Simple initialization and parametrization of sinusoidal networks via their kernel bandwidth
Abstract
Neural networks with sinusoidal activations have been proposed as an alternative to networks with traditional activation functions. Despite their promise, particularly for learning implicit models, their training behavior is not yet fully understood, leading to a number of empirical design choices that are not well justified. In this work, we first propose a simplified version of such sinusoidal neural networks, which allows both for easier practical implementation and simpler theoretical analysis. We then analyze the behavior of these networks from the neural tangent kernel perspective and demonstrate that their kernel approximates a low-pass filter with an adjustable bandwidth. Finally, we utilize these insights to inform the sinusoidal network initialization, optimizing their performance for each of a series of tasks, including learning implicit models and solving differential equations.
1 Introduction
Sinusoidal networks are neural networks with sine nonlinearities, instead of the traditional ReLU or hyperbolic tangent. They have been recently popularized, particularly for applications in implicit representation models, in the form of SIRENs (Sitzmann et al., 2020). However, despite their popularity, many aspects of their behavior and comparative advantages are not yet fully understood. Particularly, some initialization and parametrization choices for sinusoidal networks are often defined arbitrarily, without a clear understanding of how to optimize these settings in order to maximize performance.
In this paper, we first propose a simplified version of such sinusoidal networks, that allows for easier implementation and theoretical analysis. We show that these simple sinusoidal networks can match and outperform SIRENs in implicit representation learning tasks, such as fitting videos, images and audio signals. We then analyze sinusoidal networks from a neural tangent kernel (NTK) perspective (Jacot et al., 2018), demonstrating that their NTK approximates a low-pass filter with adjustable bandwidth. We confirm, through an empirical analysis this theoretically predicted behavior also holds approximately in practice. We then use the insights from this analysis to inform the choices of initialization and parameters for sinusoidal networks. We demonstrate we can optimize the performance of a sinusoidal network by tuning the bandwidth of its kernel to the maximum frequency present in the input signal being learned. Finally, we apply these insights in practice, demonstrating that “well tuned” sinusoidal networks outperform other networks in learning implicit representation models with good interpolation outside the training points, and in learning the solution to differential equations.
2 Background and Related Work
Sinusoidal networks. Sinusoidal networks have been recently popularized for implicit modelling tasks by sinusoidal representation networks (SIRENs) (Sitzmann et al., 2020). They have also been evaluated in physics-informed learning settings, demonstrating promising results in a series of domains (Raissi et al., 2019b; Song et al., 2021; Huang et al., 2021b; a; Wong et al., 2022). Among the benefits of such networks is the fact that the mapping of the inputs through an (initially) random linear layer followed by a sine function is mathematically equivalent to a transformation to a random Fourier basis, rendering them close to networks with Fourier feature transformations (Tancik et al., 2020; Rahimi & Recht, 2007), and possibly able to address spectral bias (Basri et al., 2019; Rahaman et al., 2019; Wang et al., 2021). Sinusoidal networks also have the property that the derivative of their outputs is given simply by another sinusoidal network, due to the fact that the derivative of sine function is simply a phase-shifted sine.
Neural tangent kernel. An important prior result to the neural tangent kernel (NTK) is the neural network Gaussian process (NNGP). At random initialization of its parameters , the output function of a neural network of depth with nonlinearity , converges to a Gaussian process, called the NNGP, as the width of its layers . (Neal, 1994; Lee et al., 2018). This result, though interesting, does not say much on its own about the behavior of trained neural networks. This role is left to the NTK, which is defined as the kernel given by . It can be shown that this kernel can be written out as a recursive expression involving the NNGP. Importantly, Jacot et al. (2018) demonstrated that, again as the network layer widths , the NTK is (1) deterministic at initialization and (2) constant throughout training. Finally, it has also been demonstrated that under some assumptions on its parametrization, the output function of the trained neural network converges to the kernel regression solution using the NTK (Lee et al., 2020; Arora et al., 2019). In other words, under certain assumptions the behavior of a trained deep neural network can be modeled as kernel regression using the NTK.
Physics-informed neural networks. Physics-informed neural networks (Raissi et al., 2019a) are a method for approximating the solution to differential equations using neural networks (NNs). In this method, a neural network , with learned parameters , is trained to approximate the actual solution function to a given partial differential equation (PDE). Importantly, PINNs employ not only a standard “supervised” data loss, but also a physics-informed loss, which consists of the differential equation residual . Thus, the training loss consists of a linear combination of two loss terms, one directly supervised from data and one informed by the underlying differential equations.
3 Simple Sinusoidal Networks
There are many details that complicate the practical implementation of current sinusoidal networks. We aim to propose a simplified version of such networks in order to facilitate theoretical analysis and practical implementation, by removing such complications.
As an example we can look at SIRENs, which have their layer activations defined as . Then, in order to cancel the factor, layers after the first one have their weight initialization follow a uniform distribution with range , where is the size of the layer. Unlike the other layers, the first layer is sampled from a uniform distribution with range .
We instead propose a simple sinusoidal network, with the goal of formulating an architecture that mainly amounts to substituting its activation functions by the sine function. We will, however, keep the parameter, since (as we will see in future analyses) it is in fact a useful tool for allowing the network to fit inputs of diverse frequencies. The layer activation equations of our simple sinusoidal network, with parameter , are defined as
| (1) | ||||
Finally, instead of utilizing a uniform initialization as in SIRENs (with different bounds for the first and subsequent layers), we propose initializing all parameters in our simple sinusoidal network using a default Kaiming (He) normal initialization scheme. This choice not only greatly simplifies the initialization scheme of the network, but it also facilitates theoretical analysis of the behavior of the network under the NTK framework, as we will see in Section 4.
Analysis of the initialization scheme. The initialization scheme proposed above differs from the one implemented in SIRENs. We will now show that this particular choice of initialization distribution preserves the variance of the original proposed SIREN initialization distribution. As a consequence, the original theoretical justifications for its initialization scheme still hold under this activation, namely that the distribution of activations across layers are stable, well-behaved and shift-invariant. Due to space constraints, proofs are presented in Appendix A. Moreover, we also demonstrate empirically that these properties are maintained in practice.
Lemma 1.
Given any , for and , we have .
This simple Lemma and relates to Lemma 1.7 in Sitzmann et al. (2020), showing that the initialization we propose here has the same variance as the one proposed for SIRENs. Using this result we can translate the result from the main Theorem 1.8 from Sitzmann et al. (2020), which claims that the SIREN initialization indeed has the desired properties, to our proposed initialization:111We note that despite being named Theorem 1.8 in Sitzmann et al. (2020), this result is not fully formal, due to the Gaussian distribution being approximated without a formal analysis of this approximation. Additionally, a CLT result is employed which assumes infinite width, which is not applicable in this context. We thus refrain from calling our equivalent result a theorem. Nevertheless, to the extent that the argument is applicable, it would still hold for our proposed initialization, due to its dependence solely on the variance demonstrated in Lemma 1 above.
For a uniform input in , the activations throughout a sinusoidal network are approximately standard normal distributed before each sine non-linearity and arcsine-distributed after each sine non-linearity, irrespective of the depth of the network, if the weights are distributed normally, with mean and variance , where is a layer’s fan-in.
Empirical evaluation of initialization scheme. To empirically demonstrate the proposed simple initialization scheme preserves the properties from the SIREN initialization scheme, we perform the same analysis performed by Sitzmann et al. (2020). We observe that the distribution of activations matches the predicted normal (before the non-linearity) and arcsine (after the non-linearity) distributions, and that this behavior is stable across many layers. These results are reported in detail in the Appendix B.
3.1 Comparison to SIREN
In order to demonstrate our simplified sinusoidal network has comparable performance to a standard SIREN, in this section we reproduce the main results from Sitzmann et al. (2020). Table 1 compiles the results for all experiments. In order to be fair, we compare the simplified sinusoidal network proposed in this chapter with both the results directly reported in Sitzmann et al. (2020), and our own reproduction of the SIREN results (using the same parameters and settings as the original). We can see from the numbers reported in the table that the performance of the simple sinusoidal network proposed in this chapter matches the performance of the SIREN in all cases, in fact surpassing it in most of the experiments. Qualitative results are presented in Appendix C.
It is important to note that this is not a favorable setting for simple sinusoidal networks, given that the training durations were very short. The SIREN favors quickly converging to a solution, though it does not have as strong asymptotic behavior. This effect is likely due to the multiplicative factor applied to later layers described in Section 3. We observe that indeed in almost all cases we can compensate for this effect by simply increasing the learning rate in the Adam optimizer (Kingma & Ba, 2014).
Finally, we observe that besides being able to surpass the performance of SIREN in most cases in a short training regimen, the simple sinusoidal network performs even more strongly with longer training. To demonstrate this, we repeated some experiments from above, but with longer training durations. These results are shown in Table 4 in Appendix C.
Experiment Simple Sinusoidal Network SIREN [paper] SIREN [ours] Image 50.04 49 (approx.) 49.0 Poisson (Gradient) 39.66 32.91 38.92 Poisson (Laplacian) 20.97 14.95 20.85 Video (cat) 34.03 29.90 32.09 Video (bikes) 37.4 32.88 33.75 Audio (Bach)† Audio (counting)† Helmholtz equation – SDF (room) 12.99 – 14.32 SDF (statue) 6.22 – 5.98
4 Neural tangent kernel analysis
In the following we derive the NTK for sinusoidal networks. This analysis will show us that the sinusoidal networks NTK is approximately a low-pass filter, with its bandwidth directly defined by . We support these findings with an empirical analysis as well in the following section. Finally, we demonstrate how the insights from the NTK can be leveraged to properly “tune” sinusoidal networks to the spectrum of the desired signal. Full derivations and extensive, detailed analysis are left to Appendix D.
The NTK for a simple sinusoidal network with a single hidden layer is presented in the theorem below. The NTK for siren with and hidden layers are shown in Figure 1.
Theorem 2.
We can see that for values of , the second term quickly vanishes due to the factor. This leaves us with only the first term, which has a Gaussian form. Due to the linear scaling term , this is only approximately Gaussian, but the approximation improves as increases. We can thus observe that this kernel approximates a Gaussian kernel, which is a low-pass filter, with its bandwidth defined by . Figure 1 presents visualizations for NTKs for the simple sinusoidal network, compared to a (scaled) pure Gaussian with variance , showing there is a close match between the two.
If we write out the NTK for networks with more than one hidden layer, it quickly becomes un-interpretable due to the recursive nature of the NTK definition (see Appendix D). However, as shown empirically in Figure 1, these kernels are still approximated by Gaussians with variance .
We also observe that the NTK for a SIREN with a single hidden layer is analogous, but with a form, which is also a low-pass filter.
Theorem 3.
For deeper SIREN networks, the kernels defined by the later layers are in fact Gaussian too, as discussed in Appendix D. This leads to an NTK that is approximated by a product of a sinc function and a Gaussian. These SIREN kernels are also presented in Figure 1.


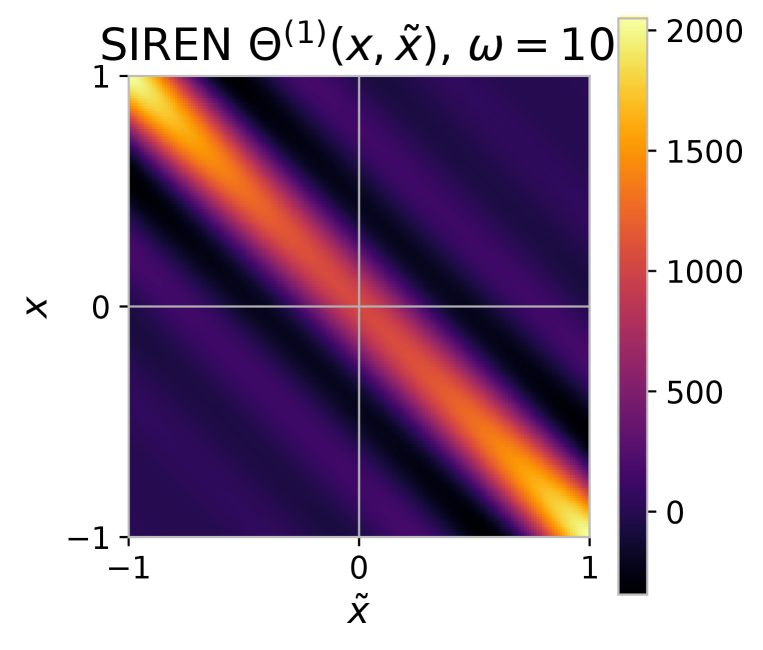









SSN
SIREN
5 Empirical analysis
As shown above, neural tangent kernel theory suggests that sinusoidal networks work as low-pass filters, with their bandwidth controlled by the parameter . In this section, we demonstrate empirically that we can observe this predicted behavior even in real sinusoidal networks. For this experiment, we generate a monochromatic image by super-imposing two orthogonal sinusoidal signals, each consisting of a single frequency, . This function is sampled in the domain to generate the image on the left of Figure 2.




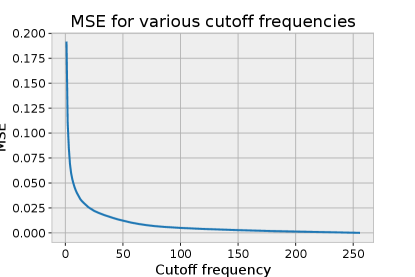
To demonstrate what we can expect from applying low-pass filters of different bandwidths to this signal, we perform a discrete Fourier transform (DFT), cut off frequencies above a certain value, and perform an inverse transform to recover the (filtered) image. The MSE of the reconstruction, as a function of the cutoff frequency, is shown in Figure 3. We can see that due to the simple nature of the signal, containing only two frequencies, there are only three loss levels. If indeed the NTK analysis is correct and sinusoidal networks act as low-pass filters, with bandwidth controlled by , we should be able to observe similar behavior with sinusoidal networks with different values. We plot the final training loss and training curves for sinusoidal networks with different in Figure 3. We can observe, again, that there are three consistent loss levels following the magnitude of the parameter, in line with the intuition that the sinusoidal network is working as a low-pass filter. This is also observable in Figure 2, where we see example reconstructions for networks of various values after training.
However, unlike with the DFT low-pass filter (which does not involve any learning), we see in Figure 3 that during training some sinusoidal networks shift from one loss level to a lower one. This demonstrates that sinusoidal networks differ from true low-pass filters in that their weights can change, which implies that the bandwidth defined by also changes with learning. We know the weights in the first layer of a sinusoidal network, given by , will change with training. Empirically, we observed that the spectral norm of increases throughout training for small values. We can interpret that as the overall magnitude of the term increasing, which is functionally equivalent to an increase in itself. In Figure 3, we observe that sinusoidal networks with smaller values of take a longer time to achieve a lower loss (if at all). Intuitively, this happens because, due to the effect described above, lower values require a larger increase in magnitude by the weights . Given that all networks were trained with the same learning rate, the ones with a smaller require their weights to move a longer distance, and thus take more training steps to achieve a lower loss.


6 Tuning
As shown in the previous section, though the bandwidth of a network can change throughout training, the choice of still influences how easily and quickly (if at all) it can learn a given signal. The value of the parameter is thus crucial for the learning of the network. Despite this fact, in SIRENs, for example, this value is not adjusted for each task (except for the audio fitting experiments), and is simply set empirically to an arbitrary value. In this section, we seek to justify a proper initialization for this parameter, such that it can be chosen appropriately for each given task.
Moreover, it is often not the case that we simply want to fit only the exact training samples but instead want to find a good interpolation (i.e., generalize well). Setting too high, and thus allowing the network to model frequencies that are much larger than the ones present in the actual signal is likely to cause overfitting. This is demonstrated empirically in Figure 4.
Consequently, we want instead to tune the network to the highest frequency present in the signal. However, we do not always have the knowledge of what is the value of the highest frequency in the true underlying signal of interest. Moreover, we have also observed that, since the network learns and its weights change in magnitude, that value in fact changes with training. Therefore, the most we can hope for is to have a good heuristic to guide the choice of . Nevertheless, having a reasonable guess for is also likely sufficient for good performance, precisely due to the ability of the network to adapt during training and compensate for a possibly slightly suboptimal choice.
Choosing from the Nyquist frequency. One source of empirical information on the relationship between and the sinusoidal network’s “learnable frequencies” is the previous section’s empirical analysis. Taking into account the scaling, we can see from Fig. 3 that around the network starts to be able to learn the full signal (freq. ). We can similarly note that at about the sinusoidal network starts to be able to efficiently learn a signal with frequency , but not the one with frequency . This scaling suggests a heuristic of setting to about of the signal’s maximum frequency.
For natural signals, such as pictures, it is common for frequencies up to the Nyquist frequency of the discrete sampling to be present. We provide an example for the “camera” image we have utilized so far in Figure 21 in Appendix E, where we can see that the reconstruction loss through a low-pass filter continues to decrease significantly up to the Nyquist frequency for the image resolution.
In light of this information, analyzing the choices of for the experiments in Section 3.1 again suggests that should be set around of the Nyquist frequency of the signal. These values of are summarized in Table 2 in the “Fitting ” column. For example, the image fitting experiment shows that, for an image of shape (and thus Nyquist frequency of for each dimension), this heuristic suggests an value of , which is the value found to work best empirically through search. We find similar results for the audio fitting experiments. The audio signals used in the audio fitting experiment contained approximately and points, and thus maximum frequencies of approximately and . This suggests reasonable values for of and , which are close to the ones found empirically to work well. In examples such as the video fitting experiments, in which each dimension has a different frequency, it is not completely clear how to pick a single to fit all dimensions. This suggests that having independent values of for each dimension might be useful for such cases, as discussed in the next section.
Finally, when performing the generalization experiments in Section 7, we show the best performing ended up being half the value of the best used in the fitting tasks from Section 3.1. This follows intuitively, since for the generalization task we set apart half the points for training and the other half for testing, thus dividing the maximum possible frequency in the training sample in half, providing further evidence of the relationship between and the maximum frequency in the input signal.
Multi-dimensional .
In many problems, such as the video fitting and PDE problems, not only is the input space multi-dimensional, it also contains time and space dimensions (which are additionally possibly of different shape). This suggests that employing a multi-dimensional , specifying different frequencies for each dimension might be beneficial. In practice, if we employ a scaling factor , we have the first layer of the sinusoidal network given by
| (2) |
where works as a multi-dimensional . In the following experiments, we employ this approach to three-dimensional problems, in which we have time and differently shaped space domains, namely the video fitting and physics-informed neural network PDE experiments. For these experiments, we report the in the form of the (already scaled) vector for simplicity.
Choosing from available information
Finally, in many problems we do have some knowledge of the underlying signal we can leverage, such as in the case of inverse problems. For example, let’s say we have velocity fields for a fluid and we are trying to solve for the coupled pressure field and the Reynolds number using a physics-informed neural network (as done in Section 7). In this case, we have access to two components of the solution field. Performing a Fourier transform on the training data we have can reveal the relevant spectrum and inform our choice of . If the maximum frequency in the signal is lower than the Nyquist frequency implied by the sampling, this can lead to a more appropriate choice of than suggested purely from the sampling.
7 Experiments
In this section, we first perform experiments to demonstrate how the optimal value of influences the generalization error of a sinusoidal network, following the discussion in Section 6. After that, we demonstrate that sinusoidal networks with properly tuned values outperform traditional physics-informed neural networks in classic PDE tasks.
7.1 Evaluating generalization
We now evaluate the simple sinusoidal network generalization capabilities. To do this, in all experiments in this section we segment the input signal into training and test sets using a checkerboard pattern – along all axis-aligned directions, points alternate between belonging to train and test set. We perform audio, image and video fitting experiments. When performing these experiments, we search for the best performing value for generalization (defined as performance on the held-out points). We report the best values on Table 2. We observe that, as expected from the discussion in Section 6, the best performing values follow the heuristic discussed above, and are in fact half the best-performing value found in the previous fitting experiments from Section 3.1, confirming our expectation. This is also demonstrated in the plot in Figure 4. Using a higher leads to overfitting and poor generalization outside the training points. This is demonstrated in Figure 4, in which we can see that choosing an appropriate value from the heuristics described previously leads to a good fit and interpolation. Setting too high leads to interpolation artifacts, due to overfitting of spurious high-frequency components.
For the video signals, which have different size along each axis, we employ a multi-dimensional . We scale each dimension of proportional to the size of the input signal along the corresponding axis.
Experiment SIREN SSN Fitting Image 16 32 Audio (Bach) 8,000 15,000 Audio (counting) 16,000 32,000 Video (cat) 8 Video (bikes) 8




7.2 Solving differential equations
Experiment Baseline SSN Burgers (Identification) 10 Navier-Stokes (Identification) Schrödinger (Inference) 4 Helmholtz (Inference) 16
Finally, we apply our analysis to physics-informed learning. We compare the performance of simple sinusoidal networks to the networks that are commonly used for these tasks. Results are summarized in Table 3. Details for the Schrödinger and Helmholtz experiments are presented in Appendix E.
7.2.1 Burgers equation (Identification)
This experiment reproduces the Burgers equation identification experiment from Raissi et al. (2019a). Here we are identifying the parameters and of a 1D Burgers equation, , given a known solution field. The ground truth value of the parameters are and .
In order to find a good value for , we perform a low-pass reconstruction of the solution as before. We can observe in Figure 5 that the solution does not have high bandwidth, with most of the loss being minimized with only the lower half of the spectrum. Note that the sampling performed for the training data () is sufficient to support such frequencies. This suggests an value in the range . Indeed, we observe that gives the best identification of the desired parameters, with errors of and for and respectively, against errors of and of the baseline. This value of also achieves the lowest reconstruction loss against the known solution, with an MSE of . Figure 5 shows the reconstructed solution using the identified parameters.


7.2.2 Navier-Stokes (Identification)
This experiment reproduces the Navier-Stokes identification experiment from Raissi et al. (2019a). In this experiment, we are trying to identify, the parameters and the pressure field of the 2D Navier-Stokes equations given by , given known velocity fields and . The ground truth value of the parameters are and .
Unlike the 1D Burgers case, in this case the amount of points sampled for the training set () is not high, compared to the size of the full solution volume, and is thus the limiting factor for the bandwidth of the input signal. Given the random sampling of points from the full solution, the generalized sampling theorem applies. The original solution has dimensions of . With the randomly sampled points, the average sampling rate per dimension is approximately , on average, corresponding to a Nyquist frequency of approximately . Furthermore, given the multi-dimensional nature of this problem, with both spatial and temporal axes, we employ an independent scaling to for each dimension. The analysis above suggests an average , with the dimensions of the problem suggesting scaling factors of . Indeed, we observe that gives the best results. With with errors of and for and respectively, against errors of and of the baseline. Figure 6 shows the identified pressure field. Note that given the nature of the problem, this field can only be identified up to a constant.


8 Conclusion
In this work, we have present a simplified formulation for sinusoidal networks. Analysis of this architecture from the neural tangent kernel perspective, combined with empirical results, reveals that the kernel for sinusoidal networks corresponds to a low-pass filter with adjustable bandwidth. We leverage this information in order to initialize these networks appropriately, choosing their bandwidth such that it is tuned to the signal being learned. Employing this strategy, we demonstrated improved results in both implicit modelling and physics-informed learning tasks.
References
- Arora et al. (2019) Sanjeev Arora, Simon S. Du, Wei Hu, Zhiyuan Li, and Ruosong Wang. Fine-Grained Analysis of Optimization and Generalization for Overparameterized Two-Layer Neural Networks. arXiv:1901.08584 [cs, stat], May 2019. URL http://arxiv.org/abs/1901.08584. arXiv: 1901.08584.
- Basri et al. (2019) Ronen Basri, David Jacobs, Yoni Kasten, and Shira Kritchman. The Convergence Rate of Neural Networks for Learned Functions of Different Frequencies. June 2019. URL https://arxiv.org/abs/1906.00425v3.
- Huang et al. (2021a) Xiang Huang, Hongsheng Liu, Beiji Shi, Zidong Wang, Kang Yang, Yang Li, Bingya Weng, Min Wang, Haotian Chu, Jing Zhou, Fan Yu, Bei Hua, Lei Chen, and Bin Dong. Solving Partial Differential Equations with Point Source Based on Physics-Informed Neural Networks. arXiv:2111.01394 [physics], November 2021a. URL http://arxiv.org/abs/2111.01394. arXiv: 2111.01394.
- Huang et al. (2021b) Xinquan Huang, Tariq Alkhalifah, and Chao Song. A modified physics-informed neural network with positional encoding. pp. 2484, September 2021b. doi: 10.1190/segam2021-3584127.1.
- Jacot et al. (2018) Arthur Jacot, Franck Gabriel, and Clement Hongler. Neural Tangent Kernel: Convergence and Generalization in Neural Networks. In Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URL https://proceedings.neurips.cc/paper/2018/hash/5a4be1fa34e62bb8a6ec6b91d2462f5a-Abstract.html.
- Jacot et al. (2020) Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks. 2020.
- Kingma & Ba (2014) Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. 2014. URL http://arxiv.org/abs/1412.6980.
- Lee et al. (2018) Jaehoon Lee, Yasaman Bahri, Roman Novak, Samuel S. Schoenholz, Jeffrey Pennington, and Jascha Sohl-Dickstein. Deep Neural Networks as Gaussian Processes, March 2018. URL http://arxiv.org/abs/1711.00165. arXiv:1711.00165 [cs, stat].
- Lee et al. (2020) Jaehoon Lee, Lechao Xiao, Samuel S. Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington. Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent. Journal of Statistical Mechanics: Theory and Experiment, 2019(12):124002, December 2020. ISSN 1742-5468. doi: 10.1088/1742-5468/abc62b. URL http://arxiv.org/abs/1902.06720. arXiv: 1902.06720.
- Neal (1994) Radford M. Neal. Priors for infinite networks. Technical Report CRG-TR-94-1, University of Toronto, 1994. URL https://www.cs.toronto.edu/~radford/ftp/pin.pdf.
- Pearce et al. (2019) Tim Pearce, Russell Tsuchida, Mohamed Zaki, Alexandra Brintrup, and Andy Neely. Expressive Priors in Bayesian Neural Networks: Kernel Combinations and Periodic Functions, June 2019. URL http://arxiv.org/abs/1905.06076. arXiv:1905.06076 [cs, stat].
- Rahaman et al. (2019) Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the Spectral Bias of Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, pp. 5301–5310. PMLR, May 2019. URL https://proceedings.mlr.press/v97/rahaman19a.html. ISSN: 2640-3498.
- Rahimi & Recht (2007) Ali Rahimi and Benjamin Recht. Random Features for Large-Scale Kernel Machines. In Advances in Neural Information Processing Systems, volume 20. Curran Associates, Inc., 2007. URL https://papers.nips.cc/paper/2007/hash/013a006f03dbc5392effeb8f18fda755-Abstract.html.
- Raissi et al. (2019a) Maziar Raissi, Paris Perdikaris, and George Em Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378, 2019a. doi: 10.1016/j.jcp.2018.10.045. URL https://linkinghub.elsevier.com/retrieve/pii/S0021999118307125.
- Raissi et al. (2019b) Maziar Raissi, Zhicheng Wang, Michael S. Triantafyllou, and George Em Karniadakis. Deep Learning of Vortex Induced Vibrations. Journal of Fluid Mechanics, 861:119–137, February 2019b. ISSN 0022-1120, 1469-7645. doi: 10.1017/jfm.2018.872. URL http://arxiv.org/abs/1808.08952. arXiv: 1808.08952.
- Sitzmann et al. (2020) Vincent Sitzmann, Julien N. P. Martel, Alexander W. Bergman, David B. Lindell, and Gordon Wetzstein. Implicit Neural Representations with Periodic Activation Functions. 2020. URL http://arxiv.org/abs/2006.09661.
- Song et al. (2021) Chao Song, Tariq Alkhalifah, and Umair Bin Waheed. A versatile framework to solve the Helmholtz equation using physics-informed neural networks. Geophysical Journal International, 228(3):1750–1762, November 2021. ISSN 0956-540X, 1365-246X. doi: 10.1093/gji/ggab434. URL https://academic.oup.com/gji/article/228/3/1750/6409132.
- Tancik et al. (2020) Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. 2020.
- Tsuchida (2020) Russell Tsuchida. Results on infinitely wide multi-layer perceptrons. PhD Thesis, The University of Queensland, December 2020. URL https://espace.library.uq.edu.au/view/UQ:cc3d959.
- Wang et al. (2021) Sifan Wang, Hanwen Wang, and Paris Perdikaris. On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks. Computer Methods in Applied Mechanics and Engineering, 384:113938, 2021.
- Wong et al. (2022) Jian Cheng Wong, Chinchun Ooi, Abhishek Gupta, and Yew-Soon Ong. Learning in Sinusoidal Spaces with Physics-Informed Neural Networks. arXiv:2109.09338 [physics], March 2022. URL http://arxiv.org/abs/2109.09338. arXiv: 2109.09338 version: 2.
Appendix A Simple Sinusoidal Network Initialization
We present here the proofs for the initialization scheme of the simple sinusoidal network from Section 3.
Lemma 4.
Given any , for and , we have .
Proof.
By definition, . For , we know that the variance of a uniformly distributed random variable with bound is given by . Thus, ∎
Theorem 5.
For a uniform input in , the activations throughout a sinusoidal networks are approximately standard normal distributed before each sine non-linearity and arcsine-distributed after each sine non-linearity, irrespective of the depth of the network, if the weights are distributed normally, with mean and variance with is the layer’s fan-in.
Appendix B Empirical evaluation of SSN initialization
Here we report an empirical analysis the initialization scheme of simple sinusoidal networks, referenced in Section 3. For this analysis we use a sinusoidal MLP with 6 hidden layers of 2048 units, and single-dimensional input and output. This MLP is initialized using the simplified scheme described above. For testing, equally spaced inputs from the range are passed through the network. We then plot the histogram of activations after each linear operation (before the sine non-linearity) and after each sine non-linearity. To match the original plot, we also plot the 1D Fast Fourier Transform of all activations in a layer, and the gradient of this output with respect to each activation. These results are presented in Figure LABEL:fig:simple_acts. The main conclusion from this figure is that the distribution of activations matches the predicted normal (before the non-linearity) and arcsine (after the non-linearity) distributions, and that this behavior is stable across many layers. We also reproduced the same result up to 50 layers.
We then perform an additional experiment in which the exact same setup as above is employed, yet the 1D inputs are shifted by a large value (i.e., ). We the show the same plot as before in Figure LABEL:fig:simple_shift. We can see that there is essentially no change from the previous plot, which demonstrates the sinusoidal networks shift-invariance in the input space, one of its important desirable properties, as discussed previously.
Appendix C Experimental Details for Comparison to SIREN
Experiment Simple Sinusoidal Network SIREN [ours] Image 54.70 52.43 Poisson (Gradient) 39.51 38.70 Poisson (Laplacian) 22.09 20.82 Video (cat) 34.64 32.26 Video (bikes) 37.71 34.07 Audio (Bach)† Audio (counting)†
Below, we present qualitative results and describe experimental details for each experiment. As these are a reproduction of the experiments in Sitzmann et al. (2020), we refer to their details as well for further information.
C.1 Image





In the image fitting experiment, we treat an image as a function from the spatial domain to color values . In the case of a monochromatic image, used here, this function maps instead to one-dimensional intensity values. We try to learn a function , parametrized as a sinusoidal network, in order to fit such an image.
Figure 7 shows the image used in this experiment, and the reconstruction from the fitted sinusoidal network. The gradient and Laplacian for the learned function are also presented, demonstrating that higher order derivatives are also learned appropriately.
Training parameters.
The input image used is , mapped to an input domain . The sinusoidal network used is a 5-layer MLP with hidden size , following the proposed initialization scheme above. The parameter is set to . The Adam optimizer is used with a learning rate of , trained for steps in the short duration training results and for steps in the long duration training results.
C.2 Poisson









These tasks are similar to the image fitting experiment, but instead of supervising directly on the ground truth image, the learned fitted sinusoidal network is supervised on its derivatives, constituting a Poisson problem. We perform the experiment by supervising both on the input image’s gradient and Laplacian, and report the reconstruction of the image and it’s gradients in each case.
Figure 8 shows the image used in this experiment, and the reconstruction from the fitted sinusoidal networks. Since reconstruction from derivatives can only be correct up to a scaling factor, we scale the reconstructions for visualization. As in the original SIREN results, we can observe that the reconstruction from the gradient is of higher quality than the one from the Laplacian.
Training parameters.
The input image used is of size , mapped from an input domain . The sinusoidal network used is a 5-layer MLP with hidden size , following the proposed initialization scheme above. For both experiments, the parameter is set to and the Adam optimizer is used. For the gradient experiments, in short and long training results, a learning rate of is used, trained for and steps respectively. For the Laplace experiments, in short and long training results, a learning rate of is used, trained for and steps respectively.
C.3 Video


These tasks are similar to the image fitting experiment, but we instead fit a video, which also has a temporal input dimension, . We learn a function , parametrized as a sinusoidal network, in order to fit such a video.
Figures 9 and 10 show sampled frames from the videos used in this experiment, and their respective reconstructions from the fitted sinusoidal networks.
Training parameters.
The cat video contains frames of size . The bikes video contains frames of size . These signals are fitted from the input domain . The sinusoidal network used is a 5-layer MLP with hidden size , following the proposed initialization scheme above. The parameter is set to . The Adam optimizer is used, with a learning rate of trained for steps in the short duration training results and for steps in the long duration training results.
C.4 Audio


In the audio experiments, we fit an audio signal in the temporal domain as a waveform . We to learn a function , parametrized as a sinusoidal network, in order to fit the audio.
Figure 11 shows the waveforms for the input audios and the reconstructed audios from the fitted sinusoidal network.
In this experiment, we utilized a lower learning rate for the first layer compared to the rest of the network. This was used to compensate the very large used (in the range, compared to the range for all other experiments). One might argue that this is re-introducing complexity, counteracting the purpose the proposed simplification. However, we would claim (1) that this is only limited to cases with extremely high , which was not present in any case except for fitting audio waves, and (2) that adjusting the learning rate for an individual layer is still an approach that is simpler and more in line with standard machine learning practice compared to multiplying all layers by a scaling factor and then adjusting their initialization variance by the same amount.
Training parameters.
Both audios use a sampling rate of Hz. The Bach audio is s long and the counting audio is approximately s long. These signals are fitted from the input domain . The sinusoidal network used is a 5-layer MLP with hidden size , following the proposed initialization scheme above. For short and long training results, training is performed for and steps respectively. For the Bach experiment, the parameter is set to . The Adam optimizer is used, with a general learning rate of . A separate learning rate of is used for the first layer to stabilize training due to the large value. For the counting experiment, the parameter is set to . The Adam optimizer is used, with a general learning rate of and a first layer learning rate of .
C.5 Helmholtz equation




In this experiment we solve for the unknown wavefield in the Helmholtz equation
| (3) |
with known wavenumber and source function (a Gaussian with and ). We solve this differential equation using a sinusoidal network supervised with the physics-informed loss , evaluated at random points sampled uniformly in the domain .
Figure 12 shows the real and imaginary components of the ground truth solution to the differential equation and the solution recovered by the fitted sinusoidal network.
Training parameters.
The sinusoidal network used is a 5-layer MLP with hidden size , following the proposed initialization scheme above. The parameter is set to . The Adam optimizer is used, with a learning rate of trained for steps.
C.6 Signed distance function (SDF)
In these tasks we learn a 3D signed distance function. We learn a function , parametrized as a sinusoidal network, to model a signed distance function representing a 3D scene. This function is supervised indirectly from point cloud data of the scene. Figures 14 and 13 show 3D renderings of the volumes inferred from the learned SDFs.
Training parameters.
The statue point cloud contains points. The room point cloud contains points. These signals are fitted from the input domain . The sinusoidal network used is a 5-layer MLP with hidden size for the statue and for the room. The parameter is set to . The Adam optimizer is used, with a learning rate of and a batch size of . All models are trained for steps for the statue experiment and for steps for the room experiment.




Appendix D Neural Tangent Kernel Analysis and Proofs
D.1 Preliminaries
In order to perform the subsequent NTK analysis, we first need to formalize definitions for simple sinusoidal networks and SIRENs. The definitions used here adhere to the common NTK analysis practices, and thus differ slightly from practical implementation.
Definition 1.
For the purposes of the following proofs, a (sinusoidal) fully-connected neural network with hidden layers that takes as input , is defined as the function , recursively given by
where . The parameters have shape and all have each element sampled independently either from (for simple sinusoidal networks) or from with some bound (for SIRENs). The are -dimensional vectors sampled independently from .
With this definition, we now state the general formulation of the NTK, which applies in general to fully-connected networks with Lipschitz non-linearities, and consequently in particular to the sinusoidal networks studied here as well. Let us first define the NNGP, which has covariance recursively defined by
with base case , and where gives the variance of the bias terms in the neural network layers (Neal, 1994; Lee et al., 2018). Now the NTK is given by the following theorem.
Theorem 6.
For a neural network with hidden layers following Definition 1, as the size of the hidden layers sequentially, the neural tangent kernel (NTK) of converges in probability to the deterministic kernel defined recursively as
where are the neural network Gaussian processes (NNGPs) corresponding to each and
Proof.
This is a standard general NTK theorem, showing that the limiting kernel recursively in terms of the network’s NNGPs and the previous layer’s NTK. For brevity we omit the proof here and refer the reader to, for example, Jacot et al. (2020).
The only difference is for the base case , due to the fact that we have an additional parameter in the first layer. It is simple to see that the neural network with hidden layers, i.e. the linear model will lead to the same Gaussian process covariance kernel as the original proof, , only adjusted by the additional variance factor . ∎
Theorem 6 demonstrates that the NTK can be constructed as a recursive function of the NTK of previous layers and the network’s NNGPs. In the following sections we will derive the NNGPs for the SIREN and the simple sinusoidal network directly. We will then use these NNGPs with Theorem 6 to derive their NTKs as well.
To finalize this preliminary section, we also provide two propositions that will be useful in following proofs in this section.
Proposition 7.
For any , ,
Proof.
Omitting from the expectation for brevity, we have
By independence of the components of and the definition of expectation,
Completing the square, we get
Since the integral and its preceding factor constitute a Gaussian pdf, they integrate to 1, leaving the final result
∎
Proposition 8.
For any , ,
Proof.
Omitting from the expectation for brevity, we have
By independence of the components of and the definition of expectation,
Now, focusing on the integral above, we have
Finally, plugging this back into the product above, we get
∎
D.2 Shallow sinusoidal networks
For the next few proofs, we will be focusing on neural networks with a single hidden layer, i.e. . Expanding the definition above, such a network is given by
| (4) |
The advantage of analysing such shallow networks is that their NNGPs and NTKs have formulations that are intuitively interpretable, providing insight into their characteristics. We later extend these derivations to networks of arbitrary depth.
D.2.1 SIREN
First, let us derive the NNGP for a SIREN with a single hidden layer.
Theorem 9.
Shallow SIREN NNGP. For a single hidden layer SIREN following Definition 1, as the size of the hidden layer , tends (by law of large numbers) to the neural network Gaussian Process (NNGP) with covariance
Proof.
We first show that despite the usage of a uniform distribution for the weights, this initialization scheme still leads to an NNGP. In this initial part, we follow an approach similar to Lee et al. (2018), with the modifications necessary for this conclusion to hold.
From our neural network definition, each element in the output vector is a weighted combination of elements in and . Conditioning on the outputs from the first layer (), since the sine function is bounded and each of the parameters is uniformly distributed with finite variance and zero mean, the become normally distributed with mean zero as by the (Lyapunov) central limit theorem (CLT). Since any subset of elements in is jointly Gaussian, we have that this outer layer is described by a Gaussian process.
Now that we have concluded that this initialization scheme still entails an NNGP, we have that its covariance is determined by , where
Now by the law of large number (LLN) the limit above converges to
where and . Omitting the distributions from the expectation for brevity and expanding the exponential definition of sine, we have
Applying Propositions 7 and 8 to each expectation above and noting that the function is even, we are left with
∎
For simplicity, if we take the case of a one-dimensional output (e.g., an audio signal or a monochromatic image) with the standard SIREN setting of , the NNGP reduces to
We can already notice that this kernel is composed of functions. The function is the ideal low-pass filter. For any value of , we can see the the first term in the expression above will completely dominate the expression, due to the exponential factor. In practice, is commonly set to values at least one order of magnitude above , if not multiple orders of magnitude above that in certain cases (e.g., high frequency audio signals). This leaves us with simply
Notice that not only does our kernel reduce to the function, but it also reduces to a function solely of . This agrees with the shift-invariant property we observe in SIRENs, since the NNGP is dependent only on , but not on the particular values of and . Notice also that defines the bandwidth of the function, thus determining the maximum frequencies it allows to pass.
The general form and the shift-invariance of this kernel can be visualized in Figure 15, along with the effect of varying on the bandwidth of the NNGP kernel.






We can see that the NTK of the shallow SIREN, derived below, maintains the same relevant characteristics as the NNGP. We first derive in the Lemma below.
Lemma 10.
For , is given by
Proof.
The proof follows the same pattern as Theorem 9, with the only difference being a few sign changes after the exponential expansion of the trigonometric functions, due to the different identities for sine and cosine. ∎
Now we can derive the NTK for the shallow SIREN.
Corollary 11.
Though the expressions become more complex due to the formulation of the NTK, we can see that many of the same properties from the NNGP still apply. Again, for reasonable values of , the term with the exponential factor will be of negligible relative magnitude. With , this leaves us with
which is of the same form as the NNGP, with some additional linear terms . Though these linear terms break the pure shift-invariance, we still have a strong diagonal and the form with bandwidth determined by , as can be seen in Figure 16.
Similarly to the NNGP, the SIREN NTK suggests that training a shallow SIREN is approximately equivalent to performing kernel regression with a kernel, a low-pass filter, with its bandwidth defined by . This agrees intuitively with the experimental observations from the paper that in order to fit higher frequencies signals, a larger is required.






D.2.2 Simple sinusoidal network
Just as we did in the last section, we will now first derive the NNGP for a simple sinusoidal network, and then use that in order to obtain its NTK as well. As we will see, the Gaussian initialization employed in the SSN has the benefit of rendering the derivations cleaner, while retaining the relevant properties from the SIREN initialization. We observe that a similar derivation of this NNGP (using cosine functions instead of sine) can be found in Pearce et al. (2019), with a focus on a Bayesian perspective for the result.
Theorem 12.
Shallow SSN NNGP. For a single hidden layer simple sinusoidal network following Definition 1, as the size of the hidden layer , tends (by law of large numbers) to the neural network Gaussian Process (NNGP) with covariance
Proof.
We again initially follow an approach similar to the one described in Lee et al. (2018).
From our sinusoidal network definition, each element in the output vector is a weighted combination of elements in and . Conditioning on the outputs from the first layer (), since the sine function is bounded and each of the parameters is Gaussian with finite variance and zero mean, the are also normally distributed with mean zero by the CLT. Since any subset of elements in is jointly Gaussian, we have that this outer layer is described by a Gaussian process.
Therefore, its covariance is determined by , where
Now by the LLN the limit above converges to
where and . Omitting the distributions from the expectation for brevity and expanding the exponential definition of sine, we have
Applying Proposition 7 to each expectation above, it becomes
∎
We an once again observe that, for practical values of , the NNGP simplifies to
This takes the form of a Gaussian kernel, which is also a low-pass filter, with its bandwidth determined by . We note that, similar to the setting from SIRENs, in practice a scaling factor of is applied to the normal activations, as described in Section 3, which cancels out the factors from the kernels, preserving the variance magnitude.
Moreover, we can also observe again that the kernel is a function solely of , in agreement with the shift invariance that is also observed in simple sinusoidal networks. Visualizations of this NNGP are provided in Figure 17.






We will now proceed to derive the NTK, which requires first obtaining .
Lemma 13.
For , is given by
Proof.
The proof follows the same pattern as Theorem 12, with the only difference being a few sign changes after the exponential expansion of the trigonometric functions, due to the different identities for sine and cosine.
∎
Corollary 14.
We again note the vanishing factor , which leaves us with
| (5) |
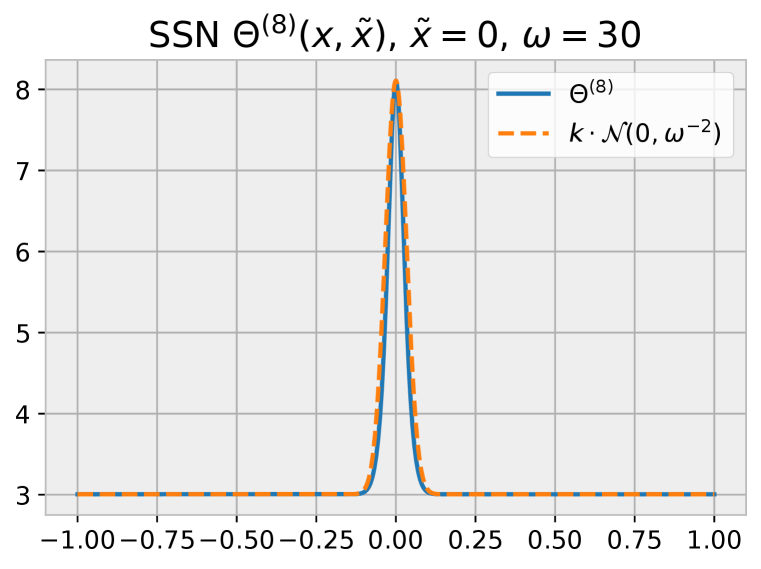
As with the SIREN before, this NTK is still of the same form as its corresponding NNGP. While again we have additional linear terms in the NTK compared to the NNGP, in this case as well the kernel preserves its strong diagonal. It is still close to a Gaussian kernel, with its bandwidth determined directly by . We demonstrate this in Figure 18, where the NTK for different values of is shown. Additionally, we also plot a pure Gaussian kernel with variance , scaled to match the maximum and minimum values of the NTK. We can observe the NTK kernel closely matches the Gaussian. Moreover, we can also observe that, at the maximum value is predicted by , as expected from the scaling factors in the kernel in Equation 5.
This NTK suggests that training a simple sinusoidal network is approximately equivalent to performing kernel regression with a Gaussian kernel, a low-pass filter, with its bandwidth defined by .
We note that even though this sinusoidal network kernel approximates a Gaussian kernel, an actual Gaussian kernel can be recovered if a combination of sine and cosine activations are employed, as demonstrated in Tsuchida (2020) (Proposition 18).






D.3 Deep sinusoidal networks
We will now look at the full NNGP and NTK for sinusoidal networks of arbitrary depth. As we will see, due to the recursive nature of these kernels, for networks deeper than the ones analyzed in the previous section, their full unrolled expressions quickly become intractable intuitively, especially for the NTK. Nevertheless, these kernels can still provide some insight, into the behavior of their corresponding networks. Moreover, despite their symbolic complexity, we will also demonstrate empirically that the resulting kernels can be approximated by simple Gaussian kernels, even for deep networks.
D.3.1 Simple sinusoidal network
As demonstrated in the previous section, simple sinusoidal networks produce simpler NNGP and NTK kernels due to their Gaussian initialization. We thus begin this section by now analyzing SSNs first, starting with their general NNGP.
Theorem 15.
SSN NNGP. For a simple sinusoidal network with hidden layers following Definition 1, as the size of the hidden layers sequentially, tends (by law of large numbers) to the neural network Gaussian Process (NNGP) with covariance , recursively defined as
Proof.
We will proceed by induction on the depth , demonstrating the NNGP for successive layers as sequentially. To demonstrate the base case , let us rearrange from Theorem 12 in order to express it in terms of inner products,
Given the definition of , this is equivalent to
which concludes this case.
Now given the inductive hypothesis, as we have that the first layers define a network with NNGP given by . Now it is left to show that as , we get the NNGP given by . Following the same argument in Theorem 12, the network
constitutes a Gaussian process given the outputs of the previous layer, due to the distributions of and . Its covariance is given by , where
By inductive hypothesis, is a Gaussian process . Thus by the LLN the limit above equals
Omitting the distribution from the expectation for brevity and expanding the exponential definition of sine, we have
Since and are jointly Gaussian, and are also Gaussian, with mean and variance
We can now rewriting the expectations in terms of normalized variables
Applying Proposition 7 to each expectation, we get
∎
Unrolling the definition beyond leads to expressions that are difficult to parse. However, without unrolling, we can rearrange the terms in the NNGP above as
Since the covariance matrix is positive semi-definite, we can observe that the exponent expressions can be reformulated into a quadratic forms analogous to the ones in Theorem 12. We can thus observe that the same structure is essentially preserved through the composition of layers, except for the factor present in the first layer. Moreover, given this recursive definition, since the NNGP at any given depth is a function only of the preceding kernels, the resulting kernel will also be shift-invariant.
Let us now derive the kernel, required for the NTK.
Lemma 16.
For , , is given by
Proof.
The proof follows the same pattern as Theorem 15, with the only difference being a few sign changes after the exponential expansion of the trigonometric functions, due to the different identities for sine and cosine. ∎
As done in the previous section, it would be simple to now derive the full NTK for a simple sinusoidal network of arbitrary depth by applying Theorem 6 with the NNGP kernels from above. However, there is not much to be gained by writing the convoluted NTK expression explicitly, beyond what we have already gleaned from the NNGP above.
Nevertheless, some insight can be gained from the recursive expression of the NTK itself, as defined in Theorem 6. First, note that, as before, for practical values of , , both converging to simply a single Gaussian kernel. Thus, our NTK recursion becomes
Now, note that when expanded, the form of this NTK recursion is essentially as a product of the Gaussian kernels,
| (6) | ||||
We know that the product of two Gaussian kernels is Gaussian and thus the general form of the kernel should be approximately a sum of Gaussian kernels. As long as the magnitude of one of the terms dominates the sum, the overall resulting kernel will be approximately Gaussian. Empirically, we observe this to be the case, with the inner term containing dominating the sum, for reasonable values (e.g., and ). In Figure 19, we show the NTK for networks of varying depth and , together with a pure Gaussian kernel of variance , scaled to match the maximum and minimum values of the NTK. We can observe that the NTKs are still approximately Gaussian, with their maximum value approximated by , as expected from the product of and kernels above. We also observe that the width of the kernels is mainly defined by .








D.3.2 SIREN
For completeness, in this section we will derive the full SIREN NNGP and NTK. As discussed previously, both the SIREN and the simple sinusoidal network have kernels that approximate low-pass filters. Due to the SIREN initialization, its NNGP and NTK were previously shown to have more complex expressions. However, we will show in this section that the kernel that arises from the shallow SIREN is gradually “dampened” as the depth of the network increases, gradually approximating a Gaussian kernel.
Theorem 17.
SIREN NNGP. For a SIREN with hidden layers following Definition 1, as the size of the hidden layers sequentially, tends (by law of large numbers) to the neural network Gaussian Process (NNGP) with covariance , recursively defined as
Proof.
Intuitively, after the first hidden layer, the inputs to every subsequent hidden layer are of infinite width, due to the NNGP assumptions. Therefore, due to the CLT, the pre-activation values at every layer are Gaussian, and the NNGP is unaffected by the uniform weight initialization (compared to the Gaussian weight initialization case). The only layer for which this is not the case is the first layer, since the input size is fixed and finite. This gives rise to the different .
For the same reasons as in the proof above, the kernels after the first layer are also equal to the ones for the simple sinusoidal network, given in Lemma 16.
Given the similarity of the kernels beyond the first layer, the interpretation of this NNGP is the same as discussed in the previous section for the simple sinusoidal network.
Analogously to the SSN case before, the SIREN NTK expansion can also be approximated as a product of kernels, as in Equation 6. The product of a function with subsequent Gaussians “dampens” the , such that as the network depth increases the NTK approaches a Gaussian, as can be seen in Figure 20.









Appendix E Experimental details
E.1 Generalization
Where not explicitly commented, details for the generalization experiments are the same for the comparisons to SIREN, described in Appendix C.
E.2 Burgers equation (Identification)
We follow the same training procedures as in Raissi et al. (2019a). The training set is created by randomly sampling points from the available exact solution grid (shown in Figure 5). The neural networks used are 9-layer MLPs with 20 neurons per hidden layer. The network structure is the same for both the and sinusoidal networks. As in the original work, the network is trained by using L-BFGS to minimize a mean square error loss composed of the sum of an MSE loss over the data points and a physics-informed MSE loss derived from the equation
| (7) |
E.3 Navier-Stokes (Identification)

We follow the same training procedures as in Raissi et al. (2019a). The training set is created by randomly sampling points from the available exact solution grid (one timestep is shown in Figure 6). The neural networks used are 9-layer MLPs with 20 neurons per hidden layer. The network structure is the same for both the and sinusoidal networks. As in the original work, the network is trained by using the Adam optimizer to minimize a mean square error loss composed of the sum of an MSE loss over the data points and a physics-informed MSE loss derived from the equations
| (8) | |||
| (9) |
E.4 Schrödinger (Inference)
This experiment reproduces the Schrödinger equation experiment from Raissi et al. (2019a). In this experiment, we are trying to find the solution to the Schrödinger equation, given by
| (10) |
Since in this case we have a forward problem, we do not have any prior information to base our choice of on, besides a maximum limit given by the Nyquist frequency given the sampling for our training data. We thus follow usual machine learning procedures and experiment with a number of small values, based on the previous experiments.
We find that gives the best results, with a solution MSE of , against an MSE of for the baseline. Figure 23 shows the solution from the sinusoidal network, together with the position of the sampled data points used for training.

Training details.
We follow the same training procedures as in Raissi et al. (2019a). The training set is created by randomly sampling points from the domain (, ) for evaluation for the physics-informed loss. Additionally, points are sampled from each of the boundary and initial conditions for direct data supervision. The neural networks used are 5-layer MLPs with 100 neurons per hidden layer. The network structure is the same for both the and sinusoidal networks. As in the original work, the network is trained first using the Adam optimizer by steps and then by using L-BFGS until convergence. The loss is composed of the sum of an MSE loss over the data points and a physics-informed MSE loss derived from Equation 10.
E.5 Helmholtz equation
Details for the Helmholtz equation experiment are the same as in the previous Helmholtz experiment in Appendix C.