11email: {liuzhuang7, jizhilong}@tal.com, 11email: yuanye_phy@hotmail.com, 11email: jfbai.bit@gmail.com 22institutetext: Huazhong University of Science and Technology
22email: xbai@hust.edu.cn
Semantic Graph Representation Learning for Handwritten Mathematical Expression Recognition
Abstract
Handwritten mathematical expression recognition (HMER) has attracted extensive attention recently. However, current methods cannot explicitly study the interactions between different symbols, which may fail when faced similar symbols. To alleviate this issue, we propose a simple but efficient method to enhance semantic interaction learning (SIL). Specifically, we firstly construct a semantic graph based on the statistical symbol co-occurrence probabilities. Then we design a semantic aware module (SAM), which projects the visual and classification feature into semantic space. The cosine distance between different projected vectors indicates the correlation between symbols. And jointly optimizing HMER and SIL can explicitly enhances the model’s understanding of symbol relationships. In addition, SAM can be easily plugged into existing attention-based models for HMER and consistently bring improvement. Extensive experiments on public benchmark datasets demonstrate that our proposed module can effectively enhance the recognition performance. Our method achieves better recognition performance than prior arts on both CROHME and HME100K datasets.
Keywords:
Handwritten Mathematical Expression Recognition, Semantic Graph, Co-occurrence Probabilities1 Introduction
Handwritten Mathematical Expression Recognition (HMER) is an important OCR task, which can be widely applied in question parsing and answer sheet correction. In recent years, with the rapid development of deep learning technology, scene text recognition approaches have achieved great progress [23, 24, 40, 8]. However, due to the ambiguities brought by crabbed handwriting and the complicated structures of handwritten mathematical expressions, HMER is still a challenging task.
Built upon the recent progress in sequence-to-sequence learning and neural networks [25, 6, 10], some studies have addressed HMER with end-to-end trained encoder-decoder models and showed significant improvement in performance. Nevertheless, the encoder-decoder framework do not fully explore the correlation between different symbols in the mathematical expression, which may be struggling when facing similar handwritten symbols or crabbed handwritings.
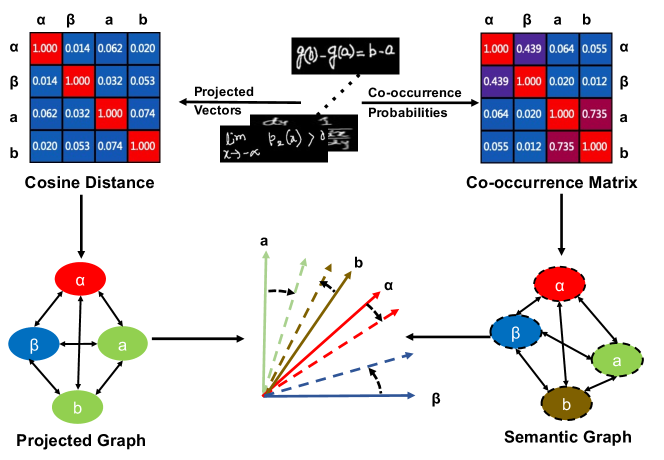
To address above issues, we argue that an effective HMER model should be improved from the following two aspects: (1) capturing semantic dependencies among different symbols in the mathematical expression; (2) integrating more semantic information to locate the regions of interest.
In this paper, we propose an simple but efficient method to improve the robustness of the model, which incorporate the learning of semantic relations among different symbols into the end-to-end training (Fig. 1). Firstly, we built a semantic graph rely on statistical co-occurrence probabilities, which can explicitly exhibit the dependencies among different symbols. Secondly, we propose a semantic aware module, which takes the visual and classification features as input and maps them into the semantic space. The cosine distance between different projected vectors suggests the correlation of symbols. Optimizing the distance to close to the corresponding graph value make the network capture the relationships between different symbols. Therefore, the search for regions of interest and the learning of symbols semantic dependencies are enhanced, which further improved the performance of the model.
The major contributions of this paper are briefly summarized as follows:
-
•
To the best of our knowledge, we are the first to use co-occurrence to represent the relationship between symbols in mathematical expression and verify the effectiveness of enhancing semantic representation learning.
-
•
We propose a semantic aware method that jointly optimizes the symbol relations learning and HMER, which can consistently improve the performance of the model for HMER.
-
•
Our proposed semantic aware module can be easily plugged into attention based models for HMER and no extra computation during the inference stage.
To be specific about the performance, we adopt DWAP [48] as the baseline network. With the help of SAM, SAM-DWAP outperforms DWAP by 2.2%, 2.8% and 4.2% on CROHME 2014, 2016 and 2019, respectively. Moreover, with adopting the latest SOTA method CAN [17] as the baseline network, our method achieves new SOTA results (58.0% on CROHME 2014, 56.7% on CROHME 2016, 58.0% on CROHME 2019). This indicates that our method can be generalized to various existing encoder-decoder models for HMER and boost their performance.
2 Related Work
HMER is a fundamental OCR task, which has attracted research interests in the past several decades. In this section, we briefly introduce previous related works on HMER.
Traditional methods on HMER could be mainly separated into two steps: a symbol segmentation/recognition step and a grammar guided structure analysis step. In the first step, several classic classification techniques were studied, such as HMM [31, 12, 9, 1], Elastic Matching [4, 28], Support Vector Machines [11], etc. In the second step, formal grammars were designed to model the 2D and syntactic structures of expression. Lavirotte et al. [13] proposed to use graph grammar to recognize mathematical expression. Chan et al. [5] incorporated correction mechanism into parser based on definite clause grammar (DCG). Yamamoto et al. [37] modeled handwritten mathematical expressions with a stochastic context-free grammar and solved the recognition problem by using the CYK algorithm. In contrast to those traditional methods, our model incorporates grammatical structure and automatically learned encoder-decoder, therefore preventing from designing cumbersome rules.
Recently, deep learning techniques rapidly boosted the performance of HEMR. The mainstream framework was encoder-decoder networks [7, 42, 48, 44, 51, 29, 26, 21, 14, 44, 16, 32]. Deng et al. [7] firstly proposed an encoder-decoder framework to convert image to LaTeX markup. A coarse-to-fine attention layer was used to reduce the attention complexity in their work. Zhang et al. [48] presented an encoder-decoder model, named WAP (Watch, Attend and Parse). In their model, the encoder is a FCN and a coverage vector is appended to the attention model. Wu et al. [33, 35] focused on the pair-wise adversarial learning strategy to improve the recognition accuracy. To alleviate the challenge of lack of data, Le et al. [16] and Li et al. [18] employed distortion, decomposition and scale augmentation techniques, which achieved significant performance promotion. Le [14] proposed a dual loss attention model, which contains a new context match loss. Context matching loss is adapted to constrain the intra-class distance and enhance the discriminative power of model. Lately, Zhang et al. [46] devised a tree-based decoder to parse mathematical expression. At each step, a parent and child node pair was generated and the relation between parent node and child node reflects the structure type. Yuan et al. [39] firstly incorporate syntax information into the encoder-decoder, which achieved higer recognition accuracy while taking into account speed. Li et al.[17] design a weakly-supervised counting module and jointly optimizes HMER task and symbol counting task. With the help of integrated global information, it puts in a impressive performance.
3 Methodology
The overall framework of our approach is shown in Fig. 2. The pipeline includes several parts: densely connected convolutional network (DenseNet) [10] is applied as encoder to extract the features. The DenseNet takes a grayscale image X of size , where and are image height and image width, respectively, and returns a 2D feature map , where . The decoder uses the feature map and gradually predicts the LaTeX markup. The Semantic Aware Module (SAM) comprises two branches with similar structure (visual branch and classification branch), which employ the visual and classification features, respectively. Visual and classification features are projected to semantic space to obtain projected visual and classification vectors, respectively. The cosine distance between projected vectors from different time steps indicates how related they are.
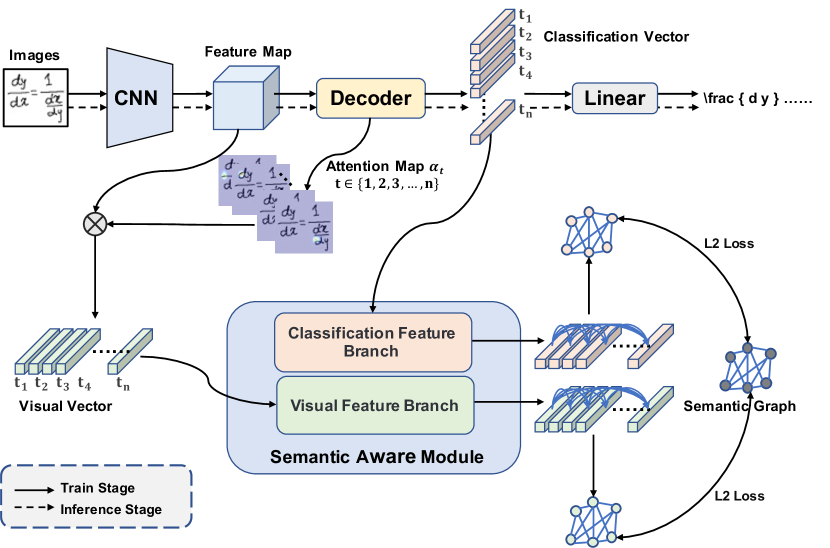
3.1 Semantic Graph
Capturing global context information has been proven to be an effective way to improve the robustness of recognition [38, 22]. However, compared with words, the use of symbols in the mathematical expressions is relatively more casual. How to express the relationships among different symbols in the mathematical expressions is an open issue to be solved. Our intuition is that the magnitude of values in the co-occurrence graph reflects the relationship between different symbols, much like how different characters in text have different collocations. Making the distances close to the probabilities is aimed at enhancing the model’s learning of the linguistic information in formulas.
Semantic graph is defined as , where represents the set of symbol nodes and represents the edges, which suggest the dependence between any two symbols. The correlation matrix of graph contains non-negative weights associated with each edge. The correlation matrix is a conditional probability matrix and the is set as , where is calculated through training set. However, is an asymmetric matrix, namely . In order to facilitate the calculation, we turn the asymmetric matrix into a symmetric matrix following:
| (1) |
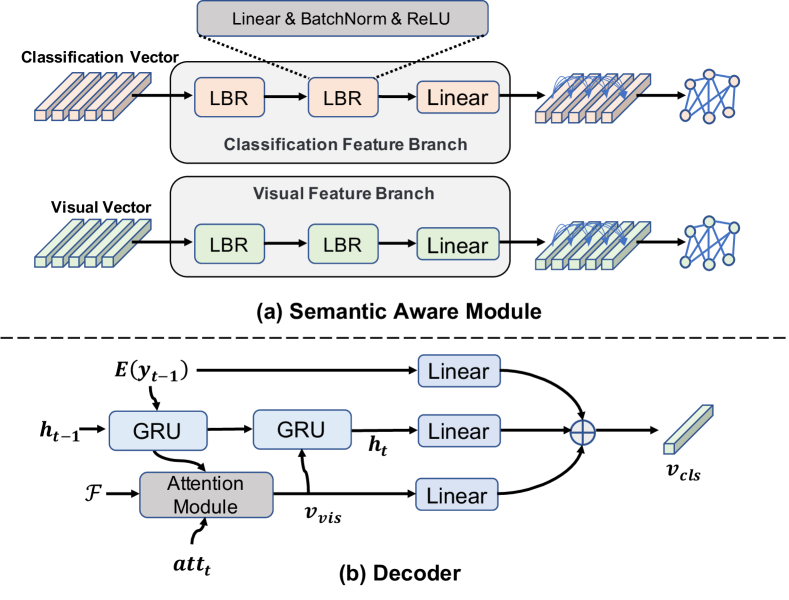
3.2 Semantic Aware Module
In this section, we present the detail of the proposed semantic aware module (SAM). As shown in Fig. 3 (a), SAM contains two branches, namely visual feature branch and classification feature branch. Each branch comprises two “LBR” block followed by a linear layer. A “LBR” block is built by stacking Linear layer, Batch Normalization and ReLU activation. We apply SAM to project the visual vectors () and classification vector () to semantic space to get projected visual vectors () and projected classification vectors ():
| (2) |
| (3) |
where is the ReLU activation and refers to Batch Normalization. , , , , and are learnable parameters.
Our goal is to optimize the projected visual vectors () and projected classification vectors (). Such that cos(, ) is close to for all i, j, where cos(, ) denotes the cosine similarity between and :
| (4) |
3.3 Decoder
Fig. 3 (b) shows the structure of decoder. The decoder mainly contains two Gated Recurrent Units (GRU) cells and an attention module. The first GRU takes the symbol embedding () and historical state () predicted in the last step as input and output a new hidden state vector :
| (5) |
Then the attention module calculates the attentional weights through its attention mechanism:
| (6) |
| (7) |
where , , and are trainable parameters. represents the feature map and refers to coverage attention [48], which equals the sum of all past attention probabilities:
| (8) |
The and are multiplied to obtain visual features vectors :
| (9) |
The second GRU takes the and as input and returns the hidden state :
| (10) |
Then we aggregate , and to obtain the classification feature vectors and symbol probabilities:
| (11) |
| (12) |
where , , and are trainable parameters.
3.4 Loss Function
The overall function consists of three parts and is defined as follows:
| (13) |
where is cross entropy classification loss of the predicted probability with respect to its ground-truth. and are L2 regression loss defined as follows:
| (14) |
| (15) |
4 Experiments
We conduct experiments on three CROHME and HME100K benchmark datasets and compare the performance with previous state-of-the-art methods. In this section, we firstly specify the datasets, implementation details and evaluation protocol in Section 4.1, 4.2 and 4.3, respectively. Then, in Section 4.4 we evaluate our method on public datasets and compare it with other state-of-the-art methods. In Section 4.5, we exhibit the ablation studies and finally, in Section 4.6 we show few cases and discuss the effectiveness of our method.
4.1 Datasets
4.1.1 CROHME Dataset.
CROHME dataset is from the competition on recognition of online handwritten mathematical expression, which is the most widely used public dataset. Images in CROHME dataset are synthesized from the handwritten stroke trajectory information in the InkML files. Therefore, the image background from CROHME dataset is clean (Fig. 4 (a)). The CROHME training set number is 8,836, while the test set contains 986, 1147 and 1199 images respectively due to different release years.
4.1.2 HME100K Dataset.
HME100K dataset is a real scene dataset and consequently, HME100K dataset are varied in color, blur, complicated background, twist (Fig. 4 (b-f)). HME100K dataset contains 74,502 images for training and 24,607 images for testing. The data size of HME100K dataset is ten times larger than CROHME dataset. The number of math symbols included in the HME100K dataset is 245, which is two times larger than that of CROHME dataset.
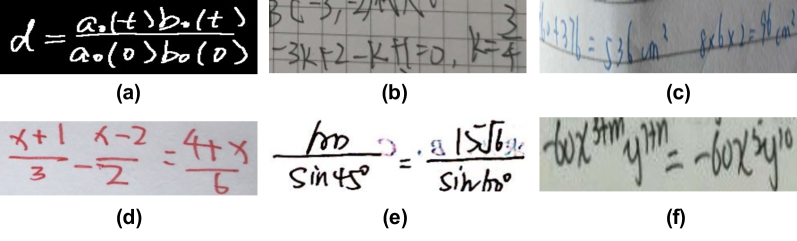
4.2 Implementation Details
The proposed methods is implemented in PyTorch. A single Nvidia Tesla V100 with 32GB RAM is used to conduct experiment. The batch size is set at 8. Both the hidden state sizes of the two GRUs and dimension of word embedding are set at 256. The Adadelta optimizer [41] is used during the training process, in which is set at 0.95 and is set at . The learning rate starts from 0 and monotonously increases to 1 at the end of the first epoch. After that the learning rate decays to 0 following the cosine schedules [50]. For CROHME dataset, the total training epoch is set to 240 and for HME100K dataset, the training epoch is set to 40.
| Method | CROHME 2014 | CROHME 2016 | CROHME 2019 | HME100K |
| UPV [19] | 37.22 | - | - | - |
| TOKYO [20] | - | 43.94 | - | - |
| PAL [34] | 39.66 | - | - | - |
| WAP [49] | 46.55 | 44.55 | - | - |
| PAL-v2 [36] | 48.88 | 49.61 | - | - |
| TAP [45] | 48.47 | 44.81 | - | - |
| DLA [15] | 49.85 | 47.34 | - | - |
| DWAP [43] | 50.10 | 47.50 | - | 61.85 |
| DWAP-TD [47] | 49.10 | 48.50 | 51.40 | 62.60 |
| DWAP-MSA [43] | 52.80 | 50.10 | 47.70 | - |
| WS-WAP [27] | 53.65 | 51.96 | - | - |
| MAN [30] | 54.05 | 50.56 | - | - |
| BTTR [52] | 53.96 | 52.31 | 52.96 | 64.10 |
| SAN [2] | 56.20 | 53.60 | 53.50 | 67.10 |
| ABM [3] | 56.85 | 52.92 | 53.96 | 65.93 |
| CAN [17] | 57.00 | 56.06 | 54.88 | 67.31 |
| SAM-DWAP (ours) | 56.80 | 55.62 | 56.21 | 68.08 |
| SAM-CAN (ours) | 58.01 | 56.67 | 57.96 | 68.81 |
4.3 Evaluation Protocol
Recognition Protocol. We employ expression recognition rate (ExpRate) to evaluate the performance of different approaches. The definition of ExpRate is the percentage of predicted mathematical expressions that exactly match the ground truth.
4.4 Comparison with State-of-the-Art
4.4.1 Results on the CROHME Datasets.
Tab. 1 summaries the performance of our method and previous methods on the CROHME dataset. Since most of the previous work does not use data augmentation, we mainly discuss the results without data augmentation.
As shown in tab. 1, using DWAP [42] as the backbone, SAM-DWAP achieves competitive results to the last SOTA method CAN [17] on CROHME 2014 and CROHME 2016. On CROHME 2019 dataset, our method ourperforms CAN by 1.33 %.
To further verify our proposed SAM is compatible with other models and can consistently bring performance improvements. We integrate SAM into CAN to construct SAM-CAN. As shown in tab. 1, SAM-CAN achieves the best performance on all CROHME test set and outperforms CAN by 1.21 %, 0.61 % and 3.08 %, respectively. This result clearly demonstrates the effectiveness of our proposed module.
4.4.2 Results on the HME100K Dataset.
| HME100K | Easy | Moderate | Hard | Total |
| Image size | 7721 | 10450 | 6436 | 24607 |
| DWAP[42] | 75.1 | 62.2 | 45.4 | 61.9 |
| DWAP-TD[46] | 76.2 | 63.2 | 45.4 | 62.6 |
| BTTR [51] | 77.6 | 65.3 | 46.0 | 64.1 |
| ABM [3] | - | - | - | 65.3 |
| SAN [39] | 79.2 | 67.6 | 51.5 | 67.1 |
| CAN [17] | - | - | - | 67.3 |
| SAM-DWAP(ours) | 79.3 | 68.4 | 54.0 | 68.1 |
| SAM-CAN(ours) | 79.8 | 69.8 | 54.0 | 68.8 |
| Method | CROHME | ||
| 2014 | 2016 | 2019 | |
| DWAP† | 54.6 | 52.8 | 52.0 |
| Vis-DWAP | 55.8 | 54.8 | 54.1 |
| Cls-DWAP | 55.6 | 55.2 | 54.7 |
| SAM-DWAP | 56.8 | 55.6 | 56.2 |
| CAN† | 57.1 | 55.3 | 54.9 |
| Vis-CAN | 57.5 | 56.3 | 56.6 |
| Cls-CAN | 57.4 | 56.5 | 55.8 |
| SAM-CAN | 58.0 | 56.6 | 57.9 |
As shown in tab. 1 and 2, we compare our prosposed method with DWAP [42], DWAP-TD [46], BTTR [51], ABM [3], SAN [39] and CAN [17] on HME100K dataset. It is clear to notice that SAM-DWAP and SAM-CAN achieves the best performance. Specifically, as shown in table 2, SAM-DWAP and SAM-CAN outperform SAN by 0.1 % and 0.6 % on easy subset, respectively. However, as the difficulty of the test subset increases, the leading margin of our method increases to 2.5 % and 2.5 % on the hard subset. This further proves the effectiveness of the proposed SAM.
4.5 Ablation Study
In this subsection, we evaluate the effectiveness of visual feature branch and classification feature branch. SAM-DWAP and SAM-CAN are the default models. Vis-DWAP and Vis-CAN have a visual feature branch but not a classification feature branch. Cls-DWAP and Cls-CAN have a classification feature branch but not a visual feature branch. DWAP† and CAN † are our reproduced results. The results are summarized in tab. 3.
4.5.1 Impact of Visual Feature Branch.
Tab. 4.5 shows adopting visual feature branch to DWAP improves the recognition performance ExpRate by 1.2 % on CROHME 2014, 2.0 % on CROHME 2016 and 2.1 % on CROHME 2019. Inserting visual feature branch into CAN also can enhance the performance by 0.4 % on CROHME 2014, 1.0 % on CROHME 2016 and 1.7 % on CROHME 2019. Hence integrating visual feature branch can effectively improve the performance.
4.5.2 Impact of Classification Feature Branch.
Tab. 4.5 shows adopting classification feature branch to DWAP improves the recognition performance ExpRate by 1.0 % on CROHME 2014, 2.4 % on CROHME 2016 and 2.7 % on CROHME 2019. Inserting visual feature branch into CAN also can enhance the performance by 0.3 % on CROHME 2014, 1.2 % on CROHME 2016 and 0.9 % on CROHME 2019. Hence integrating classification feature branch can effectively improve the performance.
4.6 Case Study
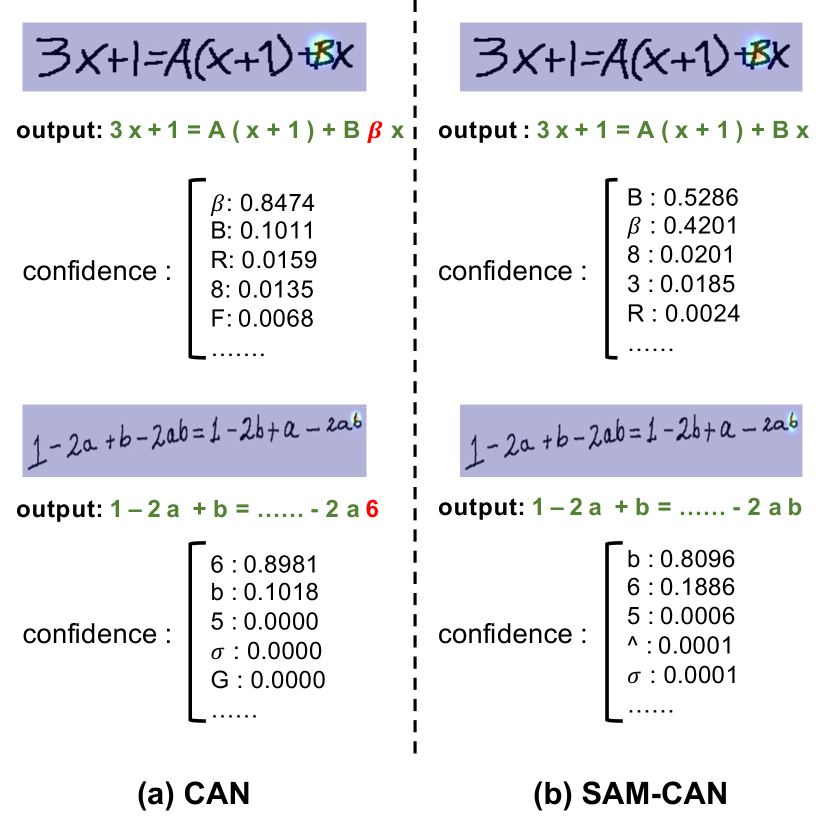
In this section, we show two examples to illustrate the effect of using SAM. As shown in Fig. 5 (a), although CAN correctly focuses on the region of interest, it misidentifies the symbol “B” as symbol “” and misidentifies the symbol “b” as symbol “6”. In contrast, the regions of interest of the SAM-CAN are similar to those of CAN, but SAM-CAN correctly predicts symbol “B” and “b”. The confidences of symbol “B” and “b” also increase from 10.1 % to 52.9 % and increase from 10.2% to 81.0%, respectively. This phenomenon indicates that adopting SAM can improve the robustness of recognition especially the recognition performance of similar symbols.
5 Conclusion
This paper has presented a simple and efficient method for handwritten mathematical expression recognition by incorporate semantic graph representation learning into end-to-end training. To our best knowledge, the proposed method is the first to learn the correlation between different symbols through symbol co-occurrence probabilities. Experiments on the CROHME dataset and HME100K dataset have validated the effectiveness and efficiency of our method.
6 Acknowledgement
This work was supported by National Key R&D Program of China, under Grant No. 2020AAA0104500 and National Science Fund for Distinguished Young Scholars of China (Grant No.62225603).
References
- [1] Alvaro, F., Sánchez, J.A., Benedí, J.M.: Recognition of on-line handwritten mathematical expressions using 2d stochastic context-free grammars and hidden markov models. Pattern Recognition Letters 35, 58–67 (2014)
- [2] Anderson, R.H.: Syntax-directed recognition of hand-printed two-dimensional mathematics. In: Symposium on Interactive Systems for Experimental Applied Mathematics: Proceedings of the Association for Computing Machinery Inc. Symposium. pp. 436–459 (1967)
- [3] Bian, X., Qin, B., Xin, X., Li, J., Su, X., Wang, Y.: Handwritten mathematical expression recognition via attention aggregation based bi-directional mutual learning. In: Proc. of the AAAI Conf. on Artificial Intelligence. pp. 113–121 (2022)
- [4] Chan, K.F., Yeung, D.Y.: Elastic structural matching for online handwritten alphanumeric character recognition. In: Proceedings. Fourteenth International Conference on Pattern Recognition (Cat. No. 98EX170). vol. 2, pp. 1508–1511. IEEE (1998)
- [5] Chan, K.F., Yeung, D.Y.: Error detection, error correction and performance evaluation in on-line mathematical expression recognition. Pattern Recognition 34(8), 1671–1684 (2001)
- [6] Chung, J., Gulcehre, C., Cho, K., Bengio, Y.: Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014)
- [7] Deng, Y., Kanervisto, A., Ling, J., Rush, A.M.: Image-to-markup generation with coarse-to-fine attention. In: International Conference on Machine Learning. pp. 980–989. PMLR (2017)
- [8] Fang, S., Xie, H., Wang, Y., Mao, Z., Zhang, Y.: Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7098–7107 (2021)
- [9] Hu, L., Zanibbi, R.: Hmm-based recognition of online handwritten mathematical symbols using segmental k-means initialization and a modified pen-up/down feature. In: 2011 International Conference on Document Analysis and Recognition. pp. 457–462. IEEE (2011)
- [10] Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4700–4708 (2017)
- [11] Keshari, B., Watt, S.: Hybrid mathematical symbol recognition using support vector machines. In: Ninth International Conference on Document Analysis and Recognition (ICDAR 2007). vol. 2, pp. 859–863. IEEE (2007)
- [12] Kosmala, A., Rigoll, G., Lavirotte, S., Pottier, L.: On-line handwritten formula recognition using hidden markov models and context dependent graph grammars. In: Proceedings of the Fifth International Conference on Document Analysis and Recognition. ICDAR’99 (Cat. No. PR00318). pp. 107–110. IEEE (1999)
- [13] Lavirotte, S., Pottier, L.: Mathematical formula recognition using graph grammar. In: Document Recognition V. vol. 3305, pp. 44–52. International Society for Optics and Photonics (1998)
- [14] Le, A.D.: Recognizing handwritten mathematical expressions via paired dual loss attention network and printed mathematical expressions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. pp. 566–567 (2020)
- [15] Le, A.D.: Recognizing handwritten mathematical expressions via paired dual loss attention network and printed mathematical expressions. In: Proc. of IEEE Intl. Conf. on Computer Vision and Pattern Recognition Workshops. pp. 566–567 (2020)
- [16] Le, A.D., Indurkhya, B., Nakagawa, M.: Pattern generation strategies for improving recognition of handwritten mathematical expressions. Pattern Recognition Letters 128, 255–262 (2019)
- [17] Li, B., Yuan, Y., Liang, D., Liu, X., Ji, Z., Bai, J., Liu, W., Bai, X.: When counting meets hmer: Counting-aware network for handwritten mathematical expression recognition. In: Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVIII. pp. 197–214. Springer (2022)
- [18] Li, Z., Jin, L., Lai, S., Zhu, Y.: Improving attention-based handwritten mathematical expression recognition with scale augmentation and drop attention. arXiv preprint arXiv:2007.10092 (2020)
- [19] Mouchere, H., Viard-Gaudin, C., Zanibbi, R., Garain, U.: Icfhr 2014 competition on recognition of on-line handwritten mathematical expressions (crohme 2014). In: Proc. of International Conference on Frontiers in Handwriting Recognition. pp. 791–796 (2014)
- [20] Mouchère, H., Viard-Gaudin, C., Zanibbi, R., Garain, U.: Icfhr2016 crohme: Competition on recognition of online handwritten mathematical expressions. In: Proc. of International Conference on Frontiers in Handwriting Recognition. pp. 607–612 (2016)
- [21] Nguyen, C.T., Nguyen, H.T., Morizumi, K., Nakagawa, M.: Temporal classification constraint for improving handwritten mathematical expression recognition. In: International Conference on Document Analysis and Recognition. pp. 113–125. Springer (2021)
- [22] Qiao, Z., Zhou, Y., Yang, D., Zhou, Y., Wang, W.: Seed: Semantics enhanced encoder-decoder framework for scene text recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13528–13537 (2020)
- [23] Shi, B., Bai, X., Yao, C.: An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence 39(11), 2298–2304 (2016)
- [24] Shi, B., Yang, M., Wang, X., Lyu, P., Yao, C., Bai, X.: Aster: An attentional scene text recognizer with flexible rectification. IEEE transactions on pattern analysis and machine intelligence 41(9), 2035–2048 (2018)
- [25] Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks (2014)
- [26] Truong, T.N., Nguyen, C.T., Phan, K.M., Nakagawa, M.: Improvement of end-to-end offline handwritten mathematical expression recognition by weakly supervised learning. In: 2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR). pp. 181–186. IEEE (2020)
- [27] Truong, T.N., Nguyen, C.T., Phan, K.M., Nakagawa, M.: Improvement of end-to-end offline handwritten mathematical expression recognition by weakly supervised learning. In: Proc. of International Conference on Frontiers in Handwriting Recognition. pp. 181–186 (2020)
- [28] Vuong, B.Q., He, Y., Hui, S.C.: Towards a web-based progressive handwriting recognition environment for mathematical problem solving. Expert Systems with Applications 37(1), 886–893 (2010)
- [29] Wang, J., Du, J., Zhang, J., Wang, Z.R.: Multi-modal attention network for handwritten mathematical expression recognition. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 1181–1186. IEEE (2019)
- [30] Wang, J., Du, J., Zhang, J., Wang, Z.R.: Multi-modal attention network for handwritten mathematical expression recognition. In: Proc. of International Conference on Document Analysis and Recognition. pp. 1181–1186 (2019)
- [31] Winkler, H.J.: Hmm-based handwritten symbol recognition using on-line and off-line features. In: 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings. vol. 6, pp. 3438–3441. IEEE (1996)
- [32] Wu, J.W., Yin, F., Zhang, Y., Zhang, X.Y., Liu, C.L.: Graph-to-graph: towards accurate and interpretable online handwritten mathematical expression recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 35, pp. 2925–2933 (2021)
- [33] Wu, J.W., Yin, F., Zhang, Y.M., Zhang, X.Y., Liu, C.L.: Image-to-markup generation via paired adversarial learning. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases. pp. 18–34. Springer (2018)
- [34] Wu, J.W., Yin, F., Zhang, Y.M., Zhang, X.Y., Liu, C.L.: Image-to-markup generation via paired adversarial learning. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases. pp. 18–34 (2018)
- [35] Wu, J.W., Yin, F., Zhang, Y.M., Zhang, X.Y., Liu, C.L.: Handwritten mathematical expression recognition via paired adversarial learning. International Journal of Computer Vision pp. 1–16 (2020)
- [36] Wu, J.W., Yin, F., Zhang, Y.M., Zhang, X.Y., Liu, C.L.: Handwritten mathematical expression recognition via paired adversarial learning. International Journal of Computer Vision 128(10), 2386–2401 (2020)
- [37] Yamamoto, R., Sako, S., Nishimoto, T., Sagayama, S.: On-line recognition of handwritten mathematical expressions based on stroke-based stochastic context-free grammar. In: Tenth international workshop on frontiers in handwriting recognition. Suvisoft (2006)
- [38] Yu, D., Li, X., Zhang, C., Liu, T., Han, J., Liu, J., Ding, E.: Towards accurate scene text recognition with semantic reasoning networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12113–12122 (2020)
- [39] Yuan, Y., Liu, X., Dikubab, W., Liu, H., Ji, Z., Wu, Z., Bai, X.: Syntax-aware network for handwritten mathematical expression recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4553–4562 (2022)
- [40] Yue, X., Kuang, Z., Lin, C., Sun, H., Zhang, W.: Robustscanner: Dynamically enhancing positional clues for robust text recognition. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIX. pp. 135–151. Springer (2020)
- [41] Zeiler, M.D.: Adadelta: an adaptive learning rate method. arXiv preprint arXiv:1212.5701 (2012)
- [42] Zhang, J., Du, J., Dai, L.: Multi-scale attention with dense encoder for handwritten mathematical expression recognition. In: 2018 24th international conference on pattern recognition (ICPR). pp. 2245–2250. IEEE (2018)
- [43] Zhang, J., Du, J., Dai, L.: Multi-scale attention with dense encoder for handwritten mathematical expression recognition. In: Proc. of Intl. Conf. on Pattern Recognition. pp. 2245–2250 (2018)
- [44] Zhang, J., Du, J., Dai, L.: Track, attend, and parse (tap): An end-to-end framework for online handwritten mathematical expression recognition. IEEE Transactions on Multimedia 21(1), 221–233 (2018)
- [45] Zhang, J., Du, J., Dai, L.: Track, attend, and parse (tap): An end-to-end framework for online handwritten mathematical expression recognition. IEEE Transactions on Multimedia 21(1), 221–233 (2018)
- [46] Zhang, J., Du, J., Yang, Y., Song, Y.Z., Wei, S., Dai, L.: A tree-structured decoder for image-to-markup generation. In: International Conference on Machine Learning. pp. 11076–11085. PMLR (2020)
- [47] Zhang, J., Du, J., Yang, Y., Song, Y.Z., Wei, S., Dai, L.: A tree-structured decoder for image-to-markup generation. In: Proc. of Intl. Conf. on Machine Learning. pp. 11076–11085 (2020)
- [48] Zhang, J., Du, J., Zhang, S., Liu, D., Hu, Y., Hu, J., Wei, S., Dai, L.: Watch, attend and parse: An end-to-end neural network based approach to handwritten mathematical expression recognition. Pattern Recognition 71, 196–206 (2017)
- [49] Zhang, J., Du, J., Zhang, S., Liu, D., Hu, Y., Hu, J., Wei, S., Dai, L.: Watch, attend and parse: An end-to-end neural network based approach to handwritten mathematical expression recognition. Pattern Recognition 71, 196–206 (2017)
- [50] Zhang, Z., He, T., Zhang, H., Zhang, Z., Xie, J., Li, M.: Bag of freebies for training object detection neural networks. arXiv preprint arXiv:1902.04103 (2019)
- [51] Zhao, W., Gao, L., Yan, Z., Peng, S., Du, L., Zhang, Z.: Handwritten mathematical expression recognition with bidirectionally trained transformer. In: International Conference on Document Analysis and Recognition. pp. 570–584. Springer (2021)
- [52] Zhao, W., Gao, L., Yan, Z., Peng, S., Du, L., Zhang, Z.: Handwritten mathematical expression recognition with bidirectionally trained transformer. In: Proc. of International Conference on Document Analysis and Recognition. pp. 570–584 (2021)