RGAT: A Deeper Look into Syntactic Dependency Information for Coreference Resolution
Abstract
Although syntactic information is beneficial for many NLP tasks, combining it with contextual information between words to solve the coreference resolution problem needs to be further explored. In this paper, we propose an end-to-end parser that combines pre-trained BERT [1] with a Syntactic Relation Graph Attention Network (RGAT) to take a deeper look into the role of syntactic dependency information for the coreference resolution task. In particular, the RGAT model is first proposed, then used to understand the syntactic dependency graph and learn better task-specific syntactic embeddings. An integrated architecture incorporating BERT embeddings and syntactic embeddings is constructed to generate blending representations for the downstream task. Our experiments on a public Gendered Ambiguous Pronouns (GAP) dataset show that with the supervision learning of the syntactic dependency graph and without fine-tuning the entire BERT, we increased the F1-score of the previous best model (RGCN-with-BERT) [2] from 80.3% to 82.5%, compared to the F1-score by single BERT embeddings from 78.5% to 82.5%. Experimental results on another public dataset – OntoNotes 5.0 demonstrate that the performance of the model is also improved by incorporating syntactic dependency information learned from RGAT.
Index Terms:
syntactic dependency information, syntactic embeddings, coreference resolution, Bert, blending embeddingsI Introduction
Coreference resolution is the task of finding all linguistic expressions that refer to the same entity in the natural language. Ambiguous pronoun resolution, which attempts to resolve gendered ambiguous pronouns in English such as ‘he’ and ‘she’, is a longstanding challenge in coreference resolution [2]. A Kaggle competition based on the task of gendered ambiguous pronouns (GAP) resolution was conducted in 2019 [3]. The effective use of Bidirectional Encoder Representations from Transformers or BERT [1] in this competition has shown significant improvement over traditional approaches. Unlike the traditional unidirectional language model, BERT is designed to pre-train deep bidirectional representations using a new masked language model (MLM), which enables the generation of deep bidirectional contextual embeddings.
At present, there are two BERT-based approaches for applying these contextual embeddings to ambiguous pronoun resolution tasks: the feature-based approach using BERT and fine-tuning BERT approach. The feature-based approach using BERT treats contextual representations derived from BERT as extra input features, which are combined in a task-specific model architecture without fine-tuning any parameters of BERT to obtain the coreference resolution for the target pronoun. For example, a model architecture combining BERT and SVM proposed in [4] obtains the correct mention for the target pronoun by applying the contextual embeddings from BERT to an SVM classifier. As for fine-tuning BERT approach, it uses BERT to model the downstream gendered pronoun reference task by plugging in the task-specific inputs and outputs into BERT and fine-tuning all the parameters end-to-end. Compared to the feature-based approach using BERT, fine-tuning BERT approach obtains more impressive performance without considering the computational cost, such as single fine-tuned BERT [5] or ensemble learning from multiple fine-tuned base BERT models [6].
However, fine-tuning the entire BERT model for a specific task is very computationally expensive and time-consuming because all parameters are jointly fine-tuned on the downstream task and need to be saved in a separate copy. For this reason, there are two improving strategies in BERT-based approach for the gendered pronoun reference task. One strategy focuses on the output representation of each layer in BERT by altering the BERT structure slightly at each layer and adding some extra parameters to change the output of each layer. Compared to fine-tuning all the parameters of BERT, this strategy can obtain a better result with less computation time, like Adapter [7] , LoRA [8] and so on. Another strategy is to explore better blending embeddings than BERT on the coreference task with the help of syntactic parsing information. Syntactic parsing information is a strong tool in many NLP tasks, such as entity extraction or relation extraction. It has also been verified that blending embeddings from BERT representations and syntactic embeddings outperform the original BERT contextual representations in the gendered pronoun reference task [2]. Since the strategy of exploring blending embeddings has a computational advantage in running many experiments with cheaper models on a pre-compute representation of BERT, it is worthwhile for us to explore again the value of blending embeddings incorporating syntactic dependency information in ambiguous pronoun resolution tasks.
Recently, Cen et al. [9] have proposed the GATNE model, which is a large-scale heterogeneous graph representations learning model to effectively aggregate neighbors of different edge types to the current node by assigning an attention mechanism. As far as we know, there has been no study has attempted to use GATNE or its variants to digest heterogeneous graph structures from the syntactic dependency graph.
Inspired by the GATNE model, we propose our Syntactic Relation Graph Attention Network model to make it suitable to generate heterogeneous syntactic embeddings for each sample data, namely RGAT. Based on that, we propose an end-to-end solution by combining pre-trained BERT with RGAT. Experiment results on the public GAP (Gendered Ambiguous Pronouns) dataset released by Google AI demonstrate that the blending embeddings which combine BERT representations and syntactic dependency graph representations outperform the original BERT-only embeddings on the pronoun resolution task, which significantly improves the baseline F1-score from 78.5% to 82.5% without fine-tuning BERT and expensive computing resource. Furtherly, to verify the effectiveness of our RGAT model for digesting syntactic dependency information in coreference resolution tasks, we also conduct another coreference resolution experiment on the public NLP dataset–OntoNotes 5.0 dataset. The experiment results demonstrate that after the syntactic embeddings learned with our RGAT model are incorporated with the benchmark model, the F1-score improves from 76.9% to 77.7%. All our experiment codes in this paper are available at https://github.com/qingtian5/RGAT_with_BERT. Our main contributions are shown below:
-
•
Our work is the first deep attempt at using heterogeneous graph representations learning with attention mechanism on syntactic dependency graph for pronoun resolution task. The syntactic embeddings derived from our RGAT model successfully boost the performance of BERT-only embeddings. This provides a new idea to further digest syntactic dependency information for reference resolution tasks.
-
•
Our work is the first to use graph attention mechanism to learn small syntactic dependency graph embeddings without expensive computation cost to solve the coreference resolution task. The supplementary experiment result on the public GAP dataset and OntoNotes 5.0 dataset shows that our adjusted model RGAT has a better generalization ability in NLP coreference resolution tasks.
-
•
Our work is the first to largely boost the performance of the ambiguous pronoun resolution task with the help of syntactic dependency information. Most previous research considers that the effect of syntactic embeddings is weak, but our work significantly improves the F1-score of the BERT + fc baseline model from 78.5% to 82.5% on the GAP dataset.
II Preliminary Wrok
II-A BERT-Based Embeddings
BERT makes use of Transformer, an attention mechanism that learns contextual relations between words in a text. When training language models, BERT uses two training strategies: Masked LM (MLM) and Next Sentence Prediction (NSP). Through these two tasks, what we need to do is how to apply BERT model to our samples to get the embedded representations.
For our ambiguous pronoun resolution task, each of our samples is taken as a long sentence, and then a [cls] token is added before the sentence. Through a pre-trained BERT model, the embedded representation of each token in the sentence is obtained. In fact, our goal is to obtain the relations between pronouns and nouns, so we only need to extract the embedded representations of the tokens related to pronouns (P) and nouns (A, B), then concatenate them, and finally get the results about the specific reference of the pronouns (P) through the fully connected layer, which are shown in Fig. 1.
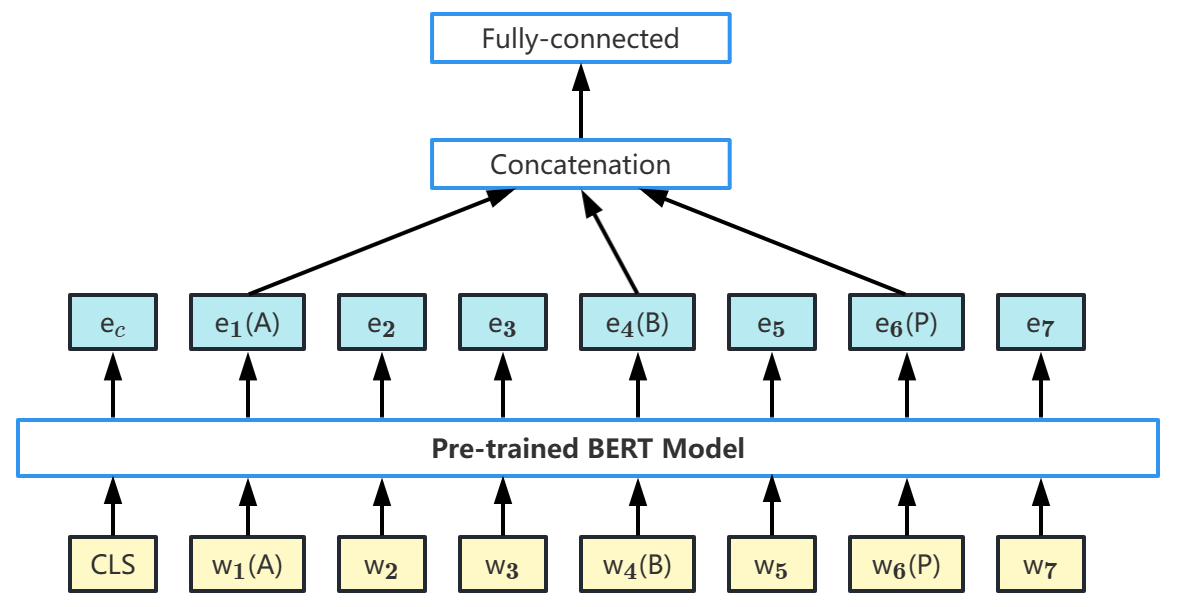
Take a sample sentence for example– “Bill(A) said Alice(B) would arrive soon, and she(P) did”, our task is to find out whether “she(P)” refers to “Bill(A)” or “Alice(B)”. As the information flows in Fig. 1, we first break the whole sentence into words and make them the input of the BERT model. The pre-trained BERT model will generate an embedding for each word. Because in our coreference resolution task, there are only three possible results: (1) P refers to A; (2) P refers to B; (3) P refers to neither A nor B. Therefore, we regard our task as a tripartite classification problem. Thus, we extract the embedding of P, A and B from the BERT outputs, then concatenate them, and last through a fully connected layer.
II-B Syntactic Dependency Information Learning
Although syntactic parsing information is beneficial to pronoun coreference resolution, how to extract syntactic embeddings and incorporate them with BERT embeddings for the coreference task is difficult. A common way of digesting syntactic parsing information is to utilize the syntactic dependency relations between words in a text, which can be easily represented as nodes and edges in a graph structure. Then graph based model can be used to learn the syntactic dependency information for the subsequent task. For the coreference resolution task, each sentence is parsed into a syntactic dependency graph, which contains three types of edges. Thus, the traditional Graph Convolutional Network (GCN) cannot handle this multi-relation graph. Xu [2] innovatively incorporated syntactic embeddings, which is digested with Gated Relational Graph Convolutional Network (Gated RGCN [10]) with BERT embeddings for their pronoun coreference task. Specifically, RGCN is used to aggregate three heterogeneous graph structures between the head world and the dependency word to obtain word syntactic embeddings [2]. The idea provided by RGCN is that the information should be treated differently for different edge types, denoted as follows:
| (1) |
where and denote the set of neighbors of node i and weight under relation respectively. It can be seen from here that although RGCN is used to solve multilateral types, it does not consider the problem of edge features, and the default is that only type feature exists for each edge.
In contrast to using pre-trained BERT embeddings and fully-connected layers for prediction, the series connection architecture of pre-trained BERT with RGCN from Xu [2] increases the F1-score by 1.8%. However, RGCN does not perform very well in digesting the weight information between multiple edges graph structures from the syntactic dependency graph. Meanwhile, Xu’s result is far less accurate than fine-tuning the entire BERT. The main problem may exist in two aspects. On the one hand, according to the RGCN model, if there are multiple different types of edges in the network, it will eventually need to generate a linear layer for each type of edge. This will lead to a linear increase in the number of model parameters. On the other hand, for some types of edge in syntactic dependency graph, the frequency of occurrence may be small, which will lead to the linear layer corresponding to this type of edge is eventually updated on only a few nodes, resulting in the problem of overfitting a small number of nodes.
Inspired by RGCN with BERT and the development of graph neural networks, we believe that the performance of syntactic parsing information on pronoun resolution can be further improved. The first reason is that syntactic information always plays a very important role in the extraction of hand-crafted features, especially in most heuristics-based methods for the pronoun resolution task [11] [12] [13]. The second reason is that many newly graph learning-based models incorporating syntactic information achieve improving results in entity extraction [14] or semantic role labelling tasks [15]. In order to solve the problems of RGCN, we will illustrate how to learn the syntactic dependency graph using our proposed RGAT model in the next section. And in section IV, we propose to use L2 regularization for parameters in the RGAT model to alleviate the problem of overfitting.
III Method
III-A Syntactic Dependency Graph
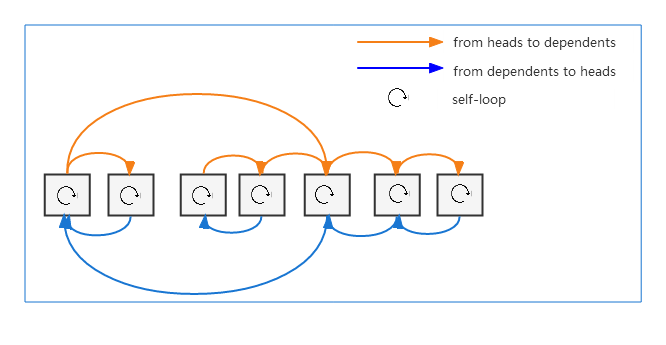
Since a dependency parse describes the syntactic relations that hold among words, many existing researches transform the dependency parse tree into the syntactic dependency graph to capture the syntactic features [2]. It is commonly assumed that there are three kinds of information flows in the syntactic dependency graph: from heads to dependents, from dependents to heads and self-loops, which are shown in Fig. 2.
For each node in the syntactic dependency graph in Fig. 2, it is linked with three different types of edges, corresponding to three different types of syntactic relations. Since we are focused on embedding learning in the syntactic dependency graph, it is important to be able to draw on strengths from such different relations and learn uniform syntactic embeddings.
III-B RGAT Model
The core idea of GATNE-T (we refer to this as GATNE in the paper) is to aggregate neighbors of different edge types to the current node and then generate different vector representations for nodes of each edge type. Inspired by the GATNE algorithm proposed by Cen [9], we adjust GATNE and propose the RGAT model applied in the syntactic dependency graph with multiple edges to learn uniform embeddings.
Generally, the RGAT model has been modified in three aspects based on the GATNE model. First, GATNE obtains the embedded representations of nodes and edges on a large graph structure data, but our RGAT model needs to adapt to different syntactic graph structures generated by different samples. Therefore, a new attention architecture is proposed to solve this problem. Second, the initial embedding representations of GATNE are randomly generated, but our goal is to solve the ambiguous pronouns coreference resolution, thus it is natural to use BERT Embeddings to initialize the node embeddings. Third, in order to take advantage of all the information, we add a shortcut module in the model so that our initialization node embeddings can also be concatenated into the final output embeddings.
Specially, the RGAT model splits the overall embedding of a certain node v on each edge type i in the syntactic dependency graph into two parts: base embedding and three edge embeddings. The base embedding of node v is shared between its three different edge types. We use BERT Embedding as the base embedding of the nodes. We follow the following aggregation steps to obtain the final syntactic embeddings of each node.
First, the representation of each node is compressed to obtain a more compact representation denoted as , which is used as the base embedding.
| (2) |
where is learnable, and is the BERT representation of node on edge type . In our work, the representation of each node from BERT is a vector of 1024 dimensions. Consistent with previous work [2], the compressed node representation dimensions are set to 256. So is a vector of 256 dimensions.
Second, following GraphSage [16], we obtain each type of edge embedding for node by aggregating from neighbors’ edge embeddings. We randomly sample neighbor nodes for each edge embedding , and then aggregate them. The aggregator function can be a sum, mean or max-pooling aggregator as follows:
| (3) |
where , is a learnable parameter, is 256, is the hyperparameter that needs to be given. In order to make the attention calculation more convenient, we compress the aggregated representation again.
Third, applying the attention mechanism to get the weight of each aggregated edge representation for each node as follows:
| (4) |
where , are learnable parameters, is the hyperparameter that needs to be given.
Fourth, combining each weighted aggregated representation with the base embedding, the final representation of each node in edge type can be represented as , which is denoted as follows:
| (5) |
where is a learnable parameter, is base embedding and is a vector with 256 dimensions.
Finally, the syntactic embedding representation of each node is aggregated from three kinds of node representation ,,, denoted as follows:
| (6) |
where the aggregator function can be a sum, mean or concatenate operation. The influence of different aggregators will be mentioned in detail in the ablation experiment in Section IV.
III-C Syntactic Embeddings
The previous RGCN model [2] only uses the information of neighbor nodes, but it brings a significant improvement in coreference resolution tasks. Therefore, we think the potential of learning syntactic structure using RGAT can be much more than that. The most important reason is that by designing attention mechanisms, we obtain more valuable information from different types of edges.
Fig. 3 explains in detail how to extract Syntactic Embeddings from information flows in syntactic dependency graph and BERT Embeddings.
For one thing, we use BERT Embeddings as the base embeddings. For another thing, we use three different types of syntactic relations to construct the syntactic relation graph with attention information to learn RGAT embeddings. In order to retain information from BERT Embeddings, we concatenate the embeddings that represent the relation graph with attention information and BERT Embeddings. Then, we concatenate different embeddings from three different kinds of edges (different color represent embeddings from different edge types in Fig. 3). Finally, the significant words embeddings (the embedding of three words – A, B, P, like in section II, Fig. 1) are concatenated as Syntactic Embedding.
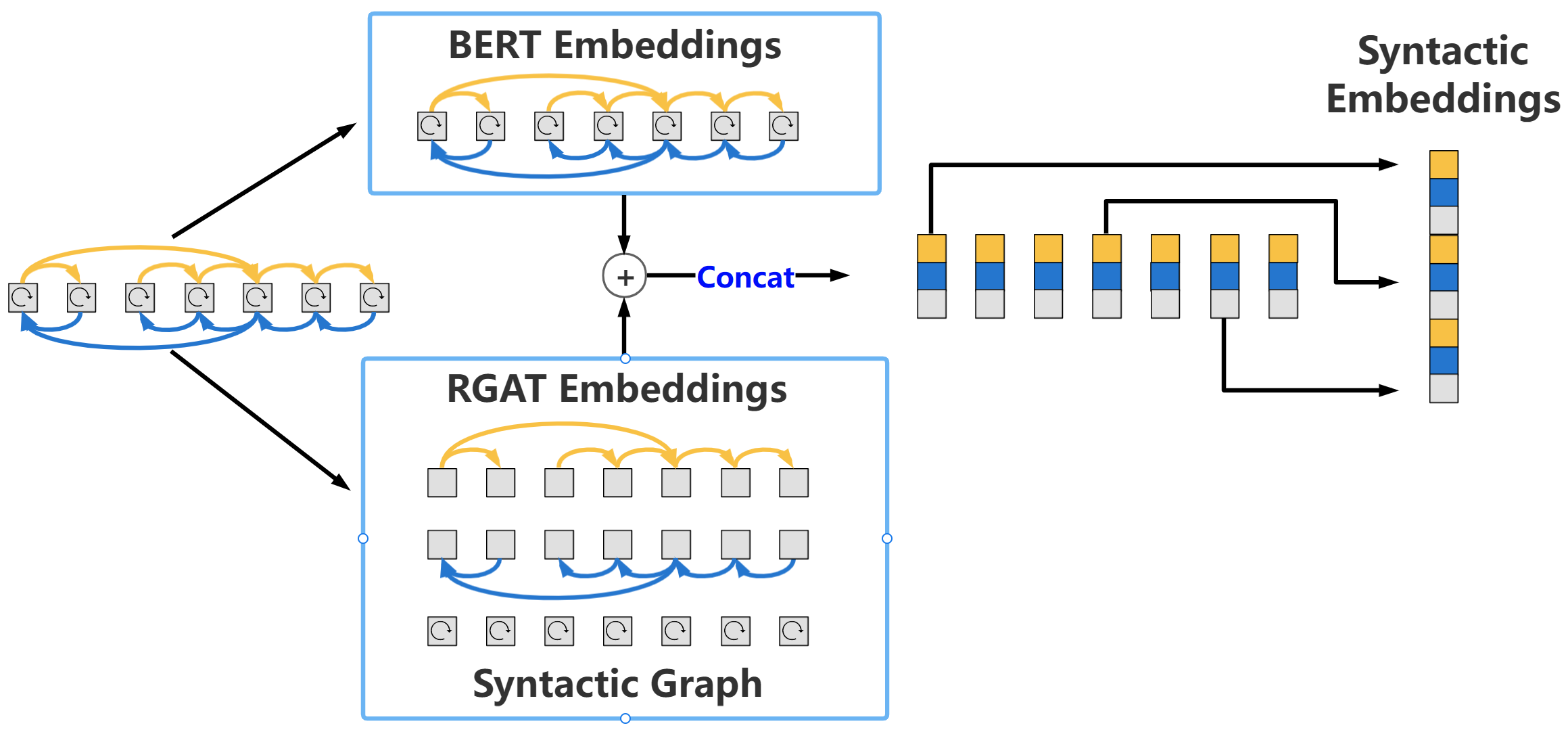
III-D Connect BERT Embeddings and Syntactic Embeddings in Series
We blend the syntactic embedding derived from the syntactic dependency graph with the pretrained BERT embeddings by connecting BERT embedding and syntactic embedding in series. This integrated architecture can help us learn better-performing embeddings when dealing with the task of pronoun resolution.
We first use the pre-trained BERT to extract context information between words and then connect with syntactic information from RGAT to form a “look again” mechanism to further obtain blending representations that are more beneficial to the current task. The specific architecture is shown in Fig. 4.
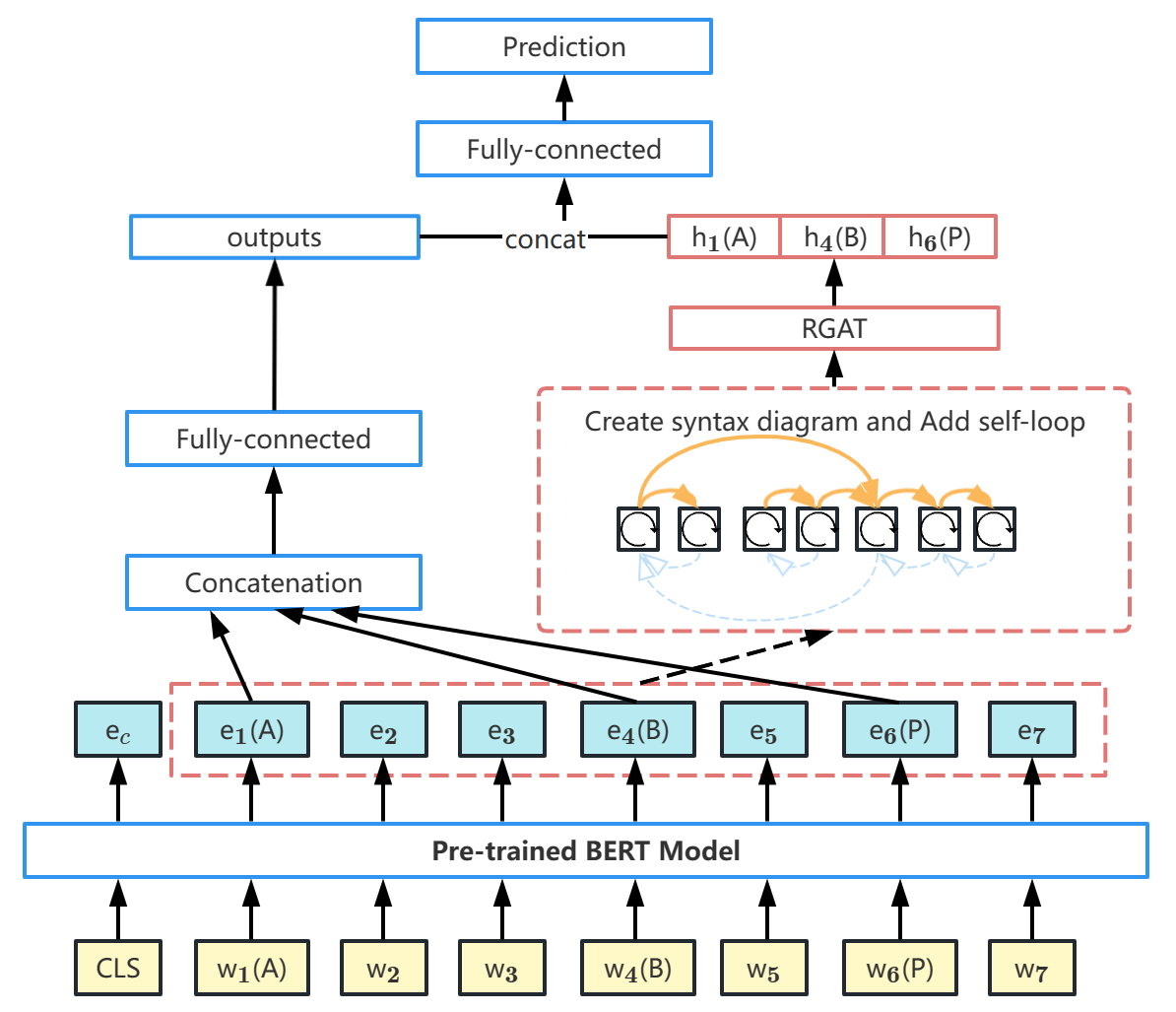
As shown in Fig. 4, the pre-trained BERT obtains the hidden feature representation, then RGAT looks at the syntactic information of the sentence again. Relying on the syntactic information derived from RGAT, we can obtain the hidden state of pronoun-related words (denoted as h1(A), h4(B), h6(P)) in the sentence. There is also a fully connected layer in parallel with the output of RGAT, which is used to get a more compact embedding representation for each pronoun-related word.
Finally, the outputs representation by RGAT are concatenated with the compact embedding representation of each pronoun-related word. The reason for concatenation is mainly because the syntactic dependency graph uses a special form of Laplace smoothing during its construction process [17], which may contain vertex-related features. Some original feature embeddings can be preserved by concatenation, and ultimately a fully connected layer is used for prediction.
IV Experiments
IV-A Experimental Setup
GAP Dataset. The first ACL workshop on Gender Bias in Natural Language Processing (2019) included a coreference task addressing Gendered Ambiguous Pronouns (GAP). The task is based on the coreference challenge defined by Webster [3] [18] and aims to benchmark the ability to address pronouns in real-word contexts in a gender-equitable way. 263 teams competed through the Kaggle competition, and the winning system ran at a speed of 0.13667, which is close to gender parity. We reviewed the approaches and their documentation of the top eleven systems, noting that they effectively use BERT [1], both through fine-tuning, feature extraction, or ensembles. In order to compare with the baseline results of the previous work on the GAP task [2] [3] [18] our work directly uses the Gendered Ambiguous Pronouns (GAP) dataset, containing all 8908 samples. The dataset contains 8908 pairs of labelled samples from Wikipedia. Consistent with previous work, 4908 samples are used as training data and 4000 samples are used as test data.
Evaluation metrics. The task is a multi-classification problem, and we use micro F1-score as the evaluation metric, which is to calculate the precision and recall of all classes together, and then calculate the micro F1-score according to the following formula.
| (7) |
| (8) |
| (9) |
| (10) |
Implementation Detail. We use the SpaCy module as a syntactic dependency analyzer in our work. For each sample, we build a syntactic dependency graph, then extract and save the needed information. Due to memory constraints, we do not put the entire syntactic dependency graph into the model for training, but first extract the features we needed from the graph, then combine them into a batch, and last sent them into the model. We use Adam [19] as the optimizer and adopt the form of warm up for the learning rate in our model. Especially, the L2 regularization result of the RGAT layer weight is added to the loss function, and the fully connected layer uses batch normalization and dropout strategy. In addition, for the number of sampling random neighbor nodes in the second step of the RGAT model, we found that each node has at most four different neighbors. Thus, in order to take into account the algorithm efficiency and the diversity of neighbor node calculations, we set the number of random samples to four. As for the aggregation method involved in the second step of GraphSage [16], we found that methods such as summation, mean, and maximum pooling basically have no different impact on the model performance. So, we simply use the aggregation method of summation. We use the “BERT-Large-Uncased” model to generate the BERT embedding representations we need. It should be noted that in our model, BERT has not been fine-tuned. The parameters of all BERT models are fixed during training. The advantage of this is that we do not need to save a separate copy of BERT-related model parameters for the GAP dataset.
In order to better improve the generalization of the model, we used the 5-fold cross validation method to split the training set into five equal parts. Each experiment takes one part for verification and the rest is used for training. Each time, the model parameters with the best performance on the validation set are applied to the test set to get the prediction result. A total of five prediction results are obtained, and the average value is taken as the final prediction result.
IV-B Ablation Studies
| Model | Type dim (m, n) | The way of link | F1-score |
|---|---|---|---|
| RGAT-with- | 5,10 | Mean/Sum | 81.5% |
| BERT | 10,20 | Mean/Sum | 81.7% |
| (ours) | 30,60 | Mean/Sum | 80.9% |
| 5,10 | Concat | 82.3% | |
| 10,20 | Concat | 82.5% | |
| 30,60 | Concat | 81.1% |
In order to be consistent with baseline work, we use the same hyperparameter configuration as RGCN-with-BERT [2]. However, in our proposed RGAT model, it is necessary to determine the dimension of the embeddings of the edge. To this end, we conduct experiments on different parameters and the results are shown in the TABLE I.
Through comparison, the dimension parameters (m, n) of the node type are set to (10.20). For the output features of three different edge types, we compare the F1-score of different aggregation methods such as averaging, summing and concatenation. Meanwhile, since the concatenation method will lead to an increase in the number of parameters, we adjust the feature dimension so that the parameters of three aggregation methods are relatively close. In the end, the mean and summing aggregation methods are found to obtain similar experiment results, while the concatenation aggregation method is found to obtain the best result.
IV-C Comparison with Other Methods
The paper proposing the GAP dataset [3] [18] introduced several baseline methods: (1) existing parsers including a rule-based system by Lee [20], as well as three neural parsers from Clark and Manning (2015) [21], Wiseman et al. (2016) [22] and Lee et al. (2017) [23]. (2) baselines based on traditional coreference cues; (3) baselines based on structural cues: syntactic distance and parallelism; (4) baselines based on Wikipedia cues; (5) Transformer models [24]. Among them, RGCN-with-BERT [2] further improves the F1-score of some baseline methods, reaching 80.3%.
We select the best three from the baseline models and the RGCN-with-BERT (Xu et al., 2019) [2] model to compare with our model. At the same time, we also compare our work with the BERT in series with a fully connected layer (BERT-fc). Experimental results show that our work achieves a large improvement over baseline models, which is shown in TABLE II.
| Model | F1-score | |
|---|---|---|
| baseline | Lee et al. (2017) [23] | 64.0% |
| Parallelism [23] | 66.9% | |
| Parallelism + URL [23] | 70.6% | |
| BERT-baseline | Bert + fc [2] | 78.5% |
| RGCN-with-BERT [2] | 80.3% | |
| ours | RGAT-with-BERT | 82.5% |
Specially, our RGAT model further leverages the structure of syntactic graphs and feature extraction information for specific referential tasks. Without fine-tuning the parameters of the original BERT model, the F1-score of the task is greatly improved from 80.3% of the previous best model to 82.5%. Compared with BERT + fc (details are in section III), it has increased from 78.5% to 82.5%.
IV-D RGAT Model Verification on OntoNotes 5.0 Dataset
OntoNotes dataset. OntoNotes 5.0 (English) is a document-level dataset from the CoNLL-2012 shared task on coreference resolution. It consists of about one million words of newswire, magazine articles, broadcast news, broadcast conversations, web data and conversational speech data, and the New Testament.
Evaluation metrics. The main evaluation is the average F1 of three metrics – , and on the test set according to the official CoNLL-2012 evaluation scripts. We briefly describe how to calculate these three metrics.
For , we can calculate its recall and precision as follows:
| (11) |
| (12) |
where is a collection of pronouns referring to the noun , is the set of pronouns that the model outputs referring to noun , and represents the intersection of and . F1-score can be calculated by formula (7).
For , we can calculate its recall and precision as follows:
| (13) |
| (14) |
For , we can calculate its recall and precision as follows:
| (15) |
| (16) |
where is a collection of pronouns referring to the noun , is the set of pronouns that the model outputs referring to noun . F1-score can be calculated by formula (7).
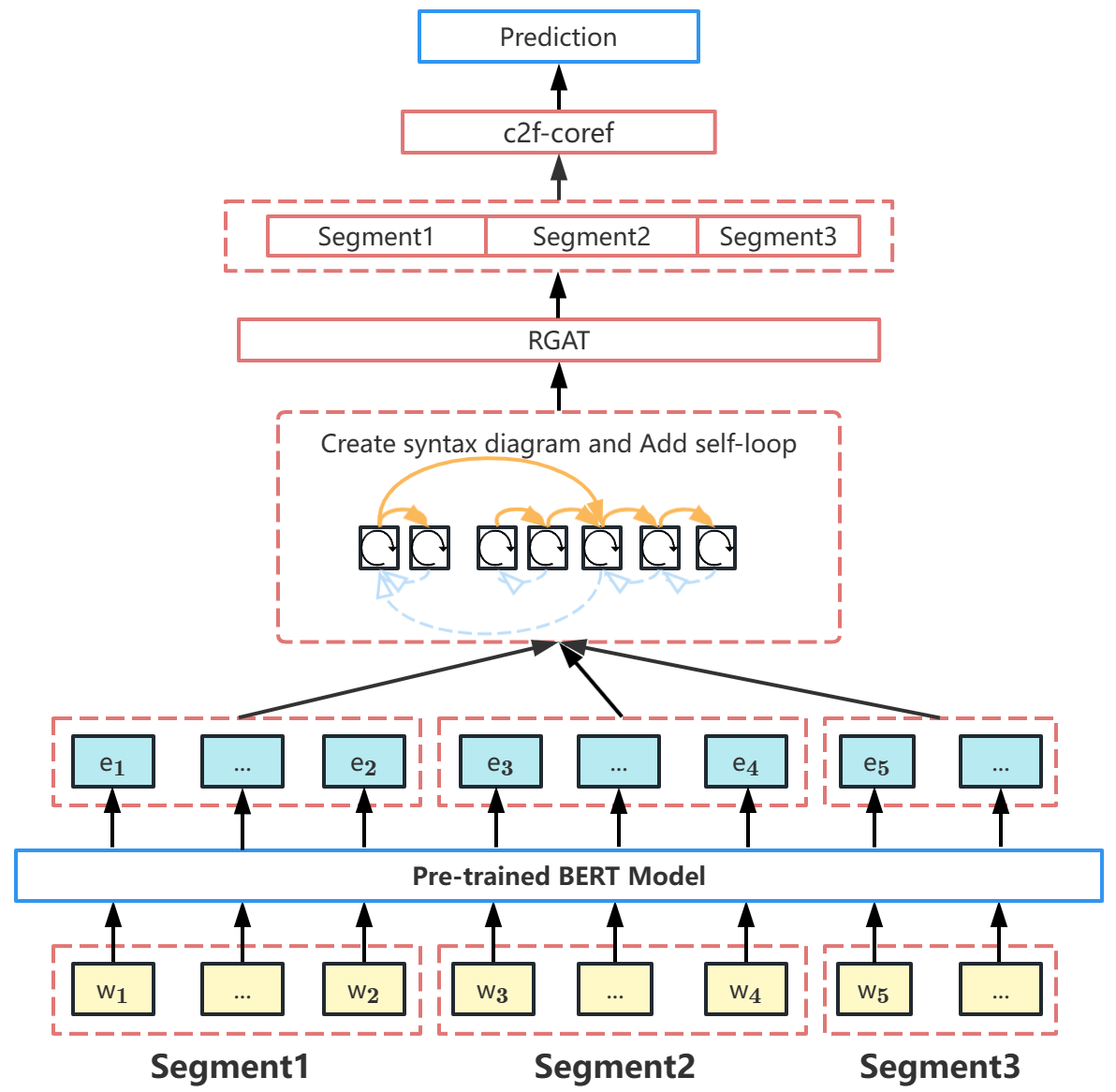
Implementation Detail. We also evaluate our models on the OntoNotes 5.0 dataset [25]. Different from the GAP dataset, the OntoNotes 5.0 examples are considerably longer and typically require multiple segments to read the entire document. We replace the entire BERT-large transformer (embeddings as input) in c2f-coref with the RGAT-with-BERT + c2f-coref (our model). The general model architecture is shown in Fig. 5.
We treat the first and last word-pieces (concatenated with the attended version of all word pieces in the span) as span representations. As shown in Fig. 5, each sample is split into three segments in our model, and each segment will be used as input to the BERT model. After passing through the RGAT model, the output will be passed through the c2f-coref architecture to get the predicted results.
Results. We compare the RGAT-with-BERT + c2f-coref system with three main baselines: (1) the original ELMo-based c2f-coref system [26], and (2) its predecessor, e2e-coref [22] and (3) the BERT-based c2f-coref system [27]. Experimental results show that our work achieves a large improvement over baseline models, which is shown in TABLE III. (P means precision, R means recall, F1 means F1-score).
| P | R | F1 | P | R | F1 | P | R | F1 | Avg.F1 | |
| e2e-coref [22] | 78.4 | 73.4 | 75.8 | 68.6 | 61.8 | 65.0 | 62.7 | 59.0 | 60.8 | 67.2 |
| c2f-coref [26] | 81.4 | 79.5 | 80.4 | 72.2 | 69.5 | 70.8 | 68.2 | 67.1 | 67.6 | 73.0 |
| Fei et al. [28] | 85.4 | 77.9 | 81.4 | 77.9 | 66.4 | 71.7 | 70.6 | 66.3 | 68.4 | 73.8 |
| EE [29] | 82.6 | 84.1 | 83.4 | 73.3 | 76.2 | 74.7 | 72.4 | 71.1 | 71.8 | 76.6 |
| BERT-base + c2f-coref [27] | 80.2 | 82.4 | 81.3 | 69.6 | 73.8 | 71.6 | 69.0 | 68.6 | 68.8 | 73.9 |
| BERT-large + c2f-coref [27] | 84.7 | 82.4 | 83.5 | 76.5 | 74.0 | 75.3 | 74.1 | 69.8 | 71.9 | 76.9 |
| RGAT-with-BERT + c2f-coref(ours) | 85.7 | 82.5 | 84.3 | 77.6 | 73.9 | 76.5 | 75.2 | 70.0 | 72.8 | 77.7 |
TABLE III shows that RGAT-with-BERT + c2f-coref outperforms the BERT-large + c2f-coref model on English by 0.8% on the OntoNotes 5.0 Dataset. The main evaluation metric is the average F1 of three metrics – , and on the test set. Given how gains on coreference resolution have been hard to come by as evidenced by baseline models in TABLE III, our model is still a considerable improvement. It is noted that compared with BERT, we only add a relatively small number of parameters, which can get a more obvious effect on the reference resolution task. Due to the limitation of computing resources, we did not tune high parameters further. In view of the experimental results, we believe that the syntactic structure can indeed help the model to further understand the coreference resolution task.
V Conclusion and Discussion
V-A Conclusions
The experiment results show that with the help of sentence syntactic dependency information, using the output representations of BERT pre-trained model, RGAT can further learn embedding representations that are more conducive to the task of pronoun resolution and improve the performance of this task.
“Gender Bias in Natural Language Processing (GeBNLP) 2019 Shared Task” is a competition to build a common reference parsing system on the GAP dataset. We employ a combination of BERT and our proposed graph neural network RGAT model to participate in this task. The RGAT model is used to digest the syntactic dependency graph, and further extract syntactic-related information from the output features by BERT, which helps us improve the accuracy of this task. Our model significantly improves the F1-score of the task from the previous best of 80.3% to 82.5% (an improvement of 2.2%). Compared with BERT plus a fully connected layer, the accuracy of fine-tuning the fully connected layer is only 78.5%, and our model has a 4.0% improvement. The results show that without fine-tuning the BERT model, the syntactic dependency graph can significantly improve the performance of the referencing problem.
For another classic dataset – OntoNotes 5.0, the comparison results of RGAT-with-BERT +c2f-coref VS. baseline BERT-large + c2f-coref indicates that syntactic structure might better encode longer contexts. These observations suggest that future research in pretraining methods may look at more effectively encoding document-level context including syntactic structure. Modelling pronouns, especially in the context of dialogue, still has a lot of potential for our model. Although our advantages are not very obvious, partly because we are limited to the c2f-coref architecture, we believe syntactic structure can effectively help our model achieve more comparable results for document modelling if we can design a suitable architecture for our model. Lastly, through the overview of training samples and our model outputs, a considerable number of errors suggest that our model is also still unable to resolve cases requiring mention paraphrasing like [27], especially considering that such learning signal is rather sparse in the training set. However, a few of these errors have been reduced. We think our model has the possibility to solve this problem.
V-B Discussion
In fact, our work provides an alternative paradigm for such similar coreference tasks or for those tasks that need to mine the role of syntactic information. Our work demonstrates it is not so necessary to fine-tune the entire BERT model and save a unique BERT model parameter for each task. Our proposed paradigm simply changes the classification header of the BERT model to graph neural networks with syntactic dependencies, and then fine-tunes the new classification header to obtain better results.
Our work is to solve the problems encountered by the current large pre-trained language model from a new perspective, that is, the pre-trained language model is too large, and it is necessary to save a new fine-tuned model parameter for each downstream task. For example, models such as LoRA [8], AdapterBias [30], and LLM-Adapters [31] all reduce the amount of parameter required for fine-tuning the model on the model itself and the output of each layer. And other models that incorporate traditional machine learning methods [4] [13] do not achieve competitive results. By comparison, our work is to use the output features of the pre-trained language model, but not to change the parameters of the model itself and the output features. Our work shows that changing the classification head can effectively reduce the amount of parameter for fine-tuning the pre-trained model and greatly improve the recognition accuracy of the task.
V-C Limitation and Future Direction
Our models and experiments have shown that syntactic dependency information plays a significant role in reference resolution tasks and that syntactic structure can optimize the embedded representation of large language models. However, there are three problems to solve in the future. (1) There is no evidence of the role of syntactic structures for other NLP tasks. (2) In this paper, supervised learning is used to optimize the embedded representations of BERT. It is a future direction to explore the unsupervised representation learning that combines BERT with syntactic structure. (3) When training, we can first save the features to the hard disk, but in inference, we do not store embedded features, so how to optimize the inference time is also a future problem.
Acknowledgment
This research was funded by Shanghai Philosophy and Social Sciences Planning Project, grant number 2020BGL009.
References
- [1] Devlin, Jacob, et al. ”Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
- [2] Xu, Yinchuan, and Junlin Yang. ”Look again at the syntax: Relational graph convolutional network for gendered ambiguous pronoun resolution.” arXiv preprint arXiv:1905.08868 (2019).
- [3] Webster, Kellie, et al. ”Mind the GAP: A balanced corpus of gendered ambiguous pronouns.” Transactions of the Association for Computational Linguistics 6 (2018): 605-617.
- [4] Mohan M, Nair J J. Coreference Resolution in Ambiguous Pronouns Using BERT and SVM[C]//2019 9th International Symposium on Embedded Computing and System Design (ISED). IEEE, 2019: 1-5.
- [5] Attree, Sandeep. ”Gendered ambiguous pronouns shared task: Boosting model confidence by evidence pooling.” arXiv preprint arXiv:1906.00839 (2019).
- [6] Ionita, Matei, et al. ”Resolving gendered ambiguous pronouns with BERT.” arXiv preprint arXiv:1906.01161 (2019).
- [7] Houlsby, Neil, et al. ”Parameter-efficient transfer learning for NLP.” International Conference on Machine Learning. PMLR, 2019.
- [8] Hu, Edward J., et al. ”Lora: Low-rank adaptation of large language models.” arXiv preprint arXiv:2106.09685 (2021).
- [9] Cen, Yukuo, et al. ”Representation learning for attributed multiplex heterogeneous network.” Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.
- [10] Schlichtkrull, Michael, et al. ”Modeling relational data with graph convolutional networks.” The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3–7, 2018, Proceedings 15. Springer International Publishing, 2018.
- [11] Hobbs, Jerry R. ”Resolving pronoun references.” Lingua 44.4 (1978): 311-338.
- [12] Lappin, Shalom, and Herbert J. Leass. ”An algorithm for pronominal anaphora resolution.” Computational linguistics 20.4 (1994): 535-561.
- [13] Haghighi, Aria, and Dan Klein. ”Simple coreference resolution with rich syntactic and semantic features.” Proceedings of the 2009 conference on empirical methods in natural language processing. 2009.
- [14] Sukthanker, Rhea, et al. ”Anaphora and coreference resolution: A review.” Information Fusion 59 (2020): 139-162.
- [15] Marcheggiani, Diego, and Ivan Titov. ”Encoding sentences with graph convolutional networks for semantic role labeling.” arXiv preprint arXiv:1703.04826 (2017).
- [16] Hamilton, Will, Zhitao Ying, and Jure Leskovec. ”Inductive representation learning on large graphs.” Advances in neural information processing systems 30 (2017).
- [17] Li, Qimai, Zhichao Han, and Xiao-Ming Wu. ”Deeper insights into graph convolutional networks for semi-supervised learning.” Thirty-Second AAAI conference on artificial intelligence. 2018.
- [18] Webster, Kellie, et al. ”Gendered ambiguous pronoun (GAP) shared task at the Gender Bias in NLP Workshop 2019.” Proceedings of the First Workshop on Gender Bias in Natural Language Processing. 2019.
- [19] Kingma, Diederik P., and Jimmy Ba. ”Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980 (2014).
- [20] Lee, Heeyoung, et al. ”Deterministic coreference resolution based on entity-centric, precision-ranked rules.” Computational linguistics 39.4 (2013): 885-916.
- [21] Clark, Kevin, and Christopher D. Manning. ”Entity-centric coreference resolution with model stacking.” Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2015.
- [22] Wiseman, Sam, Alexander M. Rush, and Stuart M. Shieber. ”Learning global features for coreference resolution.” arXiv preprint arXiv:1604.03035 (2016).
- [23] Lee, Kenton, et al. ”End-to-end neural coreference resolution.” arXiv preprint arXiv:1707.07045 (2017).
- [24] Vaswani, Ashish, et al. ”Attention is all you need.” Advances in neural information processing systems 30 (2017).
- [25] Pradhan, Sameer, et al. ”CoNLL-2012 shared task: Modeling multilingual unrestricted coreference in OntoNotes.” Joint Conference on EMNLP and CoNLL-Shared Task. 2012.
- [26] Lee, Kenton, Luheng He, and Luke Zettlemoyer. ”Higher-order coreference resolution with coarse-to-fine inference.” arXiv preprint arXiv:1804.05392 (2018).
- [27] Joshi, Mandar, et al. ”BERT for coreference resolution: Baselines and analysis.” arXiv preprint arXiv:1908.09091 (2019).
- [28] Liu, Fei, Luke Zettlemoyer, and Jacob Eisenstein. ”The referential reader: A recurrent entity network for anaphora resolution.” arXiv preprint arXiv:1902.01541 (2019).
- [29] Kantor, Ben, and Amir Globerson. ”Coreference resolution with entity equalization.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.
- [30] Fu, Chin-Lun, et al. ”AdapterBias: Parameter-efficient Token-dependent Representation Shift for Adapters in NLP Tasks.” arXiv preprint arXiv:2205.00305 (2022).
- [31] Hu, Zhiqiang, et al. ”LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models.” arXiv preprint arXiv:2304.01933 (2023).