Score-based Conditional Generation with Fewer Labeled Data by Self-calibrating Classifier Guidance
Abstract
Score-based generative models (SGMs) are a popular family of deep generative models that achieve leading image generation quality. Early studies extend SGMs to tackle class-conditional generation by coupling an unconditional SGM with the guidance of a trained classifier. Nevertheless, such classifier-guided SGMs do not always achieve accurate conditional generation, especially when trained with fewer labeled data. We argue that the problem is rooted in the classifier’s tendency to overfit without coordinating with the underlying unconditional distribution. To make the classifier respect the unconditional distribution, we propose improving classifier-guided SGMs by letting the classifier regularize itself. The key idea of our proposed method is to use principles from energy-based models to convert the classifier into another view of the unconditional SGM. Existing losses for unconditional SGMs can then be leveraged to achieve regularization by calibrating the classifier’s internal unconditional scores. The regularization scheme can be applied to not only the labeled data but also unlabeled ones to further improve the classifier. Across various percentages of fewer labeled data, empirical results show that the proposed approach significantly enhances conditional generation quality. The enhancements confirm the potential of the proposed self-calibration technique for generative modeling with limited labeled data.
1 Introduction
Score-based generative models (SGMs) capture the underlying data distribution by learning the gradient function of the log-likelihood on data, also known as the score function. SGMs, when coupled with a diffusion process that gradually converts noise to data, can often synthesize higher-quality images than other popular alternatives, such as generative adversarial networks [29, 2]. The community’s research dedication to SGMs demonstrates promising performance in image generation [29] and other fields such as audio synthesis [13, 10, 9] and natural language generation [18]. Many such successful SGMs focus on unconditional generation, which models the distribution without considering other variables [26, 7, 29]. When seeking to generate images controllably from a particular class, it is necessary to model the conditional distribution concerning another variable. Such conditional SGMs [29, 2, 1] will be the focus of this paper.
There are two major families of conditional SGMs. Classifier-free SGMs (CFSGMs) adopt specific conditional network architectures and losses [2, 6]. CFSGMs are known to generate high-fidelity images when all data are labeled. Nevertheless, our findings indicate that their performance drops significantly as the proportion of labeled data decreases. This disadvantage makes them less preferable in the semi-supervised setting, which is a realistic scenario when obtaining class labels takes significant time and costs. Classifier-guided SGMs (CGSGMs) form another family of conditional SGMs [29, 2] based on decomposing the conditional score into the unconditional score plus the gradient of an auxiliary classifier. A vanilla CGSGM can then be constructed by learning a classifier in parallel to training an unconditional SGM with the popular denoising score matching [DSM; 31] technique. The classifier can control the trade-off between generation diversity and fidelity [2]. Furthermore, because the unconditional SGM can be trained with both labeled and unlabeled data in principle, CGSGMs emerge with more potential than CFSGMs for the semi-supervised setting with fewer labeled data.
The quality of the classifier gradients is critical for CGSGMs. If the classifier overfits [17, 22, 21, 4] and predicts highly inaccurate gradients, the resulting conditional scores may be unreliable, which lowers the generation quality even if the reliable unconditional scores can ensure decent generation fidelity. Although there are general regularization techniques [33, 22, 8] that mitigate overfitting, their specific benefits for CGSGMs have not been fully studied except for a few cases [11]. In fact, we find that those techniques are often not aligned with the unconditional SGM’s view of the underlying distribution and offer limited benefits for improving CGSGMs. One pioneering enhancement of CGSGM on distribution alignment, denoising likelihood score matching [CG-DLSM; 1], calibrates the classifier with a regularization loss that aligns the classifier’s gradients to the ground truth gradients with the external help of unconditional SGMs. Despite being able to achieve state-of-the-art performance within the CGSGM family, CG-DLSM is only designed for labeled data and does not apply to unlabeled data.
In this work, we design a regularization term that calibrates the classifier internally, without relying on the unconditional SGM. Such an internal regularization has been previously achieved by the joint energy-based model [JEM; 4], which interprets classifiers as energy-based models. The interpretation allows JEM to define an auxiliary loss term that respects the underlying distribution and can unlock the generation capability of classifiers when using MCMC sampling. Nevertheless, extending JEM as CGSGM is non-trivial, as the sampling process is time-consuming and results in unstable loss values when coupled with the diffusion process of CGSGM. We thus take inspiration from JEM to derive a novel CGSGM regularizer instead of extending JEM directly.
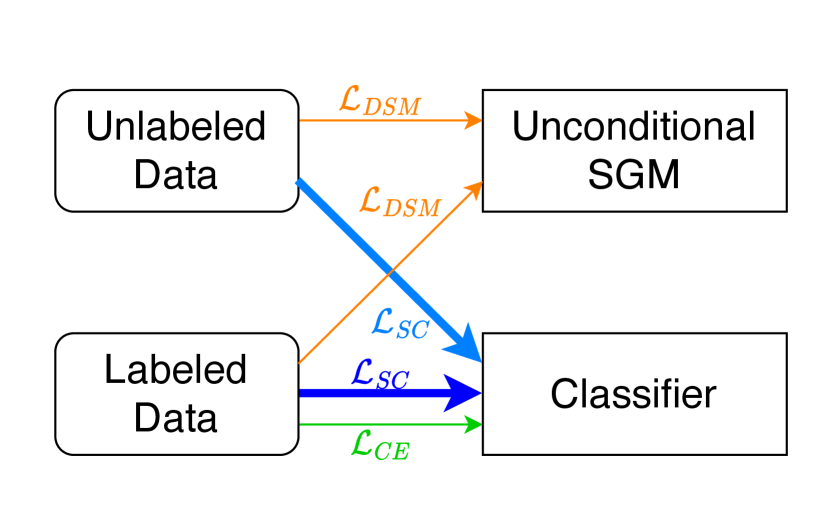
Our design broadens the JEM interpretation of classifiers to be unconditional SGMs. Then, a stable and efficient self-calibration (SC) loss (as illustrated with in Fig. 1) can be computed from the classifier internally for regularization. The SC loss inherits a sound theoretical guarantee from the DSM technique for training unconditional SGMs. Our proposed CGSGM-SC approach, as shown in Fig. 1, allows separate training of the unconditional SGM and the classifier. The approach applies the SC loss on both labeled and unlabeled data, resulting in immediate advantages in the semi-supervised setting with fewer labeled data.
Following earlier studies on CGSGMs [1], we visually study the effectiveness of CGSGM-SC on a synthesized data set. The results reveal that the CGSGM-SC leads to more accurate classifier gradients than vanilla CGSGM, thus enhancing the estimation of conditional scores. We further conduct thorough experiments on CIFAR-10 and CIFAR-100 datasets to validate the advantages of CGSGM-SC. The results confirm that CGSGM-SC is superior to the vanilla CGSGM and the state-of-the-art CGSGM-DLSM approach. Furthermore, in an extreme setting for which only of the data is labeled, CGSGM-SC, which more effectively utilizes unlabeled data, is significantly better than all CGSGMs and CFSGMs. This confirms the potential of CGSGM-SC in scenarios where labeled data are costly to obtain.
2 Background
Consider a data distribution where . The purpose of an SGM is to generate samples from via the information contained in the score function , which is learned from data. We first introduce how a diffusion process can be combined with learning a score function to effectively sample from in Section 2.1. Next, a comprehensive review of works that have extended SGMs to conditional SGMs is presented in Section 2.2, including those that incorporates classifier regularization for CGSGMs. Finally, JEM [4] is introduced in Section 2.3, highlighting its role in inspiring our proposed methodology.
2.1 Score-based Generative Modeling by Diffusion
Song et al. [29] propose to model the transition from a known prior distribution , typically a multivariate gaussian noise, to an unknown target distribution using the markov chain described by the following stochastic differential equation (SDE):
| (1) |
where is a standard Wiener process when the timestep flows from back to , denotes a time-dependent score function, and and are some prespecified functions that describe the overall movement of the distribution . The score function is learned by optimizing the following time-generalized denoise score matching (DSM) [31] loss
| (2) |
where is selected uniformly between and , , , denotes the score function of the noise distribution , which can be calculated using the prespecified and , and is a weighting function that balances the loss of different timesteps. In this paper, we use the hyperparameters from the original VE-SDE framework [29]. A more detailed introduction to learning the score function and sampling through SDEs is described in Appendix B.
2.2 Conditional Score-based Generative Models
In conditional SGMs, we are given labeled data in addition to unlabeled data , where denotes the class label. The case of is called the fully-supervised setting; in this paper, we consider the semi-supervised setting with , with a particular focus on the challenging scenario where is small. The goal of conditional SGMs is to learn the conditional score function and then generate samples from , typically using a diffusion process as discussed in Section 2.1 and Appendix B.2.
One approach for conditional SGMs is classifier-free SGM [2, 6], which parameterizes its model with a joint architecture such that the class labels can be included as inputs. Classifier-free guidance [6], also known as CFG, additionally uses a null token to indicate unconditional score calculation, which is linearly combined with conditional score calculation for some specific to form the final estimate of . CFG is a state-of-the-art conditional SGM in the fully-supervised setting. Nevertheless, as we shall show in our experiments, its performance drops significantly in the semi-supervised setting, as the conditional parts of CFG may lack sufficient labeled data during training.
Another popular family of conditional SGM is CGSGM. Under this framework, we decompose the conditional score function using Bayes’ theorem [29, 2]:
| (3) |
The term can be dropped because it is not a function of and is thus of gradient . The decomposition shows that conditional generation can be achieved by an unconditional SGM that learns the score function plus an extra conditional gradient term .
The vanilla classifier-guidance (CG) estimates with an auxiliary classifier trained from the cross-entropy loss on the labeled data and learns the unconditional score function by the denoising score matching loss , which in principle can be applied on unlabeled data along with labeled data. Nevertheless, the classifier within the vanilla CG approach is known to be potentially overconfident [17, 22, 21, 4] in its predictions, which in turn results in inaccurate gradients. This can mislead the conditional generation process and decrease class-conditional generation quality.
Dhariwal and Nichol [2] propose to address the issue by post-processing the term with a scaling parameter .
| (4) |
where is the score function and is the posterior probability distribution outputted by a classifier parameterized by . Increasing sharpens the distribution , guiding the generation process to produce less diverse but higher fidelity samples. While the tuning heuristic is effective in improving the vanilla CG approach, it is not backed by sound theoretical explanations.
Other attempts to regularize the classifier during training for resolving the issue form a promising research direction. For instance, CGSGM with denoising likelihood score matching [CG-DLSM; 1] presents a regularization technique that employs the DLSM loss below formulated from the classifier gradient and unconditional score function .
| (5) |
where the unconditional score function is estimated via an unconditional SGM . The CG-DLSM authors [1] prove that Eq. 2.2 can calibrate the classifier to produce more accurate gradients .
Robust CGSGM [11], in contrast to CG-DLSM, does not regularize by modeling the unconditional distribution. Instead, robust CGSGM leverages existing techniques to improve the robustness of the classifier against adversarial perturbations. Robust CGSGM applies a gradient-based adversarial attack to the generated during the diffusion process, and uses the resulting adversarial example to make the classifier more robust.
2.3 Reinterpreting Classifiers as Energy-based models
Our proposed methodology draws inspiration from JEM [4], which shows that reinterpreting classifiers as energy-based models (EBMs) and enforcing regularization with related objectives helps classifiers to capture more accurate probability distributions. EBMs are models that estimate energy functions of distributions [15], which satisfies . Given the logits of a classifier to be , the estimated joint distribution can be written as , where means exponential and . After that, the energy function can be obtained by
| (6) |
Then, losses used to train EBMs can be seamlessly leveraged in JEM to regularize the classifier, such as the typical EBM loss . JEM uses MCMC sampling for computing the loss and is shown to result in a well-calibrated classifier in their empirical study. The original JEM work [4] also reveals that classifiers can be used as a reasonable generative model, but its generation performance is knowingly worse than state-of-the-art SGMs.
3 The Proposed Self-calibration Methodology
In this work, we consider CGSGMs under the diffusion generation process as discussed in Section 2.1. Such CGSGMs require learning an unconditional SGM, which is assumed to be trained with denoising score matching [DSM; 31] due to its close relationship with the diffusion process. Such CGSGMs also require a time-dependent classifier that models instead of , which can be done by applying a time-generalized cross-entropy loss.
Section 2.2 has illustrated the importance of regularizing the classifier to prevent it from misguiding the conditional generation process. One naive thought is to use established regularization techniques, such as label-smoothing and Jacobian regularization [8]. Those regularization techniques that are less attached to the underlying distribution will be studied in Section 4. Our proposed regularization loss, inspired by the success of DLSM [1] and JEM [4], attempts to connect with the underlying distribution better.
3.1 Formulation of self-calibration loss
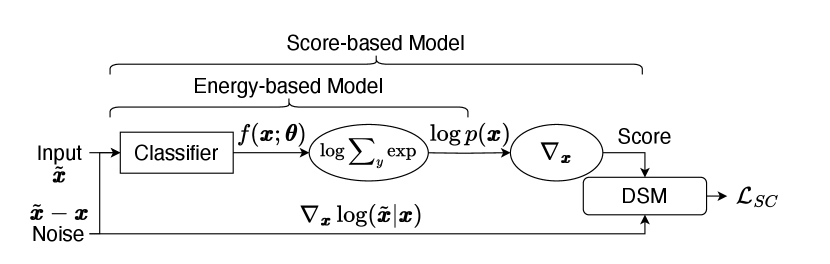
We extend JEM [4] to connect the time-dependent classifier to the underlying distribution. In particular, we reinterpret the classifier as a time-dependent EBM. The interpretation allows us to obtain a time-dependent version of within the classifier, which can be used to obtain a classifier-internal version of the score function. Then, instead of regularizing the classifier by the EBM loss like JEM, we propose to regularize by score function instead.
Under the EBM interpretation, the energy function is , where is the output logits of the time-dependent classifier. Then, the internal time-dependent unconditional score function is , where is used instead of to indicate that the unconditional score is computed within the classifier. Then, we adopt the standard DSM technique in Eq. 2.1 to “train” the internal score function, forcing it to follow its physical meaning during the diffusion process. The resulting self-calibration loss can then be defined as
| (7) |
where , , and denotes the score function of the noise centered at .
Fig. 2 summarizes the calculation of the proposed SC loss. Note that in practice, is uniformly sampled over . After the self-calibration loss is obtained, it is mixed with the cross-entropy loss to train the classifier. The total loss can be written as:
| (8) |
where is a tunable hyper-parameter. The purpose of self-calibration is to make the classifier to more accurately estimate the score function of the underlying data distribution, implying that the underlying data distribution itself is also more accurately estimated. As a result, the gradients of the classifiers are more aligned with the ground truth. After self-calibration, the classifier is then used in CGSGM to guide an unconditional SGM for conditional generation. Note that since our approach regularizes the classifier during training while classifier gradient scaling (Eq. 4) is done during sampling, we can easily combine the two techniques to enhance performance.




3.2 Comparison with related regularization methods
This section provides a comparative analysis of the regularization methods employed in DLSM [1], robust classifier guidance [11], JEM [4], and our proposed self-calibration loss.
DLSM [1]
DLSM and our proposed method both regularize the classifier to align better with unconditional SGMs’ view of the underlying distribution. DLSM achieves this by relying on the help of an external trained SGM, whereas self-calibration regularizes the classifier by using a classifier-internal SGM. Furthermore, the design of DLSM loss can only utilize labeled data, while our method is able to make use of all data.
Robust CGSGM [11]
Robust CGSGM proposes to regularize classifiers with gradient-based adversarial training without explicitly aligning with the distribution, in contrast to our self-calibration method, where direct calibration of the classifier-estimated score function is employed. Although adversarial robustness is correlated with more interpretable gradients [30], EBMs [34], and generative modeling [25], the theoretical foundation for whether adversarially robust classifiers accurately estimate underlying distributions remains ambiguous.
JEM [4]
JEM interprets classifiers as unconditional EBMs, and self-calibration further extends the interpretation to unconditional SGMs. The training stage of EBM that incorporates MCMC sampling is known to be unstable and time-consuming, whereas self-calibration precludes the need for sampling during training and substantially improves both stability and efficiency. Even though one can mitigate the instability issue by increased sampling steps and additional hyperparameter tuning, doing so largely lengthens training times.
CG-JEM
In contrast to the previous paragraph, this paragraph discusses the incorporation of JEM into the time-dependent CGSGM framework. Coupling EBM training with additional training objectives is known to introduce increased instability, especially for time-dependent classifiers considering it is more difficult to generate meaningful time-dependent data through MCMC sampling. For example, in our naive implementation of time-dependent JEM, it either (1) incurs high instability (loss diverges within steps in all runs; requires s per step) or (2) poses unaffordable resource consumption requirements (requires s per step, approximately days in total). In comparison, our proposed method only requires s per step. While enhanced stability is observed after incorporating diffusion recovery likelihood [3], the time-costly nature of MCMC sampling still remains (requires s per step).
3.3 Self-calibration for Semi-supervised Learning
In this work, we also explore the benefit of self-calibration loss in the semi-supervised setting, where only a small proportion of data are labeled. In the original classifier guidance, the classifiers are trained only on labeled data. The lack of labels in the semi-supervised setting constitutes a greater challenge to learning an unbiased classifier. With self-calibration, we better utilize the large amount of unlabeled data by calculating the SC loss with all data.
To incorporate the loss and utilize unlabeled data during training, we change the way is calculated from Eq. 8. As illustrated in Fig. 1, the entire batch of data is used to calculate , whereas only the labeled data is used to calculate . During training, we observe that when the majority is unlabeled data, the cross-entropy loss does not converge to a low-and-steady stage if the algorithm randomly samples from all training data. As this may be due to the low percentage of labeled data in each batch, we change the way we sample batches by always ensuring that exactly half of the data is labeled. Appendix C summarizes the semi-supervised training process of the classifier.
Note that even though the classifier is learning a time-generalized classification task, we can still make it perform as an ordinary classifier that classifies the unperturbed data by setting the input timestep . This greatly facilitates the incorporation of common semi-supervised classification methods such as pseudo-labeling [16], self-training, and noisy student [32]. Integrating semi-supervised classification methodologies is an interesting future research direction, and we reserve the detailed exploration of this topic for future studies.
3.4 2D toy dataset
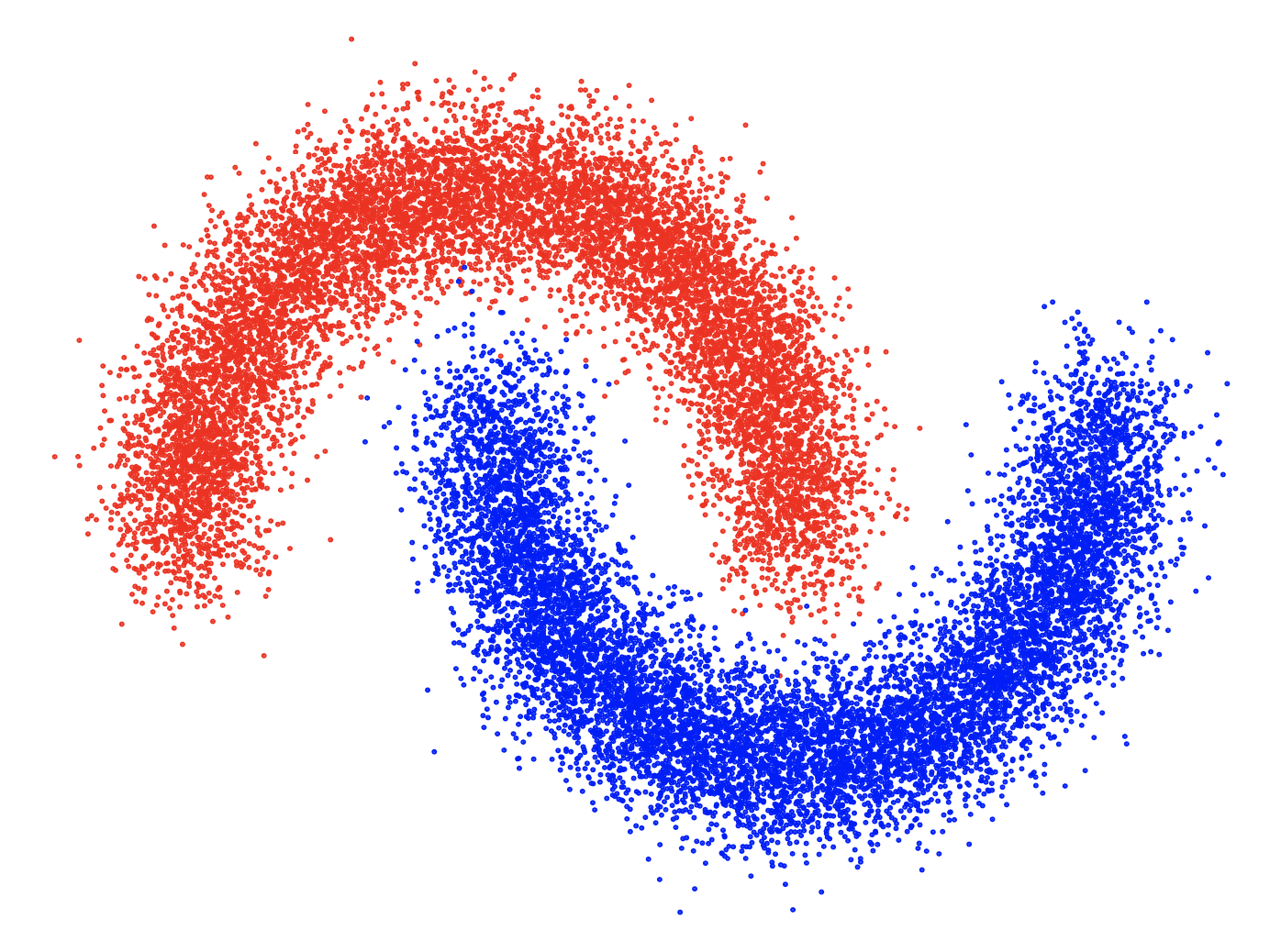
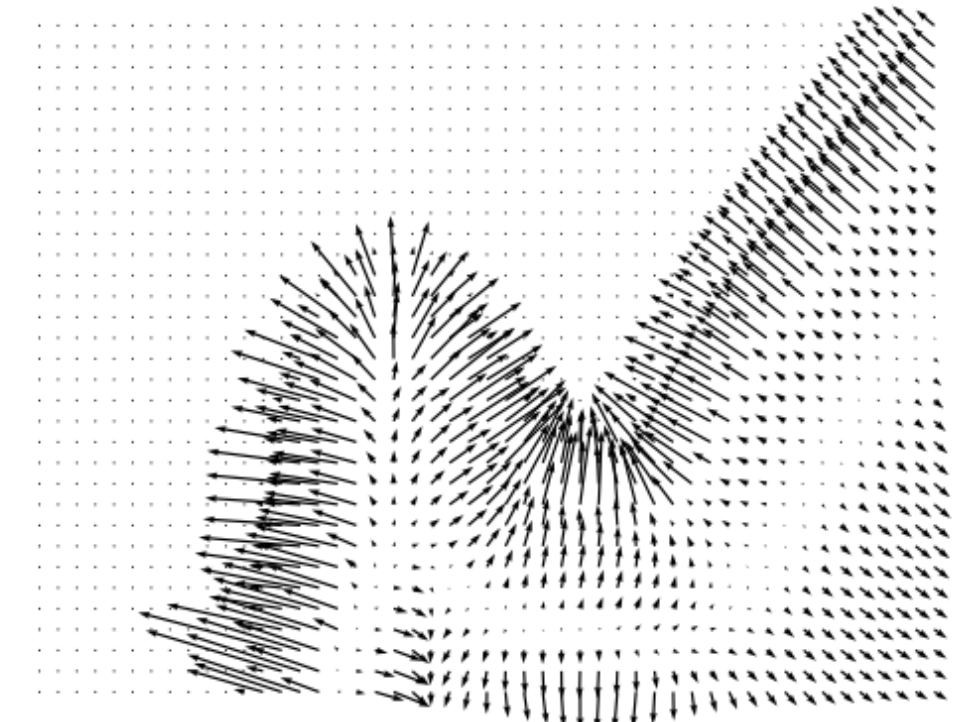
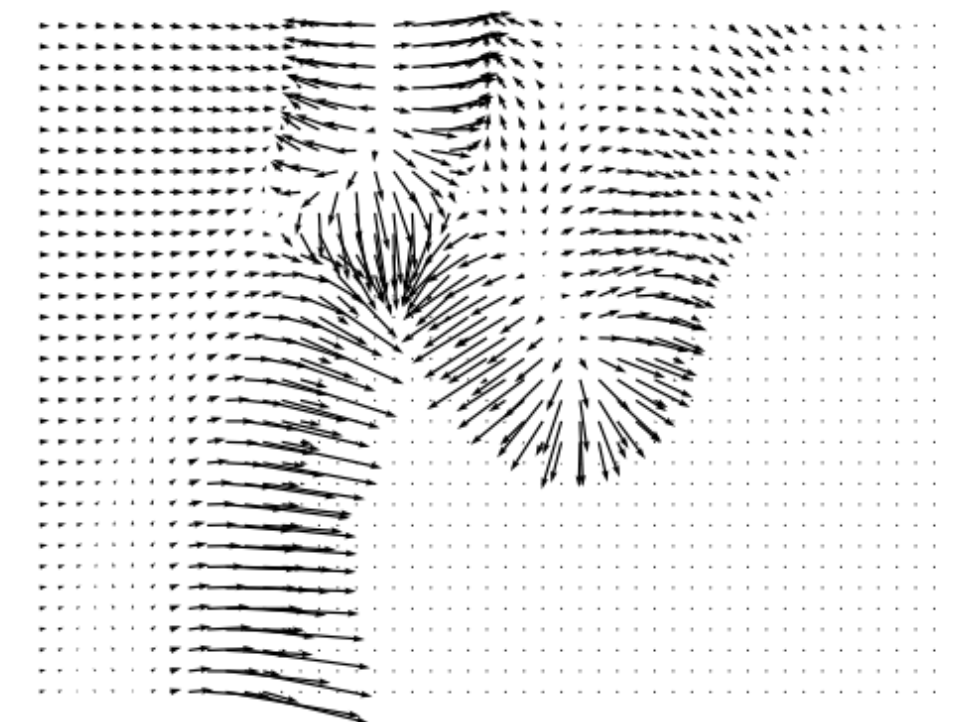
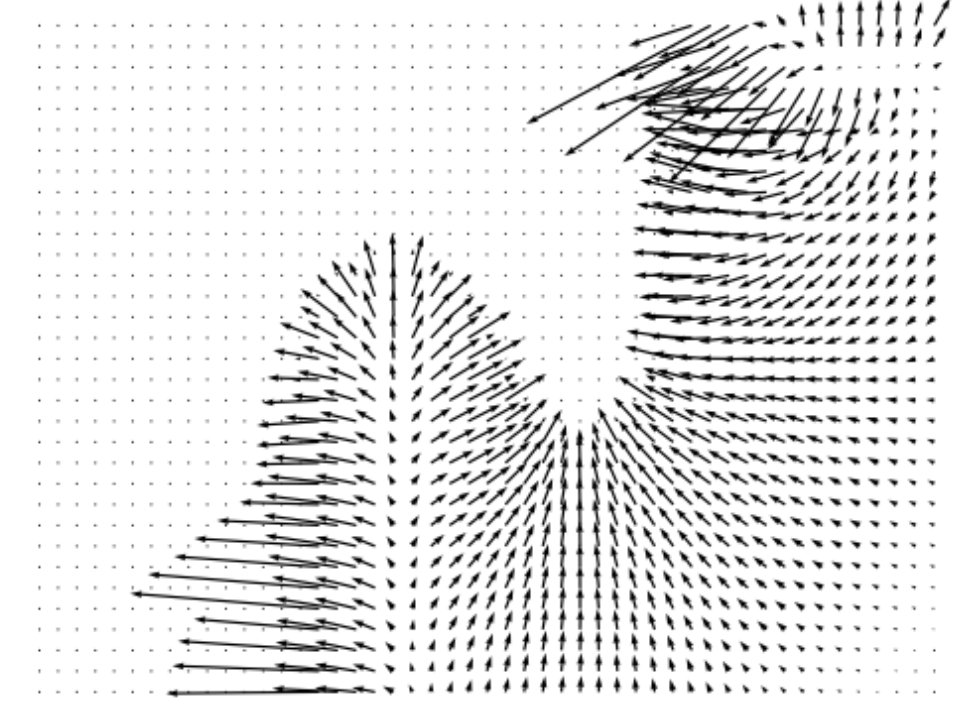
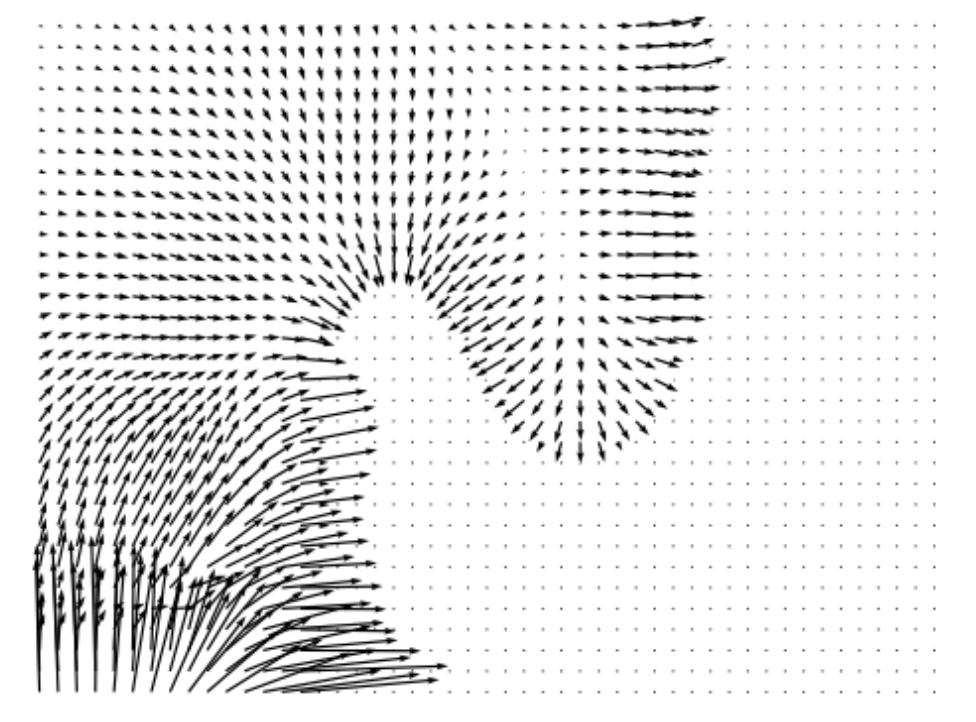
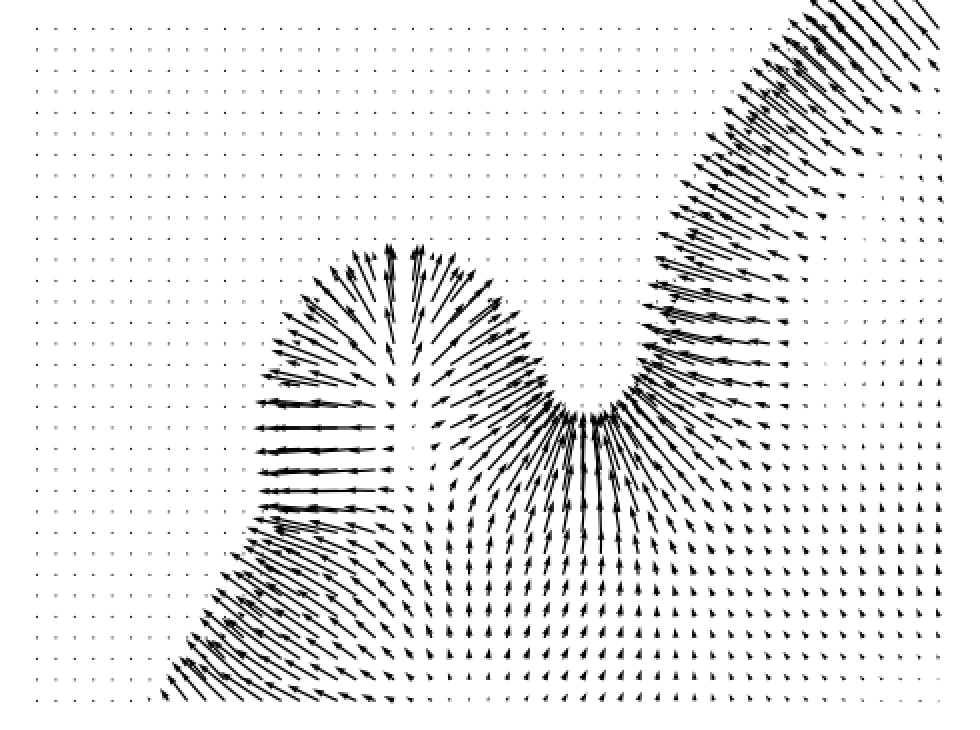
Following DLSM [1], we use a 2D toy dataset containing two classes to demonstrate the effects of self-calibration loss and visualize the training results. The data distribution is shown in Fig. 3(a), where the two classes are shown in two different colors. After training the classifiers on the toy dataset with different methods, we plot the gradients at minimum timestep estimated by the classifiers and compare them with the ground truth. Additional quantitative measurements of the toy dataset are included in Appendix E.
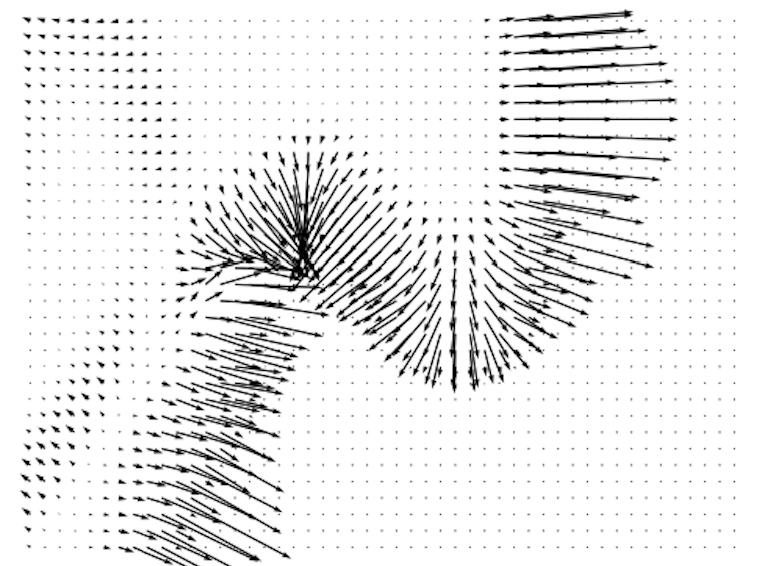
Figure 3 shows the ground truth classifier gradient and the gradients estimated by classifiers trained using different methods. Unregularized classifiers produce gradients that contain rapid changes in magnitude across the 2D space, with frequent fluctuations and mismatches with the ground truth. Such fluctuations can impede the convergence of the reverse diffusion process to a stable data point, leading SGMs to generate noisier samples. Moreover, the divergence from the ground truth gradient can misguide the SGM, leading to generation of samples from incorrect classes. Unregularized classifiers also tend to generate large gradients near the distribution borders and tiny gradients elsewhere. This implies that when the sampling process is heading toward the incorrect class, such classifiers are not able to “guide” the sampling process back towards the desired class. In comparison, the introduction of various regularization techniques such as DLSM, JEM, and the proposed self-calibration results in estimated gradients that are more stable, continuous across the 2D space, and better aligned with the ground truth. This stability brings about a smoother generation process and the production of higher-quality samples.
4 Experiments
In this section, we test our methods on the CIFAR-10 and CIFAR-100 datasets. We demonstrate that our method improves generation both conditionally and unconditionally with different percentages of labeled data. Randomly selected images of CGSGM before and after self-calibration on CIFAR-10 are shown in Appendix H. Additional experimental details are included in Appendix D.
4.1 Experimental Setup
Evaluation metrics
We adopted unconditional metrics FID [5], density, and coverage [23]. Density and coverage are designed to address the issues of precision and recall [14] to provide a more reliable interpretation of how well the generated data distribution resembles and covers the entirety of training data distribution. Besides unconditional generative performance, we evaluated the class-conditional performance of our methods using intra-FID, intra-density, and intra-coverage, which measures the average FID, density, and coverage for each class, respectively.

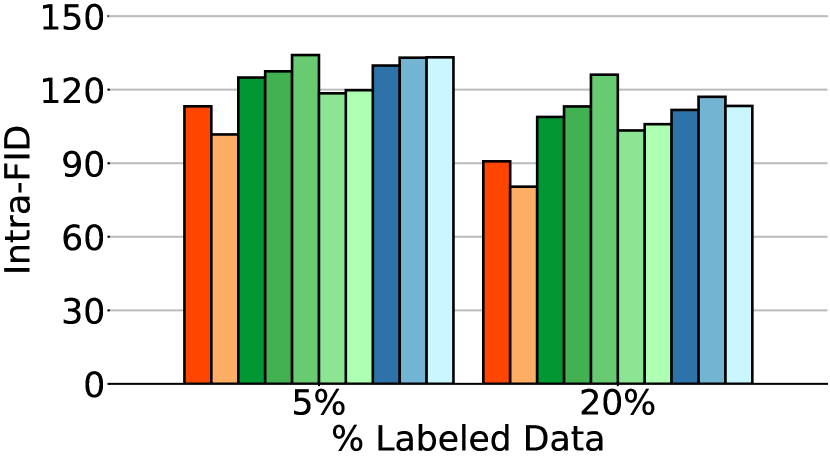
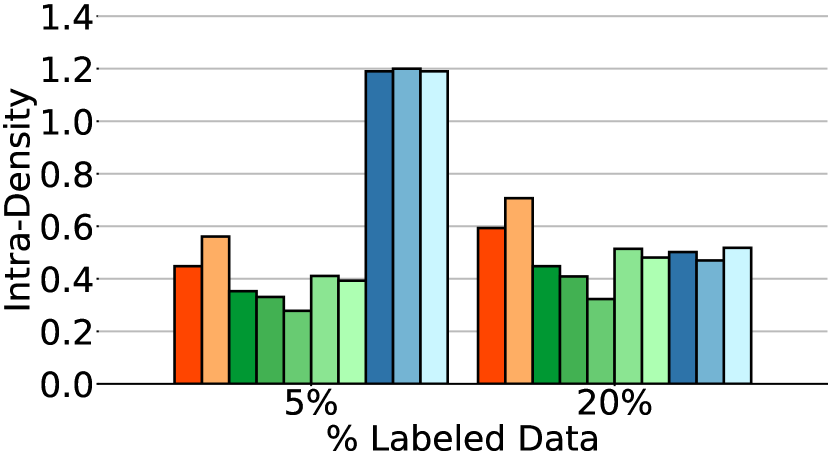
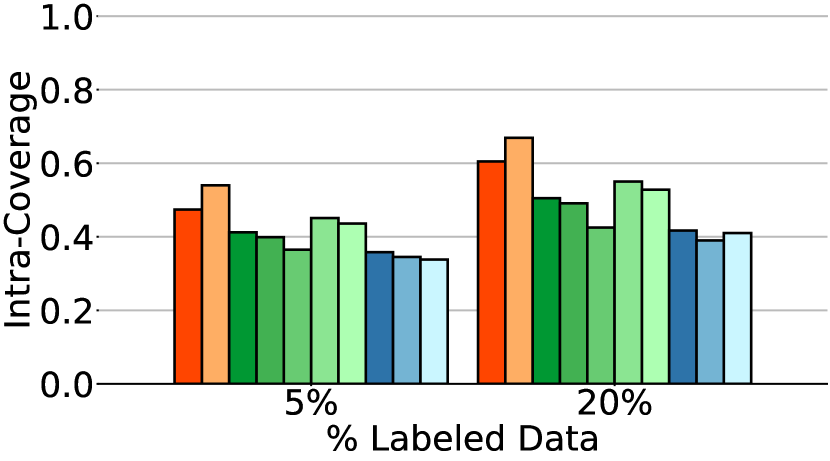
Baseline methods
CG: vanilla classifier guidance; CG-JEM: classifier guidance with JEM loss; CG-DLSM: classifier guidance with DLSM loss [1]; CG-LS: classifier guidance with label smoothing; CG-JR: classifier guidance with Jacobian regularization [8]; Cond: conditional SGMs by conditional normalization [2]; CFG-labeled: CFG [6] using only labeled data; CFG-all: CFG using all data to train the unconditional part of the model.
4.2 Results
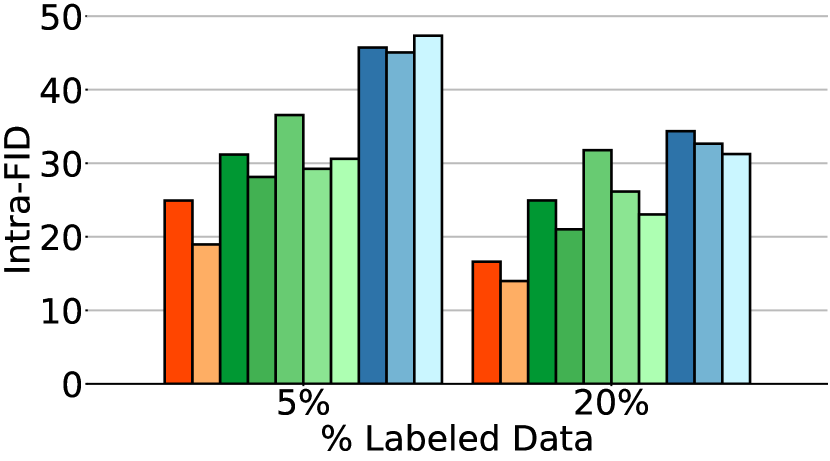
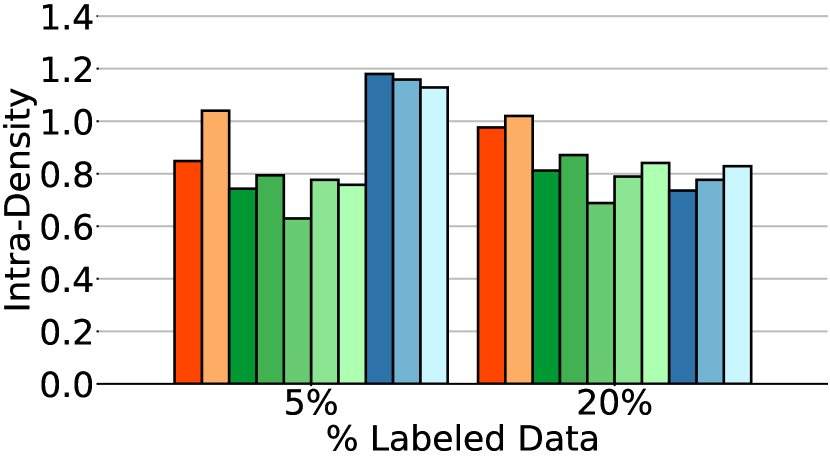
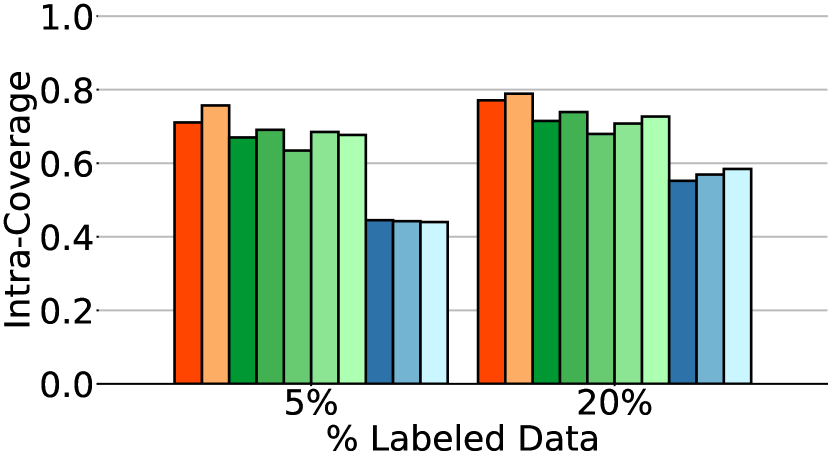
Table 1 and Fig. 4 present the performance of all methods when applied to various percentages of labeled data. CG-SC-labeled implies that self-calibration is applied only on labeled data whereas CG-SC-all implies that self-calibration is applied on all data.
Classifier-Free SGMs (CFSGMs)
The first observation from Fig. 4 is that CFSGMs, including Cond, CFG-labeled, and CFG-all, consistently excel in the intra-Density metric, demonstrating their ability to generate class-conditional images with high accuracy. However, in Table 1 and Fig. 4, we can see that when performing class-conditional generation tasks with few labeled data, there is a significant performance drop in terms of Coverage, intra-FID, and intra-Coverage for CFSGMs. CFSGMs, while generating high-quality images with high accuracy, tend to lack diversity when working with fewer labeled data. This occurs mainly due to the lack of sufficient labeled data in the training phase, causing them to generate samples that closely mirror the distribution of only the labeled data, as opposed to that of all data. This inability to generate data that covers the full variability of training data deteriorated Coverage and intra-Coverage, which also caused CFSGMs to perform poorly in terms of intra-FID, despite being able to generate class-conditional images with high accuracy.
Classifier-Guided SGMs (CGSGMs)
By leveraging both labeled and unlabeled data during training in semi-supervised settings, all CGSGMs are able to perform better in semi-supervised class-conditional generation compared to CFSGMs. Besides better performance, the diversity measures, which contain coverage, and intra-Coverage, of CGSGMs are also more consistent across various percentages of labeled data (Table 1). This demonstrates that having less labeled data does not reduce the diversity of generated images by much for CGSGMs, which is preferable over CFSGMs as the generation diversity of CFSGMs is greatly deteriorated by the reduction of labeled data.
| 5% labeled data | 20% labeled data | 100% labeled data | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | intra-FID () | FID () | Den () | Cov () | intra-FID () | FID () | Den () | Cov () | intra-FID () | FID () | Den () | Cov () |
| CG-SC-labeled (Ours) | 24.93 | 2.84 | 1.083 | 0.816 | 16.62 | 2.75 | 1.097 | 0.823 | 11.70 | 2.23 | 1.029 | 0.817 |
| CG-SC-all (Ours) | 18.95 | 2.72 | 1.191 | 0.822 | 13.97 | 2.63 | 1.090 | 0.821 | 11.70 | 2.23 | 1.029 | 0.817 |
| CG | 31.17 | 2.61 | 1.047 | 0.815 | 24.94 | 3.09 | 1.004 | 0.806 | 18.99 | 2.48 | 0.979 | 0.812 |
| CG-JEM | 28.13 | 2.70 | 1.079 | 0.817 | 21.02 | 2.75 | 1.050 | 0.817 | 23.39 | 2.16 | 0.980 | 0.813 |
| CG-DLSM | 36.55 | 2.18 | 0.992 | 0.816 | 31.78 | 2.10 | 0.975 | 0.812 | 21.59 | 2.36 | 0.943 | 0.803 |
| CG-LS | 29.24 | 2.62 | 1.068 | 0.821 | 26.15 | 4.18 | 0.971 | 0.796 | 18.10 | 2.15 | 1.005 | 0.818 |
| CG-JR | 30.59 | 2.80 | 1.066 | 0.817 | 23.03 | 2.49 | 1.056 | 0.822 | 17.24 | 2.17 | 1.007 | 0.815 |
| Cond | 45.73 | 15.57 | 1.174 | 0.459 | 34.36 | 19.77 | 0.775 | 0.567 | 10.29 | 2.13 | 1.050 | 0.831 |
| CFG-labeled | 45.07 | 15.31 | 1.169 | 0.457 | 32.66 | 18.48 | 0.832 | 0.589 | 10.58 | 2.28 | 1.101 | 0.838 |
| CFG-all | 47.33 | 16.57 | 1.144 | 0.452 | 31.24 | 17.37 | 0.863 | 0.601 | 10.58 | 2.28 | 1.101 | 0.838 |
| 5% labeled data | 20% labeled data | 100% labeled data | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | intra-FID () | FID () | Den () | Cov () | intra-FID () | FID () | Den () | Cov () | intra-FID () | FID () | Den () | Cov () |
| CG-SC-labeled (Ours) | 113.21 | 4.80 | 0.927 | 0.756 | 90.76 | 3.74 | 0.928 | 0.766 | 79.57 | 3.70 | 0.848 | 0.749 |
| CG-SC-all (Ours) | 101.75 | 4.31 | 0.968 | 0.770 | 80.42 | 3.60 | 0.941 | 0.775 | 79.57 | 3.70 | 0.848 | 0.749 |
| CG | 124.92 | 5.24 | 0.891 | 0.745 | 108.86 | 4.10 | 0.904 | 0.759 | 98.72 | 3.83 | 0.869 | 0.761 |
| CG-JEM | 127.47 | 6.01 | 0.831 | 0.723 | 113.16 | 5.08 | 0.864 | 0.754 | 106.24 | 5.40 | 0.818 | 0.730 |
| CG-DLSM | 134.11 | 4.46 | 0.862 | 0.749 | 126.12 | 7.24 | 0.802 | 0.718 | 102.85 | 3.85 | 0.847 | 0.753 |
| CG-LS | 118.52 | 4.18 | 0.933 | 0.762 | 103.39 | 3.70 | 0.963 | 0.778 | 98.53 | 3.39 | 0.907 | 0.774 |
| CG-JR | 119.78 | 4.64 | 0.926 | 0.759 | 105.91 | 3.92 | 0.941 | 0.771 | 100.34 | 3.50 | 0.892 | 0.768 |
| Cond | 129.82 | 10.58 | 1.210 | 0.404 | 111.73 | 29.45 | 0.622 | 0.451 | 64.77 | 3.02 | 0.962 | 0.806 |
| CFG-labeled | 133.03 | 11.25 | 1.220 | 0.385 | 117.09 | 32.68 | 0.611 | 0.424 | 63.03 | 2.60 | 1.040 | 0.829 |
| CFG-all | 133.18 | 10.68 | 1.210 | 0.380 | 113.38 | 30.84 | 0.612 | 0.437 | 63.03 | 2.60 | 1.040 | 0.829 |
Regularized CGSGMs vs Vanilla CGSGM
Basic regularization methods like label-smoothing and Jacobian regularization [8] show consistent but marginal improvement over vanilla CGSGM. This points out that although these methods mitigate overfitting on training data, the constraints they enforce do not align with SGMs, limiting the benefit of such methods. CG-DLSM [1], on the other hand, achieves great unconditional generation performance in all settings. However, its class-conditional performance suffers from a significant performance drop in semi-supervised settings due to its low generation accuracy, which is evident in Fig. 4(b) and Fig. 4(e). We can also see in Fig. 4 and Table 1 that by incorporating the proposed self-calibration, all conditional metrics improved substantially. Notably, CG-SC-all (Ours) consistently achieves the best conditional performance among all CGSGMs in semi-supervised settings. On average, CG-SC-all improves intra-FID by 10.16 and 23.59 over CG on CIFAR-10 and CIFAR-100, respectively. These results demonstrate that self-calibration enables CGSGMs to estimate the class-conditional distributions more accurately, even when labeled data is limited.
Leverage unlabeled data for semi-supervised settings
Intuitively, we expect incorporating unlabeled data into the computation of SC loss to enhance the quality of conditional generation. As the proportion of unlabeled data increases, we expect this benefit of leveraging unlabeled data to become more significant. As our experimental results indicate in Fig. 4 and Table 1, the utilization of unlabeled data significantly improves performance. Notably, with only 5% of the data labeled on CIFAR-10, the performance of CG-SC-all evaluated with intra-FID and intra-Density are improved by 5.98 and 0.156 over CG-SC-labeled and 12.22 and 0.296 over the original CG. The results confirm that as the percentage of labeled data decreases, the benefit of utilizing unlabeled data becomes increasingly more profound.
5 Conclusion
We tackle the overfitting issue for the classifier within CGSGMs from a novel perspective: self-calibration. The proposed self-calibration method leverages EBM interpretation like JEM to reveal that the classifier is internally an unconditional score estimator and design a loss with the DSM technique to calibrate the internal estimation. This self-calibration loss regularizes the classifier directly towards better scores without relying on an external score estimator. We demonstrate three immediate benefits of the proposed self-calibrating CGSGM approach. Using a standard synthetic dataset, we show that the scores computed using this approach are indeed closer to the ground-truth scores. Second, across all percentages of labeled data, the proposed approach outperforms the existing CGSGM. Lastly, our empirical study justifies that when compared to other conditional SGMs, the proposed approach consistently achieves the best intra-FID in the focused semi-supervised settings by seamlessly leveraging the power of unlabeled data, highlighting the rich potential of our approach.
We have presented compelling evidence supporting the superiority of CGSGM using standard CIFAR-10 and CIFAR-100 datasets. A natural question arises regarding whether this superiority can be extended to higher-resolution datasets such as ImageNet. We conjecture that achieving this extension is highly non-trivial, as previous studies [29, 28, 1, 19] have not successfully developed a satisfactory unconditional SGM on ImageNet when the resolution exceeds 32 by 32. CGSGM on high-resolution ImageNet, which naturally inherits the technical limitation from unconditional SGMs, thus remains challenging to build, despite our extensive exploration through hyperparameter tuning and analysis. In addition to responsibly reporting this limitation to the community’s attention, two immediate future directions emerge: the first involves conducting foundational research to achieve competent generation for unconditional SGMs on ImageNet, and the second explores applying the self-regularization concept to other types of conditional generative models.
6 Impact Statements
We expect our work to assist the development of real-world applications in scenarios where labeled data is scarce. However, as advancements in conditional generation methodologies introduce improved controllability over synthetic data, the proposed method may make intentional or unintentional misuse of generative models easier. For instance, fraudulent content could be generated, or privacy leaks could be caused by instructing models to synthesize data closely mirroring specific training samples.
References
- Chao et al. [2022] Chen-Hao Chao, Wei-Fang Sun, Bo-Wun Cheng, Yi-Chen Lo, Chia-Che Chang, Yu-Lun Liu, Yu-Lin Chang, Chia-Ping Chen, and Chun-Yi Lee. Denoising likelihood score matching for conditional score-based data generation. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=LcF-EEt8cCC.
- Dhariwal and Nichol [2021] Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat GANs on image synthesis. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021.
- Gao et al. [2021] Ruiqi Gao, Yang Song, Ben Poole, Ying Nian Wu, and Diederik P Kingma. Learning energy-based models by diffusion recovery likelihood. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=v_1Soh8QUNc.
- Grathwohl et al. [2020] Will Grathwohl, Kuan-Chieh Wang, Joern-Henrik Jacobsen, David Duvenaud, Mohammad Norouzi, and Kevin Swersky. Your classifier is secretly an energy based model and you should treat it like one. In ICLR, 2020.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NeurIPS, 2017.
- Ho and Salimans [2021] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. URL https://openreview.net/forum?id=qw8AKxfYbI.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. arXiv preprint arxiv:2006.11239, 2020.
- Hoffman et al. [2019] Judy Hoffman, Daniel A. Roberts, and Sho Yaida. Robust learning with jacobian regularization, 2019.
- Huang et al. [2022] Rongjie Huang, Max WY Lam, Jun Wang, Dan Su, Dong Yu, Yi Ren, and Zhou Zhao. Fastdiff: A fast conditional diffusion model for high-quality speech synthesis. 2022.
- Jeong et al. [2021] Myeonghun Jeong, Hyeongju Kim, Sung Jun Cheon, Byoung Jin Choi, and Nam Soo Kim. Diff-TTS: A Denoising Diffusion Model for Text-to-Speech. In Proc. Interspeech 2021, pages 3605–3609, 2021. doi: 10.21437/Interspeech.2021-469.
- Kawar et al. [2022] Bahjat Kawar, Roy Ganz, and Michael Elad. Enhancing diffusion-based image synthesis with robust classifier guidance, 2022. URL https://arxiv.org/abs/2208.08664.
- Kingma and Cun [2010] Durk P Kingma and Yann Cun. Regularized estimation of image statistics by score matching. In J. Lafferty, C. Williams, J. Shawe-Taylor, R. Zemel, and A. Culotta, editors, Advances in Neural Information Processing Systems, volume 23. Curran Associates, Inc., 2010.
- Kong et al. [2021] Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=a-xFK8Ymz5J.
- Kynkäänniemi et al. [2019] Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/0234c510bc6d908b28c70ff313743079-Paper.pdf.
- LeCun et al. [2006] Yann LeCun, Sumit Chopra, Raia Hadsell, M Ranzato, and Fujie Huang. A tutorial on energy-based learning. Predicting structured data, 1(0), 2006.
- Lee [2013] Dong-Hyun Lee. Pseudo-label : The simple and efficient semi-supervised learning method for deep neural networks. 2013.
- Lee et al. [2018] Kimin Lee, Honglak Lee, Kibok Lee, and Jinwoo Shin. Training confidence-calibrated classifiers for detecting out-of-distribution samples. In International Conference on Learning Representations, 2018.
- Li et al. [2022] Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori Hashimoto. Diffusion-LM improves controllable text generation. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=3s9IrEsjLyk.
- Ma et al. [2022] Hengyuan Ma, Li Zhang, Xiatian Zhu, Jingfeng Zhang, and Jianfeng Feng. Accelerating score-based generative models for high-resolution image synthesis. arXiv prepreint, 2022.
- Martens et al. [2012] James Martens, Ilya Sutskever, and Kevin Swersky. Estimating the hessian by back-propagating curvature. In ICML, 2012.
- Mukhoti et al. [2020] Jishnu Mukhoti, Viveka Kulharia, Amartya Sanyal, Stuart Golodetz, Philip Torr, and Puneet Dokania. Calibrating deep neural networks using focal loss. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, pages 15288–15299, 2020.
- Müller et al. [2019] Rafael Müller, Simon Kornblith, and Geoffrey E Hinton. When does label smoothing help? In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/f1748d6b0fd9d439f71450117eba2725-Paper.pdf.
- Naeem et al. [2020] Muhammad Ferjad Naeem, Seong Joon Oh, Youngjung Uh, Yunjey Choi, and Jaejun Yoo. Reliable fidelity and diversity metrics for generative models. 2020.
- Salimans et al. [2016] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, Xi Chen, and Xi Chen. Improved techniques for training gans. In NeurIPS, 2016.
- Santurkar et al. [2019] Shibani Santurkar, Andrew Ilyas, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. Image synthesis with a single (robust) classifier. In Neural Information Processing Systems, 2019. URL https://api.semanticscholar.org/CorpusID:199511239.
- Song and Ermon [2019] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems, pages 11895–11907, 2019.
- Song et al. [2019] Yang Song, Sahaj Garg, Jiaxin Shi, and Stefano Ermon. Sliced score matching: A scalable approach to density and score estimation. In Proceedings of the Thirty-Fifth Conference on Uncertainty in Artificial Intelligence, UAI 2019, Tel Aviv, Israel, July 22-25, 2019, page 204, 2019.
- Song et al. [2021a] Yang Song, Conor Durkan, Iain Murray, and Stefano Ermon. Maximum likelihood training of score-based diffusion models. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021a. URL https://openreview.net/forum?id=AklttWFnxS9.
- Song et al. [2021b] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021b.
- Tsipras et al. [2019] Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. Robustness may be at odds with accuracy. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=SyxAb30cY7.
- Vincent [2011] Pascal Vincent. A connection between score matching and denoising autoencoders. Neural Computation, 23(7):1661–1674, 2011. doi: 10.1162/NECO_a_00142.
- Xie et al. [2020] Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V. Le. Self-training with noisy student improves imagenet classification. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- Zhang et al. [2019] Guodong Zhang, Chaoqi Wang, Bowen Xu, and Roger Grosse. Three mechanisms of weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=B1lz-3Rct7.
- Zhu et al. [2021] Yao Zhu, Jiacheng Ma, Jiacheng Sun, Zewei Chen, Rongxin Jiang, Yaowu Chen, and Zhenguo Li. Towards understanding the generative capability of adversarially robust classifiers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 7728–7737, October 2021.
Appendix A Supplementary Experimental Results on CIFAR-10
A.1 Additional semi-supervised learning settings
In Section 4, we discussed the generative performance using 5%, 20%, and 100% labeled data from CIFAR-10. In this section, we provide further results for scenarios where 40%, 60%, and 80% of the data is labeled. Besides the evaluation metrics used in the main paper, Inception Score (IS) [24] is also provided. Note that results for CG-JEM with 40%, 60%, and 80% labeled data are not included due to limited computational resources.
| 5% labeled data | 20% labeled data | 100% labeled data | |||||||
| Method | intra-FID () | FID () | IS () | intra-FID () | FID () | IS () | intra-FID () | Acc () | IS () |
| CG-SC-labeled (Ours) | 24.93 | 2.84 | 9.78 | 16.62 | 2.75 | 9.83 | 11.70 | 2.23 | 9.82 |
| CG-SC-all (Ours) | 18.95 | 2.72 | 9.95 | 13.97 | 2.63 | 9.94 | 11.70 | 2.23 | 9.82 |
| CG | 31.17 | 2.61 | 9.98 | 24.94 | 3.09 | 9.92 | 18.99 | 2.48 | 9.88 |
| CG-JEM | 28.13 | 2.70 | 9.92 | 21.02 | 2.75 | 10.10 | 23.39 | 2.16 | 9.83 |
| CG-DLSM | 36.55 | 2.18 | 9.76 | 31.78 | 2.10 | 9.91 | 21.59 | 2.36 | 9.92 |
| CG-LS | 29.24 | 2.62 | 9.92 | 26.15 | 4.18 | 9.98 | 18.10 | 2.15 | 9.98 |
| CG-JR | 30.59 | 2.80 | 9.84 | 23.03 | 2.49 | 10.04 | 17.24 | 2.17 | 9.89 |
| Cond | 45.73 | 15.57 | 9.87 | 34.36 | 19.77 | 8.82 | 10.29 | 2.13 | 10.06 |
| CFG-labeled | 45.07 | 15.31 | 10.20 | 32.66 | 18.48 | 8.93 | 10.58 | 2.28 | 10.05 |
| CFG-all | 47.33 | 16.57 | 9.89 | 31.24 | 17.37 | 9.15 | 10.58 | 2.28 | 10.05 |
| 40% labeled data | 60% labeled data | 80% labeled data | |||||||
| Method | intra-FID () | FID () | IS () | intra-FID () | FID () | IS () | intra-FID () | Acc () | IS () |
| CG-SC-labeled (Ours) | 12.08 | 2.78 | 10.00 | 11.65 | 2.37 | 9.91 | 11.86 | 2.24 | 9.78 |
| CG-SC-all (Ours) | 12.67 | 2.72 | 10.04 | 12.22 | 2.42 | 9.95 | 12.47 | 2.25 | 9.83 |
| CG | 18.31 | 2.42 | 9.95 | 16.94 | 2.35 | 10.03 | 20.15 | 3.30 | 9.76 |
| CG-DLSM | 29.33 | 2.35 | 9.85 | 23.52 | 2.15 | 9.83 | 21.76 | 2.30 | 9.96 |
| CG-LS | 17.89 | 2.32 | 9.95 | 17.72 | 2.27 | 9.91 | 22.30 | 2.40 | 9.84 |
| CG-JR | 18.63 | 2.43 | 10.01 | 19.05 | 2.25 | 10.06 | 18.36 | 2.15 | 9.90 |
| Cond | 13.65 | 4.36 | 9.94 | 10.93 | 2.55 | 10.00 | 10.61 | 2.37 | 10.03 |
| CFG-labeled | 13.93 | 4.59 | 9.84 | 11.28 | 2.73 | 10.12 | 10.75 | 2.48 | 10.09 |
| CFG-all | 13.43 | 4.30 | 9.98 | 11.38 | 2.83 | 10.05 | 10.94 | 2.50 | 10.03 |
| 5% labeled data | 20% labeled data | 100% labeled data | ||||||||||
| Method | Den () | Cov () | intra-Den () | intra-Cov () | Den () | Cov () | intra-Den () | intra-Cov () | Den () | Cov () | intra-Den () | intra-Cov () |
| CG-SC-labeled (Ours) | 1.083 | 0.816 | 0.848 | 0.711 | 1.097 | 0.823 | 0.976 | 0.771 | 1.029 | 0.817 | 0.992 | 0.803 |
| CG-SC-all (Ours) | 1.191 | 0.822 | 1.040 | 0.757 | 1.090 | 0.821 | 1.020 | 0.789 | 1.029 | 0.817 | 0.992 | 0.803 |
| CG | 1.047 | 0.815 | 0.743 | 0.670 | 1.004 | 0.806 | 0.812 | 0.715 | 0.979 | 0.812 | 0.878 | 0.769 |
| CG-JEM | 1.079 | 0.817 | 0.794 | 0.691 | 1.050 | 0.817 | 0.871 | 0.739 | 0.980 | 0.813 | 0.781 | 0.723 |
| CG-DLSM | 0.992 | 0.816 | 0.630 | 0.634 | 0.975 | 0.812 | 0.688 | 0.680 | 0.943 | 0.803 | 0.779 | 0.734 |
| CG-LS | 1.068 | 0.821 | 0.777 | 0.685 | 0.971 | 0.796 | 0.789 | 0.708 | 1.005 | 0.818 | 0.861 | 0.767 |
| CG-JR | 1.066 | 0.817 | 0.758 | 0.677 | 1.056 | 0.822 | 0.841 | 0.727 | 1.007 | 0.815 | 0.881 | 0.766 |
| Cond | 1.174 | 0.459 | 1.180 | 0.445 | 0.775 | 0.567 | 0.736 | 0.552 | 1.050 | 0.831 | 1.040 | 0.827 |
| CFG-labeled | 1.169 | 0.457 | 1.159 | 0.442 | 0.832 | 0.589 | 0.777 | 0.569 | 1.101 | 0.838 | 1.092 | 0.831 |
| CFG-all | 1.144 | 0.452 | 1.129 | 0.440 | 0.863 | 0.601 | 0.829 | 0.585 | 1.101 | 0.838 | 1.092 | 0.831 |
| 40% labeled data | 60% labeled data | 80% labeled data | ||||||||||
| Method | Den () | Cov () | intra-Den () | intra-Cov () | Den () | Cov () | intra-Den () | intra-Cov () | Den () | Cov () | intra-Den () | intra-Cov () |
| CG-SC-labeled (Ours) | 1.080 | 0.820 | 1.040 | 0.810 | 1.000 | 0.810 | 0.962 | 0.796 | 1.030 | 0.820 | 0.992 | 0.803 |
| CG-SC-all (Ours) | 1.070 | 0.820 | 1.030 | 0.804 | 1.000 | 0.810 | 0.947 | 0.795 | 1.030 | 0.820 | 0.992 | 0.803 |
| CG | 1.030 | 0.820 | 0.909 | 0.769 | 0.920 | 0.800 | 0.817 | 0.750 | 0.980 | 0.810 | 0.878 | 0.769 |
| CG-DLSM | 0.980 | 0.810 | 0.782 | 0.732 | 0.940 | 0.810 | 0.781 | 0.737 | 0.940 | 0.800 | 0.779 | 0.734 |
| CG-LS | 1.030 | 0.820 | 0.894 | 0.768 | 0.970 | 0.810 | 0.788 | 0.737 | 1.010 | 0.820 | 0.861 | 0.767 |
| CG-JR | 1.020 | 0.820 | 0.858 | 0.752 | 0.990 | 0.810 | 0.853 | 0.760 | 1.010 | 0.820 | 0.881 | 0.766 |
| Cond | 1.050 | 0.820 | 1.040 | 0.816 | 1.050 | 0.830 | 1.040 | 0.821 | 1.050 | 0.830 | 1.040 | 0.827 |
| CFG-labeled | 1.100 | 0.830 | 1.089 | 0.822 | 1.120 | 0.840 | 1.111 | 0.834 | 1.100 | 0.840 | 1.092 | 0.831 |
| CFG-all | 1.100 | 0.830 | 1.089 | 0.820 | 1.110 | 0.830 | 1.103 | 0.830 | 1.100 | 0.840 | 1.092 | 0.831 |
Table 2 presents the results, further confirming the observations made in Section 4.2. The CFSGMs consistently exhibit high generation accuracy but suffer from significant performance drops as the labeled data percentage decreases. Conversely, the CGSGMs maintain stable performance across various settings. Furthermore, our proposed CG-SC consistently outperforms other CG-based methodologies in terms of intra-FID and generation accuracy.
A.2 Evaluation of expected calibration error
Beyond the generative performance metrics, we present the Expected Calibration Error (ECE) to assess the calibration of classifiers regarding accurate probability estimation. ECE serves as a metric that evaluates the alignment of a classifier’s confidence with its prediction accuracy. The classifier’s confidence is defined as:
where is the classifier’s logits. We then divide the classifier’s predictions based on confidence into several buckets. The average absolute difference between the confidence and prediction accuracy is calculated for each bucket. Then, given a labeled test set , ECE is defined as:
where is the number of buckets, , is the averaged classification accuracy of , and is the averaged confidence of .
| Method | 5% | 20% | 40% | 60% | 80% | 100% |
|---|---|---|---|---|---|---|
| CG-SC-labeled (Ours) | 0.369 | 0.316 | 0.087 | 0.057 | 0.063 | 0.031 |
| CG-SC-all (Ours) | 0.210 | 0.243 | 0.102 | 0.109 | 0.111 | 0.031 |
| CG | 0.460 | 0.330 | 0.269 | 0.190 | 0.163 | 0.112 |
| CG-DLSM | 0.468 | 0.343 | 0.307 | 0.237 | 0.180 | 0.183 |
| CG-LS | 0.194 | 0.257 | 0.101 | 0.063 | 0.081 | 0.050 |
| CG-JR | 0.407 | 0.348 | 0.279 | 0.225 | 0.183 | 0.173 |
We follow the setup in Grathwohl et al. [4], setting for our calculations. The results are shown in Table 3, illustrating the ECE values for all CG-based methods across various percentages of labeled data. Our observations underscore that the self-calibration method consistently enhances classifier ECE in comparison to the vanilla CG and delivers the most superior ECE in most cases. This validates our claim that self-calibrated classifiers offer a more accurate probability estimation.
Appendix B More detailed introduction on score-based generative modeling through SDE
B.1 Learning the score function
When learning the score function, the goal is to choose the best function from a family of functions , such as deep learning models parameterized by , to approximate the score function of interest. Learning is based on data assumed to be sampled from . It has been shown that this can be achieved by optimizing the in-sample version of the following score-matching loss over :
where denotes the trace of a matrix and is the Hessian matrix of log-likelihood . Calculating the score-matching loss requires computation passes for , which makes the optimization process computationally prohibitive on high-dimensional data.
Several attempts [12, 20, 31, 27] have been made to address these computational challenges by approximating or transforming score matching into equivalent objectives. One current standard approach is called denoise score matching (DSM) [31], which instead learns the score function of a noise-perturbed data distribution . DSM typically assumes that comes from the original distribution injected with a pre-specified noise . It has been proved [31] that the score function can be learned by minimizing the in-sample version of
where is the score function of the noise distribution centered at . DSM is generally more efficient than the original score matching and is scalable to high-dimensional data as it replaces the heavy computation on the Hessian matrix with simple perturbations that can be efficiently computed from data.
B.2 Generation from the score function by diffusion
Assume that we seek to sample from some unknown target distribution , and the distribution can be diffused to a known prior distribution through a Markov chain that is described with a stochastic differential equation (SDE) [29]: , where the Markov chain is computed for using the drift function that describes the overall movement and the dispersion function that describes how the noise from a standard Wiener process enters the system.
To sample from , Song et al. [29] proposes to reverse the SDE from to , which turns out to operate with another SDE (Eq. 1). Given the score function , the diffusion process in Eq. 1 can then be used to take any data sampled from the known to a sample from the unknown .
The time-dependent score function can be learned by minimizing a time-generalized (in-sample) version of the DSM loss because the diffusion process can be viewed as one particular way of injecting noise. The extended DSM loss is defined as
where is selected uniformly between and , , , denotes the score function of , and is a weighting function that balances the loss of different timesteps.
Appendix C Training algorithm for semi-supervised self-calibrating classifier
Appendix D Additional experimental details
We followed NCSN++ [29] to implement the unconditional score estimation model. We also adapted the encoder part of NCSN++ as the classifier used in CGSGM [2] and its variants, e.g., CG-DLSM or the proposed CG-SC. For the sampling method, we used Predictor-Corrector (PC) samplers [29] with 1000 sampling steps. The SDE was selected as the VE-SDE framework proposed by Song et al. [29]. The hyper-parameter introduced in Eq. 8 is tuned between for fully-supervised settings, and selected to be in semi-supervised settings due to limited computational resources. The scaling factor introduced in Eq. 4 is tuned within to obtain the best intra-FID. A similar scaling factor for classifier-free SGMs is tuned within to obtain the best intra-FID. The balancing factors of the DLSM loss and the Jacobian regularization loss are selected to be and , respectively, as suggested in the original papers. The smoothing factor of label-smoothing is tuned between for the better intra-FID.
Appendix E Quantitative measurements of toy dataset
| Method | Gradient MSE () | Gradient CS () | Cond-Score CS () |
|---|---|---|---|
| CG | 8.7664 | 0.3265 | 0.9175 |
| CG + scaling | 8.1916 | 0.3348 | 0.9447 |
| CG-SC | 7.1558 | 0.5667 | 0.9454 |
| CG-SC + scaling | 5.6376 | 0.5758 | 0.9689 |
| CG-DLSM | 8.1183 | 0.4450 | 0.9316 |
| CG-DLSM + scaling | 8.0671 | 0.4450 | 0.9328 |
| CG-JEM | 8.5577 | 0.6422 | 0.9670 |
| CG-JEM + scaling | 8.5577 | 0.6429 | 0.9709 |
Table 4 shows the quantitative measurements of the methods on the toy dataset. First, we compared the gradients estimated by the classifiers with the ground truth by calculating the mean squared error (first column) and cosine similarity (second column). The results were calculated by averaging over all . We observe that after self-calibration, the mean squared error of the estimated gradients is lower; tuning the scaling factor further improves this to . This improvement after scaling implies that the direction of gradients better aligns with the ground truth, and scaling further reduces the mismatch between the magnitude of the classifier and the ground truth. In terms of cosine similarity, self-calibration grants the classifiers an improvement of . The numerical results agree with our previous observation that after self-calibration, classifiers better align with the ground truth in terms of both direction and magnitude.
Then, we add the unconditional score of the training data distribution to the classifier gradients to calculate the conditional scores and compare the results with the ground truth. The resulting classifiers estimate conditional scores with a cosine similarity of even without self-calibration. This shows that with a well-trained unconditional SGM—in this case, where we use the ground-truth unconditional score—CGSGM is able to produce conditional scores pointing in the correct directions in most cases. This explains why the original CGSGM generates samples with decent quality. After applying self-calibration loss and the scaling method, we further improve the cosine similarity to , which we believe enhances the quality of class-conditional generation.
Appendix F Classifier-only generation by interpreting classifiers as SGMs




In this section, we show the results when taking the score estimated by a classifier as an unconditional SGM. For unconditional generation, the classifier is used to estimate the unconditional score; for conditional generation, both terms in Eq. 2.2 are estimated by classifiers. In other words, the time-dependent unconditional score can be written as
| (9) |
where is the logits of the classifier. By adding the gradient of classifier to Eq. 9, we obtain the conditional score estimated by a classifier:
Here, the conditional score is essentially the gradient of the logits. Therefore, we sample from for unconditional generation and for conditional generation.
| Method | FID () | IS () | intra-FID () | Acc () |
|---|---|---|---|---|
| 7.54 | 8.93 | |||
| 7.26 | 8.93 | 18.86 | 0.890 |
Without self-calibration, both the vanilla classifier (Fig. 5(a)) and DLSM (Fig. 5(b)) are unable to generate meaningful images when interpreted as conditional SGMs; this also occurs for unconditional generation. This shows that without related regularization, the interpretation of classifiers as SGMs is not naturally learned through the classification task. After adopting self-calibration loss as regularization, Figures 5(c) and 5(d) show that not only does become a more accurate estimator of unconditional score through direct training, also becomes a better estimator of the conditional score as a side effect. Here, we also include the quantitative measurements of unconditional and conditional classifier-only generation in Table 5.
Appendix G Tuning the Scaling Factor for Classifier Guidance
This section includes the results when tuning the scaling factor for classifier guidance with and without self-calibration under the fully-supervised setting.

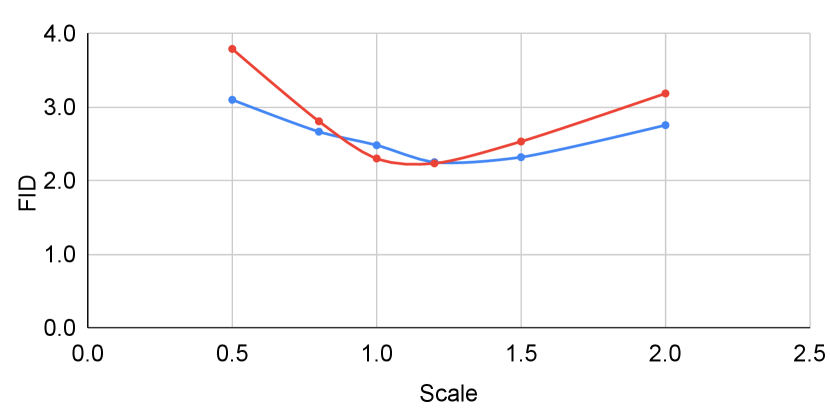
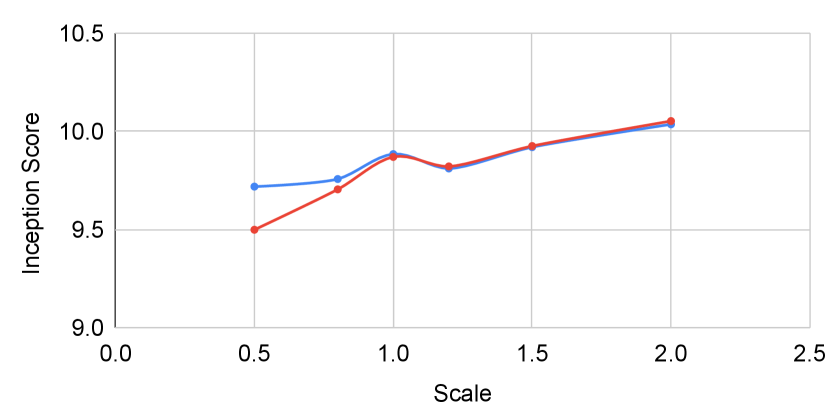
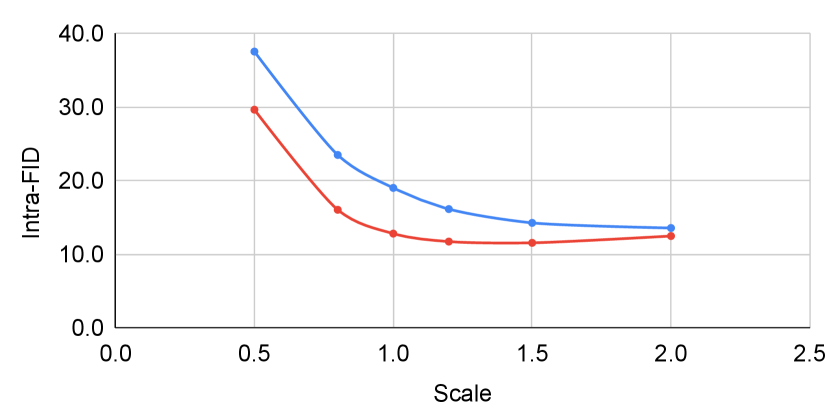
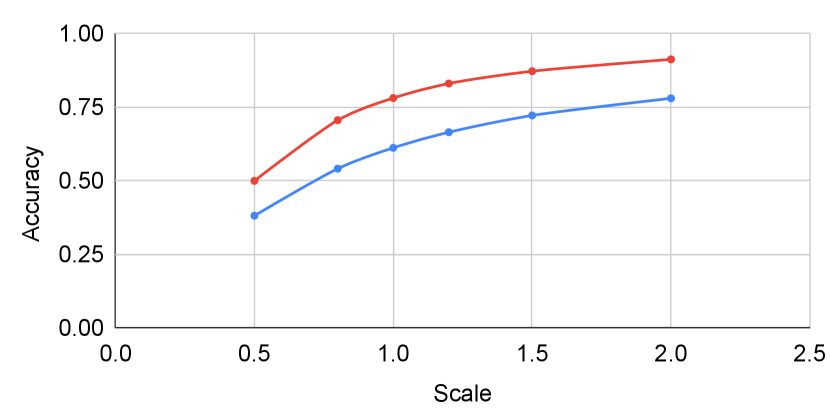
Figure 6 shows the result when tuning the scaling factor for classifier guidance. When tuning with and without self-calibration, self-calibration has little affect on unconditional performance. However, when evaluated with conditional metrics, the improvement after incorporating self-calibration becomes more significant. The improvement in intra-FID reaches whereas generation accuracy improves by as much as .
Appendix H Images generated by classifier guidance with and without self-calibration
This section includes images generated by classifier guidance with (first 6 images) and without (last 6 images) self-calibration after training on various percentages of labeled data. Each row corresponds to a class in the CIFAR-10 dataset. Generated images of all method can be found in the supplementary material.











