Semantic Segmentation of Fruits on Multi-sensor Fused Data in Natural Orchards
††thanks: Identify applicable funding agency here. If none, delete this.
Abstract
Semantic segmentation is a fundamental task for agricultural robots to understand the surrounding environments in natural orchards. The recent development of the LiDAR techniques enables the robot to acquire accurate range measurements of the view in the unstructured orchards. Compared to RGB images, 3D point clouds have geometrical properties. By combining the LiDAR and camera, rich information on geometries and textures can be obtained. In this work, we propose a deep-learning-based segmentation method to perform accurate semantic segmentation on fused data from a LiDAR-Camera visual sensor. Two critical problems are explored and solved in this work. The first one is how to efficiently fused the texture and geometrical features from multi-sensor data. The second one is how to efficiently train the 3D segmentation network under severely imbalance class conditions. Moreover, an implementation of 3D segmentation in orchards including LiDAR-Camera data fusion, data collection and labelling, network training, and model inference is introduced in detail. In the experiment, we comprehensively analyze the network setup when dealing with highly unstructured and noisy point clouds acquired from an apple orchard. Overall, our proposed method achieves mIoU on the segmentation of fruits on the high-resolution point cloud (100k-200k points). The experiment results show that the proposed method can perform accurate segmentation in real orchard environments.
Index Terms:
Semantic segmentation, deep-learning, pointnet, LiDARI Introduction
With the recent development of the LiDAR techniques, data in 3D point cloud format has been gradually used in robotics tasks under agricultural scenarios because it is robust to the variances in lighting, shadows, and other factors. The 3D point cloud can provide accurate and robust range measurements of the real world. Additionally, RGB cameras can still provide dense texture information missing from LiDAR data, which can cooperate with Lidar to receive rich information [1]. With proper extrinsic calibration of the cameras and LiDARs, the point cloud with texture information of the real world can be obtained. Semantic scene understanding is a fundamental task in many agricultural scenarios, such as growth monitoring and robotics perception tasks [2, 3, 4]. However, semantic segmentation of 3D point clouds, particularly segmentation of large-scale point clouds, is still a challenging task as 3D point clouds are generally unstructured and unordered [5, 6]. How to improve the performance of semantic segmentation of 3D point cloud data in these agricultural scenes has attracted more and more attention.
Semantic segmentation plays a core role in computer vision. It groups image pixels together which belong to the same class, which is visually meaningful areas for analysis and understanding [7]. Semantic segmentation has been widely used in robotic perception, medical image processing, autonomous driving, agricultural harvesting etc [8, 9, 10, 11]. The recent development in Convolutional Neural Networks (CNN) provides remarkable performance improvement as compared with the traditional classifiers like random forest [12]. Jonathon et al. [13] developed a fully convolutional network (FCN) for end-to-end image segmentation, which achieved a 20% increase in the segmentation performance on Pascal VOC 2012 database. Olaf et al. [14] proposed a UNet network and training strategy that highly utilizes the data augmentation with available annotated samples for biomedical image segmentation. The authors further developed the Deeplab-v3 network and applied ResNet/MobileNet as the backbone [15]. Modules with dilate convolution in the cascade were designed to capture multi-scale context by adopting multiple dilate rates. Additionally, the augments on dilate Spatial Pyramid Pooling was implemented to probe convolutional features at multiple scales.
The semantic segmentation method has also been widely applied to promote the advancement of the agricultural field. Zou et al. proposed a UNet-based algorithm to segment weeds from similar crops under a field environment [16]. The segmentation network was trained using a two-stage training method, including pre-processing and fine-tuning, which achieved an IOU of 92.92%. Wu et al. applied DeepLabV3 models with four backbones of ResNet-50, ResNet-101, Xception-65, and Xception-71 to segment abnormal leaves of hydroponic lettuce [17]. ResNet-101 had the best segmentation performance in the uniform weight assignation method with pixel accuracy of 99.2%, and mIoU of 0.8326. Peng et al. applied FCN to segment the dense grapes with different varieties, and an IOU of 75.61% was achieved on the RGB images. He also applied UNet and DeeplabV3 to compare the segmentation accuracy, which ended up with an accuracy of 77.53% and 84.26% for the IOU [18].
Even though the 2D semantic segmentation achieves compatible segmentation accuracy and robustness, its performance experiences significant degeneration while dealing with complex natural orchards, especially for highly occluded large-scale scenes. Additionally, purely 2D images can not describe the 3D space well due to a lack of depth information. Recent research has focused on the semantic segmentation of 3D point clouds. Wei et al. proposed BushNet to achieve the semantic segmentation of 3D points in a large-scale agroforestry environment [19]. It included a minimum probability of random sampling module that can quickly and randomly sample a huge point and a multi-channel attention module to improve the attention distribution accuracy and training efficiency. The segmentation accuracy was improved by 12% with the additional modules implemented. Chen et al. introduced RandLa-Net for large-scale unstructured agricultural scenes [20]. A local feature aggregation module was integrated and improved to achieve the large-scale 3D point cloud segmentation. The experiment results suggested the best segmentation accuracy of 94%, and the mIoU can reach 74%. Yu et al. designed LFPNet that can directly consume fruit point clouds in real scenes to deal with classification error, incomplete segmentation, and low-efficiency [21]. The final results achieved an average segmentation accuracy and mIOU of 80.2% and 76.4%, respectively. However, the data were collected from the facility environment with a Kinect-v2 RGB-D camera, which will experience high-performance degeneration under natural lighting conditions. The network can not be deployed to mobile devices or be used for on-site segmentation tasks.
Despite the significant importance of semantic segmentation on 3D point clouds, it has been rarely studied for scene segmentation in unstructured scenes of real orchards. The point clouds of the surrounding environment and other factors in the real orchard are highly unstructured, uneven distributed, and noisy even compared to the point clouds acquired in city scenes. These pose huge challenges in performing semantic segmentation directly on 3D point clouds.
This study proposes a PointNet-based 3D segmentation method to perform segmentation in natural orchards. Two critical challenges are solved in this work. The first challenge is how to efficiently fuse features from images and point clouds to perform semantic segmentation. Since image data can provide enriched texture information and point cloud data can provide geometrical information about the world. The second challenge is how to train the point-based semantic segmentation under imbalance class conditions efficiently. A complete point cloud data of an orchard scene may contain more than 100k points, while only a few belong to the foreground objects. Such problematic class distribution could severely affect the accuracy of the trained model. Yu et al.’s work [21] is the most similar work to our method. However, their work does not discuss the multi-sensor data fusion and training under imbalance class, which are two critical problems of 3D semantic segmentation orchard scenes. Meanwhile, their method requires a high-precision multi-viewpoint cloud that can only be obtained in ideal environments. While Our method only requires the fused RGB-point data that can be collected by LiDAR-Camera in the orchard environments.
In this paper, we propose a deep-learning-based 3D segmentation network to segment fruits in the high-resolution (100k - 200k points) colorized point clouds. We leverage the PointNet++ architecture [22], an existing SOTA deep-learning model in processing point clouds, and present an improved PointNet++ architecture that can fuse texture and geometrical information from a LiDAR-Camera visual sensor. We show that the accuracy of the PointNet-based model can be significantly improved by efficiently designing the fusion behaviour of the color and point clouds. To further promote the performance of the presented network, we utilize under-sampling and Weighted Cross-Entropy (WCE) to improve the network training efficacy. By distilling multiple network designs and training strategies, we obtain a comparatively accurate and robust 3D semantic segmentation method. Moreover, a complete implementation of the methods in terms of the LiDAR-Camera data fusion, data labelling and pre-processing, network training and inference is also introduced in detail. Our primary contributions to this paper are:
-
•
A method that can perform semantic segmentation on high-resolution colorised point cloud data from a LiDAR-Camera fused sensor.
-
•
A concise but efficient network architecture that can fuse features from image color and point cloud data.
-
•
Demonstration of the proposed method from LiDAR-Camera fusion, and data labelling, to the network training and prediction, providing an end-to-end implementation for semantic segmentation in natural orchard environments.
II Materials and Methodology
II-A Method Overview
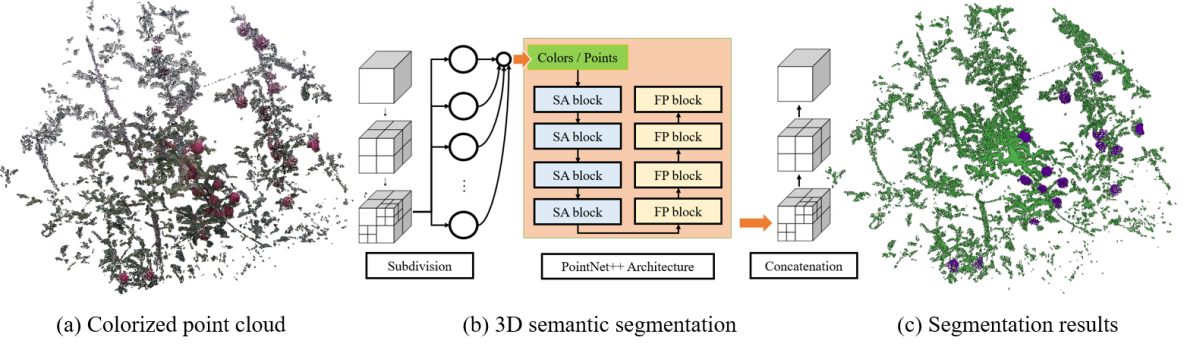
An overview of the proposed segmentation method is shown in Figure 1. The system captures sensor data from a Solid State LiDAR (SSL) Livox Mid-70 or Livox AVIA and an RGB camera. The intrinsic of the camera and extrinsic between LiDAR and camera are calibrated using the method from our previous work [23]. We seek to estimate the semantic label of points that belong to the fruits using either point cloud or fused color information. This estimation problem can be formulated as a dense semantic segmentation problem. We leverage the PointNet++ architecture to perform semantic segmentation on input data since it shows SOTA performance in processing point cloud data in many core vision perception tasks. Our method can perform semantic segmentation on raw point cloud data and point cloud with color information. Note that without loss of generality, the proposed method can also incorporate measurements from other 3D range sensors, like spinning LiDARs. Mean Intersection over Union (mIoU) is used to evaluate the performance of the network model.
II-A1 Input Data
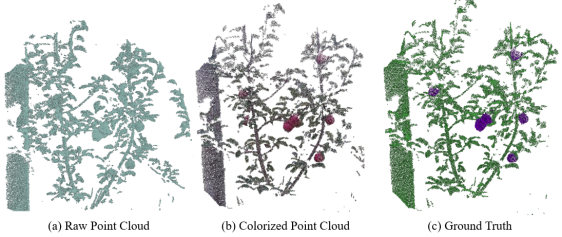
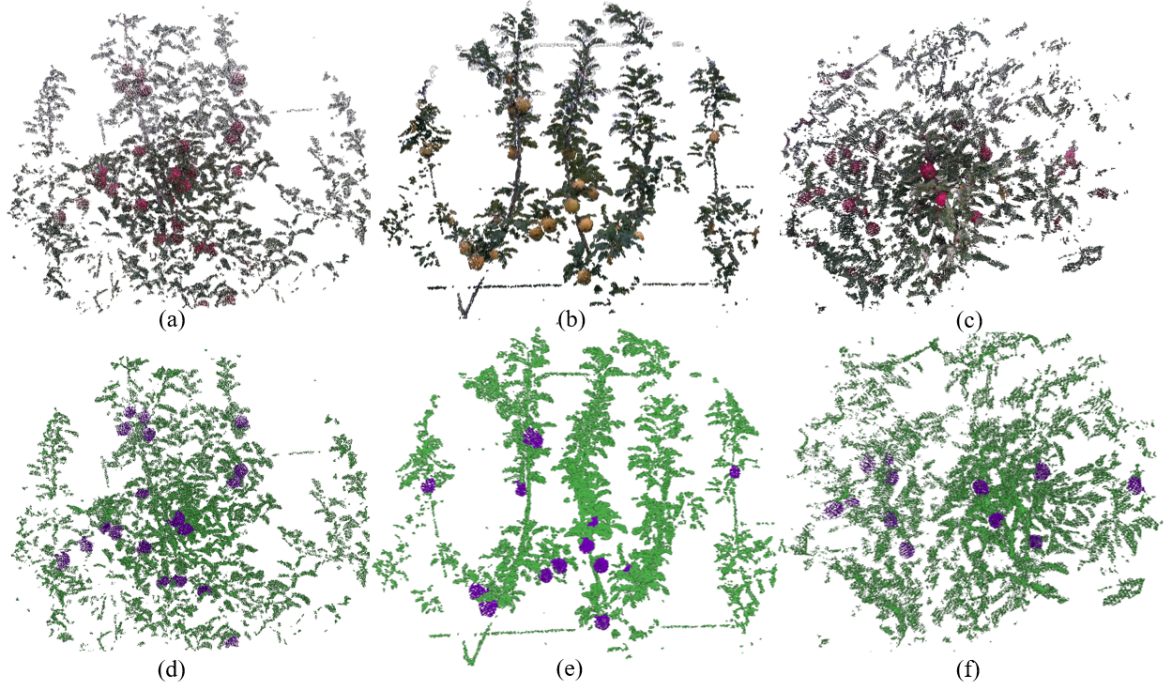
Our method uses a set of sensors to collect data from the orchard environment. The inputs of the proposed method include point clouds and 2D color images. The Livox Mid-70 or Livox AVIA measures the surrounding geometry by sweeping over the scene with a set of lasers (one line for Livox Mid-70 and six lines for Livox AVIA). The data collection frequency of the Livox Lidar is 10 HZ. For Livox Mid-70, the LiDAR-camera sensor typically requires 10 seconds to obtain sufficient points to cover one single scene. In comparison, Livox AVIA only needs 3 seconds since it has more laser channels than the former. The input points are firstly fused with color information and then added to construct a complete point cloud for the current scene. A typical complete point cloud for a working scene (the width and height of the scene are 2.5 to 3 meters, the depth of the scene is between 1.2 to 2.5 meters) normally includes 100k - 200k points after post-processing. The post-processing steps comprise outlier rejection and voxelization. The size of the voxel grid is set as to preserve the details of the local-scale geometries. An example of the raw and colorized point cloud and semantic segmentation result of the scene is shown in Figure 2.
II-A2 Partitioned Inference on Point Cloud
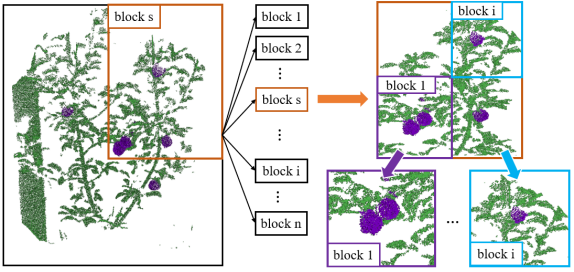
Since the point cloud of a complete scene contains more than 100k points, which cannot be processed at once. Therefore, we partition the whole point cloud of a scene into multiple blocks through the Octree. Each node of the Octree should contain the points that are not beyond the given number. The typical value of the given number is 4096 and 8192, based on different situations. Based on the value of the given number of points, we divide the segmentation into two cases: small-scale segmentation and large-scale segmentation. Small-scale segmentation stands for performing segmentation on a node that contains a number of points less than 4096. In contrast, large-scale segmentation stands for performing segmentation on the node containing either 4096 or 8192 points. Additionally, fruits always count only a small part of points in the whole point cloud. Hence performing segmentation on the large-scale point cloud is more challenging due to the presence of an imbalanced distribution of classes. Therefore, finding a suitable point number value in each node is also a critical task to secure segmentation accuracy. During the forward inference, the complete point cloud is partitioned into small blocks and fed into the network one by one until all blocks are processed. Then, the predictions of these blocks are assembled to obtain the final results. The overall procedures of the partitioned inference as shown in Figure 3.
II-B Network Architecture
II-B1 PointNet++ Architecture
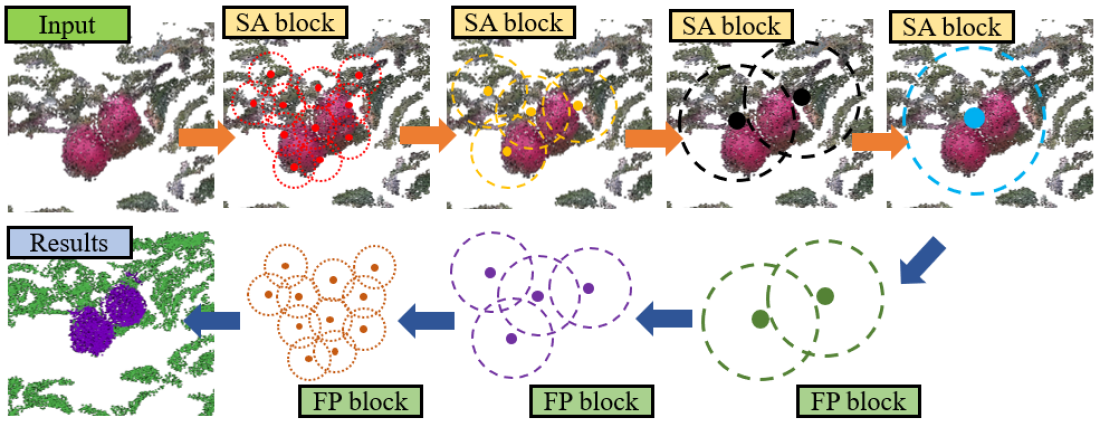
PointNet++ network uses a hierarchical feature learning strategy to extract and learn features from the point cloud, as shown in Figure 4. It builds a hierarchical grouping of points, which can progressively learn features from larger and larger local regions along the hierarchy and aggregate local and global information. However, since the point cloud is unordered, highly non-uniform, and does not have a structured neighbourhood region similar to the image. Hence the Set Abstraction (SA) layer and Feature Propagation (FP) layer are used to process the point cloud in each hierarchical level and perform dense prediction by propagating point features along the neighbour region, respectively. The base PointNet++ network has four SA layers and four FP layers to process and predict the label of each point.
The SA layer comprises three layers: the sampling layer, grouping layer, and PointNet layer. Sampling layer sample a given number of centroids from the point cloud using the iterative farthest point sampling. Iterative Farthest Point Sampling (FPS) can ensure an even distribution of centroids within the point cloud. Then, the grouping layer is used to find the neighbour points within a local region of each centroid. Different grouping methods can be used, including K Nearest Neighbor (KNN) points or points in a certain radius. After that, the PointNet layer is used to extract features from each neighbour region of the centroids. With the increase of the hierarchical level, the SA layer gradually extracts the features from a small local area to a larger global region. In this manner, PointNet++ builds a hierarchical structure to learn multi-scale features from the point set.
SA layer down-samples the points cloud by progressively increasing the local region size and reducing the number of centroids. Semantic segmentation is a dense classification task that requires labels on each point. Instead of using transpose convolution in a 2D segmentation network, PointNet++ uses the FP layer to propagate features from the centroids to the points of the local region. That is, the features of a point are from the interpolation of nearby centroids weighted based on the distance from the points to each centroid. The interpolated features of points are also concatenated with the skip-linked point features from the SA layer. Then the concatenated features are passed through a one-by-one convolution in CNNs and ReLu layers.
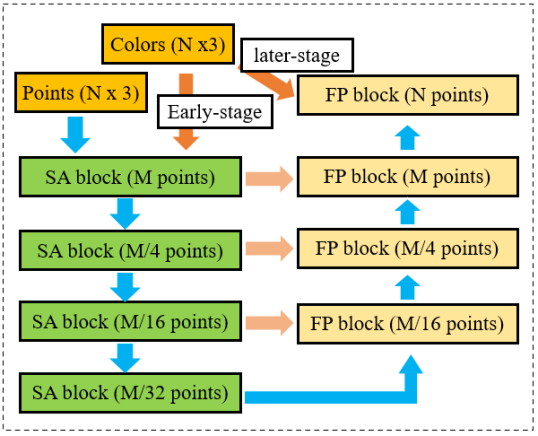
II-B2 Fusion with color Feature
The PointNet++ architecture can fuse points and other features by increasing the number of input data channels. For example, PointNet++ use the normal vector of each point within the point set in the classification of ModelNet40 dataset, and a improvement of accuracy is achieved. PointNet++ has fused the features at the beginning and the end of the network, named early-stage fusion and later-stage fusion, respectively, as shown in Figure 5. Similarly, we input XYZ and RGB values into the network together to test their effect on the segmentation performance. Unexpectedly, the segmentation accuracy of using the fusion data drops to 0.72, while the point-only network model can achieve 0.84, as listed in Table I. To investigate the reason why fusion data affect the segmentation accuracy, we respectively input color features in only early-stage fusion or later-stage fusion. Results show that later-stage fusion can improve the segmentation accuracy while the accuracy of early-stage fusion is reduced.
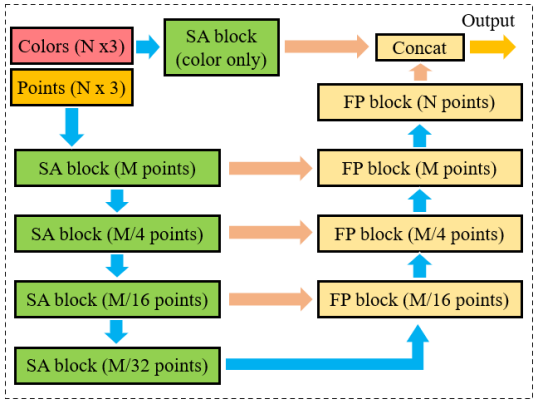
A possible reason leading to the accuracy degeneration introduced by early-stage feature fusion is the large difference between feature distributions. Since PointNet++ fuse the multi-sensor features by simply concatenating with each other and processing them with convolution operations. When those features have large differences in the distribution in feature space, this operation will affect the learning performance of the network on multi-sensor features. Therefore, we only introduce color features in later-stage fusion. Rather than directly using the RGB values on each point, we use a color-only SA block to gather color features from the neighbourhood of each point. The introduced later-stage fusion PointNet++ architecture is named as Fuse-PointNet++ model, and it achieves 0.88 on segmentation accuracy, as shown in Table I. The network architecture of the Fuse-PointNet++ model is shown in Figure 6.
II-B3 Sampling and Grouping Strategy
PointNet++ can apply FPS or Random Sampling (RS) strategy to sample centroids from a point cloud with the number of points and then uses KNN or distance to gather points within the neighbourhood of each centroid. We use the FPS method as it can sample evenly distributed centroids from the point cloud. Then, a given number of points within a certain radius is gathered to extract the local features of each centroid.
II-C Class Imbalance Training
II-C1 Training Method
Class imbalance problem occurs when one class has much more samples than other classes, which is one of the most significant issues in network training [24]. In our case, a point cloud can have up to 16k points, while only a small subset of points (less than 1k) belongs to positive samples. The imbalance class can cause training degeneration since most samples are easy negatives that contribute no useful backward gradient. Introducing a weighting factor on training loss or Under-Sampling (US) are the two common methods to deal with the class imbalance problem. Therefore, we introduce the under-sampling strategy for training data pre-processing and introduce a weighting factor on loss function to alleviate the training degeneration caused by the imbalance class problem.
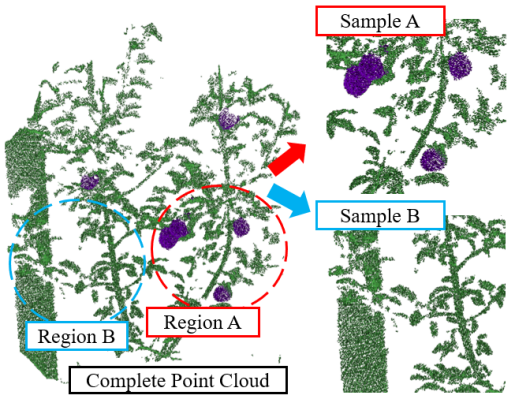
Firstly, we set the minimum number of fruits point within each training sample. That is, the training samples in the small-scale dataset (point number is 4096) should keep the points belonging to fruit larger than 1k (as shown in Figure 7), while the training samples in the large-scale dataset (point number is 8192) should have fruit points larger than 1.5k, respectively.
Secondly, we introduce the weighting factor to balance the loss value of the two classes. The loss function is formulated as follows:
| (1) |
where and are the label and prediction of the points, respectively. is the weight factor of the points in class . denotes the sign function whether points in class ( = 1) or not ( = 0). We denote the weighted cross entropy loss function as WCE in the following experiments. The preliminary results as shown in Table I show that US and WCE can improve the network training performance. A more detail experiments of parameter setup of US and WCE are introduced in the experiment.
| Input | Fusion Method | Training Method | mIoU |
|---|---|---|---|
| pc | - | - | 0.73 |
| pc | - | US | 0.79 |
| pc | - | US + WCE | 0.81 |
| pc + rgb | early+later fusion | US + WCE | 0.75 |
| pc + rgb | early fusion | US + WCE | 0.72 |
| pc + rgb | later fusion | US + WCE | 0.84 |
| pc + rgb (SA) | later fusion | US + WCE | 0.88 |
II-C2 Training Details
During the training process, the learning rate and decay rate are respectively set as 0.001 and 0.95 per epoch, and the minimum learning rate is specified as 0.0001. The Adam optimizer is used to train the network, and the batch size is set from 4 to 16 based on the different number of input points (batch sizes are 4 for 8192, and 16 for 4096, respectively) due to limited memory consumption on GPU. Data augmentation is conducted on both points and color images. For point set data, augmentations such as rotation and adding white noise are introduced, while adjustments of saturation and brightness are introduced on color information. We train the network model for 100 epochs and use the checkpoint with the best validation accuracy in the last epochs as the final network weights.
II-D System Implementations
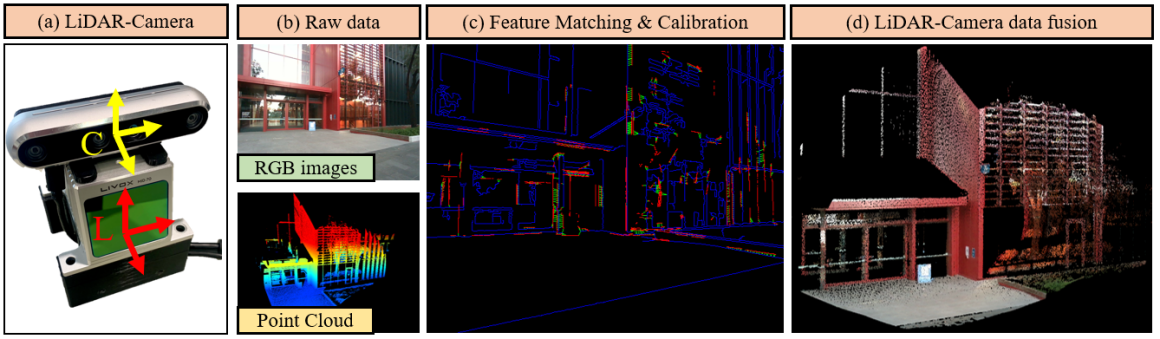
II-D1 LiDAR-camera Fusion
To build a customized and large 3D dataset, we use the LiDAR-Camera sensors that include a pin-hole camera model to acquire color images and a LiDAR for 3D points acquisition, as shown in Figure 8. The pin-hole camera model project a point from the LiDAR coordinate to a pixel on color image plane by using the equation:
| (2) |
where is the camera distortions model, is the intrinsic matrix of camera, (where and ) is the extrinsic between the LiDAR and camera. The intrinsic of the camera is evaluated firstly, and then the calibration between LiDAR and camera can be conducted in either manual or automatic way.
II-D2 Data Collection and Labelling
The data were collected in the Fankhauser apple orchard located in Melbourne, Australia, using the proposed Lidar-camera sensor. The collection time varied from 10:00 am to 4:00 pm. The distance between the vision sensor to the tree trunk ranged from 1.2 to 2.5 meters. The scanning height was adjusted to guarantee the apple trees are within the FoV of both sensors. In total, there were 152 point cloud data pairs, including ROSbag or PCD format and 152 corresponding color images. The point clouds were recorded by setting the scanning time to 10 seconds to accumulate sufficient points of the scene. Each point cloud contains approximately 100k to 200k points. The ground truth of the semantic segmentation was labelled using the open-source labelling tool on Github 1. 11footnotetext: https://github.com/Hitachi-Automotive-And-Industry-Lab/semantic-segmentation-editor
II-D3 Hardware and Software
Both the LiDARs and RGB camera (Intel Realsense D-435 or D-455) are connected with an Nvidia Xavier using the Robotic Operation System (ROS) in the Melodic version of Ubuntu 18.04. The data transmission between the Livox LiDAR and camera and Nvidia Xavier is through the Ethernet and USB port. The communication between Livox LiDARs and Intel RealSense cameras is achieved by using the Livox-ROS-Driver and Realsense-ROS-SDK, respectively. Other required packages such as LiDAR-RGB calibration and fusion nodes are also programmed and running on ROS. The network models are developed based on Tensorflow-1.15. The network training is performed using an NVIDIA RTX-3060 (6GB), and the forward inference is tested on both NVIDIA RTX-3060 and NVIDIA Xavier.
III Experiments
III-A Experiment Method
In this section, we evaluate the proposed methods in four experiments. Firstly, an ablation study of the network model on small-scale and large-scale scenes is presented. Then, the experiment of semantic segmentation on a complete point cloud is conducted. After that, the comparison studies of 3D and 2D segmentation are presented, and segmentation on data from RGB-D cameras is presented. In the experiment, each network is trained three times, and the network weights of the best validation accuracy are saved for performance evaluation. In the experiments, mIoU is used to evaluate the segmentation performance of the network.
We use 76 of 152 scenes to create the dataset for network training, and the rest of the scenes are used to perform training validation and evaluation. We randomly choose 100-200 seeds from each point cloud and create the training dataset by crop the neighbour points of each seed. The training dataset is classified into small-scale () and large-scale () datasets. Each dataset includes from 10000-15000 training samples by using the proposed pre-processing methods.
III-B Ablation Study of Model
| index | Method | mIoU | ||
|---|---|---|---|---|
| 1 | KNN | 1024 | 24 | 0.868 |
| 2 | FPS | 1024 | 24 | 0.872 |
| 3 | FPS | 1024 | 12 | 0.842 |
| 4 | FPS | 1024 | 48 | 0.857 |
| 5 | FPS | 512 | 24 | 0.833 |
| 6 | FPS | 2048 | 24 | 0.867 |
We firstly analyse the effect of network parameters on segmentation performance. Table II shows the evaluation of segmentation accuracy on centroids sampling and neighbour points grouping strategy by using the small-scale dataset (=4096) on the Fuse-PointNet++ model. Tests 1 and 2 compare the model that uses KNN and FPS sampling strategies, respectively. Experimental results show that FPS and KNN do not affect the accuracy significantly, while the network with FPS achieves a slightly higher score compared to the method of using KNN. Tests 2, 3, and 4 compare the network performance of using a different number of grouping points. Results show that the network achieves the best performance when . Tests 2, 5, and 6 compare the network performance o using a different sampling centroid. Results show that under-numbered sampling centroids would reduce the accuracy of the segmentation, while over-number of sampling centroids would not improve the segmentation accuracy but the computational consumption is significantly increased.
| index | Scale | Nor (Scale) | mIoU |
|---|---|---|---|
| 1 | 0.1 | False | 0.813 |
| 2 | 0.05 | False | 0.836 |
| 3 | 0.01 | False | 0.872 |
| 4 | 0.1 | True | 0.742 |
| 5 | 0.05 | True | 0.746 |
| 6 | 0.01 | True | 0.752 |
Table III shows the ablation experiment using a different scale of neighbour points grouping by using the Fuse-PointNet++ model on the small-scale dataset. The results of tests 1, 2, and 3 show different grouping scales can lead to different segmentation accuracy. A small grouping scale achieves a higher accuracy on segmentation results. Tests 4, 5, and 6 show the network performance by normalizing the scale of the input point cloud. Results show that the segmentation accuracy of the network with scale normalizing drops compared to the un-normalized case. Since fruits always have a physical scale in the real world, a proper grouping scale can help the network to learn local features efficiently. Meanwhile, since input clouds always have different spatial sizes and scale normalization changes the scale of the data, hence the network performance on segmentation is reduced.
| Index | Method | No. channels | mIoU |
|---|---|---|---|
| 1 | pc | - | 0.812 |
| 2 | raw RGB | 3 | 0.841 |
| 3 | W/o grouping | 32 | 0.847 |
| 4 | grouping | 32 | 0.872 |
| 5 | grouping | 16 | 0.867 |
| 6 | grouping | 64 | 0.874 |
Table IV shows the experiment result of using the different setups on color fusion by using the Fuse-PointNet++ model on the small-scale dataset. Tests 1 to 4 evaluate the segmentation accuracy of the network by using the different fusion methods. Method 1 only uses the point cloud, method 2 concatenates raw RGB values to the feature vectors, method 3 uses a one-by-one convolution operation to process color information, and method 4 applies a SA block to gather the neighbour of each point and then process the color information within this neighbour region. Experimental results show that method 3 achieves the best accuracy on network performance. These results show that grouping can help the network to gather the spatial distribution of the color features, which is similar to the convolution operations in 2D image processing. Tests 4, 5, and 6 further investigate the proper number of color channels for feature fusion. Experimental results show that although increasing feature channels can slightly improve the segmentation accuracy, it also brings higher computational requirements. Therefore, we choose the feature channel number 32 in this work.
From the results in this section, we set grouping points number =24, grouping scale as , and the fusion color feature channels as 32.
III-C Experiment on Training Strategy
This section uses different training strategies in network training and evaluates the segmentation accuracy of the obtained model. We first evaluate the training method to find the optimal parameters for WCE on the small-scale dataset. In the small-scale training dataset, the average points number of fruits in a point cloud is 1200 (minimum fruits point in training samples is 1000) and the total point number of the point cloud is 4096. We use the optimal network setup from the last section and evaluate the effect of US and WCE strategies on trained network performance, the experimental results are shown in Table V.
| Index | Method | No. pts | mIoU | ||
|---|---|---|---|---|---|
| 1 | CE | 250 | 1.0 | 1.0 | 0.757 |
| 2 | CE | 500 | 1.0 | 1.0 | 0.803 |
| 3 | WCE | 500 | 0.75 | 1.25 | 0.822 |
| 4 | CE | 1000 | 1.0 | 1.0 | 0.872 |
| 5 | WCE | 1000 | 0.85 | 1.15 | 0.877 |
| 6 | WCE | 1000 | 0.75 | 1.25 | 0.881 |
| 7 | WCE | 1000 | 0.65 | 1.35 | 0.865 |
-
1
CE stands for Cross Entropy.
-
2
No. pts is the minimum fruit points in training samples.
The results of tests 1, 2, and 4 show that the imbalance class problem would severely affect the performance of the model, while under-sampling in the data pre-processing step could largely alleviate this training degeneration. After the US on training data (test-4), the segmentation accuracy of the model is significantly improved compared to the training result without US (test-1). Tests 2 and 3, 4 and 6 compare the network performance by respectively using cross-entropy loss and WCE. Results show that WCE can improve approximately to compared to the network trained by the cross-entropy. Tests 5 to 7 compare the network performance by using different weight factors in WCE. Results show that different values in WCE can also influence network performance. For the small-scale dataset, we set and respectively as 0.75 and 1.25 since the network achieves the best accuracy when using these values.
We further evaluate the training strategies on a large (=8192) dataset. The network setup follows the same setup as the small-scale dataset. The number of centroids points in the sampling step is set as 2048 and the training batch size is 6. In the middle-scale training dataset, the average points number of fruits in a point cloud is 1800 (minimum fruits point in training samples is 1500) and the total point number of the point cloud is 8192. The experiments are shown in Table VI.
| Index | Method | No. pts2 | mIoU | |||
|---|---|---|---|---|---|---|
| 1 | 2048 | 500 | 1.0 | 1.0 | 0.667 | |
| 2 | 2048 | CE | 1000 | 1.0 | 1.0 | 0.712 |
| 3 | 2048 | CE | 1500 | 1.0 | 1.0 | 0.767 |
| 4 | 1024 | CE | 1500 | 1.0 | 1.0 | 0.722 |
| 3072 | CE | 1500 | 1.0 | 1.0 | 0.784 | |
| 6 | 2048 | WCE | 1500 | 0.75 | 1.25 | 0.786 |
| 7 | 2048 | WCE | 1500 | 0.60 | 1.40 | 0.797 |
| 8 | 2048 | WCE | 1500 | 0.50 | 1.50 | 0.808 |
| 9 | 2048 | WCE | 1500 | 0.40 | 1.60 | 0.793 |
-
1
N is the centroid number in sampling step.
-
2
No. pts is the minimum fruit points in training samples.
-
3
CE stands for Cross Entropy.
-
4
Training batch size set as 3.
Tests 1, 2, and 3 evaluate the network performance by setting a different minimum number of fruit points in data pre-processing. Results show that imbalance class problems could lead to severe performance degeneration in large-scale dataset training. Increasing the minimum number of fruits point in training samples could improve the network performance to a certain degree. Tests 3, 4, and 5 evaluate the network performance in the large-scale dataset by using different centroids numbers in the sampling step. Results show that an increase of centroids can improve the final segmentation accuracy but the computational consumption also grows. Therefore, we choose the centroids number as it achieves the balance between performance and computational efficiency. Tests 6 to 9 evaluate the network performance by using the WCE during the training process. Results show that WCE can improve the training results by re-weighting the loss. The proposed Network achieves the best accuracy (mIoU = 0.808) when and are set as 0.5 and 1.5, respectively.
III-D Segmentation in Orchards
After evaluation of the key network parameters and training strategies respectively in the small-scale and large-scale datasets, this section evaluates the network performance on semantic segmentation of the complete point cloud. The input point cloud is firstly subdivided into small blocks by the Octree algorithm, each node should contain a point that less than the given threshold. We respectively use the network trained by using the small-scale dataset (network-S) and large-scale dataset (network-L). A complete point cloud of a scene after octree subdivision always contains 15 to 30 local blocks for network-L to process, and a double number of blocks for network-S to process. The accuracy of the network-S and network-L on complete scene segmentation is shown in Table VII.
| Index | Method | No. blocks1 | mIoU |
|---|---|---|---|
| 1 | Network-S | 28.8 | 0.862 |
| 2 | Network-L | 17.4 | 0.794 |
-
1
No. blocks is the mean number of subdivided blocks of a scene.
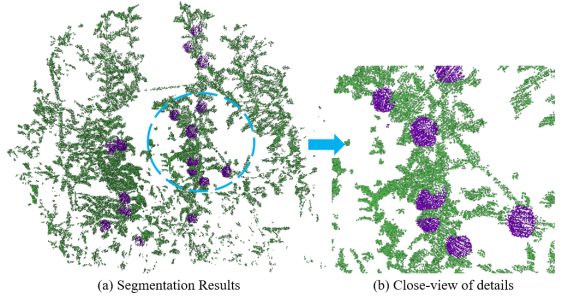
The result shows that both networks trained by small-scale and large-scale datasets have a slight accuracy reduction on complete scene segmentation compared to their performance on the evaluation dataset. The possible reason is due to the different distribution of classes between training data and the original point cloud. As the utilized data pre-processing strategy under-sampling the non-objects classes to improve the training efficacy. Overall, the complete scene segmentation by using Network-S achieved on mIoU. The visualization results of the complete scene segmentation are shown in Figure 9. Figure 10 shows the details of the segmentation result.
III-E Segmentation using RGB-D Cameras
In our previous study, a LiDAR-Camera sensor and a multi-sensor data fusion method are developed to obtain high accuracy colorized point cloud from the orchard environments. In this work, we demonstrate a pipeline and a deep-learning-based network to perform semantic segmentation on the colorized point cloud. For comparison, we evaluate the performance of the proposed network with or without RGB information on data acquired by using the Intel RealSense-D455, a stereo-depth camera that has been widely applied in many agricultural types of research. We collect the RGB-D data of a tree from different distances (0.8m and 2.0m) in orchard environments, the resolution of the color and depth images are 640 480. The accuracy of semantic segmentation by using Network-S on RGB-D data from Intel RealSense-D455 is shown in Table VIII.
| Index | Distance | mIoUpc | mIoUfused |
|---|---|---|---|
| 1 | 0.8 | 0.763 | 0.797 |
| 2 | 1.2 | 0.712 | 0.752 |
| 3 | 1.6 | 0.654 | 0.704 |
| 4 | 2.0 | 0.524 | 0.627 |
Results show that the accuracy of the segmentation drops dramatically with the increase in the distance between the sensor and the tree. Also, the network using fused data shows better accuracy compared to the network that only uses the point cloud, which shows that color information can help improve the accuracy of the segmentation when the point cloud has limited quality. These results also indicate that network using fused data has better robustness to deal with data quality degeneration in real implementations.
III-F Comparison with 2D segmentation method
We further compare the segmentation accuracy of our proposed method and the SOTA 2D segmentation network Deeplab-v3+ 2. The training data of 2D segmentation is from the 2D RGB image of each fused data. We use 76 images to train the network, 38 images for validation during training, and the rest 38 for evaluation. Image augmentation such as color adjustment in HSV space, translation, and rotation is applied. The training resolution is 512 512. We used ResNet51 as the backbone and pre-trained models from Pascal VOC and Cityscapes datasets. The mIoU of the trained network on 2D segmentation is 0.8075. The point cloud colorized by using segmentation results from 2D segmentation methods is shown in Figure 11. 22footnotetext: https://github.com/VainF/DeepLabV3Plus-Pytorch
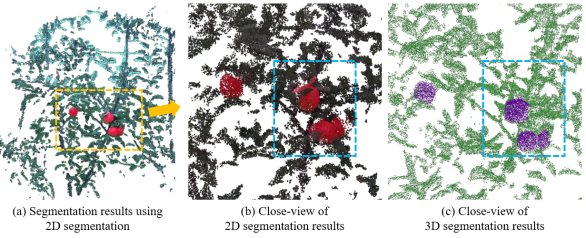
It can be seen that 3D segmentation methods achieve better accuracy on fruit segmentation compared to 2D segmentation. As shown in Figure 11, laser beam divergence angle may cause fake points near the objects’ edge. Due to lack of information from the point cloud, 2D segmentation methods have limited performance when dealing with this inherent defect of LiDAR data, while 3D segmentation capability in this condition. Meanwhile, 3D segmentation methods can also be easily integrated with SLAM, a common framework to obtain the point cloud models of large-scale scenes. 3D segmentation network can be directly applied to the colorized 3D point clouds. This means the segmentation task takes both geometry and color information into the feature extraction process, which can potentially compensate for the error caused by the noisy outlier points in 3D point clouds and by the Lidar-camera extrinsic calibration. However, 2D segmentation is conducted on RGB images initially and requires an accurate calibration between 2D to 3D data to achieve promising performance.
IV Discussions
This study proposes a deep-learning-based point cloud segmentation network to perform semantic segmentation on fused colorized point cloud data acquired using the LiDAR-Camera sensor. An octree subdivision algorithm is used to subdivide the complete scene into multiple blocks to perform segmentation on a large number of points (100k - 200k points). The point cloud from each block is processed by the network and then added together to form the final segmentation results. Multi-sensor data fusion and network training under imbalance class distribution are two critical problems that need to be solved in point cloud segmentation network training. For multi-sensor data fusion, we analyze the architecture of the PointNet++ model and develop a later-fusion strategy to fuse color features into point cloud processing, which largely improves the segmentation accuracy of the model. For network training under imbalance class distribution, we utilize the under-sampling strategy in data pre-processing and WCE loss function during training, which secures the network training performance in dealing with the imbalance class training problem.
In the experiments, we analyze the effect of different sampling and grouping strategies in SA block within the pointNet++ architecture. Results show that the insufficient number of centroids and grouping of neighbour points may lead to network performance degeneration. In contrast, the excessive number of centroids and grouping of neighbour points can largely increase the computational requirements. After that, we evaluate the network performance by applying different fusion designs in network architecture. The results show that the proposed later-stage fusion can largely improve the network accuracy using fused data from LiDAR-Camera. Moreover, we analyze the imbalance class problem in network training. The under-sampling and WCE are utilized to enhance the training efficacy of the network. Overall, with proper design of the network architecture and training strategies, the proposed Fuse-PointNet++ model achieves 0.881 on the evaluation dataset and 0.862 on complete scene segmentation from the real orchard.
For comparison, we use the 3D segmentation network on fused data from an RGB-D camera. Results show that the accuracy of the network on the RGB-D camera shows a large reduction. The possible reason for this performance degeneration is the low accuracy of the point cloud data from the RGB-D camera. This result indicates that an accurate input point clout is essential to secure the performance of the point-based segmentation network. Furthermore, we compare the segmentation performance using the SOTA 2D segmentation method. Results show that 3D segmentation achieves a better score on accuracy. Meanwhile, since 3D segmentation methods can efficiently learn the geometrical features by the multi-scale grouping operations, our proposed Fuse-PointNet++ model has better capability to classify noise points near the edge of the objects.
V Conclusion
In this work, a deep-learning-based 3D segmentation network is presented to perform fruit segmentation on a high-resolution point cloud. The proposed method can efficiently fuse the features from both objects’ texture and geometrical appearances. Meanwhile, the proposed method utilized an under-sampling data pre-processing strategy and WCE loss function to improve the training performance when dealing with imbalance class problems. Our method is evaluated in both the evaluation dataset and complete scene segmentation, which are collected by using the LiDAR-Camera sensor in apple orchards. Overall, the proposed Fuse-PointNet++ network model achieved a mIoU of 0.881 on the evaluation dataset and 0.862 on complete scene segmentation. Experimental results show that our proposed method can perform accurate semantic segmentation of fruits in real orchards environments. Future work will investigate the feature fusion and network training strategies under the imbalance class condition to improve the segmentation accuracy on the point cloud.
References
- [1] X. Wang, H. Kang, H. Zhou, W. Au, and C. Chen, “Geometry-aware fruit grasping estimation for robotic harvesting in apple orchards,” Computers and Electronics in Agriculture, vol. 193, p. 106716, 2022.
- [2] H. Zhou, X. Wang, W. Au, H. Kang, and C. Chen, “Intelligent robots for fruit harvesting: Recent developments and future challenges,” Precision Agriculture, pp. 1–52, 2022.
- [3] F. Westling, J. Underwood, and M. Bryson, “A procedure for automated tree pruning suggestion using lidar scans of fruit trees,” Computers and Electronics in Agriculture, vol. 187, p. 106274, 2021.
- [4] A. Scalisi, L. McClymont, J. Underwood, P. Morton, S. Scheding, and I. Goodwin, “Reliability of a commercial platform for estimating flower cluster and fruit number, yield, tree geometry and light interception in apple trees under different rootstocks and row orientations,” Computers and Electronics in Agriculture, vol. 191, p. 106519, 2021.
- [5] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660.
- [6] Z. Zhuang, R. Li, K. Jia, Q. Wang, Y. Li, and M. Tan, “Perception-aware multi-sensor fusion for 3d lidar semantic segmentation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 16 280–16 290.
- [7] P. Wang, P. Chen, Y. Yuan, D. Liu, Z. Huang, X. Hou, and G. Cottrell, “Understanding convolution for semantic segmentation,” in 2018 IEEE winter conference on applications of computer vision (WACV). IEEE, 2018, pp. 1451–1460.
- [8] A. Valada, J. Vertens, A. Dhall, and W. Burgard, “Adapnet: Adaptive semantic segmentation in adverse environmental conditions,” in 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 4644–4651.
- [9] S. Asgari Taghanaki, K. Abhishek, J. P. Cohen, J. Cohen-Adad, and G. Hamarneh, “Deep semantic segmentation of natural and medical images: a review,” Artificial Intelligence Review, vol. 54, no. 1, pp. 137–178, 2021.
- [10] D. Feng, C. Haase-Schütz, L. Rosenbaum, H. Hertlein, C. Glaeser, F. Timm, W. Wiesbeck, and K. Dietmayer, “Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 3, pp. 1341–1360, 2020.
- [11] G. Lin, Y. Tang, X. Zou, and C. Wang, “Three-dimensional reconstruction of guava fruits and branches using instance segmentation and geometry analysis,” Computers and Electronics in Agriculture, vol. 184, p. 106107, 2021.
- [12] R. Yamashita, M. Nishio, R. K. G. Do, and K. Togashi, “Convolutional neural networks: an overview and application in radiology,” Insights into imaging, vol. 9, no. 4, pp. 611–629, 2018.
- [13] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440.
- [14] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241.
- [15] L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrous convolution for semantic image segmentation,” arXiv preprint arXiv:1706.05587, 2017.
- [16] K. Zou, X. Chen, Y. Wang, C. Zhang, and F. Zhang, “A modified u-net with a specific data argumentation method for semantic segmentation of weed images in the field,” Computers and Electronics in Agriculture, vol. 187, p. 106242, 2021.
- [17] Z. Wu, R. Yang, F. Gao, W. Wang, L. Fu, and R. Li, “Segmentation of abnormal leaves of hydroponic lettuce based on deeplabv3+ for robotic sorting,” Computers and Electronics in Agriculture, vol. 190, p. 106443, 2021.
- [18] Y. Peng, A. Wang, J. Liu, and M. Faheem, “A comparative study of semantic segmentation models for identification of grape with different varieties,” Agriculture, vol. 11, no. 10, p. 997, 2021.
- [19] H. Wei, E. Xu, J. Zhang, Y. Meng, J. Wei, Z. Dong, and Z. Li, “Bushnet: Effective semantic segmentation of bush in large-scale point clouds,” Computers and Electronics in Agriculture, vol. 193, p. 106653, 2022.
- [20] Y. Chen, Y. Xiong, B. Zhang, J. Zhou, and Q. Zhang, “3d point cloud semantic segmentation toward large-scale unstructured agricultural scene classification,” Computers and Electronics in Agriculture, vol. 190, p. 106445, 2021.
- [21] Q. Yu, H. Yang, Y. Gao, X. Ma, G. Chen, and X. Wang, “Lfpnet: Lightweight network on real point sets for fruit classification and segmentation,” Computers and Electronics in Agriculture, vol. 194, p. 106691, 2022.
- [22] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” Advances in neural information processing systems, vol. 30, 2017.
- [23] H. Kang, X. Wang, and C. Chen, “Accurate fruit localisation for robotic harvesting using high resolution lidar-camera fusion,” arXiv preprint arXiv:2205.00404, 2022.
- [24] X. Yuan, L. Xie, and M. Abouelenien, “A regularized ensemble framework of deep learning for cancer detection from multi-class, imbalanced training data,” Pattern Recognition, vol. 77, pp. 160–172, 2018.
- [25] C. Yuan, X. Liu, X. Hong, and F. Zhang, “Pixel-level extrinsic self calibration of high resolution lidar and camera in targetless environments,” IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 7517–7524, 2021.