Selective Ensembling for Prediction Consistency
paper
Appendix A Proofs
A.1 Proof of Theorem 3.1
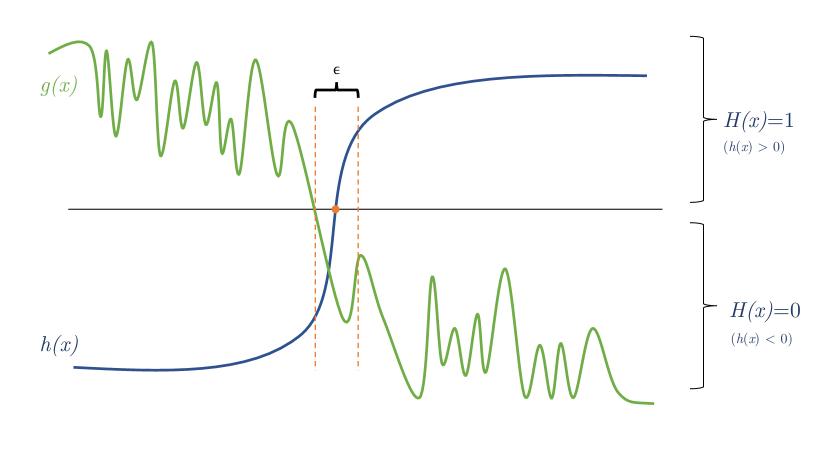
Theorem 3.1.
Let be a binary classifier and be an unrelated function that is bounded from above and below, continuous, and piecewise differentiable. Then there exists another binary classifier such that for any ,
Proof.
We partition into regions determined by the decision boundaries of . That is, each represents a maximal contiguous region for which each receives the same label from .
Recall we are given a function which is bounded from above and below. We create a set of functions such that
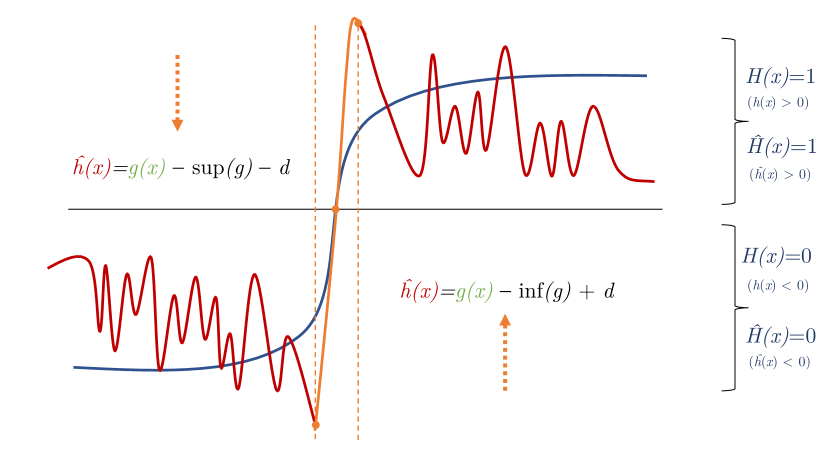
where is some small constant greater than zero. Additionally, let be the distance from to the nearest decision boundary of , i.e. . Then, we define to be:
And, as described above, we define . First, we show that . Without loss of generality, consider some where , for any . We first consider the case where .
By construction, for , . By definition of the infimum, , and thus , so .
Note that in the case where , we can follow the same argument as multiplication by a positive constant does not affect the sign. A symmetric argument follows for the case where for , ; thus, .
Secondly, we show that where . Consider the case where . By construction, . Note that this means the infimum and are constants, so their gradients are zero. Thus, . A symmetric argument holds for the case where .
It remains to prove that is continuous and piecewise differentiable, in order to be a realizable as a ReLU-network. By assumption, is piecewise differentiable, which means that are piecewise differentiable as well, as is . Thus, is piecewise-differentiable. To see that is continuous, consider the case where for some . Then . Additionally, consider the case where , i.e. is on a decision boundary of , between two regions . Then . This shows that the piecewise components of come to the same value at their intersection.Further, each piecewise component of is equal to some continuous function, as is continuous by assumption. Thus, is continuous, and we conclude our proof. ∎
We include a visual intuition of the proof in Figure 1.
A.2 Proof of Theorem 4.1
Theorem 4.1.
Let be a learning pipeline, and let be a distribution over random states. Further, let be the mode predictor, let for be a selective ensemble, and let . Then,
Proof.
is an ensemble of models. By the definition of Algorithm LABEL:prediction_algo, gathers a vector of class counts of the prediction for from each model in the ensemble. Let the class with the highest count be , with counts , and the class with the second highest count be called , with counts . runs a two-sided hypothesis test to ensure that , i.e. that is the true mode prediction over . See that
| (1) | |||||
| (2) | |||||
| (3) | |||||
| By hung2019rank | (4) | ||||
Thus,
∎
A.3 Proof of Corollary 4.2
Corollary 4.2.
Let be a learning pipeline, and let be a distribution over random states. Further, let be the mode predictor, let for be a selective ensemble. Finally, let , and let be an upper bound on the expected abstention rate of . Then, the expected loss variance, , over inputs, , is bounded by . That is,
Proof.
Since never abstains, we have by the law of total probability that
By Theorem LABEL:thm:matches_mode, we have that , thus
Finally, since is an upper bound on the expected abstention rate of , we conclude that
∎
A.4 Proof of Corollary 4.3
Corollary 4.3.
Let be a learning pipeline, and let be a distribution over random states. Further, let for be a selective ensemble. Finally, let , and let be an upper bound on the expected abstention rate of . Then,
Proof.
For , let be the event that , and let be the event that . In the worst case, and , and and are disjoint, that is, e.g., if abstains on , then . In other words, we have that
which, by union bound implies that
By Theorem LABEL:thm:matches_mode . Thus we have
Finally, since is an upper bound on the expected abstention rate of , we conclude that
∎
Appendix B Datasets
The German Credit and Taiwanese data sets consist of individuals financial data, with a binary response indicating their creditworthiness. For the German Credit dataset, there are 1000 points, and 20 attributes. We one-hot encode the data to get 61 features, and standardize the data to zero mean and unit variance using SKLearn Standard scaler. We partitioned the data intro a training set of 700 and a test set of 200. The Taiwanese credit dataset has 30,000 instances with 24 attributes. We one-hot encode the data to get 32 features and normalize the data to be between zero and one. We partitioned the data intro a training set of 22500 and a test set of 7500.
The Adult dataset consists of a subset of publicly-available US Census data, binary response indicating annual income of k. There are 14 attributes, which we one-hot encode to get 96 features. We normalize the numerical features to have values between and . After removing instances with missing values, there are examples which we split into a training set of 14891, a leave one out set of 100, and a test set of 1501 examples.
The Seizure dataset comprises time-series EEG recordings for 500 individuals, with a binary response indicating the occurrence of a seizure. This is represented as 11500 rows with 178 features each. We split this into 7,950 train points and 3,550 test points. We standardize the numeric features to zero mean and unit variance.
The Warfain dataset is collected by the International Warfarin Pharmacogenetics Consortium [nejm-warfarin] about patients who were prescribed warfarin. We removed rows with missing values, 4819 patients remained in the dataset. The inputs to the model are demographic (age, height, weight, race), medical (use of amiodarone, use of enzyme inducer), and genetic (VKORC1, CYP2C9) attributes. Age, height, and weight are real-valued and were scaled to zero mean and unit variance. The medical attributes take binary values, and the remaining attributes were one-hot encoded. The output is the weekly dose of warfarin in milligrams, which we encode as "low", "medium", or "high", following the recommendations set by nejm-warfarin.
Fashion MNIST contains images of clothing items, with a multilabel response of 10 classes. There are 60000 training examples and 10000 test examples. We pre-process the data by normalizing the numerical values in the image array to be between and .
The colorectal histology dataset contains images of human colorectal cancer, with a multilabel response of 8 classes. There are 5,000 images, which we divide into a training set of 3750 and a validation set of 1250. We pre-process the data by normalizing the numerical values in the image array to be between and .
The UCI datasets as well as FMNIST are under an MIT license, the colorectal histology and Warfarin datasets are under a Creative Commons License. [uci, colon_license, nejm-warfarin].
Appendix C Model Architecture and Hyper-Parameters
The German Credit and Seizure models have three hidden layers, of size 128, 64, and 16. Models on the Adult dataset have one hidden layer of 200 neurons. Models on the Taiwanese dataset have two hidden layers of 32 and 16. The Warfarin models have one hidden layer of 100. The FMNIST model is a modified LeNet architecture [lecun1995learning]. This model is trained with dropout. The Colon models are trained with a modified, ResNet50 [he2016deep], pre-trained on ImageNet [deng2009imagenet], available from Keras. German Credit, Adult, Seizure, Taiwanese, and Warfarin models are trained for 100 epochs; FMNIST for 50, and Colon models are trained for 20 epochs. German Credit models are trained with a batch size of 32; FMNIST 64; Adult, Seizure, and Warfarin models with batch sizes of 128; and Colon and Taiwanese Credit models with batch sizes of 512. German Credit, Adult, Seizure, Taiwanese Credit, Warfarin, and Colon are trained with keras’ Adam optimizer with the default parameters. FMNIST models are trained with keras’ SGD optimizer with the default parameters.
Note that we discuss train-test splits and data preprocessing above in Section B. We prepare different models for the same dataset using Tensorflow 2.3.0 and all computations are done using a Titan RTX accelerator on a machine with 64 gigabytes of memory.
Appendix D Metrics
We report similarity between feature attributions with Spearman’s Ranking Correlation (), Pearson’s Correlation Coefficient (), top- intersection, distance, and SSIM for image datasets. We use standard implementations for Spearman’s Ranking Correlation () and Pearson’s Correlation Coefficient () from scipy, and implement distance as well as the top- using numpy functions.
Note that and vary from -1 to 1, denoting negative, zero, and positive correlation. We display top- for =5, and compute this by taking the number of features in the intersection of the top between two models, and then diving this by . Thus top- is between 0 and 1, indicating low and high correlation respectively.
The distance has a minimum of , but is unbounded from above, and SSIM varies from -1 to 1, indicating no correlation to exact correlation respectively.
Note that we compute these metrics between two different models on the same point, for every point in the test set, over 276 different pairs of models for tabular datasets and over 40 pairs of models for image datasets. We average this result over the points in the test set and over the comparisons to get the numbers displayed in the tables and graphs throughout the paper.
D.1 SSIM
Explanations for image models can be interpreted as an image (as there is an attribution for each pixel), and are often evaluated visually [leino18influence, simonyan2014deep, sundararajan2017axiomatic]. However, pixel-wise indicators for similarity between images (such as top-k similarity between pixel values, Spearman’s ranking coefficient, or mean squared error) often do not capture how similar images are visually, in aggregate. In order to give an indication if the entire explanation for an image model, i.e. the explanatory image produced, is similar, we use the structural similarity index (SSIM) [wang2004image]. We use the implementation from [structural_similarity_index]. SSIM varies from -1 to 1, indicating no correlation to exact correlation respectively.
Appendix E Experimental Results for
We include results on the prediction of selective ensemble models for as well. We include the percentage of points with disagreement between at least one pair of models () trained with different random seeds (RS) or leave-one-out differences in training data, for singleton models () and selective ensembles () in Table 1. Notice the number of points with is again zero. We also include the mean and standard deviation of accuracy and abstention rate for in Table 2.
| mean std. dev of portion of test data with | ||||||||
|---|---|---|---|---|---|---|---|---|
| Randomness | Ger. Credit | Adult | Seizure | Tai. Credit | Warfarin | FMNIST | Colon | |
| RS | 1 | |||||||
| RS | (5, 10, 15, 20) | |||||||
| LOO | 1 | |||||||
| LOO | (5, 10, 15, 20) | |||||||
| mean accuracy (abstain as error) / std. dev | ||||||||
|---|---|---|---|---|---|---|---|---|
| Ger. Credit | Adult | Seizure | Wafarin | Tai. Credit | FMNIST | Colon | ||
| RS | 5 | |||||||
| RS | 10 | |||||||
| RS | 15 | |||||||
| RS | 20 | |||||||
| LOO | 5 | |||||||
| LOO | 10 | |||||||
| LOO | 15 | |||||||
| LOO | 20 | |||||||
| mean abstention rate / std dev | ||||||||
| Ger. Credit | Adult | Seizure | Warfarin | Tai. Credit | FMNIST | Colon | ||
| RS | 5 | |||||||
| RS | 10 | |||||||
| RS | 15 | |||||||
| RS | 20 | |||||||
| LOO | 5 | |||||||
| LOO | 10 | |||||||
| LOO | 15 | |||||||
| LOO | 20 | |||||||
Appendix F Selective Ensembling Full Results
We include the full results from the evaluation section, including error bars on the disagreement, accuracy, abstention rates of selective ensembles, in Table 3 and Table 4 respectively. We also include the results for all datasets on the accuracy of non-selective ensembling and their ability to mitigate disagreement, in Table 3 and Table 2 respectively.
| mean std. dev of portion of test data with | ||||||||
|---|---|---|---|---|---|---|---|---|
| Randomness | Ger. Credit | Adult | Seizure | Tai. Credit | Warfarin | FMNIST | Colon | |
| RS | 1 | |||||||
| RS | (5, 10, 15, 20) | |||||||
| LOO | 1 | |||||||
| LOO | (5, 10, 15, 20) | |||||||
| mean accuracy (abstain as error) / std. dev | ||||||||
|---|---|---|---|---|---|---|---|---|
| Ger. Credit | Adult | Seizure | Warfarin | Tai. Credit | FMNIST | Colon | ||
| RS | 5 | |||||||
| RS | 10 | |||||||
| RS | 15 | |||||||
| RS | 20 | |||||||
| LOO | 5 | |||||||
| LOO | 10 | |||||||
| LOO | 15 | |||||||
| LOO | 20 | |||||||
| mean abstention rate / std dev | ||||||||
| Ger. Credit | Adult | Seizure | Warfarin | Tai. Credit | FMNIST | Colon | ||
| RS | 5 | |||||||
| RS | 10 | |||||||
| RS | 15 | |||||||
| RS | 20 | |||||||
| LOO | 5 | |||||||
| LOO | 10 | |||||||
| LOO | 15 | |||||||
| LOO | 20 | |||||||
| disagreement of non-abstaining ensembles | ||||||||
|---|---|---|---|---|---|---|---|---|
| Ger. Credit | Adult | Seizure | Tai. Credit | Warfarin | FMNIST | Colon | ||
| RS | 1 | |||||||
| RS | 5 | |||||||
| RS | 10 | |||||||
| RS | 15 | |||||||
| RS | 20 | |||||||
| LOO | 1 | |||||||
| LOO | 5 | |||||||
| LOO | 10 | |||||||
| LOO | 15 | |||||||
| LOO | 20 | |||||||
| accuracy of non-abstaining ensembles | ||||||||
|---|---|---|---|---|---|---|---|---|
| Ger. Credit | Adult | Seizure | Warfarin | Tai. Credit | FMNIST | Colon | ||
| RS | 5 | |||||||
| RS | 10 | |||||||
| RS | 15 | |||||||
| RS | 20 | |||||||
| LOO | 5 | |||||||
| LOO | 10 | |||||||
| LOO | 15 | |||||||
| LOO | 20 | |||||||
Appendix G Selective Ensembles and Disparity in Selective Prediction
In light of the fact that prior work has brought to light the possibility of selective prediction exacerbating model accuracy disparity between demographic groups [jones2020selective], we present the selective ensemble accuracy and abstention rate group-by-group for several different demographic groups across four datasets: Adult, German Credit, Taiwanese Credit, and Warfarin Dosing. Results are in Table 5.
| accuracy (abstain as error) / abstention rate | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Adult Male | Adult Fem. | Ger. Cred. Young | Ger. Cred. Old | Tai. Cred. Male | Tai. Cred. Fem. | Warf. Black | Warf. White | Warf. Asian | |||||||||||
| Base | 1 | / - | / - | / - | / - | / - | / - | / - | / - | / - | |||||||||
| RS | 5 | ||||||||||||||||||
| RS | 10 | ||||||||||||||||||
| RS | 15 | ||||||||||||||||||
| RS | 20 | ||||||||||||||||||
| Base | 1 | / - | / - | / - | / - | / - | / - | / - | / - | / - | |||||||||
| LOO | 5 | ||||||||||||||||||
| LOO | 10 | ||||||||||||||||||
| LOO | 15 | ||||||||||||||||||
| LOO | 20 | ||||||||||||||||||
Appendix H Explanation Consistency Full Results
We give full results for selective and non-selective ensembling’s mitigation of inconsistency in feature attributions.
H.1 Attributions
We pictorially show the inconsistency of individual model feature attributions versus the consistency of attributions ensembles of 15 for each tabular dataset in Figure 4 and Figure 5. The former shows inconsistency over differences in random initialization, the latter shows inconsistency over one-point changes to the training set.
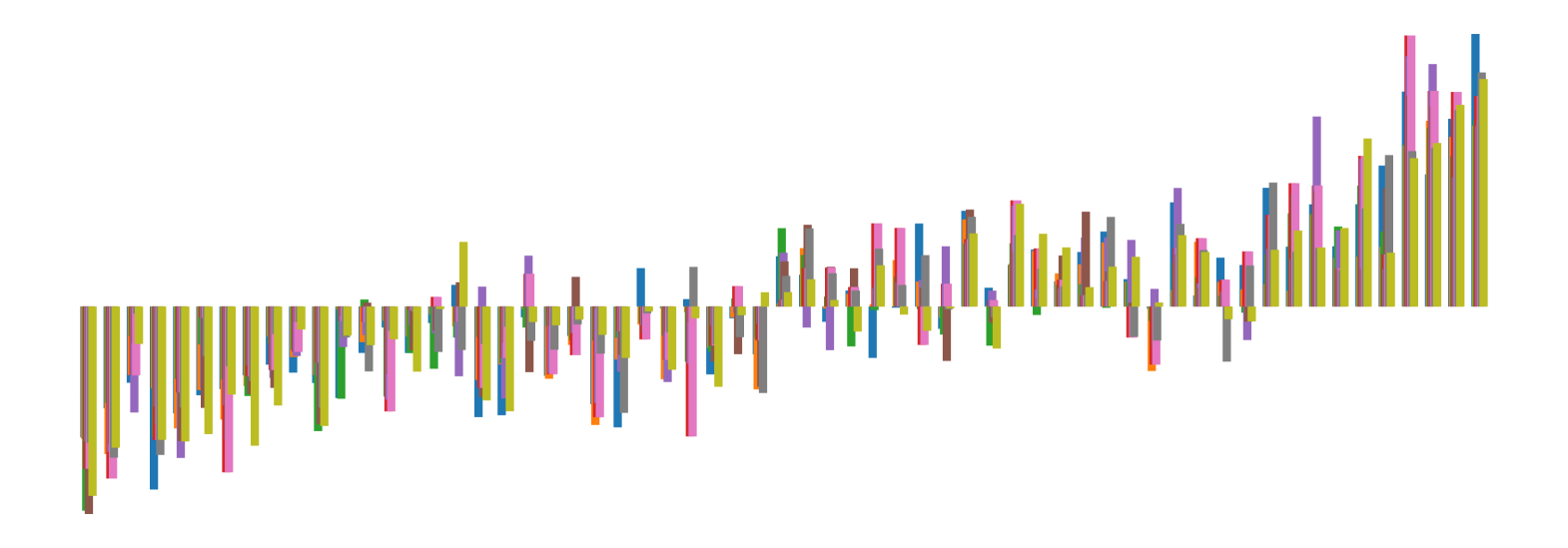
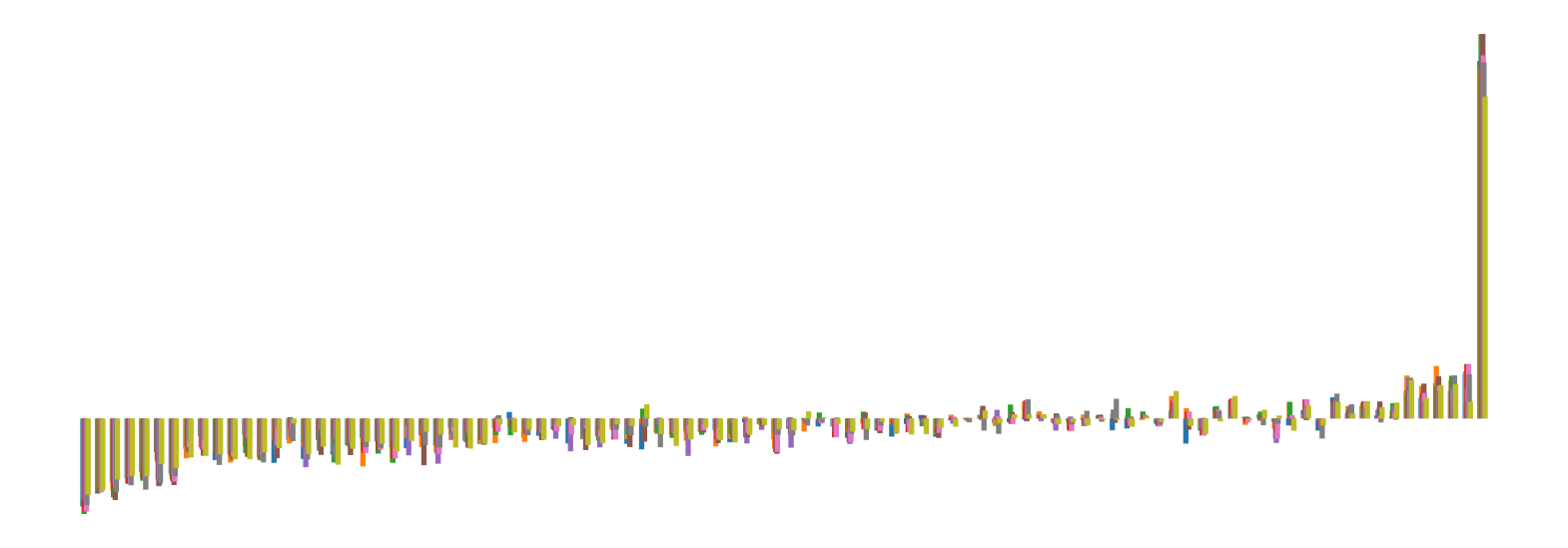
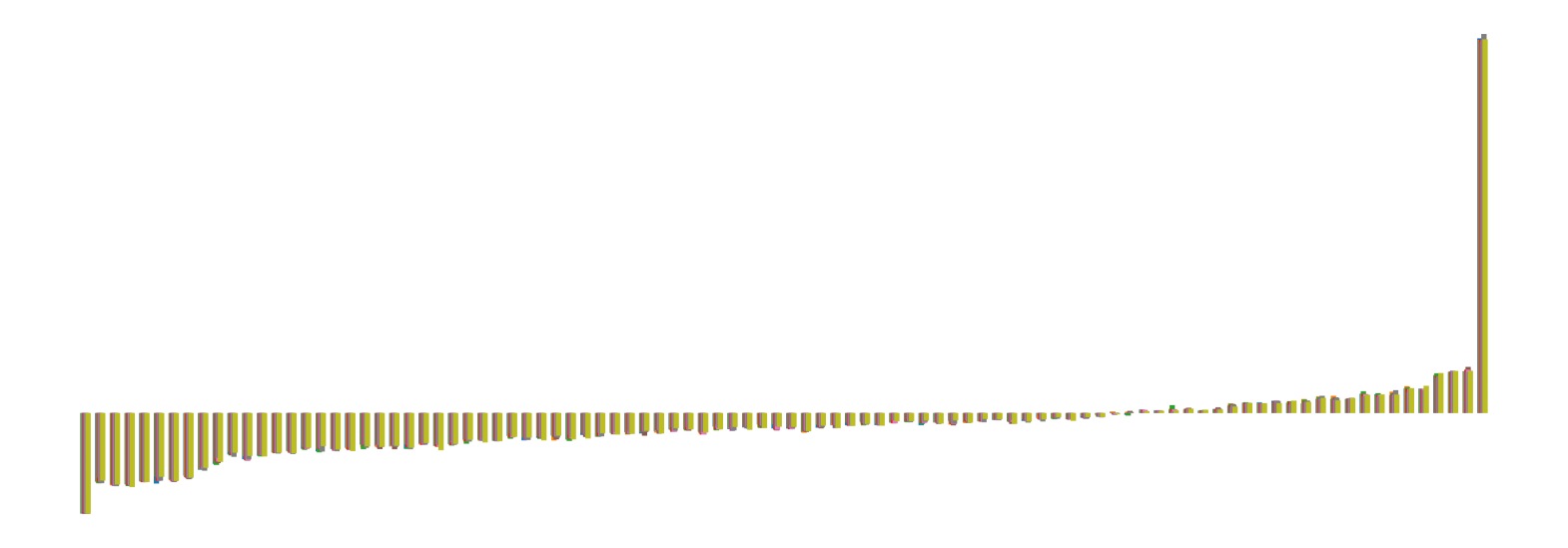
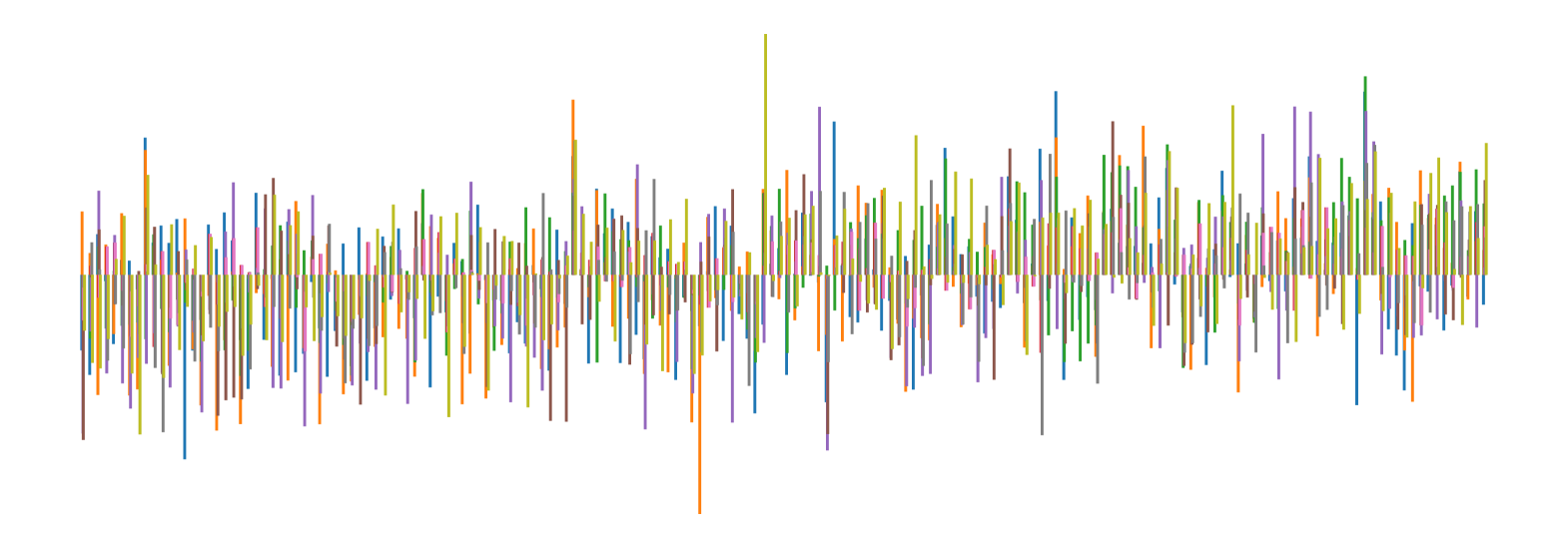
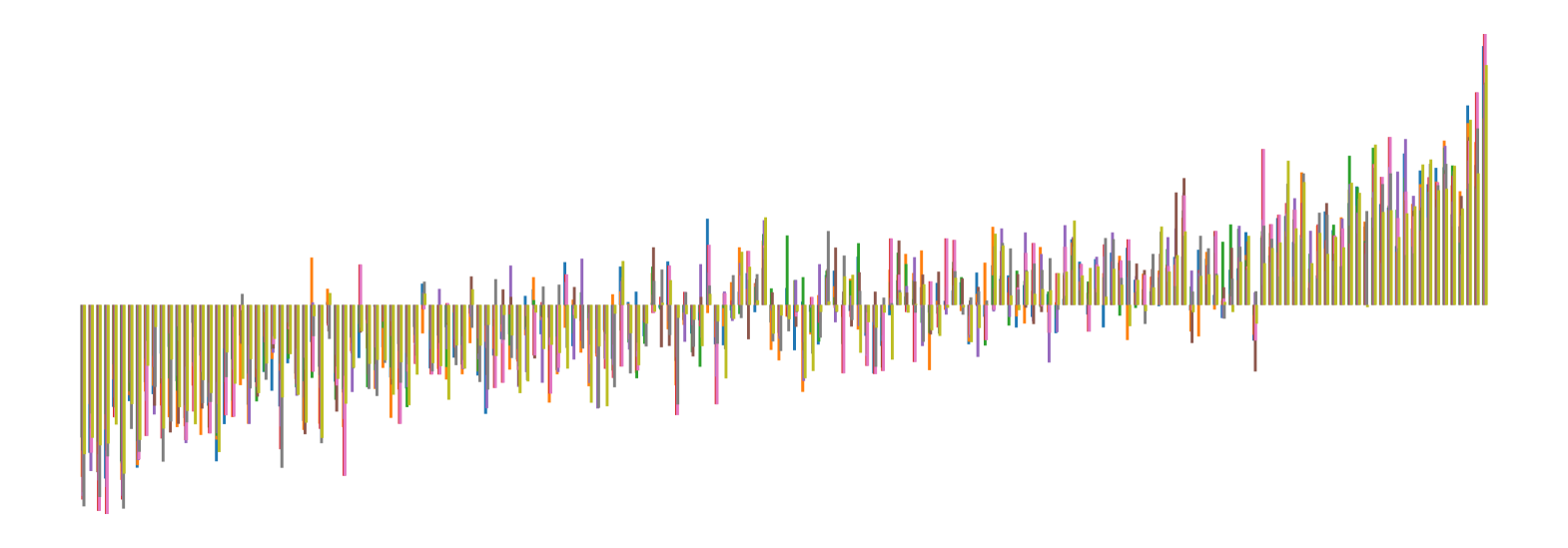
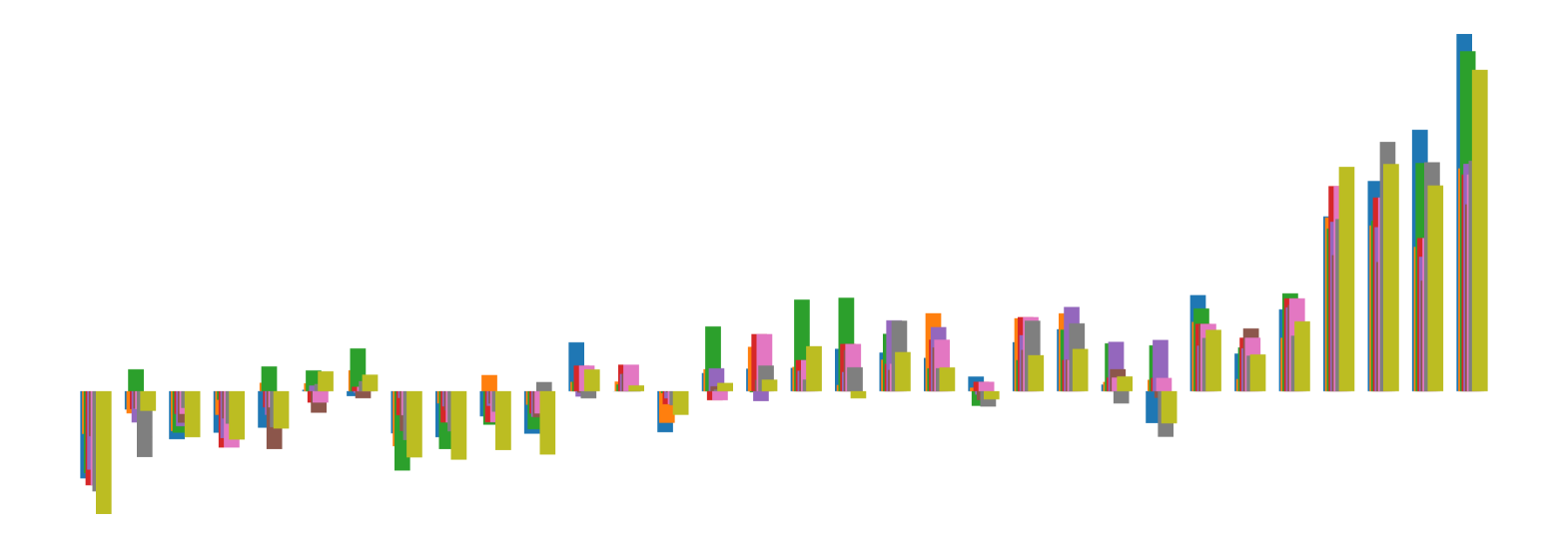
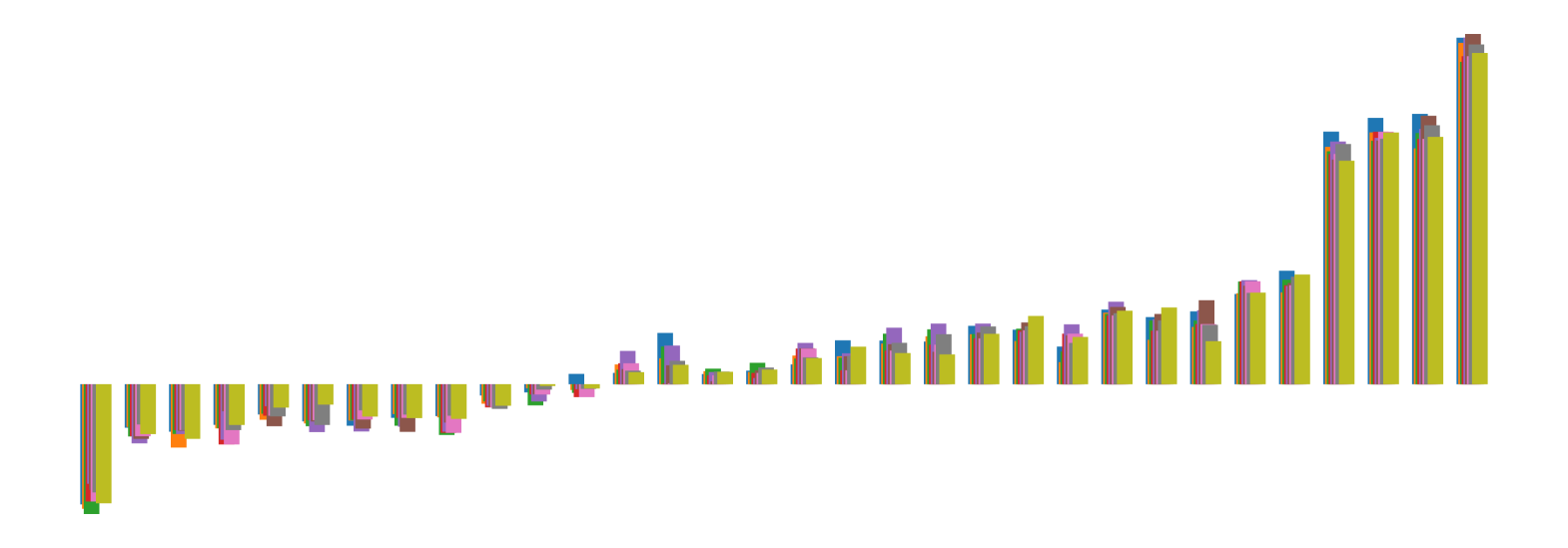
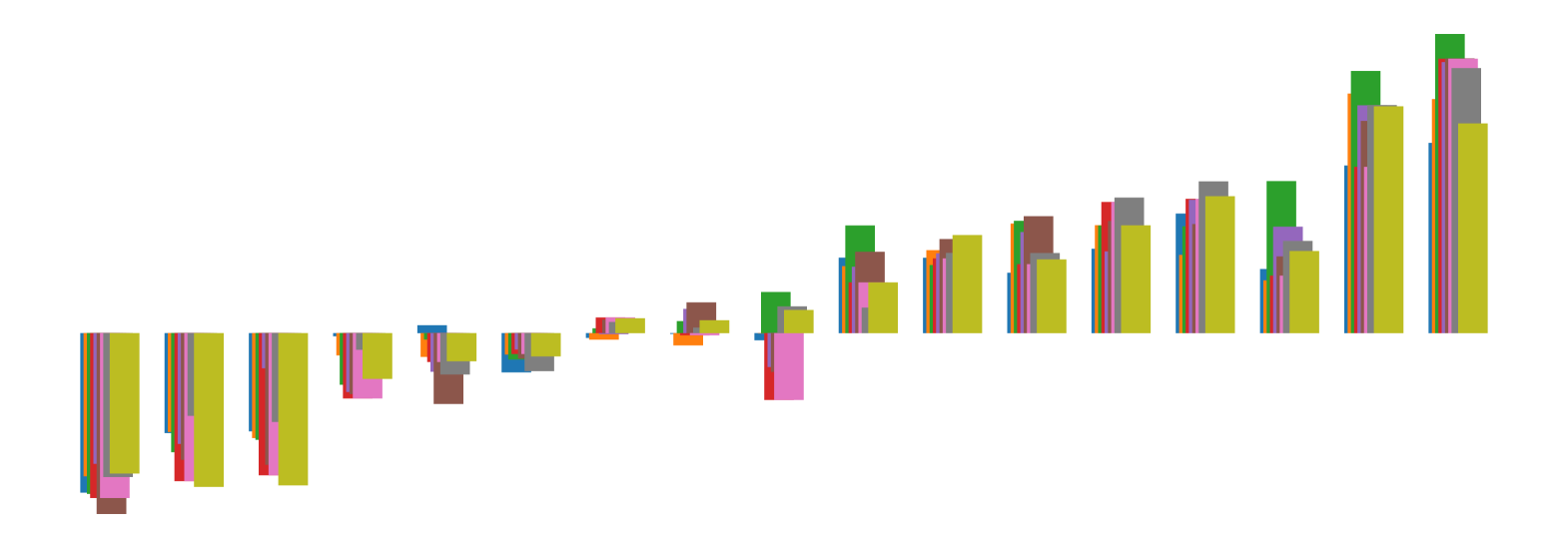
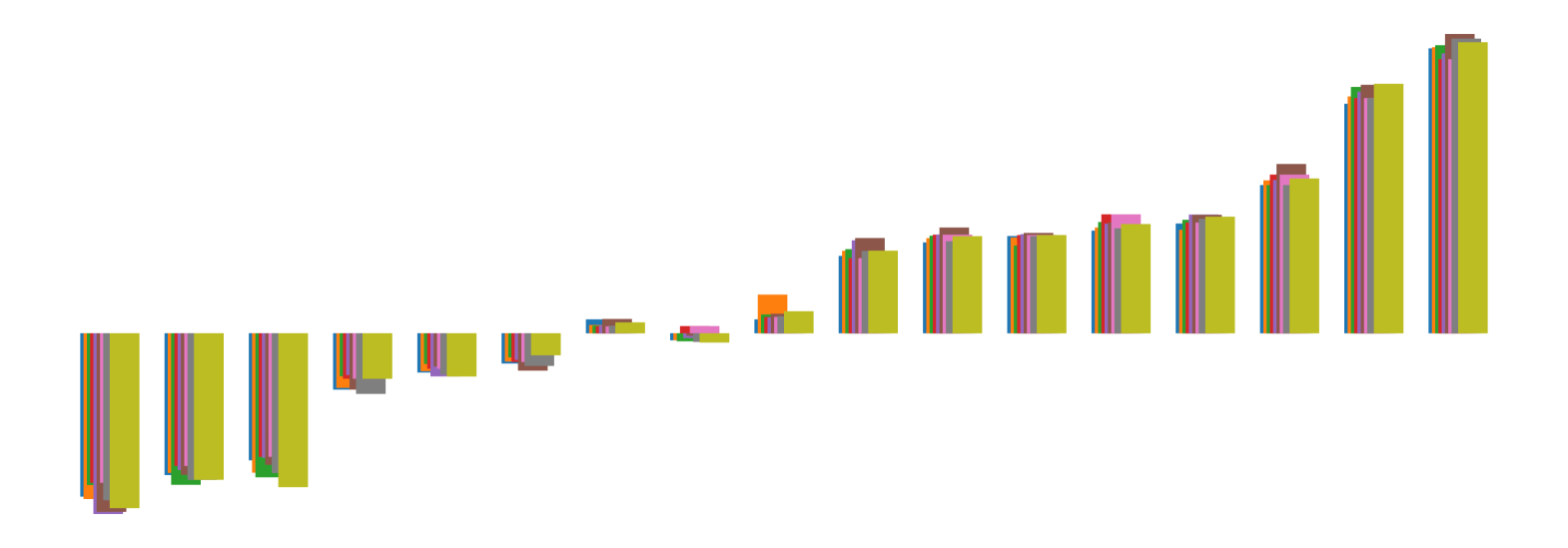
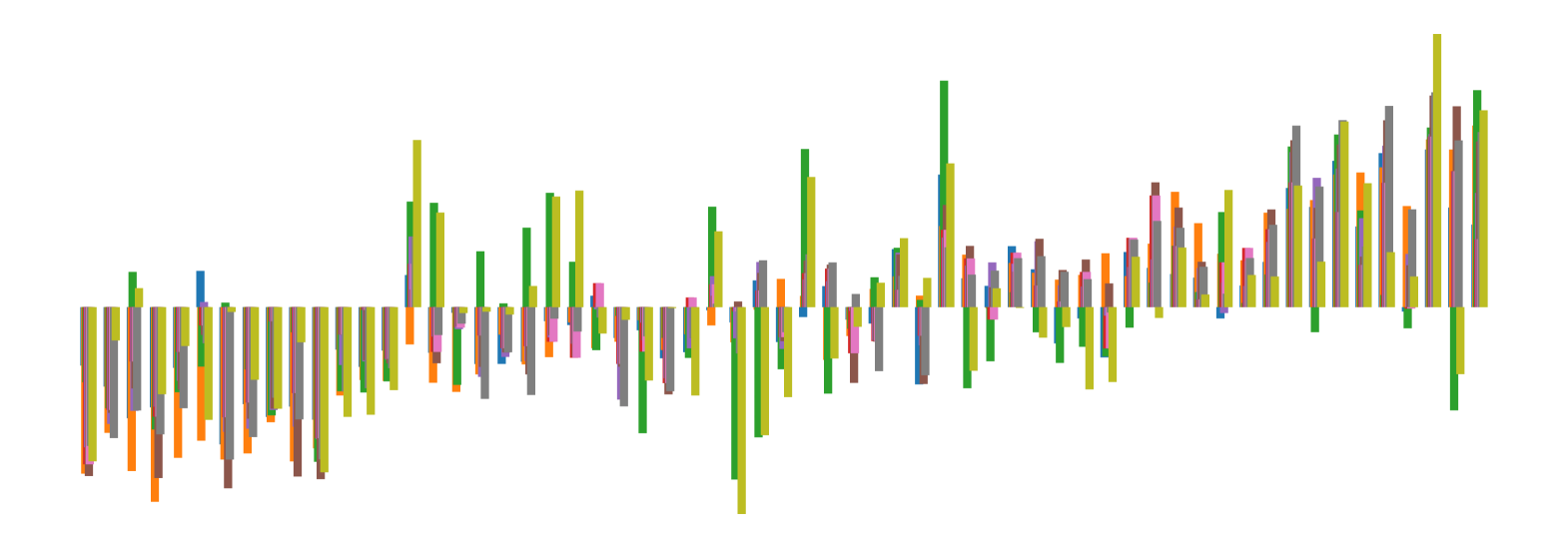
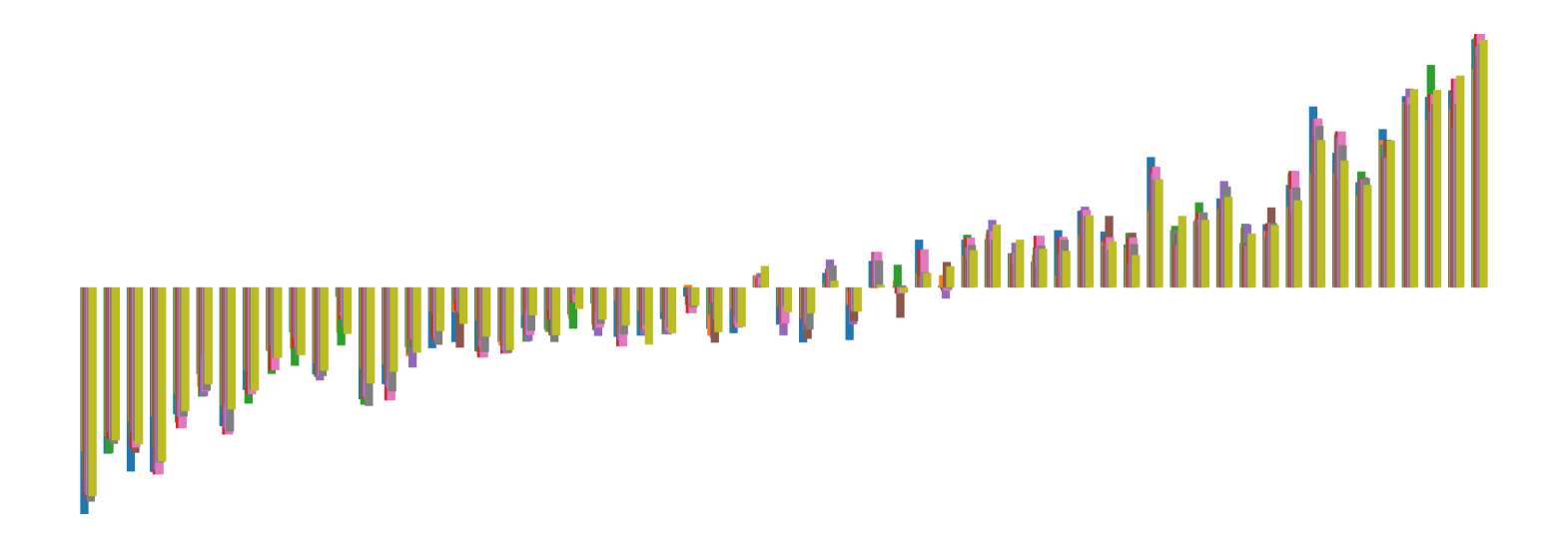
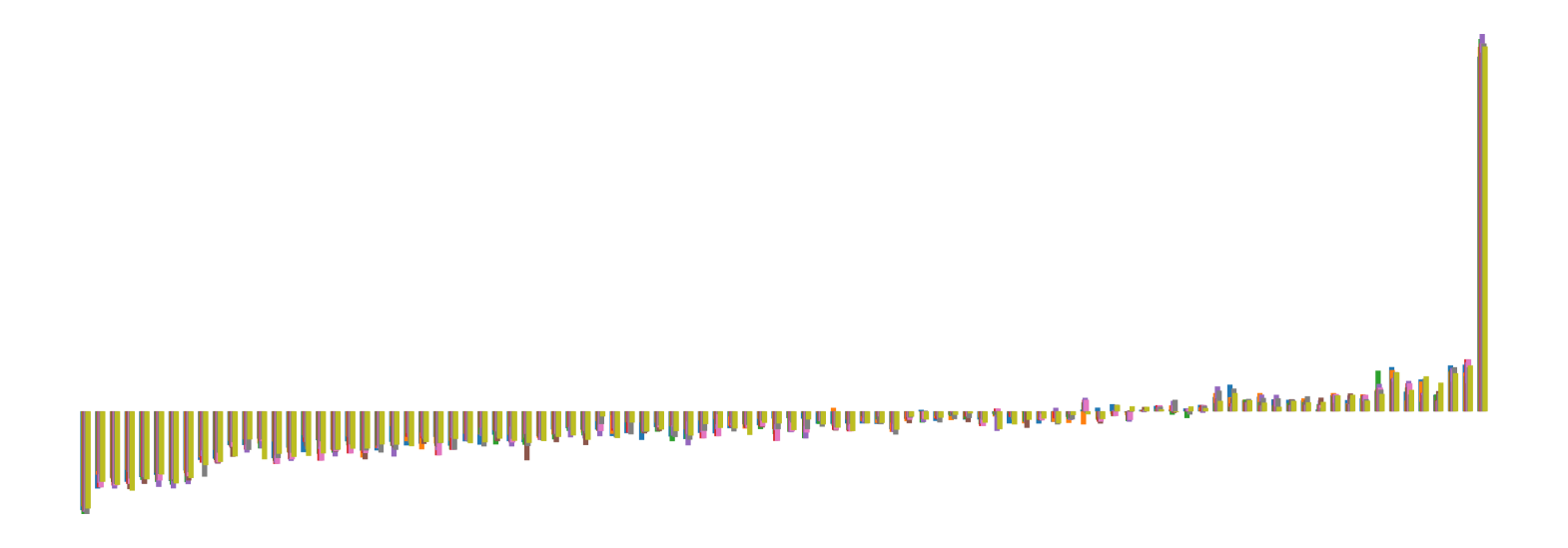
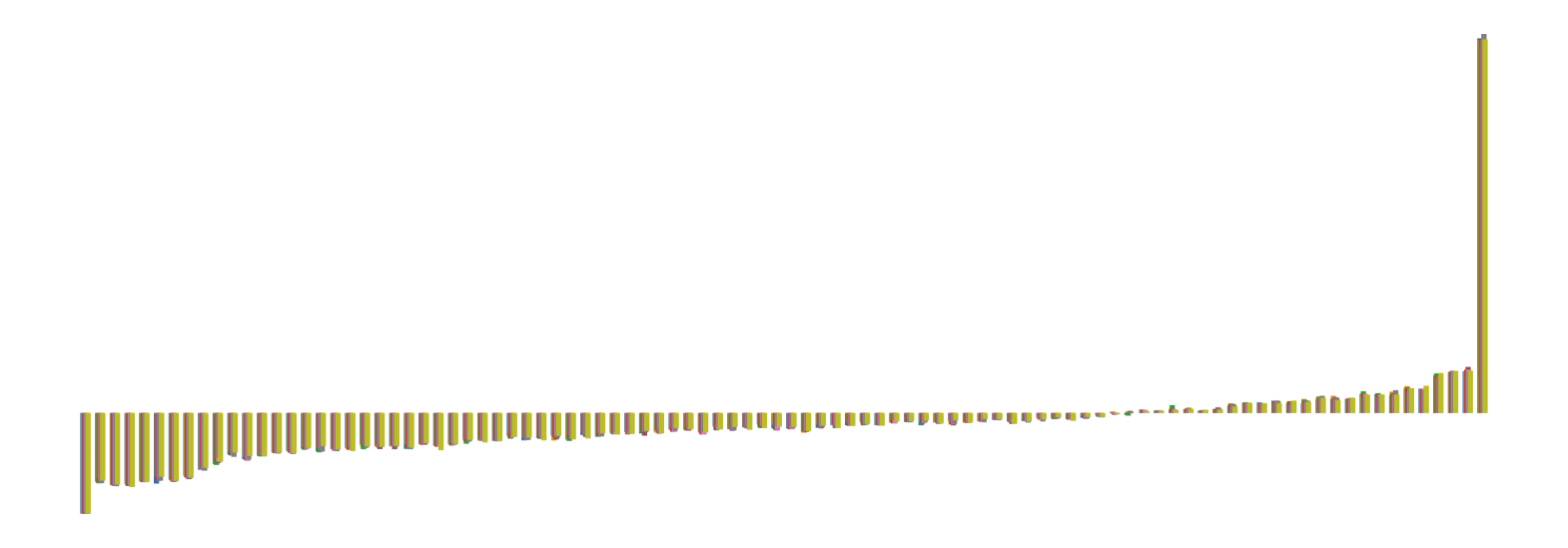
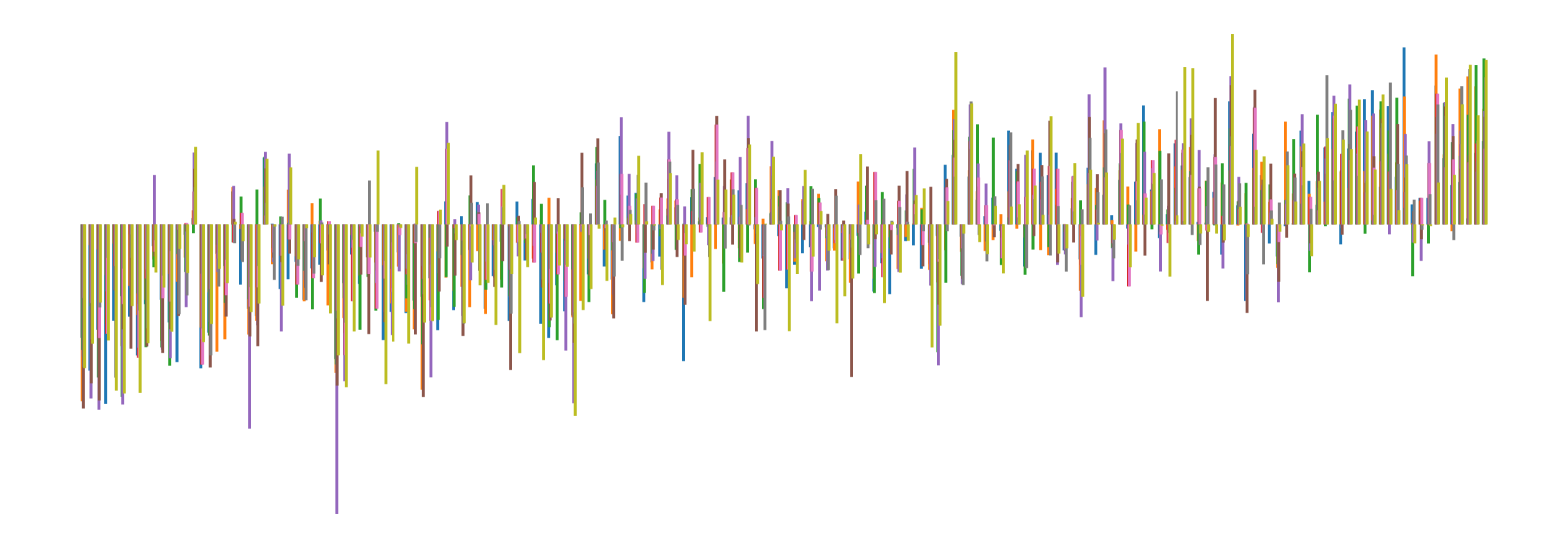
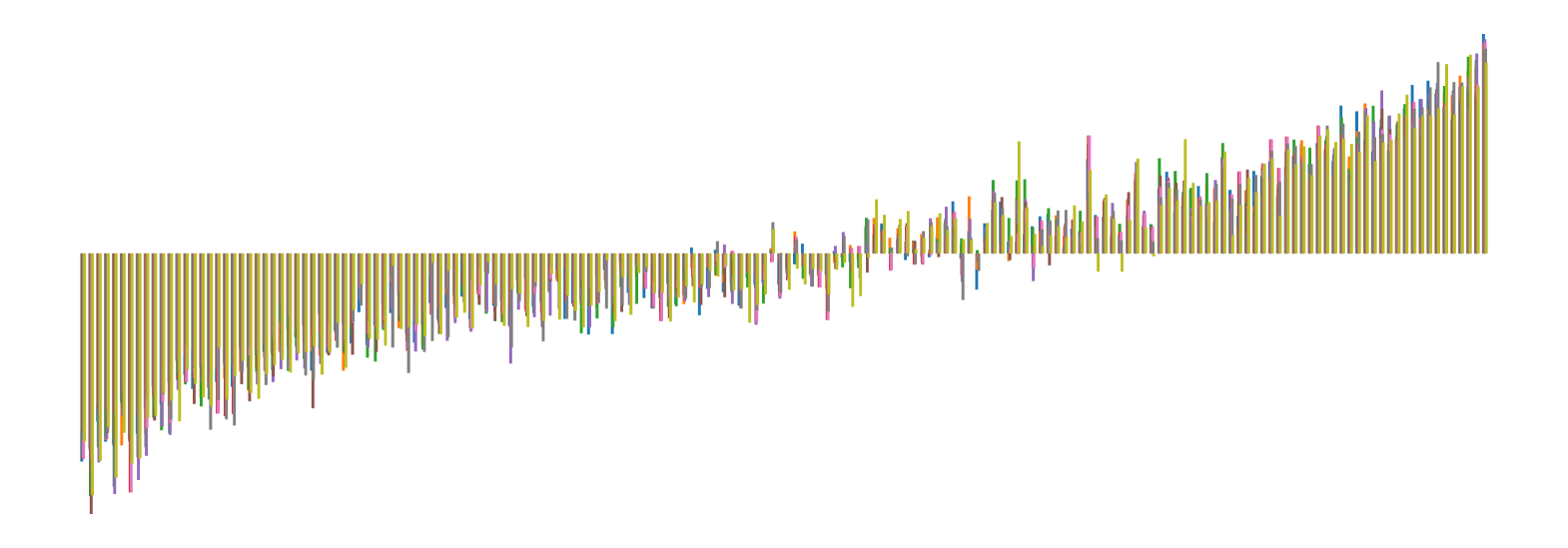
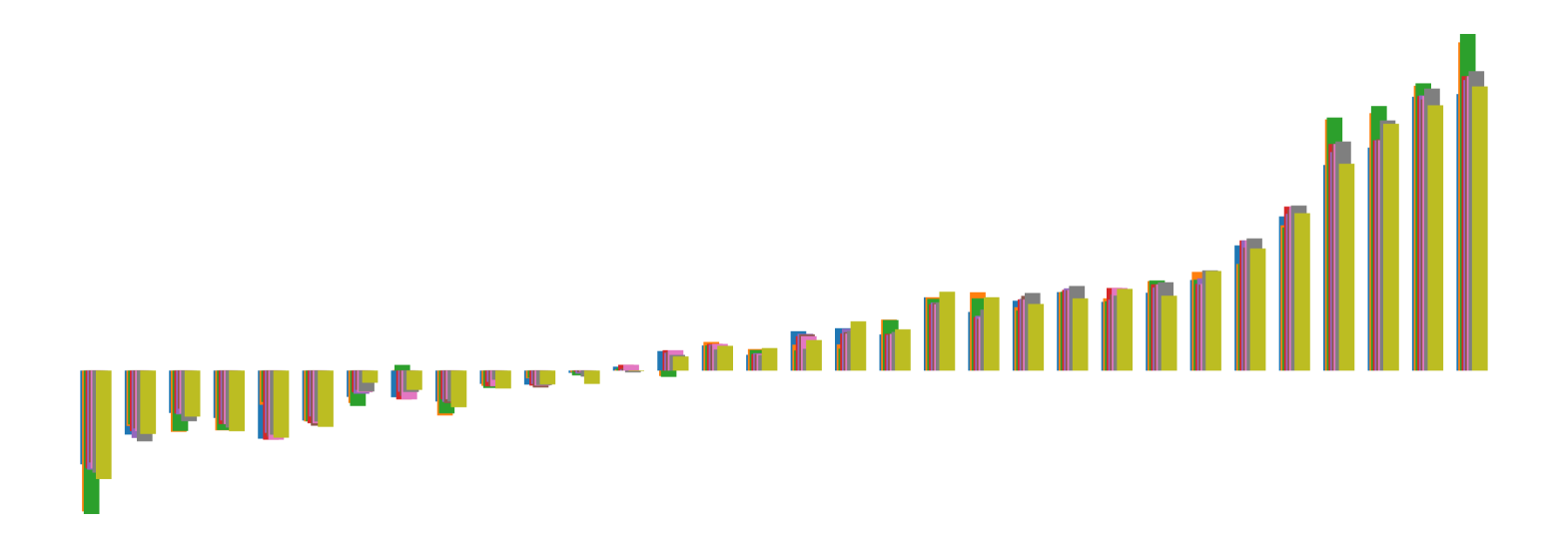
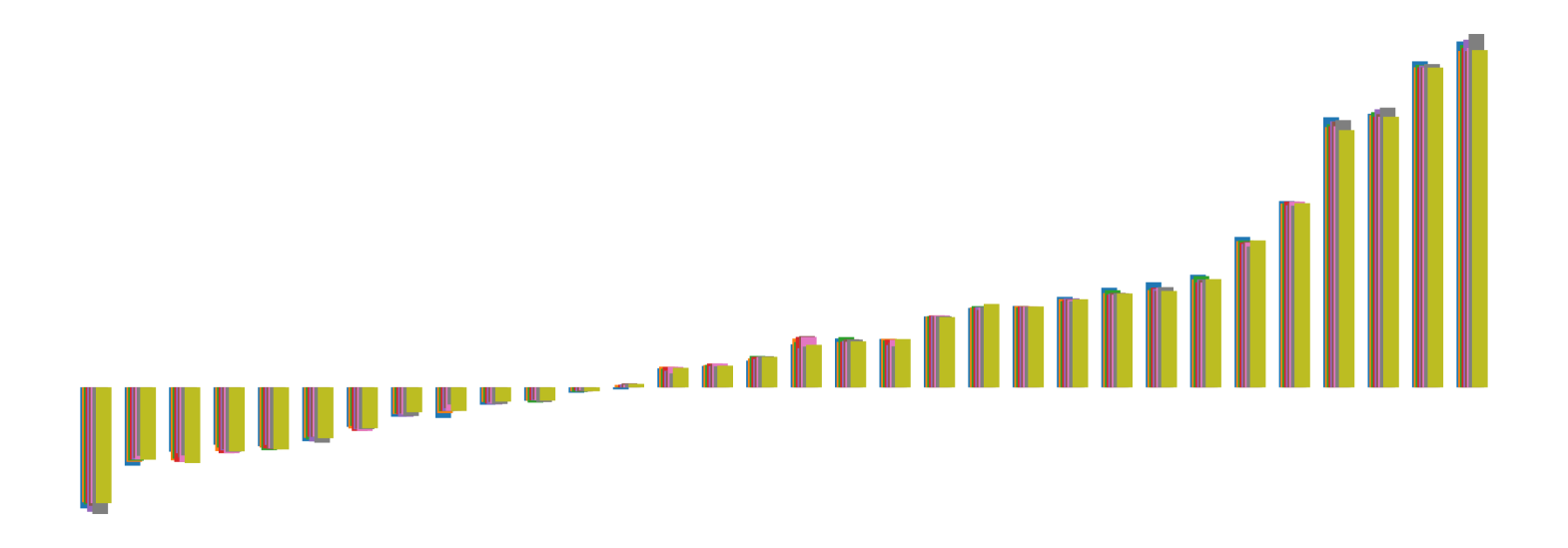
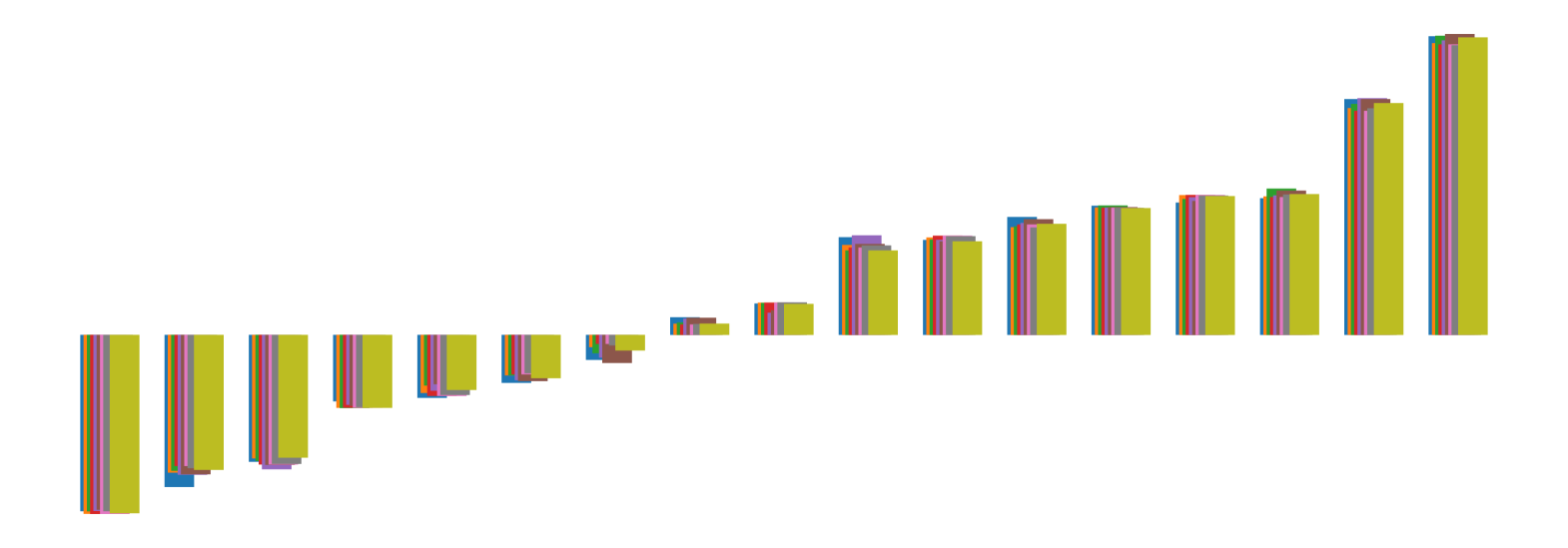
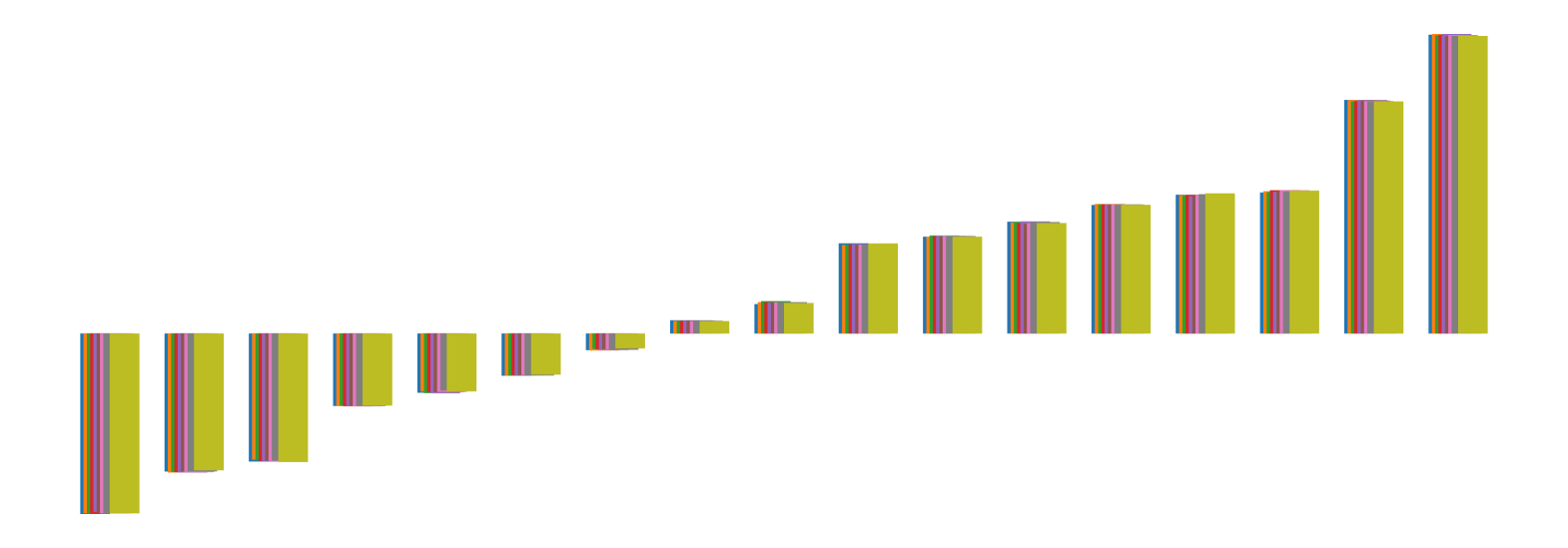
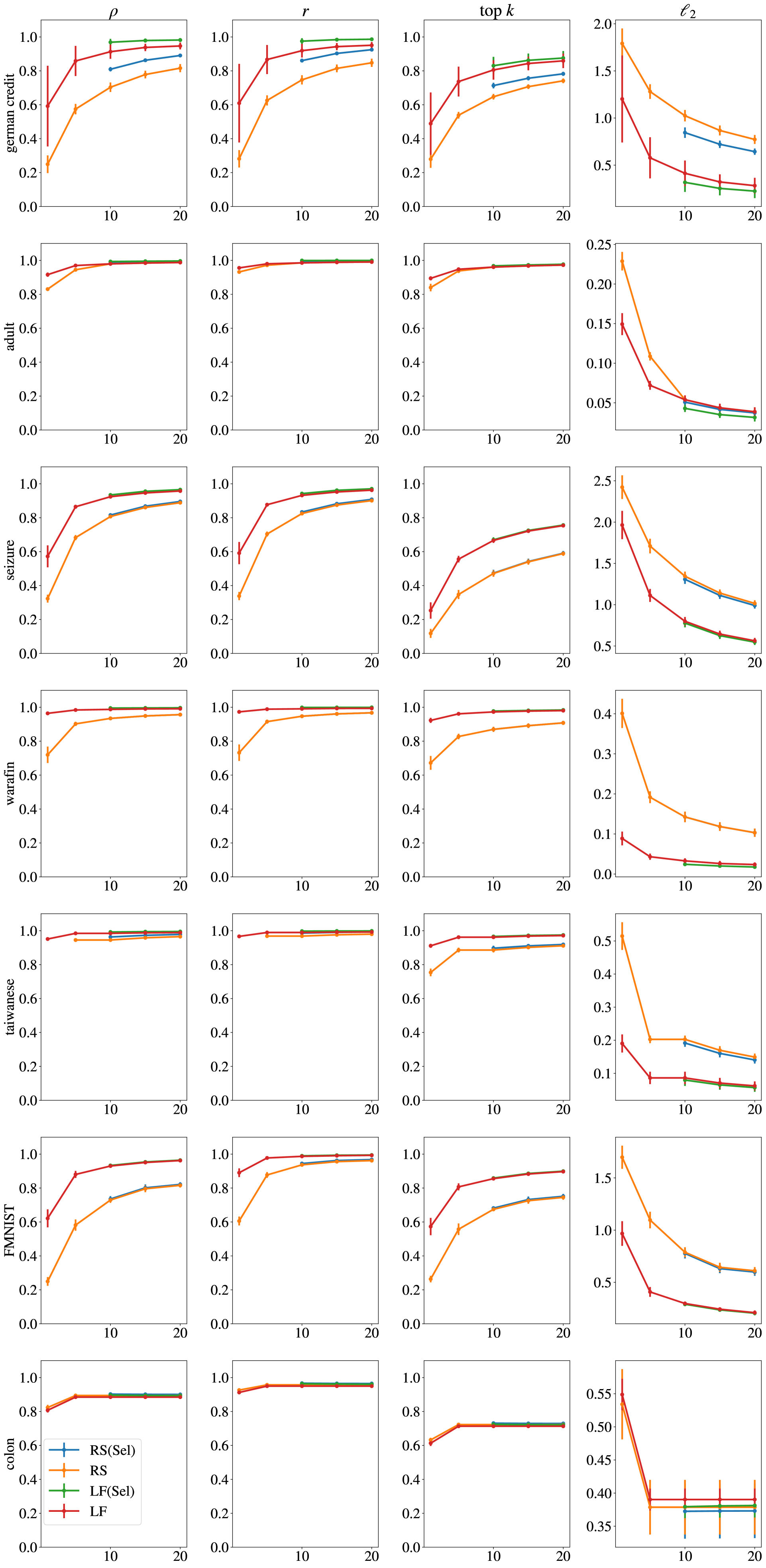
H.2 Similarity Metrics of Attributions
We display how Spearman’s ranking coefficient (), Pearson’s Correlation Coefficient (), top-5 intersection and distance between feature attributions over the same point become more and more similar with increasing numbers of ensemble models. While the comparisons to generate the similarity score is between two models on the same point, the result is averaged over this comparison for the entire test set. We average this over 276 comparisons between different models. In cases were abstention is high, indicating inconsistency on the dataset for the training pipeline, selective ensembling can further improve stability of attributions by not considering unstable points (see e.g. German Credit). We present the expanded results from the main paper, for all datasets, on all four metrics (as SSIM is only computed for image datasets, and is not computed for image datasets). We display error bars indicating standard deviation over the 276 comparisons between two models for tabular datasets, and 40 comparisons for image datasets.