ScaLA: Accelerating Adaptation of Pre-Trained Transformer-Based Language Models via Efficient Large-Batch Adversarial Noise
Abstract
In recent years, large pre-trained Transformer-based language models have led to dramatic improvements in many natural language understanding tasks. To train these models with increasing sizes, many neural network practitioners attempt to increase the batch sizes in order to leverage multiple GPUs to improve training speed. However, increasing the batch size often makes the optimization more difficult, leading to slow convergence or poor generalization that can require orders of magnitude more training time to achieve the same model quality. In this paper, we explore the steepness of the loss landscape of large-batch optimization for adapting pre-trained Transformer-based language models to domain-specific tasks and find that it tends to be highly complex and irregular, posing challenges to generalization on downstream tasks.
To tackle this challenge, we propose ScaLA, a novel and efficient method to accelerate the adaptation speed of pre-trained transformer networks. Different from prior methods, we take a sequential game-theoretic approach by adding lightweight adversarial noise into large-batch optimization, which significantly improves adaptation speed while preserving model generalization. Experiment results show that ScaLA attains 2.7–9.8 adaptation speedups over the baseline for GLUE on BERTbase and RoBERTalarge, while achieving comparable and sometimes higher accuracy than the state-of-the-art large-batch optimization methods. Finally, we also address the theoretical aspect of large-batch optimization with adversarial noise and provide a theoretical convergence rate analysis for ScaLA using techniques for analyzing non-convex saddle-point problems.
1 Introduction
There has been a large paradigm shift in AI: large-scale foundation models (Bommasani et al., 2021), such as BERT (Devlin et al., 2019) and GPT-3 (Brown et al., 2020), are trained on massive open-domain data at scale and then are adapted to a wide range of domains with additional task-specific data. Such a paradigm has led to accuracy breakthroughs in many challenging Natural Language Processing (NLP) tasks such as the General Language Understanding Evaluation (GLUE) benchmark (Wang et al., 2019a). Despite their remarkable performance in accuracy, given that these models often contain a few hundred million parameters (e.g., BERT) to over billions of parameters (e.g., GPT-3), enormous challenges have been raised in terms of their training efficiency.
To accelerate the training speed of large models, a common practice is to increase the batch size in the optimization algorithm in order to leverage multi-device training (Li et al., 2020; Liu et al., 2019; Huang et al., 2019; Shazeer et al., 2018; Shoeybi et al., 2019; Rajbhandari et al., 2019). A larger batch size supports a higher data parallelism degree that allows more workers (e.g., GPUs) to participate in computing gradients locally and then aggregate. Furthermore, most operators used in transformer networks are highly optimized in modern linear algebra frameworks. They can scale to larger batch sizes without significantly increasing the time per step (Wang et al., 2019c; Kaplan et al., 2020).
However, changing the batch size is not always straightforward, as it often makes optimization more difficult. You et al. observe that increasing batch sizes during the pre-training stage of transformer networks can easily lead to slow convergence and propose LAMB (You et al., 2019a) optimizer to speed up large-batch optimization. LAMB applies layer-wise normalization before applying gradient updates, which has been used to successfully train BERT on 1024 TPU chips in 76 minutes. Despite showing promising results, prior work primarily focuses on accelerating pre-training. However, the adaption stage still incurs non-trivial overhead (e.g., it takes tens of hours to fine-tune RoBERTa-large on MNLI (Wang et al., 2019a)) and becomes more expensive as model size increases. One natural idea is to increase the batch size during adaptation. This motivation seems well-aligned with existing works on large-batch optimization. However, our analysis indicates that the loss landscape of large-batch optimization for adapting pre-trained Transformer-based language models to domain-specific tasks is highly complex and irregular, posing challenges to generalization on downstream tasks.
To address this challenge, we make the following contributions: (1) We present a novel algorithm ScaLA that injects lightweight adversarial noise into large batch optimization to speed up the adaptation of pre-trained transformer networks. To the best of our knowledge, this is the first effort to accelerate the adaptation with large-batch adversarial noise. (2) We conduct extensive evaluation, and our results show that ScaLA accelerates the adaptation of pre-trained Transformer-networks by 2.7–9.8 times over the baseline on BERT (Devlin et al., 2019) and RoBERTa (Liu et al., 2019) over a wide range of natural language understanding (NLU) tasks. We also perform detailed ablation studies to assess the impact of our approach on both generalizability and speed. (3) We present a theoretical convergence rate analysis using techniques for analyzing non-convex saddle-point problems.
2 Background and Related Work
Despite the great success of pre-trained transformer networks such as BERT (Devlin et al., 2019), a big challenge, in general, comes from the training efficiency – even with self-attention and parallelizable recurrence (Vaswani et al., 2017), and high-performance hardware (Jouppi et al., 2017), training transformer networks can still take a significant amount of time. One effective approach to reducing training time is through data parallelism (Devlin et al., 2019; Liu et al., 2019; Shoeybi et al., 2019), which motivates studies on large-batch stochastic non-convex optimizations for transformer networks (You et al., 2019a). These studies have raised concerns with respect to its convergence, generalizability, and training stability by observing that training with a large batch could be difficult (Keskar et al., 2017; Hoffer et al., 2017; Nado et al., 2021). Different from prior works, which mostly focus on reducing the pre-training time (You et al., 2019a; Zhang & He, 2020; Gong et al., 2019; Clark et al., 2020), this work shows an effective approach to accelerate the adaptation of pre-trained models while preserving the accuracy of downstream tasks.
Efficient adaptation of pre-trained Transformer models has also been studied by several recent works including (Houlsby et al., 2019; Wang et al., 2021; Hu et al., 2021; He et al., 2021). For example, (Houlsby et al., 2019) inserts small modules called adapters to each layer of the pre-trained model, and only the adapters are trained during adaptation. (Hu et al., 2021) adds low-rank matrices to approximate parameter updates. (Pfeiffer et al., 2021) shows that it is possible to quickly adapt to new tasks without catastrophic forgetting. These methods have reported achieving comparable performance to standard fine-tuning on different sets of tasks. However, their focus is on reducing the trainable parameters per task such that each task does not need to keep a separate copy of fine-tuned model parameters. Unlike these methods, which still incur full forward/backward computation cost during adaptation, we investigate how to accelerate the adaptation speed through large-batch optimization and adversarial noise.
On a separate line of research, adversarial training was first proposed in the computer vision literature to improve a model’s robustness against adversarial attacks (Goodfellow et al., 2015; Madry et al., 2018). Recently, there has been some work that shows that adversarial training helps improve model generalizability (Cheng et al., 2019; Wang et al., 2019b; Jiang et al., 2020; Liu et al., 2020; Yao et al., 2018; Zhu et al., 2020; Liu et al., 2021; Foret et al., 2021; Chen et al., 2021). However, very few works examine how adversarial learning helps improve the adaptation speed of pre-trained Transformer models. The work most similar to ours is Zhu et al. (2020), which studies reducing the cost of adversarial training by accumulating the gradient of the parameters from each of the ascent steps and updating the parameters only once after inner ascent steps with the accumulated gradients. Unlike Zhu et al. (2020), we investigate the interplay between large-batch optimization and adversarial noise for speeding up the adaptation of pre-trained Transformer models.
3 Challenges and Motivation
In this section, we present several studies that reveal the key challenges involved in accelerating the adaptation of pre-trained Transformer networks using pre-trained BERTbase model on GLUE as an example. These insights further motivate the design of the large-batch optimization approach detailed in Section 4. The detailed hardware/software setup is described in Section 5.
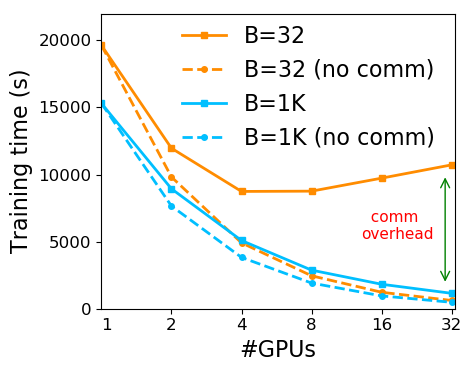
Scalability analysis. First, we carry out a scalability test by varying the number of GPU workers from 1 to 32, with and without communication. Different from pre-training, the adaptation stage often employs a much smaller batch size (e.g., 16, 32) than pre-training (e.g., 4096) (Devlin et al., 2019; Liu et al., 2019).We choose a batch size 32, as suggested by most literature for BERT fine-tuning (Devlin et al., 2019; Liu et al., 2019), and we divide the samples in the mini-batch among =1,2,4,8,16,32 GPUs. If the per-worker batch size (e.g., 16) is larger than the maximum admissible per-worker batch size (e.g., 8), we use local gradient accumulation (Goyal et al., 2017) to avoid running out of memory. Figure 1(a) shows the scalability results. For batch size 32, the training time decreases when P increases from 1 to 4. However, it quickly plateaus and even decreases with more GPUs. We find that this is because when the batch size is small, the communication overhead dominates the total execution time (e.g.,B=32 vs. B=32 (no comm)). The communication overhead is huge, especially when there is cross-machine communication (e.g., from 16 to 32), hindering the scalability of multi-GPU training. In contrast, by increasing the batch size (e.g., to 1K), the training time keeps decreasing as the number of GPUs increases because an increased batch size reduces the number of all-reduce communications to process the same amount of data and also increases the compute resource utilization per GPU (i.e., increased computation-vs-communication ratio).
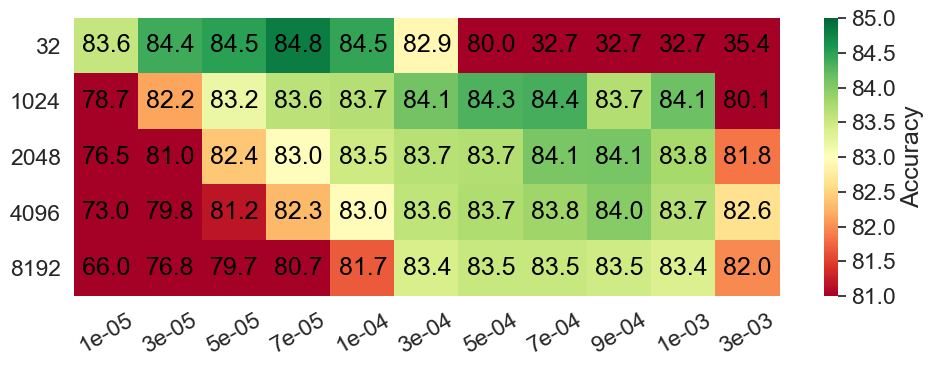
Generalizability analysis. Increasing the batch size leads to accelerated per-epoch execution time due to the efficient utilization of hardware. However, how would increasing the batch size affect the generalizability in adapting transformer networks? Since prior works on batch size scaling often focus on computer vision tasks and pre-training (Smith et al., 2018; Goyal et al., 2017; Smith, 2018; You et al., 2019a), we conduct an analysis of large-batch adaptation on pre-trained Transformers by performing a hyperparameter sweep on batch sizes 1K, 2K, 4K, 8K and learning rates 1e-4, 3e-4,5e-4, 7e-4, 9e-4, 1e-3, 3e-3, where the learning rate range covers both linear scaling (Goyal et al., 2017) and sqrt scaling (You et al., 2019a). We report the validation accuracy in Figure 1(b). We make two observations: (1) the learning rate scales roughly with the square root of the increase of the mini-batch size, although the best learning rates do not always follow the sqrt rule; (2) there is a generalization gap between the small batch and large batch accuracies, and the gap becomes larger when the batch size increases. Furthermore, methods, such as LAMB (You et al., 2019a), works well on pre-training with extremely large batch sizes () but do not close the generalization gap in adaptation (as shown in Section 5). These results pose the question: can we increase the batch size during adaptation in the interest of making adaptation more efficient but preserving generalization?
Curvature analysis. To further examine the generalization gap, we resort to the curvature analysis. Prior work (Keskar et al., 2017; You et al., 2020) correlate the low generalization with sharp minima (which are characterized by a positive curvature of large magnitude in the parameter space). The indication is that a sharp local minimum also reflects a higher sensitivity of the loss even within the neighborhood of training data points and can attribute to the difficulty in generalization. Their hypothesis was that a larger noise due to the higher variance in gradient estimates computed using small mini-batches, in contrast to gradient estimates computed using large mini-batches, encourages the parameter weights to exit out of the basin of sharp minima and towards flatter minima which have better generalization.
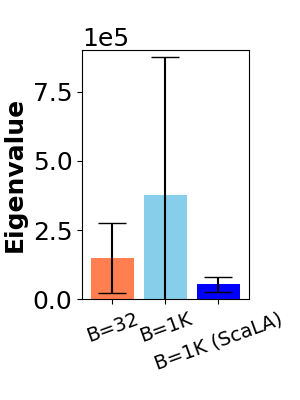
To verify this hypothesis, we quantitatively measure the steepness of loss landscape by loading the checkpoint of an adapted model and computing the curvature, i.e., properties of the second derivative of the model, with respect to its parameters, for a fixed batch of samples. Following (Yao et al., 2018), for a model , we compute the largest eigenvalue of the model’s Hessian, , using the Hessian-vector product primitive and the power method. We use the largest eigenvalue as a measure of sharpness since the corresponding (top) eigenvector characterizes the direction of the largest change in gradient at a given point in the parameter space. From Figure 1(c), the largest eigenvalue of the model trained with a large batch (e.g., 1K) is much larger (e.g., 2.6x) than the small-batch baseline and with higher deviations (e.g., 3.9x). This result confirms that large-batch adaptation makes the loss landscape of the model more prone to ill-conditioning and less robust to perturbation, which helps explain the loss in generalization.
4 The Proposed Method
Motivated by the challenges in accelerating the adaptation, in this section, we present a principled large-batch optimization method via lightweight adversarial noise for improved adaptation speed while maintaining the quality of the solutions as measured by task-appropriate accuracy metrics.
4.1 A Sequential Game-theoretic Method via Adversarial Noise
Let denote the parameter space and denote the data (mini-batch/sample) space and denote a distribution supported on . To improve the adaptation speed of pre-trained transformer models while retaining generalizability, we augment the usual stochastic optimization objective by constructing an adversarial (Keskar et al., 2017; Madry et al., 2018) regularization. In particular, we solve the following optimization problem, which is a stochastic minimax (Lin et al., 2020) optimization problem augmented with a regularization term involving a deterministic adversarial noise, instead of vanilla risk minimization:
| (1) |
where denotes the overall training objective, denotes the standard training objective, denotes the augmented objective, denotes a deterministic regularization term on the parameters controlled by a strength factor , denotes the augmented regularization and denotes samples drawn from (for simplicity, we slightly abuse the notation in using to denote the random variable, e.g. , or its empirical realizations, e.g. for any ). The overall (outer) training objective involves a minimization problem in the parameter space while being stochastic with respect to the data space. The adversarial regularization (inner) term is a deterministic maximization problem operating in the data space conditioned on a fixed parameter configuration. We emphasize that this formulation is a two-player sequential (Jin et al., 2020), not simultaneous, game wherein the goal is to optimize a transformer network that is insensitive to adversarial noise. In a given round, the first player (associated with the outer minimization) proposes a parameter configuration, and the second player (associated with the inner maximization) responds with a penalty to capture the effect of label errors due to noises in a large data batch size to undermine the performance of the transformer parameter configuration chosen by the first player.
Language expressions are quite sensitive to individual words or clauses, where noises against those would likely generate incorrect or biased training data with wrong labels (Zhang & Yang, 2018). Following prior success in applying adversarial training to NLP models (Miyato et al., 2017; Zhu et al., 2020), we apply noises to the continuous word embeddings instead of directly to discrete words or tokens. The term captures the prediction deviation from the noise. In a given round of the game, with respect to the first player’s proposal, let denote the transformer network under consideration and be a large batch of data sampled from . We construct a label for the second player as . Next, for classification tasks, we choose to be the symmetric KL divergence (Jiang et al., 2020), i.e., . We use symmetric KL divergence to measure the distributional divergence to generate adversarial noise. For regression tasks, we choose to be the squared loss, i.e., . In practice, we add an constraint on , which is achieved by simple clipping with a radius of (projection). Intuitively, a large corresponds to a situation wherein the transformer is highly sensitive to a given noise in the input, suggesting that the model parameters are close to a sharp minimum. Augmenting the original training objective with makes the first player incur an additional penalty if the outer minimization solution veers closer to sharp minima, thereby encouraging flatter solutions and better generalizability.
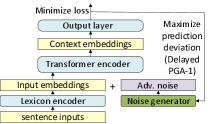
For any given outer step , let denote the parameter proposed by the first player. Since the exact inner maximization in Equation (1) is intractable for non-convex models, we adopt truncated methods as in prior works. Specifically, we use Projected Gradient Ascent (PGA) (Madry et al., 2018; Jiang et al., 2020) to solve this problem, i.e., where for is the step size sequence and projects the result of the gradient ascent update into an ball of diameter around the original input embeddings, , considered by the first player.
Practical considerations. Inspired by LAMB (You et al., 2019a), which employs group-wise adaptive learning rates to improve the adaptivity and convergence of large-batch optimizations during pre-training, we solve the outer minimization problem in Equation (1) with , where denotes the -layer of the pre-trained transformer. The learning rate sequence , is scaled by a clipping function where (e.g., and ), which ensures the norm of the update is of the same order as that of the weights. We show that ScaLA is beneficial to accelerate the adaptation under the large-batch regime with and without group-wise adaptive learning rates, but they can be combined together to deliver better results.
4.2 Reducing Adversarial Noise Overhead
Our experiments find that although injecting adversarial noise into large-batch optimization helps improve the generalizability; it may not reduce the adaptation time because the generation of adversarial noises can take a large fraction of time. This section first provides an analysis of the computational cost and then describes two approaches to reduce the time spent in generating adversarial noise, thereby further reducing the overall adaptation time.
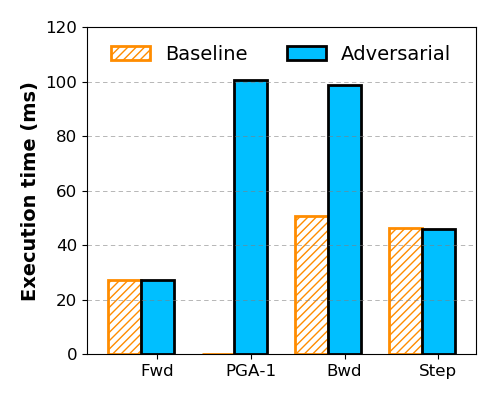
The generation of adversarial noise requires an extra PGA inner loop that standard training does not have. Figure 4 provides the time breakdown of optimization using PGA with (denoted as PGA-1). PGA-1 performs the perturbation and takes approximately the same time as making three forward passes (Fwd) through the network. This is because one step of PGA requires to make one forward and backward pass (Bwd) over the entire network. The backward pass of the optimization takes roughly twice the amount of time as the standard backward step because the back-propagation is triggered twice to calculate the noise and the gradients. The time spent on the optimizer step function remains the same. In total, the optimization would slow down training by at least 2 times, even with =1. This motivates us to look at the effectiveness of different perturbation steps as well as the usefulness of perturbation from the initial epochs.
Impact of perturbation steps. Prior works often do multiple gradient computation steps () and take several times longer training time to produce adversaries (Madry et al., 2018; Zhu et al., 2020), likely because their focus is on generalization instead of computational efficiency. Subsequently, researchers presented Curriculum Adversarial Training (CAT) (Cai et al., 2018) and Annealing-based Adversarial Training (Ye et al., 2020), which progressively increase the perturbation with various strengths, cutting the adversarial training cost while maintaining good accuracy. To investigate how CAT and similar methods affect large-scale NLP problems involving transformers, we evaluate the final accuracy and training cost of QNLI, varying the number of perturbation steps and report the results in Figure 4. Interestingly, although using a large helps to produce stronger noises, we find that this does not lead to improved accuracy, despite the fact that the training overhead still increases almost linearly. In fact, the best accuracy is achieved with .
We note that the model has two components, namely, the parameter space and data space. First, unlike the minimization in the parameter space, which is stochastic, the maximization in the data space is deterministic. Second, with respect to the testing phase, the numerical convergence in the model’s parameter space is of primary importance rather than the numerical convergence in the data space, i.e., the maximization is an auxiliary procedure that augments the training phase to make the parameter space ”aware” of effects of the batch size across epochs. Due to these two points, at a certain epoch, for a given batch, the marginal utility of an additional PGA step is low, and we are able to get away with inexact deterministic maximization. Therefore, we apply PGA-1 in our large-batch optimization scheme, given that it produces sufficiently good solutions while being much more computationally efficient.
Delayed noise injection. Given that PGA-1 still adds an overhead factor of 2, we are motivated to further reduce the overhead of adversarial noise. In particular, we investigate how useful adversarial noises are in the whole large-batch optimization process. We conduct additional experiments to measure the final accuracy corresponding to starting from a regular fine-tuning and then enabling PGA-1 for where . Our observation is that enabling PGA-1 from the beginning does not offer much improvement in accuracy, whereas adversarial noise becomes more potent as the model begins to stabilize towards the end of training (more detailed results in Appendix A.1). In general, at initialization, the model’s parameters are relatively far from their final values and are less likely to get stuck at local minima. Therefore the adversarial noises generated in the initial training iterations are quite different from the noises towards the end of training because they would not maximize the adversarial loss in Equation 1. This hypothesis suggests that we might be able to inject adversarial noise in the later training process while still leveraging it to improve generalizability. We remark that this phenomenon has been observed by prior work on computer vision tasks (Cai et al., 2018; Gupta et al., 2020).
Putting it together. Combining the formulation with the above investigations, the full procedure of ScaLA is provided in Algorithm 1, whose convergence rate is characterized in Theorem 4.1.
Theorem 4.1 (Complexity of Algorithm 1; Informal – Details in Appendix D).
Consider the problem in Equation 1. Let . Setting the outer learning rate as and scaling batch size as , for Algorithm 1, we have where is the estimator obtained from running steps of Algorithm 1 and picking uniformly at random for . Here, is the error due to the approximate inner maximization oracle, characterizes the smoothness of , is the Moreau-envelope of and .
5 Evaluation
We evaluate the effectiveness of ScaLA in adapting pre-trained transformer networks over a set of NLP tasks.
Hardware. We conduct the evaluation using 2 NVIDIA DGX-2 nodes. Each node consists of 16 NVIDIA V100 GPUs. The nodes are connected with InfiniBand using a 648-port Mellanox MLNX-OS CS7500 switch. Model/Dataset. We study adaptation on pre-trained BERTbasemodel and RoBERTalarge hosted by HuggingFace (Wolf et al., 2020). We use the GLUE benchmark (Wang et al., 2019a), which is a collection of sentence or sentence-pair natural language understanding tasks including question answering, sentiment analysis, and textual entailment. We exclude tasks that have very small datasets (e.g.,CoLA, RTE). We report the details about the hyperparameters in Appendix B.
5.1 Main Results – Adaptation Time Acceleration and Generalizability Improvement
We first compare the following schemes: (1) Single GPU + SB: This is the existing PyTorch implementation of Transformer fine-tuning from HuggingFace (HF), using small batch (SB) sizes (e.g., 32). (2) Multi-GPU + SB: This is multi-GPU PyTorch implementation using DistributedDataParallel (Li et al., 2020), and (3) Multi-GPU + LB + ScaLA: This is our approach as described in Algorithm 1, using large minibatches (LB), e.g., 1K, for adaptation. Table 1 shows results on MNLI, QNLI, QQP, and SST2, which are larger datasets and less sensitive to random seeds. refers to nodes each with GPUs for a total of homogeneous workers (e.g., 32 GPUs on 2 NVIDIA DGX-2 nodes). For a fair comparison, we reproduce BERT and RoBERTa baseline. Our reproduced baseline achieves the same or slightly higher accuracy than the originally reported results in (Devlin et al., 2019) and (Liu et al., 2019). We now discuss our results and observations.
| BERTbase | ng | bsz | MNLI-m | QNLI | QQP | SST-2 | Avg. | ||||||||
| Steps | Time | Acc. | Steps | Time | Acc. | Steps | Time | Acc/F1 | Steps | Time | Acc. | ||||
| Devlin et al. 2019 | 84.4 | 88.4 | - | 92.7 | - | ||||||||||
| Baseline (B=32) | 1x1 | 32 | 73632 | 19635 | 84.8 | 19644 | 5535 | 90.6 | 68226 | 16494 | 91/88.0 | 12630 | 2736 | 93.1 | 89.4 |
| Baseline (B=32) | 2x16 | 32 | 73632 | 8848 | 84.8 | 19644 | 2408 | 90.6 | 68226 | 11311 | 91/88.0 | 12630 | 1494 | 93.1 | 89.4 |
| ScaLA (B=1K) | 2x16 | 1K | 2301 | 1323 | 85.1 | 615 | 432 | 90.0 | 2133 | 4229 | 90.9/87.7 | 396 | 151 | 93.5 | 89.4 |
| RoBERTalarge | ng | bsz | MNLI-m | QNLI | QQP | SST-2 | Avg. | ||||||||
| Steps | Time | Acc. | Steps | Time | Acc. | Steps | Time | Acc/F1 | Steps | Time | Acc. | ||||
| Liu et al. 2020 | 90.2 | 94.7 | 92.2/- | 96.4 | - | ||||||||||
| Baseline (B=32) | 1x1 | 32 | 73632 | 43090 | 90.5 | 19644 | 14188 | 94.7 | 68226 | 40945 | 92.0/89.4 | 12630 | 4940 | 96.4 | 92.5 |
| Baseline (B=32) | 2x16 | 32 | 73632 | 18114 | 90.5 | 19644 | 4842 | 94.7 | 68226 | 16614 | 92.0/89.4 | 12630 | 3072 | 96.4 | 92.5 |
| ScaLA (B=1K) | 2x16 | 1K | 2301 | 3363 | 90.9 | 615 | 1168 | 95.1 | 2133 | 2404 | 92.3/89.8 | 396 | 401 | 96.7 | 92.9 |
ScaLA accelerates adaptation time. Compared with single-GPU training, the multi-GPU baseline leads to only modest training speedup improvements, e.g., with faster training speed for both BERT and RoBERTa, even with more compute resources. The speedup is limited because of the small mini-batches (e.g., 32) used for adaptation, which do not provide a sufficient workload to fully utilize the underlying hardware. Thus, communication overhead becomes the dominant part, and the adaptation often struggles to obtain speedups even with more workers. In contrast, ScaLA achieves up to speedups over the single-GPU baseline with 32 GPUs. When using the same number of GPUs (e.g., 32), ScaLA is 2.7–9.8 faster. The speedups come from three aspects: (1) the improved hardware efficiency for each worker from increased per-worker micro-batch size; (2) the reduced all-reduce communication overhead since it takes fewer communication rounds to process the same number of samples in one epoch; (3) the lightweight adversarial noise incurs only a small portion of the total training overhead. Finally, ScaLA obtains the speedups while achieving the same accuracy (88.4 vs. 88.4) average accuracy for BERT and higher accuracy (92.9 vs. 92.5) for RoBERTa as the baselines.
ScaLA improves generalizability. Since there are very few works on large-batch adaptation, we create several baselines to compare with ScaLA: (1) Multi-GPU + LB + Tuning LR: This configuration uses large mini-batches (e.g., 1K), and applies heuristic-based scheduling rule (e.g., square root) combined with an extensive grid search for learning rates; (2) Multi-GPU + LB + LAMB: Uses LAMB (You et al., 2019a) optimizer for large-batch adaptation. We make several observations from the results in Table 2. First, compared with the baseline accuracy reported in the paper, the accuracy of Multi-GPU + LB drops by close to 1 point (88.4 vs. 89.4, and 92.1 vs. 92.9) in average and close to 2 points for some tasks (e.g., QQP on BERT), indicating that it is challenging to obtain on-par accuracy with large-batch optimizations for adaptation despite with heavy hyperparameter tuning. Second, since LAMB is designed primarily for improving the convergence of pre-training instead of the adaptation, its ability to accelerate the adaptation has yet to be proven. In our experiments, LAMB leads to only marginal improvements (88.6 vs. 88.4, and 92.1 vs. 92.1) than the baseline and is 0.8 points lower than the small-batch baseline. This is because LAMM does not directly minimize the sharpness of the loss landscape, so it can still lead to poor generalizability during adaptation. With ScaLA, we are able to close the generalization gap from large-batch optimization (89.4 vs. 89.4, and 92.5 vs. 92.9) and achieve 0.8 points higher accuracy (89.4 vs. 88.6, 92.9 vs. 92.1) than LAMB on both BERT and RoBERTa. ScaLA improves generalizability because it introduces adversarial noise in the large-batch optimization process, which serves as a regularizer. By training the network to be robust to such perturbations, the model loss landscape is smoothed out, leading to improved generalization.
| BERTbase | ng | Batch | MNLI-m | QNLI | QQP | SST-2 | Avg. | ||||||||
| size | Steps | Time | Acc. | Steps | Time | Acc. | Steps | Time | Acc/F1 | Steps | Time | Acc. | |||
| Baseline (B=1K) | 2x16 | 1K | 2301 | 1148 | 84.3 | 615 | 349 | 89.3 | 2133 | 2892 | 89.6/86.1 | 396 | 134 | 93 | 88.4 |
| LAMB (B=1K) | 2x16 | 1K | 2301 | 1180 | 84.1 | 615 | 359 | 89.6 | 2133 | 2978 | 90.5/87.0 | 396 | 139 | 92.4 | 88.6 |
| ScaLA (B=1K) | 2x16 | 1K | 2301 | 1323 | 85.1 | 615 | 432 | 90.0 | 2133 | 4229 | 90.9/87.7 | 396 | 151 | 93.5 | 89.4 |
| RoBERTalarge | ng | Batch | MNLI-m | QNLI | QQP | SST-2 | Avg. | ||||||||
| size | Steps | Time | Acc. | Steps | Time | Acc. | Steps | Time | Acc/F1 | Steps | Time | Acc. | |||
| Baseline (B=1K) | 2x16 | 1K | 2301 | 2514 | 90.1 | 615 | 936 | 94.3 | 2133 | 1874 | 91.7/89.1 | 396 | 317 | 95.9 | 92.1 |
| LAMB (B=1K) | 2x16 | 1K | 2301 | 2646 | 90.5 | 615 | 973 | 94.5 | 2133 | 1998 | 91.3/88.5 | 396 | 324 | 96.2 | 92.1 |
| ScaLA (B=1K) | 2x16 | 1K | 2301 | 3363 | 90.9 | 615 | 1168 | 95.1 | 2133 | 2404 | 92.3/89.8 | 396 | 401 | 96.7 | 92.9 |
5.2 Experiment – Analysis Results
Ablation analysis: In this part, we study the importance of components in ScaLA. We set to 0, which denotes as w/o Delaying PGA-1. We replace the outer minimization to use ADAM (Kingma & Ba, 2015), which is noted as w/o Groupwise LR. We set to 0, which denotes as w/o PGA-1. The results are reported in Table 3.
| MNLI-m | QNLI | QQP | SST-2 | Avg. | |||||
| Time | Acc. | Time | Acc. | Time | Acc/F1 | Time | Acc. | ||
| BERT | 19635 | 84.8 | 5535 | 90.6 | 16494 | 91/88.0 | 2736 | 93.1 | 89.4 |
| ScaLA | 1323 | 85.1 | 432 | 90 | 4229 | 90.9/87.7 | 151 | 93.5 | 89.4 |
| w/o Delaying PGA-1 | 2503 | 85.2 | 726 | 90.2 | 6407 | 91.3/88.3 | 272 | 93.1 | 89.5 |
| w/o Groupwise LR | 1290 | 85.0 | 422 | 89.9 | 4212 | 90.7/87.6 | 146 | 93.0 | 89.2 |
| w/o PGA-1 | 1180 | 84.1 | 359 | 89.6 | 2978 | 90.5/87.0 | 139 | 92.4 | 88.6 |
| MNLI-m | SST-2 | |||
|---|---|---|---|---|
| Acc. | Time | Acc. | Time | |
| Baseline | 84.8 | 8848 | 93.1 | 2736 |
| FreeLb | 85.1 | 3773 | 93.3 | 389 |
| ScaLA | 85.1 | 1323 | 93.5 | 151 |
The results in Table 3 show that the removal of either design element would result in a performance drop. For example, removing PGA-1 leads to 0.8 points accuracy drop (88.6 vs. 89.4), indicating that adversarial noise is crucial for improving the generalizability of large-batch adaptation. Moreover, if we perform PGA-1 without delayed injection, the average accuracy increases by 0.1 points (89.5 vs. 89.4), but the execution time is increased by 1.5–1.9x, indicating the importance of having lightweight adversarial noise for speeding up the adaptation. Finally, removing group-wise learning rates leads to a small 0.2 points accuracy drop (89.2 vs. 89.4), indicating that ScaLA still achieves benefits without group-wise learning rates (89.2 vs. 88.6), but they are complementary to each other.
| Model |
|
|
|
|
Avg | ||||
| Baseline | 84.3 | 89.3 | 89.6/86.1 | 93 | 88.4 | ||||
| Gaussian noise | 84.5 | 89.4 | 90.3/87.0 | 92.6 | 88.7 | ||||
| ScaLA (GT) | 84.1 | 89.6 | 90.7/87.6 | 93.2 | 89.0 | ||||
| ScaLA (LP) | 85.1 | 90 | 90.9/87.7 | 93.5 | 89.4 |
Curvature analysis. We measure the steepness of the loss landscape again after applying ScaLA. As shown in Fig. 1(c), the largest eigenvalue of the model becomes much smaller (6.9) with lower deviations with ScaLA and is slightly better than the small batch baseline, which is a strong indication that our approach enforces the smoothness of the model that leads to the accuracy improvement.
Comparison with random noise. We have performed additional experiments by adding Gaussian noise to the embeddings. Table 5 that random noise indeed can improve the accuracy for MNLI-m (84.3 vs. 84.5), QNLI (89.3 vs. 89.4), and QQP (90.3/87.0 vs. 89.6/86.1) over the baseline, but it also leads to worse results on SST-2 (93. vs. 92.6). Compared with ScaLA, random noise consistently falls behind ScaLA in its ability to reduce the generalization error on all tested tasks and is on average 0.7 points lower than ScaLA (88.7 vs. 89.4). These results indicate that ScaLA’s approach of explicitly enforcing the smoothness of the loss landscape can result in better improvement.
Perturbations via ground-truth vs. label probability. We also create one-hot labels and use those to generate perturbations instead of using label probability generated by the network. Table 5 shows that using label probability (LP) consistently leads to higher accuracy than using the ground-truth (GT), e.g., 89.4 vs. 89.0 on average. Label probability leads to better generalization, probably because it provides a better measurement of the adversarial direction, which is the direction in the input space in which the label probability of the model is most sensitive to small perturbations.
Comparison with FreeLb. We include a comparison between ScaLA and FreeLb (Zhu et al., 2020). Although both FreeLb and ScaLA achieve similar accuracy, ScaLA is much faster than FreeLb (Table 4). ScaLA is faster because FreeLb is not explicitly designed for accelerating the adaptation speed and performs multiple ascent steps to calculate adversaries cross the full training process. In contrast, ScaLA takes several optimizations to reduce the adversarial noise cost to enable efficient training with large batch sizes, which improves the overall computational efficiency.
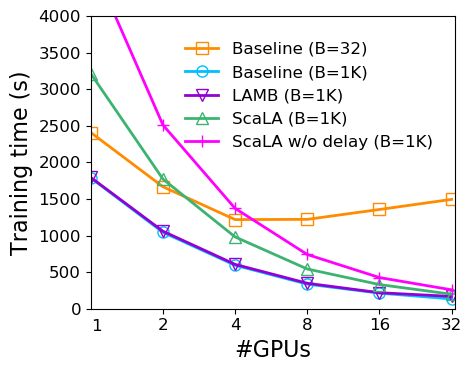
Scalability analysis varying GPUs. Figure 7 shows the scalability comparison on SST-2 after optimizations. While the speedup still plateaus at GPUs with a small batch size (e.g., ), the four large-batch configurations are able to scale well up to GPUs and take a similar amount of time with GPUs. ScaLA scales better than ScaLA without delaying PGA-, and achieves a much faster training speed, especially in the 1-16 GPU range.
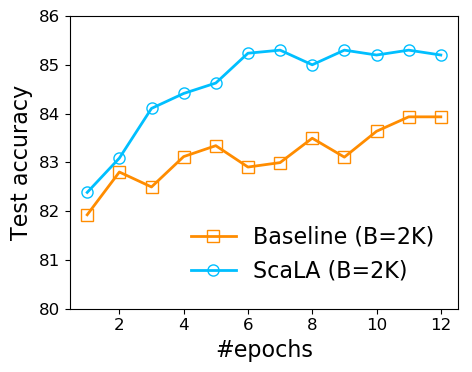
Train longer, generalize better? Despite improved adaptation speed, one may still wonder whether simply performing large-batch adaptation longer would also close the generalization gap. Figure 7 shows the comparison between ScaLA and the baseline on a batch size of 2K. ScaLA obtains an accuracy of 85.2 after 6 epochs of training, whereas the baseline has difficulty to reach 84 after training twice longer (e.g., 12 epochs). ScaLA achieves better accuracy because it explicitly penalizes model weights from getting stuck at sharp minima, leading to better generalizability.
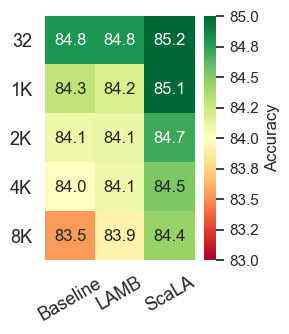
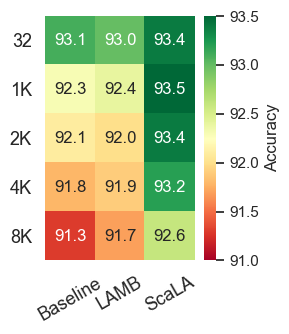
Generalizability under different batch sizes. We also evaluate how different batch sizes affect the generalizability of adapting transformers. Figure 7 shows the results on MNLI-m and SST-2. We make two major observations: (1) The accuracy tends to drop as the batch size increases. (2) While both the baseline and LAMB suffer from significant accuracy drop by drastically increasing the batch size (e.g., from 32 to 8K), ScaLA is able to mitigate the generalization gap and consistently achieves higher accuracy than the baseline (e.g., 84.4 vs. 83.5 for MNLI, and 92.6 vs. 91.3 for SST-2 at batch size 8K) and LAMB (e.g., 84.4 vs. 83.9 for MNLI, and 92.6 vs. 91.7 for SST-2 at batch size 8K). These results indicate the benefit of ScaLA is maintained by further increasing the batch size, which could bring even greater speedups when increasing the data parallelism degree.
6 Conclusions and Future Directions
In this paper, we study how to accelerate the adaptation speed of pre-trained Transformer models for NLU tasks. We introduce ScaLA, an efficient large-batch adaptation method using carefully injected lightweight adversarial noises. The experiment results show that ScaLA obtains up to 9.8 speedups on adapting transformer networks and outperforms state-of-the-art large-batch optimization methods in generalizability. Given the promising results of ScaLA on accelerating the adaptation speed, it opens new research opportunities on applying ScaLA to accelerate the more expensive pre-training tasks as well as emerging pre-trained transformer networks for computer vision domains tasks.
References
- Bommasani et al. (2021) Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- Brown et al. (2020) Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. Language models are few-shot learners. CoRR, abs/2005.14165, 2020. URL https://arxiv.org/abs/2005.14165.
- Cai et al. (2018) Cai, Q., Liu, C., and Song, D. Curriculum adversarial training. In Lang, J. (ed.), Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, July 13-19, 2018, Stockholm, Sweden, pp. 3740–3747. ijcai.org, 2018.
- Chen et al. (2021) Chen, X., Hsieh, C.-J., and Gong, B. When vision transformers outperform resnets without pre-training or strong data augmentations. CoRR, abs/2106.01548, 2021.
- Cheng et al. (2019) Cheng, Y., Jiang, L., and Macherey, W. Robust neural machine translation with doubly adversarial inputs. In Korhonen, A., Traum, D. R., and Màrquez, L. (eds.), Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pp. 4324–4333. Association for Computational Linguistics, 2019.
- Clark et al. (2020) Clark, K., Luong, M., Le, Q. V., and Manning, C. D. ELECTRA: pre-training text encoders as discriminators rather than generators. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020.
- Davis & Drusvyatskiy (2018) Davis, D. and Drusvyatskiy, D. Stochastic subgradient method converges at the rate {} on weakly convex functions. arXiv preprint arXiv:1802.02988, 2018.
- Davis & Drusvyatskiy (2019) Davis, D. and Drusvyatskiy, D. Stochastic model-based minimization of weakly convex functions. SIAM Journal on Optimization, 29(1):207–239, 2019.
- Devlin et al. (2019) Devlin, J., Chang, M., Lee, K., and Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019), pp. 4171–4186, 2019.
- Foret et al. (2021) Foret, P., Kleiner, A., Mobahi, H., and Neyshabur, B. Sharpness-aware minimization for efficiently improving generalization. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021.
- Ghadimi & Lan (2013) Ghadimi, S. and Lan, G. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM Journal on Optimization, 23(4):2341–2368, 2013.
- Gong et al. (2019) Gong, L., He, D., Li, Z., Qin, T., Wang, L., and Liu, T. Efficient training of BERT by progressively stacking. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, pp. 2337–2346, 2019.
- Goodfellow et al. (2015) Goodfellow, I. J., Shlens, J., and Szegedy, C. Explaining and harnessing adversarial examples. In Bengio, Y. and LeCun, Y. (eds.), 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015.
- Goyal et al. (2017) Goyal, P., Dollár, P., Girshick, R. B., Noordhuis, P., Wesolowski, L., Kyrola, A., Tulloch, A., Jia, Y., and He, K. Accurate, large minibatch SGD: training imagenet in 1 hour. CoRR, abs/1706.02677, 2017.
- Gupta et al. (2020) Gupta, S., Dube, P., and Verma, A. Improving the affordability of robustness training for dnns. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR Workshops 2020, Seattle, WA, USA, June 14-19, 2020, pp. 3383–3392. IEEE, 2020.
- He et al. (2021) He, J., Zhou, C., Ma, X., Berg-Kirkpatrick, T., and Neubig, G. Towards a unified view of parameter-efficient transfer learning. CoRR, abs/2110.04366, 2021.
- Hoffer et al. (2017) Hoffer, E., Hubara, I., and Soudry, D. Train longer, generalize better: closing the generalization gap in large batch training of neural networks. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V. N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 1731–1741, 2017.
- Houlsby et al. (2019) Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., de Laroussilhe, Q., Gesmundo, A., Attariyan, M., and Gelly, S. Parameter-efficient transfer learning for NLP. In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pp. 2790–2799. PMLR, 2019.
- Hu et al. (2021) Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., and Chen, W. Lora: Low-rank adaptation of large language models. CoRR, abs/2106.09685, 2021.
- Huang et al. (2019) Huang, Y., Cheng, Y., Bapna, A., Firat, O., Chen, D., Chen, M. X., Lee, H., Ngiam, J., Le, Q. V., Wu, Y., and Chen, Z. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, pp. 103–112, 2019.
- Jain & Kar (2017) Jain, P. and Kar, P. Non-convex optimization for machine learning. arXiv preprint arXiv:1712.07897, 2017.
- Jiang et al. (2020) Jiang, H., He, P., Chen, W., Liu, X., Gao, J., and Zhao, T. SMART: robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization. In Jurafsky, D., Chai, J., Schluter, N., and Tetreault, J. R. (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pp. 2177–2190. Association for Computational Linguistics, 2020.
- Jin et al. (2020) Jin, C., Netrapalli, P., and Jordan, M. What is local optimality in nonconvex-nonconcave minimax optimization? In International Conference on Machine Learning, pp. 4880–4889. PMLR, 2020.
- Jouppi et al. (2017) Jouppi, N. P., Young, C., Patil, N., Patterson, D., Agrawal, G., Bajwa, R., Bates, S., Bhatia, S., Boden, N., Borchers, A., Boyle, R., Cantin, P.-l., Chao, C., Clark, C., Coriell, J., Daley, M., Dau, M., Dean, J., Gelb, B., Ghaemmaghami, T. V., Gottipati, R., Gulland, W., Hagmann, R., Ho, C. R., Hogberg, D., Hu, J., Hundt, R., Hurt, D., Ibarz, J., Jaffey, A., Jaworski, A., Kaplan, A., Khaitan, H., Killebrew, D., Koch, A., Kumar, N., Lacy, S., Laudon, J., Law, J., Le, D., Leary, C., Liu, Z., Lucke, K., Lundin, A., MacKean, G., Maggiore, A., Mahony, M., Miller, K., Nagarajan, R., Narayanaswami, R., Ni, R., Nix, K., Norrie, T., Omernick, M., Penukonda, N., Phelps, A., Ross, J., Ross, M., Salek, A., Samadiani, E., Severn, C., Sizikov, G., Snelham, M., Souter, J., Steinberg, D., Swing, A., Tan, M., Thorson, G., Tian, B., Toma, H., Tuttle, E., Vasudevan, V., Walter, R., Wang, W., Wilcox, E., and Yoon, D. H. In-Datacenter Performance Analysis of a Tensor Processing Unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, ISCA ’17, pp. 1–12, 2017. ISBN 978-1-4503-4892-8. doi: 10.1145/3079856.3080246. URL http://doi.acm.org/10.1145/3079856.3080246.
- Kaplan et al. (2020) Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. CoRR, abs/2001.08361, 2020. URL https://arxiv.org/abs/2001.08361.
- Keskar et al. (2017) Keskar, N. S., Mudigere, D., Nocedal, J., Smelyanskiy, M., and Tang, P. T. P. On large-batch training for deep learning: Generalization gap and sharp minima. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017.
- Kingma & Ba (2015) Kingma, D. P. and Ba, J. Adam: A Method for Stochastic Optimization. In 3rd International Conference on Learning Representations, ICLR 2015, 2015.
- Li et al. (2020) Li, S., Zhao, Y., Varma, R., Salpekar, O., Noordhuis, P., Li, T., Paszke, A., Smith, J., Vaughan, B., Damania, P., and Chintala, S. Pytorch distributed: Experiences on accelerating data parallel training. Proc. VLDB Endow., 13(12):3005–3018, 2020.
- Lin et al. (2020) Lin, T., Jin, C., and Jordan, M. On gradient descent ascent for nonconvex-concave minimax problems. In International Conference on Machine Learning, pp. 6083–6093. PMLR, 2020.
- Liu et al. (2020) Liu, X., Cheng, H., He, P., Chen, W., Wang, Y., Poon, H., and Gao, J. Adversarial training for large neural language models. CoRR, abs/2004.08994, 2020.
- Liu et al. (2019) Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov, V. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692, 2019.
- Liu et al. (2021) Liu, Y., Chen, X., Cheng, M., Hsieh, C., and You, Y. Concurrent adversarial learning for large-batch training. CoRR, abs/2106.00221, 2021.
- Madry et al. (2018) Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. Towards deep learning models resistant to adversarial attacks. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018.
- Miyato et al. (2017) Miyato, T., Dai, A. M., and Goodfellow, I. J. Adversarial training methods for semi-supervised text classification. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017.
- Nado et al. (2021) Nado, Z., Gilmer, J., Shallue, C. J., Anil, R., and Dahl, G. E. A large batch optimizer reality check: Traditional, generic optimizers suffice across batch sizes. CoRR, abs/2102.06356, 2021.
- Pfeiffer et al. (2021) Pfeiffer, J., Kamath, A., Rücklé, A., Cho, K., and Gurevych, I. Adapterfusion: Non-destructive task composition for transfer learning. In Merlo, P., Tiedemann, J., and Tsarfaty, R. (eds.), Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, April 19 - 23, 2021, pp. 487–503. Association for Computational Linguistics, 2021.
- Rafique et al. (2021) Rafique, H., Liu, M., Lin, Q., and Yang, T. Weakly-convex–concave min–max optimization: provable algorithms and applications in machine learning. Optimization Methods and Software, pp. 1–35, 2021.
- Rajbhandari et al. (2019) Rajbhandari, S., Rasley, J., Ruwase, O., and He, Y. Zero: Memory optimization towards training A trillion parameter models. CoRR, abs/1910.02054, 2019.
- Rockafellar (2015) Rockafellar, R. T. Convex analysis. Princeton university press, 2015.
- Shazeer et al. (2018) Shazeer, N., Cheng, Y., Parmar, N., Tran, D., Vaswani, A., Koanantakool, P., Hawkins, P., Lee, H., Hong, M., Young, C., Sepassi, R., and Hechtman, B. A. Mesh-tensorflow: Deep learning for supercomputers. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, pp. 10435–10444, 2018.
- Shoeybi et al. (2019) Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-lm: Training multi-billion parameter language models using model parallelism. CoRR, abs/1909.08053, 2019.
- Smith (2018) Smith, L. N. A disciplined approach to neural network hyper-parameters: Part 1 - learning rate, batch size, momentum, and weight decay. CoRR, abs/1803.09820, 2018. URL http://arxiv.org/abs/1803.09820.
- Smith et al. (2018) Smith, S. L., Kindermans, P., Ying, C., and Le, Q. V. Don’t decay the learning rate, increase the batch size. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, pp. 5998–6008, 2017.
- Wang et al. (2019a) Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In 7th International Conference on Learning Representations, 2019a.
- Wang et al. (2019b) Wang, D., Gong, C., and Liu, Q. Improving neural language modeling via adversarial training. In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pp. 6555–6565. PMLR, 2019b.
- Wang et al. (2021) Wang, R., Tang, D., Duan, N., Wei, Z., Huang, X., Ji, J., Cao, G., Jiang, D., and Zhou, M. K-adapter: Infusing knowledge into pre-trained models with adapters. In Zong, C., Xia, F., Li, W., and Navigli, R. (eds.), Findings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event, August 1-6, 2021, volume ACL/IJCNLP 2021 of Findings of ACL, pp. 1405–1418. Association for Computational Linguistics, 2021.
- Wang et al. (2019c) Wang, Y., Wei, G., and Brooks, D. Benchmarking tpu, gpu, and CPU platforms for deep learning. CoRR, abs/1907.10701, 2019c.
- Wolf et al. (2020) Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jernite, Y., Plu, J., Xu, C., Scao, T. L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A. M. Transformers: State-of-the-art natural language processing. In Liu, Q. and Schlangen, D. (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, EMNLP 2020 - Demos, Online, November 16-20, 2020, pp. 38–45. Association for Computational Linguistics, 2020.
- Yao et al. (2018) Yao, Z., Gholami, A., Lei, Q., Keutzer, K., and Mahoney, M. W. Hessian-based analysis of large batch training and robustness to adversaries. In Bengio, S., Wallach, H. M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pp. 4954–4964, 2018.
- Ye et al. (2020) Ye, N., Li, Q., Zhou, X., and Zhu, Z. Amata: An annealing mechanism for adversarial training acceleration. CoRR, abs/2012.08112, 2020.
- You et al. (2019a) You, Y., Li, J., Hseu, J., Song, X., Demmel, J., and Hsieh, C. Reducing BERT pre-training time from 3 days to 76 minutes. CoRR, abs/1904.00962, 2019a.
- You et al. (2019b) You, Y., Li, J., Reddi, S., Hseu, J., Kumar, S., Bhojanapalli, S., Song, X., Demmel, J., Keutzer, K., and Hsieh, C.-J. Large batch optimization for deep learning: Training bert in 76 minutes. arXiv preprint arXiv:1904.00962, 2019b.
- You et al. (2020) You, Y., Wang, Y., Zhang, H., Zhang, Z., Demmel, J., and Hsieh, C. The limit of the batch size. CoRR, abs/2006.08517, 2020.
- Zhang & Yang (2018) Zhang, D. and Yang, Z. Word embedding perturbation for sentence classification. CoRR, abs/1804.08166, 2018.
- Zhang & He (2020) Zhang, M. and He, Y. Accelerating training of transformer-based language models with progressive layer dropping. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.
- Zhu et al. (2020) Zhu, C., Cheng, Y., Gan, Z., Sun, S., Goldstein, T., and Liu, J. Freelb: Enhanced adversarial training for natural language understanding. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020.
Appendix A Additional Results
In the part, we present results that are not included in the main text due to the space limit.
A.1 The Usefulness of Adversarial Noises at Different Epochs
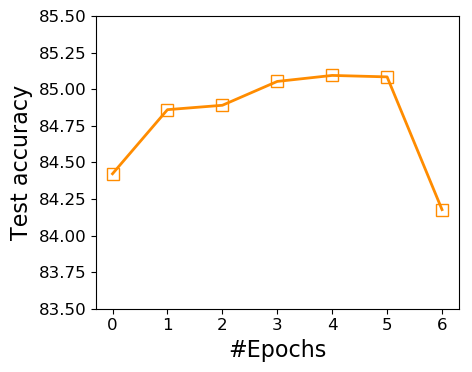
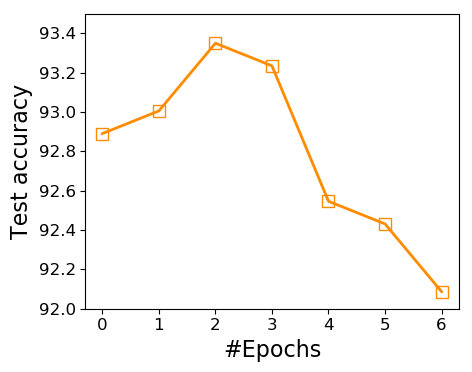
In Section 4.1, we mention that no adversaries are needed at the initial epochs of adaptation. To verify, we conduct experiments to measure the final accuracy corresponding to starting from regular training and switching to PGA-1 after epochs, where . Figure 8 shows that enabling PGA-1 from the very beginning does not offer much improvement on accuracy. However, as we delay the injection of adversarial noises, the model accuracy starts to increase. By delaying the injection of adversarial noises, we observe improved test accuracy on downstream tasks. However, it also seems that the adversarial noise should not be injected too late, which may inadvertently affect the accuracy. It is possible that a more advanced method to adaptively choose the value of is desired. However, given that (1) the primary focus of this work is to demonstrate that it is possible and effective to accelerate the adaptation of transformer networks via large-batch adaptation and adversarial noises and (2) the search space of is quite small for most downstream tasks, we leave this as an interesting research question for future exploration.
Appendix B Hyperparameters
For all configurations, we fine-tune against the GLUE datasets and set the maximum number of epochs to 6. We use a linear learning rate decay schedule with a warm-up ratio of 0.1. For ScaLA, we set , perturbation clipping radius , step size , and ={3,5}. These values worked well enough that we did not feel the need to explore more. For fairness, we perform a grid search of learning rates in the range of 1e-5, 3e-5, 5e-5, 7e-5, 9e-5, 1e-4, 3e-4 for small batch sizes and 5.6e-5, 8e-5, 1e-4, 1.7e-4, 2.4e-4, 2.8e-4, 4e-4, 5.6e-4, 1e-3 for large batch sizes. We keep the remaining hyperparameteres unchanged.
Appendix C Hyperparameter Tuning Cost for Large-Batch Adaptation with ScaLA
In this part, we investigate how large-batch adaptation affects the generalizability of transformer networks on downstream tasks. As there are various heuristics for setting the learning rates (Smith et al., 2018; Goyal et al., 2017; Smith, 2018; You et al., 2019a), and because few work studies the learning rate scaling effects on adapting pre-trained Transformer networks, we perform a grid search on learning rates 1e-4, 3e-4,5e-4, 7e-4, 9e-4, 1e-3, 3e-3 and batch sizes 1K, 2K, 4K, 8K while keeping the other hyperparameters the same to investigate how ScaLA affects the hyperparameter tuning effort.
Table 6 shows the results of using the square root scaling rule to decide the learning rates for large batch sizes vs. accuracy results with tuned learning rate results, without and with ScaLA. The first row represents the best accuracy found through fine-tuning with a small batch size 32. The next two rows correspond to fine-tuning with batch size 1024 using tuned learning rates vs. using the scaling rule. The last two rows represent fine-tuning using ScaLA with batch size 1024, also using tuned learning rates vs. the scaling rule. Even with square-root scaling, the large-batch baseline still cannot reach the small-batch accuracy (88.7 vs. 89.4). Moreover, although tuning the learning rates lead to better results on some datasets such as MNLI-m (84.9 vs. 85.1) and SST-2 (92.9 vs. 93.5), the square-root scaling rule leads to better results on other tasks such as QNLI (90.8 vs. 90) and QQP (91.4/88.4 vs. 90.9/87.7). So the best learning rates on fine-tuning tasks are not exactly sqrt. However, given that ScaLA with square-root learning rate scaling achieves on average better results than the grid search of learning rates (89.4 vs. 89.7), we suggest to use sqrt scaling for learning rates to simplify the hyperparameter tuning effort for ScaLA.
|
|
|
|
Avg | |||||
|---|---|---|---|---|---|---|---|---|---|
| Bsz=32 (tuned, baseline) | 84.8 | 90.6 | 91/88 | 93.1 | 89.4 | ||||
| Bsz=1024 (tuned, baseline) | 84.3 | 89.3 | 89.6/86.1 | 93 | 88.5 | ||||
| Bsz=1024 (scaling rule, baseline) | 83.9 | 89.2 | 90.6/87.4 | 92.5 | 88.7 | ||||
| Bsz=1024 (tuned, ScaLA) | 85.1 | 90 | 90.9/87.7 | 93.5 | 89.4 | ||||
| Bsz=1024 (scaling rule, ScaLA) | 84.9 | 90.8 | 91.4/88.4 | 92.9 | 89.7 |
Appendix D Convergence Analysis
In this section, we provide the formal statements and detailed proofs for the convergence rate. The convergence analysis builds on techniques and results in (Davis & Drusvyatskiy, 2018; You et al., 2019b). We consider the general problem of a two-player sequential game represented as nonconvex-nonconcave minimax optimization that is stochastic with respect to the outer (first) player playing while sampling from and deterministic with respect to the inner (second) player playing , i.e.,
| (2) |
Since finding the Stackelberg equilibrium, i.e., the global solution to the saddle point problem, is NP-hard, we consider the optimality notion of a local minimax point (Jin et al., 2020). Since maximizing over may result in a non-smooth function even when is smooth, the norm of the gradient is not particularly a suitable metric to track the convergence progress of an iterative minimax optimization procedure. Hence, we use the gradient of the Moreau envelope (Davis & Drusvyatskiy, 2019) as the appropriate potential function. Let . The -Moreau envelope for a function is defined as . Another reason for the choice of this potential function is due to the special property (Rockafellar, 2015) of the Moreau envelope that if its gradient almost vanishes at , such is close to a stationary point of the original function .
Assumptions: We assume that is partitioned into disjoint groups , i.e., in terms of training a neural network, we can think of the network having the parameters partitioned into (hidden) layers. The measure characterizes the training data. Let denote the noisy estimate of the true gradient . We assume that the noisy gradients are unbiased, i.e., . For each group , we make the standard (groupwise) boundedness assumption (Ghadimi & Lan, 2013) on the variance of the stochastic gradients, i.e., , . We assume that has Lipschitz continuous gradients. Specifically, let be -smooth in where denotes the -dimensional vector of (groupwise) Lipschitz parameters, i.e., , and . Let .
Super-scripts are used to index into a vector ( denotes the group index and denotes an element in group ). For any , the function clips its values, i.e., where . Let , and denote the , , and norms. We assume that the true gradients are bounded, i.e., .
First, we begin with relevant supporting lemmas. The following lemma characterizes the convexity of an additive modification of .
Lemma D.1 ((Lin et al., 2020; Jin et al., 2020; Rafique et al., 2021)).
Let with being -smooth in where is the vector of groupwise Lipschitz parameters. Then, is convex in .
The following property of the Moreau envelope relates it to the original function.
Lemma D.2 ((Rockafellar, 2015)).
Let be defined as in Lemma D.1. Let . Then, implies and with where denotes the subdifferential of .
We now present the formal version of Theorem 4.1 in Theorem D.3. Note that Lemma D.2 facilitates giving the convergence guarantees in terms of the gradient of the Moreau envelope. Recall that denotes the epochs corresponding to the outer maximization. Without loss of generality, we set the delay parameter for injection of the adversarial perturbation in Algorithm 1 as . Here, we assume that the PGA provides an -approximate maximizer.
Theorem D.3 (Groupwise outer minimization with an -approximate inner maximization oracle).
Let us define relevant constants as being the optimality gap due to initialization, being the condition number, being gradient bound, being the variance term, being clipping constants such that . For the outer optimization, setting the learning rate as and scaling batch size as , we have
| (3) |
where is the estimator obtained from running steps of Algorithm 1 and picking uniformly at random for .
-
Proof.
In this proof, for brevity, we define the vector , i.e., the gradient of the objective with respect to , evaluated at the outer step . Since evaluating gradients using mini-batches produces noisy gradients, we use to denote the noisy version of a true gradient , i.e., for a noise vector . For any outer step , we have where is an -approximate maximizer. For any , using the smoothness property (Lipschitz gradient) of , we have
(4) Let . Recall that the -Moreau envelope for is defined as and its gradient is the groupwise proximal operator given by .
Now, let . Then, plugging in the update rule for at step in terms of quantities at step , using the shorthand and conditioning on the filtration up to time , we have
(5) where we have used Hölder’s inequality along with bound (4) in , Cauchy-Schwarz inequality in , triangle inequality in , telescoping sum in . Rearranging and using in along with Hölder’s inequality,
Dividing by and rearranging,
where we define . Defining and taking expectation with respect to on both sides, we have
(6) where we have used the assumption on the variance of stochastic gradients in , Hölder’s inequality in and we define in ; denotes batch size. Now, we lower bound the left hand side using the convexity of the additive modification of .
(7) where we have used the expression for the gradient of the Moreau envelope in . Combining the inequalities from Equation (7) and Equation (6), we have
Setting the learning rate as and batch size as ,
Now, to simplify , using the inequality that for two finite sequences with positive values, along with the bounded gradients assumption, we have
where . ∎
In analyzing inexact version, as in Theorem D.3, we assumed the availability of an adversarial oracle. Next, we open up the adversarial oracle to characterize the oracle-free complexity. In order to do this, we will assume additional properties about the function as well as our deterministic perturbation space, , . Note that, for any given , , . We recall the following guarantee for generalized non-convex projected gradient ascent.
Lemma D.4 ((Jain & Kar, 2017)).
For every , Let satisfy restricted strong convexity with parameter and restricted strong smoothness with parameter over a non-convex constraint set with , ie, for . For any given , let the PGA- algorithm be executed with step size . Then after at most steps, .
Using Theorem D.3 and Lemma D.4 (together with the additional restricted strong convexity/smoothness assumptions), we have the following theorem on the full oracle-free rates for Algorithm 1.
Theorem D.5 (Groupwise outer minimization with inner maximization using projected gradient ascent).
Setting the inner iteration count as and the outer iteration count as , for a combined total of adaptive adversarial iterations, Algorithm 1 achieves .