Risk Bounds for Mixture Density Estimation on Compact Domains via the -Lifted Kullback–Leibler Divergence
Abstract
We consider the problem of estimating probability density functions based on sample data, using a finite mixture of densities from some component class. To this end, we introduce the -lifted Kullback–Leibler (KL) divergence as a generalization of the standard KL divergence and a criterion for conducting risk minimization. Under a compact support assumption, we prove an bound on the expected estimation error when using the -lifted KL divergence, which extends the results of Rakhlin et al. (2005, ESAIM: Probability and Statistics, Vol. 9) and Li & Barron (1999, Advances in Neural Information Processing Systems, Vol. 12) to permit the risk bounding of density functions that are not strictly positive. We develop a procedure for the computation of the corresponding maximum -lifted likelihood estimators (-MLLEs) using the Majorization-Maximization framework and provide experimental results in support of our theoretical bounds.
1 Introduction
Let be an abstract probability space and let be a random variable taking values in the measurable space , where is a compact metric space equipped with its Borel -algebra . Suppose that we observe an independent and identically distributed (i.i.d.) sample of random variables , where , and that each arises from the same data generating process as , characterized by the probability measure on , with density function , for some -finite . In this work, we are concerned with the estimating via a data dependent double-index sequence of estimators , where
for each , and where
| (1) |
, and . To ensure the measurability and existence of various optima, we shall assume that is Carathéodory in the sense that is -measurable for each , and is continuous for each .
In the definition above, we can identify the set as the set of density functions that can be written as a convex combination of elements of , where is often called the space of component density functions. We then interpret as the class of -component finite mixtures of densities of class , as studied, for example, by McLachlan & Peel (2004); Nguyen et al. (2020; 2022b).
1.1 Risk bounds for mixture density estimation
We are particularly interested in oracle bounds of the form
| (2) |
where is a loss function on pairs of density functions. We define the density-to-class loss
where is the closure. Here, we identify as a characterization of the rate at which the left-hand side of (2) converges to zero as and increase. Our present work follows the research of Li & Barron (1999), Rakhlin et al. (2005) and Klemelä (2007) (see also Klemelä 2009, Ch. 19). In Li & Barron (1999) and Rakhlin et al. (2005), the authors consider the case where is taken to be the Kullback–Leibler (KL) divergence
and is a maximum likelihood estimator (MLE), where
is a function of , with denoting the probability simplex in .
Under the assumption that , for some and each (i.e., strict positivity), Li & Barron (1999) obtained the bound
for constants , which was then improved by Rakhlin et al. (2005) who obtained the bound
for constants (constants are typically different between expressions).
Alternatively, Klemelä (2007) takes to be the squared norm distance (i.e., the least-squares loss):
where , for each , and choose as minimizers of the empirical risk, i.e., , where
| (3) |
Here, Klemelä (2007) establish the bound
, without the lower bound assumption on above, even permitting to be unbounded. Via the main results of Naito & Eguchi (2013), the bound above can be generalized to the -divergences, which includes the special norm distance as a special case.
On the one hand, the sequence of MLEs required for the results of Li & Barron (1999) and Rakhlin et al. (2005) are typically computable, for example, via the usual expectation–maximization approach (cf. McLachlan & Peel 2004, Ch. 2). This contrasts with the computation of least-squares density estimators of form (3), which requires evaluations of the typically intractable integral expressions . However, the least-squares approach of Klemelä (2007) permits the analysis using families of usual interest, such as normal distributions and beta distributions, the latter of which being compactly supported but having densities that cannot be bounded away from zero without restrictions, and thus do not satisfy the regularity conditions of Li & Barron (1999) and Rakhlin et al. (2005).
1.2 Main contributions
We propose the following -lifted KL divergence, as a generalization of the standard KL divergence to address the computationally tractable estimation of density functions which do not satisfy the regularity conditions of Li & Barron (1999) and Rakhlin et al. (2005). The use of the -lifted KL divergence has the possibility to advance theories based on the standard KL divergence in statistical machine learning. To this end, let be a function in , and define the -lifted KL divergence by:
| (4) |
In the sequel, we shall show that is a Bregman divergence on the space of probability density functions, as per Csiszár (1995).
Assume that is a probability density function, and let be a an i.i.d. sample, independent of , where each is a random variable with probability measure on , characterized by the density with respect to . Then, for each and , let be defined via the maximum -lifted likelihood estimator (-MLLE; see Appendix B for further discussion) , where
| (5) |
The primary aim of this work is to show that
| (6) |
for some constants , without requiring the strict positivity assumption that .
This result is a compromise between the works of Li & Barron (1999) and Rakhlin et al. (2005), and Klemelä (2007), as it applies to a broader space of component densities , and because the required -MLLEs (5) can be efficiently computed via minorization–maximization (MM) algorithms (see e.g., Lange 2016). We shall discuss this assertion in Section 4.
1.3 Relevant literature
Our work largely follows the approach of Li & Barron (1999), which was extended upon by Rakhlin et al. (2005) and Klemelä (2007). All three texts use approaches based on the availability of greedy algorithms for maximizing convex functions with convex functional domains. In this work, we shall make use of the proof techniques of Zhang (2003). Related results in this direction can be found in DeVore & Temlyakov (2016) and Temlyakov (2016). Making the same boundedness assumption as Rakhlin et al. (2005), Dalalyan & Sebbar (2018) obtain refined oracle inequalities under the additional assumption that the class is finite. Numerical implementations of greedy algorithms for estimating finite mixtures of Gaussian densities were studied by Vlassis & Likas (2002) and Verbeek et al. (2003).
The -MLLE as an optimization objective can be compared to other similar modified likelihood estimators, such as the likelihood of Ferrari & Yang (2010) and Qin & Priebe (2013), the -likelihood of Basu et al. (1998) and Fujisawa & Eguchi (2006), penalized likelihood estimators, such as maximum a posteriori estimators of Bayesian models, or -separable Bregman distortion measures of Kobayashi & Watanabe (2024; 2021).
The practical computation of the -MLLEs, (5), is made possible via the MM algorithm framework of Lange (2016), see also Hunter & Lange (2004), Wu & Lange (2010), and Nguyen (2017) for further details. Such algorithms have well-studied global convergence properties and can be modified for mini-batch and stochastic settings (see, e.g., Razaviyayn et al., 2013 and Nguyen et al., 2022a).
A related and popular setting of investigations is that of model selection, where the objects of interest are single-index sequences , and where the aim is to obtain finite-sample bounds for losses of the form , where each is a data dependent function, often obtained by optimizing some penalized loss criterion, as described in Massart (2007), Koltchinskii (2011, Ch. 6), and Giraud (2021, Ch. 2). In the context of finite mixtures, examples of such analyses can be found in the works of Maugis & Michel (2011) and Maugis-Rabusseau & Michel (2013). A comprehensive bibliography of model selection results for finite mixtures and related statistical models can be found in Nguyen et al. (2022c).
1.4 Organization of paper
The manuscript is organized as follows. In Section 2, we formally define the -lifted KL divergence as a Bregman divergence and establish several of its properties. In Section 3, we present new risk bounds for the -lifted KL divergence of the form (2). In Section 4, we discuss the computation of the -lifted likelihood estimator in the form of (5), followed by empirical results illustrating the convergence of (2) with respect to both and . Additional insights and technical results are provided in the Appendices at the end of the manuscript.
2 The -lifted KL divergence and its properties
In this section we formally define the -lifted KL divergence on the space of density functions and establish some of its properties.
Definition 1 (-lifted KL divergence).
Let , and be probability density functions on the space , where . The -lifted KL divergence from to is defined as follows:
2.1 as a Bregman divergence
Let , be a strictly convex function that is continuously differentiable. The Bregman divergence between scalars generated by the function is given by:
where denotes the derivative of at .
Bregman divergences possess several useful properties, including the following list:
-
1.
Non-negativity: for all with equality if and only if ;
-
2.
Asymmetry: in general;
-
3.
Convexity: is convex in for every fixed .
-
4.
Linearity: for .
The properties for Bregman divergences between scalars can be extended to density functions and other functional spaces, as established in Frigyik et al. (2008) and Stummer & Vajda (2012), for example. We also direct the interested reader to the works of Pardo (2006), Basu et al. (2011), and Amari (2016).
The class of -lifted KL divergences constitute a generalization of the usual KL divergence and are a subset of the Bregman divergences over the space of density functions that are considered by Csiszár (1995). Namely, let be a convex set of probability densities with respect to the measure on . The Bregman divergence between densities can be constructed as follows:
The -lifted KL divergence as a Bregman divergence is generated by the function . This assertion is demonstrated in Appendix C.1.
2.2 Advantages of the -lifted KL divergence
When the standard KL divergence is employed in the density estimation problem, it is common to restrict consideration of density functions to those bounded away from zero by some positive constant. That is, one typically considers the smaller class of so-called admissible target densities (cf. Meir & Zeevi, 1997), where
Without this restriction, the standard KL divergence can be unbounded, even for functions with bounded norms. For example, let and be densities of beta distributions on the support . That is, suppose that , respectively characterized by parameters and , where
| (7) |
Then, from Gil et al. (2013), the KL divergence between and is given by:
where is the digamma function. Next, suppose that and , which leads to the simplification
Since is strictly increasing, we observe that the right-hand side diverges as . Thus, the KL divergence between beta distributions is unbounded. The -lifted KL divergence in contrast does not suffer from this problem, and does not require the restriction to . This allows us to consider cases where are not bounded away from , as per the following result.
Proposition 2.
Let be defined as in (1). is bounded for all continuous densities .
Proof.
See Appendix C.2. ∎
Let denote the standard -norm, . As remarked previously, Klemelä (2007) established empirical risk bounds in terms of the -norm distance. Following results from Meir & Zeevi (1997) characterizing the relationship between the KL divergence in terms of the -norm distance, in Proposition 3 we establish the corresponding relationship between the -lifted KL divergence and the -norm distance, along with a relationship between the -lifted KL divergence and the -norm distance.
Proposition 3.
For probability density functions and , where is such that for all , the following inequalities hold:
Proof.
See Appendix C.3. ∎
Remark 4.
Proposition 2 highlights the benefit of the -lifted KL divergence being bounded for all continuous densities, unlike the standard KL divergence, while satisfying a relationship similar to that between the KL divergence and the norm distance. Moreover, the first inequality of Proposition 3 is a Pinsker-like relationship between the -lifted KL divergence and the total variation distance .
3 Main results
Here we provide explicit statements regarding the convergence rates claimed in (6) via Theorem 5 and Corollary 6, which are proved in Appendix A.2. We assume that is bounded above by some constant and that the lifting function is bounded above and below by constants and , respectively.
Theorem 5.
Let be a positive density satisfying , for all . For any target density satisfying , for all and where is the minimizer of over -component mixtures, the following inequality holds:
where , , and are positive constants that depend on some or all of , , and .
Corollary 6.
Let and be compact and assume the following Lipschitz condition holds: for each , and for each ,
| (8) |
for some function , where . Then the bound in Theorem 5 becomes
where and are positive constants.
Remark 7.
Our results are applicable to any compact metric space , with used in the experimental setup in Section 4.2 as a simple and tractable example to illustrate key aspects of our theory. There is no issue in generalizing to for and , or more abstractly, to any compact subset . Additionally, could even be taken as a functional compact space, though establishing compactness and constructing appropriate component classes over such spaces to achieve small approximation errors is an approximation theoretic task that falls outside the scope of our work.
From the proof of Theorem 5 in Appendix A.2, it is clear that the dimensionality of only influences our bound through the complexity of the class , specifically, the constant , which remains independent of both and . Here, is the -covering number of . In fact, the constant with respect to ( in Theorem 5) is entirely unaffected by the dimensionality of . Thus, the rates of our bound on the expected -lifted KL divergence are dimension-independent and hold even when is infinite-dimensional, as long as there exists a class such that is finite.
Corollary 6 provides a method for obtaining such a bound when the elements of satisfy a Lipschitz condition.
4 Numerical experiments
Here we discuss the computability and computation of estimation problems and provide empirical evidence towards the rates obtained in Theorem 5. Specifically, we seek to develop a methodology for computing -MLLEs, and to use numerical experiments to demonstrate that the sequence of expected -lifted KL divergences between some density and a sequence of -component mixture densities from a suitable class , estimated using observations does indeed decrease at rates proportional to and , as and increase.
The code for all simulations and analyses in Experiments 1 and 2 is available in both the R and Python programming languages. The code repository is available here: https://github.com/hiendn/LiftedLikelihood.
4.1 Minorization–Maximization algorithm
One solution for computing (5) is to employ an MM algorithm. To do so, we first write the objective of (5) as
where . We then require the definition of a minorizer for on the space , where is a function with the properties:
-
(i)
, and
-
(ii)
,
for each . In this context, given a fixed , the minorizer should possess properties that simplify it compared to the original objective . These properties should make the minorizer more tractable and might include features such as parametric separability, differentiability, convexity, among others.
In order to build an appropriate minorizer for , we make use of the so-called Jensen’s inequality minorizer, as detailed in Lange (2016, Sec. 4.3), applied to the logarithm function. This construction results in a minorizer of the form
where
and
Observe that now takes the form of a sum-of-logarithms, as opposed to the more challenging log-of-sum form of . This change produces a functional separation of the elements of .
Using , we then define the MM algorithm via the parameter sequence , where
| (9) |
for each , and where is user chosen and is typically referred to as the initialization of the algorithm. Notice that for each , (9) is a simpler optimization problem than (5). Writing , we observe that (9) simplifies to the separated expressions:
and
for each .
A noteworthy property of the MM sequence is that it generates an increasing sequence of objective values, due to the chain of inequalities
where the equality is due to property (i) of , the first in equality is due to the definition of , and the second inequality is due to property (ii) of . This provides a kind of stability and regularity to the sequence .
Of course, we can provide stronger guarantees under additional assumptions. Namely, assume that (iii) , where is an open set in a finite dimensional Euclidean space on which and is differentiable, for each . Then, under assumptions (i)–(iii) regarding and , and due to the compactness of and the continuity of on , Razaviyayn et al. (2013, Cor. 1) implies that converges to the set of stationary points of in the sense that
More concisely, we say that the sequence globally converges to the set of stationary points .
4.2 Experimental setup
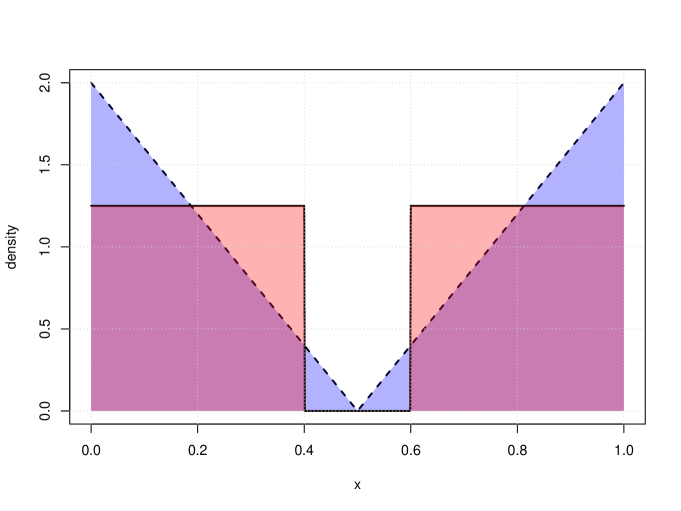
Towards the task of demonstrating empirical evidence of the rates in Theorem 5, we consider the family of beta distributions on the unit interval as our base class (i.e., (7)) to estimate a pair of target densities
and
where is the characteristic function that takes value if and , otherwise. Note that neither nor are in . In particular, when , and when , and hence neither densities are bounded away from 0, on . Thus, the theory of Rakhlin et al. (2005) cannot be applied to provide bounds for the expected KL divergence between MLEs of beta mixtures and the pair of targets. We visualize and in Figure 1.
To observe the rate of decrease of the -lifted KL divergence between the targets and respective sequences of -MLLEs, we conduct two experiments E1 and E2. In E1, our target density is set to and . For each and , we independently simulate and with each and (), i.i.d., from the distributions characterized by and , respectively. In E2, we target with -MLLEs over the same ranges of and , but with –the density of the uniform distribution. For each and , we simulate and , respectively, from distributions characterized by and .
In both experiments, we simulate replicates of each -scenario and compute the corresponding -MLLEs, , using the previously described MM algorithm. For each , we compute the corresponding negative log -lifted likelihood between the target and :
to assess the rates, and note that
where the prior term is a constant with respect to and .
To analyze the sample of observations of relationship between the values and the corresponding values of and , we use non-linear least squares (Amemiya, 1985, Sec. 4.3) to fit the regression relationship
| (10) |
We obtain asymptotic confidence intervals for the estimates of the regression parameters , , , , , under the assumption of potential mis-specification of (10), by using the sandwich estimator for the asymptotic covariance matrix (cf. White 1982).
4.3 Results
We report the estimates along with asymptotic confidence intervals for the parameters of (10) for E1 and E2 in Table 1. Plots of the average negative log -lifted likelihood values by sample sizes and numbers of components are provided in Figure 2.
| E1 | |||||
|---|---|---|---|---|---|
| Est. | |||||
| 95% CI | |||||
| E2 | |||||
| Est. | |||||
| 95% CI |
From Table 1, we observe that decreases with both and in both simulations, and that the rates at which the averages decrease are faster than anticipated by Theorem 5, with respect to both and . We can visually confirm the decreases in the estimate of via Figure 2. In both E1 and E2, the rate of decrease over the assessed range of is approximately proportional to , as opposed to the anticipated rate of , whereas the rate of decrease in is far larger, at approximately for E1 and for E2.
These observations provide empirical evidence towards the fact that the rate of decrease of is at least and , respectively, for and , at least over the simulation scenarios. These fast rates of fit over small values of and may be indicative of a diminishing returns of fit phenomenon, as discussed in Cadez & Smyth (2000) or the so-called elbow phenomenon (see, e.g., Ritter 2014, Sec. 4.2), whereupon the rate of decrease in average loss for small values of is fast and becomes slower as increases, converging to some asymptotic rate. This is also the reason why we do not include the outcomes when , as the drop in between and is so dramatic that it makes our simulated data ill-fitted by any model of form (10). As such, we do not view Theorem 5 as being pessimistic in light of these phenomena, as it applies uniformly over all values of and .
5 Conclusion
The estimation of probability densities using finite mixtures from some base class appears often in machine learning and statistical inference as a natural method for modelling underlying data generating processes. In this work, we pursue novel generalization bounds for such mixture estimators. To this end, we introduce the family of -lifted KL divergences for densities on compact supports, within the family of Bregman divergences, which correspond to risk functions that can be bounded, even when densities in the class are not bounded away from zero, unlike the standard KL divergence.
Unlike the least-squares loss, the corresponding maximum -likelihood estimation problem can be computed via an MM algorithm, mirroring the availability of EM algorithms for the maximum likelihood problem corresponding to the KL divergence. Along with our derivations of generalization bounds that achieve the same rates as the best-known bounds for the KL divergence and least square loss, we also provide numerical evidence towards the correctness of these bounds in the case when corresponds to beta densities.
Aside from beta distributions, mixture densities on compact supports that can be analysed under our framework appear frequently in the literature. For supports on compact Euclidean subset, examples include mixtures of Dirichlet distributions (Fan et al., 2012) and bivariate binomial distributions (Papageorgiou & David, 1994). Alternatively, one can consider distributions on compact Euclidean manifolds, such as mixtures of Kent (Peel et al., 2001) distributions and von Mises–Fisher distributions (Banerjee et al., 2005, Ng & Kwong, 2022). We defer investigating the practical performance of the maximum -lifted likelihood estimators and accompanying theory for such models to future work.
Acknowledgments
We express sincere gratitude to the Reviewers and Action Editor for their valuable feedback, which has helped to improve the quality of this paper. Hien Duy Nguyen and TrungTin Nguyen acknowledge funding from the Australian Research Council grant DP230100905.
References
- Amari (2016) Shun-ichi Amari. Information Geometry and Its Applications, volume 194. Springer, New York, 2016.
- Amemiya (1985) Takeshi Amemiya. Advanced econometrics. Harvard University Press, 1985.
- Banerjee et al. (2005) Arindam Banerjee, Inderjit S Dhillon, Joydeep Ghosh, Suvrit Sra, and Greg Ridgeway. Clustering on the unit hypersphere using von Mises-Fisher distributions. Journal of Machine Learning Research, 6(9), 2005.
- Bartlett & Mendelson (2002) Peter L Bartlett and Shahar Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results. Journal of Machine Learning Research, 3(Nov):463–482, 2002.
- Basu et al. (1998) Ayanendranath Basu, Ian R Harris, Nils L Hjort, and MC Jones. Robust and efficient estimation by minimising a density power divergence. Biometrika, 85(3):549–559, 1998.
- Basu et al. (2011) Ayanendranath Basu, Hiroyuki Shioya, and Chanseok Park. Statistical Inference: The Minimum Distance Approach. CRC press, Boca Raton, 2011.
- Cadez & Smyth (2000) Igor Cadez and Padhraic Smyth. Model complexity, goodness of fit and diminishing returns. Advances in Neural Information Processing Systems, 13, 2000.
- Csiszár (1995) Imre Csiszár. Generalized projections for non-negative functions. In Proceedings of 1995 IEEE International Symposium on Information Theory, pp. 6. IEEE, 1995.
- Dalalyan & Sebbar (2018) Arnak S Dalalyan and Mehdi Sebbar. Optimal kullback–leibler aggregation in mixture density estimation by maximum likelihood. Mathematical Statistics and Learning, 1(1):1–35, 2018.
- DeVore & Temlyakov (2016) Ronald A DeVore and Vladimir N Temlyakov. Convex optimization on banach spaces. Foundations of Computational Mathematics, 16(2):369–394, 2016.
- Devroye & Györfi (1985) Luc Devroye and László Györfi. Nonparametric Density Estimation: The L1 View. Wiley Interscience Series in Discrete Mathematics. Wiley, 1985.
- Devroye & Lugosi (2001) Luc Devroye and Gabor Lugosi. Combinatorial Methods in Density Estimation. Springer Science & Business Media, 2001.
- Fan et al. (2012) Wentao Fan, Nizar Bouguila, and Djemel Ziou. Variational learning for finite dirichlet mixture models and applications. IEEE transactions on neural networks and learning systems, 23:762–774, 2012.
- Ferrari & Yang (2010) Davide Ferrari and Yuhong Yang. Maximum lq-likelihood method. Annals of Statistics, 38:573–583, 2010.
- Frigyik et al. (2008) Béla A Frigyik, Santosh Srivastava, and Maya R Gupta. Functional bregman divergence and bayesian estimation of distributions. IEEE Transactions on Information Theory, 54(11):5130–5139, 2008.
- Fujisawa & Eguchi (2006) Hironori Fujisawa and Shinto Eguchi. Robust estimation in the normal mixture model. Journal of Statistical Planning and Inference, 136(11):3989–4011, 2006.
- Ghosal (2001) Subhashis Ghosal. Convergence rates for density estimation with Bernstein polynomials. The Annals of Statistics, 29(5):1264 – 1280, 2001. Publisher: Institute of Mathematical Statistics.
- Gil et al. (2013) Manuel Gil, Fady Alajaji, and Tamas Linder. Rényi divergence measures for commonly used univariate continuous distributions. Information Sciences, 249:124–131, 2013.
- Giraud (2021) Christophe Giraud. Introduction to high-dimensional statistics. CRC Press, 2021.
- Haagerup (1981) Uffe Haagerup. The best constants in the Khintchine inequality. Studia Mathematica, 70(3):231–283, 1981.
- Hunter & Lange (2004) David R Hunter and Kenneth Lange. A tutorial on mm algorithms. The American Statistician, 58(1):30–37, 2004.
- Klemelä (2007) Jussi S Klemelä. Density estimation with stagewise optimization of the empirical risk. Machine Learning, 67:169–195, 2007.
- Klemelä (2009) Jussi S Klemelä. Smoothing of multivariate data: density estimation and visualization. John Wiley & Sons, New York, 2009.
- Kobayashi & Watanabe (2021) Masahiro Kobayashi and Kazuho Watanabe. Generalized Dirichlet-process-means for f-separable distortion measures. Neurocomputing, 458:667–689, 2021.
- Kobayashi & Watanabe (2024) Masahiro Kobayashi and Kazuho Watanabe. Unbiased Estimating Equation and Latent Bias under f-Separable Bregman Distortion Measures. IEEE Transactions on Information Theory, 2024.
- Koltchinskii (2011) Vladimir Koltchinskii. Oracle Inequalities in Empirical Risk Minimization and Sparse Recovery Problems: École D’Été de Probabilités de Saint-Flour XXXVIII-2008. Lecture Notes in Mathematics. Springer, 2011.
- Koltchinskii & Panchenko (2004) Vladimir Koltchinskii and Dmitry Panchenko. Rademacher processes and bounding the risk of function learning. arXiv: Probability, pp. 443–457, 2004.
- Kosorok (2007) Michael R. Kosorok. Introduction to Empirical Processes and Semiparametric Inference. Springer Series in Statistics. Springer New York, 2007.
- Lange (2013) Kenneth Lange. Optimization, volume 95. Springer Science & Business Media, New York, 2013.
- Lange (2016) Kenneth Lange. MM optimization algorithms. SIAM, Philadelphia, 2016.
- Li & Barron (1999) Jonathan Li and Andrew Barron. Mixture Density Estimation. In S. Solla, T. Leen, and K. Müller (eds.), Advances in Neural Information Processing Systems, volume 12. MIT Press, 1999.
- Massart (2007) Pascal Massart. Concentration inequalities and model selection: Ecole d’Eté de Probabilités de Saint-Flour XXXIII-2003. Springer, 2007.
- Maugis & Michel (2011) Cathy Maugis and Bertrand Michel. A non asymptotic penalized criterion for gaussian mixture model selection. ESAIM: Probability and Statistics, 15:41–68, 2011.
- Maugis-Rabusseau & Michel (2013) Cathy Maugis-Rabusseau and Bertrand Michel. Adaptive density estimation for clustering with gaussian mixtures. ESAIM: Probability and Statistics, 17:698–724, 2013.
- McDiarmid (1989) Colin McDiarmid. On the method of bounded differences. In J.Editor Siemons (ed.), Surveys in Combinatorics, 1989: Invited Papers at the Twelfth British Combinatorial Conference, London Mathematical Society Lecture Note Series, pp. 148–188. Cambridge University Press, 1989.
- McDiarmid (1998) Colin McDiarmid. Concentration. In Michel Habib, Colin McDiarmid, Jorge Ramirez-Alfonsin, and Bruce Reed (eds.), Probabilistic Methods for Algorithmic Discrete Mathematics, pp. 195–248. Springer Berlin Heidelberg, Berlin, Heidelberg, 1998.
- McLachlan & Peel (2004) Geoffrey J McLachlan and David Peel. Finite Mixture Models. John Wiley & Sons, 2004.
- Meir & Zeevi (1997) Ronny Meir and Assaf Zeevi. Density estimation through convex combinations of densities: Approximation and estimation bounds. Neural Networks, 10:99–109, 02 1997.
- Naito & Eguchi (2013) Kanta Naito and Shinto Eguchi. Density estimation with minimization of U-divergence. Machine Learning, 90(1):29–57, January 2013.
- Ng & Kwong (2022) Tin Lok James Ng and Kwok-Kun Kwong. Universal approximation on the hypersphere. Communications in Statistics-Theory and Methods, 51:8694–8704, 2022.
- Nguyen (2017) Hien D Nguyen. An introduction to majorization-minimization algorithms for machine learning and statistical estimation. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 7(2):e1198, 2017.
- Nguyen et al. (2021) Hien D Nguyen, TrungTin Nguyen, Faicel Chamroukhi, and Geoffrey J McLachlan. Approximations of conditional probability density functions in Lebesgue spaces via mixture of experts models. Journal of Statistical Distributions and Applications, 8(1):13, August 2021.
- Nguyen et al. (2022a) Hien D Nguyen, Florence Forbes, Gersende Fort, and Olivier Cappé. An online minorization-maximization algorithm. In Proceedings of the 17th Conference of the International Federation of Classification Societies, 2022a.
- Nguyen et al. (2020) TrungTin Nguyen, Hien D Nguyen, Faicel Chamroukhi, and Geoffrey J McLachlan. Approximation by finite mixtures of continuous density functions that vanish at infinity. Cogent Mathematics & Statistics, 7:1750861, 2020.
- Nguyen et al. (2022b) TrungTin Nguyen, Faicel Chamroukhi, Hien D Nguyen, and Geoffrey J McLachlan. Approximation of probability density functions via location-scale finite mixtures in Lebesgue spaces. Communications in Statistics - Theory and Methods, pp. 1–12, 2022b.
- Nguyen et al. (2022c) TrungTin Nguyen, Hien D Nguyen, Faicel Chamroukhi, and Florence Forbes. A non-asymptotic approach for model selection via penalization in high-dimensional mixture of experts models. Electronic Journal of Statistics, 16(2):4742–4822, 2022c.
- Papageorgiou & David (1994) Haris Papageorgiou and Katerina M David. On countable mixtures of bivariate binomial distributions. Biometrical journal, 36(5):581–601, 1994.
- Pardo (2006) Leandro Pardo. Statistical Inference Based on Divergence Measures. CRC Press, Boca Raton, 2006.
- Peel et al. (2001) David Peel, William J Whiten, and Geoffrey J McLachlan. Fitting mixtures of kent distributions to aid in joint set identification. Journal of the American Statistical Association, 96:56–63, 2001.
- Petrone (1999) Sonia Petrone. Random Bernstein Polynomials. Scandinavian Journal of Statistics, 26(3):373–393, 1999.
- Petrone & Wasserman (2002) Sonia Petrone and Larry Wasserman. Consistency of Bernstein Polynomial Posteriors. Journal of the Royal Statistical Society Series B: Statistical Methodology, 64(1):79–100, March 2002.
- Qin & Priebe (2013) Yichen Qin and Carey E Priebe. Maximum -likelihood estimation via the expectation-maximization algorithm: a robust estimation of mixture models. Journal of the American Statistical Association, 108(503):914–928, 2013.
- Rakhlin et al. (2005) Alexander Rakhlin, Dmitry Panchenko, and Sayan Mukherjee. Risk bounds for mixture density estimation. ESAIM: PS, 9:220–229, 2005.
- Razaviyayn et al. (2013) Meisam Razaviyayn, Mingyi Hong, and Zhi-Quan Luo. A Unified Convergence Analysis of Block Successive Minimization Methods for Nonsmooth Optimization. SIAM Journal on Optimization, 23(2):1126–1153, 2013.
- Ritter (2014) Gunter Ritter. Robust cluster analysis and variable selection. CRC Press, Boca Raton, 2014.
- Rockafellar (1997) Ralph Tyrrell Rockafellar. Convex analysis, volume 11. Princeton University Press, Princeton, 1997.
- Shalev-Shwartz & Ben-David (2014) Shai Shalev-Shwartz and Shai Ben-David. Understanding Machine Learning: from Theory to Algorithms. Cambridge University Press, Cambridge, 2014.
- Shapiro et al. (2021) Alexander Shapiro, Darinka Dentcheva, and Andrzej Ruszczynski. Lectures on Stochastic Programming: Modeling and Theory, Third Edition. Society for Industrial and Applied Mathematics, Philadelphia, PA, July 2021.
- Stummer & Vajda (2012) Wolfgang Stummer and Igor Vajda. On bregman distances and divergences of probability measures. IEEE Transactions on Information Theory, 58(3):1277–1288, 2012.
- Sundberg (2019) Rolf Sundberg. Statistical Modelling by Exponential Families. Cambridge University Press, Cambridge, 2019.
- Temlyakov (2016) Vladimir N Temlyakov. Convergence and rate of convergence of some greedy algorithms in convex optimization. Proceedings of the Steklov Institute of Mathematics, 293:325–337, 2016.
- van de Geer (2016) Sara van de Geer. Estimation and Testing Under Sparsity: École d’Été de Probabilités de Saint-Flour XLV – 2015. Springer, 2016.
- van der Vaart & Wellner (1996) Aad W van der Vaart and Jon A Wellner. Weak Convergence and Empirical Processes: With Applications to Statistics. Springer, 1996.
- Verbeek et al. (2003) Jakob J Verbeek, Nikos Vlassis, and Ben Kröse. Efficient greedy learning of Gaussian mixture models. Neural computation, 15(2):469–485, 2003.
- Vlassis & Likas (2002) Nikos Vlassis and Aristidis Likas. A greedy EM algorithm for gaussian mixture learning. Neural Processing Letters, 15:77–87, 2002.
- White (1982) Halbert White. Maximum likelihood estimation of misspecified models. Econometrica, 50(1):1–25, 1982.
- Wu & Lange (2010) Tong Tong Wu and Kenneth Lange. The MM alternative to EM. Statistical Science, 25(4):492–505, 2010.
- Zhang (2003) Tong Zhang. Sequential greedy approximation for certain convex optimization problems. IEEE Transactions on Information Theory, 49(3):682–691, 2003.
Appendix A Proofs of main results
The following section is devoted to establishing some technical definitions and instrumental results which are used to prove Theorem 5 and Corollary 6, and also includes the proofs of these results themselves.
A.1 Preliminaries
Recall that we are interested in bounds of the form (2). Note that is a subset of the linear space
and hence we can apply the following result, paraphrased from Zhang (2003, Thm. II.1).
Lemma 8.
Let be a differentiable and convex function on , and let be a sequence of functions obtained by Algorithm 1. If
then, for each ,
We are interested in two choices for :
| (11) |
and its sample counterpart,
| (12) |
where and are realisations of and , respectively. We obtain the following important results.
Proposition 9.
Proof.
See Appendix C.4. ∎
Notice that sequences obtained via Algorithm 1 are greedy approximation sequences, and that , for each . Let be the sequence of minimizers defined by
| (13) |
and let be the sequence of -MLLEs, as per (5). Then, by definition, we have the fact that and , for set as (11) or (12), respectively. Thus, we have the following result.
Proposition 10.
As is common in many statistical learning/uniform convergence results (e.g., Bartlett & Mendelson, 2002, Koltchinskii & Panchenko, 2004), we employ the use of Rademacher processes and associated bounds. Let be i.i.d. Rademacher random variables, that is , that are independent of . The Rademacher process, indexed by a class of real measurable functions , is defined as the quantity
for . The Rademacher complexity of the class is given by .
In the subsequent section, we make use of the following result regarding the supremum of convex functions:
Lemma 11 (Rockafellar, 1997, Thm. 32.2).
Let be a convex function on a linear space , and let be an arbitrary subset. Then,
In particular, we use the fact that since a linear functional of convex combinations achieves its maximum value at vertices, the Rademacher complexity of is equal to the Rademacher complexity of (see Lemma 21). We consequently obtain the following result.
Lemma 12.
Let be i.i.d. Rademacher random variables, independent of and be defined as above. The sets and will have equal complexity, , and the supremum of the Rademacher process indexed by is equal to the supremum on the basis functions of :
Proof.
Follows immediately from Lemma 11. ∎
A.2 Proofs
We first present a result establishing a uniform concentration bound for the -lifted log-likelihood ratios, which is instrumental in the proof of Theorem 5. Our proofs broadly follow the structure of Rakhlin et al. (2005), modified as needed for the use of .
Assume that for some . For brevity, we adopt the notation: .
Theorem 13.
Let be an i.i.d. sample of size drawn from a fixed density such that for all , and let be a positive density with for all . Then, for each , with probability at least ,
where , , and are constants that each depend on some or all of , , and , and is the -covering number of with respect to the following empirical metric
Remark 14.
The bound on the term
is the same as the above, except where the empirical distance is replaced by , defined in the same way as but with replacing .
Proof of Theorem 13.
Fix and define the following quantities: , , ,
We first apply McDiarmid’s inequality (Lemma 23) to the random variable . The bound on the martingale difference is given by
The chain of inequalities holds because of the triangle inequality and the properties of the supremum. By Lemma 23, we have
so
where it follows from that . Therefore with probability at least ,
Let be i.i.d. Rademacher random variables, independent of . By Lemma 24,
By combining the results above, the following inequality holds with probability at least
Now let , such that holds for all . Additionally, let so that and note that for , the derivative of is maximal at , and equal to . Therefore, is -Lipschitz. By Lemma 22 applied to ,
where the final inequality follows from the following result, proved in Haagerup (1981):
Now, let , and note that
By again applying Lemma 22, we have
Applying Lemmas 12 and 25, the following inequality holds for some constant :
| (16) |
and combining the results together, the following inequality holds with probability at least :
| (17) |
where , , and are constants that each depend on some or all of , , and . ∎
Remark 15.
From Lemma 25 we have that . To make explicit why , let and observe
Since our basis functions are bounded by , everything greater than will have value and hence the change from to is inconsequential. However, it can also be motivated by the fact that are positive functions.
As highlighted in Remark 14, the full result of Theorem 13 relies on the empirical distances and . In the result of Theorem 5, we make use of the following result to bound and .
Proposition 16.
With this result, we can now prove Theorem 5.
Proof (of Theorem 5).
The notation is the same as in the proof of Theorem 13. The values of the constants may change from line to line.
with probability at least , by Theorem 13. Now, we can use (15) from Proposition 10 applied to the target density , obtaining the following:
Since by definition we have that , , and so with probability at least we have:
| (18) |
We can write the overall error as the sum of the approximation and estimation errors as follows. The former is bounded by (14), and the latter is bounded as above in (18). Therefore, with probability at least ,
| (19) |
As in Rakhlin et al. (2005), we rewrite the above probabilistic statement as a statement in terms of expectations. To this end, let
and . We have shown . Since ,
Setting , we have and . Hence,
where , , and are constants that depend on some or all of , , and . ∎
Remark 17.
The approximation error characterises the suitability of the class , i.e., how well functions in are able to estimate a target which does not necessarily lie in . The estimation error characterises the error arising from the estimation of the target on the basis of the finite sample of size .
Proof of Corollary 6.
Let and be compact and assume the Lipshitz condition given in (8). If is continuously differentiable, then
Setting
we have . From Lemma 20, we obtain the fact that
which by the change of variable implies
Since , using the fact that a Euclidean set of radius has covering number we have
So
and since , the integral is finite, as required. ∎
Appendix B Discussions and remarks regarding -MLLEs
In this section, we share some commentary on the derivation of the -lifted KL divergence, its advantages and drawbacks, and some thoughts on the selection of the lifting function . We also discuss the suitability of the MM algorithms in contrast to other approaches (e.g., EM algorithms).
B.1 Elementary derivation
From Equation 4, we observe that if arises from a measure with density , and if we aim to approximate with a density that minimizes the -lifted KL divergence with respect to , then we can define an approximator (referred to as the minimum -lifted KL approximator) as
noting that is a constant that does not depend on the argument . Now, observe that
since both and are densities on with respect to the dominating measure . If a sample is available, we can estimate the expectation by the sample average functional
resulting in the sample estimator for :
which serves as an alternative to Equation 5. However, the expectation is intractable, making the optimization problem computationally infeasible, especially when is multivariate (i.e., for ), as integral evaluations may be challenging to compute accurately. Thus, we approximate the intractable integral using the sample average approximation (SAA) from stochastic programming (cf. Shapiro et al., 2021, Chapter 5), yielding the Monte Carlo approximation
for a sufficiently large , where each is an independent and identically distributed random variable from the measure on with density . This approach provides an estimator for of the form
which is exactly the -MLLE defined by Equation (5) when we take . Notably, the additional samples provide no information regarding , which is the component of the objective function coupling the estimator with the target . However, it offers a feasible mechanism for approximating the otherwise intractable integral .
By setting for the SAA approximation of , the convergence rate in Theorem 5 remains unaffected. Specifically, for any ,
and
with probability at least , as noted in Remark 14. Given that both upper bounds are of order , the combined bound in the proof of Theorem 5 in Appendix A.2 is also of this order, as required.
Finally, to obtain the additional samples , we simply simulate from the data-generating process defined by . Since we can choose freely, selecting an that facilitates easy simulation (e.g., uniform over , which remains bounded away from zero on a compact set) is advisable for satisfying the requirements of our theorems.
B.2 Advantages and limitations
As discussed extensively in Sections 1 and 2, our two primary benchmarks are the MLE and the least estimator. Indeed, the MLE is simpler than the -MLLE estimator, as it takes the reduced form
and does not require a sample average approximation for intractable integrals. It is well established that the MLE estimates the minimum KL divergence approximation to the target
However, as highlighted in the foundational works of Li & Barron (1999) and Rakhlin et al. (2005), controlling the expected risk
requires that for some strictly positive constant . This requirement excludes many interesting density functions as targets, including those that vanish at the boundaries of , such as the distribution, or those that vanish in the interior of , such as examples and in Section 4.2. Consequently, the condition is restrictive and often impractical in many data analysis settings.
Alternatively, one could consider targeting the minimum estimator:
Using a sample generated from the distribution given by , the first term of the objective can be approximated by , which is relatively simple. However, the second term involves an intractable integral that cannot be approximated by Monte Carlo sampling from a fixed generative distribution, as it depends on the optimization argument . Thus, unlike the -MLLE, it is not feasible to reduce this intractable integral to a sample average, which implies the need for a numerical approximation in practice. This can be computationally complex, particularly when is intricate and is high-dimensional. Hence, the minimum -norm estimator of the form
is often computationally infeasible, though its risk
can be bounded, as shown in the works of Klemelä (2007) and Klemelä (2009), even when . In comparison with the minimum estimator and the MLE, we observe that the -MLLE allows risk bounding for targets not bounded from below (i.e., ), without requiring intractable integral expressions. The -MLLE achieves the beneficial properties of both the MLE and minimum estimators, which is the focus of our work.
Other divergences and risk minimization schemes for estimating , such as -likelihoods and likelihood, could also be considered. The likelihood, for instance, provides a maximizing estimator with a simple sample average expression, similar to the MLE and -MLLE. However, it lacks a characterization in terms of a proper divergence function, such as the KL divergence, -lifted KL divergence, or norm. Consequently, this estimator is often inconsistent, as observed in Ferrari & Yang (2010) and Qin & Priebe (2013). These studies show that the likelihood estimator may not converge meaningfully to , even when , for any fixed , unless a sequence of maximum likelihood estimators is constructed with depending on and approaching to approximate the MLE. Thus, the maximum likelihood estimator does not yield the type of risk bound we require.
Similarly, with the -likelihood (or density power divergence), the situation is comparable to that of the minimum norm estimator, where the sample-based estimator involves an intractable integral that cannot be approximated through SAA. Specifically, the minimum -likelihood estimator is defined as (cf. Basu et al., 1998):
for , which closely resembles the form of the minimum estimator. Hence, the limitations of the minimum estimator apply here as well, although a risk bound with respect to the -likelihood divergence could theoretically be obtained if the computational challenges are disregarded. In Section 1.3, we cite additional estimators based on various divergences and modified likelihoods. Nevertheless, in each case, one of the limitations discussed here will apply.
B.3 Selection of the lifting density function
The choice of is entirely independent of the data. In fact, can be any density with respect to , satisfying for every . Beyond this requirement, our theoretical framework remains unaffected by the specific choice of . In Section 4, we explore cases where is uniform and non-uniform, demonstrating convergence in both and that aligns with the predictions of Theorem 5. For practical implementation, as discussed in Appendix B.1, serves as the sampling distribution for the sample average approximation (SAA) of the intractable integral . Given its role as a sampling distribution, it is advantageous to select a form for that is easy to sample from. In many applications, we find that the uniform distribution over is an optimal choice for , as it meets the bounding conditions.
We observe that although calibrating does not improve the rate, it does influence the constants in the upper bound of the final equation of Equation 19. Specifically, for each , with probability at least ,
which contributes to the constants in Theorem 5. Letting denote the upper bound of the target (i.e., for every ), we make the following observations regarding the constants:
Here, and are per the final bound in Equation 17 in the proof of Theorem 13, while arises from the bound in Equation 15.
When is uniform, it takes the form , where , making . If is non-uniform, then necessarily , as there would exist a region of positive measure where , which implies that for some ; otherwise,
contradicting being a density function. Although we cannot control , we can choose to control and . Setting minimizes the numerators in , as deviations from uniformity increase the numerators of and while decreasing the denominators. The same reasoning applies to :
Since , any deviation from uniformity in either increases or maintains the numerators while decreasing the denominators, minimizing when is uniform. The same logic applies to , as the logarithmic function is increasing, so is minimized when is uniform.
Consequently, we conclude that the smallest constants in Theorem 5 are achieved when is chosen as the uniform distribution on . This suggests that a uniform is optimal from both practical and theoretical perspectives.
B.4 Discussions regarding the sharpness of the obtained risk bound
Similar to the role of Gaussian mixtures as the archetypal class of mixture models for Euclidean spaces, beta mixtures represent the archetypal class of mixture models on the compact interval , as established in the studies by Ghosal (2001); Petrone (1999). Just as Gaussian mixtures can approximate any continuous density on to an arbitrary level of accuracy in the -norm (Nguyen et al., 2020; 2021; 2022b), mixtures of beta distributions can similarly approximate any continuous density on with respect to the supremum norm (Ghosal, 2001; Petrone, 1999; Petrone & Wasserman, 2002). We will leverage this property in the following discussion.
Assuming the target is within the closure of our mixture class (i.e., ), setting achieves a convergence rate in expected of for the mixture maximum -lifted likelihood estimator (-MLLE) . An interesting question is whether this rate is tight and not overly conservative, given the observed rates in Table 1. We aim to investigate this question by discussing a lower bound for the estimation problem.
To approach this, we use Proposition 3 to observe that satisfies a Pinsker-like inequality:
where . Using this inequality along with Corollary 6 and the convexity of , we find that the -MLLE satisfies the following total variation bound:
for some positive constants depending on , by taking . Now, consider the specific case when , and the component class consists of beta distributions. In this case, we have (cf. Petrone & Wasserman, 2002, Eq. 5), for any continuous density function :
since
for any , with the second inequality due to Proposition 3. Thus, for a compact parameter space defining , we assume . Consequently, the rate of for expected total variation distance is achievable in the beta mixture model setting. This convergence is uniform in the sense that
where depends only on the maximum , the diameter of , and the condition , with component distributions in restricted to parameter values in .
In the context of minimum total variation density estimation on , Exercise 15.14 of Devroye & Lugosi (2001) states that for every estimator and every Lipschitz continuous density (with a sufficiently large Lipschitz constant),
for some universal constant depending only on the Lipschitz constant. This lower bound is faster than our achieved rate of , but it applies only to the smaller class of Lipschitz targets, a subset of the continuous targets satisfying .
The target from our simulations in Section 4 belongs to the class of Lipschitz targets, and thus the improved lower bound rate of from Devroye & Lugosi (2001) applies. We can compare this with for Experiment 2 in Table 1, yielding an empirical rate in of , with an exponent between and (95% confidence), over the range . Clearly, this observed rate is faster than the lower bound rate of , indicating that the faster rates observed in Table 1 are due to small values of and . As increases, the rate must eventually decelerate to at least when the target is Lipschitz on , which is only marginally faster than our guaranteed rate of . Demonstrating that is minimax optimal for certain target classes is a complex task, left for future exploration.
B.5 The KL divergence and the MLE
For any probability densities and with respect to a dominant measure on , the -lifted KL divergence is defined as
which we establish as a Bregman divergence on the space of probability densities dominated by on in Appendix C.1.
We previously demonstrated a relationship between and the distance (Proposition 3), showing that if for all , then
is the square of the distance between the densities. Given that we can always select , this bound is always enforceable. This relationship is stronger than that between the standard KL divergence and the distance, which similarly satisfies
but with the more restrictive requirement that for every , limiting its applicability to densities that do not vanish. In the proof of Proposition 3 in Appendix C.2, we show that one can write
which allows the application of the theory from Rakhlin et al. (2005) by considering the mixture density as the target and using as the approximand, where . Under this framework, the maximum likelihood estimator can be formulated as
where are independent and identically distributed samples from a distribution with density . This sampling can be performed by choosing with probability or with probability for each , where is an observation from the generative model and is an independent sample from the auxiliary density . Although the modified estimator, based on the bound from Rakhlin et al. (2005), attains equivalent convergence rates, it inefficiently utilizes observed data, as 50% of the data is replaced by simulated samples . In contrast, our -MLLE estimator maximally utilizes all available data while achieving the same bound.
B.6 Comparison of the MM algorithm and the EM algorithm
Since the risk functional is not a log-likelihood, a straightforward EM approach cannot be used to compute the -MLLE. However, by interpreting as a loss between the target mixture and the estimator , an EM algorithm can be constructed using the standard admixture framework (see Lange, 2013, Section 9.5). Remarkably, the EM algorithm for estimating , has the same form as our MM algorithm, which leverages Jensen’s inequality (cf. Lange, 2013, Section 8.3). In fact, the majorizer in any EM algorithm results directly from Jensen’s inequality (see Lange, 2013, Section 9.2), making our MM algorithm in Section 4.1 no more complex than an EM approach for mixture models.
Beyond the EM and MM methods, no other standard algorithms typically address the generic estimation of a -component mixture model in for a given parametric class . Since our MM algorithm follows a structure nearly identical to the EM algorithm for the MLE of this problem, it has comparable iterative complexity. Notably, per iteration, the MM approach requires additional evaluations for both and , and for and , so it requires a constant multiple of evaluations compared to EM, depending on whether is a uniform distribution or otherwise (typically by a factor of 2 or 4).
B.7 Non-convex optimization
We note that the -MLLE problem (and the corresponding MLE) are non-convex optimization problems. This implies that, aside from global optimization methods, no iterative algorithm–whether gradient-based methods like gradient descent, coordinate descent, mirror descent, or momentum-based variants–can be guaranteed to find a global optimum. Likewise, second-order techniques such as Newton and quasi-Newton methods also cannot be expected to locate the global solution. In non-convex scenarios, the primary assurance that can be offered is convergence to a critical point of the objective function. In our case, this assurance is achieved by applying Corollary 1 from Razaviyayn et al. (2013), as discussed in Section 4.1. Notably, this convergence guarantee is consistent with that provided by other iterative approaches, such as EM, gradient descent, or Newton’s method.
Additionally, it may be valuable to examine whether specific convergence rates can be ensured when the algorithm’s iterates approach a neighborhood around a critical value. In the context of the MM algorithm, we can affirmatively answer this question: since the -MLLE objective is twice continuously differentiable with respect to the parameter , it satisfies the local convergence conditions outlined in Lange (2016, Proposition 7.2.2). This result implies that if lies within a sufficiently close neighborhood of a local minimizer , the MM algorithm converges linearly to . This behavior aligns with the convergence guarantees offered by other iterative methods, such as gradient descent or line-search based quasi-Newton methods. Quadratic convergence rates near can be achieved with a Newton method, though this forfeits the monotonicity (or stability) of the MM algorithm, as it is well-known that even in convex settings, Newton’s method can diverge if the initialization is not properly handled.
An additional advantage of the MM algorithm over Newton’s method is its capacity to decompose the original objective into a sum of functions where each component of is separable within the summation. In other words, we can independently optimize functions that depend only on subsets of parameters, either or each for , thereby simplifying the iterative computation. This characteristic is noted after Equation 9 in the main text. Such decomposition can lead to computational efficiency by avoiding the need to compute the Hessian matrix for Newton’s method or approximations required by quasi-Newton methods. Specifically, in cases involving mixtures of exponential family distributions such as the beta distributions discussed in Section 4.2, each parameter-separated problem becomes a strictly concave maximization problem, which can be efficiently solved (see Proposition 3.10 in Sundberg, 2019).
Appendix C Auxiliary proofs
In this section, we include other proofs of claims made in the main text that are not included in Appendix A.
C.1 The -lifted KL divergence as a Bregman divergence
Let , so that . Then , and
C.2 Proof of Proposition 2
Let and . Since is positive, there exists some such that . Similarly, since is compact, there exists some positive such that . Define . Then , and
C.3 Proof of Proposition 3
Defining and as above, we have
The first inequality comes from the fundamental inequalities on logarithm for all . Indeed, let . We obtain . Then if and if . Therefore, is strictly decreasing on and is strictly increasing on . This leads to the desired inequality for all .
The next equality comes from the following identities:
The last equality is followed from
In fact, the proof of Proposition 3 follows the standard technique in the derivation of the estimation error, see for example Meir & Zeevi (1997).
Additionally, we can show that the -lifted KL divergence satisfies a Pinsker-like inequality, in the sense that
where represents the total variation distance between the densities and . Indeed, this is easy to observe since
where the inequality is due to Pinsker’s inequality:
C.4 Proof of Proposition 9
For choice (11), by the dominated convergence theorem, we observe that
Suppose that each is bounded from above by . Then, since are non-negative functions, we have the fact that . If we further have for some , then , which implies that
for every and , and thus
Similarly, for case (12), we have
By the same argument, as for , we have the fact that , for every and every , and furthermore , for any . Thus,
Appendix D Technical results
Here we collect some technical results that are required in our proofs but appear elsewhere in the literature. In some places, notation may be modified from the original text to keep with the established conventions herein.
Lemma 18 (Kosorok, 2007. Lem 9.18).
Let denote the -covering number of , the -bracketing number of , and be any norm on . Then, for all
Lemma 19 (Kosorok, 2007. Lem 9.22).
For any norm dominated by and any class of functions ,
Lemma 20 (Kosorok, 2007. Thm 9.23).
For some metric on , let be a function class:
some fixed function on , and for all and . Then, for any norm ,
Lemma 21 (Shalev-Shwartz & Ben-David (2014), Lem 26.7).
Let be a subset of and let
Then, , i.e., both and have the same Rademacher complexity.
Lemma 22 (van de Geer, 2016, Thm. 16.2).
Let be non-random elements of and let be a class of real-valued functions on . If , , are functions vanishing at zero that satisfy for all , then we have
Lemma 23 (McDiarmid, 1998, Thm. 3.1 or McDiarmid, 1989).
Suppose are independent random variables and let , for some function . If satisfies the bounded difference condition, that is there exists constant such that for all and all ,
then
Lemma 24 (van der Vaart & Wellner, 1996, Lem. 2.3.1).
Let and . If is a convex function, then the following inequality holds for any class of measurable functions :
where is the Rademacher process indexed by . In particular, since the identity map is convex,
Lemma 25 (Koltchinskii, 2011, Thm. 3.11).
Let be the empirical distance
and denote by the -covering number of . Let . Then the following inequality holds
for some constant .