Robust estimation in beta regression via maximum Lq-likelihood
Abstract
Beta regression models are widely used for modeling continuous data limited to the unit interval, such as proportions, fractions, and rates. The inference for the parameters of beta regression models is commonly based on maximum likelihood estimation. However, it is known to be sensitive to discrepant observations. In some cases, one atypical data point can lead to severe bias and erroneous conclusions about the features of interest. In this work, we develop a robust estimation procedure for beta regression models based on the maximization of a reparameterized Lq-likelihood. The new estimator offers a trade-off between robustness and efficiency through a tuning constant. To select the optimal value of the tuning constant, we propose a data-driven method which ensures full efficiency in the absence of outliers.
We also improve on an alternative robust estimator by applying our data-driven method to select its optimum tuning constant. Monte Carlo simulations suggest marked robustness of the two robust estimators with little loss of efficiency.
Applications to three datasets are presented and discussed. As a by-product of the proposed methodology,
residual diagnostic plots based on robust fits highlight outliers that would be masked under maximum likelihood estimation.
Keywords: Beta regression; Bounded influence function; Lq-likelihood; Outliers; Residuals; Robustness.
1 Introduction
Random phenomena that produce data in the unit interval are common in many research areas, including medicine, finance, economics, environment, hydrology, and psychology. Data of this type are usually rates, proportions, percentages, or fractions. A few examples are unemployment rates, the proportion of exports in total sales, the fraction of surface covered by vegetation, Gini’s index, the loss given default, health-related quality of life scores, and neonatal mortality rates. Beta regression models (Ferrari and Cribari-Neto, 2004; Smithson and Verkuilen, 2006) are widely employed for modeling continuous data bounded within the unit interval. The response variable is assumed to follow a beta distribution indexed by the mean and a precision parameter, which in turn are modeled through a variety of regression structures.
Let the response variable have a beta distribution with mean and precision parameter . The probability density function of is
| (1) |
where is the beta function. We write , , and assume that are independent. Since , the parameter is taken as a precision parameter because it is inversely related to the dispersion of , for fixed mean . The beta density (1) assumes different forms depending on the parameters. It has a single mode in if and , and its possible forms include J, inverted-J, tilde, inverted tilde, bathtub and uniform shapes. When or the beta density is unbounded at one or both of the boundaries. We will assume that the regression structures for and are, respectively,
| (2) |
| (3) |
where and are vectors of unknown regression parameters, and are vectors of covariates of lengths and (), respectively, which are assumed fixed and known. In addition, and are strictly monotonic and twice differentiable link functions. The model introduced by Ferrari and Cribari-Neto (2004) is a constant precision (or, equivalently, constant dispersion) beta regression model in the sense that , for .
Inference for the beta regression model (1)-(3) is commonly based on the maximum likelihood estimator (MLE). However, it may be highly influenced by the presence of outlying observations in the data.
As an illustration of the sensitivity of the MLE to outliers, we consider a dataset on risk management practices of 73 firms introduced and analyzed by Schmit and Roth (1990); see also Gómez-Déniz et al. (2014). The response variable is Firm cost, defined as premiums plus uninsured losses as a percentage of the total assets. Smaller values of Firm cost are attributed to firms that have a good risk management performance. We take only two covariates, namely Ind cost, a measure of the firm’s industry risk, and Size log, the logarithm of its total asset. Figure 1 displays the scatter plot of Firm cost versus Ind cost along with the fitted lines based on the MLE for a beta regression with varying precision for the full data and the data without the most eye-catching outliers, labeled in the plots as observations 15, 16 and 72.222The scatter plots were produced by setting the value of the remaining covariate at its sample median value. These observations have disproportionate effects on the fitted regression curves.
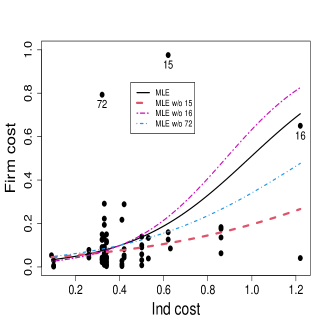
To deal with atypical observations, models based on distributions that are more flexible than the beta distribution may be employed. For instance, Bayes et al. (2012), Migliorati et al. (2018), and Di Brisco et al. (2020) proposed different kinds of mixtures of beta distributions. However, more flexibility comes at the cost of model complexity and additional parameters, making model specification, inference, and interpretation more difficult. Our approach keeps the model simple, i.e. the beta distribution remains as the postulated model, but the inference procedure is replaced by a robust method.
Ghosh (2019) proposed a robust estimator in beta regression models based on the minimization of an empirical density power divergence introduced by Basu et al. (1998). The estimator, called the minimum density power divergence estimator (MDPDE), is similar to the approach we will propose here. The main difference between the two estimation procedures is that they are based on two different families of divergences that have the Kullback-Leibler divergence as a special case. In other words, both have the MLE as a special case. Ghosh (2019) presented some simulations of the MDPDE, but only for constant precision beta regression models with fixed values for the tuning constant. Here, we propose a data-driven method to select the tuning constant of the MDPDE which ensures full efficiency in the absence of contamination. Additionally, we evaluate the performance of the MDPDE under constant and varying precision using the proposed selection algorithm.
The chief goal of this paper is to propose a new robust estimator under the beta regression model (1)-(3) with a scheme determined by the data to choose its optimum tuning constant. In Section 2, we introduce a robust estimator based on the maximization of a reparameterized Lq-likelihood, and derive some properties. In Section 3, we introduce a data-driven method to the selection of the tuning constant. In Section 4, we provide Monte Carlo evidence on the proposed robust inference approach. Section 5 contains applications of the robust estimation for three datasets. Finally, Section 6 closes the paper with some concluding remarks. Some technical details are left for an appendix. The on-line Supplementary Material contains further technical information and additional numerical results. The codes for the simulations and applications and the datasets are available at https://github.com/terezinharibeiro/RobustBetaRegression.
2 Robust inference
Let be independent observations, where comes from a postulated model indexed by a common unknown parameter . For the beta regression model, the postulated density for is given by (1)-(3), and we will denote it, from now on, by . Let denote the Lq-likelihood (Ferrari and Yang, 2010),
| (4) |
where is a tuning constant, and
is the Box-Cox transformation (Box and Cox, 1964), also called distorted logarithm. The population version of with respect to the density is
which is the -entropy of with respect to (Tsallis, 1988) and reduces to the Shannon entropy when . For , is the usual log-likelihood function and maximizing leads to the maximum likelihood estimator (MLE).
The estimator obtained by maximizing (4), will be denoted by . It comes from the estimating equation
| (5) |
where , with denoting the gradient with respect to . The score vector for corresponding to the -th observation is given by
| (7) |
where , , , and , with denoting the digamma function.
The score vector of the -th observation is weighted by , which depends on the postulated model and the tuning constant . A choice of not too close to 1 produces a robust estimation procedure, because observations that are inconsistent with the assumed model receive smaller weights. Furthermore, (5) defines an M-estimation procedure, first introduced by Huber (1964). The class of M-estimators is widely used for obtaining robust estimators, and has interesting properties such as the asymptotic normality (Huber, 1981).
The estimating function is biased unless . Hence, the estimator is not Fisher-consistent. Ferrari and La Vecchia (2012) showed that a suitable calibration function may be applied to rescale the parameter estimates and to achieve Fisher-consistency if the family of postulated distributions is closed under the power transformation. Given a density and a constant , the power transformation is defined as
| (8) |
provided that , for . For a family of postulated densities that is closed under (8) for all , let be an invertible continuous function satisfying for all in the support, which is assumed not to depend on . Note that the function maps each density with a unique power-transformed density .
The -entropy is related with the family of divergences of with respect to
Ferrari and La Vecchia (2012, Lemma 1) showed that . Consequently, the minimizer of the empirical -entropy with respect to equals the minimizer of the empirical version of . In the minimization of , the target density is the transformed density instead of . Ferrari and La Vecchia (2012, Proposition 1) show that is not Fisher-consistent for but it is Fisher-consistent for . Hence, is Fisher-consistent for . Alternatively, is obtained by maximizing the Lq-likelihood in the parameterization (La Vecchia et al., 2015). Another proof of the Fisher-consistency of is given in the Supplementary Material.
For the beta regression model (1)-(3), is the maximizer of
where , for , with
| (9) |
provided that and , or equivalently, and . Then, satisfies (8) for all , if and , i.e. if is bounded. From (2) and (3), corresponds to a modified beta regression model defined by the beta density (1) with mean and precision submodels given respectively by
and we denote it by .
Therefore, we propose the estimator that is obtained through the maximization of
| (10) |
which leads to the following estimating equation
| (11) |
where being a modified score vector for corresponding to the -th observation given by
| (13) |
The final estimator, , will be simply called the surrogate maximum likelihood estimator (SMLE).
From the theory of M-estimation, where denotes asymptotic distribution and
| (14) |
with
see Ferrari and La Vecchia (2012, Section 3.2). For the beta regression model (1)-(3), and are given in the Appendix. The matrix is well-defined provided that and , or equivalently and . These conditions hold for all , if and .
Likelihood-based tests are usually constructed from the three well-known test statistics, namely the likelihood ratio, Wald, and score statistics, and they rely on maximum likelihood estimation. Following Heritier and Ronchetti (1994) (see also Heritier et al. (2009, Section 2.5.3)), robust versions of these statistics may be derived by replacing the MLE, the log-likelihood function, the score vector, and the asymptotic covariance matrix respectively by the SMLE, the reparameterized -likelihood in (10), the estimating function in (11), and the matrix in (14). In this paper, we focus on the robust Wald statistic, referred here as the Wald-type statistic, of the null hypothesis against a two-sided alternative defined as , which has a distribution under the null hypothesis. Here, is the SMLE of and is its asymptotic standard error that is computed from (14).
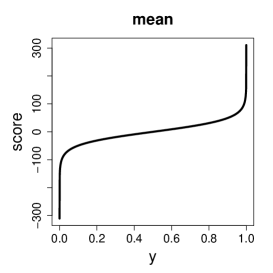
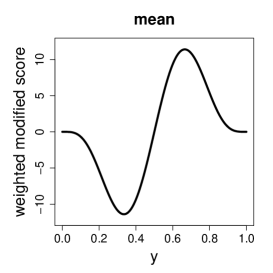
Since the MLE () and the SMLE are M-estimators, their influence functions for the beta regression model (1)-(3) are and , where and are given in (7) and (13), respectively, is the Fisher information matrix (see the Appendix), and is given in (14). The influence function measures the asymptotic bias of the estimator caused by an infinitesimal contamination introduced in the data point (Hampel et al., 2011, Section 2.1.b). The individual score vector is unbounded when or , i.e., for tending to one of the boundaries of the support set. Hence, the influence function of the MLE is also unbounded. On the other hand, for bounded beta densities the weighted modified score vector and the influence function of the SMLE are bounded, which implies that the SMLE is B-robust (Hampel et al., 2011, Section 2.1). Figure 2 illustrates the behavior of the score vector and of the weighted modified score vector for the i.i.d. case. Note that the components of the score vector grow or decrease unboundedly when approaches zero or one, while the components of the weighted modified score vector has a redescending shape, approaching zero at the boundaries. This means that observations close to zero or one may be influential in the MLE fit but not in the SMLE fit.
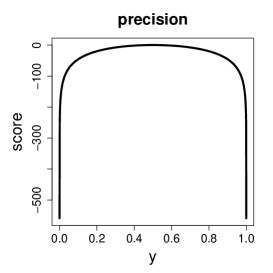
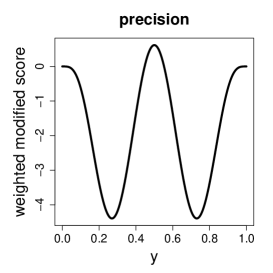
We also studied the behavior of the change-of-variance function, that measures the bias on the covariance matrix caused by an infinitesimal contamination in the data point . For the MLE, the change-of-variance function is unbounded. However, as presented in Ferrari and La Vecchia (2012, Proposition 2), the change-of-variance function of SMLE is bounded if the weighted modified score vector and its first derivative are bounded. We prove the boundedness of theses quantities for bounded beta densities, which implies that the SMLE is V-robust (Hampel et al., 2011, Section 2.5); see the Supplementary Material for details.
Ghosh (2019) proposed a robust estimator in beta regression models that minimizes an empirical version of the density power divergence introduced by Basu et al. (1998). The minimum density power divergence estimator (MDPDE) for the beta regression model (1)-(3) comes from the estimating equations
| (15) |
where . The components of may be found in Ghosh (2019), and the asymptotic covariance matrix of the MDPDE is given in the Supplementary Material. The expectation requires that and . Besides, the asymptotic covariance matrix of the MDPDE requires that and . Hence, these quantities are well-defined, for all , only for bounded beta densities.
Note that the estimating functions in (15) are unbiased. They agree with those derived from the -likelihood in (5) except for the term that plays the role of correcting the score bias. Recall that the score bias correction in the -likelihood approach adopted here is achieved by rescaling the parameter estimates or, equivalently by reparameterizing the -likelihood.
Ghosh (2019) presented simulations of the MDPDE only for constant precision beta regression models with fixed values for the tuning constant. However, in practical applications the choice of such a constant becomes a crucial issue. In Section 3, we will propose a data-driven method to select the tuning constant of the SMLE and the MDPDE which ensures full efficiency in the absence of contamination.
3 Selection of the tuning constant
An important aspect in real data applications is the choice of the optimal value of the tuning constant . Smaller values of increase robustness at the expense of reduced efficiency. La Vecchia et al. (2015) suggest to select the tuning constant closest to 1 (i.e., closest to MLE) such that the estimates of the parameters are sufficiently stable, ensuring full efficiency in the absence of contamination. This is the approach we follow here, but we standardize the estimates by ‘’ to simultaneously remove the effect of the sample size and of the magnitude of estimates of different parameters. We then propose a data-driven algorithm that starts with (MLE) and follows the steps below.
-
1.
Define an equally spaced grid for : with ;
-
2.
compute the estimates with the corresponding asymptotic standard errors, ;
-
3.
compute the vectors of standardized estimates,
and the standardized quadratic variations (SQV) defined by
-
4.
for each , check whether the stability condition defined by is satisfied, where is a pre-defined threshold;
-
5.
if the stability condition is satisfied for all , set the optimal value of at ;
-
6.
if the stability condition is not satisfied for some , set a new grid starting from the smallest for which the condition does not hold;
-
7.
repeat steps 1-6 until achieving stability of the estimates for the current grid or reaching the minimum value ; if stability is achieved, set the optimal value of at , otherwise at .
This procedure chooses the optimum value for the tuning constant that is closest to 1 (MLE) and still guarantees stability of the estimates for consecutive equally spaced values of . It may occur that such an optimal is not reached. In this case, the algorithm sets the optimal at 1 i.e. the MLE is chosen. This choice may seem unreasonable but recall that the SMLE is not expected to be robust for unbounded beta densities, which might lead to unstable estimates even for reasonably small . In such a situation, it is not advisable to replace the MLE by the SMLE. Our experience with simulated samples suggests to set the grid spacing at 0.02, the size of the grids at , the minimum value of at and the threshold at . These values were used in the simulations and applications reported below and worked very well.
4 Monte Carlo simulation results
To evaluate the performance and compare the MLE, SMLE and MDPDE, Monte Carlo simulations in the presence and absence of contamination in the data were carried out. The sample sizes considered are . The covariate values were set for the sample size and replicated twice, four times and eight times to obtain the covariate values corresponding to the sizes 160, 320, respectively. This scheme guarantees that the heteroskedasticity intensity, , be constant for all the sample sizes (Espinheira et al., 2017, 2019). For all the scenarios we employ logit and logarithmic links in the mean and precision submodels, respectively (2) and (3). The models include intercepts, i.e. , for all , and the other covariates for the mean submodel are taken as random draws from a standard uniform distribution and kept constant throughout the simulated samples. For non-constant precision scenarios, the same covariates are used in the mean and precision submodels. The percentage of contamination in the sample for all the scenarios was set at 5%. The selection of the tuning constant for SMLE and MDPDE was conducted following the proposed algorithm described in Section 3. All the results are based on 1,000 Monte Carlo replications and were carried out using the R software environment (R Core Team, 2020).
Different configurations of parameter values and patterns of data contamination were considered. We now describe the results for two scenarios; results for other scenarios are collected in the Supplementary Material.
Scenario 1: Constant precision, one covariate in the mean submodel, mean response values close to zero.
The parameter values were set at , and , which yield with and . The contaminated sample replaces the observations generated with the 5% smallest mean responses by observations generated from a beta regression model with mean (and precision ). For instance, if , then .
Scenario 2: Varying precision, two covariates in the mean and precision submodels, mean response values around 0.4.
The parameter values were set at , , , and , which result in with and with The contaminated sample replaces 5% of the sample as follows: the observations generated with the 2.5% largest values of and those generated with the 2.5% smallest values of are replaced by independent draws of a beta regression model with mean and , respectively, where , and . For instance, if , then , and if , then .
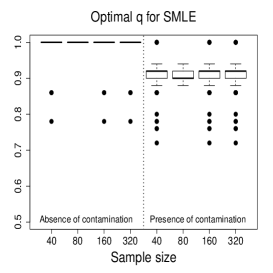
Figure 3 and Figures 4-5 display the boxplots of the parameter estimates using MLE, SMLE, and MDPDE under Scenarios 1 and 2, respectively, for the data without contamination and for the contaminated data. Some general tendencies become apparent from these figures. First, the MLE of the parameters in the mean submodel and the precision submodel may be heavily affected by contamination in the data. Second, the robust estimators behave similarly to the MLE under non contaminated data. Third, the SMLE and MDPDE have similar behavior. Fourth, the SMLE and MDPDE remain centered at the true parameter value when contamination in introduced in the data; the robustness comes at the cost of some extra variability in small samples. Fifth, the data-driven selection of the optimum tuning constants worked well. In fact, as evidenced by Figure 6 the optimal values of for the SMLE and MDPDE are equal to 1 for the great majority of the non contaminated samples and around 0.9 for contaminated samples. Recall that corresponds to the MLE. This means that the proposed mechanism is able to identify whether the sample requires a robust procedure or not, and correctly selects lower values of for contaminated samples. As a consequence, the robust estimators are full efficient in the absence of contamination. This is confirmed from a study (not shown) of the asymptotic efficiency of the robust estimators relative to the MLE measured by the ratio of the traces of the respective asymptotic covariance matrices. For all the scenarios and all the sample sizes considered, the relative asymptotic efficiency under no contaminated data is equal to 1 in almost all the cases; the smallest observed value is 0.9999.
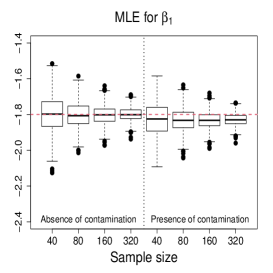
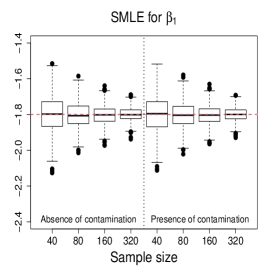
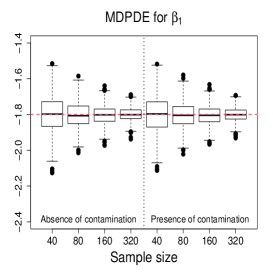

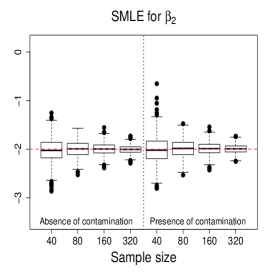
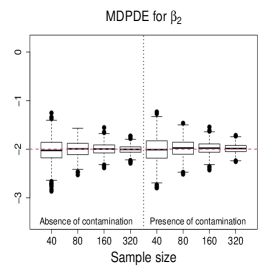
















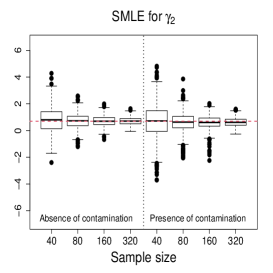




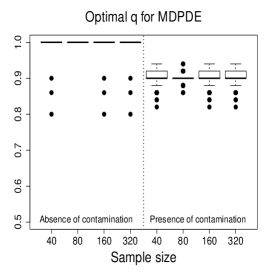
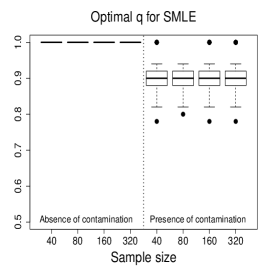
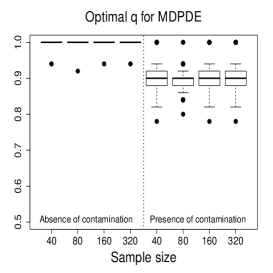
We now compare the efficiency of the estimators through their total mean squared errors (TMSE). Table 1 displays the ratios of TMSE of the MLE, SMLE and MDPDE under Scenarios 1 and 2. When the data are not contaminated, the efficiency of the three estimators is similar, i.e., the ratios of the TMSE are equal to or close to 1. However, if contamination is present, the TMSE of the robust estimators are much smaller than those of the MLE more so if the sample is large. For instance, for and Scenario 1, the TMSE of MLE is 141 times (134 times) larger than that of the SMLE (MDPDE). Under Scenario 2, the TMSE of the SMLE is smaller than that of the MDPDE for all the sample sizes.
| Scenario 1 | Scenario 2 | ||||||||||||||
| Absence of contamination | Presence of contamination | Absence of contamination | Presence of contamination | ||||||||||||
Table 2 shows the empirical levels of the Wald-type tests based on the MLE and the robust estimators. The Wald-type test of the null hypothesis against a two-sided alternative rejects H at the nominal level when exceeds the quantile of the distribution. For non contaminated data, the tests behave similarly, the empirical levels being close 5% except for the smallest sample size in Scenario 2 (the empirical levels were observed between 8% and 11%). Under contaminated data, the tests that employ the robust estimators suffer from some type I error probability inflation. On the other hand, the tests that use the MLE are erratic in most of the cases, their empirical levels being near 100%. Hence, when the data contain outliers, the usual Wald-type tests should be avoided. The Wald-type tests computed from the robust estimators are reasonably reliable, although any decision based on a -value close to the nominal level should be taken with care.
| Scenario 1 | Scenario 2 | ||||||||||||||||||||
| Abs. of cont. | Pres. of cont. | Abs. of cont. | Pres. of cont. | ||||||||||||||||||
| Estimator | |||||||||||||||||||||
| MLE | |||||||||||||||||||||
| SMLE | |||||||||||||||||||||
| MDPDE | |||||||||||||||||||||
| Scenario 1 | Scenario 2 | ||||||||||||||||||||
| Abs. of cont. | Pres. of cont. | Abs. of cont. | Pres. of cont. | ||||||||||||||||||
| Estimator | |||||||||||||||||||||
| MLE | |||||||||||||||||||||
| SMLE | |||||||||||||||||||||
| MDPDE | |||||||||||||||||||||
| Scenario 1 | Scenario 2 | ||||||||||||||||||||
| Abs. of cont. | Pres. of cont. | Abs. of cont. | Pres. of cont. | ||||||||||||||||||
| Estimator | |||||||||||||||||||||
| MLE | |||||||||||||||||||||
| SMLE | |||||||||||||||||||||
| MDPDE | |||||||||||||||||||||
| Scenario 1 | Scenario 2 | ||||||||||||||||||||
| Abs. of cont. | Pres. of cont. | Abs. of cont. | Pres. of cont. | ||||||||||||||||||
| Estimator | |||||||||||||||||||||
| MLE | |||||||||||||||||||||
| SMLE | |||||||||||||||||||||
| MDPDE | |||||||||||||||||||||
Overall, both the robust estimators performed similarly to the MLE when no contamination is present, and much better than the MLE under contamination in the data. The algorithm for the data-driven choice of the tuning constant proposed in this paper proved to be very effective for both estimators. It tends to select , i.e. the MLE, when the data are not contaminated, leading to full efficiency. When the data are contaminated, the selected tends to be reasonably smaller than 1, providing robust estimation. Both robust estimators applied with this automated selection of the tuning constant produce usable Wald-type tests, while the Wald-type tests that employ the MLE present unacceptable type I probabilities and should be avoided whenever there is any evidence of the presence of outliers.
5 Real data applications
5.1 The AIS Data
Bayes et al. (2012), Ghosh (2019), Migliorati et al. (2018) and van Niekerk et al. (2019) illustrated the sensitivity of MLE to outliers in the beta regression model with constant precision through the analysis of body fat percentages of 37 rowing athletes. The dataset, collected at the Australian Institute of Sport (AIS), is available in the package sn of software R (http://azzalini.stat.unipd.it/SN/index.html). The objective is to model the mean of the body fat percentage (BFP) as a function of the lean body mass (LBM). The authors noted substantial changes in the parameter estimates when two atypical observations are excluded from the data. Ghosh (2019) applied the MDPDE with different values of the tuning constant. Although the MDPDE displayed a robust fit, the practitioner would be uncertain of which value of the tuning constant should be chosen. Here, we will show that our proposed estimator with the optimal tuning constant selected as described in Section 3 provides a robust fit to the data.
Following the same specification of the model as in the papers mentioned above, we consider a beta regression model with constant precision given by where and are the mean and precision of the response variable BFP for the -th athlete, . We fitted the model using the MLE and SMLE for the full data and excluding combinations of the most prominent outliers: {16}, {30}, and {16, 30}. The optimal value selected for the tuning constant is for the full data, and for the data without observations 16 and 30, respectively, and 1 when both outliers are jointly deleted. These values reveal that the proposed selection method of the tuning constant correctly captures the fact that observations 16 and 30 are, individually and jointly, highly influential in the model fit. Figure 7 displays the scatter plot of LBM versus BFP along with the MLE and SMLE fitted lines for the full data and reduced data. We notice that the outlying observations lead to considerable changes in the fitted regression curves under the MLE fit. On the other hand, the SMLE fitted regression curves are almost indistinguishable.
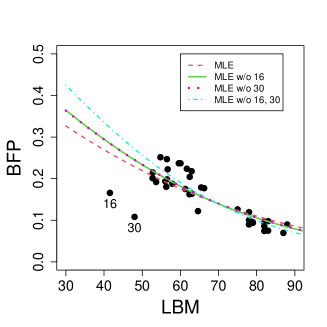
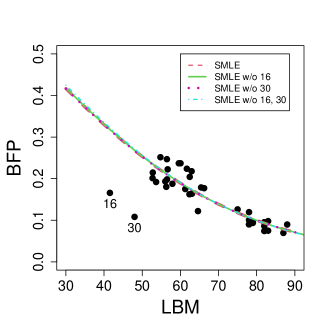
Table 3 shows the estimates, standard errors, -statistics (estimate divided by standard error) and asymptotic -values of the Wald-type test of nullity of coefficients (i.e. based on the null asymptotic distribution of the square of the -statistic, which is ) for the full data and the reduced data. We also report -values evaluated from parametric bootstrap with bootstrap replicates. In this application, the asymptotic and the bootstrap -values coincide up to the fourth decimal point.
We notice that the robust estimates present slight changes in the presence of the outlying observations 16 and 30 (individually or jointly). However, maximum likelihood estimates change drastically when outlying observations are excluded. For instance, the MLE for the coefficient of LBM is for the full data and for the data without observations 16 and 30, a relative change of . The corresponding robust estimates are and . Also, the MLE of the mean and precision intercepts suffer major changes when the two atypical observations are excluded. The estimates obtained through the robust method remain almost unchangeable when the outlying observations are deleted. Overall, the robust estimates and the corresponding standard errors for the full data and for the reduced data are close to those obtained by the MLE without outliers.
| MLE for the full dataset | SMLE for the full dataset | ||||||||
| Estimate | Std. error | -stat | -value | Estimate | Std. error | -stat | -value | ||
| mean submodel | |||||||||
| Intercept | - | - | |||||||
| LBM | () | () | |||||||
| precision submodel | |||||||||
| Intercept | - | - | |||||||
| MLE without observation 16 | SMLE without observation 16 | ||||||||
| Estimate | Std. error | -stat | -value | Estimate | Std. error | -stat | -value | ||
| mean submodel | |||||||||
| Intercept | - | - | |||||||
| LBM | () | () | |||||||
| precision submodel | |||||||||
| Intercept | - | - | |||||||
| MLE without observation 30 | SMLE without observation 30 | ||||||||
| Estimate | Std. error | -stat | -value | Estimate | Std. error | -stat | -value | ||
| mean submodel | |||||||||
| Intercept | - | - | |||||||
| LBM | () | () | |||||||
| precision submodel | |||||||||
| Intercept | - | - | |||||||
| MLE without observations 16 and 30 | SMLE without observations 16 and 30 | ||||||||
| Estimate | Std. error | -stat | -value | Estimate | Std. error | -stat | -value | ||
| mean submodel | |||||||||
| Intercept | - | - | |||||||
| LBM | () | () | |||||||
| precision submodel | |||||||||
| Intercept | - | - | |||||||
It is common practice in beta regression models to employ normal probability plots of residuals with simulated envelope to assess the goodness of fit (Espinheira et al., 2008; Ospina and Ferrari, 2012; Pereira, 2019). Following Espinheira et al. (2008), we consider the ‘standardized weighted residual 2’ given by
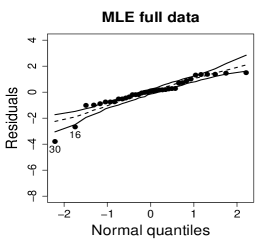
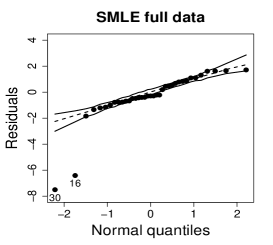
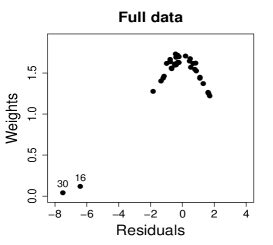
where , , and are estimates of , , and , respectively; is the -th diagonal element of , where , , , and is given in the Appendix. Figure 8 shows normal probability plots of the residuals with simulated envelopes for the MLE and SMLE fits and a plot of the estimated weights employed by the SMLE. The residual plot for the MLE reveals some lack of fit, but the outlying observations, 16 and 30, fall only slightly outside of the envelope. Hence, it masks the influence of these observations. Differently, the residual plot for the SMLE fit suggests better fit for the majority of the data and strongly highlights observations 16 and 30 as outliers. In fact, robust estimators are expected to produce good fit for most of the data but not necessarily for the outliers. Figure 8(c) shows that observations with bigger residuals tend to receive smaller weights in the robust estimation. As expected observations 16 and 30 received the smallest weights.
5.2 Tuna dataset
We consider a subset of the the data available in the Supplementary Material of Monllor-Hurtado et al. (2017) (https://doi.org/10.1371/journal.pone.0178196). Here, the response variable is the tropical tuna percentage (TTP) in longliner catches and the covariate is the sea surface temperature (SST). The data correspond to 77 observations of longliner catches in different points of the southern Indian ocean in the year 2000. One of the observations on TTP equals 1, which means that 100% of the catch is of tropical tuna, well above the second largest observed value, which is . We have no information of whether this is a correct observation or not, and hence a robust model fit that is not much influenced by this observation is required. An additional difficulty is that beta regressions are not suited for data with observations at the boundary of the unit interval. A practical strategy is to subtract or add a small value to such observations in order to locate them inside the open interval . Here, we replaced by . Since the influence function of the MLE grows unbounded when an observation approaches zero or one, it may be highly influenced by observations near the boundaries. Recall that the SMLE has bounded influence function and, hence, it may be a suitable alternative to the MLE when observations at the boundary are present and slightly moved inside the open unit interval.
First, consider a constant precision beta regression model with and , where and are the mean and precision of TTP for the -th coordinate, . Figure 9 displays the scatter plot of TTP versus SST along with the MLE and SMLE fitted lines for the full data and the data without observation 46, that corresponds to the largest TTP value. A downward displacement of the MLE curve when observation 46 is excluded is apparent from the plot. The SMLE remains virtually unchanged with the exclusion of this data point.
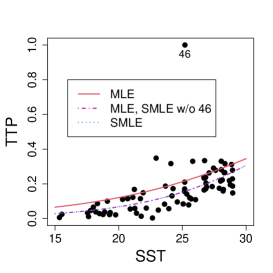
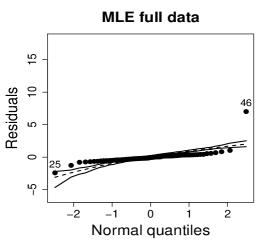
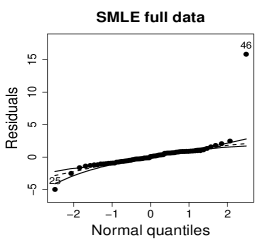
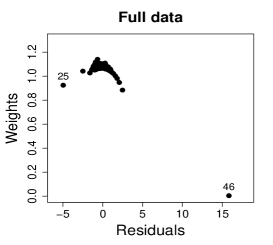
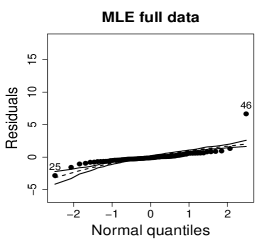
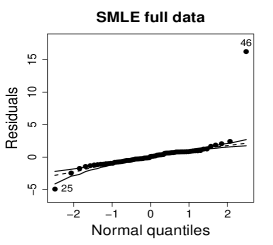
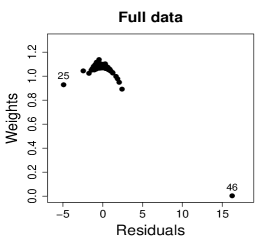
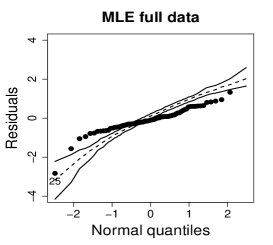
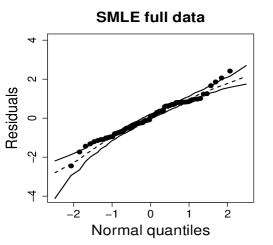
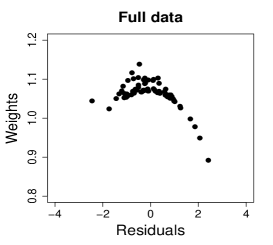
Figure 10 shows normal probability plots of the residuals and estimated weights for the fitted models employing MLE and SMLE. The panels in the left column give strong indication of lack of fit of the maximum likelihood estimation and highlights observation 46 as outlier. The panels in the central column show reasonable fit of the -likelihood estimation for all the observations except for case 46, that receives a weight close to zero. Results and plots not included here show that observation 25, which has the second largest absolute residual and falls slightly outside the envelope in the SMLE fit, does not have relevant impact in the MLE fit and, hence, its weight is close to the weights of the majority of the observations.
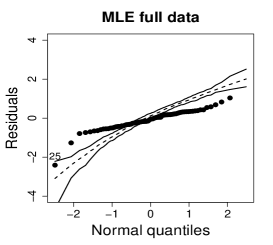
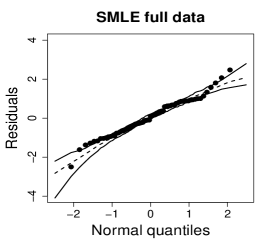
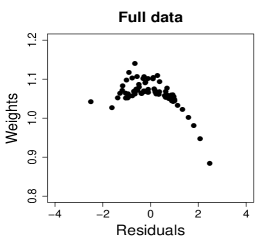
It is of interest to investigate whether the influence of observation 46 is weakened when the precision is modeled as a function of the covariate. A varying precision model might also produce better MLE fit. The beta regression model considered now assumes that and The optimum value of the tuning constant of the SMLE is for the full data and 1 for the reduced data. Hence, when observation 46 is deleted, the SMLE and the MLE coincide. Figure 11(a) displays the scatter plot of TTP versus SST along with the fitted lines based on the SMLE and MLE for the full data and the data without observation 46. As in the constant precision modeling, this observation has disproportionate influence in the MLE fit and virtually does not affect the robust estimation.
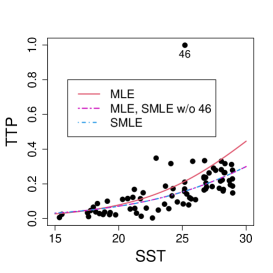
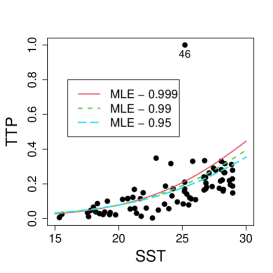
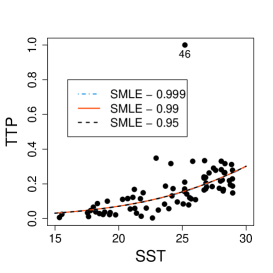
Table 4 shows the estimates, standard errors, -statistics (estimate divided by standard error) and -values of the Wald-type test of nullity of coefficients for the full data and the reduced data. Note the substantial change caused by observation 46 in the estimate of the intercept of the precision submodel when the MLE is employed; it moves the estimate from to , a relative change of . For the SMLE the estimates are, respectively, and ; the later coincides with the MLE. The maximum likelihood estimated coefficient of SST in the precision submodel is (bootstrap -value=) for the full data and (bootstrap -value=) for the data without observation 46. Note the sign change in the estimate. Also, it is clear that a single observation causes a relevant change in an inferential conclusion: for the full data the coefficient of SST in the precision submodel is highly significant, while the MLE points to a constant precision model when the outlier is deleted. The corresponding SMLE estimates are (bootstrap -value=) for the full data and (bootstrap -value=) for the data without observation 46. In both cases, there is no evidence to reject the constant precision model.
We now investigate the sensitivity of the model fits to the choice of the replacement value for the response of observation 46. Recall that we replaced 1 by . Figure 11(b)-(c) show the MLE and SMLE fitted curves for three choices of value for TTP46, namely , , and . While the SMLE fitted curves remain unchanged, the MLE fit is markedly influenced by the chosen value. Moreover, the MLE of the SST coefficient in the precision submodel moves from (bootstrap -value=) when TTP to (bootstrap -value=) when TTP, weakening the significance of SST in the precision submodel.
| MLE for the full dataset | SMLE for the full dataset | ||||||||
| Estimate | Std. error | -stat | -value | Estimate | Std. error | -stat | -value | ||
| mean submodel | |||||||||
| Intercept | - | - | |||||||
| SST | () | () | |||||||
| precision submodel | |||||||||
| Intercept | - | - | |||||||
| SST | () | () | |||||||
| MLE without observation 46 | SMLE without observation 46 | ||||||||
| Estimate | Std. error | -stat | -value | Estimate | Std. error | -stat | -value | ||
| mean submodel | |||||||||
| Intercept | - | - | |||||||
| SST | () | () | |||||||
| precision submodel | |||||||||
| Intercept | - | - | |||||||
| SST | () | () | |||||||
Figure 12 show plots of residuals and estimated weights for the MLE and SMLE fits of the varying precision beta regression model. The plots are similar to the corresponding plots of the constant precision model fits (Figure 10). We conclude that allowing the precision to be modeled as a function of SST does not improve the MLE fit and that observation 46 remains highly influential. A constant precision beta regression model coupled with the maximum reparameterized -likelihood estimation we propose lead to a robust and suitable fit to the data.
5.3 The Firm cost data
We now turn to the application introduced in Section 1.333Dataset taken from the personal page of Dr Edward W. Frees:
https://instruction.bus.wisc.edu/jfrees/jfreesbooks/Regression%20Modeling/BookWebDec2010/CSVData/RiskSurvey.csv. Consider a beta regression model with
and
where and are the mean and precision of the response variable Firm cost for the -th firm, . We fitted the model using the MLE and the SMLE for the full data and the data without combinations of the most eye-catching outliers, namely observations 15, 16, and 72. The optimal value selected for the tuning constant is for the full data and for the data without observations 16 or/and 72. When observation 15 is excluded, either individually or with one or both other outliers, the selected turns to be 1, i.e., in these cases, the SMLE and the MLE coincide. Figure 13 displays the scatter plots of Firm cost versus the covariates along with the fitted lines based on the MLE and the SMLE for the full
data and the reduced data. As anticipated in Section 1 the MLE fit is highly sensitive to the outliers. Differently, the outliers have much smaller impact on the SMLE fitted curves.
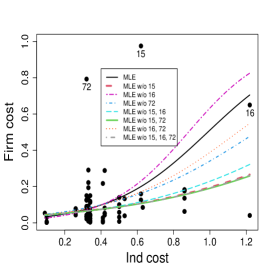
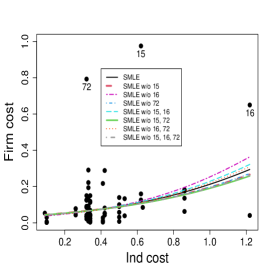
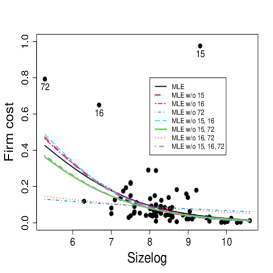
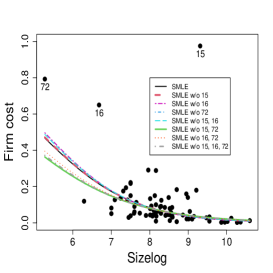
Table 5 shows the estimates, standard errors, -statistics, and -values of the Wald-type test of nullity of coefficients for the full data and the data without the subsets of observations {15} and {15, 16, 72}. The SMLE are much less influenced by the presence of outliers than the MLE. In fact, some MLE change considerably when observation 15 is excluded. For instance, the MLE for the coefficient of Size log in the precision submodel is (bootstrap -value=) for the full data and (bootstrap -value=) for the data without observation 15. Note the considerable relative change in the estimated coefficient of Size log (RC = 167%) and the change of the inferential conclusion; Size log is highly significant for the data without observation 15 and non-significant for the full data at the usual nominal levels. A similar behavior occurs when the subset {15, 16, 72} is excluded. On the other hand, the corresponding robust estimate is (bootstrap -value=) for the full data and it is equal to the MLE when observation 15 is excluded. Note that the robust inference leads to the conclusion that Size log is strongly significant in the precision model regardless of whether outliers are excluded or not. Additionally, the maximum likelihood estimated coefficient of Ind cost in the mean submodel decreases to half when observation 15 is excluded, while, in the precision submodel, it jumps from to . Overall, we notice that the robust estimates and the corresponding standard errors for the full data and for the reduced data are close to those obtained by the maximum likelihood method applied to the data without outliers. This suggests that the inference based on the robust estimation is more reliable than the maximum likelihood estimation.
| MLE for the full dataset | SMLE for the full dataset | ||||||||
| Estimate | Std. error | -stat | -value | Estimate | Std. error | -stat | -value | ||
| mean submodel | |||||||||
| Intercept | - | - | |||||||
| Ind cost | () | () | |||||||
| Size log | () | () | |||||||
| precision submodel | |||||||||
| Intercept | - | - | |||||||
| Ind cost | () | () | |||||||
| Size log | () | () | |||||||
| MLE and SMLE without observation 15 | MLE and SMLE without observations 15, 16 and 72 | ||||||||
| Estimate | Std. error | -stat | -valuea | Estimate | Std. error | -stat | -value | ||
| mean submodel | |||||||||
| Intercept | - | - | |||||||
| Ind cost | () | () | |||||||
| Size log | () | () | |||||||
| precision submodel | |||||||||
| Intercept | - | - | |||||||
| Ind cost | () | () | |||||||
| Size log | () | () | |||||||
-
a
The bootstrap -values for the coefficients of Ind cost are those computed under the SMLE. The respective bootstrap -values under the MLE are and . The remaining bootstrap -values under the SMLE and the MLE coincide.
Figure 14 shows normal probability plots of the residuals and estimated weights for the fitted models employing the MLE and the SMLE. Plots (a) and (d) suggests lack of the MLE fit and slightly displays observations 15 and 72 as outliers. Plots (b) and (e), that correspond to the SMLE fit for the full data, show that the majority of the data, including observations 16 and 72, is accommodated within the envelope. Observation 15 is clearly highlighted as an outlier. Indeed, only observation 15 receives a small weight in the robust fit; see plot (c) and (f). This behavior is expected because observations 16 and 72 do not have substantial influence in the MLE fit when observation 15 is not present in the data; see plots (a) and (c) in Figure 13.
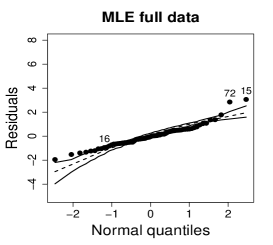
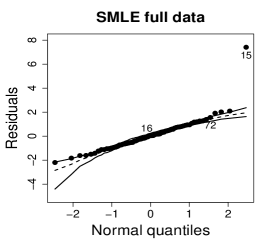
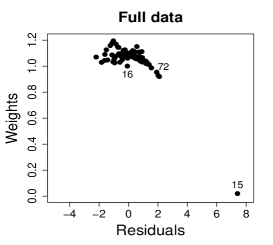
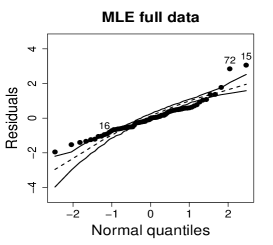
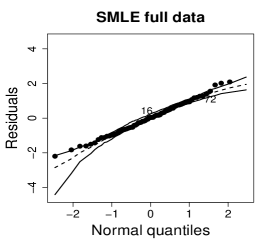
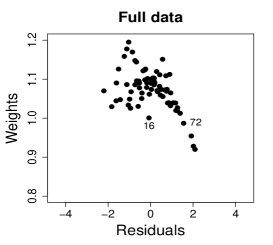
6 Concluding remarks
Maximum likelihood estimation in beta regression is heavily influenced by outliers. We have proposed a robust inference method based on a reparameterized Lq-likelihood. The reparameterization is achieved through simple modifications in the mean and precision link functions. We have demonstrated robustness properties of the proposed estimator for bounded beta densities. The robust method depends on a tuning constant that balances robustness and efficiency. The selection of such a constant is a crucial issue for practical applications. We have proposed an algorithm to select the tuning constant based on the data. The algorithm is designed to choose , that corresponds to maximum likelihood estimation, when there is no contamination in the data, and to choose a suitable value of when a robust fit is required. We have improved on the minimum power divergence estimator (Ghosh, 2019) by implementing our tuning constant selection scheme. Monte Carlo simulations and real data applications have illustrated the advantages of the robust methodology over the usual likelihood-based inference. As a by-product of the proposed approach, diagnostic tools such as normal probability plots of residuals based on robust fits have demonstrated effectiveness in highlighting outliers that would be masked under a non-robust procedure.
We emphasize that the codes and datasets used in this paper are available at the GitHub repository https://github.com/terezinharibeiro/RobustBetaRegression. Practitioners and researchers can replicate the simulations and applications and employ the proposed robust beta regression approach in their own data analyses.
The lack of robustness of the maximum likelihood estimation under data contamination renders Wald-type tests extremely oversized, hence unreliable. The proposed estimator leads to usable Wald-type tests. Likelihood ratio, score and gradient tests based on the reparameterized Lq-likelihood and the corresponding weighted modified score function in beta regression will be the subject of our future research.
A limitation of the present work is that robustness is achieved only for bounded beta densities, which fortunately are the most common in applied research. The second author has been working in an alternative robust method that preserves robustness even for beta densities that grow unboundedly at one or both of the boundaries of the support set. The work is in progress and the results will be reported elsewhere.
A usefull extension of the present work concerns inflated beta regression models (Ospina and Ferrari, 2012), that are employed when the response variable includes a non-negligible amount of observations at zero and/or one. This topic is beyond the scope of the present paper and will be dealt with in the near future.
Acknowledgments
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brazil (CAPES) - Finance Code 001 and by the Conselho Nacional de Desenvolvimento Científico e Tecnológico - Brazil (CNPq). The second author gratefully acknowledges funding provided by CNPq (Grant No. 305963-2018-0).
Appendix
We define the following diagonal matrices with their respective diagonal elements: and , with
and , with
; and , with
and , with
and , with
where
All the above matrices are well-defined provided that and . For the beta regression model (1)-(3), and we get after some algebra
where , ; see the Supplementary Material for details.
For instance, setting
where ; and with
References
- Basu et al. (1998) Basu, A., Harris, I.R., Hjort, N.L., Jones, M., 1998. Robust and efficient estimation by minimising a density power divergence. Biometrika 85, 549–559.
- Bayes et al. (2012) Bayes, C.L., Bazán, J.L., García, C., 2012. A new robust regression model for proportions. Bayesian Analysis 7, 841–866.
- Box and Cox (1964) Box, G.E., Cox, D.R., 1964. An analysis of transformations. Journal of the Royal Statistical Society B 26, 211–252.
- Di Brisco et al. (2020) Di Brisco, A.M., Migliorati, S., Ongaro, A., 2020. Robustness against outliers: A new variance inflated regression model for proportions. Statistical Modelling 20, 274–309.
- Espinheira et al. (2008) Espinheira, P.L., Ferrari, S.L.P., Cribari-Neto, F., 2008. On beta regression residuals. Journal of Applied Statistics 35, 407–419.
- Espinheira et al. (2017) Espinheira, P.L., Santos, E.G., Cribari-Neto, F., 2017. On nonlinear beta regression residuals. Biometrical Journal 59, 445–461.
- Espinheira et al. (2019) Espinheira, P.L., da Silva, L.C.M., Silva, A.O., Ospina, R., 2019. Model selection criteria on beta regression for machine learning. Machine Learning and Knowledge Extraction 1, 427–449.
- Ferrari and La Vecchia (2012) Ferrari, D., La Vecchia, D., 2012. On robust estimation via pseudo-additive information. Biometrika 99, 238–244.
- Ferrari and Yang (2010) Ferrari, D., Yang, Y., 2010. Maximum -likelihood estimation. The Annals of Statistics 38, 753–783.
- Ferrari and Cribari-Neto (2004) Ferrari, S.L.P., Cribari-Neto, F., 2004. Beta regression for modelling rates and proportions. Journal of Applied Statistics 31, 799–815.
- Ghosh (2019) Ghosh, A., 2019. Robust inference under the beta regression model with application to health care studies. Statistical Methods in Medical Research 28, 871–888.
- Gómez-Déniz et al. (2014) Gómez-Déniz, E., Sordo, M.A., Calderín-Ojeda, E., 2014. The log–Lindley distribution as an alternative to the beta regression model with applications in insurance. Insurance: Mathematics and Economics 54, 49–57.
- Hampel et al. (2011) Hampel, F.R., Ronchetti, E.M., Rousseeuw, P.J., Stahel, W.A., 2011. Robust Statistics: The Approach Based on Influence Functions. volume 196. New York: John Wiley & Sons.
- Heritier et al. (2009) Heritier, S., Cantoni, E., Copt, S., Victoria-Feser, M.P., 2009. Robust Methods in Biostatistics. volume 825. New York: John Wiley & Sons.
- Heritier and Ronchetti (1994) Heritier, S., Ronchetti, E., 1994. Robust bounded-influence tests in general parametric models. Journal of the American Statistical Association 89, 897–904.
- Huber (1981) Huber, P., 1981. Robust Statistics. New York: John Wiley & Sons.
- Huber (1964) Huber, P.J., 1964. Robust estimation of a location parameter. The Annals of Mathematical Statistics 35, 73–101.
- La Vecchia et al. (2015) La Vecchia, D., Camponovo, L., Ferrari, D., 2015. Robust heart rate variability analysis by generalized entropy minimization. Computational Statistics & Data Analysis 82, 137–151.
- Migliorati et al. (2018) Migliorati, S., Di Brisco, A.M., Ongaro, A., 2018. A new regression model for bounded responses. Bayesian Analysis 13, 845–872.
- Monllor-Hurtado et al. (2017) Monllor-Hurtado, A., Pennino, M.G., Sanchez-Lizaso, J.L., 2017. Shift in tuna catches due to ocean warming. PloS One 12, e0178196.
- van Niekerk et al. (2019) van Niekerk, J., Bekker, A., Arashi, M., 2019. Beta regression in the presence of outliers – a wieldy bayesian solution. Statistical Methods in Medical Research 28, 3729–3740.
- Ospina and Ferrari (2012) Ospina, R., Ferrari, S.L., 2012. A general class of zero-or-one inflated beta regression models. Computational Statistics & Data Analysis 56, 1609–1623.
- Pereira (2019) Pereira, G.H.A., 2019. On quantile residuals in beta regression. Communications in Statistics - Simulation and Computation 48, 302–316.
- R Core Team (2020) R Core Team, 2020. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. Vienna, Austria. URL: https://www.R-project.org/.
- Schmit and Roth (1990) Schmit, J.T., Roth, K., 1990. Cost effectiveness of risk management practices. Journal of Risk and Insurance 57, 455–470.
- Smithson and Verkuilen (2006) Smithson, M., Verkuilen, J., 2006. A better lemon squeezer? Maximum-likelihood regression with beta-distributed dependent variables. Psychological Methods 11, 54–71.
- Tsallis (1988) Tsallis, C., 1988. Possible generalization of Boltzmann-Gibbs statistics. Journal of Statistical Physics 52, 479–487.