Semantic Compression with Side Information: A Rate-Distortion Perspective
Abstract
We consider the semantic rate-distortion problem motivated by task-oriented video compression. The semantic information corresponding to the task, which is not observable to the encoder, shows impacts on the observations through a joint probability distribution. The similarities among intra-frame segments and inter-frames in video compression are formulated as side information available at both the encoder and the decoder. The decoder is interested in recovering the observation and making an inference of the semantic information under certain distortion constraints.
We establish the information-theoretic limits for the tradeoff between compression rates and distortions by fully characterizing the rate-distortion function. We further evaluate the rate-distortion function under specific Markov conditions for three scenarios: i) both the task and the observation are binary sources; ii) the task is a binary classification of an integer observation as even and odd; iii) Gaussian correlated task and observation. We also illustrate through numerical results that recovering only the semantic information can reduce the coding rate comparing to recovering the source observation.
Index Terms:
Semantic communication, inference, video compression, rate-distortion function.I Introduction
The rate limit for lossless compression of memoryless sources is commonly known as the entropy shown by Shannon in his landmark paper [1]. In addition, lossy source coding under given fidelity criterion was also introduced in the same paper. Further, the Shannon rate-distortion function was proposed in [2], characterizing the optimal tradeoff between compression rates and distortion measurements, from the perspective of mutual information.
Thereafter, the rate-distortion function was investigated when side information is available at the encoder or/and decoder, see [3, 4, 5, 6, 7, 8, 9, 10, 11] and reference therein. In the case that the side information is only available at the encoder, then no benefit could be achieved. In case of side information being only at the decoder, the corresponding rate-distortion function was considered by Wyner and Ziv in [5], with its extensions being discussed in [9, 10, 11, 6, 7, 8]. Finally, if both the encoder and decoder have access to the same side information, the optimal tradeoff is called conditional rate-distortion function, which was given by [3] and [4].
The lossy source coding theory finds applications in establishing information theoretic limits for practical compression of speech signals, images and videos etc. [12, 13, 14, 15]. Practical techniques for video compression have been explored since decades ago [16, 17, 18]. Currently, popular protocols such as HEVC, VP9, VVC and AV1 are based on partitioning a picture/frame into coding tree units, which typically correspond to 64x64 or 128x128 pixel areas. Each coding tree unit is then partitioned into coding blocks (segments) [19, 20], following a recursive coding tree representation. The aforementioned compression schemes consider both intra-correlation within one frame and inter-correlation between two consecutive frames.
Nowadays, with the development of high-definition videos, 5G communication systems and industrial Internet of Things, communication overhead and storage demand have been exponentially growing. As a result, higher compression rates are required, but it seems not possible by simply compressing a given source (e.g., a video or image) itself in light of the rate-distortion limits.
Semantic or Task-oriented compression [21, 22, 23, 24], aiming at efficiently compressing the sources according to specific communication tasks (e.g., video detection, inference, classification, decision making, etc.), has been viewed as a promising technique for future 6G systems due to its extraordinary effectiveness. Particularly, the goal of semantic compression is to recover the necessary semantic information corresponding to a certain task instead of each individually transmitted bit as in Shannon communication setups, and thus it leads to significant reduction of coding rates.
In addition to the interested semantic information, the original sources are also required in some cases such as video surveillance, for the purpose of evidence storage and verification. An effective way is to save only the most important or relevant segments of a video, and related work on semantic-based image/video segmentation can be found in [25, 26, 27]. Most recently, the classical indirect source coding problem [28] was revisited from the semantic point of view, and the corresponding rate-distortion framework for semantic information in [29, 30, 31, 32].
The current paper introduces side information into the framework of [29] and completely characterizes the semantic rate-distortion problem with side information. Motivated from the task-oriented video compression, the semantic information corresponding to the task is not observable to the encoder. In light of video segmentation, the observed source is partitioned into two parts, and the semantic information only shows influence on the more important part. Moreover, the intra-correlation and inter-correlation are viewed as side information, and they are available at both the encoder and decoder to help compression. The decoder needs to reconstruct the whole source subject to different distortion constraints for the two parts, respectively. The semantic information can be recovered upon observing the source reconstructions at the decoder. Finally, our main contributions are summarized as follows:
-
1)
We fully characterize the optimal rate-distortion tradeoff. It is further shown that separately compressing the two source parts is optimal, if the they are independent conditioning on the side information.
-
2)
The rate-distortion function is evaluated for the inference of a binary source under some specific Markov chains.
-
3)
We further evaluate the rate-distortion function for binary classification of an integer source. The numerical results show that recovering only the semantic information can reduce the coding rate comparing to recovering the source message.
-
4)
The rate-distortion function for Gaussian sources is also illustrated, which may provide more insights for future real video compression simulations.
This paper is mainly pertained to the information-theoretic aspects, and future work on the limit of real video compression is under investigation.
The rest of the paper is organized as follows. We first formulate the problem and present some preliminary results in Section II. In Section III, we characterize the rate-distortion function and some useful properties. Evaluations of the rate-distortion function for binary, integer, and Gaussian sources with Hamming/mean squared error distortions are devoted to Sections IV, V and VI, respectively. We present and analyze some plots of the evaluations in Section VII. The paper is concluded in Section VIII. Some essential proofs can be found in the appendices.
II Problem Formulation and Preliminaries
II-A Problem Formulation
Consider the system model for video detection (inference) that also requires evidence storage depicted in Fig. 1. The problem is defined as follows. A collection of discrete memoryless sources (DMS) is described by generic random variables taking values in finite alphabets according to probability distribution . In particular, this indicates the Markov chain . We interpret as a latent variable, which is not observable by the encoder. It can be viewed as the semantic information (e.g., the state of a system), which describes the features of the system. We assume that the observation of the system consists of two parts:
-
•
varies according to the semantic information , which captures the “appearance” of the features, e.g., the vehicle and red lights in the frame that captures a violation at the cross;
-
•
is the background information irrelevant to the features, e.g., buildings in the frame capturing the violation.
is the side information that can help compressing such as previous frames in the video. For length- source sequences, , the encoder has access to only the observed ones and encodes them as which will be stored at the server. Upon observing local information and receiving , the decoder reconstructs the source sequences as drawn values from , within distortions and . Given the reconstructions, the classifier is required to recover the semantic information as from alphabet with distortion constraint . Here, for simplicity, we assume a perfect classifier, i.e., it is equivalent to recover directly at the decoder as illustrated in Fig. 2.
Formally, an code is defined by the encoding function
and the decoding function
Let be the set of nonnegative real numbers. We consider bounded per-letter distortion functions , , and . The distortions between length- sequences are defined by
A nonnegative rate-distortion tuple is said to be achievable if for sufficiently large , there exists an code such that
The rate-distortion function is the infimum of coding rate for distortions such that the rate-distortion tuple is achievable. Our goal is to characterize the rate-distortion function.
II-B Preliminaries
II-B1 Conditional rate-distortion function
The elegant rate-distortion function was investigated and fully characterized in [2]. Assume the length- source sequence is independent and identically distributed (i.i.d.) over with generic random variable and be a bounded per-letter distortion measure. The rate-distortion function for a given distortion criterion is given by
| (1) |
It was proved in [2] and also introduced in [33, 34, 35, 36, 37] that is a non-increasing and convex function of .
If both the encoder and decoder are allowed to observe side information (with generic variable over jointly distributed with ), as depicted in Fig. 3, then the tradeoff is called the conditional rate-distortion function [33, 3, 4], which is characterized as
| (2) |
It is shown in [3] that the conditional rate-distortion function can also be obtained as the weighted sum of the marginal rate-distortion function of sources with distribution , i.e.,
| (3) |
where for any , is obtained from (1) through replacing the source distribution by . This property will be useful for evaluating conditional rate-distortion functions of given source distributions. If is a doubly symmetric binary source (DSBS) with parameter , i.e.,
| (4) |
then the conditional rate distortion function is given in [4] by
| (5) |
where is the entropy for a Bernoulli() distribution and is the indicator function of whether event happens.
II-B2 Rate-distortion function with two constraints
The scenario was discussed in [38, 37] that we wish to describe the i.i.d. source sequence at rate and recover two reconstructions and with distortion criteria and , respectively. The rate-distortion function is given by
| (6) |
Comparing (1) and (6), we easily see that
For the special case where and for all and , it suffice to recover only one sequence with distortion . Then both distortion constraints are satisfied since
and
This implies
| (7) |
where the second equality follows from the non-increasing property of .
When side information is available at the decoder for only one of the two reconstructions, e.g., , it was proved in [10, 7] that successive encoding (first , then ) is optimal. For the case when the two reconstructions have access to different side information respectively, the rate-distortion tradeoff was characterized in [10, 11, 9, 36].
II-B3 Rate-distortion function of two sources
The problem of compressing two i.i.d. source sequences and at the same encoder is considered in [37, Problem. 10.14]. The rate-distortion function is given therein, which is
| (8) |
It is also shown that for two independent sources, compressing simultaneously is the same as compressing separately in terms of the rate and distortions, i.e.,
| (9) |
If the two sources are dependent, the equality in (9) can be false, and the Slepian-Wolf rate region [39] indicates that joint entropy of the two source variables is sufficient and optimal for lossless reconstructions. Taking into account distortions, Gray showed via an example in [4] that the compression rate can be strictly larger than in general. At last, some related results for compressing compound sources can be found in [40].
III Optimal Rate-distortion Tradeoff
III-A The Rate-distortion Function
Theorem 1.
The rate-distortion function for compression and inference with side information is given as the solution to the following optimization problem
| (10) | ||||
| (11) | ||||
| (12) | ||||
| (13) |
where the minimum is taken over all conditional pmf and the modified distortion measure is defined by
| (14) |
Proof.
We can interpret the problem as the combination of rate-distortion with two sources ( and ), rate-distortion with two constraints ( is recovered with two constraints and ), and conditional rate-distortion (conditioning on ). Then the theorem can be obtained informally by combining the rate-distortion functions in (2), (6), and (8). For completeness, we provide a rigorous technical proof in Appendix A. ∎
III-B Some Properties
Similar to the rate-distortion function in (1), we collect some properties in the following lemma. The proof simply follows the same procedure as that for (1) in [2, 33, 34, 35, 37, 36]. We omit the details here.
Lemma 2.
The rate-distortion function is non-increasing and convex in .
Recall from (9) that compressing two independent sources is the same as compressing them simultaneously. Then one may query that whether the optimality of separate compression remains to hold here? We answer the question in the following lemma.
Lemma 3.
If forms a Markov chain, then
where the conditional rate-distortion function with two constraints is given by
and the conditional rate-distortion function is given in (2) and can be written by
Proof.
The proof is given in Appendix B. ∎
III-C Rate-distortion Function for Semantic Information
The indirect rate-distortion problem can be viewed as a special case of Theorem 1 that only recovers the semantic information , i.e., and are constants and . Denote the minimum achievable rate for a given distortion constraint by .
Consider the binary sources and assume and follow the doubly symmetric binary distribution, i.e.,
| (15) |
The transition probability can also be defined via the binary symmetric channel (BSC) in Fig. 4.
Assume , which means that has a higher probability to reflect the same value as . Let be the Hamming distortion measure. Then the evaluation of is given in the following lemma.
Let be the ordinary rate-distortion function in (1) under the distortion measure (c.f. (14)). For notational simplicity, for , define
| (16) |
Lemma 4.
For binary sources in (15) and Hamming distortion, the rate-distortion function for semantic information is
| (17) |
where
Remark 2.
By the properties of the rate-distortion function in (1) and the linearity between and , we see that is also non-increasing and convex in .
Remark 3.
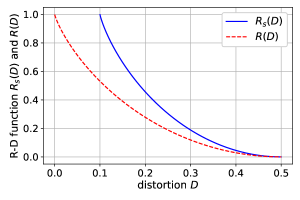
It is easy to check that for . This implies that for , where is the ordinary rate-distortion function in (1). The inequality is intuitive from the data processing inequality that under the same distortion constraint , recovering directly (with rate ) is easier than recovering it from the observation (with rate ). Moreover, we see from the lemma that , which means that the semantic information can never be losslessly recovered for . This can be induced from the fact that even we know the complete information of , the best distortion for reconstructing is the distortion between and which is equal to . The rate-distortion functions and are illustrated in Fig. 5 for , which verifies the above observations. For general source and distortion measure, we have where the equality holds only when determines . This can be easily proved by the data processing inequality and we omit the details here.
Remark 4.
We can imagine that measures the distortion between the observation and reconstruction of semantic information. Furthermore, it was shown in [28, 29, 33] that and measure equivalent distortions, i.e.,
Then we can regard the system of compressing and reconstructing as the ordinary rate-distortion problem with distortion measure . Thus, is equivalent to the ordinary rate-distortion function in (1) under distortion measure , which rigorously proves (17).
IV Case Study: Binary Sources
Assume and are doubly symmetric binary sources with distribution in (15), and are both Bernoulli sources. The reconstructions are all binary, i.e., . The distortion measures , and are all assumed to be Hamming distortion. We further assume that any two of , , and are doubly symmetric binary distributed (c.f. (4)) with parameters , and , respectively. Specifically, , , .
Consider the following two examples that only differ in the source distributions.
IV-A Conditionally Independent Sources
Assume we have the Markov chain111Note that the Markov chain indicates ., i.e., and are independent conditioning on . This assumption coincides with the intuitive understanding of and in Section II-A, that the semantic feature can be independent with the background. Then from Lemma 3, compressing and simultaneously is the same as compressing them separately in terms of the optimal compression rate and distortions, which implies the following theorem.
Theorem 5.
The rate-distortion function for the above conditionally independent sources is given by
where is defined in (16).
IV-B Correlated Sources
Similar to that in [41], evaluating the rate-distortion function for the general correlated sources can be extremely difficult. Thus, we assume the Markov chain behind the intuition that the side information can help more to the semantic related source .
Without the conditional independence of and , the optimality of separate compression in Lemma 3 may not hold. The rate-distortion function in Theorem 1 can be calculated as follows. Recall from (16) that . For simplicity, we consider only small distortions in the set
| (18) |
Theorem 6.
For , the rate-distortion function for the above correlated sources is
| (19) |
where is defined in (16).
Proof.
The proof is given in Appendix D. ∎
From the distribution of and , and the Markov chain , it is easy to check that is doubly symmetric distributed with parameter . Then comparing (19) with the rate of separate compression, we have for that
| (20) |
where the last inequality follows from the fact that is increasing in and for .
V Case Study: Binary Classification of Integers
Consider classification integers into even and odd. Let be uniformly distributed over with being even. The semantic information is a binary random variable probabilistically indicates whether is even or odd. The transition probability can be defined by BSC in Fig. 6, which is similar to that in Fig. 4 by replacing the value of with “even” and “odd”.
The binary side information is correlated with also indicating its odevity (even/odd) similar to Fig. 6 with parameter . Assume the Markov chain holds, and the Bernoulli() source is independent with . We can verify that is independent with . By Lemma 3, compressing and simultaneously is the same as compressing them separately. For simplicity, we consider only small distortions in the set
| (21) |
Theorem 7.
Proof.
The proof is given in Appendix E. ∎
VI Case Study: Gaussian Sources
Assume and are jointly Gaussian sources with zero mean and covariance matrix
| (22) |
Similarly, we assume the Markov chain , where and are jointly Gaussian sources with zero mean and covariance matrix
| (23) |
Thus is conditionally independent of given . Let the covariance of and be . The reconstructions are real scalars, i.e., . The distortion metrics are squared error.
We see from Lemma 3 that compressing and simultaneously is the same as compressing them separately in terms of the optimal compression rate and distortions. Then we have the following theorem.
Theorem 8.
For the Gaussian sources, if the Markov chain holds, the rate-distortion function is
| (24) |
where is the minimum mean squared error for estimating from , given by
| (25) |
Proof.
The proof is given in Appendix F. ∎
VII Numerical Results
In this section, we plot the rate-distortion curves evaluated in the previous sections.
VII-A Correlated Binary Sources
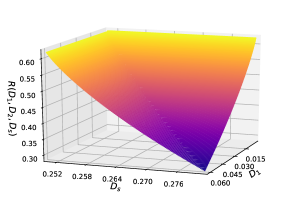
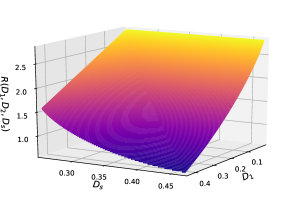
Consider the rate-distortion function for correlated binary sources in Theorem 6 with and . Fig. 7 shows the 3-D plot of the optimal tradeoff between the coding rate and distortions . We can see that the rate-distortion function is decreasing and convex in for distortions in (c.f. (18)).
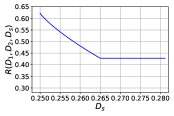
The truncated curves with and are shown in Fig. 8. We see that the rate is decreasing in until it achieves the minimum rate, which is determined by . Similar curves can also be obtained by truncating with some constant .
VII-B Binary Classification of Integers
The rate-distortion function for integer classification in Theorem 7 with , , and is illustrated in Fig. 9. Note that in both Theorem 6 and Theorem 7, indicates that can be recovered by random guessing, which further implies that can also be regarded as side information at both sides.
Comparing the rates along the and axis in Fig. 9, we see that recovering only the semantic information can reduce the coding rate comparing to recovering the source message.
Comparing Fig. 9 with Fig. 7, we see that the rate for integer classification decreases faster as increases (which is clearer at the minimum of ). This implies that is more dominant (to determine the rate) here, which is intuitive since the integer source has a larger alphabet and recovering it with different distortions requires a larger range of rates.
VII-C Gaussian Sources
Consider the rate-distortion function for Gaussian sources in Theorem 8. Let all of the variances be , all of the covariances be , and .
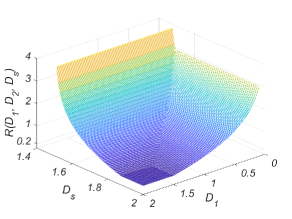
The 3-D plot of the optimal tradeoff between the coding rate and distortions is illustrated in Fig. 10. We can see that the rate-distortion function is decreasing and convex in . The minimum rate is equal to
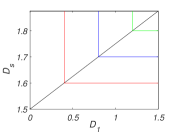
The contour plot of the rate-distortion function is shown in Fig. 11. The slanted line denotes the situations that . We see that when is more dominant (the region above the slanted line), the rate only needs to meet the distortion constraint to reconstruct . On the contrary, when is more dominant (the region below the slanted line), the rate only needs to meet the distortion constraint to reconstruct .
VIII Conclusion
In this paper, we studied the semantic rate-distortion problem with side information motivated by task-oriented video compression. The general rate-distortion function was characterized. We also evaluated several cases with specific sources and distortion measures. It is more desirable to derive the rate-distortion function for real video sources, which is more challenging due to the high complexity of real source models and choice of meaningful distortion measures. This part of work is now under investigation.
Appendix A Proof of Theorem 1
The achievability part is a straightforward extension of the joint typicality coding scheme for lossy source coding. We simply present the coding ideas and analysis as follows. Fix the conditional pmf such that the distortion constraints are satisfied, , , and . Let . Randomly and independently generate sequence triples indexed by , each according to . The whole codebook , consisting of these sequence triples, is revealed to both the encoder and decoder. When observing the source messages , find an index such that its indexing sequence satisfies . If there is more than one such index, randomly choose one of them; if there is no such index, set . Upon receiving the index , the decoder reconstruct the messages and inference by choosing the codeword indexed by . By law of large numbers, the source sequences are joint typical with probability 1 as . Then we define the “encoding error” event as
| (26) |
Then we can bound the error probability as follows
where as , the first inequality follows from the joint typicality lemma in [36], and the last inequality follows from the fact that for and . We see that as if . If the error event does not happen, i.e., the reconstruction is joint typical with the source sequences, then from the distortion constraints assumed for the conditional pmf, the expected distortions can achieve and , respectively. This proves the achievability.
Define as the rate-distortion function characterized by Theorem 1, For the converse part, we show that
| (27) | ||||
| (28) | ||||
| (29) | ||||
| (30) | ||||
| (31) |
where (27) follows from the nonnegativity of mutual information, (28) follows from the definition of , (29) follows from the convexity of , (30) follows from which is proved in [29], and the last inequality follows from the non-increasing property of . This completes the converse proof.
Appendix B Proof of Lemma 3
The Markov chain indicates that
| (32) |
Then the mutual information in (10) can be bounded by
where the inequality follows from the fact that conditioning does not increase entropy. Now, we have
For the other direction, we show that the rate-distortion quadruple is achievable. To see this, let and be the optimal distributions that achieve the rate-distortion tuples and , respectively. Now we consider the distribution which requires the Markov chain and is consistent with the condition . Then the corresponding random variables satisfy
where the first equality follows from (32), the second equality follows from the Markov chain , and the last equality follows from the optimality of and . Lastly, by the minimization in the expression of the rate-distortion function in (10), we conclude that , which completes the proof of the lemma.
Appendix C Proof of Lemma 4
As we are in the binary Hamming setting, we first calculate the values of (c.f. (14)) by
The other values follow similarly, and we obtain the distortion function
| (33) |
Then
The distortion constraint for implies . Now we can follow the rate-distortion evaluation for Bernoulli source and Hamming distortion in [37, 35] while only changing the probability and obtain
| (34) |
This proves the lemma.
Appendix D Proof of Theorem 6
Note that separately compressing correlated sources is not optimal in general, i.e., the statement in Lemma 3 does not hold here. Then we need to evaluate the mutual information in (10) over joint distributions, and we have
| (35) | |||
where denote modulo 2 addition, the second equality follows from the Markov chain , the first inequality follows from the fact that conditioning does not increase entropy, and the last inequality follows from , , and is increasing in for . By switching the roles of and , i.e., replacing the conditional information in (35) by , we can obtain similarly
Thus, the rate-distortion function is lower bounded by
| (36) |
We now show that the lower bound is tight by finding a joint distribution that meets the distortion constraints and achieves the above lower bound.
Let and for . Then there is a one-to-one correspondence between and . From generated from the source distribution , it is easy to check that as shown in Fig. 12.
Next, we construct the desired joint distribution using the test channel in Fig. 12 as follows. For , (c.f. (18)), and , consider the joint distribution defined by the following conditions
-
i.
;
-
ii.
Markov chain ;
-
iii.
The test channel in Fig. 12 with the conditional probability given as
(37) -
iv.
In order for to follow the independent Bernoulli distributions, we need to choose the distribution of as (38)-(41).
(38) (39) (40) (41) We can verify that for .
Now it remains to verify that the above distribution achieves the rate in (36) and distortions , and . From conditions i and ii, we have
From (37) and (33), it is easy to calculate the expected distortions as
| (42) | ||||
| (43) | ||||
| (44) |
On the other hand, if , we can construct the joint distribution using four conditions similarly by switching the role of and . Then the rate and distortions can be obtained accordingly. This proves the theorem.
Appendix E Proof of Theorem 7
Since Lemma 3 holds here, we first calculate the rate-distortion function for , which is
| (45) |
Now it remains to calculate . We first consider the case that and provide a lower bound of the mutual information as follows
where the last inequality follows from , is an increasing function for , and the fact that uniform distribution maximizes entropy. (Note that we can also obtain the above lower bound by directly applying the log-sum inequality.)
Next, we show the lower bound is tight by finding a joint distribution that achieves the above rate and distortions and . For , we choose and by the test channel in Fig. 13 and the Markov chain . The conditional probability of the test channel in Fig. 13 is given as
| (46) |
Solving the equations
we obtain that for , i.e., is also uniformly distributed over . For the joint distribution of and , we define
We see that for any , i.e., . Then we can verify using that the above distribution can induce the same conditional probability as defined at the beginning of this section. Thus, we have constructed a feasible that can achieve expected distortion , , and mutual information
where the first equality follows from , the third equality follows from the Markov chain , and the last equality follows from the joint distribution of and the distribution in (46).
For the other case that , we only need to switch the role of and . Then the rate and distortions can be obtained accordingly, which can prove the theorem.
Appendix F Proof of Theorem 8
The rate-distortion function in Theorem 1 satisfies
| (47) |
The second term is the solution to the quadratic Gaussian source coding problem with side information [36, Chapter 11], given as
| (48) |
where is the conditional variance of given . Note that is Gaussian conditioning on , i.e., , which implies .
For the first term, note that is lowered bounded by both
| (49) |
and
| (50) |
Obviously, (49) is the solution of the quadratic Gaussian source coding with side information similarly to (48).
We proceed to calculate (50), which is actually the semantic rate-distortion function of the indirect source coding with side information. Observing , is conditionally Gaussian as . It is shown in [42] that we can rewrite the semantic distortion as
| (51) |
where is the MMSE estimator upon observing and , and the first term on the right-hand side is the corresponding minimum mean squared error ( c.f. (25)), i.e.,
| (52) |
Then we consider a specific encoder which first estimates the semantic information using MMSE estimator and then compresses the estimation under mean squared error distortion constraint with side information. The resulting achievable rate provides an upper bound on which is
| (53) |
Furthermore, for , we have , which can be obtained by setting . For , we derive a lower bound for as follows
| (54) | |||
| (55) | |||
| (56) |
where (54) is due to the fact that the Gaussian distribution maximizes the entropy for a given variance, and (55) follows from (51) and the semantic distortion constraint. Combining the upper and lower bounds in (F) and (56), we obtain
| (57) |
Thus we have
To show the achievability, consider the following two cases.
-
•
For , we first reconstruct and subject to distortion constraints and , and hence achieve . Then we recover the semantic information by , and the semantic distortion satisfies
-
•
For , we first reconstruct and subject to distortion constraints and , and hence achieve . Then we recover , and the distortion satisfies
This establishes the achievability and thus completes the proof.
References
- [1] C. E. Shannon, “A mathematical theory of communication,” The Bell System Technical Journal, vol. 27, no. 3, pp. 379–423, 1948.
- [2] ——, “Coding theorems for a discrete source with a fidelity criterion,” IRE Nat. Conv. Rec., Pt. 4,, vol. 7, pp. 142–163, 1959.
- [3] R. M. Gray, “Conditional rate-distortion theory,” Stanford Electron. Lab., Stanford, Calif., Tech. Rep., vol. 7, pp. 6502–2, Oct. 1972.
- [4] ——, “A new class of lower bounds to information rates of stationary sources via conditional rate-distortion functions,” IEEE Transactions on Information Theory, vol. 19, no. 4, pp. 480–489, 1973.
- [5] A. Wyner and J. Ziv, “The rate-distortion function for source coding with side information at the decoder,” IEEE Transactions on Information Theory, vol. 22, no. 1, pp. 1–10, 1976.
- [6] A. D. Wyner, “The rate-distortion function for source coding with side information at the decoder—ii: General sources,” IEEE Transactions on Information Theory, vol. 38, pp. 60–80, 1978.
- [7] A. Kaspi, “Rate-distortion function when side-information may be present at the decoder,” IEEE Transactions on Information Theory, vol. 40, no. 6, pp. 2031–2034, 1994.
- [8] H. Permuter and T. Weissman, “Source coding with a side information “vending machine”,” IEEE Transactions on Information Theory, vol. 57, no. 7, pp. 4530–4544, 2011.
- [9] S. Watanabe, “The rate-distortion function for product of two sources with side-information at decoders,” IEEE Transactions on Information Theory, vol. 59, no. 9, pp. 5678–5691, 2013.
- [10] C. Heegard and T. Berger, “Rate distortion when side information may be absent,” IEEE Transactions on Information Theory, vol. 31, no. 6, pp. 727–734, 1985.
- [11] A. Kimura and T. Uyematsu, “Multiterminal source coding with complementary delivery,” in 2006 IEEE International Symposium on Information Theory and its Applications (ISITA), Seoul, Korea, Oct. 2006.
- [12] M. Tasto and P. Wintz, “A bound on the rate-distortion function and application to images,” IEEE Transactions on Information Theory, vol. 18, no. 1, pp. 150–159, 1972.
- [13] A. Aaron, S. Rane, R. Zhang, and B. Girod, “Wyner-ziv coding for video: applications to compression and error resilience,” in Data Compression Conference, 2003. Proceedings. DCC 2003, 2003, pp. 93–102.
- [14] J. D. Gibson and J. Hu, Rate Distortion Bounds for Voice and Video. Foundations and Trends in Communications and Information Theory, Jan. 2014, vol. 10, no. 4.
- [15] Y. Wang, A. Reibman, and S. Lin, “Multiple description coding for video delivery,” Proceedings of the IEEE, vol. 93, no. 1, pp. 57–70, 2005.
- [16] T.-C. Chen, P. Fleischer, and K.-H. Tzou, “Multiple block-size transform video coding using a subband structure,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 1, no. 1, pp. 59–71, 1991.
- [17] B. Zeng, Introduction to Digital Image and Video Compression and Processing, ser. The Morgan Kaufmann Series in Multimedia Information and Systems. San Francisco, CA, USA: Morgan Kaufmann, 2002.
- [18] A. Habibian, T. V. Rozendaal, J. Tomczak, and T. Cohen, “Video compression with rate-distortion autoencoders,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 7032–7041.
- [19] A. Habibi and P. Wintz, “Image coding by linear transformation and block quantization,” IEEE Transactions on Communication Technology, vol. 19, no. 1, pp. 50–62, 1971.
- [20] J. Hu and J. D. Gibson, “Rate distortion bounds for blocking and intra-frame prediction in videos,” in 2009 Conference Record of the Forty-Third Asilomar Conference on Signals, Systems and Computers, 2009, pp. 573–577.
- [21] B. Güler, A. Yener, and A. Swami, “The semantic communication game,” IEEE Transactions on Cognitive Communications and Networking, vol. 4, no. 4, pp. 787–802, 2018.
- [22] Y. Blau and T. Michaeli, “Rethinking lossy compression: The rate-distortion-perception tradeoff,” in Proceedings of the 36th International Conference on Machine Learning (ICML), vol. 97, Long Beach, CA, USA, Jun. 2019, pp. 675–685.
- [23] H. Xie and Z. Qin, “A lite distributed semantic communication system for internet of things,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 1, pp. 142–153, 2021.
- [24] Z. Weng and Z. Qin, “Semantic communication systems for speech transmission,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 8, pp. 2434–2444, 2021.
- [25] W. Wang, J. Wang, and J. Chen, “Adaptive block-based compressed video sensing based on saliency detection and side information,” Entropy, vol. 23, no. 9, 2021.
- [26] Y. Guo, Y. Liu, T. Georgiou, and M. S. Lew, “A review of semantic segmentation using deep neural networks,” International Journal of Multimedia Information Retrieval, vol. 7, pp. 87–93, 2017.
- [27] B. Zhao, J. Feng, X. Wu, and S. Yan, “A survey on deep learning-based fine-grained object classification and semantic segmentation,” International Journal of Automation and Computing, vol. 14, pp. 119–135, 2017.
- [28] H. Witsenhausen, “Indirect rate distortion problems,” IEEE Transactions on Information Theory, vol. 26, no. 5, pp. 518–521, 1980.
- [29] J. Liu, W. Zhang, and H. V. Poor, “A rate-distortion framework for characterizing semantic information,” in 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 2021, pp. 2894–2899.
- [30] P. A. Stavrou and M. Kountouris, “A rate distortion approach to goal-oriented communication,” in 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, Jun. 2022, pp. 778–783.
- [31] J. Liu, W. Zhang, and H. V. Poor, “n indirect rate-distortion characterization for semantic sources: General model and the case of gaussian observation,” ArXiv, 2022. [Online]. Available: https://arxiv.org/abs/2201.12477
- [32] P. A. Stavrou and M. Kountouris, “The role of fidelity in goal-oriented semantic communication: A rate distortion approach,” TechRxiv. Preprint, 2022. [Online]. Available: https://doi.org/10.36227/techrxiv.20098970.v1
- [33] T. Berger, Rate Distortion Theory: A Mathematical Basis for Data Compression. NJ, USA: Englewood Cliffs, NJ: Prentice-Hall,, 1971.
- [34] ——, Multiterminal source coding. in The Information Theory Approach to Communications (CISM Courses and Lectures, no. 229), G. Longo, Ed. Vienna/New York: Springer-Verlag, 1978.
- [35] R. W. Yeung, Information Theory and Network Coding. Verlag, USA: Springer, 2008.
- [36] A. El Gamal and Y.-H. Kim, Network Information Theory. Cambridge University Press, 2011.
- [37] T. M. Cover and J. A. Thomas, Elements of Information Theory 2nd Edition (Wiley Series in Telecommunications and Signal Processing). USA: Wiley-Interscience, 2006.
- [38] A. El Gamal and T. Cover, “Achievable rates for multiple descriptions,” IEEE Transactions on Information Theory, vol. 28, no. 6, pp. 851–857, 1982.
- [39] D. Slepian and J. Wolf, “Noiseless coding of correlated information sources,” IEEE Transactions on Information Theory, vol. 19, no. 4, pp. 471–480, 1973.
- [40] M. Carter, “Source coding of composite sources,” Ph.D. Dissertation, Department of Computer Information and Control Engineering, University of Michigan, Ann Arbor, MI, 1984.
- [41] A. Kipnis, S. Rini, and A. J. Goldsmith, “The indirect rate-distortion function of a binary i.i.d source,” in 2015 IEEE Information Theory Workshop - Fall (ITW), 2015, pp. 352–356.
- [42] J. Wolf and J. Ziv, “Transmission of noisy information to a noisy receiver with minimum distortion,” IEEE Transactions on Information Theory, vol. 16, no. 4, pp. 406–411, 1970.