Scaling properties of scale-free networks in degree-thresholding renormalization flows
Abstract
We study the statistical properties of observables of scale-free networks in the degree-thresholding renormalization (DTR) flows. For BA scale-free networks with different sizes, we find that their structural and dynamical observables have similar scaling behavior in the DTR flow. The finite-size scaling analysis confirms this view and reveals a scaling function with a single scaling exponent that collectively captures the changes of these observables. Furthermore, for the scale-free network with a single initial size, we use its DTR snapshots as the original networks in the DTR flows, then perform a similar finite-size scaling analysis. Interestingly, the initial network and its snapshots share the same scaling exponent as the BA synthetic network. Our findings have important guiding significance for analyzing the structure and dynamic behavior of large-scale networks. Such as, in large-scale simulation scenarios with high time complexity, the DTR snapshot could serve as a substitute or guide for the initial network and then quickly explore the scaling behavior of initial networks.
Index Terms:
Scale-free networks, degree-thresholding renormalization, finite-size scaling, scaling exponent.I Introduction
The network widely exists in both nature and human society and is a common language for describing and modeling complex systems. Its emergence contributes to a better understanding of the structure and functional attributes of the system [1, 2]. In this regard, the scale-free network [3] is undoubtedly an excellent example, and its degree distribution is usually can be described by the power-law distribution in the mathematical background. In addition, this characteristic effectively distinguishes scale-free networks from regular networks, Erdös-Rényi (ER) random networks [4], and Watts-Strogatz (WS) small-world networks [5]. As a result, scale-free networks have many peculiar properties, such as robustness under random attacks, vulnerability under target attacks [6], and faster spreading speed of virus on scale-free networks [7].
In the following years, another important property of networks, self-similarity [8], has also been discovered by borrowing concepts related to the renormalization group [9] in statistical physics. Some major works include: Song et al. [8] proposed a box-covering renormalization (BCR) method based on shortest path lengths between network nodes to reduce the size of the network, and they found that the degree distribution of real networks such as WWW remained approximately unchanged during the BCR iteration. Serrano et al. [10] presented a simple degree-thresholding renormalization (DTR) technique for mining the self-similar properties of real networks. Recently, García-Pérez et al. [11] offered a network geometric renormalization (GR) approach in the context of the hidden metric space model [10, 12, 13, 14, 15], which provides another insight for studying the structural symmetry of networks. Precisely, the BCR depends on the shortest path length between nodes, and the GR requires embedding the network into a hidden space [16]. Their core idea is to coarse-graining multiple nodes into a supernode to produce smaller-scale replica networks. In contrast, the DTR procedure induces a smaller-scale subgraph by extracting nodes larger than a given degree threshold in the initial network. Technically, the DTR procedure is easier to execute. In short, the significance of renormalization of the network is to find smaller-replicas to replace the original network, so as to effectively explore the self-similarity of the real network.
Renormalization is useful for transforming large-scale networks into smaller ones, and the DTR is especially simple and convenient in this regard. Therefore, in the context of DTR, we conduct a series of studies on synthetic and real scale-free networks. First, we find that the DTR procedure can approximately maintain the important structural properties of Barabasi-Albert (BA) [3] and Chung-Lu (CL) [17, 18] scale-free networks (see Sec. II-B). Then, our results show that some observables of BA and CL scale-free networks follow the scaling properties in the DTR flow (see Sec. III-A). The finite-size scaling (FSS) analysis confirms this view and reveals a scaling function to capture the observable’s variation (see Sec. III-B). Furthermore, for a CL or real scale-free network with a single initial size, using the DTR procedure to obtain the corresponding smaller-size subnetwork, the results show that the initial network and its subnetworks share the same scaling exponent as the BA network (see Sec. III-B). Finally, we present the conclusion of the paper and the prospect of future work (see Sec. IV).
The main contributions of the paper are summarized as follows:
a) The statistical properties of representative observables of scale-free networks under the DTR procedure are studied and show that these observables obey the scaling law.
b) For BA scale-free networks with different initial sizes, the FSS confirmed this universal scaling law and revealed a scaling function with a single exponent () to capture the behavior of observables in DTR flows. For CL scale-free networks with different initial sizes, our results show that the scaling exponent depends on its degree distribution exponent .
c) Finally, for the CL or real-world scale-free network with a single initial size, our results show that the initial network and its DTR snapshots share the same scaling exponent as the BA synthetic network.
d) From the perspective of the application, the scaling exponent obtained here can be used as the foundation for predicting the structure and dynamic characteristics of the large-scale network, which has important guiding significance for reducing the time complexity of the large-scale numerical simulation.
II Preliminaries
This section briefly introduces the BA and CL scale-free network model, then reviews the degree-thresholding renormalization (DTR) program. The statistical characteristics of their complementary cumulative degree distribution, degree-dependent clustering coefficient, and degree-degree correlations in DTR flows are further studied.
II-A Network models
As one of the most classic network model, the BA scale-free network is of great significance for exploring scale-free characteristics and evolutionary mechanisms of networks. Its generating mechanisms are dominated by two factors: growth and preferential attachment [3]. In this context, the network eventually develops into a scale-free network with a degree distribution exponent . The exact form of the degree distribution of the BA model is . For large , approximately satisfies , where the parameter is the number of links increased after adding a new node. The paper uses the Python-based NetworkX library [19] to generate a BA scale-free network.
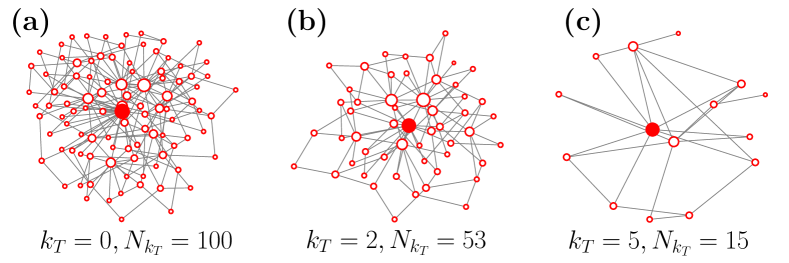
II-B Degree-thresholding renormalization
Serrano et al. [10] proposed a degree-thresholding renormalization (DTR) procedure, and suggested that some basic properties of some real scale-free networks and a class of geometric models are self-similar under this framework, such as the complementary cumulative degree distribution, degree-dependent clustering coefficient, and degree-degree correlations. The specific steps of DTR are as follows: for an initial network with nodes, given degree threshold , then, nodes with degrees are extracted from to obtain the subgraph (i.e., nodes with degrees less than or equal to are deleted), we thereby obtain a series of downscaled subnetworks, and the number of nodes contained in the subnetwork is denoted by . Starting from a BA scale-free network with 100 nodes, we delete those nodes with degrees based on the initial network, and obtain two subgraphs (see Fig. 1). The red node in the center is the hub node, which shows that the hub node always exists in the network during this process.
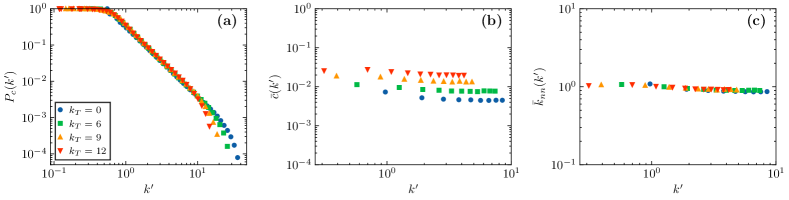
Figs. 2(a), (b) and (c) show the complementary cumulative degree distribution , degree-dependent clustering coefficient , and degree-degree correlations of a BA scale-free network and its corresponding subgraphs, respectively. Here is defined as the average of the local clustering coefficients of all nodes with degree . The degree-degree correlation is measured by normalized average nearest-neighbor degree , and the is defined as the average of the average nearest-neighbor degree of all nodes with degree value , where is the average degree of the subgraph . Following the practice in Res. [10, 11], we show the horizontal axis here with the rescaled degree . For and , the results of different subgraphs can collapse on almost the same main curve, which indicates that these two characteristics of BA networks are self-similar in the DTR flow. For , the curves of different subgraphs do not collapse well. On the contrary, these curves seem to move upward with the increase of , which also seems to reflect the essential difference between the BA scale-free network and some self-similar synthetic scale-free networks (such as model [10]). We only show the result of here, and a consistent conclusion can be obtained when the parameter is set to other values (the results can be viewed in the main sample code111The main sample code used in this paper can be accessed online in the GitHub public repository: https://github.com/cdzqf/DTR).
In addition, compared with the real scale-free network, BA scale-free network is a special case. To this end, we employ a more general scale-free network model, Chung-Lu (CL) scale-free network [17, 18], as an extension model, its degree distribution satisfies , and the exponent is used to control the heterogeneity of the network. We employ the recent algorithm presented by Fasino et al. [18] to create a series of CL networks with different sizes and degree distribution exponents. Specifically, the model needs to define a nonnegative real vector
| (1) |
where , , , , and are the upper limits of the expected values of the average degree and the largest degree, respectively. We obtain a result similar to the BA network, as shown in Fig. S1 of the Supplemental Material. Our results show that the BA and CL scale-free networks’ degree-dependent clustering coefficient seems to have weak self-similarity in the DTR flow. In contrast, the model shows good self-similarity (see Fig. S2 in the Supplemental Material).
III Results and Discussion
III-A Scaling properties of scale-free networks along the DTR flow
In this subsection, we study the statistical properties of observables of BA scale-free networks, CL scale-free networks, and real scale-free networks in the DTR flow. Our results show that these observables approximately obey the scaling law in the DTR flow. Specifically, we investigate some basic and important topological characteristics of the network, such as the largest node degree, average degree (edge density), average clustering coefficient, and the th moment of the degree distribution.
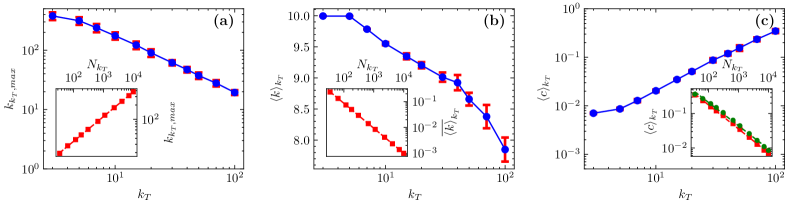
Taking the largest degree as an example, in general, the probability that a node’s degree value is equal to or higher than can be found in the network is [2]. For power-law degree distribution , we have , and the natural cutoff follows 222See equation (4.16) in Chapter 4 of the Network Science online reading document: http://networksciencebook.com/chapter/4#hubs. Thus, for a network with nodes, the largest degree satisfies . For BA scale-free networks, Fig. 3(a) shows that the largest degree of subgraph is a monotonically decreasing function as the threshold value , and the inset shows that . The result implies that the DTR procedure can maintain the scaling characteristics of the largest node degree of the initial BA scale-free network.
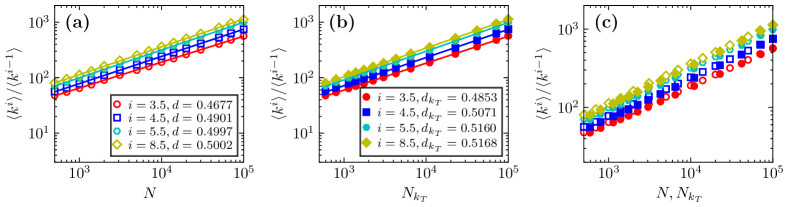
Fig. 3(b) shows the behavior of the subgraphs’ average degree in the DTR flow. Different from the results of geometric models (the average degree increases with the increase of ) [10], the BA network’s average degree slightly decreases with the increase of . The inset shows the dependence of the normalized average degree on , which approximately satisfies the power-law behavior, . Fig. 3(c) shows the average clustering coefficient of the subgraph gradually increases along the direction of DTR flow. The results of the inset show that , as shown in the red square, and the dashed line is the fitting result. Klemm et al. [22] have proved that the average clustering coefficient of the BA network meets , and the average clustering coefficient of subgraph can be calculated based on this conclusion, as shown in the green circle, our results show that the green circle and the red square roughly overlap, which implies that the DTR procedure do not change the statistical law of the average clustering coefficient for the initial BA network.
We also performed further research on the CL scale-free network and geometric model, as shown in Figs. S3 and S4 of the Supplemental Material. For CL models, except for the average degree of subgraphs, the other results are similar to BA. For the CL and model, the average degree of the subnetwork increases with the increase of [see Fig. S3(b) and Fig. S4(b)]. The subnetwork’s average degree depends on many factors, among which the structural characteristics of the network and the finite-size effect may be significant factors. In addition, from the results of BA and CL networks, it seems that the DTR cannot well retain the average clustering coefficient of initial networks [see Fig. 2(b), Fig. 3(c), Fig. S1(b), and Fig. S3(c)] but can well retain this feature of models [see Fig. S2(b) and Fig. S4(c)].
| Name | Category | |||||||
|---|---|---|---|---|---|---|---|---|
| Proteome | Biological | 4100 | 13358 | 6.52 | 2.61 | 0.6871 | 1.3956 | 1.00(1) |
| Internet | Technological | 23748 | 58414 | 4.92 | 2.17 | 0.6752 | 1.3098 | 1.00(4) |
| Caida20071105 | Technological | 26475 | 53381 | 4.03 | 2.17 | 0.7030 | 1.2677 | 1.00(5) |
| Words | Text | 7377 | 44205 | 11.98 | 2.24 | 0.8302 | 1.5289 | 1.0(1) |
| Frenchbookinter | Text | 9424 | 23841 | 5.06 | 2.43 | 0.7948 | 1.3914 | 1.00(5) |
| Japanesebookinter | Text | 3177 | 7998 | 5.03 | 2.28 | 0.8028 | 1.4240 | 1.00(5) |
| Youtube | Affiliation | 124325 | 293342 | 4.72 | 2.49 | 0.7220 | 1.3300 | 1.00(5) |
| Recordlabel | Affiliation | 186758 | 233277 | 2.5 | 2.02 | 0.8798 | 0.9633 | 1.00(5) |
Recently, Serafino et al. [16] have shown that finite-size effects usually hide the scale-free properties of real-world networks through finite-size scaling analysis and moment ratio tests. In this context, we employ the moment ratio test to verify the scale invariance of scale-free networks in DTR flows. The moment of degree distribution is helpful to understand the meaning of scale-free term [2]. Specifically, for a scale-free network, the th moment of the degree distribution is
| (2) |
Serafino et al. [16] have shown that when , the ratio of the th moment of the degree distribution to the th moment is independent of , satisfies , where . As shown in Fig. 4(a), for BA scale-free networks, the moments ratios for different th are parallel lines. Additionally, we consider the BA scale-free network with the initial size of and perform DTR procedure on it to obtain a series of subnetworks. Then, applying the moment ratio experiment to these subnetworks, as shown in Fig. 4(b), we obtain a similar result, namely , where . We display the results of Fig. 4(a) and Fig. 4(b) on the same figure, as shown in Fig. 4(c), the result shows that the DTR procedure can roughly reverse the preferential attachment evolutionary growth process of the BA network, which means that the DTR can approximately return the BA network to an earlier state.
According to the results presented in Figs. 2–4, BA networks’ degree distribution and degree-degree correlation have scale invariance in the DTR flow. The largest degree, the normalized average degree, and the average clustering coefficient approximately obey the scaling behavior in the DTR flow. These results show that the DTR downscaling process of BA networks can be approximately regarded as the opposite direction of its evolutionary growth process, which makes it possible to predict the structural characteristics of large-scale BA networks based on their small-scale subgraphs.
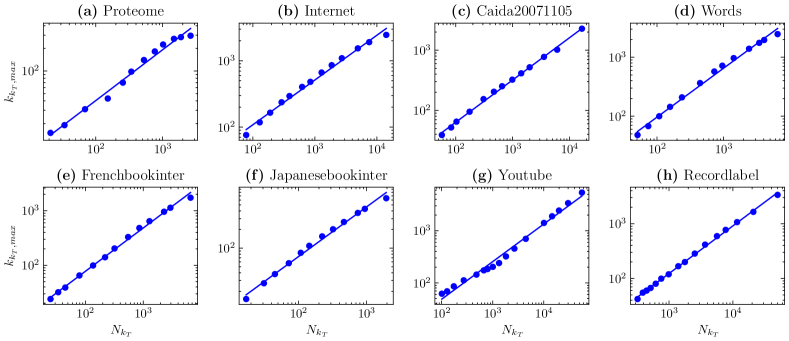
In fact, empirical studies show that the degree distribution of a large number of real-world networks approximately satisfies , and in general, the exponent . Next, we consider eight real-world scale-free networks, which belong to four different categories: Biological, Technological, Text, and Affiliation333https://icon.colorado.edu/.. The detailed topological information is shown in Table I. After examining the statistical properties of these networks and their subnetworks, respectively, a conclusion similar to Fig. 3(a) is obtained, that is, the largest degree of the subnetwork satisfies , as shown in Fig. 5. Furthermore, we also studied the dependence of the normalized average degree of subnetwork on (detailed results as shown in Fig. S5). The results further show that , where the value of is shown in Table I. However, our results also show that too large degree thresholds will cause to deviate from this power-law behavior significantly, which is obvious on Proteome, Words, Frenchbookinter, Japanebookinter, and YouTube networks. For these real networks, is also approximately true in the DTR flow, as shown in Fig. S6. Indeed, even if the scale-free network with a sufficient initial size is considered, a large degree threshold will eventually lead to the loss of their original scale invariance (or self-similarity). For this reason, the finite-size scaling (FSS) [23] analysis in the next section shows that the finite-size effect often masks the underlying scale invariance of many networks.
III-B Finite-size scaling analysis
For complex systems, some observables deviating from thermodynamic limit behavior are often observed in actual numerical simulations due to the limit of infinite size cannot be reached. Here, we show that the potential scale invariance of network observables is often masked by finite-size effects. We employ the FSS analytical tool to prove this view and reveal a scaling function with a single exponent that jointly captures the scaling behavior of these observables. Using represents a particular observable, we find that under the FSS hypothesis,
| (3) |
where is the size of the initial network, () is the relative size of the subnetwork , and the behavior of the observable is completely determined by the exponent and the scaling function . Taking six observables in our recent work [24] as examples, we next investigate the FSS behavior of these observables in the DTR flow.
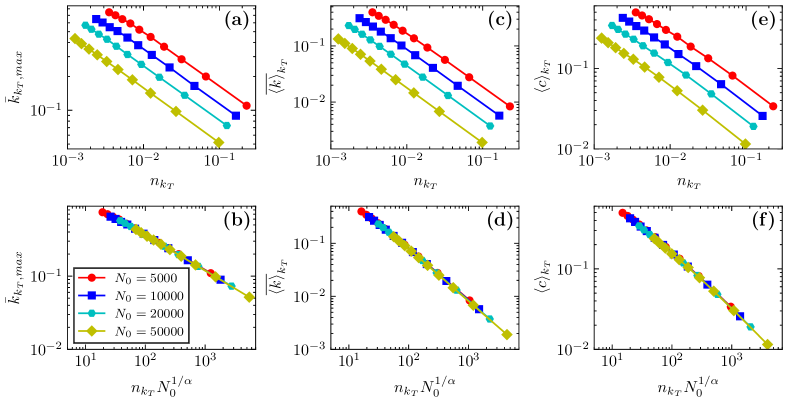
For BA scale-free networks with different initial sizes, Fig. 6(a), (c), and (e) show the dependence of structural observables (i.e., ), , and of the subnetwork on the relative size , respectively. The results show that the observable curves of different-size networks have very similar behavior in the DTR flow. Eq. (3) shows that rescaling the horizontal axis of these curves to will cause them to collapse on the same master curve [see Fig. 6(b), (d), and (f)]. Notably, these observables share the same scaling exponent, . Here, the optimal exponent is obtained by measuring the quality of the collapse plot, where the is used to measure the mean square distance between the collapse data and the master curve, and its detailed definition is shown in Ref. [25]. Precisely, rescaling the horizontal axis of the original data points to , and the between multiple rescaled curves is calculated, respectively, where the minimum point of corresponds to the optimal collapse exponent . Taking the normalized largest degree as an example [see Fig. 6(a)], Fig. S7(a) shows the dependence of the on exponent . When , achieves the minimum value, which means that different curves have the best collapse [see Fig. 6(b)]. Figs. S7(b)–S7(d) show the results of Fig. 6(b) at , , and , respectively, and the results show that the overlap quality of Fig. S7(b) is significantly better than that of Fig. S7(c) and Fig. S7(d).
As a supplement, we also consider some dynamical observables that depend on the underlying structure of the network. Such as the normalized smallest nonzero eigenvalue of the Laplace matrix, , where is the smallest nonzero eigenvalue of the Laplace matrix of the subnetwork . Previous studies have shown that, in most cases, maximizing the convergence rate to the network-homogeneous state for undirected networks is equivalent to maximizing [26]. We further consider the ratio of the largest eigenvalue of the Laplace matrix to the smallest nonzero eigenvalue , i.e., [27, 28]. This quantity is related to the stability of the network synchronization process, and it gives the time that the system needs to recover to the stable synchronization state after disturbance [29, 30]. Finally, the largest eigenvalue of the adjacency matrix determines many dynamic behaviors of the network, and its normalized form is , where is the largest eigenvalue of the subnetwork’s adjacency matrix. Castellano et al. [31] have shown that the thresholds of two highly correlated dynamic models depend on , one of which is the epidemic spreading, its threshold satisfies , and the synchronization threshold [32] for Kuramoto dynamics coupling parameter associated with . Therefore, these observables (called dynamical observables in this paper) have a crucial influence on the dynamical behavior of the underlying network structure, and investigating their scale invariance in the DTR flow is of great significance for predicting the dynamic behavior of large-scale networks.
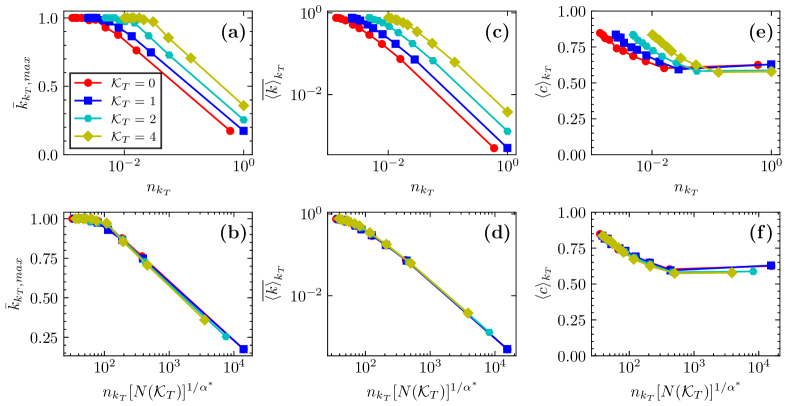
As shown in Fig. S8, we observed that the scaling behavior of these dynamic observables is similar to that in Fig. 6. Under the rescaling of Eq. (3), these curves of BA networks with different sizes could collapse onto the same master curve. In particular, an same scaling exponent, , is produced here. Our results have important guiding significance for studying the dynamic behavior of large-scale networks. For instance, in practice, one possible outcome is to predict the synchronization stability of the initial large-scale network by taking the subnetwork as the study object and combining this scaling exponent. Fig. 6 and Fig. S8 show the results of BA networks under the parameter , and a consistent conclusion can be obtained when the parameter is set to other values (see Figs. S9 and S10).
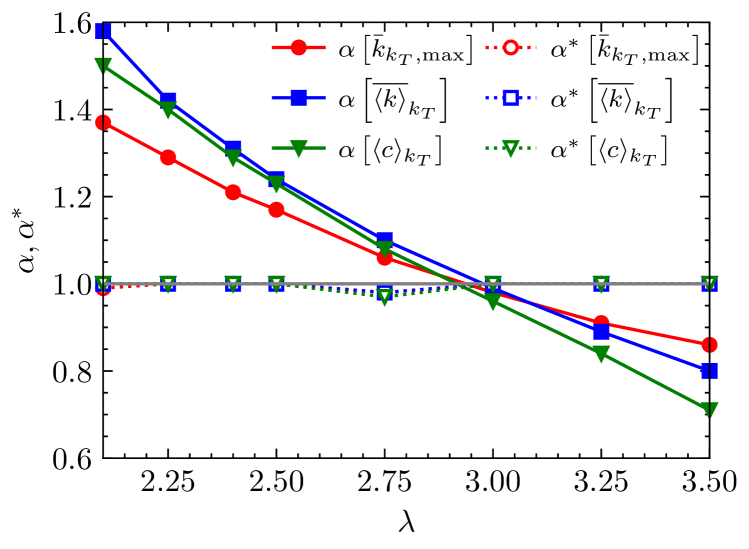
We perform the same study as Fig. 6 on CL networks with different heterogeneity exponent (Figs. S11 and S12 give the results for and , respectively), examining the dependence of scaling exponent on the heterogeneity exponent , as shown in Fig. 7 (red solid circle, blue solid square, and green solid triangle). Our results show that, for each observable, the exponent decreases gradually with the increase of the , which means that the exponent strongly depends on the heterogeneity of the network. Moreover, for different observables, the exponent has a large difference. Particularly, when , each observable corresponds to an approximately same exponent, i.e., , which is consistent with the results of BA scale-free networks.
When evaluating the scaling exponent of synthetic networks, we can obtain this result by generating a series of networks with different initial sizes. For real networks, however, there is usually a single initial size. A natural question is how to calculate the scaling exponent for a particular network with a single size. To address this issue, we conduct further research on CL scale-free networks with a single initial size. Specifically, we generate a CL scale-free network with , and then obtain the subgraph under the given degree threshold . The used here is essentially the same as the used above, with the main difference being that is a degree threshold explicitly set for a single initial network, and its value range is usually limited to a very narrow interval. For example, as shown in Fig. S13, the size of the initial network is , its three subgraphs under degree thresholds are obtained, respectively, and the size of is = 51734, 19901, and 10664, respectively. Next, we take and its three subgraphs as new initial reference networks to investigate their FSS behavior in DTR flows (see Fig. S13 and Fig. S14). Therefore, the subgraph size is within a reasonable range in this context. In other words, the subgraph size cannot be too close to , nor too small. For simplicity, we chose the appropriate so that the size of the subgraph is roughly equal to , , and (or , , and ). However, the can take on a wide range of values. For instance, for the BA scale-free network with , when , the size of the subgraph is , which is more than a hundred times smaller than the original network (see Fig. 3).
In the above context, and its subnetworks are taken as initial networks to study the FSS behavior of their observables in the DTR flow. By analogy with Eq. (3), under the FSS hypothesis, the observable satisfies,
| (4) |
where is the size of the subnetwork , and is the relative size of the remaining network after removing nodes from the subnetwork . The behavior of the observable is completely determined by the exponent and the scaling function . Interestingly, the scaling exponent of the initial network and its subnetwork is independent of the heterogeneity exponent and shares the same scaling exponent with the BA network, namely, , as shown in Fig. 7 (red hollow circle, blue hollow square, and green hollow triangle). In particular, these three topological observables considered here correspond to an approximately identical exponent .
Subsequently, we present a possible application: the exponent is obtained by FSS analysis performed on the topological observables, then combined with this exponent to predict the dynamic characteristics of the initial network. The reason is that the pure calculation of the network’s topology observables (such as the largest degree of the network) is usually a task with low computational complexity. In contrast, calculating dynamic observables (such as the eigenvalues of the network) is usually a task with high computational complexity. The significance of the scaling exponent, , is that we can predict the dynamic characteristics of the initial large-scale network with the help of the subgraph without spending extra time to calculate them separately. For example, based on and the subnetwork of the initial large-scale network , we can predict the behavior of the largest eigenvalue of the in the DTR flow, as shown in Fig. S15.
Finally, we confirm the universality of via real scale-free networks, and details of these real network datasets are shown in Table I. Fig. 8 shows the structural observables results of the Internet and its three subnetworks , where , and the results of dynamical observables are shown in Fig. S16. To ensure the subnetwork has approximately the same topology properties as the original network (see Figs. S17-S19), the value of should not be selected too large. Then we take the Internet and its three subnetworks as the research object, and perform DTR on them, respectively. By rescaling the horizontal axis according to Eq. (4), these observable curves of subnetworks and the original Internet network can collapse onto the same master curve, where the exponent . For other real scale-free networks, approximately the same exponent is obtained, as shown in Table I. The result confirms that scale-free networks and their subnetworks share the same universality class exponent.
III-C Discussion
Fig. 6 and Fig. 7 show that the corresponding scale exponent of the BA and CL synthetic network is inconsistent. Next, we give the possible reasons: the CL network is a static model, and its connection mode differs from the preferential attachment growth mode of the BA network. For the BA model, the degree increases with the age of nodes, while the DTR tends to delete the most recent nodes. Therefore, DTR can approximately return the BA network to an earlier state, implying that the artificially generated smaller-size BA network can be approximately used as a nested subgraph of the larger-size BA network. Indeed, the degree distribution shows that the scale-free network of BA with different sizes is self-similar, as shown in Fig. S20(a). This result means that the scaling exponent obtained in the DTR flow is approximately the same () whether BA networks with different sizes or the DTR snapshots are used as the original network. However, the degree distribution of CL models with different sizes has certain differences, especially in the tail [as shown in Fig. S20(b)]. This indicates that the artificially generated smaller-size CL network cannot be used as the nested subgraph of the larger-size CL network. In contrast, the subgraph extracted by DTR can be approximately used as the nested subgraph of the initial large-scale CL network [see Fig. S1(a)]. Therefore, exponents and are different for CL models. In conclusion, the results of the hollow symbol reported in Fig. 7 and the results of the real network produced in the same way in Fig. 8 describe a feature of finite-size self-similar networks in DTR flows from another perspective.
Furthermore, the BCR technique proposed by song et al. [8] connects the representation of dimensionality with the definition of distance. They use the shortest path length between nodes to define the similar distance for the network’s renormalization and define the fractal dimension of the network. Recently, considering the ultrasmall-world property of real-world networks, which cannot provide a wide range of distance values. Within the context of hidden metric spaces [10], the GR [11] technique comes into being, this method has achieved excellent results in most scenarios, which is further confirmed in a series of literature and publications [33, 34, 35, 36]. The scaling function employed in this paper is similar in spirit to the Refs. [37, 38], by comparison, our work is performed on the DTR technique. In short, all these renormalization schemes contain the idea of dimension reduction, reducing dimension redundancy, which is of great engineering significance for processing massive high-dimensional datasets.
In this work, we employ scale-free networks as research objects, and these network degree values are usually distributed in a relatively wide range. However, their degree values are usually distributed in a relatively narrow range for other homogeneous networks, such as ER random networks, the national highway network with homogeneous topology, or the European power grid with exponential degree distribution. For these networks, a small degree threshold may induce a subgraph with few nodes, which may bring inconvenience related research. On the other hand, considering that the node’s degree is a local feature of the network, the information provided by it is often limited or incomplete to a certain extent. Therefore, it may be worth studying other network features as an alternative to the degree threshold. Under these circumstances, developing a subgraph extraction or coarse-graining procedure suitable for more scenarios is the direction we still need to work hard in the future.
IV Conclusion
In this paper, we study the statistical properties of some representative observables of scale-free networks in the DTR flow, and experimental studies show that these observables obey the scaling law. First, we find that some properties of networks show scaling behavior in DTR flows. Furthermore, our results also show that some observables deviate from the pure scaling behavior in DTR flows due to the finite-size effect of networks. Interestingly, in the context of FSS analysis, we find a scaling function that always yields observed data collapse at different network sizes. Specifically, for BA scale-free networks with different initial sizes, the FSS confirmed this universal scaling law and revealed a scaling function with a single exponent to capture the behavior of observables in DTR flows. For CL scale-free networks with different initial sizes, our results show that the scaling exponent depends on its degree distribution exponent . Notably, for CL or real-world scale-free network with a single initial size, our results show that the observable of the initial network and its subnetworks share the same scaling exponent as the BA network. These results suggest that subnetworks could also be applied to perform finite-size scaling and the scaling exponent can be determined from a single snapshot of the topology. From the perspective of the application, the scaling exponent obtained here can be used as the foundation for predicting the structure and dynamic characteristics of large-scale networks, which has important guiding significance for reducing the time complexity of the large-scale numerical simulation.
References
- [1] V. Latora, V. Nicosia, and G. Russo, Complex networks: principles, methods and applications. Cambridge University Press, 2017.
- [2] A.-L. Barabási, Network Science. Cambridge University Press, 2016.
- [3] A.-L. Barabási and R. Albert, “Emergence of scaling in random networks,” science, vol. 286, no. 5439, pp. 509–512, 1999.
- [4] P. Erdös and A. Rényi, “On random graphs,” Publications Mathematicae Debrecen, vol. 6, no. 290, 1959.
- [5] D. J. Watts and S. H. Strogatz, “Collective dynamics of ‘small-world’ networks.” Nature, vol. 393, no. 6684, pp. 440–442, 1998.
- [6] R. Albert, H. Jeong, and A. Barabási, “Error and attack tolerance of complex networks,” Nature, vol. 406, no. 6794, pp. 378–382, 2000.
- [7] R. Pastor-Satorras and A. Vespignani, “Epidemic spreading in scale-free networks,” Phys. Rev. Lett., vol. 86, pp. 3200–3203, 2001.
- [8] C. Song, S. Havlin, and H. A. Makse, “Self-similarity of complex networks,” Nature, vol. 433, no. 7024, pp. 392–395, 2005.
- [9] L. P. Kadanoff, Statistical Physics: Static, Dynamics and Renormalization. World Scientific, Singapore, 2000.
- [10] M. A. Serrano, D. Krioukov, and M. Boguñá, “Self-similarity of complex networks and hidden metric spaces,” Phys. Rev. Lett., vol. 100, p. 078701, Feb 2008.
- [11] G. García-Pérez, M. Boguñá, and M. A. Serrano, “Multiscale unfolding of real networks by geometric renormalization,” Nature Physics, vol. 14, no. 6, pp. 583–589, 2018.
- [12] S. Yi, H. Jiang, Y. Jiang, P. Zhou, and Q. Wang, “A hyperbolic embedding method for weighted networks,” IEEE Transactions on Network Science and Engineering, vol. 8, no. 1, pp. 599–612, 2021.
- [13] K. Huang, Z. Wang, and M. Jusup, “Incorporating latent constraints to enhance inference of network structure,” IEEE Transactions on Network Science and Engineering, vol. 7, no. 1, pp. 466–475, 2020.
- [14] P. Cui, X. Wang, J. Pei, and W. Zhu, “A survey on network embedding,” IEEE Transactions on Knowledge and Data Engineering, vol. 31, no. 5, pp. 833–852, 2019.
- [15] D. Chen, H. Su, and Z. Zeng, “Geometric renormalization reveals the self-similarity of weighted networks,” IEEE Transactions on Computational Social Systems, pp. 1–9, 2022, to be published, doi: 10.1109/TCSS.2022.3164975.
- [16] M. Serafino, G. Cimini, A. Maritan, A. Rinaldo, S. Suweis, J. R. Banavar, and G. Caldarelli, “True scale-free networks hidden by finite size effects,” Proceedings of the National Academy of Sciences, vol. 118, no. 2, 2021.
- [17] F. Chung and L. Lu, “Connected components in random graphs with given expected degree sequences,” Annals of combinatorics, vol. 6, no. 2, pp. 125–145, 2002. [Online]. Available: https://link.springer.com/content/pdf/10.1007/PL00012580.pdf
- [18] D. Fasino, A. Tonetto, and F. Tudisco, “Generating large scale-free networks with the chung–lu random graph model,” Networks, vol. 78, no. 2, pp. 174–187, 2021.
- [19] A. Hagberg, P. Swart, and D. S Chult, “Exploring network structure, dynamics, and function using networkx,” 2008.
- [20] A. Clauset, C. R. Shalizi, and M. E. Newman, “Power-law distributions in empirical data,” SIAM review, vol. 51, no. 4, pp. 661–703, 2009.
- [21] J. Alstott, E. Bullmore, and D. Plenz, “powerlaw: a python package for analysis of heavy-tailed distributions,” PloS one, vol. 9, no. 1, p. e85777, 2014.
- [22] K. Klemm and V. M. Eguíluz, “Growing scale-free networks with small-world behavior,” Phys. Rev. E, vol. 65, p. 057102, May 2002.
- [23] H. E. Stanley, “Scaling, universality, and renormalization: Three pillars of modern critical phenomena,” Rev. Mod. Phys., vol. 71, pp. S358–S366, Mar 1999.
- [24] D. Chen, H. Su, X. Wang, G.-J. Pan, and G. Chen, “Finite-size scaling of geometric renormalization flows in complex networks,” Physical Review E, vol. 104, no. 3, p. 034304, 2021.
- [25] J. Houdayer and A. K. Hartmann, “Low-temperature behavior of two-dimensional gaussian ising spin glasses,” Phys. Rev. B, vol. 70, p. 014418, Jul 2004.
- [26] T. Nishikawa, J. Sun, and A. E. Motter, “Sensitive dependence of optimal network dynamics on network structure,” Phys. Rev. X, vol. 7, p. 041044, Nov 2017.
- [27] T. Nishikawa, A. E. Motter, Y.-C. Lai, and F. C. Hoppensteadt, “Heterogeneity in oscillator networks: Are smaller worlds easier to synchronize?” Phys. Rev. Lett., vol. 91, p. 014101, Jul 2003.
- [28] L. Donetti, P. I. Hurtado, and M. A. Muñoz, “Entangled networks, synchronization, and optimal network topology,” Phys. Rev. Lett., vol. 95, p. 188701, Oct 2005.
- [29] M. Barahona and L. M. Pecora, “Synchronization in small-world systems,” Phys. Rev. Lett., vol. 89, p. 054101, Jul 2002.
- [30] D. Shi, G. Chen, W. W. K. Thong, and X. Yan, “Searching for optimal network topology with best possible synchronizability,” IEEE Circuits and Systems Magazine, vol. 13, no. 1, pp. 66–75, 2013.
- [31] C. Castellano and R. Pastor-Satorras, “Relating topological determinants of complex networks to their spectral properties: Structural and dynamical effects,” Phys. Rev. X, vol. 7, p. 041024, Oct 2017.
- [32] J. G. Restrepo, E. Ott, and B. R. Hunt, “Onset of synchronization in large networks of coupled oscillators,” Phys. Rev. E, vol. 71, p. 036151, Mar 2005.
- [33] M. Zheng, G. García-Pérez, M. Boguñá, and M. Á. Serrano, “Scaling up real networks by geometric branching growth,” Proceedings of the National Academy of Sciences, vol. 118, no. 21, p. e2018994118, 2021.
- [34] M. Boguna, I. Bonamassa, M. De Domenico, S. Havlin, D. Krioukov, and M. Serrano, “Network geometry,” Nature Reviews Physics, vol. 3, no. 2, pp. 114–135, 2021.
- [35] M. Á. Serrano and M. Boguñá, The Shortest Path to Network Geometry: A Practical Guide to Basic Models and Applications. Cambridge University Press, 2021.
- [36] P. Almagro, M. Boguñá, and M. Serrano, “Detecting the ultra low dimensionality of real networks,” Nature Communications, vol. 13, no. 1, pp. 1–10, 2022.
- [37] F. Radicchi, J. J. Ramasco, A. Barrat, and S. Fortunato, “Complex networks renormalization: Flows and fixed points,” Phys. Rev. Lett., vol. 101, p. 148701, Oct 2008.
- [38] F. Radicchi, A. Barrat, S. Fortunato, and J. J. Ramasco, “Renormalization flows in complex networks,” Phys. Rev. E, vol. 79, p. 026104, Feb 2009.