SimCalib: Graph Neural Network Calibration based on Similarity between Nodes
Abstract
Graph neural networks (GNNs) have exhibited impressive performance in modeling graph data as exemplified in various applications. Recently, the GNN calibration problem has attracted increasing attention, especially in cost-sensitive scenarios. Previous work has gained empirical insights on the issue, and devised effective approaches for it, but theoretical supports still fall short. In this work, we shed light on the relationship between GNN calibration and nodewise similarity via theoretical analysis. A novel calibration framework, named SimCalib, is accordingly proposed to consider similarity between nodes at global and local levels. At the global level, the Mahalanobis distance between the current node and class prototypes is integrated to implicitly consider similarity between the current node and all nodes in the same class. At the local level, the similarity of node representation movement dynamics, quantified by nodewise homophily and relative degree, is considered. Informed about the application of nodewise movement patterns in analyzing nodewise behavior on the over-smoothing problem, we empirically present a possible relationship between over-smoothing and GNN calibration problem. Experimentally, we discover a correlation between nodewise similarity and model calibration improvement, in alignment with our theoretical results. Additionally, we conduct extensive experiments investigating different design factors and demonstrate the effectiveness of our proposed SimCalib framework for GNN calibration by achieving state-of-the-art performance on 14 out of 16 benchmarks.
Introduction
Graphs are ubiquitous in the real world, including social networks, knowledge graphs, traffic networks, among others. Due to the universality and expressive power of graph representations, the deep learning community has paid much attention to learning from graph-structured data and introduced various types of graph neural networks (GNNs) (Kipf and Welling 2016; Veličković et al. 2017; Hamilton, Ying, and Leskovec 2017). To date, GNNs have been successfully applied to various downstream applications with remarkable accuracy, such as drug discovery (Zhang et al. 2022b), fluid simulation (Liu et al. 2022), and recommendation system (Fan et al. 2019), to name a few.
However, in many applications, trustworthiness is as important (if no more) than accuracy, especially in safety-sensitive fields (Dezvarei et al. 2023). One of the promising solution to ensure trustworthiness of a trained model is aligning its prediction confidence with the ground truth accuracy, i.e., the model should provide the appropriate confidence to reveal whether the prediction should be trusted. Unfortunately, such an alignment is hardly achieved by modern neural networks (Guo et al. 2017; Wang et al. 2021). To mitigate the issue, a variety of calibration methods (Kull et al. 2019; Gupta et al. 2020; Zhang, Kailkhura, and Han 2020) have been proposed to calibrate pretrained deep neural networks (DNNs). However, calibration for GNNs is still underexplored. While it is possible to directly apply calibration methods designed for DNNs to GNNs by treating each node in the graph as an isolated sample, the specific challenges posed by GNN calibration remain unaddressed as the specific characteristics of graph structure, e.g., the relationship between nodes, is not well utilized for calibrating the GNN predictions.
Recently, a few works focus on GNN calibration, among which the most noticeable are CaGCN (Wang et al. 2021) and GATS (Hsu et al. 2022). Specifically, CaGCN produces nodewise temperatures by processing the pretrained classifier’s logits with another graph convolutional network (GCN), in the hope that structural information can be implicitly integrated in model calibration. Following it, GATS empirically investigates factors that influence GNN calibration, and employs an attention network to account for the influential factors. However, to date, the efforts towards such a structured prediction problem (Nowozin, Lampert et al. 2011) have mostly concentrated on empirical aspects, suffering from a lack of theoretical supports.
In this paper, we make extensive efforts from both theoretical and practical aspects to tackle the aforementioned issues. Our main contributions are summarized as follows:
-
•
We develop a theoretical approach for GNN calibration, and prove that by taking nodewise similarity into consideration we can reduce expected calibration error (ECE) effectively.
-
•
We propose two similarity-oriented mechanisms to account for both global feature-level similarity and local nodewise representation movement dynamics similarity. By incorporating them into network designs, we propose SimCalib, a novel GNN calibration method that is data-efficient, easy to implement and highly expressive.
-
•
We are the first to relate the oversmoothing problem to GNN calibration.
-
•
We conduct comprehensive experiments investigating various design factors, and demonstrate the effectiveness of SimCalib by achieving new SOTA performance on 14 out of 16 benchmarks. Particularly, compared with the previous SOTA model, SimCalib on average reduces ECE by 10.4%.
Preliminary
Problem setting
Herein we consider the problem of calibrating GNNs on semi-supervised node classification tasks. Specifically, given an undirected graph , consisting of nodes and edges , each node is associated with a feature vector . Moreover, a proper subset of nodes, denoted as , is further associated with labels , where is the ground-truth label for . And the goal of semi-supervised node classification is to infer the labels for the unlabeled nodes . A graph neural network approaches the problem by taking into account both nodewise features and structural information, i.e. adjacency matrix , and it predicts a probability distribution over all the classes for each node . The value on the -th position of the distribution, i.e. , describes the estimated probability of being in class .
For each node, induces the corresponding label prediction and confidence . Perfect calibration is defined as (Wang et al. 2021):
| (1) |
In practice, perfect calibration cannot be estimated with a finite number of samples, therefore calibration quality is often quantified by expected calibration error (ECE) instead (Naeini, Cooper, and Hauskrecht 2015; Guo et al. 2017):
| (2) |
where is the predicted probability of being in class , the inner expectation represents the ground-truth probability of belonging to , and the outer expectation iterates over all .
Nodewise temperature
To preserve the nodewise predictions, CaGCN calibrates logits by scaling them with nodewise temperatures, i.e.
| (3) |
where is the nodewise logits for produced by the pretrained classifier and is the temperature for estimated by CaGCN. A noticeable property of such a mechanism is
| (4) |
which maintains the prediction accuracy of GNNs after calibration. In this work, we follow the practice and calibrate models in the same manner.
Theoretical Results
We consider the Gaussian mixture block model(Li and Schramm 2023), which is commonly used for theoretical analysis on graphs and neural network calibration(Carmon et al. 2019; Zhang et al. 2022a).
Definition 1.
(Gaussian model). For and , the Gaussian model is defined as a distribution over :
| (5) |
where follows the Bernoulli distribution .
Assumption 1.
For two graph nodes and with the Gaussian model parameterized by , there exists a underlying linear relationship between the two nodes: , where are constants, and .
Parameter Setting 1.
We choose the model parameters that allow a classifier with non-trivial standard accuracy (e.g., ) to be learned with high probability, following the Theorem 4 of (Schmidt et al. 2018):
| (6) |
Given graphs as training samples , the estimator for Gaussian distribution parameters of node based on likelihood can be obtained as:
| (7) |
If nodes and are considered jointly, the estimator can then be obtained as:
| (8) | |||||
| (9) |
Then, considering the ECE measure for the two estimators and ,
| (10) | |||||
| (11) | |||||
| (12) |
we have the following theorem for the expected cost minimizing (ECM) classifier defined in App. Prop. 1:
Theorem 1.
Under the above parameter setting, there exist numerical constants , with and ,
| (13) |
Proof.
We defer the detailed proof to the appendix. Here we give a sketch of the proof. According to Lemma 2-5 (as proved in the appendix), with sufficiently large and high correlation ,
and is always closer to than with various . Thus,
∎
The above theorem indicates that by jointly considering nodes with high correlation, the calibration error can be reduced effectively. This motivates our design of SimCalib which explicitly considers the similarity between nodes at both global and local levels.
Related Work
Calibration for standard multi-class classification
The model calibration task was first proposed in 2017 (Guo et al. 2017). About this problem, works can be roughly classified as post-hoc and training based methods. Post-hoc methods calibrate pretrained nodewise classifiers in ways that preserve predictions, as featured by temperature scaling (TS) (Guo et al. 2017), ensemble temperature scaling (ETS) (Zhang, Kailkhura, and Han 2020), multi-class isotonic regression (IRM) (Zhang, Kailkhura, and Han 2020), spline calibration (Gupta et al. 2020), Dirichlet calibration (Kull et al. 2019), etc. In contrast, instead of transforming logits from a pretrained classifier, training based methods modify either the model architecture or the training process itself. A plethora of methods based on evidential theory (Sensoy, Kaplan, and Kandemir 2018), model ensembling (Lakshminarayanan, Pritzel, and Blundell 2017), adversarial calibration (Tomani and Buettner 2021) and Bayesian approach (Hernández-Lobato and Adams 2015; Wen et al. 2018) belongs to the category. Whereas training based methods provide more flexibility compared to post-hoc ones, a limitation is that they hardly promise accuracy-preserving, thereby requiring careful trade-off between accuracy and calibration performance.
GNN calibration
Comparatively, GNN calibration is currently less explored. Teixeira et al.(2019) empirically evaluate the post-hoc model calibration techniques developed for the standard i.i.d. setting on GNN calibration, and show that such a paradigm fails in the task due to an oversight of graph structural information. Afterwards, CaGCN (Wang et al. 2021) produces nodewise temperatures by processing nodewise logits via a graph convolutional network, to account for the graph structure. Additionally, GATS (Hsu et al. 2022) experimentally points out influential factors of GNN calibration and produces nodewise temperatures with an attention-based architecture. Furthermore, Hsu et al.(2022) propose edgewise calibration metrics. Recently, uncertainty quantification is also considered via conformal prediction (Huang et al. 2023; Zargarbashi, Antonelli, and Bojchevski 2023). However, our post-hoc calibration strategy differs from all the previous works with theoretical foundation and similarity-oriented mechanisms.
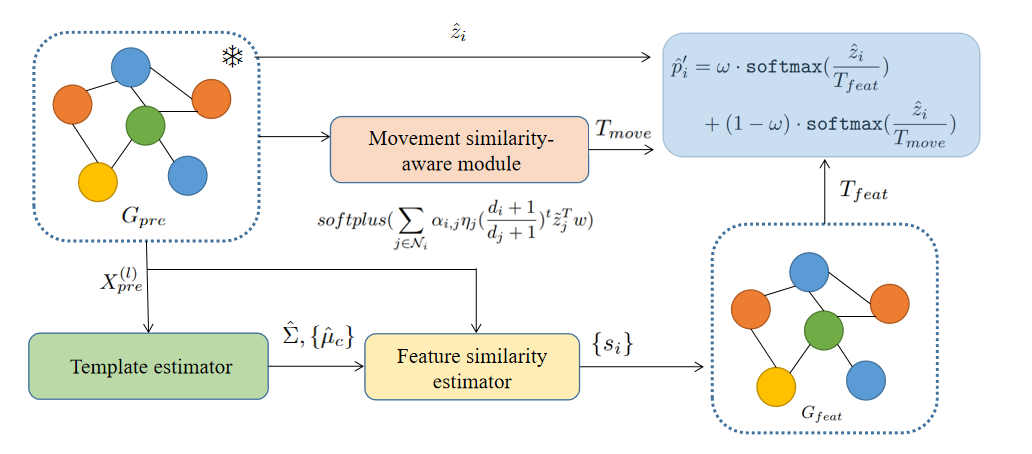
Methods
In light of our theorem, we aim at exploiting nodewise similarity in the process of GNN calibration. Thus we discuss two mechanisms, namely feature and representation movement similarities in this section.
Feature similarity propogation
An intuitive form of feature similarity is raw feature similarity. However, we find with experiments that it aligns badly with GNN predictions, and also the subsequent calibration process, thereby performing suboptimally in GNN calibration. Thus we calculate similarity based on intermediate features from the pretrained GNN classifier , which is to be calibrated, because the intermediate features are better clustered and better aligned with GNN predictions (Kipf and Welling 2016). Hereafter we denote the intermediate feature map from the -th layer of as .
A naive solution would be to feed directly into another GNN for feature processing, in the hope that implicitly takes feature similarity into account and produces nodewise temperatures :
| (14) |
Unfortunately, this renders the number of parameters for highly dependent on the number of ’s dimensions. Specifically, if, for constants , the first layer of projects from to , then will contain at least parameters, which can easily result in overfitting when gets large. Thus, we desire a feature similarity mechanism that does not rely on input feature dimension or feature semantics.
Motivated by prototypical learning (Nassar et al. 2023; Snell, Swersky, and Zemel 2017), for each class , we first take the average feature as a classwise template,
| (15) |
where , and is the intermediate feature for in . Then, we define the similarity between and templates with the assistance of a distance measure :
| (16) |
where normalizes the input vector. Naturally, we consider , the feature similarity between and template features, as a proxy of the similarity between and intermediate features of all the nodes from a class. Following Lee et al.(2018), we first compute variance matrix,
| (17) |
and then induce the Mahalanobis distance (Mahalanobis 2018) accordingly:
| (18) |
Finally, we feed and to to propagate feature-level similarities along the graph structure, i.e.,
| (19) |
where is the nodewise temperature estimate by feature-level similarity.
Representation movement similarity
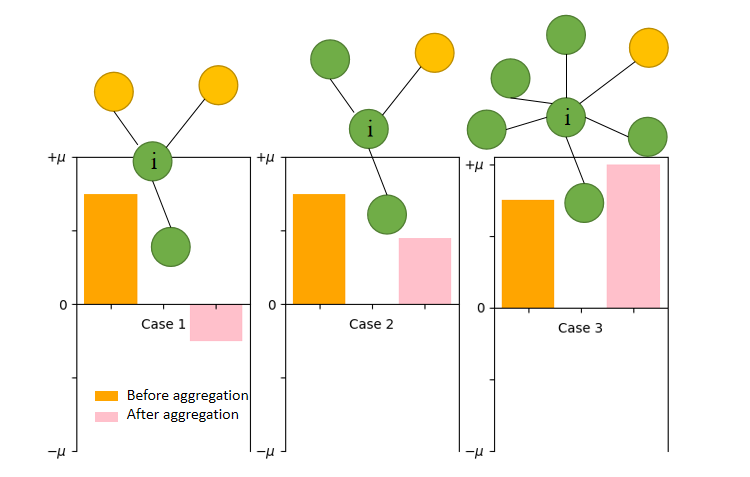
Recently, Yan et al.(2022) quantify nodewise representation movement dynamics of GNNs in node classification task, whose three cases of representation movement serve as the foundation of our representation movement similarity-aware mechanism. Hereafter, we provide the necessary backgrounds.
We denote the node degree of as , and the homophily of is defined as: , in which is ’s neighbor set. Finally, the expected relative degree of node is , where . Then, Yan claims that node representation dynamics can be grouped as three cases:
-
•
Case 1: when is low, node representations move closer to the representations of the other class, whatever value takes.
-
•
Case 2: when is high but relative degree is low, node representations still move closer to the other class but not as much as in the first case.
-
•
Case 3: only when both and are high, node representations tend to move away from the other class.
We provide Fig. 2 for an illustration. The existence of such dynamics can easily obscure information of logits and features, e.g. of case 1 from class 1 may end up having its logits similar to that of , which is of case 2 from another class. Therefore, we desire our GNN calibrator to be able to decompose effects from similar nodewise representation movement behavior and nodewise input information, producing better calibrated results. Nonetheless, one difficulty of applying the theorem is the absence of ground-truth labels during training, making unaccessible. Worse still, when applied to GNNs, both and are unable to differentiate messages from different neighbors, limiting the calibrator’s model capacity. To circumvent these problems, we approximate homophily by . The relative degree information is considered by . Furthermore, aware of correlation between ECE and distances to training nodes (Hsu et al. 2022), we estimate nodewise homophily and apply it to graph attention:
| (20) |
where is the distance from to the nearest training node, and (Xu et al. 2015). Then messages from neighbors are weighted and summed:
| (21) |
where is a hyperparameter, sorts the logits (Rahimi et al. 2020) and is a trainable parameter modeling the message from .
It is worth mentioning that representation movement dynamics was initially proven to relate to the oversmoothing problem(Yan et al. 2022), which refers to the problem that node features of GNNs converge towards the same values with the increase of model depth (Rusch, Bronstein, and Mishra 2023). Thus, the proceeding mechanism implies a relationship between oversmoothing and GNN calibration.
Our model & Calibration properties
We formalize our GNN calibrator, SimCalib, as:
| (22) |
where is a hyperparameter balancing feature and representation movement similarities. It is obvious that SimCalib is the composition of order-preserving functions and thus accuracy-preserving. We provide Fig. 1 for illustration.
Experiments
In this section, we empirically demonstrate the effectiveness of our proposed method and evaluate the effects of various network designs.
Experimental Setup
In the experiments, we apply the commonly used equal-width binning scheme from Guo et al.(2017): for any node subset , samples are regrouped into equally spaced intervals according to their confidences, formally, , to compute the expected calibration error (ECE) of the GNN:
| (23) |
where and are defined as:
| (24) |
To make a fair comparison, the evaluation protocol is mainly adopted from GATS. Specifically, we first train a series of GCNs (Kipf and Welling 2016) and GATs (Veličković et al. 2017) with node classification on eight widely used datasets: Cora (McCallum et al. 2000), Citeseer (Giles, Bollacker, and Lawrence 1998), Pubmed (Sen et al. 2008), CoraFull (Bojchevski and Günnemann 2017), and the four Amazon datasets (Shchur et al. 2018). Then we train calibrators on top of the pretrained nodewise classifiers to evaluate its calibration performance. After training, we evaluate models by ECE with equally sized bins. To reduce the influence of randomness, we randomly assign 15% of nodes as , and the rest as , and we repeat this assignment process with randomness five times for each dataset. Once has been sampled, we use three-fold cross-validation on it. Also, in each fold we randomly initialize our models five times. Therefore, this results in a total of 75 runs for experiment, the mean and standard deviation of which are finally reported. Full implementation details are presented in the Appendix.
| Dataset | Backbone | UnCal | TS | VS | ETS | CaGCN | GATS | SimCalib |
|---|---|---|---|---|---|---|---|---|
| Cora | GCN | 13.045.22 | 3.921.29 | 4.361.34 | 3.793.54 | 5.291.47 | 3.641.34 | 3.320.99 |
| GAT | 23.311.81 | 3.690.90 | 3.301.12 | 3.541.01 | 4.091.06 | 3.180.90 | 2.900.87 | |
| Citeseer | GCN | 10.665.92 | 5.151.50 | 4.921.44 | 4.651.69 | 6.861.41 | 4.431.30 | 3.941.12 |
| GAT | 22.883.53 | 4.741.47 | 4.251.48 | 4.111.64 | 5.751.31 | 3.861.56 | 3.951.30 | |
| Pubmed | GCN | 7.181.51 | 1.260.28 | 1.460.29 | 1.240.30 | 1.090.52 | 0.980.30 | 0.930.32 |
| GAT | 12.320.80 | 1.190.36 | 1.000.32 | 1.200.32 | 0.980.31 | 1.030.32 | 0.950.35 | |
| Computers | GCN | 3.000.80 | 2.650.57 | 2.700.63 | 2.580.70 | 1.720.53 | 2.230.49 | 1.370.33 |
| GAT | 1.880.82 | 1.630.46 | 1.670.52 | 1.540.67 | 2.030.80 | 1.390.39 | 1.080.33 | |
| Photo | GCN | 2.241.03 | 1.680.63 | 1.750.63 | 1.680.89 | 1.990.56 | 1.510.52 | 1.360.59 |
| GAT | 2.021.11 | 1.610.63 | 1.630.69 | 1.670.73 | 2.100.78 | 1.480.61 | 1.290.55 | |
| CS | GCN | 1.650.92 | 0.980.27 | 0.960.30 | 0.940.24 | 2.271.07 | 0.880.30 | 0.810.30 |
| GAT | 1.401.25 | 0.930.34 | 0.870.35 | 0.880.33 | 2.521.04 | 0.810.30 | 0.830.32 | |
| Physics | GCN | 0.520.29 | 0.510.19 | 0.480.16 | 0.520.19 | 0.940.51 | 0.460.16 | 0.390.14 |
| GAT | 0.450.21 | 0.500.21 | 0.520.20 | 0.500.21 | 1.170.42 | 0.42 0.14 | 0.400.13 | |
| CoraFull | GCN | 6.501.26 | 5.540.43 | 5.760.42 | 5.380.49 | 5.862.52 | 3.760.74 | 3.220.74 |
| GAT | 4.731.39 | 4.000.50 | 4.170.43 | 3.890.56 | 6.553.69 | 3.540.63 | 3.400.91 |
| Backbone | Uncal | GATS | SimCalib |
|---|---|---|---|
| GCN | 16.23 | 15.80 | 15.44 |
| GAT | 16.27 | 15.52 | 15.17 |
Performance Comparison
We benchmark SimCalib against a variety of baselines on GNN calibration tasks:
-
•
Temperature scaling(TS) applies a global temperature to scale every nodewise logits.
-
•
Vector scaling(VS) scales and adds a bias to each class in a class-wise manner.
-
•
Ensemble temperature scaling(ETS) softens probabilistic outputs by learning an ensemble of uncalibrated, TS-calibrated and uniform distribution.
-
•
Graph convolution network as a calibration function (CaGCN) uses a GCN to process logits, producing nodewise temperatures.
-
•
Graph attention temperature scaling (GATS) identifies factors that influence GNN calibration, and addresses them with graph attention mechanism.
We also report the ECEs for uncalibrated predictions as a reference. Among the baselines, TS, VS and ETS are designed for standard i.i.d. multi-class classification. CaGCN and GATS propagate information along the graph structure, and produce separate nodewise temperatures.
For all the experiments, the pretrained GNN classifiers will be frozen, and its first-layer feature map, together with the logits, will be fed into our calibration model as inputs. We train calibrators on validation sets by minimizing NLL loss, and validate it on the training set, following the common practice (Wang et al. 2021). We provide details of comparison settings and hyperparameters in Appendix. The calibration results are summarized in Table 1. We also provide the comparisons on adaptive calibration error (ACE) in Table 2.
Overall, SimCalib consistently produces well calibrated results for all the GNN backbones on every dataset. It sets a new SOTA for all experiments, with two exceptions of GAT on Citeseer(2nd best) and GAT on CS(2nd best), on which SimCalib performs worse than GATS by at most 3%. In contrast, SimCalib’s improvements are more statistically significant, reducing average ECE by 10.4% compared to GATS.
With Wilcoxon signed test (Wilcoxon 1992) backed by scipy (Virtanen et al. 2020), we claim that our model is superior to the previous SOTA model, namely, GATS, with confidence 99.9% and .
| Dataset | Backbone | SimCalib | |||||
|---|---|---|---|---|---|---|---|
| Cora | GCN | 3.580.97 | 3.861.78 | 3.301.76 | 3.87 1.77 | 4.16 1.79 | 3.320.99 |
| GAT | 2.880.88 | 3.401.32 | 3.021.27 | 3.52 1.26 | 3.681.39 | 2.900.87 | |
| Citeseer | GCN | 4.241.61 | 4.571.92 | 4.361.84 | 4.751.89 | 4.96 1.93 | 3.941.12 |
| GAT | 4.221.51 | 4.412.29 | 3.932.25 | 4.652.21 | 4.732.20 | 3.951.30 | |
| Photo | GCN | 1.500.50 | 1.420.63 | 1.380.71 | 1.52 0.65 | 1.58 0.71 | 1.360.59 |
| GAT | 1.390.58 | 1.440.55 | 1.360.54 | 1.550.54 | 1.520.59 | 1.290.55 | |
| CoraFull | GCN | 3.470.79 | 3.910.79 | 3.760.82 | 3.180.73 | 3.330.90 | 3.220.74 |
| GAT | 3.840.80 | 3.270.84 | 3.590.88 | 3.350.81 | 3.210.84 | 3.400.91 |
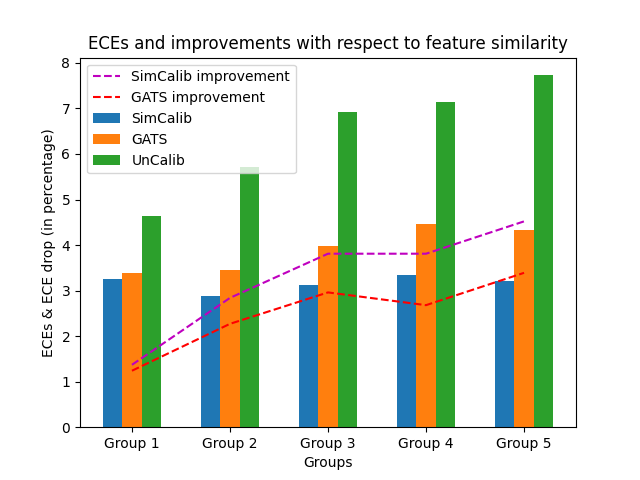
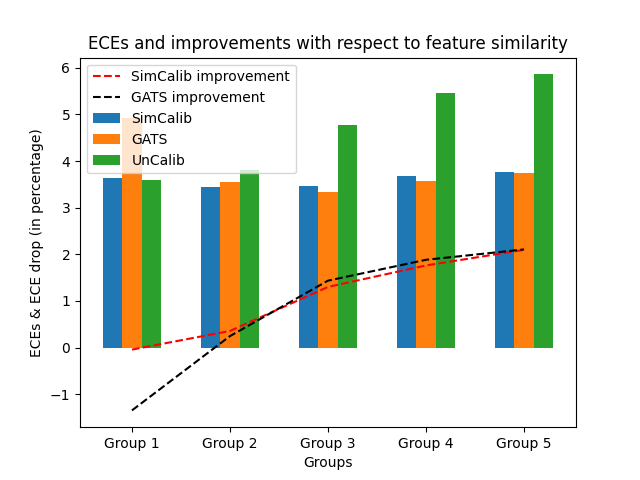
Correlation between feature similarity and calibration improvement
Furthermore, we conduct experiments on CoraFull to assess the correlation between calibration improvement and nodewise similarity. We opt for CoraFull because it is the most complicated dataset of the eight, with 19,793 nodes, 126,842 edges, 70 classes and 8710 features, which makes it well representative of the real-world scenario.
| Backbone | w=0.5 | w=0.6 | w=0.8 | w=0.9 |
|---|---|---|---|---|
| GCN | 3.340.84 | 3.220.74 | 3.320.69 | 3.560.70 |
| GAT | 3.521.02 | 3.400.91 | 3.460.79 | 3.680.66 |
In Fig. 4, we visually examine the correlation between feature similarity and calibration improvement by comparing the calibration performance of GATS, an uncalibrated GNN backbone and SimCalib. We group nodes by the Mahalanobis distances to the nearest template representation, and display the group-level ECEs as bars and ECE improvements as dashed lines. The figure shows that the miscalibration issue worsens with the decrease of feature similarity, while our calibration strategy calibrates the nodewise confidence in a consistent way. We believe that with the decrease of feature-level similarity, the samples become more outlying in the feature space, indistinguishable from samples from other classes, and thus it gets harder for the uncalibrated model to accurately tune its confidence in congruence with ground-truth prediction accuracy. In contrast, our model successfully overcomes such ambiguity in feature space by taking feature-level similarity into account, thereby consistenly calibrating samples of various feature similarity with similar expected calibration error. Therefore, this results in stronger improvement for SimCalib when feature similarity gets weaker. Although we discover a similar pattern for GATS, its ECE improvement is weaker than SimCalib when features become dissimilar. We attribute the performance gap to the feature-similarity-aware mechanism. The observation aligns with our theoretical hypothesis in that it suggests that feature similarity indeed plays a critical role in GNN calibration.
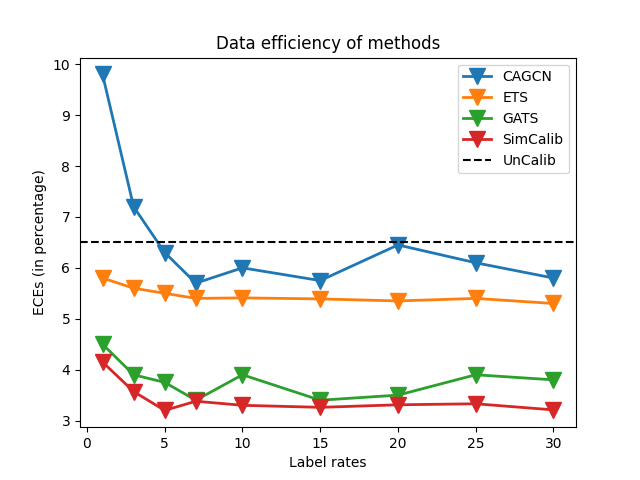
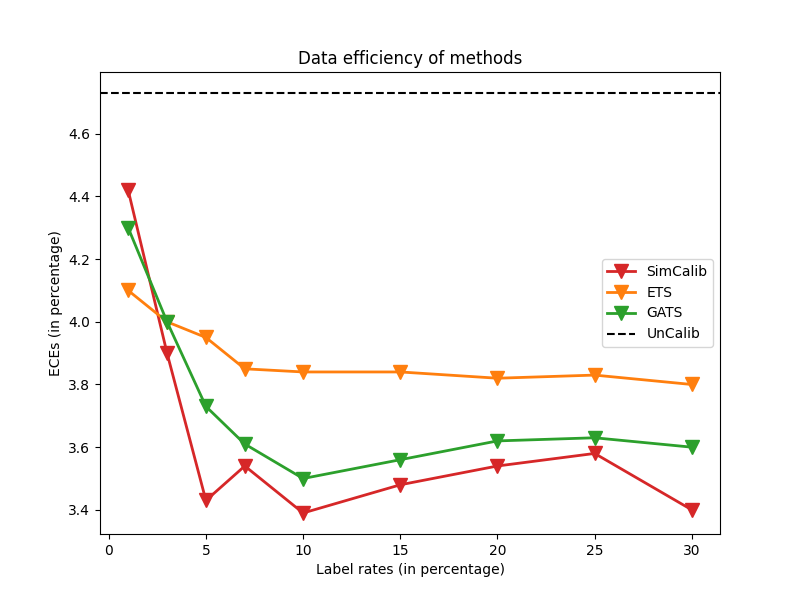
Data-efficiency and expressivity of SimCalib
In addition, we analyze the data-efficiency and expressivity of SimCalib for GNN calibration. For this, we reuse the GCN classifier pretrained on CoraFull, and compare the expected calibration errors between baselines and SimCalib, with different amounts of calibration data. The results are shown in Fig. 3. From the figure, we draw that SimCalib is both data-efficient and expressive. SimCalib does not require a lot of labels to perform decently, consistenly outperforming all the baselines under all label rates. Moreover, SimCalib also expresses robustness to label rates.
Ablation Study
To understand the effects of the two similarity-oriented mechanisms, we conduct a thorough ablation study in this section. The results are shown in Table 3 and Table 4. Overall, each mechanism plays a critical role in GNN calibration and removing any will in general decrease performance while increasing variances.
Effect of feature similarity In order to decompose the effects from number of trainable parameters and feature-similarity mechanism, we investigate the performance of two different models: SimCalib with only representation movement similarity() and SimCalib with replaced by ’s output logits(). Comparing with , we see that the calibration performance slightly improves with more trainable parameters. However, the improvements are rather moderate, unable to match the performance of SimCalib. We hypothesize that since logits information has already been integrated into the calibration process in the nodewise representation movement similarity, adding an extra branch of logits propagation only helps GNN calibration by introducing more parameters.
Effect of representation movement similarity Our representation movement similarity mechanism consists of two aspects of network designs, i.e. homophily term and relative degree , therefore we design three models to analyze the effects of various components in the representation movement similarity mechanism. Particularly, we test the calibration performance of that disables relative degree, that disables homophily, and in which neither takes effects. We can easily draw from the experiments that the integrity of representation movement similarity mechanism is important to calibration performance and removing of any results in a worsened GNN calibrator. We attribute the performance drop to the inability of the calibrator to decompose effects from nodewise input information and effects from representation movement.
Conclusions
In this work, we provide theoretical analysis on the graph calibraion problem and prove that nodewise similarity plays an important role in the solution. We consider feature and nodewise representation movement similarities, which are quantified by Gaussian-induced Mahalanobis distances and homophily & relative degrees, respectively. Based on the mechanisms, we propose a novel calibrator, SimCalib, tailored for GNN calibration. SimCalib is data-efficient, expressive and accuracy-preserving at the same time. Our extensive experiments demonstrate the effectiveness of SimCalib by achieving state-of-the-art performances for GNN calibration on various datasets and for different backbones. Moreover, our experiments exhibit a correlational relationship between nodewise similarity and calibration improvement, in alignment with our theoretical results. Our work has the potential to be employed in cost-sensitive scenarios. Additionally our work is the first to reveal a non-trivial relationship between oversmoothing and GNN calibration problems.
Acknowledgement
This work is supported by National Natural Science Foundation of China (62076144, 62306260), Shenzhen Science and Technology Program (WDZC20220816140515001, JCYJ20220818101014030), and the Center for Perceptual and Interactive Intelligence (CPII) Ltd under the Innovation and Technology Commission’s InnoHK Scheme.
References
- Bojchevski and Günnemann (2017) Bojchevski, A.; and Günnemann, S. 2017. Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking. arXiv preprint arXiv:1707.03815.
- Carmon et al. (2019) Carmon, Y.; Raghunathan, A.; Schmidt, L.; Duchi, J. C.; and Liang, P. S. 2019. Unlabeled data improves adversarial robustness. Advances in neural information processing systems, 32.
- Dezvarei et al. (2023) Dezvarei, M.; Tomsovic, K.; Sun, J. S.; and Djouadi, S. M. 2023. Graph Neural Network Framework for Security Assessment Informed by Topological Measures. arXiv preprint arXiv:2301.12988.
- Fan et al. (2019) Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; and Yin, D. 2019. Graph neural networks for social recommendation. In The world wide web conference, 417–426.
- Giles, Bollacker, and Lawrence (1998) Giles, C. L.; Bollacker, K. D.; and Lawrence, S. 1998. CiteSeer: An automatic citation indexing system. In Proceedings of the third ACM conference on Digital libraries, 89–98.
- Guo et al. (2017) Guo, C.; Pleiss, G.; Sun, Y.; and Weinberger, K. Q. 2017. On calibration of modern neural networks. In International conference on machine learning, 1321–1330. PMLR.
- Gupta et al. (2020) Gupta, K.; Rahimi, A.; Ajanthan, T.; Mensink, T.; Sminchisescu, C.; and Hartley, R. 2020. Calibration of neural networks using splines. arXiv preprint arXiv:2006.12800.
- Hamilton, Ying, and Leskovec (2017) Hamilton, W.; Ying, Z.; and Leskovec, J. 2017. Inductive representation learning on large graphs. Advances in neural information processing systems, 30.
- Hernández-Lobato and Adams (2015) Hernández-Lobato, J. M.; and Adams, R. 2015. Probabilistic backpropagation for scalable learning of bayesian neural networks. In International conference on machine learning, 1861–1869. PMLR.
- Hsu, Shen, and Cremers (2022) Hsu, H. H.-H.; Shen, Y.; and Cremers, D. 2022. A graph is more than its nodes: Towards structured uncertainty-aware learning on graphs. arXiv preprint arXiv:2210.15575.
- Hsu et al. (2022) Hsu, H. H.-H.; Shen, Y.; Tomani, C.; and Cremers, D. 2022. What Makes Graph Neural Networks Miscalibrated? Advances in Neural Information Processing Systems, 35: 13775–13786.
- Huang et al. (2023) Huang, K.; Jin, Y.; Candes, E.; and Leskovec, J. 2023. Uncertainty quantification over graph with conformalized graph neural networks. arXiv preprint arXiv:2305.14535.
- Kipf and Welling (2016) Kipf, T. N.; and Welling, M. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907.
- Kull et al. (2019) Kull, M.; Perello Nieto, M.; Kängsepp, M.; Silva Filho, T.; Song, H.; and Flach, P. 2019. Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with dirichlet calibration. Advances in neural information processing systems, 32.
- Lakshminarayanan, Pritzel, and Blundell (2017) Lakshminarayanan, B.; Pritzel, A.; and Blundell, C. 2017. Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems, 30.
- Lee et al. (2018) Lee, K.; Lee, K.; Lee, H.; and Shin, J. 2018. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Advances in neural information processing systems, 31.
- Li and Schramm (2023) Li, S.; and Schramm, T. 2023. Spectral clustering in the Gaussian mixture block model. arXiv preprint arXiv:2305.00979.
- Liu et al. (2022) Liu, Q.; Zhu, W.; Jia, X.; Ma, F.; and Gao, Y. 2022. Fluid simulation system based on graph neural network. arXiv preprint arXiv:2202.12619.
- Mahalanobis (2018) Mahalanobis, P. C. 2018. On the generalized distance in statistics. Sankhyā: The Indian Journal of Statistics, Series A (2008-), 80: S1–S7.
- McCallum et al. (2000) McCallum, A. K.; Nigam, K.; Rennie, J.; and Seymore, K. 2000. Automating the construction of internet portals with machine learning. Information Retrieval, 3: 127–163.
- Naeini, Cooper, and Hauskrecht (2015) Naeini, M. P.; Cooper, G.; and Hauskrecht, M. 2015. Obtaining well calibrated probabilities using bayesian binning. In Proceedings of the AAAI conference on artificial intelligence, volume 29.
- Nassar et al. (2023) Nassar, I.; Hayat, M.; Abbasnejad, E.; Rezatofighi, H.; and Haffari, G. 2023. PROTOCON: Pseudo-label Refinement via Online Clustering and Prototypical Consistency for Efficient Semi-supervised Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11641–11650.
- Nowozin, Lampert et al. (2011) Nowozin, S.; Lampert, C. H.; et al. 2011. Structured learning and prediction in computer vision. Foundations and Trends® in Computer Graphics and Vision, 6(3–4): 185–365.
- Paszke et al. (2019) Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; Desmaison, A.; Köpf, A.; Yang, E.; DeVito, Z.; Raison, M.; Tejani, A.; Chilamkurthy, S.; Steiner, B.; Fang, L.; Bai, J.; and Chintala, S. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv:1912.01703.
- Rahimi et al. (2020) Rahimi, A.; Shaban, A.; Cheng, C.-A.; Hartley, R.; and Boots, B. 2020. Intra order-preserving functions for calibration of multi-class neural networks. Advances in Neural Information Processing Systems, 33: 13456–13467.
- Rusch, Bronstein, and Mishra (2023) Rusch, T. K.; Bronstein, M. M.; and Mishra, S. 2023. A survey on oversmoothing in graph neural networks. arXiv preprint arXiv:2303.10993.
- Schmidt et al. (2018) Schmidt, L.; Santurkar, S.; Tsipras, D.; Talwar, K.; and Madry, A. 2018. Adversarially robust generalization requires more data. Advances in neural information processing systems, 31.
- Sen et al. (2008) Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; and Eliassi-Rad, T. 2008. Collective classification in network data. AI magazine, 29(3): 93–93.
- Sensoy, Kaplan, and Kandemir (2018) Sensoy, M.; Kaplan, L.; and Kandemir, M. 2018. Evidential deep learning to quantify classification uncertainty. Advances in neural information processing systems, 31.
- Shchur et al. (2018) Shchur, O.; Mumme, M.; Bojchevski, A.; and Günnemann, S. 2018. Pitfalls of graph neural network evaluation. arXiv preprint arXiv:1811.05868.
- Snell, Swersky, and Zemel (2017) Snell, J.; Swersky, K.; and Zemel, R. 2017. Prototypical networks for few-shot learning. Advances in neural information processing systems, 30.
- Teixeira, Jalaian, and Ribeiro (2019) Teixeira, L.; Jalaian, B.; and Ribeiro, B. 2019. Are graph neural networks miscalibrated? arXiv preprint arXiv:1905.02296.
- Tomani and Buettner (2021) Tomani, C.; and Buettner, F. 2021. Towards trustworthy predictions from deep neural networks with fast adversarial calibration. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, 9886–9896.
- Veličković et al. (2017) Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; and Bengio, Y. 2017. Graph attention networks. arXiv preprint arXiv:1710.10903.
- Virtanen et al. (2020) Virtanen, P.; Gommers, R.; Oliphant, T. E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; van der Walt, S. J.; Brett, M.; Wilson, J.; Millman, K. J.; Mayorov, N.; Nelson, A. R. J.; Jones, E.; Kern, R.; Larson, E.; Carey, C. J.; Polat, İ.; Feng, Y.; Moore, E. W.; VanderPlas, J.; Laxalde, D.; Perktold, J.; Cimrman, R.; Henriksen, I.; Quintero, E. A.; Harris, C. R.; Archibald, A. M.; Ribeiro, A. H.; Pedregosa, F.; van Mulbregt, P.; and SciPy 1.0 Contributors. 2020. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17: 261–272.
- Wang et al. (2021) Wang, X.; Liu, H.; Shi, C.; and Yang, C. 2021. Be confident! towards trustworthy graph neural networks via confidence calibration. Advances in Neural Information Processing Systems, 34: 23768–23779.
- Wen et al. (2018) Wen, Y.; Vicol, P.; Ba, J.; Tran, D.; and Grosse, R. 2018. Flipout: Efficient pseudo-independent weight perturbations on mini-batches. arXiv preprint arXiv:1803.04386.
- Wilcoxon (1992) Wilcoxon, F. 1992. Individual comparisons by ranking methods. In Breakthroughs in Statistics: Methodology and Distribution, 196–202. Springer.
- Xu et al. (2015) Xu, B.; Wang, N.; Chen, T.; and Li, M. 2015. Empirical evaluation of rectified activations in convolutional network. arXiv preprint arXiv:1505.00853.
- Yan et al. (2022) Yan, Y.; Hashemi, M.; Swersky, K.; Yang, Y.; and Koutra, D. 2022. Two sides of the same coin: Heterophily and oversmoothing in graph convolutional neural networks. In 2022 IEEE International Conference on Data Mining (ICDM), 1287–1292. IEEE.
- Zargarbashi, Antonelli, and Bojchevski (2023) Zargarbashi, S. H.; Antonelli, S.; and Bojchevski, A. 2023. Conformal Prediction Sets for Graph Neural Networks.
- Zhang, Kailkhura, and Han (2020) Zhang, J.; Kailkhura, B.; and Han, T. Y.-J. 2020. Mix-n-match: Ensemble and compositional methods for uncertainty calibration in deep learning. In International conference on machine learning, 11117–11128. PMLR.
- Zhang et al. (2022a) Zhang, L.; Deng, Z.; Kawaguchi, K.; and Zou, J. 2022a. When and how mixup improves calibration. In International Conference on Machine Learning, 26135–26160. PMLR.
- Zhang et al. (2022b) Zhang, Z.; Chen, L.; Zhong, F.; Wang, D.; Jiang, J.; Zhang, S.; Jiang, H.; Zheng, M.; and Li, X. 2022b. Graph neural network approaches for drug-target interactions. Current Opinion in Structural Biology, 73: 102327.
Appendix A Appendix
Proofs
In this section, we illustrate our mathematic derivation of Thearom 1. The proof may seem horiffying, but the idea is simple, which is to compare the ECE of joint optimization and that of separated optimization based on probability concentation inequalities (of Gaussian and Chi-square variables). Then,
Proposition 1.
The learned model predicts whenever .
Proof.
According to expected cost minimum (ECM) with equal mis-classification costs, the learned model predicts if , i.e., . ∎
Lemma 1.
For the learned model, the ECE measure is
| (25) |
Proof.
Since ,
| (26) | |||||
| (27) | |||||
| (28) | |||||
| (29) | |||||
| (30) |
thus,
| (32) |
∎
where is the probability estimation from the learned model.
Lemma 2.
There exists numerical constant , when is sufficiently large, , with high probability,
| (33) |
Proof.
Let , , then , . Let , from Eq. 9, we have , and .
Given , according to concentration inequalities , we have
thus,
| (34) |
with . ∎
Lemma 3.
With sufficiently large , , with high probability,
| (35) |
Proof.
Given , , according to concentration inequalities , , we have
hence,
| (36) |
with sufficiently large . ∎
Lemma 4.
With the parameter setting and sufficiently large ,
| (37) |
Proof.
.
| (38) | |||||
| (39) | |||||
| (40) |
Hence,
| (41) |
with probability at least . ∎
Lemma 5.
With sufficiently large and ,
| (42) |
Proof.
| (43) | |||||
| (44) | |||||
| (45) |
with , we have Hence, with sufficient large , i.e., large linear correlation between nodes,
| (46) |
∎
Theorem 1.
Under the above parameter setting, there exist numerical constants , with and ,
| (47) |
Proof.
According to Lemma 2, with sufficiently large , there exists numerical constant , such that
According to Lemma 3, with sufficiently large ,
According to Theorem 1, considering the high correlation by jointly optimizing likelihoods of correlated nodes, leads to lower ECE than separately optimizing likelihoods, with high probability . For example, given 4 graphs () with 64-dim () features and linear correlation coefficients , the probability .
Implementation Details
Throughout all the experiments, we fix the global random seed to be 10, remaining the same with GATS. The seed eliminates randomness from python, numpy, pytorch and cuda. Our experiments are run on an Ubuntu 20.04 operating system, with a Nvidia V100 GPU, 64GB RAM and i9-13900K CPU. We mainly base our code on pytorch (Paszke et al. 2019) 1.12.1 and torch geometric 2.0.1. In all the experiments, is a GNN or GAT while implements equation21 with at most 8 heads, although we find 1 or 2 heads are sufficient for most experiments. For each experiment, we do a small grid search on validation set to determine and , which can take values from and respectively. Following GATS, we train pretrained classifiers on Cora, Citeseer and Pubmed with a weight decay of 5e-4, and none on other datasets. We also conduct a coarse grid search to identify learning rate and number of heads on each dataset. All the hyperparameters are provided as a config file in our code appendix for reproducibility.
We train GATS and other baselines with the open-sourced code of GATS, and find that the outcomes do not exhibit any statistically significant difference with the results reported by GATS. Thus we adopt the reported performance from GATS as our baselines. It is worth mentioning that our network consumes twice the amount of trainable parameters as GATS, but we cannot report the performance of GATS with the same number of parameters because GATS gets its performance declined with twice the number of attention heads (Hsu et al. 2022).
Data efficiency of SimCalib
In Fig. 5, we evaluate the calibration performance of SimCalib and two baselines when applied to GAT. The uncalibrated ECE is also plotted as a dashed line as a reference. We omit CaGCN here as its poor calibration results make the performance gaps across other calibrators visually indistinguishable. From the figure, we find a slightly different phenomenon from that shown in Fig. 3, in that SimCalib performs worse (although still competitively) than ETS and GATS at extremely low label rate (1%), but catches up and outperfoms the other baselines immediately. We attribute the inferior performance of SimCalib at low label rate to containing more trainable parameters. SimCalib performs decently even with a small amount of data. Noticeably, although SimCalib takes the form of model ensembling, it significantly outperforms the other ensembling baseline, namely ETS, at most label rates, which verifies the effectiveness of our information-blending design paradigm. The figure validates that our GNN calibrator consistently produces well calibrated confidences for various backbones. Also, SimCalib is expressive for its superior performance at larger label rates.
Feature similarity and calibration improvement
In Fig. 6, we illustrate the correlation between feature similarity and calibration performance & improvement for SimCalib and GATS, when applied to a pretrained GAT on CoraFull. The uncalibrated ECE worsens with increasing dissimilarity. Also, both GNN calibrators exhibit higher improvements with more dissimilarity. However, whereas SimCalib and GATS perform similarly across 4 out of the 5 groups, SimCalib outperforms GATS at the extremely low feature-similarity scenario, where GATS tangibly reduces calibration performance compared to the uncalibrated backbone. We believe that the design of feature similarity awareness renders SimCalib robust to feature similarities, as shown in the figure.
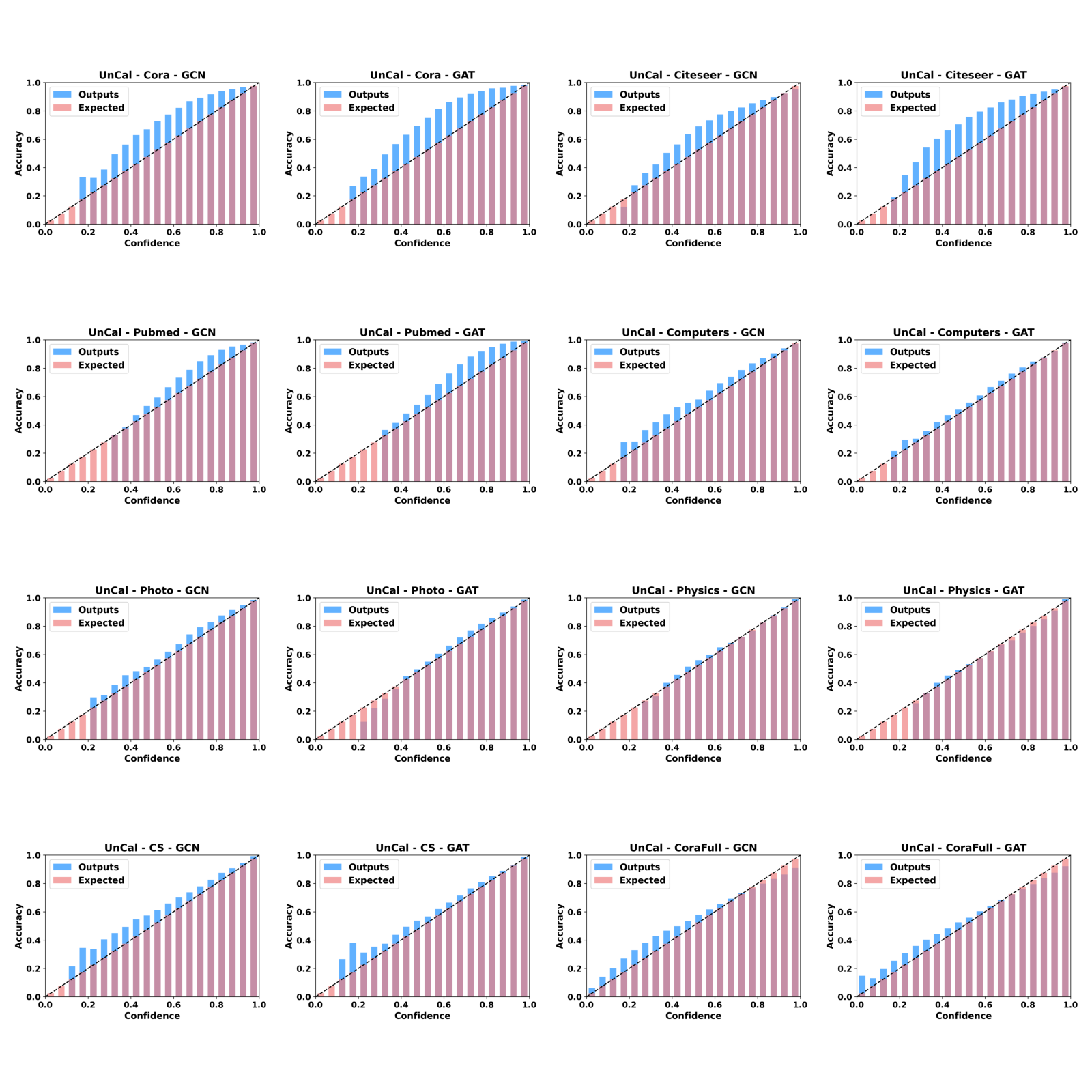
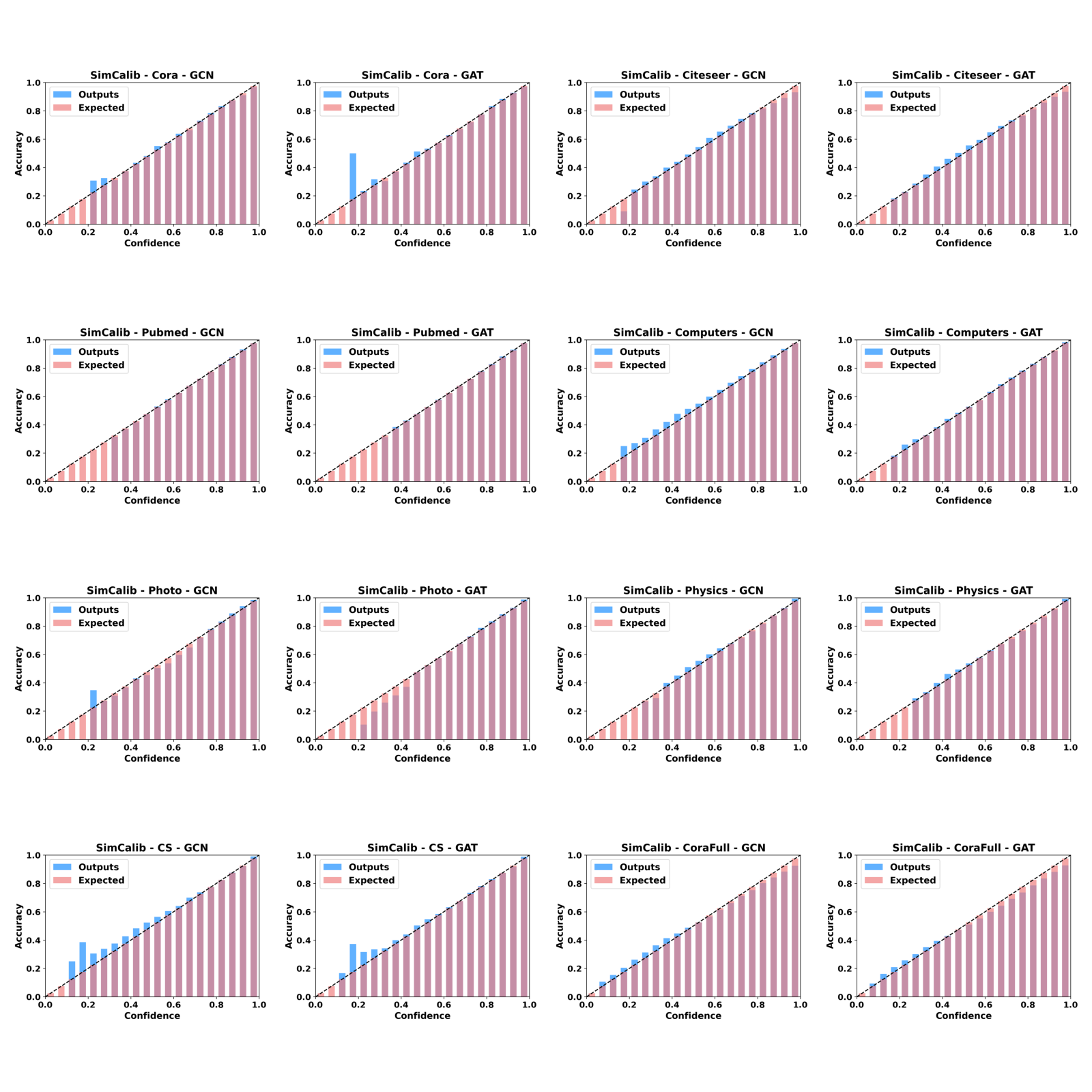
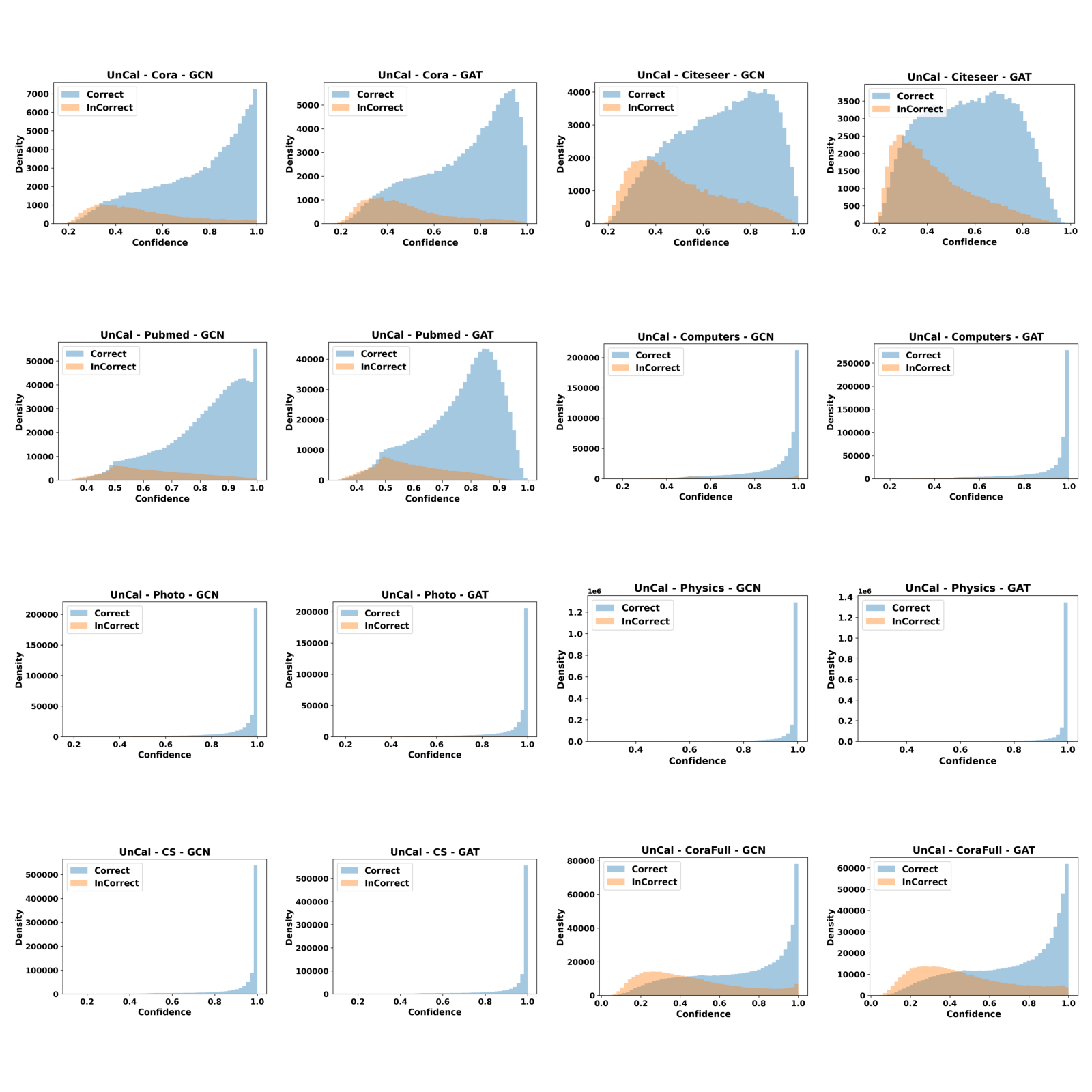
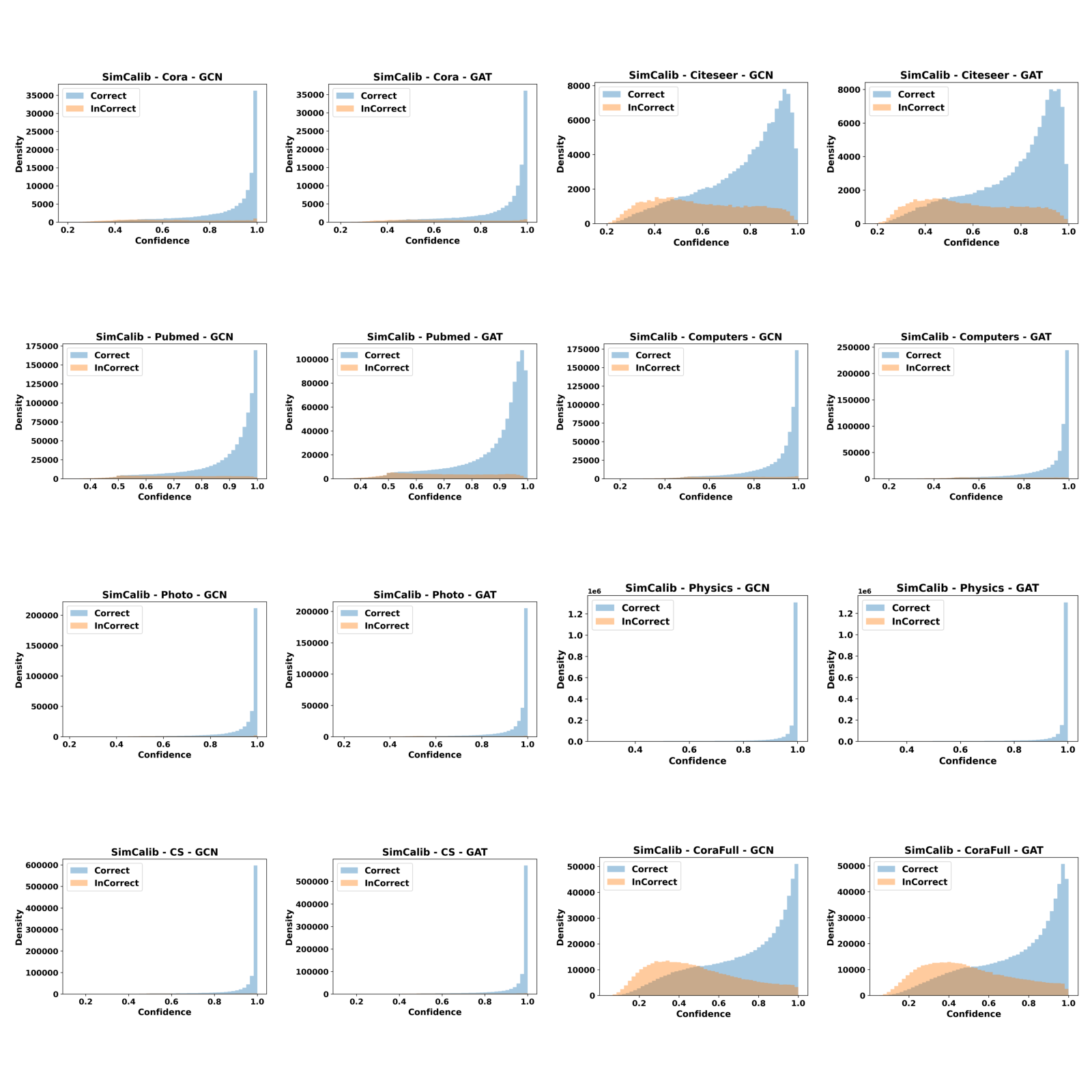
Reliability visualization
In this section, we provide reliability diagrams and confidence distributions for SimCalib and uncalibrated backbones so that readers can readily assess the improvements of SimCalib. Clearly, we can see that SimCalib consistently calibrates pretrained GNN classifiers.