Score-based Diffusion Models with Self-supervised Learning for Accelerated 3D Multi-contrast Cardiac MR Imaging
Abstract
Long scan time significantly hinders the widespread applications of three-dimensional multi-contrast cardiac magnetic resonance (3D-MC-CMR) imaging. This study aims to accelerate 3D-MC-CMR acquisition by a novel method based on score-based diffusion models with self-supervised learning. Specifically, we first establish a mapping between the undersampled k-space measurements and the MR images, utilizing a self-supervised Bayesian reconstruction network. Secondly, we develop a joint score-based diffusion model on 3D-MC-CMR images to capture their inherent distribution. The 3D-MC-CMR images are finally reconstructed using the conditioned Langenvin Markov chain Monte Carlo sampling. This approach enables accurate reconstruction without fully sampled training data. Its performance was tested on the dataset acquired by a 3D joint myocardial and mapping sequence. The and maps were estimated via a dictionary matching method from the reconstructed images. Experimental results show that the proposed method outperforms traditional compressed sensing and existing self-supervised deep learning MRI reconstruction methods. It also achieves high quality and parametric maps close to the reference maps, even at a high acceleration rate of 14.
3D cardiac magnetic resonance imaging, self-supervised, diffusion models, multi-contrast
1 Introduction
Myocardial parameter mapping, including , , , and mapping, is an important technique in cardiovascular MR imaging (CMR). It enables the quantification of MR relaxation times, serving as biomarkers for a range of cardiac pathologies[1]. Previous studies have shown that inflammation, fibrosis, and amyloid deposition can lead to increased native values[2], while conditions like iron deposition or significant fat accumulation can result in decreased values[3]. Elevated has been observed in both acute and chronic myocardial infarction[4], as well as in nonischemic myocardial diseases, including dilated and hypertrophic cardiomyopathy[5]. In contemporary CMR, there is a growing emphasis on characterizing multiple relaxation times simultaneously through the acquisition of multi-contrast (MC) images. Examples include joint myocardial and mapping [6], cardiac MR fingerprinting (MRF)[7], and CMR multitasking[8]. and parameter maps provide complementary information about the myocardium, and combining these two maps may enhance diagnostic sensitivity and increase confidence in diagnosing suspected cardiomyopathy. Furthermore, 3D-CMR can provide information of whole-hearts relative to 2D imaging with limited coverage, but it suffers from the long scan time, especially for multi-parameter mapping [9]. Therefore, accelerated 3D multi-contrast imaging of CMR is highly desirable for practical use.
One major strategy to accelerate 3D-MC-CMR is undersampling the -space data and subsequently reconstructing images from this undersampled data using regularized techniques with hand-crafted priors. Various priors have been employed in 3D-MC-CMR reconstruction, such as subspace modeling[10], patch-based[11, 12], and tensor-based low-rankness [13]. These approaches can achieve high acceleration rates while maintaining high reconstruction quality. However, constructing priors is non-trivial, and the iterative nature of these methods leads to time-consuming computations. Deep learning (DL) has emerged as a successful tool in MR reconstruction, reducing computational complexity and enhancing reconstruction quality. However, most DL-based reconstruction methods rely on supervised learning that requires extensive fully sampled datasets for training. Acquiring high-quality, fully sampled -space data for 3D-MC-CMR is challenging due to the extreme long scan time. Heart rate fluctuations and respiratory variations during the prolonged scan time of the 3D-MC-CMR imaging can lead to misalignment of the cardiac phase and instability in respiratory motion correction. Despite the use of cardiac triggering and respiratory navigation, these instabilities may still result in scan failures or compromised image quality. Therefore, these supervised learning methods are unsuitable for accelerating 3D-MC-CMR.
To address this issue, self-supervised learning methods have been adopted. One strategy directly reconstructs images from the undersampled -space data by enforcing the data consistency using the physical model in the reconstruction [14, 15]. Another strategy is training the networks with a sub-sample of the undersampled -space data acquired. A notable example is the self-supervised learning via data undersampling (SSDU) method [16]. SSDU divides the measured data into two distinct subsets: one for use in the data consistency term of the network, and the other to compute the loss function. Consequently, network training can be completed using only undersampled data. Based on SSDU, the reference [17] introduces a dual-domain self-supervised (DDSS) method which trains the network in both -space and image domain and applies it in accelerated non-cartesian MRI reconstruction.
Recently, the score-based diffusion model [18, 19] has been applied to MR reconstruction and has shown promising results in reconstruction accuracy and generalization ability. It learns data distribution rather than end-to-end mapping using the network between undersampled -space data and images, and therefore is recognized as an unsupervised learning method for solving inverse problems of MR reconstruction. Specifically, it perturbs the MR data distribution to a tractable distribution (i.e. isotropic Gaussian distribution) by gradually injecting Gaussian noise, and one can train a neural network to estimate the gradient of the log data distribution (i.e. score function). Then the MR reconstruction can be accomplished by sampling from the data distribution conditioned on the acquired -space measurement. Although treated as an unsupervised technique [20], score-based reconstruction still needs amounts of high-quality training images to estimate the score function. The image collection is also challenging for 3D-MC-CMR. A simple and straightforward strategy to solve this issue is using the reconstruction results of traditional regularized or self-supervised learning methods as training samples. However, the residual reconstruction errors may lead to discrepancy in the data distribution of diffusion models. Previous studies have shown that Bayesian neural networks predict the target with uncertainty by training the networks with random weights, provide a more comprehensive sampling over the whole distribution and may avoid the discrepancy[21].
In this study, we sought to develop a self-supervised reconstruction method for 3D-MC-CMR using the score-based model with a Bayesian convolutional neural network (BCNN). Specifically, a self-supervised BCNN was developed based on the neural network driven by SPIRiT-POCS model [22]. Then the score-based model was trained by the samples over the network parameter distribution of BCNN. To better utilize the correlations among MC images, we used a joint probability distribution of MC data instead of the independent distribution in the original score-based model. The proposed method (referred to as ”SSJDM”) was tested using the data acquired by a 3D joint myocardial and mapping sequence based on the pulse sequence used for joint and mapping [6, 23]. In particular, the readout process was the same as that in [6, 23], except that the and preparation pulse was replaced by a spin-lock and inversion preparation pulse[24]. The SSJDM method outperformed the state-of-the-art methods, including regularized and self-supervised DL reconstructions, at a high acceleration rate (R) of up to 14. The obtained and values were also comparable with the reference values.
2 Related Work
2.1 Self-supervised Learning in MRI Reconstruction
Self-supervised learning leverages only the measurement data itself for training, without requiring the fully-sampled data. In MRI reconstruction, self-supervised learning has been a long-standing topic of interest. For example, the generalized autocalibrating partially parallel acquisition (GRAPPA) uses auto-calibration signal (ACS) data from the central region of -space to train linear interpolation kernels, which are applied to the measurement data itself to recover missing -space data[25]. With the development of deep learning, linear estimations of GRAPPA kernels are replaced by non-linear estimations using a scan-specific convolutional neural network (CNN)[26, 27]. This CNN is trained using ACS data without requiring external training databases, achieving more accurate interpolation. However, relying solely on ACS data for self-supervised training can result in the loss of high-frequency information. To enhance reconstruction performance, one effective approach is to integrate physical models into the network as regularizations during training. These models, such as coil sensitivity and MR relaxometry, enforce the network to be more consistent with the principles of MR imaging physics, thereby improving its performance [14, 15]. Another approach attempts to train networks by splitting the measurements into two disjoint sets, such as the SSDU [16] and DDSS methods [17]. Additionally, researchers have investigated the interpretability of self-supervised learning. Luo et al. developed a Hankel low-rank model-driven CNN by leveraging the convolutional relationship between structured low-rank Hankel matrices and null-space filters[28]. Moreover, Gan et al. proved the convergence of deep unfolding and provided theoretical guarantees for self-supervised learning[29].
2.2 Generative Models in MRI
2.2.1 Early Generative Models
Since 2000s, generative models, particularly Generative Adversarial Networks (GAN)[30], have achieved remarkable success and have produced high-quality results in several self-supervised MRI applications, such as reconstruction, image synthesis, denoising, segmentation, and super-resolution[31, 32, 33, 34, 35]. Another widely used model is the Variational Autoencoders (VAE)[36], which can also generate high-quality samples. However, the one-step encode-decode process of VAE often results in blurry images due to the lack of high-frequency information, while GAN, relying purely on data-driven generators, is prone to mode collapse. Therefore, both models show limited applications in MRI reconstruction.
2.2.2 Diffusion Generative models
In recent years, denoising diffusion probabilistic model (DDPM) has been proposed[37]. Compared to GAN and VAE, DDPM generates high-fidelity samples thanks to its gradual noise removal process and more stable training. Additionally, when the diffusion process is treated as continuous, transforming data into a noise distribution can be modeled with a continuous-time stochastic differential equation (SDE)[38]. By learning the data distribution through a score function and solving a reverse-time SDE, a score-based diffusion model is obtained.
2.2.3 Diffusion Models in MRI Reconstruction
Given the powerful generative capabilities of diffusion models, they have been rapidly adopted for MRI reconstruction. Specifically, in the inference phase of the model, the measurement data can be treated as a condition to guide the generation of high-quality MR images using the Bayesian formula. For example, Chung et al. integrated the MRI data consistency term into the reverse SDE decoding process, guiding generated images to satisfy data consistency[19]. Wu et al. addressed challenges of unstable score-based generative model training by integrating an adaptive wavelet sub-network, applying wavelet regularization to guide Langevin dynamics sampling [39]. This enables handling undersampled and noisy input data, significantly improving reconstruction performance. Güngöra et al. developed an unconditional diffusion prior for high-fidelity image generation and utilize this prior during inference to enhance both performance and reliability under domain shifts [40]. Mardani et al. introduced a variational approach using a rigorous maximum-likelihood framework that addresses the limitations of posterior score approximation in image reconstruction. They formulated the sampling process as a stochastic optimization problem, allowing the use of off-the-shelf optimizers for faster and more adjustable sampling [41].
Another way for diffusion model-based MRI reconstruction is refining the forward and reverse processes of the diffusion model based on the physical properties of MRI, aligning it more closely with the imaging physics of MRI. For example, Cao et al. observed that in MRI reconstruction, low frequency region of -space is often fully sampled, with reconstruction focusing on recovering missing high-frequency regions[42]. They proposed a high-frequency diffusion model, restricting the diffusion process to high-frequency space. Guan et al. further coupled multiple methods for extracting high-frequency signals, and proposed the correlated and multi-frequency diffusion model to enhance MRI reconstruction accuracy in highly undersampled images by combining high-frequency operators to form a multi-frequency prior, reducing noise and accelerating convergence[43]. Cui et al.incorporated physical priors from -space data to constrain diffusion models, achieving more controlled generation. By interpolating high-frequency (HF) -space data from low-frequency (LF) data and connecting this interpolation with the reverse heat diffusion process, they developed a model to generate missing HF data with improved accuracy[44].
2.2.4 Diffusion Models in Other MR Applications
Beyond MRI reconstruction, diffusion models have also shown impressive results in other MRI applications. Levac et al. used score-based models for joint image reconstruction and motion estimation with retrospectively sub-sampled data corrupted by simulated rigid motion[45]. Liu et al. proposed a -t self-consistency diffusion model for dynamic imaging by designing a SDE in line with -t self-consistency of the dynamic data[46]. Wang et al. implemented diffusion model for quantification in the brain, framing the estimation of quantitative maps as a conditional generation task[47].
2.3 Self-supervised Diffusion Models in MRI Reconstruction
Although diffusion models do not require paired training data, they still need fully-sampled high-quality images or -space data as training datasets, which can be difficult to obtain in some practical situations. Therefore, there is a growing interest in developing diffusion models that do not require fully sampled data for training. Korkmaz et al. proposed the self-supervised diffusion reconstruction (SSDiffRecon) method [32], which formulates the conditional diffusion process as an unrolled architecture, interleaving cross-attention transformers for reverse diffusion steps with data-consistency blocks for physics-driven processing. Unlike SSDiffRecon, the proposed SSJDM method introduces stochasticity through the BCNN network in the generated training data of the diffusion model to mitigate the effects of extreme generated data, thereby enhancing the overall robustness of network training. Additionally, while SSDiffRecon is designed just for single-contrast imaging, SSJDM enables multi-contrast imaging.
3 Material and Methods
3.1 Background
Suppose the MR image, denoted as , is a random sample from a distribution , i.e., . To sample from , we can use the Langevin Markov Chain Monte Carlo (MCMC) sampling method in practical use[48]. In accelerated MRI, only the undersampled -space data, denoted as , can be obtained and therefore accessing the distribution is challenging. Fortunately, we can assume the existence of a mapping from the measurements to the image , expressed as . represents a mapping parameterized by , where follows a distribution , i.e., , and denotes Gaussian noise. Statistically, can be approximated by a distribution through variational inference accomplished using BCNN. Then by substituting the learned into the mapping mentioned above, we can employ the score-matching technique to estimate the score of , i.e. the gradient of , allowing the implementation of Langevin MCMC sampling.
3.1.1 Bayesian Convolutional Neural Network
BCNN is a type of neural network that combines traditional CNN architectures with Bayesian methods for uncertainty estimation, belonging to stochastic artificial neural networks [21]. Specifically, it treats each weight parameter in CNNs as a random variable following a prior distribution, typically Gaussian distribution. BCNN learns the distributions of the weights, which can be used to quantify the uncertainty associated with the probabilistic predictions.
To design a BCNN, the first step is choosing a CNN as the functional model, with its weights represented as , and establishing a prior distribution for the model’s parameters, denoted as . This process can be formulated as follows:
| (1) |
where represents random noise with scale . Given the training data , we can estimate the posterior distribution of the model’s parameters by Bayesian inference. Since the true posterior is often intractable, an approximate distribution is obtained by minimizing the following the Kullback-Leibler divergence (KL-divergence) [49, 50]:
| (2) |
According to [51], can be represented as a Gaussian distribution for each individual weight as:
| (3) |
where , , . However, the minimization of the KL-divergence in (2) is still difficult to find for general distributions. Empirically, the prior distribution can be selected as a Gaussian distribution with zero mean and standard deviation . Then (2) can be computed as[52]:
| (4) | ||||
3.1.2 Score-based Diffusion Model
Diffusion models learn the implicit prior of the underlying data distribution by matching its score function (). This prior can be employed for reconstructing images from undersampled measurements through a forward measurement operator and detector noise. Let denote an unknown distribution containing samples that follow an independent and identically distributed pattern. Since calculating directly is challenging, the score function can be approximated by a neural network using the denoising score matching method [53]. Then the samples belonging to can be obtained via Langevin MCMC sampling according to the following formula:
| (5) |
where represents the step size, and .
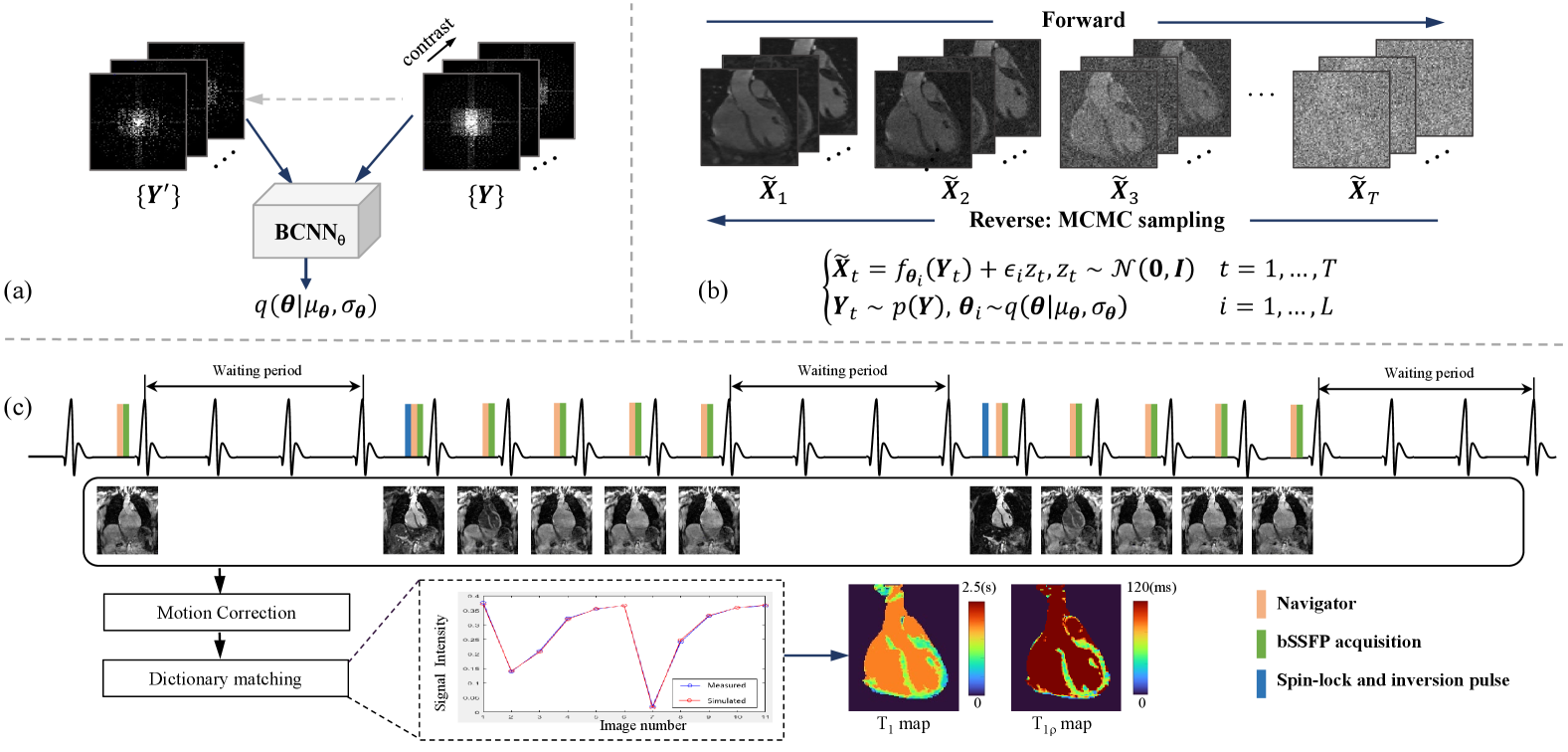
3.2 The Proposed Method
3.2.1 MRI Reconstruction Model
Let denote the multi-contrast image series to be reconstructed, where each () contains voxels. represents the number of contrasts. is the -space data, where is the measurement for each contrast image, and denotes the number of coils. The reconstruction model to recover from its undersampled measurements is typically defined as follows:
| (6) |
where represents the encoding operator given by , is the undersampling operator that undersamples -space data for each contrast image. is the Fourier transform operator, and denotes an operator which multiplies the coil sensitivity map with each contrast image coil-wise. is the Frobenius norm. denotes a combination of regularizations, and is the regularization weight. In conventional compressed sensing (CS) methods, in (6) denotes a combination of sparse[54], low-rank[12], or other-type of regularization functions. From a Bayesian perspective, can be considered as the prior model of the data, denoted as . Consequently, it’s reasonable to assume that a more precise estimation of this intricate prior data distribution would result in higher-quality samples.
Given that fully sampled is inaccessible, we are compelled to explore a label-free method for estimating . To achieve this, a mapping from to is firstly estimated, and then is approximated to characterize the correlation among the MC images.
3.2.2 Self-supervised Bayesian Reconstruction Network
Let and denote the undersampled -space data and the corresponding MR image, respectively. A secondary sub-sampling mask is applied to the measurements, resulting in . A BCNN can be trained using the sub-sampled data and the zero-filling image of to embody the representation with network parameter :
| (7) |
Then the established transformation is utilized to convert the measured to its corresponding image :
| (8) |
where and represent Gaussian noise with scales and . To train the BCNN, we first initialize the parameter from a normal Gaussian noise distribution , where denotes the -th element of . Subsequently, can be sampled through the reparameterization, i.e. . Assuming that the measurement noise follows Gaussian white noise, i.e., , and that the prior , the minimum of the KL divergence in (4) can be calculated by:
| (9) | ||||
where represents the number of training datasets.
3.2.3 MC Image Reconstruction via Score-based Model With Joint Distribution
Utilizing the above estimated , we can derive the distribution using the Bayesian equation:
| (10) |
Since evaluating the integral in (10) is computationally complex, we employ the score matching technique to approximate . The fundamental concept behind score matching [55] is to optimize the parameters of the score-matching network in such a way that closely matches the corresponding score of the true distribution, namely . The objective function to minimize is the expected squared error between these two, expressed as: . Importantly, this objective is equivalent to the following denoising score matching objective:
| (11) |
The fundamental concept here is that the gradient of the log density at different corrupted points should ideally guide us toward the clean sample . More precisely, we perturb by Gaussion noise with different scales which satisfies . Let , and the corrupted data distribution can be expressed as . It can be observed that when . We can estimate the scores of all corrupted data distributions . This is achieved by training the joint score function with the following objective:
| (12) |
After the score function is estimated, the Langevin MCMC sampling can be applied to reconstruct MC images via the following formula:
| (13) | ||||
where serves as the step size. The specific values of used in this study adhere to those outlined in[56], and the complete sampling procedure is shown in Algorithm 1.
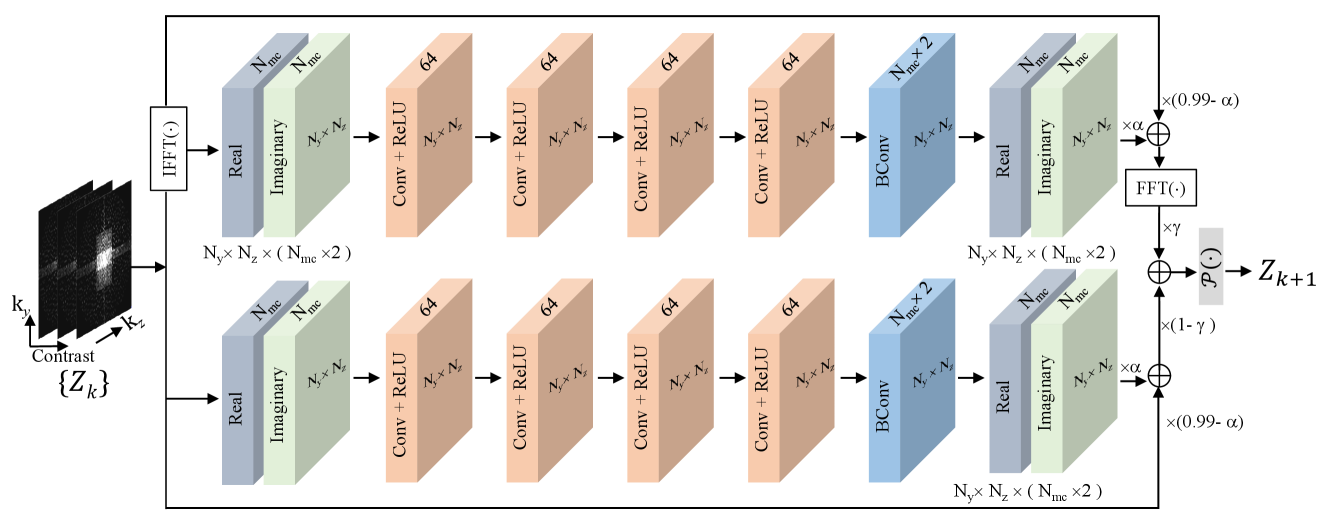
3.3 Implementation Details
Figure 1 illustrates the SSJDM framework. This framework comprises three main components: (a) the BCNN network, (b) the score matching network, and (c) the joint and mapping sequence and the parametric maps estimation procedure. Since the MRI data is complex, both real and imaginary components of the multi-contrast data are fed into the BCNN and the score matching networks. In this section, we focus on the implementation specifics of the BCNN and the score matching network[57].
The BCNN network comprises 10 blocks. Each block (as shown in Figure 2) consists of both an upper and a lower module. The upper module exploits redundancy in the image domain, while the lower module ensures inherent self-consistency in the -space. Each upper and lower module consists of four convolutional layers and a Bayesian convolutional layer, with each convolutional layer followed by a ReLU activation function. The final layer in both the upper and lower modules outputs the real and imaginary components of the multi-contrast data. To prevent gradient vanishing, we implemented a residual architecture in each module, using the paradigm of , [22], where represents the cascaded convolutional neural network part in each module. Notably, and the distribution of together form the BCNN.
We used NCSNv2 framework in [56] as the score matching network. The network input and output have channels. To establish the joint distribution, the MC images were reshaped so that the input data size of network is , where denotes the batch size, and denote the number of the partition and phase encoding lines, respectively.
4 Experiments
4.1 Data Acquisition
We implemented a 3D simultaneous cardiac and mapping sequence on a 3T MR scanner (uMR 790, United Imaging Healthcare, Shanghai, China). Figure 1(c) shows the timing diagram of the sequence, which closely resembles the one in [11] except the preparation module. Here, the preparation module used is a spin-lock and inversion pulse[24], which tips down the magnetization to the -z axis after the preparation. Then the acquired signals during magnetization recovery contain both and weightings. The sequence consists of three parts: (1) The first part acquires an image without the preparation module. (2) In the second part, the preparation module is applied with a spin-lock time (TSL) of 30 ms and an inversion time (TI) of 46 ms, followed by the acquisition of -space segments for 5 images. (3) The third part has the same procedure as the second one, except TSL = 60 ms and TI = 146 ms. At the end of each part, three heartbeats are skipped for magnetization recovery.
Images were acquired using bSSFP readout with ECG trigger and a 2D image navigator (iNAV) for respiratory motion correction [58, 11]. The iNAV was obtained using 14 ramp-up preparation pulses (duration = 46 ms) of the bSSFP in each heartbeat, which was used to correct translational motion caused by respiration before image reconstruction [11]. 51 volunteers were scanned using 12-channel cardiac and 48-channel spine coils. All cardiac channels were activated, while spine coil channels were manually selected based on the subject’s position. This led to a variation in the coil number utilized among subjects, ranging from 20 to 24. Imaging parameters were: field of view (FOV) = 300 × 300 × 96 , in-plane resolution = 1.7 × 1.7 , slice thickness = 1.7 mm, slice oversampling = 30%, TR/TE = 3.28/1.64 ms, segment number = 35, and 11 images was obtained for each acquisition.
Two 3D-MC-CMR datasets, namely the training and testing datasets, were acquired using the above sequence. The training dataset consists of prospectively undersampled -space data with R = 6 from 46 volunteers. The acquisition time for each data was approximately 18–19 minutes, depending on the volunteer’s heart rate. The testing dataset includes five prospectively undersampled -space data with R = 2.8, with an average acquisition time of 36.05 minutes. Each testing data was retrospectively undersampled at net acceleration rates of R = 6, 11, and 14, respectively. All undersampling masks used variable-density Poisson-disc sampling scheme, with 24 × 24 -space center fully sampled for coil sensitivity estimation.
Each 3D -space dataset was split into 2D slices along the frequency encoding direction by applying the inverse Fourier transform in that direction. The first 30 and last 20 slices were excluded due to the absence of coverage in the cardiac region. A total of 5,796 slices were used for training and 630 slices were used for testing, with 126 slices per subject. The coil sensitivity maps were estimated from the fully sampled -space center using ESPIRiT[59], with a kernel size of , as well as thresholds of 0.02 and 0.95 for calibration-matrix and eigenvalue decomposition.
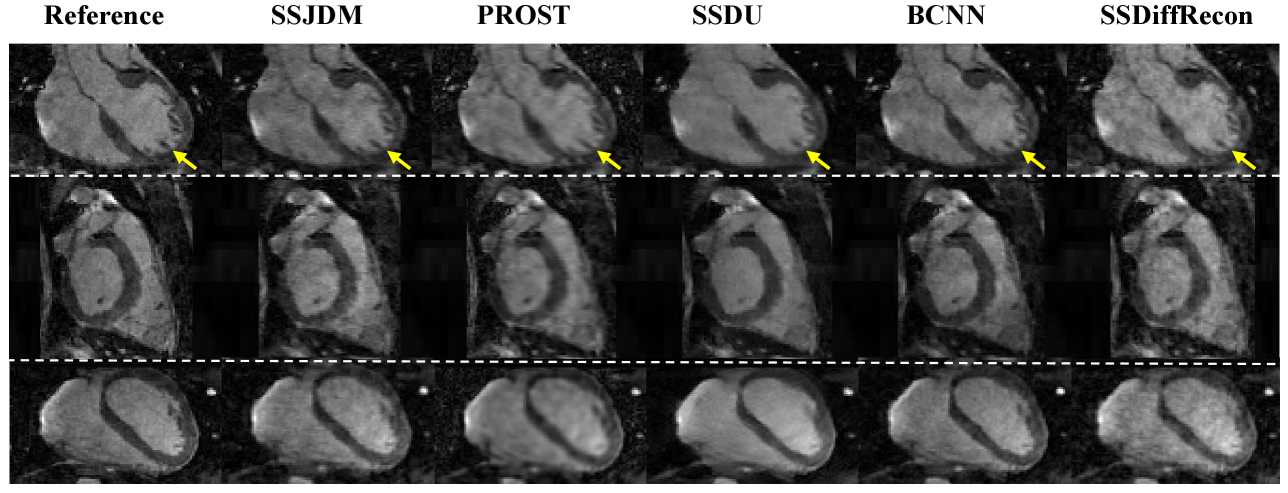
4.2 Reconstruction Experiments
To evaluate the proposed SSJDM method, it was applied to reconstruct the retrospectively undersampled testing data, followed by the estimation of and maps, as described later. The comparison methods include a traditional regularized reconstruction method (PROST[60]), a self-supervised DL method (SSDU [16]), BCNN, and a self-supervised reconstruction method with unrolled diffusion models (SSDiffRecon [61]). The images reconstructed from the testing data with R = 2.8, using an -wavelet regularized compressed sensing method implemented in the BART toolbox [62], served as the reference.
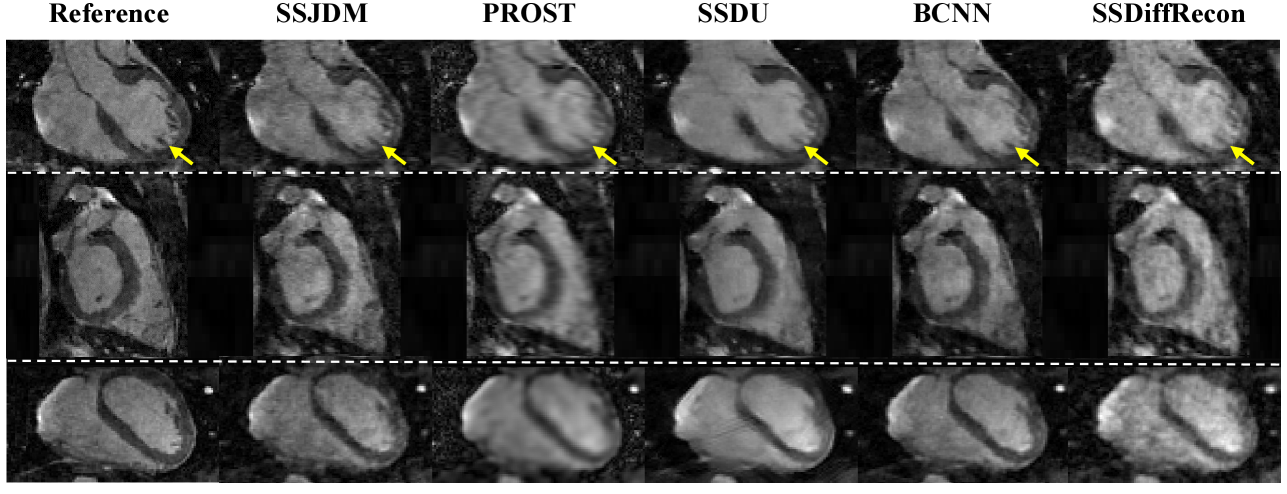
For SSJDM, the BCNN network was configured with = 0.5 and = 0.5. Following [16], we selected the subsampled mask using a variable density strategy based on Gaussian random weighting. The score matching network employed parameters , , L = 266, T = 4, and exponential moving averages (EMA) were enabled with an EMA rate of 0.999. Both networks were trained using the Adam optimizer, with a learning rate of , over 500 epochs, optimizing the respective loss functions in (9) and (12), with a batch size of 1. For the PROST method, the parameters included a conjugate gradient tolerance of , a maximum of 15 CG iterations, a penalty parameter = 0.08, regularization parameter for high-order singular value decomposition of 0.01, and a maximum of 10 alternating direction method of multipliers iterations. The SSDU methods employed a loss mask ratio of 0.4, and used the Adam optimizer with a learning rate of , and had a batch size of 1 during 100 epochs of training. The SSDiffRecon method employed a loss mask ratio of 0.95, and used the Adam optimizer with a learning rate of , and had a batch size of 1 during 2469K steps of training. SSJDM, SSDU, and SSDiffRecon experiments were conductesd using PyTorch 1.10, TensorFlow 2.10, and TensorFlow 1.14 in Python, respectively, on a workstation equipped with an Ubuntu 20.04 operating system, an Intel E5-2640V3 CPU (2.6 GHz, 256 GB memory), and an NVIDIA Tesla A100 GPU with CUDA 11.6 and CUDNN support. PROST reconstruction was implemented in MATLAB (R2021a, MathWorks, Natick, MA). Additionally, our reconstruction code for the proposed SSJDM is available at GitHub111https://github.com/YuanyuanLiuSIAT/SSJDM.
Two radiologists (6 and 4 years of CMR experience, respectively) independently scored the image quality in the reconstructed MC images based on a 5-point ordinal scale, focusing on image blurring, contrast, and clarity, as well as the clinical diagnostic value for cardiac diseases (1, Poor; 2, Fair; 3, Adequate; 4, Good; 5, Excellent.). Additionally, to evaluate the performance of SSJDM, four prospectively undersampled datasets with R = 11 and R = 14 were acquired from two other volunteers, with each volunteer contributing two datasets, one with R = 11 and another with R = 14.
4.3 and Estimation
and parametric maps were estimated using the dictionary matching method[63]. The dictionary was built by simulated MR signal evolutions generated via Bloch simulation with the imaging parameters as well as the predefined ranges of , , and values. Subject-specific dictionaries were simulated based on recorded R-R intervals and trigger delays for each scan. The dictionary for this study included 410550 atoms, covering combinations of in [50:20:700, 700:10:900, 900:5:1300, 1300:50:3000] ms, in [5:5:20, 20:0.5:60, 60:5:100, 100:10:300] ms[7], and in [40:0.5:50] ms[64, 65], with the notation [lower value: step size: upper value]. Image registration was employed to align the myocardial region in the MC images before dictionary matching. Subsequently, and maps were estimated using the pixel-wise dictionary matching.
4.4 Ablation Studies
We conducted three ablation studies to assess the impact of the BCNN network and the joint score-based model on reconstruction performance.
4.4.1 Ablation Study 1
To evaluate the impact of BCNN, we trained the score matching network using MC images reconstructed through conventional CS with total variance (TV) regularization[66].
4.4.2 Ablation Study 2
Similar to the first ablation study, we also trained the score matching network using images reconstructed with the SSDU network.
4.4.3 Ablation Study 3
To investigate the impact of the joint distribution in the score-based model, we employed a score-based model with the traditional independent distribution for reconstruction, and compared the results with SSJDM.
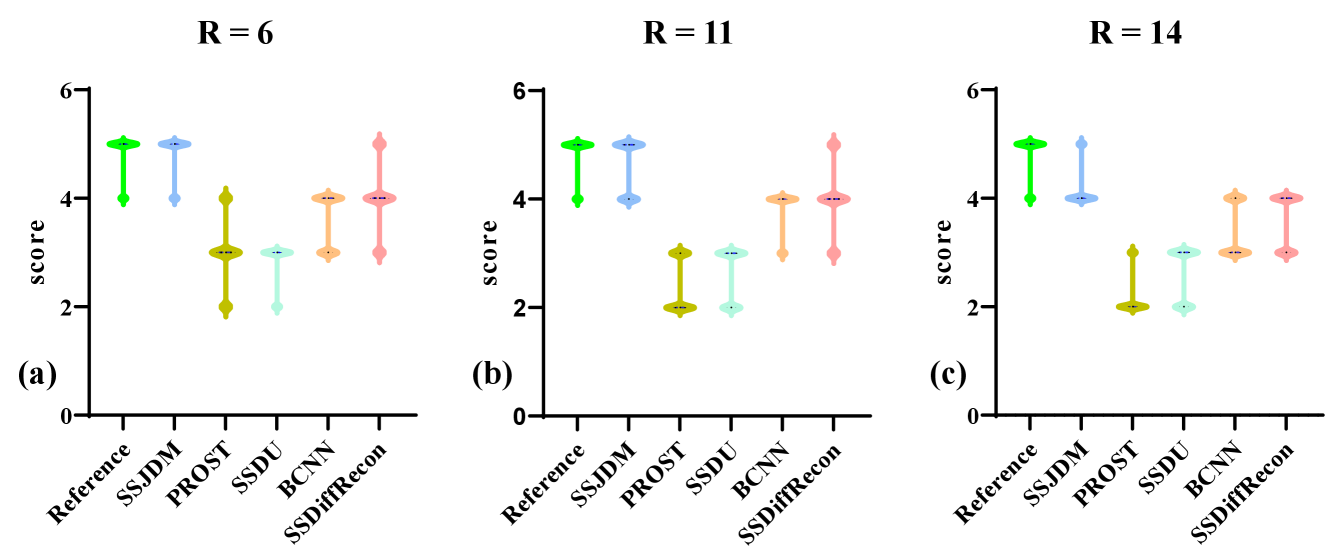
5 Results
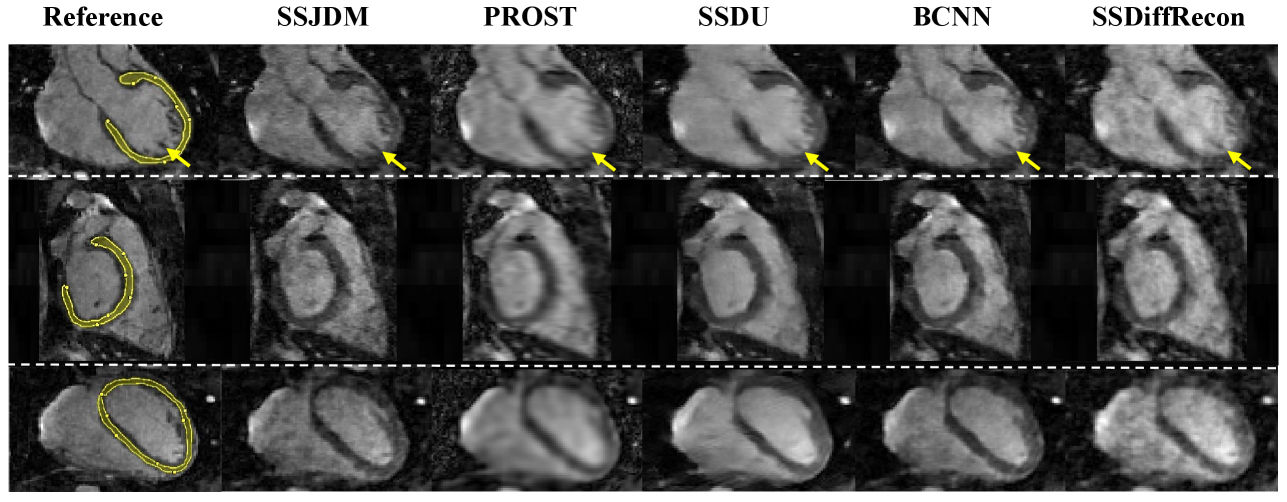
Figure 3 shows the first image after the preparation pulse with TSL = 30 ms and TI = 46 ms from one volunteer, reconstructed using the SSJDM, PROST, SSDU, BCNN, and SSDiffRecon methods at R = 6. To focus on the region of interest, the reconstruction images were cropped to display only the heart. Among the reconstructed results, the images of PROST exhibit noticeable blurring. The rest four methods successfully reconstructed images at this acceleration rate, while the images of SSJDM show sharper papillary muscles than those of SSDU, BCNN, and SSDiffRecon (indicated by the yellow arrows). Figure 4 shows the reconstructed results using the five methods at R = 11. Blurring artifacts of PROST become noticeable in scenarios with higher acceleration rates. BCNN and SSDiffRecon preserve more detailed information than SSDU, notably in the reconstructed papillary muscle area (indicated by the yellow arrows), since both methods improved SSDU by capturing data distribution for model training [21]. Images of SSJDM still exhibit sharp boundaries and high texture fidelity, highlighting the superior performance of score-based reconstruction methods in restoring image details. At an even higher acceleration rate of R = 14 (shown in Figure 5), the image quality of SSJDM degrades a little, while other methods exhibit severe blurring artifacts. Table 1 shows the average PSNR, SSIM, and RMSE values for all reconstructed images. The proposed SSJDM method qualitatively achieves the best performance among the five methods across all acceleration factors. Figure 6 shows the violin plots of the scores for the image quality evaluation study. For all acceleration rates, SSJDM gets the highest scores compared to the other four methods in terms of the blurring and overall image quality.
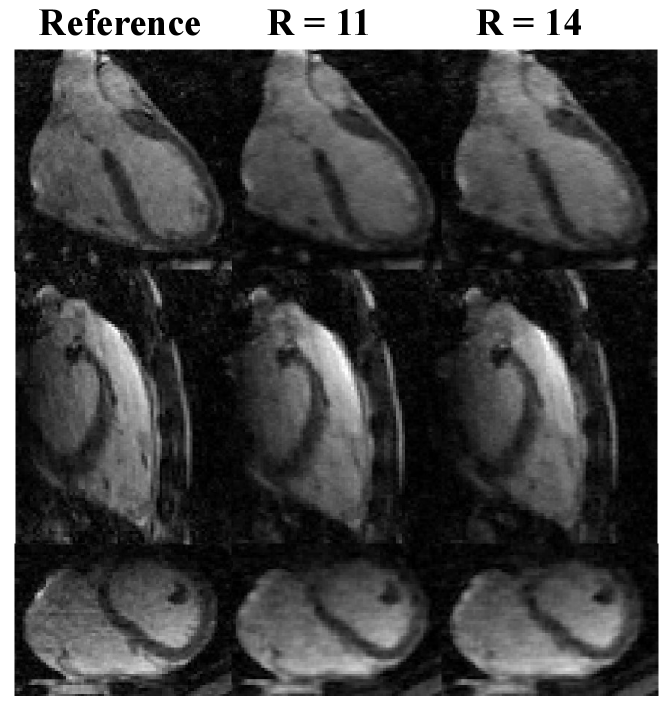
Figure 7 shows reconstructed images using SSJDM from the prospectively undersampled datasets at R = 11 and 14, which further confirms the effectiveness of the proposed SSJDM method for 3D-MC-CMR reconstruction.
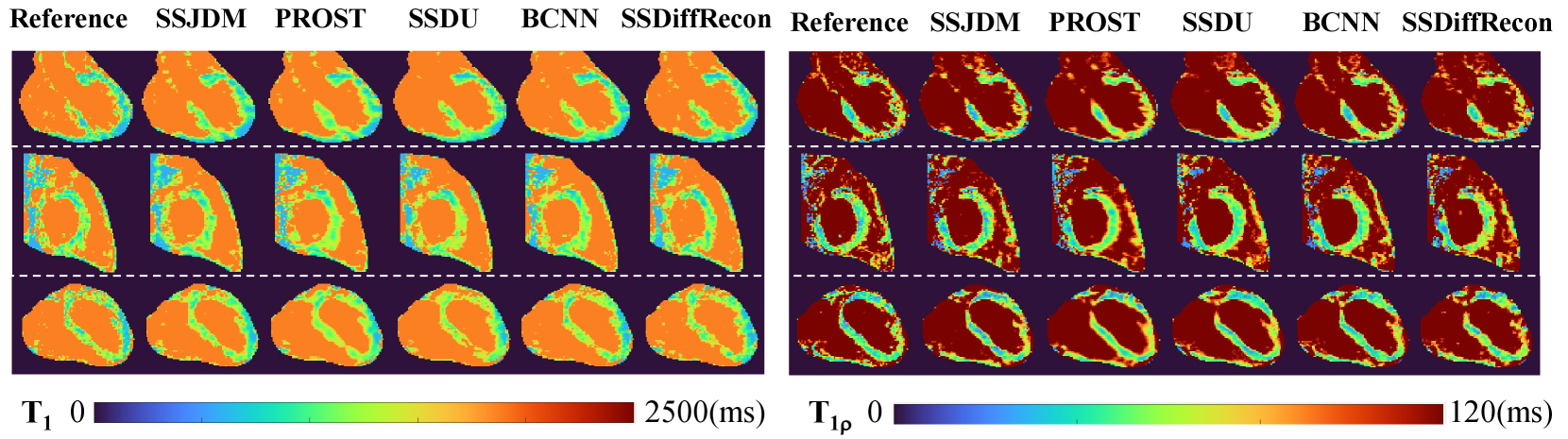
Figure 8 shows the and maps estimated from reconstructions using different methods at R = 11. Similar conclusions can be drawn from the estimated maps as those from the reconstructed MC images at the same acceleration rate shown in Figure 4. Table 2 shows the mean and standard deviation of , values using different methods in manually drawn myocardium regions at different acceleration rates and the reference values. The and values estimated from the SSJDM reconstructions are consistent with the reference values.
| Metrics | PSNR | SSIM | RMSE | |
| 6 | SSJDM | 29.659 1.056 | 0.933 0.002 | 0.033 0.004 |
| PROST | 27.096 1.575 | 0.910 0.004 | 0.044 0.007 | |
| SSDU | 27.533 2.163 | 0.917 0.004 | 0.042 0.011 | |
| BCNN | 28.273 1.824 | 0.922 0.005 | 0.037 0.010 | |
| SSDiffRecon | 27.046 1.995 | 0.921 0.009 | 0.044 0.018 | |
| 11 | SSJDM | 28.049 1.039 | 0.916 0.003 | 0.039 0.004 |
| PROST | 22.350 2.044 | 0.879 0.004 | 0.076 0.014 | |
| SSDU | 24.356 1.917 | 0.887 0.005 | 0.064 0.017 | |
| BCNN | 27.220 1.283 | 0.907 0.005 | 0.049 0.001 | |
| SSDiffRecon | 25.485 0.993 | 0.902 0.006 | 0.053 0.016 | |
| 14 | SSJDM | 27.994 0.598 | 0.910 0.002 | 0.040 0.003 |
| PROST | 21.640 1.485 | 0.868 0.002 | 0.083 0.010 | |
| SSDU | 22.694 1.213 | 0.874 0.003 | 0.080 0.013 | |
| BCNN | 25.161 1.005 | 0.891 0.003 | 0.055 0.007 | |
| SSDiffRecon | 23.861 0.510 | 0.887 0.005 | 0.066 0.006 |
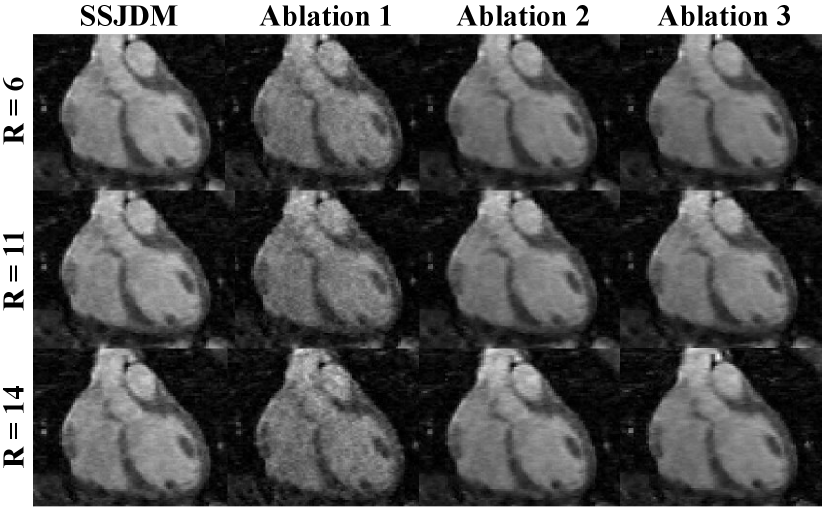
Figure 9 shows reconstructed images at R = 6, 11, and 14 using SSJDM and the methods from three ablation studies. Ablation 1 exhibits severe noise, attributed to the training data originating from conventional CS, which is prone to substantial noise amplification at higher acceleration rates[16]. Although noise is effectively mitigated by substituting the input data with reconstructions from the SSDU method, the resulting images (referred to as ”Ablation 2”) still display blurriness, especially at higher acceleration rates, such as R = 14. Images reconstructed using the independent distribution (referred to as ”Ablation 3”) exhibit slight blurring compared to SSJDM, indicating an enhanced reconstruction quality with the joint distribution.
| Reference | AF | R = 6 | R = 11 | R = 14 |
| (1037.827.1) | SSJDM | 1041.5 25.3 | 1044.0 31.4 | 1046.9 31.7 |
| PROST | 1007.6 29.8 | 1002.1 34.9 | 1000.9 36.8 | |
| SSDU | 1016.1 29.4 | 1007.6 34.1 | 1004.6 35.7 | |
| BCNN | 1024.0 25.8 | 1021.3 34.6 | 1020.0 35.4 | |
| SSDiffRecon | 1022.6 26.0 | 1020.3 35.1 | 1013.7 35.9 | |
| (56.1 3.2) | SSJDM | 56.8 4.2 | 55.2 5.1 | 54.9 5.9 |
| PROST | 59.0 4.3 | 60.0 6.0 | 63.3 7.0 | |
| SSDU | 53.6 5.0 | 52.8 5.7 | 52.5 6.1 | |
| BCNN | 57.2 4.9 | 58.5 5.6 | 59.0 6.0 | |
| SSDiffRecon | 62.1 4.9 | 59.9 5.9 | 60.5 6.5 |
6 Discussion
In this study, we proposed the SSJDM method, which utilizes a self-supervised BCNN to train the score-based model without the need for high-quality training data. This approach enabled the successful reconstruction of MC images from highly undersampled -space data. We have shown that our method can mitigate the discrepancy between the output of single-model-based methods (i.e., CS-based or generally deterministic networks-based methods) and actual data, since this method considers the stochastic nature of parameters in the reconstruction model. This enhancement leads to improved image quality of the score-based model, resulting in superior performance compared to self-supervised SSDU and BCNN approaches. The SSJDM method demonstrated favorable reconstructions in 3D cardiac imaging. It allowed for the simultaneous estimation of and parametric maps in a single scan. Moreover, the estimated and parameter values exhibited a strong consistency with those obtained from conventional 2D imaging.
Acquiring high-quality training samples is super challenging in MRI, especially in 3D cardiac imaging. The fully sampled acquisition for the 3D-MC-CMR imaging sequence in this study would be over 2 hours. This prolonged scan duration could easily induce subject motion, leading to motion artifacts. Therefore, conventional supervised reconstruction techniques are no longer suitable for such scenarios. Unsupervised learning-based imaging techniques, including self-supervised, untrained, and unpaired learning approaches, may provide an alternative to tackle this challenge. Untrained imaging methods, such as traditional CS-based methods [54], untrained neural network-based methods like deep image prior (DIP)[67], and -space interpolation with untrained neural network (K-UNN)[68], do not rely on training data and have exhibited remarkable performance. However, CS-based methods have computationally intensive processes, and optimizing the regularization parameters is non-trivial. Untrained neural network-based methods rely on the neural network structure for implicit regularization and face challenges in selecting an appropriate regularization parameter and early stopping condition when fitting the network to the given undersampled measurement. Unpaired deep learning approaches based on generative models, such as variational autoencoders[36], generative adversarial networks[69], normalizing flows[70], and the original diffusion model[37], have been introduced for MR image reconstruction. The related networks are typically trained without paired label data. However, the training process for these approaches still requires fully sampled datasets, making them different from our study and unsuitable to our application scenario. Therefore, we undertake the reconstruction of 3D-MC-CMR images in a self-supervised learning manner.
In ablation studies, we observed a degradation in reconstruction quality when training the score matching network with images reconstructed through conventional CS method. As mentioned in previous literatures, higher factors can lead to degradation in CS reconstructions, which in turn impact the performance of the trained score matching network. Employing training datasets generated by a more effective method, such as the SSUD method, can improve the reconstruction performance of the score matching network. However, the improvement is restricted because the SSDU method learns the transportation mapping with deterministic weights. Either CS or SSDU approach entails the use of a single model or a network with fixed parameters to reconstruct training samples for the score matching network. However, these approaches may fall short in adequately capturing the diversity inherent in real data. The BCNN provides a natural approach to quantify uncertainty in deep learning[21], i.e., leveraging a set of models or parameters to comprehensively represent the diversity within real data can effectively serve the purpose of ensemble learning. In this study, the proposed SSJDM method learns the transportation mapping built on the framework of Bayesian neural network with the weights treated as random variables following a certain probability distribution. In contrast, in ablation studies 1 and 2, the input data correspond to a learned transportation mapping with deterministic weights. Consequently, this self-supervised BCNN training seems to enhance the network’s generalization capacity, and this learning strategy holds potential for further improving the reconstruction performance.
This study extends our prior self-supervised research presented in [71] (referred to as ”Self-score”) from an application-oriented standpoint, given the absence of fully-sampled acquisitions in 3D-MC-CMR imaging. The SSJDM method differs from the Self-score approach by capturing the joint distribution of MC images in training the score-based model, while the Self-score method trained the model with an independent distribution. The SSJDM method achieves enhanced reconstructions, as demonstrated in the ablation study. The proposed reconstruction framework also demonstrates excellent performance in practical applications.
| Methods | Parameters | Training time (h) | Inference time (s) |
| SSJDM (GPU) | 59475756 | 250.02 | 3010.38 |
| PROST (CPU) | / | / | 16719.04 |
| SSDU (GPU) | 592129 | 132.72 | 939.32 |
| BCNN (GPU) | 29737878 | 127.35 | 1513.96 |
| SSDiffRecon (GPU) | 732570 | 140.45 | 945.01 |
There are several limitations in this study. First, the inference time is relatively long. As shown in Table 3, the training and average inference times, and number of model parameters are provided for all comparison methods. The SSJDM method consumes much longer inference time than end-to-end DL-based reconstruction methods. This limitation arises from a common drawback of score-based generative models, which require large sampling steps of the learned diffusion process to achieve the desired accuracy. Specifically, the SSJDM method captures correlations between multi-contrast images through joint distribution modeling, whereas some existing diffusion-based methods employ low-rank constraints that rely on singular value decomposition (SVD), making them more time-consuming. Consequently, SSJDM shows improved computational efficiency relative to these diffusion models with low-rank constraint. To reduce inference time, various sampling acceleration strategies have been proposed, such as consistency models[72], ordinary differential equation solver[73], demonstrating that similar results can be obtained in fewer than ten steps. However, most of their performance has not yet been evaluated in MR reconstruction. We aim to explore these sampling-acceleration strategies in our future work to reduce the inference time of the SSJDM method, making it more suitable for clinical use. Secondly, dictionary-matching for and estimation is another time-consuming procedure, depending on dictionary size and pixel count. Techniques, like dictionary compression[74] and DL network for direct mapping[75, 76], offer potential solutions to address this challenge. As this study focuses on reconstructing 3D CMR images, we’ll investigate the fast parameter estimation method in the future.
7 CONCLUSIONS
This work shows the feasibility of score-based models for reconstructing 3D-MC-CMR images from highly undersampled data in simultaneous whole-heart and mapping. The proposed method is trained in a self-supervised manner and therefore particularly suited for 3D CMR imaging that lacks fully sampled data. Experimental results showed that this method could achieve a high acceleration rate of up to 14 in simultaneous 3D whole-heart and mapping.
Supplementary Information
7.1 Motion Correction
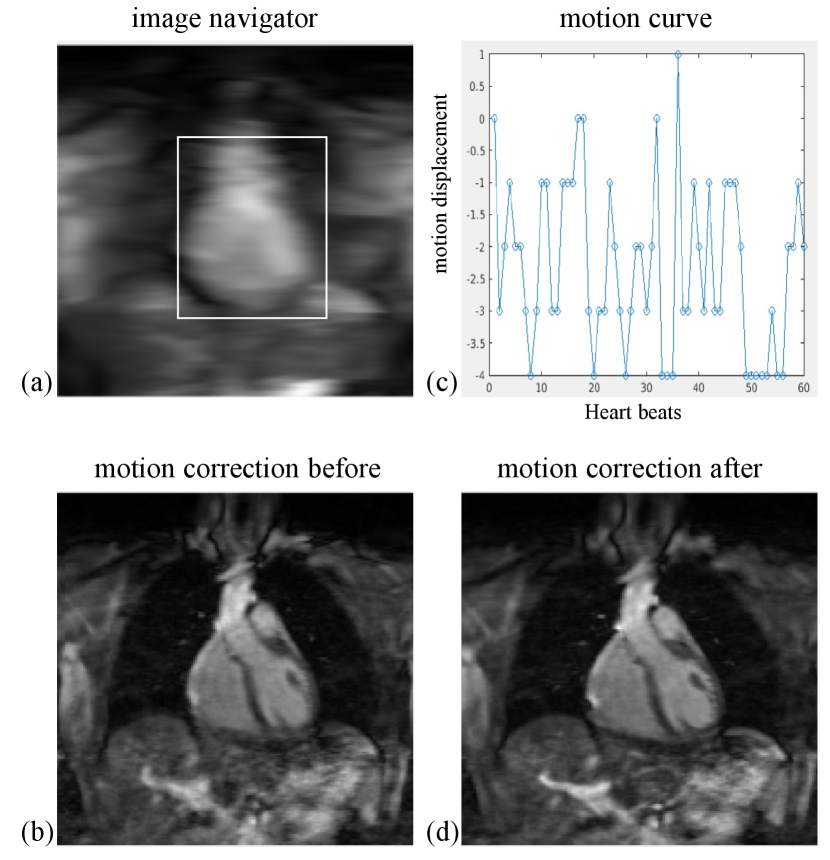
The respiratory motion correction process consists of three main steps: 1. Image Acquisition: 2D image navigators (iNAVs) [58] are acquired prior to each volume by spatially encoding the 14 ramp-up pulses of the bSSFP readout in each heartbeat. These iNAVs are low-resolution 2D images in the coronal plane, as shown in Figure S1(a). 2. Motion Estimation: The 2D translational motion, including foot-head (FH) and left-right (LR) directions, is estimated using a template-matching algorithm. A template (indicated by the white rectangle in S1(a)) is manually selected around the heart, and FH and LR beat-to-beat translations are calculated using a mutual information similarity measure. An example of an estimated FH motion curve for an MC image is provided in Figure S1 (b). 3. Motion Correction: Motion correction is applied by modulating the k-space data with a linear phase shift to align it with a reference position at end-expiration. Zero-filling reconstructions of the undersampled 3D-MC-CMR datasets before and after motion correction are shown in Figures S1(c) and S1(d), respectively.
References
- [1] S. Rao, S. Y. Tseng, A. Pednekar, S. Siddiqui, M. Kocaoglu, M. Fares, S. M. Lang, S. Kutty, A. B. Christopher, L. J. Olivieri et al., “Myocardial parametric mapping by cardiac magnetic resonance imaging in pediatric cardiology and congenital heart disease,” Circ. Cardiovas. Imag., vol. 15, no. 1, p. e012242, 2022.
- [2] P. Haaf, P. Garg, D. R. Messroghli, D. A. Broadbent, J. P. Greenwood, and S. Plein, “Cardiac mapping and extracellular volume (ECV) in clinical practice: a comprehensive review,” J. Cardiovasc. Magn. Reson., vol. 18, no. 1, p. 89, 2016.
- [3] A. Meloni, N. Martini, V. Positano, A. De Luca, L. Pistoia, S. Sbragi, A. Spasiano, T. Casini, P. P. Bitti, M. Allò et al., “Myocardial iron overload by cardiovascular magnetic resonance native segmental mapping: a sensitive approach that correlates with cardiac complications,” J. Cardiovasc. Magn. Reson., vol. 23, no. 1, p. 70, 2021.
- [4] A. Bustin, W. R. Witschey, R. B. van Heeswijk, H. Cochet, and M. Stuber, “Magnetic resonance myocardial mapping: Technical overview, challenges, emerging developments, and clinical applications,” J. Cardiovasc. Magn. Reson., vol. 25, no. 1, p. 34, 2023.
- [5] E. W. Thompson, S. Kamesh Iyer, M. P. Solomon, Z. Li, Q. Zhang, S. Piechnik, K. Werys, S. Swago, B. F. Moon, Z. B. Rodgers et al., “Endogenous cardiovascular magnetic resonance in hypertrophic cardiomyopathy,” J. Cardiovasc. Magn. Reson., vol. 23, p. 120, 2021.
- [6] M. Akçakaya, S. Weingärtner, T. A. Basha, S. Roujol, S. Bellm, and R. Nezafat, “Joint myocardial and mapping using a combination of saturation recovery and -preparation,” Magn. Reson. Med., vol. 76, no. 3, pp. 888–896, 2016.
- [7] C. Velasco, G. Cruz, B. Lavin, A. Hua, A. Fotaki, R. M. Botnar, and C. Prieto, “Simultaneous , , and cardiac magnetic resonance fingerprinting for contrast agent–free myocardial tissue characterization,” Magn. Reson. Med., vol. 87, no. 4, pp. 1992–2002, 2022.
- [8] A. G. Christodoulou, J. L. Shaw, C. Nguyen, Q. Yang, Y. Xie, N. Wang, and D. Li, “Magnetic resonance multitasking for motion-resolved quantitative cardiovascular imaging,” Nat. Biomed. Eng., vol. 2, no. 4, pp. 215–226, 2018.
- [9] G. Cruz, O. Jaubert, H. Qi, A. Bustin, G. Milotta, T. Schneider, P. Koken, M. Doneva, R. M. Botnar, and C. Prieto, “3D free-breathing cardiac magnetic resonance fingerprinting,” NMR Biomed., vol. 33, no. 10, p. e4370, 2020.
- [10] B. Zhao, W. Lu, T. K. Hitchens, F. Lam, C. Ho, and Z.-P. Liang, “Accelerated MR parameter mapping with low-rank and sparsity constraints,” Magn. Reson. Med., vol. 74, no. 2, pp. 489–498, 2015.
- [11] G. Milotta, G. Ginami, A. Bustin, R. Neji, C. Prieto, and R. M. Botnar, “3D whole-heart free-breathing qBOOST- mapping,” Magn. Reson. Med., vol. 83, no. 5, pp. 1673–1687, 2020.
- [12] T. Zhang, J. M. Pauly, and I. R. Levesque, “Accelerating parameter mapping with a locally low rank constraint,” Magn. Reson. Med., vol. 73, no. 2, pp. 655–661, 2015.
- [13] A. Phair, G. Cruz, H. Qi, R. M. Botnar, and C. Prieto, “Free-running 3D whole-heart and mapping and cine MRI using low-rank reconstruction with non-rigid cardiac motion correction,” Magn. Reson. Med., vol. 89, no. 1, pp. 217–232, 2023.
- [14] E. Martín-González, E. Alskaf, A. Chiribiri, P. Casaseca-de-la Higuera, C. Alberola-López, R. G. Nunes, and T. Correia, “Physics-informed self-supervised deep learning reconstruction for accelerated first-pass perfusion cardiac MRI,” in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent. Workshop. Springer, 2021, pp. 86–95.
- [15] F. Liu, R. Kijowski, G. El Fakhri, and L. Feng, “Magnetic resonance parameter mapping using model-guided self-supervised deep learning,” Magn. Reson. Med., vol. 85, no. 6, pp. 3211–3226, 2021.
- [16] B. Yaman, S. A. H. Hosseini, S. Moeller, J. Ellermann, K. Uğurbil, and M. Akçakaya, “Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data,” Magn. Reson. Med., vol. 84, no. 6, pp. 3172–3191, 2020.
- [17] B. Zhou, J. Schlemper, N. Dey, S. S. M. Salehi, K. Sheth, C. Liu, J. S. Duncan, and M. Sofka, “Dual-domain self-supervised learning for accelerated non-cartesian MRI reconstruction,” Med. Image Anal., vol. 81, p. 102538, 2022.
- [18] Y. Song, C. Durkan, I. Murray, and S. Ermon, “Maximum likelihood training of score-based diffusion models,” in Proc. Int. Conf. Neural Inf. Process. Syst., vol. 34, 2021, pp. 1415–1428.
- [19] H. Chung and J. C. Ye, “Score-based diffusion models for accelerated MRI,” Med. Image Anal., vol. 80, p. 102479, 2022.
- [20] Y. Song, L. Shen, L. Xing, and S. Ermon, “Solving inverse problems in medical imaging with score-based generative models,” in Proc. Int. Conf. Learn. Represent., 2022.
- [21] L. V. Jospin, H. Laga, F. Boussaid, W. Buntine, and M. Bennamoun, “Hands-on bayesian neural networks—a tutorial for deep learning users,” IEEE Comput. Intell. M., vol. 17, no. 2, pp. 29–48, 2022.
- [22] Z.-X. Cui, S. Jia, J. Cheng, Q. Zhu, Y. Liu, K. Zhao, Z. Ke, W. Huang, H. Wang, Y. Zhu et al., “Equilibrated zeroth-order unrolled deep network for parallel MR imaging,” IEEE Trans. Med. Imag., vol. 42, pp. 3540–3554, 2023.
- [23] M. Henningsson, “Cartesian dictionary-based native and mapping of the myocardium,” Magn. Reson. Med., vol. 87, no. 5, pp. 2347–2362, 2022.
- [24] Y. Yang, C. Wang, Y. Liu, Z. Chen, X. Liu, H. Zheng, D. Liang, and Y. Zhu, “A robust adiabatic constant amplitude spin-lock preparation module for myocardial quantification at 3 T,” NMR Biomed., vol. 36, no. 2, p. e4830, 2023.
- [25] M. A. Griswold, P. M. Jakob, R. M. Heidemann, M. Nittka, V. Jellus, J. Wang, B. Kiefer, and A. Haase, “Generalized autocalibrating partially parallel acquisitions (GRAPPA),” Magn. Reson. Med., vol. 47, no. 6, pp. 1202–1210, 2002.
- [26] M. Akçakaya, S. Moeller, S. Weingärtner, and K. Uğurbil, “Scan-specific robust artificial-neural-networks for k-space interpolation (RAKI) reconstruction: database-free deep learning for fast imaging,” Magn. Reson. Med., vol. 81, no. 1, pp. 439–453, 2019.
- [27] T. H. Kim, P. Garg, and J. P. Haldar, “LORAKI: Autocalibrated recurrent neural networks for autoregressive MRI reconstruction in k-space,” arXiv preprint arXiv:1904.09390, 2019.
- [28] C. Luo, H. Wang, T. Xie, Q. Jin, G. Chen, Z.-X. Cui, and D. Liang, “Matrix completion-informed deep unfolded equilibrium models for self-supervised k-space interpolation in MRI,” arXiv preprint arXiv:2309.13571, 2023.
- [29] W. Gan, C. Ying, P. E. Boroojeni, T. Wang, C. Eldeniz, Y. Hu, J. Liu, Y. Chen, H. An, and U. S. Kamilov, “Self-supervised deep equilibrium models with theoretical guarantees and applications to MRI reconstruction,” IEEE Trans. Comput. Imag., 2023.
- [30] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” Proc. Int. Conf. Neural Inf. Process. Syst., vol. 27, 2014.
- [31] E. K. Cole, J. M. Pauly, S. S. Vasanawala, and F. Ong, “Unsupervised MRI reconstruction with generative adversarial networks,” arXiv:2008.13065, 2020.
- [32] Y. Korkmaz, S. U. Dar, M. Yurt, M. Özbey, and T. Cukur, “Unsupervised MRI reconstruction via zero-shot learned adversarial transformers,” IEEE Trans. Med. Imag., vol. 41, no. 7, pp. 1747–1763, 2022.
- [33] M. Yurt, O. Dalmaz, S. Dar, M. Ozbey, B. Tınaz, K. Oguz, and T. Çukur, “Semi-supervised learning of MRI synthesis without fully-sampled ground truths,” IEEE Trans. Med. Imag., vol. 41, no. 12, pp. 3895–3906, 2022.
- [34] J. Zhang, S. Zhang, X. Shen, T. Lukasiewicz, and Z. Xu, “Multi-condos: Multimodal contrastive domain sharing generative adversarial networks for self-supervised medical image segmentation,” IEEE Trans. Med. Imag., 2023.
- [35] M. Ran, J. Hu, Y. Chen, H. Chen, H. Sun, J. Zhou, and Y. Zhang, “Denoising of 3D magnetic resonance images using a residual encoder–decoder wasserstein generative adversarial network,” Med. Image Anal., vol. 55, pp. 165–180, 2019.
- [36] D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” in Proc. Int. Conf. Learn. Represent., 2014.
- [37] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in Proc. Int. Conf. Neural Inf. Process. Syst., vol. 33, 2020, pp. 6840–6851.
- [38] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” in Proc. Int. Conf. Learn. Represent., 2021.
- [39] W. Wu, Y. Wang, Q. Liu, G. Wang, and J. Zhang, “Wavelet-improved score-based generative model for medical imaging,” IEEE Trans. Med. Imag., 2023.
- [40] A. Güngör, S. U. Dar, Ş. Öztürk, Y. Korkmaz, H. A. Bedel, G. Elmas, M. Ozbey, and T. Çukur, “Adaptive diffusion priors for accelerated MRI reconstruction,” Med. Image Anal., vol. 88, p. 102872, 2023.
- [41] M. Mardani, J. Song, J. Kautz, and A. Vahdat, “A variational perspective on solving inverse problems with diffusion models,” arXiv preprint arXiv:2305.04391, 2023.
- [42] C. Cao, Z.-X. Cui, Y. Wang, S. Liu, T. Chen, H. Zheng, D. Liang, and Y. Zhu, “High-frequency space diffusion model for accelerated MRI,” IEEE Trans. Med. Imag., 2024.
- [43] Y. Guan, C. Yu, Z. Cui, H. Zhou, and Q. Liu, “Correlated and multi-frequency diffusion modeling for highly under-sampled MRI reconstruction,” IEEE Trans. Med. Imag., 2024.
- [44] Z.-X. Cui, C. Liu, X. Fan, C. Cao, J. Cheng, Q. Zhu, Y. Liu, S. Jia, H. Wang, Y. Zhu et al., “Physics-informed DeepMRI: k-space interpolation meets heat diffusion,” IEEE Trans. Med. Imag., 2024.
- [45] B. Levac, A. Jalal, and J. I. Tamir, “Accelerated motion correction for MRI using score-based generative models,” in Proc. IEEE 20th Int. Symp. Biomed. Imag. (ISBI). IEEE, 2023, pp. 1–5.
- [46] Y. Liu, Z.-X. Cui, K. Sun, T. Zhao, J. Cheng, Y. Zhu, D. Shen, and D. Liang, “k-t self-consistency diffusion: A physics-informed model for dynamic MR imaging,” in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent. Springer, 2024, pp. 414–424.
- [47] S. Wang, H. Ma, J. A. Hernandez-Tamames, S. Klein, and D. H. Poot, “qMRI diffuser: Quantitative mapping of the brain using a denoising diffusion probabilistic model,” in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent. Workshop on Deep Generative Models. Springer, 2024, pp. 129–138.
- [48] W. K. Hastings, “Monte carlo sampling methods using markov chains and their applications,” 1970.
- [49] S. Kullback and R. A. Leibler, “On information and sufficiency,” The annals of mathematical statistics, vol. 22, no. 1, pp. 79–86, 1951.
- [50] E. J. Candès, J. Romberg, and T. Tao, “Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information,” IEEE Trans. Inform. Theory, vol. 52, no. 2, pp. 489–509, 2006.
- [51] A. Graves, “Practical variational inference for neural networks,” in Proc. Int. Conf. Neural Inf. Process. Syst., vol. 24, 2011.
- [52] C. M. Bishop and N. M. Nasrabadi, Pattern recognition and machine learning. Springer, 2006, vol. 4, no. 4.
- [53] P. Vincent, “A connection between score matching and denoising autoencoders,” Neural Comput., vol. 23, no. 7, pp. 1661–1674, 2011.
- [54] M. Lustig, D. Donoho, and J. M. Pauly, “Sparse MRI: The application of compressed sensing for rapid MR imaging,” Magn. Reson. Med., vol. 58, no. 6, pp. 1182–1195, 2007.
- [55] A. Hyvärinen and P. Dayan, “Estimation of non-normalized statistical models by score matching.” J. Mach. Learn. Res., vol. 6, no. 4, 2005.
- [56] Y. Song and S. Ermon, “Improved techniques for training score-based generative models,” in Proc. Int. Conf. Neural Inf. Process. Syst., vol. 33, 2020, pp. 12 438–12 448.
- [57] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT press, 2016.
- [58] M. Henningsson, P. Koken, C. Stehning, R. Razavi, C. Prieto, and R. M. Botnar, “Whole-heart coronary MR angiography with 2D self-navigated image reconstruction,” Magn. Reson. Med., vol. 67, no. 2, pp. 437–445, 2012.
- [59] M. Uecker, P. Lai, M. J. Murphy, P. Virtue, M. Elad, J. M. Pauly, S. S. Vasanawala, and M. Lustig, “ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA,” Magn. Reson. Med., vol. 71, no. 3, pp. 990–1001, 2014.
- [60] A. Bustin, G. Ginami, G. Cruz, T. Correia, T. F. Ismail, I. Rashid, R. Neji, R. M. Botnar, and C. Prieto, “Five-minute whole-heart coronary MRA with sub-millimeter isotropic resolution, 100% respiratory scan efficiency, and 3D-PROST reconstruction,” Magn. Reson. Med., vol. 81, no. 1, pp. 102–115, 2019.
- [61] Y. Korkmaz, T. Cukur, and V. Patel, “Self-supervised MRI reconstruction with unrolled diffusion models,” in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent., vol. 14229, 2023, p. 491–501.
- [62] M. Uecker, J. I. Tamir, F. Ong, and M. Lustig, “The BART toolbox for computational magnetic resonance imaging,” in Proc. Intl. Soc. Magn. Reson. Med., vol. 24, 2016, p. 1.
- [63] D. Ma, V. Gulani, N. Seiberlich, K. Liu, J. L. Sunshine, J. L. Duerk, and M. A. Griswold, “Magnetic resonance fingerprinting,” Nature, vol. 495, no. 7440, pp. 187–192, 2013.
- [64] G. Milotta, A. Bustin, O. Jaubert, R. Neji, C. Prieto, and R. M. Botnar, “3D whole-heart isotropic-resolution motion-compensated joint / mapping and water/fat imaging,” Magn. Reson. Med., vol. 84, no. 6, pp. 3009–3026, 2020.
- [65] Z. Lyu, S. Hua, J. Xu, Y. Shen, R. Guo, P. Hu, and H. Qi, “Free-breathing simultaneous native myocardial , and mapping with cartesian acquisition and dictionary matching,” J. Cardiovasc. Magn. Reson., vol. 25, no. 1, p. 63, 2023.
- [66] L. Feng, R. Grimm, K. T. Block, H. Chandarana, S. Kim, J. Xu, L. Axel, D. K. Sodickson, and R. Otazo, “Golden-angle radial sparse parallel MRI: combination of compressed sensing, parallel imaging, and golden-angle radial sampling for fast and flexible dynamic volumetric MRI,” Magn. Reson. Med., vol. 72, no. 3, pp. 707–717, 2014.
- [67] D. Ulyanov, A. Vedaldi, and V. Lempitsky, “Deep image prior,” in Proc. Conf. Comput. Vis. Pattern Recognit., 2018, pp. 9446–9454.
- [68] Z.-X. Cui, S. Jia, C. Cao, Q. Zhu, C. Liu, Z. Qiu, Y. Liu, J. Cheng, H. Wang, Y. Zhu et al., “K-UNN: k-space interpolation with untrained neural network,” Med. Image Anal., vol. 88, p. 102877, 2023.
- [69] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proc. Int. Conf. Comput. Vis., 2017, pp. 2223–2232.
- [70] L. Dinh, D. Krueger, and Y. Bengio, “NICE: Non-linear independent components estimation,” in Proc. Int. Conf. Learn. Represent., 2015.
- [71] Z. Cui, C. Cao, S. Liu, Z. Qingyong, J. Cheng, H. Wang, Y. Zhu, and D. Liang, “Self-score: Self-supervised learning on score-based models for MRI reconstruction,” in arXiv preprint arxiv:2209.00835, 2022.
- [72] Y. Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,” in Proc. Int. Conf. Mach. Learn, 2023.
- [73] C. Lu, Y. Zhou, F. Bao, J. Chen, C. Li, and J. Zhu, “DPM-solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps,” in Proc. Int. Conf. Neural Inf. Process. Syst., vol. 35, 2022, pp. 5775–5787.
- [74] D. F. McGivney, E. Pierre, D. Ma, Y. Jiang, H. Saybasili, V. Gulani, and M. A. Griswold, “SVD compression for magnetic resonance fingerprinting in the time domain,” IEEE Trans. Med. Imag., vol. 33, no. 12, pp. 2311–2322, 2014.
- [75] O. Cohen, B. Zhu, and M. S. Rosen, “MR fingerprinting deep reconstruction network (DRONE),” Magn. Reson. Med., vol. 80, no. 3, pp. 885–894, 2018.
- [76] Z. Fang, Y. Chen, M. Liu, L. Xiang, Q. Zhang, Q. Wang, W. Lin, and D. Shen, “Deep learning for fast and spatially constrained tissue quantification from highly accelerated data in magnetic resonance fingerprinting,” IEEE Trans. Med. Imag., vol. 38, no. 10, pp. 2364–2374, 2019.