∎
22email: worldlife@sjtu.edu.cn 33institutetext: Weiyao Lin 44institutetext: Department of Electronic Engineering, Shanghai Jiao Tong University, Shanghai China
44email: wylin@sjtu.edu.cn 55institutetext: Wenrui Dai 66institutetext: Department of Electronic Engineering, Shanghai Jiao Tong University, Shanghai China
66email: daiwenrui@sjtu.edu.cn 77institutetext: Huabin Liu 88institutetext: Department of Electronic Engineering, Shanghai Jiao Tong University, Shanghai China
88email: huabinliu@sjtu.edu.cn 99institutetext: Hongkai Xiong 1010institutetext: Department of Electronic Engineering, Shanghai Jiao Tong University, Shanghai China
1010email: xionghongkai@sjtu.edu.cn 1111institutetext: *(Corresponding author: Weiyao Lin.)
Scene Graph Lossless Compression with Adaptive Prediction for Objects and Relations
Abstract
The scene graph is a new data structure describing objects and their pairwise relationship within image scenes. As the size of scene graph in vision applications grows, how to losslessly and efficiently store such data on disks or transmit over the network becomes an inevitable problem. However, the compression of scene graph is seldom studied before because of the complicated data structures and distributions. Existing solutions usually involve general-purpose compressors or graph structure compression methods, which is weak at reducing redundancy for scene graph data. This paper introduces a new lossless compression framework with adaptive predictors for joint compression of objects and relations in scene graph data. The proposed framework consists of a unified prior extractor and specialized element predictors to adapt for different data elements. Furthermore, to exploit the context information within and between graph elements, Graph Context Convolution is proposed to support different graph context modeling schemes for different graph elements. Finally, a learned distribution model is devised to predict numerical data under complicated conditional constraints. Experiments conducted on labeled or generated scene graphs proves the effectiveness of the proposed framework in scene graph lossless compression task.
1 Introduction
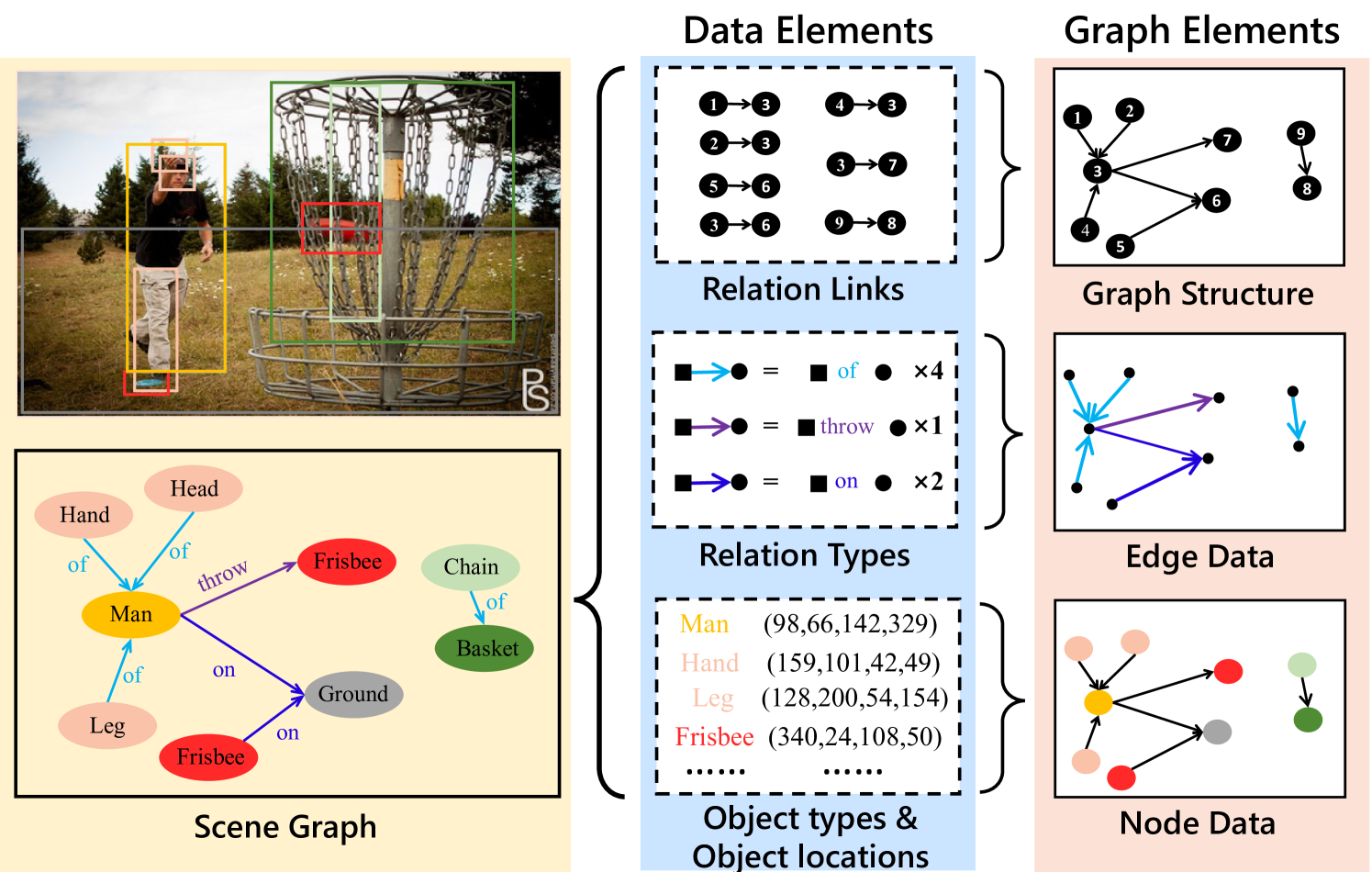
With the rapid development of computer vision, the emerging high-level visual tasks (e.g., visual question answeringDBLP:conf/emnlp/FukuiPYRDR16 ; DBLP:conf/cvpr/MarinoCP0R21 , image captioningDBLP:conf/eccv/AndersonFJG16 ; DBLP:journals/tomccap/JiangWH21 , high-precision image retrievalDBLP:conf/wacv/Wang0YSC20 ; DBLP:conf/aaai/YoonKJLHPK21 and high-level video understandingDBLP:conf/cvpr/JiK0N20 ) require understanding the relationships among objects in a scene. Scene graph, a new graph-based data structure that describes objects and their relations in a image scene, was leveraged to address this issueDBLP:journals/ijcv/KrishnaZGJHKCKL17 . Fig. 1 presents an example of scene graph composed of four data elements: relation links, relation types, object types and object locations. When organized as a scene graph, data elements are categorized into three types of graph elements: graph structure, edge data and node data.
Recently, with the rapid increase of image and video data in both data size and content complexity, their corresponding scene graphs’ data size and graph scale also increase dramatically. As a result, a massive volume of scene graphs needs to be stored in disks or transmitted over the network, calling for compression of scene graphs. Moreover, lossless compression of scene graphs is necessarily required to precisely describe the relationships in scenes. However, this requirement is challenging for existing lossless compressors. The main reasons are two-fold. First, a scene graph contains diverse types of data elements with various shapes and distributions, as shown in Fig. 1. As far as we know, there lacks a unified system to effectively compress all of these data elements at the same time. Second, objects and relations in scene graph are closely correlated. For example, the relation ‘throw’ usually describes the object ‘man’ and a throwable object, e.g., ‘frisbee’. These conditional correlations shall be exploited to reduce the redundancy among objects and relations in scene graphs during lossless compression.
For existing solutions, a naive solution employs a general-purpose lossless compressor like zlib zlib and LZMA LZMA to directly compress the scene graph into a bitstream. Nevertheless, such a solution ignores different shapes and distributions of data elements and correlations between objects and relations in scene graphs. Another possible solution is applying specialized methods for different data elements, such as using WebGraph DBLP:conf/www/BoldiV04 for compressing graph structures. Although this solution considers the data shape and distribution of the graph structure, it still fails to reduce potential redundancy among different graph elements. In summary, existing solution cannot solve the above two challenges in lossless compression of scene graphs.
To address the above challenges, a lossless compression framework for scene graphs should (1) adaptively compress different data elements in scene graphs, and (2) reduce context redundancy among objects and relations. In this paper, we consider these two requirements and propose a novel framework to achieve better lossless compression for scene graphs.
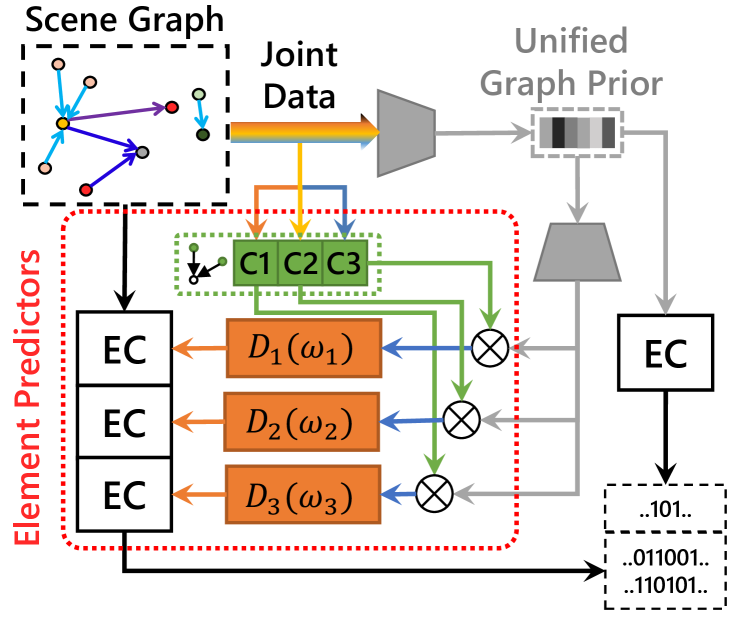
Element-adaptive Framework To this end, we propose a lossless framework that handles diverse data elements adaptively. This is achieved by designing different element predictors for distinct data elements, which learn to predict the symbol-level probabilities for each data element according to their intrinsic attributes (data shape and distribution). It empowers our framework to simultaneously process objects and relations in scene graphs, and meanwhile could be trained end-to-end. Fig. 2a illustrates a sketch of our proposed framework. Specifically, an autoencoder-based network first extracts unified graph prior of the whole graph, providing vital information for prediction. Then, the element predictors perform adaptive predictions combining unified graph prior and various forms of context information, and convert the prediction to probabilities using numerical or categorical forms of distribution modules.
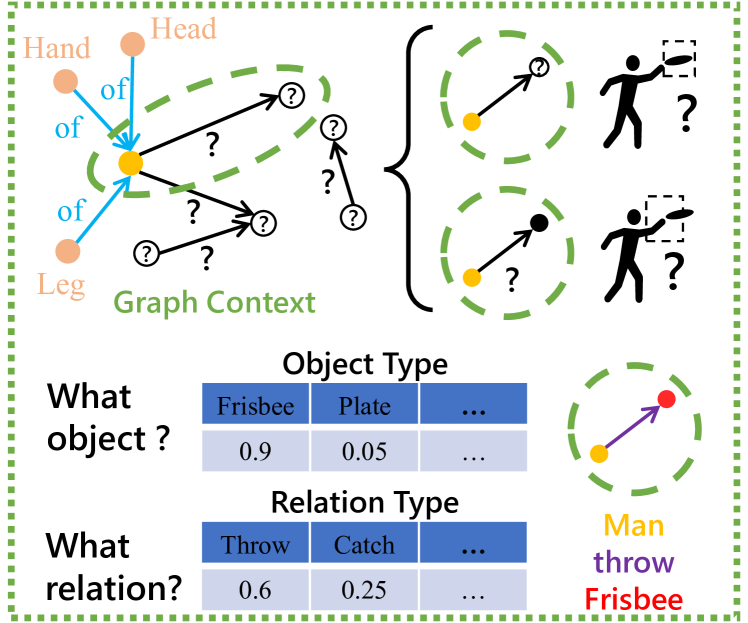
Graph Context Models We further equip our element predictors with element-specific graph context models, in order to enable this framework to reduce the heavy context redundancy in scene graphs. As presented in Fig. 2b, the distribution of data elements in graph structure is closely related with their semantic relationships. For example, as the object ‘frisbee’ is usually used by a human, this object has a higher probability of occurring at the neighborhood of object ‘man’. Similarly, knowing about object ‘frisbee’ and ‘man’, their relation type is more likely to be ‘throw’. Graph convolutionDBLP:conf/iclr/KipfW17 , which passes messages among nodes to obtain enhanced node features, is a popular solution to model such relationships. However, the element predictors in lossless compression require that the context models should be causal systems. In the case of scene graph data, it means that messages can only pass from the former nodes to latter nodes during context modeling. To address this issue, we propose a Graph Context Convolution (GCC), which conducts message passing following the causal flows. Based on GCC, we then devise element-specific context modeling schemes for the node data predictor, graph structure predictor, and edge data predictor, respectively. They empower our framework to reduce context redundancy for all graph elements in scene graphs.
Learned Distribution Model In addition, regarding numerical data (e.g., object location), it is typical for element predictors to utilize a pre-defined distribution model that fits their distribution to obtain the final probabilities. However, their distributions tend to be constrained by complicated relationships among objects in scene graphs. As shown in Fig. 2b, the location of object ‘man’ could be estimated with the knowledge ‘head of man’, ‘hand of man’ and ‘leg of man’, where the relation ‘of’ indicates that they are more likely close to each other. Therefore, the location of object ‘man’ should be distributed near the object ‘head’, ‘hand’ and ‘leg’. Furthermore, an object may be related to multiple other objects with different types of relations, resulting in a more complicated distribution. Therefore, a more general distribution model that could fit such complicated constraints is preferred. This paper proposes a learned distribution model consisting of a learnable dynamic neural network that defines a continuous distribution function.
By virtue of these designs, our proposed framework can losslessly compress diverse data elements and significantly reduce the context redundancy in scene graphs. Experiments demonstrate our framework achieves the best compression ratio compared to existing general or element-specific compression frameworks. The main contributions of this paper are:
-
•
We propose an element-adaptive framework for scene graph lossless compression, which is the first attempt in this field to our knowledge.
-
•
We devise element-specific graph context models for different graph elements, which significantly reduce the context redundancy during compression.
-
•
We propose a learned distribution model to adaptively fit the complicated distribution of numerical data in scene graphs.
The remainder of this paper is organized as follows. Section 2 reviews related works. Section 3 gives an overview of the proposed framework. Section 4 introduces the proposed graph context models for different graph elements. Section 5 introduces the learned distribution model. Section 6 shows experimental results on various datasets and corresponding analysis. Section 7 finally summarizes this paper.
2 Related Work
2.1 General-purpose Lossless Compression
General purpose lossless codecs usually convert any forms of data into a sequence of symbols, and compress the sequence into a compressed stream.
A popular tool for general-purpose lossless compression is zlib zlib , which combines LZ77 DBLP:journals/tit/ZivL77 and Huffman coding 4051119Huffman . Many later compression codecs improve such scheme by optimizing the string matching algorithm in LZ77 (such as LZMALZMA and BrotliDBLP:journals/tois/AlakuijalaFFKOS19 ) or switching to better entropy coder such as Asymmetric Numeral SystemDBLP:journals/corr/Duda13 (such as ZstdZstd ). Some other codecs designs a context-adaptive entropy coder to exploit context information. For example, PPM1096090PPM utilize a simple suffix-based context model to count symbol frequencies adaptively, while PAQMahoney2005AdaptiveWO utilize the context mixing scheme to combine predictions from many specially designed context models. Recent works also explores using neural networks to learn prior information of data or exploit context information more robustly, such as CMIXCMIX , and DzipDBLP:conf/dcc/GoyalTCO20 .
However, for scene graph data, such codecs ignore hidden redundancy between different data elements. Furthermore, context information in general-purpose compression methods are usually explored in adjacent string of symbols, while for graph-structured data like scene graphs, adjacency usually exists along graph edges. Therefore, applying general-purpose codecs is an inefficient solution for scene graph lossless compression.
2.2 Graph Structure Lossless Compression
Graph is a common form of data in many areas, such as web-page database, social network and biological data. Therefore, graph structure lossless compression has also been studied in many previous works, as reviewed in DBLP:journals/corr/abs-1806-01799 . For example, WebGraphDBLP:conf/www/BoldiV04 is a framework designed for web graph compression. Based on the locality and sparsity features of web-page URLs, WebGraph utilizes multiple compression techniques including reference compression and differential compression to exploit such features. Another compression method built on such features was -treeDBLP:conf/spire/BrisaboaLN09 , which iteratively divides the graph adjacency matrix into sub-matrices, and stops when the sub-matrix is a all-zero matrix.
Although such methods could be applied for graph structure compression, the compression of node data and edge data is usually ignored. In this work, in addition to graph structure compression, node data compression and edge data compression should also be considered.
2.3 Learning-Based Image Compression
Recently, many compression related works has been using neural networks. A large portion of those works are related to image compression. Most recent approaches of deep-learning based image compression utilize an autoencoder-based end-to-end framework DBLP:conf/iclr/BalleLS17 . Following DBLP:conf/iclr/BalleLS17 , DBLP:conf/iclr/BalleMSHJ18 proposed a hyperprior autoencoder that enables better latent prediction. Afterwards, a few works propose to improve the hyperprior model by exploiting context information from neighbouring pixels (DBLP:conf/nips/MinnenBT18 ; Chen9359473 ) or improving the distribution module with more complex distributions (DBLP:conf/cvpr/ChengSTK20 ; DBLP:journals/corr/abs-2107-06463 ). Other frameworks also explores different network structures such as context-based convolutional networks for entropy modelingLi9067005 or wavelet-like convolutional networks for image transformationDBLP:journals/tmm/Ma0X020 .
For lossless or near-lossless image compression, a straightforward solution is to apply a predictor and compress the residual 9277919 . Also, some works apply autoencoder as likelihood generative networks DBLP:conf/cvpr/MentzerATTG19 ; DBLP:conf/icml/KingmaAH19 to estimate pixel-wise probability for entropy coding in order to achieve lossless compression. Other works deploy invertable neural networks DBLP:conf/nips/HoogeboomPBW19 ; 9204799 to generate a lossless transformation of the original data for easier entropy coding.
The proposed framework is inspired by many successful learning-based compression frameworks DBLP:conf/iclr/BalleMSHJ18 ; DBLP:conf/nips/MinnenBT18 ; DBLP:conf/cvpr/MentzerATTG19 ; DBLP:conf/icml/KingmaAH19 . However, the proposed framework is specially designed for compression of the complete scene graph. To achieve this, some novel modules are proposed and designed, such as the adaptive element predictors with graph context models.
3 Proposed Framework
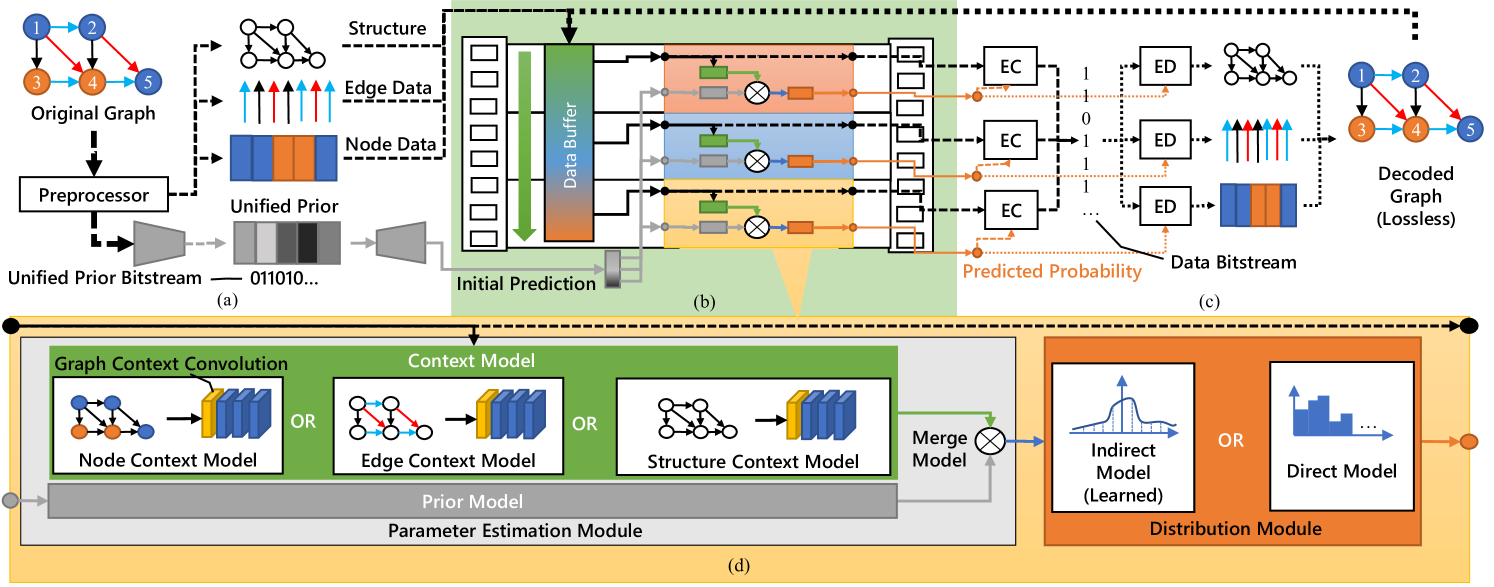
Fig. 3 illustrates the proposed framework that consists of three essential parts: i) the unified prior extractor (Fig. 3a), ii) the element predictors (Fig. 3b), and iii) the entropy coders (Fig. 3c). The unified prior extractor aims to extract critical information from the whole scene graph to provide a unified prior for subsequent compression. Then, an initial prediction for the original graph data could be produced with the unified prior. The second part comprises multiple element-adaptive predictors, designed according to each data element’s attributes (data shape & distribution) to predict symbol-wise probabilities for the entropy coder. Specifically, each element predictor consists of two main modules: the parameter estimation module and distribution module, as depicted in Fig. 3d. For the inputs of element predictors, the data buffer stores the original data (in compression) or the losslessly decompressed data (in decompression). Meanwhile, this buffer decides the order of data elements. Therefore, it also controls the order and structure of element predictors. Finally, the lossless entropy coders leverage the predicted probability to perform lossless compression and decompression on the data elements. We will elaborate on them in the following sections.
In the rest of this paper, we use normal font for scalar variables and functions, bold lowercase font for vector variables, and bold uppercase font for matrices. We reserve to represent the lower triangle part of a matrix . To avoid confusion, we use the term “decoder” to describe the generator module of the autoencoder and the term “decompressor” to describe the module in a compression framework that converts a compressed bitstream back to the original data.
3.1 Unified Prior Extractor
The unified prior extractor is expected to provide a coarse perception of the entire graph in the compressed bitstream for element predictors. We implement it with the popular autoencoder strcture. Specifically, the encoder first takes the entire preprocessed graph as input and produces a latent vector as the prior information. Then, the decoder receives the prior information and outputs an initial prediction that is fed into the element predictors to participate in the final prediction of symbol probability for lossless entropy coding. The above process is illustrated in Fig. 3a.
Furthermore, as the latent vector should be finally compressed into a bitstream, we need to calculate the entropy of the latent vector and utilize it to estimate and optimize the length of compressed unified prior bitstream during training. For latent vector , its entropy is estimated by:
| (1) |
where is the probability of latent vector . To obtain , we adopt the same factorized-prior model as DBLP:conf/iclr/BalleMSHJ18 . It learns a fixed factorized prior distribution to fit the latent vector’s distribution during training.
3.2 Element Predictors
In scene graphs, the data shapes, contextual relationships, and distributions vary from data elements. Based on this observation, we propose the element-adaptive predictors for scene graph lossless compression, which empower our framework to cope with diverse data elements adaptively in scene graphs. Specifically, each predictor consists of two modules: the parameter estimation module and the distribution module. The former obtains element-specific information according to data shape and contextual relationship, while the latter fits different data distributions of data elements based on the element-specific information.
Specifically, the parameter estimation module first merges the context information extracted from the data buffer and the initial prediction to have a complete perception of data elements. Then, it can estimate distribution parameters for data elements according to the perception. To this end, we implement parameter estimation module with three sub-models to accomplish the above process: the context model, the prior model, and the merge model. Note that we design an element-specific context model for each graph element. As shown in Fig. 3d, it has basically three options in scene graphs: the node context model, edge context model, and graph structure context model. Detailed algorithms and implementations of the parameter estimation module, especially the context model, will be discussed in Section 4.
The distribution module contains a random distribution model to fit different data distributions. It receives the estimated parameters given by the parameter estimation module and predicts symbol-wise probabilities. As shown in Fig. 3d, two forms of distribution models are available for different data distribution. One is a direct distribution model for categorical data such as object and relation types. Another is an indirect distribution model for numerical data such as object locations. Moreover, we propose a learned distribution model to tackle the complicated distribution of numerical data. Details will be discussed in Section 5.
The calculation process of the element predictor could be represented as Eq. 2.
| (2) |
where represents the distribution model, represents the data element, and represents distribution parameters calculated by the parameter estimation module, represented as Eq. 3.
| (3) |
is the parameter estimation module, and ,, are its prior model, context model and merge model respectively.
Note that there may exist other data elements than those 4 data elements in Fig. 1 in different scene graphs. For example, the ”relation weights”, namely the certainty level of the estimated relation, and the ”human pose”, namely the skeleton points on a human object. The proposed element predictor can generalize to various forms of data elements in scene graphs by reusing the proposed parameter estimation modules and distribution modules. An example of the implementation of the element predictor for some possible data elements in scene graph is described in Table 1. For example, object locations in scene graph belong to node data in graph, and is numerical data. Therefore, the element predictor for object locations should apply node context model and indirect distribution model. Relation types belong to edge data in graph, and is categorical data. Therefore, the element predictor for relation types should apply edge context model and direct distribution model. Implementations for other data elements such as object type and relation weight could also be inferred accordingly.
| Data Element | Graph Element | ||
| Object Location | Node Data | Node Context | Indirect |
| Object Type | Node Data | Node Context | Direct |
| Relation Link | Structure | Structure Context | Direct |
| Relation Type | Edge Data | Edge Context | Direct |
| Relation Weight | Edge Data | Edge Context | Direct |
3.3 Entropy Coding
Lossless coding for a scene graph is achieved by directly applying entropy coders on the scene graph data with the probabilities predicted by element predictors. The whole coding is free from any processes that may introduce data loss, such as quantization. Note that although quantization is applied in our unified prior extractor, its initial prediction output is used for probability prediction, and thus it will not affect the losslessness of the original data. Moreover, the preprocessor shown in Fig. 3a only performs node sorting for better context modeling and will not introduce any data loss. More details about this issue will be discussed in Section 4.
3.4 Optimization
For entropy coding, the entropy value indicates the length of compressed data. Consequently, the entropy of the unified prior and all data elements should be utilized to calculate the training loss, which is formulated as Eq. 5:
| (5) |
where is the entropy value of the -th data element. is the totoal number of nodes, which is used for normalization. The above loss function encourages our framework to reduce the entropy, i.e., the compression ratio.
4 Context Modeling for Graph Elements
In this section, the parameter estimation modules in predictors for different graph elements are discussed. The main difference among graph elements (graph structure, edge & node data) is the data shape, which decides how to gather the context information. Thus, we will focus on the context models in parameter estimation.
On the decompressor side, the context model uses decompressed information to estimate the probability of current data. Importantly, to ensure a correct entropy decoding, the compressor should aggregate the same information as the decompressor to produce the same probability. This requirement could be called the ‘Context Condition.’ To make all graph elements in scene graphs satisfy this condition, we devise different context models for their corresponding predictors. The following sections will elaborate on proposed context modeling approaches for all the three graph elements (node data, graph structure, and edge data).
4.1 Graph Context Convolution for Node Data
We begin by devising the context model for the node data predictor. To satisfy the context condition, the node data predictor should be a causal system. Specifically, when predicting any node, we can aggregate information from previous nodes to predict the current one. On the other hand, information from latter nodes should be excluded from aggregation. Based on the graph convolution, we devise the Graph Context Convolution (GCC), which can well aggregate context information in node data while satisfying the context condition.
Vanilla graph convolution passes messages according to the adjacency matrix of the graph. A straightforward revision to satisfy the context condition is to cut the message passing flow from the latter to former nodes. In this way, we can obtain a causal message passing flow. To this end, the solution for GCC is proposed by removing the lower triangle part of the adjacency matrix before performing message passing, represented by Eq. 6:
| (6) |
where is node features at layer n, and is the function that generates the message passing matrix, which varies with different graph convolution operations. is the adjacency matrix removing the lower triangle part, and denotes the convolution kernel parameters. Note that any self-loop in the message passing matrix should also be removed since the decompressor cannot gather information from the node itself when decoding. Specifically, for GCN-basedDBLP:conf/iclr/KipfW17 GCC operation, it can be formulated by:
| (7) |
where is the degree matrix of .
Fig. 4 illustrates an example of the GCC for node data context modeling. During decompression, when decompressing node-1, node-4 is unknown, so is unavailable in message passing. When decompressing node-2, node-1 has already been decompressed while node-4 has still not, so is used for message passing and is unavailable. When decoding node-3&4, all connecting edges are available. By adding all message passing matrices used in the decompressing steps, we can obtain (in Eq. 6) for compression.
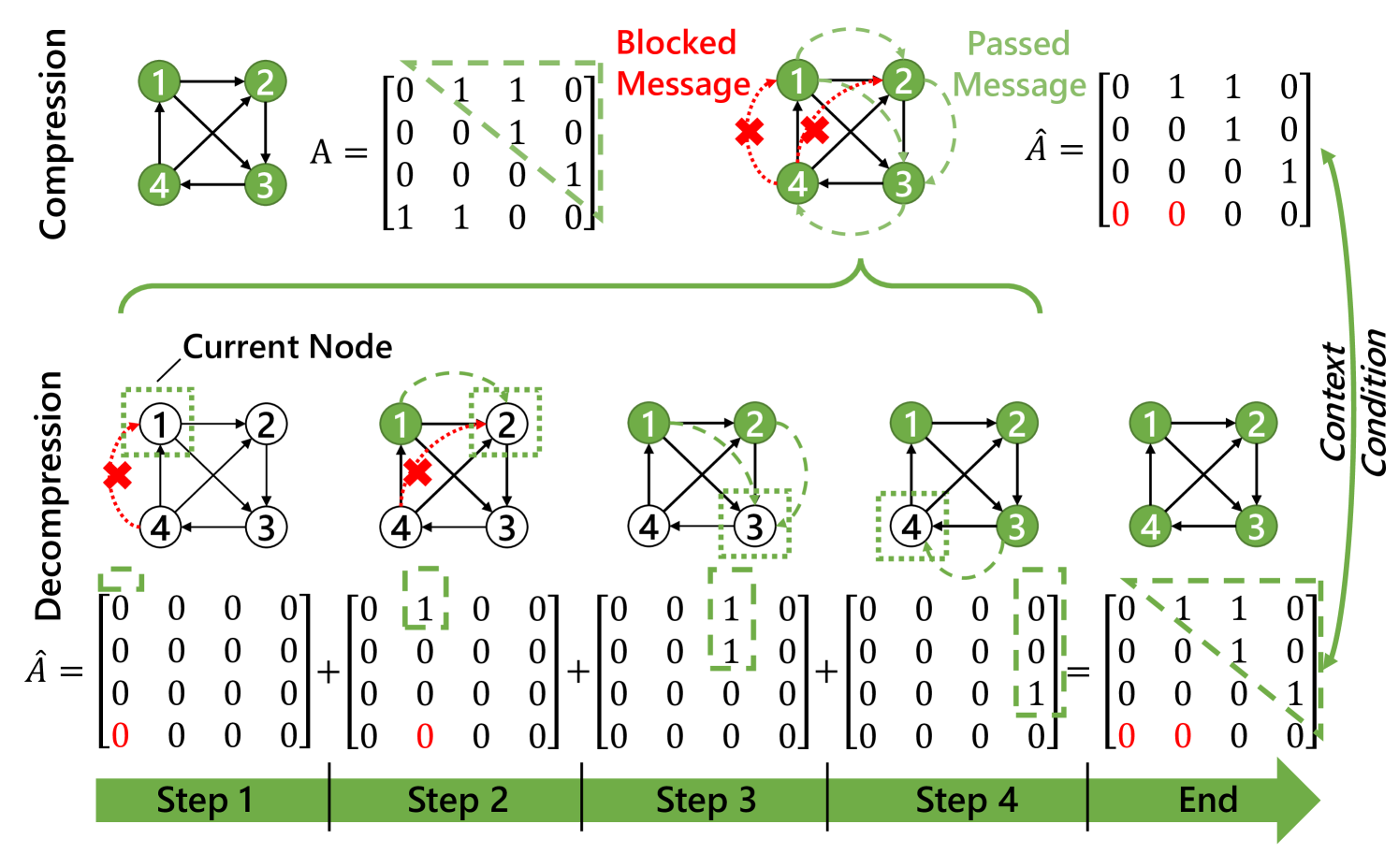
Although the implementation of GCC is relatively simple and may introduce some context information losses in practice , it’s still a lightweight and effective operation to extract node contextual information by causal message passing. Moreover, we further apply a pre-processor to address the issue of context information loss (details will be discussed in Section 4.4).
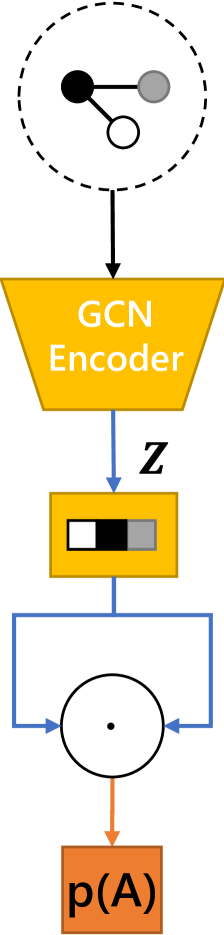
4.2 Directed Graph Context Autoencoder for Graph Structure
For graph structure, existing works usually apply graph autoencodersDBLP:journals/corr/KipfW16a to embed graph structure into a latent vector, which could be used to predict its adjacency matrix, as illustrated in Fig. 5a. However, they could only process undirected graphs, thus cannot be applied to directed graph structure in most scene graphs. Therefore, we devise the Directed Graph Context Autoencoder (DGCAE) based on GCC to embed context information for the directed graph structure in scene graphs.
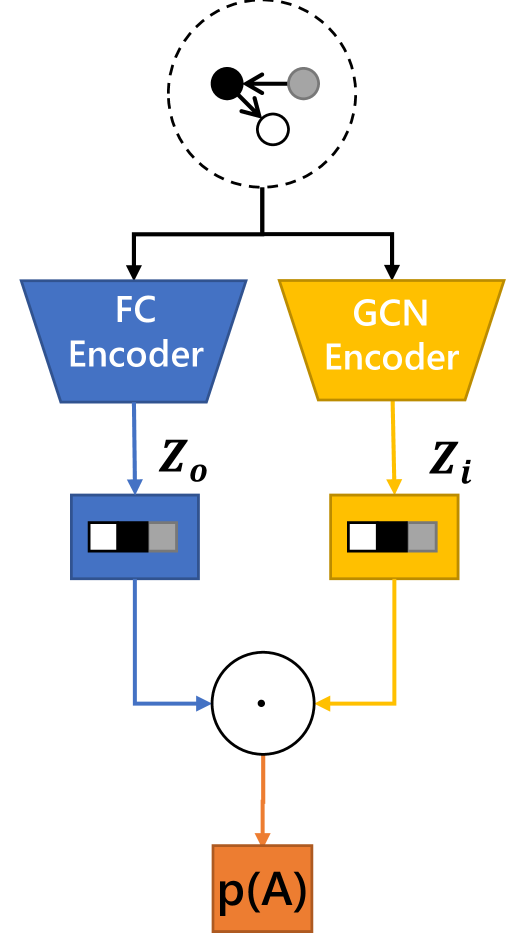
First, in order to process directed graph structure in scene graph data, we design the Directed Graph Autoencoder (DGAE). For directed graphs, the graph convolution passes messages from the out-nodes to the in-nodes along the edge direction. Therefore, the node messages are passed into the nodes pointed by directed edges. For this reason, we call such features obtained by node message passing as ‘node-in’ latent feature (denoted by ). Furthermore, in order to properly decode as an asymmetric prediction matrix for a directed graph, another ‘node-out’ latent feature (denoted by ) is then required to decode to obtain the prediction of the directed graph adjacency matrix. can be obtained by directly transforming the node data with an fully-connected encoder. The decoder can be implemented by a dot-product operation between and :
| (8) |
where is the sigmoid function. The whole pipeline of DGAE is illustrated in Fig. 5b.
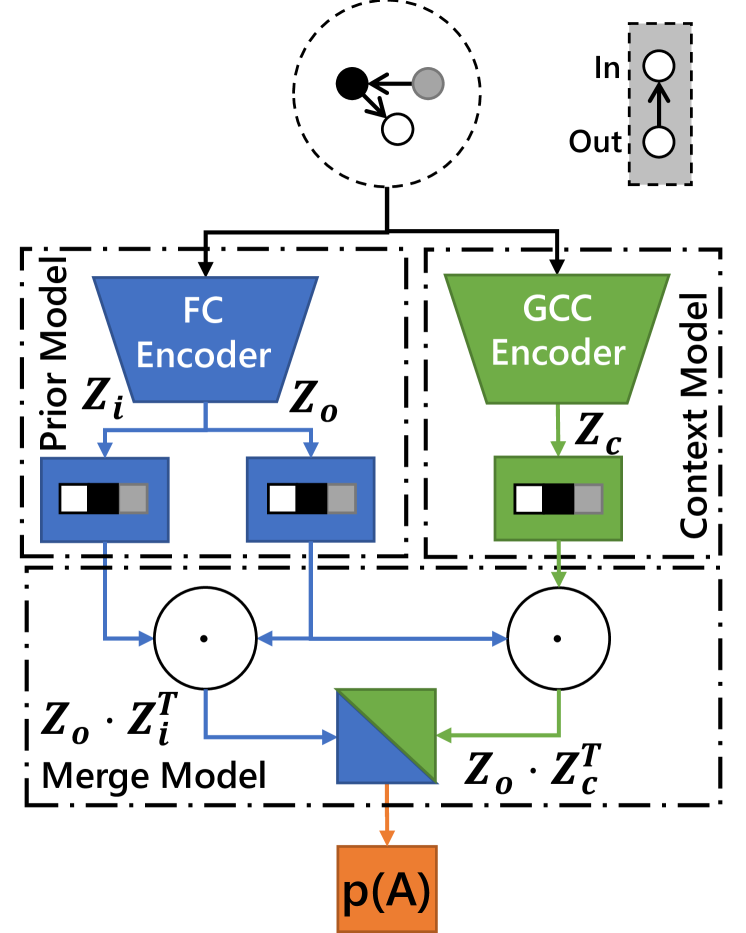
Second, to model context information for directed graphs, we further propose a DGAE variant by replacing the GCN encoder in DGAE with a GCC-based encoder. In this way, the graph structure context information can be also embedded into a latent vector (denoted as ), replacing in DGAE. However, since the proposed GCC disallows the message passing from latter nodes to former nodes, can only be used to decode edges that satisfy the context condition. Therefore, the lower triangle part of the decoded adjacency matrix cannot utilize . To deal with the lower triangle part, another autoencoder composed of fully-connected layers should be applied to obtain a pseudo node-in feature . By combining the matrices produced by both decoder, the final prior estimation result for the adjacency matrix are decoded. The decoding process could then be represented as in Eq. 9.
| (9) |
We call such variation of DGAE as Directed Graph Context Autoencoder (DGCAE), as shown in Fig. 5c.
By applying DGCAE, prediction of the graph structure in the upper half of the adjacency matrix could utilize both context information and prior information, and the lower half is predicted with prior information only. Note that DGCAE already includes the context model, prior model and merge model, as illustrated with dashed boxes in Fig. 5c, and forms a complete parameter estimation module.
4.3 Edge Graph Construction for Edge Data
Since scene graphs also contain numerous edge data, an edge data context modeling approach is necessary for the edge data predictor. However, different from node data, whose shape is independent of the graph structure, the shape of edge data is closely related to the graph structure. Similarly, the proposed GCC-based predictor cannot be directly applied to edge data context modeling. A naive idea is to convert edge data to adjacency matrices and apply the proposed DGCAE to process them. However, since most scene graphs are relatively sparse, the converted matrices may occupy much more memory than the original edge data.
Similar to graph nodes, edges that share the same node also possess a close semantic correlation. Therefore, we can also model the context information for edge data by message passing. To this end, we propose an algorithm to convert edge data to node data, which enables the GCC-based network to model edge data context information. We call such conversion as Edge Graph Construction (EGC). Specifically, it constructs a new graph by keeping the original edge data on new nodes and adding connections between edges that share the same node. Fig. 6 illustrates an example of EGC. Also, the detailed process of EGC is described in Algorithm 1.
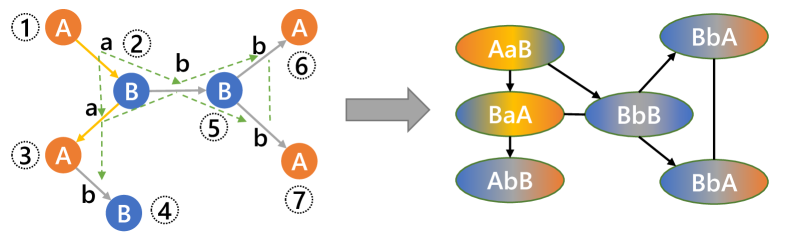
Note that in the node pairing step, both node and edge data in the original graph can be used to construct the node data in the new graph. If node data are not available at the stage of edge data predictor, we use the unified prior information instead. In the edge connection step, the newly constructed graph is generated according to the edge adjacency in the original graph. As shown in Fig. 6, for adjacent edges that forms a path (e.g., and ), EGC will connect them with directed edges. In contrast, adjacent edges that share the same out-node or in-node (e.g., and share the same out-node 2) will be connected with undirected edges.
After applying EGC, we can reuse the Graph Context Convolution (GCC) to aggregate the context information in edge data.
4.4 Preprocessor for Directed Graph Context Improvement
As discussed in Section 4.1, the Graph Context Convolution (GCC) follows causal message passing flows. Therefore, all edges that start from latter nodes to former nodes (or non-causal edges) will be dismissed in message passing, which may introduce losses to context information. In order to address this issue for GCC-based context models, a preprocessing step is proposed to preserve more context information.
Specifically, we can preserve these non-causal edges by performing a topology sorting on the original graph, which makes all edges to be causal. An example is shown in Fig. 7a, we can observe that node-3 and node-4 are swapped by topology sorting, and that should have been originally removed by GCC is preserved as after sorting. However, topology sorting requires that the graph should be an acyclic graph. To satisfy this requirement while preserving more context information, we need to remove as few edges as possible before topology sorting, namely the maximum spanning directed acyclic graph problem. Such a problem has been studied in previous researches DBLP:conf/starsem/Schluter15 and has been acknowledged as an NP-hard problem. To address this issue, we further propose a simple but efficient solution.

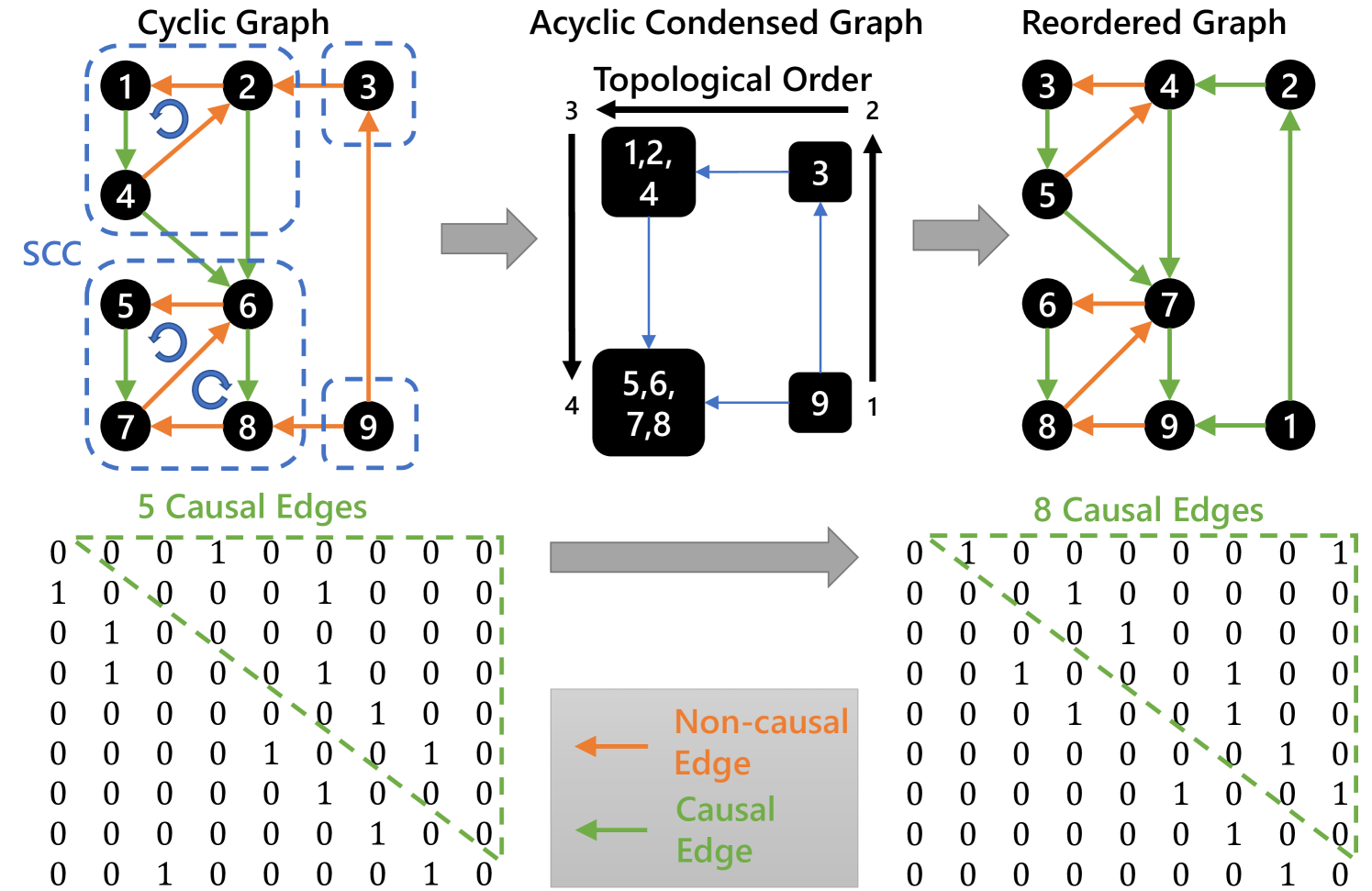
For scene graphs, a cycle tends to appear within a small group of objects that perform similar actions. It indicates that components with cycles, which form strongly connected components, are relatively small compared to the whole graph, as shown on the left side of Fig. 7b. Based on this observation, a simple workaround is applied to bypass the acyclic requirement in topology sorting. We present an example of this workaround in Fig. 7b. Specifically, by extracting all strongly connected components (SCC) from the graph, we can construct an acyclic condensed graph according to all extracted SCC, which can be sorted in topological order. In this way, we can perform topology sorting for most of the original graph nodes and obtain a reordered graph with more causal edges. The reordered graph is then compressed by our proposed framework. By virtue of the above prepossessing, we can significantly reduce the context losses resulting from GCC and thus preserve more context information of scene graphs. Note that the sorting indices are not included in the compressed data, because by reordering nodes in the graph, the topology of the new graph still equals the original one.
We adopt Kosaraju’s algorithmSHARIR198167 to implement the extraction of the strongly connected components. The reason for using this algorithm is that it could extract components and sort the extracted components in topological order in one step. The sorted components are then lined up to form a sorting sequence, which is used to reorder the original graph. The detailed process is described in Algorithm 2.
Naturally, further sorting could be performed on the extracted strongly connected components to achieve further improvement with a brute-force method, but in many cases this step is unnecessary, as most nodes have already been sorted by the proposed method, and further sorting will not bring remarkable improvement. More details can be shown in Section 6.4.2.
5 Learned Distribution Module
In this section, we introduce the design of the distribution module in the element predictors. It receives the parameters generated by the parameter estimations and outputs the final probability according to the data distribution for the lossless entropy coders. Specifically, we consider two cases of data distribution: (1) the categorical data, and (2) the numerical data. As the numerical data in scene graph may be under complicated constraints, we further propose a learned distribution model for numerical data to improve prediction.
(1) Categorical Data. For categorical data such as object types and relation types, we can utilize a direct distribution model, where the given distribution parameters directly represent symbol probabilities. In this way, the element predictor works similarly to a classification model. The entropy of such a distribution model could be represented as the cross-entropy between estimated probability and the ‘ground truth’ value given by the symbol to compress.
(2) Numerical Data. For numerical data such as object locations, using an indirect distribution model to fit the unknown continuous distribution is a common solution. The indirect distribution model defines a cumulative distribution function constructed by the given distribution parameters, and symbol probabilities are then sampled from this function. Importantly, this distribution model is expected to fit any possible data distribution to achieve the best prediction result. Data with simple distributions can be well fitted by Gaussian distribution. As for data with more complex distributions, we can adopt a mixture distribution composed of a series of simple distributions, such as the Gaussian mixture distribution. However, in scene graph data, numerical data such as object locations may deliver very complicated distributions. For example, for a simple scene graph where a person rides a bicycle behind a car, the person’s location should be constrained to be above the bicycle and behind the car, which depicts a single-sided distribution constraint. In reality, an object in the scene graph may be correlated to multiple other objects, thus indicating more complicated distribution constraints. In such cases, simple distributions and mixture distributions may not fit well, leading to sub-optimal probability prediction.
We propose a learned distribution model to amend the drawbacks of simple distributions and mixture distributions discussed above. This model defines a cumulative distribution function, where denotes the parameters of neural network. In this way, the cumulative distribution function could be represented as:
| (10) |
Nevertheless, the network parameters in are fully dynamic, which may make it hard to be optimized. To address this issue, we further split the network into two parts and . The parameters of are initialized and optimized in the traditional way. Only the parameters of are given by the parameter estimation module to adjust the distribution. Therefore, the cumulative distribution function could then be represented as:
| (11) |
Compared with the fully-dynamic model, the above split can stabilize the optimization of the whole model. In practice, the univariate non-parametric density model proposed by DBLP:conf/iclr/BalleMSHJ18 is utilized as the implementation for .
6 Experiments
In this section, we conduct extensive experiments to validate the effectiveness of our proposed framework.
6.1 Experimental Settings
6.1.1 Datasets
In order to show the proposed framework works with different kinds of scene graphs, four datasets are selected. Those datasets are created in different ways, thus have different partitions of data elements and diverse density of structure.
-
•
VisualGenome (VG)DBLP:journals/ijcv/KrishnaZGJHKCKL17 : A widely used dataset in scene graph generation works, including 10K images, each with annotated scene graphs. Following DBLP:conf/cvpr/XuZCF17 , the most frequent 150 object types and 50 relation types are selected, while all other objects and relations are discarded.
-
•
VisualGenome generated by scene graph generator (VG-Gen): Based on VisualGenome images, we apply existing scene graph generation methods to generate new scene graph datasets for experiment. This resembles real-life application of the proposed method. Scene Graph Benchmarkhan2021image , an open-source software including many scene graph generation methods, is use to generate the dataset.
-
•
VisualGenome generated by relation prediction (VG-GenRel): Different from VG-Gen, we set the relation head in Scene Graph Benchmarkhan2021image to ‘predcls’ mode to generate VG-GenRel. This mode reuses existing annotated labels of objects in VG as object detection results, and just generates relation data.
-
•
HiEveDBLP:journals/corr/abs-2005-04490 : A dataset containing annotated human objects with action labels under complex events. Scene graphs are mostly generated with (and some are manually labeled from) those annotated actions, by densely connect all objects that perform the same group-related actions with undirected edges. Objects that do not belong to such actions are removed.
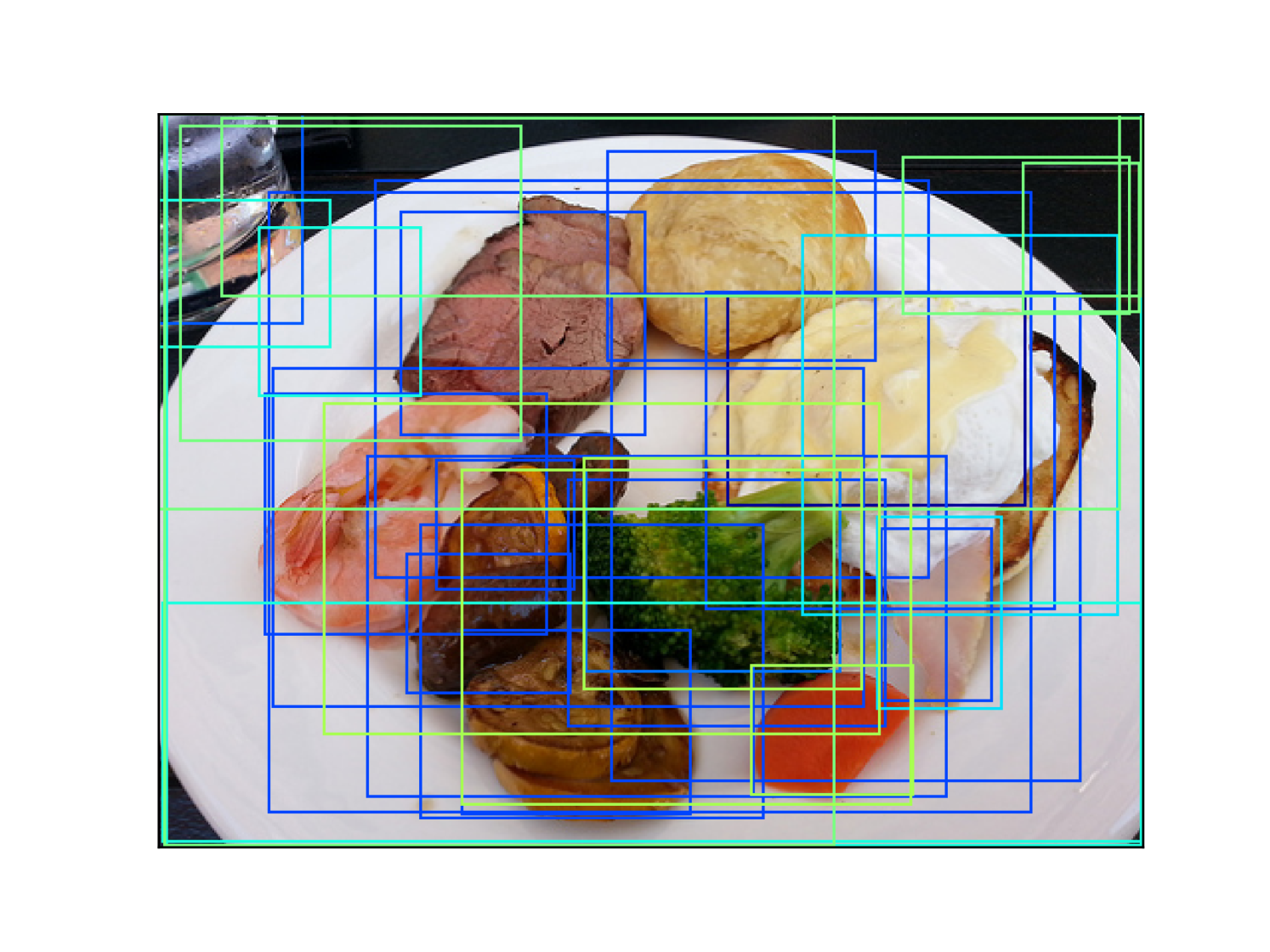
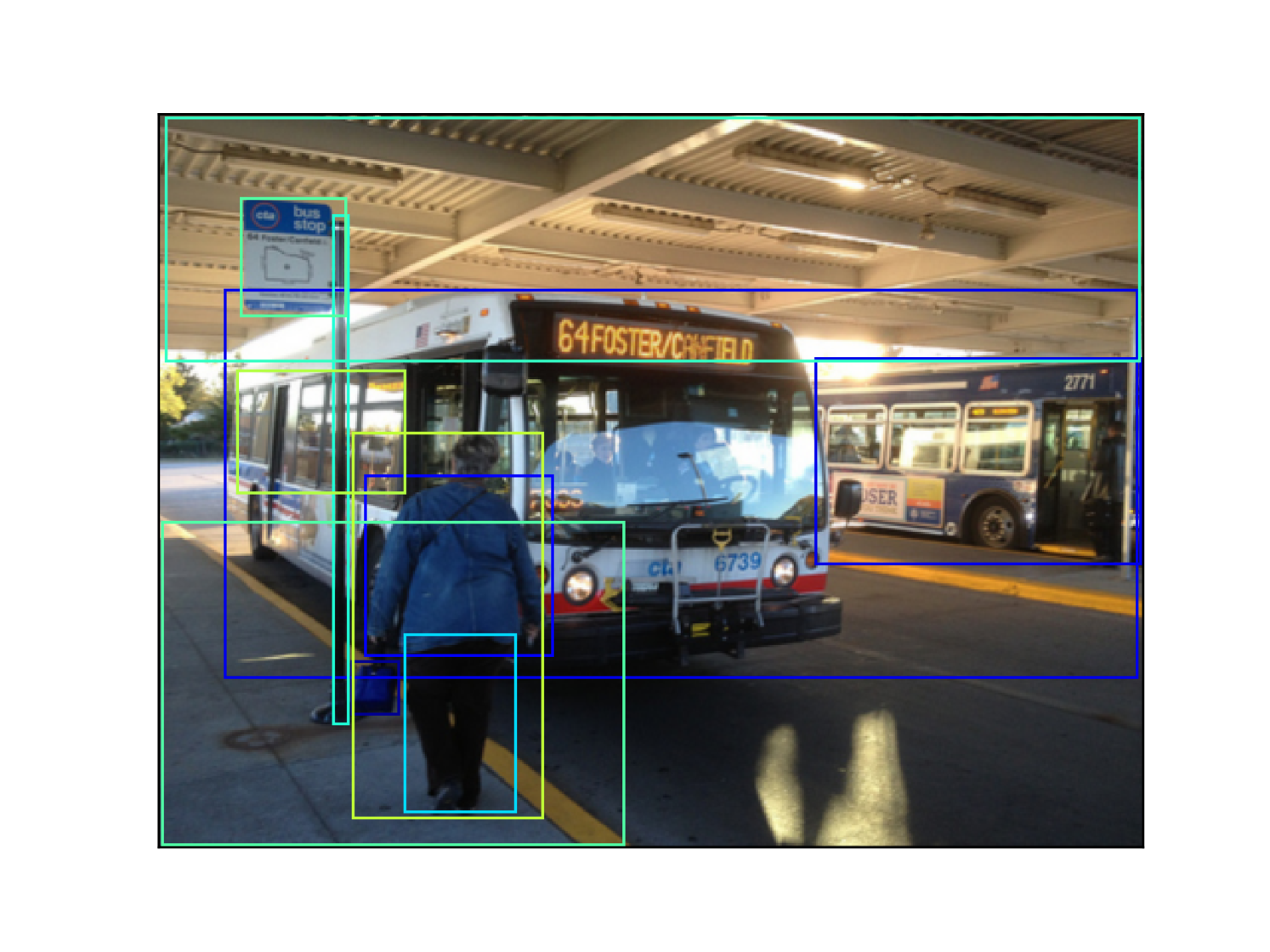
The statistics of all datasets is shown in Table 2. We also present samples of each dataset in Fig. 8. It can be seen that the VG dataset, which is created by manually labeling objects and relations, contains mainly node data. The generated VG-Gen has larger graphs with balanced node and edge data, and VG-GenRel is edge data-centric with denser graphs. HiEve is much smaller than VG, but its graphs are very dense.
| Dataset | Nodes | Edges | Graphs | Density111Average graph density, calculated for each graph by |
| VG | 1.63M | 0.89M | 95K | 5.48% |
| VG-Gen | 8.70M | 10.8M | 109K | 2.55% |
| VG-GenRel | 1.04M | 4.14M | 88K | 34.58% |
| HiEve | 9.7K | 81.8K | 1.6K | 71.10% |
| (a) |
|
|
| (b) |
|
|
| (c) |
|
|
| (d) |
|
|
6.1.2 Metrics
-
•
Compression ratio. We use the compression ratio as our main metric for lossless scene graph compression. It is calculated by dividing the length of the compressed bitstream by the length of the original bitstream. A lower ratio indicates a better compression.
-
•
Bits Per Node. As scene graph compression is closely related to the graph compression task, we also adopt the ‘Bits Per Node’ metric, which is usually applied in graph compression worksDBLP:conf/www/BoldiV04 ; DBLP:conf/spire/BrisaboaLN09 .
6.1.3 Implementation Details
The unified prior extractor is implemented with an autoencoder with both the encoder and decoder composed of 4 fully-connected layers as well as ReLU activation layers, and the latent vector channels setting to 2. For the element predictors, the GCC-based models are composed of 1 GCC layer followed by 3 fully-connected layers as well as ReLU activation layers. For the entropy coders, Asymmetric Numeral SystemDBLP:journals/corr/Duda13 is adopted as the implementation. Moreover, other meta-element in datasets that has not been compressed in the experiments, such as image sizes, are simply compressed with the zlibzlib compressor.
For all datasets, 80% of the scene graphs are used as the training set and 20% as testing set. Note that for HiEve dataset, as the generated scene graph is undirected, which means that the adjacency matrix of the graph structure is symmetric, only the upper-triangle part of the adjacency matrix as well as the corresponding relation types are compressed. The experiments are conducted with Intel i7 4700k CPU and 12GB NVIDIA GTX TITAN Xp GPU.
6.1.4 Competitors
We compare our proposed framwork with two streams of existed approaches:
-
•
General-purpose compression methods. We first choose some widely used general-purpose codecs for comparison, including zlibzlib , LZMALZMA , BrotliDBLP:journals/tois/AlakuijalaFFKOS19 and LPAQ1Mahoney2005AdaptiveWO . Moreover, a combined framework (called ‘Combined’) with the mixture of traditional specialized codecs for different elements of scene graph is compared. The combined framework use WebGraphDBLP:conf/www/BoldiV04 method for compressing graph structure, and ZstdZstd for node data and edge data. Besides, DzipDBLP:conf/dcc/GoyalTCO20 , one of the state-of-the-art learning-based general-purpose compression framework, is used for comparison.
-
•
Graph structure compression methods. Previous graph lossless compression methods like WebGraphDBLP:conf/www/BoldiV04 and k2-treeDBLP:conf/spire/BrisaboaLN09 cannot be directly applied to scene graph compression because of extra node and edge data. However, as the graph structure is the first graph element to decompress in the proposed method, the predictor and entropy coder for graph structure could be substituted by other graph structure lossless compression methods. In this way, we can compare our proposed method with a predictor based on the proposed Directed Graph Context Autoencoder (DGCAE) and other graph structure lossless compression methods in graph structure compression. When reporting the performance for graph structure compression, the random node sorting is applied to simulate different object orders in scene graphs.
6.2 Comparison Results
In this section, according to the type of competitors, we report the overall performances from two aspects.
6.2.1 Whole Scene Graph Compression
The compression ratio of our proposed framework and related competitors for the whole scene graphs are summarized in Table 3. It’s obvious that our proposed framework outperforms all traditional general-purpose compressors with a significant margin on all benchmarks. The main reason for this is that our proposed frameworks is specially designed for whole scene graph compression using element-adaptive predictors. It can also efficiently exploit graph structure to reduce context redundancy.
| Methods | Graph-based | Training | VG | VG-Gen | VG-GenRel | HiEve |
| zlibzlib | 70.58% | 44.64% | 46.02% | 22.79% | ||
| LZMALZMA | 129.25% (83.14%) | 52.38% (17.34%) | 80.24% (74.33%) | 43.97% (92.97%) | ||
| BrotliDBLP:journals/tois/AlakuijalaFFKOS19 | 64.28% (-8.92%) | 38.92% (-12.81%) | 43.31% (-5.90%) | 19.49% (-14.47%) | ||
| LPAQ1Mahoney2005AdaptiveWO | 58.01% (-17.80%) | 30.00% (-32.79%) | 40.59% (-11.81%) | 18.22% (-20.05%) | ||
| Combined (Zstd +DBLP:conf/www/BoldiV04 ) | 65.84% (-6.71%) | 39.55% (-11.41%) | 39.37% (-14.47%) | 18.94% (-16.87%) | ||
| DzipDBLP:conf/dcc/GoyalTCO20 | 44.21% (-37.35%) | 34.41% (-22.93%) | 25.11% (-45.44%) | 13.20% (-42.06%) | ||
| Ours | 30.19% (-57.23%) | 26.84% (-39.86%) | 16.99% (-63.08%) | 8.52% (-62.63%) |
6.2.2 Graph Structure Compression
The bits per node metric produced by different compression methods are summarized in Table 4. It can be observed that our proposed method surpasses all the traditional methods in graph structure compression. Meanwhile, we notice that the compression ratio of the proposed method is close to traditional graph compression methods on some datasets like VG and VG-Gen. This is because our proposed method encodes the adjacency matrix in a per-symbol manner, which may not be the most efficient way to compress sparse matrices. Unfortunately, most scene graphs in those datasets are relatively sparse, according to Table 2. This could be further improved in future works. Nevertheless, for other datasets with dense graphs, this drawback is largely resolved, and the superiority of the proposed framework is therefore prominent.
| VG | VG-Gen | |
| WebGraphDBLP:conf/www/BoldiV04 | 0.62 | 1.24 |
| k2treeDBLP:conf/spire/BrisaboaLN09 | 0.60 (-3.40%) | 1.54 (23.61%) |
| Ours | 0.54 (-13.10%) | 1.09 (-12.17%) |
| VG-GenRel | HiEve | |
| WebGraphDBLP:conf/www/BoldiV04 | 2.86 | 4.46 |
| k2treeDBLP:conf/spire/BrisaboaLN09 | 2.16 (-24.49%) | 3.45 (-22.79%) |
| Ours | 1.69 (-40.72%) | 1.40 (-68.62%) |
6.3 Ablation Study on the Entire Framework
In order to study the effectiveness of different modules in our proposed framework, we conduct experiments by removing some modules or replacing some of them with other solutions to gain further insight. First, the proposed joint compression framework could be replaced by other learning-based general-purpose compression frameworks such as DzipDBLP:conf/dcc/GoyalTCO20 . Second, the graph context modeling techniques as well as the corresponding preprocessor for context improvement discussed in Section 4 can be removed so that each element predictor uses only the initial prediction result from the unified prior extractor. Finally, the learned distribution model discussed in Section 5 could be replaced by a simple Gaussian distribution model. Experiments are then conducted with the above variants. Results are shown in Table 5.
| Datasets | Framework | Compression Ratio (Relative) |
|---|---|---|
| VG | DzipDBLP:conf/dcc/GoyalTCO20 | 44.21% |
| Ours - Context - LearnDist | 33.50% (-24.24%) | |
| Ours + Context - LearnDist | 30.93% (-30.05%) | |
| Ours + Context + LearnDist | 30.19% (-31.73%) | |
| VG-Gen | DzipDBLP:conf/dcc/GoyalTCO20 | 34.41% |
| Ours - Context - LearnDist | 30.43% (-11.56%) | |
| Ours + Context - LearnDist | 27.24% (-20.84%) | |
| Ours + Context + LearnDist | 26.84% (-21.98%) | |
| VG-GenRel | DzipDBLP:conf/dcc/GoyalTCO20 | 25.11% |
| Ours - Context - LearnDist | 20.80% (-17.17%) | |
| Ours + Context - LearnDist | 17.27% (-31.21%) | |
| Ours + Context + LearnDist | 16.99% (-32.34%) | |
| HiEve | DzipDBLP:conf/dcc/GoyalTCO20 | 13.20% |
| Ours - Context - LearnDist | 12.24% (-7.27%) | |
| Ours + Context - LearnDist | 8.56% (-35.17%) | |
| Ours + Context + LearnDist | 8.52% (-35.50%) |
We can see that the proposed joint compression framework outperforms the general-purpose compression framework DzipDBLP:conf/dcc/GoyalTCO20 in all cases, even without the graph context model and learned distribution model. This is achieved by extracting vital information from the scene graph data with the unified prior extractor and designing adaptive element predictors according to different data elements. DzipDBLP:conf/dcc/GoyalTCO20 though, is designed for general-purpose data compression with a serial context model that does not fit graph data well and ignoring different data distributions, thus does not perform well on scene graph compression.
The graph context models also contribute significantly to the proposed framework in all datasets. The main reason is that our proposed context models are designed for all element predictors to reduce context redundancy for all data elements. Especially, the relative improvement is more distinct in VG-Gen, VG-GenRel, and HiEve, both of them contain generated scene graphs. It indicates that the adopted scene graph generators are more context-aware. Therefore, those generated scene graphs could benefit more from the proposed graph context models.
The proposed learned distribution model contributes less than the context model, as this module could only benefit object location compression in those datasets. Therefore, for datasets that contain more node data (e.g., VG and VG-Gen), the learned distribution model brings larger improvements than datasets that own fewer node data (e.g., VG-GenRel and HiEve).
6.4 Ablation Study on Each Module
In order to study the effectiveness of each key module (graph context model , preprocessor and distribution model) in our proposed framework, a series of ablation studies are conducted.
6.4.1 Graph Context Modeling
In this experiment, the graph context model is disabled for some particular element predictors to validate its effectiveness. In order to keep along with Table 5, all experiments in this section are performed without the learned distribution model. The results are summarized in Table 6. Note that all experiments enables the preprocessor, including the one with all context models disabled. Thus, the result with all context models disabled in this experiment is slightly different from the ”Ours - Context - LearnDist” result in Table 5.
| Datasets | Node Data | Structure | Edge Data | Compression Ratio (Relative) |
|---|---|---|---|---|
| VG | 33.47% | |||
| 32.70% (-2.32%) | ||||
| 32.39% (-3.24%) | ||||
| 30.93% (-7.60%) | ||||
| VG-Gen | 30.48% | |||
| 27.93% (-8.35%) | ||||
| 27.85% (-8.64%) | ||||
| 27.24% (-10.63%) | ||||
| VG-GenRel | 20.78% | |||
| 18.48% (-11.07%) | ||||
| 18.42% (-11.34%) | ||||
| 17.27% (-16.88%) | ||||
| HiEve | 12.24% | |||
| 10.70% (-12.59%) | ||||
| 10.26% (-16.22%) | ||||
| 8.56% (-30.08%) |
We can see that each context model contributes to the compression process in most cases. Meanwhile, the improvements from the context model in each graph element vary with datasets. This may be because different extent of contextual relationship lies beneath the data. For example, the structure context model brings significant improvement for HiEve, while only slight improvements on VG, VG-Gen, and VG-GenRel. It proves that densely-connected graphs in HiEve are more context redundant. Besides, the edge context model in HiEve also brings a great improvement. The reason may be that most humans perform the same action in a single scene in HiEve, which leads to heavy context redundancy in edge data.
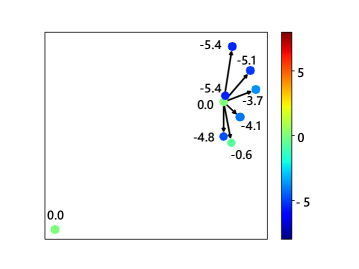
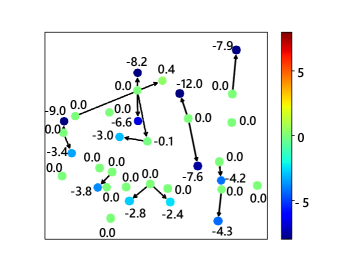
Furthermore, to explicitly present the improvement brought by the context model, a qualitative experiment is further conducted to show the disparity of probability estimation results with and without context information. Some results are illustrated in Fig. 9. Fig. 9a presents a simple graph with only 7 edges. The nodes that are pointed by edges could utilize context information from the other node, thus obtaining better compression results. Fig. 9b shows a graph with a more complicated structure. It can be seen that although some of the nodes exploiting context information appear to have worse prediction results (with labels above zero), most nodes obtain better results. The above observation further proves the quantitative results in Table 6.
6.4.2 Preprocessing
We apply different preprocessing methods to the graph and compare them with our proposed preprocessor based on strongly connected component extraction. To better evaluate the improvement of context information for different preprocessing methods, we devise the Context Improvement Rate (CIR) metric. It compares the number of causal edges that satisfy the context condition before and after preprocessing. Assuming and are the adjacency matrix before, and after preprocessing, the CIR is defined as:
| (12) |
As the complexity of brute-force solver is , the maximum size of a processed component is limited to 10 to make sure preprocessing can be completed with reasonable time and memory. And thus, all components that are larger than 10 are left unsorted. For easier comparison, we train a model checkpoint without the preprocessing step, and then all preprocessing methods are applied to this checkpoint during testing. The results are shown in Fig. 10.
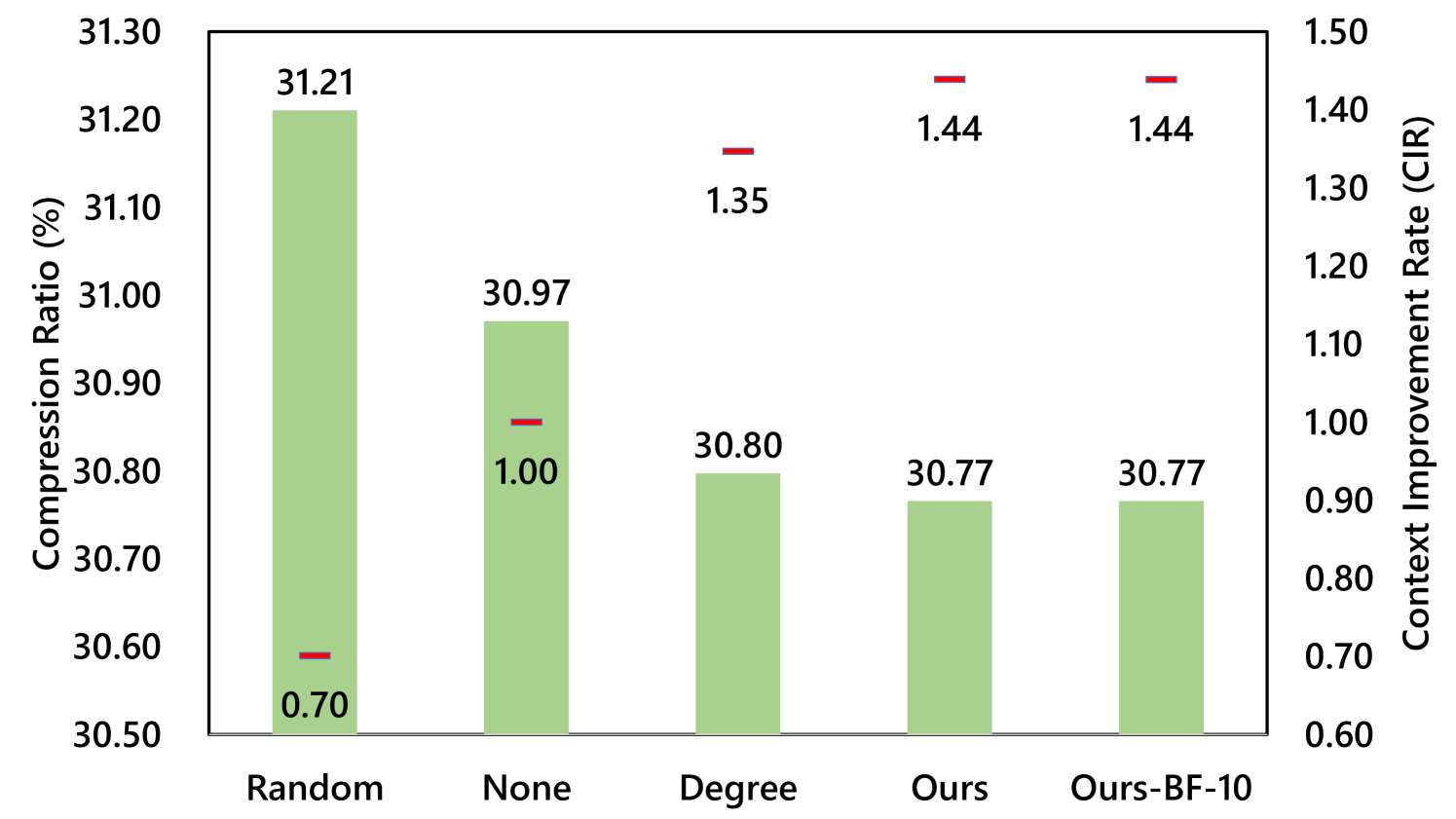
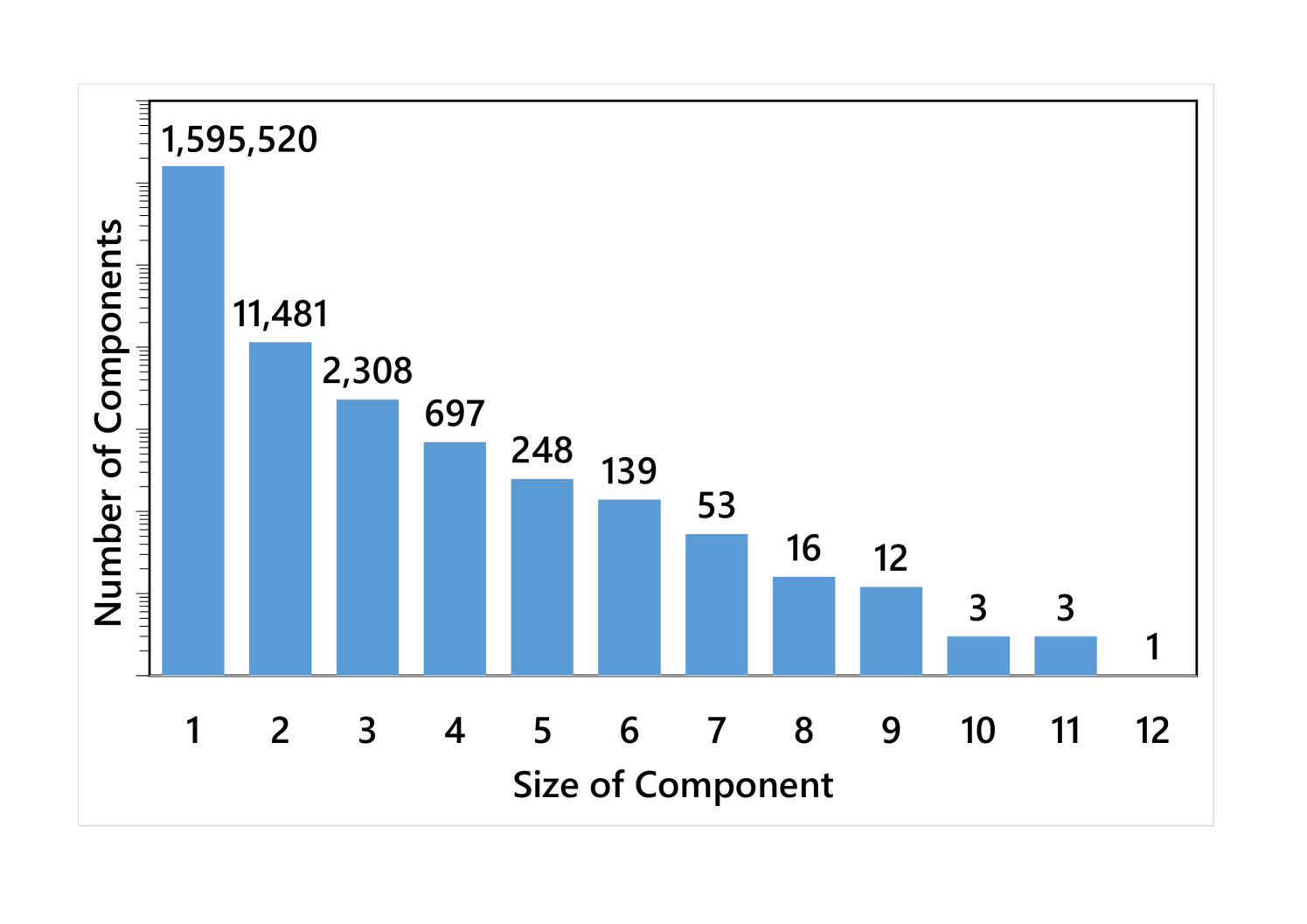
From the results, we could see that CIR is negatively correlated to the compression ratio. The proposed method performs closely to the brute-force solver in CIR, therefore achieving a near-optimal compression ratio. The main reason is that the sizes of most strongly connected components are small, which is illustrated in Fig. 11. Since above 99% nodes in VG are single components (Fig. 11), they could be successfully sorted in topological order by the proposed preprocessor.
6.4.3 Learned Distribution Model
This part tries to prove that the proposed learned distribution model contributes to numerical data compression under complicated distribution constraints in scene graphs. Specifically, we apply different distribution models for object location compression, including the Gaussian model, Laplacian model, Gaussian mixture model with 5 mixtures (GMM5), Gaussian mixture model with 10 mixtures (GMM10), the proposed fully-dynamic variant model (FullDyn), and the proposed two-part model (Ours (LearnDist)). Note that the fully-dynamic variant contains two layers (as opposed to four layers in the two-part model), simulating the removal of the two trainable layers in the proposed two-part model. For simplicity, only object location is compressed by the proposed framework in those experiments, while the element predictor for object location still utilizes other data elements. Therefore, only the compression ratio of object location is reported. The results are summarized in Table 7.
| VG | VG-Gen | |
| Gaussian | 29.95% | 28.29% |
| Laplacian | 29.87% (-0.28%) | 28.51% (0.76%) |
| GMM5 | 29.11% (-2.82%) | 27.62% (-2.39%) |
| GMM10 | 29.04% (-3.04%) | 27.56% (-2.59%) |
| FullDyn | 29.12% (-2.78%) | 27.46% (-2.95%) |
| Ours (LearnDist) | 28.98% (-3.24%) | 27.40% (-3.16%) |
| VG-GenRel | HiEve | |
| Gaussian | 34.08% | 35.17% |
| Laplacian | 34.00% (-0.24%) | 36.00% (2.37%) |
| GMM5 | 33.32% (-2.22%) | 35.25% (0.25%) |
| GMM10 | 33.00% (-3.18%) | 35.77% (1.72%) |
| FullDyn | 33.55% (-1.55%) | 41.34% (17.55%) |
| Ours (LearnDist) | 32.89% (-3.49%) | 35.02% (-0.41%) |
Generally, the complex models (GMM and the proposed models) with more distribution parameters perform better than simple models (Gaussian and Laplacian). Our proposed two-part learned model owns a slight compression ratio than the Gaussian mixture model in all datasets. As for our proposed two-part variant and the fully-dynamic variant for the distribution model, both perform similarly on VG-based datasets. However, the fully-dynamic one does not achieve ideal performance on HiEve, presumably caused by the optimization issue discussed in Section 5. Therefore, it is preferred to use the two-part variant for more stable performance. Moreover, on HiEve, all complex models except for the proposed two-part model perform worse than the simple Gaussian model, possibly because the HiEve graph only indicates the same action between two objects and does not guarantee position constraints. As most complex models are harder to optimize, they fail to model simple distributions in such cases. The proposed model contains trainable layers to help optimization under simple distributions cases, therefore achieving similar performance to the simple Gaussian model.
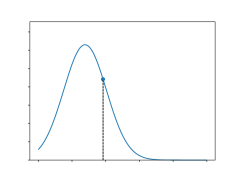
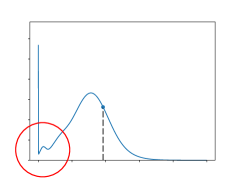
Furthermore, to explicitly present the improvement of the proposed learned distribution model, a qualitative experiment is conducted to show the predicted probability distribution function of different distribution models in our framework. The results are shown in Fig. 12. Apparently, the Gaussian model cannot cut the distribution on the value boundary (0 in the object location case as objects cannot exceed image boundary). Moreover, the Gaussian model is always symmetric along its mean value. This feature makes it unable to fit complicated conditional distribution cases well. The Gaussian mixture model performs better in fitting hard edges and complicated conditional cases, but the result still shows curves of single Gaussian modals, as shown in the red circle in Fig. 12b, which is not the best fit result. The proposed learned model shows similar fit result with Gaussian mixture model, meanwhile being more capable of fitting value boundary and conditional cases, showing asymmetric and confidential result.
6.5 Effect of the Hyperparameters
The proposed framework contains a few hyperparameters that can be adjusted for different datasets to achieve better compression results. The hyperparameter set mainly includes the unified prior extractor model parameters and the compression order of the element predictors. A series of ablation studies are conducted to reveal the effect of different hyperparameters on our proposed framework.
6.5.1 Unified Prior Extractor Implementation
The unified prior extractor extracts vital prior information from scene graphs. Therefore, the implementation of this model also affects the performance of the compression framework. The backbone network structure of the unified prior extractor controls how to extract information from the original graph, while the width of the latent vector controls how much information is extracted from the original graph. Consequently, different backbone network operations, the number of layers, and the number of latent channels are explored in this experiment. Specifically, for backbone network operations, we compare Fully-Connected layers (FC), Graph Convolution Network (GCN)DBLP:conf/iclr/KipfW17 and Jumping-Knowledge Network (JKNet)DBLP:conf/icml/XuLTSKJ18 for the encoder. The experiments are conducted on the VG dataset (mainly composed of node data) and the VG-GenRel dataset (mainly composed of edge data). The results are shown in Table 8.
| Backbone | Layer | Ch | VG | VG-GenRel |
| FC | 4 | 2 | 30.19% | 16.99% |
| FC | 4 | 4 | 30.56% (1.23%) | 16.87% (-0.73%) |
| FC | 8 | 2 | 30.21% (0.08%) | 17.05% (0.38%) |
| FC | 8 | 4 | 30.72% (1.77%) | 16.81% (-1.08%) |
| GCNDBLP:conf/iclr/KipfW17 | 4 | 2 | 30.56% (1.24%) | 17.13% (0.83%) |
| JKNetDBLP:conf/icml/XuLTSKJ18 | 4 | 2 | 30.24% (0.18%) | 17.00% (0.08%) |
Backbone Network Operations: The results shows that the convolution-based backbones cannot further improve the performance. Convolution-based backbones could improve structure compression to some extent by embedding structure information into the latent vector. Nevertheless, information for node data in the prior information is occupied by structure information. It results in a worse compression ratio for node data. Therefore, the overall result of convolution-based backbones underperforms the FC backbone, which is why we choose the simple FC backbone in our proposed framework. Note that JKNet, which performs better in graph classification than GCN, also provides better results in scene graph compression than GCN. This phenomenon indicates that there might be better choices of operations by applying better convolution-based networks.
Number of Layers: The results shows that the proposed framework cannot gain performance improvement by increasing the number of layers. The reason for this is that the FC backbone only extracts the information of node data, which is a relatively simple task and using complex models may increase the difficulty of optimization.
Number of Latent Channels: Increasing the latent channels generally results in a better compression for data elements, while making the unified prior bitstream grow. This is a trade-off that may perform differently in different datasets. From the results, it could be found that increasing latent channels may reduce the total compression ratio in VG, while in VG-GenRel, increasing latent channels causes a slightly better compression ratio. Therefore, we could adjust latent channels for different datasets in order to get a better compression ratio, while the difference is generally not significant.
6.5.2 Compression Order
The compression order of the graph elements in the scene graph affects how the context information is exploited in the element predictors, thus impacting the final compression ratio. Since graph structure is required for all context models, only the order of node data and edge data could be adjusted. Therefore, there are basically three options for compression order, the ”Edge First” order, the ”Node First” order, and the ”Parallel” order, as illustrated in Fig. 13. For example, if edge data is decompressed first, then the node data predictor could utilize decompressed edge data by applying RGCN-basedDBLP:conf/esws/SchlichtkrullKB18 context model to perform better prediction, as illustrated in Fig. 13a.
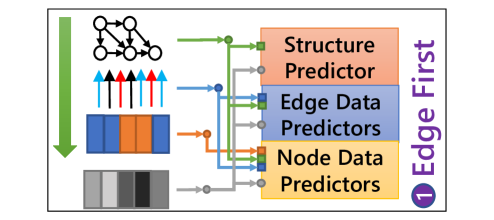
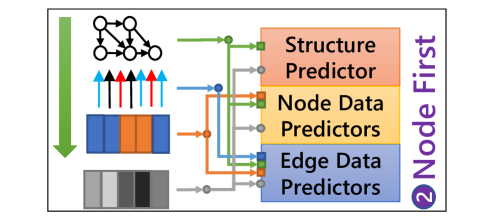
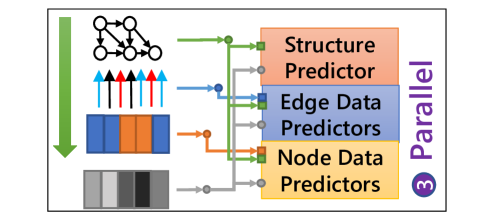
Consequently, different compression order is explored to form different structures of element predictors. The node-major dataset VG, as well as the edge-major dataset VG-GenRel, are considered for this experiment. The results are shown in Fig. 14.
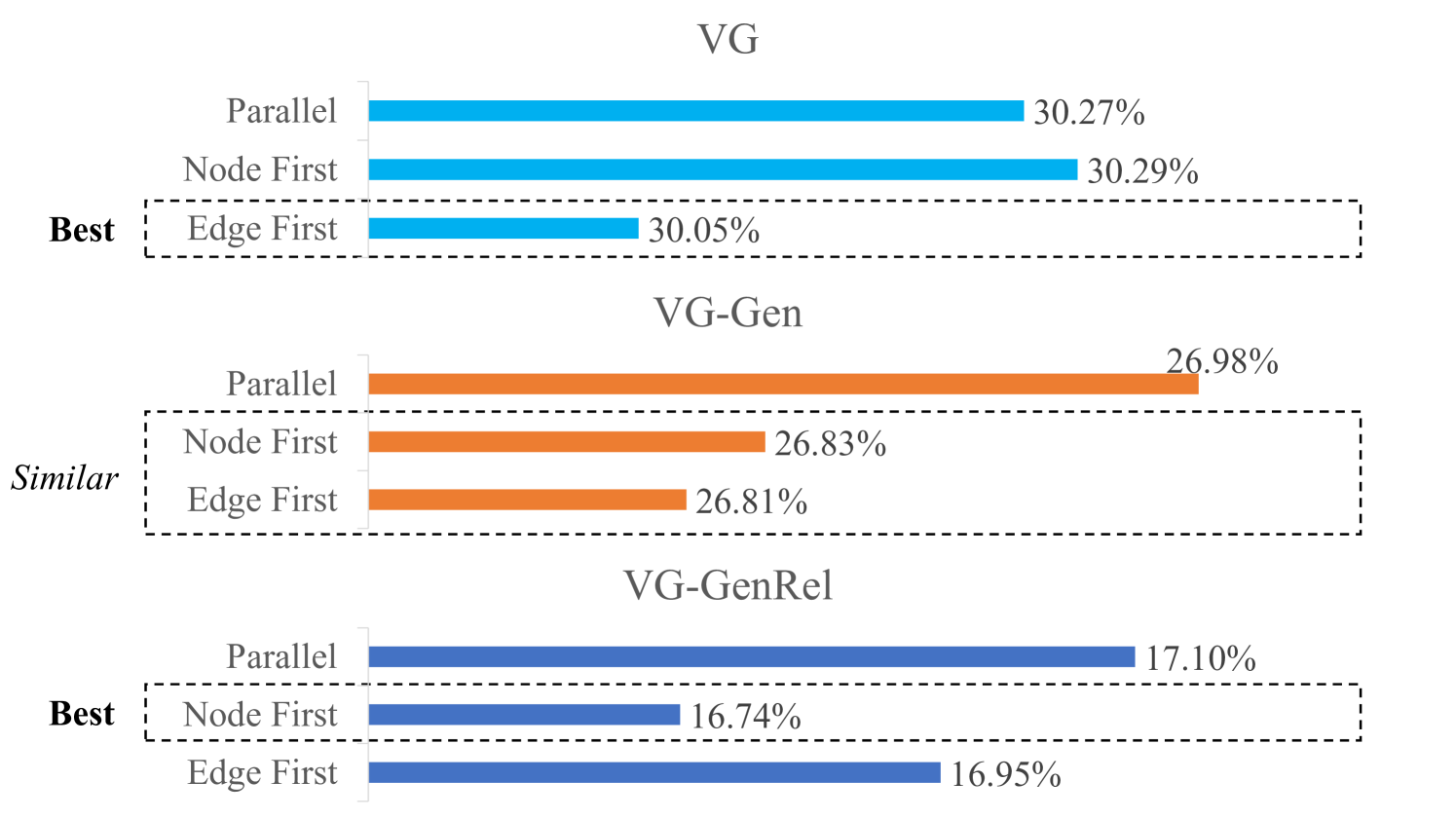
It could be found from the results that for the VG dataset, the ‘Edge First’ order provides a slightly better result than other orders. Since the majority of data in VG is node data, the node data predictor could benefit more from former edge data for prediction to reduce the total entropy using ‘Edge First’ order. Moreover, for VG-GenRel, ‘Node First’ performs better as VG-GenRel data are mainly edge data. However, although different compression orders could be selected to better compress different datasets, the difference is generally not significant.
7 Conclusion
This paper mainly introduces a novel framework for joint lossless compression of the scene graph data. The main contributions include: (1) A adaptive compression framework with element-adaptive predictors for different data elements. (2) A series of graph context modeling approaches for different graph elements to exploit context redundancy. (3) A learned distribution model to model the distribution of graph-constrained numerical data elements for better prediction. Experiments show that the proposed system outperforms state-of-the-art general-purpose codecs and combined codecs for total scene graph lossless compression, and also keep up with traditional graph structure compression methods in graph structure compression.
Declarations
Data Availability Statement
The datasets generated during and/or analysed during the current study are all available publicly. Please refer to Section 6.1.1 for further details.
References
- (1) Alakuijala, J., et al.: Brotli: A general-purpose data compressor. ACM Trans. Inf. Syst. 37(1), 4:1–4:30 (2019)
- (2) Anderson, P., Fernando, B., Johnson, M., Gould, S.: SPICE: semantic propositional image caption evaluation. In: ECCV 2016, pp. 382–398 (2016)
- (3) Ballé, J., Laparra, V., Simoncelli, E.P.: End-to-end optimized image compression. In: 5th Int. Conf. Learn. Rep. (2017)
- (4) Ballé, J., Minnen, D., Singh, S., Hwang, S.J., Johnston, N.: Variational image compression with a scale hyperprior. In: 6th Int. Conf. Learn. Rep. (2018)
- (5) Besta, M., Hoefler, T.: Survey and taxonomy of lossless graph compression and space-efficient graph representations. CoRR abs/1806.01799 (2018). URL http://arxiv.org/abs/1806.01799
- (6) Boldi, P., Vigna, S.: The webgraph framework I: compression techniques. In: WWW 2004, pp. 595–602 (2004)
- (7) Brisaboa, N.R., Ladra, S., Navarro, G.: k2-trees for compact web graph representation. In: SPIRE 2009, pp. 18–30 (2009)
- (8) Chen, T., Liu, H., Ma, Z., Shen, Q., Cao, X., Wang, Y.: End-to-end learnt image compression via non-local attention optimization and improved context modeling. IEEE Trans. Image Process. 30, 3179–3191 (2021)
- (9) Cheng, Z., Sun, H., Takeuchi, M., Katto, J.: Learned image compression with discretized gaussian mixture likelihoods and attention modules. In: 2020 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 7936–7945 (2020)
- (10) Cleary, J., Witten, I.: Data compression using adaptive coding and partial string matching. IEEE Trans. Commun. 32(4), 396–402 (1984). DOI 10.1109/TCOM.1984.1096090
- (11) Collet, Y.: Zstandard - real-time compression algorithm. https://facebook.github.io/zstd/ (2021). Accessed: 2021-12-07
- (12) Duda, J.: Asymmetric numeral systems as close to capacity low state entropy coders. CoRR abs/1311.2540 (2013). URL http://arxiv.org/abs/1311.2540
- (13) Fu, H., et al.: Learned image compression with discretized gaussian-laplacian-logistic mixture model and concatenated residual modules. CoRR abs/2107.06463 (2021)
- (14) Fukui, A., Park, D.H., Yang, D., Rohrbach, A., Darrell, T., Rohrbach, M.: Multimodal compact bilinear pooling for visual question answering and visual grounding. In: EMNLP 2016, pp. 457–468 (2016)
- (15) Goyal, M., Tatwawadi, K., Chandak, S., Ochoa, I.: DZip: Improved general-purpose lossless compression based on novel neural network modeling. In: Data Compression Conf. 2020, p. 372 (2020)
- (16) Greg Roelofs, J.l.G., Adler, M.: zlib home site. https://www.zlib.net/ (2021). Accessed: 2021-12-07
- (17) Han, X., Yang, J., Hu, H., Zhang, L., Gao, J., Zhang, P.: Image scene graph generation (SGG) benchmark (2021)
- (18) Hoogeboom, E., Peters, J.W.T., van den Berg, R., Welling, M.: Integer discrete flows and lossless compression. In: Adv. Neural Inf. Process. Syst. 32, pp. 12134–12144 (2019)
- (19) Huffman, D.A.: A method for the construction of minimum-redundancy codes. Proc. IRE 40(9), 1098–1101 (1952)
- (20) Ji, J., Krishna, R., Fei-Fei, L., Niebles, J.C.: Action genome: Actions as compositions of spatio-temporal scene graphs. In: CVPR 2020, pp. 10233–10244. Computer Vision Foundation / IEEE (2020). DOI 10.1109/CVPR42600.2020.01025
- (21) Jiang, W., Wang, W., Hu, H.: Bi-directional co-attention network for image captioning. ACM Trans. Multimedia Comput., Commun., Appl. 17(4), 125:1–125:20 (2021)
- (22) Kingma, F.H., Abbeel, P., Ho, J.: Bit-Swap: Recursive bits-back coding for lossless compression with hierarchical latent variables. In: Proc. 36th Int. Conf. Mach. Learn., pp. 3408–3417 (2019)
- (23) Kipf, T.N., Welling, M.: Variational graph auto-encoders. CoRR abs/1611.07308 (2016). URL http://arxiv.org/abs/1611.07308
- (24) Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. In: 5th Int. Conf. Learn. Rep. (2017)
- (25) Knoll, B.: Cmix. http://www.byronknoll.com/cmix.html (2022). Accessed: 2022-1-11
- (26) Krishna, R., et al.: Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 123(1), 32–73 (2017)
- (27) Li, M., Ma, K., You, J., Zhang, D., Zuo, W.: Efficient and effective context-based convolutional entropy modeling for image compression. IEEE Trans. Image Process. 29, 5900–5911 (2020)
- (28) Lin, W., et al.: Human in events: A large-scale benchmark for human-centric video analysis in complex events. CoRR abs/2005.04490 (2020)
- (29) Ma, H., Liu, D., Xiong, R., Wu, F.: iWave: CNN-Based wavelet-like transform for image compression. IEEE Trans. Multimedia 22(7), 1667–1679 (2020)
- (30) Ma, H., Liu, D., Yan, N., Li, H., Wu, F.: End-to-end optimized versatile image compression with wavelet-like transform. IEEE Trans. Pattern Anal. Mach. Intell. 44(3), 1247–1263 (2022)
- (31) Mahoney, M.V.: Adaptive weighing of context models for lossless data compression (2005). URL https://cs.fit.edu/~mmahoney/compression/cs200516.pdf
- (32) Marino, K., Chen, X., Parikh, D., Gupta, A., Rohrbach, M.: KRISP: integrating implicit and symbolic knowledge for open-domain knowledge-based VQA. In: CVPR 2021, pp. 14111–14121 (2021)
- (33) Mentzer, F., Agustsson, E., Tschannen, M., Timofte, R., Gool, L.V.: Practical full resolution learned lossless image compression. In: 2019 IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 10629–10638 (2019)
- (34) Minnen, D., Ballé, J., Toderici, G.: Joint autoregressive and hierarchical priors for learned image compression. In: Adv. Neural Inf. Process. Syst. 31, pp. 10794–10803 (2018)
- (35) Pavlov, I.: Lzma sdk (software development kit). https://www.7-zip.org/sdk.html (2021). Accessed: 2021-12-07
- (36) Schlichtkrull, M.S., Kipf, T.N., Bloem, P., van den Berg, R., Titov, I., Welling, M.: Modeling relational data with graph convolutional networks. In: ESWC 2018, pp. 593–607 (2018)
- (37) Schluter, N.: The complexity of finding the maximum spanning DAG and other restrictions for DAG parsing of natural language. In: Proc. Fourth Joint Conf. Lex. Comput. Semantics, *SEM 2015 (2015)
- (38) Sharir, M.: A strong-connectivity algorithm and its applications in data flow analysis. Comput. Math. Appl. 7(1), 67–72 (1981)
- (39) Wang, S., Wang, R., Yao, Z., Shan, S., Chen, X.: Cross-modal scene graph matching for relationship-aware image-text retrieval. In: WACV 2020, pp. 1497–1506. IEEE (2020). DOI 10.1109/WACV45572.2020.9093614
- (40) Xu, D., Zhu, Y., Choy, C.B., Fei-Fei, L.: Scene graph generation by iterative message passing. In: 2017 IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 3097–3106 (2017)
- (41) Xu, K., Li, C., Tian, Y., Sonobe, T., Kawarabayashi, K., Jegelka, S.: Representation learning on graphs with jumping knowledge networks. In: Proc. 35th Int. Conf. Mach. Learn., pp. 5449–5458 (2018)
- (42) Yoon, S., Kang, W., Jeon, S., Lee, S., Han, C., Park, J., Kim, E.: Image-to-image retrieval by learning similarity between scene graphs. In: AAAI 2021, pp. 10718–10726. AAAI Press (2021)
- (43) Zhang, X., Wu, X.: Ultra high fidelity deep image decompression with l-constrained compression. IEEE Trans. Image Process. 30, 963–975 (2021)
- (44) Ziv, J., Lempel, A.: A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 23(3), 337–343 (1977)