SDRTV-to-HDRTV via Hierarchical Dynamic Context Feature Mapping
Abstract.
In this work, we address the task of SDR videos to HDR videos(SDRTV-to-HDRTV conversion). Previous approaches use global feature modulation for SDRTV-to-HDRTV conversion. Feature modulation scales and shifts the features in the original feature space, which has limited mapping capability. In addition, the global image mapping cannot restore detail in HDR frames due to the luminance differences in different regions of SDR frames. To resolve the appeal, we propose a two-stage solution. The first stage is a hierarchical Dynamic Context feature mapping (HDCFM) model. HDCFM learns the SDR frame to HDR frame mapping function via hierarchical feature modulation (HME and HM ) module and a dynamic context feature transformation (DYCT) module. The HME estimates the feature modulation vector, HM is capable of hierarchical feature modulation, consisting of global feature modulation in series with local feature modulation, and is capable of adaptive mapping of local image features. The DYCT module constructs a feature transformation module in conjunction with the context, which is capable of adaptively generating a feature transformation matrix for feature mapping. Compared with simple feature scaling and shifting, the DYCT module can map features into a new feature space and thus has a more excellent feature mapping capability. In the second stage, we introduce a patch discriminator-based context generation model PDCG to obtain subjective quality enhancement of over-exposed regions. PDCG can solve the problem that the model is challenging to train due to the proportion of overexposed regions of the image. The proposed method can achieve state-of-the-art objective and subjective quality results. Specifically, HDCFM achieves a PSNR gain of 0.81 dB at about 100K parameters. The number of parameters is 1/14th of the previous state-of-the-art methods. The test code will be released soon.

1. Introduction
High Dynamic Range (HDR) video allows for a more realistic display and reproduction of the natural world. HDR video has a higher bit depth, wider color range, and higher brightness per pixel. Although HDR display device technology is now widely available and HDR video has many advantages, most video sources are still stored in Standard Dynamic Range (SDR) format. Therefore, converting many existing SDR videos to HDR videos can dramatically improve the user experience.
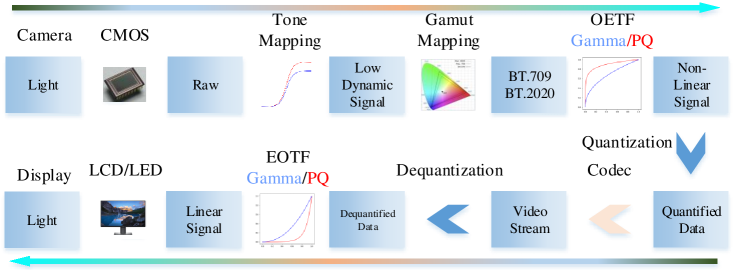
We present the process of SDR/HDR video content acquisition and playback in Fig.2. From the moment light enters the camera to the playback of the video image using the monitor, it goes through the following stages: 1) convert the light signal into a digital signal through CMOS; 2) reduce the high dynamic digital signal to a low dynamic signal by Tone Mapping(Mantiuk et al., 2008); 3) transfer the image color to the target color gamut by Gamut mapping; 4) convert linear signal to nonlinear signal by OETF (PQ, 2014; Nagata et al., 2017) ; 5) quantize digital signal and arithmetic coding(Rissanen and Langdon, 1979); 6) encode and decode by codec(Chen et al., 2018; Sullivan et al., 2012); 7) convert the decoded nonlinear signal to a linear digital signal by EOTF; 8) convert the linear signal to an optical signal for playback. The main difference between SDR and HDR is using different EOTF(Electro-Optical Transfer Function) and OETF(Optical-Electro Transfer Function).
To distinguish SDR video to HDR video from the SDR image to HDR image task, we follow the definition of method (Chen et al., 2021) and define SDR video to HDR video as SDRTV-to-HDRTV conversion. LDR-to-HDR (LDR image to HDR image) refers to the conversion of SDR image to HDR image. HDR images can play on display devices by tone mapping. The previous approach (Kim et al., 2019a, 2020a) united super-resolution with SDRTV-to-HDRTV conversion, and tried to build a pipeline from low-resolution SDR video to high-resolution HDR video. HDRTVNET(Chen et al., 2021) proposed a multi-stage scheme to complete SDRTV-to-HDRTV conversion by global tone mapping, local image enhancement, and image generation.
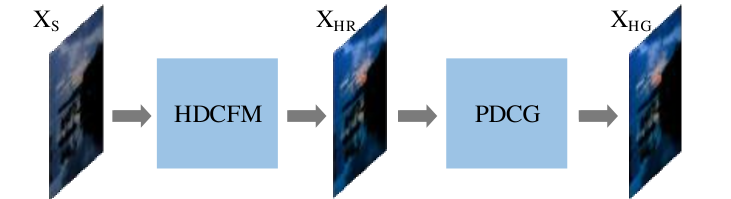
In the SDRTV-to-HDRTV conversion, the most crucial issue is to map the SDR features to the HDR feature domain, which is called feature mapping in this paper. The second issue is generating information on over-exposure areas that do not exist in SDR. An SDR video to HDR video conversion pipeline is constructed to address these two issues. The pipeline is divided into two parts, Hierarchical Dynamic Context Feature Mapping model (HDCFM) and a Patch discriminator-based Dynamic Context Generation network(PDCG). The first part obtains HDR frames with superior objective quality by feature mapping, and the second part accomplishes over-exposure area image enhancement.
Specifically, HDCFM contains the Hierarchical feature Modulation vector Estimation (HME) module, Hierarchical Modulation (HM) module, and Dynamic Context feature Transformation (DYCT) module. For HME, we construct a hierarchical modulation vector estimation module that captures the global and local image prior to estimating the global and local feature modulation vectors. For HM, the global and local modulation vectors estimated by HME are used to modulate the input features. Such feature modulation enables adaptive mapping of local images in different regions of different frames. For DYCT, we propose the joint context local feature transformation module to extract image context information and accomplish local feature transformation by dynamic convolution. HDCFM can complete feature mapping and obtain HDR frames based on the above structure. The proposed HDCFM has two advantages over the previous methods. The first is that the proposed HM and HME can perform spatially adaptive mapping using image local information. In addition, the proposed DYCT module models a more robust dynamic feature transformation: the ability to transform features directly to a new feature space instead of the previous simple feature scaling and shifting. This dramatically enhances the mapping performance of the model. Thus, a more complex mapping process can be modeled to map SDR frames to HDR frames better. For PDCG, a Patch GAN with an over-exposure mask is proposed, which can generate over-exposure region image information to obtain the higher subjective quality of HDR frames. The proposed HDCFM with a smaller number of parameters can obtain the best conversion performance. In order to compare with previous methods, we selected five evaluation metrics PSNR, SSIM, SR-SIM(Kim et al., 2019a), and HDR-VDP3(Mantiuk et al., 2011) to evaluate the proposed method.
In summary, our contributions include the following main points.
-
•
We propose a hierarchical feature modulation module that can perform spatially adaptive feature modulation on image features; local feature modulation can improve the quality of HDR reconstructed frames.
-
•
We propose a dynamic feature transformation method that can further improve the feature mapping capability of the model to obtain higher quality HDR converted frames.
-
•
We analyzed the problem of over-exposure in the SDRTV-to-HDRTV conversion. Propose a Patch discriminator-based over-exposure image generation model that can obtain a higher subjective quality HDR frame.
-
•
With about 100K parameters, the proposed method can obtain state-of-the-art results compared to previous methods.
2. Related work
Converting previous SDR videos to HDR videos is a valuable task. More and more researchers are focusing on this topic. There are several main methods for SDR to HDR conversion as follows. 1) Multi-exposure SDR images to single-frame HDR images. 2) single-frame SDR image to single-frame HDR image. 3) SDR video to HDR video. Our goal is to convert SDR video that already existed to HDR video.
LDR-to-HDR. The traditional method estimates the light source density, based on which the dynamic range is further expanded (Akyüz et al., 2007; Banterle et al., 2009, 2008; Marnerides et al., 2021). Researchers have proposed a method based on deep convolutional neural network (Liu et al., 2020a) to convert LDR images to HDR images directly. HDRCNN(Eilertsen et al., 2017; Liu et al., 2020b; Santos et al., 2020a) propose method that can recover the over-exposure area of the image. (Lee et al., 2018, 2018; Debevec and Malik, 1997; Yan et al., 2020; Niu et al., 2021) proposed methods can predict multi-exposure LDR image pairs by a single LDR image, then synthesize HDR images based on the predicted multi-exposure image pairs.
SDRTV-to-HDRTV conversion. The SDRTV-to-HDRTV conversion approach has only emerged in the last two years. (Kim et al., 2019a) proposes a GAN-based architecture that jointly achieves super-resolution and SDTV to HDRTV. (Kim et al., 2020a) proposes a hierarchical GAN architecture to accomplish super-resolution and SDRTV to HDRTV. (Chen et al., 2021) proposed a method using global feature modulation, local enhancement, and over-exposure compensation, which achieved the best performance.
Dynamic Convolution The vanilla convolutional layer learns the parameters of the convolutional kernel through big data during training. The parameters of the convolution kernel are fixed during the inference phase and do not change for different inputs; such a convolution kernel is also called a static convolution kernel. Dynamic convolution, meaning that the convolution kernel parameters are dynamically updated during the inference phase, allows the model to extract more complex features and build complex pattern recognition methods. Current researchers focus on how to construct dynamic convolution kernels (Brabandere et al., 2016; Zhou et al., 2021).
Context Convolution In convolutional neural networks, context extraction aims to extract the correlation between the current location features and the global features, thus improving the modeling capability. To extract non-local information from images (Wang et al., 2018) proposes a non-local generic module to complement the long-range dependencies to capture the global context information. (Cao et al., 2019) finds that the global relevance information obtained from different locations during non-local modeling is almost the same. Therefore, a generic feature aggregation module is proposed to extract global feature information directly instead of global relevance for each feature element. Such a modeling approach dramatically reduces the computational cost and improves the feature extraction performance.
Patch GAN The Generative Adversarial Networks (GAN) model (Goodfellow et al., 2014; Metz et al., 2017; Karras et al., 2018; Tolosana et al., 2020; Wang et al., 2020; Gui et al., 2021) has been widely used in the field of image generation in recent years, thanks to its unique architecture design. Patch GAN(Isola et al., 2017a) improves the clarity of the generated images, enabling higher resolution images. In this paper, the Patch discriminator can solve the problem of low model performance caused by the low proportion of over-exposure region.
3. Methodology
3.1. Framework
SDR frames to HDR frames can be modeled as a feature mapping and feature complement process. For this purpose, we propose a two-stage solution. The first stage converts SDR frames to HDR frames by a Hierarchical Dynamic Context Feature Mapping model HDCFM. The second stage uses a Patch discriminator-based Dynamic Context Generation model PDCG to complete the over-exposure enhancement and obtain HDR frames with higher subjective quality. The framework of the whole scheme is shown in Fig.3 and Formula (1). The main challenge of the SDRTV-to-HDRTV conversion is that the data distribution of SDR frames differs significantly from that of HDR frames and that SDR frames store less information(There are overexposure problems). is the over-exposure area mask calculated similarly as (Santos et al., 2020b). The specific motivation and architecture of each module will be described next.
| (1) | ||||
3.2. HDCFM
In this part, to transform SDR frame to HDR frame , we construct HDCFM, which can achieve the instance-space adaptive feature mapping method in the image feature space. Specifically, HDCFM can perform different feature mapping for different input and pixels at different spatial locations in the input image. A locally adaptive image feature mapping model is constructed, which can obtain high quality HDR frames.
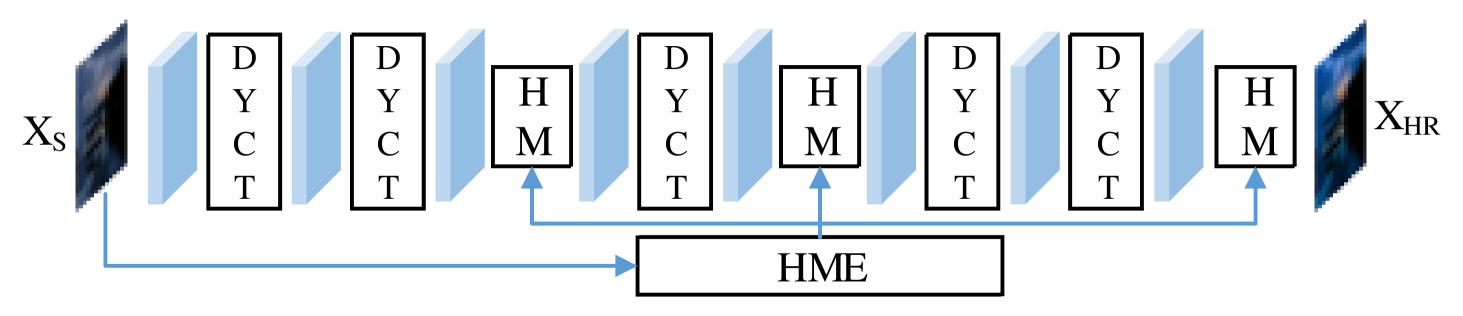
The critical point 1 of HDCFM is the hierarchical feature modulation vector estimation module HME and the hierarchical feature modulation module HM, which can accomplish hierarchical global and local feature modulation. Essentially, the SDR image features are scaled and shifted in the feature space to obtain features closer to HDR images. The critical point 2 of HDCFM lies in the dynamic feature transformation module DYCT of context features, which can accomplish dynamic feature transformation (matrix transformation). The structure of HDCFM is shown in Fig.4. The motivation and methodology of these two points will introduce next.
3.2.1. Motivation of Feature Mapping
The feature extracted from SDR video frame is in SDR feature space, and the feature extracted from HDR video frame is in HDR feature space, so SDRTV- to-HDRTV conversion can be modelled as a feature mapping. For the input SDR frame , the low dynamic feature is first obtained by convolution, and then needs to be mapped to the high dynamic feature , and finally is recovered to the image space. The feature mapping proposed in this paper consists of two parts, which are hierarchical feature modulation and local feature transformation.
3.2.2. Motivation of HM
During SDRTV-to-HDRTV conversion, pixels at different spatial locations need to be processed differently. For example, in one frame, there are both over-exposed and under-exposed areas, then different processing should be performed on the both under-exposed and over-exposed image area. To address this problem, we design HM composed of global feature modulation and local feature modulation. The global feature modulation can make macro adjustments to the image, and the local feature modulation can further complete the local fine-tuning.
3.2.3. Architecture of HM
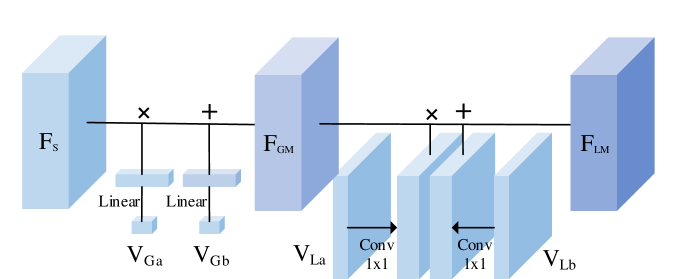
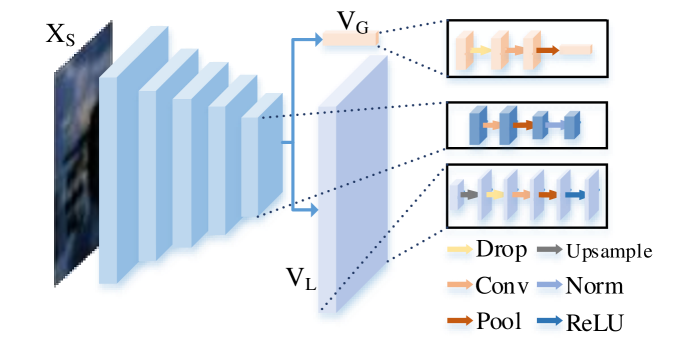
To obtain spatially adaptive feature modulation vectors, our HDCFM constructs a joint global and local hierarchical modulation vector estimation module HME. HME can predict not only the global feature modulation vectors , , but also the local feature modulation vectors , ; this gives the ability to perform different feature modulations on image features at different spatial locations. The structure of HM is shown in Fig.5. Then comes calculating the feature modulation vector by the HME module. Specifically, for the input , is obtained after five downsamples. goes through the global downsample to obtain and . passes through the upsample to obtain and . Such a calculation process is shown in Fig.6. Next, the feature modulation of is performed using HM. The HM is divided into two steps. The first step uses the global modulation parameter to dot-multiply , followed by adding the features after point multiplication using . The second step uses the local modulation parameter to dot-multiply , followed by to sum the dot-multiplied features.
3.2.4. Motivation of the DYCT Module
. The core of DYCT (Dynamic Context Feature Transformation module) is feature transformation. Firstly, we introduce the difference between feature modulation and feature transformation. Feature modulation: The modulated feature layer is obtained by dot multiplying the feature layer by the modulation vector, a simple feature mapping that only scales and shifts the features in the original feature space. So it can model a relatively single mapping process. This modeling process is shown in Fig.5. Feature transformation: feature transformation (matrix multiplication) of the input features can transform from the original feature space to the new feature space. This modeling approach has a much more robust feature mapping capability. Therefore, we propose to build a feature mapping module based on feature transformation. It can model a more complex feature mapping process and thus able to obtain better HDR transformed frames.
3.2.5. Modeling Process of the DYCT Module
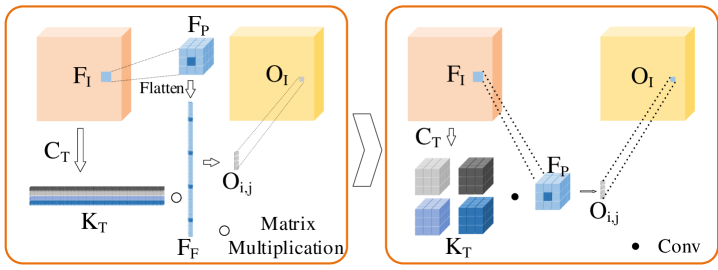
. We begin with an introduction to the local feature transformation module, as shown in the left part of Fig.7, for the local feature (with shape ) of input , is flattened to a vector of (). At the same time, we need a conditional generation module to predict the parameters of the feature transformation (in shape ). Next, is subjected to a matrix multiplication operation with , which in algebra is called the linear feature transformation, and finally, the transformed feature (with shape ) is obtained.
To further analyze the process of feature transformation, we can use the local feature transformation in convolution specific implementation form. As shown in the right Fig.7, for the input local feature , convolution kernels of shape are needed to convolve with . The output is , where is generated online by the module when inference is needed. is the number of channels in the input feature layer. We continue to analyze the generation of . In a practical application, the resolution of the input image is (), and the size of the input feature layer of the local feature transform is (). For each pixel, convolution kernels are predicted, and the shape of each convolution kernel is . The number of parameters for all convolution kernels is ( ). The total number of parameters in the 4K image processing task is , directly leading to memory out.
| Methods | Params | PSNR | SSIM | SR-SIM | HDR-VDP3 | |
| HuoPhyEO(Huo et al., 2014)TVC | - | 25.90 | 0.9296 | 0.9981 | 38.06 | 7.893 |
| Kovaleski(Kovaleski and Oliveira, 2014)SIBGRAPI | - | 27.89 | 0.9273 | 0.9809 | 28.00 | 7.431 |
| ResNet(He et al., 2016)ECCV16 | 1.37M | 37.32 | 0.9720 | 0.9950 | 9.02 | 8.391 |
| Pixel2Pixel(Isola et al., 2017b)CVPR17 | 11.38M | 25.80 | 0.8777 | 0.9871 | 44.25 | 7.136 |
| CycleGAN(Zhu et al., 2017)ICCV17 | 11.38M | 21.33 | 0.8496 | 0.9595 | 77.74 | 6.941 |
| HDRNET(Gharbi et al., 2017)TOG | 482K | 35.73 | 0.9664 | 0.9957 | 11.52 | 8.462 |
| CSRNET(He et al., 2020)ECCV20 | 36K | 35.04 | 0.9625 | 0.9955 | 14.28 | 8.400 |
| Ada-3DLUT(Zeng et al., 2020)TPAMI | 594K | 36.22 | 0.9658 | 0.9967 | 10.89 | 8.423 |
| Deep SR-ITM(Kim et al., 2019b)ICCV19 | 2.87M | 37.10 | 0.9686 | 0.9950 | 9.24 | 8.233 |
| JSI-GAN(Kim et al., 2020b)AAAI20 | 1.06M | 37.01 | 0.9694 | 0.9928 | 9.36 | 8.169 |
| HDRTVNET(Chen et al., 2021)ICCV21 | 1.41M | 37.61 | 0.9726 | 0.9967 | 8.89 | 8.613 |
| HDCFM(Proposed) | 100.63K | 38.42 | 0.9732 | 0.9974 | 7.83 | 8.5716 |
| (2) | ||||
3.2.6. Architecture of the DYCT Module
. This paragraph will introduce the specific architecture of the DYCT. To solve memory out, we borrow the idea of decoupled dynamic convolution kernels. The architecture of the whole DYCT module is shown in Fig.8. The specific process is as follows. Decompose the original convolution kernel into a combination of spatial convolution kernel (K,K,H,W) and channel convolution kernel (C,K,K), and generated by and respectively, the computation process of and is define in Formula(2). After obtaining and , the output feature layer is obtained by convolving through the decoupling convolution method proposed by (Zhou et al., 2021). During the convolution of dynamic filters, the convolution kernel weights are obtained in real-time by sample inference. This can enhance the feature mapping capability of the model. This is a convolutional implementation of the feature transformation.
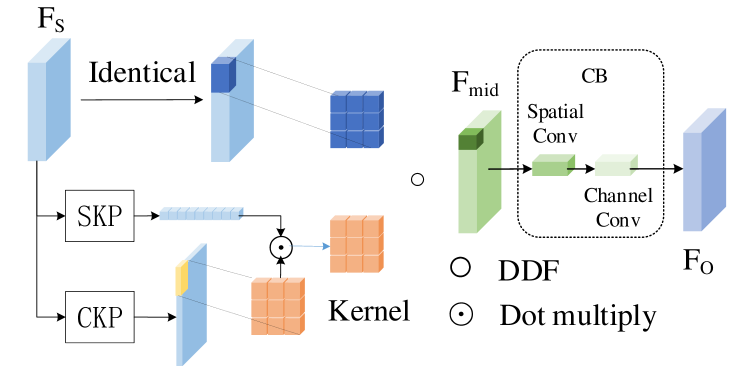
It is worth noting that only local feature transformations may lead to large differences in the transformed results for image contents that have the same color in different regions. Therefore, this paper uses a context module to count the overall feature context information and fine-tune the features. In this part, we choose the context information module proposed by (Cao et al., 2019), input to , and the output result is the final output of the DYCT module. The structure of and is similar to (Cao et al., 2019), using DDF convolution instead of vanilla convolution. This module has the advantage of being computationally small, and the computation procedure is given in Formula(2).
3.3. PDCG
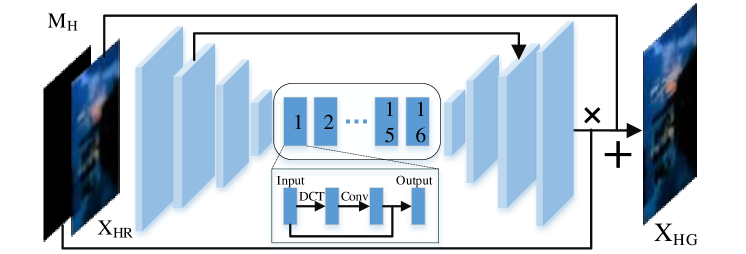
The objective quality of generated by HDCFM is very high, but still suffers from the problem of missing over-exposure information. The problem of loss of over-exposure information can cause large bright spots or even wrong colors in HDR reconstructed frames. To be able to generate over-exposure region image information, we propose the PDCG model, the structure of PDCG is shown in Fig. 9. The generation method of the over-exposure section is formally defined in Formula(3), and the mask of the over-exposure section is defined as . We input the preliminary results generated by HDCFM into the PDCG model. After three convolutions with a stride of 2, the resolution of the feature layer is reduced, and are obtained. is input into 16 blocks in series. Each block contains a DYCT module, a vanilla convolution, and a skip connection. Then perform an upsampling to obtain , add and , and continue to upsample twice to obtain the final . The entire architecture of PDCG is shown in Fig.9. We use a loss function with loss, perceptual loss , and adversarial loss combined. The definition of joint loss is shown in Formula(4), and , and are taken as 1.0, 0.5, 0.005 respectively. We use the pre-trained VGG19(Simonyan and Zisserman, 2014) on ImageNet1000(Russakovsky et al., 2015) to compute the perceptual loss, which improves the subjective quality of the reconstructed frames. Since the perceptual loss is more dependent on the model structure (Liu et al., 2021), the model trained on Imagnet to compute the perceptual loss of HDR video frames is still valid. Since the percentage of highlight regions is deficient, we use Patch-based adversarial loss to generate realistic over-exposure image.
| (3) |
| (4) |
4. Experiment


4.1. Experiment Settings
Dataset. For a fair comparison with previous methods, we use the dataset used by (Chen et al., 2021) captured HDR and SDR versions of each video; each HDR video was HDR10 with BT.2020 color gamut. Frames from the videos were extracted using FFMPEG, cropping the images to 480x480 size. 117 pairs of unduplicated images were included in the test set, each at 4K in size.
Training Setup. In the model’s training process, we use L1 as the loss function to optimize the HDCFM model. The Adam optimizer is used, the initial learning rate is set to 0.0005, and the learning rate is set to 1/2 of the initial rate every 200000 iterations; the total number of iterations is set to 1000000.
Evaluation Setup. To verify the effectiveness of the proposed method, we evaluate the effectiveness of the proposed method on the evaluation index of PSNR, SSIM, SR-SIM , and HDR-VDP3.
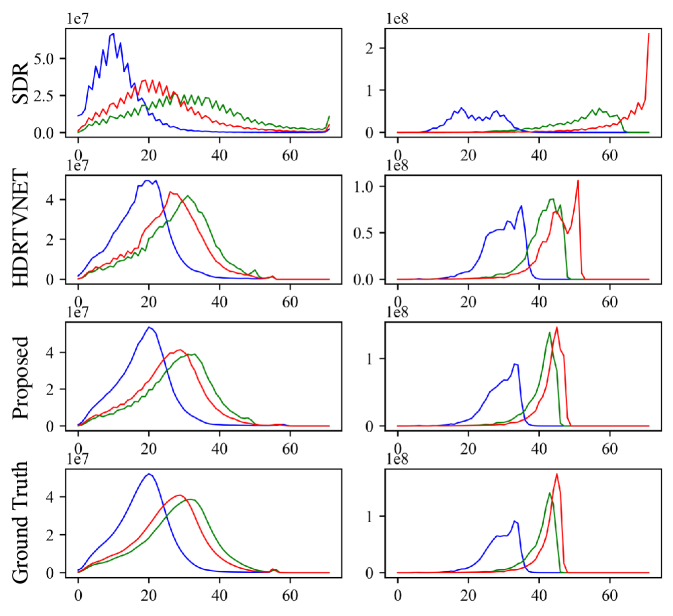

4.2. Experiment Results
Qualitative and Quantitative Results. We first compare our method in Table.1 to compare with other methods in PSNR, SR-SIM, SSIM, ,HDR-VDP3. PSNR (Peak Signal to Noise Ratio) can measure the pixel value difference between images. SSIM (Structural Similarity Index Measure) evaluates the structural similarity of two images. SR-SIM is able to evaluate the image similarity of HDR standard images. can evaluate the colour difference of HDRTV. HDR-VDP3 can assess image visual difference. Compared to HDR-VDP2, HDR-VDP3 supports the BT.2020 gamut. The test results were calculated on 117 images with a resolution of 2160x3840. We calculate HDR-VDP3 scores on linear HDR images. As Table.1, our method produces significantly better objective results, which indicates the ability of our network to accurately reconstruct HDR frames. To demonstrate the visual effect of the proposed method, we directly save the 16bit bit-depth image in PNG format, which is able to preserve all image information despite the fact that such a saving method will gray out the image. Another method is to convert 16bit to 8bit using tone mapping, but this conversion removes some overexposed areas, so the result of generating overexposed areas between different methods cannot be shown. The direct visualization method preserves all the details and the visualization results are displayed in Fig.1 and Fig.10. We also demonstrate in Fig.10 that our proposed method can construct adaptive feature mappings for localities, thus mitigating to some extent the quality degradation caused by overexposure. It can be seen that the previous method is unable to construct adaptive mapping for local images, and the HDCFM proposed in this paper is able to generate HDR frames with higher quality.
In addition, as shown in the lower right corner of Fig.11, HDCFM cannot perfectly recover the details of HDR frames when the input SDR image is overexposed due to tone mapping. Nevertheless, our results are still an improvement compared to previous state-of-the-art methods.
To further analyze the performance of the proposed method, we calculated the histogram of the generated HDR video frames. The pixel intensity distribution of the HDR video frames generated by the proposed method is closer to the ground truth, and the pixel intensity distribution is smoother. As shown in Table.1, the proposed model HDCFM outperforms the past method approach in all evaluation metrics. And the number of parameters of the HDCFM model is much smaller than that of the past method.
| M0 | M1 | M2 | M3 | M4 | PSNR | SSIM | SR-SIM | |
|---|---|---|---|---|---|---|---|---|
| ✓ | ✗ | ✗ | ✗ | ✗ | 36.88 | 0.9655 | 9.78 | 0.9967 |
| ✓ | ✓ | ✗ | ✗ | ✗ | 37.74 | 0.9705 | 8.85 | 0.9972 |
| ✓ | ✓ | ✓ | ✗ | ✗ | 38.20 | 0.9725 | 8.06 | 0.9972 |
| ✗ | ✓ | ✓ | ✓ | ✗ | 38.26 | 0.9729 | 7.90 | 0.9973 |
| ✓ | ✓ | ✓ | ✓ | ✓ | 38.42 | 0.9732 | 7.83 | 0.9974 |
Ablation Study. We performed ablation experiments on the whole model to demonstrate the effectiveness of each module of the proposed method. Table 2 shows the performance of the SDRTV-to-HDRTV transformation after the addition of different modules. M0, M1, M2, M3, M4 refer to Global Feature Modulation , Local Feature Transformation , Context Convolution, Local Feature Modulation, and Hierarchical Local Feature Modulation. With the addition of Local Feature Transformation, the objective quality is improved due to the new feature transformation method, which can model more complex color feature transformations, PSNR and SSIM are improved by 0.86 and 0.005, respectively, and is reduced by 0.93. With the addition of Context Convolution, the model captures the remote context information to extract features, and the corresponding PSNR and SSIM are improved by 1.32 and 0.007, respectively, and is reduced by 1.72. By using Local Feature modulation instead of Global Feature modulation, the model can generate local feature modulation vectors, allowing different feature modulations to be applied to different regions of the same image. This approach improves the PSNR and SSIM metrics by 1.38 and 0.0074, respectively, and reduces by 1.88. After adding the combined local and global Hierarchical Local Feature Transform, the model can perform both global and local feature modulation, and the corresponding PSNR, SSIM is improved by 1.54 and 0.0077, respectively, and is reduced by 1.95.
The proposed PDCG module is capable of generating more realistic HDR reconstruction frames that are capable of generating subjective and comfortable images of over-exposure areas. In Fig.13 we show the comparison images of the results generated by the proposed method. In areas where the content is saturated and over-exposed (the sun part and the flame part), PDCG can address the existing artifacts and overexposure problems. Therefore, HDCFM uses the overexposed content for feature mapping, and the resulting HDR frame still has overexposure. PDCG can dynamically restore HDR frames in overexposed areas, so as to obtain HDR frames with higher subjective quality.
5. Conclusion
For standard dynamic range (SDR) to high dynamic range(HDR) video. Previous methods performed global conversion of HDR frames without taking into account local information and the quality of HDR frames in overexposed areas during conversion. In this paper, we proposed a two-stage SDRTV to HDRTV scheme to address these two problems. In the first stage, a feature mapping model is proposed. Proposed method can perform non-consistent mapping for image local information, and the proposed dynamic feature transformation module is able to simulate more complex feature mapping. The converted HDR frames have a higher objective quality. In the second stage, a patch discriminator and a context-based dynamic image generation model are constructed for overexposed areas. The patch discriminator can solve the problem that the model is difficult to train due to the low percentage of highlight areas. This model can improve the subjective quality of the reconstructed frames. Comprehensive experiments show that the proposed method achieves the best performance in both objective and subjective quality.
References
- (1)
- PQ (2014) 2014. ST 2084:2014 - SMPTE Standard - High Dynamic Range Electro-Optical Transfer Function of Mastering Reference Displays. ST 2084:2014 (2014), 1–14. https://doi.org/10.5594/SMPTE.ST2084.2014
- Akyüz et al. (2007) Ahmet Oǧuz Akyüz, Roland W. Fleming, Bernhard E. Riecke, Erik Reinhard, and Heinrich H. Bülthoff. 2007. Do HDR displays support LDR content?: a psychophysical evaluation. In International Conference on Computer Graphics and Interactive Techniques.
- Banterle et al. (2009) Francesco Banterle, Kurt Debattista, Alessandro Artusi, Sumanta Pattanaik, Karol Myszkowski, Patrick Ledda, Marina Bloj, and Alan Chalmers. 2009. High Dynamic Range Imaging and Low Dynamic Range Expansion for Generating HDR Content.. In Eurographics.
- Banterle et al. (2008) Francesco Banterle, Patrick Ledda, Kurt Debattista, and Alan Chalmers. 2008. Expanding low dynamic range videos for high dynamic range applications. In Spring Conference on Computer Graphics.
- Brabandere et al. (2016) Bert De Brabandere, Xu Jia, Tinne Tuytelaars, and Luc Van Gool. 2016. Dynamic Filter Networks. arXiv:1605.09673 [cs.LG]
- Cao et al. (2019) Yue Cao, Jiarui Xu, Stephen Lin, Fangyun Wei, and Han Hu. 2019. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. 0–0.
- Chen et al. (2021) Xiangyu Chen, Zhengwen Zhang, Jimmy S. Ren, Lynhoo Tian, Yu Qiao, and Chao Dong. 2021. A New Journey From SDRTV to HDRTV. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 4500–4509.
- Chen et al. (2018) Yue Chen, Debargha Murherjee, Jingning Han, Adrian Grange, Yaowu Xu, Zoe Liu, Sarah Parker, Cheng Chen, Hui Su, Urvang Joshi, Ching-Han Chiang, Yunqing Wang, Paul Wilkins, Jim Bankoski, Luc Trudeau, Nathan Egge, Jean-Marc Valin, Thomas Davies, Steinar Midtskogen, Andrey Norkin, and Peter de Rivaz. 2018. An Overview of Core Coding Tools in the AV1 Video Codec. In 2018 Picture Coding Symposium (PCS). 41–45. https://doi.org/10.1109/PCS.2018.8456249
- Debevec and Malik (1997) Paul Debevec and Jitendra Malik. 1997. Recovering high dynamic range radiance maps from photographs. In International Conference on Computer Graphics and Interactive Techniques.
- Eilertsen et al. (2017) Gabriel Eilertsen, Joel Kronander, Gyorgy Denes, Rafal Mantiuk, and Jonas Unger. 2017. HDR image reconstruction from a single exposure using deep CNNs. In International Conference on Computer Graphics and Interactive Techniques.
- Gharbi et al. (2017) Michaël Gharbi, Jiawen Chen, Jonathan T Barron, Samuel W Hasinoff, and Frédo Durand. 2017. Deep bilateral learning for real-time image enhancement. ACM Transactions on Graphics (TOG) 36, 4 (2017), 1–12.
- Goodfellow et al. (2014) Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Networks. arXiv:1406.2661 [stat.ML]
- Gui et al. (2021) Jie Gui, Zhenan Sun, Yonggang Wen, Dacheng Tao, and Jieping Ye. 2021. A review on generative adversarial networks: Algorithms, theory, and applications. IEEE Transactions on Knowledge and Data Engineering (2021).
- He et al. (2020) Jingwen He, Yihao Liu, Yu Qiao, and Chao Dong. 2020. Conditional sequential modulation for efficient global image retouching. In European Conference on Computer Vision. Springer, 679–695.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Identity mappings in deep residual networks. In European conference on computer vision. Springer, 630–645.
- Huo et al. (2014) Yongqing Huo, Fan Yang, Le Dong, and Vincent Brost. 2014. Physiological inverse tone mapping based on retina response. The Visual Computer 30, 5 (2014), 507–517.
- Isola et al. (2017a) Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. 2017a. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1125–1134.
- Isola et al. (2017b) Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. 2017b. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1125–1134.
- Karras et al. (2018) Tero Karras, Samuli Laine, and Timo Aila. 2018. A Style-Based Generator Architecture for Generative Adversarial Networks. CoRR abs/1812.04948 (2018). arXiv:1812.04948 http://arxiv.org/abs/1812.04948
- Kim et al. (2019a) Soo Ye Kim, Jihyong Oh, and Munchurl Kim. 2019a. Deep SR-ITM: Joint Learning of Super-Resolution and Inverse Tone-Mapping for 4K UHD HDR Applications. arXiv: Image and Video Processing (2019).
- Kim et al. (2019b) Soo Ye Kim, Jihyong Oh, and Munchurl Kim. 2019b. Deep sr-itm: Joint learning of super-resolution and inverse tone-mapping for 4k uhd hdr applications. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3116–3125.
- Kim et al. (2020a) Soo Ye Kim, Jihyong Oh, and Munchurl Kim. 2020a. JSI-GAN: GAN-Based Joint Super-Resolution and Inverse Tone-Mapping with Pixel-Wise Task-Specific Filters for UHD HDR Video. In National Conference on Artificial Intelligence.
- Kim et al. (2020b) Soo Ye Kim, Jihyong Oh, and Munchurl Kim. 2020b. Jsi-gan: Gan-based joint super-resolution and inverse tone-mapping with pixel-wise task-specific filters for uhd hdr video. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 11287–11295.
- Kovaleski and Oliveira (2014) Rafael P. Kovaleski and Manuel M. Oliveira. 2014. High-Quality Reverse Tone Mapping for a Wide Range of Exposures. In 2014 27th SIBGRAPI Conference on Graphics, Patterns and Images. 49–56. https://doi.org/10.1109/SIBGRAPI.2014.29
- Lee et al. (2018) Siyeong Lee, Gwon Hwan An, and Suk-Ju Kang. 2018. Deep Recursive HDRI: Inverse Tone Mapping using Generative Adversarial Networks. In European Conference on Computer Vision.
- Liu et al. (2021) Yifan Liu, Hao Chen, Yu Chen, Wei Yin, and Chunhua Shen. 2021. Generic Perceptual Loss for Modeling Structured Output Dependencies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5424–5432.
- Liu et al. (2020a) Yu-Lun Liu, Wei-Sheng Lai, Yu-Sheng Chen, Yi-Lung Kao, Ming-Hsuan Yang, Yung-Yu Chuang, and Jia-Bin Huang. 2020a. Single-image HDR reconstruction by learning to reverse the camera pipeline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1651–1660.
- Liu et al. (2020b) Yu-Lun Liu, Wei-Sheng Lai, Yu-Sheng Chen, Yi-Lung Kao, Ming-Hsuan Yang, Yung-Yu Chuang, and Jia-Bin Huang. 2020b. Single-Image HDR Reconstruction by Learning to Reverse the Camera Pipeline. arXiv:2004.01179 [eess.IV]
- Mantiuk et al. (2008) Rafał Mantiuk, Scott Daly, and Louis Kerofsky. 2008. Display adaptive tone mapping. In ACM SIGGRAPH 2008 papers. 1–10.
- Mantiuk et al. (2011) Rafał Mantiuk, Kil Joong Kim, Allan G Rempel, and Wolfgang Heidrich. 2011. HDR-VDP-2: A calibrated visual metric for visibility and quality predictions in all luminance conditions. ACM Transactions on graphics (TOG) 30, 4 (2011), 1–14.
- Marnerides et al. (2021) Demetris Marnerides, Thomas Bashford-Rogers, and Kurt Debattista. 2021. Deep HDR Hallucination for Inverse Tone Mapping. Sensors 21 (2021), 4032.
- Metz et al. (2017) Luke Metz, Ben Poole, David Pfau, and Jascha Sohl-Dickstein. 2017. Unrolled Generative Adversarial Networks. arXiv:1611.02163 [cs.LG]
- Nagata et al. (2017) Yuji Nagata, Kenichiro Ichikawa, Takayuki Yamashita, Seiji Mitsuhashi, and Hiroyasu Masuda. 2017. Content Production Technology on Hybrid Log-Gamma. In SMPTE 2017 Annual Technical Conference and Exhibition. SMPTE, 1–12.
- Niu et al. (2021) Yuzhen Niu, Jianbin Wu, Wenxi Liu, Wenzhong Guo, and Rynson WH Lau. 2021. HDR-GAN: HDR image reconstruction from multi-exposed ldr images with large motions. IEEE Transactions on Image Processing 30 (2021), 3885–3896.
- Rissanen and Langdon (1979) Jorma Rissanen and Glen G Langdon. 1979. Arithmetic coding. IBM Journal of research and development 23, 2 (1979), 149–162.
- Russakovsky et al. (2015) Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. 2015. Imagenet large scale visual recognition challenge. International journal of computer vision 115, 3 (2015), 211–252.
- Santos et al. (2020a) Marcel Santana Santos, Tsang Ing Ren, and Nima Khademi Kalantari. 2020a. Single Image HDR Reconstruction Using a CNN with Masked Features and Perceptual Loss. ACM Trans. Graph. 39, 4, Article 80 (jul 2020), 10 pages. https://doi.org/10.1145/3386569.3392403
- Santos et al. (2020b) Marcel Santana Santos, Ren Tsang, and Nima Khademi Kalantari. 2020b. Single Image HDR Reconstruction Using a CNN with Masked Features and Perceptual Loss. ACM Transactions on Graphics 39, 4 (7 2020). https://doi.org/10.1145/3386569.3392403
- Simonyan and Zisserman (2014) Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
- Sullivan et al. (2012) Gary J. Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand. 2012. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Transactions on Circuits and Systems for Video Technology 22 (2012), 1649–1668.
- Tolosana et al. (2020) Ruben Tolosana, Ruben Vera-Rodriguez, Julian Fierrez, Aythami Morales, and Javier Ortega-Garcia. 2020. Deepfakes and beyond: A survey of face manipulation and fake detection. Information Fusion 64 (2020), 131–148.
- Wang et al. (2020) Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A Efros. 2020. Cnn-generated images are surprisingly easy to spot… for now. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8695–8704.
- Wang et al. (2018) Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. 2018. Non-local Neural Networks. arXiv:1711.07971 [cs.CV]
- Yan et al. (2020) Qingsen Yan, Lei Zhang, Yu Liu, Yu Zhu, Jinqiu Sun, Qinfeng Shi, and Yanning Zhang. 2020. Deep HDR imaging via a non-local network. IEEE Transactions on Image Processing 29 (2020), 4308–4322.
- Zeng et al. (2020) Hui Zeng, Jianrui Cai, Lida Li, Zisheng Cao, and Lei Zhang. 2020. Learning image-adaptive 3D lookup tables for high performance photo enhancement in real-time. IEEE Transactions on Pattern Analysis and Machine Intelligence (2020).
- Zhou et al. (2021) Jingkai Zhou, Varun Jampani, Zhixiong Pi, Qiong Liu, and Ming-Hsuan Yang. 2021. Decoupled Dynamic Filter Networks. arXiv:2104.14107 [cs.CV]
- Zhu et al. (2017) Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. 2017. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2223–2232.