Saliency Attack: Towards Imperceptible Black-box Adversarial Attack
Abstract.
Deep neural networks are vulnerable to adversarial examples, even in the black-box setting where the attacker is only accessible to the model output. Recent studies have devised effective black-box attacks with high query efficiency. However, such performance is often accompanied by compromises in attack imperceptibility, hindering the practical use of these approaches. In this paper, we propose to restrict the perturbations to a small salient region to generate adversarial examples that can hardly be perceived. This approach is readily compatible with many existing black-box attacks and can significantly improve their imperceptibility with little degradation in attack success rate. Further, we propose the Saliency Attack, a new black-box attack aiming to refine the perturbations in the salient region to achieve even better imperceptibility. Extensive experiments show that compared to the state-of-the-art black-box attacks, our approach achieves much better imperceptibility scores, including most apparent distortion (MAD), and distances, and also obtains significantly higher success rates judged by a human-like threshold on MAD. Importantly, the perturbations generated by our approach are interpretable to some extent. Finally, it is also demonstrated to be robust to different detection-based defenses.
1. Introduction
Deep neural networks (DNNs) have achieved significant progress in wide applications, such as image classification (Deng et al., 2009), face recognition (Parkhi et al., 2015), object detection (Redmon et al., 2016), speech recognition (Hinton et al., 2012) and machine translation (Bahdanau et al., 2015). Despite their success, deep learning models have exhibited vulnerability to adversarial attacks (Szegedy et al., 2014; Goodfellow et al., 2015; Liu et al., 2021, 2022). Crafted by adding some small perturbations to benign inputs, adversarial examples (AEs) can fool DNNs into making wrong predictions, which is a critical threat especially for some security-sensitive scenarios such as autonomous driving (Sun et al., 2020).
Existing adversarial attacks can be divided into white-box and black-box attacks according to the accessibility to the target model. White-box attacks (Szegedy et al., 2014; Goodfellow et al., 2015; Papernot et al., 2016; Carlini and Wagner, 2017; Moosavi-Dezfooli et al., 2016) have full access to the architecture and parameters of the target model, and can generate successful AEs easily via backpropagation. However, in practice, the model internals are often unavailable to attackers. This gives rise to the more realistic and challenging black-box attacks (Narodytska and Kasiviswanathan, 2017; Ilyas et al., 2018, 2019; Moon et al., 2019; Andriushchenko et al., 2020; Li et al., 2021) that only require the output of the target model.
Motivated by the fact that many real-world online application programming interfaces (APIs) often pose mandatory time or monetary limits to user queries (Ilyas et al., 2018), most recent research on black-box attacks concerns improving query efficiency, which indeed has achieved notable progress. For example, the state-of-the-art (SOTA) Square Attack (Andriushchenko et al., 2020) can succeed in untargeted attack on ImageNet dataset (Deng et al., 2009) with only tens of queries on average. On the other hand, such performance is often achieved by applying large-region or even global perturbations (e.g., random vertical stripes in Square Attack) to the original input, eventually resulting in unnatural AEs with significant visual differences from the original (see Figure 1 for some examples). In effect, imperceptibility is essential for attackers. Current online APIs usually integrate detectors into their services to detect anomalous inputs (Li et al., 2021). Those AEs with too visible perturbation are difficult to pass these detectors, not to mention human judgment, hindering the practical use of these black-box attacks.



This paper aims to address the above issue. The key insight is that we can lead black-box attacks to search in a small salient region that has the most significant influences on the model output, to achieve successful attacks with imperceptible perturbations. Concretely, it has been shown in previous DNNs visualization work (Simonyan et al., 2014) that one can generate the so-called BP-saliency map to illustrate which features can influence the model prediction by calculating derivatives of the model output with respect to the input. As shown in the first column of Figure 2, the brighter pixels in the BP-saliency map have greater impacts on the model output, and therefore perturbing them is more likely to alter the model prediction. Actually, the classical white-box attack JSMA (Papernot et al., 2016) constructs exactly such a map and iteratively selects pixels from it to perturb. Despite the fact that the BP-saliency map cannot be used for black-box attacks due to inaccessibility to model gradients, one can observe from the second column of Figure 2 that the region of bright pixels roughly represents the position of the main object in the image. That is to say, in black-box settings, we can leverage the existing salient object detection model (Zhao and Wu, 2019) that requires no information other than the input image to approximately obtain the salient region, and then restrict the perturbations to it. This approach is appealing because it is readily compatible with most existing black-box attacks. By integrating it into SOTA black-box attacks, we find the modified attacks enjoy significant improvement in attack imperceptibility, with little degradation in success rate (see the results in Table 1). Nevertheless, they still suffer from the strategy of perturbing globally, eventually generating complex and irregular perturbations that span almost the entire salient region (see Figure 5 for some examples).

To achieve more imperceptible attacks, we then seek to further restrict the perturbations to even smaller regions. The intuition is that even in the salient region, some sub-regions are more critical. For example, it has been shown that the dog face region is the brightest in the salient region of a dog image (Zhou et al., 2016), and obscuring it will dramatically change the model output (Zeiler and Fergus, 2014). Furthermore, by combining internal feature visualization with output prediction, it has been revealed in (Olah et al., 2018) that within dog face region, the ears and eyes seem to be more important than others. Therefore, it is reasonable to assume the salient region of an image is progressive with respect to its impact on model output. If we could find smaller but more salient sub-region, the perturbations will be more efficient, leading to more imperceptible attacks (see the third column of Figure 2). Thus, we propose the Saliency Attack, a novel black-box attack that recursively refines the perturbations in the salient region.
It is worth mentioning that except white-box attack JSMA, the idea of restricting perturbations to a small region has also been implemented in transfer-based attacks (Dong et al., 2020; Xiang et al., 2021), where class activation mapping (CAM) (Zhou et al., 2016) and Grad-CAM (Selvaraju et al., 2017) are adopted to generate the saliency maps. However, transfer-based attacks assume the data distribution for training the target model is available and thus could build a substitute model to approximate it, which actually belong to the grey-box setting where partial knowledge of the target model is known. As a result, they cannot be applied to the more strict black-box setting where only the model output is available (see Section 2.3 for details).
In summary, we make the following contributions in this work.
-
•
To the best of our knowledge, for crafting AEs in the black-box setting, we are the first to restrict perturbations to a salient region. This approach is readily compatible with many existing black-box attacks and significantly improves their imperceptibility with little degradation in success rate.
-
•
We propose the Saliency Attack, a novel gradient-free black-box attack that iteratively refines perturbations in salient regions to keep them minimal and essential. Compared with the SOTA black-box attacks, our approach achieves much better attack imperceptibility in terms of most apparent distortion (MAD), and distances, and also obtains significantly higher success rates judged by a human-like threshold on MAD.
-
•
We demonstrate that the perturbations generated by Saliency Attack are more robust against detection-based defenses, including Feature Squeezing and binary classifier detection.
The rest of this paper is organized as follows: Section 2 presents a literature review on black-box attacks. Next, in Section 3, we define the optimization problem of our attack and detail the proposed Saliency Attack. Section 4 shows the experimental results and analysis, followed by a conclusion in Section 5.
2. Related Work
In this part, we first overview the recent work of black-box attacks. Based on the generation method of AEs, these attacks can be divided into gradient estimation attacks and gradient-free attacks. Besides, we also introduce some work related to the imperceptibility in adversarial attacks. Finally, we discuss some methods that extract salient regions in an image.
2.1. Black-box Attacks
2.1.1. Gradient Estimation Attacks
Gradient estimation attacks first estimate the gradients by querying the target model and then use them to run white-box attacks. ZOO attack (Chen et al., 2017) first adopts symmetric difference quotient to approximate the gradients and then performs white-box Carlini-Wagner (CW) attack (Carlini and Wagner, 2017). AutoZOOM (Tu et al., 2019), a variant of ZOO, uses a random vector based gradient estimation to reduce the query number per iteration from 2D in ZOO to N+1 (D is the dimensionality and N is the sample size). To further enhance query efficiency, Ilyas et al. (Ilyas et al., 2019) propose the “tiling trick” that updates a square of pixels simultaneously instead of a single pixel. This dramatically decreases the dimensionality by a factor of ( is tile length).
2.1.2. Gradient-free Attacks
Gradient-free attacks do not estimate gradients and directly generate AEs with search heuristics according to the query result. Su et al. (Su et al., 2019) propose One-pixel attack that adopts differential evolution algorithm to perturb the most important pixel in the image. Alzantot et al. (Alzantot et al., 2019) propose GenAttack, which uses genetic algorithm to generate AEs. To improve query efficiency, Moon et al. (Moon et al., 2019) consider a discrete surrogate optimization problem that transforms the original constraint of a continuous range to a discrete set , achieving a massive reduction in the search space. This is motivated by linear program (LP) where the optimal solution is attained at an extreme point of the feasible set (Schrijver, 1999). Combing tiling trick (Ilyas et al., 2019) and discrete optimization (Moon et al., 2019), Square Attack (Andriushchenko et al., 2020) has obtained the best result on success rate and query performance so far with random search.
2.2. Attack Imperceptibility
The imperceptibility of AEs is essential for practical attackers, which has been investigated by previous studies from different perspectives. Guo et al. (Guo et al., 2019) consider low frequency perturbations as imperceptible, thus searching for AEs in frequency domain. But Zhang et al. (Zhang et al., 2020) regard imperceptibility as visual smoothness in an image and integrate Laplacian smoothing into optimization. Croce and Hein (Croce and Hein, 2019) use a combination of and norms to generate sparse and imperceptible perturbations. Besides, some studies also leverage color distance (Zhao et al., 2020) and image quality assessment (IQA) (Wang et al., 2021; Li and Chen, 2021) to improve attack imperceptibility.
On the other hand, determining how to assess the imperceptibility of AEs is still an open question. Most existing adversarial attacks use norms (, and ) to measure the human perceptual distance between the perturbed image and the original one. Nonetheless, it has been shown that norms are not suitable enough for human vision system (Sharif et al., 2018). A recent study in (Fezza et al., 2019) systematically examines various IQA metrics including norms through large-scale human evaluation on the imperceptibility of different AEs, and finds that among all the metrics the most apparent distortion (MAD) (Larson and Chandler, 2010) metric is closest to subjective scores (see Appendix A.1 for details of MAD). Hence, in this research, we adopt MAD as our main metric to assess attack imperceptibility.
2.3. Extracting Salient Region
As aforementioned, there have been white-box attacks or transfer-based attacks that restrict the perturbations to a small salient region. Specifically, white-box attack JSMA (Papernot et al., 2016) constructs a BP-saliency map by calculating derivatives of the model output w.r.t input pixels (Simonyan et al., 2014), while the two transfer-based attacks (Dong et al., 2020; Xiang et al., 2021) utilize CAM and Grad-CAM to extract salient regions, respectively. CAM (Zhou et al., 2016) replaces the final fully connected layers with convolutional layers and global average pooling of a CNN, and localizes class-specific salient regions through forward propagation. Grad-CAM (Selvaraju et al., 2017) improves CAM with on need to modify the network architecture, but it still requires access to the inner parameters of the model to calculate the gradients. Thus, CAM and Grad-CAM can only be applied to white-box attacks or transfer-based attacks, which first construct a transparent substitute model, craft AEs with gradient-based white-box attacks, and then transfer the generated AEs to the target model. It is conceivable that for transfer-based attacks, the transferability of both AEs and saliency maps highly depends on the similarity between the substitute model and the target model, which further depends on the prior knowledge of the training data distribution. Unfortunately, neither such knowledge nor model gradients are available in black-box settings. Considering the limitations of the above methods, we adopt a salient object detection model (Zhao and Wu, 2019) to directly generate the saliency map given an input image with no need to access the target model’s architecture or parameters.
3. Proposed Method
In this section, we first formulate the problem of crafting AEs for image classification models, and then detail our approach. Figure 3 illustrates the overall flowchart of Saliency Attack.

3.1. Preliminary
Given a well-trained DNN classifier , where is the dimension of the input , and is the number of classes. Let denote the predicted score that belongs to class . The classifier assigns the class that maximizes to the input . The goal of an untargeted attack is to find an AE , that results in the model misclassification from the ground-truth class , and meanwhile keeps the distance between and the benign input smaller than a threshold :
| (1) |
Note the last constraint indicates that is a valid image. In this study, we focus on norm, following (Moon et al., 2019; Andriushchenko et al., 2020). Conventionally, the task of finding can be rephrased as solving a constrained continuous problem:
| (2) |
where is the loss function. Similar to (Moon et al., 2019), we transform the continuous problem into a discrete surrogate problem, where the perturbation . Note unlike (Moon et al., 2019), where all pixels are perturbed either by or , we allow the pixels to remain unperturbed to refrain from global perturbation. Besides, only the pixels in salient regions can be perturbed. The final problem is defined as the following set maximization problem.
| (3) |
where denotes the ground set which is the set of all pixel locations (), denotes the set of pixels in salient regions, and denote the set of selected pixels with and perturbations respectively, and is the -th standard basis vector. Note that , and is the set of pixels in salient regions that are unperturbed. The goal of Equation (3) is to find and that will maximize the objective set function .
3.2. Salient Object Detection
Salient object detection aims to automatically and accurately extract salient object(s) in an image. Compared with other salient region extraction methods like BP-saliency map (Simonyan et al., 2014), CAM (Zhou et al., 2016) and Grad-CAM (Selvaraju et al., 2017), this type of models do not require any information other than the input image, which is very suitable for the black-box setting. We adopt the Pyramid Feature Attention (PFA) network111Implementation of PFA: https://github.com/sairajk/PyTorch-Pyramid-Feature-Attention-Network-for-Saliency-Detection (Zhao and Wu, 2019) that achieves the SOTA performance on multiple datasets via capturing high-level context features and low-level spatial structural features simultaneously (see Appendix A.2 for details). Specifically, given an input image, PFA can generate a saliency score between 0 and 1 for each pixel. The higher value denotes higher visual saliency. We then use a threshold to transform the saliency scores into a binary saliency mask, which determines the salient region. The binarization can be expressed as
| (4) |
where and are the saliency score and the binary mask at the -th pixel position, respectively. Thus, the salient region is the set of the pixels masked by 1.
| (5) |
3.3. Refining Perturbations in Salient Region
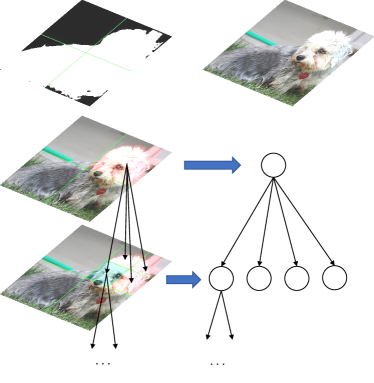
The proposed Saliency Attack is outlined in Algorithm 1. The search process (lines 6-35) recursively refines perturbations based on a tree structure for an image, which is illustrated in Figure 4. Concretely, an input image is first split into some initial blocks (a coarse grid in Figure 4), and only the blocks in salient regions are kept (lines 7-11). Then we try to add or perturbations on each initial block individually (lines 12-19) and sort them according to their influence () on model output (line 26). After that, we choose the block with most influence for further refinement if its is better than the current best (lines 27-35). We then recursively refine the current best block (line 32), split this block into smaller blocks (a finer grid in Figure 4), and again try to add a perturbation on each block individually (at this time we just flip the perturbation (lines 21-24) for convenience, e.g., to ) to find the best smaller block. The refinement process recurs until the minimal block (e.g., 1 pixel, line 30) or no smaller block has a better (line 28). Afterwards, we backtrack to the last level of split blocks and use the second-best block for further perturbation. In this way, the most important block will be explored first, and the perturbations could be as small as possible, with no need to initialize a global perturbation like Parsimonious Attack (Moon et al., 2019).
To make full use of query budget and combine the advantages of different initial block sizes (large can quickly lead to successful attacks with large perturbations, while small enables the refinement for small perturbations in finer grids), we leverage an outer iteration to run the aforementioned Refine search with decreasing (lines 2-5). During the iterations, the algorithm will stop if the generated succeeds to fool the model () or the termination condition is reached (line 2).
We use the loss function from CW attack (Carlini and Wagner, 2017) of untargeted attack for Equation (2):
| (6) |
where is the logit with respect to the ground-truth class of the original image. In this way, the loss function is imposed to leave a margin between the ground-truth class and other classes.
4. Experiments
The main goal of the experiments is to validate: (1) whether salient regions could improve the imperceptibility of existing black-box attacks; (2) whether our Saliency Attack could further enhance the imperceptibility performance. Hence, we first compare our Saliency Attack with the baselines, including SOTA black-box attacks and their modified version restricted in salient regions. Then we perform ablation studies to verify the effectiveness of salient regions and Refine search separately. Besides, we measure the hyperparameter sensitivity of our approach. Finally, we test different detection-based defenses to evaluate the imperceptibility from the defensive perspective.
4.1. Settings
We compare our Saliency Attack against SOTA black-box attacks including Boundary Attack (Brendel et al., 2018), TVDBA (Li and Chen, 2021), Parsimonious attack (Moon et al., 2019) and Square attack (Andriushchenko et al., 2020). Among them, Boundary Attack can constantly reduce the perturbation to a very small magnitude with enough queries, TVDBA tries to minimize the perturbation via integrating Structural SIMilarity (SSIM) (Wang et al., 2004) into the loss, Parsimonious Attack proposes discrete optimization to improve query efficiency, and Square Attack can achieve the current SOTA query efficiency and success rate in the black-box attack setting. In addition, we design Parsimonious-sal Attack and Square-sal Attack as baselines that restrict their perturbations in salient regions. For our Saliency Attack, the threshold to produce binary saliency masks is chosen to be 0.1. For splitting, original images are resized to , and we set the initial block size to 16. All parameters of the compared attacks remain consistent with those recommended in their papers.
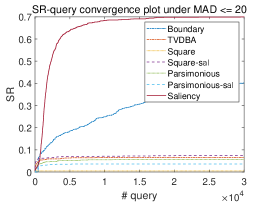
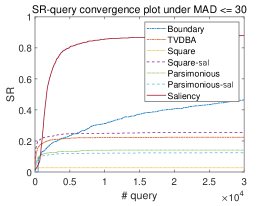
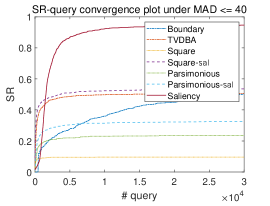
For performance metrics, we employ commonly used success rate (SR) and average number of queries (Avg. queries). To evaluate the imperceptibility of AEs, we consider , and MAD. All these three imperceptibility metrics are the smaller the better. In practice, a successful AE with imperceptible perturbation is what we need. So besides , we use a new metric . It indicates the rate of successful AEs whose MAD values are below a human-like threshold, i.e., 30, that AEs with are basically imperceptible to human eyes (See Appendix A.3).
In this study, we consider threat model on ImageNet dataset (Deng et al., 2009), and set the perturbation magnitude to 0.05 in [0,1] scale. We use Inception v3 (Szegedy et al., 2016) as the target model, and test different query budgets {3,000, 10,000, 30,000} for untargeted attack. We provide our implementation publicly222https://github.com/Daizy97/SaliencyAttack.

4.2. Results and Analysis
Some examples are shown in Figure 5. We can easily find the perturbations of original Parsimonious Attack and Square Attack are very obvious in the entire image due to global perturbation, while their modified versions are relatively more imperceptible since no perturbation exists in background regions. However, their perturbations are still complex and irregular, taking up almost all salient regions. In comparison, even restricted in the same salient regions, the perturbations generated by Saliency Attack are smaller and more critical, roughly corresponding to the bright pixels in BP-saliency map. They further represent the positions of dogs’ noses or ears, which accord with our inspiration before. Besides, the AEs of Boundary Attack contain noticeable coarse textures due to inadequate query budget, and TVDBA produces global and irregular perturbations similarly.
| Method | Budget | |||||
|---|---|---|---|---|---|---|
| Boundary | 3,000 | 100.0%0.00 | 13.6%0.04 | 68.130.74 | 99.6%0.00 | 84.964.19 |
| 10,000 | 100.0%0.00 | 30.2%0.03 | 58.820.65 | 99.7%0.00 | 71.614.03 | |
| 30,000 | 100.0%0.00 | 46.0%0.03 | 58.300.62 | 99.8%0.00 | 62.773.94 | |
| TVDBA | 3,000 | 90.1%0.01 | 23.4%0.02 | 10.640.15 | 19.0%0.00 | 37.653.63 |
| 10,000 | 96.9%0.01 | 23.7%0.02 | 10.830.18 | 19.8%0.00 | 37.873.61 | |
| 30,000 | 98.4%0.00 | 23.5%0.02 | 10.930.17 | 20.0%0.00 | 38.113.57 | |
| Parsimonious | 3,000 | 92.4%0.01 | 14.7%0.01 | 22.170.00 | 100.0%0.00 | 51.800.12 |
| 10,000 | 98.5%0.01 | 14.8%0.01 | 22.170.00 | 100.0%0.00 | 53.010.14 | |
| 30,000 | 99.8%0.01 | 14.8%0.01 | 22.170.00 | 100.0%0.00 | 53.130.14 | |
| Parsimonious-sal | 3,000 | 88.9%0.01 | 11.4%0.01 | 13.540.50 | 35.5%0.03 | 45.310.21 |
| 10,000 | 96.0%0.01 | 12.6%0.01 | 13.470.48 | 35.5%0.03 | 45.440.22 | |
| 30,000 | 99.2%0.01 | 12.9%0.01 | 13.450.48 | 35.5%0.03 | 45.280.21 | |
| Square | 3000 | 98.3%0.00 | 2.7%0.00 | 25.340.02 | 99.0%0.00 | 57.290.05 |
| 10,000 | 99.6%0.00 | 2.4%0.00 | 25.350.02 | 99.0%0.00 | 57.740.05 | |
| 30,000 | 99.8%0.00 | 3.1%0.00 | 25.330.02 | 99.0%0.00 | 56.210.04 | |
| Square-sal | 3,000 | 87.5%0.01 | 20.3%0.02 | 14.710.53 | 34.5%0.03 | 38.560.54 |
| 10,000 | 96.0%0.01 | 22.8%0.02 | 14.560.51 | 34.3%0.03 | 38.650.56 | |
| 30,000 | 96.4%0.01 | 25.9%0.01 | 14.480.51 | 34.1% 0.03 | 37.230.53 | |
| Saliency (ours) | 3,000 | 84.3%0.01 | 79.8%0.01 | 3.440.05 | 2.9%0.00 | 12.070.20 |
| 10,000 | 92.4%0.01 | 85.8%0.01 | 3.630.05 | 3.4%0.00 | 12.620.21 | |
| 30,000 | 94.8%0.01 | 87.5%0.01 | 3.810.06 | 4.0%0.00 | 13.010.20 |
The quantitative results are reported in Table 1. In this experiment, we randomly choose 10,000 images from the ImageNet validation set and divide them into ten groups. Then we calculate the mean and standard deviation (SD). The best results are recorded in bold based on Wilcoxon signed-rank test with significance level at 0.05. We can find in all query budgets, our Saliency Attack statistically significantly outperforms all the baselines with a huge gap in terms of and three imperceptibility metrics, which demonstrates the superiority of our method to refine the perturbations in salient regions. For baselines, although TVDBA, Parsimonious Attack and Square Attack can obtain a better , their successful AEs are not truly imperceptible and will be easily detected by some defenses or humans. For Boundary Attack, it can gradually make progress on , and MAD as the query budget increases, but they are still much worse than Saliency Attack. This is because it takes at least hundreds of thousands of queries for Boundary Attack to converge (Brendel et al., 2018), which is infeasible in practice. It is also obvious that Parsimonious-sal Attack and Square-sal Attack obtain better imperceptibility performance than their original version with little degradation in SR. This suggests the use of salient regions for black-box attacks is practicable.
We also plot the convergence curve of versus query number under different MAD thresholds in Figure 6. It shows that Saliency Attack can lead other attacks stably most of the time. For some baselines such as Square Attack and Parsimonious Attack, they can generate some successful AEs with very few queries due to global perturbations and some tricks like initializing perturbations with random vertical stripes (Andriushchenko et al., 2020), but they lack the ability to further improve the imperceptibility. Instead, Saliency Attack conservatively selects small regions to perturb, hence its query efficiency is a little lower than some baselines at the beginning but soon exceeds them. We further study the change of their MAD scores in Appendix A.4 and find most AEs can be improved after restricting in salient region, which also validates the effectiveness of our method.
4.3. Ablation Study
We carry out ablation studies of Saliency Attack, including refining in salient region, in non-salient region, and without saliency (refining in the whole image). We also design a greedy search as a baseline to verify our Refine search. We test multiple block sizes for greedy search and use 32 as the best choice (see Appendix A.5). The results on 1,000 randomly selected images and some examples are given in Table 2 and Figure 7. Note that refining in salient region and refining without saliency generate the same or almost the same perturbations, which means the salient regions indeed contain useful parts and enhance the query efficiency by limiting the search space. But for refining in non-salient region, its perturbation is more complex and visible with worse query efficiency and SR due to unuseful search space. Compared with greedy search, our Refine search has much better query efficiency and , which demonstrates its superiority. Therefore, we can conclude that both salient region and Refine search facilitate Saliency Attack.
| Method | Avg. queries | |||||
|---|---|---|---|---|---|---|
| Refining in salient region | 1958 | 93.6% | 86.2% | 3.71 | 3.8% | 12.88 |
| Refining in non-salient region | 3128 | 78.2% | 57.0% | 4.94 | 6.5% | 21.58 |
| Refining without saliency | 2563 | 95.5% | 79.6% | 3.84 | 4.2% | 16.35 |
| Greedy search in salient region | 2727 | 56.0% | 50.7% | 4.37 | 4.7% | 12.87 |








4.4. Hyperparameter Sensitivity
The hyperparameter is the initial block size that determines the first level of split blocks. We test the effect of different on SR, query number, and imperceptibility ( and MAD) over 1,000 randomly selected examples in Figure 8. As decreases, SR and imperceptibility can be improved, and SR reaches the peak when equals 16. This is because, with smaller initial blocks, Saliency Attack can search for perturbations more finely and accurately leading to higher SR and better imperceptibility. Meanwhile, inevitably more queries are needed, especially for sorting initial blocks. Under a limited query budget like 10,000, the remaining query budget for searching in finer blocks could be inadequate. That’s why a turning point occurs in SR.
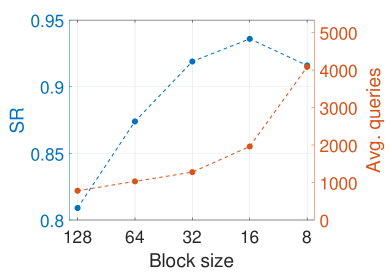
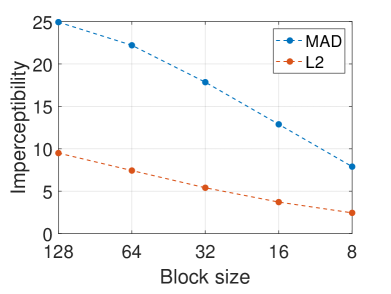
We also show some examples in Figure 9. It can be observed that as decreases, the generated perturbations become smaller but more salient. For instance, in the first row, the perturbation with roughly covers the region of the dog face, which is also the brightest region in the BP-saliency map. While the perturbation with or focuses on smaller region of the dog ear. This indicates that our Saliency Attack could find smaller and more important perturbations progressively as the decreases, which coincides with our assumption before. The perturbations are also interpretable to some extent, like perturbing the specific regions of a dog’s ears, eyes or nose.










4.5. Attacking Detection-based Defense
To further validate the imperceptibility of AEs, we attack against two detection-based defenses that attempt to detect AEs from clean images. The first is Feature Squeezing333Implementation of Feature Squeezing: https://github.com/mzweilin/EvadeML-Zoo (Xu et al., 2018). Its basic idea is to squeeze out unnecessary input features that may be utilized by an adversary to generate AEs. Comparing the model’s prediction on the original image with its prediction on the image after squeezing, the input is likely to be adversarial if the original and squeezed inputs produce substantially different outputs. Feature Squeezing adopts color bits reduction of each pixel and spatial smoothing (local and non-local smoothing) as squeezers. We use the recommended parameters () for ImageNet dataset. Another is a CNN-based binary classifier based on a Steganography detector (Boroumand et al., 2019), which is designed for detecting small noise specifically and outperforms classic classification models such as Inception-v3 or ResNet. We finetune the pretrained model444https://github.com/brijeshiitg/Pytorch-implementation-of-SRNet with AEs generated by different attacks. Concretely, we randomly select 1,000 clean images and generate the corresponding AEs with Saliency Attack and six baselines, respectively. Thus, we use pairs of clean images and AEs as the training set to finetune the model. The training is run for 100 epochs, and the learning rate is 0.001. We test another 1,000 samples and record the detection rate (DR), which is the lower the better.
| Method | Feature Squeezing DR | Classifier DR | ||
|---|---|---|---|---|
| Boundary | 100.0% | 30.2% | 64.5% | 68.0% |
| TVDBA | 96.9% | 23.2% | 26.5% | 61.9% |
| Parsimonious | 98.2% | 14.1% | 33.3% | 89.7% |
| Parsimonious-sal | 96.7% | 12.0% | 29.7% | 67.6% |
| Square | 99.7% | 1.9% | 47.8% | 85.4% |
| Square-sal | 97.1% | 22.5% | 26.1% | 63.1% |
| Saliency (ours) | 93.6% | 86.2% | 21.2% | 50.4% |
From Table 3, we can find our Saliency attack can achieve lower detection rate against both Feature Squeezing and binary classifier detection than other baselines. For Feature Squeezing, although the area of perturbation generated by Saliency Attack is quite small and thus suffering a higher risk of being denoised by squeezers, the detection rate of Saliency Attack is still better than other attacks due to our effective perturbation. For the binary classifier detector, our Saliency Attack obtains nearly accuracy/detection rate, which means the perturbation is invisible enough that the classifier will be difficult to converge and results in random guess. Therefore, our Saliency Attack is able to generate imperceptible AEs that evade different detection-based defenses.
5. Conclusion
In this paper, we propose restricting black-box attacks to perturb in salient regions to improve the imperceptibility of AEs, and propose a novel black-box attack, Saliency Attack. Experiments show that SOTA black-box attacks restricted in salient regions can indeed achieve better imperceptibility performance, while Saliency Attack further enhances this by recursively refining perturbations in salient regions. Its perturbation is much smaller, imperceptible and interpretable to some extent. Besides, we also find that the salient regions of some examples are indeed progressive with respect to their impact on model output, which is consistent with our assumption from the previous visualization studies. Finally, the evaluation demonstrates that the AEs generated by Saliency Attack are harder to be detected, which validates its imperceptibility from the defensive perspective.
Although our Refine search provides significant benefit to the imperceptibility, it inevitably consumes more queries compared with the black-box attacks with global perturbations. In the future, we will try to find better ways to balance the three objectives of query efficiency, imperceptibility and attack success rate for black-box attacks. Furthermore, we will apply the salient region to more black-box attacks to improve their imperceptibility. Our Saliency Attack could also be tested against other kinds of defenses, such as robustness-based defenses (adversarial training, network distillation, etc.), to validate its effectiveness.
References
- (1)
- Alzantot et al. (2019) Moustafa Alzantot, Yash Sharma, Supriyo Chakraborty, Huan Zhang, Cho-Jui Hsieh, and Mani B. Srivastava. 2019. GenAttack: practical black-box attacks with gradient-free optimization. In Proceedings of the Genetic and Evolutionary Computation Conference. Prague, Czech Republic, 1111–1119.
- Andriushchenko et al. (2020) Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion, and Matthias Hein. 2020. Square Attack: A Query-Efficient Black-Box Adversarial Attack via Random Search. In Proceedings of the 16th European Conference on Computer Vision, Part XXIII, Vol. 12368. Glasgow, UK, 484–501.
- Bahdanau et al. (2015) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations. San Diego, CA.
- Boroumand et al. (2019) Mehdi Boroumand, Mo Chen, and Jessica J. Fridrich. 2019. Deep Residual Network for Steganalysis of Digital Images. IEEE Transactions on Information Forensics and Security 14, 5 (2019), 1181–1193.
- Brendel et al. (2018) Wieland Brendel, Jonas Rauber, and Matthias Bethge. 2018. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models. In Proceedings of the 6th International Conference on Learning Representations. Vancouver, BC, Canada.
- Carlini and Wagner (2017) Nicholas Carlini and David A. Wagner. 2017. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy. San Jose, CA, 39–57.
- Chen et al. (2017) Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. 2017. ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security. Dallas, TX, 15–26.
- Croce and Hein (2019) Francesco Croce and Matthias Hein. 2019. Sparse and Imperceivable Adversarial Attacks. In Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, Korea (South), 4723–4731.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Miami, FL, 248–255.
- Dong et al. (2020) Xiaoyi Dong, Jiangfan Han, Dongdong Chen, Jiayang Liu, Huanyu Bian, Zehua Ma, Hongsheng Li, Xiaogang Wang, Weiming Zhang, and Nenghai Yu. 2020. Robust Superpixel-Guided Attentional Adversarial Attack. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition. Seattle, WA, 12892–12901.
- Fezza et al. (2019) Sid Ahmed Fezza, Yassine Bakhti, Wassim Hamidouche, and Olivier Déforges. 2019. Perceptual Evaluation of Adversarial Attacks for CNN-based Image Classification. In Proceedings of the 11th International Conference on Quality of Multimedia Experience. Berlin, Germany, 1–6.
- Goodfellow et al. (2015) Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations. San Diego, CA.
- Guo et al. (2019) Chuan Guo, Jared S. Frank, and Kilian Q. Weinberger. 2019. Low Frequency Adversarial Perturbation. In Proceedings of the 35th Conference on Uncertainty in Artificial Intelligence, Vol. 115. Tel Aviv, Israel, 1127–1137.
- Hinton et al. (2012) Geoffrey Hinton, Li Deng, Dong Yu, George E. Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N. Sainath, and Brian Kingsbury. 2012. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Processing Magazine 29, 6 (2012), 82–97.
- Ilyas et al. (2018) Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. 2018. Black-box Adversarial Attacks with Limited Queries and Information. In Proceedings of the 35th International Conference on Machine Learning, Vol. 80. Stockholmsmässan, Stockholm, Sweden, 2142–2151.
- Ilyas et al. (2019) Andrew Ilyas, Logan Engstrom, and Aleksander Madry. 2019. Prior Convictions: Black-box Adversarial Attacks with Bandits and Priors. In Proceedings of the 7th International Conference on Learning Representations. New Orleans, LA.
- Larson and Chandler (2010) Eric C. Larson and Damon M. Chandler. 2010. Most apparent distortion: full-reference image quality assessment and the role of strategy. Journal of Electronic Imaging 19, 1 (2010), 011006.
- Li and Chen (2021) Nannan Li and Zhenzhong Chen. 2021. Toward Visual Distortion in Black-Box Attacks. IEEE Transactions on Image Processing 30 (2021), 6156–6167.
- Li et al. (2021) Xurong Li, Shouling Ji, Meng Han, Juntao Ji, Zhenyu Ren, Yushan Liu, and Chunming Wu. 2021. Adversarial Examples versus Cloud-Based Detectors: A Black-Box Empirical Study. IEEE Transactions on Dependable and Secure Computing 18, 4 (2021), 1933–1949.
- Liu et al. (2021) Shengcai Liu, Ning Lu, Cheng Chen, Chao Qian, and Ke Tang. 2021. HydraText: Multi-objective Optimization for Adversarial Textual Attack. arXiv preprint arXiv:2111.01528 abs/2111.01528 (2021).
- Liu et al. (2022) Shengcai Liu, Ning Lu, Cheng Chen, and Ke Tang. 2022. Efficient Combinatorial Optimization for Word-Level Adversarial Textual Attack. IEEE ACM Transactions on Audio, Speech and Language Processing 30 (2022), 98–111.
- Moon et al. (2019) Seungyong Moon, Gaon An, and Hyun Oh Song. 2019. Parsimonious Black-Box Adversarial Attacks via Efficient Combinatorial Optimization. In Proceedings of the 36th International Conference on Machine Learning, Vol. 97. Long Beach, California, 4636–4645.
- Moosavi-Dezfooli et al. (2016) Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, and Pascal Frossard. 2016. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, 2574–2582.
- Narodytska and Kasiviswanathan (2017) Nina Narodytska and Shiva Kasiviswanathan. 2017. Simple Black-Box Adversarial Attacks on Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu, HI, 1310–1318.
- Olah et al. (2018) Chris Olah, Arvind Satyanarayan, Ian Johnson, Shan Carter, Ludwig Schubert, Katherine Ye, and Alexander Mordvintsev. 2018. The Building Blocks of Interpretability. Distill (2018).
- Papernot et al. (2016) Nicolas Papernot, Patrick D. McDaniel, Somesh Jha, Matt Fredrikson, Z. Berkay Celik, and Ananthram Swami. 2016. The Limitations of Deep Learning in Adversarial Settings. In Proceedings of the IEEE European Symposium on Security and Privacy. Saarbrücken, Germany, 372–387.
- Parkhi et al. (2015) Omkar M. Parkhi, Andrea Vedaldi, and Andrew Zisserman. 2015. Deep Face Recognition. In Proceedings of the 26th British Machine Vision Conference. Swansea, UK, 41.1–41.12.
- Redmon et al. (2016) Joseph Redmon, Santosh Kumar Divvala, Ross B. Girshick, and Ali Farhadi. 2016. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, 779–788.
- Schrijver (1999) Alexander Schrijver. 1999. Theory of linear and integer programming. Wiley.
- Selvaraju et al. (2017) Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2017. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy, 618–626.
- Sharif et al. (2018) Mahmood Sharif, Lujo Bauer, and Michael K. Reiter. 2018. On the Suitability of Lp-Norms for Creating and Preventing Adversarial Examples. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City, UT, 1605–1613.
- Simonyan et al. (2014) Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. 2014. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. In Proceedings of the 2nd International Conference on Learning Representations. Banff, AB, Canada.
- Su et al. (2019) Jiawei Su, Danilo Vasconcellos Vargas, and Kouichi Sakurai. 2019. One Pixel Attack for Fooling Deep Neural Networks. IEEE Transactions on Evolutionary Computation 23, 5 (2019), 828–841.
- Sun et al. (2020) Qi Sun, Arjun Ashok Rao, Xufeng Yao, Bei Yu, and Shiyan Hu. 2020. Counteracting Adversarial Attacks in Autonomous Driving. In Proceedings of the IEEE/ACM International Conference On Computer Aided Design. San Diego, CA, 83:1–83:7.
- Szegedy et al. (2016) Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. 2016. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, 2818–2826.
- Szegedy et al. (2014) Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian J. Goodfellow, and Rob Fergus. 2014. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations. Banff, AB, Canada.
- Tu et al. (2019) Chun-Chen Tu, Pai-Shun Ting, Pin-Yu Chen, Sijia Liu, Huan Zhang, Jinfeng Yi, Cho-Jui Hsieh, and Shin-Ming Cheng. 2019. AutoZOOM: Autoencoder-Based Zeroth Order Optimization Method for Attacking Black-Box Neural Networks. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, Hawaii, 742–749.
- Wang et al. (2021) Yajie Wang, Shangbo Wu, Wenyi Jiang, Shengang Hao, Yu-an Tan, and Quanxin Zhang. 2021. Demiguise Attack: Crafting Invisible Semantic Adversarial Perturbations with Perceptual Similarity. In Proceedings of the 30th International Joint Conference on Artificial Intelligence. Virtual Event / Montreal, Canada, 3125–3133.
- Wang et al. (2004) Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 13, 4 (2004), 600–612.
- Xiang et al. (2021) Tao Xiang, Hangcheng Liu, Shangwei Guo, Tianwei Zhang, and Xiaofeng Liao. 2021. Local Black-box Adversarial Attacks: A Query Efficient Approach. arXiv preprint arXiv:2101.01032 abs/2101.01032 (2021).
- Xu et al. (2018) Weilin Xu, David Evans, and Yanjun Qi. 2018. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. In Proceedings of the 25th Annual Network and Distributed System Security Symposium. San Diego, California.
- Zeiler and Fergus (2014) Matthew D. Zeiler and Rob Fergus. 2014. Visualizing and Understanding Convolutional Networks. In Proceedings of the 13th European Conference on Computer Vision, Part I, Vol. 8689. Zurich, Switzerland, 818–833.
- Zhang et al. (2020) Hanwei Zhang, Yannis Avrithis, Teddy Furon, and Laurent Amsaleg. 2020. Smooth adversarial examples. EURASIP Journal on Information Security 2020 (2020), 15.
- Zhao and Wu (2019) Ting Zhao and Xiangqian Wu. 2019. Pyramid Feature Attention Network for Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, CA, 3085–3094.
- Zhao et al. (2020) Zhengyu Zhao, Zhuoran Liu, and Martha A. Larson. 2020. Towards Large Yet Imperceptible Adversarial Image Perturbations With Perceptual Color Distance. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition. Seattle, 1036–1045.
- Zhou et al. (2016) Bolei Zhou, Aditya Khosla, Àgata Lapedriza, Aude Oliva, and Antonio Torralba. 2016. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, 2921–2929.
Appendix A Appendix
A.1. MAD Metric
Most Apparent distortion (MAD) metric (Larson and Chandler, 2010) is one of the state-of-the-art full-reference image quality assessment methods. MAD attempts to merge two separate strategies for two kinds of distorted images, respectively. For high-quality images with near-threshold distortion (just visible), MAD focuses on detection-based strategy to look for distortions in the presence of the image. While for low-quality images with suprathreshold distortion (clearly visible), MAD focuses on appearance-based strategy to look for image content in the presence of the distortions. MAD will control the weight of two strategies according to the type of distorted images. The calculation process of MAD can be summarized as following steps and we recommend interested readers to read the original literature.
-
(1)
Compute locations of visible distortions based on luminance images.
-
(2)
Combine the visibility map with local error image.
-
(3)
Decompose both the distorted and original images into log-Gabor subbands.
-
(4)
Calculate different statistics of each subband.
-
(5)
Calculate the adaptive blending score.
A.2. PFA Network for Saliency Detection
Pyramid Feature Attention (PFA) network (Zhao and Wu, 2019) is a novel salient object detection method considering the different characteristics level features. Specifically, the saliency maps from low-level features contain many noises, while the saliency maps from high-level features only get an approximate area. Therefore, PFA network first devises a context-aware pyramid feature extraction (CPFE) module to get multi-scale multi-receptive-field high-level features, and then uses channel-wise attention (CA) to select appropriate scale and receptive-field for generating saliency regions. On the other hand, to refine the boundaries of saliency regions, PFA network uses spatial attention to better focus on the effective low-level features, and obtain clear saliency boundaries. After the processing of different attention mechanisms, the high-level features and low-level features are complementary-aware and suitable to generate saliency map. Besides, an edge preservation loss is proposed to guide the network to learn more detailed information in boundary localization. With these powerful feature extraction methods and attention mechanisms, PFA network can achieve robust and effective salient object detection, outperforming SOTA methods under different evaluation metrics.
A.3. Threshold for MAD Metric
Since Boundary Attack (Brendel et al., 2018) can reduce the distortion gradually, we generate multiple adversarial examples with different MAD scores in Figure 10 to find a proper threshold for MAD metric.
























A.4. Scatter Plot of MAD Scores
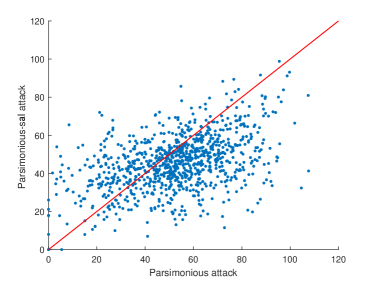
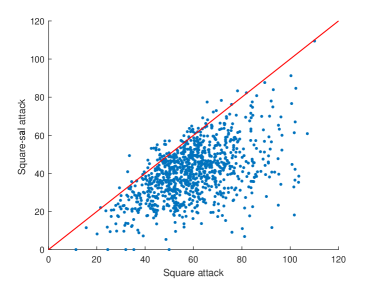
As shown in Figure 11, via restricting perturbations in salient region, 68.1% and 94.3% examples of Parsimonious-sal attack and Square-sal attack have better MAD scores compared with their original version, respectively. Since Parsimonious Attack uses a greedy local search while Square attack adopts a random search, it is obvious that limiting the search in salient regions is more helpful to Square Attack.
A.5. Greedy Search in Salient Region with Different Block Sizes
We test different block sizes for greedy search in salient region in Table 4, and choose the best one (block size equals 32) to be compared in ablation study.
| Block size | Avg. queries | |||||
|---|---|---|---|---|---|---|
| 128 | 57 | 20.6% | 18.4% | 7.32 | 12.8% | 11.50 |
| 64 | 512 | 37.4% | 31.3% | 6.37 | 10.2% | 15.18 |
| 32 | 2727 | 56.0% | 50.7% | 4.37 | 4.7% | 12.87 |
| 16 | 4039 | 35.4% | 35.2% | 1.79 | 0.8% | 4.84 |