected documents), and optimal attention mechanisms learned with simpler strategies. Our findings suggest that RAG systems can benefit from simpler architectures and training strategies as models become more powerful, enabling more scalable applications with minimal complexity.
Revisiting Robust RAG: Do We Still Need Complex Robust Training
in the Era of Powerful LLMs?
Hanxing Ding1,2††thanks: Equal contributions. Shuchang Tao11footnotemark: 1 Liang Pang1††thanks: Corresponding author Zihao Wei1,2 Liwei Chen3 Kun Xu Huawei Shen1,2 Xueqi Cheng1,2 1Key Laboratory of AI Safety, Institute of Computing Technology, Chinese Academy of Sciences 2 University of Chinese Academy of Sciences 3 Kuaishou Technology {dinghanxing18s, pangliang, weizihao22z, shenhuawei, cxq}@ict.ac.cn
"Entities should not be multiplied unnecessarily."
— Occam’s razor
1 Introduction
Modern LLMs excel in various NLP tasks, such as text generation, knowledge reasoning, and question answering Ye et al. (2024); Tao et al. (2024); Zhao et al. (2023). Their contextual relevance and coherence make them valuable tools across domains. Despite their broad applications, LLMs struggle with external knowledge integration, particularly in RAG systems where poor retrieval results can lead to inaccurate or misleading responses Xu et al. (2024); Tan et al. (2024); Ding et al. (2024). This issue exposes a key limitation in the robustness of LLMs with imperfect retrieval results.

To address this challenge, researchers have proposed various robust training methods to enhance RAG’s resilience against noisy contexts. Approaches mainly focus on selecting high-quality documents or incorporating additional adversarial loss regularization terms during training Yoran et al. (2024); Fang et al. (2024); Krueger et al. (2021); Zhu et al. (2024a); Jin et al. (2024); Zeng et al. (2024). For instance, RetRobust Yoran et al. (2024) suggests using a strategic mixture of relevant and irrelevant documents to train LLMs to withstand noisy contexts. RAAT Fang et al. (2024) and ATM Zhu et al. (2024a) introduce adversarial regularization terms to encourage consistent model performance across different document contexts, making the model less sensitive to retrieval noise.
Given the increasing capabilities of LLMs, a fundamental question emerges: do sophisticated robust training strategies remain necessary as model capacity grows? We first conduct a simple preliminary experiment to investigate this inquiry. As shown in Figure 1, we compare the EM scores of four different training strategies on the TriviaQA dataset. Notably, the performance gap () between the best and worst strategies shrinks dramatically from 14.65% to 4.36% as the model capacity increases. This significant diminishing gap suggests that powerful LLMs might naturally possess enhanced robustness, potentially challenging the necessity of complex robust training techniques.
In this paper, we present a systematic investigation into the necessity of sophisticated robust training strategies as model capabilities advance. Through extensive experiments across various language models with different capabilities levels, we uncover a counterintuitive phenomenon: while models with limited capabilities benefit from high-quality document selection and complex adversarial losses, these benefits diminish substantially as model capability increases. Notably, for highly capable models, training with randomly selected or even seemingly irrelevant documents can achieve comparable or superior performance to sophisticated training strategies.
We further conduct an in-depth study on this counter-intuitive phenomenon through a systematic analysis. Through inherent confidence calibration analysis, we discover that newer powerful models naturally exhibit superior discrimination between correct and incorrect responses. Moving to external performance, we find these models demonstrate remarkable cross-dataset generalization with basic random document training. Our visualization of attention patterns further reveals the underlying mechanism: powerful models inherently learn effective attention allocation even with simple training. These findings, from internal capabilities to external performance to mechanism analysis, indicate that powerful models may naturally possess fundamental desired capabilities, potentially reducing the need for complex training strategies.
We provide insights for future RAG development, suggesting: simplified architecture design principles for powerful models, opportunities for scalable open-domain applications with minimal supervision, and theoretical perspectives on how training requirements evolve with model scaling.
The main contributions of this work are:
-
•
Finding: We reveal that as model capabilities increase, the benefits of sophisticated training strategies diminish substantially.
-
•
Rationale: Through systematic analysis, we trace this finding to powerful models’ inherent capabilities, demonstrating that they naturally possess strong confidence calibration, generalization, and effective attention mechanisms, regardless of training sophistication.
-
•
Insights: We provide practical guidelines for future RAG development, advocating for architectural simplification with powerful models and highlighting new theoretical perspectives on model scaling laws.
2 Background
2.1 Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) enhances language model performance by incorporating external knowledge retrieval into the generation process. Given a query , a retriever selects a set of relevant document sets from a large corpus, providing additional factual grounding for the model. These retrieved documents serve as context to improve the model’s reasoning and factual accuracy. The language model then generates an answer based on the augmented input, following the conditional probability formulation:
| (1) |
where represents the generated sequence, and denotes the model parameters. The retrieval-augmented setup enables the model to dynamically condition its responses on external information, improving its ability to generate factually consistent answers. However, RAG models remain susceptible to retrieval noise, such as irrelevant or misleading documents, which can degrade performance and lead to hallucinations.
2.2 Robust Training for RAG
Document Selection Strategy
A common strategy for robust training in RAG models is to select high-quality documents from either the golden set or top-ranked passages for fine-tuning. Traditionally, supervised fine-tuning (SFT) relies on high-quality golden data, where each query is paired with a carefully curated document containing the correct answer. This ensures that the model learns from reliable sources, leading to improved factual accuracy. Naturally, leveraging such golden documents in RAG training is a straightforward and effective approach.
However, in real-world scenarios, the golden document may not always be retrieved due to limitations in the retriever. In such cases, training only on golden passages lead to unrealistic expectations during inference. A more practical approach is to incorporate top-1 retrieved documents, which better reflect what the model will encounter at test time. Even if these documents are imperfect, training on them enhances the model’s adaptability. Further, drawing from a mixture of top-ranked, lower-ranked, or randomly sampled passages, as suggested by RetRobust Yoran et al. (2024), exposes the model to diverse retrieval conditions, improving its robustness to noisy or suboptimal results. This strategy ensures that RAG models generalize better across different retrieval settings, making them more reliable in real-world applications.
Adversarial Loss Design
To enhance the robustness of RAG models against retrieval variations, robust training for RAG introduces a general training framework that combines standard SFT with a robustness-enforcing regularization term. During training, the model learns across multiple retrieval environments, which may include golden documents, top-k retrieved results, or adversarially perturbed documents. The overall training objective consists of two components: the first part is the standard training loss across different retrieval environments, and the second part is a regularization term designed to reduce model performance sensitivity to retrieval variations. Different forms of regularization strategies are detailed in Appendix B.
3 Experimental Setups
In this section, we introduce the dataset and evaluation metrics we used to assess the robustness performance of various robust training strategies.
3.1 Datasets and Evaluation Metrics
For our experiment, we evaluate on four widely-used question answering datasets: (1) single-hop QA, including NaturalQuestions (NQ) Kwiatkowski et al. (2019) and WebQuestions Berant et al. (2013); and (2) multi-hop QA, including TriviaQA Joshi et al. (2017) and HotpotQA Yang et al. (2018). All experimental results are evaluated on their development splits using the Exact Match (EM) and F1 metrics. Detailed statistics of these datasets are listed in Appendix C.1 Table 2.
3.2 RAG Pipeline
We implement a standard two-stage RAG framework with retrieval and generation phases. For retrieval, we use Contriever Izacard et al. (2022), a BERT-based dense retriever trained with unsupervised contrastive learning. Our knowledge corpus is Wikipedia-2018, preprocessed into 100-word non-overlapping passages. We encode these passages using Contriever and index them with FAISS111https://github.com/facebookresearch/faiss for efficient retrieval. During training and development, the top-20 relevant documents are retrieved for each query. For question-answering, the top-5 retrieved documents are concatenated with the query as input for answer generation. The generator prompt is detailed in Appendix C.3 Table 3.
3.3 Robust RAG Training Setups
For our experiments, we evaluate two popular robust training settings:
3.3.1 Document Selection Strategies
We explore several document selection training strategies across three categories.
For basic QA capability evaluation, we use the Base Model in a few-shot setting, where the model performs inference without RAG-specific training.
For scenarios with relevant documents, we explore four strategies:
-
•
RALM: Fine-tunes the model by prepending golden retrieval text. Queries without golden documents in the top-20 are excluded, leading to reduced training set size.
-
•
RetRobust: Following Yoran et al. (2024), this method enhances robustness by randomly selecting top-ranked, low-ranked, or random passages during training.
-
•
Top-1 Document: Uses the highest-scoring retrieved document, which may not contain the correct answer, reflecting real-world retrieval challenges.
-
•
Golden Document: Selects the most relevant document containing the correct answer. If none exist in the top-20, it defaults to the top-1 document for consistency.
| Model | RAG Scenario | HotpotQA | NQ | WebQuestions | TriviaQA | AVERAGE | |||||
| EM | F1 | EM | F1 | EM | F1 | EM | F1 | EM | F1 | ||
| Llama-2-7b-chat-hf | Base Model | 3.30 | 12.34 | 1.21 | 10.61 | 0.00 | 13.08 | 4.32 | 20.27 | 2.21 | 14.08 |
| RALM | 26.21 | 36.42 | 32.17 | 42.68 | 33.81 | 45.85 | 50.28 | 60.17 | 35.62 | 46.28 | |
| RetRobust | 31.29 | 43.65 | 37.71 | 49.49 | 36.33 | 47.98 | 57.61 | 67.52 | 40.74 | 52.16 | |
| Top-1 Doc | 31.76 | 43.95 | 40.20 | 51.89 | 41.73 | 52.76 | 52.93 | 65.41 | 41.66 | 53.50 | |
| Golden Doc | 30.67 | 42.78 | 36.50 | 47.77 | 39.93 | 52.11 | 50.25 | 63.28 | 39.34 | 51.49 | |
| \cdashline2-12 | Random Doc | 30.94 | 43.11 | 38.16 | 49.78 | 42.45 | 53.97 | 52.72 | 65.52 | 41.07 | 53.10 |
| Irrelevant Doc | 31.01 | 42.98 | 37.08 | 48.93 | 39.21 | 50.79 | 51.97 | 64.70 | 39.82 | 51.85 | |
| \cdashline2-12 | RAAT | 31.32 | 43.24 | 42.91 | 53.19 | 36.69 | 48.82 | 51.65 | 58.71 | 40.64 | 50.99 |
| IRM | 34.38 | 47.11 | 40.96 | 53.07 | 53.96 | 61.62 | 57.58 | 69.08 | 46.72 | 57.72 | |
| (Worst Best) | 16.19% | 12.89% | 21.87% | 13.19% | 48.53% | 28.43% | 13.55% | 17.66% | 15.95% | 13.20% | |
| Llama-3-8B-Instruct | Base Model | 23.31 | 32.60 | 30.04 | 41.59 | 26.98 | 43.25 | 58.80 | 66.45 | 34.78 | 45.97 |
| RALM | 27.64 | 38.10 | 35.19 | 46.10 | 47.84 | 56.98 | 54.75 | 63.27 | 41.36 | 51.11 | |
| RetRobust | 36.06 | 48.99 | 43.28 | 55.04 | 52.88 | 62.10 | 59.06 | 67.77 | 47.82 | 58.48 | |
| Top-1 Doc | 36.72 | 49.30 | 44.38 | 56.20 | 54.68 | 62.26 | 60.80 | 68.31 | 49.15 | 59.02 | |
| Golden Doc | 35.52 | 48.31 | 41.35 | 53.13 | 48.92 | 58.41 | 58.26 | 66.99 | 46.01 | 56.71 | |
| \cdashline2-12 | Random Doc | 35.98 | 49.05 | 43.37 | 55.43 | 53.24 | 62.55 | 60.62 | 68.64 | 48.30 | 58.92 |
| Irrelevant Doc | 35.31 | 47.92 | 42.45 | 54.41 | 46.76 | 57.67 | 58.97 | 66.57 | 45.87 | 56.64 | |
| \cdashline2-12 | RAAT | 32.20 | 43.81 | 42.34 | 53.31 | 48.28 | 58.17 | 54.41 | 62.45 | 44.31 | 54.44 |
| IRM | 35.19 | 48.08 | 41.13 | 53.14 | 53.96 | 61.64 | 57.15 | 69.13 | 46.86 | 58.00 | |
| (Worst Best) | 14.04% | 12.53% | 7.90% | 5.76% | 16.94% | 8.46% | 11.74% | 10.70% | 10.92% | 8.42% | |
To assess robustness against irrelevant information, we introduce two adversarial scenarios:
-
•
Random Document: Randomly selects a document from retrieved results, simulating unpredictable retrieval quality.
-
•
Irrelevant Document: Chooses a passage from another query’s retrieval results, ensuring no relevance to the current query.
3.3.2 Adversarial Loss Design
We assess two popular adversarial loss strategies:
-
•
RAAT. The regularization term in RAAT reduces the performance gap between the best and worst retrieval cases. By penalizing excessive performance disparity, RAAT ensures that the model remains stable even under challenging retrieval conditions, leading to improved robustness and generalization.
-
•
IRM. The regularization in IRM minimizes the variance in performance across different retrieval environments. By enforcing consistency, IRM mitigates sensitivity to distribution shifts, ensuring that the model performs reliably across diverse retrieval scenarios.
4 Does Sophisticated Robust Training Still Matter in Powerful Models?
To investigate whether sophisticated document selection strategies and adversarial loss designs are still essential for robust RAG performance as LLMs continue to evolve, we conduct comprehensive experiments across multiple LMs and datasets.
4.1 Do Sophisticated Document Selection Strategies Matter?
We conduct experiments to analyze the effectiveness of complex document selection strategies under Llama model families (Llama-2-7b-chat-hf and Llama-3-8B-Instruct) in Table 1, and Qwen model families in Appendix Table 4.
Training with sophisticated documents enhances LM robustness for weak models
The experimental results presented in Tables 1 and 4 provide compelling evidence that robust training significantly improves model resilience when processing noisy documents. While base models exhibit substantial performance degradation when encountering noisy documents during inference, models that undergo robust training maintain consistent and superior QA performance across various document selection strategies. A notable example is the Llama-2-7b-chat-hf model’s performance (Table 1) on the HotpotQA dataset, where training with golden documents improves the EM score from 3.3 (Base Model) to 30.67 (Golden Doc), indicating increased resilience to document noise. This pattern of improvement is consistently observed across both Llama (Table 1) and Qwen (Table 4) model families, strongly indicating that robust training effectively mitigates the base models’ inherent vulnerability to noisy documents.
Training with random documents shows surprising effectiveness
We also notice that training with randomly selected documents exhibits remarkable effectiveness across all experimental configurations. Quantitative analysis shows that with Llama-2-7b-chat-hf, this approach achieves superior performance on WebQuestions compared to more sophisticated strategies. Similar observations emerge from experiments with Qwen1.5-7B-Chat, where random document selection achieves 46.04 EM on WebQuestions, approaching the optimal performance of 47.12 EM achieved by RetRobust. The consistency of these results across distinct model architectures suggests that the efficacy of random document selection represents an inherent characteristic of contemporary RAG systems.
Diminishing returns of sophisticated document selections as models evolve
Experimental results indicate that the performance gains from sophisticated document selection strategies diminish as models evolve. For instance, comparing Llama-2-7b-chat-hf with Llama-3-8B-Instruct, the improvement in performance due to advanced document selection strategies decreases significantly, with the (Worst Best) metric for NQ dropping from 21.87% to 7.90% EM. A similar trend is observed when comparing Qwen1.5-7B-Chat to Qwen2.5-7B-Instruct, where the performance improvement from sophisticated document selection also shows a noticeable reduction. These results suggest that as models become more advanced, their ability to process and utilize information improves independently of complex document selection strategies, leading to diminished returns from such methods.
4.2 Do Adversarial Loss Functions Matter?
To investigate whether the design of complex adversarial loss functions contributes to model performance, in Table 1 and 4, we also analyze the robustness of various adversarial loss designs.
Adversarial loss significantly enhances performance for weaker models
For the weaker model (Llama-2-7b-chat-hf), incorporating adversarial loss functions such as RAAT and IRM leads to a substantial improvement in performance compared to the base model or alternative document selection strategies. Specifically, while the base model achieves an average EM / F1 of only 2.21 / 14.08, applying adversarial loss functions boosts the performance to 40.64 / 50.99 for RAAT and 46.72 / 57.72 for IRM. This highlights the effectiveness of adversarial loss in improving model robustness to noisy documents, significantly enhancing both robustness and downstream inference performance. Notably, in some cases, RAAT and IRM outperform traditional document selection strategies (e.g., top-1 Doc and golden doc), demonstrating their value in scenarios where the model needs stronger guidance to handle noisy retrievals.

Adversarial loss exhibits diminishing returns for stronger models
For the stronger models, such as Llama-3-8B-Instruct and Qwen2.5-7B-Instruct, the benefits of adversarial loss functions are less pronounced. The basic Llama-3-8B-Instruct already achieves an average EM / F1 of 34.78 / 45.97, and the introduction of adversarial losses (RAAT and IRM) results in only modest improvements, with average EM / F1 scores of 44.31 / 54.44 and 46.86 / 58.00, respectively. Similarly, Qwen2.5-7B-Instruct shows similar trends, with marginal gains from adversarial loss functions. These improvements are comparable to or even slightly worse than the performance achieved by random document selection (48.30 / 58.92) or top-1 document strategies (49.15 / 59.02). This indicates that the models’ inherent robustness reduces the impact of adversarial losses, and in some cases, may even hinder performance. We hypothesize that when the model’s internal robustness is already well-developed, additional constraints from adversarial losses may interfere with its ability to optimize on clean and relevant inputs.
Based on these findings, we conclude that both adversarial loss functions and document selection strategies are more beneficial for weaker models. For smaller models, these techniques significantly improve robustness by mitigating the impact of noisy documents. For stronger models with inherently robust performance, the advantages of complex loss designs and sophisticated document selection diminish, suggesting that simpler strategies like random document selection may be sufficient. This underscores the importance of tailoring training strategies to the model’s inherent capabilities.
4.3 Do Training Strategies Matter Across Model Scales?
Through analyzing Tables 1 and 4, we observe a counter-intuitive phenomenon: models trained with random documents outperformed those with golden documents, despite the latter containing ground truth answers typically yielding optimal results in standard SFT. To investigate whether this phenomenon extends beyond 7B-8B models, we conduct experiments across model scales from 0.5B to 70B parameters.
The results (detailed in Appendix Table 6) in Figure 2 demonstrate that for smaller models (3B parameters), training with golden documents leads to superior performance. This suggests that smaller models, limited by their inherent capabilities, benefit more from high-quality golden documents containing direct answers. However, as model size increases, we observe that training with random documents becomes more effective. This shift can be attributed to larger models’ enhanced question-answering abilities and improved robustness. These models can better generalize to downstream tasks even when trained on random documents, which may contain noisier or less structured information. This finding indicates that sophisticated document selection strategies become less crucial as model size increases, revealing an important scaling property in model training.
5 Why Sophisticated Training No Longer Matters in Powerful Models?
In this section, we conduct comprehensive experiments to delve into the reasons why sophisticated robust training strategies may no longer be crucial in powerful models.

5.1 Powerful Models Enable Natural Calibration
To understand whether powerful models inherently possess the ability to distinguish reliable from unreliable answers, we take HotpotQA dataset as an example to examine the confidence calibration capabilities for Llama2 (Llama-2-7b-chat-hf) and Llama3 (Llama-3-8B-Instruct) models. Here, confidence is the mean of token-wise probabilities in the model’s generated answer, providing a measure of the model’s certainty in its predictions Varshney et al. (2023); Xiong et al. (2024). Figure 3 reveals striking differences in their calibration patterns. In the base model, Llama2 shows poor natural calibration levels, where confidence scores for incorrect answers (95.8) abnormally exceed those for correct ones (93.8). In contrast, Llama3 demonstrates inherently better calibration, maintaining higher confidence for correct answers (97.5) than incorrect ones (91.3) without any specialized complex training.
While robust training methods (Golden Doc, Random Doc, and IRM) can effectively calibrate confidence scores and improve the gap between correct and incorrect answers for Llama2 from -2 to 12 with IRM, the marginal benefits of these complex training strategies diminish as model architectures advance. For Llama3, which already achieves a 6.2 confidence gap naturally, the improvements from these training methods become less significant. This finding strongly suggests that advances in model architecture can effectively eliminate the need for complex robustness training procedures, as newer models come with better built-in calibration capabilities.
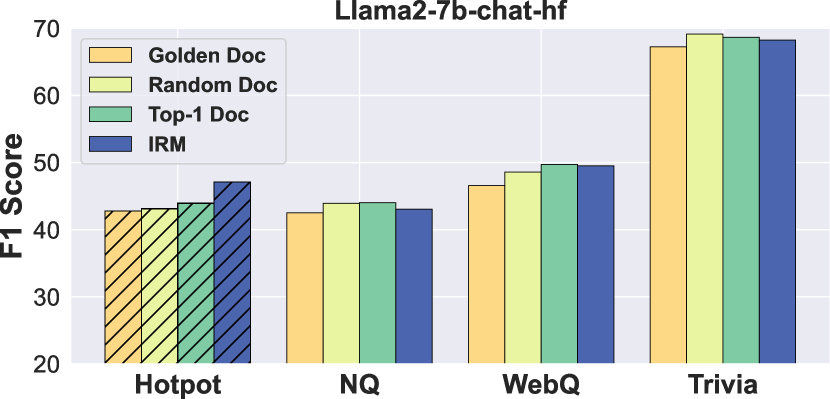

5.2 Simple Training Strategies Generalize Well in Powerful Models
We further investigate whether powerful models can maintain robust generalization across different datasets with simple training strategies. We fine-tune models on HotpotQA using four document selection approaches and evaluate their transfer performance on NQ, WebQuestions, and TriviaQA.
As shown in Figure 4, simple strategies demonstrate surprisingly strong generalization ability. Random document selection matches or even outperforms sophisticated IRM across all evaluation datasets, with performance gaps of less than 1%. For instance, in TriviaQA, random selection (69.5 F1) slightly surpasses both golden (68.2 F1) and IRM (68.7 F1) approaches. This trend becomes more pronounced in the powerful Llama-3-8B-Instruct, where the performance gap between simple and sophisticated strategies further narrows. The consistent cross-dataset performance, regardless of training strategy, indicates that model capacity, rather than training sophistication, is the key driver of generalization ability. These findings provide strong evidence that as models become more powerful, sophisticated training strategies become increasingly unnecessary.

5.3 Powerful Models Learn Effective Attention Patterns with Simple Training
To provide a direct understanding of why simple training can achieve good performance, we visualize attention distributions across different training strategies. Figure 5 reveals that both sophisticated robust training methods (IRM) and simple approaches (random doc, top-1) achieve similar attention patterns, with clear focus on Doc1 (containing the correct answer) in middle layers (9-16). In contrast, the base model fails to attend to the correct document, generating a wrong answer. This finding provides direct evidence that powerful models can learn optimal attention mechanisms even with simple training strategies, making sophisticated training methods unnecessary.


5.4 Training with Random Docs: Better Performance and Faster Convergence
We investigate why random training proves good performance from two aspects.
More random docs lead to better performance
We first vary the numbers of random documents (0 to 3) in training instances to examine how increasing random documents affects model performance. As shown in Figure 6, increasing random documents consistently improves F1 scores across both datasets. For Llama-2-7b-chat-hf, using 3 random documents (versus zero) improves F1 scores by 3 points on HotpotQA and 4 points on NQ. Llama-3-8B-Instruct shows similar gains, suggesting that powerful models can effectively learn from random documents, making sophisticated document selection relatively unnecessary.
Faster convergence with random training
The training dynamics in Figure 7 provide another evidence for why sophisticated document selection becomes unnecessary. Random document training not only achieves higher F1 scores (2-3 points improvement) but also reaches peak performance in fewer steps compared to golden document training. This faster convergence with better performance holds true for both model scales, indicating that simpler random training actually enables more efficient learning in powerful language models.
6 Insights and Future Directions
Our findings reveal a fundamental shift in RAG system: as models become more powerful, the marginal benefits of sophisticated training strategies diminish significantly. This observation has several important insights:
Simplified RAG architecture design
For powerful models, simple retrieval strategies (even random selection) can achieve comparable performance to sophisticated approaches. This enables streamlined RAG architectures by replacing elaborate document filtering mechanisms with simpler retrieval methods, substantially reducing system complexity without sacrificing performance.
Scalable RAG for open-domain tasks.
Larger models demonstrate robustness against noisy retrieval, suggesting that open-domain RAG systems can function effectively with minimal retrieval supervision. Instead of enforcing strict filtering of retrieved documents, future large-scale RAG systems can leverage weakly supervised learning, incorporating large-scale web data and noisy retrieval results to improve generalization.
Theoretical implications for model scaling.
This research reveals a previously unexplored aspect of scaling laws: the diminishing returns of complex training strategies as models grow larger. This challenges current theoretical frameworks and calls for new ones that better explain how training requirements evolve with model scale.
Broader impact on machine learning.
Our findings suggest that as models become more powerful, practitioners should prioritize architectural improvements and data quality over complex training strategies. This insight could lead to more efficient resource allocation in model development across various applications, from computer vision to natural language processing.
7 Conclusions
In this study, we systematically investigate whether complex robust training strategies remain necessary for RAG systems as model capacity grows. Our extensive experiments consistently show that while sophisticated training methods significantly enhance weaker models’ performance, their benefits diminish dramatically in more powerful models. Through the systematic analysis, we find that advanced models inherently possess strong confidence calibration, cross-dataset generalization, and effective attention patterns even with simple training. These findings suggest that RAG systems can benefit from simpler training strategies as models become more powerful, enabling more scalable applications with minimal complexity.
Limitations
While our study provides valuable insights into the impact of adversarial loss functions and document selection strategies on RAG model robustness, several limitations remain. First, our analysis is restricted to dense transformer-based models, leaving the effectiveness of these techniques on sparse models, such as mixture-of-experts (MoE) architectures, unexplored. Future work could investigate whether similar trends hold for sparsely activated models with dynamic routing mechanisms. Second, although we analyze the effectiveness of adversarial training, we do not explicitly examine its long-term stability or convergence properties, which may vary depending on hyperparameter choices and optimization dynamics. Additionally, while we demonstrate that stronger models exhibit diminishing returns from adversarial losses and document selection strategies, the precise mechanisms behind this phenomenon remain unclear. Further research is needed to understand how model capacity interacts with retrieval robustness.
Ethics Statements
Our study focuses on improving the robustness of RAG models, but several ethical considerations must be acknowledged. First, while adversarial training enhances model reliability, it does not eliminate the risk of biased or misleading outputs, particularly when retrieval sources contain inherent biases or misinformation. Future work should explore fairness-aware adversarial training to mitigate potential harms. Second, our findings suggest that stronger models require less intervention in document selection and loss design, which may influence resource allocation in real-world applications. Researchers and practitioners should ensure that model improvements do not disproportionately benefit well-resourced institutions while leaving smaller models less robust. Lastly, our experiments are conducted on widely used benchmark datasets, which may not fully reflect the diversity of real-world information needs. We encourage further research on robustness evaluation across varied domains, including low-resource languages and specialized knowledge fields, to ensure equitable advancements in RAG technology.
References
- Asai et al. (2023) Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-rag: Learning to retrieve, generate, and critique through self-reflection. CoRR, abs/2310.11511.
- Berant et al. (2013) Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. Semantic parsing on Freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1533–1544, Seattle, Washington, USA. Association for Computational Linguistics.
- Cuconasu et al. (2024) Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, and Fabrizio Silvestri. 2024. The power of noise: Redefining retrieval for RAG systems. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, pages 719–729. ACM.
- Deng et al. (2023) Jingcheng Deng, Liang Pang, Huawei Shen, and Xueqi Cheng. 2023. RegaVAE: A retrieval-augmented Gaussian mixture variational auto-encoder for language modeling. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 2500–2510, Singapore. Association for Computational Linguistics.
- Ding et al. (2024) Hanxing Ding, Liang Pang, Zihao Wei, Huawei Shen, and Xueqi Cheng. 2024. Retrieve only when it needs: Adaptive retrieval augmentation for hallucination mitigation in large language models. CoRR, abs/2402.10612.
- Fang et al. (2024) Feiteng Fang, Yuelin Bai, Shiwen Ni, Min Yang, Xiaojun Chen, and Ruifeng Xu. 2024. Enhancing noise robustness of retrieval-augmented language models with adaptive adversarial training. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10028–10039, Bangkok, Thailand. Association for Computational Linguistics.
- Izacard et al. (2022) Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised dense information retrieval with contrastive learning. Trans. Mach. Learn. Res., 2022.
- Jiang et al. (2023) Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969–7992, Singapore. Association for Computational Linguistics.
- Jin et al. (2024) Jiajie Jin, Yutao Zhu, Yujia Zhou, and Zhicheng Dou. 2024. BIDER: Bridging knowledge inconsistency for efficient retrieval-augmented LLMs via key supporting evidence. In Findings of the Association for Computational Linguistics: ACL 2024, pages 750–761, Bangkok, Thailand. Association for Computational Linguistics.
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada. Association for Computational Linguistics.
- Krueger et al. (2021) David Krueger, Ethan Caballero, Jörn-Henrik Jacobsen, Amy Zhang, Jonathan Binas, Dinghuai Zhang, Rémi Le Priol, and Aaron C. Courville. 2021. Out-of-distribution generalization via risk extrapolation (rex). In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 of Proceedings of Machine Learning Research, pages 5815–5826. PMLR.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466.
- Mallen et al. (2023) Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9802–9822, Toronto, Canada. Association for Computational Linguistics.
- Qiao et al. (2024) Zile Qiao, Wei Ye, Yong Jiang, Tong Mo, Pengjun Xie, Weiping Li, Fei Huang, and Shikun Zhang. 2024. Supportiveness-based knowledge rewriting for retrieval-augmented language modeling. CoRR, abs/2406.08116.
- Tan et al. (2024) Hexiang Tan, Fei Sun, Wanli Yang, Yuanzhuo Wang, Qi Cao, and Xueqi Cheng. 2024. Blinded by generated contexts: How language models merge generated and retrieved contexts when knowledge conflicts? In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6207–6227, Bangkok, Thailand. Association for Computational Linguistics.
- Tao et al. (2024) Shuchang Tao, Liuyi Yao, Hanxing Ding, Yuexiang Xie, Qi Cao, Fei Sun, Jinyang Gao, Huawei Shen, and Bolin Ding. 2024. When to trust LLMs: Aligning confidence with response quality. In Findings of the Association for Computational Linguistics: ACL 2024, pages 5984–5996, Bangkok, Thailand. Association for Computational Linguistics.
- Varshney et al. (2023) Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jianshu Chen, and Dong Yu. 2023. A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation. CoRR, abs/2307.03987.
- Wu et al. (2024) Jinyang Wu, Feihu Che, Chuyuan Zhang, Jianhua Tao, Shuai Zhang, and Pengpeng Shao. 2024. Pandora’s box or aladdin’s lamp: A comprehensive analysis revealing the role of RAG noise in large language models. CoRR, abs/2408.13533.
- Xiang et al. (2024) Chong Xiang, Tong Wu, Zexuan Zhong, David A. Wagner, Danqi Chen, and Prateek Mittal. 2024. Certifiably robust RAG against retrieval corruption. CoRR, abs/2405.15556.
- Xiong et al. (2024) Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2024. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
- Xu et al. (2024) Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. 2024. Knowledge conflicts for LLMs: A survey. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8541–8565, Miami, Florida, USA. Association for Computational Linguistics.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium. Association for Computational Linguistics.
- Ye et al. (2024) Hongbin Ye, Tong Liu, Aijia Zhang, Wei Hua, and Weiqiang Jia. 2024. Cognitive mirage: A review of hallucinations in large language models. In Proceedings of the First International OpenKG Workshop: Large Knowledge-Enhanced Models co-locacted with The International Joint Conference on Artificial Intelligence (IJCAI 2024), Jeju Island, South Korea, August 3, 2024, volume 3818 of CEUR Workshop Proceedings, pages 14–36. CEUR-WS.org.
- Yoran et al. (2024) Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Berant. 2024. Making retrieval-augmented language models robust to irrelevant context. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
- Zeng et al. (2024) Shenglai Zeng, Jiankun Zhang, Bingheng Li, Yuping Lin, Tianqi Zheng, Dante Everaert, Hanqing Lu, Hui Liu, Yue Xing, Monica Xiao Cheng, and Jiliang Tang. 2024. Towards knowledge checking in retrieval-augmented generation: A representation perspective. CoRR, abs/2411.14572.
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2023. A survey of large language models. CoRR, abs/2303.18223.
- Zhu et al. (2024a) Junda Zhu, Lingyong Yan, Haibo Shi, Dawei Yin, and Lei Sha. 2024a. ATM: Adversarial tuning multi-agent system makes a robust retrieval-augmented generator. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10902–10919, Miami, Florida, USA. Association for Computational Linguistics.
- Zhu et al. (2024b) Kun Zhu, Xiaocheng Feng, Xiyuan Du, Yuxuan Gu, Weijiang Yu, Haotian Wang, Qianglong Chen, Zheng Chu, Jingchang Chen, and Bing Qin. 2024b. An information bottleneck perspective for effective noise filtering on retrieval-augmented generation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1044–1069, Bangkok, Thailand. Association for Computational Linguistics.
Appendix A Related Work
A.1 Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) has been developed to enhance the reasoning and generation capabilities of LLMs by integrating external information. RAG improves the overall performance of LLMs by retrieving relevant documents that provide additional context and support for the generation process. However, dense retrievers are not always perfect and can sometimes recall irrelevant or erroneous documents, which can degrade performance Jiang et al. (2023); Deng et al. (2023); Ding et al. (2024). To mitigate this issue, adaptive retrieval techniques and robust RAG training methods have been proposed. Adaptive retrieval techniques retrieve external information only when LLMs encounter unknowns, reducing the risk of integrating misleading or incorrect information Jiang et al. (2023); Mallen et al. (2023); Asai et al. (2023). Additionally, robust training focuses on enhancing LLMs’ response to various retrieval noises, aiming to efficiently obtain adversarial examples that improve model robustness while reducing training overhead Fang et al. (2024); Zhu et al. (2024a); Xiang et al. (2024).
A.2 Robust Training for RAG Systems
The performance of LLMs in RAG systems can be compromised by irrelevant context Cuconasu et al. (2024); Wu et al. (2024). Recently, researchers have focused on this issue and proposed effective adversarial training methods to enhance the robustness of LLMs against noisy documents. RetRobust Yoran et al. (2024) suggests using a mix of relevant and irrelevant documents to train LLMs to withstand noisy contexts. RAAT Fang et al. (2024) and ATM Zhu et al. (2024a) employ adversarial training to dynamically adjust the model’s training process, aiming to maintain robustness against noise and generate accurate answers. RobustRAG Xiang et al. (2024) proposes to enhances RAG model robustness against retrieval corruption attacks through an isolate-then-aggregate strategy to achieve certifiable robustness. Additionally, there is a body of work focused on identifying key documents from noisy contexts to facilitate effective question answering through knowledge rewriting, refinement, or filtering Zhu et al. (2024b); Qiao et al. (2024); Jin et al. (2024); Zeng et al. (2024). However, these robust training approaches are primarily applied to small or weak LMs with fewer than 7 billion parameters. Thus, there’s an urgent need to explore whether complex robust training is still necessary to improve the robustness and generalization of bigger or stronger models when dealing with noisy contexts.
Appendix B Robustness Training for RAG
B.1 Retrieval-augmented Adaptive Adversarial Training
To improve the robustness of retrieval-augmented language models (RALMs) against retrieval noise, RAAT Fang et al. (2024) incorporates an adversarial loss into the standard supervised fine-tuning (SFT). The model processes one golden context and three adversarial samples at each iteration, optimizing for the most challenging perturbation. The adversarial objective follows a min-max strategy:
| (2) |
where represents the generation loss function to noisy retrievals, and represents the augmented noise context of . A regularization term controls excessive sensitivity to noise:
| (3) |
The adversarial loss combines both terms, where the regularization term helps stabilize training by mitigating excessive sensitivity to retrieval noise. The regularization term, calculated as the square of the difference between and , encourages a more balanced optimization, preventing the model from overreacting to the most challenging perturbations.
B.2 Multiagent Iterative Tuning Optimization
ATM Zhu et al. (2024a) steers the generator to have a robust perspective of useful documents for question answering with the help of an auxiliary attacker agent. The generator is trained to maximize answer correctness while minimizing its sensitivity to adversarial perturbations. It receives the user query along with a document list, which may contain both relevant and fabricated information introduced by the attacker. Its objective is to generate accurate responses as long as sufficient truthful information is present while reducing the impact of misleading or fabricated content. To achieve this, the generator learns to identify and leverage relevant documents while ignoring noisy ones, regardless of whether they originate from the original retrieval or adversarial perturbations . This can be formalized as maximizing the objective:
| (4) |
where represents the language model probability of generating an answer, and measures the divergence between outputs under different document conditions. The generator and the attacker are tuned adversarially for several iterations. After rounds of multi-agent iterative tuning, the generator can eventually better discriminate useful documents amongst fabrications.
B.3 Invariant Risk Minimization
Invariant Risk Minimization (IRM) aims to learn representations that remain stable across different environments, improving generalization under distribution shifts. To enhance the robustness of retrieval-augmented generation (RAG) across varying retrieval conditions, the V-REx objective Krueger et al. (2021) can also be adapted to enforce risk invariance across different retrieval environments. Given retrieval environments , where each corresponds to a specific retrieval scenario (e.g., golden documents, top- retrieved, noisy retrieval), we define the empirical risk of the model parameterized by . The training objective is formulated as:
| (5) | ||||
where controls the trade-off between minimizing average risk and enforcing risk invariance across retrieval environments. A higher reduces performance discrepancies caused by retrieval variations, improving generalization under both high-quality and noisy retrieval conditions.
Appendix C Appendix
C.1 Dataset Statistics
Detailed statistics of these datasets we used are listed in Table 2.
| Dataset | Type | # Train | # Dev |
| NQ | single-hop | 79,168 | 8,757 |
| WebQuestions | single-hop | 2,474 | 278 |
| TriviaQA | multi-hop | 78,785 | 8,837 |
| HotpotQA | multi-hop | 90,447 | 7,405 |
C.2 Implementation Details
For model training, we utilize the LLaMA-Factory library to facilitate efficient LLM finetuning. We train our models with a learning rate of 1e-6 and set the maximum number of epochs to 3. To optimize the training process, we employ bfloat16 precision and DeepSpeed ZeRO-3 for distributed training. The gradient accumulation steps are set to 2 with a batch size of 8. For inference, we leverage vLLM to ensure efficient model serving. We maintain the default decoding parameters for each model during inference, including the default temperature and top-p sampling probabilities, to ensure fair comparison across different model variants. All training and inference procedures are conducted on 8x NVIDIA A100 80GB GPUs.
C.3 Prompt Instruction
We present the prompt used to guide LM inference on noisy contexts in Table 3. Specifically, we concatenate the top-5 retrieved documents into a single passage, append the input question afterward, and prompt the LM to generate a concise answer.
| You need to answer my question and complete the question-and-answer pair following the format provided in the example. The answers should be short phrases or entities, not full sentences. Here are some examples to guide you. |
| Example 1: |
| Question: What is the capital of France? |
| Answer: Paris |
| Example 2: |
| Question: Who invented the telephone? |
| Answer: Alexander Graham Bell |
| Example 3: |
| Question: Which element has the atomic number 1? |
| Answer: Hydrogen |
| ### Retrieved Documents: {} |
| ### Question: {} |
| ### Answer: |
| Model | RAG Scenario | HotpotQA | NQ | WebQuestions | TriviaQA | AVERAGE | |||||
| EM | F1 | EM | F1 | EM | F1 | EM | F1 | EM | F1 | ||
| Qwen1.5-7B-Chat | Base Model | 24.15 | 34.06 | 24.31 | 35.27 | 23.02 | 38.65 | 48.43 | 57.65 | 29.98 | 41.41 |
| RALM | 24.44 | 34.23 | 29.83 | 40.22 | 44.24 | 53.46 | 46.40 | 55.96 | 36.23 | 45.97 | |
| RetRobust | 29.05 | 40.99 | 34.82 | 45.92 | 47.12 | 55.39 | 49.16 | 59.01 | 40.04 | 50.33 | |
| Top-1 Doc | 29.68 | 41.57 | 34.16 | 45.44 | 43.88 | 52.71 | 49.61 | 59.03 | 39.33 | 49.69 | |
| Golden Doc | 28.66 | 40.55 | 32.93 | 43.99 | 43.88 | 52.74 | 49.25 | 58.87 | 38.68 | 49.04 | |
| \cdashline2-12 | Random Doc | 28.83 | 40.66 | 33.96 | 45.09 | 46.04 | 53.21 | 48.75 | 58.54 | 39.40 | 49.38 |
| Irrelevant Doc | 28.12 | 39.87 | 32.74 | 43.94 | 43.88 | 52.67 | 48.33 | 58.18 | 38.27 | 48.67 | |
| \cdashline2-12 | IRM | 26.95 | 38.67 | 30.59 | 41.83 | 47.84 | 55.68 | 45.52 | 56.24 | 37.73 | 48.11 |
| (Worst Best) | 21.44% | 21.44% | 16.73% | 14.17% | 9.02% | 5.71% | 8.99% | 5.49% | 10.52% | 9.48% | |
| Qwen2.5-7B-Instruct | Base Model | 25.10 | 35.02 | 26.97 | 38.15 | 25.90 | 42.46 | 53.86 | 62.73 | 32.96 | 44.59 |
| RALM | 26.37 | 36.30 | 31.43 | 42.00 | 41.73 | 51.98 | 53.92 | 62.74 | 38.36 | 48.26 | |
| RetRobust | 30.47 | 42.26 | 34.60 | 46.00 | 45.68 | 53.80 | 54.43 | 63.63 | 41.30 | 51.42 | |
| Top-1 Doc | 30.24 | 42.61 | 34.72 | 46.20 | 46.04 | 54.13 | 53.65 | 63.01 | 41.16 | 51.49 | |
| Golden Doc | 30.28 | 41.84 | 33.77 | 45.11 | 44.60 | 53.18 | 54.35 | 63.55 | 40.75 | 50.92 | |
| \cdashline2-12 | Random Doc | 30.25 | 42.22 | 34.08 | 45.47 | 44.24 | 53.30 | 54.29 | 63.54 | 40.72 | 51.13 |
| Irrelevant Doc | 29.76 | 41.67 | 33.64 | 44.87 | 42.09 | 52.72 | 53.38 | 63.01 | 39.72 | 50.57 | |
| \cdashline2-12 | IRM | 29.58 | 41.73 | 32.79 | 44.17 | 46.40 | 54.80 | 53.45 | 64.26 | 40.56 | 51.24 |
| (Worst Best) | 15.55% | 17.38% | 10.47% | 10.00% | 11.19% | 5.43% | 1.97% | 2.42% | 7.64% | 6.70% | |
| Model | Document Distribution | HotpotQA | NQ | WebQuestion | TriviaQA | AVERAGE | |||||
| EM | F1 | EM | F1 | EM | F1 | EM | F1 | EM | F1 | ||
| Llama-2-7b-chat-hf | Base Model | 3.30 | 12.34 | 1.21 | 10.61 | 0.00 | 13.08 | 4.32 | 20.27 | 2.21 | 14.08 |
| 1 Golden Doc | 30.67 | 42.78 | 36.50 | 47.77 | 39.93 | 52.11 | 50.25 | 63.28 | 39.34 | 51.49 | |
| 1 Random Doc | 30.94 | 43.11 | 38.16 | 49.78 | 42.45 | 53.97 | 52.72 | 65.52 | 41.07 | 53.10 | |
| 0 Random + 3 Golden | 31.79 | 44.03 | 36.68 | 47.90 | 43.02 | 53.43 | 56.55 | 64.97 | 42.01 | 52.58 | |
| 1 Random + 2 Golden | 32.82 | 44.77 | 36.70 | 48.21 | 43.38 | 54.34 | 56.93 | 65.67 | 42.46 | 53.25 | |
| 2 Random + 1 Golden | 33.32 | 45.45 | 37.07 | 48.67 | 44.10 | 54.82 | 57.56 | 65.90 | 43.01 | 53.71 | |
| 3 Random + 0 Golden | 34.74 | 46.79 | 37.35 | 49.34 | 45.18 | 55.70 | 57.77 | 66.40 | 43.76 | 54.56 | |
| Llama-3-8B-Instruct | Base Model | 23.31 | 32.60 | 30.04 | 41.59 | 26.98 | 43.25 | 58.80 | 66.45 | 34.78 | 45.97 |
| 1 Golden Doc | 35.52 | 48.31 | 41.35 | 53.13 | 48.92 | 58.41 | 58.26 | 66.99 | 46.01 | 56.71 | |
| 1 Random Doc | 35.98 | 49.05 | 43.37 | 55.43 | 53.24 | 62.55 | 60.62 | 68.64 | 48.30 | 58.92 | |
| 0 Random + 3 Golden | 35.96 | 49.01 | 40.88 | 52.91 | 50.25 | 59.13 | 54.95 | 66.48 | 45.51 | 56.88 | |
| 1 Random + 2 Golden | 36.22 | 49.07 | 41.22 | 53.13 | 50.41 | 59.97 | 55.27 | 66.77 | 45.78 | 57.24 | |
| 2 Random + 1 Golden | 36.77 | 49.59 | 41.75 | 53.48 | 51.49 | 61.02 | 55.39 | 66.74 | 46.35 | 57.71 | |
| 3 Random + 0 Golden | 37.33 | 50.30 | 42.45 | 54.32 | 52.05 | 61.16 | 56.20 | 67.83 | 47.01 | 58.40 | |
| Model | RAG Scenario | HotpotQA | NQ | ||
| EM | F1 | EM | F1 | ||
| Qwen2.5-0.5B-Instruct | RetRobust | 17.69 | 26.63 | 17.16 | 25.44 |
| Top-1 Doc | 18.28 | 27.38 | 18.00 | 26.52 | |
| Golden Doc | 19.11 | 28.04 | 19.32 | 27.49 | |
| Random Doc | 18.10 | 27.23 | 16.27 | 24.62 | |
| Qwen2.5-1.5B-Instruct | RetRobust | 23.35 | 34.13 | 25.01 | 35.35 |
| Top-1 Doc | 24.08 | 34.31 | 25.53 | 35.75 | |
| Golden Doc | 23.70 | 34.03 | 25.61 | 35.52 | |
| Random Doc | 23.50 | 33.68 | 24.63 | 34.89 | |
| Qwen2.5-3B-Instruct | RetRobust | 26.29 | 37.34 | 29.46 | 40.38 |
| Top-1 Doc | 26.17 | 37.33 | 29.86 | 40.67 | |
| Golden Doc | 26.17 | 37.16 | 30.08 | 40.41 | |
| Random Doc | 26.28 | 37.26 | 29.34 | 40.09 | |
| Mistral-7B-Instruct-v0.2 | RetRobust | 35.92 | 49.03 | 43.19 | 55.51 |
| Top-1 Doc | 35.80 | 49.08 | 44.35 | 56.29 | |
| Golden Doc | 34.67 | 47.46 | 41.52 | 53.41 | |
| Random Doc | 35.52 | 48.71 | 43.87 | 55.84 | |
| Qwen2.5-32B-Instruct | RetRobust | 33.96 | 46.28 | 35.67 | 48.77 |
| Top-1 Doc | 34.47 | 46.88 | 35.90 | 48.80 | |
| Golden Doc | 33.68 | 45.62 | 35.29 | 47.69 | |
| Random Doc | 33.81 | 46.31 | 36.09 | 49.03 | |
| Llama-2-70b-chat-hf | RetRobust | 36.22 | 49.58 | 41.49 | 54.73 |
| Top-1 Doc | 35.45 | 48.75 | 40.39 | 53.92 | |
| Golden Doc | 34.27 | 47.72 | 39.23 | 51.69 | |
| Random Doc | 34.90 | 48.31 | 40.39 | 53.92 | |
| Llama-3-70B-Instruct | RetRobust | 40.78 | 54.67 | 45.84 | 59.25 |
| Top-1 Doc | 40.61 | 55.37 | 46.05 | 59.61 | |
| Golden Doc | 40.65 | 54.15 | 44.80 | 57.85 | |
| Random Doc | 39.91 | 54.71 | 43.71 | 57.86 | |
| Qwen2.5-72B-Instruct | RetRobust | 37.06 | 49.96 | 39.99 | 52.70 |
| Top-1 Doc | 37.52 | 50.30 | 39.87 | 52.81 | |
| Golden Doc | 36.73 | 49.66 | 38.86 | 51.73 | |
| Random Doc | 36.75 | 50.05 | 39.95 | 52.86 | |
| Models | RAG Scenario | HotpotQA | NQ | WebQ | TriviaQA | ||||
| Correct | Wrong | Correct | Wrong | Correct | Wrong | Correct | Wrong | ||
| Llama2-7b-chat-hf | Base Model | 93.80 | 95.82 | 95.25 | 95.87 | 0.00 | 96.21 | 94.56 | 96.04 |
| Golden Doc | 96.33 | 86.80 | 96.28 | 87.78 | 97.11 | 89.42 | 89.69 | 79.29 | |
| Random Doc | 96.45 | 84.54 | 96.06 | 85.58 | 96.13 | 89.00 | 89.22 | 78.60 | |
| IRM | 95.78 | 83.33 | 95.77 | 85.09 | 97.06 | 91.67 | 92.96 | 80.47 | |
| Llama-3-8B-Instruct | Base Model | 97.53 | 91.30 | 97.59 | 91.30 | 97.90 | 89.22 | 98.15 | 90.08 |
| Golden Doc | 96.78 | 85.82 | 96.36 | 86.48 | 94.86 | 85.89 | 93.03 | 76.31 | |
| Random Doc | 96.46 | 83.63 | 96.15 | 84.50 | 94.71 | 84.83 | 96.08 | 81.97 | |
| IRM | 95.84 | 80.68 | 95.55 | 82.33 | 98.63 | 93.16 | 89.31 | 76.55 | |
| Qwen1.5-7B-Chat | Base Model | 98.00 | 93.66 | 98.50 | 94.03 | 97.64 | 92.34 | 98.00 | 92.80 |
| Golden Doc | 96.33 | 83.87 | 95.94 | 84.39 | 94.20 | 84.82 | 92.90 | 76.17 | |
| Random Doc | 95.55 | 80.39 | 95.13 | 80.39 | 93.68 | 82.59 | 95.15 | 83.18 | |
| IRM | 95.07 | 78.05 | 93.99 | 77.91 | 98.41 | 91.10 | 89.87 | 72.35 | |
| Qwen2.5-7B-Instruct | Base Model | 98.52 | 94.54 | 98.98 | 95.42 | 97.15 | 95.54 | 98.62 | 93.80 |
| Golden Doc | 96.25 | 83.91 | 96.00 | 84.83 | 95.33 | 87.23 | 96.24 | 82.33 | |
| Random Doc | 95.92 | 80.28 | 95.57 | 80.46 | 95.28 | 84.24 | 96.51 | 82.87 | |
| IRM | 96.04 | 80.20 | 95.31 | 80.68 | 97.75 | 91.73 | 93.78 | 78.70 | |
| Model | RAG Scenario | HotpotQA | NQ | WebQuestions | TriviaQA | ||||
| EM | F1 | EM | F1 | EM | F1 | EM | F1 | ||
| Llama-2-7b-chat-hf | Base Model | 3.30 | 12.34 | 1.21 | 10.61 | 0.00 | 13.08 | 4.32 | 20.27 |
| RALM | 26.21 | 36.42 | 27.90 | 38.41 | 30.22 | 46.22 | 55.36 | 63.44 | |
| RetRobust | 31.29 | 43.65 | 30.72 | 43.69 | 30.94 | 48.52 | 59.56 | 68.58 | |
| Top-1 Doc | 31.76 | 43.95 | 31.31 | 44.02 | 30.94 | 49.73 | 59.99 | 68.67 | |
| Golden Doc | 30.67 | 42.78 | 30.59 | 42.52 | 30.22 | 46.58 | 58.59 | 67.25 | |
| Random Doc | 30.94 | 43.11 | 31.08 | 43.92 | 30.58 | 48.58 | 60.42 | 69.16 | |
| Irrelevant Doc | 31.01 | 42.98 | 31.10 | 43.41 | 29.14 | 46.70 | 59.25 | 67.92 | |
| IRM | 34.38 | 47.11 | 30.79 | 43.06 | 31.29 | 49.51 | 59.57 | 68.26 | |
| Llama-3-8B-Instruct | Base Model | 23.31 | 32.60 | 30.04 | 41.59 | 26.98 | 43.25 | 58.80 | 66.45 |
| RALM | 27.64 | 38.10 | 30.34 | 41.25 | 30.22 | 44.94 | 58.72 | 66.90 | |
| RetRobust | 36.06 | 48.99 | 34.05 | 47.10 | 31.65 | 49.53 | 61.62 | 70.99 | |
| Top-1 Doc | 36.72 | 49.30 | 34.32 | 47.12 | 30.22 | 49.96 | 62.16 | 71.28 | |
| Golden Doc | 35.52 | 48.31 | 33.78 | 46.45 | 29.86 | 47.26 | 60.72 | 69.89 | |
| Random Doc | 35.98 | 49.05 | 34.13 | 47.30 | 28.70 | 47.94 | 61.94 | 71.16 | |
| Irrelevant Doc | 35.31 | 47.92 | 33.80 | 47.03 | 31.65 | 50.63 | 61.37 | 70.77 | |
| IRM | 35.19 | 48.08 | 34.29 | 47.15 | 30.94 | 49.09 | 61.68 | 70.80 | |
| Qwen1.5-7B-Chat | Base Model | 24.15 | 34.06 | 24.31 | 35.27 | 23.02 | 38.65 | 48.43 | 57.65 |
| RALM | 24.44 | 34.23 | 25.00 | 35.02 | 23.74 | 37.56 | 49.97 | 58.42 | |
| RetRobust | 29.05 | 40.99 | 25.84 | 37.67 | 27.34 | 43.27 | 52.97 | 61.93 | |
| Top-1 Doc | 29.68 | 41.57 | 25.21 | 37.12 | 25.18 | 42.39 | 52.27 | 61.90 | |
| Golden Doc | 28.66 | 40.55 | 25.43 | 36.84 | 24.46 | 41.78 | 51.26 | 60.34 | |
| Random Doc | 28.83 | 40.66 | 25.88 | 38.04 | 26.62 | 43.43 | 52.47 | 61.78 | |
| Irrelevant Doc | 28.12 | 39.87 | 24.67 | 36.46 | 25.54 | 42.16 | 51.45 | 60.55 | |
| IRM | 26.95 | 38.67 | 25.98 | 37.63 | 25.54 | 41.77 | 52.02 | 61.37 | |
| Qwen2.5-7B-Instruct | Base Model | 25.10 | 35.02 | 26.97 | 38.15 | 25.90 | 42.46 | 53.86 | 62.73 |
| RALM | 26.37 | 36.30 | 26.98 | 37.68 | 26.98 | 42.99 | 54.43 | 62.86 | |
| RetRobust | 30.47 | 42.26 | 28.58 | 41.25 | 28.78 | 45.61 | 58.52 | 67.21 | |
| Top-1 Doc | 30.24 | 42.61 | 28.85 | 41.41 | 28.78 | 46.31 | 58.74 | 67.34 | |
| Golden Doc | 30.28 | 41.84 | 28.93 | 41.10 | 28.78 | 46.68 | 57.64 | 66.39 | |
| Random Doc | 30.25 | 42.22 | 28.73 | 41.19 | 28.42 | 44.72 | 58.40 | 67.38 | |
| Irrelevant Doc | 29.76 | 41.67 | 28.40 | 41.00 | 27.70 | 43.90 | 58.40 | 67.38 | |
| IRM | 29.58 | 41.73 | 28.77 | 41.47 | 25.54 | 42.84 | 58.28 | 67.17 | |