SeLiNet: Sentiment enriched Lightweight Network for Emotion Recognition in Images
Abstract
In this paper, we propose a sentiment-enriched lightweight network SeLiNet and an end-to-end on-device pipeline for contextual emotion recognition in images. SeLiNet model consists of body feature extractor, image aesthetics feature extractor, and multitask learning-based fusion network which jointly estimates discrete emotion and human sentiments tasks. On the EMOTIC dataset, the proposed approach achieves an Average Precision (AP) score of 27.17 in comparison to the baseline AP score of 27.38 while reducing the model size by 85%. In addition, we report an on-device AP score of 26.42 with reduction in model size by 93% when compared to the baseline.
I Introduction
Understanding the emotional states of the people in the images is an emerging research area in the domain of computer vision. Ability to correctly perceive emotions can help improve human-computer interactions. In the case of smartphones, several use cases can be built such as queries based on-device image search, dynamically uncluttering the notification panel based on user emotions, etc. Further, it has other advanced applications like modeling robot behavior as per the perceived emotion of the user.
Conventionally, researchers have used facial expressions [14, 19] based features to process human emotions. Recently, scientific studies have established that perception of emotions is also influenced by context [3, 4] such as background scene [15, 23], body posture [17], image composition [21], gait analysis [33] etc. Several previous works have achieved better performance by considering these contexts.
Previous studies show that image aesthetics assessment [11] is a crucial cue to understand the emotions evoked by the images. Aesthetics response towards images may depend upon many components such as composition, colorfulness, spatial organization, emphasis, motion, depth, or presence of humans [2, 20]. Traditional works have used low-level handcrafted visual features [1, 10, 31] to understand the aesthetics and related image emotions. Recent works based on deep learning [5, 28, 32] extract mid and global-level features such as composition, semantics, and emphasis [36] to classify image emotions. These works try to understand human emotions evoked by the pictures and are able to achieve improved results by considering the aesthetics properties of the images. Understanding the composition and semantics of the images can help capture the high-level contextual properties like the object’s spatial organization, the relationship between various local level features, etc., and thus can also be beneficial to the task of recognizing the emotional states of people in the images. Image aesthetics assessment has an impact on human sentiment also. It may be either positive, negative, or neutral. For example, images that convey a pleasant mood are generally rated high on the aesthetics scale, and vice-versa. Such images are also known to elicit positive emotions. Taking inspiration from these discussed studies, we explore image aesthetics assessment-based features along with body features to understand the sentiment and emotional states of the people in the images.
Several studies show that privacy is one of the leading concerns among people [22, 24]. With the rise in ownership of smartphones [8], this concern is particularly high among smartphone users [26, 29]. To this end, we present an end-to-end on-device novel pipeline consisting of the sentiment-enriched lightweight model called SeLiNet for human emotion understanding from the image. Our main contributions can be summarized as:
-
•
We propose a sentiment-enriched lightweight model SeLiNet and end-to-end pipeline for on-device emotion recognition in images which achieves comparable average precision(AP) score to the baseline system with a significant reduction in model size (85% ↓) and inference time(78% ↓).
-
•
We demonstrate that the image aesthetics features contribute in improving the overall performance of the task of emotion recognition in images.
-
•
We conceptualize the problem as multitask learning-based and make predictions for discrete emotions and related sentiments. We then use sentiment knowledge in the post-processing to enhance emotion predictions and show improved results.
II Related work
Emotion recognition is a well-studied task in the vision field. Traditional works have used hand-crafted features [25, 37] for the emotion recognition task. Deep learning networks have taken into account facial expressions [14, 19], gait analysis [33] and body posture [18, 30] etc. based features to predict emotions. [7] proposed facial expressions based on compound emotion detection such as ’happily disgusted’ or ’angrily surprised’ and thus provide deeper insights about expressed emotions. While most of these works have modeled emotion detection tasks as the categorical problem, some have tried to use the valence, arousal, and dominance (VAD) model [27] based on continuous emotional space.
Recently, several works have also demonstrated the importance of contextual cues in interpreting emotional states. [13] presents two-stream encoding networks capturing facial and contextual features, followed by a fusion network to predict context-aware emotion recognition. [12] also proposes similar two-stream architecture in which one stream captures body features and the other stream captures scene context from the image. A fusion network consisting of both body and scene context features is jointly used to predict discrete emotion and VAD scores. They also create and publish the EMOTIC (from EMOTions In Context) Dataset and provide a CNN-based baseline system on the same dataset. [16] proposes context aware multi-modality-based network to predict emotion. They use several context-based modalities such as the face, gait analysis, semantic context, and depth maps to model socio-dynamic interactions among agents.
In this work, we get inspiration from [12] to design our lightweight network and baseline this work for the comparison of our proposed approach on the EMOTIC dataset. [12] uses resnet50 as a feature extractor for both body and scene context. In contrast, we use the pretrained mobilenetV3_large model for extracting body features and a lightweight composition-based aesthetics feature extractor (ReLIC [35]) to keep the model size small. This baseline [12] predicts emotion and VAD scores simultaneously. We, instead make sentiment and emotion predictions together and use sentiment predictions in the post-processing module to improve emotion prediction performance. [16] reports an AP score of 35.48 on the EMOTIC dataset. However, they have used several deep neural networks to derive multiple modalities-based contexts, making the overall architecture complex for training and inferencing. Architecture is also computationally intensive, with an overall model size of 500MB (includes face detection model size), making it unsuitable for low-resource devices such as smartphones.
We have used the aesthetics feature extractor as one of the branches for our SeLiNet model. Several previous works have shown that there is an explicit connection between image aesthetics and image emotion. [6] have used emotion-assisted image aesthetics identification using multitask learning. They demonstrate that there is a link between image emotion and aesthetics, and that image emotion features can aid in aesthetics assessment tasks and vice versa. [21] use image semantics, image aesthetics, and other visual features to effectively classify the emotion types.
III Dataset
We train and report our proposed approach performance on EMOTIC [12] dataset. EMOTIC is a benchmark dataset for the context-aware emotion recognition task. It is created by taking images from MSCOCO dataset [38], Ade20k dataset [39] and images downloaded from the Google search engine, which makes the overall dataset very diverse and increases its complexity. The dataset contains roughly 23,000 images and around 33,000 annotated instances of emotions. The dataset provides bounding box information of the target person in each image and the same has multi-label annotation with 26 possible emotion categories information of the bounding box. Dataset also has annotations for continuous emotion index such as Valance, Arousal, and Dominance (VAD). Emotions are quantified on these three indexes with their scales ranging from 0 to 10. In our work, we have only considered discrete emotions as ground truth and instead added sentiment prediction as an additional task. Since the EMOTIC dataset does not provide sentiment labeling, we use a study by [9] to label the sentiment of each image based on the ground truth emotion. [9] shows each emotion can be categorized into positive, negative, and neutral sentiments. So, we label possible sentiment for each image in the dataset. We use a multi-label strategy to label sentiment because each image can have multiple emotion labels and these labels can fall under more than one sentiment. Table I shows a few examples of ground truth emotion labels and corresponding one-hot encoding for the sentiment label. We report all our evaluation results on the test set of the EMOTIC dataset.
| Image Emotion Labels |
Sentiment Encoding
[Positive,Negative,Neutral] |
|---|---|
| Confidence, Excitement | [1,0,0] |
| Peace, Sensitivity | [1,0,1] |
| Disapproval, Sadness | [0,1,0] |
IV The Proposed Method
This section details the motivation behind the problem and our proposed method.
IV-A Motivation and Problem Solving
Although multi-modality-based information [12, 13, 16] improves the performance of emotion task, the inclusion of these additional information makes the overall model architecture complex [16] and expensive in computation and memory and thus making it unfit for resource constraints systems such as mobile phones. Also, very few works focus on lightweight architectures suitable for the on-device system. Therefore, in this work, we attempted to develop a lightweight model for on-device inferencing. For our method, we derive the idea to employ image aesthetics for the emotion recognition task based on studies discussed in Section I.
We model the problem in this paper as multitask learning, which predicts both emotions and sentiments. The main idea behind predicting sentiments as an auxiliary task is: 1) To provide an additional loss factor to the emotion task during training in case of incorrect sentiment prediction; 2) To use the sentiment score in post-processing to further enhance the main task (emotion task) performance. It is also possible to infer only the sentiments of an image using the proposed multitask as standalone predictions.
IV-B The Pipeline
IV-B1 Pre-processing
The EMOTIC training dataset is highly imbalanced, with certain classes such as engagement, happiness, excitement, etc. occurring more frequently than classes like anger, and aversion. We use standard data augmentation techniques for images such as HorizontalFlip, RandomBrightnessContrast, Posterize, HueSaturationValue, etc. to address the same.
IV-B2 SeLiNet Model
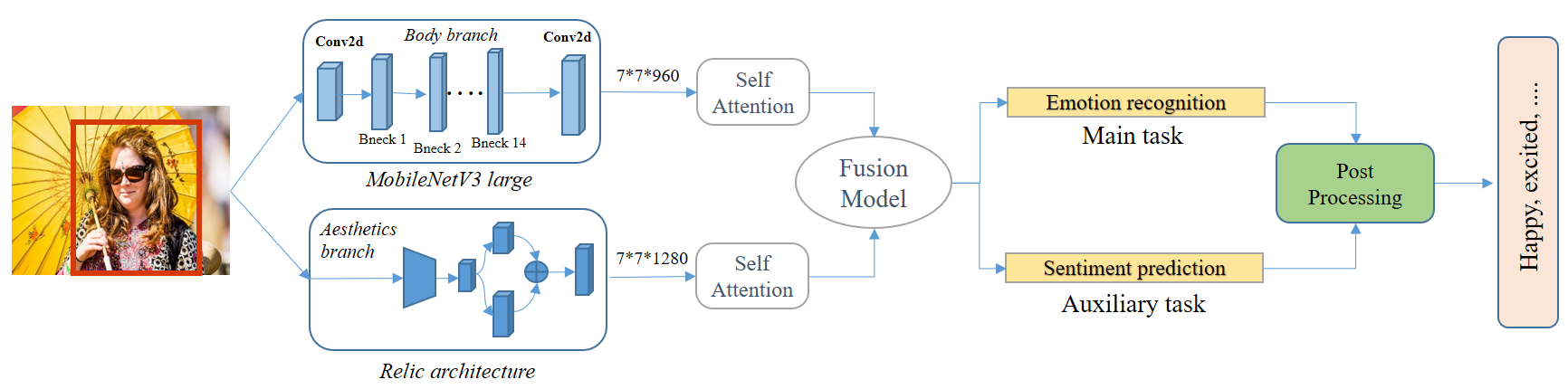
Figure 1 shows our SeLiNet architecture and end-to-end pipeline. The proposed SeLiNet model consists of a body module, aesthetics module, and fusion module which are discussed below in detail.
| Model | AP Score | Model size | Inference time |
|---|---|---|---|
| Baseline CNN [12] | 27.38 | 190 MB | 16.2 ms |
| CAAGRER [34] | 28.42 | 400 MB | NA |
| EmotiCon(GCN) [16] | 32.03 | 500 MB | NA |
| EmotiCon(Depth) [16] | 35.48 | 500 MB | NA |
| SeLiNet | 27.17 | 28.03 MB | 3.5 ms |
Body feature extractor : This branch focuses on extracting facial and body features from the input image. Extracting these features is important because they provide crucial information about the emotional state of the person in the image. The branch is based on mobilenetV3_large, trained on the ImageNet dataset with person class. We freeze weights till the second last layer and take its output with a feature map of size (960*7*7) which is then fed to a self-attention network. The attention layer outputs an attentive vector of size 960 which is followed by a dense layer of 512 units whose output is then passed to the fusion model for further processing.
Aesthetics feature extractor: The aesthetics feature extractor uses the pretrained ReLIC architecture [35] as a backbone to extract image aesthetics features. ReLIC architecture [35] is based on several Convolutional Neural Networks and tries to learn both local and global features. Local features are used to understand image composition whereas global features contribute toward the overall image properties such as texture etc. We freeze weights till second last layer and take its output as a feature map of (1280*7*7) and apply self-attention to get attentive feature vectors. The aesthetics branch outputs a 1280-size vector which is followed by a dense layer of 512 units. The output of the dense layer is then fed to the fusion model.
Fusion model : The fusion layer concatenates the output of the body and aesthetics feature extractors to get a 1024-size fused vector. This concatenation layer is then followed by two dense layers of 512 and 256 units. This last 256 dense layer is followed by two task-specific dense layers each of 128 units whose outputs are fed to emotion and sentiment classification layers respectively for the predictions. We perform detailed hyperparameter tuning to choose layers of the fusion model.
IV-B3 Post-processing
We use a boosting algorithm to modify the confidence score of the emotion prediction based on the sentiment output. We consider the top 5 confidence scores by the emotion task as E = and predictions by sentiment task as S = . Then the boosting equation is as follows.
| (1) |
Our boosting factor provides a relative boost to all emotions in that are predicted correctly in accordance with sentiment output.
V Results and Experiments
This section describes the implementation details, comparison with previous works, and ablation study for our proposed approach.
| Body Model | Aesthetic Model | Attention | Sentiment Task | Post Processing | Model Size | AP Score |
| ✓ | ✗ | ✗ | ✗ | ✗ | 12.53 MB | 22.71 |
| ✓ | ✓ | ✗ | ✗ | ✗ | 27.23 MB | 25.46 |
| ✓ | ✓ | ✓ | ✗ | ✗ | 27.91 MB | 26.30 |
| ✓ | ✓ | ✓ | ✓ | ✗ | 28.03 MB | 26.81 |
| ✓ | ✓ | ✓ | ✓ | ✓ | 28.03 MB | 27.17 |
V-A Implementation details
We use the PyTorch framework for experimentation and model development. All training and testing are carried out on an Nvidia GPU GeForce GTX 1080 Ti 11178 MB card. The aesthetics branch takes the complete image of size 224 * 224 * 3 as input. The body branch, on the other hand, requires a 128 * 128 * 3 input image which is a cropped portion of the original image containing the whole body. We set the batch size to 26 and use stochastic gradient descent(SGD) optimizer in the training. The learning rate is initialized to 0.001 with a decay rate of 0.1. The model is trained for 25 epochs and is saved based on the best validation AP score.
Loss Function : Since our problem statement is a multi-class multi-label on the EMOTIC dataset, we experimented with standard binary cross entropy(BCE) loss and L2 loss (suggested by [12]). We observe that L2 loss gives better results than BCE.
| (2) |
Where is dynamic weights per batch which are defined as:
The combined loss of emotion and sentiment task is referred to as the total loss. Based on the experiments, we set equals to 0.8 which gives better results.
| (3) |
V-B Comparison with previous works
As shown in Table II, [12] reports an AP score of 27.38 on the emotion recognition task using a CNN-based baseline system. We try to reproduce their work using the code available on Github 111https://github.com/Tandon-A/emotic. Using the same configuration discussed in the work, we get an AP score of 25.38 with a model size of nearly 191MB and an inference time of 16.2 ms on GPU. In contrast, using our approach, we achieve an AP score of 27.17 with a model size of only 28.03 MB, a reduction of 85.32% when compared to the baseline. Our approach is faster by nearly 78% compared to the baseline. In Table II, we also provide a comparison of our proposed model with other works. Although [16] shows better performance, it involves more than three modalities as input to the model making the overall system complex in computation and training and cost-intensive in terms of memory and inference time. In comparison, our work provides for the lightweight model with only two modalities as input and gives comparable performance to the baseline.
For our sentiment sub-task on the EMOTIC dataset, we achieve an AP score of 93.53, 73.82, and 19.13 for Positive, Negative, and Neutral sentiment respectively. Positive and Negative sentiments report better performance compared to Neutral. It is due to the small number of emotions categorized in the neutral sentiment leading to a lower training sample.
V-C Ondevice Performance
Our end-to-end on-device pipeline is evaluated on a Samsung S21 smartphone (Android SDK 30, 12 GB RAM, 256 GB ROM, Octa-core, Exynos2100 chip). SeLiNet model, quantized using the PyTorch framework, reports an on-device AP score of 26.42 on the same test set of EMOTIC dataset with a model size of 11.34 MB and on-device inference time of 65 ms. Although the AP score drops marginally by nearly 2.76 % due to quantization, there is a reduction of model size ( of the quantized model) by more than 52% which is a huge gain. Also, in comparison to the baseline system, [12], we achieve a comparable AP score by quantized model while reducing the model size by nearly 93%.
V-D Ablation Study
Table III describes the ablation study regarding the different configurations of the architecture. The addition of the aesthetics branch results in a nearly 12% increase in AP score. Our proposed multi-task learning has improved the AP score by at least 3%. Thus, it demonstrates that all of the components are required to achieve the best results.
V-E Error Analysis
We observe that the performance of our model slightly degrades for the categories such as embarrassment, surprise, yearning, etc. compared to [16]. Possible reasons are 1) The number of original training images is insufficient to learn diverse features. 2) Owing to complex nature of these emotions, additional cues may be required. [16] demonstrates that taking into account multiple modalities leads to better predictions.
The difficult nature of the emotion recognition task and the requirement of multiple contexts are supported by the study conducted by [16] where if only the facial context is considered out of three discussed contexts, then the AP score drops from 35.48 to 24.06. The baseline by [12] has used Resnet50 for both body and scene context feature extraction. But, when we replace Resnet50 with ResNet18, the AP score falls to 17.23, indicating that shallower models are insufficient for the task. Considering the above details, SeLiNet performs fairly well despite being lightweight.
V-F Conclusion
We present a lightweight model SeLiNet and an end-to-end pipeline to predict the emotional states of people in images for on-device inferencing. Our proposed approach achieves an AP score of 27.17, which is comparable to the baseline system with a 85% smaller memory footprint and much faster inference time. We also show that aesthetics assessment of the images can be helpful information to understand image emotion. Using multitasking learning, we further improve our model results. In future work, we will like to capture additional contextual information such as object detection, deeper semantic analysis, and its impact on image emotion recognition tasks.
References
- [1] Joel Aronoff. How we recognize angry and happy emotion in people, places, and things. Cross-cultural Research - CROSS-CULT RES, 40:83–105, 2006.
- [2] Osten Axelsson. Towards a psychology of photography: Dimensions underlying aesthetic appeal of photographs. Perceptual and motor skills, 105:411–34, 2007.
- [3] L. F. Barrett. How emotions are made: The secret life of the brain. Houghton Mifflin Harcourt, 2017.
- [4] Lisa Barrett, Batja Mesquita, and Maria Gendron. Context in emotion perception. Current Directions in Psychological Science, 20:286–290, 2011.
- [5] Qiuyu Chen, Wei Zhang, Ning Zhou, Peng Lei, Yi Xu, Yu Zheng, and Jianping Fan. Adaptive fractional dilated convolution network for image aesthetics assessment. 2020.
- [6] Yunlong Chen, Yuanyuan Pu, Zhengpeng Zhao, Dan Xu, Man, and Wenhua Qian. Image aesthetic assessment based on emotion-assisted multi-task learning network. Association for Computing Machinery, 2021.
- [7] Shichuan Du and Aleix Martinez. Compound facial expressions of emotion: From basic research to clinical applications. Dialogues in Clinical Neuroscience, 17:443–455, 2015.
- [8] Wadzani Gadzama, Bitrus Joseph, and Ngubdo Aduwamai. Global smartphone ownership, internet usage and their impacts on humans. 2019.
- [9] Magrizef Gasah and Aslina Baharum. A conceptual framework for emotional connection towards e-learning mobile application design for children. Journal of Software and Systems Development, 2018:1–17, 2018.
- [10] Alan Hanjalic. Hanjalic, a.: Extracting moods from pictures and sounds: towards truly personalized tv. ieee signal processing magazine 23, 90-100. Signal Processing Magazine, IEEE, 23:90 – 100, 2006.
- [11] Dhiraj Joshi, Ritendra Datta, Elena Fedorovskaya, Quang-Tuan Luong, J.Z. Wang, Jia Li, and Jiebo Luo. Aesthetics and emotions in images. Signal Processing Magazine, IEEE, 28:94 – 115, 2011.
- [12] Ronak Kosti, Jose M. Alvarez, Adria Recasens, and Àgata Lapedriza. Context based emotion recognition using emotic dataset. 2020.
- [13] Jiyoung Lee, Seungryong Kim, Sunok Kim, Jungin Park, and Kwanghoon Sohn. Context-aware emotion recognition networks. pages 10142–10151, 2019.
- [14] Zisheng Li, Jun-ichi Imai, and Masahide Kaneko. Facial-component-based bag of words and phog descriptor for facial expression recognition. The Journal of The Institute of Image Information and Television Engineers, 64:1353 – 1358, 2009.
- [15] Takahiko Masuda, Phoebe Ellsworth, Batja Mesquita, Janxin Leu, Shigehito Tanida, and Ellen Veerdonk. Placing the face in context: Cultural differences in the perception of facial emotion. Journal of Personality and Social Psychology, 94:365–381, 2008.
- [16] Trisha Mittal, Pooja Guhan, Uttaran Bhattacharya, Rohan Chandra, Aniket Bera, and Dinesh Manocha. Emoticon: Context-aware multimodal emotion recognition using frege’s principle. pages 14222–14231, 2020.
- [17] Costanza Navarretta. Individuality in Communicative Bodily Behaviours, pages 417423. 2012.
- [18] Mihalis A. Nicolaou, Hatice Gunes, and Maja Pantic. Continuous prediction of spontaneous affect from multiple cues and modalities in valence-arousal space. T. Affective Computing, 2:92–105, 2011.
- [19] M Pantic and Léon Rothkrantz. Expert system for automatic analysis of facial expression. Image and Vision Computing, 18:881–905, 2000.
- [20] Gabriele Peters. Aesthetic primitives of images for visualization. pages 316–325, 2007.
- [21] Tianrong Rao, Min Xu, and Dezhi Xu. Learning multi-level deep representations for image emotion classification. 2016.
- [22] Dillip Kumar Rath and Ajit Kumar. Information privacy concern at individual, group, organization, and societal level - a literature review. 2021.
- [23] Ruthger Righart and Beatrice Gelder. Rapid influence of emotional scenes on encoding of facial expressions: An erp study. Social cognitive and affective neuroscience, 3:270–8, 2008.
- [24] Noora Sami and Mohamed E. The impact of privacy concerns and perceived vulnerability to risks on users privacy protection behaviors on sns: A structural equation model. International Journal of Advanced Computer Science and Applications, 7, 2016.
- [25] Caifeng Shan, Shaogang Gong, and Peter Mcowan. Facial expression recognition based on local binary patterns: A comprehensive study. Image and Vision Computing, 27: 803–816, 2009.
- [26] Janice Sipior, Burke Ward, and Linda Volonino. Privacy concerns associated with smartphone use. Journal of Internet Commerce, 13:177–193, 2014.
- [27] Mohammad Soleymani, Sadjad Esfeden, Yun Fu, and Maja Pantic. Analysis of eeg signals and facial expressions for continuous emotion detection. IEEE Transactions on Affective Computing, 7:1–1, 2015.
- [28] Hossein Talebi and Peyman Milanfar. Nima: Neural image assessment. IEEE Transactions on Image Processing, PP, 2017.
- [29] Matina Tsavli, Pavlos Efraimidis, Vasilios Katos, and Lilian Mitrou. Reengineering the user: Privacy concerns about personal data on smartphones. Information and Computer Security, 23:394–405, 2015.
- [30] Luc Van Gool and Beatrice Gelder. Recognizing emotions expressed by body pose: A biologically inspired neural model. Neural networks : the official journal of the International Neural Network Society, 21:1238–46, 2008.
- [31] WeiningWang and Qianhua He. A survey on emotional semantic image retrieval. pages 117 – 120, 2008.
- [32] Munan Xu, Jia-Xing Zhong, Yurui Ren, Shan Liu, and Ge Li. Context-aware attention network for predicting image aesthetic subjectivity. pages 798–806. ACM, 2020.
- [33] Shihao Xu, Jing Fang, Xiping Hu, Edith Ngai, Yi Guo, Victor Leung, Jun Cheng, and Bin Hu. Emotion recognition from gait analyses: Current research and future directions. 2020.
- [34] Minghui Zhang, Yumeng Liang, and Huadong Ma. Context-aware affective graph reasoning for emotion recognition. pages 151–156, 2019.
- [35] Lin Zhao, Meimei Shang, Fei Gao, Rongsheng Li, Fei Huang, and Jun Yu. Representation learning of image composition for aesthetic prediction. Computer Vision and Image Understanding, 199:103024, 2020.
- [36] Sicheng Zhao, Yue Gao, Xiaolei Jiang, Hongxun Yao, Tat-Seng Chua, and Xiaoshuai Sun. Exploring principles-of-art features for image emotion recognition. MM 2014 - Proceedings of the 2014 ACM Conference on Multimedia, pages 47–56, 2014.
- [37] Lin Zhong, Qingshan Liu, Peng Yang, Bo Liu, and Dimitris Metaxas. Learning multiscale active facial patches for expression analysis. volume 45, pages 2562–2569, 2012.
- [38] T. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, et al., ”Microsoft coco:Common objects in context”, ECCV, pp. 740-755, 2014.
- [39] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso and A. Torralba, ”Semantic understanding of scenes through the ade20k dataset”, arXiv preprint arXiv:1608.05442, 2016