Seismic Inversion by Multi-dimensional Newtonian Machine Learning
Abstract
Newtonian machine learning (NML) is a wave-equation inversion method that inverts single-dimensional latent space (LS) features of the seismic data for retrieving the subsurface background velocity model. The single-dimensional LS features mainly contain the kinematic information of the seismic data, which are automatically extracted from the seismic signal by using an autoencoder network. Because its LS feature dimension is too small to preserve the dynamic information, such as the waveform variations, of the seismic data. Therefore the NML inversion is not able to recover the high-wavenumber velocity details. To mitigate this problem, we propose to invert multi-dimensional LS features, which can fully represent the entire characters of the seismic data. We denote this method as multi-dimensional Newtonian machine learning (MNML). In MNML, we define a new multi-variable connective function that works together with the multi-variable implicit function theorem to connect the velocity perturbations to the multi-dimensional LS feature perturbations. Numerical tests show that (1) the multi-dimensional LS features can preserve more data information than the single-dimensional LS features; (2) a higher resolution velocity model can be recovered by inverting the multi-dimensional LS features, and the inversion quality is comparable to that of FWI; (3) the MNML method requires a much smaller storage space than conventional FWI because only the low-dimensional representations of the high-dimensional seismic data are needed to be stored. The disadvantage of MNML is that it can more easily get stuck in local minima compared to the NML method. So we suggest a multiscale inversion approach that inverts for higher dimensional LS features as the iteration count increase.
Seismic Inversion by Multi-dimensional Newtonian Machine Learning
Example \leftheadChen & Saygin \rightheadMNML inversion
1 Introduction
Full waveform inversion (FWI) can recover a high-resolution subsurface model by minimizing the waveform difference between the observed and predicted seismic data (Tarantola,, 1984; Virieux and Operto,, 2009; Warner et al.,, 2013; Pérez Solano and Plessix,, 2019). However, the FWI misfit function is highly nonlinear and characterized by many local minima. To mitigate these effects and acquire a reliable high-resolution image, a straightforward solution is to transform the complex data waveform to a simpler form. In this regard, Luo and Schuster, 1991a inverted the background velocity model using wave equation traveltime inversion. To mitigate the cycle-skipping problem, Bunks et al., (1995) proposed a multiscale inversion method that split the seismic data into different frequency ranges, inverting the low-frequency data first and then gradually inverting the higher-frequency information with an increase in the number of iterations. Instead of inverting the seismic waveforms, Wu et al., (2014) inverted the data envelope because it contains fewer complicated features than the original data waveform. They also reported that the seismic envelope contains stronger low-frequency information than the original waveform, which would increase the robustness of seismic inversion. Warner and Guasch, (2016) used a matching filter to transform the predicted data waveforms to the observed data waveforms. The velocity model can be updated by forcing the matching filter to be a zero-lag delta function. Moreover, a series of skeletonized inversion methods are developed and show many successful applications of inverting skeletonized data for various subsurface properties, such as velocity (Luo and Schuster, 1991b, ) and quality factor Q (Dutta and Schuster,, 2016). Feng and Schuster, (2019) used the traveltimes of seismic reflection events to invert for the subsurface velocity and anisotropy parameters. Li et al., (2016) recovered the S-wave velocity model by minimizing the dispersion residuals from the observed and predicted surface waves. Liu et al., (2018) and Liu et al., (2020) extended the dispersion inversion to 3D considering the cases for both flat and irregular surfaces. Dutta and Schuster, (2016) used the peak frequency shift information of early arrivals to extract the subsurface Qp model. Similarly, Li et al., (2017) found the optimal Qs model using the peak-frequency shifts between the observed and predicted surface waves.
The above-mentioned inversion methods which extract the simplified data information, or skeletonized information, from seismic waveform are based on human knowledge and experience. Recently, machine learning provides opportunities for automatically extracting the skeletonized information from seismic data without human interference. Machine learning can identify important features and patterns from the data, and then a wave equation methodology can be used to invert these patterns for the subsurface velocity model.
Pattern recognition has been widely used in many fields, such as computer vision, speech, and face recognition. In the seismic domain, Valentine and Trampert, (2012) showed that an unsupervised neural network, such as an autoencoder, can be trained to learn a non-linear transformation that transforms the high-dimensional seismic traces to its low-dimensional representations. These low-dimensional representations preserve critical information contained in the seismic traces. Chen and Schuster, (2020) showed that the critical information is related to the kinematic information of the seismic data, such as traveltimes, for one-dimensional LS features, and suggested that the one-dimensional LS features can be used to recover the subsurface background velocity model. However, the high-wavenumber velocity details are missing in their inversion because the one-dimensional LS features are not able to preserve the dynamic information of the seismic data, such as the waveform variations.
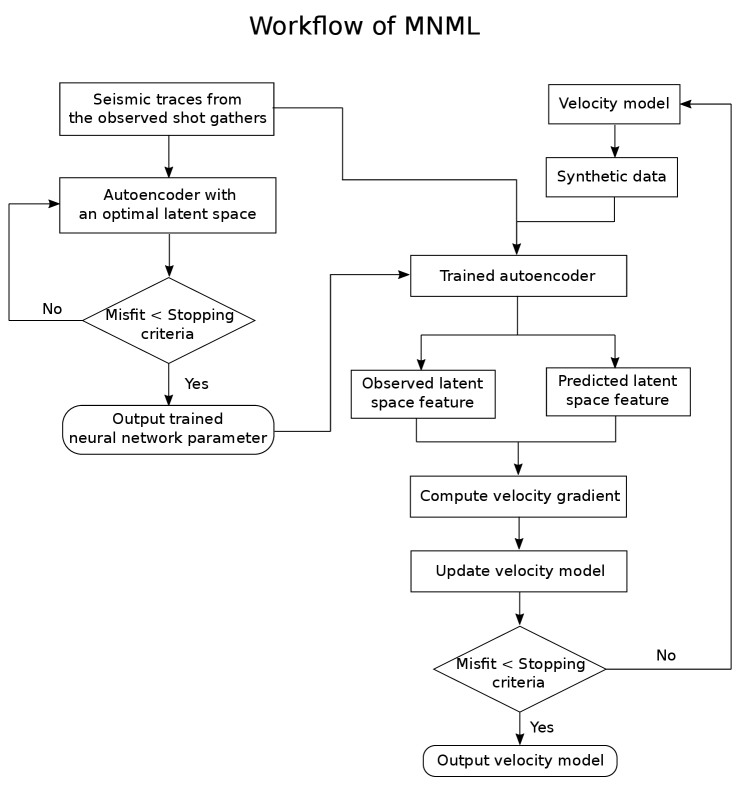
To recover the high-wavenumber velocity details, we now present a multi-dimensional Newtonian machine learning (MNML) method that uses an autoencoder with a multi-dimensional LS to preserve the entire content of the seismic data. The high-level strategy of MNML inversion is shown in Figure 1, where and correspond to the forward and adjoint modeling operator. The MNML misfit function computes the spatial distance of the multi-dimensional LS features between the observed and predicted data in a multi-dimensional LS. This spatial distance quantifies the accuracy of the inverted model, which becomes zero when the inverted model is close enough to the true model. As there are no partial differential equations (PDE) that contains both the LS feature and the velocity parameter terms, so we define a multi-variable connective function that works together with the multi-variable implicit function theorem (Guo,, 2016) to compute the derivative between the LS features and the velocity parameters. The gradient formula of the MNML method is represented as a matrix, where indicates the dimension of the LS vector. Numerical tests on both synthetic and real data demonstrate that the MNML method can effectively recover the high-wavenumber velocity model with a spatial resolution similar to a FWI tomogram. Moreover, MNML demands much less memory storage than FWI because the multi-dimensional LS features are at least 100 times smaller than the original seismic data. But a disadvantage of MNML inversion compared to the NML and conventional skeletonized inversion methods is that it is easier to getting stuck in local minima, because the multi-dimensional LS features are associated with many more events in the seismic traces than the single-dimensional LS features. To mitigate this problem, we propose a multiscale inversion approach which first uses NML inversion to recover the background velocity model, then uses MNML to reconstruct the high-wavenumber velocity details.
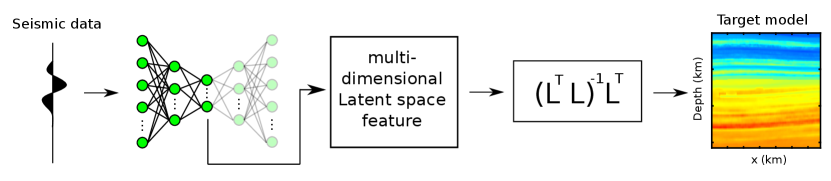
In the following sections, we first describe the theory of autoencoders and then illustrate the effect of the LS dimension on the data reconstruction errors of autoencoder. Next, we introduce the theory of the MNML method and finally present both synthetic and field data tests. We conclude the MNML method and propose our future research in the last section.
2 Theory
2.1 Autoencoder
An example of a three-layer autoencoder architecture is shown in Figure 2, which includes an encoder network, latent space, and decoder network. The pink box emphasizes the encoder network that compresses the input data to a lower-dimensional space by using several neural layers. The number of neurons in each layer gradually decreases. The green box represents the latent space which contains the lowest-dimensional representation of the input data. The compressed data is then passed to the decoder network (purple box) to get the decoded waveform that has the same dimension as the input data. The decoder network is often the mirror of the encoder network which is composed of several neural layers with an increasing number of neurons in each layer. The misfit function of the autoencoder computes the differences between the input and decoded data , and the training process stops when the misfit reduces to a certain threshold. For a well-trained autoencoder, it should be able to extract the effective low-dimensional representation of the high-dimensional seismic data.
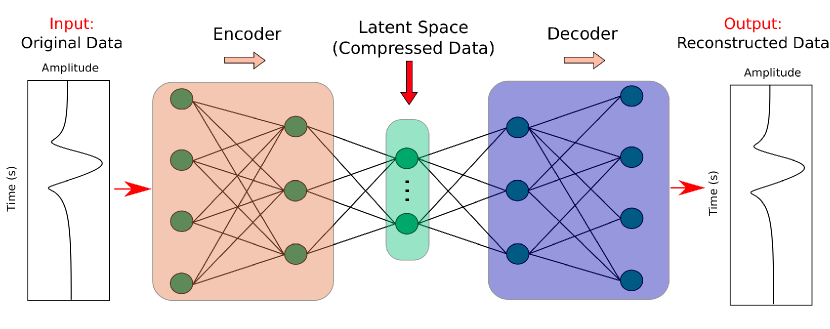
2.2 Reconstruction ability of autoencoder
The reconstruction ability of an autoencoder is affected by several factors, such as the number of neural layers, the number of neurons in each layer, and the LS dimension. Here we only discuss and analyze how the LS dimension affects the reconstruction ability of an autoencoder. We design two autoencoders with the same encoder and decoder network, where each consists of multi-perceptrons. We set one of the autoencoder’s LS dimensions to two (la=2) and another one to four (la=4). Two thousand seismic traces are used to train these two autoencoders, and a subset of the training data is shown in Figure 3a. Figure 3b shows the decoded waveform from the autoencoder with a two-dimensional LS. It shows that the first arrival energy has been well recovered, but some reflection events are missing. Because the two-dimensional LS is too small to preserve the reflection energies. These missing reflection events can be clearly seen in Figure 3c which shows the data difference between the input and decoded data. Figure 3d shows the decoded waveform from the autoencoder with a four-dimensional LS, where both the first-arrival and reflection energies have been well recovered. Its data residual given in Figure 3e shows that the differences of the reflection events are largely minimized compared to Figure 3c. Therefore we conclude that an autoencoder with a larger LS dimension can better preserve and reconstruct input data information than an autoencoder with a smaller LS.
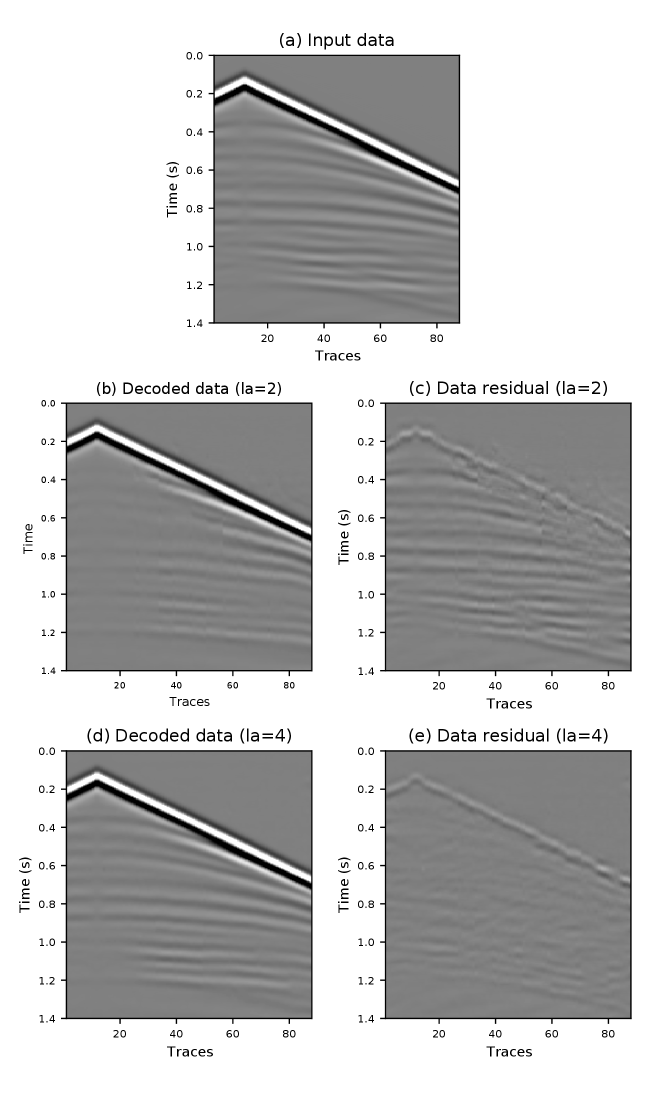
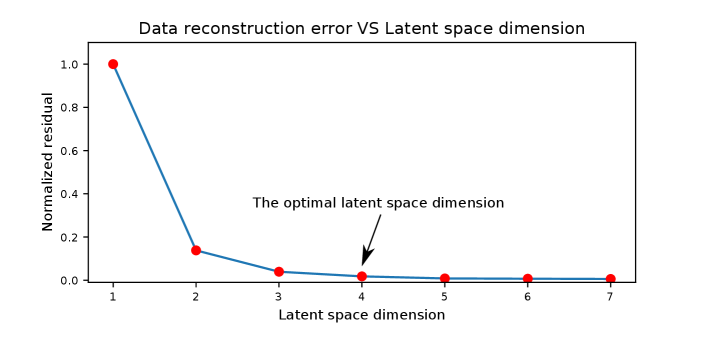
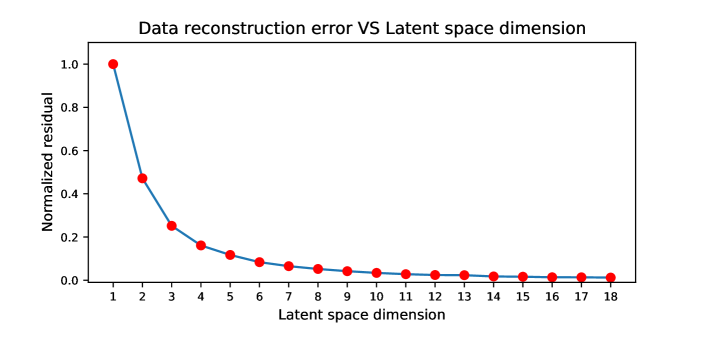
However, the data reconstruction ability of an autoencoder increases slowly when the LS dimension reaches a certain level. Figure 4 shows a curve that describes the data reconstruction error versus the LS dimension changes for this example. It shows that the reconstruction error drops rapidly when the LS dimension goes from one to four. But when the LS dimension is larger than four, the reconstruction error barely changes. This phenomenon suggests that the four-dimensional LS is good enough to preserve and reconstruct the entire information of the input data, and this four-dimensional LS is considered as the optimal LS dimension.
2.3 Misfit Function
A seismic trace can be viewed as a data point in a dimensional space, where is the number of time samples of a seismic trace. Therefore the FWI misfit function measures the spatial distance between the observed and predicted data point in an dimensional space. Similarly, the MNML method measures the spatial distance of the LS feature of the observed and predicted trace in a dimensional space, where indicates the dimensionality of the LS features which is much smaller than . Figure 5 illustrates a keystone idea underlying the MNML method. An autoencoder compresses the high-dimensional observed and predicted seismic trace to a two-dimensional LS. The spatial distance between the compressed observed and predict two-dimensional LS features can be used to quantify the accuracy of the inverted model. A large distance means that the inverted model is far away from the true model, but a small distance indicates a strong similarity between the true and inverted model. In general, for the MNML method, the LS dimension could be an arbitrary number that is larger than one and smaller than . However, we can find the optimal LS dimension according to the relationship between the LS dimension and data reconstruction error of the autoencoder, which is demonstrated in Figure 4. We identify the optimal dimension as the ’elbow’ point of the curve which shows a relatively small decrease in data reconstruction error with increasing dimension.
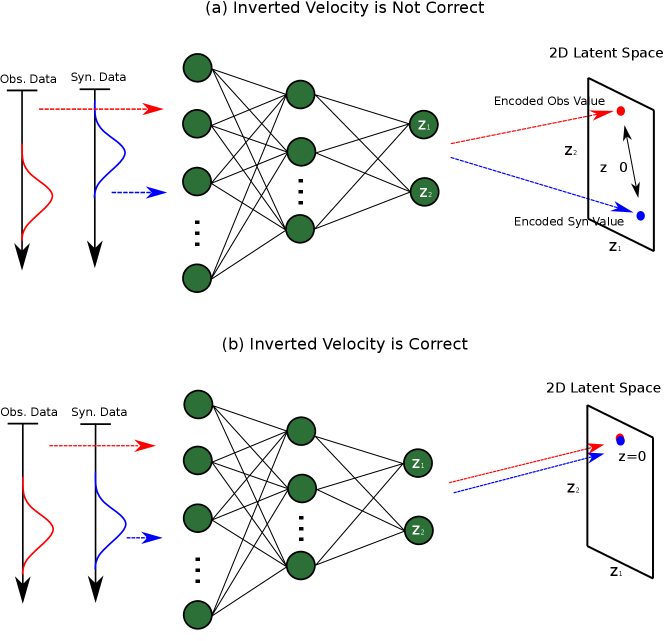
The misfit function of the MNML method can be written as
| (1) |
where represents the multi-dimensional LS feature difference of the observed and predicted data. The locations of the source and receiver are represented by and , respectively, where and indicate the source and receiver index. Here, indicates the dimension index of the multi-dimensional LS feature. For simplicity, we assume the LS feature dimension equals two. Then equation 1 can be re-written as
| (2) |
The gradient can be found by taking the derivative of the misfit to the velocity as
| (3) |
Equation 3 shows that the velocity gradient calculation is carried out at each LS dimension.
2.4 Connective Function
To compute the gradient , we need to define the relationship between the velocity perturbation and the multi-dimensional LS feature perturbation mathematically. To do so, we build a multi-variable connective function that measures the similarity between the observed and predicted seismic data through cross-correlation:
| (4) |
where indicates a predicted seismic trace recorded at the receiver location for a source at . The subscripts and represent the LS feature values of this trace for the first and second LS dimensions, respectively. Similarly, represents the observed seismic trace at the same source-receiver location with the LS feature value equal to , where is the difference between the observed and predicted multi-dimensional LS features. This difference will be zero () if the velocity model we build is accurate enough, otherwise . We need to (1) find the optimal LS feature difference that maximize equation 4; then (2) recover the accurate velocity model by minimizing the difference. The optimal difference can be found by setting equation as
| (5) |
Rewriting equation 5 in matrix form and combining it with the multi-variable implicit function theorem (Krantz and Parks,, 2012; Guo,, 2016) , we can get the Fréchet derivatives
| (6) |
The detailed derivations from equations 5 and 6, and the formulas for the partial derivatives on the right-hand-side of equation 6 can be found in the Appendix B.
2.5 Gradient
| (7) |
If we assume and are weakley correlated, then . Therefore equation 8 can be re-written as
| (8) |
where and are the weighting parameters. For a more general -dimensional case, its gradient formula can be found by extending equation 8 to -dimensions
| (9) |
The Fréchet derivative of the first-order acoustic equation can be written as (Chen and Schuster,, 2020)
| (10) |
where and represent the density and velocity, respectively. The particle velocity is indicated by , is the Green’s function, and means temporal convolution. Substituting equation 10 into equation 9 allows the MNML gradient to be expressed as
| (11) |
where denotes the virtual source at the receiver location. For each LS dimension, a local virtual source is computed by weighting its LS feature difference on the partial derivative , and then re-scale its value by dividing the weighting parameter . The final virtual source can be obtained by summing all the local virtual sources at each LS dimensions together. Once we have the gradient, the velocity model can be updated by using the steepest descent formula
| (12) |
where represents the iteration index and indicates the step length.
2.6 Workflow of MNML
The workflow of the MNML inversion is shown in Figure 6, where an autoencoder is trained to generate multi-dimensional LS features of the seismic data. The seismic traces in the observed shot gathers are often used to train and validate the autoencoder network. This autoencoder is only trained once and its parameters are fixed during the MNML inversion. At each iteration of the MNML inversion, we feed the observed and predicted data to the well-trained autoencoder to get their LS features. We then compute the velocity gradient using equation 11 and update the current velocity model. We stop the inversion when the LS feature misfit goes below a certain threshold.
3 Numerical Tests
We now use both synthetic and field data to test the effectiveness of the MNML method in recovering a high-resolution velocity model. We also compare the MNML results with the FWI results to demonstrate that the image resolution recovered by the MNML method is similar to FWI.
3.1 Checkerboard tests
We first test the MNML method on the data generated by checkerboard models with three different acquisition geometries to demonstrate the capability of the MNML method in dealing with different acquisition systems.
3.1.1 Crosswell checkerboard test
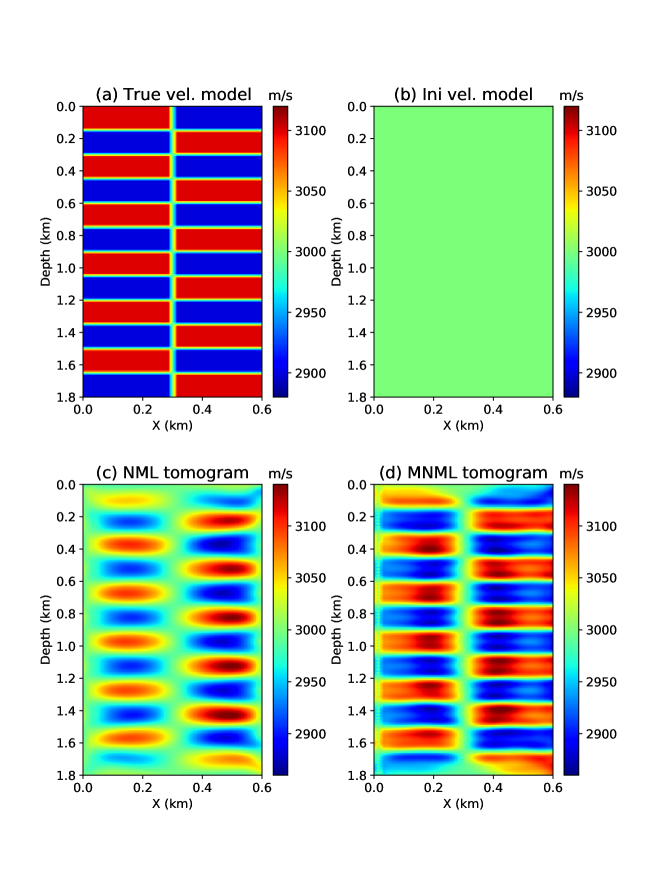
Figures 7a and 7b show the true and initial velocity models for the checkerboard test with a crosswell geometry. The source well is at x = 10 m with 89 shots evenly deployed along the well. Each shot contains 179 receivers that are equally distributed on the receiver well at x = 590 m. The finite-difference modeling method is used to generate the seismic data and a 15 Hz Ricker wavelet is used as the seismic source. The NML method is first used to recover the velocity model. The NML inverted result is shown in Figure 7c where the low-wavenumber velocity information has been well recovered, but the high-wavenumber details are missing. The MNML method uses the NML tomogram as the initial model and inverts for the high-wavenumber velocity details by using higher-dimensional LS features. Figure 7d shows the MNML inverted model where the high-wavenumber velocity details are well recovered.
3.1.2 Early arrival surface geometry checkerboard test
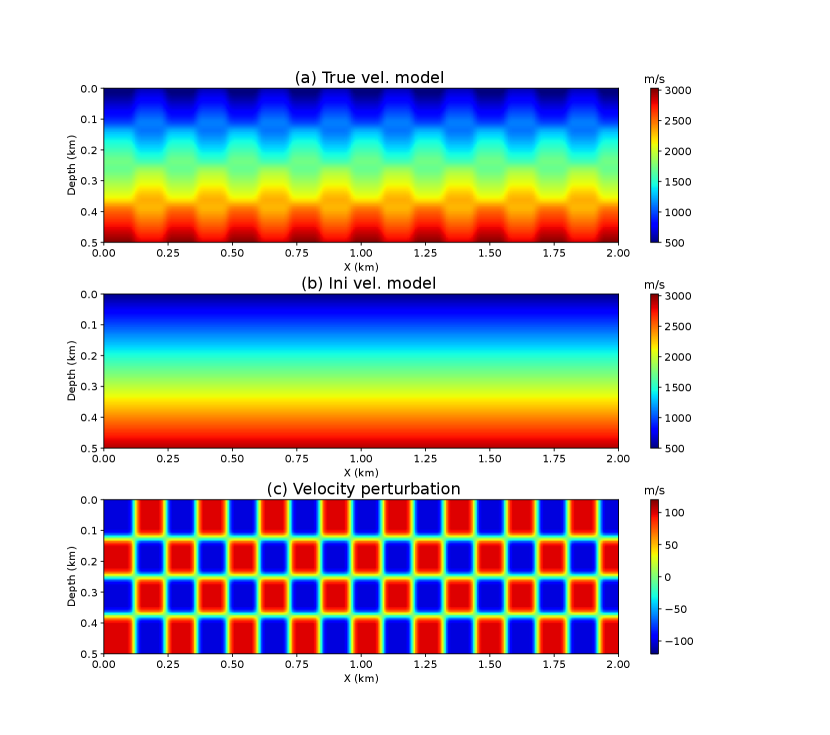
In the second checkerboard test, the sources and receivers are evenly deployed on the surface with fixed intervals of 16 m and 8 m, respectively. The true and initial velocity models are shown in Figure 8a and 8b. The velocity perturbation shows in Figure 8c is computed by doing the subtraction between the true and initial velocity models, which is the aim of the NML and MNML inversion. The source function used in the finite-difference modeling is a Ricker wavelet with a peak frequency of 12 Hz. Figures 9a and 9b show the velocity model and velocity perturbations recovered by the NML method. Similar to the previous test, the NML result mainly contains the low-wavenumber velocity information. However, the velocity model and velocity perturbations recovered by the MNML method given in Figure 9c and 9d have recovered more high-resolution velocity details.
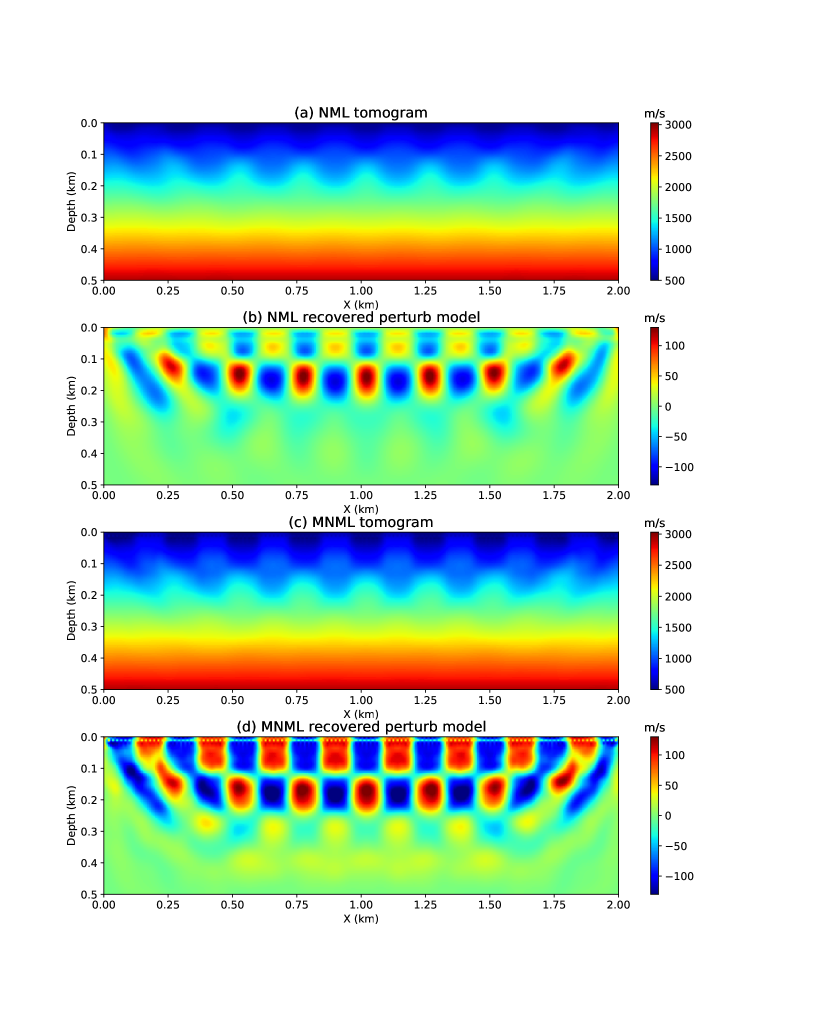
3.1.3 Reflection energy surface geometry checkerboard test
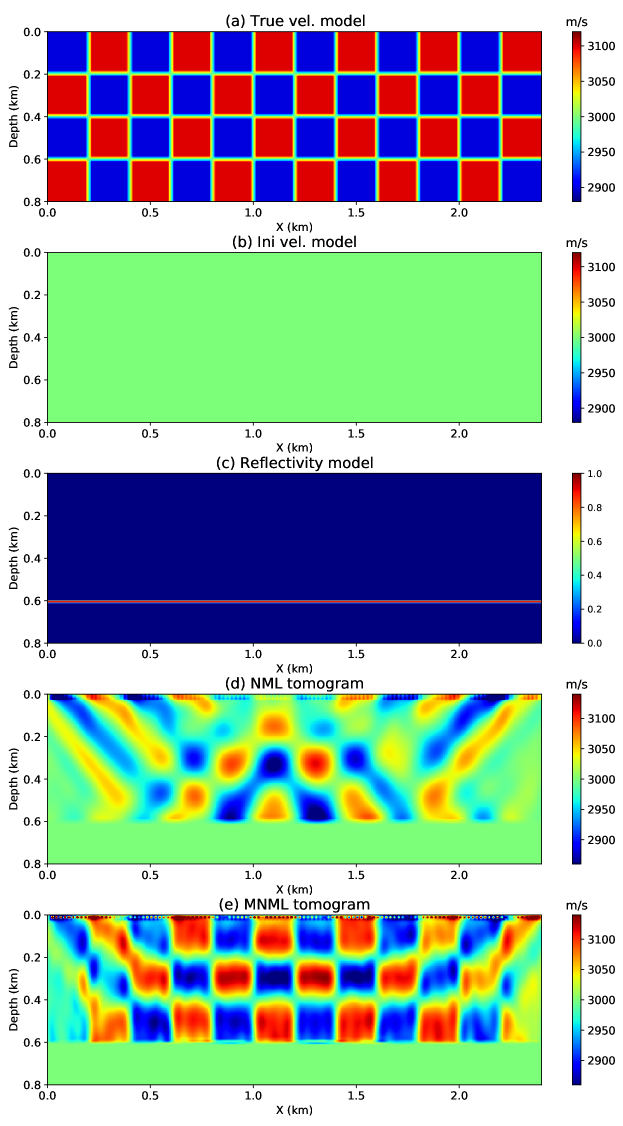
The surface acquisition geometry is still employed in this test, but a reflection inversion engine is used for velocity inversion. The Born modeling method is used to generate the observed data using the true velocity and reflectivity models shown in Figures 10a and 10c, respectively. The observed dataset contains 119 shot gathers, each shot gather has 239 receivers. The sources and receivers are evenly distributed on the surface with source and receiver intervals of 20 m and 10 m, respectively. A 15 Hz Ricker wavelet is used as the source wavelet. The initial model given in Figure 10b is a homogeneous model with a velocity equals to 3000 m/s. The NML method is first used to recover the subsurface velocity model. As we expected, the NML tomogram shown in Figure 10d only recovered the low-wavenumber velocity information. Based on the NML tomogram, the MNML result given in Figure 10e has well recovered more high-wavenumber velocity details. Therefore, the whole velocity content can be well recovered by the NML and MNML methods working together.
3.2 Pluto model
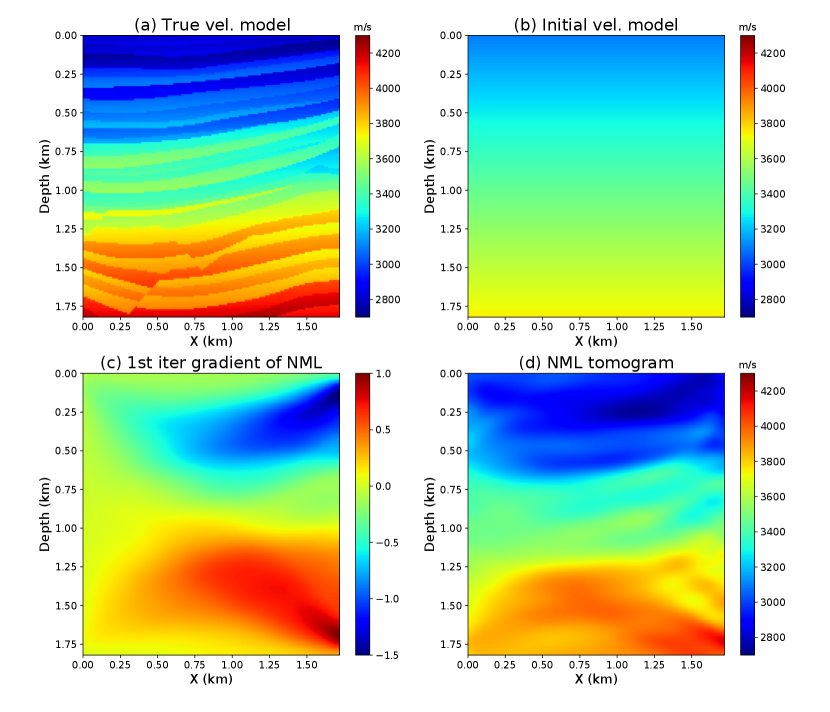
A portion of the Pluto model is selected as the true velocity model (shown in Figure 11a) to test the MNML method. A crosswell acquisition system is used to generate the seismic data. The source well is deployed at x=10 m which contains 59 shots at an equal interval of 30 m. Each shot has 177 receivers evenly distributed in the receiver well, which is located at x = 1750 m. A 20-Hz Ricker wavelet is used as the seismic source, and a linearly increasing velocity model is used as the initial velocity model. The minimum and maximum velocity of the initial model are equal to 3100 m/s and 3700 m/s, respectively. The acoustic finite-difference modeling is used to generate the observed data based on the true model.
3.2.1 NML inversion
We first use the NML method to reconstruct the background velocity model. A three-layer autoencoder with a one-dimensional LS is designed to extract the one-dimensional LS feature from the seismic data. The first, second, and third encoder layers have dimensions of , , and , respectively. The decoder network architecture is the mirror of the encoder network. The training dataset is composed of the envelope of the observed traces. During the training, the dataset is randomly separated into more than 200 mini-batches with a size of 50. The Adam optimizer is used to iteratively update the network. We stop the training when the reconstruction error barely decreases anymore, and achieved a training and validation accuracy of and , respectively. Figures 11c and 11d show the first iteration gradient and inverted velocity model of the NML method, which are dominated by the low-wavenumber velocity update. The NML inverted background model is used as the initial model for the MNML and FWI methods in the next step of inversion.
3.2.2 MNML inversion
In this section, we use the MNML method to recover the high-wavenumber velocity details based on the NML inverted background model. We build a new autoencoder that has the same encoder and decoder network as the previous autoencoder. But we set its LS dimension to five (la=5), which is the optimal LS dimension found by looking at the ”data reconstruction error versus LS dimension” curve. The training dataset contains the original observed seismic traces, and the same training strategy is used for the autoencoder (la=5) training. The reason we use the original seismic data for training rather than its envelope is that the ten-dimensional LS feature has a stronger capability in representing complex features in the seismic data.
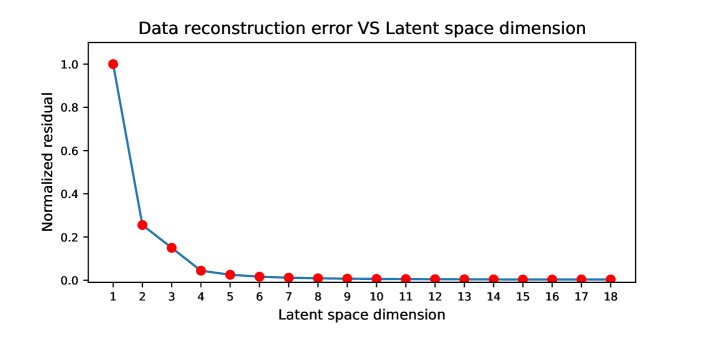
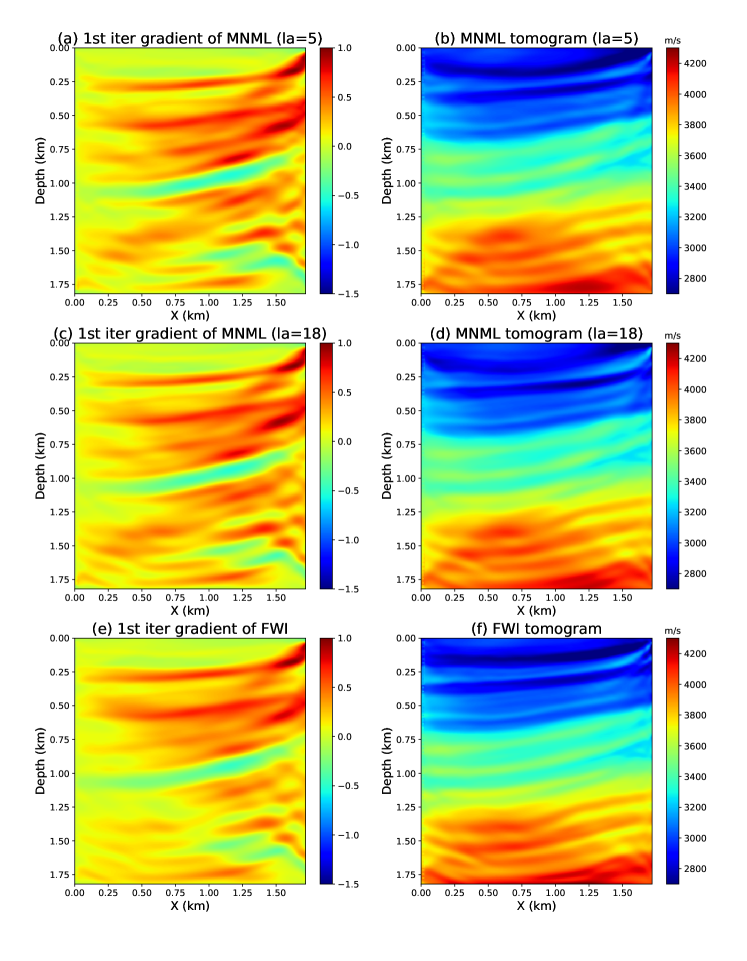
Figure 13a shows the first iteration gradient of MNML (la=5) which is dominated by the high-wavenumber updates. The inverted MNML tomogram (la=5) given in Figure 13b shows a dramatic resolution increase compared to the NML result. This suggests that the six-dimensional LS features contain more model information from the seismic data than the one-dimensional LS feature. To demonstrate that the six-dimensional LS is the optimal LS, we build another autoencoder with an eighteen-dimensional LS (la=18) and repeat the MNML inversion workflow. The MNML (la=18) gradient and tomogram given in Figures 13b and 13b are very similar to the MNML (la=5) results, which means the six-dimensional LS features are sufficient to recover the high-wavenumber velocity details of the model.
To quantify the MNML inverted result, we use the FWI method to invert the seismic dataset and obtained a high-resolution model which is used as a benchmark model. Figures 13e and 13f show the FWI gradient after the 1st iteration and the FWI tomogram, which has the same level of image resolution compared to the MNML (la=5) tomogram. This suggests that the resolution of the MNML method is comparable to the FWI method.
3.3 Friendswood field data
The field data test uses a crosswell dataset collected by Exxon in Texas (Chen et al.,, 1990). The source and receiver wells are 305 m deep and separated by 183 m from each other. There are 97 shots fired at a shot interval of 3 m from z=9 m to z=305 m using downhole explosive charges. Each shot has 96 receivers distributed in the receiver well (Chen and Schuster,, 2020). The seismic data are recorded for 0.375 s with a time interval of 0.25 ms. The data contains extreme noise and tube waves. We first bandpass the data to 80-400 Hz to remove the extreme linear noise. We then use a nine-point median filter to remove the tube wave. Finally, we separate the up and down-going waves using FK filtering. A similar processing workflow with more details can be found in Cai and Schuster, (1993); Dutta and Schuster, (2014); Chen and Schuster, (2020). We plot one example of the raw and processed data in Figures 14a and 14b, respectively.

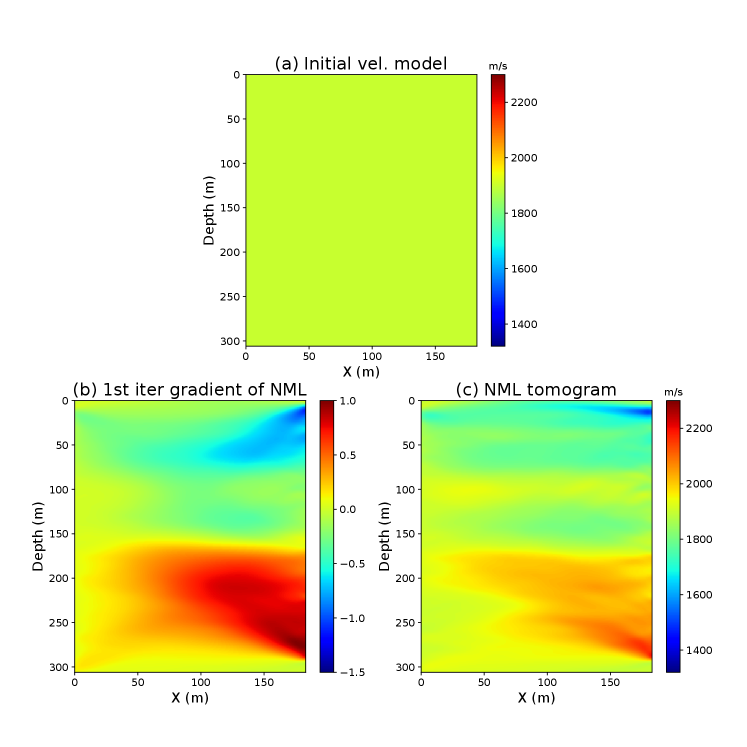
We assume the initial model is a homogeneous model with a velocity equals to 1900 m/s. We first use the NML method to recover the background velocity model. We design an autoencoder with four encoder and decoder layers and a single-dimensional LS. The first to the fourth encoder layers have a dimension of , , , , and the decoder network is the mirror of the encoder network. The training dataset contains the envelope of the observed seismic traces. We use the same training strategy described above to train this autoencoder. Figures 16c and 16d show the first iteration gradient and NML tomogram, which mainly contains the low-wavenumber velocity information.
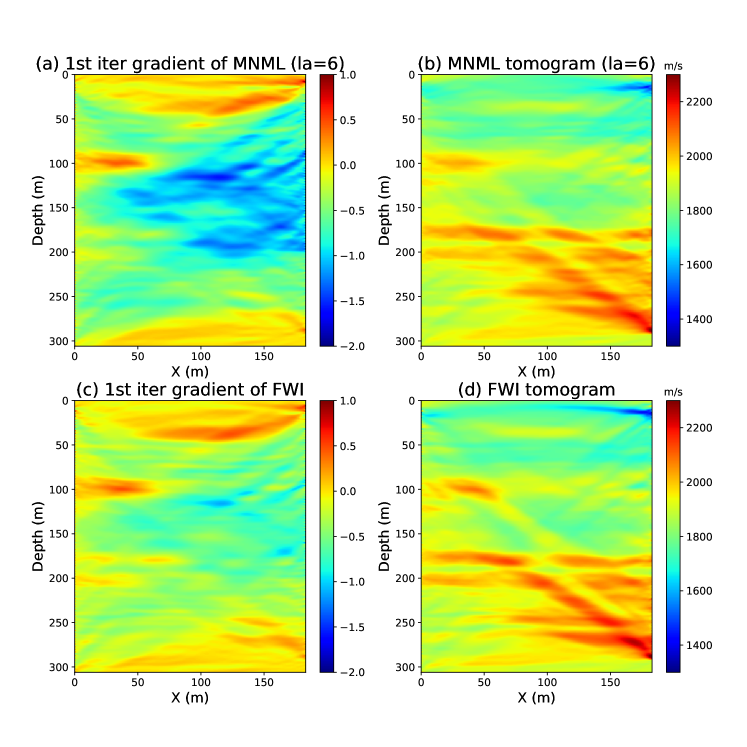
To reconstruct the high-wavenumber velocity details, we apply the MNML method on the NML background tomogram. We build a new autoencoder with a six-dimensional LS (la=6) but keep the encoder and decoder network the same as the previous autoencoder used in the NML. The training dataset for MNML includes the observed seismic traces rather than its envelopes. Figures 17a and 17b show the first iteration gradient and MNML tomogram (la=6), which contains the high-wavenumber velocity details. The MNML tomogram (la=6) shows a noticeable resolution increase compared to the NML tomogram. To validate the robustness of the MNML tomogram, we compare it with the FWI tomogram shown in Figure 17d. Same as the MNML inversion, FWI also uses the NML background tomogram as the starting model. The FWI tomogram is almost identical to the MNML tomogram (la=6), which means the MNML tomogram is correct.
4 Conclusion
We present a multi-dimensional Newtonian machine learning (MNML) inversion method that inverts a multi-dimensional latent space (LS) feature to reconstruct the high-wavenumber velocity details of the subsurface model. An autoencoder with a multi-dimensional LS is trained to extract the low-dimensional representations from the high-dimensional seismic traces. The compressed data contains more information, such as the waveform variations, of the input seismic data than the one-dimensional LS. To compute the MNML gradient, a multi-variable connective function and the multi-variable implicit function theorem are used to mathematically connect the LS feature perturbations to the velocity perturbations. Numerical results show that the MNML method can recover the higher-wavenumber velocity information, and the resolution of the MNML tomogram is comparable to the FWI tomogram. However, MNML requires a much smaller storage space than FWI because only the low-dimensional representations of the seismic data need to be saved in the computer.
A potential problem of MNML is that it may get stuck in the local minima compared to the NML method and conventional skeletonized inversions. This is mainly due to the reason that more nonlinear characteristics of the seismic data, such as the waveform variations, are contained in the multi-dimensional LS feature. So the MNML misfit function has more local minima than the NML misfit function. Therefore we suggest a multiscale inversion approach that gradually uses a higher dimensional LS feature for inversion.
Multi-variable implicit function theorm The terms and in gradient cannot be directly calculated as there is no governing equation which includes both , and velocity . However, the connective function in equation 4 implicitly connect , with . Equation 5 can be rewritten as
| (13) |
where and are function of , and . Moreover, the latent space variables and are also the function of velocity :
| (14) |
Differentiating equation 13 we get
| (15) |
Then we differentiate equation 15 with respect to to obtain
| (16) |
Equation 16 can be re-written in matrix-vector multiplication form as
| (17) |
To solve and , we get
| (18) |
Connective function derivation The optimal difference can be found by solving equation as
| (19) |
We can re-write equation 19 as a system of equations
| (20) |
Combing equation 20 with the multi-variable implicit function theorem (Guo,, 2016), we get the gradient formula for each LS dimension as
| (21) |
where
| (22) |
and
| (23) |
References
- Bunks et al., (1995) Bunks, C., F. M. Saleck, S. Zaleski, and G. Chavent, 1995, Multiscale seismic waveform inversion: Geophysics, 60, 1457–1473.
- Cai and Schuster, (1993) Cai, W. and G. T. Schuster, 1993, Processing friendswood cross-well seismic data for reflection imaging: 92–94.
- Chen et al., (1990) Chen, S., L. Zimmerman, and J. Tugnait, 1990, Subsurface imaging using reversed vertical seismic profiling and crosshole tomographic methods: Geophysics, 55, 1478–1487.
- Chen and Schuster, (2020) Chen, Y. and G. T. Schuster, 2020, Seismic inversion by newtonian machine learning: Geophysics, 85, 1–59.
- Dutta and Schuster, (2014) Dutta, G. and G. T. Schuster, 2014, Attenuation compensation for least-squares reverse time migration using the viscoacoustic-wave equation: Geophysics, 79, S251–S262.
- Dutta and Schuster, (2016) ——–, 2016, Wave-equation q tomography: Geophysics, 81, R471–R484.
- Feng and Schuster, (2019) Feng, S. and G. T. Schuster, 2019, Transmission+ reflection anisotropic wave-equation traveltime and waveform inversion: Geophysical Prospecting, 67, 423–442.
- Guo, (2016) Guo, B., 2016, Multi-variable implicit function theorem for a system of equations: CSIM annual meeting, 99–102.
- Krantz and Parks, (2012) Krantz, S. G. and H. R. Parks, 2012, The implicit function theorem: history, theory, and applications: Springer Science & Business Media.
- Li et al., (2017) Li, J., G. Dutta, and G. Schuster, 2017, Wave-equation qs inversion of skeletonized surface waves: Geophysical Journal International, 209, 979–991.
- Li et al., (2016) Li, J., Z. Feng, and G. Schuster, 2016, Wave-equation dispersion inversion: Geophysical Journal International, 208, 1567–1578.
- Liu et al., (2020) Liu, Z., J. Li, S. M. Hanafy, K. Lu, and G. Schuster, 2020, 3d wave-equation dispersion inversion of surface waves recorded on irregular topography: Geophysics, 85, R147–R161.
- Liu et al., (2018) Liu, Z., J. Li, S. M. Hanafy, and G. Schuster, 2018, 3d wave-equation dispersion inversion of surface waves: 4733–4737.
- (14) Luo, Y. and G. T. Schuster, 1991a, Wave equation inversion of skeletalized geophysical data: Geophysical Journal International, 105, 289–294.
- (15) ——–, 1991b, Wave-equation traveltime inversion: Geophysics, 56, 645–653.
- Pérez Solano and Plessix, (2019) Pérez Solano, C. and R.-É. Plessix, 2019, Velocity-model building with enhanced shallow resolution using elastic waveform inversion—an example from onshore oman: Geophysics, 84, R977–R988.
- Schuster, (2017) Schuster, G., 2017, Seismic inversion: Society of Exploration Geophysicists.
- Tarantola, (1984) Tarantola, A., 1984, Inversion of seismic reflection data in the acoustic approximation: Geophysics, 49, 1259–1266.
- Valentine and Trampert, (2012) Valentine, A. P. and J. Trampert, 2012, Data space reduction, quality assessment and searching of seismograms: autoencoder networks for waveform data: Geophysical Journal International, 189, 1183–1202.
- Virieux and Operto, (2009) Virieux, J. and S. Operto, 2009, An overview of full-waveform inversion in exploration geophysics: Geophysics, 74, WCC1–WCC26.
- Warner and Guasch, (2016) Warner, M. and L. Guasch, 2016, Adaptive waveform inversion: Theory: Geophysics, 81, R429–R445.
- Warner et al., (2013) Warner, M., A. Ratcliffe, T. Nangoo, J. Morgan, A. Umpleby, N. Shah, V. Vinje, I. Štekl, L. Guasch, C. Win, et al., 2013, Anisotropic 3d full-waveform inversion: Geophysics, 78, R59–R80.
- Wu et al., (2014) Wu, R.-S., J. Luo, and B. Wu, 2014, Seismic envelope inversion and modulation signal model: Geophysics, 79, WA13–WA24.