Semi-Supervised Class Discovery
Abstract
One promising approach to dealing with datapoints that are outside of the initial training distribution (OOD) is to create new classes that capture similarities in the datapoints previously rejected as uncategorizable. Systems that generate labels can be deployed against an arbitrary amount of data, discovering classification schemes that through training create a higher quality representation of data. We introduce the Dataset Reconstruction Accuracy, a new and important measure of the effectiveness of a model’s ability to create labels. We introduce benchmarks against this Dataset Reconstruction metric. We apply a new heuristic, class learnability, for deciding whether a class is worthy of addition to the training dataset. We show that our class discovery system can be successfully applied to vision and language, and we demonstrate the value of semi-supervised learning in automatically discovering novel classes.
1 Introduction
An ongoing transition in machine learning research has been from hand-labeling datasets from which our models learn to having an algorithm create a dataset from which our models learn. The process of dataset creation is time consuming, expensive and ad-hoc. Progress in self-supervised (Radford et al., 2019) (Devlin et al., 2018) and semi-supervised (Berthelot et al., 2019) learning has enabled us to pre-train in an infinite data training regime where the main limit to our training is computation time. They’ve led us to techniques that allow us to automatically label unlabeled data points. In contrast with the standard semi-supervised approach of taking advantage of additional samples whose classes are already known, we take advantage of data that is from classes that have never been seen at a model’s original training time, creating a learning algorithm that automatically generates an effective learning environment.
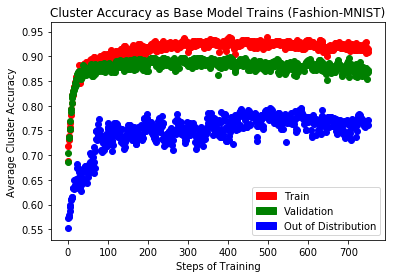
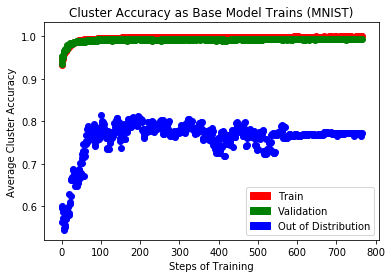
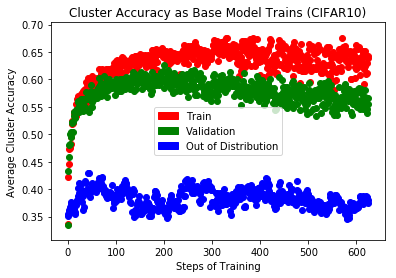
One major advantage of this technique is transforming out-of-distribution data into in-distribution data. Data that is out-of-distribution leads to an inability to make claims about a model’s confidence or performance on that data, making’ it hard to trust your model’s confidence and calibration (Snoek et al., 2019). Bringing out-of-distribution data points into the training dataset and training on them is one way to rectify uncertainty estimates in a multi-class setting where new classes can be productively added to the training distribution.
The self-supervised infinite training data regime has been a boon to transfer learning research (Raffel et al., 2019). The features developed in training on classes similar to the classes to be discovered aid in accomplishing faster learning on those classes. We accomplish a kind of transfer learning in line with self-taught learning (Raina et al., 2007), where data from classes not found in training improve model performance. Much of the success of deep learning in vision can be attributed to the availability of large-scale labeled data (Sun et al., 2017), and so developing the ability to construct large-scale datasets is incredibly important.
This approach can be seen as conditional generative modeling for labels, where we condition on the existing labeled data. This allows the trained model to learn a prior for data representation that comes from human labels, where the trained model pushes classes with human labels to be linearly separable in a way that can generalize to data that hasn’t been labeled, imitating the heuristics that a human uses to select and distinguish between classes. In contrast, unsupervised data labeling techniques can’t impose a prior which is influenced by what a human would have done. One major difference from generative modeling is that here, we generate partitions. One partition is over the in-distribution space, covered by existing classes and their datapoints. The other partition is over the out-of-distribution space, which is a partition generated by a clustering algorithm. That partition will progressively merge with the in-distribution partition.
There is evidence that dataset size is still a major limiting factor to the effectiveness of deep learning models (Sun et al., 2017). One reason much work in vision is on the classification task (as opposed to the more general task of identifying all objects in an image) is that it’s challenging to get quality labeled datasets. Techniques like class discovery can help overcome that challenge.
Our major contributions are demonstrating the value & potential of semi-supervised learning backed by deep metric learning in class discovery, demonstrating a method that is general across language and vision, introducing a new class feature which can be used to distinguish class quality, introducing the Dataset Reconstruction Accuracy measure, and demonstrating the value of creating a feedback loop between learning on discovered classes to create a better model for representing OOD data and using that improved representation to discover classes more effectively.
2 Related Work
2.1 Semi-Supervised Learning
There is a recent wave in approaches for self-supervised and semi-supervised learning (Berthelot et al., 2019), which are relevant because our method is initialized in a semi-supervised fashion before it continues in a self-supervised fashion. Our method, however, differs dramatically from regular self-supervised learning where all classes are present in the training dataset and the model merely learns to slot unlabeled datapoints into those pre-existing classes.
In regular semi-supervised learning, the data set can be divided into two parts: the points for which labels are provided, and the points that are in the same domain as but the labels of which are not known.
In contrast with conventional semi-supervised learning, we consider for which the data is not necessarily in the same domain as the , and a correct existing class label is not available to the model.
2.2 Deep Metric Learning
We employ deep metric learning, using data to learn a similarity measure on which we cluster. Clustering in deep networks has occurred in other contexts. Learning Discrete Representations via Information Maximizing Self-Augmented Training (IMSAT) uses deep clustering to learn a discrete representation that is invariant to perturbations (Hu et al., 2017). Deep Clustering for Unsupervised Learning of Visual Features improves representation quality by creating labels for existing data points and training on said labels, though they do not train on datapoints outside the original training distribution. Their work offered initial proof that representations can be improved by training on classes discovered via clustering (Caron et al., 2018).
Deep Metric Learning via Facility Location (Song et al., 2016) introduced Normalized Mutual Information, a measure for comparing discovered classes to existing class labels.
2.3 Open World Classification
Our system is related to the closed-world assumption (Scheirer et al., 2012), where our classifier does not make the assumption that all classes which appear in the test data must have appeared during training. Our system stretches this to a case where the initial training distribution does not include all classes, but where classes are introduced to the training distribution after being created by our model. Unseen Class Discovery in Open World Classification unmakes this assumption but focuses on finding the correct number of outstanding classes, rather than finding the data points which belong to those classes. (Shu et al., 2018) Towards Open World Recognition (Bendale & Boult, ) sets the frame for engineering open world systems but does not discover new object categories itself, leaving that to human labeling. iCaRL: Incremental Classification and Representation Learning (Rebuffi et al., ) focuses on incremental concept discovery, but does not discover the classes itself. Simultaneous Class Discovery and Classification of Microarray Data Using Spectral Analysis (Qiu & Plevritis, 2009) both discovers classes (with a spectral analysis technique) and classifies those classes. No deep metric learning is used to represent the data, but the application to microarray data is an example of the value of the technique.
2.4 Bayesian Nonparametrics
2.5 Continual and Lifelong Learning
We present a continual learning and lifelong learning system, which is influenced by the continual learning frontier. For example, Continual Unsupervised Representation Learning (Rao et al., 2019) aims to create an algorithm that discovers new concepts over its lifetime, using a generative model of past classes to avoid catastrophic forgetting. We show the advantage of leveraging a combination of human-labeled data and algorithm-labeled data in a similar setting.
2.6 Self-Supervised Learning
Self-Supervised learning has seen lots of recent success, especially in language (Radford et al., 2019) (Devlin et al., 2018). Extensions to vision have mainly focused on pretext tasks like prediction context (Doersch et al., 2015), image rotation (Gidaris et al., 2018), or architecture design (Kolesnikov et al., 2019).
Our work is inspired by the transition to the pre-training with infinite training data regime achieved by these models, though it creates a task by using a system of machine learning algorithms (embedding + clustering) to generate the label rather than taking it directly from the training data. This differentiates of from other mergers of self-supervised and semi-supervised learning, such as Self-Supervised Semi-Supervised Learning (Zhai et al., 2019).
2.7 Semi-Supervised Clustering
Metric-based semi-supervised clustering also focused on using some labeled data to aid unsupervised learning. There was rich activity in the field in the early 2000s (Ex., (Bilenko et al., 2004)). Rather than learning new classes, the goal is to fit existing classes well and learn new clusters around them. Metrics were often learned with an SVM and deep metric learning was rare.
2.8 Task Generation
There is a thread in intrinsic motivation research where an agent is trained to generate new tasks that it is capable of performing in an environment and then learn on those tasks (Held et al., 2018), (Schmidhuber, 1991), (Schmidhuber, 2013), (Clune, 2019). Our system has similar properties and motivations, though we focus on the multi-class classification task.
3 Method
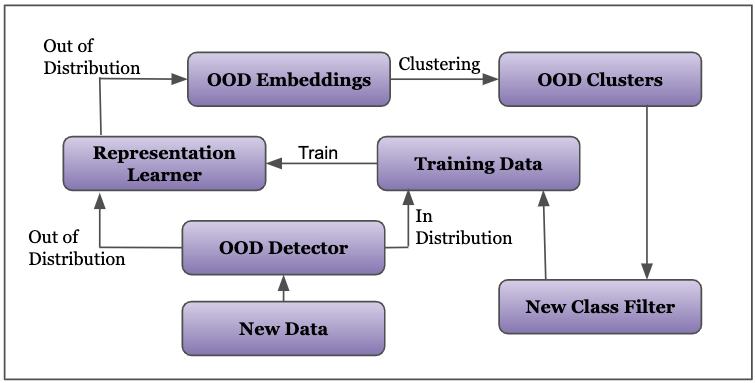
As depicted in Figure 2, our method consists of a representation learning, an out-of-distribution (OOD) detector, generated OOD embeddings, a clustering algorithm generating clusters of OOD embeddings, a filtering of those clusters as new class candidates, and a dynamically updating training dataset from which the representation learner learns. We describe many of those parts in detail in the following sections.
3.1 Representation Learner
Our representation learner is trained to classify over all of the current training data. It will create embeddings of our OOD data, whether the domain is images or language. The representation learners employed include a small CNN and Resnet50 (He et al., 2016) for image data, and the TextCNN (Kim, 2014) for text data.
3.2 OOD Detector
We take advantage of (Hendrycks & Gimpel, 2016)’s work in out of distribution detection, which evaluates a given data points as being whether out-of-distribution by thresholding its predictive confidence (i.e., the maximum predictive probability) with a pre-computed cut-off value. Specifically, this method computes the cut-off value as the 95% quantiles of predictive confidence of the training data, and using that confidence level to evaluate new data as being out of distribution. For example, our model may show that 95% of training datapoints have a class that is predicted with a probability of 80% or above. We would then treat new datapoints whose top class is predicted with 80% or less as out of distribution. In general, progress in OOD Detection (Ex. (Liang et al., 2017; Lee et al., 2018)) will lead to more effective class discovery systems, as more data points will correctly be placed into the data store from which new classes are created.
3.3 Discrete Class Creation
We use the clustering method K-means to transform a high dimensional set of embeddings into new classes to be evaluated. K-means gives a higher quality of candidate classes, as measured by correspondence to the original class set in comparison to other clustering methods like Hierarchical Agglomerative Clustering. Hierarchical clustering returns a hierarchy with multiple levels of class candidates, which allows for mode discovery and a choice of what level at which to define a label set. For us, this was not worth the drop in the quality of discovered clusters.
We initialize k-means with a k-means++ initialization, focusing the initial clusters on regions that are far from one another.
We run k-means 10 times with different centroid seeds, using the result that performs best on a measure of inertia. Inertia is the sum of squared distances of samples to their closest cluster center.
3.4 Class Addition Heuristic
Carefully choosing which new class candidates are worth adding to the training dataset is important to preserving the quality of the training set. We explore three major heuristics. The first is class learnability, which asks whether a model trained on the candidate classes can effectively learn to predict whether a datapoint is from the candidate class. Here we ask if a class, when added to the training dataset, leads to an improvement in the ability of the representation learner trained on that dataset to quickly adapt to new tasks. The third is a measure of cluster density, assuming that denser clusters are more likely to contain datapoints that are similar to each other and so will have a higher quality. This led to a negative result, where denser clusters were not related to cluster accuracy. One important realization is that all three are features of clusters. The can be used in tandem or be put through a machine learning model that predicts a cluster’s value.
3.5 Evaluating Performance with Dataset Reconstruction Accuracy
We use two major measures to evaluate class discovery performance in this paper.
The first major evaluation measure is cluster accuracy. We measure the amount of overlap that a given out-of-distribution cluster has with the removed class that it has the most overlap with. For example, an MNIST class with 6 ’9’ values and 4 ’7’ values would be mapped to class 9 and given a cluster accuracy of 60% (6/10). Multiple clusters are allowed to be mapped to the same unseen original class label.
Second, we introduce the dataset label reconstruction accuracy to measure the efficacy of our class discovery system. Dataset reconstruction asks what the overall overlap of the original class labels are with the labels discovered and assigned during class discovery. This overlap score is determined by maximum overlap. For example, if a cluster is discovered, the entire cluster is assigned to a new label. The check against the original dataset comes from comparing with the ground truth labels of the datapoints for each class. The class with the plurality of labels represented has every datapoint in the new cluster assigned to it.
One very important advantage of the dataset reconstruction score over cluster accuracy is its generality. It’s easy to imagine class discovery systems being created, for example, via raw discrete latent variable models. In that case, comparing discrete latent variable models to this technique would require a measure that wasn’t centered on clustering.
Let training labels where is equal to the number of training datapoints. Let OOD labels where is equal to the number of OOD data points whose correct class label is not available to the model. and which correspond to the labels that the system discovered itself. Let the normalized cluster size be the weighting of each discovered cluster based on the number of datapoints in the cluster and be the accuracy of those clusters, which is the maximum overlap against the true label set. We compute the dataset reconstruction accuracy through an indicator function for whether a discovered label matches the true label distribution or not, which is
In our case, we use clustering to compute the datset reconstruction accuracy over K clusters, giving us:
4 Experiments
Cluster Accuracy vs. Class Count during Training Class Count MNIST Fashion-MNIST CIFAR10 2 0.4282 0.5063 0.3536 3 0.4958 0.6495 0.3403 4 0.6497 0.6931 0.3971 5 0.7197 0.7005 0.4013
4.1 Datasets
We evaluate the method on both image and language modalities. We consider MNIST (LeCun, ), Fashion-MNIST (Xiao et al., 2017), CIFAR 10 (Krizhevsky & Hinton, 2010) for image, and CLINC out-of-scope (OOS) intent detection benchmark (Larson et al., 2019) for language.
There are a few settings for experiments, where our datasets are split according to the experiment. In the default setting, half of the classes of (MNIST, Fashion-MNIST, CFAIR10) have the labels stripped from their datapoints. In self-supervised style, a supervised training set is composed of the other 5 classes. An oracle correctly determines the split between in distribution data and out-of-distribution data.
In the second setting, an OOD detector determines whether data points are slotted into existing classes or pooled with other out of distribution data points for assignment to new class labels. This is required for the dynamic model because if it creates two classes which are have an identical ground truth label it will struggle to differentiate them from one another and training will stall.
On the CLINC OOS dataset, 120 classes are used during training and 30 classes are used for class discovery evaluation, as well as an out-of-scope class which contains random user utterances that do not match any of the known intents.
4.2 Number of Initial Classes Effects
This important experiment shows that if you are able to successfully label new classes, your ability to discover new classes improves. The difference between training on 2 classes and training on 5 classes led to an increase from 43% accuracy to 71% accuracy in the small CNN case on MNIST (See Table 1). This dramatic impact from the addition of training data shows the potential of effective class discovery systems that dynamically feed back on themselves as they become more capable of discovering classes with each new class they discover.
Dataset Reconstruction Accuracy during Discovery Classes Discovered MNIST Fas.-MNIST CIFAR10 No Added Classes 0.8473 0.8290 0.6714 Added 1 Class 0.8813 0.8549 0.6796 Added 2 Classes 0.8958 0.8578 0.6921 Added 3 Classes 0.9054 0.8589 0.7053 Added 4 Class 0.9078 0.8644 0.7188 Added 5 Classes 0.9113 0.8695 0.7319
4.3 Other Experimental Methodology
The representation learner used in our experiments is either Resnet50 (He et al., 2016) or a small CNN. The small CNN has a single convolutional layer with 32 filters and a Relu activation, followed by a flattening and a dense layer with 128 neurons and a relu activation.
We apply an Adam optimizer with a learning rate of , beta 1 of , beta 2 of , and epsilon of . Our error metric is the cross entropy loss function.
Our OOD baseline detector has its threshold set to 95% confidence on the training data.
The number of clusters in all vision experiments is 15. This hyperparameter has a fairly strong effect on both cluster accuracy (higher accuracy with higher ) and on dataset reconstruction score, so it’s kept constant through baseline comparisons.
We use Tensorflow 2.0 for all of our neural network models (Abadi et al., 2016). For our linear models and clustering we use Scikit-Learn (Pedregosa et al., 2011).
An optimial hyperparameter sweep (ex., for the number of clusters or hyperparameters for the representation learner) would optimize for the dataset reconstruction accuracy in the setting where you’re limited to creating a number of classes that is equal to the number of classes removed from the dataset.
All models were trained on a single GPU or CPU at a time. Our main compute infrastructure was a set of Nvidia p100 GPUs.
4.4 Compared Methods
We compare 3 methods for generating new classes via clustering, assuming an oracle allows you to correctly determine which datapoints are not from the existing class label set. These results are displayed in Table 3.
’Random embedding’ uses an untrained single convolutional layer followed by a single feedforward layer to embed the image. ’Semi-Supervised’ trains that same model on the first 5 classes from each dataset. ’Dynamic’ trains on the first 5 classes for an epoch, discovers and adds the most learnable cluster, and then trains on the entire dataset until 5 new classes have been added.
4.5 Static vs. Dynamic Class Discovery
One simple approach to class discovery is to create classes over all the out of distribution datapoints at once, assigning every OOD datapoint to a new label. That approach can be made dynamic by choosing (for example) one new class at a time. Once that class is chosen, a re-training process integrates that class into the existing representation learner. That retrained model is used to generate and select another class, in an ongoing process.
We show results from both setups. In the static setting, an overall dataset label reconstruction accuracy on MNIST of 84.73%. In the dynamic setting, we see an overall dataset label reconstruction accuracy of 91.13%.
As the dynamic model adds and trains on new classes, its ability to recover the labels over the entire training dataset improves.
4.6 Learnability as a Class Evaluation Technique
One major challenge is finding new classes that are pure, where most data points correspond to a coherent concept. If discovered classes are impure, the training process will encounter incorrect and noisy labels. Training on those labels can be difficult, and lead to a degradation in training accuracy as well as a slower training process (Zhang et al., 2016). Do note, however, that the incorrect labels will be closer to correct than randombly permuted labels, because they will have been close datapoints in the embedding space.
We introduce a new technique, learnability, as a test of the quality of a cluster which could be added as a new class. The heuristic is as follows: Treat all of the clusters that come out of the OOD dataset as classes to be learned by a fresh, untrained model. Train that model on the clusters, treating the clusters that can be easily learned (for which you obtain a high accuracy) as better options for inclusion that clusters that are challenging to learn.
This will lead to selecting new classes that are separable from the rest of the data. Including existing classes in this set is also an option, which can check for the separability of discovered classes with existing classes as well as separation from potential classes.
Using learnability, MNIST reconstruction accuracy is . Choosing random clusters leads to an accuracy of . Fashion-MNIST learnability reconstruction accuracy is , while the random baseline gives . The difference on CIFAR 10 is to .
Random Static vs. Dynamic Performance Method MNIST Fas.-MNIST CIFAR10 Random Embedding 0.8473 0.8290 0.6714 Semi-Supervised 0.8700 0.8604 0.6576 Dynamic 0.9113 0.8695 0.7319
4.7 Application to Language
We next show that the class discovery method also applies to the language modality. In particular, we consider the real-world task of intent detection in goal-oriented dialog modeling, where the goal is to classify a given user utterance to one of the many pre-defined task categories (i.e., intents), so that the dialog manager can direct the downstream flow of the conversation accordingly toward certain task fulfillment modules (Zhao et al., 2019). In this context, the ability of a dialog agent to automatically discover novel user intent is important for the continuous improvement and refinement of the system. For example, the discovered novel intent types (see, e.g., Table 5) can be used by the dialog system to implement new response and behavior for the discovered class.
We consider the CLINC Out-of-scope (OOS) benchmark (Larson et al., 2019), which contains 150 intent categories with 150 utterance in each category, and an extra 1200 out-of-domain utterances which do not match any of the known intents. For the representation learner, we consider the standard 1-layer, 128-hidden-unit TextCNN (Kim, 2014) with filter sizes 3, 4, 5 and initialize the word embeddings using GloVe (Pennington et al., 2014). We train the model on 120 randomly-sampled classes from the OOS dataset, and evaluate the quality of the learned representation on the rest of the 30 classes. The model was trained for 200 epochs with minibatch size 128 and step size 0.001 using Adam optimizer, and reached a final classification accuracy of 0.9466. For class discovery, we apply K-means with 30 clusters on the TextCNN’s hidden representation for the 30 hold-out classes, and compute the label rediscover accuracy of the resulting clusters against the ground truth labels.
To evaluate the benefit of semi-supervision to class discovery, we compare the result against five popular or the state-of-the-art unsupervised approaches in text domain. Specifically, we consider the classic methods of Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF), which are based on the term frequency (TF) and term frequency–inverse document frequency (TF-IDF) representations of the utterances, respectively. Next, we consider two standard token-level embedding approaches word2vec (Mikolov et al., 2013) and GloVe (Pennington et al., 2014), where we compute the sentence-level embedding using the TF-IDF-weighted average of the token-level embeddings. Finally, we consider the state-of-the-art sentence embedding approach Universal Sentence Encoder (USE) (Larson et al., 2019). Universal Sentence Encoder is pre-trained jointly on large-scale web corpuses and on natural language inference tasks, and has illustrated state-of-the-art performance in multiple natural language tasks including semantic textual similarity, opinion polarity classification and phrase level sentiment analysis. For all the embedding methods, we perform clustering using K-means with 30 clusters.
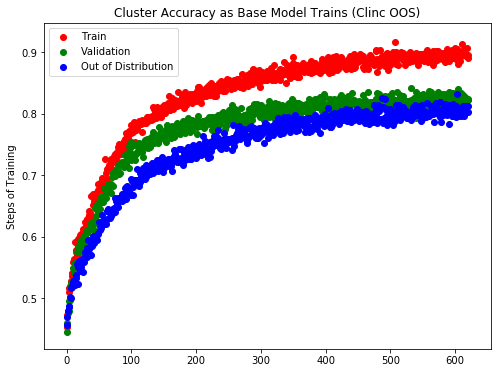
We repeat each of the above methods for 20 times and report their mean and standard deviation of label rediscover accuracy in Table 4. As shown, the class discovery accuracy based on the semi-supervised TextCNN embedding outperforms the both classic and token-level approaches by a clear margin, and is on-par with Universal Sentence Encoder, despite not being pre-trained on large-scale corpus like USE. In particular, we notice that the GloVe-initialized TextCNN outperforms the original GloVe by around , illustrating the benefit of semi-supervision in improving the representation quality of the learned embedding.
| Method | Label Rediscovery Accuracy |
|---|---|
| Random (Baseline) | 0.2105 |
| LDA | 0.5712 0.0066 |
| NMF | 0.7478 0.0066 |
| word2vec | 0.7194 0.0089 |
| GloVe | 0.7629 0.0085 |
| Univ. Sent. Encoder | 0.8127 0.0108 |
| TextCNN (Ours) | 0.8123 0.0076 |
Finally, to illustrate the proposed approach’s practical utility in discovering novel intent domains, we perform class discovery on the out-of-scope utterances in the OOS data. Specifically, we apply K-means to the TextCNN representation of the out-of-scope utterances, with the number of clusters determined using the elbow method based on silhouette score (de Amorim & Hennig, 2015). We estimate the learnability of the discovered clusters based on the out-of-sample classification accuracy of a logistic regression model, and report the top clusters (with classification accuracy ). We show example utterances in the top clusters in Table 5 and report the full content of the discovered clusters in the Supplementary. We observe that the learnability heuristic is able to select utterance clusters with consistent lexical and syntactical patterns, which tend to correspond to groups of semantically coherent user requests in the context of spoken dialogues. How to incorporate further a priori common sense knowledge (e.g., knowledge graph groundings) into this semi-supervised framework to further improve the semantic precision of the discovered utterance clusters an interesting avenue for future research.
Intent Domains Example Utterances Anecdote who is the coach of the chicago bulls who formulated the theory of relativity can you tell me who sells dixie paper plates who invented the internet which company has gone up the most today Text Messages read text please read me the last text message i received read my friend’s text message please read the text message i just received save my text on my laptop hard drive Phone Inquiries what’s the average battery life of an android phone how do i make my android phone more secure how does my current htc phone compare to other android phones what battery percentage is my phone at what are some good games for my android phone Bank Account i jot got hired and need help with my retirement account i have to roll over my 401k to a new account and i don’t know how do you know if it is possible to close my savings account please take all my money out of my checking account and close the account set a warning for when my bank account starts running low
5 Conclusion
Class Discovery is an underserved problem which shows promise to become a major self-supervised learning and semi-supervised learning application. Its success can lead to a new major training style for both language and vision tasks.
We have demonstrated the value of semi-supervised learning to discover a human prior for labeling data. We show that self-supervised learning can continually advance the quality of the representation learned by our model and leveraged that representation to improve the self-supervised process, leveraging a novel heuristic that takes advantage of the clusters that the easiest to learn. Our Dataset Reconstruction Accuracy makes it straightforward to compare different class discovery systems, and we use it to demonstrate our progress on this problem. This is one step forward in what we hope is a impactful future for class discovery.
References
- Abadi et al. (2016) Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., et al. Tensorflow: A system for large-scale machine learning. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), pp. 265–283, 2016.
- (2) Bendale, A. and Boult, T. Towards open world recognition.
- Berthelot et al. (2019) Berthelot, D., Carlini, N., and Goodfellow, I. MixMatch: A holistic approach to Semi-Supervised learning. 2019.
- Bilenko et al. (2004) Bilenko, M., Basu, S., and Mooney, R. J. Integrating constraints and metric learning in semi-supervised clustering. In Proceedings of the twenty-first international conference on Machine learning, pp. 11, 2004.
- Blei (2003) Blei, D. M. Latent dirichlet allocation. J. Mach. Learn. Res., 3:993–1022, 2003.
- Blei (2011) Blei, D. M. Distance dependent chinese restaurant processes. J. Mach. Learn. Res., 12:2461–2488, 2011.
- Caron et al. (2018) Caron, M., Bojanowski, P., Joulin, A., and Douze, M. Deep clustering for unsupervised learning of visual features. July 2018.
- Clune (2019) Clune, J. Ai-gas: Ai-generating algorithms, an alternate paradigm for producing general artificial intelligence. arXiv preprint arXiv:1905.10985, 2019.
- de Amorim & Hennig (2015) de Amorim, R. C. and Hennig, C. Recovering the number of clusters in data sets with noise features using feature rescaling factors. Information Sciences, 324:126–145, December 2015. ISSN 0020-0255. doi: 10.1016/j.ins.2015.06.039. URL http://www.sciencedirect.com/science/article/pii/S0020025515004715.
- Devlin et al. (2018) Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Doersch et al. (2015) Doersch, C., Gupta, A., and Efros, A. A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, pp. 1422–1430, 2015.
- Gidaris et al. (2018) Gidaris, S., Singh, P., and Komodakis, N. Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728, 2018.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- Held et al. (2018) Held, D., Geng, X., Florensa, C., and Abbeel, P. Automatic goal generation for reinforcement learning agents. 2018.
- Hendrycks & Gimpel (2016) Hendrycks, D. and Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv preprint arXiv:1610.02136, 2016.
- Hu et al. (2017) Hu, W., Miyato, T., Tokui, S., Matsumoto, E., and Sugiyama, M. Learning discrete representations via information maximizing Self-Augmented training. February 2017.
- Kim (2014) Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1746–1751, Doha, Qatar, October 2014. Association for Computational Linguistics. doi: 10.3115/v1/D14-1181. URL https://www.aclweb.org/anthology/D14-1181.
- Kolesnikov et al. (2019) Kolesnikov, A., Zhai, X., and Beyer, L. Revisiting self-supervised visual representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 1920–1929, 2019.
- Krizhevsky & Hinton (2010) Krizhevsky, A. and Hinton, G. Convolutional deep belief networks on cifar-10. Unpublished manuscript, 40(7):1–9, 2010.
- Larson et al. (2019) Larson, S., Mahendran, A., Peper, J. J., Clarke, C., Lee, A., Hill, P., Kummerfeld, J. K., Leach, K., Laurenzano, M. A., Tang, L., and Mars, J. An Evaluation Dataset for Intent Classification and Out-of-Scope Prediction. arXiv:1909.02027 [cs], September 2019. URL http://arxiv.org/abs/1909.02027. arXiv: 1909.02027.
- (21) LeCun, Y. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/.
- Lee et al. (2018) Lee, K., Lee, K., Lee, H., and Shin, J. A simple unified framework for detecting Out-of-Distribution samples and adversarial attacks. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 31, pp. 7167–7177. Curran Associates, Inc., 2018.
- Liang et al. (2017) Liang, S., Li, Y., and Srikant, R. Enhancing the reliability of out-of-distribution image detection in neural networks. June 2017.
- Mikolov et al. (2013) Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In NIPS, 2013.
- Pedregosa et al. (2011) Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., et al. Scikit-learn: Machine learning in python. Journal of machine learning research, 12(Oct):2825–2830, 2011.
- Pennington et al. (2014) Pennington, J., Socher, R., and Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1532–1543, Doha, Qatar, October 2014. Association for Computational Linguistics. doi: 10.3115/v1/D14-1162. URL https://www.aclweb.org/anthology/D14-1162.
- Qiu & Plevritis (2009) Qiu, P. and Plevritis, S. K. Simultaneous class discovery and classification of microarray data using spectral analysis. J. Comput. Biol., 16(7):935–944, July 2009.
- Radford et al. (2019) Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9, 2019.
- Raffel et al. (2019) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683, 2019.
- Raina et al. (2007) Raina, R., Battle, A., Lee, H., Packer, B., and Ng, A. Y. Self-taught learning: transfer learning from unlabeled data. In Proceedings of the 24th international conference on Machine learning, pp. 759–766, 2007.
- Rao et al. (2019) Rao, D., Visin, F., Rusu, A., Pascanu, R., Teh, Y. W., and Hadsell, R. Continual unsupervised representation learning. In Advances in Neural Information Processing Systems, pp. 7645–7655, 2019.
- (32) Rebuffi, S.-A., Kolesnikov, A., Sperl, G., and Lampert, C. H. iCaRL: Incremental classifier and representation learning.
- Scheirer et al. (2012) Scheirer, W. J., de Rezende Rocha, A., Sapkota, A., and Boult, T. E. Toward open set recognition. IEEE transactions on pattern analysis and machine intelligence, 35(7):1757–1772, 2012.
- Schmidhuber (1991) Schmidhuber, J. Curious model-building control systems. In Proc. international joint conference on neural networks, pp. 1458–1463, 1991.
- Schmidhuber (2013) Schmidhuber, J. Powerplay: Training an increasingly general problem solver by continually searching for the simplest still unsolvable problem. Frontiers in psychology, 4:313, 2013.
- Shu et al. (2018) Shu, L., Xu, H., and Liu, B. Unseen class discovery in open-world classification. January 2018.
- Snoek et al. (2019) Snoek, J., Ovadia, Y., Fertig, E., Lakshminarayanan, B., Nowozin, S., Sculley, D., Dillon, J., Ren, J., and Nado, Z. Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift. In Advances in Neural Information Processing Systems, pp. 13969–13980, 2019.
- Song et al. (2016) Song, H. O., Jegelka, S., Rathod, V., and Murphy, K. Deep metric learning via facility location. December 2016.
- Sun et al. (2017) Sun, C., Shrivastava, A., Singh, S., and Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE international conference on computer vision, pp. 843–852, 2017.
- Xiao et al. (2017) Xiao, H., Rasul, K., and Vollgraf, R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
- Zhai et al. (2019) Zhai, X., Oliver, A., Kolesnikov, A., and Beyer, L. S4L: Self-Supervised Semi-Supervised learning. May 2019.
- Zhang et al. (2016) Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. Understanding deep learning requires rethinking generalization. arXiv preprint arXiv:1611.03530, 2016.
- Zhao et al. (2019) Zhao, Y. J., Li, Y. L., and Lin, M. A Review of the Research on Dialogue Management of Task-Oriented Systems. Journal of Physics: Conference Series, 1267:012025, July 2019. ISSN 1742-6596. doi: 10.1088/1742-6596/1267/1/012025. URL https://doi.org/10.1088%2F1742-6596%2F1267%2F1%2F012025.