SemCoder: Training Code Language Models with Comprehensive Semantics Reasoning
Abstract
Code Large Language Models (Code LLMs) have excelled at tasks like code completion but often miss deeper semantics such as execution effects and dynamic states. This paper aims to bridge the gap between Code LLMs’ reliance on static text data and the need for semantic understanding for complex tasks like debugging and program repair. We introduce a novel strategy, monologue reasoning, to train Code LLMs to reason comprehensive semantics, encompassing high-level functional descriptions, local execution effects of individual statements, and overall input/output behavior, thereby linking static code text with dynamic execution states. We begin by collecting PyX, a clean Python corpus of fully executable code samples with functional descriptions and test cases. We propose training Code LLMs not only to write code but also to understand code semantics by reasoning about key properties, constraints, and execution behaviors using natural language, mimicking human verbal debugging, i.e., rubber-duck debugging. This approach led to the development of SemCoder, a Code LLM with only 6.7B parameters, which shows competitive performance with GPT-3.5-turbo on code generation and execution reasoning tasks. SemCoder achieves 79.3% on HumanEval (GPT-3.5-turbo: 76.8%), 63.6% on CRUXEval-I (GPT-3.5-turbo: 50.3%), and 63.9% on CRUXEval-O (GPT-3.5-turbo: 59.0%). We also study the effectiveness of SemCoder’s monologue-style execution reasoning compared to concrete scratchpad reasoning, showing that our approach integrates semantics from multiple dimensions more smoothly. Finally, we demonstrate the potential of applying learned semantics to improve Code LLMs’ debugging and self-refining capabilities. Our data, code, and models are available at: https://github.com/ARiSE-Lab/SemCoder.
1 Introduction
Recent advancements in code language models (Code LMs) (chen2021evaluating, ; nye2021work, ; guo2024deepseekcoder, ; rozière2024code, ; lozhkov2024starcoder, ) have revolutionized the field of programming (githubcopilot, ; amazoncodewhisperer, ; chatgpt, ). These models, trained primarily on vast corpora of programming-related text such as source code and docstrings kocetkov2022stack , excel at automating tasks like code generation.
Unfortunately, the reliance on static text data limits the ability of existing Code LMs to understand what the programs are actually doing, especially to reason about the deeper semantics intrinsic to code execution. The lack of semantic understanding unsurprisingly often leads to poor performance in debugging and repairing errors in generated code gu2024counterfeit . Code LMs struggle with reasoning about program semantics in both static and dynamic settings. In a static setting, the challenge lies in understanding the intended behavior of the code without running it, requiring deep comprehension of code syntax and static semantic properties (e.g., program dependency graph, etc.) (ayewah2008using, ; Johnson2013why, ). A dynamic setting involves observing and interpreting the code’s behavior during execution, including tracking variable changes, identifying runtime errors, and detecting performance issues ni2024next . Even when the execution traces are exposed to the model, ni2024next observed that Code LMs could not effectively interact with the real executions, struggling to leverage the dynamic execution traces for debugging.
Fifty years ago, Terry Winograd envisioned the future AI programmer: “The key to future programming lies in systems which understand what they are doing (winograd1973breaking, )". In this paper, we explore constructing such a programming system, backed up by language models, not only to write programs but also to understand what they are doing (a.k.a., semantics). Our key insight is that Code LMs should mimic how pragmatic human developers work: starting with general specifications, breaking them down into sub-tasks with expected properties and constraints, implementing code line by line while reasoning about the effects of each line, and checking overall correctness by examining execution effects (hunt2000pragmatic, ). To achieve this, we introduce a novel strategy to train Code LMs to reason comprehensive program semantics.
We train SemCoder, a novel semantic-aware Code LM. We incorporate different modalities of program semantics: (i) High-Level Functional Descriptions: We train SemCoder to understand high-level functional descriptions bi-directionally by both generating code from natural language and summarizing code as natural language. This involves teaching models to grasp a program’s purpose, akin to how a human developer outlines software high-level approximate semantics; (ii) Key Properties and Constraints: we train SemCoder to extract the functional properties and constraints of a program, which should hold for all scenarios and corner cases. (iii) Overall Execution Behavior: we train SemCoder to understand the local impact of individual code statements, recognizing how each line affects variables, control flow, and memory usage. By grasping these effects, models can better predict code execution semantics. We train the model to learn both abstract and concrete semantics, teaching it the general purpose of a statement and illustrating it with concrete examples.
Curating Executable Code Dataset
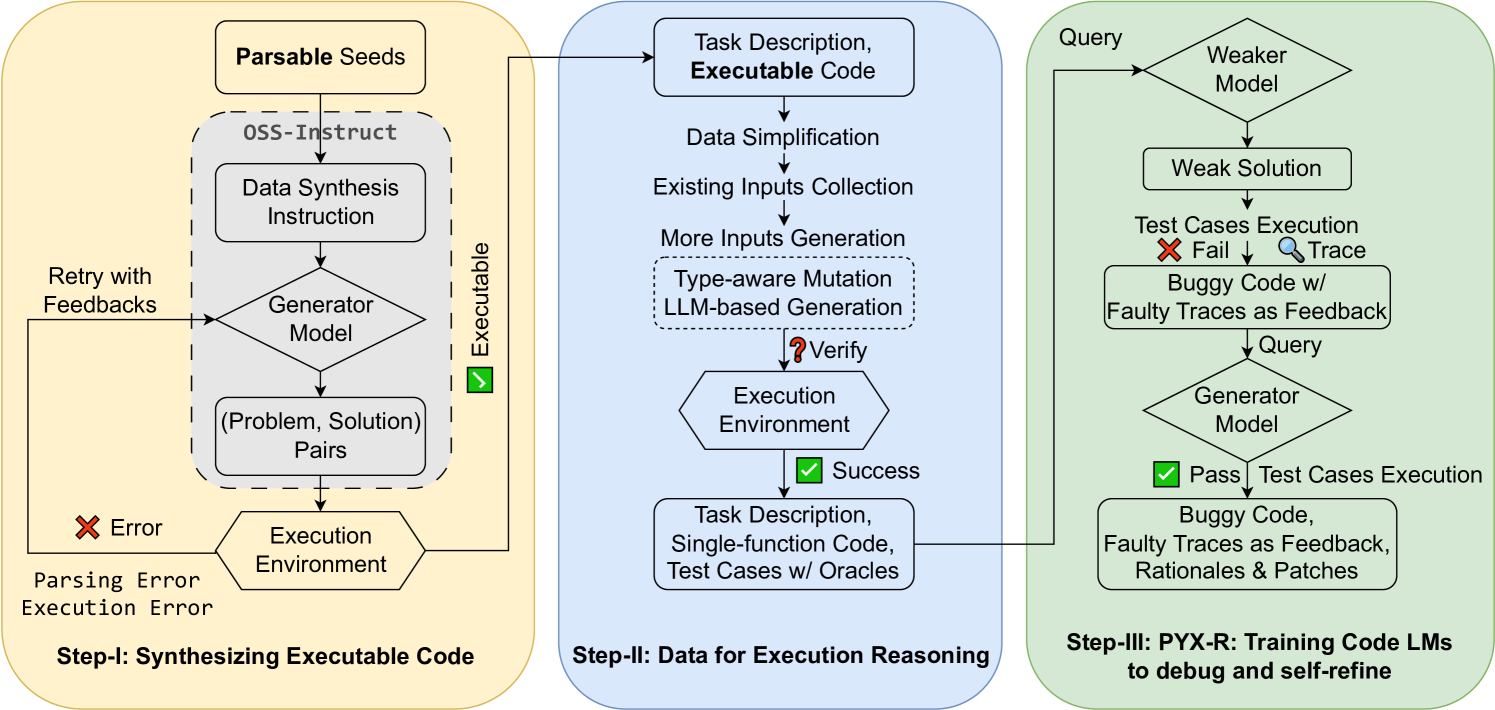
We collect PyX, a synthetic dataset capturing comprehensive program semantics with executable code samples and unit tests. Inspired by existing datasets wei2023magicoder ; luo2023wizardcoder , we use a powerful LLM to synthesize NL-to-code pairs. To ensure quality, PyX includes only executable samples. It also generates unit tests and detailed execution traces, recording program states after each statement. From PyX, we further construct a debugging dataset, PyX-R. PyX-R includes buggy code snippets generated by Code LMs, corresponding debugging rationales, and refine plans ni2024next leading to patches. By fine-tuning Code LMs on PyX-R, we aim to develop programming assistants that debug and patch faulty code in a human-like manner, advancing the capabilities of current Code LMs in iterative programming.
Learning Program Semantics
To learn program semantics, we propose monologue reasoning: Code LMs try to understand and explain the code semantics to themselves. Code LMs will summarize the program functionalities, highlight the key properties and constraints, and reason code execution step-by-step, inspired by rubber duck debugging hunt2000pragmatic . The code execution reasoning will be performed in two directions: (i) forward monologue: SemCoder uses source code and inputs to verbally simulate execution, explaining each line’s impact, executed lines, variable changes, and final output, and (ii) backward monologue: given the final output, SemCoder reasons about possible previous states abstractly, capturing essential characteristics without precise enumeration. This abstract reasoning is crucial for understanding complex operations like sorting or aggregation, where the previous state cannot be uniquely determined. Overall, monologue reasoning equips Code LMs with a human-like understanding of control flow, state transitions, and complex operations, bridging the gap between static code analysis and dynamic execution reasoning.
We show that, by training on this approach, SemCoder can generate, reason about execution, debug and refine code in a more intuitive and effective manner, pushing the boundaries of what current Code LMs can achieve in different software engineering tasks.
Performance of SemCoder
SemCoder, while having only 6.7B parameters, exhibits exceptional performance in code generation and execution reasoning tasks, surpassing larger models like GPT-3.5-turbo and various open-source models. For code generation, SemCoder variants achieve a pass@1 of 79.3% on HumanEval chen2021evaluating , outperforming GPT-3.5-turbo’s 76.8%, and with 27.5% on LiveCodeBench-Lite jain2024livecodebench , outperforming GPT-3.5-turbo’s 23.9%. For execution reasoning, SemCoder variants score 63.6%, 65.1%, 61.2% on CRUXEval-I, CRUXEval-O, and LiveCodeBench-CodeExecution, respectively, significantly outperforming baseline models including GPT-3.5-turbo and showcasing its superior understanding of program executions. The innovative monologue reasoning technique, where the model verbalizes code semantics from high-level functionalities to low-level execution details, greatly enhances execution reasoning, outperforming existing trace reasoning formats like scratchpad nye2021work and NExT ni2024next . The monologue reasoning approach also allows SemCoder to flexibly handle abstract semantics and non-deterministic program states, which existing methods struggle with. Additionally, SemCoder excels in debugging and self-refinement, improving code generation accuracy iteratively by verbally rubber-duck debugging by itself without the need for dynamic tracing. We empirically reveal that SemCoder’s static monologue reasoning is comparably effective as attaching real traces ni2024next for bug fixing. Besides the effectiveness, monologue reasoning has unique advantages by design: (1) it is purely static reasoning and does not require dynamic tracing, (2) it compacts the execution reasoning by focusing on key properties related to the bug rather than checking all redundant program states and concrete variable values, and (3) it provides a human-readable explanation for better understanding.
Our main contribution is the development of SemCoder, a semantic-aware Code LM designed to enhance understanding and reasoning about program semantics. We introduce Monologue Reasoning, a novel code reasoning approach that connects static source code with its runtime behavior through detailed verbal descriptions of code properties and runtime behaviors. To expose comprehensive program semantics at different levels, we curate PyX, a collection of executable code samples with functional descriptions and execution traces. SemCoder demonstrates superior performance in code generation and execution reasoning tasks, surpassing larger open-source models. SemCoder also excels in debugging and self-refinement by leveraging knowledge from its semantic-aware training. Our work highlights the potential of integrating deep semantic understanding into Code LMs to improve their effectiveness in complex programming tasks.
2 Program Semantics

Program semantics refers to the meaning or behavior of a computer program, describing what it does when it runs, including input processing, computations, and output hennessy1990semantics ; winskel1993formal . Understanding program semantics is crucial for ensuring programs behave correctly and meet their intended purpose.
Program semantics can be represented in various modalities. A high-level description outlines a program’s intended functionality, while fine-grained semantics detail the actions and side effects of each line of code, including data manipulation and state changes. This detailed understanding helps developers write better code and aids in code reviewing, debugging, and team communication. Fine-grained semantics can be concrete or abstract. Concrete semantics (e.g., program traces) capture actual execution effects, while abstract semantics focus on key input-output relationships and overall program effects, abstracting away lower-level details gunter1992semantics ; stoy1981denotational . Following the existing literature on program semantics hennessy1990semantics ; winskel1993formal , we curate the following semantics.
Approximate Semantics
describes the overall objectives of a program, often articulated through docstrings or documentation mcconnell2004code ; thomas2019pragmatic . These Natural Language descriptions provide an overview of the program’s goals and anticipated results, ensuring that the implementation aligns with the intended high-level functionalities (blue box in Figure 1).
Symbolic Semantics
represents complex functionality and logic in a way that both humans and machines can interpret consistently. It refers to the layer of meaning derived from the symbols, syntax, and structure of source code (pink box in Figure 1). It describes how code represents high-level functionality and logic by focusing on those constructs within the source code that symbolize particular behaviors, concepts, or operations in the program design.
Operational Semantics
describe how the individual steps in a source code execute plotkin1981structural ; hennessy1990semantics ; winskel1993formal . It focuses on describing the concrete execution of a program in a step-by-step manner, detailing how each action transforms the program’s state. This approach is particularly useful for reasoning about the dynamic behavior of programming languages (yellow box in Figure 1).
Abstract Semantics
is a way to describe program behavior at a higher level of abstraction nielson2015principles ; cousot1977abstract ; gunter1992semantics ; stoy1981denotational . Unlike concrete semantics, which provides detailed descriptions of the program’s execution on specific inputs, abstract semantics focuses on the essential aspects of program behavior while ignoring low-level details. This approach is to reason about program properties and constraints (red box in Figure 1 that always hold.
3 PyX: Semantic-aware Training Dataset
Capturing program semantics requires executing source code with unit tests. Real-world datasets are challenging due to diverse configurations, lack of unit tests, and limited documentation min2023beyond . Thus, we use a synthetic dataset to capture program semantics. Here, we detail the process of gathering high-quality data for learning multi-modal code semantics. Similar to wei2023magicoder ; luo2023wizardcoder , we first synthesize NL to Code pairs. Then, we use the Python interpreter to filter out defective samples, ensuring comprehensive semantic coverage. See Appendix F for more details and analysis, including Figure 4 which depicts the data collection procedure.
3.1 Synthesizing Executable Code
Synthesizing instructional data (NL to code) with existing LLMs is common for obtaining large datasets for instruction tuning CodeLLMs wei2023magicoder ; luo2023wizardcoder . However, current methods do not guarantee the quality of generated code. For instance, out of 43.1k Python solutions from wei2023magicoder , about 11.6k (26.9%) are inexecutable despite instructions to produce "correct" and "self-contained" code (Table 7 in Appendix F shows the top 10 error types). To build SemCoder, we train it only with executable data, as good data leads to better generation gunasekar2023textbooks ; yu2024large . We improve the OSS-Instruct data generation process wei2023magicoder , which prompts an LLM to create a programming task and solution inspired by a seed snippet. Instead of randomly sampling lines from existing programs, we parse them into ASTs and sample subtrees to obtain parsable seeds. We execute the generated code, retaining only successfully executed samples, and use the generator model’s debugging capability to retry until the code runs correctly. With the low-cost supervision from the Python interpreter, we build a higher-quality instruction tuning dataset for semantic-aware model training. Step I of Figure 4 in Appendix F summarizes this process. Table 2 in Appendix F compares our PyX with OSS-Instruct in details.
3.2 Dataset with Operational Semantics
We select a subset of PyX to construct data to learn the execution reasoning (See Step-II of Figure 4 in Appendix F).
Data Selection
We apply the following filtering criteria to select programs with clean execution flow from our executable dataset: (i) Only programs without external resource interactions (e.g., keyboard input, file system changes) are included, as our trace representation only captures variable state changes. (ii) Programs must have no randomness, ensuring predictable behavior.
Input Generation
Our executable dataset typically has one or two example inputs per program. To model operational semantics accurately and avoid bias, we need a diverse input set to expose different execution traces. We expand the input set using type-aware mutation and LLM-based input generation, similar to liu2024your as detailed in Appendix F.
3.3 PyX-R: Training Code LLMs to Rubber-duck Debug and Self-refine
We construct a debugging dataset, PyX-R, to train Code LLMs for debugging and self-refinement, aiming to improve their iterative programming capabilities. We collect buggy solutions by sampling LLM for problems in PyX and keep those responses that fail at least one of the tests. We perform rejection sampling with LLM to collect rubber-duck debugging rationales for buggy programs and their input sets. PyX-R only includes those rationales that lead to correct patches, verified by differential testing against the ground truth. We provide an example of PyX-R data in Appendix F.
4 SemCoder: Learning Comprehensive Semantics
4.1 Natural Language to Code
We train SemCoder to translate high-level functional descriptions into executable code, known as the natural language to code task wei2023magicoder ; luo2023wizardcoder . Using PyX samples, we provide well-defined problem descriptions that specify (1) the task’s overall objective, (2) implementation constraints, and (3) expected outcomes with test cases. These descriptions give a holistic view of the task, forming the basis for the model’s understanding.

4.2 Monologue Reasoning to Comprehensively Understand Code Semantics
We train SemCoder to understand code semantics through monologue reasoning: Given the source code and executable inputs/outputs, the model needs to reason code from high-level abstraction to low-level details, from static perspective to dynamic perspective. Note that the original natural language description of the problem will not be provided to generate monologues.
First, SemCoder summarizes the high-level functionalities to understand the approximate semantics. Then, SemCoder will explain the abstract semantics as key properties and constraints that always hold for all executions. Finally, SemCoder describes the operational semantics by articulating state changes during execution for the provided execution input/output. Inspired by rubber-duck debugging, this approach explains program states transition more smoothly than structured formats like Scratchpad austin2021program , avoiding redundant program states (e.g., numpy array with hundreds of elements) and concrete values (e.g., float numbers) while focusing on key properties that contribute to the code understanding. We detail such effectiveness in Section 6.2. We provide partial monologues for illustration in Figure 2 and full monologues in Appedix LABEL:sec:detail_ex_mnl.
4.2.1 Forward Monologue
We provide SemCoder with the source code and input, and it learns to reason the operational semantics by verbally simulating the execution step by step and predicting the execution output (Figure 2 yellow box).
Execution Coverage
To ensure comprehensive understanding, forward monologue covers those lines with side effects, contributing to a thorough control flow understanding and enforcing a detailed code walkthrough, similar to a developer’s debugging process.
Natural Execution Orders
To mimic natural code execution, forward monologue follows the natural order of reasoning. For loops, it explains each iteration with specific values, addressing lines executed multiple times differently. This ensures an accurate, context-aware execution path, similar to how developers mentally simulate execution behavior, helping to detect issues like infinite loops or incorrect condition handling.
Program State Transition
Understanding code side effects is crucial for grasping program state evolution. Forward monologue indicates changes in variable values when a line is executed, enhancing its ability to simulate real execution effects. This focus on side effects helps capture dynamic semantics, providing granular, step-by-step explanations of state changes, thus improving debugging and refinement based on observed behavior.
Final Output
Finally, the model predicts the program’s final output after explaining the execution process to validate the correctness of intermediate logic.
4.2.2 Backward Monologue
While forward execution is mostly deterministic, the previous program state cannot always be determined from the current state, such as an unsorted list from its sorted version. Therefore, we design the backward monologue to be flexibly abstract (See Figure 2, blue box).
Abstract Intermediate Constraints
In our backward monologue reasoning, we use abstract intermediate constraints when previous program states can’t be uniquely determined from the current state, such as after sorting or aggregation. We train the model to describe these constraints abstractly. This abstraction captures essential characteristics and patterns, allowing the model to reason about multiple possible previous states. This approach enhances the model’s flexibility and generalization, improving its ability to handle diverse and complex program reasoning tasks.
Concrete Input
For a given output, the model learns to predict concrete input values that satisfy the input abstract constraints. This step bridges the gap between abstract reasoning and concrete execution. This ensures it understands patterns and can generate practical examples, enhancing its robustness for real-world tasks like debugging and testing. This capability mirrors how human developers perform backward reasoning for debugging bohme2017where .
4.2.3 Monologue Annotation Using LLM
To annotate the monologue required for training SemCoder, we employ a method of rejection sampling casella2004generalized ; neal2000slice through a large language model. We leverage the power of LLM to automatically annotate numerous samples for training SemCoder, while we have an execution-based golden standard to verify the quality of annotated monologues, ensuring they are informative and valuable, thereby enhancing SemCoder’s ability to reason about program executions both forward and backward.
For forward monologue annotation, we feed code samples from our PyX dataset into an LLM, prompting it to generate a detailed explanation of state changes and transition logic, ending with a final output prediction. We then execute the code; if the actual output matches the LLM’s prediction, we accept the monologue, ensuring it accurately reflects the program’s execution. If the output does not match, the monologue is rejected. This method ensures the monologue is comprehensive and suitable for training SemCoder. We follow a similar strategy for backward monologue annotation.
To enhance our monologue annotation process, we provide the LLM with few-shot examples when generating forward and backward monologues. These examples follow our defined rules, explicitly detailing execution lines, variable changes, and reasoning steps for forward monologues, and abstract constraints with specific examples for backward monologues. This guidance ensures the LLM adheres to our structured reasoning steps. We also use system instructions to ensure the LLM follows the procedures illustrated in the few-shot examples.
4.3 Joint Training with Comprehensive Semantics
SemCoder is trained with the combined data of natural-language-to-code samples, forward monologues, and backward monologues, using the standard next-token prediction objective radford2019gpt2 . Our training has an emphasis on learning the program semantics, where the training loss is accumulated only by cross-entropy loss on code and monologue tokens together. We also include a task-specific prefix as part of the model input so that the model is better aware of which types of program semantics it should learn to capture and predict for the current sample. See Appendix LABEL:sec:task_specific_prefix for concrete prefixes.
5 Experiments
Code Generation and Execution Reasoning
For code generation evaluation, we consider EvalPlus liu2024your and the code generation task in LiveCodeBench-Lite (LCB-Lite for short)jain2024livecodebench . For execution reasoning, we employ CRUXEval gu2024cruxeval and the code execution task in LiveCodeBench (LCB-Exec for short) jain2024livecodebench . We prompt the baseline models to perform chain-of-thought reasoning wei2023chainofthought motivated by two-shot examples, and zero-shot prompt SemCoder to perform monologue reasoning. Inferences all follow the benchmark’s original settings.
Rubber-duck Debugging and Self-refine
We evaluate iterative programming capabilities in a setting similar to self-refinement/self-debugging chen2023teaching ; ding2024cycle —models generate code, test it, rubber-duck debug the erroneous solution, and refine their code based on the root cause analysis. Using EvalPlus liu2024your , we perform five iterative refinements using greedy decoding. We evaluate models with both zero-shot prompting and fine-tuned using PyX-R settings.
Models
SemCoder loads the 6.7B base version of DeepSeekCoder as the initial checkpoint and continues to optimize it with the proposed program semantic training. Similar to Magicoder wei2023magicoder , we train two versions of SemCoder, the base version and the more advanced SemCoder-. The base version of SemCoder is completely trained with PyX. The advanced SemCoder- is trained with an extended dataset that includes PyX, Evol-instruct wei2023magicoder , and partial CodeContest li2022competition . Evol-instruct is a decontaminated version of evol-codealpaca-v1 theblackcat102evolcode , which contains numerous instruction-following data. To increase the diversity of coding problems, we sample solutions from CodeContest li2022competition , resulting in 4.3k problems with at least one correct, LLM-generated solution.
Configuration and Empirically Settings
All SemCoder variants are trained for 2 epochs on a server with eight NVIDIA RTX A6000 GPUs, using a learning rate of 5e-5 with a cosine decay to 5e-6 during the program semantics training. For self-refinement fine-tuning, SemCoder and baseline Code LLMs are trained for 2 epochs with a learning rate of 1e-5. We use a batch size of 512, a maximum context length of 2,048. Similar to wei2023magicoder , we use GPT-3.5-turbo to synthesize coding problems. To minimize the cost, we use GPT-4o-mini to generate code solution and monologue reasoning texts, which are typically longer sequences than the problem descriptions.
6 Evaluation
6.1 Overall Performance
In this section, we report the overall performance of SemCoder for code generation and execution reasoning tasks and compare it with baseline Code LLMs.
Baselines and Evaluation Metric
We consider four families of open-source Code LLMs as baselines: Code Llama rozière2024code , StarCoder2 lozhkov2024starcoder , DeepSeekCoder guo2024deepseekcoder , and Magicoder wei2023magicoder . Despite SemCoder having only 6.7B parameters, we include 6.7B, 7B, and 13B variants, both base and instruct versions, if publicly available, totaling 13 open-source models. We also compare SemCoder to GPT-3.5-turbo for code generation and execution reasoning to measure the performance gap with closed-source models. Results are reported with pass@1.
| Model | Size | Code Generation | Execution Reasoning | ||||
| HEval (+) | MBPP (+) | LCB-Lite | CXEval-I | CXEval-O | LCB-Exec | ||
| GPT-3.5-Turbo | - | 76.8 (70.7) | 82.5 (69.7) | 23.9 | 50.3 | 59.0 | 43.6 |
| CodeLlama-Python | 13B | 42.7 (38.4) | 63.5 (52.6) | 10.6 | 40.5 | 36.0 | 23.2 |
| CodeLlama-Inst | 13B | 49.4 (41.5) | 63.5 (53.4) | 12.5 | 45.6 | 41.2 | 25.7 |
| StarCoder2 | 15B | 46.3 (37.8) | 55.1 (46.1) | 16.0 | 46.9 | 46.2 | 33.6 |
| StarCoder2-Inst | 15B | 67.7 (60.4) | 78.0 (65.1) | 15.5 | 47.1 | 50.9 | 29.6 |
| CodeLlama-Python | 7B | 37.8 (35.4) | 59.5 (46.8) | 7.1 | 40.4 | 34.0 | 23.0 |
| CodeLlama-Inst | 7B | 36.0 (31.1) | 56.1 (46.6) | 10.6 | 36.0 | 36.8 | 30.7 |
| StarCoder2 | 7B | 35.4 (29.9) | 54.4 (45.6) | 11.6 | 38.2 | 34.5 | 26.3 |
| Magicoder-CL | 7B | 60.4 (55.5) | 64.2 (52.6) | 11.4 | 34.0 | 35.5 | 28.6 |
| Magicoder--CL | 7B | 70.7 (67.7) | 68.4 (56.6) | 12.1 | 42.0 | 35.8 | 30.0 |
| DeepSeekCoder | 6.7B | 47.6 (39.6) | 72.0 (58.7) | 20.3 | 39.5 | 41.2 | 36.1 |
| DeepSeekCoder-Inst | 6.7B | 73.8 (70.7) | 74.9 (65.6) | 21.1 | 41.9 | 43.2 | 34.0 |
| Magicoder-DS | 6.7B | 66.5 (60.4) | 75.4 (61.9) | 25.5 | 45.5 | 41.9 | 38.8 |
| Magicoder--DS | 6.7B | 76.8 (71.3) | 75.7 (64.4) | 23.3 | 44.6 | 43.5 | 38.4 |
| SemCoder (Ours) | 6.7B | 73.2 (68.9) | 79.9 (65.3) | 22.4 | 62.5 | 65.1 | 59.7 |
| SemCoder- (Ours) | 6.7B | 79.3 (74.4) | 79.6 (68.5) | 27.5 | 63.6 | 63.9 | 61.2 |
SemCoder Achieves Dominant Performance in Code Generation and Execution Reasoning
We show the main evaluation results in Table 1. SemCoder reports dominant performance in execution reasoning, significantly better than other open-source baselines, including those with 2 more parameters. We also collect results for larger models (e.g., CodeLlama-34B) from the benchmark to compare with SemCoder in Appendix Table 6.
Comparing SemCoder with its initial checkpoint, DeepSeekCoder-6.7B, our semantic-heavy training strategy brings much stronger execution reasoning capabilities, resulting in a 23.0% absolute improvement for input prediction and 23.9% and 23.6% absolute improvement for CRUXEval-O and LCB-Exec, respectively. Notably, both variants of SemCoder outperform GPT-3.5-turbo for execution reasoning with a significant margin.
SemCoder also demonstrates remarkable performance in code generation: SemCoder achieves 79.9 pass@1 in MBPP, outperforming all open-source baselines, and the advanced version SemCoder- achieves pass@1 of 79.3 and 74.4 for HumanEval base and plus, respectively, significantly beating other models, including GPT-3.5-turbo. These impressive results support Terry Winograd’s vision in 1973 winograd1973breaking that training models to thoroughly understand programs produces more reliable and accurate programming assistants.
Execution Reasoning Requires Comprehensive Understanding of Code Semantics
We show results of input/output prediction without reasoning in Appendix Table 5. Interestingly, when comparing the results with reasoning vs. w/o reasoning, we found that the free-form chain-of-thought can hardly help model reason about execution, even if it takes more inference-time computation to generate more tokens. In contrast, monologue reasoning significantly improves the execution reasoning capability by up to 21.7% absolute improvement in output prediction. This empirically reveals that thorough understanding of code execution requires systematic reasoning over comprehensive semantics.
6.2 Effectivenss of Monologue Reasoning
In this section, we perform ablation studies to demonstrate the effectiveness of monologue reasoning.
Baselines
We consider two baseline execution reasoning approaches: scratchpad nye2021work and NeXT’s trace format ni2024next . NeXT adds numeric order to state changes and omits intermediate loop states. We also create a template to concise execution traces, replacing monologue reasoning with concrete program states. Examples are in Appendix LABEL:sec:baseline_trace. Additionally, we report few-shot prompting results on the base Code LM using chain-of-thought reasoning wei2023chainofthought without our execution reasoning data.
| Method | CRUXEval-I | CRUXEval-O | LCB-Exec |
| Few-shot Prompting | 39.5 | 41.2 | 36.1 |
| Finetune | |||
| w/ Scratchpad nye2021work | 48.8 | 50.6 | 39.9 |
| w/ NeXT ni2024next | 49.4 | 50.9 | 32.2 |
| w/ Concise Trace | 52.1 | 55.6 | 35.9 |
| w/ Monologue Reasoning (Ours) | 61.8 | 63.5 | 58.5 |
Experiments
We first construct different formats of execution reasoning using the same PyX samples that construct monologues. Then we fine-tune deepseek-coder-6.7b-base on these different execution reasoning data for 3 epochs and compare their results on input and output prediction using CRUXEval.
Monologue Reasoning is More Effective Than Learning Concrete Program States
Results in Table 2 show that, while all baselines improve execution reasoning, our monologue reasoning outperforms them in input and output prediction with clear margins. The main reason is that monologues describe state transitions smoothly in natural language while keeping track of only key properties and values, which is easier for code LLMs to learn and understand and consequently enhance execution reasoning. In contrast, baselines provide only concrete states with redundant information and values while not explaining the causal relations of these transitions, so code LLMs struggle to capture the correlation among them.
When we manually check the monologues, which are structured to ensure correct outcomes (Section 4.2.3, we observe that the intermediate logic could be occasionally flawed – the model sometimes makes wrong assumptions about code properties but still reaches the correct result. In contrast, all baselines are guaranteed to have correct intermediate steps, as they are realistic execution traces (See Appendix A for limitation and future work). Empirically, however, the model learns more effectively from the monologues. This highlights the potential benefits of emphasizing key property correctness and model-friendly data format when jointly training code LLMs with distinct semantics.
6.3 Debugging and Self-Refinement
We format the debugging process as verbally and statically explaining why the bug happens hunt2000pragmatic to evaluate the code LMs’ reasoning capability rather than the tool-using capability that performs dynamic execution with tracers or debuggers. Then the model should fix the bug according to its own reasoning, i.e., self-refine. We provide an example in Appendix F (Example-2) to illustrate how this task is performed.
Experiments
We consider four state-of-the-art instruction-tuned code LMs as baselines: Llama-3.1-Instruct-8B dubey2024llama3herdmodels , DeepSeekCoder-Instruct-6.7B, Magicoder-DS-6.7B, and Magicoder-S-DS-6.7B. We evaluate their static debug and self-refine capabilities on EvalPlus with five iterations. We first evaluate with zero-shot prompting and then also fine-tune with PyX-R to illustrate its value.
| Model | Self-Refine | |
| HEval (+) | MBPP (+) | |
| Magicoder-DS | 65.2 (60.4) | 78.3 (65.9) |
| Magicoder--DS | 77.4 (70.1) | 79.9 (68.8) |
| DeepSeekCoder-Inst | 77.4 (73.2) | 80.4 (69.6) |
| Llama-3.1-Inst | 76.8 (68.9) | 77.8 (65.6) |
| SemCoder | 75.6 (71.3) | 83.1 (67.2) |
| SemCoder- | 84.8 (79.3) | 86.8 (74.3) |
| Model | Self-Refine | |
| HEval (+) | MBPP (+) | |
| Magicoder-DS | 78.8 (64.3) | 83.1 (66.7) |
| Magicoder--DS | 83.5 (76.2) | 84.4 (71.4) |
| DeepSeekCoder-Inst | 83.5 (75.6) | 84.9 (69.6) |
| Llama-3.1-Inst | 76.8 (68.9) | 76.7 (61.4) |
| SemCoder | 76.8 (69.5) | 81.7 (65.9) |
| SemCoder- | 85.4 (79.3) | 87.0 (73.5) |
SemCoder Reports Promising Performance in Debugging and Self-Refinement
In Table 3, SemCoder- outperforms all baselines, more notably in the zero-shot setting. This result illustrates that the SemCoder’s monologue reasoning augments general-purpose instruction tuning with code semantics reasoning capabilities. Appendix D demonstrates SemCoder’s continuous code refinement throughout iterations, showcasing the potential of learned program semantics for complex programming tasks.
PyX-R Improves Iterative Programming Capability
Fine-tuning Code LMs on PyX-R significantly improves iterative programming performance due to the monologue-style debugging rationale and well-aligned patches. PyX-R helps Code LMs understand and analyze bugs from source code and execution traces, aiming to inspire better iterative programming capabilities. We notice that PyX-R provides limited improvement to SemCoder variants and Llama-3.1-Inst, and we speculate that these models are already trained with high-quality reasoning, and the occasional errors in PyX-R debugging rationale restrict these models from becoming significantly better (See Appendix A).
Monologue Reasoning vs. Execution Traces for Debugging
We perform additional experiments by replacing the monologue reasoning part (See “### Execution Simulation" in Appendix F Example 2) in the debugging rationale with real traces, following the format of NExT ni2024next and fine-tuning code LMs again. Results are in Appendix C.1. We notice that monologue reasoning is comparably effective as attaching execution traces. Besides the effectiveness, monologue reasoning has unique advantages by design: (1) it is purely static reasoning and does not require dynamic tracing, (2) it compacts the execution reasoning by focusing on key properties related to the bug rather than checking all redundant program states and concrete variable values, and (3) it provides a human-readable explanation for better understanding.
7 Related Work
Code LLMs and Training Data
Many open source Code LLMs, such as CodeGen nijkamp2022codegen , StarCoder li2023starcoder ; lozhkov2024starcoder , Code Llama rozière2024code , and DeepSeek Coder guo2024deepseekcoder , are proposed. Specialized models austin2021program ; chen2021evaluating ; li2022competition have also been developed for tasks like code generation, summarization, output prediction, and competitive programming following the success of GPT-3 brown2020gpt3 . These models are trained only on source code and related text, lacking execution context. This limits their understanding of program semantics, leading to security issues and debugging failures. We aim to bridge this gap by training Code LMs on both static source code and dynamic execution traces. An orthogonal line of research curates synthetic instruction-following data to enhance Code LLM performance. Code Alpaca codealpaca has 20k instruction-response pairs, Evol-Instruct-Code luo2023wizardcoder expands this to 80k pairs, and OSS-Instruct wei2023magicoder includes 75k diverse pairs from the Stack dataset kocetkov2022stack . However, these datasets focus on natural-language-to-code tasks with little coverage of code execution and unverified solutions. To improve correctness, Zheng et al. zheng2024opencodeinterpreter created a multi-turn conversation dataset with compiler error messages, and Wei et al. wei2024starcoder2-instruct incorporated execution by generating test cases and filtering invalid pairs. Yet, no dataset includes simulating and understanding execution traces. We aim to fill this gap (see Section 3).
Learning and Reasoning about Program Executions
Before LLMs, (zaremba2015learning, ; graves2014neural, ) predict simple program outputs using RNNs, GNNs, small transformers, and neural Turing machines. Austin et al. austin2021program fine-tuned LLMs for execution output prediction with minimal performance gains. Early models predicted final outputs without revealing execution traces. Nye et al. nye2021work introduced the Scratchpad method for intermediate results, and others liu2023code ; ding2024traced fine-tuned UniXcoder guo2022unixcoder for execution traces but didn’t evaluate for code generation tasks. We fine-tune a Code LLM to understand program semantics, excelling in code generation, output prediction, and input prediction (see Section 4). Another approach uses execution feedback for debugging Code LLMs. Self-Debugging chen2023teaching shows that natural language explanations or unit test results help self-refinement, but execution traces reduce performance. LeTI wang2024leti and CYCLE ding2024cycle fine-tune with execution feedback to improve performance, especially for smaller models. NExT ni2024next generates debugging rationales to mitigate the negative impact of execution traces. Our work shows that a model trained on code generation, output prediction, and input prediction excels in understanding execution feedback and self-refinement (see Table 3).
8 Conclusion
We train SemCoder to simultaneously learn different modalities of program semantics: Approximate, Symbolic, Operational, and Abstract. We show that such semantics-oriented joint training cultivates a comprehensive understanding of program semantics — SemCoder or SemCoder- achieves SOTA performance, among all less-than-15B open-source models, in not only the code generation and input/output prediction but also tasks that require deep knowledge of both source code and execution execution reasoning like debugging and self-refinement.
Acknowledgement
This work was supported in part by, DARPA/NIWC-Pacific N66001-21-C-4018, multiple Google Cyber NYC awards, an Columbia SEAS/EVPR Stimulus award, NSF CNS–1845995, CNS-2247370, CCF-2221943, CCF-2313055, CCF-1845893, and CCF-2107405. Any opinions, findings, conclusions, or recommendations expressed herein are those of the authors and do not necessarily reflect those of DARPA, or NSF.
References
- (1) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code, 2021.
- (2) Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. Show your work: Scratchpads for intermediate computation with language models, 2021.
- (3) Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. Deepseek-coder: When the large language model meets programming – the rise of code intelligence, 2024.
- (4) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, and Gabriel Synnaeve. Code llama: Open foundation models for code, 2024.
- (5) Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries. Starcoder 2 and the stack v2: The next generation, 2024.
- (6) GitHub. Github copilot: Your ai pair programmer. https://github.com/features/copilot, 2021.
- (7) Amazon. Amazon codewhisperer: Your ai-powered productivity tool for the ide and command line. https://aws.amazon.com/codewhisperer/, 2022.
- (8) OpenAI. Chatgpt. https://chatgpt.com/, 2022.
- (9) Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, et al. The stack: 3 tb of permissively licensed source code. arXiv preprint arXiv:2211.15533, 2022.
- (10) Alex Gu, Wen-Ding Li, Naman Jain, Theo X. Olausson, Celine Lee, Koushik Sen, and Armando Solar-Lezama. The counterfeit conundrum: Can code language models grasp the nuances of their incorrect generations?, 2024.
- (11) Nathaniel Ayewah, William Pugh, David Hovemeyer, J. David Morgenthaler, and John Penix. Using static analysis to find bugs. IEEE Software, 25(5):22–29, 2008.
- (12) Brittany Johnson, Yoonki Song, Emerson Murphy-Hill, and Robert Bowdidge. Why don’t software developers use static analysis tools to find bugs? In 2013 35th International Conference on Software Engineering (ICSE), pages 672–681, 2013.
- (13) Ansong Ni, Miltiadis Allamanis, Arman Cohan, Yinlin Deng, Kensen Shi, Charles Sutton, and Pengcheng Yin. Next: Teaching large language models to reason about code execution, 2024.
- (14) Terry Winograd. Breaking the complexity barrier again. In Proceedings of the 1973 Meeting on Programming Languages and Information Retrieval, SIGPLAN ’73, page 13–30, New York, NY, USA, 1973. Association for Computing Machinery.
- (15) Andrew Hunt and David Thomas. The pragmatic programmer: from journeyman to master. Addison-Wesley Longman Publishing Co., Inc., USA, 2000.
- (16) Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Source code is all you need. arXiv preprint arXiv:2312.02120, 2023.
- (17) Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568, 2023.
- (18) Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974, 2024.
- (19) Matthew Hennessy. The semantics of programming languages: an elementary introduction using structural operational semantics. John Wiley & Sons, Inc., 1990.
- (20) Glynn Winskel. The formal semantics of programming languages: an introduction. MIT press, 1993.
- (21) Carl A Gunter. Semantics of programming languages: structures and techniques. MIT press, 1992.
- (22) Joseph E Stoy. Denotational semantics: the Scott-Strachey approach to programming language theory. MIT press, 1981.
- (23) Steve McConnell. Code complete. Pearson Education, 2004.
- (24) David Thomas and Andrew Hunt. The Pragmatic Programmer: your journey to mastery. Addison-Wesley Professional, 2019.
- (25) Gordon D Plotkin. A structural approach to operational semantics. Aarhus university, 1981.
- (26) Flemming Nielson, Hanne R Nielson, and Chris Hankin. Principles of program analysis. springer, 2015.
- (27) Patrick Cousot and Radhia Cousot. Abstract interpretation: a unified lattice model for static analysis of programs by construction or approximation of fixpoints. In Proceedings of the 4th ACM SIGACT-SIGPLAN symposium on Principles of programming languages, pages 238–252, 1977.
- (28) Marcus J Min, Yangruibo Ding, Luca Buratti, Saurabh Pujar, Gail Kaiser, Suman Jana, and Baishakhi Ray. Beyond accuracy: Evaluating self-consistency of code llms. In The Twelfth International Conference on Learning Representations, 2023.
- (29) Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. Textbooks are all you need. arXiv preprint arXiv:2306.11644, 2023.
- (30) Yue Yu, Yuchen Zhuang, Jieyu Zhang, Yu Meng, Alexander J Ratner, Ranjay Krishna, Jiaming Shen, and Chao Zhang. Large language model as attributed training data generator: A tale of diversity and bias. Advances in Neural Information Processing Systems, 36, 2024.
- (31) Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in Neural Information Processing Systems, 36, 2024.
- (32) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. ArXiv preprint, abs/2108.07732, 2021.
- (33) Marcel Böhme, Ezekiel O. Soremekun, Sudipta Chattopadhyay, Emamurho Ugherughe, and Andreas Zeller. Where is the bug and how is it fixed? an experiment with practitioners. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2017, page 117–128, New York, NY, USA, 2017. Association for Computing Machinery.
- (34) George Casella, Christian P. Robert, and Martin T. Wells. Generalized accept-reject sampling schemes. Lecture Notes-Monograph Series, 45:342–347, 2004.
- (35) Radford M. Neal. Slice sampling, 2000.
- (36) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI preprint, 2019.
- (37) Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I. Wang. Cruxeval: A benchmark for code reasoning, understanding and execution. arXiv preprint arXiv:2401.03065, 2024.
- (38) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023.
- (39) Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug, 2023.
- (40) Yangruibo Ding, Marcus J. Min, Gail Kaiser, and Baishakhi Ray. Cycle: Learning to self-refine the code generation, 2024.
- (41) Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. ArXiv preprint, abs/2203.07814, 2022.
- (42) theblackcat102. The evolved code alpaca dataset. https://huggingface.co/datasets/theblackcat102/evol-codealpaca-v1, 2023.
- (43) Meta Llama Team. The llama 3 herd of models, 2024.
- (44) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis. In International Conference on Learning Representations, pages 1–25, 2023.
- (45) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161, 2023.
- (46) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, pages 1–25, 2020.
- (47) Sahil Chaudhary. Code alpaca: An instruction-following llama model for code generation. https://github.com/sahil280114/codealpaca, 2023.
- (48) Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, and Xiang Yue. Opencodeinterpreter: Integrating code generation with execution and refinement, 2024.
- (49) Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Harm de Vries, Leandro von Werra, Arjun Guha, and Lingming Zhang. Starcoder2-instruct: Fully transparent and permissive self-alignment for code generation, 2024.
- (50) Wojciech Zaremba and Ilya Sutskever. Learning to execute, 2015.
- (51) Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines, 2014.
- (52) Chenxiao Liu, Shuai Lu, Weizhu Chen, Daxin Jiang, Alexey Svyatkovskiy, Shengyu Fu, Neel Sundaresan, and Nan Duan. Code execution with pre-trained language models, 2023.
- (53) Yangruibo Ding, Benjamin Steenhoek, Kexin Pei, Gail Kaiser, Wei Le, and Baishakhi Ray. Traced: Execution-aware pre-training for source code. In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering, pages 1–12, 2024.
- (54) Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. Unixcoder: Unified cross-modal pre-training for code representation. arXiv preprint arXiv:2203.03850, 2022.
- (55) Xingyao Wang, Hao Peng, Reyhaneh Jabbarvand, and Heng Ji. Leti: Learning to generate from textual interactions, 2024.
- (56) Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations, 2024.
- (57) bigcode-project/bigcode-dataset. https://github.com/bigcode-project/bigcode-dataset. (Accessed on 05/17/2024).
Appendix A Limitations and Future Work
Process Supervision for Intermediate Reasoning Steps
We manually review the monologues in PyX and the rubber-duck debugging rationales in PyX-R, which are structured to ensure correct outcomes (see Section 4.2.3). While the final answers are accurate, we observed that the intermediate reasoning steps are occasionally flawed. Sometimes, the model makes incorrect assumptions about code properties but still reaches the right result, i.e., correct execution input/output and correct patch. Conceptually, such subtle mistakes in the intermediate reasoning steps might have negative impacts on further improving models’ code reasoning capability.
We encourage future work to propose automatic and efficient process supervision approaches [56] specifically for code reasoning, which will be useful to further improve the quality of monologues in PyX.
Curation of Monologue Annotation
The monologue annotation data (Section 4.2.3) is crucial for SemCoder to excel at the output prediction and input prediction tasks. However, we rely on a more powerful LLM, GPT-3.5-Turbo or GPT-4o-mini to generate these annotations and employ rejection sampling from its responses, since our base model is relatively small with 6.7B parameters.
We encourage future work to try our semantic-oriented joint training on a larger base model, so that it will be possible to generate the monologue annotations using the base model itself like Ni et al. [13] did to bootstrap high-quality reasoning for self-refinement.
Incorporating Execution Reasoning into Code Generation
We demonstrate that training on input and output prediction tasks are indirectly beneficial for both natural-language-to-code generation and downstream tasks like self-refinement. However, there is a more direct way to further improve the performance in code generation and self-refinement — we can ask the model to first self-verify its own solution by generating forward monologue (Section 4.2.1) for the test cases given in the natural language specification before finalizing the solution.
We encourage future work to explore the possibility of using a model’s own execution reasoning ability to directly assist its code generation and self-refinement process.
Appendix B Broader Impacts
Social Impact
In this work, we train a semantic-aware Code LMs. We make all the data, code, and model checkpoints available publicly. The artifact could be used to deploy automated programming assistants that improve the developers’ productivity. It is possible but unlikely that the Code LMs will generate buggy or wrong code, but we suggest to use our models as “copilot" to assist with human developers rather than completely relying on the model for full automation.
Safeguards
Our data is synthesized using a commercial LLM, i.e., GPT-3.5-turbo, which has been aligned by the releasing company, OpenAI, to avoid leaking personal or malicious information. We regard our data has minimal risk of being misused due to its synthetic instinct.
Appendix C More Evaluation Results
C.1 Debug and Self-refine w/ Real Execution Traces
| Model | Self-Refine | |
| HEval (+) | MBPP (+) | |
| Magicoder-DS | 72.0 (66.5) | 83.3 (67.5) |
| Magicoder--DS | 81.7 (74.4) | 83.9 (72.0) |
| DeepSeekCoder-Inst | 84.8 (79.9) | 85.4 (70.4) |
| Llama-3.1-Inst | 76.2 (69.5) | 82.8 (66.7) |
| SemCoder | 78.0 (70.7) | 83.6 (66.4) |
| SemCoder- | 86.0 (80.5) | 87.0 (73.3) |
C.2 Input/Output Prediction Without Reasoning
In Table 5, we present the results of direct prediction for execution input and output without reasoning.
| Model | Size | Execution Reasoning | ||
| CRUXEval-I | CRUXEval-O | LCB-Exec | ||
| GPT-3.5-Turbo | - | 49.0 | 49.4 | 39.2 |
| CodeLlama-Python | 13B | 38.5 | 39.7 | 36.1 |
| CodeLlama-Inst | 13B | 47.5 | 40.8 | 33.8 |
| StarCoder2 | 15B | 47.2 | 46.9 | 34.7 |
| StarCoder2-Inst | 15B | 47.4 | 47.1 | 8.1 |
| CodeLlama-Python | 7B | 37.3 | 34.6 | 31.1 |
| CodeLlama-Inst | 7B | 34.8 | 35.6 | 30.1 |
| StarCoder2 | 7B | 34.2 | 35.6 | 34.0 |
| Magicoder-CL | 7B | 32.0 | 35.6 | 32.4 |
| Magicoder--CL | 7B | 36.2 | 34.8 | 30.5 |
| DeepSeekCoder | 6.7B | 42.2 | 43.6 | 44.5 |
| DeepSeekCoder-Inst | 6.7B | 34.9 | 40.8 | 41.1 |
| Magicoder-DS | 6.7B | 41.2 | 43.4 | 38.4 |
| Magicoder--DS | 6.7B | 42.1 | 44.4 | 39.2 |
| SemCoder (Ours) | 6.7B | 46.9 | 47.9 | 38.0 |
| SemCoder- (Ours) | 6.7B | 47.6 | 46.6 | 40.7 |
C.3 Comparison with Larger Open-Sourced Models and Closed-Source Models
| Model | Size | Code Generation | Execution Reasoning | ||
| HEval (+) | MBPP (+) | CRUXEval-I | CRUXEval-O | ||
| GPT-3.5-Turbo-1106 | - | 76.8 (70.7) | 82.5 (69.7) | 49.0 / 50.3 | 49.4 / 59.0 |
| Claude-3-Opus | - | 82.9 (77.4) | 89.4 (73.3) | 64.2 / 73.4 | 65.8 / 82.0 |
| GPT-4-0613 | - | 88.4 (79.3) | - | 69.8 / 75.5 | 68.7 / 77.1 |
| GPT-4-Turbo-2024-04-09 | - | 90.2 (86.6) | - | 68.5 / 75.7 | 67.7 / 82.0 |
| CodeLlama | 34B | 51.8 (43.9) | 69.3 (56.3) | 47.2 / 50.1 | 42.4 / 43.6 |
| DeepSeekCoder | 33B | 51.2 (44.5) | - | 46.5 / - | 48.6 / - |
| DeepSeekCoder-Inst | 33B | 81.1 (75.0) | 80.4 (70.1) | 46.5 / - | 49.9 / - |
| SemCoder (Ours) | 6.7B | 68.3 (62.2) | 79.9 (65.9) | 51.2 / 52.6 | 48.1 / 56.6 |
| SemCoder- (Ours) | 6.7B | 81.1 (76.2) | 78.8 (66.9) | 48.1 / 54.5 | 44.9 / 54.1 |
Appendix D SemCoder Continuously Refines Code Qualities
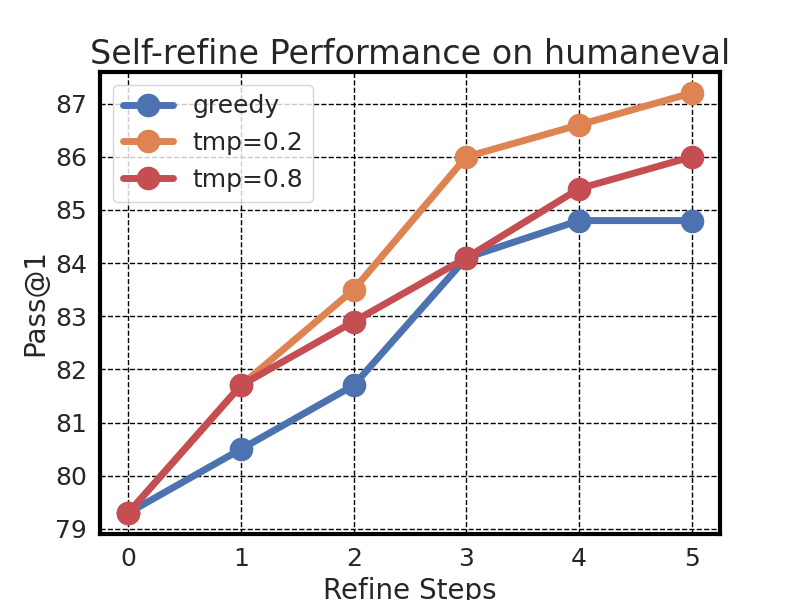
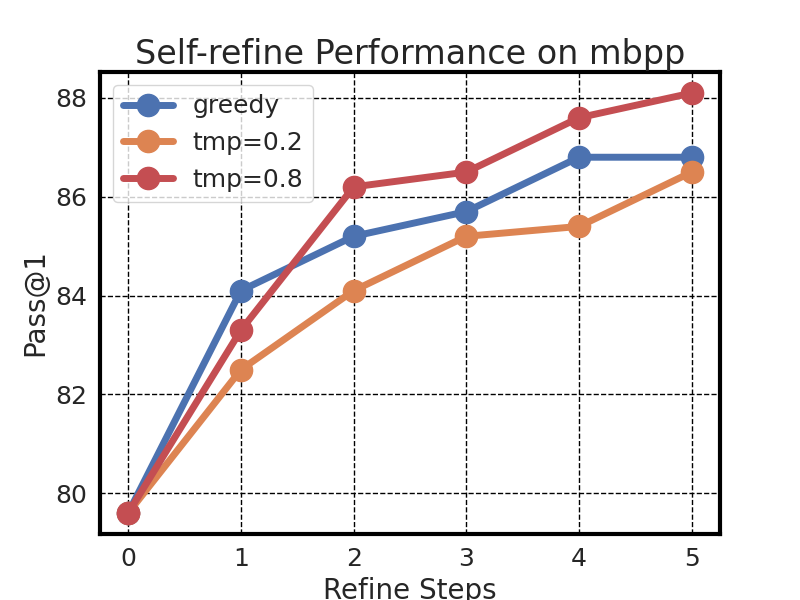
We studied SemCoder’s code generation accuracy at each step of refinement with varied temperatures. The results are plotted in Figure 3. We observed that SemCoder is capable of continuously refining its own errors, and the increase does not stop when the temperature is high, which indicates the SemCoder has strong debugging and self-refine capabilities and a high temperate better leverages such capabilities for iterative programming.
Appendix E Executability Analysis of OSS-Instruct
| Error | #Cases out of 43.1k |
| Type | Python samples |
| ModuleNotFoundError | 3417 |
| NameError | 1954 |
| FileNotFoundError | 1052 |
| ImportError | 979 |
| EOFError | 743 |
| SyntaxError | 672 |
| IndentationError | 506 |
| AttributeError | 213 |
| TypeError | 196 |
| ValueError | 132 |
Appendix F Details on PyX
The whole data collection pipeline is shown in Figure 4. Here we also document more details about PyX.
Prompt for Data Synthesis
We follow the prompt in OSS-Instruct for data synthesis, but with two modifications: 1) For problem design, instruct the model to avoid interaction with external resources or requirement of uncommon third-party libraries to increase the probability of getting executable code. 2) For giving solutions, instruct the model to show its thought process before writing code to produce more aligned natural language along with the code in the dataset. Table LABEL:tab:pyx_prompt details our prompts with an example in PyX.
Input Set Expansion
To enlarge the input set, we first initialize the input corpus with all known valid inputs. Then, for type-aware mutation, we alter known inputs based on type-specific heuristics. For LLM-based generation, we prompt the model with the function and several known inputs to generate more. We verify new inputs by executing them, retaining only those that execute successfully without exceptions. We alternate between type-aware mutation and LLM-based generation until reaching a predefined threshold, combining mutation’s efficiency with LLM generation’s robustness. The generated inputs and their outputs serve as unit tests for the NL-described task in future steps.
Coverage of Inputs
Our input generation method only considers diversity in terms of variable values but does not try to fully exercise different execution paths in an executable code, like what the coverage-guided testing usually does. However, our dataset only consists of relatively short single-function programs that do not have complicated branches. We find that our generated inputs can achieve average branch coverage and average line coverage of 93%, 96% respectively, which shows that our approach is light-weight yet effective for the current setting.
Parsable and Executable code seeds
One notable difference between OSS-Instruct and PyX is we only select parsable code seeds to sample programming challenges and code solutions, which results in a slightly higher yield rate for executable code. We also try to quantify the effects of this difference, and the results are in Table 8. We can see that training on PyX performs just marginally better than OSS-Instruct and its Python subset. We, therefore, conclude that training only with executable code does not necessarily improve the natural language to code performance, but our work requires this feature to expose the full semantics of code.
| Dataset | Problems | Seed | Solution | Performance | ||
| Parse | Parse | Execute | HumanEval (+) | MBPP (+) | ||
| OSS-Instruct | 75k | - | - | Partially | 67.1 (61.0) | 77.5 (64.3) |
| OSS-Instruct-Python | 43k | 48% | 97% | 73% | 66.5 (59.8) | 78.6 (65.9) |
| PyX (Ours) | 32k | 100% | 100% | 100% | 70.1 (64.0) | 78.6 (65.1) |
Data De-duplication
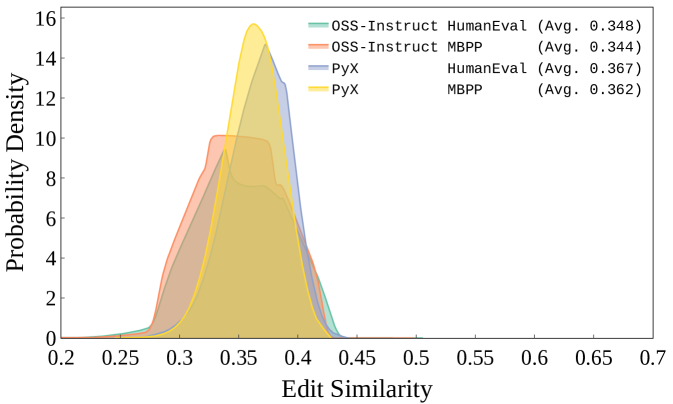
We follow the data decontamination process of [16] and [57] to clean our dataset. To examine the similarity between our instruction tuning dataset and the testing benchmarks, we evaluate the "edit similarity" between them, specifically by scaling the metric fuzz.partial_token_sort_ratio provided by thefuzz library. For each sample in our dataset, its similarity to a benchmark is computed as the maximum cosine similarity to any sample in the benchmark. We apply the same analysis to OSS-Instruct for comparison. Figure 5 shows that the similarity between our dataset and the two benchmarks is on par with OSS-Instruct, where the majority has less than 0.4 similarity, which indicates that the performance improvement brought by our dataset is not from data leakage or benchmark data imitation.
Categories
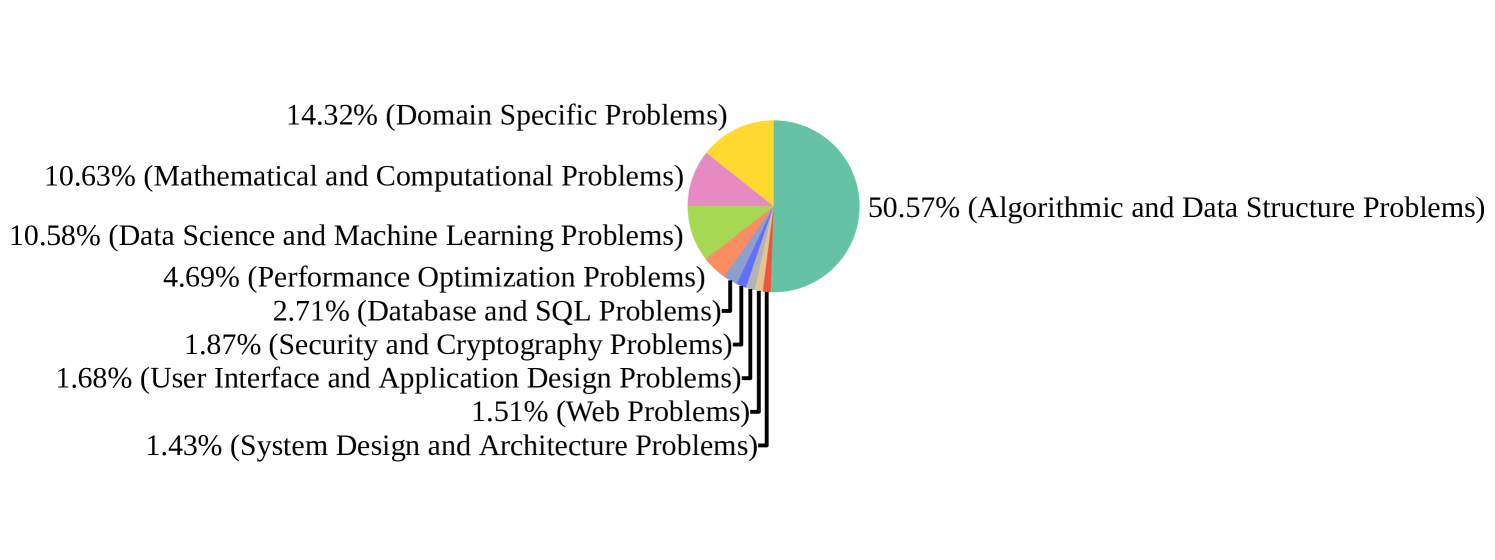
To study the effect of executability filtering, we categorize all samples in our dataset following [16] shown by Figure 6. Compared to OSS-Instruct, the categorical distribution shifts by an increase in algorithmic and data structure problems, data science and machine learning problems, and mathematical and computational problems, and a decrease in the remaining categories, which is expected since interactions with external resources commonly required in scenarios like database, web and UI design are not allowed in our execution environment.
Data Statistics
We perform decontamination on the PyX, and monologue samples (we remove the samples that share the same input and output pair with CRUXEval). PyX includes 32,489 natural language to code pairs. We generated 29,945 forward monologues and 31,022 backward monologues using rejection sampling. SemCoder is trained with 93.4k samples, and SemCoder- with 214.1k samples. PyX-R contains 18,473 debugging samples, each with the original description, buggy code, debugging rationale, and final patch.
| Example 1: An example of PyX sample generation |
| User Prompt: |
| Model Response: |