Reward Shaping for User Satisfaction in a REINFORCE Recommender
Abstract
How might we design Reinforcement Learning (RL)-based recommenders that encourage aligning user trajectories with the underlying user satisfaction? Three research questions are key: (1) measuring user satisfaction, (2) combatting sparsity of satisfaction signals, and (3) adapting the training of the recommender agent to maximize satisfaction. For measurement, it has been found that surveys explicitly asking users to rate their experience with consumed items can provide valuable orthogonal information to the engagement/interaction data, acting as a proxy to the underlying user satisfaction. For sparsity, i.e, only being able to observe how satisfied users are with a tiny fraction of user-item interactions, imputation models can be useful in predicting satisfaction level for all items users have consumed. For learning satisfying recommender policies, we postulate that reward shaping in RL recommender agents is powerful for driving satisfying user experiences. Putting everything together, we propose to jointly learn a policy network and a satisfaction imputation network: The role of the imputation network is to learn which actions are satisfying to the user; while the policy network, built on top of REINFORCE, decides which items to recommend, with the reward utilizing the imputed satisfaction. We use both offline analysis and live experiments in an industrial large-scale recommendation platform to demonstrate the promise of our approach for satisfying user experiences.
1 Introduction
Recommender systems at heart aim at creating a good user experience by surfacing users with the right content at the right time and under the right context. It is thus critical for the system to identify what defines the user experience, more specifically the underlying user utilities of the platform. Most recent advances in recommender systems have relied on implicit user feedback, such as clicks or dwell time, as proxies to capture user utilities (Covington et al., 2016; Yi et al., 2014). Although this data measures what users do, it can fail to capture what users say they want — which are potentially very different (Lalmas, 2019). As a result, recommender models learned solely based on user engagement data can be misaligned with the true user utilities.
Given a specified objective, or else reward function, which captures the long-term user utility, recommender systems can be formulated as Reinforcement Learning (RL) agents deciding on actions to take (i.e., contents to show to users) given certain user states (i.e., latent representation at a specific time/context), with the goal of maximizing said cumulative reward (Chen et al., 2019; Liu et al., 2018; Ie et al., 2019; Zhao et al., 2018). There are several challenges especially exacerbated in industrial recommendation settings which makes the application of RL for recommendation rather unique compared to other application areas like games (Mnih et al., 2015; Silver et al., 2018) and robotics (Gu et al., 2017). The action space is extremely large and ever-changing; user preferences change over time; and data are extremely sparse for the enormous action and state space. Only recently there have been major advances addressing these challenges and showcasing RL approaches for recommendation (Chen et al., 2019; Liu et al., 2018).
Besides addressing these challenges, the key in building recommender agents lies in defining the reward function guiding the learning of the agent policy. Although we do get to observe some proxy signals indicating when a recommendation, or a series of recommendations was successful (e.g., the user clicked on the recommended content, they shared it with their social network etc.), there is a disconnect between the implicit feedback we observe, and what the user really wants. The proximity between the proxy signals we include in the agent’s reward function and the true user utility, will largely determine the extent to which the RL recommender can optimize for what users want.
However, despite the importance of the reward function for building recommendation agents, there has been relatively little work on reward shaping for RL recommenders. Most works treat the reward function as a black-box, which is given, and often assume that dense engagement signals are indicative of how much users value their experience. This assumption has been recently challenged in non-RL settings, underlying that post-engagement signals and/or satisfaction survey responses together with implicit behavioral signals give a clearer picture of user utilities (Guo & Agichtein, 2012; Lalmas, 2019; Wen et al., 2019).
In this paper, we put the reward front and center, and highlight it as a key tool for optimizing for what users actually want. Satisfaction data as collected by user responses to satisfaction surveys provide an important view as to how the user felt about the recommendation, as opposed to how they behaved while interacting with it. These surveys are shown uniformly to all users, and ask users to rate on a scale how satisfying they found a sampled item from their recent engagement history. In our systems, such survey data can offer more representativeness compared to post-engagement signals, as most users tend to not engage in post-click actions such as likes, dismissals. Furthermore, optimizing for satisfaction as measured by surveys can substantially move post-engagement related metrics as well. Based on the above, both behavioral signals, and satisfaction signals should be incorporated into the reward.
However, before we can utilize satisfaction signals into the reward, we need to highlight a major challenge inherently associated with them — sparsity. The volume of satisfaction data is orders of magnitude smaller compared with engagement data volume; in our case study, roughly one out of thousands of engagement signals will come with a satisfaction response. This is due to a number of reasons. First, it is disruptive to ask users about every item they recently consumed. Second, response rate can be very low in an environment where primary user intention is to consume content rather than providing feedback. As a result, we only have access to a small amount of survey responses covering an extremely small fraction of the user-item interaction pairs. Given this extreme sparsity, simply supplementing the existing reward signals that focus on engagement with the sparse satisfaction signals is not going to be effective in shifting towards optimizing for user satisfaction. Instead, personalized satisfaction models are required to impute for each user how they would rate their satisfaction level with each consumed item, had they responded to a survey.
Here, we propose augmenting a classic policy network trained with REINFORCE with a satisfaction imputation network to predict user satisfaction and include the prediction into the reward for the policy network, while training both networks concurrently in a multi-task learning setup. Together we offer the following contributions:
-
•
Reward Shaping as a tool to align with user utilities: We highlight reward shaping as a tool to guide RL-based recommender agents in selecting satisfying actions for the users (Sections 4.2, 4.3, 6), which has been largely overlooked in advances on RL recommenders. In the process, we draw attention to common challenges associated with defining, measuring, and modeling user satisfaction.
-
•
Satisfaction Imputation networks at scale: We offer satisfaction imputation networks to combat sparsity of available utility signals capturing satisfaction, and demonstrate their usage to a top- REINFORCE recommender with an extremely large state and action space (Section 4.4). We include offline analysis providing insights on design choices important when building a good satisfaction imputation network (Section 5).
-
•
Benefits in Live Experiments: We provide evidence from A/B experiments in a large-scale recommendation platform with a two-stage nomination-ranking recommendation setup, that when we replace a REINFORCE nominator with dense engagement-based reward and without a satisfaction imputation network with our proposed architecture (Figure 2), the number of satisfying nominations increases, while nominations with low satisfaction score decrease. This leads to a statistically significant improvement in satisfying user experiences, and decrease in unsatisfying experiences (Section 6).
2 Related Work
Here, we give an overview of the most closely related works.
Reinforcement Learning (RL). Problems in which an agent learns to interact with the environment, with the interactions having long-term consequences, are a natural fit to be framed as Reinforcement Learning ones (Sutton & Barto, 2018). Classical approaches to RL problems include value-based approaches such as Q-learning (Mnih et al., 2013), and policy-based ones such as policy gradient (Williams, 1992). Deep RL combines the promise of deep neural networks to help RL achieve ground-breaking success in games and robotics applications (Mnih et al., 2015, 2016; Silver et al., 2018; Gu et al., 2017). We build our work on top of a policy-based approach, namely REINFORCE (Williams, 1992), following its prior success in recommendation settings (Chen et al., 2019). The imputation network we introduce has deep connections with value learning approaches (Mnih et al., 2013), where a state-action value network is learned. The estimations of this network are utilized as part of our policy’s reward; as a result, we still need the off-policy correction component (Chen et al., 2019). An alternative approach we leave for future work is employing Actor-Critic or its variants (Mnih et al., 2016; Sutton et al., 2000; Schulman et al., 2015).
Reinforcement Learning in Recommendation. Although there have been many successes in RL for applications like games (Mnih et al., 2015; Silver et al., 2018) and robotics (Gu et al., 2017), only recently some successes of RL for recommendation have been demonstrated (Dulac-Arnold et al., 2015). The main work we build on top of is a policy-gradient-based approach correcting for off-policy skew with importance weighting (Chen et al., 2019).This work demonstrated the value of REINFORCE and top- off-policy correction in a large-scale industrial recommendation platform with an extremely large action space. Other recent works have demonstrated the value of deep RL approaches for recommendation, such as Actor-Critic (Liu et al., 2018), Deep Q-learning (Zheng et al., 2018), and hierarchical RL (Zhang et al., 2019). Also, novel RL approaches have been proposed for the more complicated problem of slate recommendation (Ie et al., 2019), as well as for page-wise recommendation (Zhao et al., 2018). Despite the recent promise of RL for recommendation, the majority of works do not draw attention to the important aspect of reward shaping, which is key for aligning system objectives with underlying user utilities; this is the focus of our paper.
Reward Shaping. The importance of reward shaping, i.e., shaping the original sparse, delayed reward signals as in-time credit assignment for successful RL algorithms has been emphasized early on (Ng et al., 1999; Mataric, 1994; Dorigo & Colombetti, 1994). This is a general term encompassing the incorporation of domain knowledge into RL to guide the policy learning. Carefully designing the reward function is critically important as: (i) a misspecified reward leads to sub-optimal policy; (ii) an under-specified reward leads to unexpected behavior (Hadfield-Menell et al., 2017). While RL for robotics and games has relied on hand-crafted reward or imitation learning (Schaal, 1999) to effectively guide the agent to success, the perils of a misspecified reward function in the design of recommender RL agents have not received a lot of attention. Motivated by the need to bridge the RL for recommendation line of work with the recent discussions on measuring and modeling user satisfaction to properly capture user experience (Mehrotra et al., 2019; Lalmas, 2019; Mehrotra et al., 2018; Garcia-Gathright et al., 2018), we provide a reward shaping approach for imputing user satisfaction into the reward of an RL recommender, along with using the ground truth engagement proxy signals.
3 Background
We start by introducing useful background on RL for Recommendation, and notations.
3.1 Recommendation as an RL problem
The recommender system’s goal is to decide which contents to recommend to the incoming user requests, given some representation of the user profile, the context, and their interaction history up to this point, as captured by the sequence of items (e.g. videos, news articles, products) they have interacted with, along with the corresponding feedback (e.g., time spent watching/reading), so as to maximize the cumulative rewards experienced by the users.
In RL terms, we formulate the recommendation problem as a Markov Decision Process (MDP) 111It is in fact a Partially Observed MDP (POMDP) (Sutton & Barto, 2018) as the states are not fully observed.:
| Recommendation MDP | |
|---|---|
| Action | item(s) available for recommendation |
| State | user interests and context |
| State Transition | unknown dynamics capturing how user state changes from to , conditioned on and |
| Reward | immediate reward obtained by performing action for state |
The goal is to find a policy capturing the probability distribution over the action space, i.e, items to recommend, given the current user state , so to maximize the expected cumulative reward,
| (1) |
where , and the expectation is taken over user trajectories obtained by acting according to the policy: , .
We build our method on top of the REINFORCE recommender introduced in (Williams, 1992). Let the policy assume a functional form, mapping states to actions, parameterized by . Using the log-trick, the gradient of the expected cumulative reward with respect to the policy parameters can be derived analytically (Williams, 1992):
| (2) |
To reduce variance in the gradient estimate a common practice is to discount the future reward with a discount :
| (3) |
where
| (4) | |||||
Equation 3 gives an unbiased estimate of the policy gradient in online RL, where the gradient of the policy is computed on trajectories collected by the policy we are learning. In practice, due to infrastructure limitations or production concerns, the trajectories available for learning are collected from a different logging policy, or mixture of such policies, denoted by instead. Thus, we operate in an offline RL setting, making the policy gradient as given by Eq. 3 no longer unbiased. To address this skew, importance weighting is adopted (Munos et al., 2016). In this work, we also operate in batch offline RL, applying top- off-policy correction, and we defer readers to (Chen et al., 2019) for details.
4 Imputing Satisfaction in Reward
We now turn to the main focus of this paper, i.e, shaping the reward of a REINFORCE recommender to drive user satisfaction. We start by describing how we parameterize the policy network (Section 4.1); next we highlight the role of reward in REINFORCE for capturing long-term user utility (Section 4.2); and emphasize the challenges associated with considering satisfaction as a proxy to user utility (Section 4.3). Motivated by these challenges, we propose to augment the policy network with a satisfaction imputation network (Section 4.4).
4.1 Policy Parameterization
We closely follow the setup in (Beutel et al., 2018; Chen et al., 2019) to parameterize the policy. A Recurrent Neural Network (RNN) is used to encode the user’s interaction history, capturing the changing user preferences. The output of the RNN is concatenated with the latent embeddings encoding context, which capture features like time of the day, device type. The concatenation of user sequential preferences and context embeddings is mapped to a lower dimensional representation via multiple Rectified Linear Units. This represents the user state . Conditioned on the user state , the policy is then modeled with a softmax,
| (5) |
where are the action embeddings, and is a temperature term controlling the smoothness of the learned policy.
4.2 Reward
Reward plays a paramount role in determining the final learned policy. As shown in Equation (3), the gradient from each state-action pair is weighted by the cumulative discounted reward .
As prescribed in Equation (4), depends on the immediate rewards associated with the state-action pairs as well as the discounting factor . In the absence of a user utility oracle, a key design choice is which proxy signals to use to define the immediate reward. For each recommendation, the user could leave different signals indicating their experience with the item. Examples include implicit engagement-related signals, such as click, time spent engaging (reading/watching/listening), post-engagement actions, e.g., shares/likes/dislikes/comments, and they could leave explicit feedback in surveys asking them about their satisfaction level with the consumed item.
4.3 Value of Satisfaction Signals, and Challenges
It is easy to see that if the proxy signals used in the reward are solely engagement-focused, the policy will learn to choose actions that only drive engagement. This is not ideal as what users do (engagement) can be quite different from what they say they want (satisfaction), thus neglecting other important facets of the user experience.
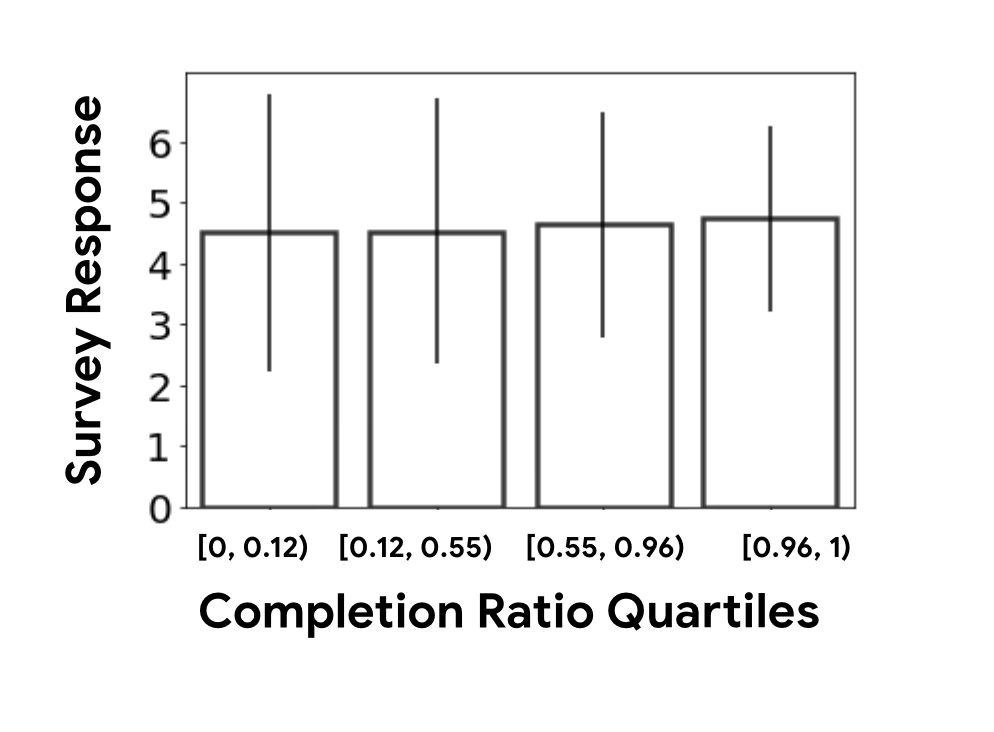
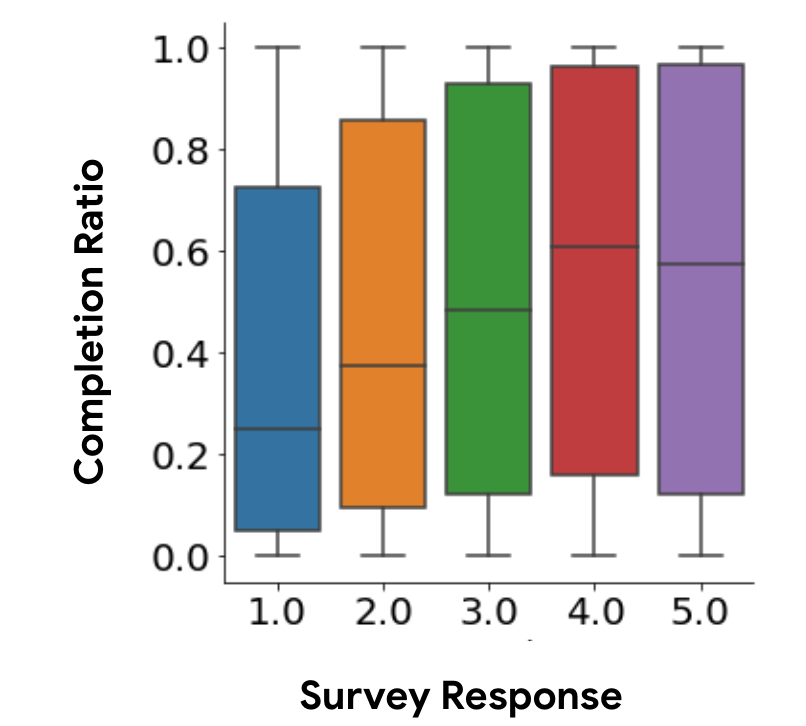
Figure 1 illustrates this point. More than two million interactions with survey responses on a commercial recommendation platform were collected and analyzed. For the sake of this example, we consider completion ratio (e.g., time spent on the item out of total length of the item) as one useful behavioral signal, and study its relationship with satisfaction signals as measured by survey responses in the scale of one to five. As shown in (Figure 1 right), grouping interactions by survey response rating, we find the higher the survey value, the higher the median completion ratio; however, we also see that per survey response value the range of associated completion ratios is quite large. This becomes more evident when grouping interactions with their associated survey responses based on the corresponding quantiles of completion ratios, (Figure 1 left). Based on the plotted 95% confidence intervals, interactions belonging in the exact same quantile of completion ratios (i.e., same user behavior), have quite different associated satisfaction levels (Figure 1 left).
It is worth pointing out that behavior signals alone fail to capture other sides of how the user felt about the interaction, e.g., did they find the content misleading, useful, did it provide some longer term value to them. It is therefore critical to consider both behavioral and satisfaction signals, and appropriately balance them when defining the reward.
Also, we opt for survey data rather than post-engagement signals as better proxies for user satisfaction as we have found that they can offer more representativeness—most users tend to not engage in post-click actions such as likes, dismissals. Having said that, although we demonstrate the effectiveness of reward shaping with imputation networks for survey signals, the same technique is equally applicable for other proxy reward signals exhibiting similar concerns, such as likes, dislikes, shares or dismissals. What is more, in our case study, we find that satisfaction as measured by survey responses highly correlates with goodness as measured by post-engagement signals. Thus, we are able to significantly increase likes, and decrease dislikes/dismissals, even without explicitly optimizing for them (Section 6).
If for each item the user interacted with in the trajectory, besides implicit engagement signals , we also had access to explicit satisfaction signals , we could define the immediate reward as a function of the two, i.e.,
| (6) |
where can include operators such as transformations on the raw signal (e.g., raising to a power, hinge, sigmoid) and combination functions (e.g., addition, multiplication) on the two reward signals.
While the engagement signals are often dense, satisfaction signals are extremely sparse, as they are derived from user-provided responses to satisfaction surveys. These surveys are shown uniformly to all users, asking them to rate on a scale how satisfying they found a sampled item from their recent engagement history. In our case study, roughly one out of thousands of engagement signals will come with a satisfaction response. This is because in a primarily content consumption-focused recommender platform, it would be disruptive to ask users to rate every item consumed. Furthermore, users tend to not respond to surveys— response rate is around 2% in our case.
4.4 Satisfaction Imputation Model
This inherent sparsity of a subset of signals makes simply including them in the reward when present, ineffective.
To address this challenge, we propose the use of an imputation network to densify the satisfaction signals, and include the imputed satisfaction signals in the reward instead.
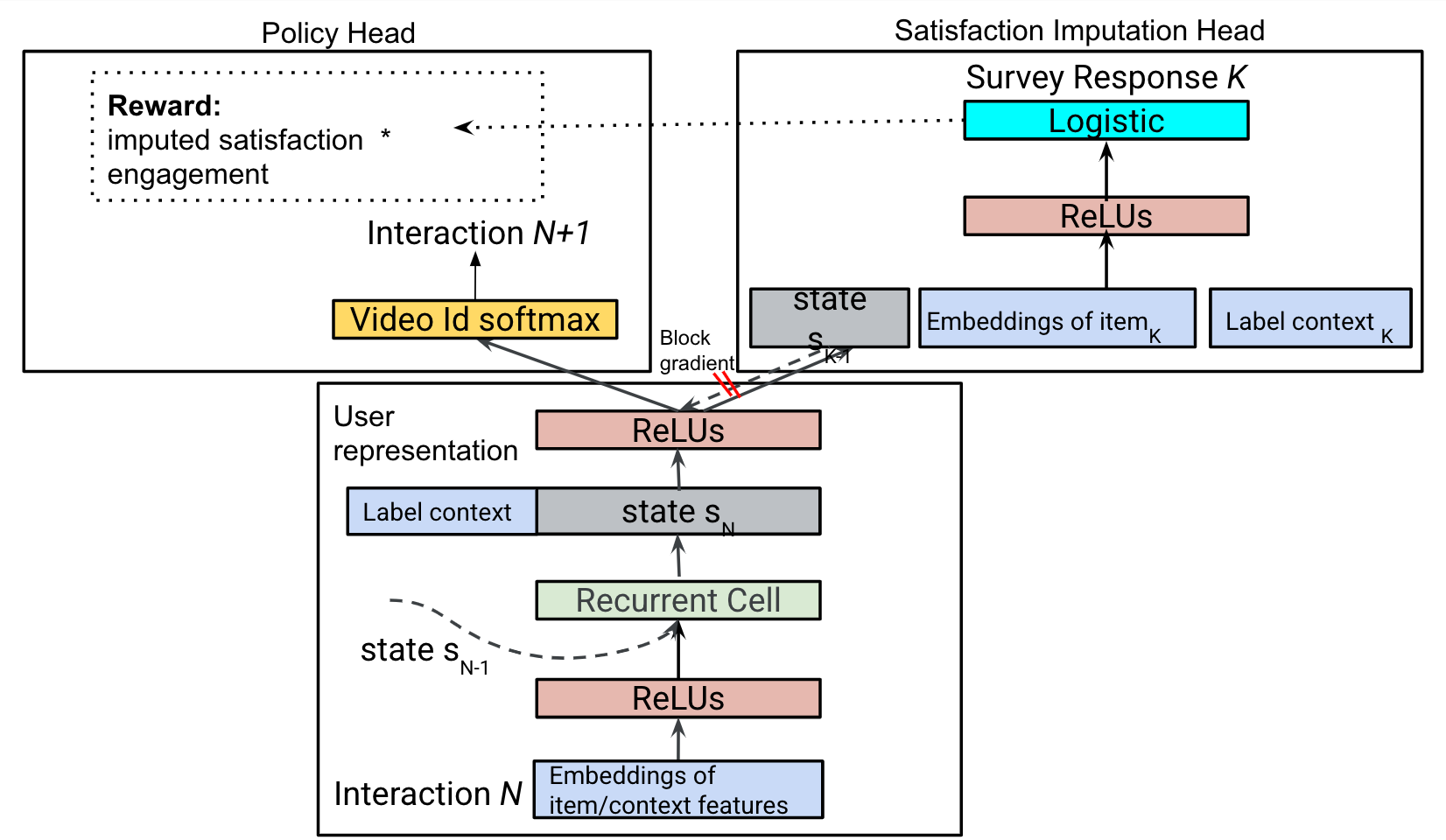
The role of the imputation network is to map user state and action pairs to satisfaction scores, i.e., survey responses present in the satisfaction data . One can imagine learning a completely separate imputation model on this data, and then utilize these imputations directly on the reward of the policy network. The alternative which we opt for is to extend the policy network with a satisfaction imputation head and have parameters shared between the two. This is quite appealing as given that the data used to train the policy head are of much higher volume compared to those used to train the imputation head, we hypothesize that transferring the learned user state and action embeddings from the dense task to the sparse one can be quite useful (Pan & Yang, 2009).
Concretely, we propose a multi-task shared-bottom architecture with two heads, the policy head and the satisfaction imputation head, each having their own task-specific parameters while sharing majorities of the state and action representations. As shown in Figure 2 (bottom), the shared bottom encodes the sequential history of the user, as well as context information. The policy head in Figure 2 (upper left) is identical to the standalone policy network described in Section 4.1, with the only change being in its reward. The imputation head in Figure 2 (upper right) is used to infer the satisfaction score for each state-action pair in the collected trajectories. Then, the imputed satisfaction score combined with engagement signals forms the reward used to train the policy network.
We train the imputation head by gathering the corresponding state , and action embeddings for any state-action pair associated with a survey response in the batch, and learning a mapping from these embeddings to the corresponding survey response i.e., . As shown in Figure 2 (upper right), we prevent the imputation head from influencing the policy parameterization by stopping its gradient from flowing to these shared-bottom embeddings. To give the imputation head its own parameters to learn the mapping , we concatenate the embeddings, i.e., , and send them through multiple Rectified Linear Units (ReLU), and a final dense layer to map to the ground truth survey response. The ReLU layers and the dense layer are learned by optimizing an appropriate loss function . For our case study, consists of survey responses in the scale of 1 to 5, with user studies showing that values of 4 and 5 are considered satisfying, whereas lower values show dissatisfaction. So, we considered a logistic loss, with a sigmoid for the last layer, to predict satisfying versus unsatisfying:
| (7) |
The policy head is learned via REINFORCE,
| (8) |
where denotes the imputed reward, and does the off-policy importance weighting. We decompose as
| (9) |
i.e., the ground truth engagement reward , and the satisfaction reward predicted by the imputation network.
The satisfaction imputation and the policy head are trained concurrently to optimize the (weighted) sum of the two losses.In practice, to prevent a poorly estimated imputation head from corrupting the policy head, we start the training of the policy head with engagement only reward , and include the imputed only after the imputation head is properly trained.
5 What makes a good Satisfaction Imputation Model?
We now present some experimental findings on what makes a good satisfaction imputation model. To evaluate its predictive accuracy, we create a hold-out set consisting of user trajectories for users with at least one associated survey response. The AUC ROC achieved by the imputation model on the hold-out set is used as the offline evaluation metric.
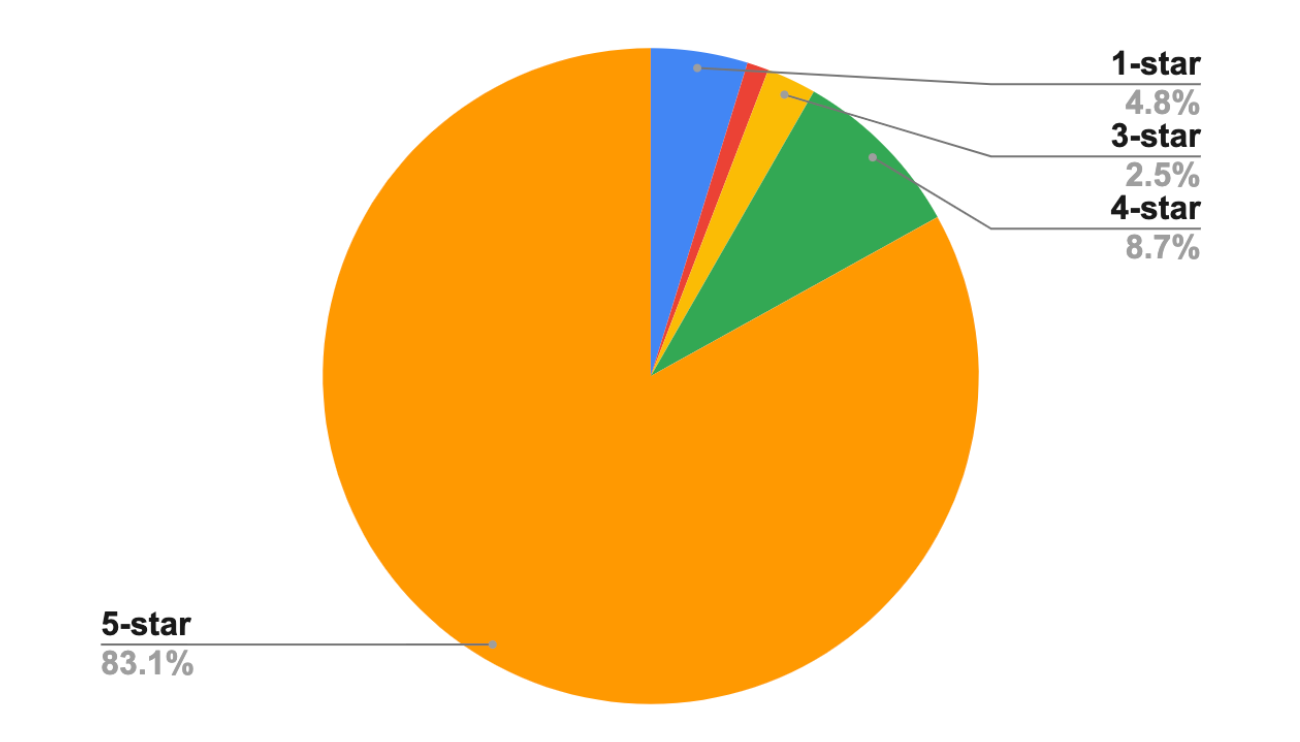
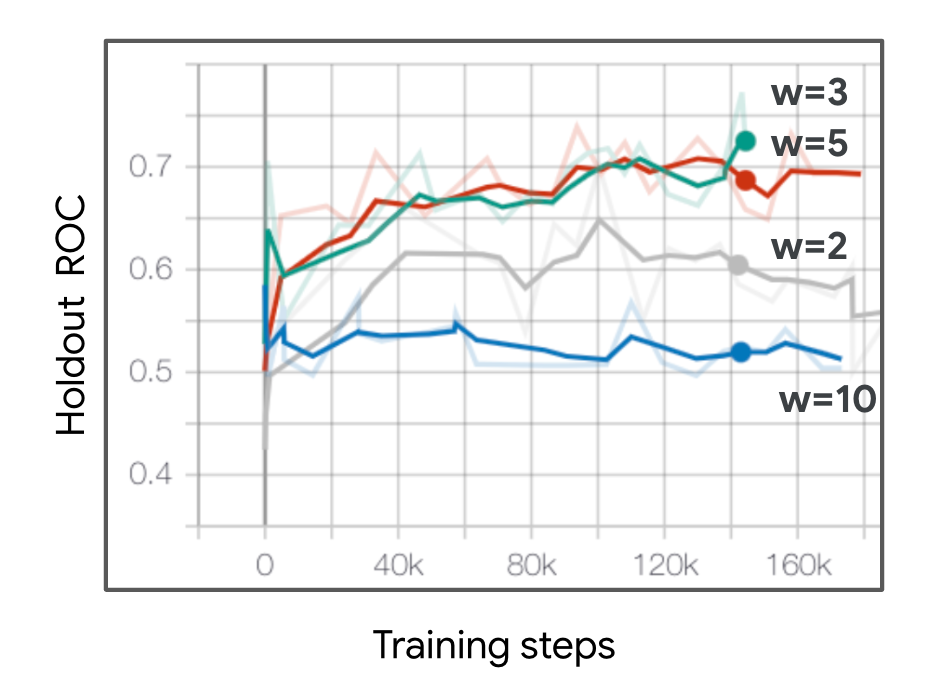
Loss Function. One challenge associated with the survey response data is the class imbalance problem. In our case study, the majority of responses recorded are in the higher spectrum (Figure 3, left). One hypothesis is that users tend to respond to surveys about items they find highly satisfying (Paulhus, 1991). This creates a natural imbalance of survey values in the satisfaction data, leading the model to focus more on survey responses of higher values. An under-specified model can predict every item to be satisfying as a result. One simple approach to address this is through cost-sensitive learning (Elkan, 2001), in which the negative class of non-satisfying state-action pairs are weighted more. We calibrate the prediction after to reflect the ground-truth distribution of satisfying vs non-satisfying survey responses (Chapelle et al., 2014). Figure 3 right compares the performance of the satisfaction head with different weights on the negative class. We found a weight of 3 or 5 perform the best according to the holdout AUC ROC.
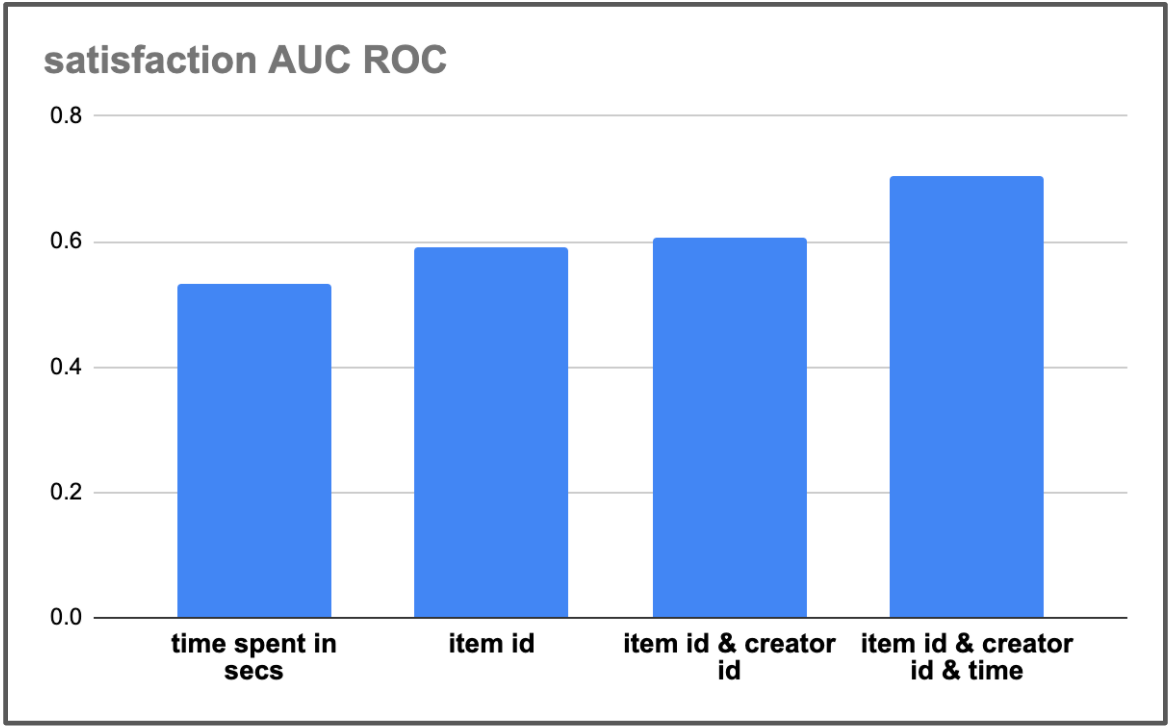
Action Features. Figure 4 left summarizes the predictive power of different action features, i.e., time spent, item id and creator id, on the quality of the satisfaction imputation head. We can see that when using a single feature to predict survey response, the continuous feature of the time the user spent interacting with the item is less informative compared to discrete features representing the item such as the embedding of the item id. The AUC ROC of a satisfaction imputation with item id as the only feature is further improved when including other features representing the item on the survey—we notice a slight improvement when including the creator id embedding, and a considerable improvement when also including time spent in seconds interacting with the item, on top of item id and creator id embeddings.
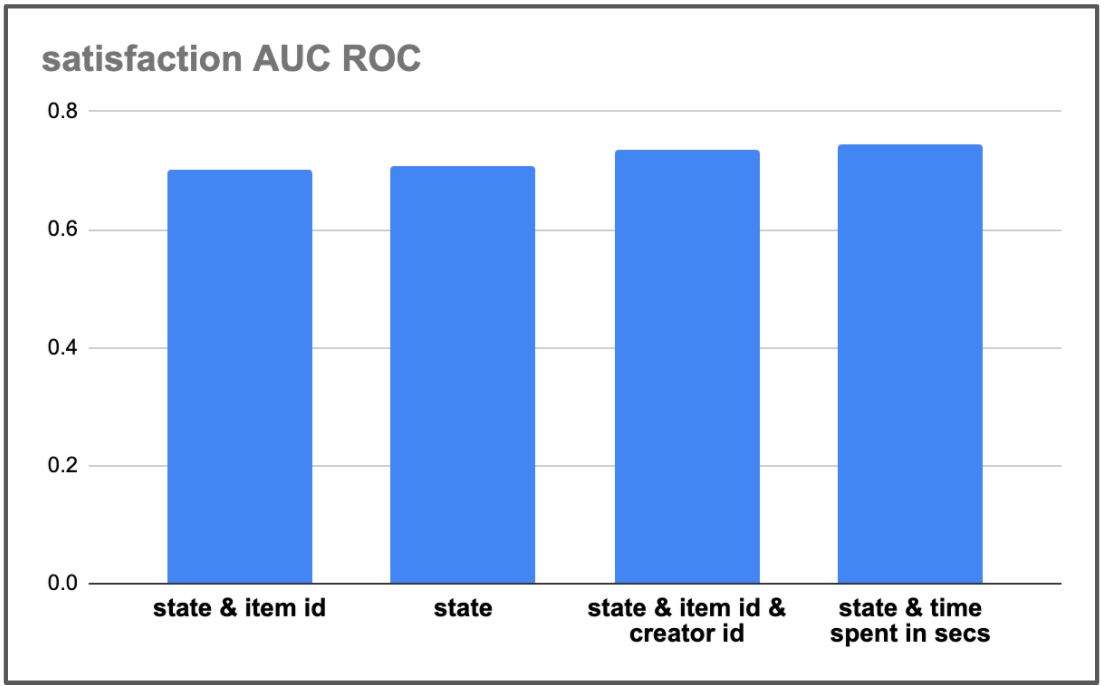
User State. We also evaluate the importance of including user state in learning the imputation model (Figure 4 right). We can see that when using as features only the user state, as captured by the RNN over the sequence up until this point, concatenated with the label context embedding, we get the same hold out AUC ROC as the one achieved by using all features representing the action (Figure 4 left, last bar). Concatenating the user state with action embeddings further improves the imputation model’s predictive power. Thus, in what follows, our satisfaction imputation model will utilize both user state and action embeddings as features.
6 Live Experiments
Our case study involves a large scale two-stage recommender platform, where at the first stage multiple candidate generators retrieve potential candidates from the entire corpus; and the second stage involves a ranker model ranking the candidates and providing a final top- recommendation list to be shown to the user.
To study the extent to which our approach can improve real user experiences, we apply our reward shaping approach onto a RL-based candidate generator, and conducted a series of A/B experiments. The control arm runs a REINFORCE agent learned using engagement-only reward. In the experiment arm, we test our proposed approach of augmenting the policy network with a satisfaction imputation head (Figure 2), and utilizing the imputed satisfaction reward along with the ground truth behavioral signals into the policy’s reward, described in 4.4.
Experiments are run for over a month on a fixed set of randomly assigned user traffic to study the long-term effect. During this period, the model is trained continuously, with new interactions being used as training data with a lag under 24 hours.
Online Satisfied Engagement Metric. For evaluating whether the user experiences are improved, one could look at ground truth survey responses. An experiment which increases the average survey response over the experiment period would be considered driving more user satisfaction. In fact our experiment increases 5 star survey responses on average by 0.48% and decreases 1 and 2 star survey responses by 1.89%. However, we again run into the key challenge associated with survey responses which is sparsity. If we only measure on user-item pairs for which the users have responded to in a survey, we would only be looking at a very small percentage of the user interactions. To tackle this, we instead rely on a model-based metric predicting a survey response for each of the items the user has interacted with, and combining that with engagement metrics measured live. It is worth pointing out, the model used for measuring online satisfaction metric is independent of the imputation network we built, with a considerably different feature set and architecture. We cannot utilize the predictions of this model directly into our reward, due to infrastructure complexities and freshness requirements.
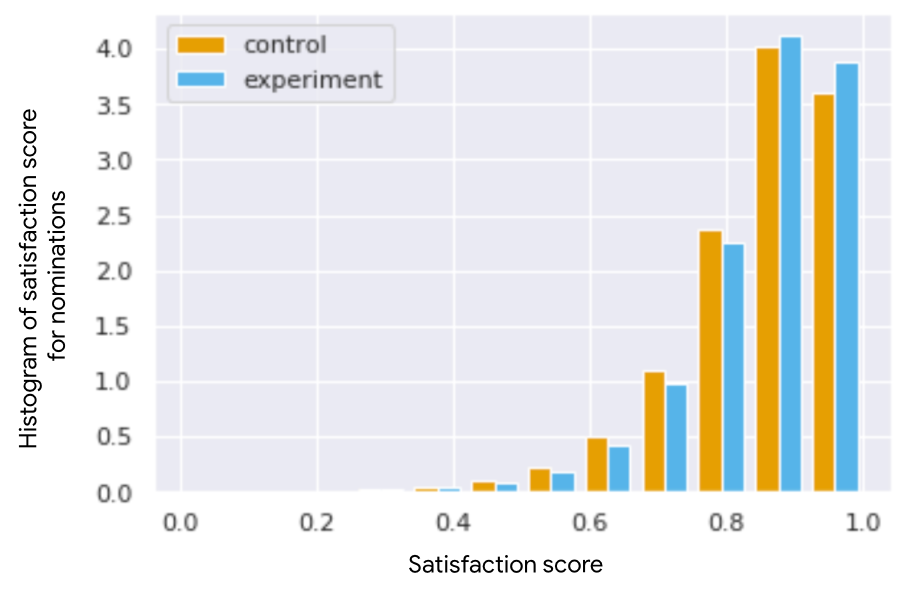
Satisfaction Improvements. In Figure 5 we show how the distribution of ground truth satisfaction scores over nominations coming from the control model (REINFORCE with engagement-reward) versus the experiment (our approach optimizing for a combination of satisfaction and engagement) compare. The x-axis represents the ground truth satisfaction probability score (used to calculate the live satisfied engagement time metric, and distinct from our imputation model predictions), with scores close to 1.0 indicating users being satisfied with their interactions, and close to 0.0 being unsatisfied. We can see that in both experiment and control arms, the majority of interactions are predicted to have a score larger than 0.5, indicating satisfying experience. Nevertheless, we can clearly see that our experiment increases the number of nominations with satisfaction scores greater or equal to 0.9, and decreases respectively nominations with a score less than 0.9. This demonstrates that our proposed imputation head is able to identify items which are satisfying to the users and shift the policy to select more satisfying items, further validating its predictive accuracy.
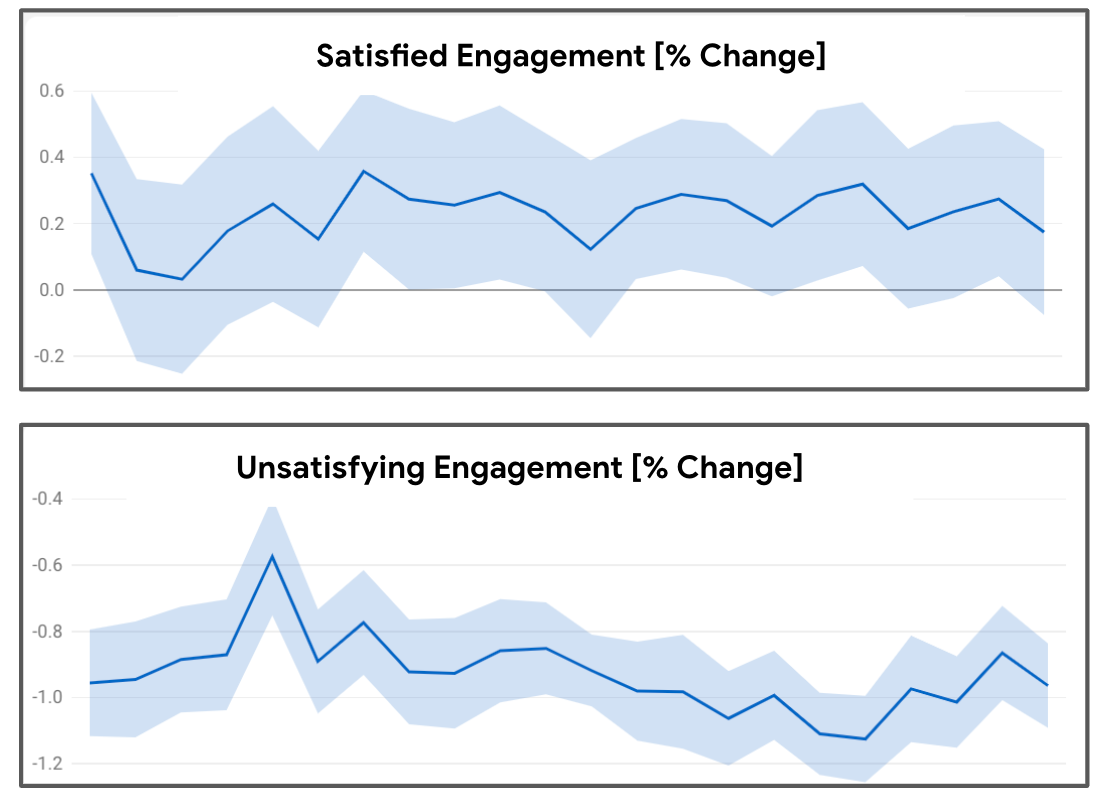
Figure 6 compares the control and experiment arm on a live metric combining the model-based satisfaction metric and behavioral-based implicit engagement signals. We find that on average, satisfied engagement is increased by 0.23%, while unsatisfying engagement is decreased by 0.93%. Both results are statistically significant, signifying the value of reward shaping in driving user utility as specified by the reward.
Furthermore, metrics orthogonal to the ground truth satisfaction scores, measuring other facets of user experience, significantly move towards the right direction: likes on items increase by 0.53%, while dislikes are decreased by 1.11% and dismissals decrease by 3.03%. Note that we did not include these signals into the features or labels of our satisfaction imputation model. This further supports the point made in Section 1 that optimizing for satisfaction signals correlates well with improvements in post-engagement actions.
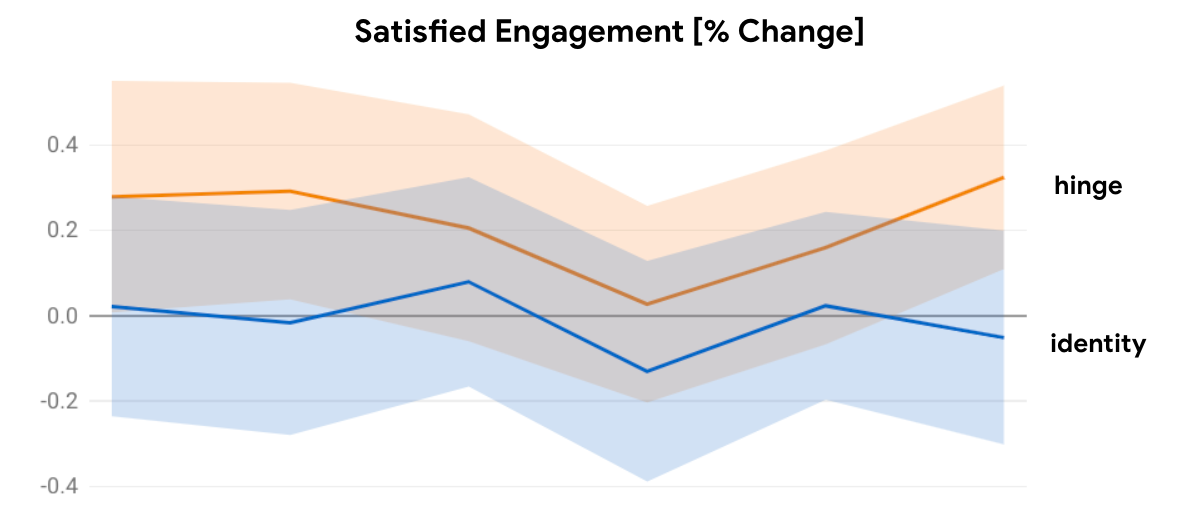
We found that an important design choice in the reward is the transformation function over the predicted satisfaction signal by the imputation network, i.e., the probability of an item being satisfying to the user. Simply multiplying the engagement reward signals by the imputed probability of the item being satisfying (identity function) only decreases non-satisfied engagement, but did not lead to statistically significant improvements in satisfied engagement. It is critical to further differentiate highly satisfying items from less satisfying ones to allow the model to clearly prefer selecting such items. We found that in practice a simple hinge function performed the best, i.e., when imputed probability of an item being satisfying to the user is larger than a threshold, multiply with the probability, else completely zero out the engagement reward (Figure 7). The threshold was tuned offline based on the ground truth response distribution, and the imputation network’s predictions. We report results based on threshold set to 0.75.
Furthermore, we validated in live experiments some of our choices made offline. We found that predicting the probability of an item found satisfying by the user performed better than predicting the actual survey response they will give, i.e., cross-entropy loss gave better results compared to a square loss. We hypothesize that this could be the case due to better alignment with the loss used to train the model-based Satisfied Engagement live metric. Also, balancing the data to give more weight to unsatisfying survey responses and calibrating the prediction to account for the balancing (Figure 3) was important for live improvements. Finally, we found that raising the satisfaction reward term to an exponent larger than 1 gave us slightly better results when using the identity transformation function; but for the hinge function, the improvement was not statistically significant.
7 Conclusions
In this paper, we considered the problem of driving long-term user satisfaction in a reinforcement learning recommender. We posited that reward shaping is a powerful tool for aligning the RL recommender’s objective with what users want. We argued that engagement signals only, as typically considered by existing RL literature, are not able to capture the full aspects of user experience on the recommendation platform. Instead, satisfaction signals, capturing how users felt about items they have interacted with, should be incorporated into the reward. We highlighted that a key challenge associated with such signals, when trying to incorporate them into the reward, is their sparsity—only a small percentage of the user-item interactions has associated survey response value. To combat the sparsity, we proposed to extend a state-of-the-art REINFORCE recommender with a satisfaction imputation network, imputing for every interacted item the user’s satisfaction score. We offered insights based on offline model improvements, and demonstrated via live experiments in a commercial large-scale recommender that including satisfaction imputation into the reward indeed drives more satisfying user experiences.
References
- Beutel et al. (2018) Beutel, A., Covington, P., Jain, S., Xu, C., Li, J., Gatto, V., and Chi, E. H. Latent cross: Making use of context in recurrent recommender systems. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, pp. 46–54, 2018.
- Chapelle et al. (2014) Chapelle, O., Manavoglu, E., and Rosales, R. Simple and scalable response prediction for display advertising. ACM Transactions on Intelligent Systems and Technology (TIST), 5(4):1–34, 2014.
- Chen et al. (2019) Chen, M., Beutel, A., Covington, P., Jain, S., Belletti, F., and Chi, E. H. Top-k off-policy correction for a reinforce recommender system. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, pp. 456–464, 2019.
- Covington et al. (2016) Covington, P., Adams, J., and Sargin, E. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems, pp. 191–198, 2016.
- Dorigo & Colombetti (1994) Dorigo, M. and Colombetti, M. Robot shaping: Developing autonomous agents through learning. Artificial intelligence, 71(2):321–370, 1994.
- Dulac-Arnold et al. (2015) Dulac-Arnold, G., Evans, R., van Hasselt, H., Sunehag, P., Lillicrap, T., Hunt, J., Mann, T., Weber, T., Degris, T., and Coppin, B. Deep reinforcement learning in large discrete action spaces. arXiv preprint arXiv:1512.07679, 2015.
- Elkan (2001) Elkan, C. The foundations of cost-sensitive learning. In International joint conference on artificial intelligence, volume 17, pp. 973–978. Lawrence Erlbaum Associates Ltd, 2001.
- Garcia-Gathright et al. (2018) Garcia-Gathright, J., St. Thomas, B., Hosey, C., Nazari, Z., and Diaz, F. Understanding and evaluating user satisfaction with music discovery. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pp. 55–64, 2018.
- Gu et al. (2017) Gu, S., Holly, E., Lillicrap, T., and Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In 2017 IEEE international conference on robotics and automation (ICRA), pp. 3389–3396. IEEE, 2017.
- Guo & Agichtein (2012) Guo, Q. and Agichtein, E. Beyond dwell time: estimating document relevance from cursor movements and other post-click searcher behavior. In Proceedings of the 21st International conference on World Wide Web, pp. 569–578, 2012.
- Hadfield-Menell et al. (2017) Hadfield-Menell, D., Milli, S., Abbeel, P., Russell, S. J., and Dragan, A. Inverse reward design. In Advances in neural information processing systems, pp. 6765–6774, 2017.
- Ie et al. (2019) Ie, E., Jain, V., Wang, J., Narvekar, S., Agarwal, R., Wu, R., Cheng, H.-T., Chandra, T., and Boutilier, C. Slateq: A tractable decomposition for reinforcement learning with recommendation sets. In Proceedings of the Twenty-eighth International Joint Conference on Artificial Intelligence (IJCAI-19), pp. 2592–2599, Macau, China, 2019. See arXiv:1905.12767 for a related and expanded paper (with additional material and authors).
- Lalmas (2019) Lalmas, M. Metrics, engagement & personalization. In REVEAL workshop, The ACM Conference Series on Recommender Systems, 2019.
- Liu et al. (2018) Liu, F., Tang, R., Li, X., Zhang, W., Ye, Y., Chen, H., Guo, H., and Zhang, Y. Deep reinforcement learning based recommendation with explicit user-item interactions modeling. arXiv preprint arXiv:1810.12027, 2018.
- Mataric (1994) Mataric, M. J. Reward functions for accelerated learning. In Machine learning proceedings 1994, pp. 181–189. Elsevier, 1994.
- Mehrotra et al. (2018) Mehrotra, R., McInerney, J., Bouchard, H., Lalmas, M., and Diaz, F. Towards a fair marketplace: Counterfactual evaluation of the trade-off between relevance, fairness & satisfaction in recommendation systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, pp. 2243–2251, 2018.
- Mehrotra et al. (2019) Mehrotra, R., Lalmas, M., Kenney, D., Lim-Meng, T., and Hashemian, G. Jointly leveraging intent and interaction signals to predict user satisfaction with slate recommendations. In Proceedings of The Web Conference 2019, pp. 1256–1267, 2019.
- Mnih et al. (2013) Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., and Riedmiller, M. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
- Mnih et al. (2015) Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., et al. Human-level control through deep reinforcement learning. nature, 518(7540):529–533, 2015.
- Mnih et al. (2016) Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D., and Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In International conference on machine learning, pp. 1928–1937, 2016.
- Munos et al. (2016) Munos, R., Stepleton, T., Harutyunyan, A., and Bellemare, M. Safe and efficient off-policy reinforcement learning. In Advances in Neural Information Processing Systems, pp. 1054–1062, 2016.
- Ng et al. (1999) Ng, A. Y., Harada, D., and Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. In ICML, volume 99, pp. 278–287, 1999.
- Pan & Yang (2009) Pan, S. J. and Yang, Q. A survey on transfer learning. IEEE Transactions on knowledge and data engineering, 22(10):1345–1359, 2009.
- Paulhus (1991) Paulhus, D. L. Measurement and control of response bias. 1991.
- Schaal (1999) Schaal, S. Is imitation learning the route to humanoid robots? Trends in cognitive sciences, 3(6):233–242, 1999.
- Schulman et al. (2015) Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438, 2015.
- Silver et al. (2018) Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science, 362(6419):1140–1144, 2018.
- Sutton & Barto (2018) Sutton, R. S. and Barto, A. G. Reinforcement learning: An introduction. MIT press, 2018.
- Sutton et al. (2000) Sutton, R. S., McAllester, D. A., Singh, S. P., and Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Advances in neural information processing systems, pp. 1057–1063, 2000.
- Wen et al. (2019) Wen, H., Yang, L., and Estrin, D. Leveraging post-click feedback for content recommendations. In Proceedings of the 13th ACM Conference on Recommender Systems, pp. 278–286, 2019.
- Williams (1992) Williams, R. J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8(3-4):229–256, 1992.
- Yi et al. (2014) Yi, X., Hong, L., Zhong, E., Liu, N. N., and Rajan, S. Beyond clicks: dwell time for personalization. In Proceedings of the 8th ACM Conference on Recommender systems, pp. 113–120, 2014.
- Zhang et al. (2019) Zhang, J., Hao, B., Chen, B., Li, C., Chen, H., and Sun, J. Hierarchical reinforcement learning for course recommendation in moocs. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pp. 435–442, 2019.
- Zhao et al. (2018) Zhao, X., Xia, L., Zhang, L., Ding, Z., Yin, D., and Tang, J. Deep reinforcement learning for page-wise recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems, pp. 95–103, 2018.
- Zheng et al. (2018) Zheng, G., Zhang, F., Zheng, Z., Xiang, Y., Yuan, N. J., Xie, X., and Li, Z. Drn: A deep reinforcement learning framework for news recommendation. In Proceedings of the 2018 World Wide Web Conference, pp. 167–176, 2018.