Safe Learning for Uncertainty-Aware Planning via Interval MDP Abstraction
Abstract
We study the problem of refining satisfiability bounds for partially-known stochastic systems against planning specifications defined using syntactically co-safe Linear Temporal Logic (scLTL). We propose an abstraction-based approach that iteratively generates high-confidence Interval Markov Decision Process (IMDP) abstractions of the system from high-confidence bounds on the unknown component of the dynamics obtained via Gaussian process regression. In particular, we develop a synthesis strategy to sample the unknown dynamics by finding paths which avoid specification-violating states using a product IMDP. We further provide a heuristic to choose among various candidate paths to maximize the information gain. Finally, we propose an iterative algorithm to synthesize a satisfying control policy for the product IMDP system. We demonstrate our work with a case study on mobile robot navigation.
Index Terms:
Automata, Hybrid systems, Markov processes, Gaussian process learningI Introduction
Abstraction-based approaches for verification and synthesis of dynamical systems offer computationally tractable methods for accommodating complex specifications [1]. In particular, Interval Markov Decision Processes (IMDP) [2], which allow for an interval of transition probabilities, provide a rich abstraction model for stochastic systems. As compared to stochastic control[3], abstraction-based methods allow for more complex specifications to be considered and have been widely used for hybrid stochastic systems [4].
The transition probability intervals in IMDP abstractions have typically modeled the uncertainty which arises from abstracting the dynamics of continuous states in discrete regions [5]. However, partially-known stochastic systems, which show promise for modeling a wide range of real-world systems, add unknown dynamics which contribute further uncertainty. Previous works model this uncertainty by assuming that some prior data on the dynamics are available [6].
The paper [7] is the first to address the problem of modeling unknown dynamics in stochastic hybrid systems via the use of IMDP abstraction in combination with Gaussian process (GP) regression [8]. GP regression can approximate unknown functions with arbitrary accuracy and also provides bounds on the approximation uncertainty [9].
The main contribution of this work is to develop a method for sampling the unknown dynamics of a stochastic system online in order to reduce abstraction error and increase the probability of satisfying a syntactically co-safe linear temporal logic (scLTL) specification [2].
Our goal is to find a control policy which guarantees the satisfaction of a scLTL specification with sufficient probability. However, we assume a stochastic noise which creates unavoidable perturbation. The system also has unknown dynamics which we estimate with Gaussian processes. This creates an estimation error which increases uncertainty in state transitions and which we aim to reduce by sampling the unknown dynamics. Thus, this paper focuses on the problem of safe learning to allow online exploration rather than a static planning problem using previously collected data samples as in [7].
Our approach is as follows. First, we estimate the unknown dynamics of the system using Gaussian processes and construct a high-confidence IMDP abstraction. We then develop an algorithm for finding nonviolating cycles in a product IMDP of the system abstraction combined with a finite automaton of the scLTL specification which allow the dynamics of the system to be sampled without violating the specification. We develop a heuristic for evaluating candidate cycles in order to maximize the uncertainty reduction gained from sampling. Finally, we propose an iterative method to sample the state-space, thereby decreasing the uncertainty of a GP estimation of the unknown dynamics until a satisfying control policy for the system can be synthesized or a terminating condition such as a maximum number of iterations has been reached. We utilize sparse GPs [10] to improve computational efficiency. We demonstrate our method on a case study of robotic motion planning.
II Problem Setup
Consider a discrete-time, partially-known system
| (1) |
where is the system state, is the control action, is the known dynamics, is the unknown dynamics to be learned via GP regression, is stochastic noise, and time is indexed with brackets. This system has applications in, e.g., biology [11], communications [12], and robotics [13].
Assumption 1
1) Each dimension of , is an independent, zero mean random variable with stationary, symmetric, and unimodal distribution and is -sub-Gaussian, i.e., the distribution tail decays at least as fast as a Gaussian random variable with variance .
2) Given a data set where is an observation of perturbed by -sub-Gaussian noise, it is possible to construct an estimate of and bound the estimation error between and by some high-confidence bound . Thus,
| (2) |
are high-confidence bounds on , i.e., with high confidence. For simplicity, we drop the superscript when the dataset is clear.
Assumption 2
The state-space is bounded and is partitioned into hyper-rectangular regions defined as
| (3) |
where the inequality is taken elementwise for lower and upper bounds and is a finite index set of the regions. Each region has a center . Additionally, the system possesses a labeling function which maps hyper-rectangular regions to observations .
Define feedback controllers as
| (4) |
The choice thus produces a control action which compensates for the known and estimated dynamics to reach the center of region , although the actual state update will be perturbed as shown in Figure 1.
Our ultimate goal is to apply a sequence of feedback controllers so that the resulting sequence of observations satisfies a control objective specified as a syntactically co-safe LTL (scLTL) formula over the observations .
Definition 1 (Syntactically co-safe LTL [2, Def. 2.3])
A syntactically co-safe linear temporal logic (scLTL) formula over a set of observations is recursively defined as
where is an observation and , , and are scLTL formulas. We define the next operator as meaning that will be satisfied in the next state transition, the until operator as meaning that the system satisfies until it satisfies , and the eventually operator as .
ScLTL formulas are characterized by the property that they are satisfied in finite time. It is well-known that scLTL satisfaction can be checked using a finite state automaton:
Definition 2 (Finite State Automaton [2, Def. 2.4])
A finite state automaton (FSA) is a tuple , where
-
•
is a finite set of states,
-
•
is the initial state,
-
•
is the input alphabet, which corresponds to observations from the scLTL specification,
-
•
is a transition function, and
-
•
is the set of accepting (final) states.
A sequence of inputs (a word) from is said to be accepted by an FSA if it ends in an accepting state. A scLTL formula can always be translated into a FSA that accepts all and only those words satisfying the formula. We use scLTL specifications in this paper because they are well-suited to robotic motion planning tasks which are satisfied in finite time. Additionally, the simpler structure of an FSA as opposed to the Büchi and Rabin automata of general LTL enables the methods we propose below.
Definition 3 (Interval Markov Decision Process)
An Interval Markov Decision Process (IMDP) is a tuple where:
-
•
is a finite set of states,
-
•
is a finite set of actions,
-
•
are lower and upper bounds, respectively, on the transition probability from state to state under action ,
-
•
is a set of initial states,
-
•
is a finite set of atomic propositions or observations,
-
•
is a labeling function.
The set of actions corresponds to the set of all valid feedback controllers for the system. We do not assume that all actions are available at each state. Therefore, each state has a subset of available actions.
Definition 4 (High-Confidence IMDP Abstraction)
Consider stochastic system (1), partitions (3), and the family of feedback controllers (4) where is an estimate of . Further, suppose that and are high-confidence bounds on which satisfy (2). Then, an IMDP is a high-confidence IMDP abstraction of (1), if:
-
•
The set of states for the abstraction is the index set of partitions, i.e. partition is abstracted as state , and the set of observations and labeling function for the abstraction are the same as for the system,
-
•
For all , the set of actions is the set of one-step reachable regions at under its feedback controllers,
-
•
For all and all :
| (5) | ||||
| (6) | ||||
where denotes probability with respect to .
Verification and synthesis problems for IMDP systems evaluated against scLTL specifications are often solved using graph theoretic methods on a product IMDP:
Definition 5 (PIMDP)
Let be an IMDP and be an FSA. The product IMDP (PIMDP) is defined as a tuple
, where
-
•
if and otherwise
-
•
if and otherwise
-
•
is a set of initial states of , and
-
•
is the set of accepting (final) states.
We can now formulate our proposed problem:
Problem 1
Design an iterative algorithm to sample and learn the unknown dynamics of system (1) without violating the scLTL specification and synthesize a control policy which satisfies with some desired threshold probability or prove that no such control policy exists.
To solve this problem, we construct a high-confidence IMDP abstraction of the system (1) using a GP estimation of the unknown dynamics. We then formulate a method to sample the state-space without violating the specification, updating the GP estimation until a satisfying control policy can be synthesized.
III Abstraction of System as IMDP
In this section, we detail our approach to abstracting a system of the form (1) into a high-confidence IMDP.
We first need to determine an approximation of , the unknown dynamics. At each time step of system (1), we know , , and . Therefore, we can define
Then, we construct a Gaussian process estimation for by considering a dataset of samples .
Definition 6 (Gaussian Process Regression)
Gaussian Process (GP) regression models a function as a distribution with covariance . Assume a dataset of samples , where is the input and is an observation of under Gaussian noise with variance . Let be a matrix defined elementwise by and for , let . Then, the predictive distribution of at a test point is the conditional distribution of given , which is Gaussian with mean and variance given by
| (7) | ||||
| (8) |
where is the identity and .
In practice, GP regression has a complexity of . To mitigate this, we use sparse Gaussian process regression [10]:
Definition 7 (Sparse Gaussian Process Regression)
A sparse Gaussian process uses a set to approximate a GP of a larger dataset . Given inducing points with and covariance matrix , the predictive distribution of the unknown function has mean and variance
where is a matrix defined elementwise by for all . For , let . The parameters , , and are optimized to minimize the Kullback-Leibler divergence (evaluated at the inducing points) between , the posterior of under the sparse GP; and , the posterior of under a GP with the full dataset . We refer the reader to [10] for a detailed treatment of sparse Gaussian process theory. The computational complexity of sparse GP regression is , so by fixing the algorithm is linear in . We note that sparse GP regression introduces error into the estimation; however, in practice this error does not affect the validity of our methods.
Given some dataset , we construct an estimation of the unknown dynamics independently in each coordinate and determine high-confidence bounds on the estimation error
for each . We also determine high-confidence lower and upper bounds on as
The parameter is calculated as
| (9) |
for noise -sub-Gaussian, the number of GP samples, high-confidence parameter , information gain constant , and RKHS constant as detailed in Lemma 1, [7]. Note that the same parameter is used to determine high-confidence bounds on both the estimation error and itself.
For each region in the state-space, we select a high-confidence error bound for the unknown dynamics as
In practice, we compute this bound by sampling throughout the state-space, introducing a trade-off between approximation error and computation complexity. We now construct transition probability intervals assuming that the high-confidence bounds on unknown dynamics always hold:
Theorem 1 (Construction of Transition Probabilities)
Consider and action . Lower bound and upper bound transition probabilities from to under are given by
| (10) |
| (11) |
where is the -th coordinate of and similarly for , we recall is the probability density function of the stochastic noise , and and are the lower and upper boundary points for region . We define and as
| (12) | ||||
| (13) | ||||
where is the 1-norm and is a high-confidence error bound on the unknown dynamics satisfying Assumption 1.
Then, the transition probability bounds
(10)–(11) satisfy the constraints for high-confidence IMDP abstractions in (5)–(6).
Proof: The righthand side of the bound in equation (5) can be rewritten as
| (14) | ||||
| (15) | ||||
| (16) | ||||
| (17) | ||||
| (18) | ||||
| (19) |
where (14) is the righthand side of (5); (15) follows after expanding the feedback controller expression using (4) and simplifying; (16) follows by assumption of high-confidence error bound and the definition of and from Assumption 1 and taking ; (17) follows by assumption that each is independent and denotes probability with respect to , where we recall that and are the lower and upper corners of the region , and is the -th coordinate of and similarly for and ; (18) follows from the fact that the hyper-rectangular constraint is equivalent to independent constraint along each coordinate; and (19) follows from the definition .
Now, because the probability distribution for each random variable is assumed unimodal and symmetric, is minimized when the distance between and the midpoint of is maximized, i.e., when is maximized, subject to the constraint . Substituting , and observing that , this is exactly the maximizing point specified by in (12). Thus, the expression in (19) is equivalent to
| (20) |
which in turn is equivalent to the righthand side of (10), establishing the bound in (5). An analogous argument establishes that (11) satisfies (6). ∎
IV Safe Sampling of PIMDP
IV-A Probability of Satisfaction Calculation
Given a high-confidence IMDP abstraction of the system and a FSA of a desired scLTL specification, we construct a PIMDP using Definition 5. We first introduce the concept of control policies and adversaries:
Definition 8 (Control Policy)
A control policy of a PIMDP is a mapping , where is the set of finite sequences of states of the PIMDP.
Definition 9 (PIMDP Adversary)
Given a PIMDP state and action , an adversary is an assignment of transition probabilities to all states such that
In particular, we use a minimizing adversary, which realizes transition probabilities such that the probability of satisfying the specification is minimal, and a maximizing adversary, which maximizes the probability of satisfaction.
To find safe sampling cycles in the PIMDP, we calculate
which is the probability that a random path starting at PIMDP state satisfies the scLTL specification under a maximizing control policy and minimizing adversary .
Additionally, we will also use the best case probability of satisfaction under a maximizing control policy and adversary:
To calculate these probabilities, we use a value iteration method proposed in Section V, [14].
IV-B Nonviolating Sub-Graph Generation
We note that scLTL specifications may generate FSA states which are absorbing and non-accepting, i.e., it is impossible to satisfy the specification once one of these states is reached. Such states may also exist in PIMDP constructions even without appearing in the corresponding FSA. We define these states as those which have zero probability of satisfying the scLTL specification under any control policy and adversary:
We can then define a notion of specification nonviolation:
Definition 10 (Nonviolating PIMDP)
A PIMDP is nonviolating with respect to a scLTL specification if there exists no failure states in .
Our algorithm for calculating a nonviolating PIMDP is as follows. We first initialize a set of failure states. Then, we loop through all non-failure states and prune actions which have nonzero upper-bound transition probability to failure states. We check if this pruning has left any states with no available actions, designating these also as failure states to prune. The process continues until no new failure states are found. Our nonviolating sub-graph is the set of all unpruned states with their remaining actions.
IV-C Candidate Cycle Selection
Now that we have a nonviolating sub-graph of our PIMDP, we want to select a path which we can take in order to sample the state-space indefinitely while maximizing the information gain of our Gaussian process. To do this, we first recall the concept of maximal end components [15]:
Definition 11 (End Component [15])
An end component of a finite PIMDP is a pair with and such that
-
•
for all states ,
-
•
and implies ,
-
•
The digraph induced by is strongly connected.
Definition 12 (Maximal End Component (MEC) [15])
An end component of a finite PIMDP is maximal if there is no end component such that and and for all .
PIMDP abstractions have the property that any infinite path will eventually stay in a single MEC. We propose the following heuristic in order to select a MEC to cycle within. First, we calculate from our initial state to each candidate MEC. We reject any MEC which we cannot reach with probability 1, or, in case no MECs can be reached with probability 1, we immediately select the MEC with the highest reachability probability. If multiple candidate MECs remain, we then calculate the Gaussian process covariance between the centers of the IMDP states in each remaining candidate MEC and the accepting IMDP state . We sum the covariances for all states in each MEC and select the MEC with the highest total covariance score, which corresponds to maximum information gain [16], defined as reduction of GP uncertainty at the accepting state. We generate a control policy by selecting the actions at each state which give the maximum probability of reaching the MEC. Once in the MEC, we use a controller which cycles through the available actions.
By applying the algorithms detailed above to calculate a non-violating PIMDP and MEC, we generate a control policy which samples the state-space indefinitely without violating the specification, solving the second part of Problem 1.
IV-D Iterative Sampling Algorithm
We now detail our complete method to solve Problem 1. Given a scLTL specification which we want to satisfy with probability , we construct a PIMDP using a high-confidence IMDP abstraction of the system in Eq. (1) and an FSA which models . Then, we calculate reachability probabilities under a minimizing adversary from the initial states in the PIMDP to the accepting states. If , then the control policy selects the actions which produce at each state and the problem is solved. Otherwise, we calculate a control policy to sample the state-space without violating the specification using the methods in previous sections. We follow the calculated control policy for a predetermined number of steps and sample the unknown dynamics at each step. We batch update the GP with the data collected, reconstruct transition probability intervals for each state, and recalculate reachability probabilities for our initial states. If , a satisfying control policy is found; otherwise, we repeat the process above. Our iterative algorithm ends when ; the GP approximation has low enough uncertainty to know that a successful control policy cannot be synthesized, i.e., when the reachability probability under a maximizing adversary is less than the desired ; or a maximum number of iterations has been reached.
V Case Study
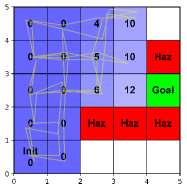
Suppose we have a mobile robot in a 2D state-space with position . The state-space is partitioned into a set of 25 hyper-rectangular regions corresponding to IMDP states. The dynamics of the robot are
| (21) |
where models the unknown effect of the slope of the terrain. The control action is generated by the family of controllers in Section II where the set of available target regions are those left, right, above, or below each region.
Within the state-space, we have one goal region with the atomic proposition Goal and a set of hazard regions labeled with Haz. These yield the scLTL specification
| (22) |
An illustration of the state-space is shown in Figure 2. We choose a low-dimensional case study in order to illustrate our methodology. Future works will refine our algorithms on applications with higher-dimensional state-spaces.
The true is sampled from two randomly generated Gaussian processes (one for each dimension) with bounded support and squared exponential kernel ,
| (23) |
We choose hyperparameters and .
We estimate the unknown dynamics with two sparse Gaussian processes with the same kernel as the true dynamics. We sample the GPs at 100 points in each region to determine error bounds. We set the number of inducing points and choose our high-confidence-bound parameter . Each iteration of the algorithm takes 250 steps, so the total number of data samples is the number of iterations times 250. Our stochastic noise is independently drawn from two truncated Gaussian distributions, one for each dimension, and both with and bounded support .
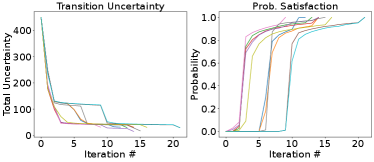
We next apply the iterative algorithm described in Section IV-D, setting the desired probability of satisfying the specification to 1. Our algorithm successfully finds a satisfying feedback control strategy in an average of 15 iterations (calculated over 10 runs). The algorithm is implemented in Python on a 2.5 GHz Intel Core i9 machine with 16 GB of RAM and a Nvidia RTX 3060 GPU, and requires on average 1 minute 14 seconds to complete.
Figure 2 depicts the expansion of the safe cycle used to sample the state-space. Initially, only the left two columns of states are safe and reachable. As the algorithm progresses, more states and actions are added to the safe cycle, moving the system closer to the goal until the unknown dynamics can be estimated with enough certainty to achieve a probability of satisfying the specification of 1.
The left plot in Figure 3 depicts the total transition probability uncertainty for the system after each iteration
| (24) |
The right plot in Figure 3 shows the probability of satisfying the specification after each iteration.
VI Conclusion
In this work, we developed a method to safely learn unknown dynamics for a system motivated by the robotic motion-planning problem. Our approach uses an IMDP abstraction of the system and a finite state automaton of scLTL specifications. We designed an algorithm for finding nonviolating paths within a product IMDP construction which can be used to sample the state-space and construct a Gaussian process approximation of unknown dynamics. We then detailed an algorithm to iteratively sample the state-space to improve the probability of satisfying a desired specification and demonstrated its use with a case study of robot navigation. Our approach can be used with any system for which a high-confidence IMDP abstraction can be constructed as well as any objective which can be written as a scLTL specification. Future work will apply these methods to models of bipedal walking robots utilizing region-based motion planning [13].
References
- [1] P. Tabuada, Verification and Control of Hybrid Systems: A Symbolic Approach, 1st ed. Springer Publishing Company, Incorporated, 2009.
- [2] C. Belta, B. Yordanov, and E. Göl, Formal Methods for Discrete-Time Dynamical Systems, ser. Studies in Systems, Decision and Control. Springer International Publishing, 2017.
- [3] C. Mark and S. Liu, “Stochastic MPC with distributionally robust chance constraints,” IFAC, vol. 53, no. 2, pp. 7136–7141, 2020.
- [4] A. Lavaei, S. Soudjani, A. Abate, and M. Zamani, “Automated verification and synthesis of stochastic hybrid systems: A survey,” 2021.
- [5] C. Baier, B. Haverkort, H. Hermanns, and J.-P. Katoen, “Model-checking algorithms for continuous-time Markov chains,” IEEE Transactions on Software Engineering, vol. 29, no. 6, pp. 524–541, Jun. 2003.
- [6] M. Ahmadi, A. Israel, and U. Topcu, “Safety assessemt based on physically-viable data-driven models,” in 56th IEEE CDC, Dec. 2017, pp. 6409–6414.
- [7] J. Jackson, L. Laurenti, E. Frew, and M. Lahijanian, “Strategy synthesis for partially-known switched stochastic systems,” in Proceedings of HSCC ’21, pp. 1–11.
- [8] C. K. I. Williams and C. E. Rasmussen, “Gaussian processes for regression,” in Advances in neural information processing systems 8. MIT press, 1996, pp. 514–520.
- [9] A. K. Akametalu, J. F. Fisac, J. H. Gillula, S. Kaynama, M. N. Zeilinger, and C. J. Tomlin, “Reachability-based safe learning with Gaussian processes,” in 53rd IEEE CDC, Dec. 2014, pp. 1424–1431.
- [10] F. Leibfried, V. Dutordoir, S. John, and N. Durrande, “A tutorial on sparse gaussian processes and variational inference,” 2021, arXiv: 2012.13962.
- [11] A. A. Julius, A. Halasz, M. S. Sakar, H. Rubin, V. Kumar, and G. J. Pappas, “Stochastic modeling and control of biological systems: The lactose regulation system of Escherichia Coli,” IEEE Transactions on Automatic Control, vol. 53, no. Special Issue, pp. 51–65, 2008.
- [12] E. Altman, T. Başar, and R. Srikant, “Congestion control as a stochastic control problem with action delays,” Automatica, vol. 35, no. 12, pp. 1937–1950, 1999.
- [13] A. Shamsah, J. Warnke, Z. Gu, and Y. Zhao, “Integrated Task and Motion Planning for Safe Legged Navigation in Partially Observable Environments,” 2021, arXiv: 2110.12097.
- [14] M. Lahijanian, S. B. Andersson, and C. Belta, “Formal Verification and Synthesis for Discrete-Time Stochastic Systems,” IEEE Transactions on Automatic Control, vol. 60, no. 8, pp. 2031–2045, Aug. 2015.
- [15] C. Baier and J.-P. Katoen, Principles of Model Checking. MIT Press, 2008.
- [16] N. Srinivas, A. Krause, S. M. Kakade, and M. W. Seeger, “Information-theoretic regret bounds for gaussian process optimization in the bandit setting,” IEEE Transactions on Information Theory, vol. 58, no. 5, p. 3250–3265, May 2012.
[Algorithm Psuedocodes] Algorithm 1 calculates a sub-graph of a PIMDP which is nonviolating with respect to a scLTL specification. It takes as input a PIMDP construction along with upper bounds on the maximum probability of satisfying the specification for each state. In lines 1–2, failure states which have are identified. Next, in lines 4–10, non-failure states are looped through and any of their actions which have a nonzero upper bound probability of reaching the set of failure states are removed. In lines 12–17, states which have no actions remaining are added to the set of failure states and the algorithm returns to line 3. The loop from lines 3–18 repeats until no new failure states are identified. The algorithm returns the remaining non-failure states and actions as the nonviolating sub-graph.
Algorithm 2 calculates a maximum end component of a PIMDP to sample along with a corresponding control policy, maximizing the information gain with respect to learning the unknown dynamics. It takes as input a nonviolating sub-graph of a PIMDP. In line 1, the maximal end components of the sub-graph are identified. In lines 3–8, a lower bound on the maximum probability of reaching each MEC from the initial state of the original PIMDP is calculated. Those MECs which have are added to the list of candidate MECs. In lines 9–11, if there are no candidate MECs found, then the algorithm selects the MEC with the highest as the MEC to cycle in. If there are candidate MECs, then in lines 12–17 each candidate MEC is assigned a score equal to the sum of the covariances between each state in the MEC and the accepting state of the PIMDP. The MEC with the maximum covariance score is selected as the MEC to cycle in. In line 18, a control policy for the selected MEC is calculated which selects the actions at each state outside the MEC which have maximum probability of reaching the MEC. For states within the MEC, the control policy cycles through the actions at each state which are available in the MEC. The algorithm returns the selected MEC along with its corresponding control policy.
Algorithm 3 performs an iterative procedure to safely learn the unknown dynamics of the system (1) until a given scLTL specification can be satisfied with sufficient probability. It takes as input the system dynamics, a scLTL specification, and a desired probability of satisfaction . In line 1, an IMDP abstraction of the system and a FSA of the specification are constructed. Then, the IMDP and FSA are combined into a PIMDP construction. Finally, a GP estimation of the unknown dynamics is initialized with its hyperparameters. In lines 2–3, lower and upper bounds and are calculated for the initial state in the PIMDP. If the lower bound probability is less than the desired , the loop in lines 4–18 is entered. In lines 5–7, if the upper bound probability is less than , then the specification cannot be satisfied with sufficient probability regardless of how well the unknown dynamics are learned. Thus, the algorithm returns that no satisfying control policy exists. Otherwise, in lines 8–9, a nonviolating sub-graph of the PIMDP is calculated using Algorithm 1 and a MEC to cycle in along with its corresponding control policy is calculated from this sub-graph using Algorithm 2. In lines 10–13, this control policy is used to take a predefined number of steps to sample the unknown dynamics. In lines 14–15, the GP estimation is updated using these samples, and transition probability intervals are recalculated for each state in the PIMDP. In lines 16–17, and are recalculated for the initial state. If , the loop terminates and the algorithm returns a control policy calculated in lines 19–21 which selects the actions at each state which have maximum probability of satisfying the specification. If , the loop repeats from line 4. If the maximum number of iterations of the loop is reached, the algorithm terminates without determining a satisfying control policy or the nonexistence thereof.