RoME: Role-aware Mixture-of-Expert Transformer for Text-to-Video Retrieval
Abstract
Seas of videos are uploaded daily with the popularity of social channels; thus, retrieving the most related video contents with user textual queries plays a more crucial role. Most methods consider only one joint embedding space between global visual and textual features without considering the local structures of each modality. Some other approaches consider multiple embedding spaces consisting of global and local features separately, ignoring rich inter-modality correlations.
We propose a novel mixture-of-expert transformer RoME that disentangles the text and the video into three levels; the roles of spatial contexts, temporal contexts, and object contexts. We utilize a transformer-based attention mechanism to fully exploit visual and text embeddings at both global and local levels with mixture-of-experts for considering inter-modalities and structures’ correlations. The results indicate that our method outperforms the state-of-the-art methods on the YouCook2 and MSR-VTT datasets, given the same visual backbone without pre-training. Finally, we conducted extensive ablation studies to elucidate our design choices.
Index Terms:
Video understanding, video retrieval, transformer, multi-modal, hierarchical, cross-modal.I Introduction
Video content has become significantly abundant with the usage of mobile phones and social media. The rapid growth and the complex nature of videos have motivated various research such as video retrieval, visual question answering, video captioning, etc. Specifically, text-to-video retrieval aims to retrieve relevant video clips, given that a user text query becomes even more compelling since it is used daily by billions of users over various video-based applications. In this work, we focus only on text-to-video retrieval as the text allows semantic queries, which are commonly used to search for relevant videos.
Semantic mapping and embedding are necessary to align textual and video features to achieve reasonable text-to-video retrieval performance. The traditional models [1, 2] are inadequate to retrieve compositional video clips since they make use of the textual queries only in the form of keywords. Thus, many recent works utilize fine-grained textual descriptions [3, 4, 5, 6, 7]. However, these works apply only one joint embedding space for text and video matching, which causes the loss of fine-grained details [8, 4, 9]. Although there are some current methods with multiple embedding spaces, they treat each space individually without considering their correlations. For instance, [3] uses only global features and soft attention at every level, lacking interaction between visual features. [10] uses only self-attention to model correlations between visual features, which would make the model computationally expensive.
We propose a novel Role-aware Mixture-of-Expert transformer model (RoME) for the text-to-video retrieval task by exploiting different experts from textual and visual representations. This paper is an extension of our ICIP paper [11] with the following summary of the innovations:
1) Firstly, as in our conference version [11], we also disentangle the video and textual features into hierarchical structures with the motivation from various cognitive science studies [12, 13] showing that people perceive events hierarchically from the object, scene, and event. Then, we calculate the similarities between the corresponding embedding levels in the text and video.
2) Secondly, different from our conference version, which applies the same attention scheme at both global and local level features, we only use inter-modality attention for the global level features which depict scenes and events, while we use intra- and inter-modality attention for the local level features, which contains fine-grained action and object. The intuition behind this is that global features are complementary to local representations through contexts; however, the local features are usually noise which can influence the global representations if applied symmetrically.
3) Thirdly, we strengthen our model by applying the weighted sum to the video encodings, which is better than the common approach of simply averaging the embeddings. While the previous approach assumes that encoding level is equally important, our results show that contribution of each level is different and could change based on the dataset.
4) Lastly, we conduct a more comprehensive experiment and outperform all the SOTA methods at YouCook2 and MSR-VTT datasets when using the same visual features to demonstrate our method’s strong performance.
II Related Work
For images, the technique by Lee et al. [14] retrieves image-text by embedding visual regions and words in a shared space. Images with corresponding words and image regions show a high degree of resemblance. Karpathy et al. [15] deconstruct images and sentences into several areas and words in their proposal to use maximum alignment to calculate global matching similarity. And image descriptions are broken down into various roles by Wu et al. [16]. For videos, before the deep learning era, the researchers [1, 2] used only textual keywords to retrieve short video clips with simple actions. However, it is insufficient to address video clips with complex actions since many works use natural language as queries.
These works [7, 17] typically applies only one embedding space to measure the gap between text and video. Although some of them use multimodal features from the video, having joint embedding space causes the loss of the fine-grained. For instance, Mithun et al. [4] and Liu et al. [8] utilize multimodal features, including image, motion, and audio. Dong et al. [9] use mean pooling, biGRU, and CNN as three branches to encode consecutive videos and texts. In addition to this semantic gap, Luo et al. [18] use only self-attentions among all modalities, and their method is highly dependent on pre-training. Kim et al. [19] use only soft-attentions and ignore interaction between visual features. While Yang et al. [20] utilize a fine-grained alignment with an extra loss and exploit special arrangement for hard negatives, they still use only self-attentions among all modalities by ignoring the interaction between visual features. Various other works focused on aligning local features to close the semantic gap [21, 22], however, with partial progress to the problem. The sequential interaction of videos and texts is proposed to be combined by Yu et al. [22].
Various methods [23, 24, 25] apply BERT models to the vision encoders for better video and text matching. For instance, Sun et al. [23] transform visual features into visual tokens and feed them into the network along with textual tokens. However, visual tokens may not handle the fine-grained details. To address this, Zhu et al. [24] uses local visual features in a similar BERT-like network by ignoring global features. Rather than transformer-based approaches, some studies such as Tan et al. [26] utilize LSTM and GNNs to exploit cross-modal features. Liu et al. [8] utilizes only a gating mechanism to modulate embeddings as an alternative. However, it is challenging to capture high-level inter-modality information. Moreover, pre-training is used to bring a boost to the results. While a giant instructional dataset [6] is common among the community, Alayrac et al. [27] exploit another huge dataset on audio [28]. Various studies focus on improving the quality of pre-training as well. While Gabeur et al. [29] mask their modalities respectively, Wang et al. [30] exploit object features for that aim. However, we are motivated on development without pre-training, although our work can benefit from pre-trained models with experimental results in Sec. IV.
Some recent works have multiple embedding spaces and use both global/local features with various attention-based mechanisms. For example, Ging et al. [31] exploit cross-attentions and self-attentions even though the interaction between visual features is limited. However, the action and object-related features are not considered. For fine-grained action retrieval, Wray separates action phrases into verbs and nouns, but this is difficult to apply to sentences with more intricate compositions. The hierarchical modeling of movies and paragraphs is proposed by Zhang et al. [32]; however, it does not apply to the breakdown of single sentences. Gabeur et al. [10] use only self-attentions to learn the text-video correspondence even with many visual modalities. Also, having a large input size because of many visual expert features causes a high computation power due to the nature of transformers. Gabeur et al. [10] develop their model based on Miech et al. [5]. While the latter uses word2vec vectors and gated units, the former uses transformers in the textual and visual encoding part. Second, Gabeur et al. exploit three more video experts than Miech et al.. Chen et al. [3] uses only global 2D CNN features as a visual backbone and ignores interaction between visual feature levels. They suggest transforming textual and visual features into three semantic roles. Many works use various frozen video expert features as well. For instance, while [8, 10] use seven video expert features, [33, 5] use four of them. Our method could be named as a mixture of experts because we exploit the contextual interaction between the experts at every hierarchical level. These video experts could also be used in other vision-language-related tasks, such as video captioning [34] and VQA [35].
Lastly, Our recent effort [11] exploits fine-grained details in the global and local visual features, has multiple embedding spaces to close the semantic gap, and utilizes specially arranged transformers to make use of modality-specific and modality-complement features. However, our earlier work uses these transformers regardless of the hierarchical level. In other words, the same mechanisms are applied at every level. Moreover, the model simply averages the similarity scores at every level by ignoring the importance of the discriminative feature in the various expert features. Furthermore, it lacks extensive experiments and ablations to justify the contributions. The limitations of [11] are addressed with the extension in this paper. Our method exploits intra-modality correlation at the global level by preventing noise from local fine-grained local features with self-attention. Likewise, we utilize inter-modality correlations at the local-level features with the Mixture-of-Expert model to combine the local and global video experts. Besides, apply weighted sum to the video experts along with extensive experiments and ablations.
III Method
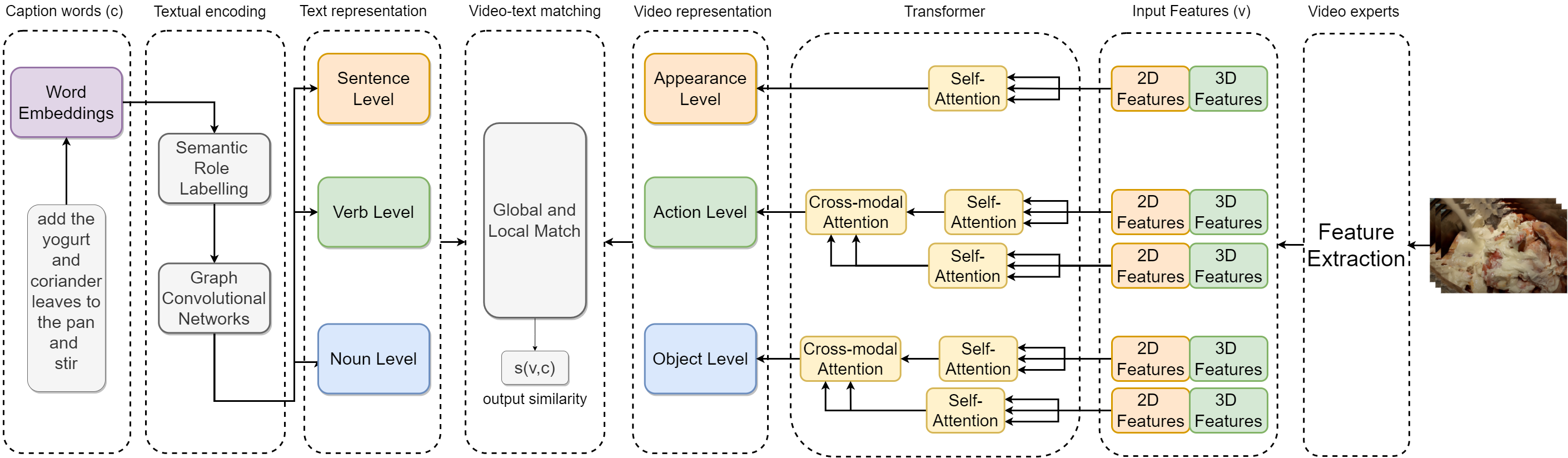
Figure 1 introduces our model, which has three main parts: textual encoding, video encoding, and text-video matching.
III-A Textual Encoding
To comply with disentangled video features, we also disentangle the textual features hierarchically. Every video clip has at least one descriptive textual sentence in a hierarchically structured way. For instance, while a sentence could define global features, action and entity-related words would define the local features.
By following recent works [11, 3], we utilize [36] for handling semantic role labeling to disentangle the structure of sentences in the form of graphs. To exploit the semantic relationship among the words, verbs are connected to the sentence by showing the temporal relations with their directed edges, and then the objects are connected to verbs. We define the relationship between actions and entities as , in which refers to action nodes and refers to verb nodes. Before applying GCN, we use bidirectional LSTM to have contextualized word embeddings. While we apply soft attention for sentence-level embedding, we implement max-pooling over verbs and objects for their corresponding embeddings.
Rather than using relational GCN [37] by learning weight matrix for each semantic role which would be computationally expensive, we follow Chen et al. [3] to utilize factorised weights in two steps. Firstly, the semantic role matrix , which is specific matrix for different semantic roles are multiplied with initialized node embeddings {, , } in Eq. 1. is an one-hot vector referring to the edge type from node to . refers to element-wise multiplication.
| (1) |
Secondly, a graph attention network is applied to neighbor nodes. Then matrix, which is shared across all relations types, is used to exploit attended nodes in Eq. 2. refers to the outcome after attention is implemented for every node.
| (2) |
After applying these two formulas, we gather the textual representation for global and local features; for sentences, verbs, and words, respectively.
III-B Video Encoding
While disentangling language queries into hierarchical features is relatively easy, parsing videos into hierarchical features could be challenging. We propose different transformer models for global and local levels. While we use only intra-modality features at the global level, we utilize both intra-modality and inter-modality specific features at the local levels.
The intuition behind this is that while the global features could guide the local representations through the cross-modal attention at the action or object level, the local features may give noise to the global representations when used at the appearance level. We use transformer encoder and decoders to implement this idea as inspired from [38, 10, 39, 34].
Calculating appearance-level video encodings is relatively easy. The 2D feature is fed into the self-attention layer to encode into . Then, a feed-forward layer FF outputs the final contextualized appearance feature. Normalization of the layer is done under the Norm function.
| (3) | ||||
We follow Vaswani et al. [38]’s multi-headed attention layers as formulated in Eq. 4. During the training process, all the W matrices are learned. While query Q is the same as key K and value V in the self-attention layers, the query Q could be from another source in the cross-modal attention layers. Layer normalization and the residual connection are also applied after every attention layer.
| (4) | ||||
Complementary features are applied with cross-modal attention to calculate the verb and noun level encodings. For instance, we explain the formula for verb level in Eq. LABEL:eq:encoder. First, the appearance level and noun level features are concatenated. Then, a multi-headed self-attention is applied, followed by a feed-forward layer FF. This generates context-specific feature of the verb level.
| (5) | ||||
Then, self-attention of verb level features is calculated as in the first row of Eq. LABEL:eq:encoder.
Finally, cross-modal attention is applied such that the contextualized verb-level features would attend to the contextualized appearance and object-level features. Then, a feed-forward linear layer FF and layer normalization are applied. We repeat the same process to calculate the noun-level embeddings. Then, these three-level video embeddings are used in the video-text matching part.
| (6) | ||||
III-C Video-Text Matching
Some works such as [3, 11] average the similarities of the different embedding levels, assuming that they are equally important. Other works [10, 5] apply weighted sum but predicted from textual encodings. On the other hand, we apply weighted sum to the video encodings as the video encodings, especially at the local level, become contextualized via cross-modal attention with the other modalities. The guidance of the textual encodings may not be necessary.
We simply use cosine similarity with the video and textual embeddings to calculate the matching score by adding a weighting calculated on video embeddings only. We utilize contrastive ranking loss [3] in training by aiming to have positive and negative pairs larger than a pre-set margin. If and symbolize visual and textual representation, the positive pairs and the negative pairs could be presented like following, and / , respectively. A pre-set margin is referred to as to calculate the contrastive loss.
| (7) |
| (8) |
represents the weight for the ith video expert feature. We feed the expert encodings into a linear layer and then apply a softmax operation. Since we have three linear layers, we would calculate three different weights.
IV Experiments
We share our experimental results on YouCook2 and MSR-VTT datasets for the video retrieval task and present various ablations results.
IV-A Implementation Details
YouCook2 dataset: This dataset [40] is collected from YouTube only from cooking-related videos with 89 different recipes. They are all captured in various kitchen environments from the third-person viewpoint. The video clips are labeled by imperative English sentences along with temporal boundaries referring to the actions. The annotation was done manually by humans. Video clips are extracted by using the formal annotation file. We feed our model with the validation dataset for evaluation following the other studies since the test set is not publicly available. Normally, the dataset has 10,337 clips and 3,492 clips in the training and validation set, respectively. However, some of the raw videos are not available due to being removed or becoming private. This makes 8% of training clips and 7% of validation clips missing in total. Thus, we use 9,496 clips and 3,266 clips in the training and validation set, respectively.
MSR-VTT dataset: It [41] contains 10K video clips with 20 descriptions for each video and collected by a commercial video search engine. The annotation is done by humans. This dataset has various train/test splits. One of the most used splits is called 1k-B. It has 6,656 clips for training and 1,000 clips for testing. The full split, which is another widely used split, contains 6,513 video clips for training, 497 for validation, and 2990 for testing. While we test our method mostly in this 1k-B split, we also report in the full split as well.
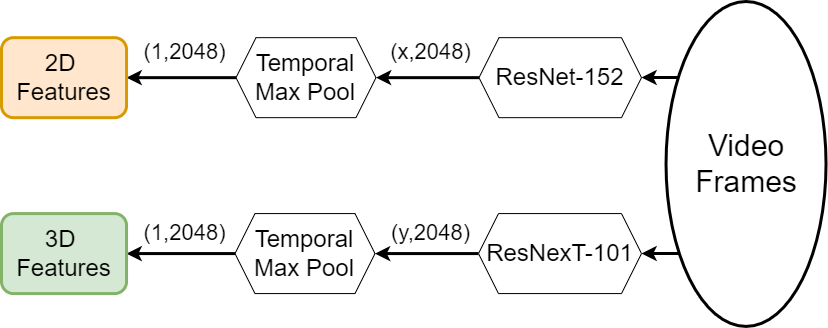
Video features: We extract our own features from the raw videos of YouCook2 by following Miech et al. [6]. To extract appearance features we use two dimensional Convolutional Neural Networks of ResNet-152 [42] model, pre-trained on Imagenet [43]. To extract action level features we utilize three dimensional Convolutional Neural Networks of ResNeXt-101 [44] model, pre-trained on Kinetics [45]. Later on, we implement max-pooling on temporal dimension, making the dimension (1, 2048) for each feature set. The process is also depicted in Figure 2. For MSR-VTT, we gather appearance level features of ResNet-152 model from Chen et al. [3] and action level features of ResNeXt-101 model from Liu et al. [8], respectively.
Evaluation metrics. Given a textual query, we rank all the video candidates such that the video associated with the textual query is ranked as high as possible. Recall (R@k) and Median Rank (MedR) are used to evaluate the model. For instance, R@k is calculated if the ground truth video is in the first kth in the ranking list, where k is {1,5,10}. Higher recall values refer to better performance. MedR denotes the median rank of correctly predicted video clips in the list. The lower MedR is, the performance is better.
Training. Glove embeddings [46] is used to set the word embedding with the size of 300 for the textual embedding. To parse the text embeddings hierarchically, we follow [3, 11]. Graph convolutions are applied with two layers, outputting 1024 dimensions. We apply a linear layer to each video expert feature embeddings to be compatible with the textual layer, making their dimension 1024 as well. The margin is set to . Our mini-batch size is 32. While the epoch is 100 for the YouCook2 dataset, it is 50 for the MSR-VTT dataset.
IV-B Experiments on YouCook2
Table I compares our approach with SOTA methods for video retrieval task on YouCook2 dataset. It includes all the methods that report their results without pre-training. The above part of Table I shows the methods when using the same feature set. We overpass all the recent papers in all metrics, except the last metric for one work [31], using the same feature backbone. Please note that the HGR method by Chen et al. [3] is reported by Satar et al. [11]. All the models in the table use pre-extracted features; in other words, they are not end-to-end models, making the comparison fair.
The lower part of Table I introduces the results with pre-training and different visual feature backbones. We see higher results for two reasons. UniVL [18], COOT [31], and TACo [20] methods use S3D features pre-trained on HowTo100M. Since HowTo100M is similar to YouCook2 as an instructional video dataset, it would be more useful than pre-training on Kinetics. On the other hand, MMVC [33] uses S3D features pre-trained on Kinetics. However, this model exploits additional audio and Automatic Speech Recognition (ASR) features which could boost the performance.
| Text-to-Video Retrieval | |||||||||
| Method | Visual Backbone | Batch Size | R@1↑ | R@5↑ | R@10↑ | MdR↑ | |||
| Random | - | - | 0.03 | 0.15 | 0.3 | 1675 | |||
|
|
32 | 3.4 | 10.8 | 17.8 | 76 | |||
| Satar et al., 2021 [11] |
|
32 | 4.5 | 13.2 | 20.0 | 85 | |||
| Miech et al., 2019 [6] |
|
- | 4.2 | 13.7 | 21.5 | 65 | |||
| HGR*, 2020 [3] |
|
32 | 4.8 | 14.0 | 20.3 | 85 | |||
| HGR*, 2020 [3] |
|
32 | 4.7 | 14.1 | 20.0 | 87 | |||
| HGLMM, 2015 [47] | Fisher Vectors | - | 4.6 | 14.3 | 21.6 | 75 | |||
| Satar et al., 2021 [11] |
|
32 | 5.3 | 14.5 | 20.8 | 77 | |||
| SwAMP, 2021 [19] |
|
128 | 4.8 | 14.5 | 22.5 | 57 | |||
| TACo, 2021 [20] |
|
128 | 4.9 | 14.7 | 21.7 | 63 | |||
| COOT, 2020 [31] |
|
32 | 5.9 | 16.7 | 24.8 | 49.7 | |||
| RoME |
|
32 | 6.3 | 16.9 | 25.2 | 53 | |||
| UniVL (FT-Joint), 2020 [18] | S3D (HowTo100M) | 32 | 7.7 | 23.9 | 34.7 | 21 | |||
| MMCV, 2022 [33] | S3D (Kinetics) | 32 | 16.6 | 37.4 | 48.3 | 12 | |||
| COOT, 2020 [31] | S3D (HowTo100M) | 64 | 16.7 | 40.2 | 52.3 | 9 | |||
| TACo, 2021 [20] | S3D (HowTo100M) | 128 | 16.6 | 40.3 | 53.1 | 9 | |||
IV-C Experiments on MSR-VTT
Table II compares our approach with SOTA methods when using the same feature set on the MSR-VTT dataset. These include all the methods that report text-to-video retrieval results without pre-training. We overpass all the methods in all metrics. In particular, our method surpasses the performance by 2.9% on R@1 over the CE method [8], which uses four features, even though we only use two of them. Moreover, our method improves the performance by 1.9% on R@1 over the best SOTA approach [20].
For the full split, we overpass all the methods that we have similar feature sets. However, we surpass the CE method [8] only in the first two metrics. One of the main reasons that CE overpasses our method in the last two metrics could be the advantage of using various other visual experts such as audio and ASR. Secondly, the testing set becomes tripled than 1k-B split, increasing the advantage of having many visual expert features. Thirdly, our models’ textual encoding part may not handle having twenty captions for each video clip, as it is included in MSR-VTT. A transformer-based approach such as BERT may perform better, although we did not apply any experiments with BERT. Moreover, it is hard to make a comparison among some approaches. For example, Alayrac et al. [7] report their result when pre-trained on HowTo100M and a zero-shot setting. TeachText-CE [48] uses various textual feature experts as long as seven different visual feature experts, making it hard to compare with our result, which is still added to the table for reference. Nevertheless, we overpass the CE method in the first two metrics, which could be more critical in real-world applications.
| Text-to-Video Retrieval | |||||||||
| Method | Visual Backbone | Batch Size | R@1↑ | R@5↑ | R@10↑ | MdR↓ | |||
| Split 1k-B | |||||||||
| Random | - | - | 0.1 | 0.5 | 1.0 | 500 | |||
| MoEE, 2018 [5] |
|
- | 13.6 | 37.9 | 51.0 | 10 | |||
| JPoSE, 2019 [49] | TSN + Flow | - | 14.3 | 38.1 | 53.0 | 9 | |||
| UniVL (v1*), 2020 [18] |
|
- | 14.6 | 39.0 | 52.6 | 10 | |||
| SwAMP, 2021 [19] |
|
128 | 15.0 | 38.5 | 50.3 | 10 | |||
| CE, 2019 [8] |
|
- | 18.2 | 46.0 | 60.7 | 7 | |||
| TACo, 2021 [20] |
|
128 | 19.2 | 44.7 | 57.2 | 7 | |||
| RoME |
|
32 | 21.1 | 50.0 | 63.1 | 5 | |||
| Full Split | |||||||||
| Random | - | - | 0.1 | 0.5 | 1.0 | 500 | |||
| Dual Encoding, 2019 [9] | Resnet-152 (ImageNet) | 128 | 7.7 | 22.0 | 31.8 | 32.0 | |||
| Alayrac et al., 2020 [7] |
|
- | 9.9 | 24.0 | 32.4 | 29.5 | |||
| HGR, 2020 [3] | Resnet-152 (ImageNet) | 128 | 9.2 | 26.2 | 36.5 | 24 | |||
| CE, 2019 [8] |
|
- | 10.0 | 29.0 | 42.2 | 16 | |||
| RoME |
|
32 | 10.7 | 29.6 | 41.2 | 17 | |||
| TeachText-CE, 2021 [48] |
|
64 | 11.8 | 32.7 | 45.3 | 13.0 | |||
IV-D Experiments for Video-to-Text Retrieval
Although the video-to-text retrieval task is not our primary motivation, we report it in Table III to show that our model could also be used in this aim. For YouCook2, only one method reports their video-to-text retrieval results when there is no pre-training, which is reported by [11]. We overpass the compared methods in all metrics with a high margin on both datasets without pre-training.
| Video-to-Text Retrieval | |||||||||
| Method | Visual Backbone | Batch Size | R@1↑ | R@5↑ | R@10↑ | MdR↓ | |||
| YouCook2 | |||||||||
| HGR*, 2020 [3] |
|
32 | 4.1 | 13.0 | 19.0 | 85 | |||
| HGR*, 2020 [3] |
|
32 | 4.2 | 13.2 | 18.9 | 84 | |||
| RoME |
|
32 | 4.9 | 15.9 | 24.1 | 55 | |||
| MSR-VTT | |||||||||
| JPoSE, 2019 [49] | TSN + Flow | - | 16.4 | 41.3 | 54.4 | 8.7 | |||
| CE, 2019 [8] |
|
- | 18.0 | 46.0 | 60.3 | 6.5 | |||
| RoME |
|
32 | 27.9 | 58.5 | 73.1 | 4 | |||
IV-E Ablation Studies
We share extensive ablation studies about design choices on weighted sum, model design, and video feature settings.
IV-E1 Ablation on Weighting Encodings
Some recent papers add weighting to only textual representation. We do an ablation study by adding weighting to the only visual representation, only textual representation, and both. Our results in Table IV indicate: 1) Applying weighted sum over textual or visual encodings generally performs better than average weighting. It justifies the idea that every embedding level impacts the model differently. 2) Weighted sum on only visual encodings brings slightly higher results than having weighted sum on only textual encodings. We assume it is because it ignores discriminate signals from the video experts by making the model text-dependent when using weighted sum on only textual encodings.
| Visual Features | |||||||||
| Weighting Option | Appearance | Action | Object | R@1↑ | R@5↑ | R@10↑ | MdR↓ | ||
| YouCook2 | |||||||||
| Average | 2D + 3D | 2D + 3D | 2D + 3D | 6 | 16.7 | 24.6 | 55 | ||
|
2D + 3D | 2D + 3D | 2D + 3D | 5.9 | 16.8 | 24.7 | 54 | ||
|
2D + 3D | 2D + 3D | 2D + 3D | 6.1 | 17 | 24.8 | 52 | ||
|
2D + 3D | 2D + 3D | 2D + 3D | 6.3 | 16.9 | 25.2 | 53 | ||
| MSR-VTT | |||||||||
| Average | 2D + 3D | 2D + 3D | 2D + 3D | 20.8 | 49.1 | 62.8 | 6 | ||
|
2D + 3D | 2D + 3D | 2D + 3D | 20.6 | 49.0 | 62.3 | 6 | ||
|
2D + 3D | 2D + 3D | 2D + 3D | 21.1 | 49.7 | 62.9 | 6 | ||
|
2D + 3D | 2D + 3D | 2D + 3D | 21.1 | 50.0 | 63.1 | 5 | ||
If we examine the calculated weights of each visual level on the YouCook2 dataset, the results are around 0.45, 0.30, and 0.25 for appearance, action, and object levels, respectively. The weights are calculated in Eq. 7 and 8, Sec.III. While the 2D feature contributes the most, the other two feature levels affect the results considerably and similarly. It is because the dataset contains crucial objects and actions. The calculated weights of the visual encodings in the MSR-VTT dataset are around 0.47, 0.43, and 0.10 for appearance action and object levels, showing the same importance for appearance features. However, while action features contribute more, the contribution of object-level features decreases sharply. It is mainly due to the nature of the dataset, where there are fewer objects but more continual actions.
IV-E2 Ablation on Model Design
Our proposed model suggests that different attention methods for global and local feature levels increase the result. We could see this increase in Table V. The model we use for ablation studies applies only self-attention for every level. We compare this model with our proposed model, where we use self-attention in the appearance level but cross-modal and self-attention for the other two levels. Average weighting is applied for both models. All the feature experts have the dimensions of 2048, which makes the comparison fair. The results are improved by proposing different attention mechanisms for global and local levels.
| Visual Features | |||||||||
| Attention | Appearance | Action | Object | R@1↑ | R@5↑ | R@10↑ | MdR↓ | ||
| YouCook2 | |||||||||
| Self-attention for all levels | 2D + 3D | 2D + 3D | 2D + 3D | 6 | 16.2 | 24.5 | 55 | ||
|
2D + 3D | 2D + 3D | 2D + 3D | 6 | 16.7 | 24.6 | 55 | ||
| MSR-VTT | |||||||||
| Self-attention for all levels | 2D + 3D | 2D + 3D | 2D + 3D | 20.4 | 48.1 | 62.6 | 6 | ||
|
2D + 3D | 2D + 3D | 2D + 3D | 20.8 | 49.1 | 62.8 | 6 | ||
IV-E3 Ablation on Visual Feature Settings
While all the variations in our model surpass the baseline in the same feature set, the highest result comes with a concatenated 2D and 3D feature setting in the Table VI, showing that early fusion gives a boost since the features are correlated. Average weighting is applied to the models.
| Visual Features | |||||||||
| Attention | Appearance | Action | Object | R@1↑ | R@5↑ | R@10↑ | MdR↓ | ||
|
2D | 2D | 2D | 5.7 | 16.7 | 24.1 | 56 | ||
|
2D | 3D | RoI | 5.7 | 16.6 | 24.2 | 54 | ||
|
2D + 3D | 2D + 3D | 2D + 3D | 6 | 16.7 | 24.6 | 55 |
IV-E4 Extended Ablations
The following ablation presents comprehensive insights on visual feature setting and model design choice. The above part shows that our visual feature setting choice, which is the concatenation of 2D and 3D features, brings higher results even on a different model design than our proposed model. Similarly, the below part indicates that our model design choice performs better even using different feature settings than our proposed approach. Average weighting is applied to the models. These results support our two arguments that using self-attention only at the global level with cross-modal and self-attention at the local levels along with concatenated 2D and 3D features brings the best results.
| Visual Features | |||||||||
| Attention | Appearance | Action | Object | R@1↑ | R@5↑ | R@10↑ | MdR↓ | ||
| Visual Feature Setting Ablation on Another Model Design | |||||||||
| Self-attention for all levels | 2D | 2D | 2D | 5.5 | 16.3 | 24.1 | 58 | ||
| Self-attention for all levels | 2D | 3D | RoI | 5.3 | 16.2 | 23.1 | 57 | ||
| Self-attention for all levels | 2D + 3D | 2D + 3D | 2D + 3D | 6 | 16.2 | 24.5 | 55 | ||
| Model Design Ablation on Another Feature Setting | |||||||||
| Self-attention for all levels | 2D | 3D | RoI | 5.3 | 16.3 | 23.1 | 57 | ||
|
2D | 3D | RoI | 5.7 | 16.6 | 24.2 | 54 | ||
V Conclusion
In this work, we propose a novel hierarchical MoE transformer to transform the text and video features into three semantic roles and then align them in three joint embedding spaces. To better use the intra-modality and inter-modality video features, we employ self-attention and cross-modal attention at the local levels and only use self-attention at the global level. Moreover, the weighted sum of the video features boosts the results by exploiting the discriminative video features. Our approach surpasses SOTA methods on the YouCook2 and MSR-VTT datasets by using the same visual feature set without pre-training. We also share an extensive ablation study allowing us to have deeper insights.
Acknowledgments
This research is supported by the Agency for Science, Technology and Research (A*STAR) under its AME Programmatic Funding Scheme (Project A18A2b0046).
References
- [1] X. Chang, Y. Yang, A. Hauptmann, E. Xing, and Y. Yu, “Semantic concept discovery for large-scale zero-shot event detection,” in IJCAI, 2015.
- [2] A. Habibian, T. Mensink, and C. G. M. Snoek, “Composite concept discovery for zero-shot video event detection,” ICMR, 2014.
- [3] S. Chen, Y. Zhao, Q. Jin, and Q. Wu, “Fine-grained video-text retrieval with hierarchical graph reasoning,” in CVPR, 2020.
- [4] N. C. Mithun, J. Li, F. Metze, and A. K. Roy-Chowdhury, “Learning joint embedding with multimodal cues for cross-modal video-text retrieval,” in Proceedings of the 2018 ACM on ICMR, 2018, p. 19–27. [Online]. Available: https://doi.org/10.1145/3206025.3206064
- [5] A. Miech, I. Laptev, and J. Sivic, “Learning a text-video embedding from incomplete and heterogeneous data,” arXiv:1804.02516, 2018.
- [6] A. Miech, D. Zhukov, J.-B. Alayrac, M. Tapaswi, I. Laptev, and J. Sivic, “Howto100m: Learning a text-video embedding by watching hundred million narrated video clips,” in ICCV, 2019.
- [7] A. Miech, J. B. Alayrac, L. Smaira, I. Laptev, J. Sivic, and A. Zisserman, “End-to-end learning of visual representations from uncurated instructional videos,” in CVPR, 2020.
- [8] Y. Liu, S. Albanie, A. Nagrani, and A. Zisserman, “Use what you have: Video retrieval using representations from collaborative experts,” in arXiv, 2019.
- [9] J. Dong, X. Li, C. Xu, S. Ji, Y. He, G. Yang, and X. Wang, “Dual encoding for zero-example video retrieval,” in CVPR, 2019, pp. 9338–9347.
- [10] V. Gabeur, C. Sun, K. Alahari, and C. Schmid, “Multi-modal Transformer for Video Retrieval,” in ECCV, 2020.
- [11] B. Satar, Z. Hongyuan, X. Bresson, and J. H. Lim, “Semantic role aware correlation transformer for text to video retrieval,” in 2021 IEEE International Conference on Image Processing (ICIP), 2021, pp. 1334–1338.
- [12] C. Kurby and J. Zacks, “Segmentation in the perception and memory of events,” Trends in cognitive sciences, vol. 12, pp. 72–9, 03 2008.
- [13] J. M. Zacks, B. Tversky, and G. Y. Iyer, “Perceiving, remembering, and communicating structure in events.” Journal of experimental psychology. General, vol. 130 1, pp. 29–58, 2001.
- [14] K.-H. Lee, X. Chen, G. Hua, H. Hu, and X. He, “Stacked cross attention for image-text matching,” arXiv preprint arXiv:1803.08024, 2018.
- [15] A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 4, p. 664–676, apr 2017. [Online]. Available: https://doi.org/10.1109/TPAMI.2016.2598339
- [16] H. Wu, J. Mao, Y. Zhang, Y. Jiang, L. Li, W. Sun, and W.-Y. Ma, “Unified visual-semantic embeddings: Bridging vision and language with structured meaning representations,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 6602–6611.
- [17] A. Rouditchenko, A. Boggust, D. F. Harwath, D. Joshi, S. Thomas, K. Audhkhasi, R. S. Feris, B. Kingsbury, M. Picheny, A. Torralba, and J. R. Glass, “Avlnet: Learning audio-visual language representations from instructional videos,” in Interspeech, 2021.
- [18] H. Luo, L. Ji, B. Shi, H. Huang, N. Duan, T. Li, J. Li, T. Bharti, and M. Zhou, “Univl: A unified video and language pre-training model for multimodal understanding and generation,” arXiv preprint arXiv:2002.06353, 2020.
- [19] M. Kim, “Swamp: Swapped assignment of multi-modal pairs for cross-modal retrieval,” arXiv preprint arXiv:2111.05814, 11 2021.
- [20] J. Yang, Y. Bisk, and J. Gao, “Taco: Token-aware cascade contrastive learning for video-text alignment,” ICCV 2021, 08 2021.
- [21] Y. Song and M. Soleymani, “Polysemous visual-semantic embedding for cross-modal retrieval,” 2019.
- [22] Y. Yu, J. Kim, and G. Kim, “A joint sequence fusion model for video question answering and retrieval,” in ECCV, 2018.
- [23] C. Sun, A. Myers, C. Vondrick, K. Murphy, and C. Schmid, “Videobert: A joint model for video and language representation learning,” in ICCV, 2019.
- [24] L. Zhu and Y. Yang, “Actbert: Learning global-local video-text representations,” in CVPR, 2020.
- [25] Y. Wang, S. Joty, M. Lyu, I. King, C. Xiong, and S. C. Hoi, “VD-BERT: A Unified Vision and Dialog Transformer with BERT,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Online: Association for Computational Linguistics, Nov. 2020, pp. 3325–3338. [Online]. Available: https://aclanthology.org/2020.emnlp-main.269
- [26] R. Tan, H. Xu, K. Saenko, and B. A. Plummer, “wman: Weakly-supervised moment alignment network for text-based video segment retrieval,” 2020. [Online]. Available: https://openreview.net/forum?id=BJx4rerFwB
- [27] J.-B. Alayrac, A. Recasens, R. Schneider, R. Arandjelović, J. Ramapuram, J. D. Fauw, L. Smaira, S. Dieleman, and A. Zisserman, “Self-supervised multimodal versatile networks,” 2020.
- [28] J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in ICASSP, 2017, pp. 776–780.
- [29] V. Gabeur, A. Nagrani, C. Sun, K. Alahari, and C. Schmid, “Masking modalities for cross-modal video retrieval,” 2021. [Online]. Available: https://arxiv.org/abs/2111.01300
- [30] A. J. Wang, Y. Ge, G. Cai, R. Yan, X. Lin, Y. Shan, X. Qie, and M. Z. Shou, “Object-aware video-language pre-training for retrieval,” 2021. [Online]. Available: https://arxiv.org/abs/2112.00656
- [31] S. Ging, M. Zolfaghari, H. Pirsiavash, and T. Brox, “Coot: Cooperative hierarchical transformer for video-text representation learning,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 22 605–22 618. [Online]. Available: https://proceedings.neurips.cc/paper/2020/file/ff0abbcc0227c9124a804b084d161a2d-Paper.pdf
- [32] B. Zhang, H. Hu, and F. Sha, “Cross-modal and hierarchical modeling of video and text,” 2018. [Online]. Available: https://arxiv.org/abs/1810.07212
- [33] V. Gabeur, A. Nagrani, C. Sun, K. Alahari, and C. Schmid, “Masking modalities for cross-modal video retrieval,” in Winter Conference on Applications of Computer Vision (WACV), 2022.
- [34] V. Iashin and E. Rahtu, “Multi-modal dense video captioning,” in CVPR Workshops, 2020.
- [35] W. Wang, H. Bao, L. Dong, and F. Wei, “VLMo: Unified vision-language pre-training with mixture-of-modality-experts,” 2021.
- [36] P. Shi and J. Lin, “Simple bert models for relation extraction and semantic role labeling,” 2019.
- [37] M. Schlichtkrull, T. Kipf, P. Bloem, R. v. d. Berg, I. Titov, and M. Welling, “Modeling relational data with graph convolutional networks,” in ESWC, Proceedings. Springer/Verlag, 2018, pp. 593–607.
- [38] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in NIPS, 2017.
- [39] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in HLT-NAACL, 2019. [Online]. Available: https://www.aclweb.org/anthology/N19-1423
- [40] L. Zhou, C. Xu, and J. Corso, “Towards automatic learning of procedures from web instructional videos,” in AAAI, 2018, pp. 7590–7598. [Online]. Available: https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/17344
- [41] J. Xu, T. Mei, T. Yao, and Y. Rui, “Msr-vtt: A large video description dataset for bridging video and language.” IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), June 2016. [Online]. Available: https://www.microsoft.com/en-us/research/publication/msr-vtt-a-large-video-description-dataset-for-bridging-video-and-language/
- [42] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016.
- [43] J. Deng, W. Dong, R. Socher, L. Li, K. L., and L. F.-F., “Imagenet: A large-scale hierarchical image database,” in CVPR, 2009, pp. 248–255.
- [44] K. Hara, H. Kataoka, and Y. Satoh, “Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?” in CVPR, 2018, pp. 6546–6555.
- [45] J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” in CVPR, 2017, pp. 4724–4733.
- [46] J. Pennington, R. Socher, and C. Manning, “Glove: Global vectors for word representation,” in EMNLP. ACL, 2014, pp. 1532–1543. [Online]. Available: https://www.aclweb.org/anthology/D14-1162
- [47] B. Klein, G. Lev, G. Sadeh, and L. Wolf, “Associating neural word embeddings with deep image representations using fisher vectors,” in CVPR, 2015.
- [48] I. Croitoru, S.-V. Bogolin, M. Leordeanu, H. Jin, A. Zisserman, S. Albanie, and Y. Liu, “Teachtext: Crossmodal generalized distillation for text-video retrieval,” IEEE, 2021.
- [49] M. Wray, D. Larlus, G. Csurka, and D. Damen, “Fine-grained action retrieval through multiple parts-of-speech embeddings,” in ICCV, 2019.
VI Biography Section
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b776106d-77a4-4a8b-a127-350ff2f048f4/burak.jpg) |
Burak Satar is a third-year Ph.D. candidate majoring in video understanding with multi-modal features in a joint program at the School of Computer Science and Engineering Nanyang Technological University, Singapore and Institute for Infocomm Research, A*STAR Singapore, under SINGA scholarship. He received his M.Sc. degree in Electronic Engineering in 2018. His research interests include causality in vision, multimedia retrieval, and computer vision. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b776106d-77a4-4a8b-a127-350ff2f048f4/hongyuan.jpg) |
Hongyuan Zhu received the B.S.degree in software engineering from the University of Macau, in 2010, and the Ph.D. degree in computer engineering from Nanyang Technological University, Singapore, in 2014. He is currently a Research Scientist with the Institute for Infocomm Research, A*STAR, Singapore. His research interests include multimedia content analysis and segmentation. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b776106d-77a4-4a8b-a127-350ff2f048f4/hanwang.png) |
Hanwang Zhang is currently an Assistant Professor at the School of Computer Science and Engineering, Nanyang Technological University, Singapore. He was a research scientist at the Department of Computer Science, Columbia University, USA. He received the B.Eng (Hons.) degree in computer science from Zhejiang University, Hangzhou, China, in 2009, and the Ph.D. degree in computer science from the National University of Singapore in 2014. His research interest includes computer vision, multimedia, and social media. Dr. Zhang is the recipient of the Best Demo runner-up award in ACM MM 2012, the Best Student Paper award in ACM MM 2013, the Best Paper Honorable Mention in ACM SIGIR 2016, and TOMM best paper award 2018. He is also the winner of Best Ph.D. Thesis Award of School of Computing, National University of Singapore, 2014. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b776106d-77a4-4a8b-a127-350ff2f048f4/joohwee.jpg) |
Joo Hwee Lim received his B.Sc. (1st Class Honours) and M.Sc. (by research) degrees in Computer Science from the National University of Singapore and his Ph.D. degree in Computer Science & Engineering from the University of New South Wales. He joined Institute for Infocomm Research (I2R), Singapore (and its predecessors) in October 1990. His research experience includes connectionist expert systems, neural-fuzzy systems, handwritten recognition, multi-agent systems, content-based image retrieval, scene/object recognition, and medical image analysis, with over 280 international refereed journal and conference papers and 25 patents (awarded and pending). He is currently Principal Scientist and Department Head (Visual Intelligence) at I2R, A*STAR, Singapore, and an Adjunct Professor at the School of Computer Science and Engineering, Nanyang Technological University, Singapore. He was also the co-Director of IPAL (Image, Pervasive Access Lab), a French-Singapore Joint Lab (UMI 2955, Jan 2007 to Jan 2015). He was bestowed the title of ’Chevalier dans l’ordre des Palmes Academiques’ by the French Government in 2008 and the National Day Commendation Medal by the Singapore Government in 2010. |