Search Methods for Policy Decompositions
Abstract
Computing optimal control policies for complex dynamical systems requires approximation methods to remain computationally tractable. Several approximation methods have been developed to tackle this problem. However, these methods do not reason about the suboptimality induced in the resulting control policies due to these approximations. We introduced Policy Decomposition, an approximation method that provides a suboptimality estimate, in our earlier work. Policy decomposition proposes strategies to break an optimal control problem into lower-dimensional subproblems, whose optimal solutions are combined to build a control policy for the original system. However, the number of possible strategies to decompose a system scale quickly with the complexity of a system, posing a combinatorial challenge. In this work we investigate the use of Genetic Algorithm and Monte-Carlo Tree Search to alleviate this challenge. We identify decompositions for swing-up control of a 4 degree-of-freedom manipulator, balance control of a simplified biped, and hover control of a quadcopter.
I Introduction
Computing global optimal control policies for complex systems quickly becomes intractable owing to the curse of dimensionality [1]. One approach to tackle this problem is to compute several local controllers using iLQG [2] or DDP [3] and combine them to obtain a global policy [4, 5, 6]. Another approach is to compute policies as functions of some lower-dimensional features of the state; either hand designed [7], or obtained by minimizing some projection error [8]. As can be inferred from Tab. I, none of these methods predict nor reason about the effect of the respective simplifications on the closed-loop behavior of the resulting policy. For linear systems or linear approximations of nonlinear systems, [9] and [10] identify subspaces within the state-space for which the optimal control of the lower-dimensional system and that of the original system closely resemble. Reduction methods that assess the suboptimality of the resulting policies when applied to the full nonlinear system have not been explored.
| method | output | suboptimality | run time |
|---|---|---|---|
| iLQG [2] / DDP [3] | Trajectory | unknown | |
| Trajectory based DP[4] [5] | Policy | unknown | unknown |
| Model Reduction [7][8] | Policy | unknown | |
| Policy Decomposition [11] | Policy | estimated |
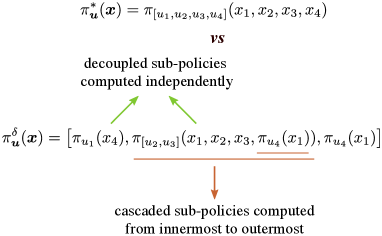
In our earlier work we introduced Policy Decomposition, an approximate method for solving optimal control problems with suboptimality estimates for the resulting control policies [11]. Policy Decomposition proposes strategies to decouple and cascade the process of computing control policies for different inputs to a system. Based on the strategy the control policies depend on only a subset of the entire state of the system (Fig. 1), and can be obtained by solving lower-dimensional optimal control problems leading to reduction in policy compute times. We further introduced the value error, i.e. the difference between value functions of control policies obtained with and without decomposing, to assess the closed-loop performance of possible decompositions. This error cannot be obtained without knowing the true optimal control, and we estimate it based on local LQR approximations. The estimate can be computed without solving for the policies and in minimal time, allowing us to predict which decompositions sacrifice minimally on optimality while offering substantial reduction in computation.
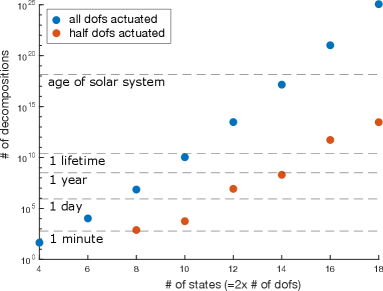
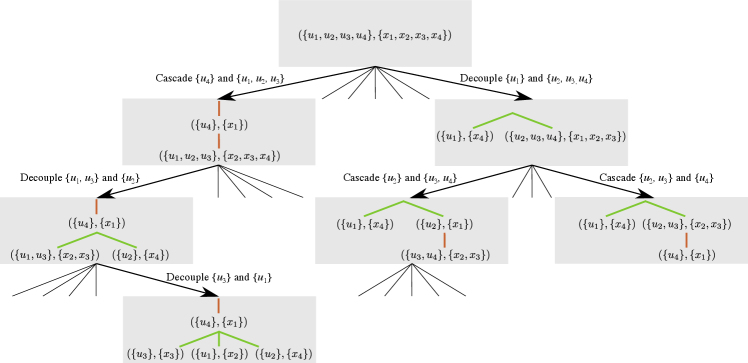
The number of possible decompositions that can be constructed with just the two fundamental strategies of cascading and decoupling shown in Fig. 1, turns out to be substantial even for moderately complex systems. Exhaustive search by evaluating the value error estimates for all possible decompositions becomes impractical for systems with more than state variables (Fig. 2). We thus explore the use of Genetic Algorithm (GA) [12] and Monte-Carlo Tree Search (MCTS) [13] to efficiently find promising decompositions. We first review the main ideas behind Policy Decomposition in Sec. II. Sec. III introduces input-trees, an abstraction to represent any decomposition, and discusses how GA and MCTS search over the space of input-trees. We find decompositions for the control of a 4 degree-of-freedom manipulator, a simplified biped and a quadcopter in Sec. IV, and conclude with some directions for future work in Sec. V.
II Policy Decomposition
Consider the general dynamical system
| (1) |
with state and input . The optimal control policy for this system minimizes the objective function
| (2) |
which describes the discounted sum of costs accrued over time, where is the goal state, and the input that stabilizes the system at . The discount factor characterizes the trade-off between immediate and future costs.
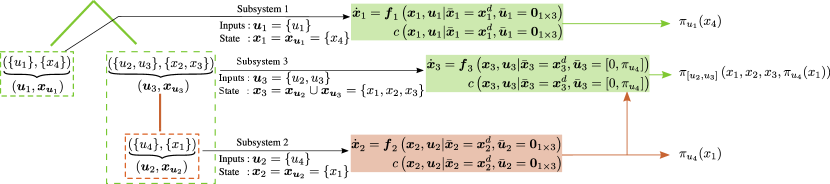
Policy Decomposition approximates the search for one high-dimensional policy with a search for a combination of lower-dimensional sub-policies of smaller optimal control problems that are much faster to compute. These sub-policies are computed in either a cascaded or decoupled fashion and then reassembled into one decomposition policy for the entire system (Fig. 1). Any sub-policy is the optimal control policy for its corresponding subsystem,
| (3) |
where and are subsets of and , only contains the dynamics associated with , and the complement state is assumed to be constant. The complement input comprises of inputs that are decoupled from and those that are in cascade with . The decoupled inputs are set to zero and sub-policies for the cascaded inputs are used as is while computing . In general, where are inputs that appear lower in the cascade to , and . Note, (i) can contain multiple sub-policies, (ii) these sub-policies can themselves be computed in a cascaded or decoupled fashion, and (iii) they have to be known before computing . We represent policies with lookup tables and use Policy Iteration [1] to compute them. Dimensions of the tables are suitably reduced when using a decomposition.
Value error, , defined as the average difference over the state space between the value functions and of the control policies obtained with and without decomposition,
| (4) |
directly quantifies the suboptimality of the resulting control. cannot be computed without knowing , the optimal value function for the original intractable problem. Thus, an estimate is derived by linearizing the dynamics (Eq. 1) about the goal state and input, . As the costs are quadratic, the optimal control of this linear system is an LQR, whose value function can be readily computed [14]. Value error estimate of decomposition is
| (5) |
where is the value function for the equivalent decomposition of the linear system [11]. Note that, .
III Searching For Promising Decompositions
We first introduce an intuitive abstraction for decompositions that allows us to search over the space of possibilities. A decomposition can be represented using an input-tree where all nodes except the root node are tuples of disjoint subsets of inputs and state variables . Inputs that lie on the same branch are in a cascade where policies for inputs lower in the branch (leaf node being the lowest) influence the policies for inputs higher-up. Inputs that belong to different branches are decoupled for the sake of policy computation. A sub-tree rooted at node characterizes a subsystem with control inputs and state , where are state variables belonging to nodes in the sub-tree. Note, and may be empty if it does not belong to a leaf-node. Fig. 3 depicts the input-tree for the decomposition shown in Fig. 1 and describes the resulting subsystems. Policies are computed in a child-first order, starting from leaf nodes followed by their parents and so on. Finally, input-trees can be easily enumerated, allowing us to count the number of possible decompositions for a system (See Sec. VI-A).
Search for promising decompositions, requires algorithms that can operate over the combinatorial space of possibilities. Several methods have been proposed to tackle such problems [15, 16]. Genetic Algorithm (GA) is one such method that has been used for solving a variety of combinatorial optimization problems [17, 18]. GA starts off with a randomly generated set of candidate solutions and suitably combines promising candidates to find better ones. A top-down alternative to GA is to start from the original system and decompose it step-by-step. The search for good decompositions can then be posed as a sequential decision making problem for which a number of algorithms exist, especially in the context of computer games [19]. Among these, Monte-Carlo Tree Search (MCTS) [13] methods have been shown to be highly effective for games that have a large number of possible moves in each step, a similar challenge that we encounter when generating decompositions from the original system. Here, we describe the requisite adaptations to GA and MCTS for searching over the space of input-trees.
III-A Genetic Algorithm
GA iteratively evolves a randomly generated initial population of candidates, through selection, crossovers and mutations, to find promising ones. In this case, the candidates are input-trees. We generate the initial population by uniformly sampling from the set of all possible input-trees for a system (Sec. III-C). The quality of an input tree is assessed using a fitness function that accounts for value error estimates as well as estimates of the policy compute times for the corresponding decomposition. Moreover, we add a memory component to GA using a hash table, that alleviates the need to recompute fitness values for previously seen candidates. Typical GA components include operators for crossover and mutation. We introduce mutation operators for input-trees but exclude crossovers as we did not observe any improvement in search performance on including them.
III-A1 Fitness Function
The fitness function for a decomposition is a product of two components
| (6) |
where and quantify the suboptimality of a decomposition and potential reduction in policy computation time respectively. , is the value error estimate (Eq. 5) scaled to the range , and is the ratio of estimates of floating point operations required to compute policies with and without decomposition . We use lookup tables to represent policies and policy iteration [1] to compute them, and can thus be derived using the size of the resulting tables, maximum iterations for policy evaluation and update, and number of actions sampled in every iteration of policy update. Note that where lower values indicate a more promising decomposition.
III-A2 Mutations
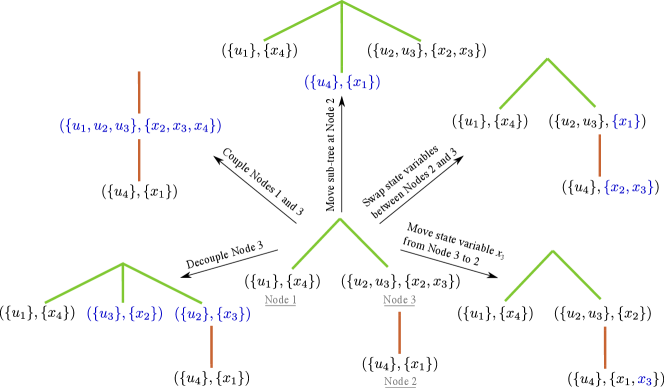
Valid mutations to input-trees are
-
(i)
Swap state variables between nodes
-
(ii)
Move a single state variable from one node to another
-
(iii)
Move a sub-tree
-
(iv)
Couple two nodes
-
(v)
Decouple a node into two nodes
Fig. 4 depicts the above operations applied to the input-tree depicted in Fig. 3. In every GA iteration, a candidate selected for mutation is modified using only one operator. Operators (i), (ii) and (iii) each have a 25 chance of being applied to a candidate. If neither of these three operators are applied then two distinct inputs are randomly selected and depending on whether they are decoupled or coupled operators (iv) or (v) are applied respectively.
III-A3 Hashing Input-Trees
III-B Monte-Carlo Tree Search
MCTS takes the top-down approach, and creates a search tree of input-trees with an input-tree representing the undecomposed system at its root. It builds the search tree by doing rollouts i.e. a sequence of node expansions starting from the root till a terminal node is reached. After each rollout a backup operation is performed whereby a value function for every node in the explored branch is computed/updated. The value function for a node captures the quality of solutions obtained in the sub-tree rooted at that node, and is used during rollouts to select nodes for expansion. Here, we describe the strategy for expanding nodes, the role of value functions during rollouts, the backup operation performed at the end of a rollout, and some techniques to speed-up search.
III-B1 Node Expansion
Expanding a node for decomposition entails evaluating the fitness (Eq. 6) and enumerating possible child nodes. These children are constructed by splitting the input and the state variable sets into two, for any of the leafs in , and arranging them in a cascaded or decoupled fashion. Fig. 5 depicts an example search tree obtained from MCTS rollouts. We use the UCT strategy [21],
| (7) |
to pick a node to expand. Here, , i.e. the value function for the node in the search tree corresponding to , is the best fitness value observed in the sub-tree rooted at that node. is initialized to . denotes the number of times was visited. We break ties randomly.
III-B2 Backup
At the end of each rollout the value functions for nodes visited during the rollout are updated as follows
starting from the terminal node and going towards the root of the search tree. Value function of the root node is the fitness value of the best decomposition identified in the search.
III-B3 Speed-up Techniques
To prevent redundant rollouts, we remove a node from consideration in the UCT strategy (Eq. 7) if all possible nodes reachable through it have been expanded. Similar to GA, we use a hash table to avoid re-evaluating fitness for previously seen input-trees.
III-C Uniform Sampling of Input-Trees
The strategy to sample input-trees is tightly linked to the process of constructing them, which entails partitioning the set of control inputs into groups, arranging the groups in a tree, and then assigning the state variables to nodes of the tree. To ensure uniform sampling, probabilities of choosing a partition and tree structure are scaled proportional to the number of valid input-trees resulting from said partition and structure. Finally, an assignment of state variables consistent with the tree structure is uniformly sampled (Sec. VI-C).
IV Results and Discussion
We test the efficacy of GA and MCTS in finding promising policy decompositions for three representative robotic systems, a 4 degree-of-freedom manipulator (Fig. 7(a)), a simplified model of a biped (Fig. 6(a)), and a quadcopter (Fig. 8(a)). We run every search algorithm 5 times for a period of 300, 600 and 1200 seconds for the biped, manipulator and quadcopter respectively. We report the number of unique decompositions discovered. Moreover, we derive policies for the best decomposition, i.e. the one with the lowest fitness value (Eq. 6), in each run and report the suboptimality estimates (Eq. 5) as well as the policy computation times (Tab. V). Tabs. II, III and IV list the best decompositions across all runs for the three systems.
Overall, in comparison to MCTS and random sampling GA consistently identifies decompositions that are on par, if not better in terms of suboptimality estimates, but offer greater reduction in policy computation times, and discovers the most number of unique decompositions. Furthermore, for the biped and the manipulator, GA evaluates only a small fraction of all possible decompositions but consistently identifies the one with the lowest fitness value. Here, we analyze the decompositions identified through the search methods. For details regarding policy computation see Sec. VI-D.
IV-1 Biped
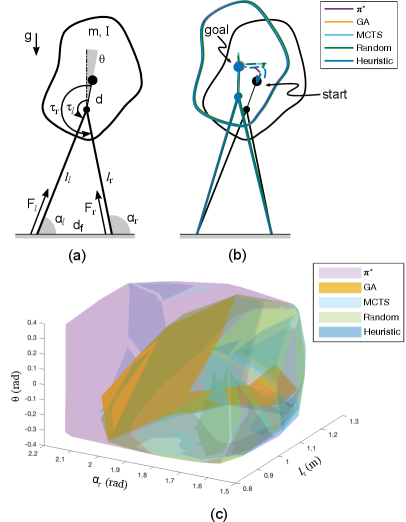
We design policies to balance the biped (Fig. 6(a)) in double stance. Sec. VI-D1 details the biped dynamics. From Tab II, the best decompositions discovered by GA and MCTS regulate the vertical behavior of the biped using leg force , the fore-aft behavior using the other leg force and a hip-torque , and regulate the torso using the remaining hip torque. These decompositions are similar to the heuristic approach (Tab. II, row 5) of regulating the centroidal behavior using leg forces and computing a torso control in cascade [22], but offer major reduction in complexity. It takes about 1.7 hours to derive the optimal policy whereas decompositions found by GA and MCTS reduce the computation time to seconds (Tab. V, row 1). But, the reduction comes at the cost of smaller basins of attraction (Fig. 6(c)).
| method | with the lowest fitness value | policy parameters |
|---|---|---|
| 52,865,904 | ||
| GA | 736 | |
| MCTS | 736 | |
| Random | 736 | |
| Heuristic | , | 26,522,860 |
IV-2 Manipulator
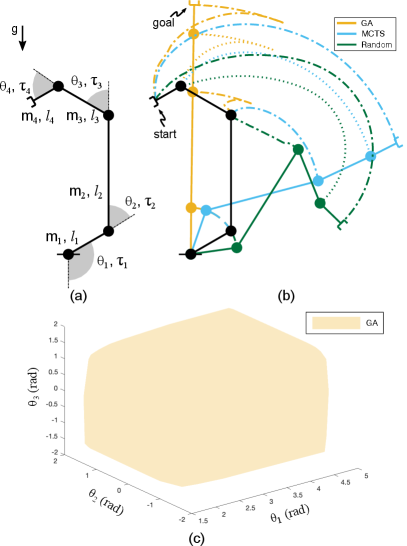
For the manipulator (Fig. 7(a)), we desire control policies that drive it to an upright position. Sec. VI-D2 details the dynamics parameters. Due to computational limits, we are unable to derive the optimal policy. But, the completely decentralized strategy identified by GA (Tab. III, row 2), requires less than 15 seconds to compute torque policies (Tab. V, row 2, column 2) and has a wide basin of attraction (Fig. 7(c)). Random sampling too identifies a decentralized strategy (Tab. III, row 4), allowing policies to be computed in minimal time, but has a very high value error estimate, resulting in poor performance on the full system (Fig. 7(b), green trajectory diverges). The strategy discovered by MCTS couples policy computation for the - and the - joint torques (Tab. III, row 3), and in fact has a lower value error estimate than the one found by GA. But, the resulting policies perform poorly on the full system (Fig. 7(b), cyan trajectory diverges). The LQR value error estimate (Eq. 5) only accounts for the linearized system dynamics and is agnostic to the bounds on control inputs, and thus decompositions with low suboptimality estimates need not perform well on the full system. This issue can be alleviated by filtering decompositions shortlisted through search using the DDP based value error estimate discussed in [11]. While the DDP based estimate is better, it too does not provide guarantees but rather serves as an improved heuristic.
| method | with the lowest fitness value | policy parameters |
|---|---|---|
| GA | 884 | |
| MCTS | 97682 | |
| Random | 884 |
IV-3 Quadcopter
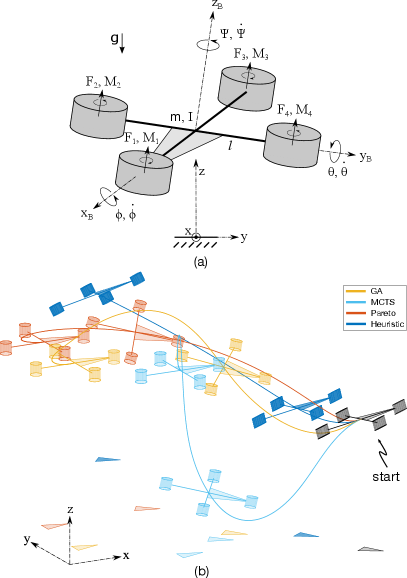
The quadcopter (Fig. 8(a)) is required to stabilize its attitude and come to rest. We identify decompositions to simplify computing policies for the net thrust and the roll, pitch and yaw inducing differential thrusts , and respectively. Sec. VI-D3 details the system modelling. Solving for the optimal policy is beyond our computational limits. However, we discovered almost optimal decompositions with just 20 minutes of search and derived policies using them in less than 3 hours (Tab V, row 3). As depicted in Tab. IV, the best decompositions discovered by GA and MCTS both decouple the yaw control. But the one found by GA further cascades and roll control with the pitch control , offering additional reduction in computation. Random sampling finds decompositions that have lower suboptimality estimates than the ones found by GA and MCTS (Tab. V, row 3) and lower fitness values as well, but they require significantly higher compute than we can afford. We are thus unable to report policy compute times for these decompositions in Tab. V and also omit it from Tab. IV. In general, our fitness criteria (Eq. 6) can skew the search towards decompositions that are almost optimal but offer little/no reduction in computation, or towards those that greatly reduce computation but are highly suboptimal. A workaround is to compute a Pareto front of decompositions over the objectives and (Eq. 6). We derived such a Pareto front using the NSGA II [23], sifted through the front in increasing order of , and found a decomposition (Tab. IV, row 4) that fit our computational budget. Closed-loop trajectories for decompositions in Tab IV are shown in Fig. 8(b). Decompositions discovered by search are non-trivial and in fact the trivial heuristic (Tab. IV, row 5) to independently regulate roll, pitch, yaw and height with , , and respectively, fails to stabilize the attitude and bring the quadcopter to rest (Fig. 8, blue).
| method | with the lowest fitness value | policy parameters |
|---|---|---|
| GA | , , | 14817796 |
| MCTS | , | 42707812 |
| Pareto | , , , | 14263214 |
| Heuristic | 2352 |
| GA | MCTS | Random | |||||||
| time (sec) | found | time (sec) | found | time (sec) | found | ||||
| Biped | |||||||||
| Manipulator | |||||||||
| Quadcopter | - | - |
V Conclusions and Future Work
We addressed the combinatorial challenge of applying Policy Decomposition to complex systems, finding non-trivial decompositions to compute policies for otherwise intractable optimal control problems. We introduced an intuitive abstraction, viz input-trees, to represent decompositions and a metric to gauge their fitness. Moreover, we put forth a strategy to uniformly sample input-trees and operators to mutate them, facilitating the use of GA in search for promising ones. We also offered another perspective to the search problem whereby decompositions are constructed by incrementally decomposing the original complex system, reducing the search to a sequential decision making problem. We showcased how MCTS can be used to tackle it. Across three example systems, viz a simplified biped, a manipulator and a quadcopter, GA consistently finds the best decompositions in a short period of time. Our work makes Policy Decomposition a viable approach to systematically simplify policy synthesis for complex optimal control problems.
We identified three future research directions that would further broaden the applicability of Policy Decomposition. First, to extend the framework to handle optimal trajectory tracking problems. Second, to weigh in the effect of sensing and actuation noise in evaluating the fitness for different decompositions. Finally, the conduciveness to decomposition often depends on the choice of inputs. In case of the quadcopter, policy computation for the rotor forces is not readily decomposable but it is so for the linearly transformed inputs , , and . Simultaneously discovering mappings from the original inputs to a space favorable for decomposition would be very useful.
VI APPENDIX
VI-A Counting Possible Policy Decompositions
For a system with states and inputs, the number of possible decompositions resolves to
| (8) |
where . This formula results from the observations that any viable decomposition splits the inputs of a system into input groups, where can range from 2 to , and there are ways to distribute the inputs into groups [24]; the input groups can then be arranged into input-trees with leaf-nodes leading to possible trees per grouping; the states can be assigned to each such tree with leaf-nodes in different ways.
VI-B Hash Keys For Input-Trees
For a system with inputs, we use a binary connectivity matrix to encode the graph. If input belongs to node in the input-tree, then the row in has entries for all other inputs that belong to as well as for inputs that belong to the parent node of . For the input-tree in Fig. 3 the connectivity matrix is
We define the binary state-dependence matrix to encode the influence of the state variables on the inputs. The row in corresponds to input and has entries for all state variables that belong to the node . For the input-tree in Fig. 3 the state-dependence matrix is
The matrices and uniquely encode an input-tree.
VI-C Uniform Random Sampling of Input-Trees
For a system with inputs and state variables we first sample , i.e. the number of input groups in an input-tree, with probability proportional to the number of possible input-trees with input groups (each entry in the outermost summation in Eq. 8). Next, we generate all partitions of the inputs into groups and pick one uniformly at random. Input groups constitute the sets in an input-tree. Subsequently, we sample the number of leaf-nodes , with probabilities proportional to the number of input-trees with input groups and leaf-nodes (each entry in the second summation in Eq. 8). To sample the tree structure we use Prufer Codes [25]. Specifically, we uniformly sample a sequence of numbers of length with exactly distinct entries from . Finally, for assigning state variables to different nodes of the input-tree we uniformly sample a label for every variable from . Variables with the label are grouped to form sets . We re-sample labels if a state assignment is invalid i.e. no variables are assigned to leaf-nodes of the input-tree.
VI-D Policy Computation Details
Here, we report the dynamics parameters for each system and other relevant details. Policies are represented using lookup tables and computed using policy iteration [1]. Dimensions of the lookup tables are suitably reduced when using a decomposition versus jointly optimizing the policies. Policies are computed using Matlab on an RTX 2080 Ti. Our code is available at https://github.com/ash22194/ Policy-Decomposition
VI-D1 Balancing control for Biped
The biped (Fig. 6(a)) weighs , has rotational inertia , and hip-to-COM distance . Legs are massless and contact the ground at fixed locations m apart. A leg breaks contact if its length exceeds m. In contact, legs can exert forces () and hip torques () leading to dynamics , , and , where and . The control objective is to balance the biped midway between the footholds.
VI-D2 Swing Up control for Manipulator
We design policies to swing up a fully actuated 4 link manipulator. Dynamic parameters are kg and m. Torque limits are , , and .
VI-D3 Hover control for a Quadcopter
We derived policies to stabilize the attitude of the quadcopter while bringing it to rest at a height of 1m. The system is described by its height , attitude (roll , pitch and yaw ), translational velocities , and attitude rate (, , ). The quadcopter need not stop at a fixed location. Inputs to the system are the net thrust and the roll, pitch and yaw inducing differential thrusts , and , with limits , and . Policies for rotor forces can be derived from policies for , , and through a linear transformation. The quadcopter weighs 0.5 kg, has rotational inertia kgm2, and wing length . Rotor moments , where . Dynamics are described in [26].
References
- [1] D. P. Bertsekas, Dynamic programming and optimal control. Belmont, MA: Athena Scientific, 1995, vol. 1, no. 2.
- [2] E. Todorov and W. Li, “A generalized iterative lqg method for locally-optimal feedback control of constrained nonlinear stochastic systems,” in IEEE ACC, 2005.
- [3] Y. Tassa, N. Mansard, and E. Todorov, “Control-limited differential dynamic programming,” in IEEE ICRA, 2014.
- [4] C. G. Atkeson and C. Liu, “Trajectory-based dynamic programming,” in Modeling, simulation and optimization of bipedal walking. Berlin, Heidelberg: Springer, 2013.
- [5] R. Tedrake, I. R. Manchester, M. Tobenkin, and J. W. Roberts, “Lqr-trees: Feedback motion planning via sums-of-squares verification,” IJRR, vol. 29, no. 8, 2010.
- [6] M. Zhong, M. Johnson, Y. Tassa, T. Erez, and E. Todorov, “Value function approximation and model predictive control,” in IEEE ADPRL, April 2013.
- [7] M. Stilman, C. G. Atkeson, J. J. Kuffner, and G. Zeglin, “Dynamic programming in reduced dimensional spaces: Dynamic planning for robust biped locomotion,” in IEEE ICRA, 2005.
- [8] J. Bouvrie and B. Hamzi, “Kernel methods for the approximation of nonlinear systems,” SIAM SICON, vol. 55, no. 4, 2017.
- [9] N. Xue and A. Chakrabortty, “Optimal control of large-scale networks using clustering based projections,” arXiv:1609.05265, 2016.
- [10] A. Alla, A. Schmidt, and B. Haasdonk, “Model order reduction approaches for infinite horizon optimal control problems via the hjb equation,” in Model Reduction of Parametrized Systems. Berlin, Heidelberg: Springer, 2017.
- [11] A. Khadke and H. Geyer, “Policy decomposition: Approximate optimal control with suboptimality estimates,” in IEEE-RAS Humanoids, 2020.
- [12] M. Mitchell, An introduction to genetic algorithms. MIT press, 1998.
- [13] C. B. Browne, E. Powley, D. Whitehouse, S. M. Lucas, P. I. Cowling, P. Rohlfshagen, S. Tavener, D. Perez, S. Samothrakis, and S. Colton, “A survey of monte carlo tree search methods,” IEEE T-CIAIG, vol. 4, no. 1, 2012.
- [14] M. Palanisamy, H. Modares, F. L. Lewis, and M. Aurangzeb, “Continuous-time q-learning for infinite-horizon discounted cost linear quadratic regulator problems,” IEEE Trans. Cybern., vol. 45, 2015.
- [15] F. Glover and M. Laguna, Tabu Search. Boston, MA: Springer, 1998.
- [16] C. Blum and A. Roli, “Metaheuristics in combinatorial optimization: Overview and conceptual comparison,” ACM Comput. Surv., vol. 35, no. 3, Sept. 2003.
- [17] C. D. Chapman, K. Saitou, and M. J. Jakiela, “Genetic Algorithms as an Approach to Configuration and Topology Design,” J. Mech. Des, vol. 116, no. 4, Dec. 1994.
- [18] K. Stanley and R. Miikkulainen, “Evolving neural networks through augmenting topologies,” Evol. Comput., vol. 10, no. 2, 2002.
- [19] B. Bouzy and T. Cazenave, “Computer go: An ai oriented survey,” Artificial Intelligence, vol. 132, no. 1, 2001.
- [20] T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein, Introduction to Algorithms, Third Edition, 3rd ed. The MIT Press, 2009.
- [21] L. Kocsis and C. Szepesvári, “Bandit based monte-carlo planning,” in ECML. Berlin, Heidelberg: Springer, 2006.
- [22] W. C. Martin, A. Wu, and H. Geyer, “Experimental evaluation of deadbeat running on the atrias biped,” IEEE RAL, vol. 2, no. 2, 2017.
- [23] K. Deb, “Multi-objective optimisation using evolutionary algorithms: an introduction,” in Multi-objective evolutionary optimisation for product design and manufacturing. Springer, 2011.
- [24] R. P. Stanley, “What is enumerative combinatorics?” in Enumerative combinatorics. Boston, MA: Springer, 1986.
- [25] N. Biggs, E. K. Lloyd, and R. J. Wilson, Graph Theory, 1736-1936. Oxford University Press, 1986.
- [26] T. Luukkonen, “Modelling and control of quadcopter,” Independent research project in applied mathematics, Espoo, vol. 22, 2011.