Safe Human-Robot Collaborative Transportation via
Trust-Driven Role Adaptation
Abstract
We study a human-robot collaborative transportation task in presence of obstacles. The task for each agent is to carry a rigid object to a common target position, while safely avoiding obstacles and satisfying the compliance and actuation constraints of the other agent. Human and robot do not share the local view of the environment. The human policy either assists the robot when they deem the robot actions safe based on their perception of the environment, or actively leads the task.
Using estimated human inputs, the robot plans a trajectory for the transported object by solving a constrained finite time optimal control problem. Sensors on the robot measure the inputs applied by the human. The robot then appropriately applies a weighted combination of the human’s applied and its own planned inputs, where the weights are chosen based on the robot’s trust value on its estimates of the human’s inputs. This allows for a dynamic leader-follower role adaptation of the robot throughout the task. Furthermore, under a low value of trust, if the robot approaches any obstacle potentially unknown to the human, it triggers a safe stopping policy, maintaining safety of the system and signaling a required change in the human’s intent. With experimental results, we demonstrate the efficacy of the proposed approach.
I Introduction
Human robot collaborative tasks have been a focus of major research work in robotics [1, 2, 3]. For such tasks, roles of the agents are important, especially so in collaborative transportation. This is due to the fact that the transported object poses a compliance constraint that must be satisfied. Only follower or helper role of the robot can be seen in [4, 5, 6, 7]. In these works, the human knows the full environment and is the lead planner in the task. The robot follows the human by minimizing its felt forces and torques, and has no planning algorithms of its own. However, such fixed role assignment can be debilitating in situations when both agents have partial environment information, or if the human wants to lower their efforts in the task. Therefore shared and/or switching roles are introduced in [8, 9, 10, 11, 12, 13, 14]. In such switching role assignments, it is essential for the robot to make predictions of the human’s intent from the human’s observed behavior and then adapt its policy accordingly during the task. Such human intent prediction related work are also available in the literature [15, 16, 17, 18, 19]. Obstacle avoidance in such human-robot collaborative tasks was studied in [20, 21], etc. However, to the best of our knowledge, the presence of unknown obstacles in the environment, inferring these obstacle positions from haptic feedback data and then explicitly incorporating the obstacle avoidance constraints in the robot’s planning problem have not been addressed.
In this paper, we propose a Model Predictive Control (MPC) based strategy for a human-robot joint transportation task, as shown in Fig. 1. The environment has obstacles partially known to each agent. The human’s policy is allowed to be a combination of compliance and leadership, based on the human’s intent during the task. The robot only estimates the compliant human behavior, and operates on a policy based on a computed trust value and also its proximity to obstacles. This allows for a dynamic leader-follower role of the robot throughout the task, depending on the learned value of trust from applied human inputs. The trust is low if the actual human inputs differ highly from the robot’s estimates, and vice versa. Our proposed framework can be summarized as:
-
•
We design a two mode policy for the robot. The first mode is the nominal operation mode, where the robot solves an MPC problem for its control synthesis. The cost function in the MPC optimization problem adapts based on the corrective inputs of the human to the robot’s inputs. This enables the robot to plan trajectories that adapt with the human’s behavior.
-
•
The control applied by the robot in the first mode is a function of the trust value, similar to [10]. That is, after solving the MPC problem, the robot appropriately applies a weighted combination of the human’s and its own planned actions, where the weights are adapted based on the deviation between robot’s estimated and the actual human inputs.
-
•
The second mode of the robot’s policy is a safe stopping backup, which is triggered when the robot nears obstacles under a low value of trust on its estimated human’s inputs. This safe stop mode enables the robot to decelerate the object, avoid collisions, and signal a required change in intent to the human via the haptic feedback.
We highlight that the robot obtains a follower’s role for low trust value, including safe stopping backup. On the other hand, it asserts a leader’s role for high trust value, relying more on its MPC planned inputs. These leader-follower roles switch dynamically throughout the task as a function of the trust value. In Section IV, with experiments on a UR5e robot, we demonstrate the efficacy of our proposed approach. We present an experiment where with pre-assigned fixed roles the agents collide with obstacles, whereas a combination of trust-driven and safe stop policies manages to complete the task safely.
II Problem Formulation
In this section, we formulate the collaborative obstacle avoidance problem. We restrict ourselves to the case of two agents. The case of collaborative transportation with multiple agents is left as a subject of future research.
II-A Environment Modeling
Let the environment be contained within a set . In this work, we assume that the obstacles in the environment are static, although the proposed framework can be extended to dynamic obstacles. At any time step , let the set of obstacle constraints known to the human and the robot (detected at and stored until ) be denoted by and , respectively. We denote:
where is the task duration limit and is the set of obstacle constraints to be avoided at during the task. The approach proposed in this paper focuses on the challenging situation where no agent has the full information of all the detected obstacles in , i.e., and .
II-B System Modeling
We model both the human and the robot transporting a three dimensional rigid object. Let and be the orthogonal unit bases vectors defining the inertial and the transported object fixed coordinate frames, respectively. Let be the position of the center of mass of the transported object in the inertial frame, be the velocity of the center of mass relative to the inertial frame, expressed in the body-frame as
| (1) |
Furthermore, let the Euler angles be the roll, pitch, yaw angles describing the orientation of the body w.r.t. the inertial frame, and be the angular velocity of the body-fixed frame w.r.t. the inertial frame, expressed in the body-fixed frame as
| (2) |
We denote , with matrix
Let be the force components along the inertial axes applied at the body’s center of mass, are the torques about the body fixed axes, and be the moment of inertia of the body expressed in the body frame, given by . Then the equations of motion of the object transported are written as follows:
| (3) | ||||
with being the mass of the body and the angular velocity and rotation matrices given by
respectively, where and have been abbreviated. Using (3), the state-space equation for the transported object is compactly written as:
| (4) |
with states and inputs at time given by:
We discretize (4) with the sampling time of of the robot to obtain its discrete time version:
| (5) |
Given any input to the center of mass of the object, we decouple it into the corresponding human inputs and robot inputs , such that . We consider constraints on the inputs of the robot and the human given by and for all . The set can be learned from human demonstrations’ data.
III Robot’s Policy Design
We detail the steps involved in control synthesis by the robot in this section. The robot computes the net (i.e., from both the human and the robot) optimal forces and torques to be applied to the center of mass of the transported body by solving a constrained finite time optimal control problem in a receding horizon fashion. The robot’s portion of those net optimal inputs are affected by its proximity to obstacles potentially unknown to the human and an estimate of the human’s assisting input. We elaborate these steps next.
III-A MPC Planner and Human’s Inputs Estimation
The constrained finite time optimal control problem that the robot solves at time step with a horizon of is given by:
| (6) | ||||
where is a set of positions defining the transported object, , is the target state, are the weight matrices, and inferred obstacle zone penalty is defined in Section III-D. Once an optimal input is computed, the robot utilizes the following assumption to estimate the human’s inputs.
Assumption 1
The human’s compliant inputs at time step are computed as
| (7) |
where fraction remains constant throughout the task.
The fraction can be roughly estimated from collected trial data where the human limits to playing a complying role in the task111If the human actively leads the task, potentially forcing/opposing robot’s actions, human inputs may be drastically different from its approximate (7).. Thus, the robot’s estimate of the human policy inherently considers that the human is trying to minimize their felt forces and torque in the task to assist the robot, while reacting to the surrounding obstacles in in a way which is consistent with the MPC planned trajectory by the robot. Utilizing Assumption 1, the robot computes its actions at as:
| (8) |
III-B Trust Value via Difference in Estimated and Actual Human Behavior
Since the robot does not perfectly know the human’s intentions and the configuration of obstacles in the vicinity of the human, it does not apply its computed MPC input to system (4) directly. Instead, it checks the deviation of its estimated human inputs from the actual closed-loop inputs applied by the human. The latter can be measured using force and torque sensors on the robot. As the applied human inputs at the current time step are not available for this computation, the robot approximates222For sample period , this can constitute a reasonable approximation. this deviation by:
The trust value is then computed as:
| (9) |
where is a chosen threshold deviation. The robot uses this trust value to apply a weighted combination of its computed MPC inputs , and inputs proportional to as detailed later in equation (LABEL:eq:mpc_pol_formulation). This trust-driven combination of inputs is motivated by works such as [22, 23, 24]. The robot additionally deploys a safe stopping policy, in case the computed trust value is below a chosen threshold, and it nears obstacles potentially unknown to the human. These two modes of the robot’s policy are detailed in the next section.
III-C Trust-Driven and Safe Stop Modes of the Robot Policy
At time step , we denote the inertial position coordinates of the robot’s seen point on the object closest to any obstacle in as . After finding a solution to (6) and computing using (8), the robot utilizes (9) and applies its closed-loop input computed as follows:
| (10) |
to system (5) in closed-loop with chosen gains , where denotes the Euclidean projection of onto set , and the robot’s safe stop policy triggering condition (SS) is given by:
| (11) |
with distance and velocity thresholds and . That is, when point approaches any obstacle at a high velocity under a low trust , the robot actively tries to decelerate the the object and bring it to a halt. From policy (LABEL:eq:mpc_pol_formulation), we make the following observations:
-
1.
A large trust value (e.g., closer to 1), corresponds to the case when the robot’s estimates of the human’s inputs align with the actual human’s inputs. This means that the human is taking on a follower role, trusting on the robot’s actions. The robot trusts the computed inputs from the MPC problem (6) and takes the leader’s role in the task.
-
2.
A small trust value (e.g., close to 0) corresponds to the case when the robot’s predictions of the human’s inputs do not align with the actual human’s inputs. This means that the human is taking on the leader’s role, either reacting to obstacles nearby or actively leading the task. The robot does not trust the computed inputs from the MPC problem (6) and takes the follower’s role (unless the safe stop policy condition is triggered).
Policy (LABEL:eq:mpc_pol_formulation) is motivated by [12], and qualitatively has the properties of joint impedance and admittance, similar to [25]. We see that satisfying condition 1 increases the efficacy of the robot’s solution to (6), i.e., . To that end, we add the inferred obstacle zone penalty to (6), adapting the cost to be optimized by inferring information on potential obstacles at the human’s vicinity. This is elaborated next.
III-D Increasing Trust via Inferred Obstacle Zone Penalty
At time step , we denote the inertial position coordinates of the human by . We also denote the first three force components of the human input by . Motivated by the obstacle learning work of [26], we add the extra term to the cost in (6) at every time step. This term is to be chosen when , and the human applies forces along directions which are more than a user specified threshold radians apart from its expected ones. We then choose the term as follows:
| (12) |
with choices of the random parameter (introduces noise in the direction vector), control gain , and condition (IO) being
Intuitively, we assume that if the human unexpectedly pushes against the robot, they are attempting to avoid some obstacle unknown to the robot. The robot uses these force measurements and generates virtual obstacle points that are placed relative to the human’s location at a distance scaled by the negative force vector, plus some noise. These virtual obstacle points are the robot’s estimates of potential obstacles in the human’s vicinity, due to which the human’s input is significantly different from the estimate . Introducing the penalty can improve the MPC planner (6), increasing the value of and enabling more effective role of the robot in the task.
IV Experimental Results
In this section, we present experimental validation results with our proposed approach. The experiments are conducted with a UR5e robot. Since there is not an exact shared baseline for this problem formulation of a human-robot collaborative transportation task with partial obstacle information, we avoid directly comparing against controllers from other related work. We use the following set of parameters shown in Table I for the considered experimental scenario.
| Parameter | Value |
|---|---|
| 100s, 0.05s | |
| 20 | |
| 0.5 | |
| 0.15m, 0.05m/s, rad | |
| 1, 10, 0.005 | |
| (20,20,20,1,1,1) | |
| (10,10,10,100,100,100) |
IV-A Trust-Driven Policy vs Pure MPC Policy
For this section, two obstacles are placed between the agents and the target, as shown in the rendered experiment space in Fig. 2b. We first show the benefits of using the trust-driven policy mode, where the robot utilizes the trust value to apply a weighted combination of its MPC inputs and the human’s inputs to the system. The baseline for comparison is a pure MPC policy, with the robot solving MPC problem (6) and applying its optimal input (8), being agnostic to the responses of the human.
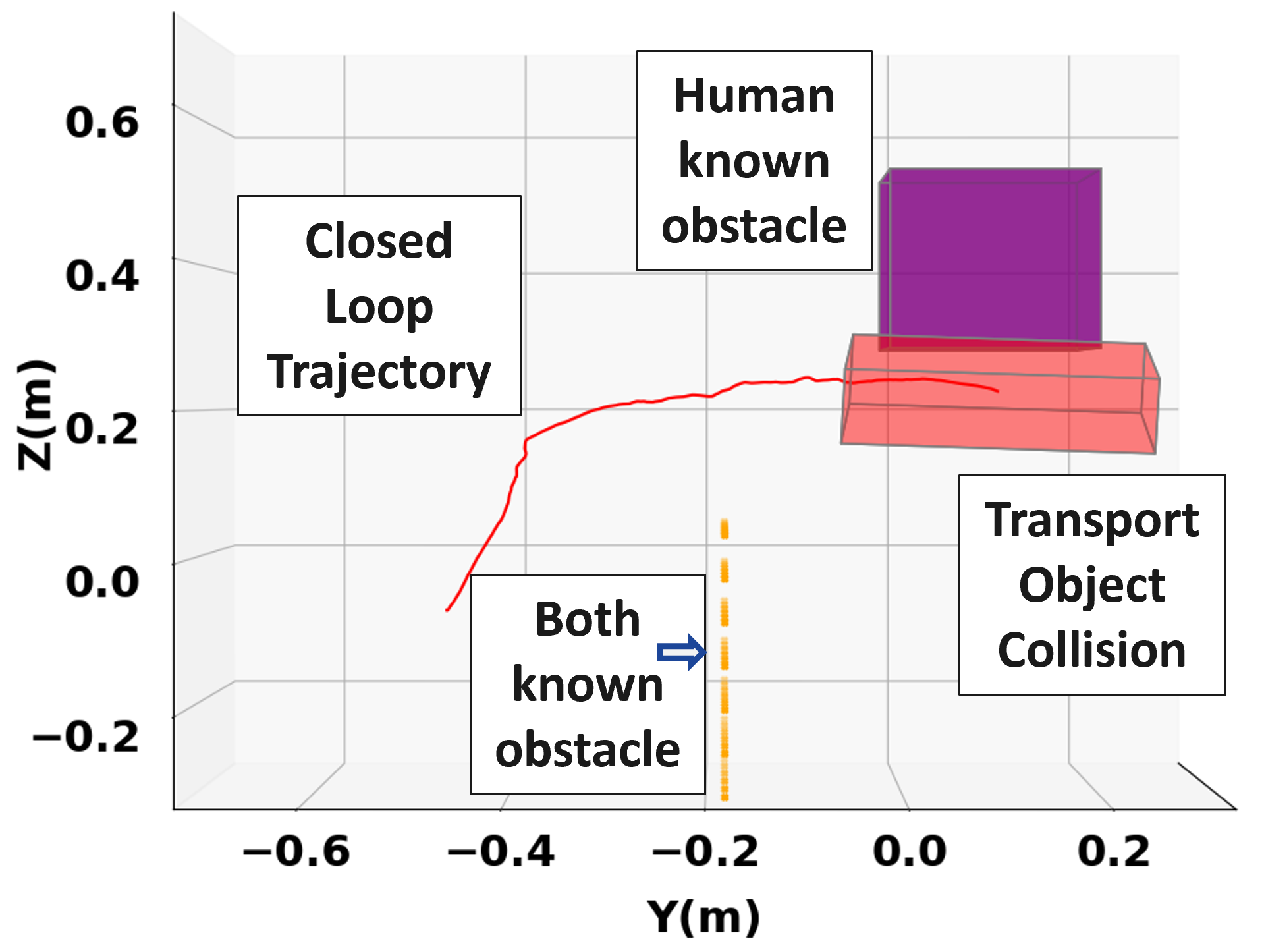
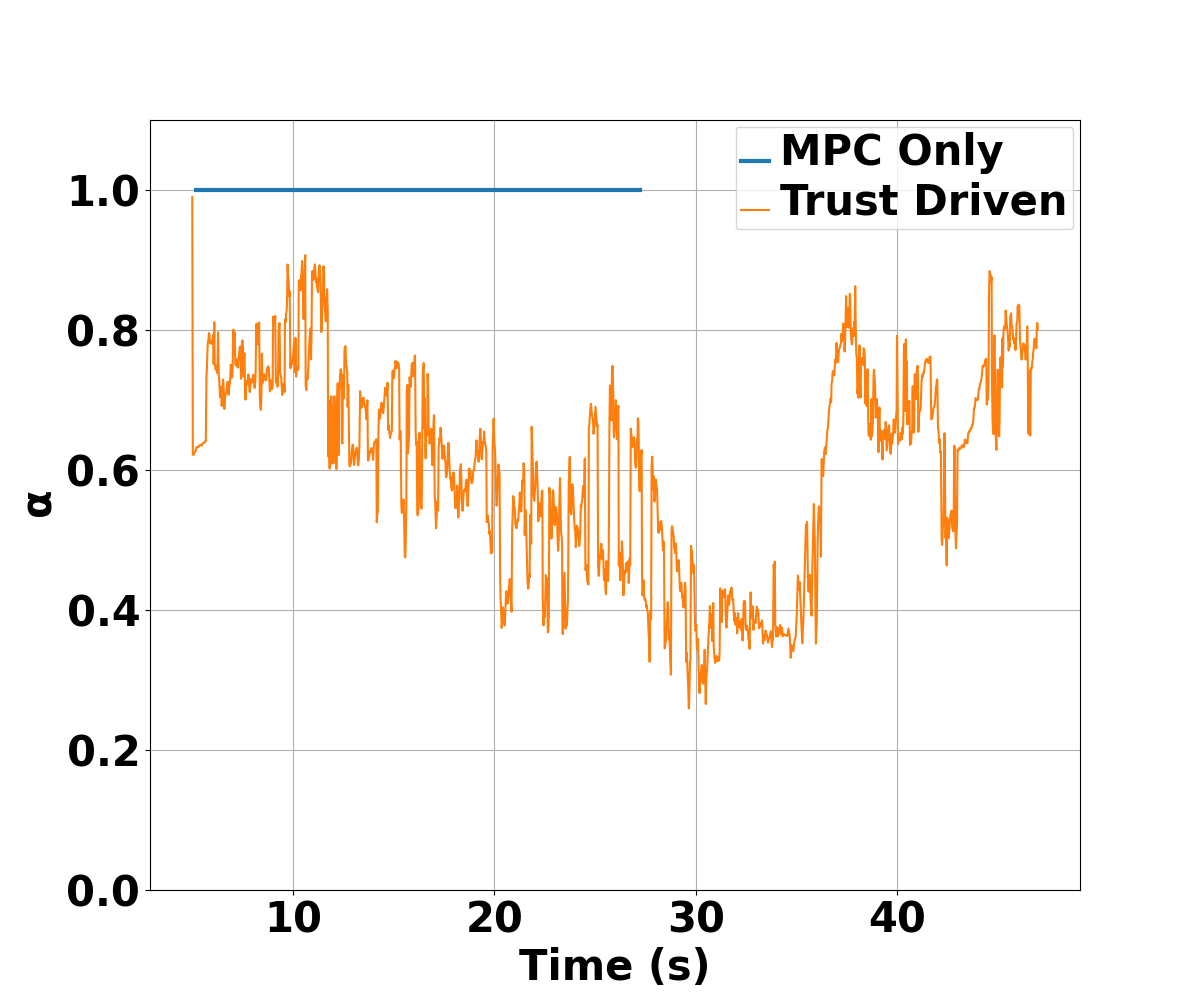
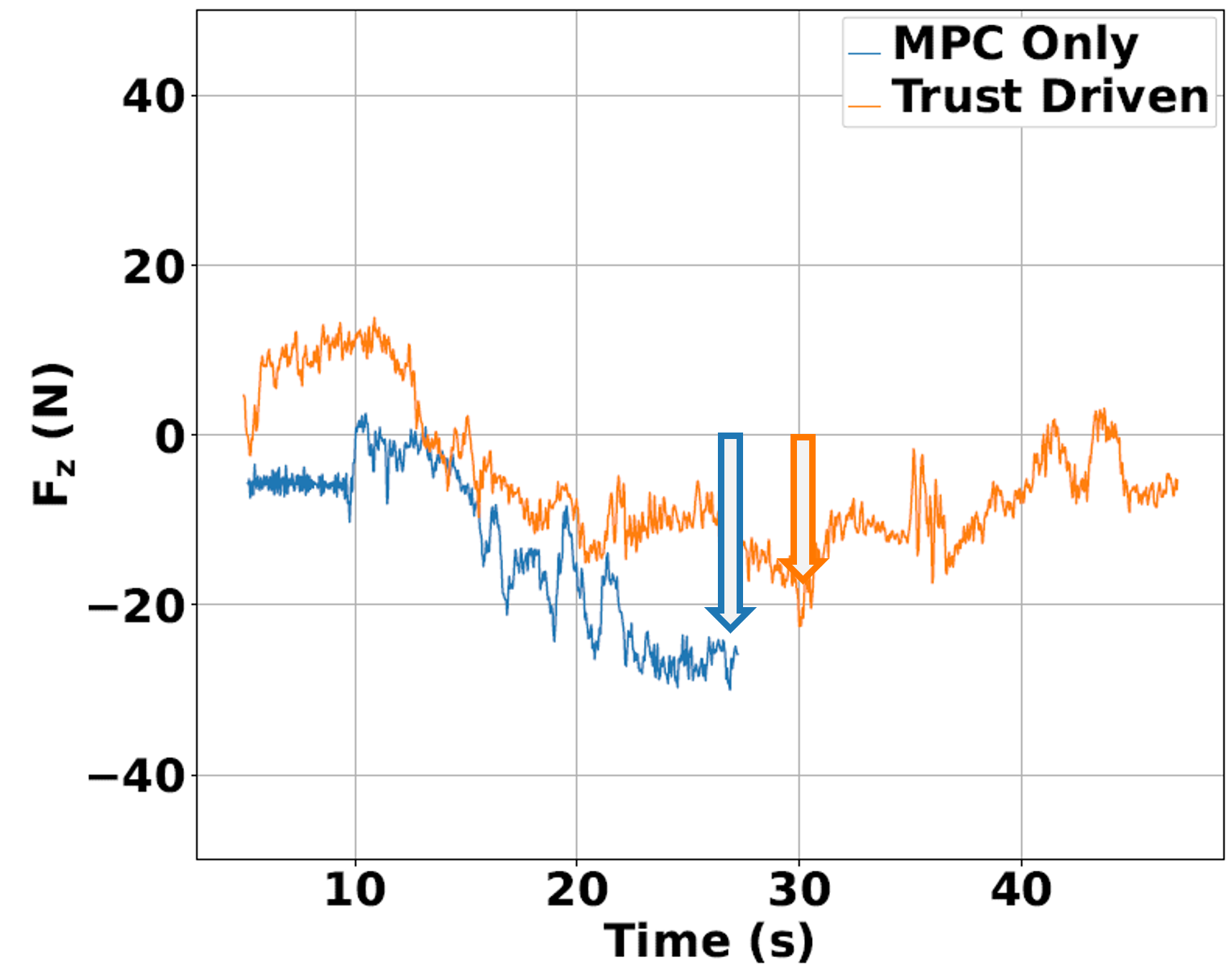
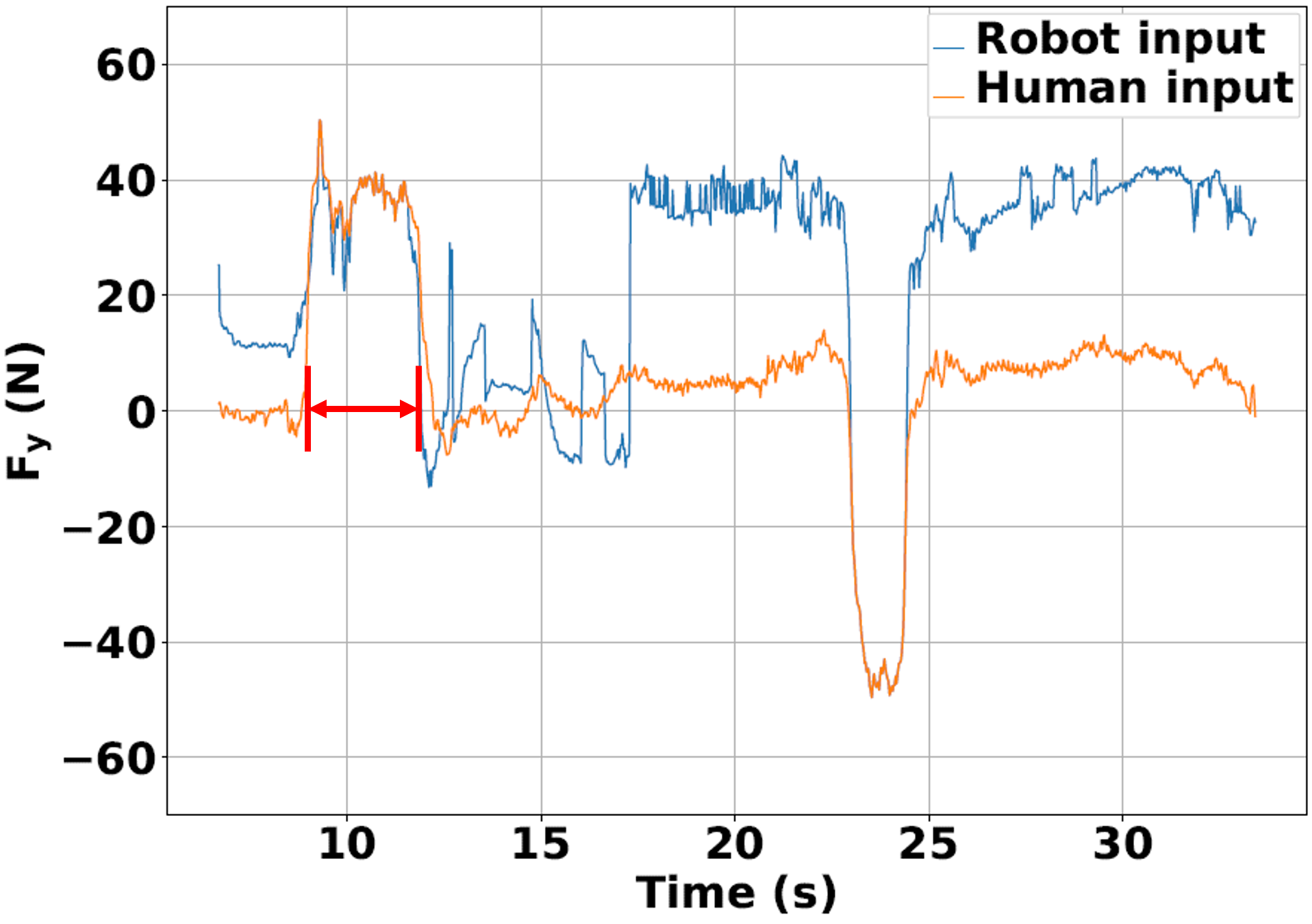
In the considered scenario in Fig. 2, the purple box obstacle located between is known only by the human. Both agents are aware of the dotted wall obstacle at m. In Fig. 2a, the robot is operating with the pure MPC baseline policy, agnostic to the human’s actions. As a consequence, the planned trajectory by the robot results in the human colliding with this obstacle, as seen in Fig. 2a. Resisting force values by the human in Fig. 2d indicate the human’s opposition to the robot’s actions. On the other hand, with our proposed trust-driven policy mode, the robot is cognizant of the human’s intentions. The evolution of as the human navigates in the proximity of the box obstacle is shown in Fig. 2c. When the transport object nears the obstacle (around 30 sec), the robot distrusts its estimate of the human policy with a computed and applies more of the measured human input in (LABEL:eq:mpc_pol_formulation). Collision is averted as a consequence, as seen in Fig. 2b. Lower force magnitudes in Fig. 2d further indicate that the human’s resistance to robot’s actions during this collision avoidance is lowered, as the robot lowers the contribution of its MPC inputs in (LABEL:eq:mpc_pol_formulation) with a low value of .
IV-B The Safe Stop Mode in Action
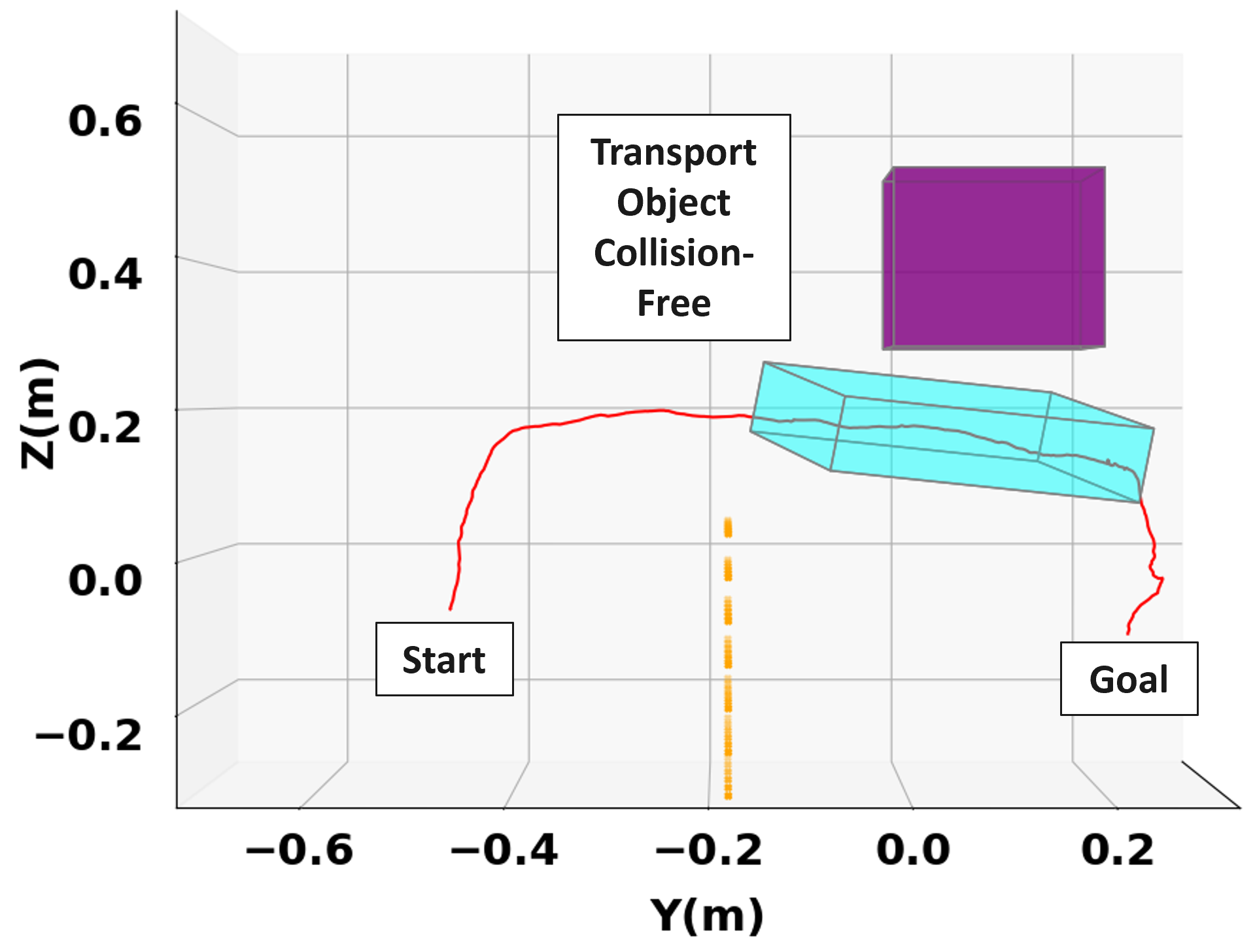
To highlight the safety benefits of adding the safe stop policy mode in (LABEL:eq:mpc_pol_formulation), we consider the scenario shown in Fig. 3. For this scenario, only one simulated obstacle wall at m is in the experiment space which the human does not see. The human decides to drive the transport object towards the goal via the shortest path without being aware that it is leading towards the wall.
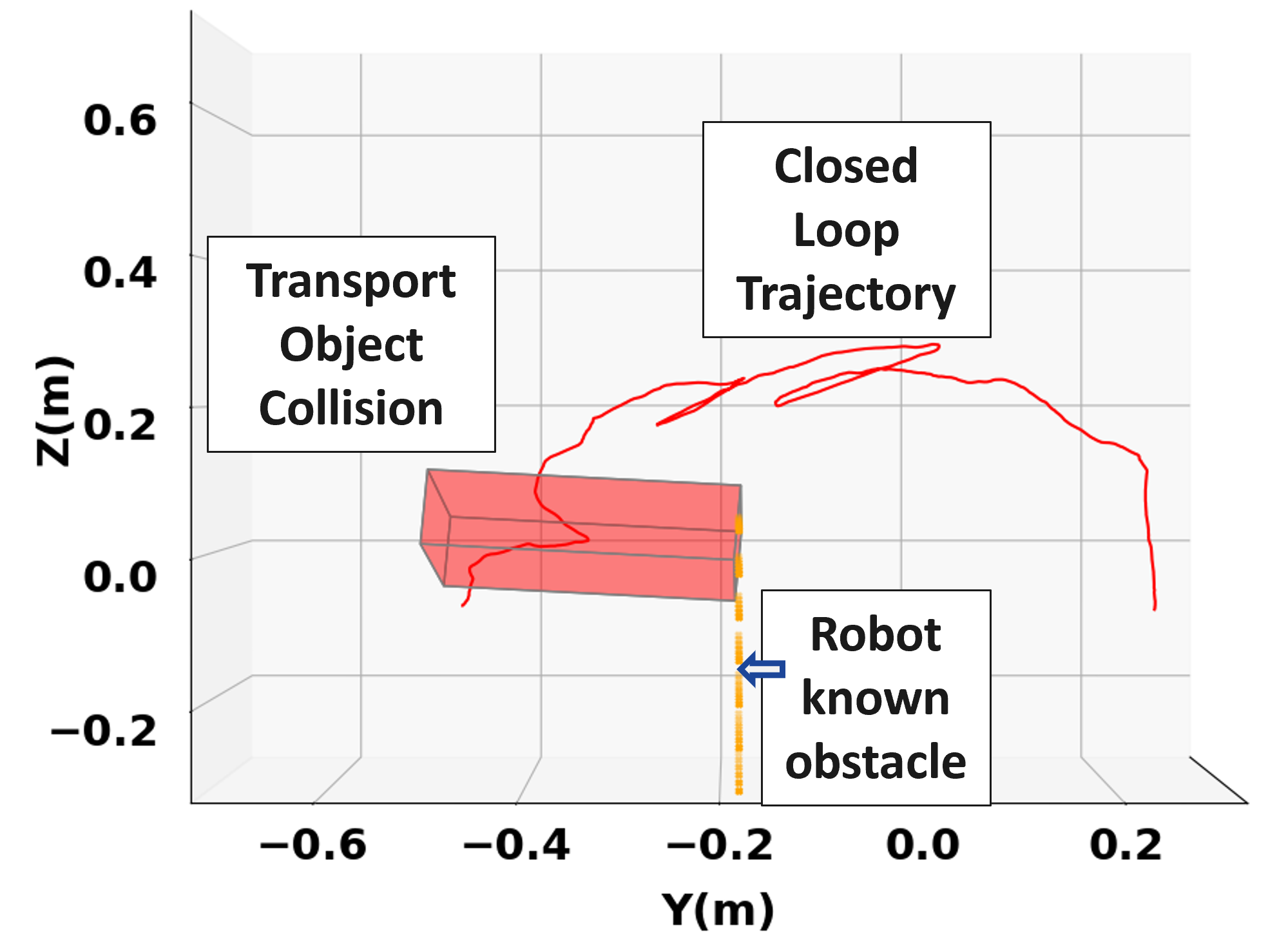
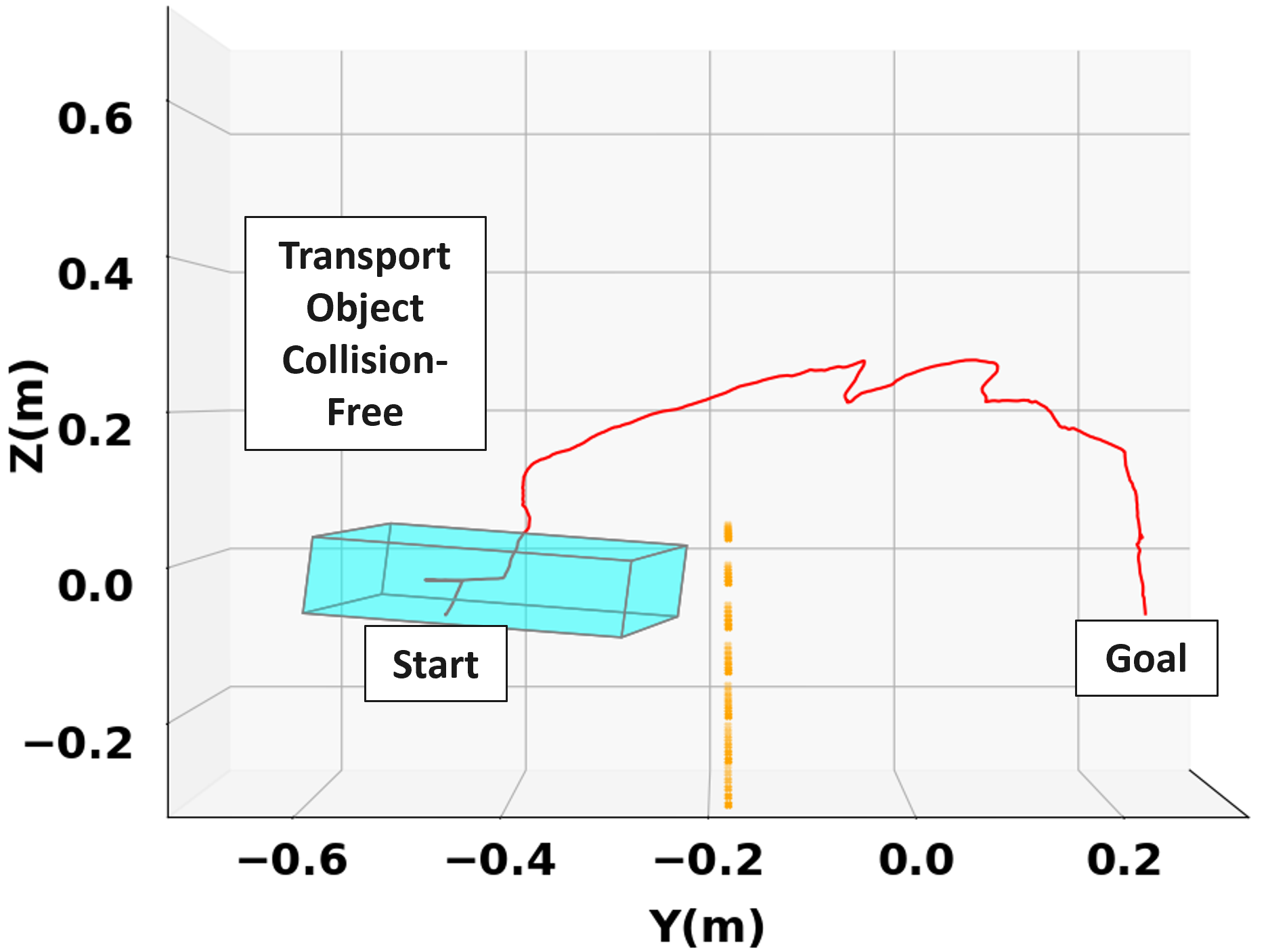
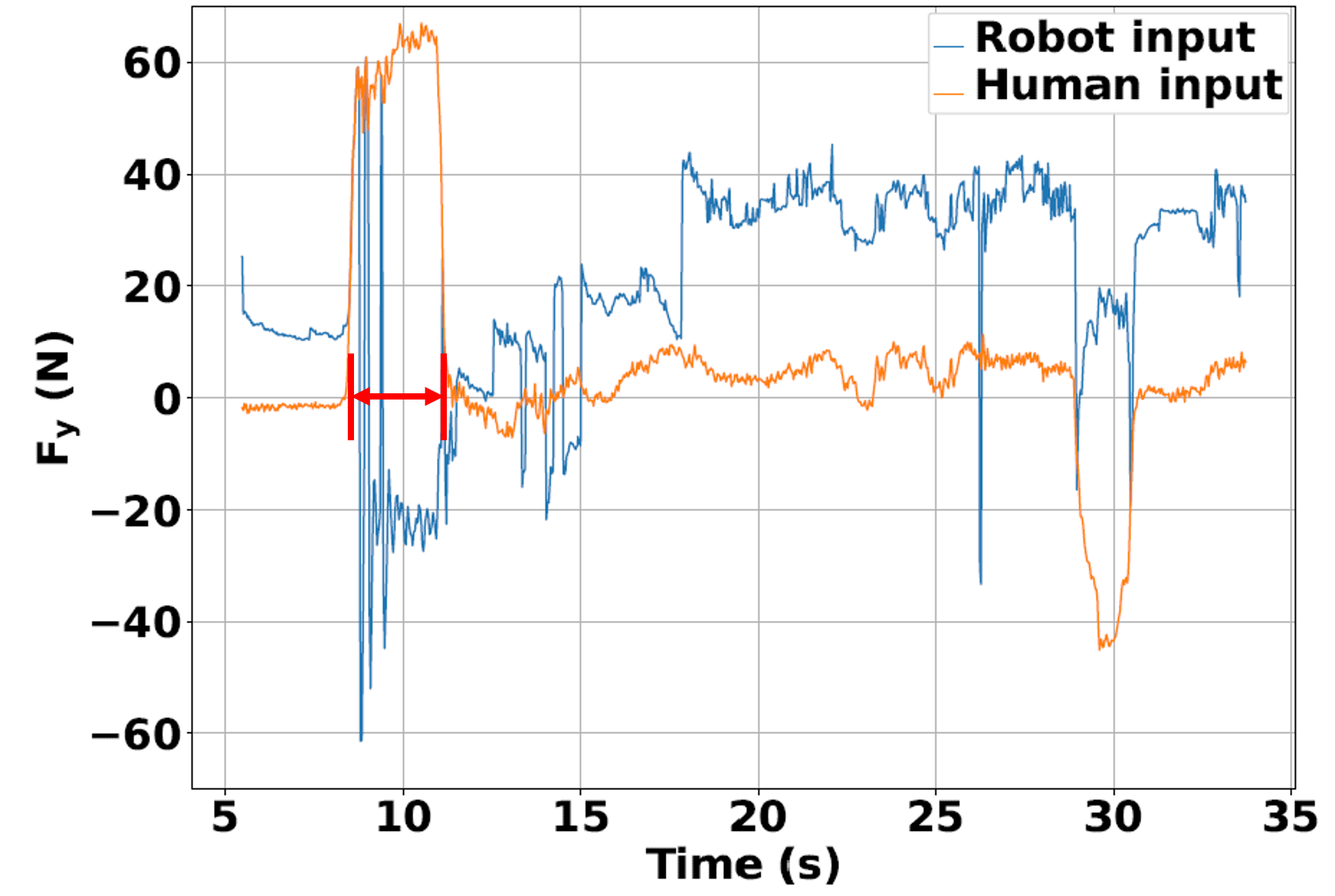
Without activating the safe stop policy backup, the robot’s inputs continue to comply with the inputs from the human, as shown in the force plots in Fig. 3c. As a result, the transported object collides with the obstacle wall, as seen in Fig. 3a. On the other hand, in Fig. 3b we see that utilizing the safe stop policy mode manages to prevent this collision and maintain safety in the transportation task. This safety retaining effect of the safe stop mode can be explained from Fig. 3d, where next to the obstacle wall when condition (SS) is triggered (around 10 sec), we no longer see the robot’s applied forces complying with the human’s forces. Instead, the robot applies a decelerating safe stop input, which results in the collision avoidance. The task is completed successfully.
IV-C Randomized Analysis
In order to generalize the validity of the above results beyond the considered example, we carried out the transportation task and analyzed the closed loop behaviors of the proposed controller with 100 configurations of randomized start, goal and obstacle positions. In some cases, the obstacles are purely simulated for faster testing purposes. The detailed results are shown in Table II where we use three metrics to compare the 100 trials. A Collision-Free Success is a trial where the transport object is brought to the target state without hitting obstacles. Peak Human Force is the largest magnitude of force applied by the human throughout a given trial. The Duration of Intervening Forces is the length of time in which the human has applied more than 30N in a given trial.
| Feature | MPC Only |
|
||
|---|---|---|---|---|
| Collision-Free Successes () | 51 | 88 | ||
| Avg. Peak Human Force (N) | 63.276 | 53.835 | ||
| Avg. Duration of Intervening Forces (s) | 5.934 | 2.265 |
Table II shows that the proposed approach results in a 37% increase in the number of Collision-Free Successes. Moreover, the average value of the Peak Human Force lowers by 14.9% with the proposed approach, indicating decreased opposition of the human during the task. The results show that the average Duration of Intervening Forces shortens by 61.8% with our approach. The robot cedes some of the control authority to the human as the trust value decreases. This occurs when the human does something unexpected to the robot. On the other hand, with the pure MPC approach, the robot attempts to follow its optimal trajectory even in the case where a collision with an object known only by the human is imminent. Thus, the human needs to continuously apply the intervening force for longer periods of time when no trust value is used.
V Conclusion
We proposed a framework for a human-robot collaborative transportation task in presence of obstacles in the environment. The robot plans a trajectory for the transported object by solving a constrained finite time optimal control problem and appropriately applies a weighted combination of the human’s applied and its own planned inputs. The weights are chosen based on the robot’s trust value on its estimates of the human’s inputs. This allows for a dynamic leader-follower role adaptation of the robot throughout the task. With experimental results, we demonstrated the efficacy of the proposed approach.
Acknowledgments
We thank Vijay Govindarajan and Conrad Holda for all the helpful discussions. This work was funded by ONR-N00014-18-1-2833, and NSF-1931853. This work is also supported by AFRI Competitive Grant no. 2020-67021-32855/project accession no. 1024262 from the USDA National Institute of Food and Agriculture. This grant is being administered through AIFS: the AI Institute for Next Generation Food Systems (https://aifs.ucdavis.edu).
References
- [1] A. Bauer, D. Wollherr, and M. Buss, “Human–robot collaboration: a survey,” International Journal of Humanoid Robotics, vol. 5, no. 01, pp. 47–66, 2008.
- [2] N. Jarrasse, V. Sanguineti, and E. Burdet, “Slaves no longer: review on role assignment for human–robot joint motor action,” Adaptive Behavior, vol. 22, no. 1, pp. 70–82, 2014.
- [3] T. B. Sheridan, “Human–robot interaction: status and challenges,” Human factors, vol. 58, no. 4, pp. 525–532, 2016.
- [4] O. Khatib, “Mobile manipulation: The robotic assistant,” Robotics and Autonomous Systems, vol. 26, no. 2-3, pp. 175–183, 1999.
- [5] K. Kosuge and Y. Hirata, “Human-robot interaction,” in 2004 IEEE International Conference on Robotics and Biomimetics. IEEE, 2004, pp. 8–11.
- [6] Y. Maeda, T. Hara, and T. Arai, “Human-robot cooperative manipulation with motion estimation,” in Proceedings 2001 IEEE/RSJ International Conference on Intelligent Robots and Systems. Expanding the Societal Role of Robotics in the the Next Millennium (Cat. No. 01CH37180), vol. 4. Ieee, 2001, pp. 2240–2245.
- [7] K. Yokoyama, H. Handa, T. Isozumi, Y. Fukase, K. Kaneko, F. Kanehiro, Y. Kawai, F. Tomita, and H. Hirukawa, “Cooperative works by a human and a humanoid robot,” in 2003 IEEE International Conference on Robotics and Automation (Cat. No. 03CH37422), vol. 3. IEEE, 2003, pp. 2985–2991.
- [8] P. Evrard and A. Kheddar, “Homotopy switching model for dyad haptic interaction in physical collaborative tasks,” in World Haptics 2009-Third Joint EuroHaptics conference and Symposium on Haptic Interfaces for Virtual Environment and Teleoperator Systems. IEEE, 2009, pp. 45–50.
- [9] S. O. Oguz, A. Kucukyilmaz, T. M. Sezgin, and C. Basdogan, “Haptic negotiation and role exchange for collaboration in virtual environments,” in 2010 IEEE haptics symposium. IEEE, 2010, pp. 371–378.
- [10] A. Mörtl, M. Lawitzky, A. Kucukyilmaz, M. Sezgin, C. Basdogan, and S. Hirche, “The role of roles: Physical cooperation between humans and robots,” The International Journal of Robotics Research, vol. 31, no. 13, pp. 1656–1674, 2012.
- [11] L. Beton, P. Hughes, S. Barker, M. Pilling, L. Fuente, and N. Crook, “Leader-follower strategies for robot-human collaboration,” in A World with Robots. Springer, 2017, pp. 145–158.
- [12] B. Sadrfaridpour, M. F. Mahani, Z. Liao, and Y. Wang, “Trust-based impedance control strategy for human-robot cooperative manipulation,” in Dynamic Systems and Control Conference, vol. 51890. American Society of Mechanical Engineers, 2018, p. V001T04A015.
- [13] M. Kwon, M. Li, A. Bucquet, and D. Sadigh, “Influencing leading and following in human-robot teams.” in Robotics: Science and Systems, 2019.
- [14] E. M. Van Zoelen, E. I. Barakova, and M. Rauterberg, “Adaptive leader-follower behavior in human-robot collaboration,” in 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN). IEEE, 2020, pp. 1259–1265.
- [15] A. Freedy, E. DeVisser, G. Weltman, and N. Coeyman, “Measurement of trust in human-robot collaboration,” in 2007 International Symposium on Collaborative Technologies and Systems. IEEE, 2007, pp. 106–114.
- [16] J. Mainprice and D. Berenson, “Human-robot collaborative manipulation planning using early prediction of human motion,” in 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2013, pp. 299–306.
- [17] J. F. Fisac, A. Bajcsy, S. L. Herbert, D. Fridovich-Keil, S. Wang, C. J. Tomlin, and A. D. Dragan, “Probabilistically safe robot planning with confidence-based human predictions,” arXiv preprint arXiv:1806.00109, 2018.
- [18] A. Bajcsy, D. P. Losey, M. K. O’Malley, and A. D. Dragan, “Learning robot objectives from physical human interaction,” in Conference on Robot Learning. PMLR, 2017, pp. 217–226.
- [19] X. Yu, Y. Li, S. Zhang, C. Xue, and Y. Wang, “Estimation of human impedance and motion intention for constrained human–robot interaction,” Neurocomputing, vol. 390, pp. 268–279, 2020.
- [20] F. Flacco, T. Kröger, A. De Luca, and O. Khatib, “A depth space approach to human-robot collision avoidance,” in 2012 IEEE International Conference on Robotics and Automation. IEEE, 2012, pp. 338–345.
- [21] L. Wang, B. Schmidt, and A. Y. Nee, “Vision-guided active collision avoidance for human-robot collaborations,” Manufacturing Letters, vol. 1, no. 1, pp. 5–8, 2013.
- [22] A. D. Dragan and S. S. Srinivasa, “A policy-blending formalism for shared control,” The International Journal of Robotics Research, vol. 32, no. 7, pp. 790–805, 2013.
- [23] S. Nikolaidis, A. Kuznetsov, D. Hsu, and S. Srinivasa, “Formalizing human-robot mutual adaptation: A bounded memory model,” in ACM/IEEE International Conference on Human-Robot Interaction. IEEE, 2016, pp. 75–82.
- [24] D. R. Scobee, V. R. Royo, C. J. Tomlin, and S. S. Sastry, “Haptic assistance via inverse reinforcement learning,” in 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2018, pp. 1510–1517.
- [25] C. Ott, R. Mukherjee, and Y. Nakamura, “A hybrid system framework for unified impedance and admittance control,” Journal of Intelligent & Robotic Systems, vol. 78, no. 3, pp. 359–375, 2015.
- [26] M. Bujarbaruah, Y. R. Stürz, C. Holda, K. H. Johansson, and F. Borrelli, “Learning environment constraints in collaborative robotics: A decentralized leader-follower approach,” in International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 1636–1641.