Sampling-Based Decomposition Algorithms for Arbitrary Tensor Networks
Abstract
We show how to develop sampling-based alternating least squares (ALS) algorithms for decomposition of tensors into any tensor network (TN) format. Provided the TN format satisfies certain mild assumptions, resulting algorithms will have input sublinear per-iteration cost. Unlike most previous works on sampling-based ALS methods for tensor decomposition, the sampling in our framework is done according to the exact leverage score distribution of the design matrices in the ALS subproblems. We implement and test two tensor decomposition algorithms that use our sampling framework in a feature extraction experiment where we compare them against a number of other decomposition algorithms.
1 Introduction
Tensor decomposition has emerged as an important tool in data mining and machine learning [24, 4, 5, 11]. Applications in data mining include network analysis, web mining, topic modeling and recommendation systems. Tensor decomposition is used widely in machine learning for things like parameter reduction in neural networks, understanding of deep neural network expressiveness, supervised learning and feature extraction.
Due to the multidimensional nature of tensors, they are inherently plagued by the curse of dimensionality. For example, representing a tensor with modes requires numbers. This exponential dependence on makes its way into algorithms for computing tensor decompositions. Alternating least squares (ALS) is arguably the most popular and successful approach for computing a wide range of tensor decompositions. When decomposing a tensor , each iteration of ALS involves solving a sequence of least squares problems for which the entries of feature as the dependent variables. The per-iteration cost of ALS therefore naturally inherits the exponential dependence on .
A large number of papers have sought to reduce the cost of tensor decomposition by leveraging techniques from randomized numerical linear algebra. One particularly interesting line of work [3, 14, 9, 19, 18] seeks to construct ALS algorithms with a per-iteration cost which is sublinear in the number of tensor entries, i.e., . Since any algorithm considering all entries of immediately incurs a cost of , these works have all resorted to sampling-based techniques. More precisely, they all sample the ALS subproblems according to the leverage score distribution (or an approximation thereof). This is done efficiently by taking advantage of the special structure of the design matrices in the ALS subproblems for tensor decomposition.
The previous works discussed above develop methods for specific tensor decompositions: The CP decomposition in [3, 14, 18], Tucker decomposition in [9], and the tensor ring decomposition in [19, 18]. In this paper, we consider all decompositions that can be expressed in tensor network (TN) format. The TN format allows for a very wide range of decompositions, including the CP, Tucker, tensor train and tensor ring decompositions. The following summarizes our contributions:
-
•
We first show how to efficiently sample rows of any tall-and-skinny matrix which is in TN format according to the exact leverage score distribution.
-
•
We then show how this sampling technique can be used to yield ALS algorithms with a per-iteration cost which is input sublinear for all TN decompositions that satisfy certain mild assumptions.
The decomposition framework we present builds on the work in [18]. That paper is notable since it provided the first sampling-based ALS methods for CP and tensor ring decomposition with a per-iteration cost depending polynomially on ; the dependence in earlier works was exponential [3, 14, 19]. We are able to substantially simplify the scheme in [18] by entirely avoiding the complicated recursive sketching procedure that it relies on. This makes implementation easier and is also what ensures that the sampling is done according to the exact leverage score distribution rather than an approximation of it. The simplification is also what paves the way for generalization to arbitrary TN formats.
2 Related Work
Cheng et al. [3] develop the first ALS method for CP decomposition with an input sublinear per-iteration cost. Their method uses a mixture of leverage score and row-norm sampling applied to the matricized-tensor-times-Khatri–Rao product (MTTKRP) which arises as a key computational kernel in CP decomposition. Larsen and Kolda [14] use leverage score sampling to reduce the size of each ALS subproblem. Their method has improved theoretical guarantees compared to those in [3] as well as improved scalability due to various practical improvements. Malik and Becker [19] propose a sampling-based ALS method for tensor ring decomposition which also uses leverage score sampling to reduce the size of the ALS subproblems.
All three papers [3, 14, 19] require a number of samples which scales exponentially with the number of input tensor modes, , for performance guarantees to hold. This translates into a per-iteration cost which is for the CP decomposition [3, 14] and for the tensor ring decomposition [19], where is the relevant notion of rank. For low-rank decompositions (), the cost will be input sublinear despite this exponential cost, but for higher rank it might not be (recall that, unlike in matrix decomposition, we can have in tensor decomposition). Malik [18] develop methods for both CP and tensor ring decomposition which avoid this exponential dependence on , instead improving it to a polynomial dependence. This is achieved by sampling from a distribution much closer to the exact leverage score distribution than the previous works [3, 14, 19] do. Since our work builds on and improves the scheme in [18], it also has a polynomial dependence on when used for CP and tensor ring decomposition (see Tables 1 and 2).
Fahrbach et al. [9] develop a method for efficient sampling of ridge regression problems involving Kronecker product design matrices. They use these techniques to achieve an efficient sampling-based ALS method for regularized Tucker decomposition.
Efficient sketching of structured matrices is an active research area with applications beyond tensor decomposition. The recent work by Ma and Solomonik [16] is particularly interesting since it proposes structured sketching operators for general TN matrices. These operators take the form of TNs made up of Gaussian tensors and are therefore dense. When used in ALS for tensor decomposition, their sketching operators therefore need to access all entries of the data tensor in each least squares solve which leads to a per-iteration cost which is at least linear in the input tensor size (and therefore exponential in ).
Due to space constraints, we have focused on previous works that develop sampling-based ALS methods here. There is a large number of works that develop randomized tensor decomposition methods using other techniques. For a comprehensive list of such works, see [18, Sec. 2]. For an overview of work on structured sketching, see [20, Sec. 1.2].
3 Preliminaries
3.1 General Notation
By tensor, we mean a multidimensional array containing real numbers. We refer to a tensor with indices as an -way tensor and we say that it is of order or that it has modes. We use bold uppercase Euler script letters (e.g., ) to denote tensors of order 3 or greater, bold uppercase letters (e.g., ) to denote matrices, bold lowercase letters (e.g., ) to denote vectors, and regular lowercase letters to denote scalars (e.g., ). We denote entries of an object either in parentheses or with subscripts. For example, is the entry on position in the 3-way tensor , and is the th entry in the vector . We use a colon to denote all entries along a particular mode. For example, denotes the th row of the matrix . Superscripts in parentheses will be used to denote a sequence of objects. For example, is a sequence of tensors and is the th canonical basis vector. The values that a tensor’s indices can take are referred to as dimensions. For example, if then the dimensions of modes 1, 2 and 3 are , and respectively. Note that dimension does not refer to the number of modes, which is 3 for . For a positive integer , we use the notation . For indices , the notation will be used to denote the linear index corresponding to the multi-index . The pseudoinverse of a matrix is denoted by . We use , and to denote the Kronecker, Khatri–Rao and Hadamard matrix products which are defined in Section A.
3.2 Tensor Networks
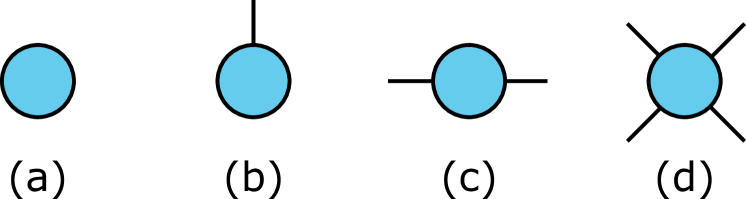
A tensor network (TN) consists of tensors and connections between them that indicate how they should be contracted with each other. Since the mathematical notation easily gets unwieldy when working with TNs, it is common practice to use graphical representations when discussing such networks. Figure 1 shows how scalars, vectors, matrices and tensors can be represented graphically. A circle or node is used to represent a tensor, and dangling edges are used to indicate modes of the tensor.
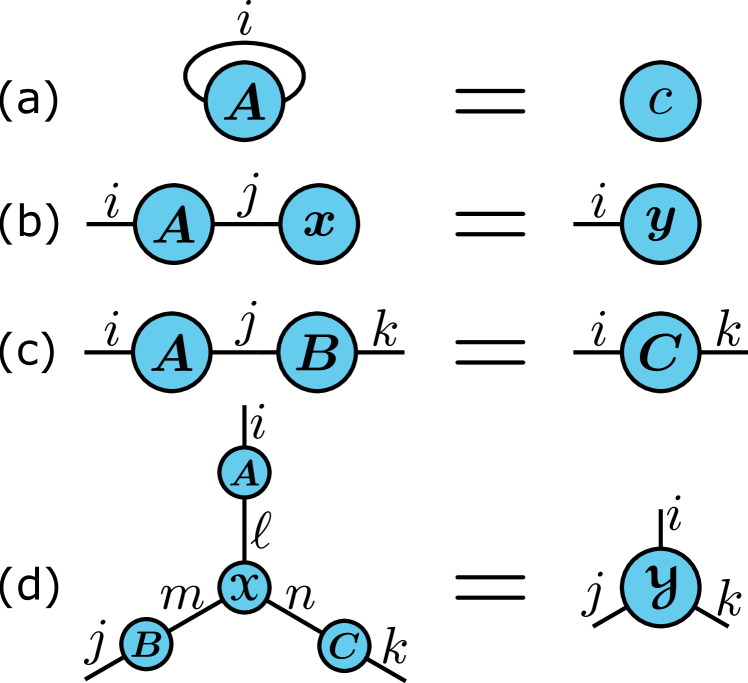
Contraction between two tensors or a tensor with itself can be represented by connecting the appropriate dangling edges. This is illustrated in Figure 2. In mathematical notation, these contractions can be written elementwise as
-
(a)
,
-
(b)
,
-
(c)
,
-
(d)
.
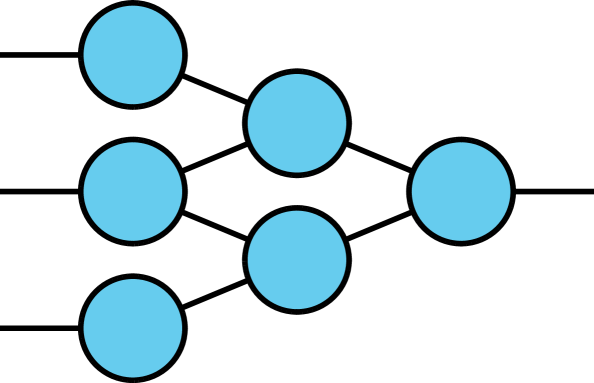
To reduce computational cost when contracting a TN, it is optimal to contract two tensors at a time [26].
Determining the optimal contraction order is NP-hard, and developing heuristics for this problem is an active research area [26, 21].
There are several software packages that compute exact or approximate optimal contraction orders, e.g., NCON [25] for Matlab and the opt_einsum package for Python111Available at https://github.com/dgasmith/opt_einsum..
A TN matrix is a matrix which is represented by a TN. The dangling edges in such a network represent either rows or columns of the matrix. Figure 3 shows an example of a TN matrix with dangling edges pointing to the left representing rows and dangling edges pointing right representing columns. Suppose there are and dangling edges representing rows and columns, respectively, and let . Let denote the -way TN representing the matrix, and let be a length- vector with the first entries enumerating the modes of corresponding to rows and the remaining entries enumerating those modes that correspond to columns. The matrix represented by is then given elementwise by
| (1) |
and is of size . For example, if the mode dimensions corresponding to the dangling edges in Figure 3 is 100, then the matrix represented by the TN is of size .
Graphical TN notation does not specify the order in which the modes corresponding to dangling edges should appear when the tensor is represented as a multidimensional array. A similar ambiguity exists for the TN matrices where it is not clear how the row and column modes should be permuted. In both cases, any ordering can be used as long the choice is consistent in all computations.
3.3 Leverage Score Sampling
In the context of least squares, leverage scores indicate how important the rows of the design matrix are. By sampling according to this importance metric, it is possible to compute a good approximation (with high probability) to the least squares solution using a random subset of the equations of the full least squares problem. We provide the necessary preliminaries on leverage score sampling in this section and refer the reader to [17, 29] for further details.
Definition 3.1.
The th leverage score of a matrix is defined as for , where is the th canonical basis vector of length .
Definition 3.2.
Let and let be a vector with entries . Then is the leverage score distribution on row indices of . Let be a random map such that each is independent and distributed according to . The random matrix defined elementwise via
| (2) |
is the leverage score sampling matrix for . In (2), is the indicator function which is 1 if the random event occurs and 0 otherwise.
The following result is well-known and variants have appeared throughout the literature [6, 7, 8, 14].
Theorem 3.3.
Let be a matrix and suppose is the leverage score sampling matrix for . Moreover, let , and define and
| (3) |
If , then with probability at least it holds that .
4 Proposed Sampling Method
In this section, we propose an efficient method for sampling rows of a tall-and-skinny TN matrix according to its leverage scores. The method is useful when is so large that costs and storage on the order are too expensive, and is small enough that costs and storage on the order are affordable. In this setting it is infeasible to sample the rows of directly via the probability distribution in Definition 3.2 since doing so would require computing the pseudoinverse of which costs . Moreover, once that pseudoinverse is computed, we would be required to compute, store and sample according to a length- vector of probabilities.
In view of Definition 3.1, note that
| (4) |
where . This formulation is the basis for our sampling method. As we show in Section 4.1, the matrix can be computed efficiently when is a TN matrix. Once is computed, we can again leverage the TN structure of to draw samples from its leverage score distribution via the formula in (4) without forming a length- probability vector. We describe how this is done in Section 4.2.
4.1 Computing
When is a TN matrix, it is straightforward to represent the Gram matrix in such a format as well. This can be done by linking up the dangling column edges of with the corresponding dangling row edges of . For example, suppose is the TN matrix in Figure 3. The graphical representation of is then a horizontal mirror image of Figure 3. The resulting Gram matrix is illustrated in Figure 4.
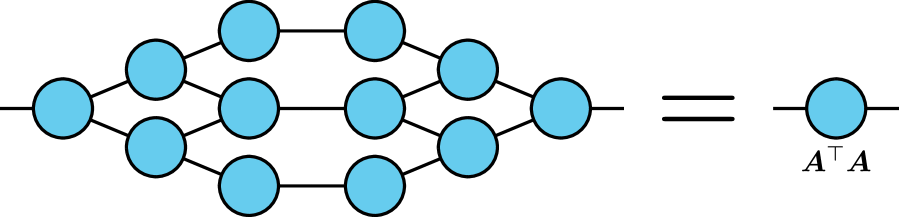
A dense representation of the Gram matrix can be computed by contracting its TN representation. For a wide range of TN matrices, this will be much more efficient that computing naïvely by first forming as a dense matrix and then carrying out a dense matrix-matrix multiplication between and . Once is computed, its pseudoinverse is affordable to compute via standard methods.
4.2 Drawing Samples Efficiently
We now describe how to sample rows of according to its leverage score distribution without needing to form . In order to keep the notation simple, we will assume without loss of generality that the modes of the TN describing the matrix are arranged so that
Sampling a row of is therefore equivalent to sampling a multi-index with each .
In a nutshell, our sampling scheme sequentially samples each index one after another by conditioning on the previously drawn indices. This allows us to sample from the leverage score distribution while at the same time avoid forming the full probability vector of length .
In the following we use to denote the probability that the first index is . We use to denote the conditional probability that the th index is given that the previous indices are . Let . From Definition 3.2 and the formula in (4) we would like to sample row with probability
Therefore, we want the first index to be with probability
| (5) |
The matrix can easily be formulated as a TN matrix by linking up the TNs for and with . Moreover, the summation in (5) in amounts to adding an additional contractions to the TN representation of . All in all, this results in a TN matrix with only two dangling edges. The desired probabilities then lie along the diagonal of this matrix: . The dense representation of can be computed efficiently by contracting the underlying network (it is sufficient to only compute diagonal entries which further reduces the cost). An example of what this looks like when is the TN matrix in Figure 3 is illustrated in Figure 5. The first index is then drawn according to the probability distribution .
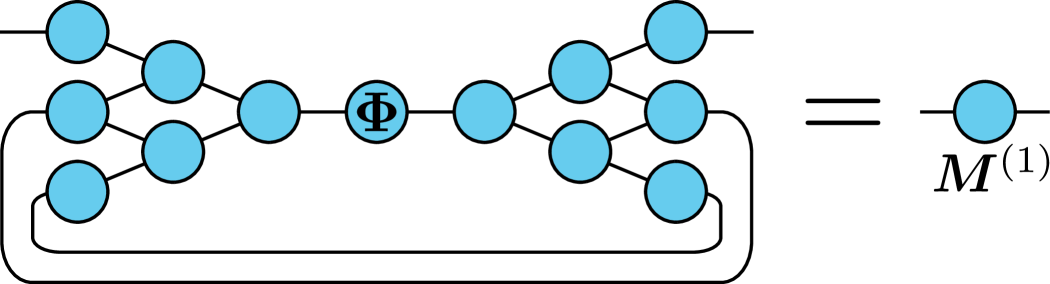
The next step is to draw subsequent indices conditionally on the previously drawn indices. Suppose we have drawn . When sampling the th index we compute the probabilities
| (6) |
for each . Since it is sufficient to compute the numerator in (6) for each and then normalize them so that they add up to 1. Note that
| (7) |
As earlier, this can be represented as a TN by adding additional contractions over the indices to the TN representation of . Moreover, since the indices are fixed, this effectively eliminates the corresponding modes of the underlying tensor representation by reducing their dimensionality to 1. This results in a TN matrix with only two dangling edges, with the desired joint probabilities laying along the diagonal: (again, the cost can be reduced by only computing the diagonal elements of ). Figure 6 illustrates what this looks like when we are computing the probability for the example from Figure 5 with fixed.
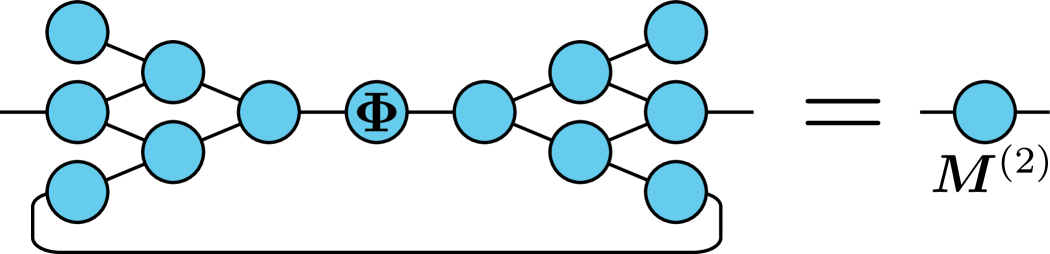
This sampling procedure is carried out until all indices have been drawn, which corresponds to drawing a single row index . The procedure is then repeated until the desired number of samples has been drawn. Note that the distribution remains the same for all samples, so in order to speed up the overall sampling procedure it is a good idea to draw for all samples immediately.
The efficiency of the proposed sampling scheme relies on the possibility to efficiently contract the TNs corresponding to the Gram matrix computation and the probability distributions in (5) and (6). For a large class of tensor networks, this will be possible. We discuss the computational complexity of these contractions for the TN matrices that arise for CP and tensor ring decompositions in Section B.
5 Application to Tensor Decomposition
TNs can be used to express a very wide range of tensor decompositions, including the CP [10], Tucker [27], tensor train [23] and tensor ring decompositions [31].
Suppose is a data tensor that we want to decompose into some TN format consisting of tensors . We use to denote this TN. This decomposition problem can be formulated as the optimization problem
| (8) |
where is a straightforward generalization of the matrix Frobenius norm to tensors (see Section A). In general, this is a difficult non-convex optimization problem which is hard to solve. A popular approach to finding an approximate solution to (8) is to iteratively update one tensor at a time via alternating least squares (ALS). Minimizing the objective in (8) with respect to a single tensor at a time turns it into a linear least squares problem:
| (9) |
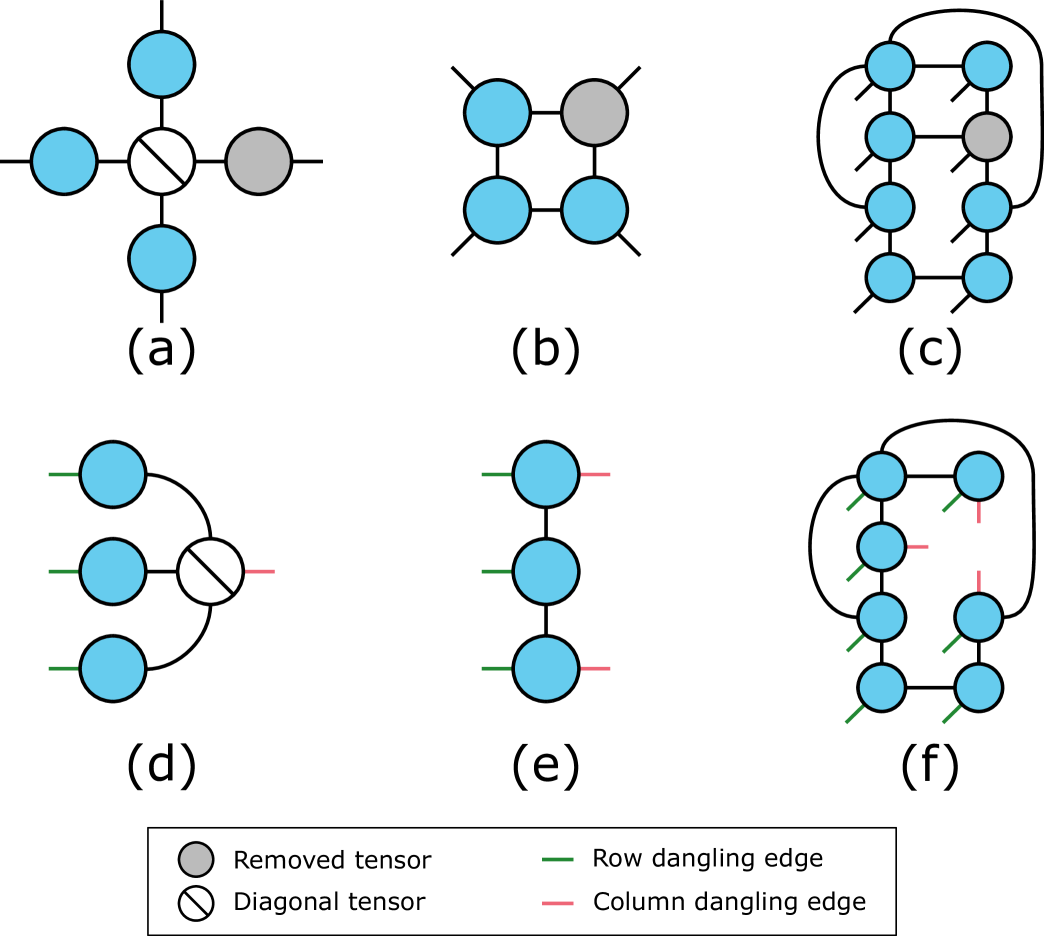
where and are appropriate matricizations of and , respectively, and is a TN matrix which depends on the tensors . For example, for the CP and Tucker decompositions, takes the form of a Khatri–Rao and Kronecker product matrix, respectively [12]. Figure 7 shows examples of three tensor decompositions (top plots) and examples of what a TN matrix corresponding to each decomposition looks like (bottom plots). Algorithm 1 provides a high-level ALS algorithm for computing any TN decomposition.
ALS is the “workhorse approach” to tensor decomposition [12]. ALS-based methods for various decompositions are implemented in many leading tensor software packages, including Tensor Toolbox [2] and Tensorlab [28] for Matlab and TensorLy [13] for Python. ALS typically works well, especially when the data tensor is not too large. However, as previously discussed, each iteration of ALS depends on all entries of . If has modes each of dimension , then contains entries. Algorithms for tensor decomposition therefore inherit this exponential dependence on . In the case of ALS, each iteration computed via (9) requires access to all entries of . Moreover, for every iteration, it requires forming the matrix and then solving a linear system involving this matrix.
As discussed in Section 2, several previous works have sought to address the curse of dimensionality in ALS algorithms by sampling the least squares problem in (9). These works develop methods for specific tensor decompositions. By contrast, our sampling framework described in Section 4 can be used to develop a sampling-based decomposition scheme for any TN decomposition. This is done by independently sampling each least squares problem on line 1 in Algorithm 1 according to the leverage scores of the TN matrix . The sampling is done by first determining the indices to sample by applying our techniques in Section 4. Letting represent the sampling operation, the next step is to compute and . The final step is to solve the sampled least squares problem
| (10) |
In order to make the discussion in Sections 4 and 5 a bit more concrete, we now apply these ideas to the CP decomposition.
Example 5.1.
Suppose is an -way tensor and that we want to compute a rank- CP decomposition of it. Figure 7 (a) shows what the CP decomposition looks like when . Mathematically, for an arbitrary it takes the form
| (11) |
where are the elements in the diagonal tensor in the middle of Figure 7 (a), and the other tensors now have two modes and are therefore denoted by and referred to as factor matrices. The values of the diagonal elements can be incorporated into the factor matrices, and we therefore assume that they are all equal to 1 without loss of generality. The design matrices now take the form
The corresponding unfoldings are defined elementwise via
The TN corresponding to the Gram matrix can be efficiently contracted via the well-known formula
| (12) |
where denotes elementwise product. Drawing a row index for corresponds to drawing a multi-index with each . It is straightforward to show that the appropriate sampling probabilities in (5) and (7) are now given by
This formula appears in Lemma 10 of [18], but in that formula is an approximation of . This also explains why a different normalization constant is used in [18]. The proof, however, remains the same.
5.1 Computational Complexity Examples
In this section we give the computational complexity of our proposed approach when used for CP and tensor ring decomposition. This allows us to compare our work with [18] which also considers these two decompositions. Tables 1 and 2 present the computational complexity of various methods for CP and tensor ring decomposition, respectively, when doing a rank- decomposition of an -way cubic tensor of size . For a precise definition of the rank for each decomposition, see (11) and (14). Our approaches for CP and tensor ring decomposition are called TNS-CP and TNS-TR, respectively, where TNS stands for Tensor Network Sampling. The complexities for our methods are computed in Section B. The complexities for the competing methods are taken from Tables 1 and 2 in [18]. For the randomized methods, the complexities reflect the parameter choices required for theoretical performance guarantees; see the respective cited works for further details.
As mentioned in Section 2, the primary contribution of [18] was to reduce the dependence on in the per-iteration cost from exponential to polynomial in ALS for CP and tensor ring decomposition. Our methods further improve on that cost by reducing the dependence on . The improvement is due to the avoidance of the complicated recursive sketching step used in [18]. Note that all methods other than ours and those by [18] have an exponential dependence on .
| Method | Complexity |
|---|---|
| CP-ALS [12] | |
| SPALS [3] | |
| CP-ARLS-LEV [14] | |
| CP-ALS-ES [18] | |
| TNS-CP (our) |
6 Experiments
We run the same feature extraction and classification experiment as in [18]. The experiment considers 7200 images from the COIL-100 dataset [22]. These images depict 100 different objects (e.g., a toy car, an onion, a tomato), each photographed from 72 different angles. Each image is 128 by 128 pixels and has three color channels. We arrange these images into a tensor of size and then decompose it using either a rank-25 CP decomposition or a rank- tensor ring decomposition. For the CP decomposition, we treat the rows of the factor matrix as feature vectors for each image. We treat 90% of the images as labeled and use them to classify the images in the remaining 10% using a -nearest neighbor algorithm with and 10-fold cross validation. The tensor ring decomposition is used in the same way, but instead of the CP factor matrix we now use the core tensor corresponding to the first mode and reshape the slices into length-25 feature vectors. Further details on the experiment setup are given in Section C.
Table 3 shows the run time, relative decomposition error (Err.) and classification accuracy (Acc.) for a number of different CP and tensor ring decomposition methods. The algorithms for our TNS-CP and TNS-TR were implemented222Our code is available at https://github.com/OsmanMalik/TNS. by modifying the codes for CP-ALS-ES and TR-ALS-ES by [18] appropriately.
| Method | Time (s) | Err. | Acc. (%) |
|---|---|---|---|
| CP-ALS (Ten. Toolbox) | 48.0 | 0.31 | 99.2 |
| CPD-ALS (Tensorlab) | 71.9 | 0.31 | 99.0 |
| CPD-MINF (Tensorlab) | 108.6 | 0.33 | 99.7 |
| CPD-NLS (Tensorlab) | 112.1 | 0.31 | 92.6 |
| CP-ARLS-LEV | 28.6 | 0.32 | 97.7 |
| CP-ALS-ES | 29.0 | 0.32 | 98.3 |
| TNS-CP (our) | 23.5 | 0.32 | 98.3 |
| TR-ALS | 10278.4 | 0.31 | 99.5 |
| TR-ALS-Sampled | 5.3 | 0.33 | 98.0 |
| TR-ALS-ES | 29.7 | 0.33 | 97.2 |
| TNS-TR (our) | 14.5 | 0.33 | 97.3 |
All methods achieve roughly the same decomposition error, with the randomized methods typically having a slightly higher error. All methods except CPD-NLS yield similar classification accuracy. It is clear that our methods are faster than CP-ALS-ES and TR-ALS-ES from [18], corroborating the improved complexity reported in Tables 1 and 2.
7 Conclusion
We have presented a sampling-based ALS approach for decomposing a tensor into any TN format. The generality of the framework is notable—all previous works on randomized tensor decomposition we are aware of develop methods for specific decompositions. Additionally, unlike most previous sampling-based ALS algorithms in the literature, our framework makes it possible to do the sampling according to the exact leverage scores. Our approach simplifies and generalizes the scheme developed in [18]. Both complexity analyses and numerical experiments confirm the improved run time we are able to achieve compared to [18] when we use our framework for CP and tensor ring decomposition.
There are many exciting avenues for future research. One direction is to adapt and implement our method for use in a high-performance distributed memory setting. Another interesting direction is designing an exact leverage score sampling scheme for general TN matrices that avoid the cost that we incur when computing the pseudoinverse . Such methods are known for certain matrices with Kronecker product structure [20], but for general TN matrices such results are not known.
Acknowledgments
OAM was supported by the LDRD Program of Lawrence Berkeley National Laboratory under U.S. DOE Contract No. DE-AC02-05CH11231. VB was supported in part by the U.S. DOE, Office of Science, Office of Advanced Scientific Computing Research, DOE Computational Science Graduate Fellowship under Award No. DE-SC0022158. RM was supported by NSF Grant No. 2004235.
References
- Ahmadi-Asl et al. [2020] S. Ahmadi-Asl, A. Cichocki, A. H. Phan, M. G. Asante-Mensah, F. Mousavi, I. Oseledets, and T. Tanaka. Randomized algorithms for fast computation of low-rank tensor ring model. Machine Learning: Science and Technology, 2020.
- Bader et al. [2021] B. W. Bader, T. G. Kolda, and others. MATLAB Tensor Toolbox, Version 3.2.1. Available online at https://www.tensortoolbox.org, 2021.
- Cheng et al. [2016] D. Cheng, R. Peng, Y. Liu, and I. Perros. SPALS: Fast alternating least squares via implicit leverage scores sampling. In Advances In Neural Information Processing Systems, pages 721–729, 2016.
- Cichocki et al. [2016] A. Cichocki, N. Lee, I. Oseledets, A.-H. Phan, Q. Zhao, and D. P. Mandic. Tensor networks for dimensionality reduction and large-scale optimization: Part 1 low-rank tensor decompositions. Foundations and Trends in Machine Learning, 9(4-5):249–429, 2016.
- Cichocki et al. [2017] A. Cichocki, A.-H. Phan, Q. Zhao, N. Lee, I. Oseledets, M. Sugiyama, and D. P. Mandic. Tensor networks for dimensionality reduction and large-scale optimization: Part 2 applications and future perspectives. Foundations and Trends in Machine Learning, 9(6):431–673, 2017.
- Drineas et al. [2006] P. Drineas, M. W. Mahoney, and S. Muthukrishnan. Sampling algorithms for regression and applications. In Proceedings of the Seventeenth Annual ACM-SIAM Symposium on Discrete Algorithm, pages 1127–1136, 2006.
- Drineas et al. [2008] P. Drineas, M. W. Mahoney, and S. Muthukrishnan. Relative-error CUR matrix decompositions. SIAM Journal on Matrix Analysis and Applications, 30(2):844–881, 2008.
- Drineas et al. [2011] P. Drineas, M. W. Mahoney, S. Muthukrishnan, and T. Sarlós. Faster least squares approximation. Numerische Mathematik, 117(2):219–249, 2011.
- Fahrbach et al. [2022] M. Fahrbach, T. Fu, and M. Ghadiri. Subquadratic Kronecker regression with applications to tensor decomposition. Preprint arXiv:2209.04876, 2022.
- Hitchcock [1927] F. L. Hitchcock. The expression of a tensor or a polyadic as a sum of products. Journal of Mathematics and Physics, 6(1-4):164–189, 1927.
- Ji et al. [2019] Y. Ji, Q. Wang, X. Li, and J. Liu. A survey on tensor techniques and applications in machine learning. IEEE Access, 7:162950–162990, 2019.
- Kolda and Bader [2009] T. G. Kolda and B. W. Bader. Tensor decompositions and applications. SIAM Review, 51(3):455–500, Aug. 2009.
- Kossaifi et al. [2019] J. Kossaifi, Y. Panagakis, A. Anandkumar, and M. Pantic. TensorLy: Tensor learning in Python. Journal of Machine Learning Research, 20(26):1–6, 2019.
- Larsen and Kolda [2022] B. W. Larsen and T. G. Kolda. Practical leverage-based sampling for low-rank tensor decomposition. SIAM Journal on Matrix Analysis and Applications, 43(3):1488–1517, 2022.
- Li and Sun [2020] C. Li and Z. Sun. Evolutionary topology search for tensor network decomposition. In Proceedings of the 37th International Conference on Machine Learning, volume 119, pages 5947–5957. PMLR, 2020.
- Ma and Solomonik [2022] L. Ma and E. Solomonik. Cost-efficient Gaussian tensor network embeddings for tensor-structured inputs. Preprint arXiv:2205.13163, 2022.
- Mahoney [2011] M. W. Mahoney. Randomized algorithms for matrices and data. Foundations and Trends in Machine Learning, 3(2):123–224, 2011.
- Malik [2022] O. A. Malik. More efficient sampling for tensor decomposition with worst-case guarantees. In Proceedings of the 39th International Conference on Machine Learning, volume 162, pages 14887–14917. PMLR, 2022.
- Malik and Becker [2021] O. A. Malik and S. Becker. A sampling-based method for tensor ring decomposition. In Proceedings of the 38th International Conference on Machine Learning, volume 139, pages 7400–7411. PMLR, 2021.
- Malik et al. [2022] O. A. Malik, Y. Xu, N. Cheng, S. Becker, A. Doostan, and A. Narayan. Fast algorithms for monotone lower subsets of Kronecker least squares problems. Preprint arXiv:2209.05662, 2022.
- Meirom et al. [2022] E. Meirom, H. Maron, S. Mannor, and G. Chechik. Optimizing tensor network contraction using reinforcement learning. In Proceedings of the 39th International Conference on Machine Learning, volume 162, pages 15278–15292. PMLR, 2022.
- Nene et al. [1996] S. A. Nene, S. K. Nayar, and H. Murase. Columbia object image library (COIL-100). Technical Report CUCS-006-96, Columbia University, 1996.
- Oseledets [2011] I. V. Oseledets. Tensor-train decomposition. SIAM Journal on Scientific Computing, 33(5):2295–2317, 2011.
- Papalexakis et al. [2016] E. E. Papalexakis, C. Faloutsos, and N. D. Sidiropoulos. Tensors for data mining and data fusion: Models, applications, and scalable algorithms. ACM Transactions on Intelligent Systems and Technology (TIST), 8(2):1–44, 2016.
- Pfeifer et al. [2014a] R. N. Pfeifer, G. Evenbly, S. Singh, and G. Vidal. NCON: A tensor network contractor for MATLAB. Preprint arXiv:1402.0939, 2014a.
- Pfeifer et al. [2014b] R. N. C. Pfeifer, J. Haegeman, and F. Verstraete. Faster identification of optimal contraction sequences for tensor networks. Phys. Rev. E, 90:033315, 2014b.
- Tucker [1963] L. R. Tucker. Implications of factor analysis of three-way matrices for measurement of change. Problems in measuring change, 15(122-137):3, 1963.
- Vervliet et al. [2016] N. Vervliet, O. Debals, L. Sorber, M. Van Barel, and L. De Lathauwer. Tensorlab 3.0. Available online at https://www.tensorlab.net, Mar. 2016.
- Woodruff [2014] D. P. Woodruff. Sketching as a tool for numerical linear algebra. Foundations and Trends in Theoretical Computer Science, 10(1-2):1–157, 2014.
- Yuan et al. [2019] L. Yuan, C. Li, J. Cao, and Q. Zhao. Randomized tensor ring decomposition and its application to large-scale data reconstruction. In IEEE International Conference on Acoustics, Speech and Signal Processing, pages 2127–2131. IEEE, 2019.
- Zhao et al. [2016] Q. Zhao, G. Zhou, S. Xie, L. Zhang, and A. Cichocki. Tensor ring decomposition. Preprint arXiv:1606.05535, 2016.
Appendix A Additional Notation
Let and be two matrices. Their Kronecker product is denoted by and defined as
Suppose now that and , i.e., and have the same number of columns. The Khatri–Rao product of and is denoted by and defined as
The Khatri–Rao product is sometimes called the columnwise Kronecker product for obvious reasons.
Now, suppose that and are of the same size. The Hadamard product, or elementwise product, of and is denoted by and defined elementwise in the obvious way:
The Frobenius norm is a standard matrix norm that can be easily extended to tensors. For a tensor it is defined as
Appendix B Detailed Complexity Analysis
Here we provide further details on the complexity analysis in Section 5.1.
B.1 CP Decomposition
Suppose we are decomposing an -way cubic tensor of size using a rank- CP decomposition. As mentioned in Example 5.1, the entries of the diagonal tensor (see Figure 7 (a)) can be treated as ones without loss of generality. The update in (10) therefore involves updating one of the CP factor matrices , .
Computing
Computing the Gram matrix via (12) costs . When doing this computation, we store all the Gram matrices for no additional computational cost for later use. Computing the pseudoinverse costs an additional . The total cost of computing is therefore .
Drawing Samples
Solving Sampled Least Squares Problem
Adding It All Up
The costs above are for solving one least squares problem of the form (10). Each ALS iteration requires solving such systems. Consequently, the per-iteration cost for our proposed method is
| (13) |
where we have used the fact that the sample size must satisfy (see Theorem 3.3) to simplify the complexity expression. Since has columns, the bound on from Theorem 3.3 is . Inserting this into (13) gives the per-iteration cost
which is what we report in Table 1.
B.2 Tensor Ring Decomposition
Suppose that we are decomposing an -way cubic tensor of size using a tensor ring decomposition with all ranks set to . The decomposition takes the form
| (14) |
where each is now a 3-way tensor of size , and where each summation index goes from 1 to . See [31] for further details on the tensor ring decomposition.
Computing
For the tensor ring decomposition, the TN representation of is shown in Figure 7 for the case . Figure 8 illustrates how we contract the TN corresponding to the Gram matrix for an arbitrary . Each edge we eliminate in subplot (a) costs . Since there are pairs to contract, this brings the total cost of the step in (a) to . Each step in the sequence of contractions in (b) costs . Since such contractions are required, the total cost of step (b) is . Once the matrix in (c) is computed, it costs to compute its pseudoinverse, i.e., less than the cost of the step in (b). Adding up the costs for the steps in (a) and (b) and the cost of the pseudoinverse brings the total cost for computing to .
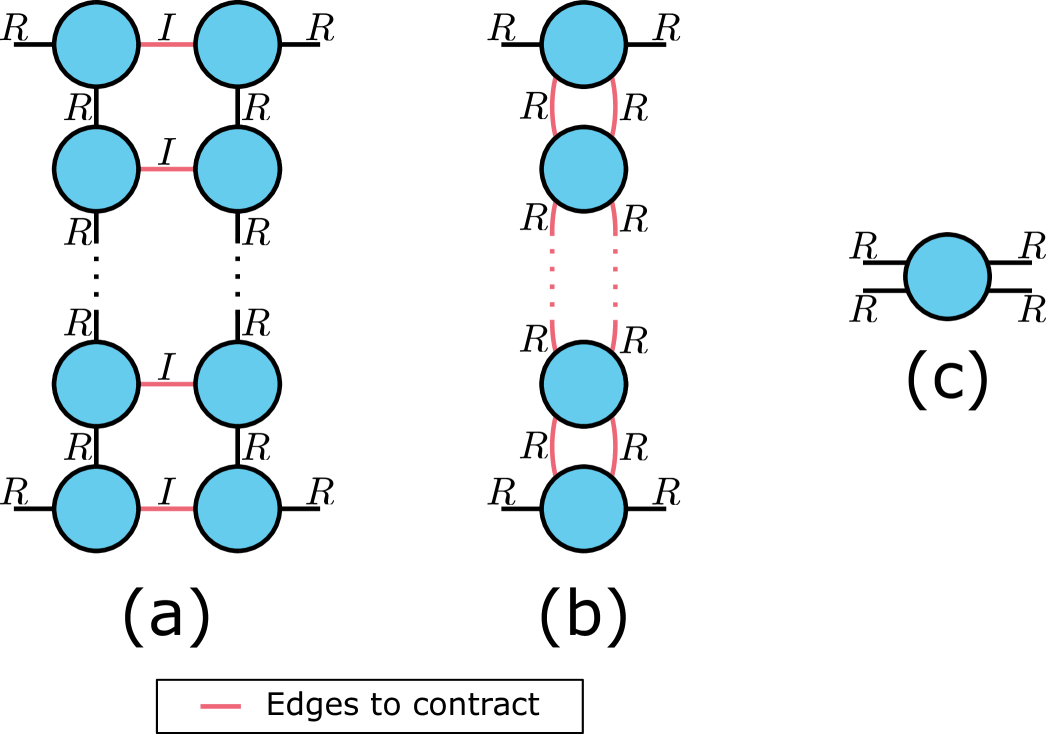
Drawing Samples
The cost is the same as the sampling cost for TR-ALS-ES in [18], but without the one-time costs in that paper333The Gram matrices in [18] are precisely what we compute when we do the contractions in Figure 8 (a). These can be saved during that step, which is why the one-time costs of computing those Gram matrices is already accounted for from the computation of .. The cost is therefore ; see [18, Sec. C.2] for details.
Solving Sampled Least Squares Problem
Adding It All Up
The costs above are for solving one least squares problem of the form (10). Each ALS iteration requires solving such systems. Consequently, the per-iteration cost for our proposed method is
| (15) |
Since has columns, the bound on in Theorem 3.3 is . Inserting this into (15) gives the per-iteration cost
which is what we report in Table 2.
B.3 Some Remarks on Tables 1 and 2
All methods in Table 1 except CP-ALS are randomized. The theoretical guarantees for CP-ARLS-LEV, CP-ALS-ES and TNS-CP are all of the same type: They provide relative-error guarantees of the form in Theorem 3.3 for each least squares solve on line 1 in Algorithm 1 when it is adapted to CP decomposition. For these three methods, the meaning of the variables and are therefore identical. SPALS, by contrast, has weaker additive-error guarantees. Expressed using the same notation as in Theorem 3.3, their guarantees take the form
| (16) |
where the statement in (16) holds with probability at least when the number of samples is large enough. The constant has the same meaning as for the other three randomized methods, but has a different meaning than : The latter is a relative-error accuracy parameter while the former is an additive-error accuracy parameter.
For the three methods TR-ALS-Sampled, TR-ALS-ES and TNS-TR in Table 2, the parameters and are all used in the sense of Theorem 3.3.
The number of iterations, denoted by #it, required to reach a certain accuracy or fulfill certain termination criteria may differ between the various methods. For example, the deterministic ALS methods—by virtue of being exact and non-random—may require fewer iterations to reach a certain accuracy. Similarly differences may exist between the various randomized ALS methods, and between the different decomposition types.
Appendix C Further Details on Experiment
C.1 Competing Methods
We provide some further details on the methods we compare against below.
-
•
CP-ALS. This is an implementation of the standard ALS method for CP decomposition without any randomization. It comes with the Tensor Toolbox for Matlab [2] which can be downloaded at https://www.tensortoolbox.org.
-
•
CPD-ALS, -MINF, -NLS. These methods use three different minimization approaches to compute the CP decomposition. They are all available in the Tensorlab package for Matlab [28] which can be downloaded at https://www.tensorlab.net/.
-
•
CP-ARLS-LEV. This the method proposed in [14]. We use the implementation by Malik [18] which is available at https://github.com/OsmanMalik/TD-ALS-ES.
-
•
CP-ALS-ES. This is the method for CP decomposition proposed in [18]. We use the code available at https://github.com/OsmanMalik/TD-ALS-ES.
-
•
TR-ALS. This is a standard ALS methods for tensor ring decomposition, which was proposed in [31]. We use the implementation by Malik and Becker [19] which is available at https://github.com/OsmanMalik/tr-als-sampled.
-
•
TR-ALS-Sampled. This is the sampling-based approach for tensor ring decomposition proposed in [19]. We use the code available at https://github.com/OsmanMalik/tr-als-sampled.
-
•
TR-ALS-ES. This is the method for tensor ring decomposition proposed in [18]. We use the code available at https://github.com/OsmanMalik/TD-ALS-ES.
C.2 Parameter Choices
We sample rows in all ALS subproblems for the sampling-based CP decomposition methods (CP-ARLS-LEV, CP-ALS-ES and TNS-CP). For the sampling-based tensor ring methods (TR-ALS-Sampled, TR-ALS-ES and TNS-TR) we use samples in the ALS subproblems. Both CP-ALS-ES and TR-ALS-ES require an intermediate embedding via a recursive sketching procedure. For both methods, we use an embedding dimension of 10000 for these intermediate steps, as suggested in [18].
C.3 Hardware/Software and Dataset
The experiments are run in Matlab R2021b on a laptop computer with an Intel Core i7-1185G7 CPU and 32 GB of RAM.
The COIL-100 dataset [22] is available for download at https://www.cs.columbia.edu/CAVE/software/softlib/coil-100.php.