remarkRemark \newsiamremarkhypothesisHypothesis \newsiamthmclaimClaim \newsiamthmexampleExample \headersSemi-Riemannian Manifold OptimizationT. Gao, L.-H. Lim, and K. Ye
Semi-Riemannian Manifold Optimization
Abstract
We introduce in this paper a manifold optimization framework that utilizes semi-Riemannian structures on the underlying smooth manifolds. Unlike in Riemannian geometry, where each tangent space is equipped with a positive definite inner product, a semi-Riemannian manifold allows the metric tensor to be indefinite on each tangent space, i.e., possessing both positive and negative definite subspaces; differential geometric objects such as geodesics and parallel-transport can be defined on non-degenerate semi-Riemannian manifolds as well, and can be carefully leveraged to adapt Riemannian optimization algorithms to the semi-Riemannian setting. In particular, we discuss the metric independence of manifold optimization algorithms, and illustrate that the weaker but more general semi-Riemannian geometry often suffices for the purpose of optimizing smooth functions on smooth manifolds in practice.
keywords:
manifold optimization, semi-Riemannian geometry, degenerate submanifolds, Lorentzian geometry, steepest descent, conjugate gradient, Newton’s method, trust region method90C30, 53C50, 53B30, 49M05, 49M15
1 Introduction
Manifold optimization [12, 2] is a class of techniques for solving optimization problems of the form
| (1) |
where is a (typically nonlinear and nonconvex) manifold and is a smooth function over . These techniques generally begin with endowing the manifold with a Riemannian structures, which amounts to specifying a smooth family of inner products on the tangent spaces of , with which analogies of differential quantities such as gradient and Hessian can be defined on in parallel with their well-known counterparts on Euclidean spaces. This geometric perspective enables us to tackle a constrained optimization problem Eq. 1 using methodologies of unconstrained optimization, which becomes particularly beneficial when the constraints (expressed in ) appear highly nonlinear and nonconvex.
The optimization problem Eq. 1 is certainly independent of the choice of Riemannian structures on ; in fact, all critical points of on are metric independent. From a differential geometric perspective, equipping the manifold with a Riemannian structure and studying the critical points of a generic smooth function is highly reminiscent of the classical Morse theory [27, 33], for which the main interest is to understand the topology of the underlying manifold; the topological information needs to be extracted using tools from differential geometry, but is certainly independent of the choice of Riemannian structures. It is thus natural to inquire the influence of different choices of Riemannian metrics on manifold optimization algorithms, which to our knowledge has never been explored in existing literature. This paper stems from our attempts at understanding the dependence of manifold optimization on Riemannian structure. It turns out that most technical tools for optimization on Riemannian manifolds can be extended to a larger class of metric structures on manifolds, namely, semi-Riemannian structures. Just as a Riemannian metric is a smooth assignment of inner products to tangent spaces, a semi-Riemannian metric smoothly assigns to each tangent space a scalar product, which is a symmetric bilinear form but without the constraint of positive definiteness; our major technical contribution in this paper is an optimization framework built upon the rich differential geometry in such weaker but more general metric structures, of which standard unconstrained optimization on Euclidean spaces and Riemannian manifold optimization are special cases. Though semi-Riemannian geometry has attracted generations of mathematical physicists for its effectiveness in providing space-time model in general relativity [35, 9], to the best of our knowledge, the link with manifold optimization has never been explored.
A different yet strong motivation for investigating optimization problems on semi-Riemannian manifolds arises from the Riemannian geometric interpretation of interior point methods [31, 41]. For a twice differentiable and strongly convex function defined over an open convex domain in an Euclidean space, denote by and for the gradient and Hessian of , respectively. The strong convexity of ensures which defines a local inner product by
With respect to this class of new local inner products, which can be interpreted as turning into a Riemannian manifold , the gradient of takes the form
The negative manifold gradient coincides with the descent direction satisfying the Newton’s equation
| (2) |
at . In other words, the Newton method, which is second order, can be interpreted as a first order method in the Riemannian setting. Such equivalence between first and second order methods under coordinate transformation is also known in other contexts such as natural gradient descent in information geometry; see [40] and the references therein. Extending this geometric picture beyond the relatively well-understood case of strongly convex functions requires understanding optimization on semi-Riemannian manifolds as a first step; we expect the theoretical foundation laid out in this paper will shed light upon gaining deeper geometric insights on the convergence of non-convex optimization algorithms.
The rest of this paper is organized as follows. In Section 2 we provide a brief but self-contained introduction to Riemannian optimization and semi-Riemannian geometry. Section 3 details the algorithmic framework of semi-Riemannian optimization, and proposes semi-Riemannian analogies of the Riemannian steepest descent and conjugate gradient algorithms; the metric independence of some second-order algorithms are also investigated. We specialize the general geometric framework to submanifolds in Section 4, in which we characterize the phenomenon (which does not exist in Riemannian geometry) of degeneracy for induced semi-Riemannian structures, and identify several (nearly) non-degenerate examples to which our general algorithmic framework applies. We illustrate the utility of the proposed framework with several examples in Section 5 and conclude with Section 6. More examples and some omitted proofs are deferred to the Supplementary Materials.
2 Preliminaries
2.1 Notations
We denote a smooth manifold using or . Lower case letters such as or will be used to denote vectors or points on a manifold, depending on the context. We write and for the tangent and cotangent bundles of , respectively. For a fibre bundle , will be used to denote smooth sections of this bundle. Unless otherwise specified, we use or to denote a semi-Riemannian metric. For a smooth function , notations and stand for semi-Riemannian gradients and Hessians, respectively, when they exist; and will be reserved for Riemannian gradients and Hessians, respectively. More generally, will be used to denote the Levi-Civita connection on the semi-Riemannian manifold, while denotes for the Levi-Civita connection on a Riemannian manifold. We denote anti-symmetric (i.e. skew-symmetric) matrices and symmetric matrices of size -by- with and , respectively. For a vector space , and stands for alternated or symmetrized copies of , respectively.
2.2 Riemannian Manifold Optimization
As stated at the beginning of this paper, manifold optimization is a type of nonlinear optimization problems taking the form of Eq. 1. The methodology of Riemannian optimization is to equip the smooth manifold with a Riemannian metric structure, i.e. positive definite bilinear forms on the tangent spaces of that varies smoothly on the manifold [28, 10, 38]. The differentiable structure on facilitates generalizing the concept of differentiable functions from Euclidean spaces to these nonlinear objects; in particular, notions such as gradient and Hessian are available on Riemannian manifolds and play the same role as their Euclidean space counterparts.
The algorithmic framework of Riemannian manifold optimization has been established and investigated in a sequence of works [13, 44, 12, 2]. These algorithms typically builds upon the concepts of gradient, the first-order differential operator defined by
and Hessian, the covariant derivative of the gradient operator defined by
as well as a retraction from each tangent plane to the manifold such that (1) for all , and (2) the differential map of is identify at . On Riemannian manifolds it is natural to use the exponential mapping as the retraction, but any general map from tangent spaces to the Riemannian manifold suffices; in fact, the only requirement implied by conditions (1) and (2) is that the retraction map coincides with the exponential map up to the first order.
The optimality conditions for unconstrained optimization on Euclidean spaces in terms of gradients and Hessians can be naturally translated into the Riemannian manifold setting:
Proposition 2.1 ([8], Proposition 1.1).
A local optimum of Problem Eq. 1 satisfies the following necessary conditions:
-
(i)
if is first-order differentiable;
-
(ii)
and if is second-order differentiable.
Following [8], we call satisfying condition (i) in Proposition 2.1 a (first-order) critical point or stationary point, and a point satisfying condition (i) in Proposition 2.1 a second-order critical point.
The heart of Riemannian manifold optimization is to transform the nonlinear constrained optimization problem Eq. 1 into an unconstrained problem on the manifold . Following this methodology, classical unconstrained optimization algorithms such as gradient descent, conjugate gradients, Newton’s method, and trust region methods have been generalized to Riemannian manifolds; see [2, Chapter 8]. For instance, the dynamics of the iterates generated by gradient descent algorithm on Riemannian manifolds essentially replaces the descent step with its Riemannian counterpart . Other differential geometric objects such as parallel-transport, Hessian, and curvature render themselves naturally en route to adapting other unconstrained optimization algorithms to the manifold setting. We refer interested readers to [2] for more details.
2.3 Semi-Riemannian Geometry
Semi-Riemannian geometry differs from Riemannian geometry in that the bilinear form equipped on each tangent space can be indefinite. Classical examples include Lorentzian spaces and De Sitter spaces in general relativity; see e.g. [35, 9]. Although one may think of Riemannian geometry as a special case of semi-Riemannian geometry as all Riemannian metric tensors are automatically semi-Riemannian, the existence of a semi-Riemannian metric with nontrivial index (see definition below) actually imposes additional constraints on the tangent bundle of the manifold and is thus often more restrictive—the tangent bundle should admit a non-trivial splitting into the direct sum of “positive definite” and “negative definite” sub-bundles. Nevertheless, such metric structures have found vast applications in and beyond understanding the geometry of spacetime, for instance, in the study of the regularity of optimal transport maps [21, 20, 3].
Definition 2.2.
A symmetric bilinear form on a vector space is non-degenerate if
The index of a symmetric bilinear form on is the dimension of the maximum negative definite subspace of ; similarly, we denote for the dimension of the maximum positive definite subspace of . A scalar product on a vector space is a non-degenerate symmetric bilinear form on . The signature of a scalar product on with index is a vector of length with the first entries equaling and the rest of entries equaling . A subspace is said to be non-degenerate if the restriction of the scalar product to is non-degenerate.
The main difference between a scalar product and an inner product is that the former needs not possess positive definiteness. The main issue with this lack of positivity is the consequent lack of a meaningful definition for “orthogonality” — a vector subspace may well be the orthogonal complement of itself: consider for example the subspace spanned by in equipped with a scalar product with signature . The same example illustrates that the property of non-degeneracy is not always inheritable by subspaces. Nonetheless, the following is true:
Lemma 2.3 (Chapter 2, Lemma 23, [35]).
A subspace of a vector space is non-degenerate if and only if .
Definition 2.4 (Semi-Riemannian Manifolds).
A metric tensor on a smooth manifold is a symmetric non-degenerate tensor field on of constant index. A semi-Riemannian manifold is a smooth manifold equipped with a metric tensor.
Example 2.5 (Minkowski Spaces ).
Consider the Euclidean space and denote for the -by- diagonal matrix with the first diagonal entries equaling and the rest entries equaling , where and . For arbitrary , define the bilinear form
It is straightforward to verify that this bilinear form is nondegenerate on , and that such defined is a semi-Riemannian manifold. This space is known as the Minkowski space of signature .
Example 2.6.
Consider the vector space of matrices , where and , . Define a bilinear form on by
This bilinear form is non-degenerate on , because for any we have
where is the identity matrix of size -by-, denotes for the Kronecker product, and is the vectorization operator that vertically stacks the columns of a matrix in . The non-degeneracy then follows from Example 2.5. This example gives rise to a semi-Riemannian structure for matrices in .
The non-degeneracy of the semi-Riemannian metric tensor ensures that most classical constructions on Riemannian manifolds have their analogies on a semi-Riemannian manifold. Most fundamentally, the “miracle of Riemannian geometry” — the existence and uniqueness of a canonical connection — is beheld on semi-Riemannian manifolds as well. Quoting [35, Theorem 11], on a semi-Riemannian manifold there is a unique connection such that
| (3) |
and
| (4) |
for all . This connection is called the Levi-Civita connection of and is characterized by the Koszul formula
| (5) | ||||
Geodesics, parallel-transport, and curvature of can be defined via the Levi-Civita connection on in an entirely analogous manner as on Riemannian manifolds.
Differential operators can be defined on semi-Riemannian manifolds much the same way as on Riemannian manifolds. For any , where is a semi-Riemannian manifold, the gradient of , denoted as , is defined by the equality (c.f. [35, Definition 47])
| (6) |
The Hessian of can be similarly defined, also similar to the Riemannian case ([35, Definition 48, Lemma 49]), by , or equivalently
| (7) |
Since the Levi-Civita connection on is torsion-free, is a symmetric tensor field on , i.e.,
One way to compare the semi-Riemannian and Riemannian gradients and Hessians, when both metric structures exist on the same smooth manifold, is through their local coordinate expressions. In fact, the local coordinate expressions for the two types (Riemannian/semi-Riemannian) of differential operators can be unified as follows. Let be a local coordinate system around an arbitrary point , and denote and for the components of the Riemannian and semi-Riemannian metric tensors, respectively; the Christoffel symbols will be denoted as and , respectively. Direct computation reveals
| (8) | ||||
Using the music isomorphism induced from the (Riemannian or semi-Riemannian) metric, the Hessians can be cast in the form of -tensors on as
Remark 2.7.
Notably, for any , if we compute the Hessians and in the corresponding geodesic normal coordinates centered at , Eq. 8 implies that the two Hessians take the same coordinate form since both and vanish at . For instance, has the same geodesics under the Euclidean or Lorentzian metric (straight lines), and the standard coordinate system serves as geodesic normal coordinate system for both metrics; see Example 2.10. In particular, the notion of geodesic convexity [39, 46] is equivalent for the two different of metrics; this equivalence is not completely trivial by the well-known first and second order characterization (see e.g. [46, Theorem 5.1] and [46, Theorem 6.1]) since geodesics need not be the same under different metrics.
Proposition 2.8.
On a smooth manifold admitting two different Riemannian or semi-Riemannian structures, an optimization problem is geodesic convex with respect to one metric if and only if it is also geodesic convex with respect to another.
Proof 2.9.
Denote the two metric tensors on as and , respectively. Both and can be Riemannian or semi-Riemannian, respectively or simultaneously. For any , let and be the geodesic coordinates around with respect to and , respectively. Denote for the Jacobian of the coordinate transformation between the two normal coordinate systems. The coordinate expressions of a tangent vector in the two normal coordinate systems are linked by (Einstein summation convention adopted)
Therefore
which establishes the desired equivalence.
Example 2.10 (Gradient and Hessian in Minkowski Spaces).
Consider the Euclidean space . Denote for the -by- diagonal matrix with the first diagonal entries equaling and the rest diagonal entries equaling . We compute and compare in this example the gradients and Hessians of differentiable functions on . We take the Riemannian metric as the standard Euclidean metric, and the semi-Riemannian metric given by . For any , the gradient of is determined by
Furthermore, since in this case the semi-Riemannian metric tensor is constant on , the Christoffel symbol vanishes (c.f. [35, Chap 3. Proposition 13 and Lemma 14]), and thus for all , where
By the definition of Hessian, for all we have
from which we deduce the equality . In fact, the equivalence of the two Hessians also follows directly from Remark 2.7, since the geodesics under the Riemannian and semi-Riemannian metrics coincide in this example (see e.g. [35, Chapter 3 Example 25]). In particular, the equivalence between the two types of geodesics and Hessians imply the equivalence of geodesic convexity for the two metrics.
3 Semi-Riemannian Optimization Framework
This section introduces the algorithmic framework of semi-Riemannian optimization. To begin with, we point out that the first- and second-order necessary conditions for optimality in unconstrained optimization and Riemannian optimization can be directly generalized to semi-Riemannian manifolds. We then generalize several Riemannian manifold optimization algorithms to their semi-Riemannian counterparts, and illustrate the difference with a few numerical examples. We end this section by showing global and local convergence results for semi-Riemannian optimization.
3.1 Optimality Conditions
The following Proposition 3.1 should be considered as the semi-Riemannian analogy of the optimality conditions Proposition 2.1 .
Proposition 3.1 (Semi-Riemannian First- and Second-Order Necessary Conditions for Optimality).
Let be a semi-Riemannian manifold. A local optimum of Problem Eq. 1 satisfies the following necessary conditions:
-
(i)
if is first-order differentiable;
-
(ii)
and if is second-order differentiable.
Proof 3.2.
- (i)
-
(ii)
If is a local optimum of Eq. 1, then there exists a local neighborhood of such that for all . Without loss of generality we can assume that is sufficiently small so as to be geodesically convex (see e.g. [10, §3.4]). Denote for a constant-speed geodesic segment connecting to that lies entirely in . The one-variable function admits Taylor expansion
where the last equality used . Letting on , the smoothness of ensures that
which establishes .
The formal similarity between Proposition 3.1 and Proposition 2.1 is not entirely surprising. As can be seen from the proofs, both optimality conditions are based on geometric interpretations of the same Taylor expansion; the metrics affect the specific forms of the gradient and Hessian, but the optimality conditions are essentially derived from the Taylor expansions only. Completely parallel to the Riemannian setting, we can also translate the second-order sufficient conditions [26, §7.3] into the semi-Riemannian setting without much difficulty. The proof essentially follows [26, §7.3 Proposition 3], with the Taylor expansion replaced with the expansion along geodesics in Proposition 3.1 (ii); we omit the proof since it is straightforward, but document the result in Proposition 3.3 below for future reference. Recall from [26, §7.1] that is a strict relative minimum point of on if there is a local neighborhood of on such that for all .
Proposition 3.3 (Semi-Riemannian Second-Order Sufficient Conditions).
Let be a second differentiable function on a semi-Riemannian manifold , and is a an interior point. If and , then is a strict relative minimum point of .
The formal similarity between the Riemannian and semi-Riemannian optimality conditions indicates that it might be possible to transfer many technologies in manifold optimization from the Riemannian to the semi-Riemannian setting. For instance, the equivalence of the first-order necessary condition implies that, in order to search for a first-order stationary point, on a semi-Riemannian manifold we should look for points at which the semi-Riemannian gradient vanishes, just like in the Riemannian realm we look for points at which the Riemannian gradient vanishes. However, extra care has to be taken regarding the influence different metric structures have on the induced topology of the underlying manifold. For Riemannian manifolds, it is straightforward to check that the induced topology coincides with the original topology of the underlying manifold (see e.g. [10, Chap 7 Proposition 2.6]), whereas the “topology” induced by a semi-Riemannian structure is generally quite pathological — for instance, two distinct points connected by a light-like geodesic (a geodesic along which all tangent vectors are null vectors (c.f. Definition 4.1)) has zero distance. An exemplary consequence is that, in search of a first-order stationary point, we shouldn’t be looking for points at which vanishes since this does not imply .
3.2 Determining the “Steepest Descent Direction”
As long as gradients, Hessians, retractions, and parallel-transports can be properly defined, one might think there exists no essential difficulty in generalizing any Riemannian optimization algorithms to the semi-Riemannian setup, with the Riemannian geometric quantities replaced with their semi-Riemannian counterparts, mutatis mutandis. It is tempting to apply this methodology to all standard manifold optimization algorithms, including but not limited to first-order methods such as steepest descent, conjugate gradient descent, and quasi-Newton methods, or second-order methods such as Newton’s method and trust region methods. We discuss in this subsection how to determine a proper descent direction for steepest-descent-type algorithms on a semi-Riemannian manifold. Some exemplary first- and second-order methods will be discussed in the next subsection.
As one of the prototypical first-order optimization algorithms, gradient descent is known for its simplicity yet surprisingly powerful theoretical guarantees under mild technical assumptions. A plausible “Semi-Riemannian Gradient Descent” algorithm that naïvely follows the paradigm of Riemannian gradient descent could be designed as simply replacing the Riemannian gradient with the semi-Riemannian gradient defined in Eq. 6, as listed in Algorithm 1. Of course, a key step in Algorithm 1 is to determine the descent direction in each iteration. However, while negative gradient is an obvious choice in Riemannian manifold optimization, the “steepest descent direction” is a slightly more subtle notion in semi-Riemannian geometry, as will be demonstrated shortly in this section.
A first difficulty with replacing by is that needs not be a descent direction at all: consider, for instance, an illustrative example of optimization in the Minkowski space (Euclidean space equipped with the standard semi-Riemannian metric): the first order Taylor expansion at gives for any small
| (9) |
but in the semi-Riemannian setting the scalar product term may well be negative, unlike the Riemannian case. In order for the value of the objective function to decrease (at least in the first order), we have to pick the descent direction to be either or , whichever makes .
Though the quick fix by replacing with would work generically in many problems of practical interest, a second, and more serious issue with choosing as the descent direction lies inherently at the indefiniteness of the metric tensor. For standard gradient descent algorithms (e.g. on Euclidean spaces with standard metric, or more generally on Riemannian manifolds), the algorithm terminates after becomes smaller than a predefined threshold; for norms induced from positive definite metric tensors, is equivalent to characterizing , implying that the sequence is truly approaching a first order stationary point. This intuition breaks down for indefinite metric tensors as no longer implies the proximity between and . Even though one can fix this ill-defined termination condition by introducing an auxiliary Riemannian metric (which always exists on a Riemannian manifold), when is a null vector (i.e. , see Definition 4.1), the gradient algorithm loses the first order decrease in the objection function value (see Eq. 9); the validity of the algorithm then relies upon second-order information, with which we lose the benefits of first-order methods. As a concrete example, consider the unconstrained optimization problem on the Minkowski space equipped with a metric of signature :
Recall from Example 2.10 that
which is a direction parallel to the isolines of the objective function . Thus the semi-Riemannian gradient descent will never decrease the objective function value.
To rectify these issues, it is necessary to revisit the motivating, geometric interpretation of the negative gradient direction as the direction of “steepest descent,” i.e. for any Riemannian manifold and function on differentiable at , we know from vector arithmetic that
| (10) |
In the semi-Riemannian setting, assuming is equipped with a semi-Riemannian metric , we can also set the descent direction leading to the steepest decrease of the objective function value. It is not hard to see that in general
| (11) |
In fact, in both versions the search for the “steepest descent direction” is guided by making the directional derivative as negative as possible, but constrained on different unit spheres. The precise relation between the two steepest descent directions is not readily visible, for the two unit spheres could differ drastically in geometry. In fact, for cases in which the unit ball is noncompact, the “steepest descent direction” so defined may not even exist.
Example 3.4.
Consider the optimization problem over the Minkowski space equipped with a metric of signature
At , recall from Example 2.10 that . Over the unit ball under this Lorentzian metric, the scalar product as . Even worse, since the scalar product approaches , it is not possible to find a descent direction with for some pre-set threshold .
One way to fix this non-compactness issue is to restrict the candidate tangent vectors in the minimization of to lie in a compact subset of the tangent space . For instance, one can consider the unit sphere in under a Riemannian metric. Comparing the right hand sides of Eq. 10 and Eq. 11, descent directions determined in this manner will be the negative gradient direction under the Riemannian metric, thus in general has nothing to do with the semi-Riemannian metric; moreover, if a Riemannian metric has to be defined laboriously in addition to the semi-Riemannian one, in principle we can already employ well-established, fully-functioning Riemannian optimization techniques, thus bypassing the semi-Riemannian setup entirely. While this argument might well render first-order semi-Riemannian optimization futile, we emphasize here that one can define steepest descent directions with the aid of “Riemannian structures” that arise naturally from the semi-Riemannian structure, and thus there is no need to specify a separate Riemannian structure in parallel to the semi-Riemannian one, though this affiliated “Riemannian structure” is highly local.
The key observation here is that one does not need to consistently specify a Riemannian structure over the entire manifold, if the only goal is to find one steepest descent direction in that tangent space — in other words, when we search for the steepest descent direction in the tangent space of a semi-Riemannian manifold , it suffices to specify a Riemannian structure locally around , or more extremely, only on the tangent space , in order for the “steepest descent direction” to be well-defined over a compact subset of . These local inner products do not have to “patch together” to give rise to a globally defined Riemannian structure. A very handy way to find local inner products is through the help of geodesic normal coordinates that reduce the local calculation to the Minkowski spaces. For any , there is a normal neighborhood containing such that the exponential map is a diffeomorphism when restricted to , and one can pick an orthonormal basis (with respect to the semi-Riemannian metric on ), denoted as , such that , where , , are the Kronecker delta’s, and . Without loss of generality, assume is a semi-Riemannian manifold of order , where , and that , . The normal coordinates of any are determined by the coefficients of with respect to the orthonormal basis . It is straightforward (see [35, Proposition 33]) to verify that
where denotes the semi-Riemannian metric tensor components and stands for the Christoffel symbols. Under this coordinate system, it is straightforward to verify that the scalar product between tangent vectors can be written as
where and (Einstein’s summation convention implicitly invoked). The local Riemannian structure can thus be defined as
| (12) |
Essentially, such a local inner product is defined by imposing orthogonality between positive and negative definite subspaces of and “reversing the sign” of the negative definite component of the scalar product. Making such a modification consistently and smoothly over the entire manifold is certainly subject to topological obstructions; nevertheless, locally (in fact, pointwise) defined Riemannian structures suffice for our purposes, and in practical applications we can simply the workflow by choosing an arbitrary orthonormal basis in the tangent space in place of the geodesic frame. The orthonormalization process, of course, is adapted for the semi-Riemannian setting; see [35, Chapter 2, Lemma 24 and Lemma 25] or Algorithm 2. The output set of vectors satisfies
where are the Kronecker symbols, and . A generic approach which works with high probability is to pick a random linearly independent set of vectors and apply a (pivoted) Gram-Schmidt orthogonalization process with respect to the indefinite scalar product; see Algorithm 3.
In geodesic normal coordinates, the gradient takes the form
and choosing the steepest descent direction reduces to the problem
of which the optimum is obviously attained at
For the simplicity of statement, we introduce the notation
for , where is an orthonormal basis for the semi-Riemannian metric tensor on . Using this notation, the descent direction we will choose can be written as
| (13) |
Note that, by [35, Lemma 3.25], with respect to an orthonormal basis we have in general
which is consistent with our previous discussion that the steepest descent direction in the semi-Riemannian setting is not in general. Intuitively, the “steepest descent direction” is obtained by reversing signs of components of the gradient that “corresponds to” the negative definite subspace, and then rescale according to the induced Riemannian metric. This leads to the routine Algorithm 4 for finding descent directions.
Remark 3.5.
The definition certainly depends on the choice of the orthonormal basis with respect to the semi-Riemannian metric tensor. In other words, if we choose a different orthonormal basis with respect to the same semi-Riemannian metric on , the resulting descent direction will also be different. In practical computations, we could pre-compute an orthonormal basis for all points on the manifold, but that will complicate the proofs for convergence since the amount of descent will be uncomparable to each other across tangent vectors. A compromise is to cover the entire semi-Riemannian manifold with a chart consisting of geodesic normal neighborhoods, and extend the definition Eq. 13 from at a single point to over the geodesic normal neighborhood around each point, with the orthonormal basis given by geodesic normal frame fields [35, pp.84-85] defined over each normal neighborhood. Under suitable compactness assumptions, this construction essentially defines a Riemannian structure on the semi-Riemannian manifold by means of partition of unity and
| (14) |
The arbitrariness of the choice of geodesic normal frame fields makes this Riemannian structure non-canonical, but the bilinear form is symmetric and coercive, and can thus be used for performing steepest descent in the semi-Riemannian setting.
Remark 3.6.
For Minkowski spaces, it is easy to check that the descent direction output from Algorithm 4 coincides with exactly. In this sense Algorithm 1 can be viewed as a generalization of the Riemannian steepest descent algorithm. In fact, the pointwise construction of positive-definite scalar products in each tangent space Eq. 12 indicates that the methodology of Riemannian manifold optimization can be carried over to settings with weaker geometric assumptions, namely, when the inner product structure on the tangent spaces need not vary smoothly from point to point. From this perspective, we can also view semi-Riemannian optimization as a type of manifold optimization with weaker geometric assumptions.
Remark 3.7.
Algorithm 1 can indeed be viewed as an instance of a more general paradigm of line-search based optimization on manifolds [42, §3]. Our choice of the descent direction in Algorithm 4 ensures that the objective function value indeed decreases, at least for sufficiently small step size, which further facilitates convergence.
Example 3.8 (Semi-Riemannian Gradient Descent for Minkowski Spaces).
Recall from Example 2.10 that the semi-Riemannian gradient of a differentiable function on Minkowski space is . If we choose the standard canonical basis for , the descent direction produced by Algorithm 4 and needed for Algorithm 1 is
and thus the semi-Riemannian gradient descent coincides with the standard gradient descent algorithm on the Euclidean space if the standard orthonormal basis is used at every point of . Of course, if we use a randomly generated orthonormal basis (under the semi-Riemannian metric) at each point, the semi-Riemannian gradient descent will be drastically different from standard gradient descent on Euclidean spaces; see Section 5.1 for an illustration.
When studying self-concordant barrier functions for interior point methods, a useful guiding principle is to consider the Riemannian geometry defined by the Hessian of a strictly convex self-concordant barrier function [31, 11, 41, 32]; in this setting, descent directions produced from Newton’s method can be equivalently viewed as gradients with respect to the Riemannian structure. When the barrier function is non-convex, however, the Hessians are no longer positive definite, and the Riemannain geometry is replaced with semi-Riemannian geometry. It is well known that the direction computed from Newton’s equation Eq. 2 may not always be a descent direction if is not positive definite [48, §3.3], which is consistent with our observation in this subsection that semi-Riemannian gradients need not be descent directions in general. In this particular case, our modification Eq. 13 can also be interpreted as a novel variant of the Hessian modification strategy [48, §3.4], as follows. Denote the function under consideration as , where is a connected, closed convex subset with non-empty interior and contains no straight lines. Assume is non-degenerate on , which necessarily implies that is of constant signature on . At any , the negative gradient of with respect to the semi-Riemannian metric defined by the Hessian of is , where and stand for the gradient and Hessian of with respect to the Euclidean geometry of . Our proposed modification first finds a matrix satisfying
where is the constant signature of on , and then set
| (15) |
which is guaranteed to be a descent direction since
From Eq. 15 it is evident that the semi-Riemannian descent direction is obtained from by replacing the inverse Hessian with . This is close to Hessian modification in spirit, but also drastically different from common Hessian modification techniques that adds a correction matrix to the true Hessian ; see [48, §3.4] for more detailed explanation.
3.3 Semi-Riemannian Conjugate Gradient
Using the same steepest descent directions and line search strategy, we can also adapt conjugate gradient methods to the semi-Riemannian setting. See Algorithm 5 for the algorithm description. Note that in Algorithm 5 we used the Polak-Rebière formula to determine , but alternatives such as Hestenes-Stiefel or Fletcher-Reeves methods (see e.g. [12, §2.6] or [42]) can be easily adapted to the semi-Riemannian setting as well, since none of the major steps in Riemannian conjugate gradient algorithm relies essentially on the positive-definiteness of the metric tensor, except that the (steepest) descent direction needs to be modified according to Eq. 13. We noticed in practice that Polak-Rebière and formulae tend to be more robust and efficient than the Fletcher-Reeves formula for the choice of , which is consistent with general observations of nonlinear conjugate gradient methods [48, §5.2].
Remark 3.9.
For Minkowski spaces (including Lorentzian spaces) with the standard orthonormal basis, both steepest descent and conjugate gradient methods coincide with their counterparts on standard Euclidean spaces, since they share identical descent directions, parallel-transports, and Hessians of the objective function.
Remark 3.10.
Algorithm 5 can also be applied to self-concordant barrier functions for interior point methods, when the objective function is not necessarily strictly convex but has non-degenerate Hessians. In this context, where the semi-Riemannian metric tensor is given by the Hessian of the objective function, Algorithm 5 can be viewed as a hybrid of Newton and conjugate gradient methods, in the sense that the “steepest descent directions” are determined by the Newton equations but the actual descent directions are combined using the methodology of conjugate gradient methods. To the best of our knowledge, such a hybrid algorithm has not been investigated in existing literature.
3.4 Metric Independence of Second Order Methods
In this subsection we consider two prototypical second-order optimization methods on semi-Riemannian manifolds, namely, Newton’s method and trust region method. Surprisingly, both methods turn out to produce descent directions that are independent of the choice of scalar products on tangent spaces. We give a geometric interpretation of this independence from the perspective of jets in Section 3.4.2.
3.4.1 Semi-Riemannian Newton’s Method
As an archetypal second-order method, Newton’s method on Riemannian manifolds has already been developed in detail in the early literature of Riemannian optimization [2, Chap 6]. The rationale behind Newton’s method is that the first order stationary points of a differentiable function are in one-to-one correspondence with the minimum of when the metric is positive-definite (i.e., when is a Riemannian manifold). Thus by choosing the direction to satisfy the Newton equation we ensure that is a descent direction
and the right hand side is strictly negative as long as . The main difficulty in generalizing this procedure to the semi-Riemannian setting is similar with the difficulty we faced in Section 3.2: when the metric is indefinite, has nothing to do with , and thus one can no longer find the stationary points of by minimizing . The approach we’ll adopt to fix this issue is also similar to that in Section 3.2: instead of minimizing , we will focus on the coercive bilinear form .
Let be a local geodesic normal coordinate frame centered at , i.e. for any
Then we have
| (16) |
and thus for any tangent vector we have
where in the last equality we used the fact that for all . Therefore, as long as we pick to satisfy Newton’s equation
| (17) |
we can ensure decrease in the value of Eq. 16. In other words, we can obtain a descent direction for semi-Riemannian optimization using the same Newton’s equation as for Riemannian optimization, with the only difference that Riemannian gradient and Hessian get replaced with their semi-Riemannian counterparts.
Given that our semi-Riemannian Newton’s method builds upon the “Riemannian surrogate” Eq. 16, it is not surprising that the semi-Riemannian Newton’s method reduces to the ordinary Newton’s method on Minkowski spaces, and the geodesics and parallel-transports stays the same as their Riemannian counterparts (i.e. when the scalar product is positive definite). This is best illustrated in the following calculation.
Example 3.11 (Semi-Riemannian Newton’s Method for Minkowski Spaces).
Recalling the definitions of semi-Riemannian gradient and Hessians from Example 2.10, the descent direction needed in Algorithm 6 is determined by
for all . This calculation made it clear that the semi-Riemannian Newton’s method coincides with the standard Newton’s method.
The metric independence demonstrated in Example 3.11 reflects a more general phenomenon of metric independence in Newton’s method as formulated in [41, §1.6]. Though the discussion in phenomenon of metric independence in Newton’s method as formulated in [41, §1.6] is restricted to the Riemannian case (scalar product required to be positive definite), it is straightforward to see that the metric independence persists under non-degenerate change of semi-Riemannian structures. In fact, if we denote for the Jacobian matrix of a non-degenerate coordinate transformation at , it is straightforward to check from the coordinate expressions of semi-Riemannian gradient and Hessian Eq. 8 that the Newton equation Eq. 17 in the new coordinate system takes the form , which yields the same descent direction as Eq. 17. In the Riemannian regime, this metric independence is often attributed to the fact that second-order approximation is independent of inner products (see e.g. [41, §1.6]); we provide a general and unified differential geometric interpretation of this independence in terms of jets in Section 3.4.2.
3.4.2 Jets and the Metric Independence of Trust Region Method
It is well known that first-order and Newton’s methods suffer from various drawbacks from a numerical optimization methods, such as slow local convergence and/or prohibitive computational cost in determining the descent direction. It is thus argued (c.f. [2], [1]) that it could be more efficient to consider successive optimization of local models of the cost function on the domain of the problem. Trust region methods, which considers quadratic local models through approximate Taylor expansions of the cost function, fall into this category (see e.g. [48] and the references therein). This methodology has also been generalized to Riemannian manifolds for manifold optimization [1, 2, 19, 18]. In a nutshell, at each point the Riemannian trust-region method strives to find the descent direction by solving locally the quadratic optimization problem on the tangent plane :
| (18) |
where is the inner product specified by the Riemannian metric tensor, is the induced norm, and is the radius of the trust region which is updated through the iterations according to certain technical criteria (e.g. the geometry of the manifold, the approximation quality of the local model, etc.).
When generalizing trust region methods to semi-Riemannian optimization, again we are faced with the difficulties for the other methods discussed previously, such as the non-compactness of the “metric ball” of bounded radius . This can be resolved by introducing a positive definite inner product accompanying the indefinite metric tensor as in Section 3.2 and Section 3.4.1, then restrict the search for the descent direction to a bounded domain defined by the norm induced from the inner product. Denoting for the induced norm on , the local quadratic optimization problem in the semi-Riemannian setting can be written as
| (19) |
We argue that this local quadratic model coincides with the Riemannian model Eq. 18 with the (frame-field-dependent) Riemannian structure Eq. 14. In fact, the verification is straightforward by picking geodesic normal coordinate systems under the Riemannian and semi-Riemannian metric (which ensures the Christoffel symbols vanish at ) and a change-of-coordinate argument as in the proof of Proposition 2.8, together with the coordinate expressions Eq. 8. This implies that a trust region method based on Eq. 19 for the semi-Riemannian manifold can be interpreted and analyzed using more or less the same techniques in existing literature of Riemannian trust region methods. The only subtlety here is the frame dependence of locality of the Riemannian structures accompanying the semi-Riemannian metric; nevertheless, this technicality can be resolved by noticing the direct dependence of the local Riemannian structure with the smooth semi-Riemannian structure.
The argument we gave in this section can be carried out to establish the “metric independence” of trust region methods on manifolds. While it is certainly desirable to pick a metric on the manifold so as to enable numerical implementations of the optimization algorithms, at the end of the day the only influence of the metric enters the trust region methods through choosing the size of the trust region, which eventually does not matter after the region radius update rules are carried out (which ultimately depends on the value distribution of the cost function only). One geometric explanation for this phenomenon is through the notion of jets (see e.g. [43, 47, 36]), which characterizes the manifold analogy of “polynomial approximation” for smooth functions. Though the formal invarance of under change of coordinates breaks down for derivatives greater than or equal to the second order, it turns out that one can define equivalence classes of “Taylor polynomial expansion modulo higher order terms” by the matching of a fixed number of lower order derivatives at a fixed point. More concretely, consider an arbitrary point and denote for a coordinate system around , and assume without loss of generality that for all . By a direct calculate, one can verify that the second order Taylor expansion
| (20) |
is formally preserved under change of coordinates up to cubic polynomials. This indicates that, as long as we interpret the big- notation in Eq. 20 as containing not only “metrically” terms (characterized by the local smooth structure or the metric tensor thereof) but also polynomials of degree in the components of , then the expansion Eq. 20 makes sense geometrically as an element in the polynomial ring modulo ideals generated by cubic polynomials. (In fact, for fixed , the union of -jets over all points on the manifold form a fibre bundle often referred to as a jet bundle.) For the purpose of trust region methods this equivalence relation suffices for specifying local models, as equivalent polynomials (as the same jet) give rise to local models of the same order (see e.g. [2, Proposition 7.1.3]). It then follows that, for distinct Riemannian or semi-Riemannian metrics on the same smooth manifold and under geodesic normal coordinates chosen respectively with respect to the metric structures, the local models Eqs. 18 and 19 correspond to the same jet and will metrically differ from each other in terms of cubic geodesic distances only, whenever the metrics involved are all Riemannian. When at least one of the metric tensors involved is semi-Riemannian, the metric comparison has to be carried out with extra caution (e.g. with respect to the metric structure induced by another Riemannian structure) since coordinate polynomials are no longer bounded by “semi-Riemannian norms” of the same order, again due to the indefiniteness of the semi-Riemannian metric tensor.
4 Semi-Riemannian Optimization on Submanifolds
Submanifolds of Euclidean spaces are most often encountered in practical applications of manifold optimization. A key difference between Riemannian and semi-Riemannian geometry is that the non-degeneracy of the metric tensor can not be inherited by sub-manifolds as easily from semi-Riemannian ambient manifolds: for a submanifold of , any Riemannian metric on induces a Rimannian metric on since is positive definite at every point , but a semi-Rimannian metric on could become degenerate when restrict to ; this degeneracy is the main obstruction to finding a well-defined “orthogonal projection” which is essential for (i) relating gradients on the manifold with gradients in the ambient space, and (ii) defining geodesics on submanifolds. Semi-Riemannian manifolds with degeneracy are of interest to the theory of general relativity and mathematical physics; see [22, 23, 24, 25, 45] and the references therein. This section provides some characterization of degenerate semi-Riemannian manifolds (see Definition 4.3) in terms of their degenerate bundles (see Definition 4.4). The goal is to identify non-degenerate semi-Riemannian submanifolds of Minkowski spaces for which our algorithmic framework in Section 3 applies. As demonstrated in the computation in this section and Appendix B, unfortunately, semi-Riemannian structures inherited from the ambient Minkowski space are degenerate for most matrix Lie groups. Nonetheless, many interesting hypersurfaces (co-dimension one submanifolds) of Minkowski spaces admit non-degenerate induced semi-Riemannian structures, or degenerate ones but with degeneracy contained in a set of measure zero; the semi-Riemannian optimization framework introduced in Section 3 applies seamlessly to these examples, some of which we illustrate in Section 5.
4.1 Degeneracy of Semi-Riemannian Submanifolds
Theories of Riemannian and semi-Riemannian geometry build upon the non-degeneracy of metric tensors. However, physical models of spacetime renders itself naturally to the occurrence of singularities, as pointed out in general relativity [37, 15, 17, 16]. A lot of work in semi-Riemannian geometry are thus devoted to the development of singular semi-Riemannian geometry — the geometry of semi-Riemannian manifolds with degeneracy in their metric tensors, either with constant signature [22, 23, 24] or more generally, with possibly variable signature [25, 45]. In special cases such as null hypersurfaces of Lorentzian manifolds, specific techniques such as rigging [14, 6] have been developed, but generalizing these special constructions to other degenerate semi-Riemannian submanifolds is much less straightforward, if possible at all. For the simplicity of exposition, we’ll confine our discussion to the constant signature scenario regardless of whether singularities occur.
Definition 4.1.
A symmetric bilinear form on a vector space is said to have signature if the maximum positive definite subspace is of dimension , the maximum negative definite subspace is of dimension , and the dimension of the degenerate subspace with respect to this bilinear form
is of dimension . A vector is said to be (1) degenerate if ; (2) null if but ; (3) timelike if ; (4) spacelike if .
Definition 4.2.
Let be a subspace of a vector space equipped with a bilinear form . Denote for the type of the bilinear form on obtained from restricting to . We say that is (1) degenerate if ; (2) nondegenerate if ; (3) timelike if and ; (4) spacelike if , , and .
Definition 4.3 (Degenerate Semi-Riemannian Manifolds).
A degenerate semi-Riemannian manifold is a smooth manifold equipped with a possibly degenerate tensor field. This tensor field will be referred to as the degenerate metric tensor of the degenerate semi-Riemannian manifold; the signature of the degenerate metric tensor will also be referred to as the signature of the manifold when no confusion exists. Unless otherwise specified, the degenerate metric tensor is of constant signature in the rest of this paper.
When the context is clear, we will occasionally omit the adjective “degenerate” when referring to degenerate semi-Riemannian manifolds and the degenerate metric tensor on it, since non-degenerate semi-Riemannian manifolds are special cases of degenerate ones with .
Definition 4.4 (Degenerate Bundle, [24] Definition 3.1).
The degenerate bundle of a (possibly degenerate) semi-Riemannian manifold is defined as the distribution
| (21) |
We say is integrable if the distribution is integrable. We denote by the linear space and we call the set of point such that the degenerate locus of .
As in the setup of Riemannian manifold optimization, for practice it is of primary interest to understand the differential geometry of submanifolds of an ambient manifold for which most differential geometric quantities can be characterized explicitly. In the context of semi-Riemannian geometry, a first technical subtlety with the notion of “semi-Riemannian submanifolds” is that the induced semi-Riemannian metric tensor may well suffer from certain degeneracy even when the ambient semi-Riemannian geometry is non-degenerate. The main difficulty lies at the non-existence of a canonical “orthogonal projection” from the ambient to the submanifold tangent spaces — this complicates the definitions of normal bundles, second fundamental forms, as well as extrinsic characterizations of intrinsic geometric concepts such as affine connections, geodesics, and parallel-translates. For instance, it is well-known that covariant derivatives on a semi-Riemannian submanifold can be obtained from calculating the covariant derivatives on the ambient semi-Riemannian manifold and then projecting the result to the tangent spaces of the submanifold (see e.g. [35, Chapter 4, Lemma 3]), but this characterization breaks down if the projection operator can not be properly defined. In fact, on a degenerate semi-Riemannian manifold there does not exist in general a semi-Riemannian analogue of the Levi-Civita (metric-compatible and torsion-free) connection, even for a degenerate semi-Riemannian submanifold of a non-degenerate semi-Riemannian manifold. Such an analogue, if exists, is called a Koszul derivative of the degenerate semi-Riemannian manifold; a semi-Riemannian manifold admitting a Koszul derivative is called a singular semi-Riemannian manifold in [22, 23, 24]. In general, a singular semi-Riemannian manifold admits more than one Koszul derivatives, and any two Koszul derivatives on differ from each other by a map from to the degenerate bundle ; see e.g. [22, Proposition 3.5]. Note that though it is tempting to define a connection on a degenerate semi-Riemannian manifold through the Koszul formula Eq. 5, the formula defines a Koszul derivative if and only if the metric tensor is Lie parallel along all sections of the degenerate bundle ([24, Theorem 3.4]). Another useful (necessary but insufficient) criterion for the existence of a Koszul derivative on a degenerate semi-Riemannian manifold is the integrability the degenerate bundle: as shown in [24, Corollary 3.6], if a semi-Riemannian manifold admits a Koszul derivative, then is integrable.
A large class of examples of semi-Riemannian manifolds commonly encountered in scientific computation are matrix Lie groups. They admit semi-Riemannian structures of arbitrary signature since tangent bundles of Lie groups are trivial. For instance, it is straightforward to verify that the semi-Riemannian structure on specified in Example 2.6 induces a non-degenerate semi-Riemannian structure on the general linear group , though non-degeneracy becomes evident for almost all interesting matrix subgroups of . We demonstrate the ubiquity of such degeneracy in the following two examples; more examples of matrix Lie groups are deferred to Section B.2.
Example 4.5 (Indefinite Orthogonal Group).
Let , , and . Define the indefinite orthogonal group of signature as
| (22) |
where is defined in Example 2.6. The Lie algebra of this Lie group can be easily verified as
| (23) |
The tangent space at an arbitrary is thus
| (24) | ||||
Equipping with bilinear form specified in Example 2.6, the Lie group structure on induces a left-invariant semi-Riemannian metric on by
| (25) | ||||
For the ease of notation, we shall drop the sub-script unless there is a potential risk of confusion. This semi-Riemannian metric will be referred to as the natural semi-Riemannian metric on . The degenerate bundle of this semi-Riemannian structure can be easily determined as follows. Let be a skew-symmetric matrix such that for an arbitrary . Setting
we have that must be symmetric, i.e.
| (26) |
Writing in the partitioned form
where
satisfying
Plugging this partitioned form into Eq. 26 gives
from which it follows that the degenerate bundle of takes the form
In particular, this indicates that the natural semi-Riemannian structure on is degenerate. By checking at the identity it is clear that , hence the degenerate bundle is not integrable. It then follows from [24, Corollary 3.6] that equipped with the natural semi-Riemannian metric does not admit a Koszul derivative.
Example 4.6 (Orthogonal Group).
Let , , and . The manifold structure on the orthogonal group is well-known:
Equip with the same left-invariant semi-Riemannian metric as in Example 4.5:
In this example, again the semi-Riemannian metric is degenerate. In fact, by a similar argument as in Example 4.5 one has
| (27) |
and again, is not integrable. In fact, one can also easily verify that the involution is orthogonal to with respect to the natural Riemannian (not semi-Riemannian!) metric on . Again, from [24, Corollary 3.6] we know that with semi-Riemannian metric Eq. 27 does not admit a Koszul derivative.
Remark 4.7.
Example 4.6 is a special case of a more general practice: one can equip with a semi-Riemannian structure with replaced with in Example 4.5, where but and . Again this is due to the triviality of the tangent bundle of the Lie group for any integers and .
Remark 4.8.
It is natural to ask at this point whether a given manifold of interest, such as or , admits a semi-Riemannian structure of a particular type for which a Koszul derivative exists. We are not aware of general results of this sort. Some related work (e.g. [34, 7, 4]) have been devoted to the existence of left-invariant Lorentz metrics satisfying certain curvature sign conditions, following the seminal work of Milnor [29]. Bi-invariant semi-Riemannian metrics on Lie groups have also been widely explored since the 1910s; see [30, §1.4] for a brief survey.
Remark 4.9.
Though the notion of orthogonality breaks down for degenerate semi-Riemannian submanifolds, the tangent bundle of any semi-Riemannian manifold of type admits a direct sum decomposition , where is a sub-bundle of with rank . In this case, the restriction of the semi-Riemannian metric on gives rise to a non-degenerate semi-Riemannian metric of type . We will fully leverage this partial non-degeneracy in the semi-Riemannian optimization algorithm presented in this paper.
4.1.1 Gradient and Hessian of Submanifolds of Minkowski Spaces
When is a non-degenerate semi-Riemannian submanifold of a Minkowski space , gradient and Hessian of a twice differentiable function on can be computed explicitly from the gradient and Hessian of on the ambient Minkowski space , thanks to the non-degeneracy which ensures for any that the tangent space has an orthogonal complement in , and thus and on can be orthogonally projected onto . Specifically, the same argument as in [2, §3.6.1] indicates that the semi-Riemannian gradient of on is exactly the orthogonal projection to the tangent space of of the semi-Riemannian gradient of as a function defined on the Minkowski space ; a similar argument yields the fact that the Hessian of is the composition of the Hessian of on the Minkowski space composed with the orthogonal projection from to the tangent space of .
Example 4.10 (Euclidean Sphere in Minkowski Spaces).
Consider the standard Euclidean sphere
as a submanifold of , the Minkowski space equipped with inner product as defined in Example 2.5. For any , the tangent space can be specified as
and thus the projection from to is
For with , the projection operator is not defined since is a null vector. Nevertheless, this occurs only for a set of measure zero on , which means they almost never occur in practice. In our numerical experiments on (see Section 5.2), we just randomly perturb the point so that the optimization trajectory stays away from the degenerate locus. This works perfectly as long as the optimum is not on the degenerate locus. If unavoidable, we can also temporarily resort to the Riemannian orthogonal projection for with . For a twice differentiable function , if we denote and for the semi-Riemannian gradient and Hessian of on the ambient Minkowski space (following Example 2.10), then the semi-Riemannian gradient and Hessian of on are and , respectively.
4.1.2 Geodesics and Parallel-Transports
Regardless of whether the semi-Riemannian submanifold under consideration is degenerate, we can define analogies of geodesics and parallel-transports on them by means of their semi-normal bundles. To this end, for semi-Riemannian manifold and its submanifold we denote by and the tangent bundles of and , respectively. Let , we define the semi-normal space of in at to be
We also define the semi-normal distribution of in to be
Consider the linear map
where the first map is the inclusion and the second map is the quotient map. The following observation is straightforward by definition.
Lemma 4.11.
Fibres of the degenerate bundle of (c.f. Definition 4.4) at can be written as
In particular, if is an open submanifold of , then is a non-degenerate semi-Riemannian submanifold of .
Hence we have an injective map
and thus is a sub-distribution of the normal bundle . If is constant with respect to , then is a sub-bundle of and will be referred to as the semi-normal bundle of with respect to . We define the analogy of geodesics on (possibly degenerate) semi-Riemannian submanifolds as curves with accelerations in the semi-normal bundle — when the semi-Riemannian submanifold becomes non-degenerate these geodesics reduces to standard semi-Riemannian geodesics.
Definition 4.12.
For a given and , if a smooth curve satisfies and
for all , then is called an embedded geodesic curve on passing through with the tangent direction . Here is the covariant derivative of along on the ambient semi-Riemannian manifold .
Definition 4.13.
Let be a curve passing through on and let be a given tangent vector. A parallel transportation of along the curve is a vector field such that and
We remark that on a (semi-)Riemannian manifold , a geodesic passing through with the tangent direction is traditionally defined by the second order ODE with initial condition:
| (28) |
where is the covariant derivative uniquely determined by the metric . In the meanwhile, a well-known fact (cf. [35, Corollary 10]) is that if is isometrically embedded in a (semi-)Riemannian manifold then Eq. 28 is equivalent to the condition that is always perpendicular to , i.e.
for all . Here is the covariant derivative on along the curve . From this second perspective, Definition 4.12 and Definition 4.13 are natural generalizations of geodesics and parallel-transports from nondegenerate to degenerate semi-Riemannian geometry. Of course, it is in general not possible to obtain closed-form expressions for the embedded geodesic curves and parallel-transports; see Section B.2 for some examples. These definitions apply to the particular case when the semi-Riemannian structure under consideration is actually Riemannian, and thus the optimization methods are also applicable to degenerate Riemannian manifolds.
4.2 Semi-Riemannian Hypersurfaces of Minkowski Spaces
In this subsection we describe the semi-Riemannian geometry of submanifolds of codimension one in the Minkowski space (see Example 2.5), which are prototypical examples of semi-Riemannian manifolds. Throughout this subsection denotes a submanifold of . Unraveling the definition of semi-normal and normal bundles yields:
Proposition 4.14.
For each , we have
where
and
In particular, is a vector bundle on of rank .
Corollary 4.15.
Let be a hypersurface (submanifolds of co-dimension one), and . Then either or .
Proof 4.16.
By Lemma 4.11 we have , but by Proposition 4.14, we know is one-dimensional.
Example 4.17 (Euclidean Spheres in Minkowski Spaces).
It is conceivable that hypersurfaces, and in particular those linear ones — known as hyperplanes — play an important role in semi-Riemannian geometry as they can provide rich yet elementary examples of non-degenerate semi-Riemannian sub-manifolds. In fact, generically speaking, hyperplanes inherit non-degenerate semi-Riemannian structures from the ambient Minkowski spaces; we defer a simple proof to supplementary materials. It makes use of a handy criterion for the non-degeneracy of semi-Riemannian structures on hypersurfaces which we establish as follows. First of all, we point out that Proposition 4.14 can be equivalently interpreted in terms Gauss maps: for closed sub-manifolds with , denote and define the Gauss map
and the semi-Gauss map
Proposition 4.14 states essentially the commutativity of the following diagram:
| (29) |
Denote by the quadratic hypersurface in defined by
The degeneracy of semi-Riemannian structures on hypersurfaces is totally determined by the intersections of semi-normal bundles with . More concretely, it follows directly from the definitions that
Proposition 4.18.
If , then is the degenerate locus of . In particular, is non-degenerate if and only if , where is the image of the Gauss map of .
In the remainder of this section we provide two classes of hypersurfaces, namely, pseudo-spheres and pseudo-hyperbolic spaces, in the Minkowski space that are different from hyperplanes. For both examples we obtain closed form expressions for embedded geodesic curves and parallel-transports (see Definition 4.12 and Definition 4.13) needed for implementing the algorithmic framework proposed in Section 3. Numerical experiments demonstrating the efficacy of the semi-Riemannian optimization framework on these hypersurfaces can be found in Section 5.
4.2.1 Pseudo-spheres
Let be the hypersurface in defined by the equation
Here we write as . In the literature, is called the unit pseudo-sphere in , and (resp. ) is known asx the de Sitter (resp. Anti-de Sitter) space. The tangent space is characterized by
for each . Hence we also have
This together with Proposition 4.18 implies the following
Lemma 4.19.
For any positive integers and , is a non-degenerate semi-Riemannian sub-manifold of .
We now turn to investigating the embedded geodesics on .
Proposition 4.20.
The embedded geodesic passing through with tangent direction is
| (30) |
where .
Proof 4.21.
First, it is straightforward to verify that and . Next we notice that
since . This implies that is indeed a curve on . Lastly, by taking second derivative, we have
and hence . Therefore, is the geodesic curve passing through with tangent direction .
We now compute the parallel translation on . Let be a point on and let be a tangent vector on at . We denote by the geodesic curve passing through with tangent direction . Let be the parallel transportation of along . By definition, we must have that and . This implies
| (31) | ||||
| (32) |
Differentiating Eq. 31, we obtain and hence
Since parallel translation preserves inner product, we see that and
| (33) |
Integrating Eq. 33 and using the initial condition that to get
Proposition 4.22.
Let be the geodesic passing through with tangent direction . The parallel transport of along the is
More precisely, we have
4.2.2 Pseudo-hyperbolic Spaces
The unit pseudo-hyperbolic space in is defined by the equation
The tangent space of at a point is
Let be the map defined by
It is straightforward ([35, Lemma 24]) to verify that is an anti-isometry between and , whose inverse is . Therefore we have
Corollary 4.23.
For any positive integers , the pseudo-hyperbolic space is a non-degenerate semi-Riemannian sub-manifold of .
Moreover, geodesics and parallel transports on can be easily obtained from those on via the anti-isometry .
Corollary 4.24.
Let be a point on and let be a tangent direction of at . The geodesic curve passing through with tangent direction is
Corollary 4.25.
Let be the geodesic on passing through with tangent direction . The parallel transport of along is
5 Numerical Experiments
We demonstrate in this section the feasibility of the proposed semi-Riemannian optimization framework through various conceptual or numerical experiments.
5.1 Minkowski Spaces
Although we know from Example 3.8 that the semi-Riemannian descent direction coincides with the negative Riemannian gradient when the standard orthonormal basis is chosen and fixed at every point of , the two types of gradients nevertheless differ from each other if we follow the random orthonormal basis construction Algorithm 2. To illustrate the difference between Riemannian and semi-Riemannian optimization on Minkowski spaces, we solve a simple quadratic convex optimization problem
| (34) |
on equipped with the standard semi-Riemannian metric of signature . Here is a randomly generated symmetric positive definite matrix, and we apply both steepest descent Algorithm 1 and conjugate gradient Algorithm 5, using random orthonormal bases in subrountine Algorithm 4 for finding descent directions and Armijo’s rule for line search. The semi-Riemannian optimization trajectories vary from instances to instances due to the randomness in basis construction, but global convergence to the global minimum is empirically observed. We illustrate in Fig. 1 the comparison among trajectories of Riemannian/semi-Riemannian steepest descent and conjugate gradient algorithms for one random instance.
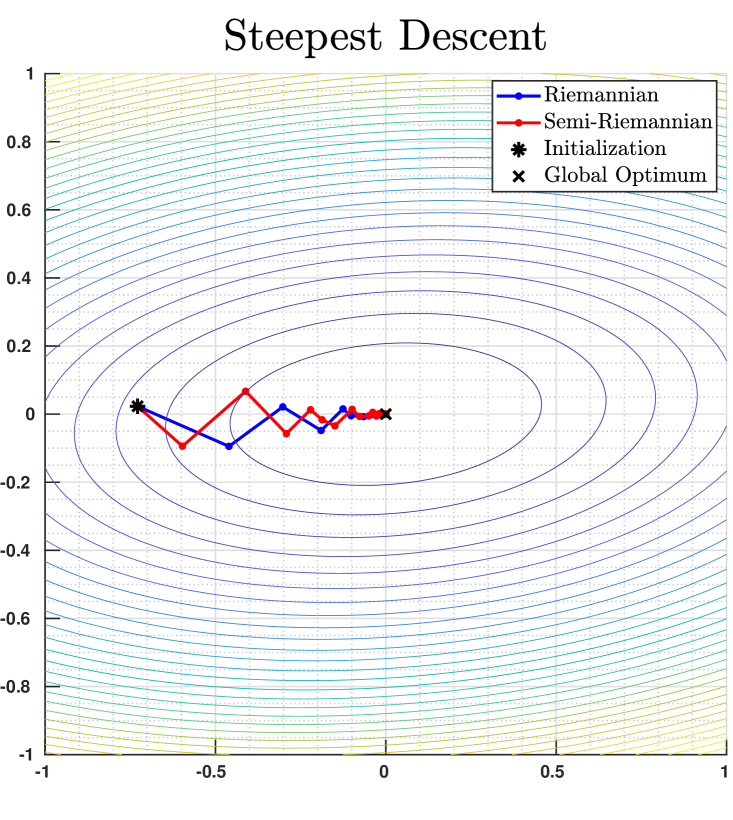
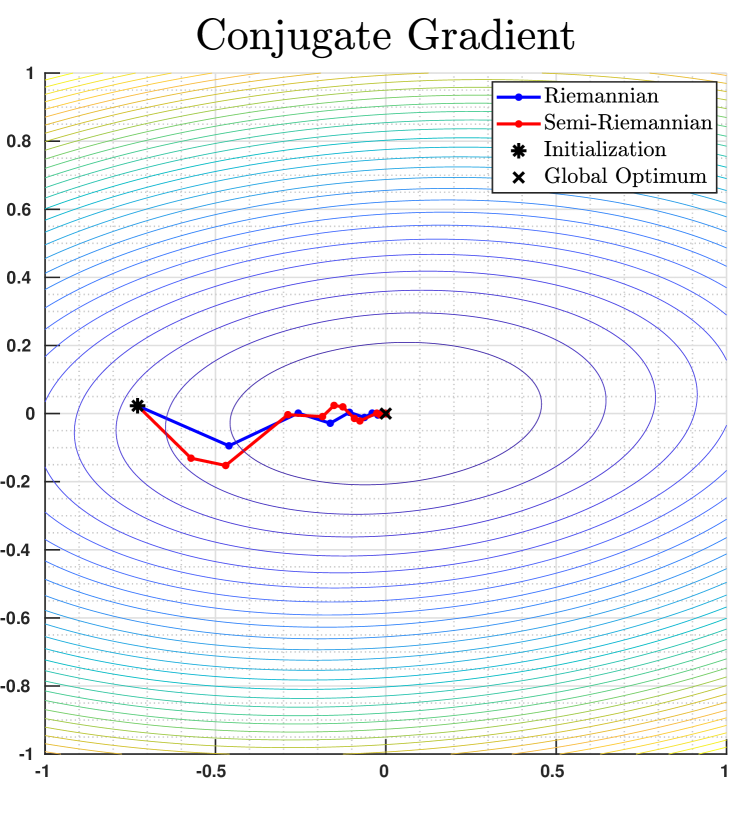
5.2 Euclidean Spheres in Minkowski Spaces
The calculations in Example 4.17 imply that the unit Euclidean sphere is nondegenerate as a semi-Riemannian submanifold in except for a degenerate locus of measure zero. Let be a differentiable function on , and denote for the gradient of in the ambient Euclidean space. As shown in Example 2.10, the semi-Riemannian gradient of in the Minkowski space can be written as , and the descent directions in the ambient space take the form . Recall from Example 4.10 and Example 4.17 that, unless is a null vector (which is a set of measure zero), the fibre of the degenerate bundle vanishes at and thus we can project to a unique tangent vector in by Lemma 2.3. This indicates that the optimization trajectory falls outside of the degenerate locus with probability , as long as the optimum in not inside the degenerate locus.
To illustrate the feasibility of our proposed semi-Riemannian optimization framework, we solve the problem
| (35) |
using semi-Riemannian steepest descent and conjugate gradient methods, where is a randomly generated symmetric (but not necessarily positive definite) matrix. Obviously, the maximum of Eq. 35 is attaned at the eigenvector associated with the maximum eigenvalue of the matrix , and hence we can visualize and compare the convergence dynamics of Riemannian and semi-Riemannian optimization schemes by keeping track of the -discrepancy between solutions obtained at each iteration and the true maximizer. As there does not seem to exist explicit expressions for the semi-Riemannian geodesic and parallel-transport on (see Table 1), we use Riemannian geodesic and parallel transport on ; generically, these choices do not essentially affect the convergence of manifold optimization algorithms, which allows for arbitrary retractions [2, 8] and general parallel-transports [42, 19]. Apart from the random basis generation inherent to the local semi-Riemannain Gram-Schmidt orthonormalization Algorithm 2, for there also exist multiple semi-Riemannian structures on which induce distinct semi-Riemannian structures on ; our experimental results in Fig. 2 suggest that all semi-Riemannian structures ensure convergence, though the convergence rates may differ. A deeper investigation of the depenence of convergence rate on the choice of semi-Riemannian structures appears highly intriguing but is beyond the scope of this paper; we defer such exploration to future work.
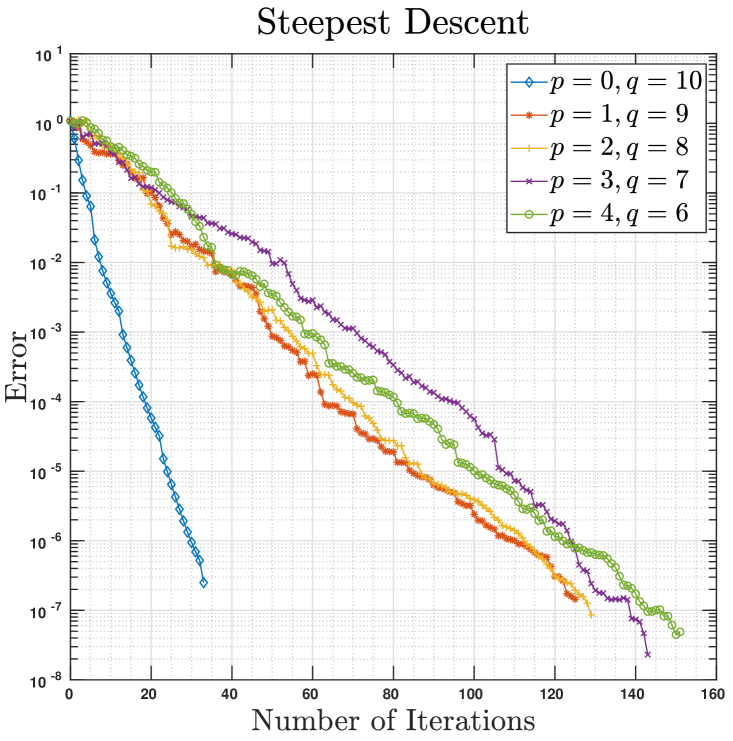
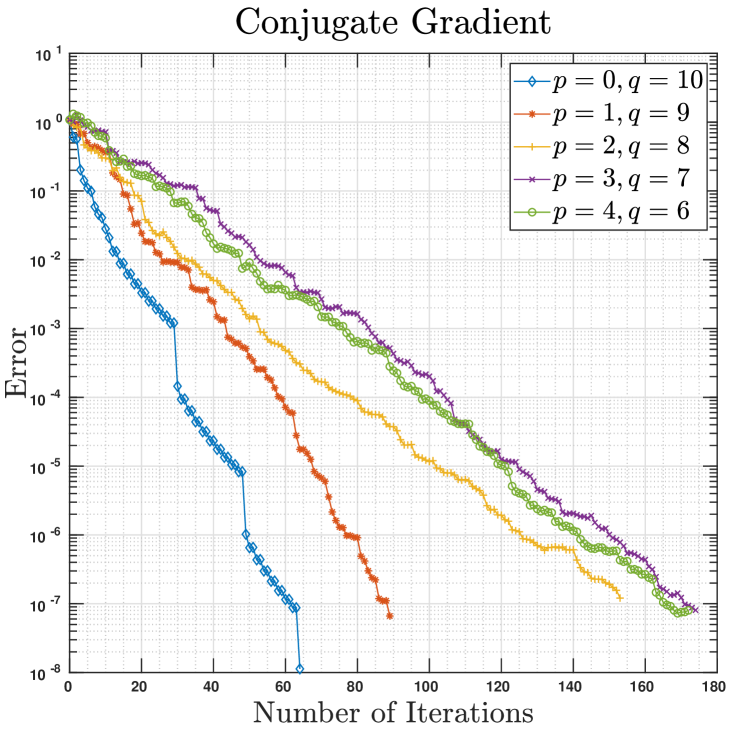
5.3 Pseudo-spheres in Minkowski Spaces
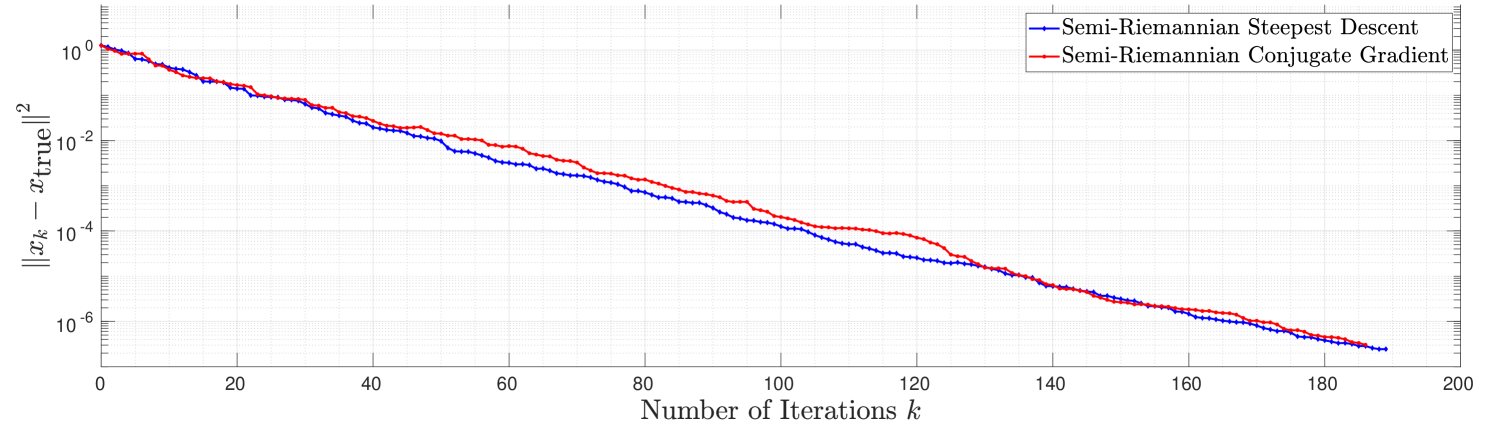
Since the pseudo-spheres (Section 4.2.1) and pseudo-hyperbolic spaces (Section 4.2.2) differ from each other only by an anti-isometry [35, Lemma 24], we will only consider pseudo-spheres in this numerical experiment. Note that, given an arbitrary point and a tangent direction , it is generally difficult to calculate Riemannian geodesics on pseudo-spheres explicitly (except for some particular cases where e.g. Clairaut’s relation holds, see [10, Chapter 3 Ex. 1]), but semi-Riemannian geodesics adopt closed-form expression Eq. 30 and thus can be used as retractions for semi-Riemannian optimization algorithms. We consider the problem
| (36) |
where is the Euclidean distance between and an arbitrarily chosen point that does not lie on . An illustration of the convergence of semi-Riemannian steepest descent and conjugate gradient methods (in semi-log scale) for a random instance of Eq. 36 with and can be found in Fig. 3, where the vertical axis marks the squared Euclidean distance between and the ground truth solution computed using the constrained optimization routine fmincon provided in the Matlab optimization toolbox. This numerical experiment indicates that the convergence rates of both semi-Riemannian first-order methods are linear for Eq. 36.
6 Conclusion
Motivated by the metric independence of Riemannian optimization algorithms and the Riemannian geometry of self-concordant barrier functions, we developed an algorithmic framework for optimization on semi-Riemannian manifolds in this paper, which includes Riemannian manifold optimization and standard unconstrained optimization in Euclidean spaces as special cases. We proposed a modification to the semi-Riemannian gradients for obtaining descent directions, and used this methodology to devise steepest descent and conjugate gradient algorithms for semi-Riemannian manifold optimization. We also showed that second-order methods such as Newton’s method and trust region methods are invariant with respect to difference choices of semi-Riemannian (including Riemannian) metrics. We provided numerical experiments to demonstrate the feasibility of the proposed algorithmic framework on non-degenerate semi-Riemannian submanifolds of Minkowski spaces. We defer more rigorous theoretical analysis, as well as broader ranges of applications of, semi-Riemannian manifold optimization to future work.
Software
MATLAB code for the surface registration algorithm is publicly available at https://github.com/trgao10/SemiRiem.
Acknowledgments
The authors would like to thank Lin Lin (UC Berkeley) for inspirational discussions.
References
- [1] P.-A. Absil, C. G. Baker, and K. A. Gallivan, Trust-Region Methods on Riemannian Manifolds, Foundations of Computational Mathematics, 7 (2007), p. 303–330.
- [2] P.-A. Absil, R. Mahony, and R. Sepulchre, Optimization Algorithms on Matrix Manifolds, Princeton University Press, 2009.
- [3] N. Ahmad, H. K. Kim, and R. J. McCann, Optimal Transportation, Topology and Uniqueness, Bulletin of Mathematical Sciences, 1 (2011), p. 13–32.
- [4] R. Albuquerque, On Lie Groups with Left Invariant Semi-Riemannian Metric, in Proceedings 1st International Meeting on Geometry and Topology, 1998, p. 1–13.
- [5] E. Andruchow, G. Larotonda, L. Recht, and A. Varela, The Left Invariant Metric in the General Linear Group, Journal of Geometry and Physics, 86 (2014), p. 241–257.
- [6] C. Atindogbe, M. Gutiérrez, and R. Hounnonkpe, New Properties on Normalized Null Hypersurfaces, Mediterranean Journal of Mathematics, 15 (2018), p. 166, https://doi.org/10.1007/s00009-018-1210-0, https://doi.org/10.1007/s00009-018-1210-0.
- [7] F. Barnet et al., On Lie Groups That Admit Left-Invariant Lorentz Metrics of Constant Sectional Curvature, Illinois Journal of Mathematics, 33 (1989), p. 631–642.
- [8] N. Boumal, P.-A. Absil, and C. Cartis, Global Rates of Convergence for Nonconvex Optimization on Manifolds, IMA Journal of Numerical Analysis, (2016).
- [9] S. M. Carroll, Spacetime and Geometry: An Introduction to General Relativity, San Francisco, USA: Addison-Wesley (2004), 2004.
- [10] M. P. Do Carmo, Riemannian Geometry, Springer, 1992.
- [11] J. J. Duistermaat, On Hessian Riemannian Structures, Asian Journal of Mathematics, 5 (2001), pp. 79–91.
- [12] A. Edelman, T. A. Arias, and S. T. Smith, The Geometry of Algorithms with Orthogonality Constraints, SIAM Journal on Matrix Analysis and Applications, 20 (1998), p. 303–353.
- [13] D. Gabay, Minimizing a Differentiable Function over a Differential Manifold, Journal of Optimization Theory and Applications, 37 (1982), p. 177–219.
- [14] M. Gutiérrez and B. Olea, Induced Riemannian Structures on Null Hypersurfaces, Mathematische Nachrichten, 289 (2016), pp. 1219–1236.
- [15] S. W. Hawking, The Occurrence of Singularities in Cosmology, Proc. R. Soc. Lond. A, 294 (1966), p. 511–521.
- [16] S. W. Hawking and G. F. R. Ellis, The Large Scale Structure of Space-Time, vol. 1, Cambridge University Press, 1973.
- [17] S. W. Hawking and R. Penrose, The Singularities of Gravitational Collapse and Cosmology, Proc. R. Soc. Lond. A, 314 (1970), p. 529–548.
- [18] G. Heidel and V. Schulz, A Riemannian Trust-Region Method for Low-Rank Tensor Completion, Numerical Linear Algebra with Applications, (2017), p. e2175.
- [19] W. Huang, P.-A. Absil, and K. A. Gallivan, A Riemannian Symmetric Rank-One Trust-Region Method, Mathematical Programming, 150 (2015), p. 179–216.
- [20] Y. Kim and R. McCann, Continuity, Curvature, and the General Covariance of Optimal Transportation, Journal of the European Mathematical Society, 12 (2010), p. 1009–1040.
- [21] Y.-H. Kim, R. J. McCann, and M. Warren, Pseudo-Riemannian Geometry Calibrates Optimal Transportation, Mathematical Research Letters, 17 (2010), p. 1183–1197, https://doi.org/10.4310/MRL.2010.v17.n6.a16.
- [22] D. N. Kupeli, Degenerate Manifolds, Geometriae Dedicata, 23 (1987), p. 259–290.
- [23] D. N. Kupeli, Degenerate Submanifolds in Semi-Riemannian Geometry, Geometriae Dedicata, 24 (1987), p. 337–361.
- [24] D. N. Kupeli, On Null Submanifolds in Spacetimes, Geometriae Dedicata, 23 (1987), p. 33–51.
- [25] J. C. Larsen, Singular Semi-Riemannian Geometry, Journal of Geometry and Physics, 9 (1992), p. 3–23.
- [26] D. G. Luenberger and Y. Ye, Linear and Nonlinear Programming, vol. 2, Springer, 1984.
- [27] J. Milnor, Morse Theory, vol. 51, Princeton university press, 1963.
- [28] J. Milnor, Morse Theory, vol. 51 of Annals of Mathematic Studies, Princeton University Press, 1973.
- [29] J. Milnor, Curvatures of Left Invariant Metrics on Lie Groups, Advances in Mathematics, 21 (1976), p. 293–329, https://doi.org/10.1016/S0001-8708(76)80002-3.
- [30] N. Miolane and X. Pennec, Computing Bi-Invariant Pseudo-Metrics on Lie Groups for Consistent Statistics, Entropy, 17 (2015), p. 1850–1881.
- [31] Y. Nesterov and A. Nemirovskii, Interior-Point Polynomial Algorithms in Convex Programming, vol. 13, Siam, 1994.
- [32] Y. E. Nesterov and M. J. Todd, On the Riemannian Geometry Defined by Self-Concordant Barriers and Interior-Point Methods, Foundations of Computational Mathematics, 2 (2002), pp. 333–361.
- [33] L. Nicolaescu, An Invitation to Morse Theory, Springer Science & Business Media, 2011.
- [34] K. Nomizu, Left-Invariant Lorentz Metrics on Lie Groups, Osaka Journal of Mathematics, 16 (1979), p. 143–150.
- [35] B. O’Neill, Semi-Riemannian Geometry with Applications to Relativity, vol. 103 of Pure and Applied Mathematics, Academic Press, 1983.
- [36] R. S. Palais, Seminar on Atiyah-Singer Index Theorem.(AM-57), vol. 57, Princeton University Press, 2016.
- [37] R. Penrose, Gravitational Collapse and Space-Time Singularities, Physical Review Letters, 14 (1965), p. 57.
- [38] P. Petersen, Riemannian Geometry, vol. 171 of Graduate Texts in Mathematics, Springer New York, 2006.
- [39] T. Rapcsak, Geodesic Convexity in Nonlinear Optimization, Journal of Optimization Theory and Applications, 69 (1991), p. 169–183.
- [40] G. Raskutti and S. Mukherjee, The Information Geometry of Mirror Descent, IEEE Transactions on Information Theory, 61 (2015), pp. 1451–1457.
- [41] J. Renegar, A Mathematical View of Interior-Point Methods in Convex Optimization, vol. 3, Siam, 2001.
- [42] W. Ring and B. Wirth, Optimization Methods on Riemannian Manifolds and Their Application to Shape Space, SIAM Journal on Optimization, 22 (2012), p. 596–627, https://doi.org/10.1137/11082885X.
- [43] D. J. Saunders, The Geometry of Jet Bundles, vol. 142, Cambridge University Press, 1989.
- [44] S. T. Smith, Optimization Techniques on Riemannian Manifolds, Fields institute communications, 3 (1994), p. 113–135.
- [45] O. C. Stoica, On Singular Semi-Riemannian Manifolds, International Journal of Geometric Methods in Modern Physics, 11 (2014), p. 1450041.
- [46] C. Udriste, Convex Functions and Optimization Methods on Riemannian Manifolds, vol. 297, Springer Science & Business Media, 1994.
- [47] R. Vakil, A Beginner’s Guide to Jet Bundles from the Point of View of Algebraic Geometry, Notes, (1998).
- [48] S. Wright and J. Nocedal, Numerical Optimization, Springer Science, 35 (1999), p. 7.
Appendix A Genericity Non-degeneracy of Semi-Riemannian Structures on Hyperplanes of Minkowski Spaces
We begin with a brief discussion for the Gauss map defined in Section 4.2. Consider . Since if and only if is perpendicular to with respect to the Euclidean metric on , is a closed subset of . More precisely, we have
Proposition A.1.
Let be the canonical projection onto the second factor. The following facts hold:
-
(1)
;
-
(2)
If is compact, then is a closed map, (i.e. mapping closed sets to closed sets). In particular, is a closed subset if is compact.
The non-degeneracy of a generic hyperplane can be easily obtained as a corollary of Proposition 4.18. Recall that hyperplanes can be characterized as
and we denote
for the normal vector of . Obviously, vector lies in if and only if satisfies the equation , or equivalently, the equation .
Corollary A.2.
A generic hyperplane in is non-degenerate.
Proof A.3.
If is a hyperplane, then the image of its Gauss map is a single point , which is the line determined by the normal vector of . Since is a hypersurface in , we see that the normal vector of a generic hyperplane does not lie on and hence a generic hyperplane is non-degenerate.
Appendix B Additional Examples
The following Table 1 summarizes the examples computed in this paper.
| Manifolds | Non-degenerate | Geodesics | Paral. Transp. |
|---|---|---|---|
| (generic) hyperplane | yes | ✓ | ✓ |
| sphere | no | ✗ | ✗ |
| pseudo-sphere | yes | ✓ | ✓ |
| pseudo-hyperbolic space | yes | ✓ | ✓ |
| indefinite orthogonal group | no | ✓ | ✗ |
| orthogonal group | no | ✓ | ✗ |
| special linear group | yes () | ✓ | ✗ |
| symplectic group | no | ✓ | ✗ |
| SPD matrices | no | ✓ | ✗ |
B.1 Semi-Riemannian Geometry of Symmetric Positive Definite Matrices
Let be the manifold consisting of all symmetric positive definite matrices. A matrix is symmetric positive definite if and only if there exists some such that . The tangent space of at is . Hence if we regard as a semi-Riemannian sub-manifold of with respect to the semi-Riemannian metric with signature , then the semi-normal space of at is
It is straightforward to compute the intersection of and . Hence we obtain the following:
Proposition B.1.
The degenerate bundle of in is
In particular, is a degenerate semi-Riemannian sub-manifold of .
Proposition B.2.
If a geodesic passing through with the tangent direction exists, then and can be written as
for some suitable matrix-valued function such that and
for each .
Proof B.3.
Let be a geodesic curve passing through with the tangent direction . Then must satisfies the following conditions:
Hence for some matrix-valued function . Therefore, we must have
Since , we see that if and only if
B.2 Semi-Riemannian Geometry of Matrix Lie Groups
As discussed in Section 4.1, matrix Lie groups provide another class of rich examples for manifolds admitting semi-Riemannian structures. In this section we illustrate how to apply the semi-Riemannian manifold optimization framework developed in Section 3 to some common matrix Lie groups, despite the degeneracy of their inherited sub-Riemannian structures, by means of projection to semi-normal bundles. We begin with a general discussion on the semi-normal bundle of matrix Lie groups, then specialize to several examples.
Let be a matrix Lie group. We denote by the Lie algebra of . Then the tangent space of at a point is simply . For each fixed positive integer , there is a left-invariant semi-Riemannian metric of signature on defined by
Since the bilinear form is left-invariant, we have the following
Lemma B.4.
For each , we have
Let be the Riemannian metric on defined by
We denote by the normal bundle of in . We can relate the normal bundle and the semi-normal of bundle of in by the following:
Proposition B.5.
For each , we have
In particular, is a vector bundle on of rank .
Proof B.6.
lies in if and only if for all . This implies that if and only if and this completes the proof.
Let be a geodesic passing through with tangent direction . Then by definition, is characterized by the following relations:
and the initial condition , . To compute geodesics explicitly for matrix Lie groups, we need the following simple but handy observations.
Lemma B.7.
If is a given geodesic, then there exists a unique curve in such that and .
Proof B.8.
Since , we can write for a curve in . By differentiating , we obtain
This implies that .
Proposition B.9.
If is a geodesic passing through with tangent direction , then , where is the curve in determined in Lemma B.7.
Corollary B.10.
The geodesic curve passing through with direction in Eq. 40 is of constant speed.
Proof B.11.
Corollary B.12.
Proof B.13.
The following characterization of the parallel transport of a tangent vector along a geodesic on can be easily obtained by unravelling Definition 4.13.
Lemma B.14.
Let be a parallel transport of along a geodesic curve passing through with tangent direction . Then
where is a curve in such that and . Here is the curve in determined in Lemma B.7.
B.2.1 Indefinite Orthogonal Groups
The definition of indefinite orthogonal groups can be found in Example 4.5. In this subsection we derive explicit formulae for the geodesic in following Definition 4.12.
Proposition B.15.
For each , we have
Proof B.16.
By Lemma B.4, it is sufficient to prove
as is left-invariant. To this end, we notice that by Proposition B.5
Now consists of all matrices of the form where is symmetric, we may conclude that
Let be a geodesic curve passing through with direction for some skew-symmetric matrix . By Proposition B.9 and Proposition B.15, the curve can be written as
| (37) |
where is a curve in such that
| (38) |
We partition a skew-symmetric matrix as where , and .
Lemma B.17.
Proof B.18.
We parametrize as where . Since is symmetric, we have
This implies that
from which we obtain , and
Therefore, we obtain
By Proposition B.9, we obtain the following:
Proposition B.19.
The geodesic curve passing through with direction is unique and is
| (40) |
Corollary B.20.
The curve is a geodesic curve passing through with direction if and only if .
Proof B.21.
If is a geodesic curve, then from Proposition B.19, it is straightforward to verify that . Conversely, if , then Eq. 40 is reduced to
In particular, if (resp. ), then always holds and Corollary B.20 shows that geodesics in (resp. ) are of the form for some skew-symmetric matrix . Moreover, Corollary B.20 already shows a big difference between Riemannian geometry and non-Riemannian geometry of (cf. [5, Theorem 2.14]).
B.2.2 Orthogonal Groups
By Proposition B.19, the geodesic passing through a point with tangent direction exists. We will see that this is not always true. To that end, we consider for example. First, according to Lemma B.4 and Proposition B.5, we have the following
Proposition B.22.
For each , the semi-normal space of at is
Now if is a geodesic curve passing through with tangent direction where , then
where is skew-symmetric satisfying
Hence we have
which implies
Therefore, we may conclude that
Proposition B.23.
On , a geodesic passing through with the tangent direction exists if and only if the skew symmetric matrix satisfies the relation
If such a exists, then if of the form
where is a curve in the linear subspace such that . The square of the speed of is and the energy of is .
In particular, if and we take , then by Proposition B.23 becomes
which is exactly the geodesic curve on with the usual Riemannian metric
where and .
B.2.3 Special Linear Groups with
We notice that the Lie algebra of consists of all traceless matrices, which implies that
Therefore, from Lemma B.4 and Proposition B.5, we have the following
Proposition B.24.
For each , the semi-normal space of at is
In particular,
Hence is a non-dengerate semi-Riemannian sub-manifold of if and only if .
By Proposition B.24 and [35, Corollary 10], we obtain the following
Corollary B.25.
If , then the geodesic passing through with the tangent direction exists and it is unique.
If is a geodesic curve passing with the tangent direction , then
where satisfying
| (41) |
for some real valued function . Moreover, from (41), we also have
Together with the fact that as , we may conclude that
| (42) |
Proposition B.26.
If and is a geodesic curve passing through with the tangent direction , then .
Next we consider the simplest case where and , we may write and so that the ODE in (41) becomes
This implies that and . Hence we may conclude that
Proposition B.27.
An embedded geodesic on passing through with tangent direction exists if and only if . Moreover, if such exists, then it is unique and
The square of the speed of is and the energy is .
B.2.4 Symplectic Group
We recall that the symplectic group is the group of matrices satisfying
where . The Lie algebra of is
and the normal space is
Without loss of generality, we may assume that .
Proposition B.28.
For each , we have
and
In particular, is a degenerate semi-Riemannian sub-manifold of .
Proof B.29.
Next we describe geodesics on .
Proposition B.30.
Let be a geodesic passing through with the tangent direction . If we write as where are symmetric matrices and is an matrix. We also partition as
where and . Then
where , and