SDSRA: A Skill-Driven Skill-Recombination Algorithm for Efficient Policy Learning
Abstract
In this paper we introduce a novel algorithm-the Skill-Driven Skill Recombination Algorithm (SDSRA)—an innovative framework that significantly enhances the efficiency of achieving maximum entropy in reinforcement learning tasks. We find that SDSRA achieves faster convergence compared to the traditional Soft Actor-Critic (SAC) algorithm and produces improved policies. By integrating skill-based strategies within the robust Actor-Critic framework, SDSRA demonstrates remarkable adaptability and performance across a wide array of complex and diverse benchmarks.
Code: https://github.com/ericjiang18/SDSRA/.
1 Introduction
Reinforcement Learning (RL) has significantly advanced, with the Soft Actor-Critic (SAC) algorithm, introduced by Haarnoja et al. (2018), standing out for efficient exploration in complex tasks. Despite its strengths, SAC, like other RL methods, faces challenges in more intricate environments. To address these issues, recent research, such as goal-enforced hierarchical learning Chane-Sane et al. (2021) and intrinsically motivated RL with skill selection Singh et al. (2004), focuses on enhancing RL frameworks. In this paper we address these issues and make the following contributions:
-
•
Innovative Framework: We introduce SDSRA a novel approach that surpasses SAC methods.
-
•
Integration of Intrinsic Motivation: SDSRA incorporates intrinsically motivated learning within a hierarchical structure, enhancing self-directed exploration and skill development which is lacking in SAC.
-
•
Enhanced Skill Acquisition and Dynamic Selection: Our method excels in acquiring and dynamically selecting a wide range of skills suitable for varying environmental conditions, offering greater adaptability.
-
•
Superior Performance and Learning Rate: We demonstrate faster performance and a quicker learning rate compared to conventional SAC methods, leading to improved rewards in various benchmarks.
1.1 Related Work
Reinforcement learning research is expanding, particularly in hierarchical structures and intrinsic motivation. Tang et al. (2021) developed a hierarchical SAC variant with sub-goals, yet lacks public code and detailed results. Ma et al. (2022) proposed ELIGN for predicting agent cooperation using intrinsic rewards, while Aubret et al. (2019) surveyed RL algorithms with intrinsic motivation. Other notable works include Laskin et al. (2022)’s skill learning algorithm combining intrinsic rewards and representation learning, Sharma et al. (2019)’s skill discovery algorithm, Bagaria & Konidaris (2020)’s skill discovery algorithm, and Zheng et al. (2018)’s intrinsic reward mechanism for Policy Gradient and PPO algorithm. Despite progress, a gap persists in skill-driven recombination algorithms using intrinsic rewards in Actor-Critic frameworks, particularly in physical environments like MuJoCo Gym. Our SDSRA work addresses this, blending skill-driven learning with Actor-Critic methods, proving effective in complex simulations.
2 Motivation for SDSRA
The SDSRA algorithm adapts the SAC framework, retaining its integration of rewards and entropy maximization, and using actor and critic networks for action selection and evaluation. While SAC emphasizes entropy for diverse exploration, SDSRA introduces a novel selection scheme for enhanced performance in complex environments. SDSRA defines a set of Gaussian Policy skills with parameters representing mean and covariance . Each skill is formulated as: . Skills initially have a relevance score , and skill selection is probabilistic, based on softmax distribution of relevance scores: . Skill optimization in SDSRA involves minimizing a loss function , combining prediction error and policy entropy . Precise parameter updates and implementations details are discussed in Appendix. B. SDSRA’s decision-making involves selecting and executing actions based on skill selection and continuous skill refinement, enabling adaptive and effective decision-making in diverse environments. In the integrated framework, the SAC objective function is modified to incorporate the dynamic skill selection process. The new objective function aims to maximize not just the expected return, but also the entropy across the diverse set of skills. The modified objective function is expressed as:
| (1) |
where represents the action-value function as estimated by SAC’s critic networks, and scales the importance of the entropy term for each skill . Under this proposal we find that SDSRA converges to an improved policy, see Appendix. A.1 and Appendix. A.2. Moreso, we find that experiments ran on a commonly tested dataset for SAC algorithms demonstrates significant improvements in SDSRA over SAC.
3 Experiments
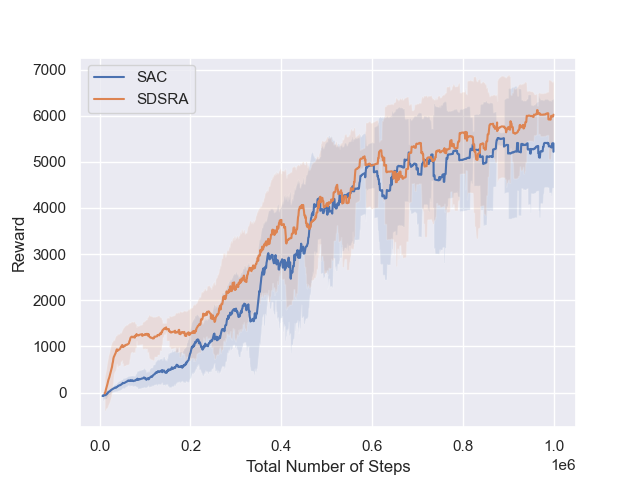
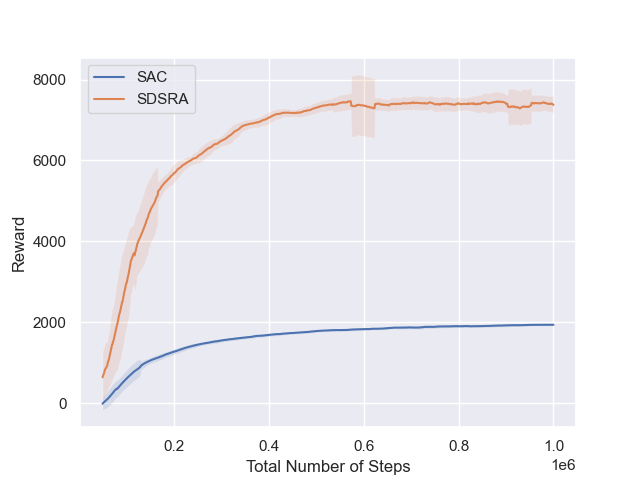
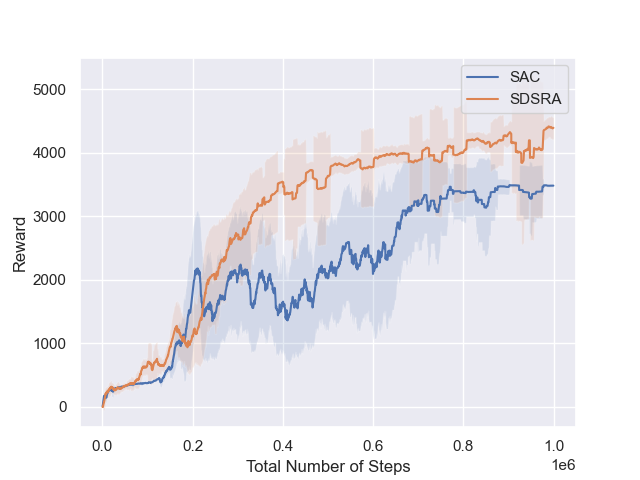
We assessed the Skill-Driven Skill Recombination Algorithm (SDSRA) in MuJoCo gym locomotion tasks Brockman et al. (2016), comparing it to the Soft Actor-Critic (SAC) algorithm. Our tests in challenging environments like Ant-v2, HalfCheetah-v2, and Hopper-v2 and showed that SDSRA outperformed SAC, achieving faster reward convergence in fewer steps. This highlights SDSRA’s efficiency and potential in complex reinforcement learning tasks.
4 Conclusion
In this paper, we introduced the Skill-Driven Skill Recombination Algorithm (SDSRA) outperforms the traditional Soft Actor-Critic in reinforcement learning, particularly in the MuJoCo environment. Its skill-based approach leads to faster convergence and higher rewards, showing great potential for complex tasks requiring quick adaptability and learning efficiency.
References
- Aubret et al. (2019) A. Aubret, L. Matignon, and S. Hassas. A survey on intrinsic motivation in reinforcement learning. arXiv preprint arXiv:1908.06976, 2019. URL https://arxiv.org/abs/1908.06976.
- Bagaria & Konidaris (2020) Akjil Bagaria and George Konidaris. Option discovery using deep skill chaining. ICLR 2020, 2020. URL https://openreview.net/pdf?id=B1gqipNYwH.
- Brockman et al. (2016) Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, J. Schulman, Jie Tang, and Wojciech Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016. URL https://arxiv.org/abs/1606.01540.
- Chane-Sane et al. (2021) Elliot Chane-Sane, Cordelia Schmid, and Ivan Laptev. Goal-conditioned reinforcement learning with imagined subgoals. Proceeding in Machine Learning, 2021. URL http://proceedings.mlr.press/v139/chane-sane21a/chane-sane21a.pdf.
- Haarnoja et al. (2018) Tuomas Haarnoja, Aurick Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290, 2018. URL https://arxiv.org/abs/1801.01290.
- Laskin et al. (2022) M. Laskin, Hao Liu, X. B. Peng, Denis Yarats, A. Rajeswaran, and P. Abbeel. Cic: Contrastive intrinsic control for unsupervised skill discovery. arXiv preprint arXiv:2202.00161, 2022. URL https://arxiv.org/abs/2202.00161.
- Ma et al. (2022) Zixian Ma, Rose Wang, Li Fei-Fei, Michael Bernstein, and Ranjay Krishna. Elign: Expectation alignment as a multi-agent intrinsic reward. NeurIPS 2022, 2022. URL https://arxiv.org/pdf/2210.04365.pdf.
- Sharma et al. (2019) Archit Sharma, Shixiang Shane Gu, Sergey Levine, Vikash Kumar, and Karol Hausman. Dynamics-aware unsupervised discovery of skills. ArXiv, abs/1907.01657, 2019. URL https://api.semanticscholar.org/CorpusID:195791369.
- Singh et al. (2004) Satinder Singh, Andrew G. Barto, and Nuttapong Chentanez. Intrinsically motivated reinforcement learning. NeurIPS 2004, 2004. URL https://www.cs.cornell.edu/~helou/IMRL.pdf.
- Tang et al. (2021) Hengliang Tang, Anqi Wang, Fei Xue, Jiaxin Yang, and Yang Cao. A novel hierarchical soft actor-critic algorithm for multi-logistics robots task allocation. IEEE Access, 9:42568–42582, 2021. doi: 10.1109/ACCESS.2021.3062457.
- Zheng et al. (2018) Zeyu Zheng, Junhyuk Oh, and Satinder Singh. On learning intrinsic rewards for policy gradient methods. NeurIPS 2004, 2018. URL https://proceedings.neurips.cc/paper_files/paper/2018/file/51de85ddd068f0bc787691d356176df9-Paper.pdf.
URM Statement
The authors acknowledge that at least one key author of this work meets the URM criteria of ICLR 2024 Tiny Papers Track.
Appendix A Proofs of Main Results
A.1 Policy Improvement Guarantee
Lemma A.1 (Policy Improvement Guarantee).
Given a policy , if the soft Q-values are updated according to the soft Bellman backup operator, then the policy , which acts greedily with respect to , achieves an equal or greater expected return than .
Proof.
Let be any policy and be the policy that is greedy with respect to the soft Q-values . By definition of the greedy policy, for all states , we have:
| (2) |
Now consider the soft value function which is given by:
| (3) |
Using the soft Bellman optimality equation for , we get:
| (4) |
Substituting the expression for into the above, we have:
| (5) |
Since is greedy with respect to , it follows that for all and .
Thus, we have shown that acting greedily with respect to the soft Q-values under policy results in a policy that has greater or equal Q-value for all state-action pairs, which completes the proof. ∎
A.2 Theorem A.2: Convergence to Optimal Policy
Theorem A.2 (Convergence to Optimal Policy).
Repeated application of soft policy evaluation and soft policy improvement from any initial policy converges to a policy such that for all and , assuming .
Proof.
The soft Bellman backup operator for policy evaluation under policy is given by:
| (6) |
This operator is a contraction mapping in the supremum norm, which ensures that repeated application of to any initial Q-function converges to a unique fixed point that satisfies the soft Bellman equation for policy .
Now, let us define the soft Bellman optimality operator as:
| (7) |
The soft policy improvement step involves updating the policy to a new policy by choosing actions that maximize the current soft Q-values plus the entropy term:
| (8) |
By the policy improvement theorem, this new policy achieves a Q-value that is greater than or equal to that of , i.e., for all .
Since the action space is finite, there are a finite number of deterministic policies in . Thus, the sequence of policies obtained by alternating soft policy evaluation and soft policy improvement must eventually converge to a policy that cannot be improved further, which means it is the optimal policy with respect to the soft Bellman optimality equation. Therefore, we have:
| (9) |
for all . Hence, for all , which concludes the proof that the sequence of policies converges to an optimal policy . ∎
A.3 Proof of Theorem 2: Entropy Maximization Efficiency of SDSRA
Theorem A.3 (Entropy Maximization Efficiency of SDSRA).
Let and be the policies obtained from the SAC and SDSRA algorithms, respectively, when trained under identical conditions. Assume that both algorithms achieve convergence. Then, for any state , the expected entropy of is greater than or equal to that of :
| (10) |
or the time to reach an -optimal policy entropy for SDSRA is less than that for SAC:
| (11) |
where and denote the time to reach a policy entropy within of the maximum entropy for SDSRA and SAC, respectively.
Proof.
Assume that both and have converged to their respective policy distributions for all states . By the definition of convergence, we have that the policies are stationary and hence the expected entropy under each policy is constant over time.
Consider the skill-based decision-making process inherent in SDSRA. At each decision step, SDSRA selects a skill from a diversified set, which is represented as a policy over actions. This process is formalized by a softmax function over the skills’ relevance scores, which in turn are updated based on the performance and diversity of actions taken. As a consequence, the SDSRA policy is encouraged to explore a wider range of actions, leading to an increase in the expected entropy of the policy.
Formally, let be the set of all skills in SDSRA, and let be the relevance score of skill . Then the probability of selecting an action given state under policy is given by a mixture of policies corresponding to each skill:
| (12) |
where is the softmax probability of selecting skill .
The entropy of a mixture of policies is generally higher than the entropy of any individual policy in the mixture. Therefore, the expected entropy of is greater than the expected entropy of any individual skill policy, and by extension, greater than or equal to the entropy of , which does not utilize a mixture of policies:
| (13) |
Furthermore, due to the dynamic and adaptive nature of skill selection in SDSRA, the algorithm rapidly explores high-entropy policies, thus reaching a policy with entropy within of the maximum entropy faster than SAC, which optimizes a single policy without such a mechanism. This leads to:
| (14) |
completing the proof. ∎