Robustness against outliers
in ordinal response model via divergence approach
Abstract
This study deals with the problem of outliers in ordinal response model, which is a regression on ordered categorical data as the response variable. “Outlier” means that the combination of ordered categorical data and its covariates is heterogeneous compared to other pairs. Although the ordinal response model is important for data analysis in various fields such as medicine and social sciences, it is known that the maximum likelihood method with probit, logit, log-log and complementary log-log link functions, which are often used, is strongly affected by outliers, and statistical analysts are forced to limit their analysis when there may be outliers in the data.
To solve this problem, this paper provides inference methods with two robust divergences (the density-power and -divergences). We also derive influence functions for the proposed methods and show conditions on the link function for them to be bounded and to redescendence. Since the commonly used link functions satisfy these conditions, the analyst can perform robust and flexible analysis with our methods. In addition, and this is a result that further highlights our contributions, we show that the influence function in the maximum likelihood method does not have redescendence for any link function in the ordinal response model. Through numerical experiments using artificial and two real data, we show that the proposed methods perform better than the maximum likelihood method with and without outliers in the data for various link functions.
Keywords: density-power divergence; -divergence; influence function; link function; ordered category; outlier; robust inference
Mathematics Subject Classification: Primary 62F35 ; Secondary 62J12
1 Introduction
Ordered categorical data has become popular in a wide range of fields such as medicine, sociology, psychology, political sciences, economics, marketing, and so on (Breiger,, 1981; Ashby et al.,, 1989; Uebersax,, 1999). Ordered categorical data are, for example, the progression of a disease expressed as stage 1, 2, 3, or 4, or opinions on a policy expressed as opposition, neutrality, or approval. In addition, when continuous data are summarized into categorical data, such as ages 0-20, 21-40, 41-60, 61-80, and 80 or more, the categorical data are ordered categorical data. For this reason, ordered categorical data are often considered to be discretized values of latent continuous variables.
There have been many studies on how to analyze ordered categorical data from half a century ago to the present (McCullagh,, 1980; Albert and Chib,, 1993; Tomizawa et al.,, 2006; Agresti,, 2010; Agresti and Kateri,, 2017; Baetschmann et al.,, 2020). This paper focuses on one of the most commonly used methods, the ordinal response model, that is a regression on ordered categorical data as a response variable. The ordinal response model is one of the frameworks of generalized linear models, and is called the ordinal regression model, or the cumulative link model since it connects the cumulative probability of belonging to a certain category to the covariates with the “link” function (McCullagh,, 1980). The link functions most often used in data analysis are the probit link, which is the distribution function of the standard normal distribution, the logit link, which is the distribution function of the standard logistic distribution, the log-log link, which is the distribution function of the right-skewed Gumbel distribution, and the complementary log-log link, which is the distribution function of the left-skewed log-Weibull distribution. The formulation of the ordinal response model and its details are described in Section 2.
Outliers can be caused by various reasons, such as typos in the values and misrecognition of units. Since it is well known that the maximum likelihood method is strongly affected by outliers, another statistical method that can appropriately deal with outliers is required nowadays. There have been many studies on how to deal with outliers, for example, the well-known inferences based on Huber-type loss and robust divergences (Hampel et al.,, 1986; Basu et al.,, 1998; Jones et al.,, 2001; Fujisawa and Eguchi,, 2008; Huber and Ronchetti,, 2009; Ghosh and Basu,, 2013; Maronna et al.,, 2019; Castilla et al.,, 2021), but most of them have focused on continuous, binary, or counted data, with few focusing on ordered categorical data.
Of course, the ordinal response model is not an exception to the model affected by outliers, although the response variable is discrete type data. The maximum likelihood method in the ordinal response model with the commonly used link functions, such as above mentioned is strongly affected by outliers. Although outliers in discrete data may be harder to imagine than in continuous data, an ”outlier” in the ordered response model is defined as a combination of ordered categorical data and its covariates that is heterogeneous relative to other pairs (Riani et al.,, 2011). This may be taken to mean that the combination of ordered categorical data and its covariates is inconsistent. Unless otherwise noted, we use the same definition of outliers in this paper.
There are various methods to check whether an inference method is robust against outliers, and often an influence function (Hampel,, 1974) may be used in linear regression. Simply put, the influence function is an index to check the “influence” of data on an inference method, and its value must be bounded at least to be robust against outliers. This is because if the value diverges for a given data, the result of the inference depends almost entirely on the data without regard to other data.
As mentioned earlier, there are few studies on outliers in the ordinal response model, but there are studies that derive the conditions for the inference method and link function such that the influence function is bounded in the ordinal response model as well. Croux et al., (2013) and Iannario et al., (2017) proposed the weighted maximum likelihood methods using the Student, 0/1, and Huber weights so that the influence function in the ordinal response model is bounded. However, these papers do not specify the algorithms to perform their inference methods, which makes it difficult for practitioners who wish to implement the robust ordinal response model. We also attempted to implement their inference methods, but found it extremely difficult to converge the numerical optimization algorithm to compute their estimators.
Scalera et al., (2021) derived a class of link functions for bounded influence functions in the maximum likelihood method in the ordinal response model. However, the class does not include probit, logit, log-log and complementary log-log link functions which are commonly used in the analysis. That is, analysts cannot perform robust and flexible modeling for ordered categorical data. We have also confirmed that misspecification of the link function causes a substantial bias in the parameter estimation, although this is not discussed in depth here. This is also the case in the framework of binary regression, which is discussed in Czado and Santner, (1992), and confirms that the flexibility in the choice of the link function is very important.
The boundedness of the influence function is an important property to ensure that the result of inference is not too much sensitive by only certain data, but it does not mean that data that are largely outliers compared to other data do not influence the result of inference at all. In other words, even if the influence function is bounded, there is still some influence from outliers. Therefore, it is desirable for the influence function to satisfy not only boundedness but also redescendence (Maronna et al.,, 2019), which means that the influence of large outliers on inference can be ignored. In this paper, we consider a class of link functions for the influence function to satisfy redescendence in the ordinal response model in the maximum likelihood method, and show that such a class does not exist (Theorem 3 in Section 4).
Since the influence function for the maximum likelihood method in the ordinal response model does not satisfy redescendence, it is necessary to consider another inference method. The weighted maximum likelihood methods of Croux et al., (2013) and Iannario et al., (2017) do not satisfy redescendence because the weights used are the Student, 0/1, and Huber types (Maronna et al.,, 2019), although the influence function is bounded. Thus, we propose inference methods in the ordinal response model with two robust divergences, the density-power (DP) (Basu et al.,, 1998) and -divergences (Jones et al.,, 2001; Fujisawa and Eguchi,, 2008), which are expected to satisfy the redescendence of their influence functions.
Although recently, Pyne et al., (2022) proposed an inference method in the ordinal response model using the DP divergence, they did not discuss the condition for link functions to satisfy boundedness and redescendence of the influence function in their method. Our contribution is not only to derive the condition for link functions satisfying boundedness and redescendence of the influence function in the DP divergence (Theorem 4 in Section 4), but also to propose an inference method in the ordinal response model using the -divergence, which is also commonly used for robust inference, and derive the condition of link functions to achieve robust inference (Theorem 5 in Section 4), and compare the performance between the DP and -divergences. The derivation of this condition provides a guideline for practitioners to decide which of the various link functions to use when conducting robust analysis against outliers using the ordinal response model. It will also help to answer the question of whether the DP or -divergences should be used. Of course, the algorithm of our proposed methods can be used by anyone since the programming code described using the is available on the GitHub repository (https://github.com/t-momozaki/RORM).
The paper is organized as follows Section 2 introduces the ordinal response model and its maximum likelihood method. Section 3 introduces two robust divergences, the DP and -divergences, and proposes estimators based on these divergences. We also briefly show that the proposed estimators are robust against outliers. Section 4 derives the influence functions of the proposed methods and considers the robustness of the proposed methods in terms of the influence functions. Section 5 considers the asymptotic properties of the proposed estimators and the testing procedures. Section 6 conducts some numerical experiments using artificial and two real data for the proposed methods and evaluates the performance of the proposed methods. Section 7 provides the conclusion and some remarks.
2 Ordinal response model and its maximum likelihood method
In this section, we discuss the ordinal response model and the maximum likelihood method, a parameter estimation method commonly used in the model.
Consider the following latent variable model for ordered categorical data () as the response variable.
| (1) |
for , where is called the (continuous) latent variable,
, , (known) and has the density function , and are the cutpoints. For the identification, in the there is no error scale and the latent model has no the intercept term. Note that the observed data is , where and , and the latent variable is unobserved. The parameters to be estimated in this model are , where .
The probability mass function of given with is
where the indicator function and
Namely, the likelihood function for the ordinal response model is expressed as
| (2) |
The maximum likelihood estimator (MLE) of are obtained as that minimizes the negative log-likelihood function. That is, noting the constraint the MLE is obtained by
It is well known that the MLE is strongly affected by the outliers in the observations (). This is because if is large enough, i.e., if is outliers compared to the other data, then takes a large value and the entire objective function is strongly affected by the outlier .
Remark (Optimization with the ordering constraint).
There exist various methods for optimization algorithms with the ordering constraint such as the cutpoints in the ordinal response model, including those using matrix notation (Christensen,, 2018), but in this paper we use the Franses and Paap, (2001)’s method, which reparameterize the cutpoints as follows.
Then the likelihood function (2) for the ordinal response model can be expressed as
where with , and we can obtain the MLE of by
This minimization problem can be easily solved by using the optim function in the stats library of the R programming language. All the following minimization problems will be solved using the above reparameterization, but to simplify the notation, we will use before reparameterization throughout this paper.
3 Estimators via robust divergence for the ordinal response model
This section introduces two robust divergences, the DP and -divergences, proposes robust estimators for the ordinal response model using these divergences, and describes their properties against outliers. Section 3.1 describes the case using the DP divergence, and Section 3.2 describes the case using the -divergence.
3.1 Case: Density-Power divergence
Suppose that , , and are the underlying probability density (or mass) functions of , given , and , respectively. Let be the probability density (or mass) function of given with parameter . This paper uses the definition of the DP cross entropy
| (3) |
for . Using the DP cross entropy, the DP divergence is defined as
About the properties of the DP divergence, see Basu et al., (1998).
Using the DP divergence, the target parameter can be considered by
and when , .
Suppose that the observed data are randomly drawn from the underlying distribution . Then, from the formulation (3), the DP cross entropy is empirically estimated by
Namely, the DP estimator is defined by
Based on the above, we propose the following DP-estimator for the ordinal response model.
| (4) |
where the empirically estimated DP cross entropy
| (5) |
We briefly confirm that the proposed DP-estimator is robust against outliers. Suppose that is large enough, i.e., is outliers compared to the other data. Then, the empirically estimated DP cross entropy (5) is expressed as
since takes a small value. Namely, the objective function in (4) is expressed by removing the outliers , and as a result, the effect of the outliers can be ignored in the parameter estimation.
3.2 Case: -divergence
Suppose that , , and are the underlying probability density (or mass) functions of , given , and , respectively. Let be the probability density (or mass) function of given with parameter . This paper uses the definition of the -cross entropy of Kawashima and Fujisawa, (2017) as follows.
| (6) |
for . Using the -cross entropy, the -divergence is defined as follows.
About the properties of the -divergence, see Fujisawa and Eguchi, (2008) and Kawashima and Fujisawa, (2017).
Using the -divergence, the target parameter can be considered by
and when , .
Suppose that the observed data are randomly drawn from the underlying distribution . Then, from the formulation (6), the -cross entropy is empirically estimated by
Namely, the -estimator is defined by
| (7) |
Based on the above, we propose the following -estimator for the ordinal response model.
| (8) |
where the empirically estimated -cross entropy
| (9) |
We briefly confirm that the proposed -estimator is robust against outliers. Suppose that is large enough, i.e., is outliers compared to the other data. Then, the empirically estimated -cross entropy (9) is expressed as
since takes a small value. Namely, the objective function in (8) is expressed by removing the outliers , and as a result, the effect of the outliers can be ignored in the parameter estimation.
4 Influence functions for the ordinal response model
The influence function is classically often used as a measure of robustness of an estimator, and it is required that the influence function is bounded for the observations (see, Hampel,, 1974). This is because the influence function represents the effect on the estimator when there are a few outliers in the observed values. Furthermore, it preferably has the redescendence, that is the property that large outliers have little effect on the parameter estimation (Maronna et al.,, 2019).
This section derives the respective influence functions in the ordinal response model using the DP and -divergences, and discusses the robustness of each proposed estimation method against outliers in terms of the influence functions. The influence functions are plotted and compared. Before that, we describe notations for the discussion and discuss the influence function in the maximum likelihood method.
Suppose that are generated from the true distribution , and consider the contaminated model , where is the contamination ratio and is the contaminating distribution degenerated at . The influence function in the ordinal response model using the maximum likelihood method is expressed as follows.
where
and is the fisher information matrix. Note that since is the expected value for the distribution , is constant and bounded with respect to . That is, for the boundedness of the influence function , the function must be bounded.
The influence function of the parameter () in the maximum likelihood method for the ordinal response model is expressed as follows.
| (10) |
The influence function of the parameter () in the maximum likelihood method for the ordinal response model is expressed as follows.
| (11) |
In order for these influence functions (10) and (11) to be bounded in the maximum likelihood method, the conditions for the distribution of in the latent variable model (1) were derived by Scalera et al., (2021).
Theorem 1 (Proposition 3.2 of Scalera et al.,, 2021).
The influence function for (10) is bounded if and only if
| (12) |
where the is the density function of .
Theorem 2 (Proposition 3.1 of Scalera et al.,, 2021).
The influence function for (11) is bounded if and only if
| (13) |
where the is the density function of .
The distributions that satisfy the conditions (12) and (13) include the Student’s -distribution where the degree of freedom is sufficiently small (Scalera et al.,, 2021). When the distribution is the Student’s -distribution, since the influence function of is for large outliers, the influence function of is bounded for , however the parameter estimation is always affected by outliers constantly. Of course, the same is true for .
Although Scalera et al., (2021) mention the boundedness of the influence functions in the maximum likelihood method, they do not mention redescendence. Hence, we further give the following theorem on the redescendence of the influence functions in the maximum likelihood method.
Theorem 3.
The proof is given in Appendix A.1.
Remark (Redescendence of the influence function of the maximum likelihood method in the ordinal response model).
There are various studies on heavy-tailed distributions, and recently the log-regularly varying function (Desgagné,, 2015) whose order of tail is same as , such as the log-Pareto truncated normal distribution proposed by Gagnon et al., (2020) and the extremely heavily-tailed distribution proposed by Hamura et al., (2022) is well known. However, even if these distributions are applied to , the influence function of for the maximum likelihood method in the ordinal response model do not have redescendence. It is also known that is of constant order for regularly varying and log-regularly varying functions (O’Hagan and Pericchi,, 2012; Desgagné,, 2015). Therefore, when Student’s -distribution or the heavy tailed distributions described above is applied to the distribution , when and , or and , the influence function of is zero for large outliers.
4.1 Case: Density-Power divergence
In the similar manner as in the maximum likelihood method, the influence function using the DP divergence is expressed as follows.
where
and is the conditional expectation for the conditional distribution . Thus, the influence functions of the parameters () and () for the ordinal response model with the DP divergence are expressed by
| (14) |
and
| (15) |
respectively.
Here, the following theorem holds for the influence functions (14) and (15) using the DP divergence.
Theorem 4.
The proof is given in Appendix A.2.
Theorem 4 ensures that the proposed method using the DP divergence is robust against outliers in terms of the influence function. That is, the estimator of the proposed method is hardly affected by the large outliers.
4.2 Case: -divergence
In the similar manner as in the maximum likelihood method, the influence function using the -divergence is expressed as follows.
where
Thus, the influence functions of the parameters () and () for the ordinal response model with the -divergence are expressed by
| (17) |
and
| (18) |
respectively.
Theorem 5.
Theorem 5 ensures that the proposed method using the -divergence is robust against outliers in terms of the influence function. That is, the estimator of the proposed method is hardly affected by the large outliers.
4.3 Numerical experience of influence functions
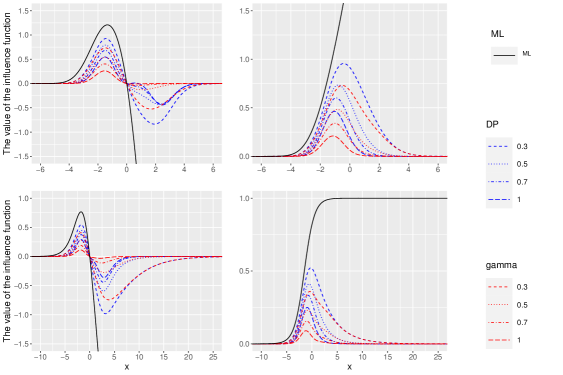
Sections 4.1 and 4.2 prove that the influence functions for the ordinal response model using the DP and -divergences are bounded and redescendent under the conditions (16) and (19). In this section, we plot and compare these influence functions. Note that when and , the methods with the DP and -divergences are the equivalent to the maximum likelihood method, respectively.
The following settings are considered in plotting the influence functions. The ordinal response generated by (1), where (i.e., using one covariate) and , has 4 categories. For the distribution of the error term in (1), the standard normal distribution and the standard logistic distribution are used.
Figure 1 plots the influence function (vertical axis) for each parameter against the covariate (horizontal axis) with the maximum likelihood (black), the DP divergence (blue), and the -divergence (red). The first and second rows of Figure 1 show the standard normal and standard logistic distributions for , respectively. The first and second columns are the influence function of and , respectively. The line type differs according to the tuning parameter in the divergences, “dash” for , “dot” for , “dot-dash” when , and “long-dash” when . In plotting the influence functions, we set .
Since conditions (16) and (19) are satisfied when distribution is the standard normal distribution or the standard logistic distribution, as can be seen from Figure 1, the influence functions with the DP and -divergences are both bounded and redescendence. On the other hand, since the standard normal distribution does not satisfy the conditions (12) and (13), the influence function in the maximum likelihood method is not bounded, as can be seen from Figure 1, and since the standard logistic distribution satisfies only the condition (13), the influence function of is not bounded and that of is bounded.
In addition, since the order of (or ) is smaller when the distribution is lighter in conditions (16) and (19), from the proof of Theorems 4 and 5 (see Appendix A.2), the influence function converges to zero faster when is lighter. Thus, since the standard normal distribution is lighter than the standard logistic distribution, the first row of Figure 1 converges to zero faster than the second row.
For the influence functions with the DP and -divergences, when the tuning parameters and are the same value, the influence function with the -divergence takes smaller values when is around , but when , the influence functions with the DP and -divergences take the same value.
5 Asymptotic properties for proposed robust estimators and their test procedures
This section presents the asymptotic distributions of the proposed DP and -estimators and proposes the test procedures using them.
5.1 Case: Density-Power divergence
Under general regularity conditions (Huber and Ronchetti,, 2009), the proposed DP-estimator (4) is asymptotically a multivariate normal distribution, i.e.,
| (20) |
where the asymptotic covariance matrix is
with
and
Since the estimator of the asymptotic covariance matrix is
where
and
and is consistent for , then with the equation (20), is asymptotically a multivariate normal distribution .
Hence under the null hypothesis for ,
where is the -th element on the diagonal of , is the submatrix of related to the coefficient parameters , and is the -th element of the proposed DP-estimator of .
5.2 Case: -divergence
Under general regularity conditions (Huber and Ronchetti,, 2009), the proposed -estimator (4) is asymptotically a multivariate normal distribution, i.e.,
| (21) |
where the asymptotic covariance matrix is
with
and
Since the estimator of the asymptotic covariance matrix is
where
and
and is consistent for , then with the equation (21), is asymptotically a multivariate normal distribution .
Hence under the null hypothesis for ,
where is the -th element on the diagonal of , is the submatrix of related to the coefficient parameters , and is the -th element of the proposed -estimator of .
6 Numerical Experiments
This section shows the performance of the proposed robust ordinal response model with the DP and -divergences by means of numerical experiments with artificially generated data and two real data.
6.1 Simulation study
This section performs some simulation studies of the proposed methods, referring to Section 5 of Scalera et al., (2021). We consider the following latent variable model (1) for ordered categorical data with five categories (i.e., ) as the response variable.
where , , and are mutually independent. The random variable has standard normal, logistic, and Gumbel distributions, and in this numerical experiment we use the link function suitable for the each error distribution. That is, probit link for normal distribution, logit link for logistic distribution, and log-log link for Gumbel distribution are used. This is because the misspecification of the link function causes a substantial bias in the parameter estimation, apart from the effect of outliers on the inference. The development of an inference method that is robust to both outliers and the misspecification of link functions is the future work. The true values of the regression coefficients and cutoff parameters are set as follows according to the distribution has.
-
•
When has the normal distribution:
-
•
When has the logistic distribution:
-
•
When has the Gumbel distribution:
We generate 200 observations with the above settings, and then generate outliers in the covariate for 5 and 10 percent of the total observations (i.e., 10 and 20 outliers) from and replace them with at random.
Using the link functions corresponding to the error distributions of , we compare the maximum likelihood method with the proposed methods using the DP and -divergences, using bias, mean squared error (MSE), and percentage of correctly classified responses (CCR):
where is the number of iterations ( in this simulation), is the index for each parameter, is the estimated value of the parameter at the th iteration, is the predicted ordinal response using and the newly generated non-outlier covariates and at the th iteration, is the validation data at the th iteration, and is an indicator function that returns 1 when is true and 0 otherwise.
The maximum likelihood method using the cauchit link, which is the distribution function of the Cauchy distribution and the link function whose influence function is bounded in shown by Scalera et al., (2021), is also included in the comparison. This is because as mentioned earlier, the misspecification of the link function certainly causes a substantial bias in the parameter estimation, but as shown in our simulation results to be presented later, it seems to perform better in the prediction than using a link function whose influence function is not bounded.
Tables 1 to 3 summarize the simulation results for the settings described above. Tables 1, 2, and 3 show the results when has the normal distribution, logistic distribution, and Gumbel distribution, respectively. When the outlier ratio is 0, the maximum likelihood methods with suitable links minimize bias and MSE and have high CCR values in most cases, no matter which distribution follows. Notably, however, the proposed methods with the DP and -divergences also perform as well as the maximum likelihood methods. Since it is difficult to determine whether there are outliers or not in most cases in real data, it is a very desirable property that the estimation accuracy is equivalent to that of the maximum likelihood method even when there are no outliers in reality. When the cauchit link is used in the maximum likelihood method, the bias and MSE are still large due to the misspecification of the link function, but CCR is not that much worse than other methods.
When the data contain outliers, this simulation suggests that the maximum likelihood methods are considerably affected by the outliers. In addition, the maximum likelihood method with the cauchit link misspecifies the link function, resulting in considerably larger values of bias and MSE. On the other hand, as Scalera et al., (2021) also mentioned, since the influence function in the maximum likelihood method with the cauchit link is bounded, the prediction accuracy in terms of CCR values is better than that of the maximum likelihood method with correctly specified links. However, it can be seen from Tables 1 to 3 that our proposed methods are more accurate in terms of bias, MSE, and CCR. It is particularly noteworthy that the maximum likelihood method with the cauchit link gives considerably worse CCR values when the outlier ratio increases, while our proposed methods show almost no decrease in the CCR values. This may be because, as shown in Section 4, the proposed methods whose influence functions satisfy not only boundedness but also redescendence are more robust than the maximum likelihood method with the cauchit link.
Comparing the methods using the DP and -divergences, it is found that there is little difference in all the values of the bias, MSE, and CCR. However, although the difference is really small, the values of the bias and MSE are smaller for the method using the DP divergence, while the value of the CCR is larger for the method using -divergences. This tendency may slightly change depending on the selection of the tuning parameters, and , as described in Remark below, but our empirical results are generally good when the values of and are set at around .
Next, we conduct a numerical experiment that is almost the same as the data generation process described above, but this time the outlier ratio in the covariate is fixed at 5% and the mean of the normal distribution of outliers is varied. Tables 4, 5, and 6 show the results for the mean parameter values of 5, 10, and 20 with the probit, logit, and log-log link functions. When the value of the mean parameter is set to 20, the settings are the same as those in the middle panels of Tables 1 to 3, and hence these values are reproduced in the tables. The results in Tables 4 to 6 are consistent with the results of the theorems on the influence function in Section 4. Since the maximum likelihood method with the probit, logit, and log-log links does not satisfy boundedness, the accuracy of inference on the bias, MSE, and CCR becomes worse for larger values of outliers. In contrast, the influence function of our method with the DP and -divergences satisfies both boundedness and redescendence, and the inference accuracy is robust to increasing values of outliers. Moreover, since our method can ignore the influence of outliers more as the value of outliers increases, the inference accuracy is better for most of the indices when the value of the mean parameter of the contaminated normal distribution is 20 than for the other cases.
Remark (Selection of tuning parameters, and ).
The DP and -divergences use tuning parameters and , respectively, to control the robustness against outliers. Basu et al., (1998) mentioned that if the value of tuning parameter is smaller than necessary, the effect of outliers on the estimators obtained by using these divergences cannot be adequately removed, on the contrary, if a larger tuning parameter value is used than necessary, the statistical efficiency of the estimators will be lost instead. Namely, there is a trade-off between robustness and efficiency. Therefore, we would like to lightly discuss how to choose tuning parameters.
A simple and well-known method for selecting tuning parameters is to use the asymptotic relative efficiency, which is calculated using the asymptotic variance of the estimator in the robust divergence-based method and the asymptotic variance of the estimator in the maximum likelihood method. Another well-known method is the method using cross-validation, but it is not straightforward when outliers exist in the data, so we have to find appropriate values of tuning parameters through trial and error. Recently, Sugasawa and Yonekura, (2021) improved the method proposed by Warwick and Jones, (2005) and Basak et al., (2021) for selecting tuning parameters based on the asymptotic approximation of the mean square error in a simple normal model and linear regression, and proposed a method for selecting tuning parameters based on the asymptotic approximation of the Hyvärinen score (Shao et al.,, 2019; Dawid and Musio,, 2015) using unnormalized models based on robust divergence. The extension of their method to the ordinal response model will be the subject of future work.
| Bias | MSE | CCR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tuning | ||||||||||||||||||
| Outlier Ratio 0% | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | * | * | * | * | * | * | * | * | * | * | * | * | * | ** | |||
| DP | ||||||||||||||||||
| ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ||||
| Outlier Ratio 5% | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | * | * | |||||||||||||||
| DP | * | * | * | * | ** | ** | ** | ** | ** | ** | ** | |||||||
| ** | ** | ** | ** | ** | ** | ** | * | * | * | * | * | * | * | * | ||||
| ** | ||||||||||||||||||
| Outlier Ratio 10% | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | |||||||||||||||||
| DP | * | * | * | ** | * | * | * | * | ** | ** | * | * | * | * | ||||
| ** | ** | ** | ** | ** | ** | ** | * | * | ** | ** | ** | ** | * | |||||
| ** | ||||||||||||||||||
| Bias | MSE | CCR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tuning | ||||||||||||||||||
| Outlier Ratio 0% | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | * | * | * | * | * | * | * | * | * | * | * | * | * | ||||
| DP | ||||||||||||||||||
| ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ||||
| Outlier Ratio 5% | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | |||||||||||||||||
| DP | * | * | * | * | * | * | ** | ** | ** | ** | ** | ** | ** | ** | ||||
| ** | ** | ** | ** | ** | ** | * | * | * | * | * | * | * | * | |||||
| ** | ||||||||||||||||||
| Outlier Ratio 10% | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | ** | |||||||||||||||||
| DP | * | * | * | * | * | * | * | * | * | * | * | * | * | * | ||||
| ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | ** | |||||
| * | ||||||||||||||||||
| Bias | MSE | CCR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tuning | ||||||||||||||||||
| Outlier Ratio 0% | ||||||||||||||||||
| ML | ** | ** | ** | |||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | * | * | * | * | * | * | * | * | * | * | ** | ||||||
| DP | * | |||||||||||||||||
| ** | * | * | ** | ** | ** | ** | ** | ** | * | ** | ** | ** | ** | ** | ||||
| ** | ||||||||||||||||||
| Outlier Ratio 5% | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | |||||||||||||||||
| DP | * | * | * | * | * | * | * | ** | ** | ** | ** | ** | ** | ** | ** | |||
| * | * | * | * | * | * | * | * | * | * | * | * | * | * | |||||
| Outlier Ratio 10% | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ** | |||||||||||||||||
| DP | * | |||||||||||||||||
| DP | * | * | * | * | * | * | * | * | ** | ** | * | * | * | * | ** | |||
| ** | ** | ** | ** | ** | ** | ** | * | ** | ** | ** | ** | * | ||||||
| Bias | MSE | CCR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tuning | ||||||||||||||||||
| Mean 5 | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | * | * | |||||||||||||||
| DP | * | * | * | * | ** | ** | * | ** | ** | ** | ** | ** | ||||||
| ** | ** | ** | ** | ** | * | ** | * | * | * | ** | * | |||||||
| * | * | ** | ||||||||||||||||
| Mean 10 | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | * | * | * | ||||||||||||||
| DP | * | * | * | * | ** | * | ** | ** | ** | ** | ** | |||||||
| ** | ** | ** | ** | ** | * | * | * | ** | * | ** | * | |||||||
| * | * | * | ||||||||||||||||
| Mean | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | * | * | |||||||||||||||
| DP | * | * | * | * | ** | ** | ** | ** | ** | ** | ** | |||||||
| ** | ** | ** | ** | ** | ** | ** | * | * | * | * | * | * | * | * | ||||
| ** | ||||||||||||||||||
| Bias | MSE | CCR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tuning | ||||||||||||||||||
| Mean | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | * | ** | * | ** | ||||||||||||||
| DP | ** | ** | * | ** | ||||||||||||||
| DP | ** | ** | * | ** | ** | ** | * | * | ||||||||||
| ** | * | * | ** | * | ** | * | ** | ** | ||||||||||
| * | * | * | * | * | ||||||||||||||
| Mean | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | * | * | ||||||||||||||||
| DP | * | * | ** | ** | ||||||||||||||
| DP | * | ** | * | ** | ||||||||||||||
| * | ** | * | * | * | ** | * | * | |||||||||||
| * | ||||||||||||||||||
| Mean | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | |||||||||||||||||
| DP | * | * | * | * | * | * | ** | ** | ** | ** | ** | ** | ** | ** | ||||
| ** | ** | ** | ** | ** | ** | * | * | * | * | * | * | * | * | |||||
| ** | ||||||||||||||||||
| Bias | MSE | CCR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tuning | ||||||||||||||||||
| Mean | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | ||||||||||||||||||
| DP | * | * | * | * | * | * | * | ** | ** | ** | ** | ** | ** | ** | ||||
| ** | ** | ** | ** | ** | ** | ** | * | * | * | * | * | * | * | ** | ||||
| * | ||||||||||||||||||
| Mean | ||||||||||||||||||
| ML | ** | |||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | ||||||||||||||||||
| DP | * | * | * | * | * | * | * | ** | ** | ** | ** | ** | ** | * | ||||
| ** | ** | ** | ** | ** | ** | ** | * | * | * | * | * | * | * | * | ||||
| Mean | ||||||||||||||||||
| ML | ||||||||||||||||||
| ML Cauchit | ||||||||||||||||||
| DP | * | |||||||||||||||||
| DP | * | * | * | * | * | * | * | ** | ** | ** | ** | ** | ** | ** | ** | |||
| * | * | * | * | * | * | * | * | * | * | * | * | * | * | |||||
6.2 Real data analysis
This section shows the robustness and usefulness of the proposed robust ordinal response with the DP and -divergences through the analysis of two real datasets: Boston housing data (Harrison and Rubinfeld,, 1978) and Affairs data (Fair,, 1978).
The Boston housing data is often used to evaluate the performance of robust inference methods in models with the continuous data as the response variable, such as the linear regression (Hashimoto and Sugasawa,, 2020; Hamura et al.,, 2022; Kawakami and Hashimoto,, 2022), but in this case, the response variable, the corrected median value of owner-occupied homes in USD 1000’s is applied to the ordinal response model assuming that it is obtained as the ordered categorical data with five categories. The Boston housing data has 14 variables including one binary variable. The Affairs data contains 3 continuous, 2 binary, 2 ordered categorical, and 2 multinomial categorical variables. We set one of the ordered categorical data, the self rating of marriage as the response variable. In the two real data, the continuous data are standardized to have mean 0 and variance 1, the ordered categorical data in the covariates is numerically transformed using the Likert sigma method, and the multinomial categorical data are transformed using the dummy variables. In analyzing the two sets of real data, we use the commonly-used symmetric link functions, the probit and logit links.
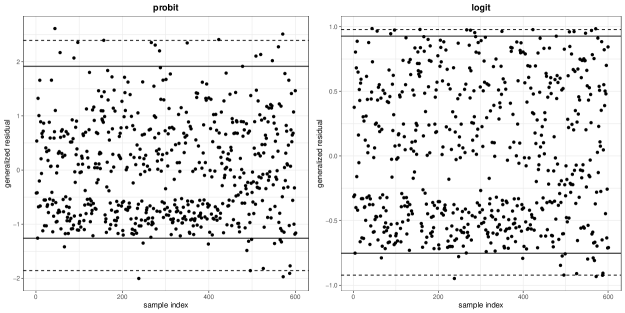
The generalized residuals (Franses and Paap,, 2001) plots with two link functions for two real datasets are shown in Figures 2 and 3. The solid and dashed lines in these figures indicate 95% and 99% intervals of the generalized residuals, respectively. In Subsections 6.2.1 and 6.2.2, the original data and the modified data in which individuals with the values of the generalized residuals larger than the 95% interval (solid line) in Figures 2 and 3 are removed are used for the data analyses.
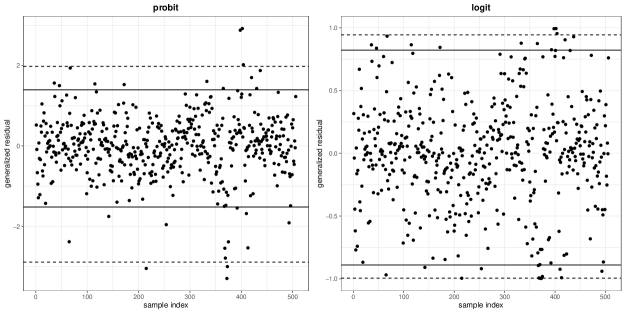
6.2.1 Boston housing data
In this section, we consider the Boston data (Harrison and Rubinfeld,, 1978) that contains 506 individuals and 14 variables including one binary variable. As mentioned above, the Boston housing data is often used in the numerical experiments of the robust inference methods for the continuous data as the response variable (Hashimoto and Sugasawa,, 2020; Hamura et al.,, 2022; Kawakami and Hashimoto,, 2022). Hence, we transform the continuous response variable, the corrected median value of owner-occupied homes in USD 1000’s to the the ordered categorical response variable with five categories (). We also standardize 12 continuous valued covariates as mean 0 and variance 1. For the link function in the data analysis, we use the commonly-used symmetric link functions, the probit and logit links.
Table 7 shows the estimates of each parameter when applying the maximum likelihood method and the proposed robust ordinal response model with the DP and -divergences () for the probit and logit links to the original Boston housing data and the modified data excluding individuals whose values of the generalized residuals are larger than the 95% interval (Figure 2). The values in the row of “Distance” in the column of each method are on the left, the sum of squares of the differences between the estimated values of each parameter applying the ML to the modified data and the corresponding method to the original data divided by the number of parameters, and on the right, that between the estimated values of each parameter applying the corresponding method to the original and modified data divided by the number of parameters. Since these two values are the same in the ML, they are listed only in the “original” column. The smaller these two values are, the less sensitive the inference method is to outliers.
It can be seen from Table 7 that the values of each “Distance” are smaller for all of our proposed methods, both with the probit and logit links, compared to ML. Namely, our proposed methods with the robust divergences are able to eliminate the influence of data that appear to be outliers. Furthermore, for the same tuning parameter values, the inferences with the -divergence have smaller values of the ”Distance” than those with the DP-divergence. The reason why the values of “Distance” are not closer to zero may be that it is difficult to identify outliers by using the generalized residuals for high-dimensional data, and therefore, the data whose values of the generalized residuals are larger than the 95% interval do not always coincide with the data whose influence on the inference is removed by the proposed methods.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
6.2.2 Affairs data
Consider the Affairs data (Fair,, 1978) that contains 601 observations and 9 variables including 3 continuous, 2 binary, 2 ordered categorical, and 2 multinomial categorical variables. We analyze the data with the self rating of marriage as the ordered categorical response variable, and then we standardize 3 continuous valued covariates as mean 0 and variance 1, transform one ordered categorical covariate by the Likert sigma method, and create dummy variables from the multinomial categorical covariates. For the link function in the data analysis, we use the commonly-used symmetric link functions, the probit and logit links.
Table 8 shows the estimates of each parameter when applying the maximum likelihood method and the proposed robust ordinal response model with the DP and -divergences () for the probit and logit links to the original Affairs data and the modified data excluding individuals whose values of the generalized residuals are larger than the 95% interval (Figure 3). The values in the row of “Distance” in the column of each method are on the left, the sum of squares of the differences between the estimated values of each parameter applying the ML to the modified data and the corresponding method to the original data divided by the number of parameters, and on the right, that between the estimated values of each parameter applying the corresponding method to the original and modified data divided by the number of parameters. Since these two values are the same in the ML, they are listed only in the “original” column. The smaller these two values are, the less sensitive the inference method is to outliers.
It can be seen from Table 8 that the values of each “Distance” are smaller for all of our proposed methods, with both the probit and logit links, compared to ML. Namely, our proposed methods with the robust divergences are able to eliminate the influence of data that appear to be outliers. The values of ”Distance” in our proposed inference methods with the DP and -divergences are about the same. The reason why the values of “Distance” are not closer to zero may be that it is difficult to identify outliers by using the generalized residuals for high-dimensional data, and therefore, the data whose values of the generalized residuals are larger than the 95% interval do not always coincide with the data whose influence on the inference is removed by the proposed methods.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
7 Conclusion and remarks
This study examined the problem of outliers in ordinal response model, which is a regression on ordered categorical data as the response variable. Scalera et al., (2021) derived the condition for the link functions to make the influence function in the maximum likelihood method bounded in the ordinal response model, but the probit link, logit link, complementary log-log link, and log-log link, which are commonly used, do not satisfy the condition. Thus, when outliers exist in the data, the maximum likelihood method imposes restrictions on the link function, and that induces misspecification of the link function under such situations. In our numerical experiments, we also confirmed that the misspecification of the link function induces a substantial bias in the estimation of the parameters.
Scalera et al., (2021) mentions the boundedness of the influence function in the maximum likelihood method for the ordinal response model, and we further show that the influence function does not satisfy redescendence (Theorem 3 in Section 4). This means that the maximum likelihood method in the ordinal response model cannot completely eliminate the influence of large outliers, and in fact, in our numerical experiments, as the outlier ratio increases, the accuracy of the prediction becomes worse even if the cauchit link which has the bounded influence function is used.
To solve these problems and to realize robust inference in the ordinal response model against outliers, we proposed inference methods in the ordinal response model using the DP and -divergences. We also derived the influence functions for the methods with the DP and -divergences, and derived the conditions for the link functions to satisfy boundedness and redescendence (Theorems 4 and 5 in Section 4). The commonly used link functions satisfy the conditions, and our method allows practitioners using ordinal response models to perform robust against outliers and flexible analysis.
Numerical experiments were conducted to evaluate the performance of our proposed methods with the DP and -divergences using bias, mean square error (MSE), and percentage of correctly classified responses (CCR). In the absence of outliers, both methods perform as well as the maximum likelihood method, and in the presence of outliers, the results are almost unaffected by outliers. As for the difference between the methods using the DP and -divergences, the bias value is slightly smaller when the DP divergence is used, but the MSE value is moderately larger than that using the -divergence. In numerical experiments with two real data sets, the Boston housing and Affairs data, we also confirmed that our proposed methods with two robust divergences give the robust inference results that remove the influence of data that appear to be outliers.
Acknowledgement
We thank Prof. Shounosuke Sugasawa and Prof. Kaoru Irie of the University of Tokyo for their very helpful comments. This work was JSPS Grant-in-Aid for Early-Career Scientists Grant Number JP19K14597 and JSPS Grant-in-Aid for Scientific Research (B) Number 21H00699.
Appendix
A.1 Proof of Theorem 3
First, consider the influence function of (10) for . From appendix of Scalera et al., (2021), for the influence function of to have redescendence, the order of must be smaller than 1, where is the first derivative of . This means that when the order of the tail of the function is equal to , the influence function of has redescendence, however, no such distributions exist since distributions with order of tail more slowly than are improper.
Next, consider the influence function of (11) for . Since from Lagrange’s theorem for such that and , for the influence function of to have redescendence, the order of must be . However, such a distribution is improper, and such a distribution does not exist.
∎
A.2 Proof of Theorem 4
First, consider the influence function (14) of . It is clear that holds when the condition (16) holds. If here and note that goes to infinity of the same order as , since is clearly bounded, the second term of equation (14) becomes zero for .
Since from Lagrange’s theorem,
for such that , then
| (A.1) |
and is of the same order as for . Thus, if the condition (16) holds, i.e., if there exists a certain such that , then for the equation (A.1) becomes
Therefore, if the condition (16) holds, the first term of equation (14) is zero for and then the influence function of using the DP divergence is also zero.
For the influence function (15) of , it becomes zero for in the similar manner. Namely, the influence functions (14) and (15) in the ordinal response model with the DP divergence are redescendent.
Moreover, the influence functions (14) and (15) are bounded since they are clearly continuous and their values are zero for .
∎
References
- Agresti, (2010) Agresti, A. (2010). Analysis of Ordinal Categorical Data, volume 656. John Wiley & Sons.
- Agresti and Kateri, (2017) Agresti, A. and Kateri, M. (2017). Ordinal probability effect measures for group comparisons in multinomial cumulative link models. Biometrics, 73(1), 214–219.
- Albert and Chib, (1993) Albert, J. H. and Chib, S. (1993). Bayesian analysis of binary and polychotomous response data. Journal of the American Statistical Association, 88(422), 669–679.
- Ashby et al., (1989) Ashby, D., West, C. R., and Ames, D. (1989). The ordered logistic regression model in psychiatry: rising prevalence of dementia in old people’s homes. Statistics in Medicine, 8(11), 1317–1326.
- Baetschmann et al., (2020) Baetschmann, G., Ballantyne, A., Staub, K. E., and Winkelmann, R. (2020). feologit: A new command for fitting fixed-effects ordered logit models. The Stata Journal, 20(2), 253–275.
- Basak et al., (2021) Basak, S., Basu, A., and Jones, M. (2021). On the ’optimal’ density power divergence tuning parameter. Journal of Applied Statistics, 48(3), 536–556.
- Basu et al., (1998) Basu, A., Harris, I. R., Hjort, N. L., and Jones, M. (1998). Robust and efficient estimation by minimising a density power divergence. Biometrika, 85(3), 549–559.
- Breiger, (1981) Breiger, R. L. (1981). The social class structure of occupational mobility. American Journal of Sociology, 87(3), 578–611.
- Castilla et al., (2021) Castilla, E., Jaenada, M., and Pardo, L. (2021). Estimation and testing on independent not identically distributed observations based on Rényi’s pseudodistances. arXiv preprint arXiv:2102.12282, .
- Christensen, (2018) Christensen, R. H. B. (2018). Cumulative link models for ordinal regression with the r package ordinal. Submitted in Journal of Statistical Software, 35.
- Croux et al., (2013) Croux, C., Haesbroeck, G., and Ruwet, C. (2013). Robust estimation for ordinal regression. Journal of Statistical Planning and Inference, 143(9), 1486–1499.
- Czado and Santner, (1992) Czado, C. and Santner, T. J. (1992). The effect of link misspecification on binary regression inference. Journal of Statistical Planning and Inference, 33(2), 213–231.
- Dawid and Musio, (2015) Dawid, A. P. and Musio, M. (2015). Bayesian model selection based on proper scoring rules. Bayesian Analysis, 10(2), 479–499.
- Desgagné, (2015) Desgagné, A. (2015). Robustness to outliers in location–scale parameter model using log-regularly varying distributions. The Annals of Statistics, 43(4), 1568–1595.
- Fair, (1978) Fair, R. C. (1978). A theory of extramarital affairs. Journal of Political Economy, 86(1), 45–61.
- Franses and Paap, (2001) Franses, P. H. and Paap, R. (2001). Quantitative Models in Marketing Research. Cambridge University Press.
- Fujisawa and Eguchi, (2008) Fujisawa, H. and Eguchi, S. (2008). Robust parameter estimation with a small bias against heavy contamination. Journal of Multivariate Analysis, 99(9), 2053–2081.
- Gagnon et al., (2020) Gagnon, P., Desgagné, A., and Bédard, M. (2020). A new bayesian approach to robustness against outliers in linear regression. Bayesian Analysis, 15(2), 389–414.
- Ghosh and Basu, (2013) Ghosh, A. and Basu, A. (2013). Robust estimation for independent non-homogeneous observations using density power divergence with applications to linear regression. Electronic Journal of Statistics, 7, 2420–2456.
- Hampel, (1974) Hampel, F. R. (1974). The influence curve and its role in robust estimation. Journal of the American Statistical Association, 69(346), 383–393.
- Hampel et al., (1986) Hampel, F. R., Ronchetti, E. M., Rousseeuw, P. J., and Stahel, W. A. (1986). Robust Statistics. Wiley Online Library.
- Hamura et al., (2022) Hamura, Y., Irie, K., and Sugasawa, S. (2022). Log-regularly varying scale mixture of normals for robust regression. Computational Statistics and Data Analysis, 173, 107517.
- Harrison and Rubinfeld, (1978) Harrison, J. D. and Rubinfeld, D. L. (1978). Hedonic housing prices and the demand for clean air. Journal of Environmental Economics and Management, 5(1), 81–102.
- Hashimoto and Sugasawa, (2020) Hashimoto, S. and Sugasawa, S. (2020). Robust bayesian regression with synthetic posterior distributions. Entropy, 22(6), 661.
- Huber and Ronchetti, (2009) Huber, J. and Ronchetti, E. M. (2009). Robust Statistics, Second Edition. Wiley.
- Iannario et al., (2017) Iannario, M., Monti, A. C., Piccolo, D., and Ronchetti, E. (2017). Robust inference for ordinal response models. Electronic Journal of Statistics, 11(2), 3407–3445.
- Jones et al., (2001) Jones, M., Hjort, N. L., Harris, I. R., and Basu, A. (2001). A comparison of related density-based minimum divergence estimators. Biometrika, 88(3), 865–873.
- Kawakami and Hashimoto, (2022) Kawakami, J. and Hashimoto, S. (2022). Approximate gibbs sampler for bayesian huberized lasso. arXiv preprint arXiv:2204.00237, .
- Kawashima and Fujisawa, (2017) Kawashima, T. and Fujisawa, H. (2017). Robust and sparse regression via -divergence. Entropy, 19(11), 608.
- Maronna et al., (2019) Maronna, R. A., Martin, R. D., Yohai, V. J., and Salibián-Barrera, M. (2019). Robust Statistics: Theory and Methods (with R). John Wiley & Sons.
- McCullagh, (1980) McCullagh, P. (1980). Regression models for ordinal data. Journal of the Royal Statistical Society: Series B (Methodological), 42(2), 109–127.
- O’Hagan and Pericchi, (2012) O’Hagan, A. and Pericchi, L. (2012). Bayesian heavy-tailed models and conflict resolution: A review. Brazilian Journal of Probability and Statistics, 26(4), 372–401.
- Pyne et al., (2022) Pyne, A., Roy, S., Ghosh, A., and Basu, A. (2022). Robust and efficient estimation in ordinal response models using the density power divergence. arXiv preprint arXiv:2208.14011, .
- Riani et al., (2011) Riani, M., Torti, F., and Zani, S. (2011). Outliers and robustness for ordinal data. Modern Analysis of Customer Surveys: with applications using R, , 155–169.
- Scalera et al., (2021) Scalera, V., Iannario, M., and Monti, A. C. (2021). Robust link functions. Statistics, 55(4), 963–977.
- Shao et al., (2019) Shao, S., Jacob, P. E., Ding, J., and Tarokh, V. (2019). Bayesian model comparison with the hyvärinen score: Computation and consistency. Journal of the American Statistical Association, 114, 1826–1837.
- Sugasawa and Yonekura, (2021) Sugasawa, S. and Yonekura, S. (2021). On selection criteria for the tuning parameter in robust divergence. Entropy, 23(9), 1147.
- Tomizawa et al., (2006) Tomizawa, S., Miyamoto, N., and Ouchi, M. (2006). Decompositions of symmetry model into marginal homogeneity and distance subsymmetry in square contingency tables with ordered categories. REVSTAT–Statistical Journal, 4(2), 153–161.
- Uebersax, (1999) Uebersax, J. S. (1999). Probit latent class analysis with dichotomous or ordered category measures: Conditional independence/dependence models. Applied Psychological Measurement, 23(4), 283–297.
- Warwick and Jones, (2005) Warwick, J. and Jones, M. (2005). Choosing a robustness tuning parameter. Journal of Statistical Computation and Simulation, 75(7), 581–588.