RSTAM: An Effective Black-Box Impersonation Attack on Face Recognition using a Mobile and Compact Printer
Abstract.
Face recognition has achieved considerable progress in recent years thanks to the development of deep neural networks, but it has recently been discovered that deep neural networks are vulnerable to adversarial examples. This means that face recognition models or systems based on deep neural networks are also susceptible to adversarial examples. However, the existing methods of attacking face recognition models or systems with adversarial examples can effectively complete white-box attacks but not black-box impersonation attacks, physical attacks, or convenient attacks, particularly on commercial face recognition systems. In this paper, we propose a new method to attack face recognition models or systems called RSTAM, which enables an effective black-box impersonation attack using an adversarial mask printed by a mobile and compact printer. First, RSTAM enhances the transferability of the adversarial masks through our proposed random similarity transformation strategy. Furthermore, we propose a random meta-optimization strategy for ensembling several pre-trained face models to generate more general adversarial masks. Finally, we conduct experiments on the CelebA-HQ, LFW, Makeup Transfer (MT), and CASIA-FaceV5 datasets. The performance of the attacks is also evaluated on state-of-the-art commercial face recognition systems: Face++, Baidu, Aliyun, Tencent, and Microsoft. Extensive experiments show that RSTAM can effectively perform black-box impersonation attacks on face recognition models or systems.
1. Introduction
Face recognition has advanced significantly in recent years with the development of deep neural networks (Parkhi et al., 2015; Schroff et al., 2015; Liu et al., 2017; Wang et al., 2018; Deng et al., 2019). In our daily lives, face recognition has been used in a wide range of applications due to the excellent performance currently available. These applications include security-sensitive applications such as mobile phone unlocking and payment, door locks, airport and railway station check-in, financial industry authentication, and other similar applications. Unfortunately, many studies (Goodfellow et al., 2014b; Madry et al., 2018; Carlini and Wagner, 2017; Dong et al., 2018) have found that deep neural networks are vulnerable to adversarial examples. Unsurprisingly, face recognition based on deep neural networks is also vulnerable to adversarial examples (Dong et al., 2019b; Zhong and Deng, 2020; Yang et al., 2021).
Dong et al. (Dong et al., 2019b), Zhong et al. (Zhong and Deng, 2020), and Yang (Yang et al., 2021) generate adversarial examples with strong perturbations by decision-based attack, gradient-based attack, and generative adversarial network (GAN) (Goodfellow et al., 2014a), respectively, which can effectively perform digital adversarial attacks on face recognition. However, implementing these global perturbations in the physical world is unrealistic. Therefore, they cannot be employed in actual attacks. In most cases, these methods are used to evaluate the security of face recognition rather than to carry out actual attacks. Recently, many methods for physical attacks on face recognition have also been proposed (Sharif et al., 2016, 2019; Nguyen et al., 2020; Komkov and Petiushko, 2021; Yin et al., 2021). Sharif et al. (Sharif et al., 2016, 2019) and Komkov et al. (Komkov and Petiushko, 2021) are perfect for white-box physical attacks, but they are hard to perform black-box attacks on face recognition models or systems. Nevertheless, realistic face recognition environments are commonly in a black-box state. Nguyen et al. (Nguyen et al., 2020) used a projector to perform adversarial light projection physical attacks, but such attacks are not convenient in reality. Yin et al. (Yin et al., 2021) can implement transferable physical attacks on face recognition, but physical attacks on commercial face recognition systems are not ideal. Similarly, Yin et al. (Yin et al., 2021) perform poorly when confronted with low-quality face images.
We summarize that an effective adversarial attack method on face recognition should be capable of conducting black-box attacks, physical attacks, impersonation attacks, convenient attacks, attacks on low-quality target images, and attacks against commercial systems. Previous studies have shown that it is not easy to effectively implement black-box physical impersonation attacks on face recognition. To address these challenges simultaneously, we propose an effective black-box impersonation attack method on face recognition, called RSTAM, which implements a physical attack employing an adversarial mask printed by a mobile and compact printer. To begin, we design an initial binary mask, as shown in Figure 1. Secondly, we propose a random similarity transformation strategy, which can enhance the diversity of the inputs and thus the transferability of the adversarial masks. Following that, we propose a random meta-optimization strategy for ensembling several pre-trained face models to generate more transferable adversarial masks. Finally, we perform experiments on two high-resolution face datasets CelebA-HQ (Karras et al., 2018), Makeup Transfer (MT) (Li et al., 2018), and two low-quality face datasets LFW (Huang et al., 2008), CASIA-FaceV5 (of Automation, 2009). Meanwhile, we perform evaluations on five state-of-the-art commercial face recognition systems: Face++ (Face++, 2022), Baidu (Baidu, 2022), Aliyun (Aliyun, 2022), Tencent (Tencent, 2022) and Microsoft (Microsoft, 2022). Our experiments show that our proposed method RSTAM can effectively perform black-box impersonation attacks on commercial face recognition systems and low-pixel target images. Moreover, RSTAM can implement convenient physical attacks through the use of a Canon SELPHY CP1300 (CP1300, 2022), a mobile and compact printer. The main contributions of our work are summarized as follows.
-
•
We design an initial binary mask for the adversarial masks.
-
•
We propose a random similarity transformation strategy that can improve the transferability of the adversarial masks by increasing the diversity of the inputs. Moreover, we use only one hyperparameter to control the random similarity transformation with four degrees of freedom (4DoF).
-
•
We propose a random meta-optimization strategy to perform an ensemble attack using several pre-trained face models. This strategy enables us to extract more common gradient features from the face models, thereby increasing the transferability of the adversarial masks.
-
•
Experiments demonstrate that RSTAM is an effective attack method on face recognition capable of performing black-box attacks, physical attacks, convenience attacks, impersonation attacks, attacks on low-quality images, and attacks against state-of-the-art commercial face recognition systems.
2. Related Works
2.1. Adversarial Attacks
Adversarial attacks fall into two broad categories: white-box attacks and black-box attacks. For white-box attack methods, they have full access to the target model and and the majority of them are gradient-based attacks, such as Fast Gradient Sign Method (FGSM) (Goodfellow et al., 2014b), Projected Gradient Descent (PGD) (Madry et al., 2018), and Carlini & Wagner’s method (C&W) (Carlini and Wagner, 2017). FGSM is a single-step gradient-based attack method that shows that linear features of deep neural networks in high-dimensional space are sufficient to generate adversarial examples. PGD is a multi-step extension of the FGSM attack that generates more powerful adversarial examples for white-box attacks. C&W is an optimization-based attack method that also happens to be a gradient-based attack method. However, in practice, what exists is more of a black-box scenario. White-box attack methods tend to lack transferability and fail to attack target models with unknown parameters and gradients. Therefore, more researchers have focused on black-box attack methods.
Black-box attack methods can be classified into three categories: transfer-based, score-based, and decision-based. The transfer-based attacks generate the adversarial examples with a source model and then transfer them to a target model to complete the attack, in which we do not need to know any parameters or gradients of the target model. MI-FGSM (Dong et al., 2018) suggests incorporating momentum into the attack process to stabilize the update direction and increase the transferability of the generated adversarial examples. DI2-FGSM (Xie et al., 2019) first proposes improving the transferability of the adversarial examples by increasing the diversity of the inputs. The translation-invariant attack method (TI-FGSM) (Dong et al., 2019a) and the affine-invariant attack method (AI-FGSM) (Xiang et al., 2021) are used to further improve the transferability and robustness of adversarial examples. Score-based attacks can simply know the output score of the target model and estimate the gradient of the target model by querying the output score (Ilyas et al., 2018; Cheng et al., 2019; Li et al., 2019). Decision-based attacks assume that the attack is performed in a more challenging situation where only the output labels of the classifier are known. Boundry Attack (Brendel et al., 2018) and Evolutionary Attack (Dong et al., 2019b) are effective methods for dealing with this attack setting.
2.2. Adversarial Attacks on Face Recognition
Adversarial attacks on face recognition come in two common forms: dodging attacks and impersonation attacks. The purpose of dodging attacks is to reduce the confidence of the similarity of the same identity pair in order to evade face recognition. Impersonation attacks attempt to fool face recognition by using one identity to mimic another. Both technically and practically, impersonation attacks are more challenging and practical than dodging attacks. As a result, we concentrate on impersonation attack methods. Dong et al. (Dong et al., 2019b) proposed a decision-based adversarial attack on face recognition. Zhong et al. (Zhong and Deng, 2020) increased the diversity of agent face recognition models by using the dropout (Srivastava et al., 2014) technique to improve the transferability of the adversarial examples. Yang et al. (Yang et al., 2021) introduced a GAN (Goodfellow et al., 2014a) to generate adversarial examples for impersonation attacks on face recognition. Dong et al. (Dong et al., 2019b), Zhong et al. (Zhong and Deng, 2020), and Yang et al. (Yang et al., 2021) are the digital-based attacks on face recognition, which makes them hard to implement in the real world. At this point, there are also many researchers who have proposed methods for physical-based attacks on face recognition. Sharif et al. (Sharif et al., 2016, 2019) proposed a way to perform real-physical attacks on face recognition by printing out a pair of eyeglass frames. Komkov et al. (Komkov and Petiushko, 2021) proposed a physical attack method that can print an adversarial sticker using a color printer and put it on a hat to complete the attack. Nguyen et al. (Nguyen et al., 2020) proposed an adversarial light projection attack method that uses a projector for physical attack. Yin et al. (Yin et al., 2021) generated eye makeup patches by GAN and printed them out and stuck them around the eyes to perform physical attacks. Methods (Sharif et al., 2016, 2019; Komkov and Petiushko, 2021) are perfect for white-box physical attacks. But realistic environments are often black-box situations and they are hard to attack with black-box face recognition models or systems. Although the method (Yin et al., 2021) can perform a transferable black-box attack, it is ineffective for low-pixel face images and for commercial face recognition systems.
Compared with the previous methods, we propose an adversarial attack method on face recognition, RSTAM, which can effectively accomplish the black-box impersonation attack, both on low-pixel face pictures and on commercial face recognition systems. Furthermore, RSTAM can carry out a physical attack with the help of a mobile and compact printer.
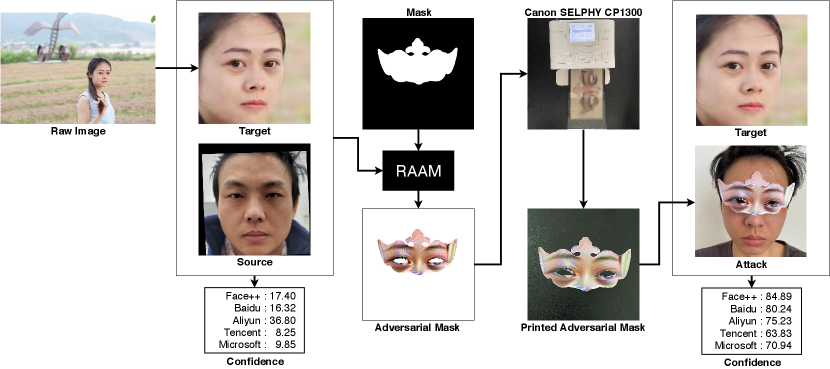
An example of RSTAM attack.
3. Methodology
3.1. Overview
Figure 1 shows an example of the RSTAM. The raw image of the target identity is from a social network. Firstly, we apply the facial landmark detection method (Jin et al., 2021) to generate corresponding facial landmarks of the raw image. Then we obtain the aligned target image according to the facial landmarks. Similarly, we can use the facial landmarks in the source image to obtain the eye region of the attacker. After that, we use our proposed method RSTAM to generate an adversarial mask and print out the adversarial mask using the Canon SELPHY CP1300 (CP1300, 2022), which is a mobile and compact printer. Finally, the attacker with the printed adversarial mask is obtained. We can see from Figure 1 that the similarity confidence between the attack and the target is high on all five commercial face recognition systems, with Face++ (Face++, 2022) 84.89%, Baidu (Baidu, 2022) 80.24%, Aliyun (Aliyun, 2022) 75.23%, Tencent (Tencent, 2022) 63.83%, and Microsoft (Microsoft, 2022) 70.94%. Figure 1 further shows that we can effectively perform physical impersonation attacks on the commercial face recognition systems using a photo of the target identity on a social network.
3.2. Adversarial Mask
In this section, we will give a detailed description for the adversarial mask. Let denote a face image of the target identity, denote a source image of the attacker, denote an attack image of the attacker with an adversarial mask and denote a face recognition model that extracts a normalized feature representation vector for an input image . Our goal for the aversarial mask attack is to solve the following constrained optimization problem,
| (1) | ||||
where is a cosine similarity loss function,
| (2) |
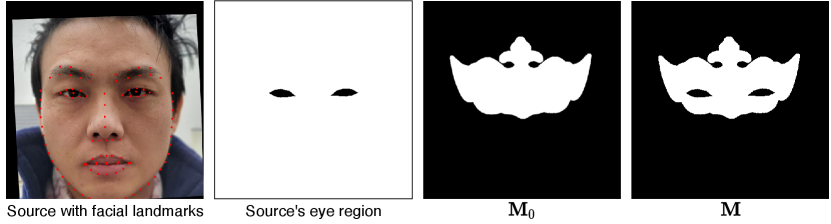
An example of mask.
is the element-wise product, and is a binary mask. The binary mask is used to constrain that only one pixel can be perturbed when its corresponding position is 1 in . We design an initial binary mask , and then use the initial binary mask and the facial landmarks of the source image to generate the corresponding binary mask . Figure 2 shows an example of the binary mask we generate using the initial binary mask and the facial landmarks of the source image.
Let denote an adversarial mask. We can generate an adversarial mask with the -norm perturbations (Goodfellow et al., 2014b; Madry et al., 2018) by performing a multi-step update as
| (3) | ||||
where is a perturbation step size, is the sign function, denotes element-wise clipping, aiming to restrict with in the -bound of . is a perturbation bound, .
3.3. Random Similarity Transformation
The similarity transformation, which has four degrees of freedom (4DoF), consists of translational, rotational, and scaling transformations. It is commonly used for face alignment (Tadmor et al., 2016; Liu et al., 2017). Many previous studies (Xie et al., 2019; Gao et al., 2020; Dong et al., 2019a; Xiang et al., 2021) have demonstrated that the transferability of adversarial examples can be greatly improved by increasing the diversity of the inputs. In order to improve the transferability of the adversarial masks, we propose a random similarity transformation strategy to increase the diversity of the inputs. Moreover, our strategy requires only one hyperparameter to control the random similarity transformation with 4DoF. Let denote the uniformly distributed random sampling function from to and denote a hyperparameter. At each iteration we can obtain a random similarity transformation matrix by the following strategy,
| (4) | ||||
where and are the width and height of the input image. Let denote one coordinate of the input image. We can use the similarity transformation matrix to obtain the corresponding transformed coordinates ,
| (5) |
Finally, we generate the transformed input image by bilinear interpolation.
3.4. Adversarial Mask with Random Similarity Transformation (RSTAM)
Xie et al. (Xie et al., 2019) first found that the transferability of adversarial examples could be further improved by increasing the diversity of inputs. Methods (Dong et al., 2019a; Gao et al., 2020; Xiang et al., 2021) also demonstrate this finding. From the description in Section 3.2, we can consider that the adversarial masks are a type of the adversarial examples, so we can also use this finding as well. For the adversarial mask attack on face recognition, we propose a random similarity transformation strategy to enhance the diversity of the input face images, which is described in Section 3.3. Using this strategy we propose the adversarial mask attack method with random similarity transformation, RSTAM. Algorithm block 1 describes the detailed algorithm for the -bound RSTAM, RSTAM∞. Similarly, the RSTAM attack can also use the -norm perturbations, RSTAM2. In RSTAM2, we get by
| (6) |
When multiple pre-trained face models are available, it is natural to consider using the ensemble idea to obtain more transferable adversarial examples. Ensemble methods are also often used in research and competitions to improve performance and robustness (Dietterich, 2000; Seni and Elder, 2010). Dong et al. (Dong et al., 2018) demonstrated that the transferability of adversarial examples can be effectively improved by applying ensemble methods. However, the number of pre-trained models available is limited. Therefore, Dong’s hard ensemble method is still prone to “overfitting” pre-trained face models. Meta-learning has been proposed as a framework to address the challenging few-shot learning setting (Finn et al., 2017; Sun et al., 2019; Jamal and Qi, 2019). Inspired by meta-learning, we propose a random meta-optimization strategy for ensembling several pre-trained face models to generate adversarial masks. Different from meta-learning, which is used to update the parameters of the neural network model, the random meta-optimization strategy assumes the network model as data and then updates the adversarial masks directly. Algorithm block 2 describes in detail the RAAM algorithm for performing ensemble attacks using the random meta-optimization strategy.
4. Experiments
4.1. Experimental Setup
Datasets. In the experiments, we use four public face datasets, which contain two high-resolution face datasets CelebA-HQ (Karras et al., 2018), Makeup Transfer (MT) (Li et al., 2018), and two low -quality face datasets LFW (Huang et al., 2008), CASIA-FaceV5 (of Automation, 2009).
-
•
CelebA-HQ is a high-quality version of CelebA (Liu et al., 2015) that consists of 30,000 images at resolution.
-
•
LFW is made up of 13,233 low-quality facial images gathered from the internet. There are 5749 identities in this collection, with 1680 people having two or more photos.
-
•
MT is a facial makeup dataset that includes 3834 female face images, with 2719 makeup images and 1115 non-makeup images.
-
•
CASIA-FaceV5 contains 2500 facial images of 500 subjects from Asia and all face images are captured using Logitech USB camera.
In order to evaluate the performance of the attacks, we randomly select 500 different identity pairs from the CelebA-HQ and LFW datasets, respectively. Furthermore, we randomly select 1000 different identity makeup images from the MT dataset to make up 500 different identity pairs, and 500 subjects of CASIA-FaceV5 are randomly paired into 250 different identity pairs for the experiment.
Face Recognition Models and Face Recognition Systems. In our experiments, we use five face recognition models, FaceNet (Schroff et al., 2015), MobileFace, IRSE50, IRSE101, and IR151 (Deng et al., 2019), and five commercial face recognition systems, Face++ (Face++, 2022), Baidu (Baidu, 2022), Aliyun (Aliyun, 2022), Tencent (Tencent, 2022) and Microsoft (Microsoft, 2022). Because the API of Aliyun’s face recognition system is not available to individual users, we only use the web application of Aliyun’s face recognition system for our experiments. In Microsoft’s face recognition system, we use “recognition_04” face recognition model and “detection_03” face detection model, which are the latest versions of Microsoft’s face recognition system. All other face recognition systems use the default version.
Evaluate Metrics.
For impersonation attacks on face recognition models, the attack success rate () (Deb et al., 2020; Zhong and Deng, 2020; Yin et al., 2021) is reported as an evaluation metric,
| (7) |
where is the number of pairs in the face dataset, denotes the indicator function, is a pre-determined threshold. For each victim facial recognition model, will be determined at 0.1% False Acceptance Rate () on all possible image pairs in LFW, i.e. FaceNet 0.409, MobileFace 0.302, IRSE50 0.241, and IR152 0.167.
For the evaluation of attacks on face recognition systems, we report the mean confidence scores () on each dataset as an evaluation metric,
| (8) |
where conf is a confidence score between the target and the attack returned from the face recognition system API, is the number of pairs in the face dataset.
Implementation Details. We first resize all the input images from all datasets to and normalize to . The following is the setting of our main comparison method in the experiment.
-
•
PASTE is the standard baseline that we use to directly paste the target image’s associated binary mask region onto the attacker’s source image and then perform the impersonation attack.
-
•
AM∞ is the adversarial mask attack method with the -bound. The perturbation step size is set to 0.003. The number of iterations is set to 2000. the perturbation bound is set to 0.3. The target face model uses IRSE101 and the remaining models, FaceNet, MobileFace, IRSE50 and IR151, are used as victim models for the black box attack.
-
•
RSTAM∞ is the -bound RSTAM. The hyperparameter is set to 0.2. Other settings are the same as on AM∞.
-
•
RSTAM uses all five face recognition models as target face models without using the random meta-optimization ensemble strategy. Assume that the target face models , we can get the update gradient as
(9) Other settings are the same as on RSTAM∞.
-
•
RSTAM is the -bound RSTAM with using the random meta-optimization ensemble strategy. The target models use all five face recognition models. Other settings are the same as on RSTAM∞.
-
•
RSTAM2 is the -bound RSTAM. The perturbation step size is set to 2. Other settings are the same as on RSTAM∞.
-
•
RSTAM is the -bound RSTAM with using the random meta-optimization ensemble strategy. The perturbation step size is set to 2. Other settings are the same as on RSTAM.
Additionally, we implement our codes based on the open source deep learning platform PyTorch (Paszke et al., 2019).
4.2. Digital-Environment Experiments
In this section, we will present the outcomes of the black-box impersonation attack in the digital world. Firstly, we will report quantitative results and qualitative results in the datasets CelebA-HQ, LFW, MT, and CASIA-FaceV5, respectively. Next, we will report the results of the hyperparameter sensitivity experiments.
Quantitative Results. Table 1-4 show the quantitative results on digital images. Table 1 shows the results of the black-box impersonation attack on the CelebA-HQ dataset, which is a high-definition multi-attribute face dataset including annotations with 40 attributes per image. The images in this collection span a wide range of position variants as well as background clutter. We can see from Table 1 that the of RSTAM∞ for Face Models is much higher than PASTE benchmark and AM∞, 64.20% (RSTAM∞) vs. 27.40% (PASTE) vs. 31.60% (AM∞) on FaceNet, 63.20% vs. 48.00% vs. 43.80% on MobileFace, 91.00% vs. 54.80% vs. 59.60% on IRSE50, and 91.80% vs. 41.20% vs. 51.20% on IR151. The hard ensemble attack method RSTAM increases the on Face++ (74.24% vs. 71.94%) and Baidu (72.54% vs. 70.80%) but decreases on Tencent (49.50% vs. 50.63%) and Microsoft (49.12% vs. 53.97%) for the Face Systems in Table 1. Thus, we can think that the hard ensemble attack method is not the best ensemble attack method, and the ensemble attack method RSTAM based on our proposed random meta-optimization strategy can further improve the performance of the ensemble attack method, 74.76% (RSTAM) vs. 74.24% (RSTAM) on Face++, 72.83% vs. 72.54% on Baidu, 50.88% vs. 49.50 on Tencent, and 50.58% vs. 49.12% on Microsoft. Lastly, we can also see in Table 1 that the -bound RSTAM has better attack performance than the -bound in the black-box attack on commercial face recognition system.
Table 2 provides the results of the black-box impersonation attack on the low-quality face dataset LFW. From Table 2, we can observe that the RSTAM attack is still effective on low-quality face images. The of RSTAM on LFW can reach 70.29% in Face++, 70.08% in Baidu, 51.45% in Tencent and 50.13% in Microsoft.
Table 3 presents the results of the black box impersonation attack on the female makeup face images of the MT dataset and Table 4 presents the results of the attack on the Asian face dataset CASIA-FaceV5. Compared with the multi-attribute datasets CelebA-HQ and LFW, the Face Models show lower robustness under relatively single-attribute face datasets MT and CASIA, and PASTE can then achieve a higher . In contrast, commercial face recognition systems show similar robustness to single-attribute face datasets and multi-attribute face datasets. It can also be demonstrated that RSTAM, our proposed black-box impersonation attack method, can effectively work with single-attribute or multi-attribute datasets, high-quality or low-quality images, face recognition models, and commercial face recognition systems.
| Face Models | Face Systems | |||||||
| FaceNet | MobileFace | IRSE50 | IR151 | Face++ | Baidu | Tencent | Microsoft | |
| PASTE | 27.40 | 48.00 | 54.80 | 41.20 | 66.21 | 61.98 | 30.37 | 29.60 |
| AM∞ | 31.60 | 43.80 | 59.60 | 51.20 | 65.66 | 61.44 | 33.42 | 32.87 |
| RSTAM∞ | 64.20 | 63.20 | 91.00 | 91.80 | 71.94 | 70.80 | 50.63 | 53.97 |
| RSTAM | - | - | - | - | 74.24 | 72.54 | 49.50 | 49.12 |
| RSTAM | - | - | - | - | 74.76 | 72.83 | 50.88 | 50.58 |
| RSTAM2 | 60.80 | 62.4 | 89.4 | 91.80 | 71.18 | 70.75 | 52.60 | 55.67 |
| RSTAM | - | - | - | - | 74.80 | 72.90 | 51.94 | 52.19 |
| Face Models | Face Systems | |||||||
| FaceNet | MobileFace | IRSE50 | IR151 | Face++ | Baidu | Tencent | Microsoft | |
| PASTE | 24.00 | 36.40 | 44.20 | 21.20 | 58.90 | 51.86 | 27.70 | 22.13 |
| AM∞ | 28.00 | 36.60 | 49.40 | 33.60 | 59.65 | 52.85 | 31.04 | 26.37 |
| RSTAM∞ | 59.20 | 50.80 | 85.40 | 89.00 | 66.11 | 66.94 | 47.34 | 48.88 |
| RSTAM | - | - | - | - | 69.59 | 69.45 | 48.20 | 45.78 |
| RSTAM | - | - | - | - | 70.00 | 69.82 | 49.45 | 47.71 |
| RSTAM2 | 57.60 | 52.00 | 84.80 | 89.00 | 65.56 | 66.93 | 51.16 | 53.18 |
| RSTAM | - | - | - | - | 70.29 | 70.08 | 51.45 | 50.13 |
| Face Models | Face Systems | |||||||
| FaceNet | MobileFace | IRSE50 | IR151 | Face++ | Baidu | Tencent | Microsoft | |
| PASTE | 86.40 | 61.80 | 71.30 | 42.00 | 63.87 | 55.98 | 28.15 | 28.16 |
| AM∞ | 87.00 | 61.20 | 77.40 | 54.80 | 63.62 | 57.07 | 31.26 | 31.41 |
| RSTAM∞ | 94.40 | 79.00 | 95.60 | 92.20 | 71.26 | 65.81 | 46.43 | 49.06 |
| RSTAM | - | - | - | - | 72.59 | 67.39 | 45.37 | 47.74 |
| RSTAM | - | - | - | - | 73.06 | 67.98 | 46.08 | 48.90 |
| RSTAM2 | 93.80 | 79.40 | 94.20 | 92.20 | 70.73 | 66.17 | 48.23 | 51.84 |
| RSTAM | - | - | - | - | 73.12 | 68.18 | 47.44 | 50.65 |
| Face Models | Face Systems | |||||||
| FaceNet | MobileFace | IRSE50 | IR151 | Face++ | Baidu | Tencent | Microsoft | |
| PASTE | 92.40 | 80.80 | 89.20 | 66.40 | 59.53 | 52.02 | 27.99 | 42.82 |
| AM∞ | 92.00 | 79.20 | 90.80 | 72.40 | 63.44 | 56.52 | 34.05 | 46.01 |
| RSTAM∞ | 97.20 | 87.60 | 98.40 | 97.60 | 71.70 | 68.27 | 42.59 | 57.34 |
| RSTAM | - | - | - | - | 72.84 | 69.91 | 44.39 | 57.77 |
| RSTAM | - | - | - | - | 73.31 | 70.26 | 44.96 | 58.88 |
| RSTAM2 | 97.20 | 90.00 | 98.80 | 98.00 | 71.44 | 69.41 | 47.29 | 62.62 |
| RSTAM | - | - | - | - | 73.82 | 70.76 | 46.71 | 60.87 |

digital-attack
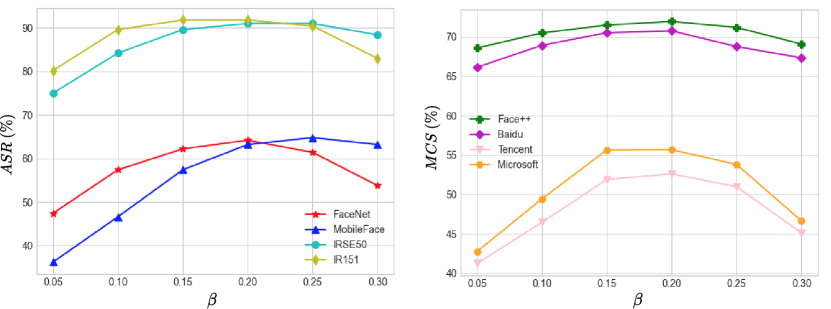
fig:beta
Qualitative Results. The results of the qualitative are shown in Figure 3. As illustrated in Figure 2, the confidence scores between the targets and the attacks generated via RSTAM are much higher than the confidence scores between the targets and the sources. The confidence scores of the attacks using RSTAM are mostly greater than 70%. In particular, the confidence score between the attack and the target can reach 97.39% on the LFW using RSTAM for the Tencent face recognition system.
Sensitivity of the Hyperparameter .
The hyperparameter is used to control the random similarity transformation with 4DoF, which plays an important role in RSTAM. We perform sensitivity experiments for the hyperparameter using RSTAM∞ on the CelebA-HQ dataset. The results of the hyperparameter sensitivity experiments are shown in Figure 4. As shown in Figure 4, we suggest that the hyperparameter is set between 0.15 and 0.25. In all experiments except the sensitivity experiment of , we set the hyperparameter to 0.2.
env-setting

phy-att
4.3. Physical-Realizability Experiments
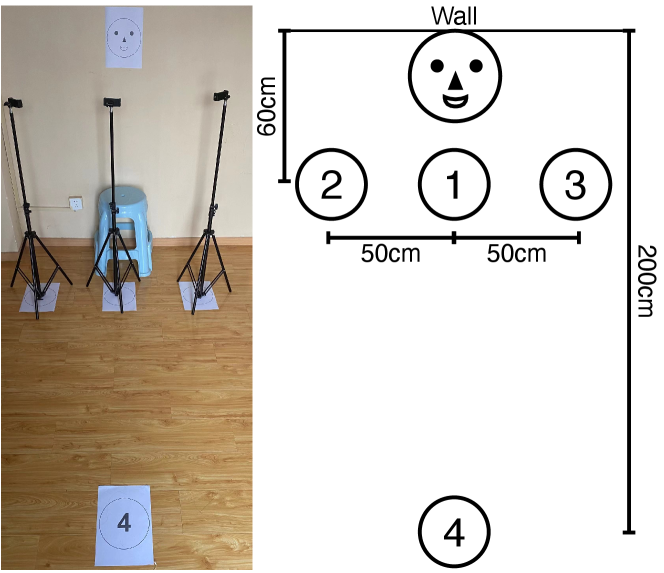
The successful completion of an attack in the digital world does not guarantee that it can be applied to the physical world. Moreover, compared to digital attacks, physical attacks have more practical value in the real world. Therefore, we use a mobile and compact printer, Canon SELPHY CP1300, to print out adversarial masks to carry out experiments on physical attacks. The setup of the physical environment is shown in Figure 5. For shooting, the camera makes use of the iPhone 11 Pro Max’s 12 MP front-facing camera as well as a Bluetooth remote control.
Figure 5 shows the visualization results of our physical black-box impersonation attacks against the five state-of-the-art commercial face recognition systems. The target and source are the same as in Figure 1. Although the printed adversarial masks exhibit distortion in comparison to the digital adversarial masks, the confidence scores of the physical attacks at position ① are not much reduced, and even increase on RSTAM and RSTAM against the Face++. This also shows that RSTAM is effective in using a mobile and compact printer to implement physical attacks in a realistic environment. Except for the attack on the Tencent face system, RSTAM can maintain a high confidence score for commercial face recognition systems at various positions. Moreover, RSTAM can have good attack performance at the long-range position ④, where the face is of low quality. Similarly, in the physical world, the RSTAM and RSTAM ensemble attack methods based on random meta-optimization strategy have superior attack performance.
5. Conclusions
In this paper, we propose a black-box impersonation attack method on face recognition, RSTAM. In order to improve the transferability of the adversarial masks, we propose a random similarity transformation strategy for increasing the input diversity and a random meta-optimization strategy for ensembling several pre-trained face models to generate more general adversarial masks. Finally, we perform experimental validation on four public face datasets: CelebA, LFW, MT, CASIA-FaceV5, and five commercial face recognition systems: Face++, Baidu, Aliyun, Tencent, and Microsoft. The experiments adequately demonstrate that RSTAM is an effective attack on face recognition. Furthermore, RSTAM can be easily implemented as a physical black-box impersonation attack using a mobile and compact printer. We can also find that the current commercial face recognition systems are not very secure. We can easily collect real face images of target identities from social networks and then complete the impersonation attacks with RSTAM. Therefore, our further work will focus on how to effectively defend against RSTAM and achieve a more robust and secure face recognition model.
References
- (1)
- Aliyun (2022) Aliyun. 2022. https://vision.aliyun.com/facebody, Last accessed on 2022-03-29.
- Baidu (2022) Baidu. 2022. https://ai.baidu.com/tech/face, Last accessed on 2022-03-29.
- Brendel et al. (2018) Wieland Brendel, Jonas Rauber, and Matthias Bethge. 2018. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models. In International Conference on Learning Representations (ICLR).
- Carlini and Wagner (2017) Nicholas Carlini and David Wagner. 2017. Towards evaluating the robustness of neural networks. In IEEE Symposium on Security and Privacy (SP). IEEE, 39–57.
- Cheng et al. (2019) Shuyu Cheng, Yinpeng Dong, Tianyu Pang, Hang Su, and Jun Zhu. 2019. Improving black-box adversarial attacks with a transfer-based prior. Neural Information Processing Systems (NeurIPS) 32 (2019).
- CP1300 (2022) Canon SELPHY CP1300. 2022. https://www.usa.canon.com/internet/portal/us/home/products/details/printers/mobile-compact-printer/cp1300-bkn, Last accessed on 2022-03-29.
- Deb et al. (2020) Debayan Deb, Jianbang Zhang, and Anil K Jain. 2020. Advfaces: Adversarial face synthesis. In IEEE International Joint Conference on Biometrics (IJCB). IEEE.
- Deng et al. (2019) Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 4690–4699.
- Dietterich (2000) Thomas G Dietterich. 2000. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems. Springer, 1–15.
- Dong et al. (2018) Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. 2018. Boosting adversarial attacks with momentum. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 9185–9193.
- Dong et al. (2019a) Yinpeng Dong, Tianyu Pang, Hang Su, and Jun Zhu. 2019a. Evading defenses to transferable adversarial examples by translation-invariant attacks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 4312–4321.
- Dong et al. (2019b) Yinpeng Dong, Hang Su, Baoyuan Wu, Zhifeng Li, Wei Liu, Tong Zhang, and Jun Zhu. 2019b. Efficient decision-based black-box adversarial attacks on face recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 7714–7722.
- Face++ (2022) Face++. 2022. https://www.faceplusplus.com, Last accessed on 2022-03-29.
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of International Conference on Machine Learning (ICML). PMLR, 1126–1135.
- Gao et al. (2020) Lianli Gao, Qilong Zhang, Jingkuan Song, Xianglong Liu, and Heng Tao Shen. 2020. Patch-wise attack for fooling deep neural network. In European Conference on Computer Vision. Springer, 307–322.
- Goodfellow et al. (2014a) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014a. Generative adversarial nets. Neural Information Processing Systems (NeurIPS) 27 (2014).
- Goodfellow et al. (2014b) Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014b. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014).
- Huang et al. (2008) Gary B Huang, Marwan Mattar, Tamara Berg, and Eric Learned-Miller. 2008. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Workshop on faces in ‘Real-Life’ Images: detection, alignment, and recognition.
- Ilyas et al. (2018) Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. 2018. Black-box adversarial attacks with limited queries and information. In Proceedings of International Conference on Machine Learning (ICML). PMLR, 2137–2146.
- Jamal and Qi (2019) Muhammad Abdullah Jamal and Guo-Jun Qi. 2019. Task agnostic meta-learning for few-shot learning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Jin et al. (2021) Haibo Jin, Shengcai Liao, and Ling Shao. 2021. Pixel-in-Pixel Net: Towards Efficient Facial Landmark Detection in the Wild. International Journal on Computer Vision (IJCV) (Sep 2021). https://doi.org/10.1007/s11263-021-01521-4
- Karras et al. (2018) Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. 2018. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In International Conference on Learning Representations (ICLR).
- Komkov and Petiushko (2021) Stepan Komkov and Aleksandr Petiushko. 2021. AdvHat: Real-World Adversarial Attack on ArcFace Face ID System. In International Conference on Pattern Recognition (ICPR). IEEE Computer Society, 819–826.
- Li et al. (2018) Tingting Li, Ruihe Qian, Chao Dong, Si Liu, Qiong Yan, Wenwu Zhu, and Liang Lin. 2018. Beautygan: Instance-level facial makeup transfer with deep generative adversarial network. In ACM International Conference on Multimedia (ACM MM). 645–653.
- Li et al. (2019) Yandong Li, Lijun Li, Liqiang Wang, Tong Zhang, and Boqing Gong. 2019. Nattack: Learning the distributions of adversarial examples for an improved black-box attack on deep neural networks. In Proceedings of International Conference on Machine Learning (ICML). PMLR, 3866–3876.
- Liu et al. (2017) Weiyang Liu, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song. 2017. Sphereface: Deep hypersphere embedding for face recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 212–220.
- Liu et al. (2015) Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. 2015. Deep Learning Face Attributes in the Wild. In IEEE International Conference on Computer Vision (ICCV).
- Madry et al. (2018) Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards Deep Learning Models Resistant to Adversarial Attacks. In International Conference on Learning Representations (ICLR).
- Microsoft (2022) Microsoft. 2022. https://azure.microsoft.com/en-us/services/cognitive-services/face, Last accessed on 2022-03-29.
- Nguyen et al. (2020) Dinh-Luan Nguyen, Sunpreet S Arora, Yuhang Wu, and Hao Yang. 2020. Adversarial light projection attacks on face recognition systems: A feasibility study. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 814–815.
- of Automation (2009) CAS Institute of Automation. 2009. CASIA-FaceV5. http://biometrics.idealtest.org, Last accessed on 2022-03-29.
- Parkhi et al. (2015) Omkar M Parkhi, Andrea Vedaldi, and Andrew Zisserman. 2015. Deep face recognition. (2015).
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Neural Information Processing Systems (NeurIPS) 32 (2019).
- Schroff et al. (2015) Florian Schroff, Dmitry Kalenichenko, and James Philbin. 2015. Facenet: A unified embedding for face recognition and clustering. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 815–823.
- Seni and Elder (2010) Giovanni Seni and John F Elder. 2010. Ensemble methods in data mining: improving accuracy through combining predictions. Synthesis Lectures on Data Mining and Knowledge Discovery 2, 1 (2010), 1–126.
- Sharif et al. (2016) Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, and Michael K Reiter. 2016. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In ACM SIGSAC Conference on Computer and Communications Security. 1528–1540.
- Sharif et al. (2019) Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, and Michael K Reiter. 2019. A general framework for adversarial examples with objectives. ACM Transactions on Privacy and Security (TOPS) 22, 3 (2019), 1–30.
- Srivastava et al. (2014) Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research 15, 1 (2014), 1929–1958.
- Sun et al. (2019) Qianru Sun, Yaoyao Liu, Tat-Seng Chua, and Bernt Schiele. 2019. Meta-transfer learning for few-shot learning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 403–412.
- Tadmor et al. (2016) Oren Tadmor, Tal Rosenwein, Shai Shalev-Shwartz, Yonatan Wexler, and Amnon Shashua. 2016. Learning a metric embedding for face recognition using the multibatch method. In Neural Information Processing Systems (NeurIPS). 1396–1397.
- Tencent (2022) Tencent. 2022. https://cloud.tencent.com/product/facerecognition, Last accessed on 2022-03-29.
- Wang et al. (2018) Hao Wang, Yitong Wang, Zheng Zhou, Xing Ji, Dihong Gong, Jingchao Zhou, Zhifeng Li, and Wei Liu. 2018. Cosface: Large margin cosine loss for deep face recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 5265–5274.
- Xiang et al. (2021) Wenzhao Xiang, Hang Su, Chang Liu, Yandong Guo, and Shibao Zheng. 2021. Improving Robustness of Adversarial Attacks Using an Affine-Invariant Gradient Estimator. arXiv preprint arXiv:2109.05820 (2021).
- Xie et al. (2019) Cihang Xie, Zhishuai Zhang, Yuyin Zhou, Song Bai, Jianyu Wang, Zhou Ren, and Alan L Yuille. 2019. Improving transferability of adversarial examples with input diversity. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2730–2739.
- Yang et al. (2021) Lu Yang, Qing Song, and Yingqi Wu. 2021. Attacks on state-of-the-art face recognition using attentional adversarial attack generative network. Multimedia Tools and Applications 80, 1 (2021), 855–875.
- Yin et al. (2021) Bangjie Yin, Wenxuan Wang, Taiping Yao, Junfeng Guo, Zelun Kong, Shouhong Ding, Jilin Li, and Cong Liu. 2021. Adv-Makeup: A New Imperceptible and Transferable Attack on Face Recognition. International Joint Conference on Artificial Intelligence (IJCAI) (2021).
- Zhong and Deng (2020) Yaoyao Zhong and Weihong Deng. 2020. Towards transferable adversarial attack against deep face recognition. IEEE Transactions on Information Forensics and Security 16 (2020), 1452–1466.