AND \savesymboltheoremstyle \newdateformatmydate\twodigit\THEDAY \shortmonthname[\THEMONTH], \THEYEAR \restoresymboltheoremtheoremstyle
Revisiting some classical linearizations of the quadratic binary optimization problem
Abstract
In this paper, we present several new linearizations of a quadratic binary optimization problem (QBOP), primarily using the method of aggregations. Although aggregations were studied in the past in the context of solving system of Diophantine equations in non-negative variables, none of the approaches developed produced practical models, particularly due to the large size of associate multipliers. Exploiting the special structure of QBOP we show that selective aggregation of constraints provide valid linearizations with interesting properties. For our aggregations, multipliers can be any non-zero real numbers. Moreover, choosing the multipliers appropriately, we demonstrate that the resulting LP relaxations have value identical to the corresponding non-aggregated models. We also provide a review of existing explicit linearizations of QBOP and presents the first systematic study of such models. Theoretical and experimental comparisons of new and existing models are also provided.
1 Introduction
Let be an matrix and be an -vector. Then, the quadratic binary optimization problem (QBOP) with linear constraints is to
| Maximize | |||
| Subject to: |
where is a polyhedral set, and . Unless otherwise stated, we assume that the matrix is symmetric and its diagonal elements are zeros. Since our focus is primarily on the linearization problem associated with QBOP, for simplicity, we assume that is the unit cube in . i.e. . However, the theoretical results in this paper extend to any set that is polyhedral in nature. Consequently, most of the discussions in this paper will be on the quadratic unconstrained binary optimization problem (QUBO) with the understanding that the corresponding results extend directly to the more general case of QBOP. For a state-of-the-art discussion on QUBO, we refer to the book [44].
The terminology ‘linearization’ in the context of QBOP generally refers to writing a QBOP as an equivalent mixed integer linear program (MILP). There is another notion of ‘linearization’ associated with QBOP where conditions are sought on the existence of a row vector such that for all binary [29, 30, 45, 12, 6, 48]. The notion of linearization considered in this paper is the former.
A linearization, (i.e. an equivalent MILP formulation) of QBOP is said to be explicit if it contains a variable, say , corresponding to the product for each such that if and zero otherwise. There is another class of linearization studied for QBOP, called compact linearization that does not use the variables [3, 5, 9, 11, 20, 27, 28, 35]. Compact linearizations are investigated by many researchers, particularly in obtaining strong linear programming (LP) relaxation bounds [3, 5, 9, 28] that matches the roof duality bound [1]. The major advantage of a compact linearization is that it has relatively less number of variables and constraints, compared to explicit linearizations. However, many such models use numbers of large absolute values in defining bounds on variables or expressions and this could lead to numerical difficulties. In a companion paper, we present a through analysis of existing as well as new compact linearizations [47]. These formulations provide strong relaxations, but requires to use SDP solvers. Researchers also studied convex reformulations [9, 10] of QBOP making use of results from semidefinite programming.
Our main focus in this paper is to study explicit formulations in a systematic way both from theoretical as well as computational perspectives. Though traditional explicit linearizations have a large number of constraints and variables, some of them provide strong upper bounds when the integrality constraints are relaxed. For example, the Glover-Woolsey linearization [24] (also called the standard linearization) have an LP relaxation value that matches other lower bounds such as the roof duality bound [1]. Since explicit formulations use the variables, insights gained from the polyhedral structure of the Boolean quadric Polytope [41] and valid inequalities derived from the support graph of the matrix [26] can be readily used to strengthen the corresponding LP relaxations and to aid development of branch and cut algorithms.
We distinguish between two classes of explicit formulations. In one case, the variables defines the product precisely for all feasible solutions of the model. i.e. takes zero or one values only and precisely when . We call MILP formulations having this property as precise models. In another class of MILP models, the above definition of the variables is guaranteed only when is an optimal solution of the model. We call such MILP formulations the optimality restricted models. Optimality restricted models normally have lesser number of constraints and mostly run faster than precise models. When the model is solved to optimality, the optimal solution and the objective function value produced are indeed accurate under both precise and optimality restricted models. On the other hand, if optimality is not reached and a solver terminates the program due to, say time limit restrictions, the objective function value of the best solution produced, say , may not be equal to for an optimality restricted model. To get the precise objective function value of such a (heuristic) solution, one may need to recompute . After recomputing, the resulting objective function value is unpredictable and could be significantly worse or significantly better than the value reported by the solver. Later, we will illustrate this with an example. Thus, it is important to study both precise and optimality restricted models separately.
The MILP formulations are not simply a tool to compute an exact optimal solution. Considering the significant power of modern day MILP solvers such as Gurobi and Cplex, they are often used to obtain heuristic solutions by imposing time restrictions or could be used in developing sophisticated matheuristics [36]. For such purposes, precise models are more valuable. However, to simply compute an optimal solution, optimality restricted models are, in general, more useful. Because of this, after discussing each precise model, we also present a corresponding optimality restricted model, whenever applicable.
In this paper, we present the first systematic experimental and theoretical study of explicit linearizations of QUBO. Starting with a review of existing explicit linearizations of QUBO, we present different ways of generating new explicit linearizations and analyze the quality of them from an LP relaxation point of view. One class of our new explicit linearizations uses only general constraints which matches the number of general constraints in many of the compact formulations [3, 5, 9, 28] and also have a LP relaxation bound that matches the bound of the standard linearization. To the best of our knowledge, no such compact explicit linearizations are known before. We also present detailed and systematic experimental analysis using all of the explicit linearizations we obtained offering insights into the relative merits of these models.
One of the techniques we use in obtaining new linearizations is by making use of selective aggregation of constraints. Weighted aggregation that preserve the set of feasible solutions of a Diophantine system in non-negative variables have been investigated by many researchers [15, 59, 22, 32, 51, 40, 42, 37]. While theoretically interesting, such an approach never worked well in practice, particularly due to the large coefficients associated with the aggregations and weaker LP relaxation bounds that results in. We show that selective aggregation of constraints provides a valid MILP model for QUBO for any selection of weights in the aggregation. In particular, by choosing these weights carefully, we can achieve an LP relaxation bound that is the same as that of the non-aggregated model. Our work also have linkages with surrogate duality providing strong duality relationship, unlike weak duality generally seen in MILP [14, 18, 19, 21].
2 Basic Explicit MILP models
Let us now discuss four basic explicit linearizations of QUBO and their corresponding optimality restricted versions. Linearizing the product of binary variables is achieved by replacing it with a variable and introduce additional constraints to force to take 0 or 1 values only in such a way that if and only if . The process of replacing by a single variable as discussed above is called linearization of the product . The product can be linearized in many ways. Perhaps the oldest such linearization technique was discussed explicitly by Watters [55], which was implicit in other works as well [13, 16, 17, 25, 58]. To linearize the product , Watters [55] introduced the constraints (which is implicit in the work of Dantzig [13])
| (1) | ||||
| (2) | ||||
| (3) |
This leads to the following linear programming formulation of QUBO [13, 55].
| DW: Maximize | ||||
| Subject to: | (4) | |||
| (5) | ||||
| (6) | ||||
| (7) |
This formulation has at most general constraints and binary variables.
Using a disaggregation of constraints (2), Glover and Woolsey [23] proposed to linearize the product by introducing the constraints
| (8) | ||||
| (9) | ||||
| (10) | ||||
| (11) |
Note that is now a continuous variable and the number of constraints for each pair is increased by one. This leads to the following programming formulation of QUBO [23].
| GW: Maximize | ||||
| Subject to: | (12) | |||
| (13) | ||||
| (14) | ||||
| (15) | ||||
| (16) |
where . Since is symmetric, for . The formulation GW has general constraints, an increase compared to DW. GW also has binary variables and continuous variables. Note that the constraints (13) and (14) are the restatements of the constraints (9) and (10) when taken over all the pairs and . We use this representation to aid easy presentation of some of our forthcoming results. In the literature the constraints (9) and (10) are normally used instead of (13) and (14) when describing GW. GW is perhaps the most popular linearization studied in the literature for QUBO and is often called the standard linearization or Glover-Woolsey linearization.
A variation of GW, often attributed to the works of Fortet [16, 17] can be stated as follows.
| FT: Maximize | ||||
| Subject to: | (17) | |||
| (18) | ||||
| (19) | ||||
| (20) | ||||
| (21) |
The constraints (19) implies In fact, we can replace constraints (19) by
| (22) |
The formulation FT has general constraints, binary variables, and continuous variables. The number of constraints reduces to when constraints (19) is replaced by (22).
Let us now propose a new basic linearization of QUBO. Note that DW can be viewed as pairwise aggregation of the constraints (9) and (10) of GW along with additional binary restriction on the variables. Using this line of reasoning and applying pairwise aggregation of constraints (13) and (14) of GW, we get the linearization
| PK: Maximize | ||||
| Subject to: | (23) | |||
| (24) | ||||
| (25) | ||||
| (26) |
Theorem 1.
PK is a valid MILP formulation of QUBO.
Proof.
PK has at most general constraints, binary variables, and continuous variables. Unlike DW, the variables in PK are continuous and it is the most compact basic linearization of QUBO.
2.1 Optimality restricted variations of the basic models
In Section 1, we discussed the concept of optimality restricted variations of a linearization of QUBO, their merits and drawbacks, and why is it important and relevant to investigate them separately from exact models. Let us now discuss the optimality restricted variations derived from the four basic linearization models discussed in this section earlier. Let and . First note that for DW, the binary restriction of variables can be relaxed to for . This provides an optimality restricted variation of DW. To see why this works, note that when , , without requiring to be binary. Likewise, when , , without requiring to be binary. The binary restriction is relevant only when precisely one of or is 1. In this case constraint (5) becomes . The binary restriction then force to be zero. But, in this case, if then will take value at optimality regardless, is binary or not. In fact, we can simplify the model further. Note that the general linearization constraints (1) and (2) can be rewritten as
Thus, at the optimality, constraint (4) is not active if and hence can be removed. Similarly, constraint (5) can be removed if . Thus, an optimality restricted version of DW can be stated as
| ORDW: Maximize | ||||
| Subject to: | (28) | |||
| (29) | ||||
| (30) | ||||
| (31) | ||||
| (32) |
The formulation ORDW has general constraints and binary variables.
While the optimality restricted model ORDW guarantees an optimal solution, if the solver is terminated before reaching an optimal solution, the value from the resulting best solution found need not be equal to . Consequently, the reported objective function value could be erroneous and the correct QUBO objective function value needs to be recomputed using the available values of . Let us illustrate this with an example. Consider the instance EX1 of QUBO with
where . Suppose that we use ORDW to solve EX1 and terminate the solver at the solution . Note that this is a feasible solution to ORDW (but not feasible for DW) with objective function value 0. But the QUBO objective function value of this solution is , which is arbitrarily larger than the value solver produced for the model ORDW when terminated prematurely.
Thus, when MILP models in optimality restricted form are used, it is important to recompute the objective function value in order to use the model as a heuristic by choosing the best solution produced within a given time/space limit. For precise models like DW, such an issue does not arise.
Let us now look at an optimality restricted version of GW. Note that the linearization constraints in GW can be restated as
Thus, constraints (12) and (16) are redundant at optimality if and constraints (13) and (14) are redundant at optimality if . Removing these redundant constraints, GW can be restated in the optimality restricted form as
| ORGW: Maximize | ||||
| Subject to: | (33) | |||
| (34) | ||||
| (35) | ||||
| (36) | ||||
| (37) |
The formulation ORGW has at most general constraints. Precisely, the number of general constraints will be
The main linearization constraints of FT can be stated as
Thus, constraints (17) and (21) are redundant at optimality if and (18) and (19) are redundant at optimality if . Removing these redundant constraints, FT can be restated in a modified form as
| ORFT: Maximize | ||||
| Subject to: | (38) | |||
| (39) | ||||
| (40) | ||||
| (41) | ||||
| (42) |
The model ORFT has general constraints, binary variables, and continuous variables.
The linearization constraint (23) of PK can be written as
Thus, the constraints (23) and (26) are redundant at optimality for . For , if at least one of , from the optimality sense, , but if , then the other linearization constraint
will become and will be satisfied with equality by an optimal solution in this case. Thus, here upper bound restrictions on are not required. Since is symmetric, and hence they have the same sign. As a result, constraint (24) is redundant at optimality for . To avoid unboundedness, we need to add the constraint . Thus, the optimality restricted version of PK can be stated as
| ORPK: Maximize | ||||
| Subject to: | (43) | |||
| (44) | ||||
| (45) | ||||
| (46) |
The number of general constraints and continuous variables in ORPK is and respectively.
3 Linearization by Weighted Aggregation
Let us now discuss some general techniques to generate new explicit linearizations of QUBO from DW, GW, FT and PK using weighted aggregation of selected constraints and thereby reducing the total number of constraints in the resulting model. In general, for integer (binary) programs, weighted aggregation of constraints alter the problem characteristics and the resulting models only provide an upper bound. This is the principle used in surrogate constraints and related duality [14, 18, 19, 21]. Precise aggregations are also studied in the literature but are not suitable for practical applications. Interestingly, by selecting constraints to be aggregated carefully, we show that new precise formulations for QUBO can be obtained with interesting theoretical properties and have practical value.
An unweighted aggregation model derived from GW was presented by Glover and Woolsey [24] using constraints (13) and (14) with amendments provided by Goldman [25]. To the best of our knowledge, no other aggregation models (weighted or unweighted) are discussed in the literature for explicit linearizations of QUBO using general weights. The effect of these aggregations on the quality of the corresponding LP relaxations will be discussed later.
3.1 Weighted aggregation of type 1 linearization constraints
Recall that all of the four basic models have the constraints
and we call them type 1 linearization constraints. Let . Consider the system of linear inequalities
| (47) |
obtained by weighted aggregation of type 1 linearization constraints.
Let DW() be the mixed integer linear programs obtained from DW by replacing constraints set (4) by (47). When , both and are not defined. If by the symmetry of , . Thus, is defined if and only if is defined. Moreover, when both and are defined, if and only if .
Theorem 2.
DW() is a valid formulation of QUBO.
Proof.
For any pair with we have to show that . Suppose . Choose any . By constraint set (5) we have
Since and we have and . Now, suppose . Choose any . From the constraint set (47),
If for some , then . Since , and hence . But we already established that if then , a contradiction. If then there exists a such that which is impossible as established above. Thus for all . Thus, for all . Thus, for any if then . Since we have . Thus, if and following similar analysis we get . This completes the proof. ∎
Let PK() be the mixed integer linear programs obtained from PK by replacing constraints set (23) with (47) and by adding the upper bound constraints for
Theorem 3.
PK() is a valid formulation of QUBO.
Proof.
If for any , then by constraints (24) yielding for any . Now suppose . Then, from constraints (47)
If then . If , then which implies , a contradiction. Thus and this contradicts the upper bound restriction on . If then there exists a such that , a contradiction. Thus, for all . Thus, if then . If then . Using similar arguments with we get . Thus, if then and this concludes the proof. ∎
The upper bound of 1 on the variables is required for this formulation to be valid. Consider the instance EX2 of QUBO with
choose , all other for . If the constraints is not used, an optimal solution obtained by the formulation PK() is , , rest of the with objective function value 8. But the optimal objective function value of this problem is 6 with and as optimal solution.
Let GW() be the mixed integer linear program obtained from GW by replacing constraints set (12) by (47).
Theorem 4.
GW() is a valid formulation of QUBO.
Proof.
Finally, let FT() be the mixed integer linear programs obtained respectively from FT by replacing constraints set (17) by (47).
Theorem 5.
FT() is a valid formulation of QUBO.
Proof.
When for all , we have the unit-weight special cases of DW(),GW(), FT() and PK(). In this case, the aggregated constraint is
| (48) |
Note that the number of general constraints is in each of the models DW() and PK(), a reduction from for DW and PK. The number of general constraints in FT() and GW() is a reduction from constraints in FT and GW.
3.2 Weighted aggregation of type 2 linearization constraints
The collection of linearization constraints in our basic models that are not of type 1 are called type 2 linearization constraints. For DW and PK, there is only one class of type 2 linearization constraints. For GW and FT there are two classes of type 2 linearization constraints. In such cases, there are different types of aggregations possible.
Let us start with aggregation of type 2 linearization constraints (24) from PK.
For , consider the inequality
| (49) |
Let PK() be the MILP obtained from PK by replacing (24) with (49) and adding the constraints . The notation PK() indicates type 1 linearization constraints are not aggregated and type 2 linearization constraints are aggregated using parameter values represented by .
Theorem 6.
PK() is a valid MILP model for QUBO.
Proof.
For the special case of PK() where for all , the constraint (49) becomes
| (50) |
PK() have at most general constraints, a reduction from for PK.
Although the weighted aggregation of type 2 linearization constraints produced the valid MILP model PK() for QUBO, weighted aggregation of type 2 linearization constraints of DW need not produced a valid MILP model for QUBO. Let . Consider
| (51) |
Let DW() be MILP obtained from DW replacing constraints (5) by (51). Then, DW() is not a valid MILP model for QUBO. For example, consider the instance(EX3) of QUBO where
An optimal solution to the formulation DW() obtained from this instance is with objective function value 2 where . Note that, . The optimal objective optimal function value for this problem is 1.
Weighted aggregation of type 2 linearization constraints (18) in FT yields another MILP formulation of QUBO. Let . Now consider the inequality
| (52) |
Let FT() be the MILP obtained from FT by replacing the inequality (18) in FT with (52) and adding an upper bound of 1 on all variables.
Theorem 7.
FT() is a valid MILP formulation of QUBO.
Proof.
FT() have at most general constraints and upper-bound constraints. We can also use weighted aggregation of constraints (19) in FT to yield a valid MILP model for QUBO. Let . Now consider the inequality
| (53) |
Let FT() be the MILP obtained from FT by replacing constraints (19) with (53) and FT()be the MILP obtained by replacing constraints (18) by (52) and (19) by (53) along with the addition of .
Theorem 8.
FT() and FT() are valid MILP formulations of QUBO.
We skip the proof of this theorem as it is easy to construct.
FT() has general constraints and both FT() and FT() have general constraints. The corresponding unweighted versions of these formulations can be obtained by using .
Now, we will explore the weighted aggregation of the type 2 linearization constraints (13) and (14) of GW. Let and for all (note that since is assumed to be symmetric, ). Now, consider the inequality
| (54) |
Let GW() be the MILP obtained from GW by replacing (13) and (14) in GW by (54) and adding the upper bound constraints for all and .
Theorem 9.
GW() is a valid MILP model for QUBO.
Proof.
Unlike GW(), the aggregation of (53) and the following constraint
| (55) |
need not produce a valid MILP model corresponding to FT.
Note that PK() is the same as GW(). When for all and , GW() becomes the Glover-Woolsey aggregation discussed in [24] along with the amendments proposed by Goldman [25].
Let us now consider weighted aggregation of constraints (13) and (14) of GW separately. Consider the inequalities
| (56) | ||||
| (57) |
In GW, replace constraints (13) and (14) by (56) and (57) and add the upper bound restriction for all . Let GW() be the resulting model.
Theorem 10.
GW() is a valid MILP model for QUBO.
Proof.
When constraints (56) and (57) guarantees that . When constraints (56) and (57) are redundant. However, in this case, from constraints (12) and the upper bound restrictions on we have and . Thus, if we have . If and , using constraint (56) and (57) corresponding to , we have and the result follows. ∎
When for all , we have the corresponding unit weight case. Aggregating only (13) and replacing by (56) and leaving (14) unaltered is also a valid formulation for QUBO and we denote this by GW(). Likewise, aggregating only (14) as (57) while leaving (13) unaltered is another valid formulation and we denote this by GW(). For each of the above variations, we also have the corresponding unit-weight cases (i.e. and for all ). We are skipping the proofs for these two formulations. The number of general constraints for GW(), GW(), and GW()(GW() ) are respectively.
3.3 Simultaneous weighted aggregations
Simultaneously aggregating type 1 and type 2 constraints in our basic models also lead to valid MILP formulations of QUBO with significantly reduced number of constraints. This is however not applicable for DW since type 2 linearization constraints cannot be aggregated the way we discussed aggregations here. Let us first examine simultaneous aggregation in the context of GW. Let GW() be the MILP obtained by replacing constraints (12) with (47) and replacing constraints (13) and (14) with (54) and adding the upper bound restrictions . That is,
| GW(): Maximize | ||||
| Subject to: | (58) | |||
| (59) | ||||
| (60) | ||||
| (61) |
Theorem 11.
GW() is a valid MILP model for QUBO.
Proof.
GW() have general constraints, upper bound constraints, binary variables, and continuous variables. This is the most compact among the explicit formulations.
Other variations of GW() are also interesting. For example, we can replace (59) by (56) and (57) and let GW() be the resulting model which is valid for QUBO. The model GW() obtained by replacing (59) by (56) and (14) is yet another valid MILP for QUBO. Likewise, the model GW() obtained by replacing (59) by (57) and (13) is also a valid model for QUBO.
Let us now combine the two types of weighted aggregations in FT (i.e. inequalities (47) and (52)). The resulting MILP formulation is
| FT(): Maximize | ||||
| Subject to: | (62) | |||
| (63) | ||||
| (64) | ||||
| (65) | ||||
| (66) |
Theorem 12.
FT() is a valid MILP formulation of QUBO.
Proof.
FT() have at most general constraints and upper bound constraints.Using similar arguments, it can be shown that FT() is a valid formulation of QUBO as well. Let FT() be the MILP obtained from FT() by replacing (64) with (55). From the basic model FT, another possible aggregation can be obtained by using following constraint instead:
| (67) |
It may be noted that FT() is a valid formulation of QUBO if the constraint (64) in FT() is replaced by (55). But, using (67) instead does not give a valid formulation of QUBO. This can be established using example EX4. The number of general constraints in FT() is .
Finally, it is possible to generate a combined aggregation model from PK, PK(). However, such a model is a special case of GW() with , hence will be a valid formulation of QUBO.
4 Optimality restricted variations and aggregations
Let us now discuss the optimality restricted variations of the weighted aggregation based models discussed in section 3. This needs to be done with more care. In this case, we are loosing some of the advantage gained by optimality restricted variations discussed earlier while gaining some other advantages.
4.1 Weighted aggregation of type 1 constraints
Note that under the optimality restricted variations, the number of type 1 constraints are reduced. Let us consider weighted aggregation of these reduced type 1 linearization constraints. Let for . Now consider the inequality
| (68) |
obtained by the weighted aggregation of the type 1 linearization constraints in optimality restricted variations of the basic models. Unlike the precise basic models, for the optimality restricted variations of the basic models, if we replace the type 1 linearization constraints by (68), the resulting MILP need not be a valid model for QUBO. To see this, consider the MILP model ORDW and replace constraints (28) by (68). Let ORDW-A be the resulting MILP. Interestingly, ORDW-A is not a valid MILP model for QUBO. To see this, consider the instance of QUBO (EX6) with
where for . An optimal solution to the corresponding ORDW-A is with objective function value 7 but the optimal objective function value for this QUBO is 6. Here, . Also, and . However, we can still use (68) to replace constraints (28) provided we put back all remaining constraints from the corresponding basic model rather than the optimality restricted model. More precisely, consider the model ORDW()
| Maximize | ||||
| Subject to: | (69) | |||
| (70) | ||||
| (71) | ||||
| (72) |
Theorem 13.
ORDW() is a valid MILP formulation of QUBO.
Proof.
Let DW-R be the MILP obtained from DW by replacing constraints (4) by constraints (28). Based on our discussion on optimality restricted models, it can be verified that DW-R is a valid MILP model for QUBO. Clearly, every feasible solution of DW-R is a feasible solution of ORDW(). We now show that every feasible solution of ORDW() is a feasible solution of DW-R. For this, it is sufficient to show that every feasible solution of ORDW() satisfies
| (73) |
If then inequality (73) is clearly satisfied. Suppose . Then, from (69),
But then, as in the proof of Theorem 2, we can show that for all and hence (73) is satisfied and the proof follows. ∎
The difference between ORDW() and DW() is minor. For the former, there are less number of variables in the aggregated constraints and hence this part of the coefficient matrix could sometimes be sparse. Otherwise, aggregation did not achieve much.
It is also interesting to note that even if we replace constraints (28) in ORDW by the full weighted aggregation constraint (47), still we do not get a valid MILP formulation of QUBO. Details on this are omitted.
Similarly, let ORPK(), ORFT(), and ORGW() be the MILP obtained respectively from PK, FT, and GW by replacing the type 1 linearization constraints with
| (74) |
Theorem 14.
ORPK(), ORFT(), and ORGW() are valid optimality restricted MILP models for QUBO
Proof.
The proof is similar to that of theorem 13, where we create ORPK()-R1, ORFT()-R1 and ORGW()-R2, where instead of using the type 2 constraints and lower bound constraints from the respective basic model instead of optimality restricted model of the same. Further proceed with the same idea as theorem 13. ∎
We want to emphasize that, as in the case of ORDW(), the type 2 linearization constraints used in ORPK(), ORFT(), and ORGW() are those corresponding to their respective basic models rather than the optimality restricted versions of these basic models as using the latter will lead to invalid MILP. The only optimality restricted part used is inequality (74). To clarify this observation, let us consider EX4 once again, where for . The solution is , , rest of the with objective function value 35. But the optimal value of this problem is 34 with and .
4.2 Weighted aggregation of type 2 constraints
Recall that we cannot aggregate type 2 linearization constraints from DW to yield a valid MILP formulation for QUBO. This negative result carries over to ORDW as well. Let us now examine weighted aggregation of type 2 linearization constraints of ORPK. That is,
| ORPK(): Maximize | ||||
| Subject to: | (75) | |||
| (76) | ||||
| (77) | ||||
| (78) | ||||
| (79) |
Notice that in the model above the lower bound constraints are required in full and cannot be used corresponding to the optimality restricted model of PK. As seen in the example EX6, if
where for and the lower bounds are used as . The solution obtained from the corresponding formulation is , , rest of the with the optimal objective function value as 8. But the optimal value of this problem is 3 with solution and .
It may be noted that constraint is redundant for PK model. Since PK and ORPK are the valid models for QUBO. The model ORPK-R given below is also valid for QUBO
| ORPK-R: Maximize | ||||
| Subject to: | (80) | |||
| (81) | ||||
| (82) | ||||
| (83) | ||||
| (84) |
Theorem 15.
ORPK() is a valid optimality restricted MILP formulation of QUBO.
Proof.
Clearly, every feasible solution of ORPK-R is a feasible solution of ORPK(). Now, we will prove that every solution of ORPK() is also satisfies for ORPK-R. It is sufficient to show that the feasible solution of ORPK() satisfies (81). If , constraint (81) is clearly satisfied. On the other hand, if , then (76) becomes:
As , if , then . This satisfies (81). ∎
The number of general constraints for the model ORPK( is at most n+.
The optimality restricted version of GW() is denoted by ORGW() and it can be stated as
| Maximize | ||||
| Subject to: | (85) | |||
| (86) | ||||
| (87) | ||||
| (88) |
Theorem 16.
ORGW() is valid optimality restricted MILP formulation of QUBO.
Proof.
In ORGW, if we replace (37) by (88), we get a new formulation similar to the case of Theorem 15. It can be easily noticed that it is a valid formulation for QUBO. Let us name this as ORGW-R. Clearly, every feasible solution of ORGW-R is a feasible solution of ORGW(). Now, we need to show that every feasible solution of ORGW() is also a feasible for ORGW-R. It is sufficient to show that every feasible solution of ORGW() also satisfies constraints (34) and (35). If , then constraint (86) gives , which satisfies constraints (34) and (35). Also, if , these constraints are clearly satisfied.∎
| (89) | ||||
| (90) |
we also get optimality restricted models ORGW(), ORGW() and ORGW() corresponding to GW(), GW() and GW(). It can be shown that the models ORGW(), ORGW() and ORGW() are valid optimality restricted MILP models for QUBO using similar ideas as Theorem 16. The number of general constraints for the model ORGW() and ORGW() is at most and respectively. For ORGW() and ORGW(), the number of general constraints is .
The optimality restricted version of FT() is given by
| ORFT(): Maximize | ||||
| Subject to: | (91) | |||
| (92) | ||||
| (93) | ||||
| (94) | ||||
| (95) | ||||
| (96) |
Theorem 17.
ORFT() is a valid MILP model for QUBO.
Proof.
By adding, the constraints (96) to ORFT, we get another valid formulation of QUBO, say ORFT-R similar to the case of Theorem 15. Clearly, every feasible solution of ORFT-R is a feasible solution of ORFT(). To prove the other side, it is sufficient to show that every feasible solution of ORFT() satisfies constraints (39) and (40). If , using constraints (92), and from constraints (94) . This satisfies constraints (39) and (40). ∎
The number of general constraints for the model ORFT() is at most . We can get the optimality restricted aggregations in ORFT() and ORFT() corresponding to the models FT() and FT(). Their validity can be proved using the similar ideas as in Theorem 17. For ORFT() and ORFT(), the number of general constraints is .
4.3 Simultaneous weighted optimality restricted aggregations of type 1 and type 2 constraints
Let us now examine simultaneous aggregation of type 1 and type 2 linearization constraints in the context of optimality restricted models. Recall that when type 1 linearization constraints are aggregated (either full version or the optimality restricted version) we must use full type 2 linearization constraints. Thus, for the simultaneous aggregations, it is necessary that we use aggregation of full type 2 linearization constraints, along with full bound constraints on variables. Let us start with the optimality restricted version of simultaneous aggregation of PK. Let ORPK() be:
| ORPK(): Maximize | ||||
| Subject to: | (97) | |||
| (98) | ||||
| (99) | ||||
| (100) | ||||
| (101) |
Theorem 18.
ORPK() is a valid formulation of QUBO.
Proof.
Notice that after adding to ORPK(), we still get a valid formulation for QUBO. Let us call it ORPK()-R. We need to show that every feasible solution of ORPK() is a solution of ORPK()-R. For this, we prove that every feasible solution of ORPK() satisfies , . Clearly, if using constraints (98). The required constraint set is satisfied. On the other hand, if , then (98) combined with (101) assures that the required constraint is satisfied. Other side of the proof is pretty obvious hence the result follows. ∎
Similar to the above model, we have optimality restricted aggregation of GW() which is given as under:
| ORGW(): Maximize | ||||
| Subject to: | (102) | |||
| (103) | ||||
| (104) | ||||
| (105) |
Theorem 19.
ORGW() is a valid formulation for QUBO.
Proof.
Similar to the Theorem 18, add to ORGW() and form ORGW()-R Then, every feasible solution of ORGW() is a feasible solution for ORGW(). Further, we want to show that every feasible solution of ORGW() satisfies constraints (13) and (14). If using constraints (103) and (104). The required constraint set is satisfied. On the other hand, if , then (103) combined with (105) assures that the required constraint is satisfied. Hence, the model is valid.
Other variations of ORGW() are also interesting. As we did for the exact simultaneous models in section 3, we can replace (103) by (56) and (57) and let ORGW() be the resulting model which is valid for QUBO. The model GW() obtained by replacing (103) by (56) and (14) is yet another valid MILP for QUBO. Likewise, the model GW() obtained by replacing (103) by (57) and (13) is also a valid model for QUBO. ∎
Similar to GW and PK, simultaneous aggregated models can be constructed for FT as well. The formulation ORFT() is given as
| ORFT(): Maximize | ||||
| Subject to: | (106) | |||
| (107) | ||||
| (108) | ||||
| (109) | ||||
| (110) |
Theorem 20.
ORFT() is a valid formulation for QUBO.
The proof of this theorem is similar to that of Theorem 18 and hence, is omitted. ORFT() and ORFT() are two other valid optimality restricted models for QUBO, which are derived along the same lines as we have discussed other models. Details on these are omitted.
5 Linear Programming Relaxations
Linear programming relaxations (LP relaxations) of the MILP models we have discussed so far provide valid upper bounds on the optimal objective function value of QUBO. Such bounds can be effectively used in specially designed enumerative algorithmic paradigms such as branch-and-bound, branch and cut, etc. The linear programming relaxation of GW provides an upper bound for the optimal objective function value of QUBO that matches with the roof duality bound [1]. Many researchers have tried to obtain MILP formulations of QUBO with the corresponding LP relaxation bound matches with that of GW [3, 5, 9, 28] and almost all of these are compact type linearizations. No explicit linearizations, other than the standard linearization itself is known to have this property. We now show that FT and PK and shares this property along with the weighted aggregation models for appropriately chosen weights.
For any mathematical programming model , its optimal objective function value is denoted by . Also, if is an MILP, its LP relaxation is denoted by . Two MILP models and are said to be LP-equivalent if for all instances of and . is said to be stronger than (for maximization problems), if for all instances of and with strict inequality holds for at least one instance. and are said to be incomparable if there exist instances of and such that and also there exists instances P1 and P2 such that .
Let us now analyse the LP relaxations of our basic models and their optimality restricted counterparts.
5.1 LP relaxation of basic models
Our next lemma shows that the models DW, GW, FT, and PK are respectively LP-equivalent to their corresponding optimality restricted forms ORDW, ORGW, ORFT, and ORPK.
Lemma 21.
, , , and
Theorem 22.
Proof.
For any indices and , the constraint and of are given by
Thus and hence . Thus, every feasible solution of is feasible for establishing that
On the other hand, we will show that every optimal solution of must be also a feasible solution of Suppose not, then there exist an optimal solution, say with objective value , such that at least one constraint of is violated. As the given solution is a feasible solution of , assume that for some pair constraint (19) is violated:
Since we assume the matrix to be symmetric. Without loss of generality, assume that . Then, we can construct other solution for such that and
| (111) |
Clearly, for a small this is a feasible solution as
| (112) |
The optimal value of this solution will be which contradicts the fact that is an optimal solution of . Thus, every optimal solution of must be a feasible solution of . Hence . ∎
Punnen, Pandey, and Friesen [49] studied the effect of LP relaxations of MILP models of QUBO under different equivalent representations of the matrix . Recall that we assumed that is a symmetric matrix. Interestingly, when is not necessarily symmetric, FT could provide a stronger LP relaxation. To see this, consider the instance of QUBO (EX7) where
where . Then, has an optimal solution with objective function value 0, whereas is an optimal solution to with objective function value This shows that could be arbitrarily bad compared to . We now show that is stronger than .
Theorem 23.
. Further, could be arbitrarily bad compared to .
Proof.
Note that constraint (5) in DW is the sum of the constraints (9) and (10). Thus, every feasible solution of is also feasible to . Thus, . Now consider the example (EX8) where
Then, is an optimal solution to with objective function value whereas for , is an optimal solution with objective function value . ∎
Recall that any solution to can be represented by the ordered pair where is a vector and is an ordered list consisting of .
Lemma 24.
Let be an optimal solution to . If for some indices and then and .
Proof.
Let and . The the objective function of can be written as
Without loss of generality assume that . Thus, and . Since is symmetric, note that . If possible, assume that . If we can increase the value of to for arbitrarily small to yield a feasible solution to with objective function value larger than that of , a contradiction. Likewise, if we can decrease the value of to to yield a feasible solution with objective function value larger than that of , a contradiction. Thus, . The equality follows by symmetry. ∎
Lemma 25.
If is an optimal solution to and for some indices and then . Further, is also an optimal solution to where , and for all .
Proof.
The proof of Lemma 25 implicitly used the fact that is symmetric.
Theorem 26.
.
Proof.
The constraint (24) in is the sum of the constraints (13) and (14) in . Thus every feasible solution is also feasible to and hence . Now, let be an optimal solution to . If is a feasible solution to , the proof is over. So, suppose that is not a feasible solution to . Let such that the solution violates at least one of the constraints pair
| (113) | ||||
| (114) |
for all . Note that for any pair both of these constraints cannot be violated simultaneously. Thus, precisely one of these constraints is violated. By assumption, . Let and hence . By Lemma 25, we can construct an alternative optimal solution to such that constraints (113) and (114) are satisfied for all . Further, is also an optimal solution to with the property that the number of constraints violated in is reduced by one. Repeating this process, we can construct a feasible solution in which is an optimal solution to . Thus and the result follows. ∎
Theorem 26 need not be true if the underlying matrix is not symmetric. . This can be illustrated using the same example as the one constructed for a corresponding result for FT. Here gives an optimal solution , with objective function value . Thus, gives tighter bound than in this case.
5.2 LP relaxations of weighted aggregation based models
In the preceding section, we have shown that the LP relaxations of GW, FT, and PK yield the same objective function value. Weighted aggregation models are expected to produce weaker bounds. We now show that careful choices of the multipliers used in some of our weighted aggregation models can provide a LP relaxation bound matching the LP relaxation bound of GW. Before discussing these results, let us prove a property from linear programming duality which is related surrogate duality [14, 18, 19].
Consider the linear program
| P: Maximize | |||
| Subject to: |
where the matrix and vectors and are of appropriate dimensions. Let be a given non-negative row vector. Now consider the continuous knapsack problem obtained from as
| CKP(): Maximize | |||
| Subject to: |
Theorem 27.
If P has an optimal solution with an optimal dual solution , then CKP() also has an optimal solution. Further, the optimal objective function values of P and CKP() are the same.
Now, consider the linear program
| : Maximize | |||
| Subject to: |
where for . Let be a given non-negative row vectors in , for . Now consider the new linear program obtained from using weighted aggregation of constraints . Then can be written as
| : Maximize | |||
| Subject to: |
Theorem 28.
When is the part of an optimal dual solution of that is associated with the constraint block , the optimal objective function values of and are the same.
The proof of the theorem 27 and theorem 28 are skipped due to space constraints. The proofs can be found in the upcoming thesis[31]
Let us now analyze the quality of LP relaxations of the MILP models generated by weighted aggregations.
Theorem 29.
If the multipliers in the weighted aggregation models is used as corresponding optimal dual variables associated with those constraints then the resulting aggregated model will have the same objective function value as the corresponding original model. In particular,
-
(i)
If in the type 1 aggregation models is selected as the dual variable associated with the corresponding aggregated constraint in the corresponding models (DW,GW,FT, and PK), then , .
-
(ii)
If , and in the type 2 aggregation models are selected as the dual variable associated with the corresponding aggregated constraint in the corresponding models (GW,FT, and PK), .
-
(iii)
If , , and in the simultaneous aggregation models are selected as the dual variable associated with the corresponding aggregated constraint in the corresponding models (GW,FT, and PK), .
It may be noted that when the multipliers () are chosen as the corresponding dual variables, as discussed in Theorem 29, it could invalidate the corresponding MILP models since these multipliers could be zero for some and . Note that the validity of these MILP models is guaranteed only when the multipliers are strictly positive. Thus, if any of the multipliers are zero we need to correct it to an appropriately selected value or find an alternative optimal dual solution (if exists) which is not zero. The choice of needs to be made by taking into consideration numerical issues associated with the solver used and the tightness of the LP relaxation bound required. In practice, when the optimal dual variables used have value zero, it needs to be adjusted to appropriate positive values as discussed earlier, to maintain the validity of the models. Depending on the level of adjustments, the LP relaxation values may deteriorate a little bit.
6 Experimental analysis
In addition to the theoretical analysis of our MILP models for QUBO, we have also carried out extensive experimental analysis to assess the relative merits of these models. The objectives of the experiments were two fold. First we wanted we assess the ability of the models to solve the problems optimally, with a given time threshold. Another objective is to assess the heuristic value of the models. That is, given an upper threshold for running time, identify if any of the models consistently produced better solutions. We are not comparing the models with best known specially designed QUBO solvers as it will be an unfair comparison. However, we believe the insights gained from our experiments can be used to introduce further refinements to existing QUBO solvers or design new ones with improved capabilities.
All of our computational experiments were carried out on different PCs with same configurations. That is, with Windows 10 Enterprise 64-bit operating system with Intel(R) Core(TM) i7-3770 3.40GHz processor and 16 GB memory. Gurobi 9.5.1 was used as the MILP solver on Anaconda’s spyder IDE with Gurobipy interface. Parameter for ’Presolve’ and ’Cuts’ was set to 0 throughout these experiments. This is to eliminate bias coming from adding well-known cuts generated based on the Boolean quadric polytope [41]. We considered three classes of test instances. This include the well-known Beasley instances[56] and Billionet and Elloumi instances[56], in addition to instances which we generated which we call balanced data set. To limit the experimental runs, we did not test some simultaneous aggregations of FT, that are FT(), FT(), ORFT() and ORFT() since they have similar behaviour as GW models.
We used the notational convention MU() to represent unweighted aggregation of the weighted model M() where M represents the model and and represents weights/parameters used for the aggregation. For the experiments, on the weighted versions, the weights are taken as optimal dual variables for the respective constraints in the LP relaxation of the model. All of the optimal dual variables with zero value are replaced by 1. For unweighted versions, all the multipliers are taken as 1.
6.1 Balanced Data Set
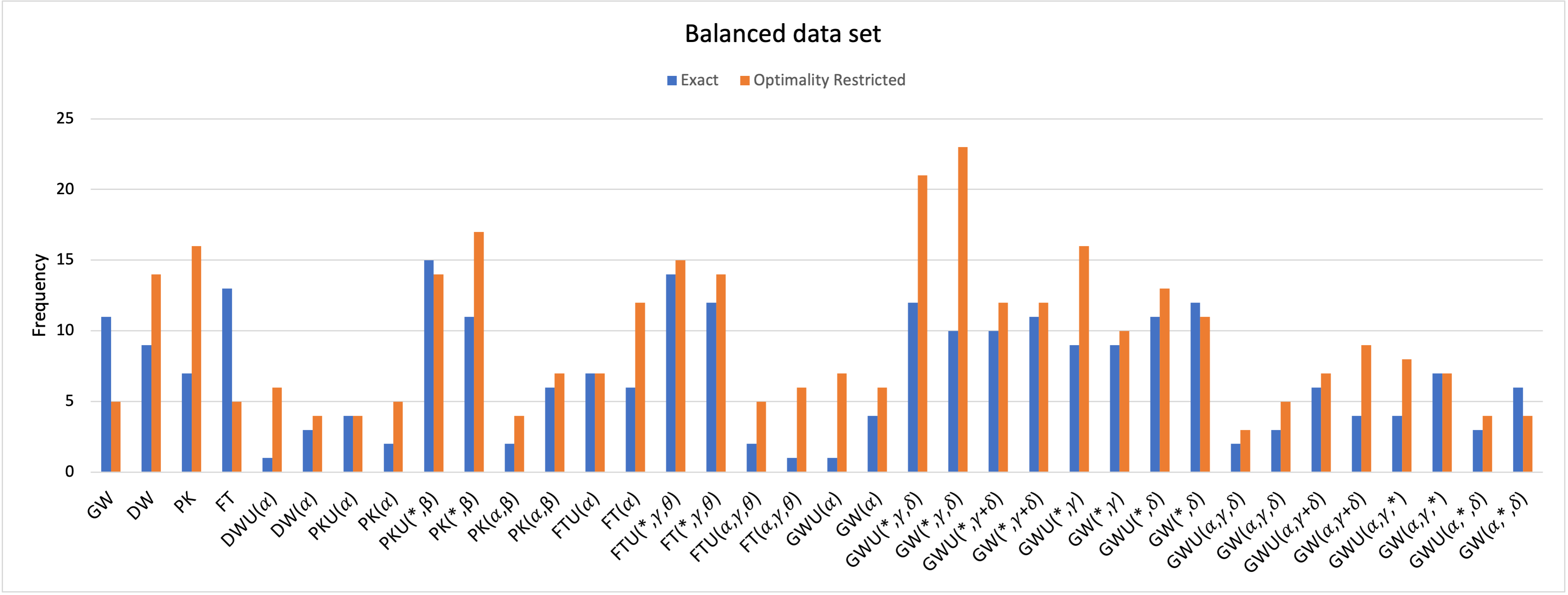
This data set is generated with the following characteristics: for all i, for all with symmetric and having diagonal elements zero. Ten different problem sizes are considered. After generating a pair , we solved the corresponding . If all variables turned out to be half-integral, the generated model is accepted into the data set; otherwise the model is discarded. For each problem size (i.e. ) five different instances are constructed. The balanced data set we generated will be made available for researchers for future experimental analysis. The time limit was set to 30 minutes for and 1 hour for all other instances in this set.
Figue 1 shows the experimental results corresponding to the Balanced Data Set for the models discussed in Section 2,3 and 4. For this data set, it is observed that for the smaller instances (50), most of the models reached optimality, however, for 60, for all the instances time limit was reached and the best objective function value is used for the comparison. It can be noticed that among the basic models discussed in section 2, the optimality restricted version of PK model was the best model.
Overall, the type two aggregations of PK, both unweighted and weighted, performed well here. In general, it can be noted that all the models where type 1 constraints are aggregated never worked better as compared to the aggregations based on Type 2 constraints. For the aggregations of GW, particularly, exact type 2 aggregations performed better than the others. Hansen and Meyer [28]) indicated that replacing constraints (13) and (14) in GW by
| (115) | ||||
| (116) |
yields a valid formulation for QUBO and stated it as the Glover-Woolsey aggregation. They showed that the LP relaxation of this model yields very weak upper bound and discarded it from their further experiments. We first observe that the model discussed in [28] as Glover-Woolsey aggregation is not precisely the Glover-Woolsey aggregation and that model need not produce an optimal solution for QUBO. For example consider the QUBO with and . An optimal solution to this problem by this formulation is with objective function value 2 where as is a better solution with optimal objective function value 1 as the former does not give an optimal solution to the original QUBO because . However, the correct Glover-Woolsey aggregation (with amendments from Goldman [25]) in fact performs computationally better, as can be observed from bar chart 1.
Overall, when we compare all models together, optimality restricted version of GW() turned out to be better formulation with weighted version having a frequency of 23 and unweighted version with frequency 21 for this data set. For the basic models, exact and optimality restricted models performed the same for this data set. While for the aggregations, the optimality restricted models performed better. For the exact models, unweighted aggregations were better but for the optimality restricted models, weighted aggregations showed better results. Overall, optimality restricted versions of the aggregated and basic models both outperformed other models for this data set. As mentioned earlier, the bar chart clearly shows most of the type 1 constraints based aggregations and some simultaneous aggregations did not perform well in this experiment, so we discarded PK(), GW(), GW(), GW(), GW(), FT() and their respective unweighted and optimality restricted versions from next experiments.
6.2 Beasley Data Set[56]
The data for this experiment is from OR Library[7]. More details of data set can be found in Angelika[56] and Beasley[8]. We selected instances, n=50,100, 250, 500 and all the coefficients are uniformly distributed integers in [-100,100]. The time limit was set to 30 minutes for n=50 and 1 hour for all other instances.
For n=50 and 100, most of the models produced an optimal solution before reaching the time limit and hence comparison is done based on the run times.
For n=250 and 500, optimality is not reached so we look for the models that give the tightest bounds. Hence, we categorize the comparison on basis of run time and best bounds.
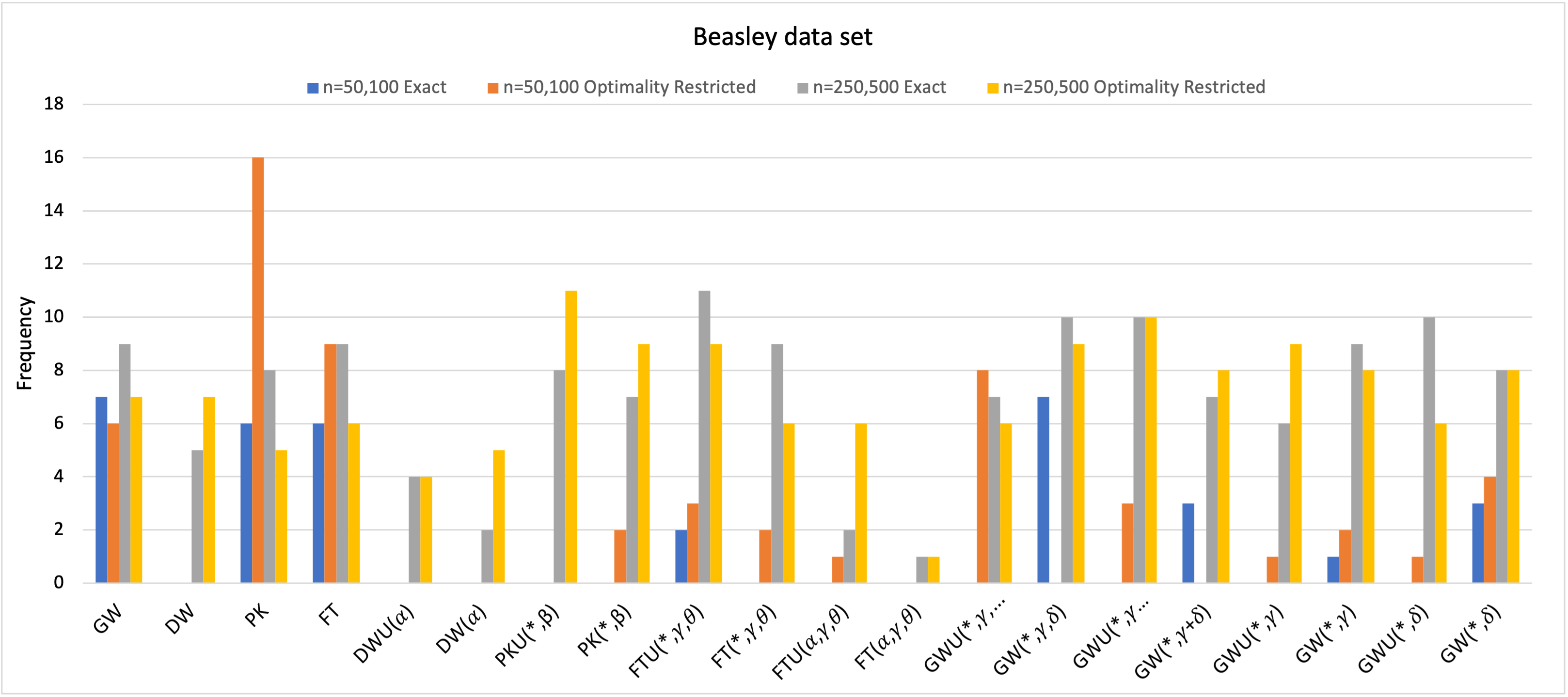
From the figure 2 for smaller instances(n=50,100), it is evident that PK model is the best most number of times overall but among
the aggregations optimality restricted version of GW() was the best. Further, it may be noted that
for this data set, optimality restricted models have better run times.
For n=250 and 500 ,unweighted version of the optimality restricted version of PK() and exact version of FT() gave the
best bound often.
Overall, ORPK and GW() were the best with frequency 21 and 17 respectively out of 40. For the basic models, for n=50,100 optimality restricted models performed better whereas for n=250,500 the exact models were better. For the aggregations, for n=50,100 optimality restricted models performed better while for n=250,500 exact and optimality restricted models were the same. Also for the aggregations, overall unweighted models were better but for exact models for n=50,100 weighted models were better.
6.3 Billionet and Elloumi instances[56]
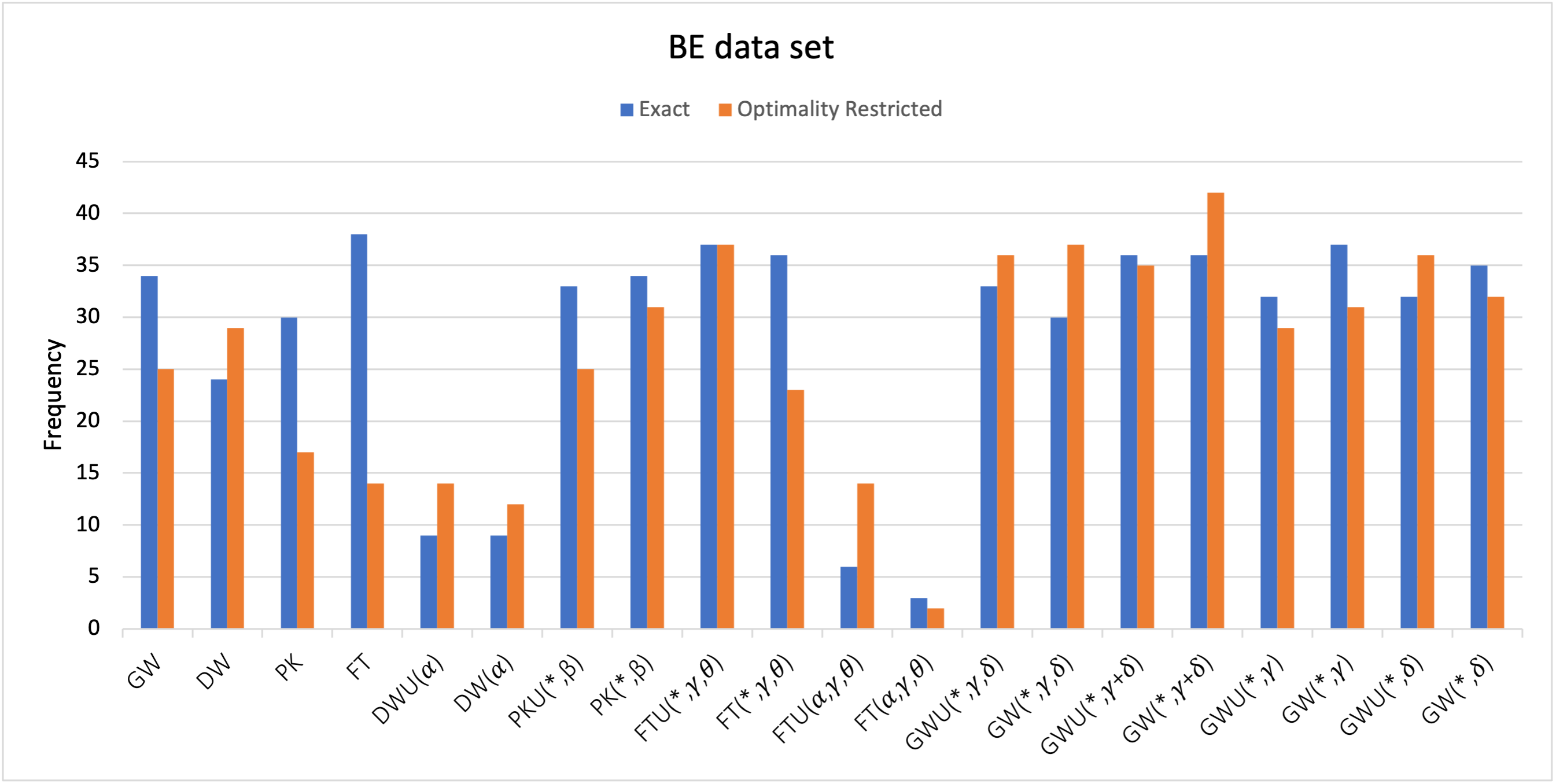
The third data set we used is Billionet and Elloumi instances [56, 43]. Overall there are 80 instances in this data set with different and density. We have selected the problems with n=100,120,150,200,250 where diagonal coefficients are from [-100,100] while off-diagonal coefficients are from [-50,50]. The density of instances is taken as 1 for n=100, 0.3 and 0.8 for n=120,150,200 and 0.1 for n=250. The time limit was set 1 hour for all of the instances. For this data set, all the instances reached the time limit. So the comparison is done with respect to value of heuristic solutions.
Overall, from figure 3 optimality restricted version of GW() is the best with 42 frequency followed by basic model FT with 38 frequency. It is worth noting that all the aggregations of GW and PK gave good solutions and results are either better than or at least comparable to GW. Also, unweighted formulations performed better than weighted formulations for this data set. For the basic models, exact models were better. For the weighted aggregations, exact and optimality restricted models behaved the same but for unweighted aggregations optimality restricted models were better. Also for the aggregations, in general unweighted models were better for this data set.
On considering the analysis for all the data sets it is evident that type 2 aggregations of GW and PK performed better overall.
Conclusion
In this paper, we have presented various MILP formulations for QBOP. This includes some basic models and models obtained by the selective aggregation of constraints of the basic models. Unlike the aggregation based models studied in the literature for general integer programs, our models provide viable alternatives to practical problem solving. Theoretical and experimental analysis on the models has been carried out to assess the relative strength of the model. We also developed new benchmark instances which will be made available through Github for future experimental work. The applicability of the basic strategies we used in this paper goes beyond QUBO to other quadratic models ( e.g. [38, 57]) as well as models that are not explicitly quadratic. More details about this will be reported in a sequel. Our computational results disclose that aggregation based models, particularly the type 2 aggregation based models, performed well along with the advantage of having same LP relaxation bound as their corresponding Basic models when choosing the multipliers as optimal dual variables. The aggregation methods suggested in this paper can be used in other integer programming models. For example, the stable set problem, vertex cover problem, facility location, among others. For details on such applications, we refer to the forthcoming Ph.D. thesis [31] and our followup papers.
Acknowledgments
This work was supported by an NSERC discovery grant awarded to Abraham P. Punnen. A preliminary reduced version of this paper was released as a technical report of the mathematics department, Simon Fraser University.
References
- [1] W. P. Adams and P. M. Dearing, On the equivalance between roof duality and Lagrangian duality for unconstrained 0-1 quadratic programming problems, Discrete Applied Matheamtics 48 (1994) 1–20.
- [2] W.P. Adams, R.J. Forrester, A simple recipe for concise mixed 0-1 linearizations, Operations Research Letters 33 (2005) 55–61.
- [3] W.P. Adams, R. Forrester and F. Glover, Comparisons and enhancement strategies for linearizing mixed 0-1 quadratic programs, Discrete Optimization 1 (2004) 99–120.
- [4] W. P. Adams and S. M. Henry, Base-2 Expansions for Linearizing Products of Functions of Discrete Variables, Operations Research 60 (2012) 1477–1490.
- [5] W.P. Adams and H.D. Sherali, A tight linearization and an algorithm for 0–1 quadratic programming problems, Management Science 32 (1986) 1274–1290.
- [6] W. P. Adams and L Waddell. Linear programming insights into solvable cases of the quadratic assignment problem Discrete Optimization 14(2014), 46–60.
- [7] John E. Beasley, Or-library. http://people.brunel.ac.uk/ mastjjb/jeb/info. html, 1990.
- [8] J. E. Beasley, Heuristic algorithms for the unconstrained binary quadratic programming problem. Technical report, The Management School, Imperial College, London SW7 2AZ, England, 1998
- [9] A. Billionnet, S. Elloumi, and M-C. Plateau, Quadratic 0-1 programming: Tightening linear or quadratic convex reformulation by use of relaxations, RAIRO Operations Research 42 (2008) 103–121.
- [10] A. Billionnet, S. Elloumi, M.-C. Plateau, Improving the performance of standard solvers for quadratic 0–1 programs by a tight convex reformulation: the QCR method, Discrete Applied Mathematics 157 (2009) 1185–1197.
- [11] W. Chaovalitwongse, P. Pardalos, O.A. Prokopyev, A new linearization technique for multi-quadratic 0–1 programming problems, Operations Research Letters 32 (2004) 517–522
- [12] E. Çela, V.G. Deineko and G.J. Woeginger, Linearizable special cases of the QAP Journal of Combinatorial optimization 31 (2016) 1269–1279.
- [13] G.B. Dantzig, On the significance of solving linear programming problems with some integer variables, Econometrica 28 (1960) 30–44.
- [14] M. E. Dyer, Calculating surrogate constraints, Mathematical Programming 19 (1980) 255–278.
- [15] A. A. Elimam and S. E. Elmaghary, On the reduction method for integer linear programs, Discrete Applied Mathematics 12 (1982) 241–260.
- [16] R. Fortet, Applications de l’algèbre de boole en recherche opérationelle, Revue Francaise Recherche Opérationelle 4 (1959) 5–36.
- [17] R. Fortet, L’algèbre de boole et ses applications en recherche opérationnelle, Cahiers du Centre d’Etudes de Recherche Opérationnelle 4 (1960) 17–26.
- [18] F. Glover, Surrogate Constraints, Operations Research 16 (1968) 741–749.
- [19] F. Glover, Surrogate Constraint Duality in Mathematical Programming, Operations Research 23 (1975) 434–451.
- [20] F. Glover, Improved linear integer programming formulations of nonlinear integer problems, Management Science 22 (1975) 455–460.
- [21] F. Glover, Tutorial on surrogate constraints approaches for optimization graphs, Research report, Journal of Heuristics 9 (2003) 175–227.
- [22] F. Glover and D. A. Babayev, New results for aggregating integer-valued equations, Annals of Operations Research 58 (1995) 227–242.
- [23] F. Glover and E. Woolsey, Converting the 0–1 polynomial programming problem to a 0–1 linear program, Operations Research 22 (1974) 180–182.
- [24] F. Glover and E. Woolsey, Further reduction of zero-one polynomial programming problems to zero-one linear programming problems, Operations Research 21 (1973) 141–161.
- [25] A. J. Goldman, Linearization in 0-1 Variables: A Clarification, Operations Research 31 (1983) 946–947.
- [26] S. Gueye and P. Michelon, A linearization framework for unconstrained quadratic (0-1) problems, Discrete Applied Mathematics 157 (2009) 1255–1266.
- [27] S. Gueye and P. Michelon, “Miniaturized” Linearizations for Quadratic 0/1 Problems, Annals of Operations Research 140 (2005) 235–261.
- [28] P. Hansen and C. Meyer, Improved compact linearizations for the unconstrained quadratic 0–1 minimization problem, Discrete Applied Mathematics 157 (2009) 1267–1290.
- [29] H. Hu and R. Sotirov, The linearization problem of a binary quadratic problem and its applications, Annals of Operations Research 307 (2021) 229–249.
- [30] S. N. Kabadi and A. P. Punnen, An algorithm for the QAP linearization problem, Mathematics of Operations Research 36 (2011) 754-761.
- [31] N. Kaur, Aggregation properties of 0-1 integer programming problems and connections with binary quadratic programs, Forthcoming PhD. thesis,Simon Fraser University 2024
- [32] K. E. Kendall and S. Zionts, Solving integer programming problems by aggregating constraints, Operations Research 25 (1977) 346–351.
- [33] G. Kochenberger, J-K. Hao, F. Glover, M. Lewis, Z. Lu, H. Wang and Y. Wang, The Unconstrained Binary Quadratic Programming Problem: A Survey, Journal of Combinatorial Optimization 28 (2014) 58–81.
- [34] A. N. Letchford, The Boolean quadric polytope, in The Quadratic Unconstrained Binary Optimization Problem: Theory, Algorithms, and Applications, A. P. Punnen (ed.), Springer, Switzerland, 2022.
- [35] L Liberti, Compact linearization for binary quadratic problems, 4OR 5 (3) (2007) 231–245.
- [36] V. Maniezzo, M. A. Boschetti, and T. Stützle, Matheuristics: Algorithms and Implementations, Springer 2021.
- [37] G. B. Mathews, On the partition of numbers, Proceedings of the London Mathematical Society 28 (1897) 486–490.
- [38] F. de Meijer and R. Sotirov, SDP-Based Bounds for the Quadratic Cycle Cover Problem via Cutting-Plane Augmented Lagrangian Methods and Reinforcement Learning, INFORMS Journal on Computing 33 (2021) 262–1276.
- [39] K. G. Murty, Linear Programming, Whiley, 1983.
- [40] D. C. Onyekwelu, Computational viability of a constraint aggregation scheme for integer linear programming problems, Operations Research 31 (1983) 795–801.
- [41] M. Padberg, The boolean quadric polytope: Some characteristics, facets and relatives, Mathematical Programming 45 (1989) 134–172.
- [42] M. W. Padberg, Equivalent knapsack-type formulations of bounded integer linear programs: An alternative approach, Naval Research Logistics Quarterly 19 (1973) 699–708.
- [43] P. M. Pardalos and G. P. Rodgers, Computational aspects of a branch and bound algorithm for quadratic zero-one programming. Computing 45 (1990) 131–144.
- [44] A. P. Punnen (ed.), The Quadratic Unconstrained Binary Optimization Problem: Theory, Algorithms, and Applications, Springer, Switzerland, 2022.
- [45] A. P. Punnen, and S. N. Kabadi, , A linear time algorithm for the Koopmans–Beckmann QAP linearization and related problems, Discrete Optimization 10 (2013) 200–209.
- [46] A. P. Punnen and N. Kaur, Revisiting some classical explicit linearizations for the quadratic binary optimization problem, Research Report, Department of Mathematics, Simon Fraser University, 2022.
- [47] A. P. Punnen and N. Kaur, Revisiting compact linearizations of the quadratic binary optimization problem, Research Report, Department of Mathematics, Simon Fraser University, 2022.
- [48] A. P. Punnen, B. D Woods and S. N. Kabadi, A characterization of linearizable instances of the quadratic traveling salesman problem.(2017), arXiv:1708.07217
- [49] A. P. Punnen, P. Pandey, and M. Friesen, Representations of quadratic combinatorial optimization problems: A case study using the quadratic set covering problem, Computers & Operations Research 112 (2019) 104769.
- [50] A. P. Punnen and R. Sotirov, Mathematical programming models and exact algorithms, in The Quadratic Unconstrained Binary Optimization Problem: Theory, Algorithms, and Applications, A. P. Punnen (ed.), Springer, Switzerland, 2022.
- [51] I. G. Rosenberg, Aggregation of equations in integer programming, Discrete Mathematics 10 (1974) 325–341.
- [52] H.D. Sherali and W.P. Adams, A Reformulation-Linearization Technique for Solving Discrete and Continuous Nonconvex Problems. Kluwer Academic Publ., Norwell, MA (1999)
- [53] H. Sherali, W. Adams, A hierarchy of relaxations between the continuous and convexhull representations for zero-one programming problems, SIAM Journal of Discrete Mathematics 3 (1990) 411–430.
- [54] H. Sherali, W. Adams, A hierarchy of relaxations and convex hull characterizations for mized-integer zero-one programming problems, Discrete Applied Mathematics 52 (1994) 83–106.
- [55] L. J. Watters, Reduction of integer polynomial programming problems to zero-one linear programming problems, Operations Research 15 (1967)
- [56] A. Wiegele, Biq Mac library – a collection of Max-Cut and quadratic 0-1 programming instances of medium size, (2007)
- [57] Q. Wu, Y. Wang, and F. Glover, Advanced Tabu Search Algorithms for Bipartite Boolean Quadratic Programs Guided by Strategic Oscillation and Path Relinking, INFORMS Journal on Computing 32 (2019) 74–89.
- [58] W. I. Zangwill, Media selection by decision programming, Journal of Advertising Research 5 (1965) 30–36.
- [59] N. Zhu and K. Broughan, On aggregating two linear Diophantine equatios, Discrete Applied Mathematics 82 (1998) 231–246.