Scratching Visual Transformer’s Back with Uniform Attention
Abstract
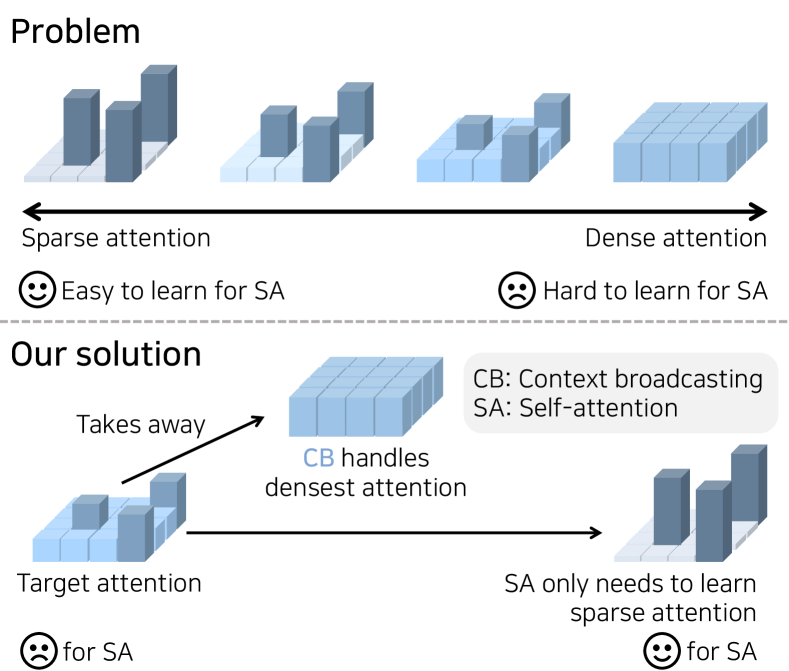
The favorable performance of Vision Transformers (ViTs) is often attributed to the multi-head self-attention (), which enables global interactions at each layer of a ViT model. Previous works acknowledge the property of long-range dependency for the effectiveness in . In this work, we study the role of in terms of the different axis, density. Our preliminary analyses suggest that the spatial interactions of learned attention maps are close to dense interactions rather than sparse ones. This is a curious phenomenon because dense attention maps are harder for the model to learn due to . We interpret this opposite behavior against as a strong preference for the ViT models to include dense interaction. We thus manually insert the dense uniform attention to each layer of the ViT models to supply the much-needed dense interactions. We call this method Context Broadcasting, . Our study demonstrates the inclusion of takes the role of dense attention and thereby reduces the degree of density in the original attention maps by complying in . We also show that, with negligible costs of (1 line in your model code and no additional parameters), both the capacity and generalizability of the ViT models are increased.
1 Introduction
After the success of Transformers [59] in language domains, Dosovitskiy et al. [13] have extended to Vision Transformers (ViTs) that operate almost identically to the Transformers but for computer vision tasks. Recent studies [13, 57] have shown that ViTs achieve superior performance on image classification tasks. Further, the universal nature of ViTs’ input has demonstrated its potential to multi-modal input extensions [2, 15, 27, 32].
The favorable performance is often attributed to the multi-head self-attention () in ViTs [13, 57, 60, 8, 51, 45], which facilitates long-range dependency111Long-range dependency is described in the literature with various terminologies: non-local, global, large receptive fields, etc.. Specifically, is designed for long-range interactions of spatial information in all layers. This is a structurally contrasting feature with a large body of successful predecessors, convolutional neural networks (CNNs), which gradually increase the range of interactions by stacking many fixed and hard-coded local operations, i.e., convolutional layers. Raghu et al. [45] and Naseer et al. [40] have shown the effectiveness of the self-attention in ViTs for the global interactions of spatial information compared to CNNs.
Unlike previous works [45, 40] that focused on the effectiveness of long-range dependency, we study the role of density in spatial attention. “Long-range” can be either “sparse” or “dense”. We examine whether the learned attention of ViTs is dense or sparse. Our preliminary analysis based on the entropy measure suggests that the learned attention maps tend to be dense across all spatial locations. This is a curious phenomenon because denser attention maps are harder to learn by the softmax operation. Its gradients become larger (less stable) around denser attention maps. In other words, ViTs are trying hard to learn dense attention maps despite the difficulty of learning them through gradient descent.
While dense attention is unlikely to be learned via gradient descent, it is easy to implement it manually. We insert uniform attention explicitly, the densest form of attention, to confirm our observation of the effort of learning dense attention. We call our module Context Broadcasting (). The module adds the averaged token to every individual token at intermediate layers. We find that when is added to ViT, reduces the degree of density in attention maps in all layers preserving the long-range dependency. takes over the role of the dense global aggregation from self-attention, as illustrated in Fig. 1. also makes the overall optimization for a ViT model easier and improves its generalization.
brings consistent gains in the image classification task on ImageNet [48, 47, 5] and the semantic segmentation task on ADE20K [68, 69]. Overall, seems to help a ViT model divert its resources from learning dense attention maps to learning other informative signals. We also demonstrate that our module improves the Vision-Language Transformer, ViLT [32], on a multi-modal task, VQAv2 [17]. Such benefits come with only negligible costs. Only 1 line of code needs to be inserted in your model.py. No additional parameters are introduced; only a negligible number of operations are. Our contributions are as follows:
2 Related Work
Transformers.
Since the seminal work of the Transformers [59], it has been the standard architecture in the natural language processing (NLP) domain. Dosovitskiy et al. [13] have pioneered the use of Transformers in the visual domain with their Vision Transformers (ViTs). The way of ViTs work is almost identical to the original Transformers, where ViTs tokenize non-overlapping patches of the input image and apply the Transformers architecture on top. The Transformers with multi-head self-attention () are especially appealing in computer vision because their non-convolutional neural architectures do not have conventional hard-coded operations, such as convolution and pooling with fixed local kernel sizes. Cordonnier et al. [10] and Ramachandran et al. [46] corroborate that the expressiveness of even includes convolution.
There have been attempts to understand the algorithmic behaviors of ViTs, including , by contrasting them with CNNs [45, 10, 40, 41, 58]. Raghu et al. [45] empirically demonstrate early aggregation of global information and much larger effective receptive fields [37] over CNNs. Naseer et al. [40] show highly robust behaviors of ViTs against diverse nuisances, including occlusions, distributional shifts, adversarial and natural perturbations. Intriguingly, they attribute those advantageous properties to large and flexible receptive fields by in ViTs and interactions therein. Similarly, there have been studies that attribute the effectiveness of to global interaction in many visual scene understanding tasks [57, 8, 51, 45, 33, 4, 31]. Distinctively, we study the role of the density of the attention.
Attention module.
The global context is essential to capture a holistic understanding of a visual scene [55, 44, 49, 60, 7], which aids visual recognition. To capture the global context, models need to be designed to have sufficiently large receptive fields to interact and aggregate all the local information. Prior arts have proposed to enhance the interaction range of CNNs by going deeper [50, 19, 28, 53] or by expanding the receptive fields [63, 11, 60, 34, 30]. Hu et al. [26] squeeze spatial dimensions by pooling to capture the global context. Cao et al. [7] notice that the attention map of the non-local block is similar regardless of query position and propose a global context block.
Our study focuses on the ViT architecture, which comprises concise layers and can serve as versatile usage, such as unified multi-modal Transformers [2, 15, 27, 32]. The receptive field of in ViTs inherently covers the entire input space, which may facilitate the learning of global interactions and the modeling of global context more efficiently than CNNs [39]. However, the current global context modeling in ViTs may not be straightforward. Our research presents a few indications that while self-attention favors learning dense global interactions, it is challenging to achieve this due to . To ascertain the benefits of dense global interaction, we explicitly inject it and observe an improvement of performance. Moreover, we observe the allocation of capacities to better interactions.
3 Method
We first motivate the need for dense interactions for the ViTs in Sec. 3.1. Then, we propose a simple, lightweight module and a technique to inject explicitly dense interactions into ViTs in Sec. 3.2. Finally, we demonstrate how uniform attention affects to the ViT model in Sec. 3.3.

3.1 Motivation
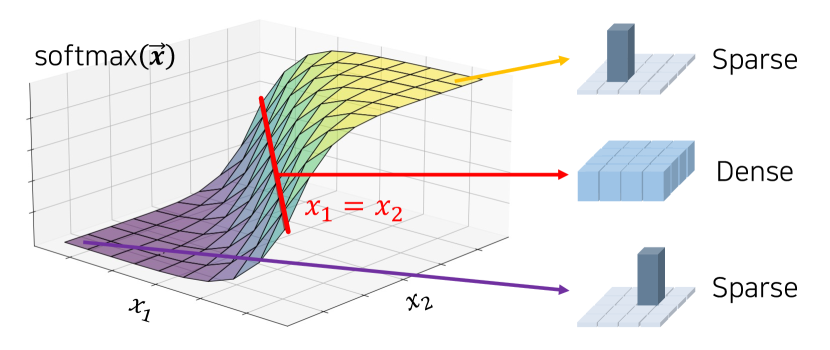
The self-attention operations let ViTs conduct spatial interactions without limiting the spatial range in every layer. Long-range dependency, or global interactions, signifies connections that reach distant locations from the reference token. Density refers to the proportion of non-zero interactions across all tokens. Observe that “global” does not necessarily mean “dense” or “sparse” because an attention map can be sparsely global. We illustrate their difference in Fig. 2. The question of interest is the type of interaction that self-attention learns.
Before delving into the study of density, we examine which multi-head self-attention () or multi-layer perceptron () blocks further increase the capacity of the model. Our preliminary observation highlights the benefit of studying . We then measure the layer-wise entropy of the attention to investigate the spatial interaction characteristics that ViTs prefer to learn.
MSA vs. MLP.
and in ViTs are responsible for spatial and channel interactions, respectively. We examine adding which block, either or , increases the performance of ViTs more. We train the eight-layer ViT on ImageNet-1K for 300 epochs with either an additional or layer inserted at the last layer. The additional number of parameters and FLOPs are nearly equal. In Fig. 3, we plot the training loss and top-1 accuracy. We observe that the additional enables lower training loss and higher validation accuracy than the additional . This suggests that, given a fixed budget in additional parameters and FLOPs, the ViT architecture seems to prefer to have extra spatial interactions rather than channel interactions. It leads us to investigate the spatial interactions of .
Which type of spatial interactions does learn?
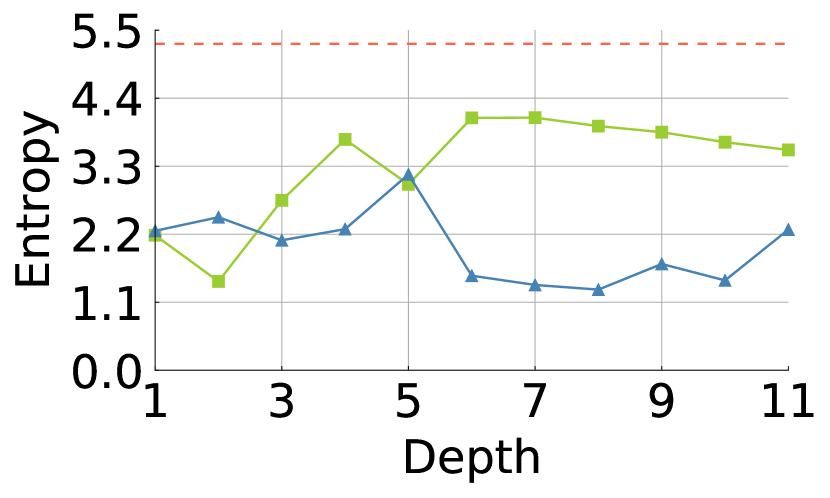
Here, we examine the types of spatial interactions that are particularly preferred by . Knowing the type of interactions will guide us on how we could improve attention performance. While previous studies [45, 40] have focused on the effectiveness of long-range dependency in , we focus on the density in . We measure the dispersion of attention according to the depth through the lens of entropy. Low entropy indicates that the attention is sparse, whereas high entropy suggests that the attention is dense. Entropy provides a more objective view rather than relative and subjective measures such as visualization [38, 18].

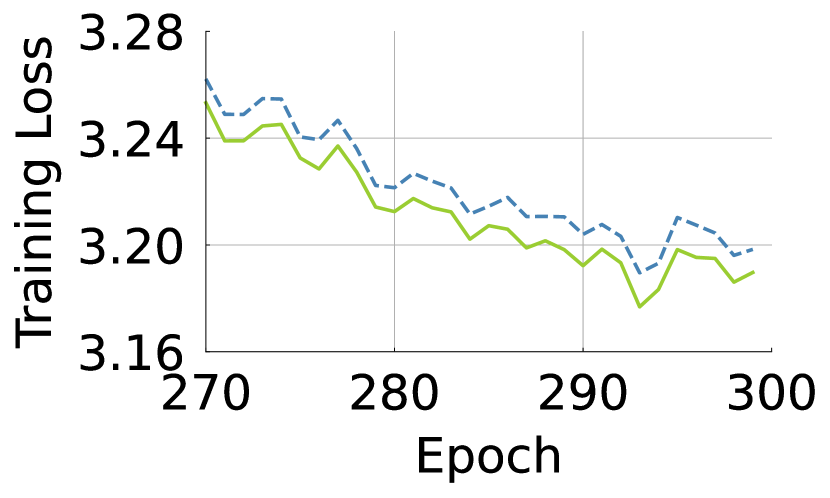
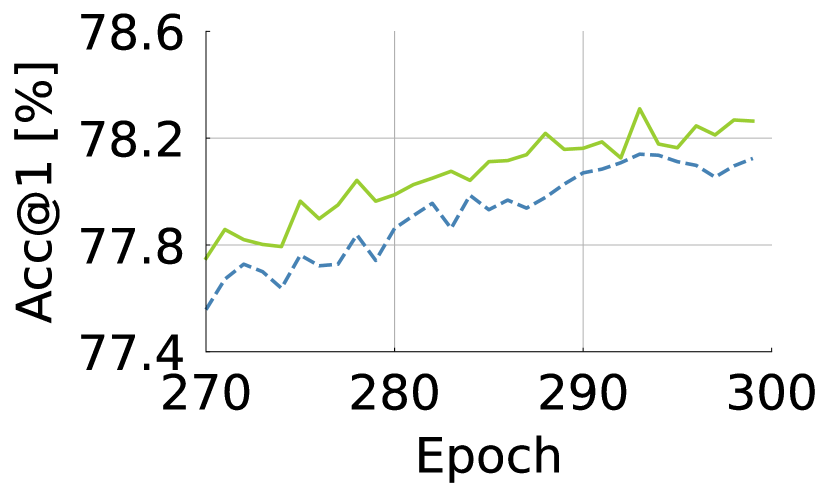
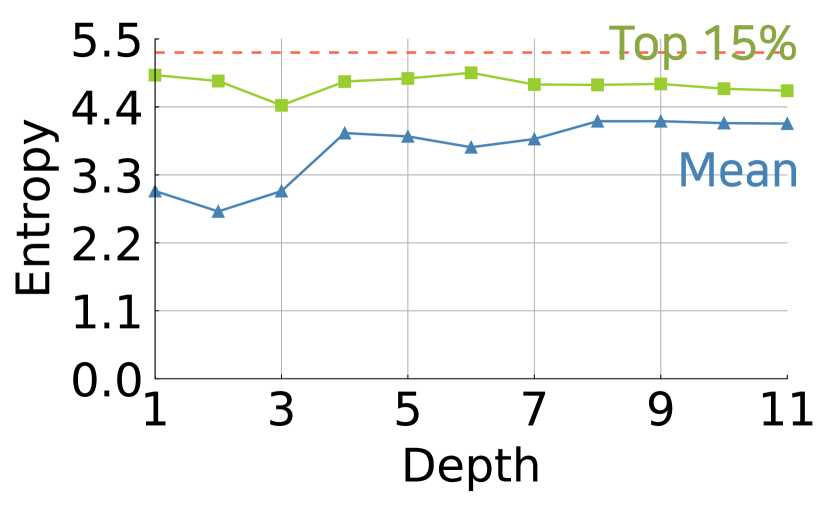
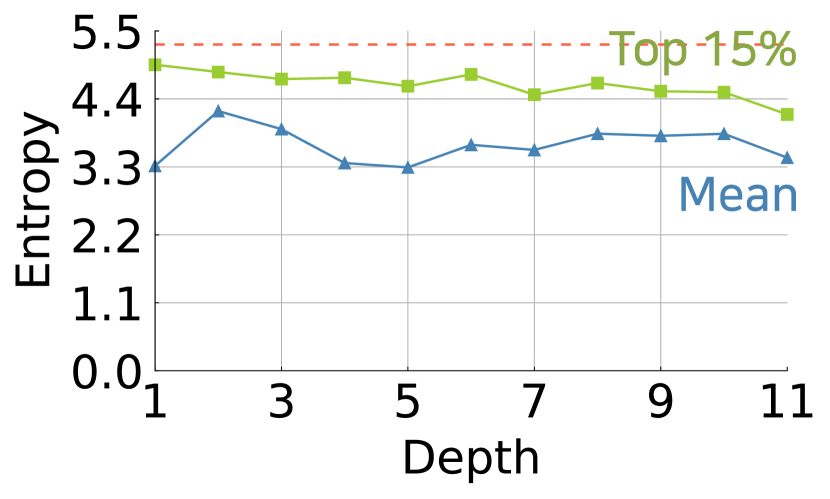
Figure 4 shows the trends of the average and percentile entropy values across the heads and tokens for each layer in ViT-S/-B [13, 57]. We observe that attention maps tend to have greater entropy values as high as 4.4 on average, towards the maximal entropy value, , where N is the number of tokens and 197. The top 15% of entropy values are much close to the maximal entropy value corresponding to uniform attention. It is remarkable that a majority of the attention in ViTs has such high entropy values; it suggests that tends to learn the dense interactions.
Steepest gradient around the uniform attention.
The extreme form of dense interactions is the uniform distribution. To examine the difficulty of finding the uniform distribution for the self-attention in , we delve into the characteristics of the function. In a nutshell, we show that the gradient magnitude is the largest around the inputs inducing a uniform output. We further formalize this intuition below. The self-attention consists of the row-wise softmax operation where is the collection of dot products of queries and keys, possibly with a scale factor . For simplicity, we consider the softmax over a single row: . The gradient of with respect to the input is for . We measure the magnitude of the gradient using the nuclear norm where are the singular values of . Note that is a real, symmetric, and positive semi-definite matrix. Thus, the nuclear norm coincides with the sum of its eigenvalues, which in turn is the trace: . With respect to the constraint that and for all , the nuclear norm is maximal when for every . Figure 5 describes the function in 2D input. This shows that uniform attention with softmax can be easily broken by a single gradient step, meaning it is the most unstable type of attention to learn, in the optimization point of view.
Conclusion.
We have examined the density of the interactions in the layers. We found that further spatial connections benefit ViT models more than further channel-wise interactions. layers tend to learn dense interactions with higher entropies. ViT’s preference for dense interactions is striking, given the difficulty of learning dense interactions: the gradient for the layer is steeper with denser attention maps. This implies that dense attention maps are hard to learn but seem vital to ViTs.
3.2 Explicitly Broadcasting the Context
We observe the curious phenomena: learns dense interaction, though it is unstable in terms of the gradient. We decide to inject uniform attention because (1) uniform attention is the densest attention and is unstable in terms of gradient view, but (2) humans can supply uniform attention easily, and (3) uniform attention requires no additional parameters and small computation costs. We do this through the broadcasting context with the module.
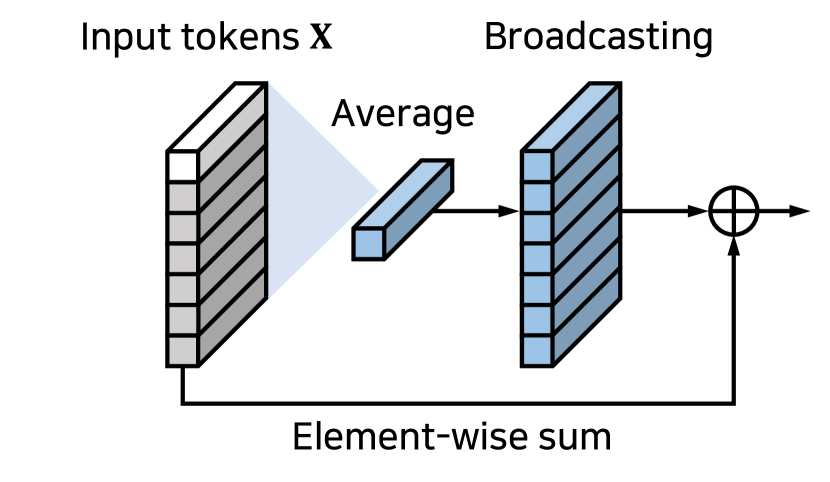
Context Broadcasting ().
Given a sequence of tokens , our module supplies the averaged token back onto the tokens as follows:
| (1) |
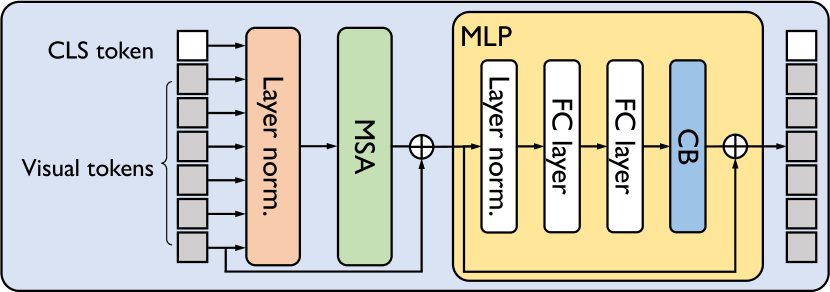
where is the token in . Figure 6(a) illustrates our module. The module is placed at the end of block (See Fig. 6(b)). Our analysis in Sec. 4.1 shows that the insertion of increases the performance of ViTs regardless of its position. As we shall see, the performance increase is most significant when it is inserted after the block.
Computational efficiency.
X = 0.5 * X + 0.5 * X.mean(dim=1, keepdim=True). It does not increase the number of parameters and incurs negligible additional operations for inference and training.
with dimension scaling.
Although we focus on the simplest form, we propose another variant of dense interaction by introducing a minimal number of parameters. The proposed injects the dense interaction into all channel dimensions, but some channel dimensions of a token would require dense interaction, whereas others would not. We then introduce weights to scale the channels, , to infuse uniform attention selectively for each dimension as follows: where is the element-wise product. introduces few parameters: 0.02% additional parameters for ViT-S.
3.3 How Does Uniform Attention Affect ViT?
In the following experiments, we delve into the effect of uniform attention. We train ViTs on ImageNet-1K during 300 epochs following the DeiT setting [57].
Does uniform attention help?
To examine the effectiveness of the uniform attention, we inject the uniform attention in several ways to ViT-S as follows: (A) We replace one of the multi-head self-attention heads to be which reduces the number of parameters corresponding to the replaced head, (B) adjust the number of parameters of (A) to be comparable to the original ViT, (C) append to as an extra head which increases the number of parameters, and infuse and . Table 1 shows the top-1 accuracy at ImageNet-1K. In (A), (B), (C), , and improve the accuracy consistently. The result explicitly tells us the broad benefits of injecting dense interactions into ViTs.
| Module | # Params [M] | Acc@1 [%] |
| ViT-S | 22 | 79.9 |
| (A) | 21 | 80.1 |
| (B) | 22 | 80.3 |
| (C) | 29 | 80.6 |
| (ours) | 22 | 80.8 |
| (ours) | 22 | 80.4 |

Attention entropy according to the depth.
We have observed in Sec. 3.1 that the entropy of learned attention in ViT models tends to be high. From that, we have hypothesized that ViTs may benefit from an explicit injection of uniform attention. We examine now whether our module lowers the burden of the self-attention to learn dense interactions. We compare the entropy of the attention maps between ViT models with and without our module. Figure 7(a) shows layer-wise entropy values on ViT-S with and without our module. The insertion of lowers the entropy values significantly, especially in deeper layers. It seems that relaxes the representational burden for the block and lets focus on sparse interactions.
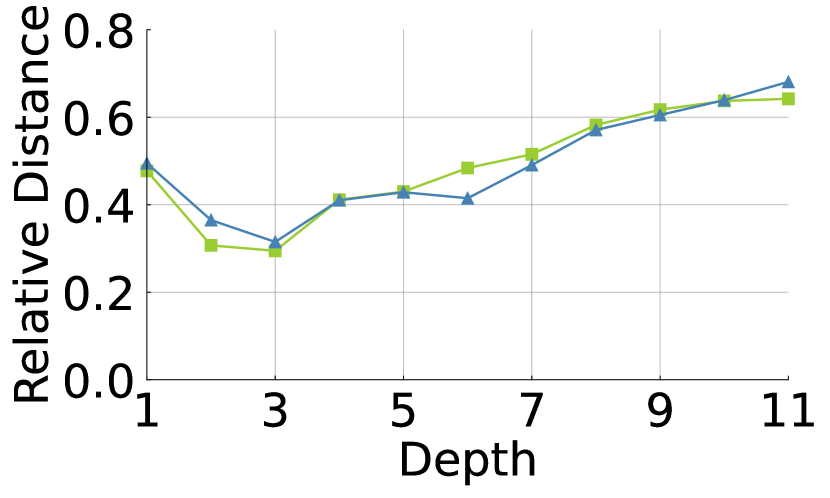
Relative distance according to the depth.
We compute the relative distance of spatial interactions to see whether affects the range of spatial interactions. We define the distance as follows: , where is the number of spatial tokens, is the weight of attention between -th and -th tokens, and is the normalized coordinate of -th token. We exclude the case of self-interaction to analyze interactions of other tokens. As shown in Fig. 7(b), ViT-S and have a similar tendency. Injecting the dense global interactions into ViT does not hurt the range of interactions.

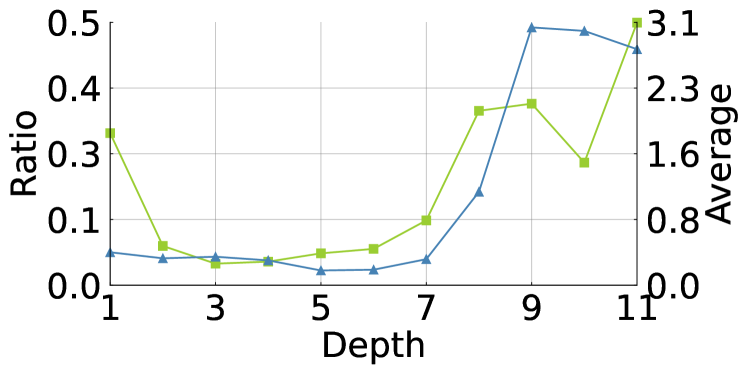

Analysis on dimension scaling.
We analyze the magnitude of scaling weights in to identify the trend of the need for uniform attention according to depth. We measure the ratio of the quantile of and , . The ratio tells us how much high and low values of scaling weights are similar. We also compute the average of scaling weights according to depth. The average is related to the importance of uniform attention. As shown in Fig. 8, the ratio and average increase along with the depth. This indicates upper layers prefer dense interactions more than lower ones. The result coincides with the above observation of entropy analysis, as shown in Fig. 7(a).
| Model | No module | ||
| ViT-Ti | 72.2 | 73.2 | 73.4 |
| ViT-S | 79.9 | 80.5 | 80.8 |
| ViT-B | 81.8 | 82.0 | 82.1 |
Deeper Layers Need More Dense Interaction.
As shown in Fig. 7(a) and Fig. 8, we observe that ViTs prefer dense interactions in the deeper layers. We compare infusing to all layers and upper layers. We denote the insertion of all layers as . As shown in Table 2, achieves 1.2%p, 0.9%p, and 0.3%p higher accuracy than the vanilla ViT-Ti/-S/-B, respectively. also increases the top-1 accuracy further by 0.2%p, 0.3%p, and 0.1%p compared to ViT-Ti/-S/-B with . Inserting in deeper layers improves the performance further; thus, deeper layers benefit more from the dense interactions.
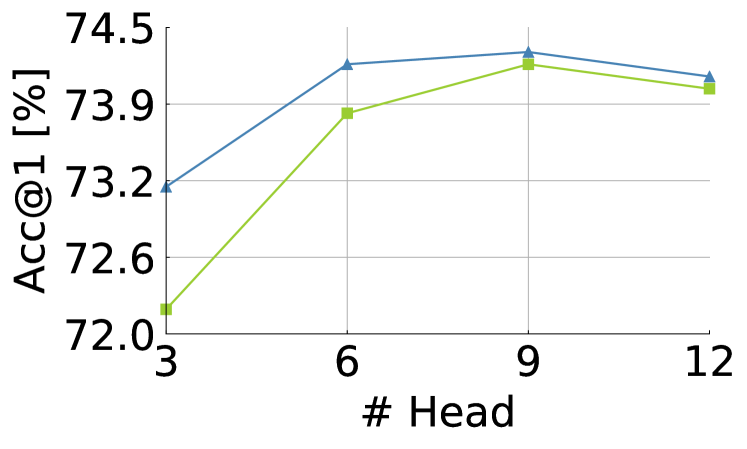
Accuracy according to the number of heads.
can model abundant spatial interactions between tokens as the number of attention heads increases. To examine the relationship between the number of heads and spatial interactions in , we train ViT-Ti with and without by adjusting the number of heads of . As shown in Fig. 9, the accuracy gap increases as the number of heads decreases. Our proposed module is, therefore, more effective in a lower number of heads rather than the large number of heads.
| Extra resources | SE | |
| Extra parameters | Yes | No |
| Computation costs | High | Low |
| Implementation difficulty | Easy | 1 line |
| Module | Acc@1 [%] |
| ViT-S | 79.9 |
| + SE [26] | 80.3 |
| + | 80.8 |
Comparison against SE.
The SE module [26] shares a certain similarity to : both are modular attachments to neural network architecture. However, SE is designed to model the channel inter-dependency by exploiting pooling to construct a channel descriptor, two FC layers, and a sigmoid function. See the comparison between and SE in Table 3(a). Finally, we compare the performance of the models with SE and . As shown in Table 3(b), and SE improve the accuracy by 0.9%p and 0.4%p, respectively. Both modules improve the performance of ViT models, but the improvement is greater for .
Conclusion.
We observe that the global dense interaction enhances the performance of ViTs and diverts the role of to sparse interaction without reducing the distance of interaction. It validates that the injection of useful interactions helps focus on other interactions. We believe exploring other sophisticated explicit interactions will further benefit . In Sec. 4, we present the results of typical experiments based on our simple module.
4 Experiments
In Sec. 4.1, we experiment with which location we put our module in. In Secs. 4.2-4.4, we evaluate our modules on image classification, semantic segmentation, and object detection tasks. Sec. 4.5 provides the visualization of attention maps from ViT-S fine-tuned on segmentation task. In Sec. 4.6, we show results on the robustness benchmarks, including occlusion and adversarial attack. In Secs. 4.7 and 4.8, we evaluate our module on the vision-language Transformer for the Visual Question Answering task and on other architectures.
| Module | Position | FLOPs [G] | Acc@1 [%] | |
| ViT-S | ✗ | ✗ | 4.6 | 79.9 |
| ✓ | ✗ | 4.6 | 80.5 | |
| ✗ | ✓ | 4.6 | 80.1 | |
| ✓ | ✓ | 4.6 | 80.1 | |
| Module | Position | FLOPs [G] | Acc@1 [%] | ||
| ViT-S | ✗ | ✗ | ✗ | 4.6 | 79.9 |
| ✓ | ✗ | ✗ | 4.6 | 79.9 | |
| ✗ | ✓ | ✗ | 4.6 | 80.5 | |
| ✗ | ✗ | ✓ | 4.6 | 80.5 | |
| Architecture | # Params [M] | FLOPs [G] | Acc@1 [%] | Acc@5 [%] | IN-V2 [%] | IN-ReaL [%] |
| ViT-Ti | 5.7 | 1.3 | 72.2 | 91.1 | 59.9 | 80.1 |
| 5.7 | 1.3 | 73.4 | 91.9 | 61.3 | 81.0 | |
| 5.7 | 1.3 | 73.5 | 91.9 | 61.4 | 81.2 | |
| ViT-S | 22.0 | 4.6 | 79.9 | 95.0 | 68.1 | 85.7 |
| 22.0 | 4.6 | 80.8 | 95.4 | 69.3 | 86.2 | |
| 22.0 | 4.6 | 80.4 | 95.1 | 68.7 | 85.9 | |
| ViT-B222We increase the warm-up epochs for learning stability in ViT-B. | 86.6 | 17.6 | 81.8 | 95.6 | 70.5 | 86.7 |
| 86.6 | 17.6 | 82.1 | 95.7 | 71.1 | 86.9 | |
| 86.6 | 17.6 | 82.1 | 95.8 | 71.1 | 86.9 |
4.1 Where to Insert CB in a ViT
We study the best location for with respect to the main blocks for ViT architectures: and . We train ViT-S with our module positioned on , , and both and validate on ImageNet-1K. For simplicity, we infuse into all layers. Note that this setting is different from the experiment in Table 1. We place to the main block without complex adjustments. As shown in Table 4(a), improves the performance regardless of blocks but achieves higher accuracy by 0.4%p in an block than either in an block or both. It is notable, though, that adding increases the performance regardless of the location. We have chosen as the default location of our module for the rest of the paper. This means that the self-attention and uniform attentions conduct their operation in and alternately. The alternation pattern considering the responsibility of modules can be found in prior work [4, 43].
Now, we study the best position of the module within an block, which consists of two fully-connected (FC) layers and the Gaussian Error Linear Unit (GELU) non-linear activation function [21]. Omitting the activation function for simplicity, we have three possible positions for : . We train ViT-S with located at , , and , and validate on ImageNet-1K. Table 4(b) shows the performance; and increase accuracy by 0.6%p compared to the vanilla ViT-S. demands four times larger computation costs than because an layer expands its channel dimensions four times rather than and . We conclude that inserting at of tends to produce the best results overall.
Why is the improvement of the rear position larger than others? We conjecture that the gradient signal propagates to all parameters when is located at the of compared to being at the other places. For simplicity, we assume a single layer composed of the and blocks. If is located at , the preceding weights in the and block are updated by the gradient signals by uniform attention. If is located at , the subsequent weights in the corresponding block cannot receive the gradient signals during training.
Why is the improvement of and similar? There is no non-linear function (e.g., GELU) between and positions. Since uniform attention is the addition of a globally averaged token, the output is identical wherever is located at and . Therefore, the accuracy of both positions is similar.
As a further study, we compare infusing to all layers or upper layers. to upper layers achieves higher top-1 accuracy compared to to all layers in ViT-Ti/-S/-B.333The experiment can be found in Appendix. Inserting in deeper layers improves the performance further; thus, deeper layers benefit more from the dense interactions.
4.2 Image Classification
We train ViTs [13] with our module on the ImageNet-1k training set and report accuracy on the validation set. We adopt strong regularizations following the DeiT [57]. We apply the random resized crop, random horizontal flip, Mixup [65], CutMix [64], random erasing [67], repeated augmentations [25], label-smoothing [52], and stochastic depth [29]. We use AdamW [36] with betas of (0.9, 0.999), a learning rate of , and a weight decay of . The one-cycle cosine scheduling is used to decay the learning rate during the total epochs of 300. We implement based on [42] and [61] on 8 V100 GPUs. We use library to count the number of FLOPs. More details and additional experiments can be found in Appendix.
ViT-Ti/-S/-B [13] with our modules trained on ImageNet-1K are further validated on ImageNet-V2 [47] and ImageNet-Real [5]. Table S12 shows our modules and improve both precision and robustness of a model. does not add extra parameters, and increases only a few parameters; our modules demand negligible computation costs yet are effective for image classification. The results signify our observations about the preference and learning difficulty of dense global attention and injecting dense attention explicitly are all valid.
| Backbone | # Params [M] | mIoU [%] | |
| 40K | 160K | ||
| ViT-Ti | 34.1 | 35.5 | 38.9 |
| 36.5 | 39.0 | ||
| 36.1 | 39.8 | ||
| ViT-S | 53.5 | 41.5 | 43.3 |
| 41.9 | 43.9 | ||
| 41.6 | 43.1 | ||
| ViT-B | 127.0 | 44.3 | 45.0 |
| 45.1 | 45.6 | ||
| 44.6 | 45.3 | ||
4.3 Semantic Segmentation
We validate our method for semantic segmentation on the ADE20K dataset [68, 69] consisting of 20K training and 5K validation images. For a fair comparison, we follow the protocol of XCiT [14] and Swin Transformer [35]. We adopt UperNet [62] and train for 40K iterations or 160K for longer training. Hyperparameters are the same as XCiT: the batch size of 16, AdamW with betas of (0.9, 0.999), the learning rate of , weight decay of 0.01, and polynomial learning rate scheduling. We set the head dimension as 192, 384, and 512 for ViT-Ti/-S/-B, respectively. Table 6 shows the results with 40K and 160K training settings.
We observe that ViT-Ti/-S/-B with increase mIoU by 1.0, 0.4, and 0.8 for 40K iterations and 0.1, 0.6, and 0.6 for 160K iterations, respectively. Similarly, improves mIoU except for 160K iterations in ViT-S. Infusing the context shows improvement in semantic segmentation; the performance improvement of ViT-B is not marginal, especially. The result would be related to the prior work [9, 66], which introduces the global context by atrous convolution and pyramid module. not only performs the dense interactions across tokens, which the original self-attention is hard to learn, but also supplies the global context.
| Model | APb | AP | AP | APm | AP | AP |
| ViT-Ti | 34.8 | 57.4 | 36.5 | 32.5 | 54.3 | 33.7 |
| + | 35.1 | 57.9 | 36.8 | 32.8 | 54.4 | 34.2 |
4.4 Object detection
We fine-tune the pre-trained ViT-Ti on the COCO dataset and evaluate the performance of object detection and instance segmentation in Table 7. COCO consists of 118K training and 5K validation images with 80 categories. We follow the protocol of XCiT [14] and Swin Transformer [35]. We adopt Mask R-CNN with FPN and train models for 12 epochs ( schedule) using AdamW with learning rate and weight decay 0.05. We do not apply to a block where features are feed-forwarded to FPN. Ours consistently improves performance. In object detection, improves 0.3, 0.5, and 0.3 in APb, AP, and AP, respectively. In instance segmentation, improves 0.3, 0.1, and 0.5 in APm, AP, and AP, respectively.
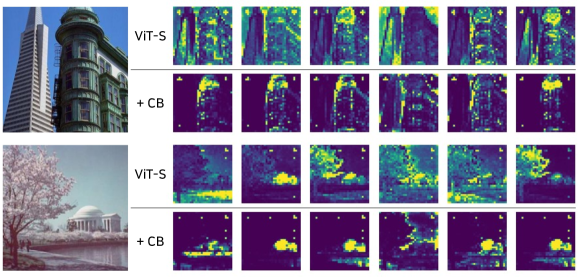
4.5 Segmentation Attention Visualization
We visualize the attention maps to understand how changes the interactions of rather than entropies. We use the pre-trained ViT-S on ADE20K to extract the attention maps. The visualized attentions are extracted from the last layers before Feature Pyramid Network (FPN). See Fig. 10 for a comparison. We apply the same thresholding and min-max normalization in visualization for a fair comparison. ViT-S without needs dense aggregations more than ViT-S with . The visualization also validates that takes over the dense aggregations from the original self-attention. This implies that splits the burden of self-attention.
| Architecture | Occ [%] | ImageNet-A [%] | FGSM [%] |
| ViT-S | 73.0 | 19.0 | 27.2 |
| 73.7 | 19.1 | 27.8 | |
| 74.0 | 21.2 | 32.3 |
4.6 Evaluating Model Robustness
We evaluate the robustness of and with respect to center occlusion (Occ), ImageNet-A [22], and an adversarial attack [16]. For Occ, we zero-mask the center patches of every validation image. ImageNet-A is the collection of challenging test images that an ensemble of ResNet50s has failed to recognize. We employ the fast sign gradient method (FGSM [16]) for the adversarial attack. Table S13 shows the results of the robustness benchmark. increases by 0.7, 0.1, and 0.6 of Occ, ImageNet-A, and FGSM, respectively. does 1.0, 2.2, and 5.1, respectively.
| Noise Type | ViT-S | |
| Nothing | 43.3 | 43.9 |
| Shot Noise | 40.22 0.15 | 41.09 0.09 |
| Gaussian Noise (sigma=5.0) | 42.55 0.08 | 43.44 0.08 |
| Gaussian Noise (sigma=10.0) | 40.22 0.07 | 41.07 0.06 |
| Gaussian Blur (sigma=1.0) | 42.29 | 43.26 |
| Gaussian Blur (sigma=2.0) | 40.83 | 41.44 |
We also evaluate the robustness on ADE20K using input perturbations [20], e.g., shot noise, Gaussian noise, and Gaussian blur. We run the experiments by five times on random noise and report the mean and confidence interval of 95%. Table 9 shows the performance of mIoU. The performance gap of ViT-S with and without increases from 0.6 up to 0.97. This shows that our 1 line of code can improve the ViT models’ robustness against input perturbation in the semantic segmentation task.
4.7 Vision-Language Transformer
| Architecture | Acc [%] |
| ViLT [32] | 71.28 |
| (Image) | 71.44 |
| (Text) | 71.46 |
| (Both) | 71.42 |
Transformer becomes the standard architecture for multi-modal learning because of the succinct structure. For example, Transformer employs modality-specific linear projection [32, 27, 24, 2]. We evaluate our module on the Vision-Language Transformer, ViLT [32]. We fine-tune the pre-trained ViLT on VQAv2 [17] using the official code. Table 10 shows the results of the performance. We first reproduce the baseline and reach the reported number (71.26). Our module is applied to the image, text, and both tokens, and in all cases, it improves the accuracy by 0.16, 0.18, and 0.14, respectively, compared with the baseline accuracy.
4.8 Other Architectures
We evaluate on PiT [23] and Mixer [54]. PiT-B is the variant of the original Vision Transformer introducing spatial dimension reduction. Mixer is pioneering work of the feed-forward architectures [54, 56], mainly consisting of FC layers. The structure of feed-forward architecture follows ViT except for . Spatial interactions of feed-forward are done through transposing visual data followed by an FC layer. We insert our module at in PiT and Mixer [54]. For a fair comparison, we reproduce the baseline Mixer-S/16 with the DeiT training regime [57] and train ours with the same one. Our module increases the performance of those architectures, as shown in Table 11.
5 Conclusion
We look closer at the spatial interactions in ViTs, especially in terms of density. We have been motivated by the preliminary exploration and observations that suggest ViT models prefer dense interactions. We also show that, at least from the optimization point of view, uniform attention is perhaps the most challenging attention for softmax-based attention to learn. The preference and optimization difficulty of learning dense interactions are not aligned. It leads us to introduce further dense interactions manually by a simple module: Context Broadcasting (). Inserted at intermediate layers of ViT models, adds the averaged token to tokens. Additionally, we propose a dimension scaling version of , called , to infuse the dense interactions selectively. It turns out that our simple module improves the ViT performances across various benchmarks, including image classification, semantic segmentation, and visual-language tasks. only takes 1 line of code, a few more FLOPs, and zero parameters using this module. We hope that our module will further improve your ViT models and that our observations provide insights for modeling the token interactions of ViTs.
Our work introduces the simplest form of dense interaction that complement self-attention. One may propose a more sophisticated and effective module that makes self-attention focus on the crucial interactions that should be only dealt with by self-attention, intractable otherwise. We believe that this would be an exciting research direction.
Acknowledgment
N. Hyeon-Woo, K. Y.-J. and T.-H. Oh were partly supported by Institute of Information communications Technology Planning Evaluation (IITP) grant funded by the Korea government(MSIT) (No.2022-0-00124, Development of Artificial Intelligence Technology for Self-Improving Competency-Aware Learning Capabilities; No.2022-0-00290, Visual Intelligence for Space-Time Understanding and Generation based on Multi-layered Visual Common Sense; No. 2020-0-00004, Development of Previsional Intelligence based on Long-term Visual Memory Network).
References
- [1] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. Tensorflow: A system for large-scale machine learning. In USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2016.
- [2] Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. NeurIPS, 2021.
- [3] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: Visual Question Answering. In ICCV, 2015.
- [4] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. Vivit: A video vision transformer. In ICCV, 2021.
- [5] Lucas Beyer, Olivier J Hénaff, Alexander Kolesnikov, Xiaohua Zhai, and Aäron van den Oord. Are we done with imagenet? arXiv preprint arXiv:2006.07159, 2020.
- [6] James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018.
- [7] Yue Cao, Jiarui Xu, Stephen Lin, Fangyun Wei, and Han Hu. Global context networks. IEEE TPAMI, to appear.
- [8] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020.
- [9] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE TPAMI, 40(4):834–848, 2017.
- [10] Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self-attention and convolutional layers. In ICLR, 2020.
- [11] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. In ICCV, 2017.
- [12] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
- [13] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- [14] Alaaeldin El-Nouby, Hugo Touvron, Mathilde Caron, Piotr Bojanowski, Matthijs Douze, Armand Joulin, Ivan Laptev, Natalia Neverova, Gabriel Synnaeve, Jakob Verbeek, and Herve Jegou. XCit: Cross-covariance image transformers. In NeurIPS, 2021.
- [15] Rohit Girdhar, Mannat Singh, Nikhila Ravi, Laurens van der Maaten, Armand Joulin, and Ishan Misra. Omnivore: A single model for many visual modalities. In CVPR, 2022.
- [16] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. ICLR, 2014.
- [17] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering. In CVPR, 2017.
- [18] Haoyu He, Jing Liu, Zizheng Pan, Jianfei Cai, Jing Zhang, Dacheng Tao, and Bohan Zhuang. Pruning self-attentions into convolutional layers in single path. arXiv preprint arXiv:2111.11802, 2021.
- [19] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [20] Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. arXiv preprint arXiv:1903.12261, 2019.
- [21] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- [22] Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. CVPR, 2021.
- [23] Byeongho Heo, Sangdoo Yun, Dongyoon Han, Sanghyuk Chun, Junsuk Choe, and Seong Joon Oh. Rethinking spatial dimensions of vision transformers. In ICCV, 2021.
- [24] Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Martin Eisenschlos. Tapas: Weakly supervised table parsing via pre-training. arXiv preprint arXiv:2004.02349, 2020.
- [25] Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, Torsten Hoefler, and Daniel Soudry. Augment your batch: Improving generalization through instance repetition. In CVPR, 2020.
- [26] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, 2018.
- [27] Ronghang Hu and Amanpreet Singh. Unit: Multimodal multitask learning with a unified transformer. In ICCV, 2021.
- [28] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In CVPR, 2017.
- [29] Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. In ECCV, 2016.
- [30] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei, and Wenyu Liu. Ccnet: Criss-cross attention for semantic segmentation. In ICCV, 2019.
- [31] Ji-Yeon Kim, Hyun-Bin Oh, Dahun Kim, and Tae-Hyun Oh. Mindvps: Minimal model for depth-aware video panoptic segmentation. In IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2023.
- [32] Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision-and-language transformer without convolution or region supervision. In ICML, 2021.
- [33] Kevin Lin, Lijuan Wang, and Zicheng Liu. End-to-end human pose and mesh reconstruction with transformers. In CVPR, 2021.
- [34] Wei Liu, Andrew Rabinovich, and Alexander C Berg. Parsenet: Looking wider to see better. arXiv preprint arXiv:1506.04579, 2015.
- [35] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021.
- [36] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2019.
- [37] Wenjie Luo, Yujia Li, Raquel Urtasun, and Richard Zemel. Understanding the effective receptive field in deep convolutional neural networks. NeurIPS, 2016.
- [38] Xu Ma, Huan Wang, Can Qin, Kunpeng Li, Xingchen Zhao, Jie Fu, and Yun Fu. A close look at spatial modeling: From attention to convolution. arXiv preprint arXiv:2212.12552, 2022.
- [39] Yuxin Mao, Jing Zhang, Zhexiong Wan, Yuchao Dai, Aixuan Li, Yunqiu Lv, Xinyu Tian, Deng-Ping Fan, and Nick Barnes. Transformer transforms salient object detection and camouflaged object detection. arXiv preprint arXiv:2104.10127, 2021.
- [40] Muhammad Muzammal Naseer, Kanchana Ranasinghe, Salman H Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Intriguing properties of vision transformers. In NeurIPS, 2021.
- [41] Namuk Park and Songkuk Kim. How do vision transformers work? In ICLR, 2022.
- [42] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In NeurIPS, 2019.
- [43] Aditya Prakash, Kashyap Chitta, and Andreas Geiger. Multi-modal fusion transformer for end-to-end autonomous driving. In CVPR, 2021.
- [44] Andrew Rabinovich, Andrea Vedaldi, Carolina Galleguillos, Eric Wiewiora, and Serge Belongie. Objects in context. In ICCV, 2007.
- [45] Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks? NeurIPS, 2021.
- [46] Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jon Shlens. Stand-alone self-attention in vision models. NeurIPS, 32, 2019.
- [47] Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? In ICML, 2019.
- [48] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015.
- [49] Jamie Shotton, John Winn, Carsten Rother, and Antonio Criminisi. Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context. IJCV, 81(1):2–23, 2009.
- [50] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2014.
- [51] Robin Strudel, Ricardo Garcia, Ivan Laptev, and Cordelia Schmid. Segmenter: Transformer for semantic segmentation. In CVPR, 2021.
- [52] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In CVPR, 2016.
- [53] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In ICML, 2019.
- [54] Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision. In NeurIPS, 2021.
- [55] Antonio Torralba. Contextual priming for object detection. IJCV, 53(2):169–191, 2003.
- [56] Hugo Touvron, Piotr Bojanowski, Mathilde Caron, Matthieu Cord, Alaaeldin El-Nouby, Edouard Grave, Gautier Izacard, Armand Joulin, Gabriel Synnaeve, Jakob Verbeek, et al. Resmlp: Feedforward networks for image classification with data-efficient training. arXiv preprint arXiv:2105.03404, 2021.
- [57] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve Jegou. Training data-efficient image transformers & distillation through attention. In ICML, 2021.
- [58] Shikhar Tuli, Ishita Dasgupta, Erin Grant, and Thomas L Griffiths. Are convolutional neural networks or transformers more like human vision? arXiv preprint arXiv:2105.07197, 2021.
- [59] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
- [60] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In CVPR, 2018.
- [61] Ross Wightman. Pytorch image models. https://github.com/rwightman/pytorch-image-models, 2019.
- [62] Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. In ECCV, 2018.
- [63] Fisher Yu and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. In ICLR, 2016.
- [64] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regularization strategy to train strong classifiers with localizable features. In ICCV, 2019.
- [65] Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. In ICLR, 2018.
- [66] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In CVPR, 2017.
- [67] Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. In AAAI, 2020.
- [68] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In CVPR, 2017.
- [69] Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ade20k dataset. IJCV, 127(3):302–321, 2019.
A Details of Experiments Setup
This section provides information on datasets and models used in the main paper with hyper-parameters of the training.
A.1 Datasets
ImageNet-1K. ImageNet-1K [48] is the popular large-scale classification benchmark dataset, and the license is custom for research and non-commercial. ImageNet-1K consists of 1.28M training and 50K validation images with 1K classes. We use the training and the validation sets to train and evaluate architectures, respectively.
ImageNet-V2. ImageNet-V2 [47] is new test data for the ImageNet benchmark. Each of the three test sets in ImageNet-V2 comprises 10,000 new images. After a decade of progress on the original ImageNet dataset, these test sets were collected. This ensures that the accuracy scores are not influenced by overfitting and that the new test data is independent of existing models.
ImageNet-ReaL. ImageNet-ReaL [5] develops a more reliable method for gathering annotations for the ImageNet validation set and is under the Apache 2.0 license. It re-evaluates the accuracy of previously proposed ImageNet classifiers using these new labels and finds their gains are smaller than those reported on the original labels. Therefore, this dataset is called the “Re-assessed Labels (ReaL)” dataset.
ADE20K. ADE20K [68, 69] is a semantic segmentation dataset, and the license is custom research-only and non-commercial. This contains over 20K scene-centric images that have been meticulously annotated with pixel-level objects and object parts labels. There are semantic categories, which encompass things like sky, road, grass, and discrete objects like person, car, and bed.
A.2 Models
Dosovitskiy et al. [13] have proposed ViT-B. Touvron et al. [57] have proposed tiny and small ViT architectures named as ViT-Ti and ViT-S. The ViT architecture is similar to Transformer [59] but has patch embedding to make tokens of images. Specifically, ViT-Ti/-S/-B have 12 depth layers with 192, 384, and 768 dimensions, respectively. Heo et al. [23] have proposed a variant of ViT by reducing the spatial dimensions and increasing the channel dimensions. ViTs consist of a patch embedding layer, multi-head self-attention () blocks, multi-layer perceptron () blocks, and layer normalization () layers. Our module is the modification of block. Our module only requires 1 line modification at the end of the layer.
A.3 Hyper-parameters
Touvron et al. [57] have proposed data-efficient training settings with strong regularization, such as MixUp [65], CutMix [64], and random erasing [67]. We adopt the training setting of DeiT [57] and denote ViT-Ti/-S/-B with module. We do not use repeated augmentation for ViT-Ti/-S with ours. For ViT-B with ours, we increase the warmup epochs from 5 to 10 and the drop path. In distillation, we use the same hyper-parameters except for the drop path of ViT-B with ours to 0.2.
B Additional Experiments
This section provides additional experiments we cannot report due to page limitations.

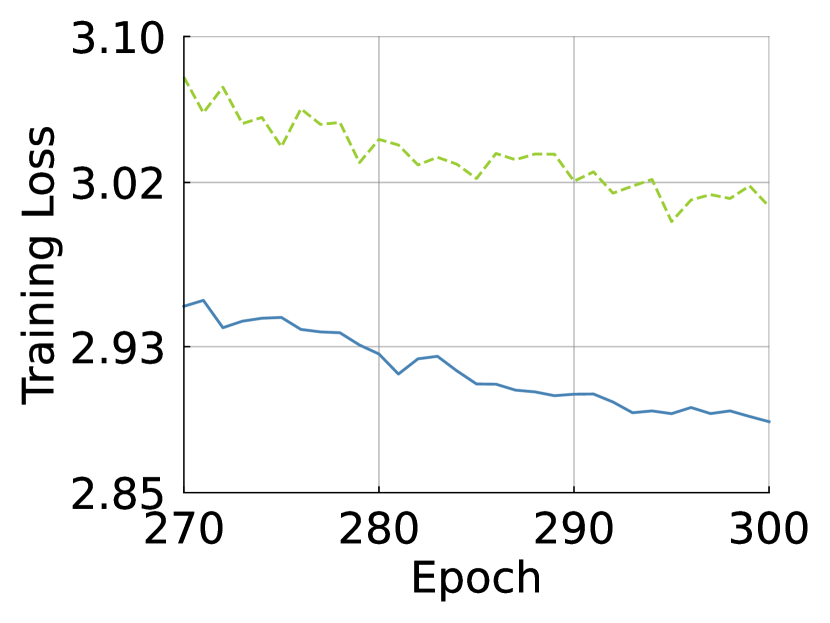
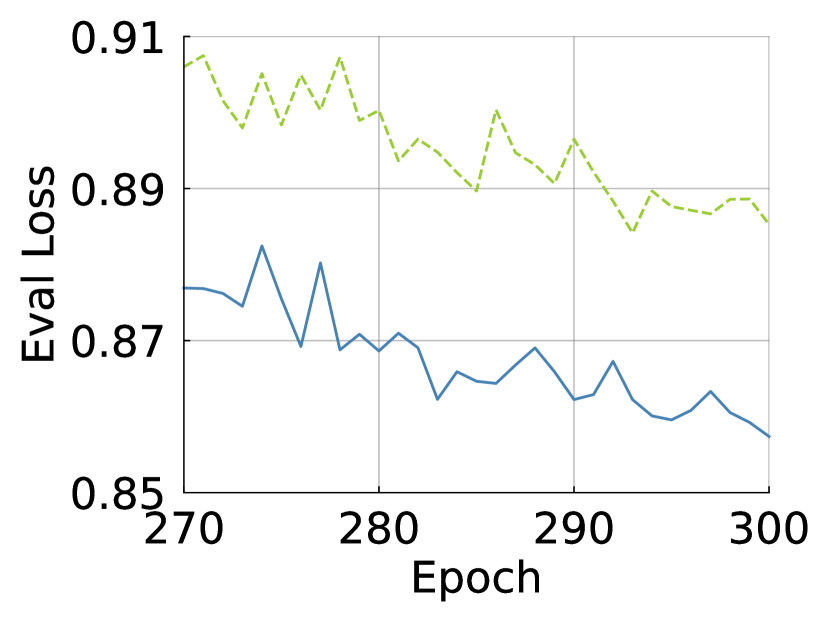
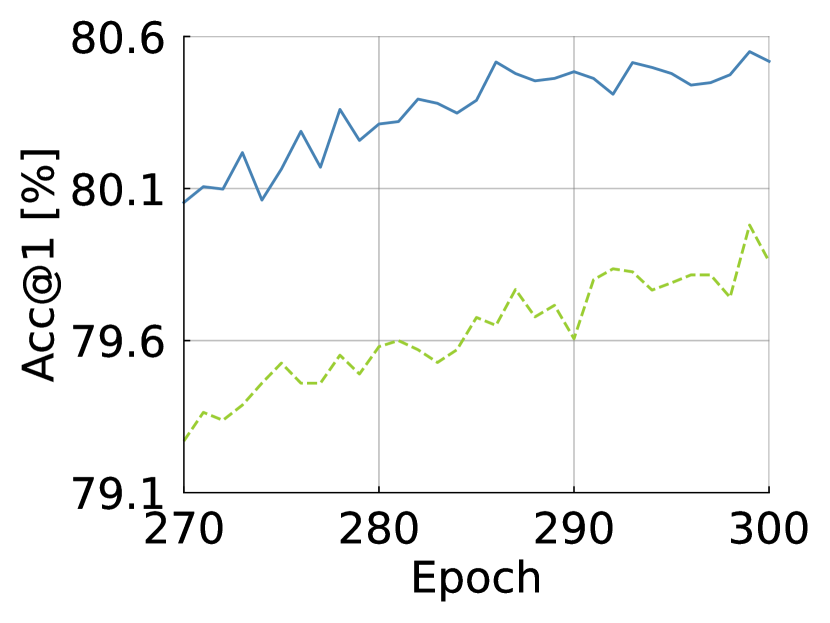
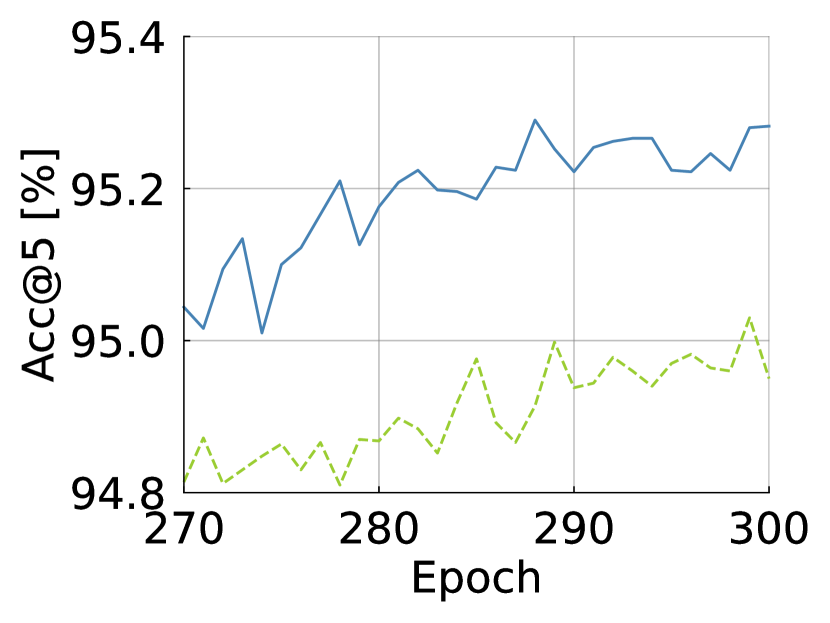
B.1 Training Curve
We draw the training curve to see if improves the capacity and convergence of ViTs. As shown in Fig. S11, increases the top-1/-5 accuracies across epochs and decreases both training and evaluation losses more. The curves show that improves the capacity of ViTs.
| Architecture | # Params [M] | FLOPs [G] | Acc@1 [%] | Acc@5 [%] | IN-V2 [%] | IN-ReaL [%] |
| ViT-Ti |
5.9 | 1.3 | 74.5 | 91.9 | 62.4 | 82.1 |
| 5.9 | 1.3 | 74.7 | 92.3 | 62.5 | 82.3 | |
| 5.9 | 1.3 | 75.3 | 92.5 | 63.4 | 82.8 | |
| ViT-S |
22.4 | 4.6 | 81.2 | 95.4 | 69.8 | 86.9 |
| 22.4 | 4.6 | 81.3 | 95.6 | 70.2 | 87.0 | |
| 22.4 | 4.6 | 81.6 | 95.6 | 70.9 | 87.3 | |
| ViT-B |
87.3 | 17.6 | 83.4 | 96.4 | 72.2 | 88.1 |
| 87.3 | 17.6 | 83.5 | 96.5 | 72.3 | 88.1 | |
| 87.3 | 17.6 | 83.6 | 96.5 | 73.4 | 88.3 |
| Architecture | Occ [%] | ImageNet-A [%] | FGSM [%] |
|
ViT-S |
74.6 | 21.5 | 11.8 |
| 75.1 | 22.6 | 13.0 | |
| 75.1 | 23.6 | 15.5 |
B.2 Distilled Performance
We follow the specification of ViT-Ti/-S from DeiT [57].
As shown in Table S12, our modules and improve performance compared to the distilled ViTs consistently.
Table S13 shows the results of the robustness benchmark in ViT-S![]() .
increases 0.5, 1.1, and 2.2 of Occ, ImageNet-A, and FGSM, respectively.
does 0.5, 2.1, and 4.7, respectively.
.
increases 0.5, 1.1, and 2.2 of Occ, ImageNet-A, and FGSM, respectively.
does 0.5, 2.1, and 4.7, respectively.
B.3 Architecture generalizability.
To show further applicability of our module, We compare PVT, LocalViT-Ti, PVTv2, and Swin trained w/ and w/o ours on ImageNet-1K; we set the default epochs to 120.444We set 150 epochs for LocalViT. PVT uses a pyramid structure as CNN backbones, LocalViT-Ti puts the convolution layer (local operation), PVTv2 is the improved version of the PVT placing convolutional layer, and Swin employs a hierarchical structure and local attention. Table S14 shows that our module consistently improves performance.
| Model | Hierarchy | Local | ACC@1[%] |
| PVT-S | ✓ | 76.7 | |
| + Ours | ✓ | 77.3 | |
| LocalViT-Ti | ✓ | 69.4 | |
| + Ours | ✓ | 72.5 | |
| PVTv2-B1 | ✓ | ✓ | 76.4 |
| + Ours | ✓ | ✓ | 76.5 |
| Swin-Ti | ✓ | ✓ | 79.3 |
| + Ours | ✓ | ✓ | 79.5 |
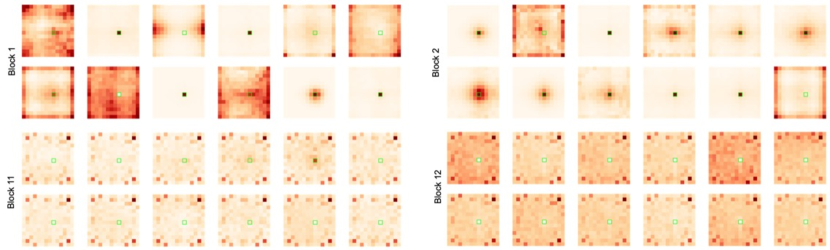

B.4 Discussion on Attention Visualization
The visualization of the attention map is not the first attempt. As shown in Fig. S12, He et al. [18] and Ma et al. [38] visualized the attention across layers or architectures. He et al. [18] reported that the deeper layers attend the dense global regions, and shallow layers attend the sparse local regions in DeiT-B. Ma et al. [38] reported that the attention weights are sparse in DeiT-B compared to DeiT-B-Distill. Despite the fact that they analyze the same architecture, DeiT-B, He et al. and Ma et al. argued the different statements on sparsity. They use different criteria depending on what they want to compare in relative ways. Thereby, it has been open discussion in the community about sparsity characteristics of attention maps in Transformers due to those subjective visualization-based analyses.
Based on the visualization, the statements of He et al. and Ma et al. are conditional on the reference of an attention visualization. These conditional statements can be changed by choosing a different reference; thus, our observation is not contrary to theirs. To compare more general ways, we employ an objective measure, i.e., entropy measure; high entropy implies dense interactions and vice versa. It is our contribution. Our entropy analysis in Sec. 3 supports the visualization (Fig. 10), where lowers the entropy and helps attend to more informative signals.
| Architecture | Accuracy |
| ViT-S | 74.73 |
| + | 75.43 |
B.5 Classification on CIFAR-100
We train ViT-S from scratch on CIFAR-100. CIFAR-100 consists of 50,000 training and 10,000 validation images with 100 classes. Table S15 shows the accuracy on CIFAR-100. improves the performance by 0.7%p more.
B.6 Discussion on Position of
We conclude the position of to the end of the block. We provide our intuition and discussion about Table 3-(b), which shows performance depends on position in the block.
Gradient signals.
We think that the gradient signals are dependent on the position of . For simplicity, we assume a single layer composed of the and block. Let the layer consist as follows: .
-
•
Case 1, : If is located at , the subsequent weights in the corresponding block cannot receive the gradient signals during training.
-
•
Case 2, : If is located at , the preceding weights in the block are updated by the gradient signals by uniform attention.
Why is the improvement of and similar?
There is no non-linear function (e.g., GELU) between and positions. Since uniform attention is the addition of a globally averaged token, the output is identical wherever is located at and . Therefore, the accuracy of both positions is similar. Nonetheless, at achieves a bit higher top-5 accuracy than at . As aforementioned, we suspect the position provides the gradient induced by uniform attention to weights of the MLP block.
| Module | Position | FLOPs [M] | Acc@1 [%] | Acc@5 [%] | |
| ViT-S | ✗ | ✗ | 1260 | 79.9 | 95.0 |
| + | ✓ | ✗ | +0.9 | 80.5 | 95.3 |
| ✗ | ✓ | +0.9 | 80.1 | 95.0 | |
| ✓ | ✓ | +1.8 | 80.1 | 95.0 | |
| + | ✓ | ✗ | +0.9 | 80.4 | 95.1 |
| ✗ | ✓ | +0.9 | 80.0 | 95.0 | |
| ✓ | ✓ | +1.8 | 80.0 | 95.0 | |
| + | ✓ | ✗ | +1.8 | 80.5 | 95.0 |
| ✗ | ✓ | +1.8 | 80.4 | 95.3 | |
| ✓ | ✓ | +3.6 | - | - | |
| Module | Position | FLOPS [M] | Acc@1 [%] | Acc@5 [%] | ||
| ViT-S | ✗ | ✗ | ✗ | 1260 | 79.9 | 95.0 |
| + | ✓ | ✗ | ✗ | +0.9 | 79.9 | 94.8 |
| ✗ | ✓ | ✗ | +3.6 | 80.5 | 95.2 | |
| ✗ | ✗ | ✓ | +0.9 | 80.5 | 95.3 | |
| + | ✓ | ✗ | ✗ | +0.9 | 80.3 | 94.9 |
| ✗ | ✓ | ✗ | +3.6 | 80.2 | 95.1 | |
| ✗ | ✗ | ✓ | +0.9 | 80.4 | 95.1 | |
| + | ✓ | ✗ | ✗ | +1.8 | 80.5 | 95.0 |
| ✗ | ✓ | ✗ | +7.3 | 80.1 | 95.1 | |
| ✗ | ✗ | ✓ | +1.8 | 80.3 | 95.0 | |
B.7 Utilizing the Class Token
Since the class token evolves by interacting with entire tokens for tasks, we think that the class token could be utilized to complement spatial interactions of attention. We propose two additional baselines employing the class token.
The first one is the multiplication of the class token with each visual token, similar to the gating mechanism. We denote the first as and formalize it as follows: , where is the class token and is one vector. The second one is the combination of the class and average token denoted as : . These modules are also parameter-free and computation efficient.
Firstly, we analyze the positions of and ; we locate the modules at the end of blocks. Table S16 lists FLOPs and validation accuracy of and . Both and improve the top-1 accuracy regardless of positions except for the failure case of at both and layers. These modules have the best top-1 accuracy at , consistent with our module.
We investigate different positions in an layer with and . Table S17 lists FLOPs and validation accuracies of , , and . The best accuracy occurs at for our module and and for . At the best positions of respective modules, our module achieves 0.1%p higher top-1 accuracy than and demands half of the FLOPs than .