RLTIR: Activity-based Interactive Person Identification via Reinforcement Learning Tree
Abstract
Identity recognition plays an important role in ensuring security in our daily life. Biometric-based (especially activity-based) approaches are favored due to its fidelity, universality, and resilience. However, most existing machine learning-based approaches rely on a traditional workflow where models are usually trained once for all, with limited involvement from end-users in the process and neglecting the dynamic nature of the learning process. This makes the models static and can not be updated in time, which usually leads to high false positive or false negative. Thus, in practice, an expert is desired to assist with providing high-quality observations and interpretation of model outputs. It is expedient to combine both advantages of human experts and the computational capability of computers to create a tight-coupling incremental learning process for better performance. In this study, we develop RLTIR, an interactive identity recognition approach based on reinforcement learning, to adjust the identification model by human’s guidance. We first build a base tree-structured identity recognition model. And an expert is introduced in the model for giving feedback upon model outputs. Then, the model is updated according to strategies that are automatically learned under a designated reinforcement learning framework. To the best of our knowledge, it is the very first attempt to combine human expert knowledge with model learning in the area of identity recognition. The experimental results show that the reinforced interactive identity recognition framework outperforms baseline methods with regards to recognition accuracy and robustness.
Index Terms:
Person identification, human feedback, reinforcement learning.I Introduction
Person identification plays a key role in ensuring security and safety in realms of household security, finance, and national defense, which makes a host of studies been proposed. Recent research works on human intrinsic and extrinsic properties have explored and been demonstrating promising performance. For instance, physiological characteristics [1], brain waves [2], and people’s certain behavior patterns [3]. Most approaches are data-driven and comply with the traditional machine learning workflow. The signals and data featuring properties are first collected from various sources like wearable sensors [4] or wireless sensing devices like Wi-Fi [5]. The relevant features are then identified by domain experts or extracted automatically by algorithms to represent the acquired data. Finally, the identification models are built upon machine learning or deep learning algorithms by taking these features as inputs. However, existing works with the workflow mentioned above are mostly static and therefore limited in handling the changing dynamics of newly observed continuous data. In real-world biometric (especially activity-based) person identification tasks, the environment semantics are naturally highly dynamic. For instance, for a gait-based identification system, the gait of a person will vary a lot in different situations. If the recognition model can not be effectively adjusted and updated accordingly, it would misidentify a person and comprise the entire identification system. Thus, the static models usually lead to accuracy decreasing in real-life usages.
Except for the updating way of retraining the model after collecting enough amount of data [6], some previous works explored adaptive recognition systems [7]. The assumption of these works is that there exist adequate samples to be selected before the model is updated. Nevertheless, in a real person identification system, samples are produced in a streaming manner, so that the current samples are usually not enough for retraining a static model or selecting templates. Updating the model after data accumulation is very time-consuming and unpractical. Thus, it is critical for identification systems to be self-adaptive and adjusted timely by current data, which has not been solved very well.
To track the evolving environment more quickly and accurately with streaming data, the participation of a person with extensive knowledge and ability (called an expert), would be helpful to calibrate and justify the recognition system. The expert sits in the loop of recognition and provides reliable feedback based on the identification results, by which the recognition model is updated accordingly. Though the idea is suitable for enabling the dynamic recognition systems with limited streaming samples, some challenges still remain:
-
•
How to effectively incorporate expert feedback in the person identification system without retraining the recognition model.
-
•
How to find the optimal updating strategy considering both recent and historical expert feedback. The strategy should balance both the immediate and future model performance at the same time.
-
•
How to improve identification performance as much as possible by keeping human efforts minimal.
To tackle the first challenge, we treat the human-in-the-loop recognition and updating procedure as sequential interactions between the human expert and the identity recognition agent. To simplify the problem, we mainly consider vector-form streaming data such as gait information. A tree-structured model [8] is deployed to be the base recognition model due to its explainability and scalability. To address the second and third challenges, a reinforcement learning (RL) based approach is leveraged to automatically learn the model updating strategies according to the human feedback. In the Markov Decision Process (MDP) [9], an action can be determined by an RL algorithm based on the state and reward, which is similar to the updating strategy selection procedure based on the interaction between identification agent and human expert. Therefore, RL is appropriate to select optimal model updating strategies by reasonably combining the current identification model performance and human efforts.
In summary, we propose a novel framework which exploits Reinforcement Learning methods to update a Tree-structured Identity Recognition model (RLTIR) according to human feedback in a dynamic environment. The main contributions of the present work are as follows:
-
•
We propose a self-updating interactive person identification model, namely RLTIR, which can adapt to a dynamic environment, including intra-class variations and new emerging people. Driven by the quality expert feedback, the recognition model can be adjusted in real time. Compared with existing adaptive recognition methods that need to accumulate adequate samples, our method is more suitable for improving person identification performance with streaming data.
-
•
We develop optimal updating strategies under a reinforcement learning framework. The updating process with human expert feedback is mapped into a Markov Decision Process, which can select the most suitable updating strategy automatically at each timestamp with consideration of the current and future performance of the recognition model.
-
•
We evaluate the proposed approach on two datasets, including a local dataset and a public dataset. The experimental results illustrate that our model consistently outperforms the state-of-the-art methods on person identification. We also demonstrate the necessity of the feedback, robustness, and efficiency of the proposed model through a set of empirical studies.
The remainder of this paper is organized as follows. Section II introduces literature related to this paper. Section III presents problem definition and the generic framework of RLTIR. Section IV details methodology of the RLTIR method. Section V evaluates the proposed method by conducting extensive experiments on the local and public dataset and provides analysis of the experimental results. Section VII gives the conclusion and proposes the future work.
II Related Work
Person identification has been a highly popular research topic. In recent years, biometric-based methods are usually used for identity recognition because of convenience and privacy. The methods utilizing fingerprints, irises, and facial features require the user to be close to the sensing device. Thus, the recent advances in device-free approaches have been extensively studied due to convenience and portability [10, 11, 12]. Device-free approaches learn the signature of individual behaviors from the variations caused by human-environment interactions under people’s behavior patterns in an obtrusive way [13, 14]. Human activities like gait information [15, 16] and keystroke dynamics [17] provide a convenient, low cost, and universal solution for person identification. People can be detected based on changes of the corresponding signal pattern. However, compared to systems based on face images and fingerprints with robust feature sets, signals of activities are not immutable, and there exist changes during the data collection for the same person. Different from the static models that need to be retrained, our proposed method can improve the recognition performance to promote the practicality and stability of the activity-based person identification in a better way.
To adapt to the dynamic environment, self-adaptive systems are proposed, which have been extensively studied in many works [18, 19, 20]. Self-adaptive methods can be utilized in recognition systems to improve the performance from the perspective of model structure. For example, B. Freni et al. [21] and G. Orrù et al. [22] designed self-updating methods for template-based face recognition systems. A. Mhenni et al. [23] proposed a novel user-dependent template update strategy for keystroke recognition. Most of methods require adequate samples before updating strategies are carried out. In a real person identification system, samples are always produced in a streaming manner, so that updating the model after data accumulation is time-consuming. To achieve the real information of the current data, we borrowed the idea from the human-in-the-loop systems [24, 25], which arranged humans to annotate samples for obtaining or updating a training set. Active learning is a classical learning paradigm leveraged in human-in-the-loop systems. The most typical applications are computer vision, machine translation, outlier detection [26, 27, 28, 29], etc. The difference is that we set the human in both training and test process for model adaptation other than training set adaptation. In this way, our method can timely adjust the identification system only by existing and current data without accumulation of the new data.
Our work leverage reinforcement learning to bridge human guidance and the model adaptation process. Some existing studies combined traditional machine learning algorithms with reinforcement learning to obtain more interpretable and optimal models. Take the tree-structured model for an example, the splitting features and values were predicted for each non-leaf node orderly by employing reinforcement learning-based methods [30, 31, 32]. The common purpose of these works is to learn the model-building procedures and model parameters. The tree’s structure won’t be changed after training, while our model can be adapted during the test process. Sendi et al. [33] presented a deep ensemble method based on an argumentation of combining machine learning algorithms with a multi-agent system to improve classification performance. However, the framework can not be directly employed because the interaction between the human and the identification model should be considered in our framework.
III Framework Overview
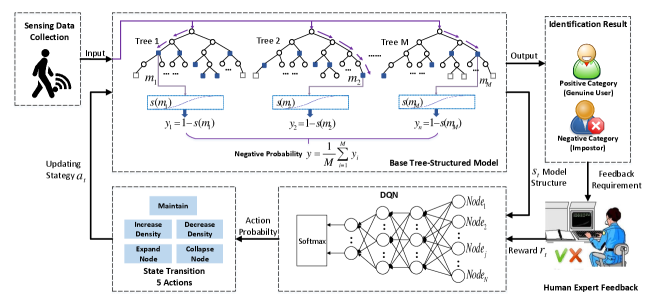
The purpose of the method is to propose a new idea for timely improving activity-based person identification performance with streaming data based on the human-in-the-loop mechanism. To simplify the problem, it is assumed that only one person is identified at a given time. The overall proposed RLTIR framework is shown in Fig. 1. The workflow includes three components: base tree-structured identification model, human expert feedback, and model updating.
Tasks like sensing devices, data collection, and feature extraction are out of the scope of this article. We assume that useful features have been extracted in order to avoid interference caused by features. Most activity-based person identification systems identify persons one by one, and extract features as vector form. Considering the flexibility of the updating structure, we build a base tree-structured classification model for streaming vector-form instances of each person. For each enrolled person, the identification results are binary: positive (genuine user) and negative (impostor). The identification result is produced according to the base identification model. The feedback on the correctness of the identification result will be given by a human expert if the result is judged as not reliable enough. The feedback will be combined with the current model structure for model updating.
For the model updating, we aim to select optimal updating strategies according to model structure changes and human expert feedback. Similarly, the core idea of the Markov Decision Process (MDP) is deciding which action to perform based on state changes in the environment and rewards obtained after performing the action. Thus, to ensure that the identity recognition model can be updated timely and reasonably by human expert feedback, we transform the sequential interactions between the human expert and the identification model as an MDP. Model structures and parameters are regarded as state . And we set five actions for model updating, including Maintain, Increase Density, Decrease Density, Expand Node, and Collapse Node. Deep Q-learning Network (DQN) [9] is employed to select the updating strategy for the feedback in each iteration. The detailed updating process is demonstrated in section IV-C. The procedure is iteratively executed to timely improve the model performance without retraining the model.
IV Methodology
This section introduces the three components of the proposed framework in detail. All the notations used in the proposed method are listed in Table I.
| Parameters | Explanation |
|---|---|
| An instance need to be identified | |
| The maximum depth of each tree | |
| The minimum depth of each tree | |
| The depth of all terminal nodes in a tree, | |
| The number of trees in a tree-based classifier | |
| The chosen feature for children node splitting | |
| The splitting value of the chosen feature | |
| The depth of a node located in | |
| The density of a node | |
| An adaptive parameter for adaptation of | |
| The number of instances scattered in a node | |
| The negative probability of an instance | |
| The uncertainty of an identification result | |
| The feedback provided by the human expert | |
| The number of positive feedback | |
| The number of negative feedback | |
| Time window size for refreshing the node | |
| An adaptive parameter for node refreshing | |
| The information on base tree model structure | |
| The selected model updating strategy | |
| The reward calculated by human feedback | |
| The reward decay in DQN | |
| The replay memory in DQN | |
| The action-value function in DQN | |
| The loss function of DQN | |
| The parameters need to be learned in DQN | |
| The learning rate of DQN | |
| The target replace step of DQN |
IV-A Base Tree-Structured Identification Model
Tree-structured model is a good candidate for person identification due to its explainability and scalability. As a such, the model can be effectively updated with justifications. The identification system builds a base tree-structured classifier for each enrolled user. Each classifier contains several trees to avoid contingency. The output of each tree is the probability of the current instance belonging to the corresponding user. Given the initial training set of an enrolled person, a random space tree is built by the feature space that has been extracted from sensing signals. The initialization of the workspace and procedures of tree growth are similar to those in the previous work [8].
Each instance of a person is scattered into a specific region according to its feature vector. In the literature, the number of instances scattered in a region is related to the density of the node [34]. The basic assumption is that instances of an impostor (negative category) are more possibly located in lower density regions rather than those of the genuine user (positive category). The negative probability of an instance is calculated by density from all the trees, which is used for clarifying the enrolled user and impostors. The instance with a high negative probability will be recognized as an impostor.
A terminal node is designed for the convenience of model updating with the feedback. The depth of the terminal node is usually smaller than that of the leaf node. When an instance is fed into the tree, it traverses from the root node to a terminal node, then the profiles of nodes along the path are updated. The traversing direction of the instance is determined by randomly chosen feature and splitting value . records characteristics and variables of the corresponding node. A terminal node will be returned when the traversing depth equals . In a tree, each instance corresponds to only one terminal node.
In this part, we introduce the calculation of negative probability by returned terminal nodes. Let represents the number of trees in a base identification model for an enrolled user. Suppose an instance locates in a terminal node of the -th tree . The density of the node is
| (1) |
where represents the number of instances scattered in the corresponding node; denotes the depth of the node. The negative probability of the instance in the -th tree is
| (2) |
where is the cumulative distribution function of the logistic distribution, defined as:
| (3) |
where and are the expected value and standard variance of for feature space . In the streaming environment, these values are incrementally calculated [35]. Regarding the base identification model that contains trees, the final negative probability for the instance is
| (4) |
After negative probabilities of all the training instances were attained from the model, a threshold is determined. When the negative probability of a new instance is calculated, the corresponding person is identified as the genuine user if the score is lower than the threshold; Otherwise, the person is identified as an impostor.
IV-B Human Feedback Mechanism
A human expert is arranged to make the person identification system timely adapt to the dynamic environment. Although the feedback is the golden standard for improving the model performance in our method, it is unnecessary to give feedback for all the instances. Too much feedback will increase the burden of the human expert, whereas too little feedback can be not enough to improve the model. Intuitively, instances that are more likely to be misidentified require more feedback. We leverage uncertainty [36] to evaluate the necessity of feedback for the instance. The instance with higher uncertainty is more likely given feedback by the human.
To evaluate the uncertainty of an instance, we consider the relationship between the negative probability of the instance and the number of historical feedback in the corresponding node. According to Equation 2, is the negative probability. Suppose there has existed some feedback from the expert, the number of positive and negative feedback are and . In theory, the negative probability should equal the ratio of negative feedback to all feedback, i.e., . The uncertainty of the identification result is formulated as the difference between the expected probability and the reported probability
| (5) |
Considering trees in the base identification model, the final uncertainty of the instance is
| (6) |
A threshold is set to decide whether the instance needs feedback. If is bigger than the threshold, the model will request feedback from the human expert.
Given the feedback, the model will get access to an instance-feedback pair , where . or denotes that the person is recognized by the expert as positive or negative category. The identification model will be adjusted according to the feedback before getting access to future instances.
IV-C Model Updating based on Reinforcement Learning
The updating ways for the base tree-structured model are organized from aspects of the tree structure and the density of the terminal node. However, it is not advisable to blindly choose updating strategies. It is necessary to find an appropriate strategy to ensure that the model is optimally optimized considering both current and future performance.
We leverage reinforcement learning to update the identification model not only because the procedure of strategy selection is similar to the MDP, but also because reinforcement learning is able to balance the current and future performance. More formally, we introduce the crucial components of our deep reinforcement learning structure for the updating strategy selection:
1) State : At each timestamp , state is defined as nodes of the operational tree structure, where each node contains a set of elements . is a boolean value for recording if the instance has gone through the node. Other elements have been illustrated in Table I.
2) Action : Action is defined as a strategy to update the model at timestamp . We define five actions: ‘Maintain’, ‘Increase/Decrease Density’, ‘Expand/Collapse Node’. ‘Maintain’ means , i.e., the model remains unchanged. ‘Increase/Decrease Density’ means that the negative probability of the terminal node will be increased or decreased. ‘Expand/Collapse Node’ means that the terminal node is replaced by its children node or parent node. The updating processes of each action are shown in Algorithm 1. The actions of each tree in the same classifier are independent.
3) Reward : Human feedback is related to the reward to evaluate if the updating strategy is optimal. The base classifier is an ensemble model with trees. The final result is attained from results of trees. Thus, we set and to represent the reward of the whole model and each tree. If the classifier identifies the person correctly, ; Otherwise, . is designed the same as . For each tree in the classifier, .
4) Policy : When a strategy is implemented on the current , can be achieved. At timestamp , the state transition only chooses one action following the policy .
| Dataset | Index | Method | Precision | Recall | F1-Score | AUC | FNR | FPR |
|---|---|---|---|---|---|---|---|---|
| 1 | (Filippov et al. 2018) | 0.6800 | 0.4139 | 0.4869 | 0.6195 | 0.5861 | 0.1749 | |
| 2 | (Wang et al. 2017) | 0.5200 | 0.2209 | 0.2933 | 0.6018 | 0.7791 | 0.0173 | |
| 3 | (Zhang et al 2019) | 0.7693 | 0.4573 | 0.5716 | 0.7125 | 0.5427 | 0.0322 | |
| 4 | (Hejazi et al. 2017) | 0.6252 | 0.8479 | 0.7104 | 0.6508 | 0.1521 | 0.5463 | |
| 5 | (Xu et al. 2019) | 0.5434 | 0.6310 | 0.5728 | 0.5511 | 0.3689 | 0.5289 | |
| Gait | 6 | (Liu et al. 2010) | 0.4650 | 0.1523 | 0.2209 | 0.5676 | 0.8477 | 0.0170 |
| 7 | (Hossain and Chetty 2012) | 0.5014 | 0.5665 | 0.5157 | 0.5147 | 0.4335 | 0.5370 | |
| 8 | (Hsu et al. 2019) | 0.4916 | 0.5260 | 0.4969 | 0.5097 | 0.4740 | 0.5067 | |
| 9 | (Hossain et al. 2018) | 0.6652 | 0.7328 | 0.6833 | 0.6705 | 0.4166 | 0.3947 | |
| 10 | (Anzar et al. 2016)) | 0.8394 | 0.8161 | 0.7007 | 0.7488 | 0.3388 | 0.1476 | |
| 11 | Ours_nofeed | 0.7126 | 0.8800 | 0.7124 | 0.7219 | 0.3200 | 0.3585 | |
| 12 | Ours (RLTIR) | 0.8542 | 0.7785 | 0.7306 | 0.7607 | 0.4593 | 0.0869 | |
| 1 | (Filippov et al. 2018) | 0.8286 | 0.2231 | 0.3498 | 0.76051 | 0.7769 | 0.0127 | |
| 2 | (Wang et al. 2017) | 0.8945 | 0.8384 | 0.8064 | 0.8169 | 0.2615 | 0.0466 | |
| 3 | (Zhang et al. 2019) | 0.9277 | 0.8796 | 0.8987 | 0.8943 | 0.1203 | 0.0310 | |
| 4 | (Hejazi et al. 2017) | 0.6686 | 0.8784 | 0.7579 | 0.7225 | 0.1216 | 0.4333 | |
| 5 | (Xu et al. 2019) | 0.7742 | 0.6835 | 0.8033 | 0.7417 | 0.4164 | 0.1245 | |
| CMU | 6 | (Liu et al. 2010) | 0.8813 | 0.8672 | 0.8067 | 0.8789 | 0.2328 | 0.0931 |
| 7 | (Hossain and Chetty 2012) | 0.7929 | 0.8355 | 0.8089 | 0.7967 | 0.1644 | 0.2422 | |
| 8 | (Hsu et al. 2019) | 0.7891 | 0.7931 | 0.7881 | 0.7907 | 0.2069 | 0.2118 | |
| 9 | (Hossain et al. 2018) | 0.8707 | 0.8616 | 0.8274 | 0.8819 | 0.1383 | 0.0238 | |
| 10 | (Anzar et al. 2016)) | 0.9207 | 0.8808 | 0.8906 | 0.9194 | 0.1325 | 0.0232 | |
| 11 | Ours_nofeed | 0.9287 | 0.8985 | 0.9165 | 0.9174 | 0.1613 | 0.0207 | |
| 12 | Ours (RLTIR) | 0.9661 | 0.8726 | 0.9199 | 0.9235 | 0.1473 | 0.0149 |
We employ DQN as the optimization policy to update all the five Q-values (corresponding to the five candidate strategies in ) at each step. The structure of each tree is stored as a matrix: the raw data represents each node of the tree, and the column data represents elements of each node. We follow the standard assumption that delayed rewards are discounted by a factor at each time step. Action-value function is defined as the expected return based on model structure and updating strategy . The optimal action-value function has the maximum expected return by the optimal policy. However, the state space in our framework is enormous because tree structures are diverse with different elements of nodes. Thus, we use the Bellman equation [37] to estimate for each state-action pair. We utilize deep neural networks with parameters as function approximator, i.e., . The Q-network is trained by minimizing a loss function:
| (7) |
where is the target for the current iteration. The derivatives of loss function with parameters are presented as follows:
| (8) | ||||
where are previous parameters, which are updated when optimizing the loss function. Then, we utilize stochastic gradient descent to optimize the function efficiently. Besides, we design the deep neural network as four layers. Except for the input layer, a simple RNN layer is employed in the first layer considering correlations and orders among nodes; The second and third layers are full-connected layers. We adopt Relu activate function in the first two layers, and use the softmax activate function in the last layer. The detailed procedure of the RLTIR framework is shown in Algorithm 2.
V Experiments
V-A Experimental Settings
V-A1 Datasets
We utilized two datasets to evaluate the RLTIR framework. The first dataset was collected from the practical person identification scenario. The second one is a public keystroke dataset named CMU [17] for person identification.
The first dataset was manually attained according to the previous work [16]. The work proves that the acoustic signal is effective for person identification by extracting gait patterns of the person. Therefore, we collected similar data with the same device and experimental settings in the previous work. We recruited 50 volunteers aged between 20 and 30 years in our laboratory. 256-dimensional features mentioned in [16] were extracted from the original signal. We recorded 50 times for each volunteer in different sessions, to guarantee that gait information for each person changes temporally in our dataset. The final dataset totally contains 2,500 instances. In the beginning, only 30 people were enrolled and the rest of the persons were considered as new possible enrolled users. In the test process, when a new user appeared, we created a classifier for that user. CMU [17] is a public dataset containing 51 users with 8 sessions. In each session, 50 instances were collected for each user. There are 20,400 instances in the dataset.
In the training process, for the classifier of a specific enrolled user, we randomly extracted 30% of all available data of the user. And several data from the other enrolled ones were extracted, which accounts for 20% of the training set of this user. For each classifier, the test set consisted of the rest 70% data of the corresponding enrolled user and the same number of the randomly selected data from the other persons (including the new possible enrolled users). A student was arranged as a human expert. He gave feedback on whether the current instance was recognized correctly. The feedback was recorded through an interface. If the instance was recognized correctly, the expert clicked “Yes”, otherwise clicked “No”.
V-A2 Evaluation Metrics and Baselines
The performance of the proposed method was evaluated by six metrics: Precision, Recall, F1-score, Area Under Curve (AUC), False Positive Rate (FPR), False Negative Rate (FNR). The baseline methods are as follows:
1. (Filippov et al. 2018) [38] extracted features of interaction with a device’s touch screen for user authentication. Isolated forest technique is employed to fit the touch pattern recognition model;
2. (Wang et al. 2017) [39] presented XRec which leverages user behavioral patterns of using an App. XRec employs random forest to classify device pairs;
3. (Zhang et al. 2019) [40] investigated the sensors and features to improve the recognition accuracy of indoor activities and utilized XGBoost to recognize these activities;
4. (Hejazi et al. 2017) [41] found that one-class SVM can be a robust recognition algorithm for ECG biometric verification with sufficient samples;
5. (Xu et al. 2019) [16] used fine-grained gait information to identify human beings. SVM classifier was utilized to be the identification model;
6. (Liu et al. 2010) [42] developed a fall incident detection system with the help of the KNN classifier;
7. (Hossain and Chetty 2012) [43] proposed an MLP-based human-identification scheme from long-range gait profiles in surveillance videos;
8. (Hsu et al. 2019) [44] introduced a system that automatically collects behavior-related data and provides CNN-based algorithms for identifying activities in homes;
9. (Hossain et al. 2018) [45] proposed a deep active learning-enabled activity recognition model. For fairness, we only added the most informative and meaningful sample into the training set when retrained the model was retrained.
10. (Anzar et al. 2016) [46] proposed an adaptive online template-updated method using the Gaussian mixture model (GMM) to minimize classification errors and intra-class variations.
11. Ours_nofeed is our proposed RLTIR framework without human feedback;
V-B Method Performance Evaluation
V-B1 Overall Comparison
We compared the proposed framework with the methods mentioned above. RLTIR framework has the ability to update model structure incrementally, but most of the other methods are static. For equality, the training set of baselines contained 80% of the instances of an enrolled user, while 30% of the instances of the enrolled user were contained in the training set for RLTIR. We repeated the experiments 50 times and calculated average results. The overall identification results of the two datasets are shown in Table II. It can be observed that:
(1) For the Gait dataset, the proposed RLTIR framework achieves the best performance on Precision, F1-score, and AUC. Our method without feedback achieves the highest Recall. Although Hejazi’s method and Liu’s model attain better performances on FNR and FPR respectively, both of them perform not well on other metrics. Because the test dataset is imbalanced and the two methods identify almost all data as the same category.
(2) For the CMU dataset, our method performs better than other baselines on almost all the metrics except for Recall and FNR. Anzar’s model also achieves considerable performance, so it can be proved that the self-updating mechanism is helpful to improve the performances of the model.
V-B2 Parameter Analysis
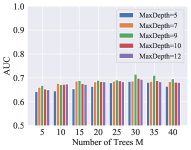
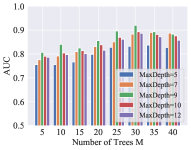
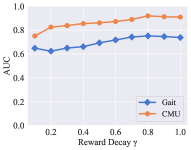
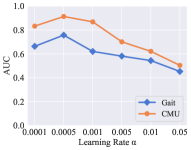
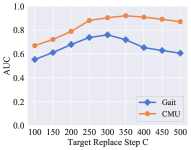
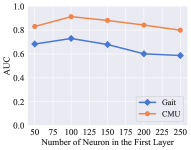
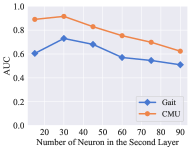
For the base tree-structured identification model, the maximum depth of a tree and the number of trees affect the performance of the model. The experimental results on the two datasets are shown in Fig. 2. The model reaches the best performance when is 9 and is 30 in all of the datasets. The performance decreases when the maximum depth of a tree is too deep, because the instance is identified partly according to historical instances scattered into terminal nodes, and a large will cause many abundant children nodes. The performance is improved with the increasing number of trees until reaches 30.
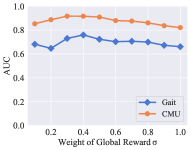
For the updating process, we considered the weight of global reward , reward decay , learning rate , target replace step , and the number of neuron in the first two layers of DQN. Fig. 3 shows the experimental results of these parameters. The change trends of the model on the two datasets within each parameter is roughly similar. The weight of global reward and reward decay do not influence the recognition performance in a wide range. The performance of our model is sensitive to four kinds of parameter settings: learning rate , target replace step , the number of neurons in the first layer, and the number of neurons in the second layer. Among all the six parameters, the learning rate is the most insensitive parameter to our model.
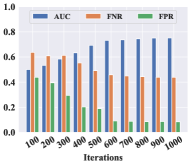
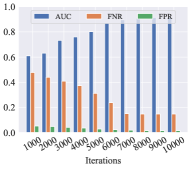
V-B3 Feedback Analysis
To evaluate the effectiveness of the human feedback, we explored changes in the model performance during iterations on three metrics (AUC, FNR, and FPR), which are shown in Fig. 4. The figure illustrates that model performances on the two datasets are optimized with the increasing number of iterations. The performance achieves stability after reaching a certain number of iterations. It proves that the feedback is efficient for improving identification performance in a dynamic environment, including intra-class variations and newly enrolled users. And optimal updating strategies are gradually learned with the training of the DQN.
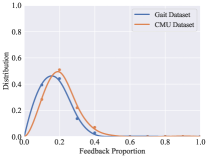
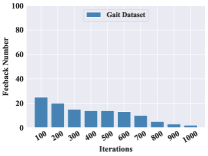
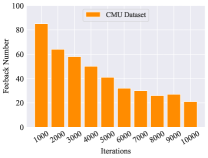
Although the evaluation results in Table II have proved that the RLTIR framework outperforms, it is impractical if the frequency of feedback is high. We hope that the model can be improved with only a few human intervention and the number of feedback will decrease with learning updating strategies constantly. To evaluate the burden of human experts, the overall distribution of the feedback proportion in the testing set and changes in the amount of the feedback during iterations were explored. Fig. 5 reveals that the proportion of feedback from the whole testing set is almost less than 35%. That means the expert gives feedback without taking much effort. Fig. 5 and Fig. 5 show that feedback number decreases relatively with increasing updating iterations. After reaching a certain number of iterations, the amount of feedback tends to stabilize. It reveals that the identification performances can be improved with a limited amount of feedback.
V-B4 Robustness Evaluation
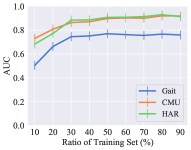
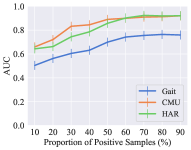
We also evaluated if the RLTIR method is robust on the size of the dataset and distribution of categories. we first changed the ratio of the training set to the overall dataset. Fig. 6 illustrates that the RLTIR framework is not sensitive to the size of training data as long as the ratio is higher than 30%. For category distribution, the proportion of positive samples represents the balance between positive and negative categories. Fig. 6 demonstrates changes in the AUC metric with the different distribution of categories. It is obvious that the proposed method is more appropriate for imbalance category distribution, especially when there are few negative samples.
V-B5 Efficiency Evaluation
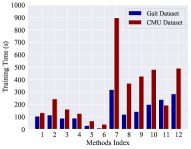
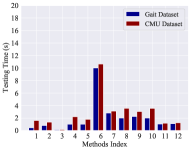
Efficiency refers to the required training time and identification time, including the updating process. Low efficiency will limit the suitability for practical deployment. We focused on the running time of our method and compared it with the baselines. The experiments were conducted on a computer with Intel i5-6500 3.2GHz CPU. The required training time and testing time for each method are given in Fig. 7 and Fig. 7 respectively. The x-axis denotes the index of the methods shown in Table II). Fig. 7 illustrates that approaches utilizing deep neural networks take much more training time than others because these approaches contain more parameters and more complex structures. Fig. 7 presents that the testing time of our model is around 1 second, which is shorter than most of the other baselines. In addition, Anzar’s self-updating method (No.10) costs more time on testing because it requires data accumulation and template selection. Summarily, our model is practical and efficient even considering the time cost of the updating process.
VI Discussion
In this work, a novel method is proposed for activity-based person identification by combining human feedback with model updating process. In parallel, some limitations remain. In this section, we will discuss the limitations and potentials of the proposed method, and give the future direction of our work at the same time.
-
•
Multiple categories recognition. In this paper, the main application scenario is recognizing if the instance belongs to the person or the current activity. In other words, recognition results only contain two categories: positive and negative. In the real world, authentication is more important than identity recognition. To address authentication problem, the model needs to be improved to fit multiple classification, so that the model could directly identify which person the instance belonging to. Simply expanding our proposed method to multiple categories recognition by building a model for each recognition entities will lead to a significant increase in testing time. Therefore, transferring the binary recognition model to a multiple recognition model considering feedback mechanism and updating strategy learning is a meaningful research issue.
-
•
Reliability of feedback. An important component in our proposed model is feedback mechanism. The identification accuracy can be largely improved by updating the model accordingly, especially compared to existing approaches. Hence, the degree of improvement on the model depends on the reliability of feedback to some extent. In this work, we assumed the human participated in the system is an expert, so that every feedback from the human is reliable enough to improve the model. However, in the real world, the reliability of feedback from different experts is diverse. Thus, the model will be improved if it judges the reliability of the feedback and accepts the feedback with different probability. It remains an open issue for further study.
VII Conclusion
In this paper, we propose a novel framework RLTIR for activity-based person identification by learning updating strategies incrementally based on guidance from the human expert. The human expert gives feedback to the instance with high uncertainty. The classifier is updated according to optimal strategies learned by a reinforcement learning process. In this way, the model can be improved reasonably over time, which is a benefit for adapting dynamic environment. The proposed approach is evaluated over two datasets (a local collected dataset and a public dataset). Experimental results illustrate that our model achieves the best performance and achieves considerable robustness and efficiency with a few human efforts.
For future work, we will transfer the binary classifier to a multi-class classifier considering feedback mechanism and updating strategy learning, so that the model will be suitable for the authentication problem. Besides, the reliability of feedback from different experts is diverse. Thus, the model will be improved if it judges the reliability of the feedback and accepts the feedback with different probability, which remains an open issue for further study.
Acknowledgment
This work was supported in part by the National Science Fund for Distinguished Young Scholars (No. 61725205), the National Natural Science Foundation of China (No. 61960206008, No. 61772428, No. 61972319, No. 61902320), and the China Scholarship Council (award to Qingyang Li for 16 months’ study abroad at the University of New South Wales).
References
- [1] N. Almudhahka, M. Nixon, and J. Hare, “Human face identification via comparative soft biometrics,” in 2016 IEEE International Conference on Identity, Security and Behavior Analysis (ISBA). IEEE, 2016, pp. 1–6.
- [2] X. Zhang, L. Yao, S. S. Kanhere, Y. Liu, T. Gu, and K. Chen, “Mindid: Person identification from brain waves through attention-based recurrent neural network,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 2, no. 3, p. 149, 2018.
- [3] W. Wang, A. X. Liu, and M. Shahzad, “Gait recognition using wifi signals,” in Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing. ACM, 2016, pp. 363–373.
- [4] A. Brutti and A. Cavallaro, “Online cross-modal adaptation for audio–visual person identification with wearable cameras,” IEEE Transactions on Human-Machine Systems, vol. 47, no. 1, pp. 40–51, 2016.
- [5] T. Xin, B. Guo, Z. Wang, P. Wang, J. C. K. Lam, V. Li, and Z. Yu, “Freesense: a robust approach for indoor human detection using wi-fi signals,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 2, no. 3, p. 143, 2018.
- [6] S. Wen, T. M. Kurc, L. Hou, J. H. Saltz, R. R. Gupta, R. Batiste, T. Zhao, V. Nguyen, D. Samaras, and W. Zhu, “Comparison of different classifiers with active learning to support quality control in nucleus segmentation in pathology images,” AMIA Summits on Translational Science Proceedings, vol. 2018, p. 227, 2018.
- [7] P. H. Pisani, A. Mhenni, R. Giot, E. Cherrier, N. Poh, A. C. P. d. L. Ferreira de Carvalho, C. Rosenberger, and N. E. B. Amara, “Adaptive biometric systems: Review and perspectives,” ACM Computing Surveys (CSUR), vol. 52, no. 5, pp. 1–38, 2019.
- [8] S. C. Tan, K. M. Ting, and T. F. Liu, “Fast anomaly detection for streaming data,” in IJCAI Proceedings-International Joint Conference on Artificial Intelligence, vol. 22, no. 1, 2011, p. 1511.
- [9] H. Van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” in Thirtieth AAAI conference on artificial intelligence, 2016.
- [10] D. Zhang, H. Wang, and D. Wu, “Toward centimeter-scale human activity sensing with wi-fi signals,” Computer, vol. 50, no. 1, pp. 48–57, 2017.
- [11] D. Wu, D. Zhang, C. Xu, H. Wang, and X. Li, “Device-free wifi human sensing: From pattern-based to model-based approaches,” IEEE Communications Magazine, vol. 55, no. 10, pp. 91–97, 2017.
- [12] W. Shao, T. Nguyen, K. Qin, M. Youssef, and F. D. Salim, “Bledoorguard: a device-free person identification framework using bluetooth signals for door access,” IEEE Internet of Things Journal, vol. 5, no. 6, pp. 5227–5239, 2018.
- [13] D. He, B. Donmez, C. C. Liu, and K. N. Plataniotis, “High cognitive load assessment in drivers through wireless electroencephalography and the validation of a modified n-back task,” IEEE Transactions on Human-Machine Systems, vol. 49, no. 4, pp. 362–371, 2019.
- [14] D. Wang, X. Pei, L. Li, and D. Yao, “Risky driver recognition based on vehicle speed time series,” IEEE Transactions on Human-Machine Systems, vol. 48, no. 1, pp. 63–71, 2017.
- [15] P. Cao, W. Xia, M. Ye, J. Zhang, and J. Zhou, “Radar-id: human identification based on radar micro-doppler signatures using deep convolutional neural networks,” IET Radar, Sonar & Navigation, vol. 12, no. 7, pp. 729–734, 2018.
- [16] W. Xu, Z. Yu, Z. Wang, B. Guo, and Q. Han, “Acousticid: Gait-based human identification using acoustic signal,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 3, no. 3, pp. 1–25, 2019.
- [17] K. Killourhy and R. Maxion, “Why did my detector do that?!” in International Workshop on Recent Advances in Intrusion Detection. Springer, 2010, pp. 256–276.
- [18] T. R. D. Saputri and S.-W. Lee, “The application of machine learning in self-adaptive systems: A systematic literature review,” IEEE Access, vol. 8, pp. 205 948–205 967, 2020.
- [19] H. Wang, Y. Li, and J. Qian, “Self-adaptive resource allocation in underwater acoustic interference channel: A reinforcement learning approach,” IEEE Internet of Things Journal, vol. 7, no. 4, pp. 2816–2827, 2019.
- [20] X. Sun, Y. Li, N. Wang, Z. Li, M. Liu, and G. Gui, “Towards self-adaptive selection of kernel functions for support vector regression in iot based marine data prediction,” IEEE Internet of Things Journal, 2020.
- [21] B. Freni, G. L. Marcialis, and F. Roli, “Template selection by editing algorithms: A case study in face recognition,” in Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR). Springer, 2008, pp. 745–754.
- [22] G. Orrù, G. L. Marcialis, and F. Roli, “A novel classification-selection approach for the self updating of template-based face recognition systems,” Pattern Recognition, vol. 100, p. 107121, 2020.
- [23] A. Mhenni, E. Cherrier, C. Rosenberger, and N. E. B. Amara, “Analysis of doddington zoo classification for user dependent template update: Application to keystroke dynamics recognition,” Future Generation Computer Systems, vol. 97, pp. 210–218, 2019.
- [24] V. Ambati, “Active learning and crowdsourcing for machine translation in low resource scenarios,” 2011, 2011.
- [25] C. Zhang, W. Tavanapong, G. Kijkul, J. Wong, P. C. de Groen, and J. Oh, “Similarity-based active learning for image classification under class imbalance,” in 2018 IEEE International Conference on Data Mining (ICDM). IEEE, 2018, pp. 1422–1427.
- [26] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017.
- [27] Y. Wu, M. Schuster, Z. Chen, Q. V. Le, M. Norouzi, W. Macherey, M. Krikun, Y. Cao, Q. Gao, K. Macherey et al., “Google’s neural machine translation system: Bridging the gap between human and machine translation,” arXiv preprint arXiv:1609.08144, 2016.
- [28] Y. Liu, Z. Li, C. Zhou, Y. Jiang, J. Sun, M. Wang, and X. He, “Generative adversarial active learning for unsupervised outlier detection,” IEEE Transactions on Knowledge and Data Engineering, 2019.
- [29] S. D. Bhattacharjee, A. Talukder, and B. V. Balantrapu, “Active learning based news veracity detection with feature weighting and deep-shallow fusion,” in 2017 IEEE International Conference on Big Data (Big Data). IEEE, 2017, pp. 556–565.
- [30] Z. Jie, X. Liang, J. Feng, X. Jin, W. Lu, and S. Yan, “Tree-structured reinforcement learning for sequential object localization,” in Advances in Neural Information Processing Systems, 2016, pp. 127–135.
- [31] Z. Xiong, W. Zhang, and W. Zhu, “Learning decision trees with reinforcement learning,” in NIPS Workshop on Meta-Learning, 2017.
- [32] G. Liu, O. Schulte, W. Zhu, and Q. Li, “Toward interpretable deep reinforcement learning with linear model u-trees,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2018, pp. 414–429.
- [33] N. Sendi, N. Abchiche-Mimouni, and F. Zehraoui, “A new transparent ensemble method based on deep learning,” Procedia Computer Science, vol. 159, pp. 271–280, 2019.
- [34] K. Wu, K. Zhang, W. Fan, A. Edwards, and S. Y. Philip, “Rs-forest: A rapid density estimator for streaming anomaly detection,” in Data Mining (ICDM), 2014 IEEE International Conference on. IEEE, 2014, pp. 600–609.
- [35] B. Welford, “Note on a method for calculating corrected sums of squares and products,” Technometrics, vol. 4, no. 3, pp. 419–420, 1962.
- [36] S. Shalev-Shwartz et al., “Online learning and online convex optimization,” Foundations and Trends® in Machine Learning, vol. 4, no. 2, pp. 107–194, 2012.
- [37] R. Bellman, “Dynamic programming,” Science, vol. 153, no. 3731, pp. 34–37, 1966.
- [38] A. I. Filippov, A. V. Iuzbashev, and A. S. Kurnev, “User authentication via touch pattern recognition based on isolation forest,” in 2018 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus). IEEE, 2018, pp. 1485–1489.
- [39] X. Wang, T. Yu, M. Zeng, and P. Tague, “Xrec: Behavior-based user recognition across mobile devices,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 1, no. 3, pp. 1–26, 2017.
- [40] W. Zhang, X. Zhao, and Z. Li, “A comprehensive study of smartphone-based indoor activity recognition via xgboost,” IEEE Access, vol. 7, pp. 80 027–80 042, 2019.
- [41] M. Hejazi, S. Al-Haddad, S. J. Hashim, A. F. A. Aziz, and Y. P. Singh, “Non-fiducial based ecg biometric authentication using one-class support vector machine,” in 2017 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA). IEEE, 2017, pp. 190–194.
- [42] C.-L. Liu, C.-H. Lee, and P.-M. Lin, “A fall detection system using k-nearest neighbor classifier,” Expert systems with applications, vol. 37, no. 10, pp. 7174–7181, 2010.
- [43] E. Hossain and G. Chetty, “A multi-modal gait based human identity recognition system based on surveillance videos,” in 2012 6th International Conference on Signal Processing and Communication Systems. IEEE, 2012, pp. 1–4.
- [44] C.-Y. Hsu, R. Hristov, G.-H. Lee, M. Zhao, and D. Katabi, “Enabling identification and behavioral sensing in homes using radio reflections,” in Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, 2019, pp. 1–13.
- [45] H. S. Hossain, M. A. Al Haiz Khan, and N. Roy, “Deactive: scaling activity recognition with active deep learning,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 2, no. 2, pp. 1–23, 2018.
- [46] S. Anzar, K. Amala, R. Rajendran, A. Mohan, P. Ajeesh, F. Aziz et al., “Efficient online and offline template update mechanisms for speaker recognition,” Computers & Electrical Engineering, vol. 50, pp. 10–25, 2016.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8ebb9487-9f0e-4c84-9347-527f0fbd63d2/Qingyang.png) |
Qingyang Li received the bachelor’s degree from Northwestern Polytechnical University, Xi’an, China, in 2016. She is currently a Ph.D. student with the School of Computer Science, Northwestern Polytechnical University. Her research interests include ubiquitous computing, data mining, and artificial intelligence. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8ebb9487-9f0e-4c84-9347-527f0fbd63d2/Zhiwen.png) |
Zhiwen Yu received the Ph.D. degree in computer science from Northwestern Polytechnical University, Xi’an, China, in 2005. He is currently a Professor and the Dean of the School of Computer Science, Northwestern Polytechnical University, Xi’an, China. He was an Alexander Von Humboldt Fellow with Mannheim University, Germany, and a Research Fellow with Kyoto University, Kyoto, Japan. His research interests include ubiquitous computing, HCI, and mobile sensing and computing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8ebb9487-9f0e-4c84-9347-527f0fbd63d2/Lina.png) |
Lina Yao received the Ph.D. degree in computer science from the University of Adelaide, Australia, in 2014. She is currently a Lecturer of Computer Science and Engineering with the School of Computer Science and Engineering, University of New South Wales, Sydney, Australia. Her research interests include machine learning and data mining with applications to the Internet of Things, brain–computer interface, information filtering and recommending, and human activity recognition. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8ebb9487-9f0e-4c84-9347-527f0fbd63d2/Bin.png) |
Bin Guo received the Ph.D. degree in computer science from Keio University, Minato, Japan, in 2009, He was a Postdoctoral Researcher with the Institut TELECOM SudParis, Essonne, France. He is currently a Professor with Northwestern Polytechnical University, Xi’an, China. His research interests include ubiquitous computing, mobile crowd sensing and computing, and HCI. |