Sequential Treatment Effect Estimation with Unmeasured Confounders
Abstract
This paper studies the cumulative causal effects of sequential treatments in the presence of unmeasured confounders. It is a critical issue in sequential decision-making scenarios where treatment decisions and outcomes dynamically evolve over time. Advanced causal methods apply transformer as a backbone to model such time sequences, which shows superiority in capturing long time dependence and periodic patterns via attention mechanism. However, even they control the observed confounding, these estimators still suffer from unmeasured confounders, which influence both treatment assignments and outcomes. How to adjust the latent confounding bias in sequential treatment effect estimation remains an open challenge. Therefore, we propose a novel Decomposing Sequential Instrumental Variable framework for CounterFactual Regression (DSIV-CFR), relying on a common negative control assumption. Specifically, an instrumental variable (IV) is a special negative control exposure, while the previous outcome serves as a negative control outcome. This allows us to recover the IVs latent in observation variables and estimate sequential treatment effects via a generalized moment condition. We conducted experiments on datasets and achieved significant performance in one- and multi-step prediction, supported by which we can identify optimal treatments for dynamic systems.
1 Introduction
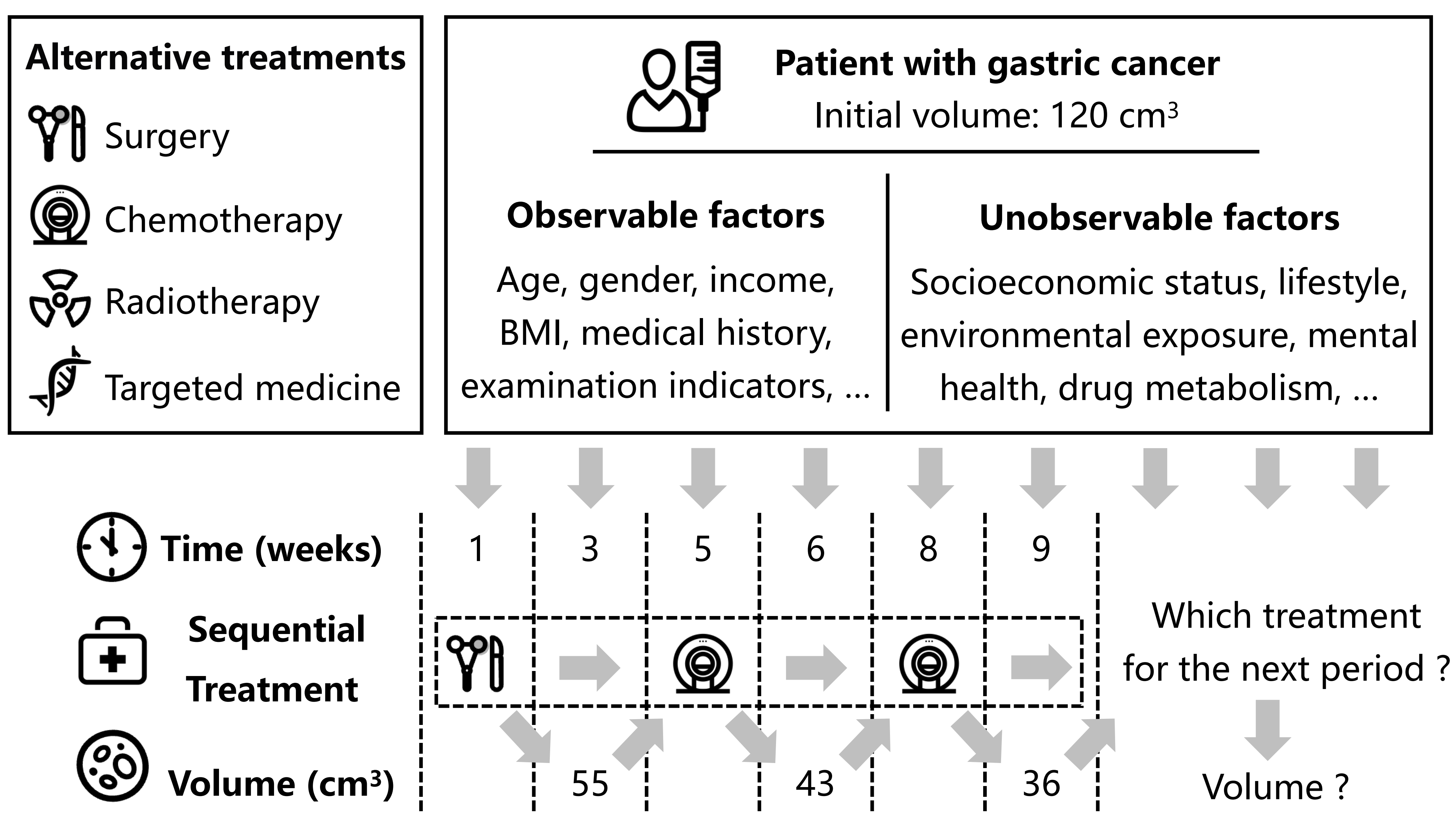
Sequential decision-making is fundamental to many real-world applications, including personalized medicine (Huang & Ning, 2012; Feuerriegel et al., 2024), financial investment (Ang et al., 2006; Gârleanu & Pedersen, 2013), and policy making (Jeunen et al., 2020; Hizli et al., 2023). These scenarios involve decisions that must dynamically adapt to evolving conditions, where the outcomes of previous decisions directly influence subsequent choices. For example, we consider a cancer patient undergoing treatment, as illustrated in Figure 1. The medical team must regularly adjust the treatment plan based on the patient’s condition (confounders) to control tumor volume (outcome) (Geng. et al., 2017). After surgery, if the tumor grows to , the team may choose chemotherapy for the next stage after comprehensively considering the patient’s current health and expected treatment effects. Similar settings arise in various domains, such as financial investment, where decisions must adapt to fluctuating market conditions, and supply chain management, where strategies are adjusted dynamically based on demand and logistical feedback. Understanding the causal effects of sequential treatments is crucial for optimizing decision-making in such scenarios. However, accurately estimating these effects is complicated by the presence of unmeasured confounders that simultaneously influence treatment assignments and outcomes but remain unobserved. Unmeasured confounding introduces significant bias into causal estimates, leading to unreliable conclusions and potentially suboptimal or harmful decisions (Robins & Greenland, 1986; Kuroki & Pearl, 2014).
Several studies have explored causal effect estimation from observational time series data. One significant challenge in these settings is the time dependency of variables, where all variables are influenced not only by causal relationships but also by their prior values over time. Early works leveraged the Markov property to simplify this issue, modeling the problem as a state transition chain where outcomes depend only on the immediate past (Battocchi et al., 2021; Tran et al., 2024). More broadly, autoregressive models like RNNs (Elman, 1990) and LSTMs (Hochreiter & Schmidhuber, 1997) incorporate all historical data to estimate future outcomes, with approaches such as ACTIN (Wang et al., 2024) adapting LSTMs for causal inference in time sequences. However, these methods often face computational challenges when handling high-dimensional, long time series data. Recently, transformers (Vaswani et al., 2017) have emerged as a more powerful tool for identifying long-time dependence and periodic patterns due to its attention mechanism, which dynamically captures the relationships between different positions in a sequence and flexibly allocates their weights. However, these approaches (Melnychuk et al., 2022; Shirakawa et al., 2024) rely on the unconfoundedness assumption, which presumes that all confounders are observed. In practice, this assumption is rarely met due to the difficulty of measuring critical latent factors, leading to biased causal effect estimates and unreliable findings.
Unmeasured confounding remains a critical challenge in causal inference, particularly in sequential treatment settings. For example, as illustrated in Figure 1, in cancer care, factors like socioeconomic status, mental health, and unmonitored lifestyle habits significantly influence treatment decisions and outcomes, yet these factors are often difficult or impossible to quantify or measure. Ignoring these variables would lead to biased estimates of causal effects, distorting the true relationships between treatments and outcomes. While existing approaches, such as Time Series Deconfounder (Bica et al., 2020), have made strides in addressing unmeasured confounding, they are often constrained by assumptions that may not hold in real-world scenarios, such as restrictive data requirements or limited flexibility in model design. Additionally, many of these methods face challenges with scalability and robustness, particularly when applied to high-dimensional, long time series data where the complexity of relationships between variables increases exponentially.
To address these challenges, we propose a novel framework: the Decomposing Sequential Instrumental Variable Framework for Counterfactual Regression (DSIV-CFR). This framework builds on the common negative control assumption, treating instrumental variables (IVs) as special negative control exposures and prior outcomes as negative control outcomes. These relationships allow the recovery of instrumental variables from observed covariates, enabling the framework to mitigate bias introduced by unmeasured confounders. DSIV-CFR effectively decomposes the problem into manageable tasks using generalized moment conditions, making it robust for handling high-dimensional, time-dependent data. Unlike existing methods, DSIV-CFR does not rely on the unconfoundedness assumption, ensuring reliable causal effect estimates even in the presence of latent confounders. Through extensive experiments on synthetic and real-world datasets, we demonstrate that DSIV-CFR significantly outperforms existing methods, providing a scalable, accurate, and practical solution for optimizing sequential decision-making in dynamic systems.
Contributions of this paper can be concluded as follows:
-
•
We systemically study the problem of sequential treatment effect estimation, particularly the complex causal relationships among variables in time series data under unmeasured confounders.
-
•
We proposed a novel method, DSIV-CFR, which effectively addresses the bias caused by unobserved confounders by leveraging instrumental variables and prior outcomes as negative controls, enabling accurate estimation of sequential treatment effects.
-
•
Extensive experiments demonstrate the superiority of DSIV-CFR in mitigating unmeasured confounding bias, improving causal estimation accuracy, and identifying optimal treatment strategies in dynamic systems.
2 Related Work
Treatment effect estimation for time series data. There is a comprehensive survey (Moraffah et al., 2021) that explores some basic problems about causal inference for time series analysis. Variations of treatments in these scenarios include time-invariant and time-varying ones. Time-invariant treatment refers to an intervention that occurs at a specific time and remains unchanged afterward. To estimate the effect of such treatment, the difference-in-difference method (Ashenfelter, 1978; Athey & Imbens, 2006) is one of the mostly used tools in economics, which depend on parallel trends assumption. Estimation of effects for time-varying treatment is most relevant to this paper. One solution to model the time series data is to utilize the Markov assumption, where the complex temporal issue can be simplified as a problem of state transitions between adjacent timestamps (Battocchi et al., 2021; Tran et al., 2024), i.e. the data at time is influenced only by the data at time . The other way is to apply autoregressive models to connect causal models at a single timestamp, where all historical information serves as input to affect the current time point . For example, Time Series Deconfounder (Bica et al., 2020) uses RNN (Elman, 1990) can be regarded as an extension of Deconfounder (Wang & Blei, 2019) to address the temporal sequences. LSTM (Hochreiter & Schmidhuber, 1997) is also applied to extend the ideas of CFR (Shalit et al., 2017) to the estimation of causal effects in time series data (Wang et al., 2024). In recent works (Melnychuk et al., 2022; Shirakawa et al., 2024), transformer (Vaswani et al., 2017) serves as a more powerful tool to model complex time series when estimating the treatment effect.
Treatment effect estimation with unobserved confounders. Instrumental variable (IV) is a powerful tool to address latent confounding bias. It is independent of unmeasured confounders, serves as a cause of treatment, but has no influence on the outcome. However, standard IV methods require a predefined, strong, and valid IV, which is often difficult to find in real-world applications. Therefore, many researchers have studied the generation or synthesis of IV to address this problem. For example, ModelIV (Hartford et al., 2021) identifies valid IVs by selecting those in the tightest cluster of estimation points, assuming that these candidates yield approximately causal effects, thus relaxing the requirement for more than half of the candidates to be valid. AutoIV (Yuan et al., 2022) generates IV representations by learning a disentangled representation from the observational data on the basis of independence conditions. However, sometimes the representations learned by this methodology may be a reverse IV rather than a true IV. That is, there is a causal link from the treatment variable that leads to the so-called IV. Negative control is another tool that is widely used to address the issue of unmeasured confounding. Negative control refers to observational variables that could serve as proxies to indirectly indicate the effects of unmeasured confounders (Miao et al., 2018). A cross-moment approach (Kivva et al., 2023) is introduced, which also leverages the idea of negative controls to mitigate the impact of unobserved confounders. Moreover, negative controls can be naturally extended to time series data analysis (Miao et al., 2024). In this context, the treatment applied at the next moment can be regarded as a negative control exposure, while the outcome at the previous timestamp serves as a negative control outcome.
3 Problem Setup
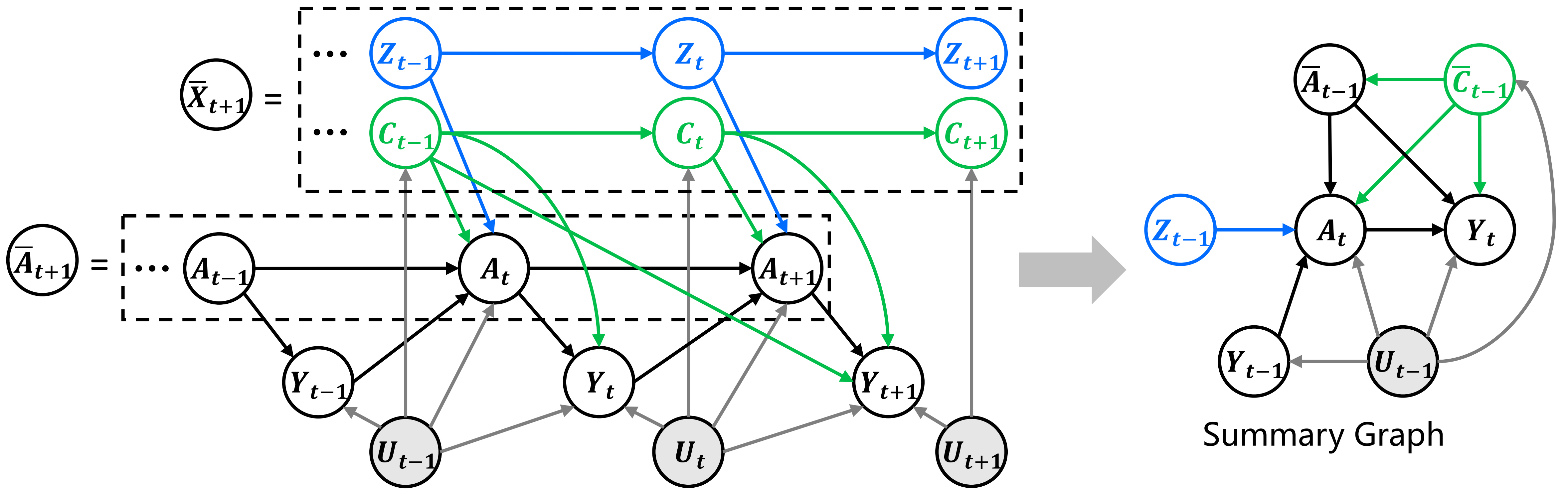
In this paper, we aim to study the cumulative treatment effects of sequential treatments under unmeasured confounders. For observational data, as shown in Figure 2, we can observe collected over time steps. Among the observational variables, represents the treatments applied at timestamp on units. Generally in this paper, the superscript denotes the index of each unit, while the subscript denotes the timestamp. and are the observed covariates and factual outcomes. In the presence of unmeasured confounders, there exists a set of latent variables , which are missing and may simultaneously affect both the treatments and the outcomes and . These unobserved confounders introduce dependencies that confuse causal inference. In this paper, we use to denote the history of the treatment variable up to time . Similarly, we define ,, and . For simplicity, we use to denote observed history before treatment is applied. In the sequential treatment effect problem, the sequential value on act as confounders that jointly influence both the current treatment and the outcome .
One classical solution to reduce bias from is to use a predefined IV, leveraging its exogeneity to infer causal effects. However, it is hard to find such IVs in reality. Therefore, we aim to recover IVs from observations by decomposing them into the following two parts111In time series analysis, and are considered two independent sources of , with the mapping relationships assumed to be static, meaning they remain unchanged over time.: (1) confounders that . (2) instruments that affect but are not influenced by . Under the proposed time-series framework, we reconstruct them as a summary graph, which is shown in the right of Figure 2. The components of this summary graph include newly applied treatment , outcome of interest , instruments , confounders , and auxiliary information . Our task is to predict the counterfactual outcome for the choice of optimal treatment given :
| (1) |
We make the following assumptions throughout this paper.
Assumption 3.1.
(Consistency). If a unit receives a treatment, i.e. , then the observed outcomes are identical to the potential outcomes .
Assumption 3.2.
(Overlap). For any intervention, there is always a positive probability of receiving it given confounders, i.e. .
Assumption 3.3.
(Sequential Latent Ignorability). By controlling all confounders, including observed ones and unobserved ones , the effect of treatment on the outcome could be estimated without bias. Formally, for all .
Assumption 3.4.
(Additive Noise Model). Error terms are independent of each other, that is, the unobserved confounders from the previous time point do not affect the next ones. Formally, and . To estimate the potential outcome, we also assume .
Assumption 3.5.
(Time-invariant Relationship). The function of the treatment effect, denoted as , does not change over time, although its value fluctuates due to the confounding heterogeneity of .
Proposition 3.6 (IV Decomposition).
Following the IV conditions, if all variables are observable, we can decompose the instrument from the observed covariates as follows: and .
These conditions imply that the instrument variable is independent of the outcome given the appropriate set of covariates, including the unmeasured confounders . However, in practice, we cannot directly identify the instrument due to . As a result, instrumental variable identification becomes challenging and would require additional assumptions. Motivated by the idea of negative control (Miao et al., 2018, 2024), we utilize a pair of proxy variables, including negative control exposure and negative control outcome, to help identify causal effects.
Assumption 3.7.
(Negative Control). Negative controls comprise negative control exposures (NCE) and negative control outcomes (NCO). NCE cannot directly affect the outcome , and neither NCE nor treatment can affect NCO. The effect of unmeasured confounders on NCE and , as well as on NCO and , is proportional.
Generally, we can treat the instrument as a special case of NCE, while previous outcome can also be regarded as a special case of NCO.
Theorem 3.8 (IV Identification).
Based on the negative control assumptions, given , we can decompose the instrument from the observed covariates as follows: and .
Proof.
Under Assumptions 3.1-3.5 and 3.7, we assume that the function of on and is the same, and the outcome feedback function can be reformulated as:
| (2) |
where denotes the unmeasured common causes of treatment and outcome . Given and , we can reformulate the decomposition condition in Proposition 3.6 as follows:
| (3) |
Therefore, we can identify IV from:
| (4) |
Then, we can use the instrument to help us isolate the direct causal effect from unmeasured confounding bias. ∎
By taking the expectation of both sides of Equation (2) conditioned on , given Assumption 3.4 , we have:
| (5) |
where is the conditional treatment distribution. Equation (5) expresses an inverse problem for the function in terms of and (Newey & Powell, 2003). A standard approach is two-stage regression: using observed confounders and instrument to predict conditional treatment distribution , and then regressing outcome with estimated treatment sampled from and observed confounders, i.e . It can be regarded as a special form of the generalized method of moments (Hall, 2003), abbreviated as GMM. In the context of negative controls (Miao et al., 2024), we would like to extend this consistent estimation by applying GMM.
4 Methodology
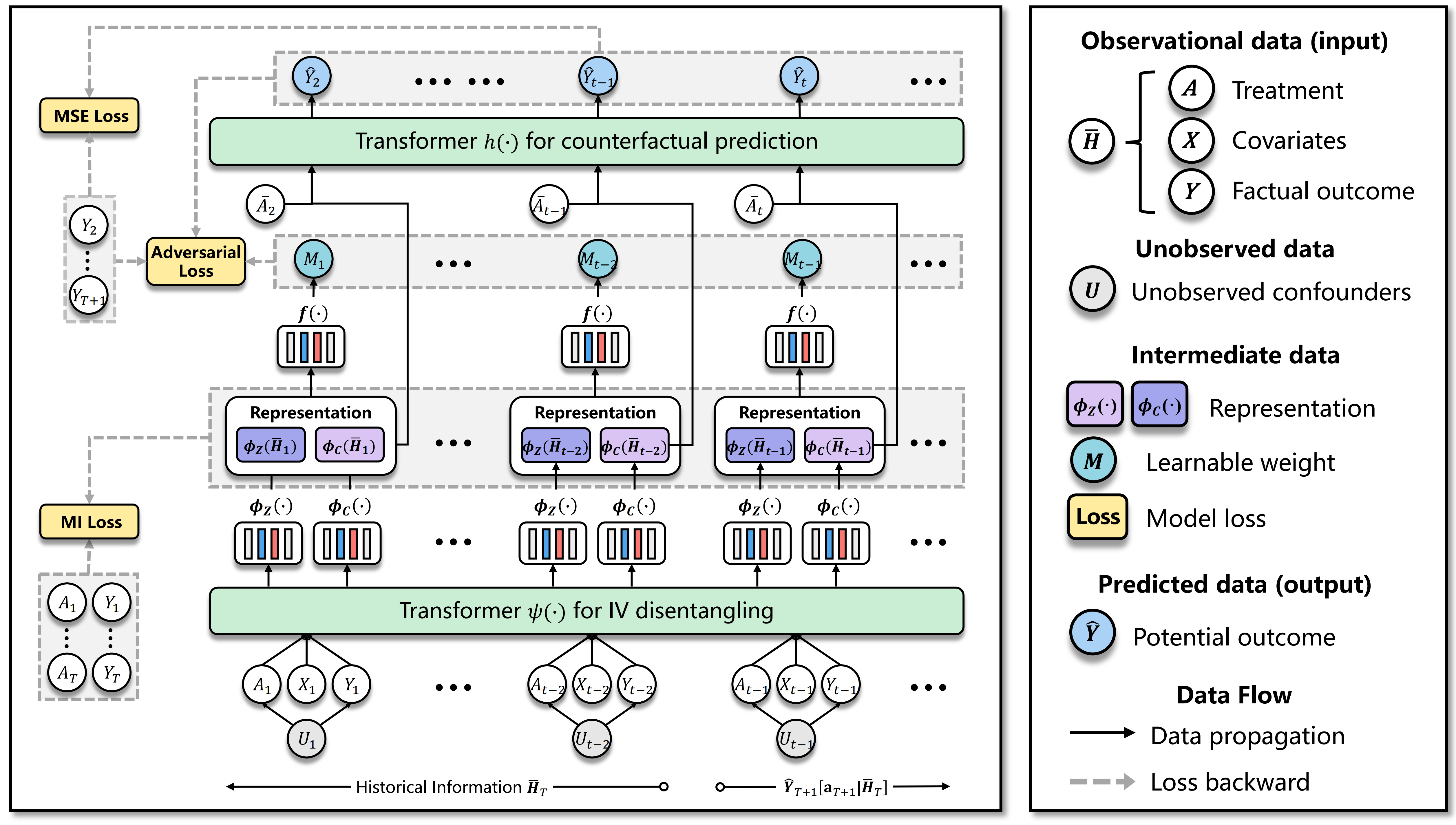
Our proposed method, the Decomposing Sequential Instrumental Variable framework for Counterfactual Regression (DSIV-CFR), is illustrated in Figure 3. It consists of two key modules designed to address the challenges of sequential treatment effect estimation with unmeasured confounders. The first module focuses on leveraging transformers to model long sequential dependencies and learning the representations of instrumental variables (IVs) and confounders. The second module employs the generalized method of moments (GMM) to estimate counterfactual outcomes while effectively utilizing the learned representations.
4.1 Long Sequential Modeling for Learning IV and Confounder Representations
In our setting for estimating the effect of sequential treatment, the relationships between variables are influenced not only by immediate past values but also by long-term dependencies. To capture these complex dependencies, we employ transformer (Vaswani et al., 2017; Melnychuk et al., 2022) as our backbone, which has shown state-of-the-art performance in modeling long-range interactions in sequential data. Specifically, we build a -layer transformer with heads. The input to this module consists of the observed covariates, treatment variables, and outcomes at each time step, i.e., . In each head , we calculate the keys , queries , and values from a linear transformation of to obtain:
| (6) |
where is the dimensionality. We use the concatenation as the output of this sub-module with heads:
| (7) |
The feed-forward layer with ReLU activation is then used for the non-linear transformations of MHA. Techniques such as layer normalization (Ba et al., 2016) and dropout (Srivastava et al., 2014) are also applied to enhance the stability and robustness of model training. The output of this module is a basic embedding , which is then followed by and to further disentangle IVs and confounders.
Learning IV Representation. Two conditions the IV should be satisfied: (1) Relevance. Instruments are required to be correlated with treatment . Inspired by AutoIV (Yuan et al., 2022), we encourage the information of related to to enter the IV representations by minimizing the additive inverse of contrastive log-ratio upper bound (Cheng et al., 2020):
| (8) |
The variational distribution is determined by parameters to approximate the true conditional distribution . Log-likelihood loss function of variational approximation is defined as:
| (9) |
(2) Exclusion. As mentioned in Theorem 3.8, we require . Similarly,
| (10) |
where is the weight of sample pair to achieve the conditional independence mentioned above. It is determined by the discrepancy between and in the RBF kernel:
| (11) |
The hyper-parameter is used to control the width of the Gaussian function, which we set to in the experiments.
Learning Confounder Representation. There are also two restrictions that should be taken into account: (1) . Therefore, we minimize:
| (12) |
| (13) |
(2) We require in Theorem 3.8.
| (14) |
where and are approximated by and , respectively.
The overall loss function of these mutual information restrictions could be concluded as:
| (15) |
where and is denoted as the length of historical time series. To optimize the parameters of variational distributions, i.e. , we combine all the variational approximation loss as:
| (16) |
where the definitions of , , , and are similar to that of in Equation (9), and we have omitted them due to space limitations. Using contrastive learning with upper bound for modeling representation, we automatically separate and from by Equation (14), while ensuring the validity of by Equation (8)-(10) and the confounding properties by Equation (12)-(13). Although we have stated the static relationships between , and in Section 3, our model is also applicable to the situation where the relationships are dynamic.
| Dataset | Type of | # Train | # Validation | # Test | ||||
|---|---|---|---|---|---|---|---|---|
| Simulation | binary | |||||||
| Tumor growth | continuous | |||||||
| Cryptocurrency | continuous | unknown | ||||||
| MIMIC-III | binary | unknown |
| Method | Simulation | Tumor | Cryptocurrency | MIMIC-III |
|---|---|---|---|---|
| Time Series Deconfounder | ||||
| Causal Transformer | ||||
| ACTIN | ||||
| ORL | ||||
| Deep LTMLE | ||||
| DSIV-CFR | ||||
| * Lower = better (best in bold) | ||||
4.2 GMM for Counterfactual Regression
As discussed in Section 3, we establish a GMM framework to accurately estimate the potential outcome in the presence of unmeasured confounders. We also apply a transformer as the backbone of the estimator mentioned in Equation (5). It is designed to predict the potential outcome from treatment and a wealth of historical information , which can be seen as the confounders illustrated on the right of Figure 2. The basic prediction error is taken into account:
| (17) |
which could be viewed as a second-order moment constraint. To further implement the process described by Equation (5), we build a bridge function to obtain learnable weights . Objective is defined as:
| (18) |
where is the weight of the -th sample in .
5 Experiments
5.1 Baselines
In Section 2, we discussed several works of causal inference on time series data. We applied these methods as baselines for the comparison of our DSIV-CFR, including Time Series Deconfounder (Bica et al., 2020), surrogate-based approach (Battocchi et al., 2021), Causal Transformer (Melnychuk et al., 2022), ACTIN (Wang et al., 2024), ORL (Tran et al., 2024), and Deep LTMLE (Shirakawa et al., 2024). More details are concluded in Appendix B.
5.2 Datasets
To comprehensively evaluate the performance of all models under various data conditions, we applied both synthetic data and real-world datasets. Statistics of these datasets are summarized in Table 1. The process of data generation for the fully-synthetic dataset, which we call Simulation dataset, is described in Appendix B.
Tumor growth (Geng. et al., 2017). Following previous works (Melnychuk et al., 2022; Wang et al., 2024), we also applied a tumor growth simulator for data generation. We select the patient type and two static features as covariates. Treatments include chemotherapy and radiation therapy. Outcome of interest is the tumor volume. Considering the range of data, we normalized and .
Cryptocurrency222Cryptocurrency is available at https://github.com/binance/binance-public-data. We also collected real-life time series data of Bitcoin and Ethereum from July , to October , . Covariates include the opening price, lowest price, highest price, closing price, and trading volume for the day. Treatment refers to the positions held by individuals, while the outcome of interest is the return rate (%). We manually divided the complete sequence into time segments of length , setting the time gap to as well to prevent data leakage.
MIMIC-III (Johnson et al., 2016). It is a comprehensive, publicly available database containing de-identified health data from patients admitted to critical care units at a large tertiary care hospital. Referring to data processing in the Causal Transformer (Melnychuk et al., 2022), we obtain covariates on the vital signs of patients. Vasopressor and mechanical ventilation are two treatments taken into account. We also choose blood pressure as the outcome.
5.3 Experimental Results
5.3.1 One-step-ahead prediction
Our targeted estimand is the counterfactual outcome in the future time step, denoted as . To evaluate the performance of these estimators, we use the MSE metric defined in Equation (17). To ensure the robustness and reliability of our experimental results, we independently repeated each experiment times, each with a different random seed. Finally, we report the mean and standard deviation (std) of MSE in the format of mean ± std. The experimental results of the four datasets are summarized in Table 2, which comprehensively indicates the performance of the model in the diverse settings. It can be seen that our DSIV-CFR outperforms the state-of-the-art baselines on all datasets by a large margin.
The average running time of this experiment is detailed in Table 4 (Appendix D). Although the introduction of mutual information loss and adversarial loss has led to a time increase, it is justified by the significant improvement in model performance. Generally, the overall training time remains within an acceptable range.
Since many baselines rely on the unconfoundedness assumption, i.e. do not consider the unmeasured confounders, we conducted an additional trial for fairness. We set all the confounding variables to be observable and retested these methods. Even in this case, where the baselines have access to more information than our approach, DSIV-CFR still achieves better performance.
5.3.2 Hyper-parameter analysis
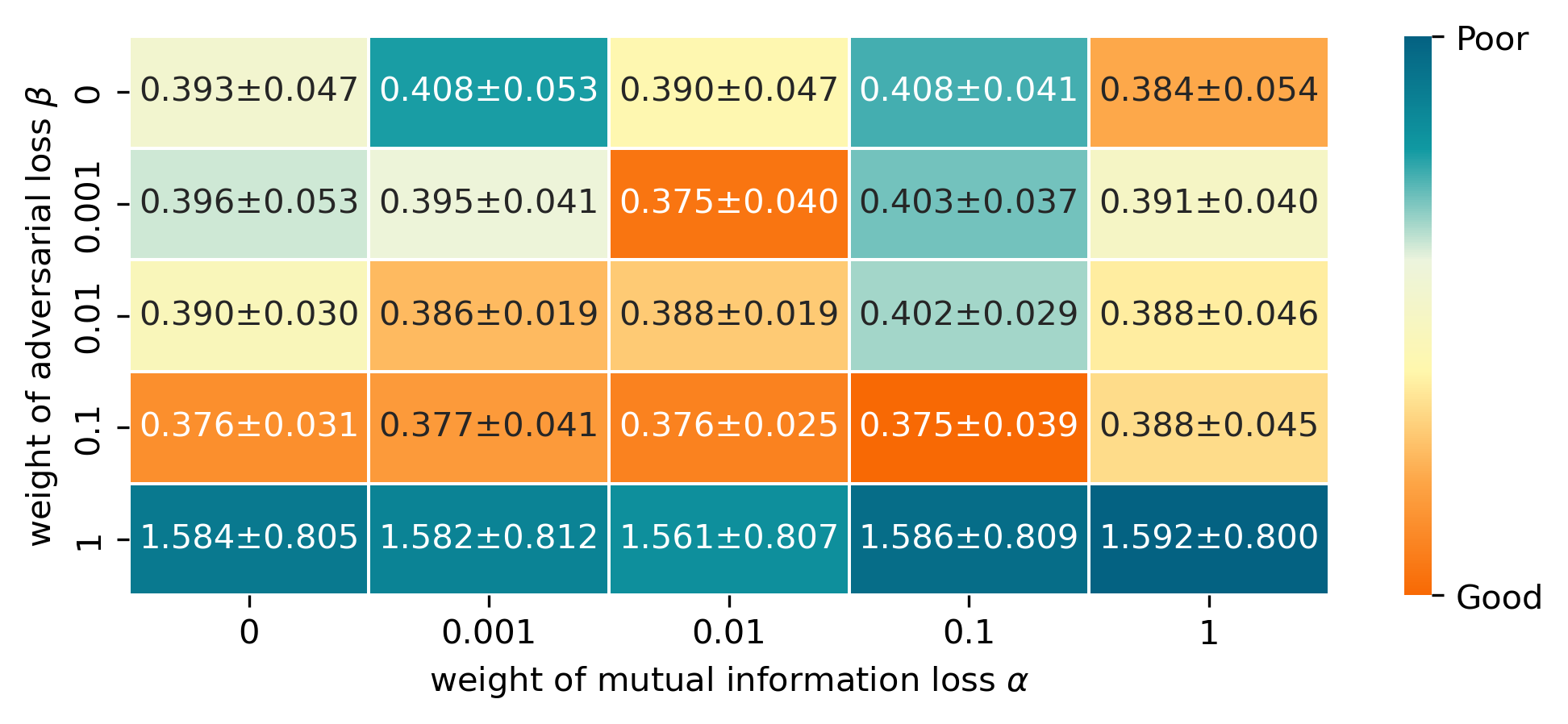
We explore the combination of and , which control the significance of mutual information constraints () for IV decomposition and adversarial function learning () in the GMM framework, respectively. When or is set to , it indicates that the corresponding module is ablated. Such evaluation is conducted with the Cryptocurrency dataset. According to Figure 4, the effectiveness of each module could be validated. If the two losses are moderately incorporated, model performance will be better than focusing solely on MSE. The best performance is achieved by setting and . However, if their weights are blindly increased, it may create a conflict with the primary objective, which is to minimize the prediction error.
5.3.3 Sequential treatment decision making
CT (Melnychuk et al., 2022) and ACTIN (Wang et al., 2024) can be extended to predict the future outcomes steps ahead, i.e. . The main idea is to additionally predict the next values of . In this way, in subsequent steps, the estimated values and are used in place of the required observations to continue the cycle of prediction. Although our method could also be easily extended in the aforementioned manner, i.e. iteratively repeating the estimation of single time step to obtain the result of the ultimate moment, we attempted to directly predict the future outcomes of sequential treatments. We naturally consider applying this model to a downstream task, i.e. decision-making for the optimal sequential treatments in the next time period. Implementations of such methodology extension is clarified in Appendix C. We conducted an experiment on multi-step-ahead decision-making and set to . To obtain the oracle outcomes of all possible treatment sequences, we use the simulated dataset and selected the two baselines (CT and ACTIN) tailored for the similar task. of decision making compared to the oracle are illustrated in Figure 5. Our method also performs well and achieves results that are close to the oracle.

6 Conclusion
The presence of unmeasured confounders is a critical challenge of estimating the cumulative effects of time-varying treatments with time series data. We propose DSIV-CFR, a novel method that leverages negative controls and mutual information constraints to decompose IVs and confounders from the observations. DSIV-CFR accurately estimates the future potential outcome with unmeasured confounders through a modular design that combines transformers for sequential dependency modeling and GMM for counterfactual estimation with the learned IVs. This model can also be naturally extended for sequential treatment decision making, which holds significant potential for real-world scenarios.
Impact Statement
This paper introduces a novel DSIV-CFR, which estimates the future potential outcome on time series data with unobserved confounders. This advancement in machine learning could improve decision making in various fields such as medicine, finance, and meteorology. For example, in personalized medicine, DSIV-CFR is able to predict the counterfactual outcome in the future of the treatment that may be taken for the next period, with the help of historical records. In this way, it allows doctors to provide better treatment strategies. The limitation of our method lies in the constraints mentioned in Assumption 3.4. If , the estimate of potential outcome will be biased, but it still works to provide a consistent estimate of treatment effect.
References
- Ang et al. (2006) Ang, A., Hodrick, R. J., Xing, Y., and Zhang, X. The cross-section of volatility and expected returns. The journal of finance, 61(1):259–299, 2006.
- Ashenfelter (1978) Ashenfelter, O. Estimating the effect of training programs on earnings. The Review of Economics and Statistics, 60(1):47–57, 1978.
- Athey & Imbens (2006) Athey, S. and Imbens, G. W. Identification and inference in nonlinear difference-in-differences models. Econometrica, 74(2):431–497, 2006.
- Ba et al. (2016) Ba, L. J., Kiros, J. R., and Hinton, G. E. Layer normalization. CoRR, abs/1607.06450, 2016. URL http://arxiv.org/abs/1607.06450.
- Battocchi et al. (2021) Battocchi, K., Dillon, E., Hei, M., Lewis, G., Oprescu, M., and Syrgkanis, V. Estimating the long-term effects of novel treatments. In Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pp. 2925–2935, 2021.
- Bica et al. (2020) Bica, I., Alaa, A. M., and van der Schaar, M. Time series deconfounder: Estimating treatment effects over time in the presence of hidden confounders. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pp. 884–895. PMLR, 2020.
- Cheng et al. (2020) Cheng, P., Hao, W., Dai, S., Liu, J., Gan, Z., and Carin, L. CLUB: A contrastive log-ratio upper bound of mutual information. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pp. 1779–1788. PMLR, 2020.
- Elman (1990) Elman, J. L. Finding structure in time. Cogn. Sci., 14(2):179–211, 1990.
- Feuerriegel et al. (2024) Feuerriegel, S., Frauen, D., Melnychuk, V., Schweisthal, J., Hess, K., Curth, A., Bauer, S., Kilbertus, N., Kohane, I. S., and van der Schaar, M. Causal machine learning for predicting treatment outcomes. Nature Medicine, 30(4):958–968, 2024.
- Gârleanu & Pedersen (2013) Gârleanu, N. and Pedersen, L. H. Dynamic trading with predictable returns and transaction costs. The Journal of Finance, 68(6):2309–2340, 2013.
- Geng. et al. (2017) Geng., C., Paganetti, H., and Grassberger, C. Prediction of treatment response for combined chemo- and radiation therapy for non-small cell lung cancer patients using a bio-mathematical model. Scientific Reports, 7(1):13542, 2017.
- Hall (2003) Hall, A. R. Generalized method of moments. A companion to theoretical econometrics, pp. 230–255, 2003.
- Hartford et al. (2021) Hartford, J. S., Veitch, V., Sridhar, D., and Leyton-Brown, K. Valid causal inference with (some) invalid instruments. In Meila, M. and Zhang, T. (eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 of Proceedings of Machine Learning Research, pp. 4096–4106. PMLR, 2021.
- Hizli et al. (2023) Hizli, C., John, S. T., Juuti, A. T., Saarinen, T. T., Pietiläinen, K. H., and Marttinen, P. Causal modeling of policy interventions from treatment-outcome sequences. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pp. 13050–13084. PMLR, 2023.
- Hochreiter & Schmidhuber (1997) Hochreiter, S. and Schmidhuber, J. Long short-term memory. Neural Comput., 9(8):1735–1780, 1997.
- Huang & Ning (2012) Huang, X. and Ning, J. Analysis of multi-stage treatments for recurrent diseases. Statistics in medicine, 31(24):2805–2821, 2012.
- Jeunen et al. (2020) Jeunen, O., Rohde, D., Vasile, F., and Bompaire, M. Joint policy-value learning for recommendation. In KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, August 23-27, 2020, pp. 1223–1233. ACM, 2020.
- Johnson et al. (2016) Johnson, A. E., Pollard, T. J., Shen, L., wei H. Lehman, L., Feng, M., Ghassemi, M., Moody, B., Szolovits, P., Celi, L. A., and Mark, R. G. Mimic-iii: a freely accessible critical care database. Scientific Data, 3(1):160035, 2016.
- Kivva et al. (2023) Kivva, Y., Salehkaleybar, S., and Kiyavash, N. A cross-moment approach for causal effect estimation. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023.
- Kuroki & Pearl (2014) Kuroki, M. and Pearl, J. Measurement bias and effect restoration in causal inference. Biometrika, 101(2):423–437, 2014.
- Melnychuk et al. (2022) Melnychuk, V., Frauen, D., and Feuerriegel, S. Causal transformer for estimating counterfactual outcomes. In International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pp. 15293–15329. PMLR, 2022.
- Miao et al. (2018) Miao, W., Geng, Z., and Tchetgen, E. J. T. Identifying causal effects with proxy variables of an unmeasured confounder. Biometrika, 105(4):pp. 987–993, 2018.
- Miao et al. (2024) Miao, W., Shi, X., Li, Y., and Tchetgen, E. T. A confounding bridge approach for double negative control inference on causal effects, 2024. URL https://arxiv.org/abs/1808.04945.
- Moraffah et al. (2021) Moraffah, R., Sheth, P., Karami, M., Bhattacharya, A., Wang, Q., Tahir, A., Raglin, A., and Liu, H. Causal inference for time series analysis: problems, methods and evaluation. Knowl. Inf. Syst., 63(12):3041–3085, 2021.
- Newey & Powell (2003) Newey, W. K. and Powell, J. L. Instrumental variable estimation of nonparametric models. Econometrica, 71(5):1565–1578, 2003.
- Robins & Greenland (1986) Robins, J. M. and Greenland, S. The role of model selection in causal inference from nonexperimental data. American Journal of Epidemiology, 123(3):392–402, 1986.
- Shalit et al. (2017) Shalit, U., Johansson, F. D., and Sontag, D. A. Estimating individual treatment effect: generalization bounds and algorithms. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 of Proceedings of Machine Learning Research, pp. 3076–3085. PMLR, 2017.
- Shirakawa et al. (2024) Shirakawa, T., Li, Y., Wu, Y., Qiu, S., Li, Y., Zhao, M., Iso, H., and van der Laan, M. J. Longitudinal targeted minimum loss-based estimation with temporal-difference heterogeneous transformer. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024.
- Srivastava et al. (2014) Srivastava, N., Hinton, G. E., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res., 15(1):1929–1958, 2014.
- Tran et al. (2024) Tran, A., Bibaut, A., and Kallus, N. Inferring the long-term causal effects of long-term treatments from short-term experiments. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 5998–6008, 2017.
- Wang et al. (2024) Wang, X., Lyu, S., Yang, L., Zhan, Y., and Chen, H. A dual-module framework for counterfactual estimation over time. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024.
- Wang & Blei (2019) Wang, Y. and Blei, D. M. The blessings of multiple causes. Journal of the American Statistical Association, 114(528):1574–1596, 2019.
- Yuan et al. (2022) Yuan, J., Wu, A., Kuang, K., Li, B., Wu, R., Wu, F., and Lin, L. Auto IV: counterfactual prediction via automatic instrumental variable decomposition. ACM Trans. Knowl. Discov. Data, 16(4):74:1–74:20, 2022.
Appendix A Pseudo-Code
As stated in Section 4, we propose a novel DSIV-CFR method to accurately estimate the effect of sequential treatment in the presence of unmeasured confounders. It comprises two key modules. The first module utilizes transformers to model long sequential dependencies and captures the representations of instrumental variables (IVs) and confounders. The second module then employs the Generalized Method of Moments (GMM) to estimate counterfactual outcomes by effectively leveraging the learned representations. The detailed pseudo-code of DSIV-CFR is provided in Algorithm 1.
Appendix B Implementation details of experiments
Baselines. We have concluded some details of the baselines applied in this paper, which are shown in Table 3. Among them, Time Series Deconfounder (Bica et al., 2020), abbreviated as TSD, considers the scenario with unobserved confounders, while other methods all rely on the unconfoundedness assumption. We also clarify their backbones for modeling the time series data. Implementations of them are all available at the given links. Although there is also a surrogate-based method (Battocchi et al., 2021), we have not included it in the baselines for comparison temporarily, as we have not found its open-source code.
| Method | Consider | Backbone | Open-source |
|---|---|---|---|
| TSD | RNN | https://github.com/vanderschaarlab/mlforhealthlabpub/tree/main/alg/time_series_deconfounder | |
| CT | Transformer | https://github.com/Valentyn1997/CausalTransformer | |
| ACTIN | LSTM | https://github.com/wangxin/ACTIN | |
| ORL | RL | https://github.com/allentran/long-term-ate-orl | |
| DLTMLE | Transformer | https://github.com/shirakawatoru/dltmle-icml-2024 |
Data generation for one-step ahead prediction. For each moment, we generate -dimensional IVs and -dimensional confounders , each dimension of which follows a uniform distribution . There are also unobserved confounders of dimensions, and each dimension is randomly sampled from . Specifically,
| (20) |
As for the training and validation data, their treatments of each time step is simulated by the following process.
| (21) |
The coefficients are randomly generated. We initialized that and . To evaluate the counterfactual prediction capabilities of each model, sequences are randomly generated in the test set. In all sets, the generation of can be described as :
| (22) |
Appendix C Sequential treatment decision making
Methodology extension. Our method can be naturally extended to make decisions about determining the optimal treatment plan steps ahead. Specifically, the treatment taken into consideration is a sequence of length , where each dimension can independently take one of possible treatments. For example, in our setting, we set the time window to and the treatment to be binary (). We first traverse all of the possible alternatives, infer the corresponding outcomes, and select the optimal one. For each subsequent moment, we still use the transformer in Section 4.1 to learn a basic representation of the observations , followed by and to obtain the IVs and confounders . It is important to note that, since IVs are exogenous variables, the covariates for decomposition, i.e. , must be observable in our setting. If we were to predict on our own, as in the case of CT (Melnychuk et al., 2022), it would not include the IVs. We then modify the counterfactual regression module mentioned in Section 4.2, where the second transformer to directly predict the -step-ahead outcome by . As for the adversarial loss, we rebuild the bridge function to learn the weights . The other parts of our DSIV-CFR remain unchanged, as described in the previous sections.
Data generation for five-step ahead decision making. The dimension of , , and are , , and , respectively. Each dimension of and follows a uniform distribution . As for the training and validation sets, we respectively generate and samples roughly following the data generation process described in Appendix B, except that will be affected by the interventions in the prior time steps, which can be expressed by the following formulation:
| (23) |
where coefficients are randomly generated. These two sets include the information of . To generate the test set for evaluation of decision making, we first generate the historical information of time steps following the aforementioned steps. Afterwards, for each treatment plan in the alternatives , we directly apply the assigned interventions instead of inferring them with Equation (21), to iteratively calculate by Equation (22). The oracle is recorded as , meaning the maximum outcome at timestamp after the optimal treatment plan is applied. This set includes records covering information of . The evaluation results of model’s early decision making ability compared with the oracle are visualized in Figure 6.
Real-world applications. Our model is capable of forecasting future outcomes over multiple steps ahead and identifying the optimal treatments through exhaustive computation. This capability endows it with broad applicability and significant potential for generalization. For example, in the field of autonomous driving, our model can predict the future states of the road environment, such as the trajectories of vehicles and pedestrians, as well as changes in traffic signals. This allows it to plan the optimal driving route in advance. In the medical field, the model can predict the progression of a patient’s condition and calculate the best treatment plan ahead of time. In the economic and financial sectors, the model can be used to forecast market trends and changes in economic indicators, thereby assisting investors in devising optimal investment strategies.
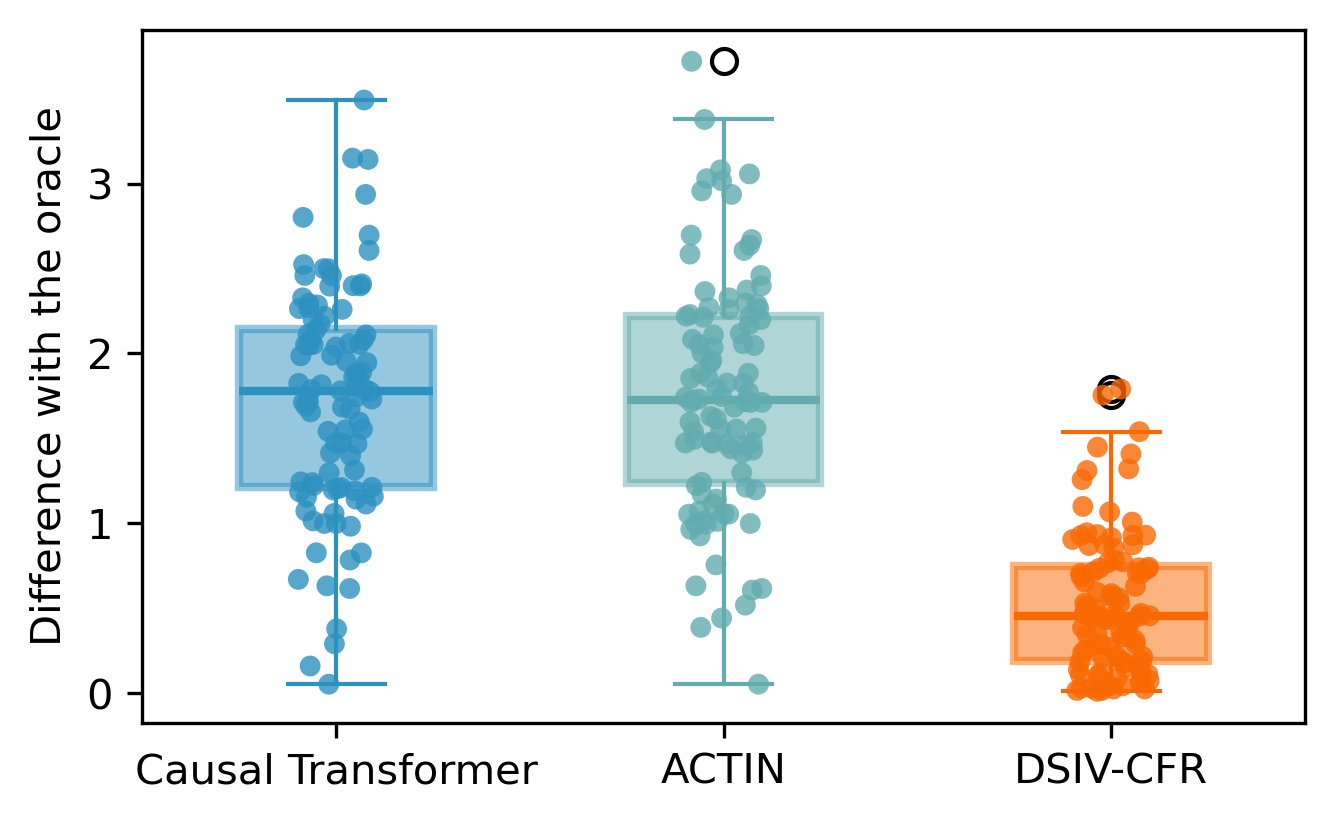
| Statistics of policy making results compared to oracle | ||||
|---|---|---|---|---|
| Min | Max | Avg | Std | |
| CT | ||||
| ACTIN | ||||
| DSIV-CFR | ||||
| * Lower = better (best in bold) | ||||
Appendix D Time complexity
When conducting the experiment of one-step-ahead outcome prediction, we also record the training time of each method included in evaluation. Results are shown in Table 4. The larger sample size, longer time series, and higher feature dimensionality could require more time for training. In addition, and consume much longer time than , but they play an important role in improving the model performance.
| Method | Simulation | Tumor | Cryptocurrency | MIMIC-III |
|---|---|---|---|---|
| Time Series Deconfounder | ||||
| Causal Transformer | ||||
| ACTIN | ||||
| ORL | ||||
| Deep LTMLE | ||||
| DSIV-CFR |
Appendix E Experimental results without unmeasured confounders
Many relevant methods do not take into account the impact of unobserved confounders. However, in the evaluation data used in Table 2, there exists the influence of on . Therefore, we set as observable, satisfying the unconfoundedness assumption, and re-evaluated the performance of the baselines. Results are reported in Table 5. If contains a significant amount of important information, it can be beneficial for improving the performance of outcome prediction. However, if it contains more noise, it may instead lead to a decline in performance.
| Method | Input | Simulation | Tumor |
|---|---|---|---|
| Time Series Deconfounder | |||
| Causal Transformer | |||
| ACTIN | |||
| ORL | |||
| Deep LTMLE | |||
| DSIV-CFR | |||
| * Lower = better (best in bold) | |||