Semi-Data-Aided Channel Estimation for
MIMO Systems via Reinforcement Learning
Abstract
Data-aided channel estimation is a promising solution to improve channel estimation accuracy by exploiting data symbols as pilot signals for updating an initial channel estimate. In this paper, we propose a semi-data-aided channel estimator for multiple-input multiple-output communication systems. Our strategy is to leverage reinforcement learning (RL) for selecting reliable detected symbols among the symbols in the first part of transmitted data block. This strategy facilitates an update of the channel estimate before the end of data block transmission and therefore achieves a significant reduction in communication latency compared to conventional data-aided channel estimation approaches. Towards this end, we first define a Markov decision process (MDP) which sequentially decides whether to use each detected symbol as an additional pilot signal. We then develop an RL algorithm to efficiently find the best policy of the MDP based on a Monte Carlo tree search approach. In this algorithm, we exploit the a-posteriori probability for approximating both the optimal future actions and the corresponding state transitions of the MDP and derive a closed-form expression for the best policy. Simulation results demonstrate that the proposed channel estimator effectively mitigates both channel estimation error and detection performance loss caused by insufficient pilot signals.
Index Terms:
Multiple-input multiple-output (MIMO), channel estimation, data-aided channel estimation, reinforcement learning, Monte Carlo tree search.I Introduction
Multiple-input multiple-output (MIMO) communication is one of the core technologies in modern wireless standards. The use of multiple antennas significantly improves both the capacity and the reliability of wireless systems by providing spatial multiplexing and diversity gains [2, 3, 4]. A key requirement to enjoy these benefits is accurate channel state information (CSI) at both transmitter and receiver. For example, the capacity of MIMO communication systems increases linearly with the number of either transmit or receive antennas under the premise that perfect CSI is available at both the transmitter and receiver [2, 3].
To obtain accurate CSI at the receiver (CSIR), various channel estimation techniques have been developed for MIMO communication systems [5, 6, 7, 8, 9, 15, 14, 10, 11, 12, 13, 16, 17]. One of the most popular and widely adopted technique is pilot-aided channel estimation [5, 6, 7, 8]. The fundamental idea of this technique is to send pilot signals, known as a priori at the receiver, and then to estimate the CSI from received signals observed during pilot transmission. A representative example of this technique is the least-squares (LS) channel estimator that minimizes the sum of squared errors in the estimated CSIR [7, 8]. Another example is the linear minimum-mean-squared-error (LMMSE) channel estimator which is a linear estimator that minimizes the mean-squared-error (MSE) of the estimated CSIR based on the first-order and the second-order channel statistics [7, 8]. The accuracy of the CSIR obtained from pilot-aided channel estimation improves with the number of the pilot signals available in a communication system. In addition, the larger the number of spatially multiplexed data streams utilized in MIMO systems, the larger the number of pilot signals required for accurate CSIR. Despite this requirement, in practical MIMO communication systems, only a small portion of radio resources are allocated for pilot transmission, while most of the radio resources are allocated for transmitting data (non-pilot) signals.
Data-aided channel estimation is a promising solution to overcome the limitation of pilot-aided channel estimation due to an insufficient number of pilot signals [9, 10, 11, 12, 13, 14, 15, 16, 17]. The basic strategy of the data-aided channel estimation is to exploit data symbols as additional pilot signals to update an initial channel estimate obtained from pilot-aided channel estimation. This strategy allows the receiver to enjoy the effect of increasing the number of pilot signals and therefore has a potential to provide more accurate CSIR compared to the pilot-aided channel estimation without sacrificing radio resource for data transmission. A non-iterative data-aided channel estimation was first investigated in [9]. In this method, data symbols are reconstructed by properly encoding and modulating the outputs of channel decoder, so that the reconstructed data symbols are utilized as pilot signals for channel estimation. The performance of this method, however, is degraded under the presence of decoding error which leads to the mismatch between the reconstructed and transmitted data symbols. To resolve this problem, iterative data-aided channel estimation has been studied in [15, 13, 16, 14, 17], which iteratively performs channel estimation and data detection to mitigate both channel estimation and decoding errors. In [15], an iterative turbo channel estimation technique was developed in which soft-decision symbols are utilized as pilot signals at each iteration. A similar iterative approach was also developed in [16] by selectively utilizing soft-decision symbols as pilot signals according to an MSE-based criterion. The common limitation of these iterative data-aided channel estimators is that they increase not only the computational complexity of receive processing, but also communication latency.
Recently, deep-learning-based channel estimation has also drawn increasing attention in order to circumvent the limitation of pilot-aided channel estimation [18, 19, 22, 21, 20, 23, 24, 25, 26]. A basic idea of this technique is to learn a channel from training samples, each of which describes the input-output relation of a communication system. The most prominent feature of the deep-learning-based channel estimation is that it can be readily incorporated into complicated communication systems, e.g., massive MIMO, millimeter-wave, and doubly-selective channels [22, 21, 20]. The use of deep learning, however, requires a huge training set to optimize neural networks and therefore increases both computational complexity and communication latency. To resolve this drawback, a model-driven deep learning approach was studied in [23, 24, 25, 26]. This approach effectively reduces the size of training set by learning only the parameters of a model for estimating the channel. Specifically, a joint optimization with data detection and channel estimation was introduced in [25] based on a Bayesian model. A similar channel estimation method for millimeter-wave MIMO systems was introduced in [26]. Although these model-driven channel estimators effectively mitigate the limitation of the deep learning-based channel estimation, the use of deep learning still brings non-negligible computational complexity and communication latency that may not be affordable in practical systems.
This paper presents a new type of data-aided channel estimation for MIMO communication systems, referred to as semi-data-aided channel estimation, which reduces communication latency caused by iterative data-aided channel estimation. The basic strategy of the presented channel estimator is to leverage reinforcement learning (RL) for selecting reliable detected symbol vectors only among the symbols in the first part of data block. The most prominent feature of the presented channel estimator is that it does not utilize the channel decoder outputs and therefore facilitates an early update of a channel estimate even before the end of data block transmission. Simulation results demonstrate that the presented channel estimator effectively mitigate both channel estimation error and detection performance loss caused by insufficient pilot signals. The major contributions of this paper are summarized as follows:
-
•
We present a Markov decision process (MDP) to sequentially determine the best selection of detected symbol vectors for minimizing the MSE of the semi-data-aided channel estimation. To this end, we adopt a binary action that indicates whether to exploit each detected symbol vector as an additional pilot signal, while defining a reward function as the MSE reduction of the channel estimate. With this MDP, we successfully formulate a symbol vector selection problem for the semi-data-aided channel estimation as a sequential decision-making problem that can be efficiently solved via RL.
-
•
We propose a novel RL algorithm to efficiently find the best policy of the presented MDP. The underlying challenge is that the state transition of the presented MDP is unknown at the receiver due to the lack of knowledge of transmitted symbol vectors. In the proposed algorithm, we tackle this challenge by leveraging a Monte Carlo tree search (MCTS) approach in [27, 28, 29] which looks ahead the rewards of near-future actions, while approximating the rewards of distant-future actions via Monte Carlo simulations. We modify the original MCTS approach by exploiting a-posteriori probability (APP), computed from data detection, for approximating both the optimal future actions and the corresponding state transitions of the MDP. The most prominent advantage of the proposed RL algorithm is that the best policy for each state has a closed-form expression that can be readily computed at the receiver.
-
•
We present two additional strategies for enhancing the advantages of the semi-data-aided channel estimation operating with the proposed RL algorithm. In the first strategy, we develop a low-complexity policy that approximates the optimal policy of the presented MDP based on Monte Carlo sampling. Utilizing this new policy, we further reduce the computational complexity required in the proposed RL algorithm. In the second strategy, we utilize an updated channel estimate for re-detecting the symbol vectors that are not selected by the proposed RL algorithm. Utilizing this strategy, we further improve data detection performance when employing the semi-data-aided channel estimation, without a significant increase in the computational complexity.
-
•
In simulations, we evaluate the normalized MSE (NMSE) and block-error-rate (BLER) of the proposed channel estimator for a coded MIMO communication system. Our simulation results demonstrate that the proposed channel estimator significantly reduces the NMSE in channel estimation, while improving the BLER of the system, compared to conventional pilot-aided channel estimation. It is also shown that the proposed RL algorithm effectively selects detected symbol vectors that can improve the performance of the semi-data-aided channel estimation. We also investigate the robustness of the proposed channel estimator in time-varying channels and demonstrate that the proposed channel estimator reduces performance degradation in time-varying environment by tracking temporal channel variations during data transmission.
An RL algorithm for optimizing the symbol vector selection of data-aided channel estimation was first introduced in our prior work [1]. In this algorithm, the optimal policy of the MDP is derived under a simplistic assumption that underestimates the effect of future actions and rewards. In this paper, we generalize the RL algorithm in [1] by employing the MCTS approach which provides a more accurate evaluation of the effect of the future actions and rewards. In addition to this major change, we newly introduce the semi-data-aided channel estimation strategy to further reduce the delay required for updating the channel estimate and also introduce the data re-detection strategy to improve detection performance after the symbol vector selection.
The remainder of this paper is organized as follows. Section II introduces system model and preliminaries considered in this paper. In Section III, we formulate an optimization problem that adaptively selects the detected symbols for the semi-data-aided channel estimator. An efficient RL algorithm to solve the optimization problem is proposed in Section IV. Simulation results are presented in Section V to verify the effectiveness of the proposed channel estimator. The conclusion is finally presented in Section VI.
Notation
Matrices and represent the all-zero matrix and the identity matrix, respectively. Superscripts and denote the transpose and the conjugate transpose, respectively. Operators , , , and denote the expectation of a random variable, the probability of an event, the cardinality of a set, and the Frobenius norm, respectively. denotes the inverse operation. The set represents the set of complex numbers.
II System Model and Preliminaries
In this section, we introduce a MIMO communication system considered in this work. The LMMSE channel estimator and the maximum-a-posteriori-probability (MAP) data detector are presented for the considered system. We then describe the challenge of the LMMSE channel estimator to achieve the optimal performance.
II-A System model
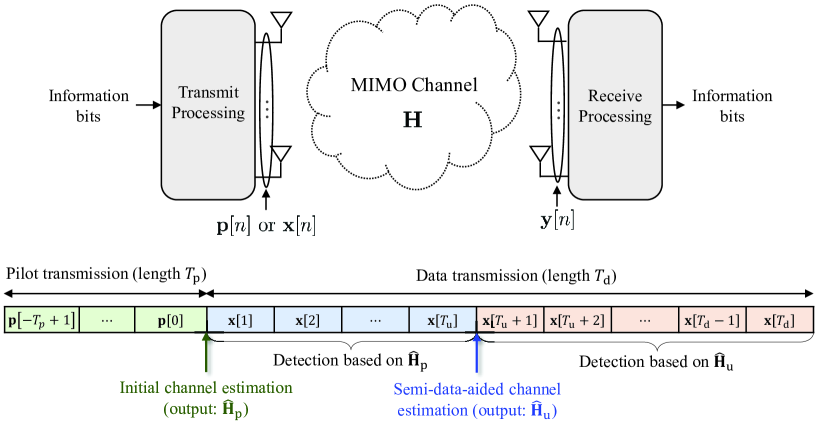
We consider a MIMO communication system in which a transmitter equipped with antennas communicates with a receiver equipped with antennas, as illustrated in Fig. 1. We model the wireless channel of the considered system as a frequency-flat Rayleigh fading channel denoted by where the entries of are independent and identically distributed (i.i.d.) random variables with the distribution of . We assume a block fading channel in which the entries of keep constant during a transmission frame.
A transmission frame consists of a pilot block with length followed by a data block with length , as illustrated in Fig. 1. A set of time slot indices associated with the pilot block and the data block is denoted by and , respectively. Let be the pilot signal sent at time slot such that . Then the received signal at time slot is given by
| (1) |
where is a circularly symmetric complex Gaussian noise vector at time slot . For the data transmission, the transmitter generates data symbol vectors after symbol mapping of information bits. Let be the data symbol vector sent at time slot , where is a constellation set such that . Then the received signal at time slot during the data transmission is given by
| (2) |
II-B LMMSE Channel Estimator
The LMMSE channel estimator is a linear estimator that minimizes the MSE of a channel estimate. This method has been widely adopted in wireless communication systems as it provides a good trade-off between estimation accuracy and computational complexity [7, 8]. Let a matrix that concatenates received signals observed during the pilot transmission. From (1), is expressed as
| (3) |
where , and . From (3), the LMMSE channel estimator is given by
| (4) |
where the expectation is taken with respect to channel and noise distributions. Consequently, the LMMSE channel estimate is computed as
| (5) |
If the entries of are i.i.d. with , the MSE of the LMMSE channel estimate is computed as
| (6) |
where and are the -th row of and , respectively. As can be seen from (II-B), the MSE of the LMMSE channel estimate decreases with the number of the pilot signals .
II-C Maximum-A-Posteriori-Probability (MAP) Data Detector
In this work, we assume that the receiver employs the MAP data detection method which finds the symbol vector with the maximum APP for a received signal. This method is optimal in terms of minimizing detection error probability and therefore has a potential to maximize the performance of a channel estimator presented in Sec. IV. Nevertheless, as will be discussed later, the applicability of the presented channel estimator is not limited to the MAP data detection method.
Let be a vector in with where . The APP of the event for the given received signal is expressed as
| (7) |
where the equality (a) holds when the probability of transmitting each symbol vector is equal (i.e., , ). Since , the probability in (II-C) is given by
| (8) |
for . This probability is also known as the likelihood function. By applying (8) into (II-C), the APP is computed as
| (9) |
Then the MAP detection rule is given by
| (10) |
In practical communication systems, the receiver cannot compute the exact APP in (9) as it requires perfect information of . As an alternative approach, an approximate APP is utilized for data detection, which is computed based on the MIMO channel estimate from (5) as follows:
| (11) |
Unfortunately, when employing the pilot-aided channel estimation with an insufficient number of the pilot signals, channel estimation error (i.e., ) is inevitable at the receiver, as shown in (II-B). Because this error leads to a mismatch between the true APP in (9) and the approximate APP in (11), the use of the approximate APP results in detection performance degradation. Moreover, the degree of the performance degradation increases as the number of the pilot signals, , reduces. To resolve this problem, in the following sections, we will present a novel channel estimation approach that utilizes detected symbol vectors to reduce the channel estimation error caused by insufficient pilot signals.
III Optimization Problem for Semi-Data-Aided Channel Estimation
Data-aided channel estimation is a well-known approach to reduce channel estimation error when the number of pilot signals is insufficient. The fundamental idea of the data-aided channel estimation is to exploit detected symbol vectors as additional pilot signals for updating a channel estimate. On the basis of the same idea, in this section, we present a new type of the data-aided channel estimation, referred to as semi-data-aided channel estimation, which enables fast update of the channel estimate with the selective use of detected symbol vectors. In what follows, we first elaborate on the basic idea of the semi-data-aided channel estimation and an optimization problem to maximize its performance. We then reformulate the optimization problem as an MDP in order to adopt RL to solve this problem.
III-A Semi-Data-Aided Channel Estimation
Our key observation is that not every detected symbol vector is a good candidate for a pilot signal because some detected symbol vectors differ from the transmitted symbol vectors due to data detection error. Another important observation is that once the receiver obtains a sufficient number of additional pilot signals, increasing the number of the pilot signals gives no significant improvement in channel estimation accuracy. Motivated by these observations, in the semi-data-aided channel estimation, we exploit only the detected symbol vectors that are beneficial for improving the channel estimation accuracy. Meanwhile, we select these symbol vectors only among the first detected symbol vectors, while utilizing the updated channel estimate for detecting the remaining symbol vectors, as illustrated in Fig. 1. We refer to this strategy as a semi-data-aided channel estimation because it utilizes only a portion of detected symbol vectors, unlike the conventional data-aided channel estimation. The most prominent advantage of our strategy is that a channel estimate is updated after the transmission of symbol vectors; thereby, our strategy significantly reduces the delay required for updating the channel estimate compared to conventional data-aided channel estimation methods that updates the channel estimates after the end of data block transmission (i.e., time slots). Moreover, the semi-data-aided channel estimation does not utilize the outputs of a channel decoder, implying that the repetitions of channel decoding process is not necessary. Because of this feature, the computational complexity of the semi-data-aided channel estimation is lower than those of conventional data-aided channel estimation methods which require to repeat the channel decoding process (e.g., [10, 11, 12, 15, 16, 17]).
III-B Optimization Problem for Symbol Vector Selection
A key to the success of the semi-data-aided channel estimation is to optimize the selection of detected symbol vectors so that the accuracy of an updated channel estimate can be maximized. A direct optimization of the symbol vector selection, however, is very challenging in practical systems due to the lack of knowledge of transmitted symbol vectors and also due to high computational complexity. To shed some light on this challenge, we formulate an optimization problem for the symbol vector selection to minimize the error of the updated channel estimate. Let be a vector whose -th entry indicates whether to utilize the detected symbol vector at time slot , , in the semi-data-aided channel estimation. If the receiver utilizes only the detected symbol vectors indicated by as additional pilot signals, the LMMSE channel estimate is updated as
| (12) |
where , , and is the index of the -th nonzero entry in a vector . Note that is the number of nonzero entries in . Based on the above notations, a symbol vector selection problem for minimizing the MSE of the updated channel estimate is formulated as
| (13) |
where the expectation is taken with respect to channel and noise distributions. The first key observation is that the distribution of depends on the transmitted symbol vectors associated with ; thereby, solving the optimization problem in (13) requires perfect knowledge of the first transmitted symbol vectors at the receiver. Another important observation is that the number of possible choices for symbol vector selection is given by which exponentially increases with the number of symbol vector candidates. These observations reveal that directly solving the problem in (13) is very challenging at the receiver in practical systems.
III-C MDP for Symbol Vector Selection
To circumvent the aforementioned challenge, we reformulate the optimization problem in (13) as an MDP which sequentially decides whether to use each detected symbol vector when its reward is a reduction in channel estimation error. In Sec. IV, we will demonstrate how this MDP allows the receiver to approximately but efficiently solves the original problem in (13) using an RL approach. Details of our MDP formulation are elaborated below.
III-C1 State
The state set of the MDP associated with time slot is defined as
| (14) |
where is the candidate index for the next transition at the -th nonzero entry in a vector such that . In (III-C1), is the set of the actions until the time slot . If , it indicates that the detected symbol vector at time slot will be exploited as additional pilot signals for the data-aided channel estimation. Using this definition, the LMMSE channel estimate obtained at the state is given by
| (15) |
where .
III-C2 Reward Function
The reward function of the MDP is defined as the MSE reduction of the channel estimate when transiting from the current state to the next state. Based on this definition, the reward function associated with the state transition from to is given by
| (16) |
III-C3 Action
The action set of the MDP is defined as which indicates whether to exploit the current detected symbol vector as an additional pilot signal. For example, the action with implies that the detected symbol vector will be exploited as the pilot signal.
III-C4 State Transition
From the definitions of the state and action, the current state is updated using the detected symbol vector when ; otherwise, the current state remains unchanged. Thus, the state that can be transited to the current is given by
| (17) |
III-C5 Optimal Policy
The optimal policy of the MDP for a state is defined as
| (18) |
where is the Q-value function that represents the optimal sum of the rewards obtained after taking the action at the state . By the definition in (17), can be expressed as
| (19) |
where is a discounting factor, and is the optimal value function which is the optimal sum of the rewards that can be obtained from the state with . The optimal value function for a state can be recursively computed as follows:
| (20) |
where is the probability of choosing action at the state according to the optimal policy. In Fig. 2, we depict the state-action diagram of the MDP defined above. In this figure, the state is transited to the next state when taking an action . Particularly, when , the state is transited to the state by exploiting the transmitted symbol index . Based on the state transition and the optimal policy in (18), the states are transited to the next states until the end of data subblock.
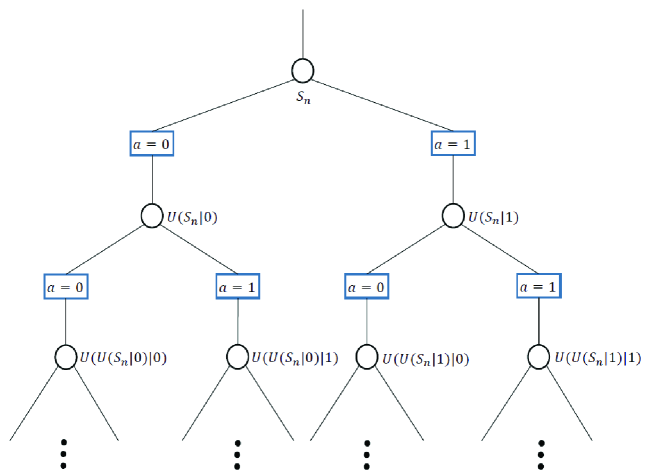
Characterizing the optimal policy of the above MDP faces two major challenges in practical communication systems. First, the state transition is unknown at the receiver due to the lack of information of the transmitted symbol vectors. Second, the number of the states in this MDP exponentially increases with the length of (see Fig. 2). To circumvent these challenges, in the following section, we design a computationally-efficient algorithm to solve the MDP without perfect knowledge on the state transition and the reward function.
IV Proposed Channel Estimator via Reinforcement Learning
RL is a type of machine learning that can find the optimal policy of an MDP with unknown or partial information on an environment’s dynamics [27]. In this section, we propose an efficient RL algorithm to approximately but efficiently determine the optimal policy of the MDP in Sec. III-C. We then present the semi-data-aided channel estimator that utilizes the proposed RL algorithm for optimizing the symbol vector selection. We also introduce an additional strategy to improve detection performance after the symbol vector selection in the semi-data-aided channel estimator.
IV-A Proposed RL Algorithm
The key idea of the proposed RL algorithm is to exploit the APP computed from data detection for approximately determining the optimal policy based on MCTS [27, 28, 29]. In the proposed algorithm, we particularly modify the original MCTS to make this approach applicable for the receiver in practical systems. In what follows, we elaborate on the details of the proposed RL algorithm applied to determine the optimal policy for the state with .
IV-A1 Tree Policy and Rollout Policy
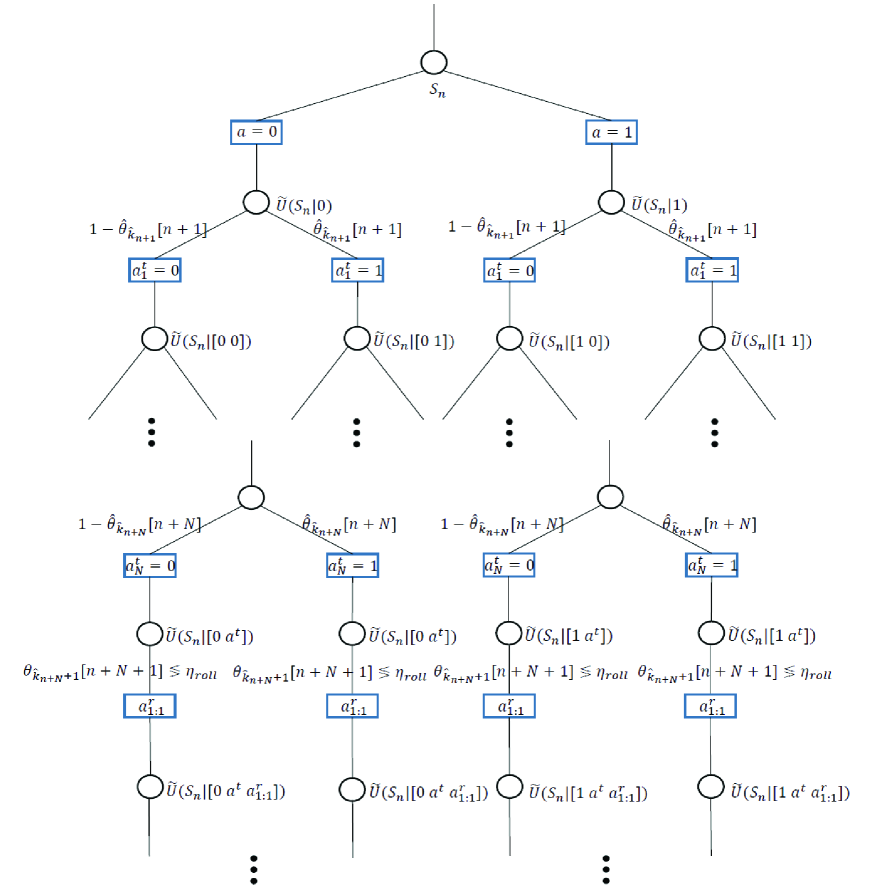
The basic idea of MCTS is to determine the best action at the current state by looking ahead the rewards of near-future actions according to a tree policy, while approximating the rewards of distant-future actions according to a rollout policy [27]. Typically, the tree policy is designed to mimic the optimal policy, while the design of the rollout policy focuses more on computational simplicity and tractability. To design an effective tree policy for the proposed algorithm, our intuition is that the higher the reliability of the detected symbol vector is, the higher the probability of selecting the corresponding symbol vector as an additional pilot signal is. Inspired by this intuition, we exploit the APP computed from data detection as a measure of the reliability of the detected symbol vector. We then set the tree policy of the proposed algorithm as
| (21) |
for every state with , where is the number of the near-future actions taken according to the tree policy. We also denote the sequence of actions randomly chosen by the tree policy in (21) by . To determine an effective rollout policy, we introduce a pre-determined threshold such that . We then choose the action if the APP is higher than and otherwise, i.e.,
| (22) |
for every state associated with time slot . Our rollout policy is useful to reduce the computational complexity of the value function estimation after state transitions. Meanwhile, this policy also mimics the behavior of the tree policy (21) if the detected symbol vector is reliable enough (i.e., ). We denote the sequence of actions determined by the rollout policy in (22) by .
IV-A2 Approximation for Monte Carlo Simulations
In the original MCTS, the optimal value function is estimated through Monte Carlo simulations according to the tree policy and the rollout policy [27]. Unfortunately, a receiver in practical communication systems cannot adopt such simulation-based approach because executing the Monte Carlo simulations requires perfect information of the transmitted symbol vectors at the receiver. To circumvent this limitation, we introduce a virtual state that can mimic the effect of Monte Carlo simulations without actual execution. The virtual state is defined as the state that can be arrived when the true symbol vector exactly behaves like its expectation:
| (23) |
for . We refer to the expectation in (23) as an expected symbol vector at time slot . Since the receiver cannot compute the exact APP due to the lack of perfect channel knowledge, we use an approximate APP for tracking both the tree policy and the rollout policy. When tracking the tree policy, we use an accurate estimate based on a new channel estimate obtained by taking the series of actions according to the tree policy. Let be the sequence of the actions chosen by the tree policy in (21). When taking the actions in from the state , the LMMSE channel estimate is given by
| (24) |
where
Based on the channel estimate in (24), the APP estimate used for tracking the tree policy is determined as
| (25) |
Unlike the tree policy, we use the initial estimate of the APP in (11) when tracking the rollout policy, in order to reduce a required computational complexity. Utilizing the above strategy, we approximate the expected symbol vector as
| (26) |
Under the assumption of for , the virtual state arrived when taking the sequence of actions from the state is given by
| (27) |
where
By using our policies (21), (22) and virtual state in (27), we depict the state-action diagram of our MCTS approach in Fig. 3. The tree policy that mimics the optimal policy is applied for the time indices . Because the tree policy considers the effect of both actions, the number of states to compute is proportional to . In contrast, the rollout policy only considers the reliable state which has a higher APP and therefore requires a much lower computational complexity.
IV-A3 Optimal Policy
Based on the MCTS approach explained above, we characterize the optimal policy of the MDP in Sec. III-C in a closed-form expression. This result is given in the following theorem:
Theorem 1
Proof:
See Appendix A. ∎
The optimal policy in (28) determines the best action at the current state by considering the average reward of all possible future actions that can be chosen by the tree policy. In this context, the weight in (29) represents the probability of taking a certain sequence of actions, , according to the tree policy in (21). As can be seen from Theorem 1, the most prominent feature of the proposed RL algorithm is that the optimal policy has a closed-form expression which can be computed in a deterministic way at the receiver in practical systems.
IV-A4 Low-Complexity Policy
A major limitation of the optimal policy in (28) is that the complexity of computing the policy increases exponentially with the number of the near-future actions, . Therefore, computing this policy is not affordable if is large, implying that we cannot arbitrarily increase the value of to improve the performance of the proposed RL algorithm. To circumvent this limitation, we develop a low-complexity policy that approximates the optimal policy in (28) based on Monte Carlo sampling. Recall that the weighted sum in (28) is nothing but the expectation of because is the probability of obtaining an action sequence from the tree policy in (21). Motivated by this observation, we randomly draw samples of according to the tree policy. We then compute the empirical mean of by averaging the values of computed for samples. Let be the empirical mean determined by the Monte Carlo sampling approach. Then the optimal policy is approximately determined as . We refer to this policy as a low-complexity policy for the state . The complexity required for determining the low-complexity policy increases linearly with the number of samples, , and is independent from . Therefore, the overall complexity of the proposed RL algorithm can be significantly reduced by harnessing the low-complexity policy with . It is also possible to reduce a mismatch between the optimal policy and the low-complexity policy by increasing at the cost of the complexity.
Remark (Applicability to other data detection methods): A key requirement of the proposed RL algorithm is the APPs that can be directly obtained from the MAP data detection method. Despite this requirement, the proposed RL algorithm is universally applicable to any other soft-output data detection method which computes the log-likelihood ratios (LLRs) of transmitted data bits. In this case, the proposed RL algorithm can utilize the APPs computed from the LLRs which can be readily performed at the receiver with a slight increase in the computational complexity.
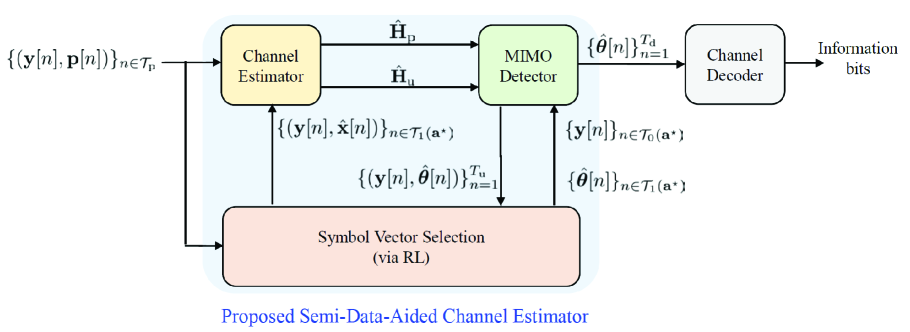
IV-B Proposed Channel Estimator
The proposed channel estimator adopts the RL algorithm in Sec. IV-A for optimizing the selection of detected symbol vectors utilized as additional pilot signals. The proposed channel estimator is summarized in Algorithm 1. In particular, depending on the choice of a policy determination strategy, the receiver computes either the optimal policy in Step or the low-complexity policy in Steps –. In Step , we consider the most probable state transition for the unknown transmitted symbol vector. To address this, the detected symbol vector is assumed to be the same as the transmitted symbol vector if the action is chosen according to the optimal policy. The corresponding state is given by,
| (31) |
Finally, at time slot , we can obtain the updated channel estimate .
IV-C Re-Detection of Unselected Symbol Vectors
An important byproduct of the proposed semi-data-aided channel estimator is the set of detected symbol vectors that are not selected as pilot signals for channel estimation. Since these vectors are turned out to be not reliable, we can treat them as incorrectly detected symbol vectors. Motivated by this observation, to further improve detection performance, we utilize the final channel estimate determined by Algorithm 1 for re-detecting received signals associated with the symbol vectors not selected by the proposed RL algorithm. Suppose that the final state and the channel estimate of Algorithm 1 is given by and , respectively. Then the set of time slot indices associated with the unselected symbol vectors is expressed as
| (32) |
where is the -th entry of . The optimal MAP data detection is performed again based on for the received signals associated with time slots in . This strategy yields
| (33) |
where
| (34) |
In Fig. 4, we illustrate the overall receive processing with the proposed semi-data-aided channel estimator and the re-detection strategy, where and . Although the re-detection process requires an additional complexity, this process is executed only once more for a portion of received signals. Therefore, the complexity of our strategy is still lower than that of iterative data-aided channel estimation (e.g., [11, 12, 13, 14, 15, 16]) which requires multiple executions of channel estimation and data detection for the whole received signals.
V Simulation Results
In this section, using simulations, we evaluate the NMSE and BLER of the proposed channel estimator in a coded MIMO system with the MAP data detection method. In these simulations, we consider 4-QAM for symbol mapping and assume that , , , , and . For channel coding, we adopt the rate turbo code based on parallel concatenated codes with feedforward and feedback polynomial in octal notation. For performance comparison, we consider the following methods:
-
•
PCSI: This is an ideal case in which perfect channel state information is available at the receiver (i.e., ).
-
•
Pilot-CE: This is a conventional pilot-aided channel estimator described in Sec. II-B.
-
•
Semi-CE (Opt): This is a semi-data-aided channel estimator when correctly detected symbol vectors are utilized as additional pilot signals by assuming perfect knowledge of transmitted symbol vectors. This can be interpreted as the true optimal policy of the MDP in Sec. III-C.
-
•
Semi-CE (Pro, Opt): This is a semi-data-aided channel estimator when detected symbol vectors are selected according to the optimal policy determined by the proposed RL algorithm. A re-detection strategy discussed in Sec. IV-C is also adopted.
-
•
Semi-CE (Pro, Low): This is a semi-data-aided channel estimator when detected symbol vectors are selected according to the low-complexity policy determined by the proposed RL algorithm. A re-detection strategy discussed in Sec. IV-C is also adopted.
-
•
Semi-CE (All): This is a semi-data-aided channel estimator when all the expected symbol vectors in (23) are utilized as additional pilot signals.
-
•
Iter-CE: This is an iterative data-aided channel estimator in which the best virtual pilots are utilized as additional plot signals for every iteration. The number of iterations is set as . This method is a slight modification of the method proposed in [16].
We set the parameters of the proposed RL algorithm as unless specified otherwise. We define a per-bit signal-to-noise ratio (SNR) as , and also define NMSE as .
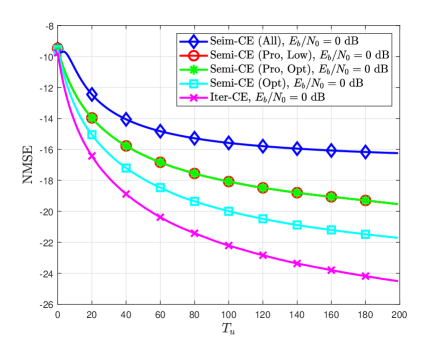
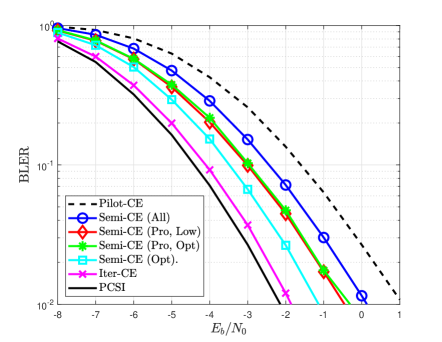
Fig. 5 compares the NMSE and BLER of various channel estimators for different per-bit SNRs. Fig. 5 shows the proposed channel estimator has better NMSE and BLER performances than the conventional pilot-aided channel estimator by exploiting detected symbol vectors as additional pilot signals. It is also shown that the proposed channel estimator outperforms Semi-CE (All) which exploits all the detected symbol vectors without a proper selection. Meanwhile, the SNR gap between the proposed channel estimator and Semi-CE (Opt) is only dB. These results demonstrate that the proposed RL algorithm effectively selects a set of detected symbol vectors that can improve the performance of the semi-data-aided channel estimation. Another interesting observation is that Semi-CE (Pro, Low) has a similar performance to Semi-CE (Pro, Opt); this result implies that the low-complexity policy, whose complexity is proportional to , well approximates the optimal policy, whose complexity is proportional to , by leveraging a Monte Carlo sampling method. Although Iter-CE achieves the best performance among the considered channel estimators, it significantly increases both the delay and computational complexity of the overall receive processing because this estimator requires repeated executions of both data detection and channel decoding.
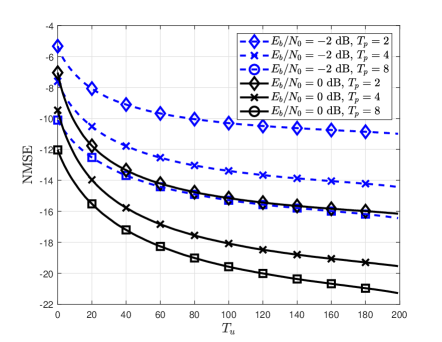
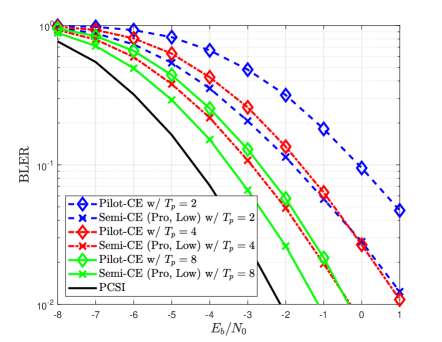
Fig. 6 compares the NMSE and BLER of various channel estimators for different pilot lengths. Fig. 6 shows that the proposed channel estimator provides significant performance gain compared to the conventional pilot-aided channel estimator regardless of the pilot length. It is also shown that a larger NMSE reduction is achieved in the case of dB than in the case of dB. The reason behind this result is that the number of reliable detected symbol vectors increases as the detection performance improves, which allows the use of a more accurate MCTS approach in the proposed RL algorithm. Another interesting observation in Fig. 6(b) is that the proposed channel estimator with even outperforms Pilot-CE with , which implies that the proposed estimator requires fewer pilot signals to achieve the same BLER performance.
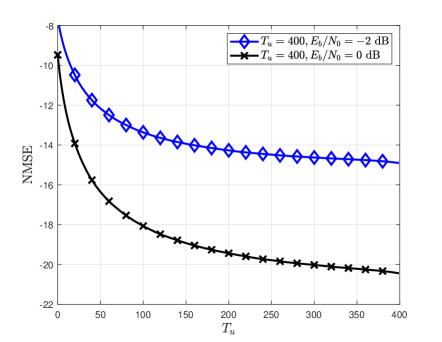
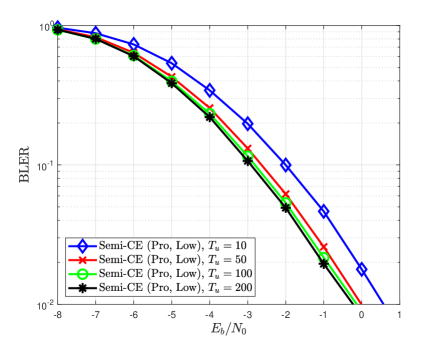
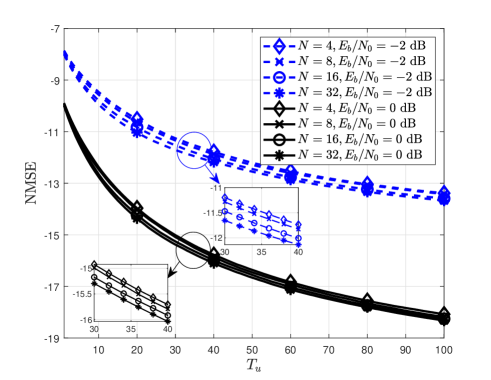
Fig. 7 compares the NMSE and BLER of the proposed channel estimator for different . Fig. 6(a) shows that the NMSE performance of the proposed channel estimator improves with . This gain is attained by increasing the number of detected symbol vectors that can be utilized as additional pilot signals. Thanks to this gain, in Fig. 6(b), it is shown that the BLER performance with the proposed channel estimator also improves with . Another important observation is that the improvement of both the NMSE and BLER performances decreases as increases. This result implies that once a sufficient number of additional pilot signals are attained, there is no significant gain by increasing the number of pilot signals, while the computational complexity of data-aided channel estimation is proportional to . Considering this fact, the semi-data-aided channel estimation is an effective strategy for adjusting the performance-complexity trade-off of data-aided channel estimation, by controlling the length of .
Fig. 8 compares the NMSE of the proposed channel estimator for different numbers of the near-future actions, , in the MCTS approach. Fig. 8 shows that the NMSE performance of the proposed channel estimator improves with because increasing this number allows the proposed RL algorithm to accurately estimate near-future rewards. This performance gain, however, is attained at the cost of the computational complexity required for determining the best policy for the MDP. Considering this trade-off, in our simulations, we set which provides sufficient accuracy for the estimation of the near-future rewards, while preventing from a significant increase in the computational complexity.
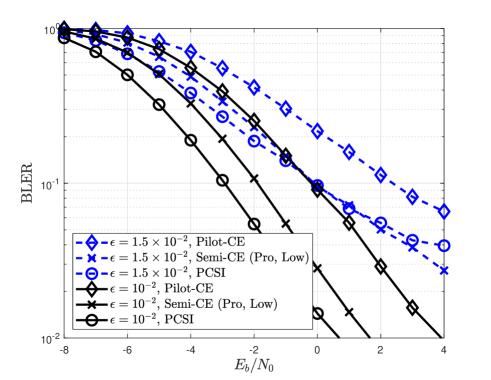
Fig. 9 compares the BLER of various channel estimators in time-varying channels. To model these channels, we adopt the first-order Gaussian-Markov process in [31, 32] in which the channel matrix at time slot is given by
| (35) |
for , where is a temporal correlation coefficient, and is an i.i.d. Gaussian random matrix with zero mean and unit variance. In this simulation, the temporal correlation coefficient is set as or . Note that PCSI in Fig. 9 assumes perfect CSIR only at the beginning of data transmission (i.e., ), while it does not assume perfect channel tracking during data transmission. Fig. 9 shows that the BLER performance loss due to channel estimation error is more severe when the wireless channel varies over time because accurate channel estimation is more challenging in time-varying channels. In particular, when , PCSI at still shows severe degradation in the BLER performance if the receiver does not properly track temporal channel variations. Unlike this, the proposed channel estimator is shown to be robust against temporal channel variations because it has a potential to track the channel variations during the first time slots, by exploiting detected symbol vectors as additional pilot signals.
VI Conclusions
In this paper, we have proposed a semi-data-aided LMMSE channel estimator for MIMO systems. The key idea of the proposed estimator is to selectively exploit detected symbol vectors as additional pilot signals, while optimizing this selection via RL. To this end, we have defined the MDP for symbol vector selection and then developed a novel RL algorithm based on the MCTS approach. Using simulations, we have demonstrated that the proposed channel estimator reduces the NMSE in channel estimation, while improving the BLER of the system, compared to conventional pilot-aided channel estimation. Meanwhile, the proposed channel estimator significantly reduces communication latency for updating a channel estimate compared to conventional iterative data-aided channel estimators. An important future research direction is to develop a semi-data-aided channel estimator for wideband systems by modifying both the MDP and the proposed RL algorithm. It would also be interesting to develop a semi-data-aided channel estimator for time-varying systems by properly defining the reward function of the MDP to consider the effect of temporal channel variations.
Let be the error covariance matrix between and , where are the -th row of . This covariance matrix does not depend on the index of a receive antenna because the channel and the noise distributions are assumed to be equal across different receive antennas. Therefore, the MSE of the channel estimate at the state is given by
| (36) |
Utilizing this fact, the reward function in (16) associated with the state transition from to is computed as
| (37) |
Meanwhile, when , the future reward in (20) can be expressed by exploiting (21), (22), and (27) as
| (38) |
where is a sub-vector of when . We assume that is the empty set with a slight abuse of notation. By applying (37) and (VI) into (19) and (20), the Q-value is obtained as
| (39) |
Then the optimal policy in (18) is expressed as
| (40) |
where
| (41) | ||||
| (42) |
The remaining task is to characterize in (41). From (17) and (27), the virtual state is characterized as
| (43) |
Therefore, from (2) and (VI), the distribution of is given by
| (44) |
Using this fact, the error covariance matrix in (41) is expressed as
| (45) |
where
and both (a) and (b) come from (VI). By using the error covariance matrix in (45), in (41) is rewritten as
| (46) |
By the matrix inversion lemma, the matrix is rewritten as
| (47) |
From (47), the first term of the right-hand-side (RHS) of (VI) is expressed as
| (48) |
where with . The second term of the RHS of (VI) is expressed as
| (49) |
where . The last term of the RHS of (VI) is computed as
| (50) |
where , , and . Applying (48)–(VI) into (41) yields
| (51) |
Finally, we obtain the result in (28) from (40) with (51) and (42), where and .
References
- [1] Y.-S. Jeon, J. Li, N. Tavangaran, and H. V. Poor, “Data-Aided Channel Estimator for MIMO Systems via Reinforcement Learning,” in Proc. IEEE Int. Conf. Commun. (ICC), Dublin, Ireland, Jun. 2020.
- [2] G. J. Foschini, “Layered Space-Time Architecture for Wireless Communication in a Fading Environment When Using Multi-Element Antennas,” Bell Labs Tech. J., vol. 1, no. 2, pp. 41–-59, Aut. 1996.
- [3] I. E. Telatar, “Capacity of Multi-Antenna Gaussian Channels,” Europ. Trans. Telecommun., vol. 10, pp. 585–-595, Nov./Dec. 1999.
- [4] L. Zheng and D. N. C. Tse, “Diversity and Multiplexing: A Fundamental Tradeoff in Multiple-Antenna Channels,” IEEE Trans. Inf. Theory, vol. 49, no. 5, pp. 1073-–1096, May 2003.
- [5] O. Simeone, Y. Bar-Ness and U. Spagnolini, “Pilot-Based Channel Estimation for OFDM Systems by Tracking the Delay-Subspace,” IEEE Trans. Wireless Commun., vol. 3, pp. 315–325, Jan. 2004.
- [6] H. M. Kim, D. Kim, T. K. Kim, and G. H. Im, “Frequency Domain Channel Estimation for MIMO SC-FDMA Systems With CDM Pilots,” J. Commun. Networks, vol. 16, no. 4, pp. 447–457, Aug. 2014.
- [7] M. Biguesh and A. B. Gershman, “Training-Based MIMO Channel Estimation: A Study of Estimator Tradeoffs and Optimal Training Signals,” IEEE Trans. Signal Process., vol. 54, no. 3, pp. 884-–893, Mar. 2006.
- [8] M. K. Ozdemir and H. Arslan, “Channel Estimation for Wireless OFDM Systems,” IEEE Commun. Surveys Tuts., vol 9, no. 2, pp. 18–-48, Jul. 2007.
- [9] A. Dowler, A. Nix, and J. McGeehan, “Data-Derived Iterative Channel Estimation with Channel Tracking for a Mobile Fourth Generation Wide Area OFDM System,” in Proc. IEEE Global Telecommun. Conf. (GLOBECOM), Dec. 2003.
- [10] M. Liu, M. Crussière, and J.-F. Hélard, “A Novel Data-Aided Channel Estimation With Reduced Complexity for TDS-OFDM System,” IEEE Trans. Broadcast., vol. 58, no. 2, pp. 247–260, Jun. 2012.
- [11] D. Kim, H. M. Kim, and G. H. Im, “Iterative Channel Estimation with Frequency Replacement for SC-FDMA Systems,” IEEE Trans. Commun., vol. 60, no. 7, pp. 1877–1888, Jul. 2012.
- [12] D. Verenzuela, E. Björnson, X. Wang, M. Arnold, and S. t. Brink, “Massive-MIMO Iterative Channel Estimation and Decoding (MICED) in the Uplink,” IEEE Trans. Commun., vol. 68, no. 2, pp. 854–870, Feb. 2020.
- [13] J. Ma and L. Ping, “Data-Aided Channel Estimation in Large Antenna Systems,” IEEE Trans. Signal Process., vol. 62, no. 12, pp. 3111–3124, Jun. 2014.
- [14] C. Huang, L. Liu, C. Yuen, and S. Sun, “Iterative Channel Estimation Using LSE and Sparse Message Passing for mmWave MIMO Systems,” IEEE Trans. Signal Process., vol. 67, no. 1, pp. 245–259, Jan. 2018.
- [15] M. Zhao, Z. Shi, and M. C. Reed, “Iterative Turbo Channel Estimation for OFDM System over Rapid Dispersive Fading Channel,” IEEE Trans. Wireless Commun., vol. 7, no. 8, Aug. 2008.
- [16] S. Park, B. Shim, and J. W. Choi, “Iterative Channel Estimation Using Virtual Pilot Signals for MIMO-OFDM Systems,” IEEE Trans. Signal Process., vol. 63, no. 12, pp. 3032–3045, Jun. 2015.
- [17] S. Park, J. W. Choi, J. Y. Seol, and B. Shim, “Expectation-Maximization-based Channel Estimation for Multiuser MIMO Systems,” IEEE Trans. Commun., vol. 65, no. 6, pp. 2397–2410, Jun. 2017.
- [18] D. Neumann, T. Wiese, and W. Utschick, “Learning the MMSE Channel Estimator,” IEEE Trans. Signal Process., vol. 66, no. 11, pp. 2905–2917, Jun. 2018.
- [19] J. Zhang, X. Ma, J. Qi, and S. Jin, “Designing Tensor-Train Deep Neural Networks for Time-Varying MIMO Channel Estimation,” IEEE J. Sel. Topics Signal Process., vol. 15, no. 3, pp. 759–773, Apr. 2021.
- [20] H. He, C. K. Wen, S. Jin, and G. Y. Li, “Deep Learning-Based Channel Estimation for Beamspace mmWave Massive MIMO Systems,” IEEE Wireless Commun. Lett., vol. 7, no. 5, pp. 852–855, Oct. 2018.
- [21] Y. Yang, F. Gao, X. Ma, and S. Zhang, “Deep Learning-Based Channel Estimation for Doubly Selective Fading Channels,” IEEE Access, vol. 7, pp. 36579–36589, Mar. 2019.
- [22] C. J. Chun, J. M. Kang, and I. M. Kim, “Deep Learning-Based Channel Estimation for Massive MIMO Systems,” IEEE Wireless Commun. Lett., vol. 8, no. 4, pp. 1228–1231, Aug. 2019.
- [23] Y. Qiang, X. Shao, and X. Chen, “A Model-Driven Deep Learning Algorithm for Joint Activity Detection and Channel Estimation,” IEEE Commun. Lett., vol. 24, no. 11, pp. 2508–2512, Nov. 2020.
- [24] Y. Wei, M. Zhao, M. Zhao, M. Lei, and Q. Yu, “An AMP-Based Network With Deep Residual Learning for mmWave Beamspace Channel Estimation,” IEEE Wireless Commun. Lett., vol. 8, no. 4, pp. 1289–1292, Aug. 2019.
- [25] H. He, C.-K. Wen, S. Jin, and G. Y. Li, “Model-Driven Deep Learning for MIMO Detection,” IEEE Trans. Signal Process., vol. 68, pp. 1702–1715, Feb. 2020.
- [26] X. Ma, Z. Gao, F. Gao, and M. D. Renzo, “Model-Driven Deep Learning Based Channel Estimation and Feedback for Millimeter-Wave Massive Hybrid MIMO Systems,” IEEE J. Sel. Areas Commun., vol. 39, no. 8, pp. 2388–2406, Aug. 2021.
- [27] R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction, Cambridge, MA: The MIT Press, 2018.
- [28] C. B. Browne et al., “A Survey of Monte Carlo Tree Search Methods,” IEEE Trans. Comput. Intell. AI in Games, vol. 4, no. 1, pp. 1–43, Mar. 2012.
- [29] T. Vodopivec, S. Samothrakis, and B. Ster, “On Monte Carlo Tree Search and Reinforcement Learning,” J. Artif. Intell. Res., vol. 60, pp. 881–936, Dec. 2017.
- [30] Y.-S. Jeon, N. Lee, and H. V. Poor, “Robust Data Detection for MIMO Systems with One-Bit ADCs: A Reinforcement Learning Approach,” IEEE Trans. Wireless Commun., vol. 19, no. 3, pp. 1663–1676, Mar. 2020.
- [31] M. Dong, L. Tong, and B. M. Sadler, “Optimal Insertion of Pilot Symbols for Transmissions over Time-Varying Flat Fading Channels,” IEEE Trans. Signal Process., vol. 52, no. 5, pp. 1403–1418, May 2004.
- [32] T. K. Kim, Y.-S. Jeon, and M. Min, “Training Length Adaptation for Reinforcement Learning-Based Detection in Time-Varying Massive MIMO Systems With One-Bit ADCs,” IEEE Trans. Veh. Technol., vol. 70, no. 7, pp. 6999–7011, Jul. 2021.