Robust ADAS: Enhancing Robustness of Machine Learning-based Advanced Driver Assistance Systems for Adverse Weather
Abstract
In the realm of deploying Machine Learning-based Advanced Driver Assistance Systems (ML-ADAS) into real-world scenarios, adverse weather conditions pose a significant challenge. Conventional ML models trained on clear weather data falter when faced with scenarios like extreme fog or heavy rain, potentially leading to accidents and safety hazards. This paper addresses this issue by proposing a novel approach: employing a Denoising Deep Neural Network as a preprocessing step to transform adverse weather images into clear weather images, thereby enhancing the robustness of ML-ADAS systems. The proposed method eliminates the need for retraining all subsequent Depp Neural Networks (DNN) in the ML-ADAS pipeline, thus saving computational resources and time. Moreover, it improves driver visualization, which is critical for safe navigation in adverse weather conditions. By leveraging the UNet architecture trained on an augmented KITTI dataset with synthetic adverse weather images, we develop the Weather UNet (WUNet) DNN to remove weather artifacts. Our study demonstrates substantial performance improvements in object detection with WUNet preprocessing under adverse weather conditions. Notably, in scenarios involving extreme fog, our proposed solution improves the mean Average Precision (mAP) score of the YOLOv8n from 4% to 70%.
Index Terms— Advanced Driver Assistance Systems, Machine Learning, Adverse Weather, Weather Robustification, UNet, Object Detection
1 Introduction
A major challenge in deploying ML-ADAS in the real world are adverse weather conditions [1, 2]. An object detector, such as the models in the popular YOLO [3, 4, 5, 6] series, trained on clear weather images will inevitably fail to make predictions in adverse weather like extreme fog. This is because DNNs adapt to the domain presented in the training dataset and even a slight shift in the target domain will fall outside of the DNN’s knowledge domain [7]. For example, if the dataset contains only clear weather images, then the robustness of this model against adverse weather becomes an issue leading to potential accidents and safety risks. Thus, all of our DNNs need to be robustified to experience minimal performance losses in adverse weather.
An even bigger challenge is obtaining a dataset that consists of different weather conditions. Naturally, it is unsafe driving in extreme weather like rainstorms or dense fog. This is why no road scene dataset is publicly available to robustify ML-ADAS features. Some attempts have been made in the field of object detection [8]. However, these datasets only record mild weather conditions where safe driving is still possible. To offer ADAS functionalities in the real world, we need to address extreme weather cases. Furthermore, a complex ML-ADAS comprises of additional functionalities like Lane Lines Detection and Distance Estimation which do not have extensive adverse weather datasets. For this reason, we decide to use multiple image augmentations to simulate adverse weather conditions and create a synthetic dataset. We shortlist fog, rain, and snow as the conditions to simulate.
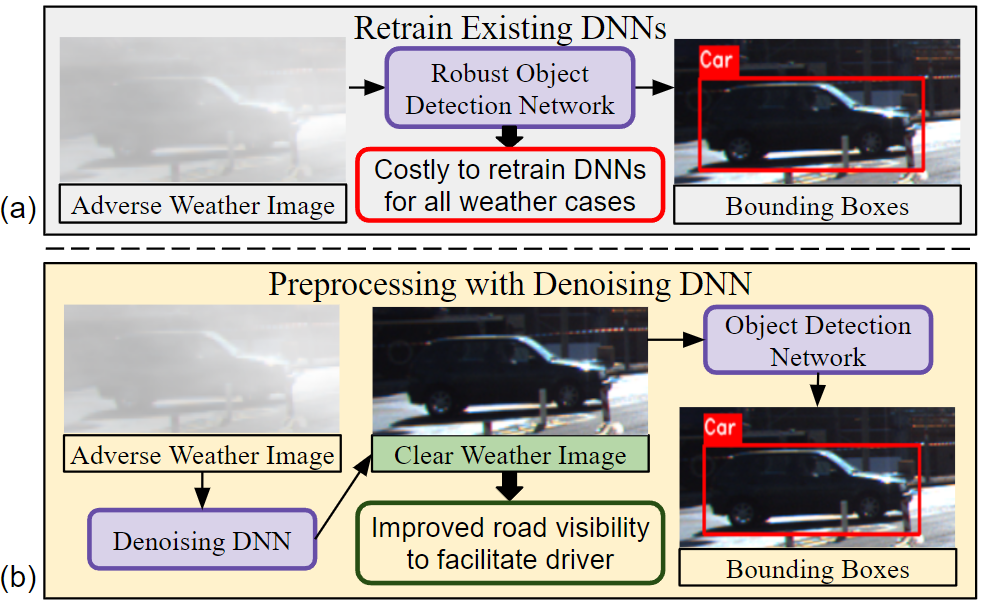
Figure 1 highlights the strategies to address the domain shift. One approach, demonstrated in Figure 1a, is to retrain all the DNNs in the system on images under different weather conditions. With this, all DNNs adapt to all weather domains. However, this process is extremely computationally expensive and time consuming. Furthermore, there is no facilitation for the driver in terms of observing the road scene ahead. While the driver may be alerted with audio cues from the robust ML-ADAS DNNs, they will still be operating blind. Thus, visualizing an enhanced road scene with all adverse weather-related noise completely removed still takes precedence in driver facilitation.
Therefore, as described in Figure 1b, instead of retraining all networks, we develop a Denoising DNN that essentially processes the input adverse weather image and provides a clear weather image. Using this module as a preprocessing step before feeding the image to all subsequent ML-ADAS DNNs retains the performance of these networks since they receive filtered images belonging to the clear weather domain. Therefore, we avoid the costly step of retraining all the subsequent DNNs in the pipeline. Most importantly, with this approach, we are able to display the clear weather images to the driver for additional visual facilitation. Additionally, it allows us to use state-of-the-art open-source models for lane segmentation, object detection and depth estimation.
Designing an ADAS for edge devices is subjected to multiple real-world constraints in terms of real-time performance, energy efficiency, and safety. Thus, our primary objective is to implement the optimal trade-off between these constraints that ensures the highest degree of safety possible. Considering this, one potential drawback of our strategy described in Figure 1b is the added latency of the new DNN used for image enhancement. We address this drawback by reducing the scope of the problem: we divide the input image into crops and the WUNet processes this batch of crops instead of the entire image. This allows us to shrink the network in proportion to the reduction in input image size. The details of this scheme are described in Section II.
1.1 Motivational Case Study
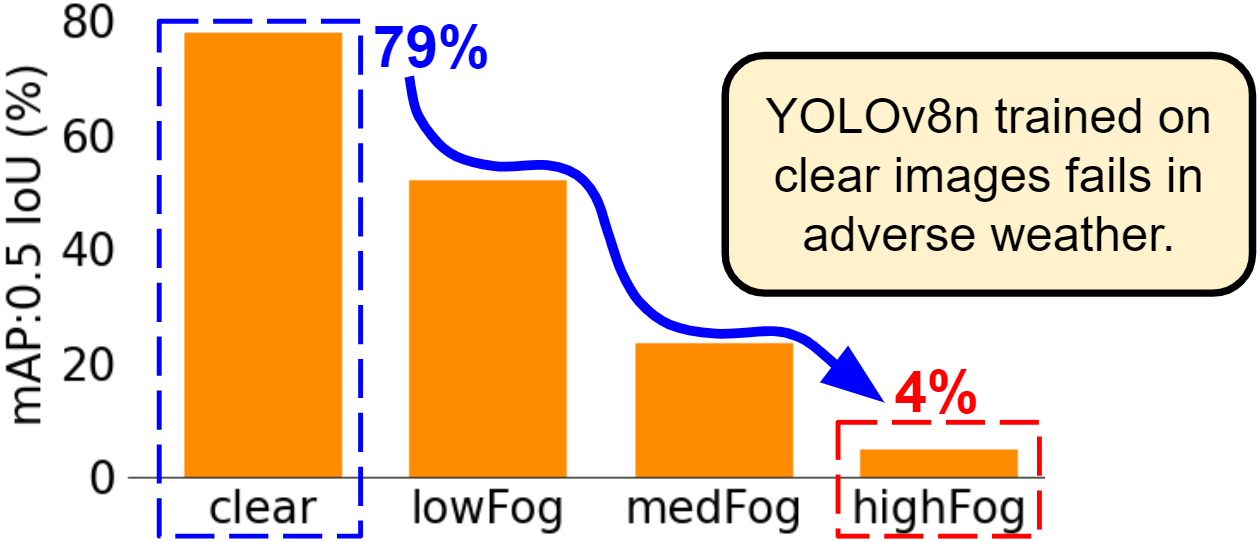
In Figure 2, we demonstrate that a highly accurate object detector trained on clear images fails to retain its accuracy when employed in adverse weather conditions. In such critical conditions, the driver relies heavily on the assistance of the ML-ADAS. However, with a 4% mAP, there is a high risk of collisions with oncoming traffic since the system is essentially blind; it cannot detect anything. Thus, it is evident that there is a need to robustify ML-ADAS DNNs against adverse weather to guarantee driver safety after deployment in the real world. The object detector, YOLOv8n, specifications and the extended KITTI dataset for adverse weather conditions is described in Section III.
1.2 Our Novel Contributions
To robustify an ML-ADAS system against multiple adverse weather conditions without retraining all DNNs employed, we propose a preprocessing DNN to construct clear images in adverse weather. Our proposed WUNet is based on the popular UNet architecture and trained on the KITTI dataset extended with augmentations to create synthetic adverse weather images. In extreme fog, the WUNet preprocessing boosts object detection performance from 4% to 70% mAP over the 0.5 IoU threshold. Details on the experimental setup can be found in Evaluation and Discussion. In summary, we make the following key contributions.
-
1.
WUNet: we develop a preprocessing DNN to construct clear images in adverse weather, before feeding the input image to the ML-ADAS modules.
-
2.
We synthesize an adverse weather dataset by extending the KITTI dataset to include foggy, rainy, and snowy images.
-
3.
We devise an in-depth evaluation scheme to measure a denoising algorithm’s impact on object detection performance in varying weather adversities.
-
4.
We demonstrate potential to decrease the complexity of a UNet to decrease latency for the specific task of weather-related artifact/noise removal by processing an input image as a batch of crops instead of the whole image.
2 Methodology for Robustifying against Adverse Weather
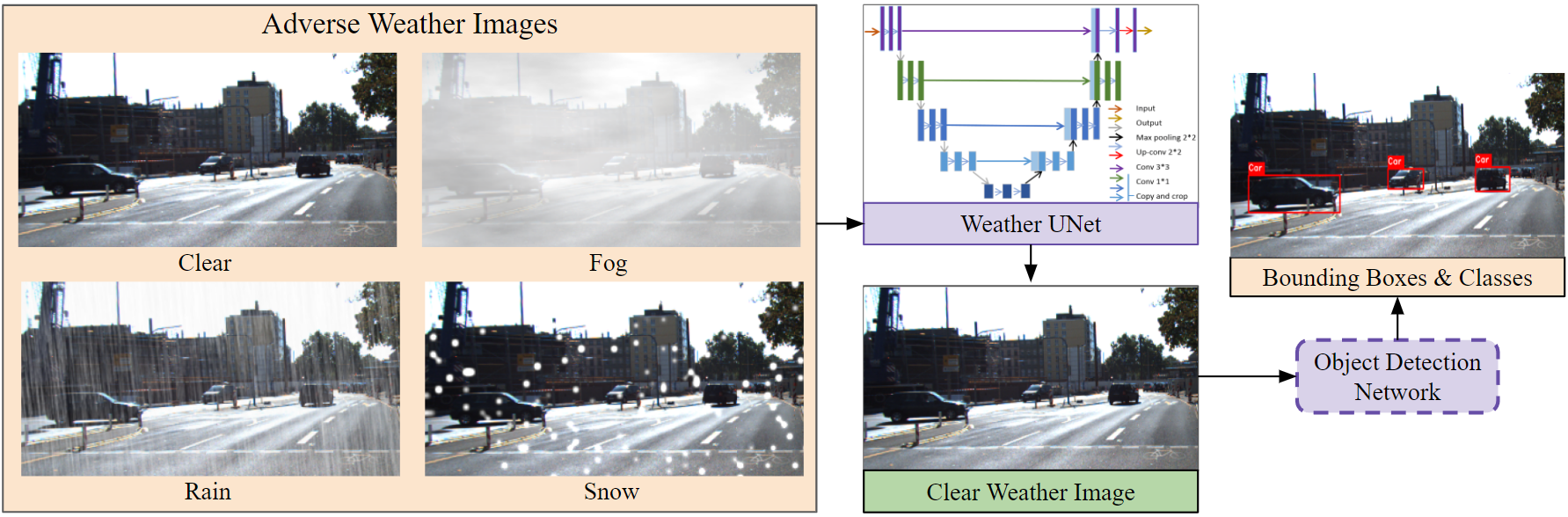
Figure 3 visualizes our proposed solution. We employ the popular UNet encoder-decoder architecture [9] to build our Weather UNet (WUNet) to images from all weather conditions and generate a clear image. This image can then be used by the object detector and any other subsequent DNNs to avoid retraining costs. Further details are discussed in the following sections.
2.1 Data Generation
To address the limitation of publicly available datasets, we decide to create a synthetic dataset containing adverse weather images. With the advent of computer vision, there are multiple open-source image augmentation libraries to choose from. However, we choose the imgaug library based on its effectiveness in producing photo-realistic weather conditions [10]. With this extensive dataset, we can train a DNN to learn to map adverse weather images to their clear counterparts. In this way, we obtain clear images that not only facilitate the driver visually, but also improve performance for all ML-ADAS features.
2.2 Model Selection
While similar efforts have been made to create preprocessing denoising DNNs, often the use-case is restricted to just one weather condition like fog removal [11]. In contrast, we aim to address all weather cases with one DNN. The popular UNet encoder-decoder architecture performs well in similar tasks such as image super-resolution and depth estimation, where the emphasis is on image reconstruction [12, 9]. Since its functionality aligns with our strategy, we adopt it in our pipeline.
2.3 Studying Color Representations
Training a WUNet on RGB and HSV images entails distinct approaches due to differences in color representation. RGB represents colors using three channels: red, green, and blue, which are additive. In contrast, HSV (Hue, Saturation, Value) represents colors based on perceptually relevant attributes like hue, saturation, and brightness, offering a more intuitive representation. Our exploration will involve training separate WUNet models on RGB and HSV images to discern how each representation affects performance. We plan to compare the models’ ability to generate a clear image from an adverse weather image using the Mean-Squared Error (MSE) metric and comparing the prediction with the original image. Overall, we aim to gain insights into the advantages and limitations of using RGB versus HSV for image enhancement.
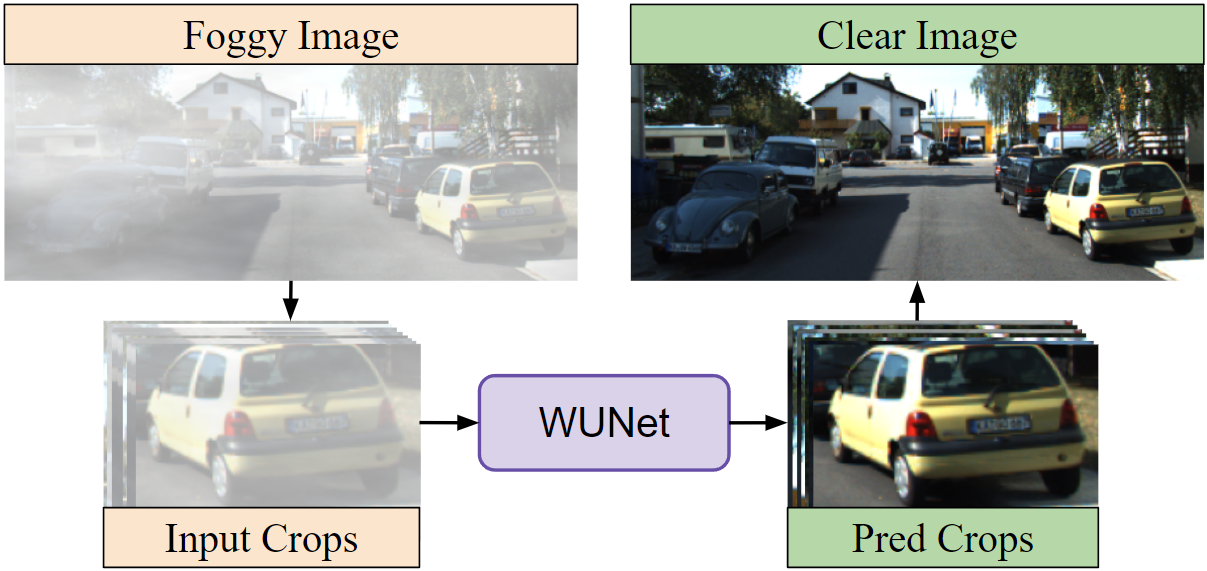

2.4 Mitigating Cost
As mentioned earlier, the main drawback of this approach, as opposed to retraining the detector, is the additional cost of the WUNet. Figure 4 highlights our strategy to mitigate the additional latency introduced by the WUNet. Before implementing any DNN compression techniques like pruning and quantization [13], we will study if the WUNet can be reduced in size with a reduction in the scope of the problem. We hypothesize that there will be no difference in WUNet performance when it processes the input image as a whole, compared with dividing it into equal-sized crops and processing this batch of crops instead. We aim to highlight that a DNN does not need to learn an extremely complex function to remove weather artifacts. Thus, with less information as input, the DNN does not need to be as large and can be reduced in size. Our study aims to highlight this potential to shrink the UNet architecture specifically in the task of noise removal. We will evaluate the difference between WUNet versions trained on either whole images or crops.
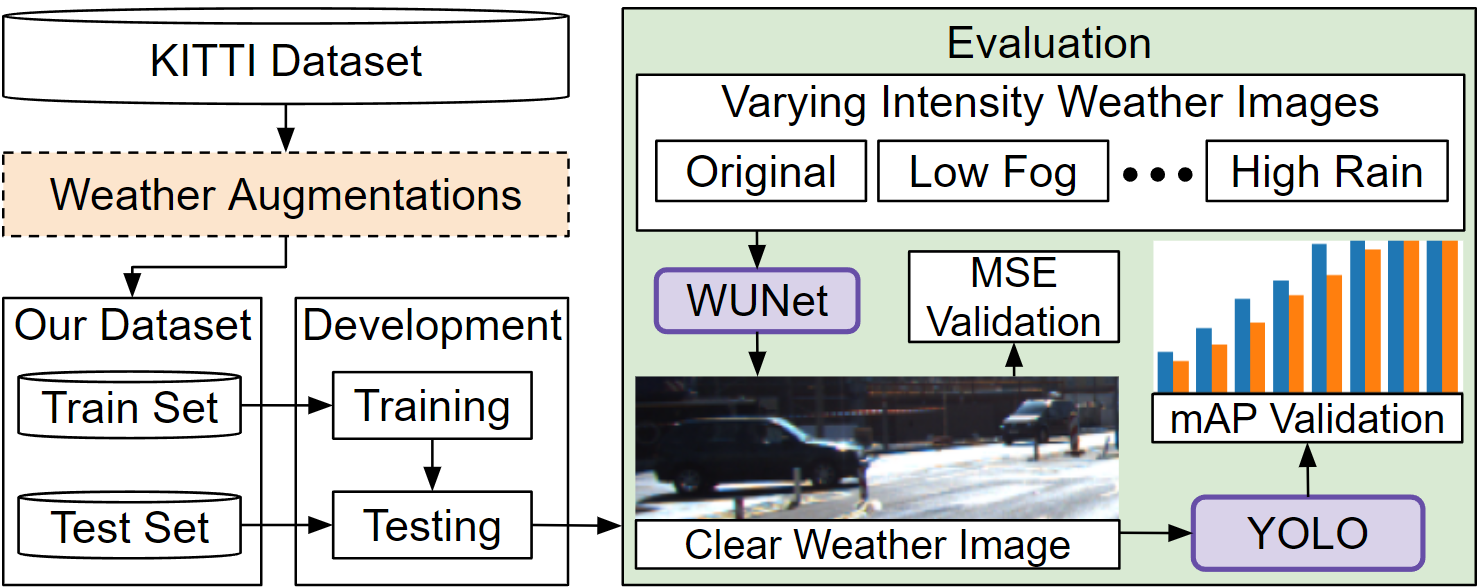
3 Evaluation and Discussion
Figure 6 describes our entire evaluation pipeline in detail. Building on the KITTI Object Detection dataset, we add synthetic adverse weather images through multiple image augmentations to create an extended dataset. Then, we use this extended dataset to train the WUNet. The evaluation phase consists of the same test set as the base KITTI dataset, but in different weather adversities. The performance of an object detector trained on the base KITTI dataset is measured on the weather validation sets with and without the WUNet preprocessing. The following sections describe this pipeline in more detail.
3.1 Dataset
We rely on the KITTI dataset because it consists of only clear weather images in the day time [14]. This is an important characteristic because it enables us to clearly evaluate the object detector’s performance when trained on clear images and tested on adverse weather. Consequently, the impact of the WUNet on object detection becomes clear as well.
Using the train/test split provided by the authors of Dist-YOLO [15], we obtain 6699 images in our train, and 782 images in our test set. Next, we extend this base dataset with synthetic adverse weather images using the imgaug library [10]. We use the Fog, Rain, and Snowflakes augmentations on each image in the dataset, with the instantiation parameters for each augmentation being sampled randomly between low and extreme adversity. Along with the original, these three synthetic versions are saved with the same ground truth annotations as the original image. Thus, our dataset now consists of 26796 images in the train, and 3128 images in the test set encompassing varying intensities of each adverse weather condition. While training the WUNet, a sample is defined as the augmented image (fog, rain, snow, or original) and its ground truth is the original image. For training the object detector, the sample is defined as the image and its ground truth are the corresponding bounding box annotations in the KITTI dataset.
Furthermore, we create a total of 10 validation sets, consisting of 782 images each, by tuning the hyperparameters in the augmentations. These sets are the normal set which is the unaltered KITTI test set, and low, medium, and high intensity variations of each of the three weather augmentations. Figure 5 displays samples from our high adversity validation sets. With this, we can conduct an in-depth evaluation of the WUNet’s weather artifact removal performance in different intensities of different weather conditions.
3.2 Experimental Setup
All experiments were conducted on the NVIDIA GeForce RTX 4090 GPU. The WUNet was trained on the extended and augmented KITTI dataset using the Adam optimizer for 200 epochs with a batch size of 24, learning rate of 0.01, and input image size of (640,200) pixels. Note that the WUNets trained on crops have input image size of (160,100) and a total of 214,368 train and 25,024 test images. This is because we arbitrarily divide each image in the augmented dataset into 8 crops, with each crop being a sample instead of the whole image. In this case, we use batch size of 160. In all experiments, we use the mean-squared loss to supervise training. The WUNet that performs the best on the test set is chosen to be evaluated end-to-end with the object detector.
For object detection, we employ the YOLOv8 variant of size nano (n), small (s), and medium (m) from the open-sourced Ultralytics framework [5]. These detectors have been trained over the base KITTI dataset with the same training settings as the base WUNet except for a 0.001 learning rate. We present the performance evaluation results of each of these variants in Table 1.
| YOLOv8 variant | mAP over 0.5 IoU (%) | Parameters (millions) |
| n | 79.97 | 3.2 |
| s | 83.46 | 11.2 |
| m | 83.80 | 25.9 |
Since YOLOv8n has the lowest mAP score, it has the greatest sensitivity to weather artifacts. Thus, we use this variant in our evaluation of the WUNet end-to-end to examine the artifact removal performance in the worst case of highest detector sensitivity.
3.3 End-to-End Evaluation with YOLOv8n
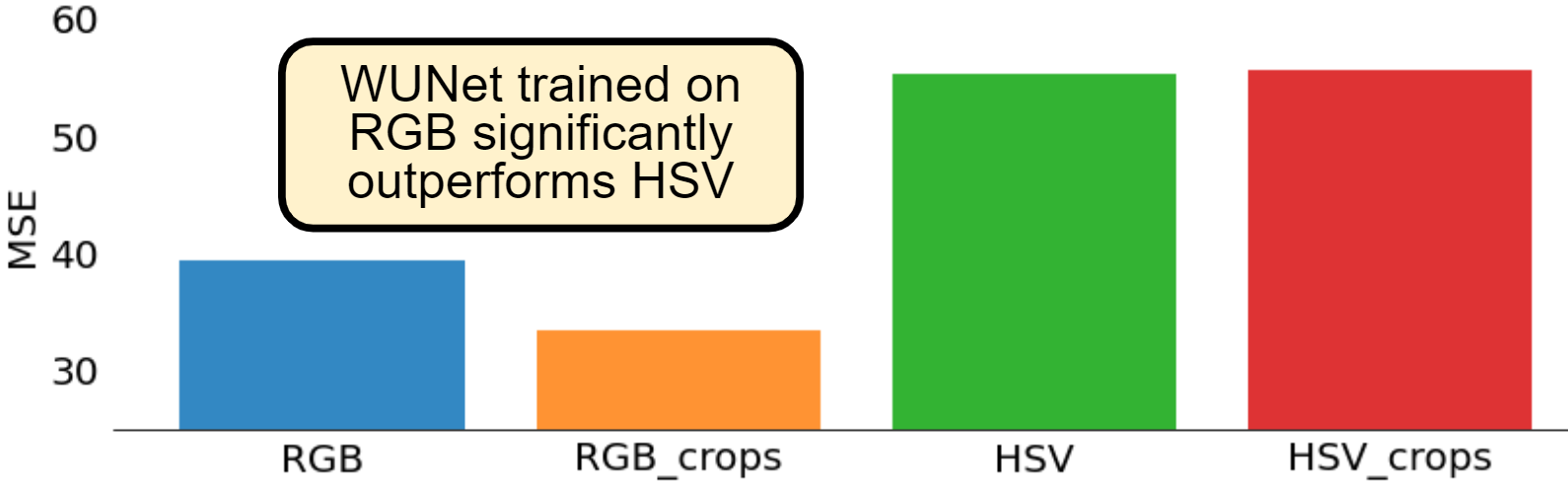
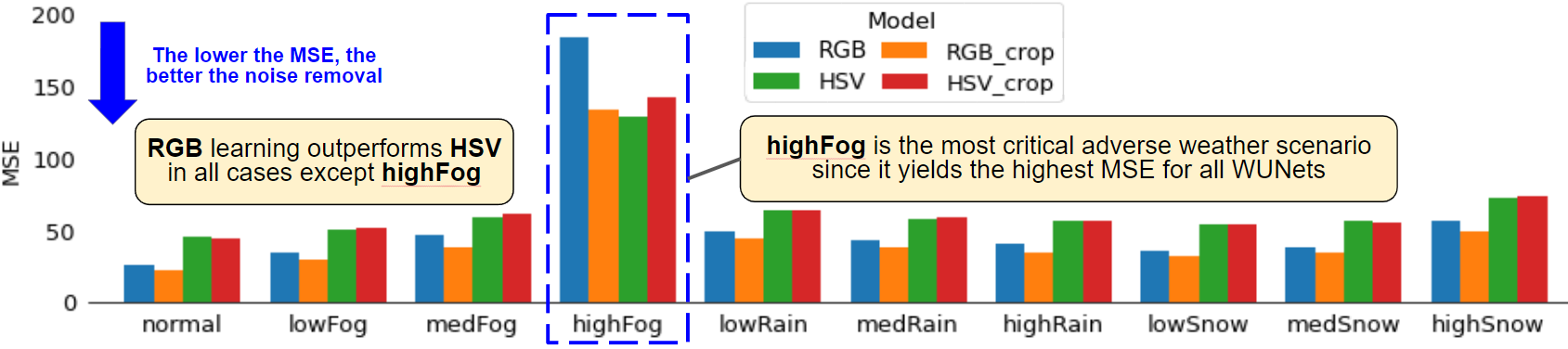
Figure 7 summarizes the MSE evaluation results we obtain with training each WUNet variant. With MSE validation, we aim to measure the WUNet’s ability to generate high quality clear images. The lower the MSE, the greater the WUNet’s ability in removing weather artifacts. We observe that the RGB learned WUNets outperform the HSV variants by at least 40%. Furthermore, within the RGB WUNets, training over crops yields 15% lower MSE than training over the whole image. This is most likely because of a larger dataset in the case of crops, but we establish that processing via crops is a valid scheme. Figure 8 provides a closer inspection where we observe MSE error in our 10 varying adversity sets. Most notably, we observe that the most challenging and critical case to address is high fog. Next, we aim to employ the YOLOv8n’s mAP performance as a metric to further determine the quality of the clear images produced.
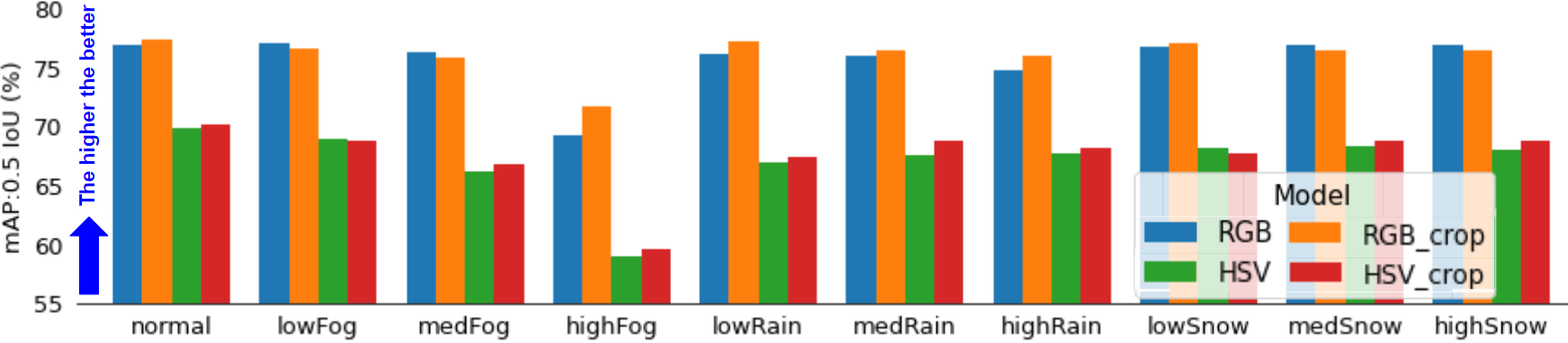
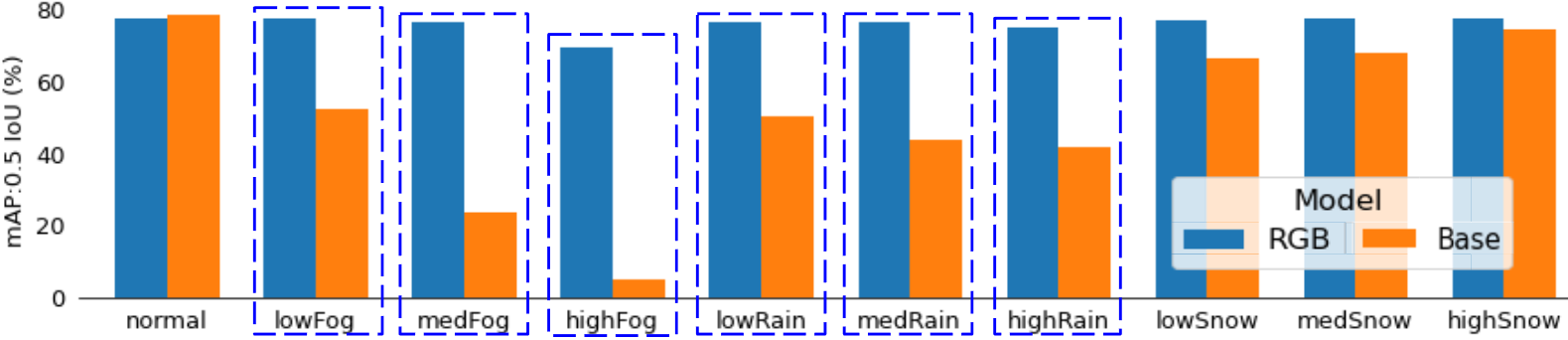
We compare the performance of YOLOv8n, with and without each WUNet variant’s preprocessing, over all the 10 cases. Note that YOLOv8n was trained only on the base KITTI dataset that consists of clear images. The validation set that corresponds to this is the normal set and we expect the highest performance here (Table 1). Figure 9 summarizes our findings. Averaged over all cases, the RGB variants achieve 76% mAP compared to the HSVs’ 67%. Again, we observe that RGB-learning outperforms HSV-learning, with at least a 9% increase in mAP in all categories. Most importantly, we have verified that the WUNet can process images as crops and retain the same performance as processing the entire image. This allows us to continue our work to shrink the size of the WUNet to increase network efficiency.
Lastly, Figure 10 highlights the improvements in YOLOv8n’s accuracy by using the simple RGB WUNet in the pipeline. Our results verify that the YOLOv8n trained on clear images is needs to be robustified against cases like extreme fog. Inference on the clear image provided by the WUNet compared to the extremely foggy image improves mAP score from 4% to 70%, a 1650% improvement. Overall, the most significant performance boosts are seen in all fog and rain cases especially.
3.4 Future Work
Building upon this project, we will evaluate the WUNet on a larger dataset like the Pascal VOC dataset [16]. This will allow us to compare our results to the current state-of-the-art works like the Image-Adaptive YOLO that use larger datasets, as opposed to the KITTI dataset [11]. Additionally, research needs to be conducted to assess the DNN’s performance in terms of its efficiency and additional latency impact on overall system. We have already established that the WUNet is able to process images as a batch of crops which allows us to shrink the network’s size by a factor that is directly proportional to the size of the crop relative to the original image size. This is because removing weather related artifacts from the image does not require learning a very complex function. Thus, we will tune the parameters of network size and image-crop size specifically.
4 Conclusion
In conclusion, our study addresses the critical challenge of deploying ML-ADAS in adverse weather conditions. We demonstrate that ML-ADAS systems trained solely on clear weather data are ill-equipped to handle adverse conditions such as extreme fog or heavy rain, posing significant safety risks. To mitigate these risks, we propose a novel approach leveraging a Denoising DNN as a preprocessing step to generate clear weather images from adverse weather inputs, without the need for retraining all subsequent DNNs in the ML-ADAS pipeline. This strategy not only avoids the computational cost and time-consuming process of retraining, but also enhances driver visualization, crucial for safe navigation.
Through extensive experimentation and evaluation, we demonstrate the efficacy of our approach using the UNet architecture, trained on an extended KITTI dataset augmented with synthetic adverse weather images. Our findings indicate significant performance improvements in object detection under adverse weather conditions, with the WUNet preprocessing leading to a substantial increase in mAP scores, particularly in scenarios involving extreme fog where we boost a 4% mAP to 70%.
In light of our findings, we propose future research directions, including evaluation on larger datasets and further optimization of network parameters, i.e. input image size and size of the network specifically, for enhanced efficiency and performance. Overall, our study offers valuable insights and a promising solution to enhance the robustness and safety of ML-ADAS systems in adverse weather conditions, paving the way for safer autonomous driving experiences in challenging environments.
Acknowledgements
This work was partially supported by the NYUAD Center for Artificial Intelligence and Robotics (CAIR), funded by Tamkeen under the NYUAD Research Institute Award CG010, and the NYUAD Center for Interacting Urban Networks (CITIES), funded by Tamkeen under the NYUAD Research Institute Award CG001.
References
- [1] Sotiris Karavarsamis, Ioanna Gkika, Vasileios Gkitsas, Konstantinos Konstantoudakis, and Dimitrios Zarpalas, “A survey of deep learning-based image restoration methods for enhancing situational awareness at disaster sites: The cases of rain, snow and haze,” Sensors, vol. 22, no. 13, 2022.
- [2] Muhammad Ahmed, Khurram Azeem Hashmi, Alain Pagani, Marcus Liwicki, Didier Stricker, and Muhammad Zeshan Afzal, “Survey and performance analysis of deep learning based object detection in challenging environments,” Sensors, vol. 21, no. 15, 2021.
- [3] Joseph Redmon and Ali Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
- [4] Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao, “Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7464–7475.
- [5] Glenn Jocher, Ayush Chaurasia, and Jing Qiu, “YOLO by Ultralytics,” Jan. 2023.
- [6] Abolfazl Younesi, Mohsen Ansari, MohammadAmin Fazli, Alireza Ejlali, Muhammad Shafique, and Jörg Henkel, “A comprehensive survey of convolutions in deep learning: Applications, challenges, and future trends,” arXiv preprint arXiv:2402.15490, 2024.
- [7] Mohamed Akrout, Amal Feriani, Faouzi Bellili, Amine Mezghani, and Ekram Hossain, “Domain generalization in machine learning models for wireless communications: Concepts, state-of-the-art, and open issues,” IEEE Communications Surveys & Tutorials, 2023.
- [8] Xin Yang, Wending Yan, Yuan Yuan, Michael Bi Mi, and Robby T. Tan, “Semantic segmentation in multiple adverse weather conditions with domain knowledge retention,” 2024.
- [9] Olaf Ronneberger, Philipp Fischer, and Thomas Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 2015, pp. 234–241.
- [10] Alexander B. Jung, Kentaro Wada, Jon Crall, Satoshi Tanaka, Jake Graving, Christoph Reinders, Sarthak Yadav, Joy Banerjee, Gábor Vecsei, Adam Kraft, Zheng Rui, Jirka Borovec, Christian Vallentin, Semen Zhydenko, Kilian Pfeiffer, Ben Cook, Ismael Fernández, François-Michel De Rainville, Chi-Hung Weng, Abner Ayala-Acevedo, Raphael Meudec, Matias Laporte, et al., “imgaug,” https://github.com/aleju/imgaug, 2020, Online; accessed 01-Feb-2020.
- [11] Wenyu Liu, Gaofeng Ren, Runsheng Yu, Shi Guo, Jianke Zhu, and Lei Zhang, “Image-adaptive yolo for object detection in adverse weather conditions,” 2022.
- [12] Xiaodan Hu, Mohamed A Naiel, Alexander Wong, Mark Lamm, and Paul Fieguth, “Runet: A robust unet architecture for image super-resolution,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019, pp. 0–0.
- [13] Maurizio Capra, Beatrice Bussolino, Alberto Marchisio, Guido Masera, Maurizio Martina, and Muhammad Shafique, “Hardware and software optimizations for accelerating deep neural networks: Survey of current trends, challenges, and the road ahead,” IEEE Access, vol. 8, pp. 225134–225180, 2020.
- [14] Andreas Geiger, Philip Lenz, and Raquel Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
- [15] Marek Vajgl, Petr Hurtik, and Tomáš Nejezchleba, “Dist-yolo: Fast object detection with distance estimation,” Applied Sciences, vol. 12, no. 3, 2022.
- [16] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc) challenge,” International Journal of Computer Vision, vol. 88, no. 2, pp. 303–338, June 2010.