Simple Yet Effective Neural Ranking and Reranking Baselines for Cross-Lingual Information Retrieval
Abstract.
The advent of multilingual language models has generated a resurgence of interest in cross-lingual information retrieval (CLIR), which is the task of searching documents in one language with queries from another. However, the rapid pace of progress has led to a confusing panoply of methods and reproducibility has lagged behind the state of the art. In this context, our work makes two important contributions: First, we provide a conceptual framework for organizing different approaches to cross-lingual retrieval using multi-stage architectures for mono-lingual retrieval as a scaffold. Second, we implement simple yet effective reproducible baselines in the Anserini and Pyserini IR toolkits for test collections from the TREC 2022 NeuCLIR Track, in Persian, Russian, and Chinese. Our efforts are built on a collaboration of the two teams that submitted the most effective runs to the TREC evaluation. These contributions provide a firm foundation for future advances.
1. Introduction
Cross-lingual information retrieval (CLIR) is the task of searching documents in one language with queries from a different language—for example, retrieving Russian documents using English queries. Typically, a CLIR system exists as part of an overall pipeline involving machine translation, related human language technologies, and sometimes human experts, that together help users satisfy information needs with content in languages they may not be able to read. Research on cross-lingual information retrieval dates back many decades (Hull and Grefenstette, 1996; Federico and Bertoldi, 2002; Wang and Oard, 2006; Nie, 2010), but there has been a recent revival of interest in this challenge (Yu and Allan, 2020; Galus̆c̆áková et al., 2021), primarily due to the advent of multilingual pretrained transformer models such as mBERT (Devlin et al., 2019) and XLM-R (Conneau et al., 2020).
A nexus of recent research activity for cross-lingual information retrieval is the TREC NeuCLIR Track, which ran for the first time at TREC 2022 but has plans for continuing in 2023 and perhaps beyond. The track provides a forum for a community-wide evaluation of CLIR systems in the context of modern collections and systems, dominated today by neural methods. NeuCLIR topics (i.e., information needs) are expressed in English, and systems are tasked with retrieving relevant documents from corpora in Chinese, Persian, and Russian.
Perhaps as a side effect of the breakneck pace at which the field is advancing, we feel that there remains a lack of clarity in the IR community about the relationship between different retrieval methods (e.g., dense vs. sparse representations, “learned” vs. “heuristic” vs. “unsupervised”, etc.) and how they should be applied in different retrieval settings. Furthermore, the increasing sophistication of today’s retrieval models and the growing complexity of modern software stacks create serious challenges for reproducibility efforts. This not only makes it difficult for researchers and practitioners to compare alternative approaches in a fair manner, but also creates barriers to entry for newcomers. These issues already exist for mono-lingual retrieval, where documents and queries are in the same language. With the added complexity of cross-lingual demands, the design choices multiply (choice of models, training regimes, application of translation systems, etc.), further muddling conceptual clarity and experimental reproducibility.
Contributions
Our work tackles these challenges, specifically focused on helping both researchers and practitioners sort through the panoply of CLIR methods in the context of modern neural retrieval techniques dominated by deep learning. Our contributions can be divided into a “conceptual” and a “practical” component:
Conceptually, we provide a framework for organizing different approaches to cross-lingual retrieval based on the general design of multi-stage ranking for mono-lingual retrieval. These architectures comprise first-stage retrievers that directly perform top- retrieval over an arbitrarily large collection of documents, followed by one or more reranking stages that refine the rank order of candidates generated by the first stage.
Recently, Lin (Lin, 2021) proposed that retrieval techniques can be characterized by the representations that they manipulate—whether dense semantic vectors or sparse lexical vectors—and how the weights are assigned—whether heuristically, as in the case of BM25, or by a neural network that has been trained with labeled data. Translated into the cross-lingual case, this leads naturally to three main approaches to first-stage retrieval: document translation, query translation, and use of language-independent representations. While these approaches date back many decades, there are “modern twists” based on learned representations that take advantage of powerful pretrained transformer models.
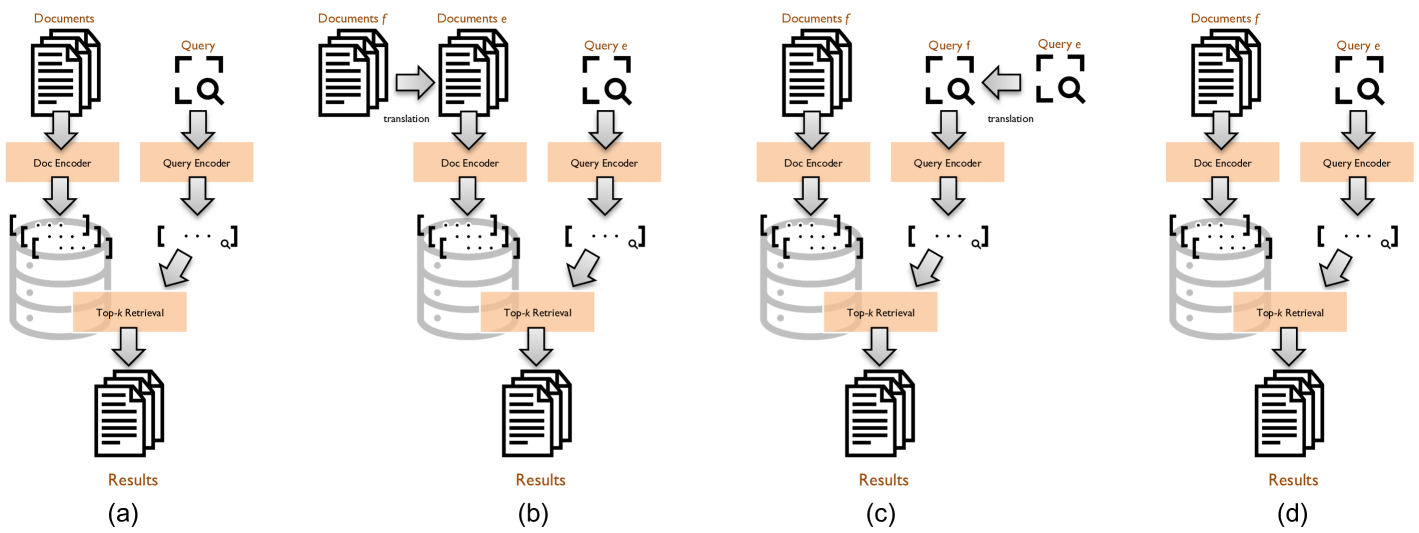
For mono-lingual retrieval, a standard multi-stage architecture applies rerankers to the output of first-stage retrievers, like those discussed above. In a cross-lingual context, we describe how cross-lingual rerankers can be designed and built using existing multilingual models. Results fusion forms the final component of our conceptual framework. Within a multi-stage architecture, there arises a natural question of when fusion should be performed: this manifests in the early vs. late fusion techniques that we examine.
Practically, we provide a number of reproducible baselines in the context of the above conceptual framework for the TREC 2022 NeuCLIR test collection, including variants of the highest-scoring runs that were submitted to the evaluation. These reproducible baselines have been incorporated into the Anserini and Pyserini IR toolkits. Our efforts are built on a collaboration of the two teams that submitted the most effective runs to the TREC evaluation.
We hope that this work provides a solid foundation for future work, both in terms of offering a conceptual framework and reference implementations that the community can further build on.
2. Mono-Lingual Retrieval Overview
Since mono-lingual retrieval architectures provide the starting point for cross-lingual retrieval, it makes sense to begin with an overview of modern mono-lingual methods. Here, we adopt the standard formulation of the (mono-lingual) retrieval task (also called ad hoc retrieval). From a finite but arbitrarily large collection of documents , the system’s task, given query , is to return a top- ranking of documents that maximizes some metric of quality such as nDCG or average precision.
Rerankers
The earliest applications of neural networks to tackle ad hoc retrieval in a data-driven manner date back to the mid 2000s in the context of learning to rank (Burges et al., 2005). Since then, search engine design has been dominated by multi-stage ranking architectures (Matveeva et al., 2006; Wang et al., 2010), where a first-stage retriever (often, just BM25 retrieval) generates candidate documents that are then reranked by one or more stages, typically by machine-learned models. In the “transformer era”, for example, BERT (Nogueira and Cho, 2019; Nogueira et al., 2019a) and T5 (Nogueira et al., 2020) can be used in exactly this manner. Use of pretrained transformers for reranking requires feeding the model both the query and the candidate text, and this style of model application is known as a cross-encoder.
Bi-encoder architectures
An important recent innovation for passage retrieval was the introduction of so-called dense retrieval models that take advantage of a bi-encoder design (contrasted with the cross-encoder design discussed above): DPR (Karpukhin et al., 2020) and ANCE (Xiong et al., 2021) are two early examples. With sufficient labeled data, we can learn encoders (typically, transformer-based models) that project queries and documents into a dense (semantic) representation space (e.g., 768 dimensions) where relevance ranking can be recast as nearest-neighbor search over representation vectors.
After the introduction of dense retrieval models, researchers soon realized that transformer-based encoders could also be coaxed to generate sparse representations, where the vector basis, for example, spans the input vocabulary space. Another way to view these so-called sparse retrieval models is to contrast them with BM25: whereas BM25 term weights are assigned using a heuristic scoring function, sparse retrieval models assign term weights that are learned using pretrained transformers such as BERT. Examples of these learned sparse retrieval models include DeepImpact (Mallia et al., 2021), uniCOIL (Lin and Ma, 2021; Zhuang and Zuccon, 2021), SPLADE (Formal et al., 2022), as well as many others.
Recently, Lin (Lin, 2021) made the observation that dense retrieval models, sparse retrieval models, and traditional bag-of-words models (e.g., BM25) are all parametric variations of a bi-encoder architecture, which is shown in Figure 1(a). In all three classes of models, “encoders” take queries or documents and generate vector representations. There are two major axes of differences, the first of which lies in the basis of the representation vector: dense retrieval models generate dense (semantic) representations whereas sparse retrieval models and bag-of-words model ground their representation vectors in lexical space. The other major axis of variation is whether these representations are learned: yes in the case of dense and sparse retrieval models, but no in the case of traditional bag-of-words models. The conceptual framework for mono-lingual retrieval provides us with a basis for organizing cross-lingual retrieval approaches, which we discuss next.
3. Cross-Lingual Retrieval Methods
The cross-lingual information retrieval task is formalized in a similar manner as the mono-lingual retrieval task. We assume a collection of documents in language comprised of . The system is given a query in language , which we denote for clarity, and its task is to return a top- ranking of documents from that maximizes some metric of quality such as nDCG or average precision. Throughout this work, refers to English and refers to some non-English language (e.g., Russian), but this need not be the case in general.
Building from the design of the mono-lingual retrieval architecture presented in the previous section, our discussions begin with three possible designs for first-stage retrieval: document translation, query translation, and the use of language-independent representations. We then overview cross-encoders for reranking the output of first-stage retrievers and finally conclude with some thoughts about fusion techniques.
To further ground cross-lingual retrieval techniques, we provide some details about the TREC 2022 NeuCLIR evaluation. Given English queries, participants are tasked with retrieving from three separate corpora comprising Persian, Russian, and Chinese newswire documents curated from the Common Crawl between August 1, 2016 and July 31, 2021. The corpora are modest in size, with 2.23 million documents in Persian, 4.63 million documents in Russian, and 3.18 million documents in Chinese.
Information needs (i.e., topics, in TREC parlance) were developed following a standard process for building retrieval test collections (Voorhees, 2002; Harman, 2011). The organizers released 114 topics, originally developed in English, which were then translated into Persian, Russian, and Chinese—both by humans and automatically by Google Translate. The topics comprise “title” and “description” fields, where the former are akin to keyword queries and the latter are roughly sentence-long articulations of the information need. By design, all topics are aligned, in the sense that for each topic, we have translations in all three languages. However, it was not the case that all topics were evaluated for all languages: In total, the organizers released relevance judgments for 46 topics in Persian, 45 topics in Russian, and 49 topics in Chinese.
3.1. Document Translation
A very simple approach to cross-lingual information retrieval is known as document translation: Given in language and the corpus in language , we can translate the entire corpus into language , i.e., , and then perform mono-lingual retrieval in language . This design is shown in Figure 1(b), where the primary addition is a document translation phase that feeds into the document side of the bi-encoder architecture.
While translating the entire corpus can be time-consuming, it only needs to be performed once and can be viewed as an expensive pre-processing step, like other computationally demanding document expansion techniques such as doc2query (Nogueira et al., 2019b). Any translation technique can be used, including off-the-shelf MT systems. Generally, since documents are comprised of well-formed sentences, automatic translation output can be quite fluent, depending on the quality of the underlying system. This stands in contrast to query translation (see below), where quality often suffers because queries are usually much shorter (hence lacking context) and systems are not usually trained on such inputs.
Once has been translated into , we now have a mono-lingual retrieval task since queries are also in . In our case, the three corpora are in Persian, Russian, and Chinese, and we used the English translations provided by the NeuCLIR Track organizers, generated by the SockEye MT system. From the NeuCLIR topics, we extracted three types of English queries: only the “title” field, only the “description” field, and both. Our experiments used two retrieval models and pseudo-relevance feedback:
BM25
Despite the advent of numerous neural ranking models, this traditional “bag-of-words” model remains a robust baseline.
SPLADE
We chose SPLADE++ Ensemble Distil (Formal et al., 2022) due to its zero-shot capabilities. The SPLADE family of models is a sparse neural retrieval model that learns both document and query expansion controlled by a regularization term.
Pseudo-relevance feedback (PRF)
On top of results from both BM25 and SPLADE, we apply pseudo-relevance feedback. While RM3 is a popular choice and has been well studied in the context of neural methods (Yang et al., 2019), in this work we instead apply Rocchio feedback, for two reasons: First, Rocchio feedback has been demonstrated to be an effective pseudo-relevance feedback approach for dense vector representations, and applying Rocchio to lexical representations provides conceptual unity. In contrast, there is no equivalent RM3 variant for dense vectors, which makes comparing sparse and dense PRF more difficult. Second, previous work has shown that Rocchio is at least as effective as RM3 (Liu, 2022), so we gain simplicity and consistency without sacrificing effectiveness.
3.2. Query Translation
The flip side of document translation is known as query translation: Given in language and the corpus in language , we can translate the query into language , i.e., , and then perform mono-lingual retrieval in language . This design is shown in Figure 1(c), where we add a query translation component that feeds the query side of the bi-encoder architecture.
Query translation is much more computationally efficient than document translation, but has the disadvantages already discussed—queries may be more difficult to translate given that they may not be well-formed sentences. However, this approach enables more rapid experimentation since the introduction of a new translation model does not require re-translation of the entire corpus.
One challenge of query translation is that we need a good mono-lingual retrieval model in , which by definition is non-English. While BM25 can provide a baseline (in the bag-of-words space of language ), effective learned retrieval models are more difficult to come by since less manually labeled data are available in non-English languages.
Our experiments consider both human and machine translations of the topics provided by the track organizers. From each type of translation, we can create three types of queries: “title”, “description”, and “both” (similar to the document translation case above). Thus, we have a total of six variations: {human translation, machine translation} {title, description, both}. With these conditions, we experimented with two different retrieval models as well as pseudo-relevance feedback:
BM25
Again, this traditional “bag-of-words” model remains a robust baseline.
SPLADE
To build SPLADE models in non-English languages, we first need to start with a good pretrained language model for that language. Thus, the models used here are first trained from scratch with the MLM+FLOPS loss (Lassance et al., 2023) using a corpus concatenation of (i) the NeuCLIR corpus of the target language, (ii) the MS MARCO translations (Bonifacio et al., 2021) for the target language, and (iii) the Mr. TyDi (Zhang et al., 2021) corpus of the target language (if available). Finally, we fine-tuned on the target language version of MS MARCO, expecting to have similar zero-shot properties as similar experiments in English. A separate model was created for each language.111SPLADE and pretrained models are made available at https://huggingface.co/naver/modelname with modelname = neuclir22-{pretrained,splade}-{fa,ru,zh}
Pseudo-relevance feedback
As in the document translation case, we can apply pseudo-relevance feedback on top of either BM25 or SPLADE. For the same reasons discussed above, Rocchio was chosen as the feedback method.
3.3. Language-Independent Representations
Starting from the bi-encoder design for mono-lingual retrieval shown in Figure 1(a), one might wonder if it were possible for the document and query encoders to generate some sort of language-independent semantic representation that would support direct relevance matching across languages. With the advent of pretrained multilingual transformers, this is indeed possible. For example, we can apply the document encoder to documents in (in language ), and apply the query encoder to a query in , and directly conduct relevance ranking on the representations. Thus, we can perform cross-lingual retrieval without explicit query or document translation. This is shown in Figure 1(d).
The most straightforward implementation of this approach is to train a DPR model (Karpukhin et al., 2020), but starting from a multilingual transformer backbone such as mBERT. To our knowledge, Asai et al. (2021) was the first to propose such an approach. More recently, Zhang et al. (2022) built on this basic design and introduced different approaches to exploit cross-lingual transfer by “pre–fine-tuning” on English data before further fine-tuning on the target languages using non-English data. Although Zhang et al. focused on mono-lingual retrieval in non-English languages, many of the lessons learned are applicable to the cross-lingual case as well.
Specifically, for this work, we pre–fine-tuned a multilingual DPR model initialized from an XLM-R (Conneau et al., 2020) backbone,222https://huggingface.co/xlm-roberta-large dubbed xDPR. The model was trained on the MS MARCO passage dataset (Bajaj et al., 2018), where both query and passage encoders share parameters.
With this trained model, we separately encoded the corpora in Persian, Russian, and Chinese. It is perhaps worth emphasizing that the same model was used in all three cases. For query encoding, we have a number of design choices. Similar to document translation and query translation, we can use “title”, “description”, or “both”. Furthermore, we can encode queries either in or . In the first case, we are asking the encoder to directly project queries into the semantic space occupied by the documents. In the second case, the query starts off in , so the model is encoding a sequence in into the semantic space occupied by documents. Thus, for each language, we arrive at a total of nine variations: {original query, human translation, machine translation} {title, description, both}.
3.4. Reranking
In a standard multi-stage ranking architecture, the first-stage retriever generates a ranked list of candidates that are then processed by one or more reranking stages that aim to improve the ranking. Reranking is also applicable in the cross-lingual case, but depending on the first-stage retriever, the candidate query/document pairs may either be in or . In cases where both the queries and documents are in , we can use a mono-lingual English reranker.
For the first-stage retrievers based on document translation, our experiments used monoT5, which is based on T5 (Raffel et al., 2020). Reranking is performed in English with the following prompt:
| Query: {query_text} Document: {doc_text} Relevant: |
The model is asked to generate either the “true” or “false” token, from which we can extract the probability of relevance used to sort the candidates. When the monoT5 model is fine-tuned on the MS MARCO passage dataset, it achieves state-of-the-art results on the TREC Deep Learning Tracks (Craswell et al., 2019; Craswell et al., 2020), as well as impressive zero-shot effectiveness on BEIR (Jeronymo et al., 2023) and many other datasets (Roberts et al., 2019; Zhang et al., 2020; Rosa et al., 2021, 2022).
For reranking first-stage retrievers based on query translation, we used a variant based on the multilingual version of T5 called mT5, which was pretrained on the multilingual mC4 dataset (Xue et al., 2021); otherwise, we use the same reranking approach. To fine-tune mT5 for reranking, we employed a similar strategy as Bonifacio et al. (2021) using mMARCO, the multilingual version of the MS MARCO dataset. For our experiments, we used the XXL model with 13B parameters.
3.5. Fusion
Researchers have known for many decades that fusion techniques, which combine evidence from multiple individual runs, can improve effectiveness (Bartell et al., 1994; Vogt and Cottrell, 1999). Fusion works particularly well when the individual runs are based on different underlying techniques, such as in the case of dense vs. sparse retrieval models (Gao et al., 2021; Ma et al., 2022). Given that our first-stage retrievers are all based on very different approaches, we would expect fusion to yield substantial boosts in effectiveness, although this does not appear to be borne out experimentally.
Within a multi-stage architecture, there arises a natural question of when fusion should be performed. One possible approach is to independently rerank the output of each first-stage retriever, and then fuse those results; we call this late fusion. Another possible approach is to first fuse the output of the first-stage retrievers, and then rerank the combined results; we call this early fusion. The effectiveness difference between the two approaches is an empirical question, but late fusion is more computationally intensive because it requires more reranking.
4. Implementation Details
All the first-stage and fusion retrieval conditions described in this paper are implemented in Anserini (Yang et al., 2018) and Pyserini (Lin et al., 2021). Anserini is a Java-based toolkit built around the open-source Lucene search library to support reproducible information retrieval research. Pyserini provides a Python interface to Anserini and further augments its capabilities by including support for dense retrieval models. Together, the toolkits are widely adopted by researchers in the IR and NLP communities.
For document translation using BM25, our implementation uses Lucene’s default analyzer for English, which performs tokenization, stemming, etc. Retrieval is performed with Pyserini’s default BM25 parameters (, ). For query translation, note that since we are indexing non-English text, analyzers in are required. Fortunately, Lucene already has analyzers implemented for all three languages, which we used out of the box. The same BM25 parameters were used.
All SPLADE models were implemented in Lucene using the standard “fake documents” trick (Mackenzie et al., 2021). Token weights were used to generate synthetic documents where the token was repeated a number of times equal to its weight (after quantizing into integers). For example, if “car” receives a weight of ten from the encoder, we simply repeat the token ten times. These fake documents are then indexed with Anserini as usual, where the weight is stored in the term frequency position of the postings in the inverted index. Top- retrieval is implemented by using a “sum of term frequency” scoring function in Lucene, which produces exactly the same output as ranking by the inner product between query and document vectors. Anserini provides the appropriate abstractions that hide all these implementation details.
Support for dense retrieval is provided in Pyserini with the Faiss toolkit (Johnson et al., 2019); all xDPR runs were conducted with flat indexes. For both BM25 and SPLADE models, Anserini exposes the appropriate bindings for performing retrieval in Python, and Pyserini provides appropriate interfaces that abstract over and unify retrieval using dense and sparse models (i.e., they are merely parametric variations in the command-line arguments). Pyserini additionally provides implementations of reciprocal rank fusion, and thus the entire infrastructure makes mixing-and-matching different experimental conditions quite easy.
| nDCG@20 | Persian | Russian | Chinese | ||||||||
| PRF | title | desc | both | title | desc | both | title | desc | both | ||
| document translation — BM25 | |||||||||||
| (1a) | official Sockeye translation | ✗ | 0.3665 | 0.2889 | 0.3670 | 0.3693 | 0.2060 | 0.3080 | 0.3705 | 0.3070 | 0.3723 |
| (1b) | official Sockeye translation | ✓ | 0.3532 | 0.3127 | 0.3720 | 0.3589 | 0.2627 | 0.3188 | 0.3802 | 0.3206 | 0.3806 |
| document translation — SPLADE | |||||||||||
| (2a) | official Sockeye translation | ✗ | 0.4627 | 0.4618 | 0.4802 | 0.4865 | 0.4193 | 0.4573 | 0.4233 | 0.4299 | 0.4236 |
| (2b) | official Sockeye translation | ✓ | 0.4438 | 0.4675 | 0.4645 | 0.4836 | 0.4243 | 0.4604 | 0.4204 | 0.4142 | 0.4206 |
| query translation — BM25 | |||||||||||
| (3a) | human translation (HT) | ✗ | 0.3428 | 0.2843 | 0.3429 | 0.3668 | 0.3138 | 0.3665 | 0.2478 | 0.2068 | 0.2572 |
| (3b) | machine translation (MT) | ✗ | 0.3331 | 0.2974 | 0.3700 | 0.3564 | 0.2972 | 0.3605 | 0.1830 | 0.1498 | 0.1754 |
| (3c) | human translation (HT) | ✓ | 0.3356 | 0.2885 | 0.3408 | 0.3572 | 0.3366 | 0.3630 | 0.2544 | 0.1985 | 0.2734 |
| (3d) | machine translation (MT) | ✓ | 0.3374 | 0.3300 | 0.3612 | 0.3426 | 0.3257 | 0.3764 | 0.1861 | 0.1464 | 0.1785 |
| query translation — SPLADE | |||||||||||
| (4a) | human translation (HT) | ✗ | 0.4301 | 0.4413 | 0.4788 | 0.4594 | 0.3922 | 0.4214 | 0.3110 | 0.2935 | 0.3143 |
| (4b) | machine translation (MT) | ✗ | 0.4437 | 0.4300 | 0.4728 | 0.4452 | 0.3792 | 0.4156 | 0.2843 | 0.2527 | 0.2929 |
| (4c) | human translation (HT) | ✓ | 0.4348 | 0.4232 | 0.4146 | 0.4322 | 0.4133 | 0.4316 | 0.3198 | 0.2926 | 0.3077 |
| (4d) | machine translation (MT) | ✓ | 0.4193 | 0.4121 | 0.4444 | 0.4337 | 0.3965 | 0.4075 | 0.2920 | 0.2562 | 0.3029 |
| language-independent representations — xDPR | |||||||||||
| (5a) | d: original corpus, q: English | ✗ | 0.1522 | 0.1847 | 0.1804 | 0.2967 | 0.2913 | 0.2866 | 0.2200 | 0.2192 | 0.2185 |
| (5b) | d: original corpus, q: HT | ✗ | 0.2776 | 0.2900 | 0.2953 | 0.3350 | 0.3276 | 0.3307 | 0.3197 | 0.3129 | 0.3035 |
| (5c) | d: original corpus, q: MT | ✗ | 0.2721 | 0.2968 | 0.3055 | 0.3619 | 0.3348 | 0.3542 | 0.3025 | 0.2785 | 0.3013 |
| (5d) | d: original corpus, q: English | ✓ | 0.1694 | 0.1996 | 0.1993 | 0.3116 | 0.3085 | 0.3045 | 0.2442 | 0.2343 | 0.2312 |
| (5e) | d: original corpus, q: HT | ✓ | 0.3083 | 0.2988 | 0.3197 | 0.3349 | 0.3544 | 0.3578 | 0.3376 | 0.3463 | 0.3380 |
| (5f) | d: original corpus, q: MT | ✓ | 0.3136 | 0.3012 | 0.3181 | 0.3727 | 0.3690 | 0.3793 | 0.3268 | 0.3041 | 0.3345 |
| Recall@1000 | Persian | Russian | Chinese | ||||||||
| PRF | title | desc | both | title | desc | both | title | desc | both | ||
| document translation — BM25 | |||||||||||
| (1a) | official Sockeye translation | ✗ | 0.7335 | 0.6319 | 0.7652 | 0.7409 | 0.5780 | 0.7255 | 0.7567 | 0.6639 | 0.7567 |
| (1b) | official Sockeye translation | ✓ | 0.8111 | 0.7638 | 0.8248 | 0.7908 | 0.6780 | 0.7798 | 0.8129 | 0.7404 | 0.8011 |
| document translation — SPLADE | |||||||||||
| (2a) | official Sockeye translation | ✗ | 0.8478 | 0.8796 | 0.8860 | 0.8538 | 0.8376 | 0.8513 | 0.7997 | 0.7597 | 0.7922 |
| (2b) | official Sockeye translation | ✓ | 0.8592 | 0.8735 | 0.8703 | 0.8686 | 0.8238 | 0.8544 | 0.8038 | 0.7623 | 0.8067 |
| query translation — BM25 | |||||||||||
| (3a) | human translation (HT) | ✗ | 0.7128 | 0.7027 | 0.7373 | 0.7125 | 0.6655 | 0.7421 | 0.4759 | 0.4577 | 0.4940 |
| (3b) | machine translation (MT) | ✗ | 0.7254 | 0.6815 | 0.7424 | 0.7332 | 0.6210 | 0.7373 | 0.3829 | 0.2989 | 0.4028 |
| (3c) | human translation (HT) | ✓ | 0.7691 | 0.7520 | 0.8092 | 0.7381 | 0.7276 | 0.7770 | 0.5230 | 0.5113 | 0.5327 |
| (3d) | machine translation (MT) | ✓ | 0.7672 | 0.7033 | 0.7829 | 0.7439 | 0.7136 | 0.7959 | 0.4361 | 0.3748 | 0.4341 |
| query translation — SPLADE | |||||||||||
| (4a) | human translation (HT) | ✗ | 0.7652 | 0.8173 | 0.8239 | 0.7739 | 0.7200 | 0.7612 | 0.6803 | 0.6602 | 0.6551 |
| (4b) | machine translation (MT) | ✗ | 0.8045 | 0.8172 | 0.8437 | 0.7725 | 0.7150 | 0.7669 | 0.6424 | 0.5919 | 0.6312 |
| (4c) | human translation (HT) | ✓ | 0.7897 | 0.8175 | 0.8245 | 0.7946 | 0.7209 | 0.7776 | 0.7100 | 0.7205 | 0.7029 |
| (4d) | machine translation (MT) | ✓ | 0.8099 | 0.8117 | 0.8350 | 0.7918 | 0.7090 | 0.7590 | 0.6861 | 0.6096 | 0.6535 |
| language-independent representations — xDPR | |||||||||||
| (5a) | d: original corpus, q: English | ✗ | 0.4910 | 0.5445 | 0.5393 | 0.5704 | 0.5627 | 0.5834 | 0.4161 | 0.4359 | 0.4386 |
| (5b) | d: original corpus, q: HT | ✗ | 0.6288 | 0.6780 | 0.7088 | 0.6196 | 0.5825 | 0.6368 | 0.5773 | 0.5841 | 0.6031 |
| (5c) | d: original corpus, q: MT | ✗ | 0.6333 | 0.6453 | 0.6850 | 0.6285 | 0.5649 | 0.6300 | 0.5420 | 0.5382 | 0.5873 |
| (5d) | d: original corpus, q: English | ✓ | 0.4702 | 0.4981 | 0.5347 | 0.6251 | 0.5971 | 0.6212 | 0.4330 | 0.4714 | 0.4593 |
| (5e) | d: original corpus, q: HT | ✓ | 0.6409 | 0.6612 | 0.7212 | 0.6541 | 0.5915 | 0.6346 | 0.6088 | 0.5939 | 0.6310 |
| (5f) | d: original corpus, q: MT | ✓ | 0.6686 | 0.6516 | 0.7071 | 0.6784 | 0.6032 | 0.6475 | 0.5744 | 0.5375 | 0.6109 |
5. Results
Our results are organized into following progression: first-stage retrievers, reranking, and fusion. We report retrieval effectiveness in terms of nDCG@20, the official metric of the NeuCLIR evaluation, and recall at a cutoff of 1000 hits (recall@1000), which quantifies the effectiveness upper bound of reranking. The organizers also measured mean average precision (MAP) as a supplemental metric; we followed this procedure as well. Overall, the findings from nDCG@20 and MAP were consistent, and so for brevity we omit the MAP results in our presentation.
In Section 3, we describe a vast design space for first-stage variants that can feed many reranking and fusion approaches. It is not practical to exhaustively examine all possible combinations, and thus our experiments were guided by progressive culling of “uninteresting” settings, as we’ll describe.
Finally, a word on significance testing: We are of course cognizant of its importance, but we are equally aware of the dangers of multiple hypothesis testing. Due to the large number of conditions we examine, a standard technique such as the Bonferroni correction is likely too conservative to detect significant differences, especially given the relatively small topic size of NeuCLIR. For most of our experiments, we did not perform significance testing and instead focused on general trends that are apparent from our large numbers of experimental conditions. We applied significance testing more judiciously, to answer targeted research questions. To be clear, the results we report are the only tests we conducted—that is, we did not cherry-pick the most promising results. In all cases, we used paired -tests () with the Bonferroni correction.
5.1. First-Stage Retrievers
We begin by examining the output of individual first-stage retrievers. Tables 1 and 2 present results in terms of nDCG@20 and recall@1000, respectively. Each block of rows is organized by the general approach. The columns show metrics grouped by language, and within each block, we report the results of using queries comprised of the “title” field, the “description” field, and both.
Document translation
Recall that in the document translation condition, we are indexing the machine-translated documents provided by the NeuCLIR organizers, which are in English. The BM25 conditions in rows (1ab) and the SPLADE conditions in rows (2ab) differ only in the retrieval model applied to the translated corpus. For BM25, we see that “title” and “both” query conditions yield about the same effectiveness (both metrics) on Persian and Chinese, but “both” is worse on Russian. For all languages, it appears that “description” queries perform worse. For SPLADE, interestingly, for Persian and Chinese, there does not appear to be much of an effectiveness gap between the three types of queries for both metrics. This is likely because the retrieval model includes query expansion, and so the benefits from having richer descriptions of the information need diminish.
The comparisons between (a) vs. (b) rows highlight the impact of pseudo-relevance feedback. We see that, at best, PRF yields a small improvement for BM25 in terms of nDCG@20, and for SPLADE, PRF actually decreases effectiveness. However, looking at the recall figures in Table 2, it does appear that PRF boosts recall. This behavior is expected, as PRF is primarily a recall-enhancing device.
Query translation
With BM25, shown in rows (3a)–(3d), we see that “title” and “both” conditions are generally on par for Russian and Chinese for both metrics. For SPLADE, shown in rows (4a)–(4d), there does not appear to be a consistent finding: in some cases, “both” beats “title”, and the opposite in other cases. However, it does appear that “description” alone is generally less effective in terms of nDCG@20.
With query translation, there is a natural comparison between human translations and machine translations. In rows (3) and (4), these are the (a) and (c) conditions versus the (b) and (d) conditions. It does not appear that for Persian and Russian, machine-translated queries are consistently less effective than human translations, for both BM25 and SPLADE. In some cases, we actually observe machine-translated queries outperforming their human-translation counterparts. For BM25, note that since the queries are bags of words, the fluency of the translations is not important, so long as the correct content terms are present. For SPLADE, the model appears to be robust to possibly disfluent translations. In Chinese, however, there does seem to be a noticeable gap between human and machine translations, with the human translations generally yielding better results.
Finally, consistent with the document translation case, pseudo-relevance feedback does not appear to improve nDCG@20, but does improve recall. Once again, this is expected.
Language-Independent Representations
The final blocks in Tables 1 and 2 show the effectiveness of xDPR. Recall our experimental design: on the document end, the original corpus in is encoded with the model. On the query end, there are three options: directly encode the English query, encode the human-translated (HT) query, or encode the machine-translated (MT) query. These are shown in rows (5a), (5b), and (5c), respectively. We see quite a big difference in effectiveness between row (5a) and row (5b), which indicates that there is a big loss in trying to encode queries in directly into the semantic space occupied by documents in , compared to encoding queries in . Clearly, the model is not able to adequately encode text with the same meaning in different languages (the query translations) into the same semantic space. Regardless of configuration, the dense retrieval models appear to be far less effective than the BM25 and SPLADE models, for both translation types, across both metrics. However, we see that pseudo-relevance feedback does appear to increase effectiveness, which is consistent with previous work (Li et al., 2021; Li et al., 2022) on vector PRF.
5.2. Reranking
| nDCG@20 | Persian | Russian | Chinese | ||||
| 1st | rerank | 1st | rerank | 1st | rerank | ||
| document translation — BM25 | |||||||
| (1a) | official Sockeye translation | (0.3670, 0.7652) | 0.5350 | (0.3080, 0.7255) | 0.5662 | (0.3723, 0.7567) | 0.4955 |
| document translation — SPLADE | |||||||
| (2a) | official Sockeye translation | (0.4802, 0.8860) | 0.5545 | (0.4573, 0.8513) | 0.5714 | (0.4236, 0.7922) | 0.5026 |
| query translation — BM25 | |||||||
| (3a) | human translation (HT) | (0.3429, 0.7373) | 0.5346 | (0.3665, 0.7421) | 0.5745 | (0.2572, 0.4940) | 0.4300 |
| (3b) | machine translation (MT) | (0.3700, 0.7424) | 0.5551 | (0.3605, 0.7373) | 0.5742 | (0.1754, 0.4028) | 0.3831 |
| query translation — SPLADE | |||||||
| (4a) | human translation (HT) | (0.4788, 0.8239) | 0.5722 | (0.4214, 0.7612) | 0.5823 | (0.3143, 0.6551) | 0.4980 |
| (4b) | machine translation (MT) | (0.4728, 0.8437) | 0.5932 | (0.4156, 0.7669) | 0.5767 | (0.2929, 0.6312) | 0.5132 |
| language-independent representations — xDPR | |||||||
| (5a) | d: original corpus, q: English | (0.1804, 0.5393) | 0.4630 | (0.2866, 0.5834) | 0.5305 | (0.2185, 0.4386) | 0.4440 |
| (5b) | d: original corpus, q: HT | (0.2953, 0.7088) | 0.5614 | (0.3307, 0.6368) | 0.5617 | (0.3035, 0.6031) | 0.5008 |
| (5c) | d: original corpus, q: MT | (0.3055, 0.6850) | 0.5644 | (0.3542, 0.6300) | 0.5337 | (0.3013, 0.5873) | 0.5087 |
| nDCG@20 | Recall@1000 | ||||||
| Persian | Russian | Chinese | Persian | Russian | Chinese | ||
| (1a) | DT–BM25 | 0.3670 | 0.3080 | 0.3723 | 0.7652 | 0.7255 | 0.7567 |
| (2a) | DT–SPLADE | 0.4802 | 0.4573 | 0.4236 | 0.8860 | 0.8513 | 0.7922 |
| (3b) | QT–BM25 | 0.3700 | 0.3605 | 0.1754 | 0.7424 | 0.7373 | 0.4028 |
| (4b) | QT–SPLADE | 0.4728 | 0.4156 | 0.2929 | 0.8437 | 0.7669 | 0.6312 |
| (5a) | dense–e | 0.1804 | 0.2866 | 0.2185 | 0.5393 | 0.5834 | 0.4386 |
| (5c) | dense–f | 0.3055 | 0.3542 | 0.3013 | 0.6850 | 0.6300 | 0.5873 |
| (6a) | RRF(1a, 2a): DT–BM25, DT–SPLADE | 0.4462 | 0.4180 | 0.4189 | 0.8936 | 0.8670 | 0.8536 |
| (6b) | RRF(3b, 4b): QT–BM25, QT–SPLADE | 0.4610 | 0.4598 | 0.2981 | 0.8703 | 0.8368 | 0.6692 |
| (6c) | RRF(1a, 3b): DT–BM25, QT–BM25 | 0.3795 | 0.3635 | 0.2736 | 0.7901 | 0.7686 | 0.7366 |
| (6d) | RRF(2a, 4b): DT–SPLADE, QT–SPLADE | 0.5165 | 0.4921 | 0.4178 | 0.9009 | 0.8508 | 0.7938 |
| (6e) | RRF(1a, 2a, 3b, 4b): DT, QT | 0.4897 | 0.4857 | 0.4397 | 0.9285† | 0.8880 | 0.8637† |
| (6f) | RRF(5a, 5c): dense | 0.2640 | 0.3469 | 0.2731 | 0.6814 | 0.6493 | 0.5693 |
| (6g) | RRF(1a, 2a, 3b, 4b, 5a, 5c): DT, QT, dense | 0.4926 | 0.5142† | 0.4541 | 0.9291† | 0.8818 | 0.8704† |
In the previous section, we examined first-stage retrieval settings for 18 3 54 different conditions, for each language. It is impractical to report reranking results for every single condition, and thus we made a few choices to focus our attention: We considered only conditions that take advantage of both title and description fields, which appear to be more robust than title-only queries. We also focused on runs without PRF, since PRF represents additional computational costs (both latency and index size).
For each language, this reduces the number of first-stage retrievers under consideration to nine. We applied reranking on these runs, including the title and description fields in the input template to the reranking models. We informally, but not exhaustively, examined other conditions, but they did not appear to alter our overall findings. For example, we tried reranking the first-stage retrieval results with pseudo-relevance feedback, but the results were not noticeably better (even though they exhibited higher recall).
Reranking results are shown in Table 3. Under the effectiveness of the first-stage retriever (“1st” columns), we report (nDCG@20, recall@1000): the first quantifies candidate ranking quality and the second quantifies the upper bound effectiveness of a reranker. We see that reranking improves effectiveness by large margins, but this is expected as the effectiveness of cross-encoders in various settings is well known (see Section 3.4).
One interesting observation, however, is that reranking reduces the effectiveness gap between the best and worst first-stage retrievers. For example, starting with BM25, which is clearly less effective than SPLADE, the reranker is able to “make up” for the lower quality candidates, such that the end-to-end effectiveness is relatively close to reranking SPLADE results (at least in terms of nDCG). In fact, in some cases, reranking xDPR results yields scores that are even higher than reranking BM25 results. While “coupling effects” between the first-stage retriever and reranker have been previously noted in the literature (Gao et al., 2021; Pradeep et al., 2022), this finding affirms the need for further explorations.
5.3. Fusion
With fusion, the design space of possible combinations is immense and impractical to exhaustively explore. To provide continuity, we focus only on the first-stage retrievers in the reranking experiments. In the space of fusion techniques, we settled on reciprocal rank fusion, which is a simple, effective, and robust approach (Cormack et al., 2009).
| Persian | Russian | Chinese | ||||||||
| 1st | early | late | 1st | early | late | 1st | early | late | ||
| (4a) | QT–SPLADE = best single | 0.4728 | 0.5932 | 0.4156 | 0.5767 | 0.2929 | 0.5132 | |||
| (6c) | RRF(1a, 3b): DT–BM25, QT–BM25 | 0.3795 | 0.5869 | 0.5723 | 0.3635 | 0.5788 | 0.5890 | 0.2736 | 0.5257† | 0.4150 |
| (6d) | RRF(2a, 4b): DT–SPLADE, QT–SPLADE | 0.5165 | 0.5823 | 0.6122 | 0.4921 | 0.5729 | 0.5915 | 0.4178 | 0.5379 | 0.5272 |
| (6e) | RRF(1a, 2a, 3b, 4b): DT, QT | 0.4897 | 0.5901 | 0.5911 | 0.4857 | 0.5728 | 0.5853 | 0.4397 | 0.5394 | 0.5058 |
| (6f) | RRF(5a, 5c): dense | 0.2640 | 0.5621† | 0.4573 | 0.3469 | 0.5438 | 0.5162 | 0.2731 | 0.5077† | 0.4470 |
| (6g) | RRF(1a, 2a, 3b, 4b, 5a, 5c): DT, QT, dense | 0.4926 | 0.5893 | 0.5626 | 0.5142 | 0.5676 | 0.5840 | 0.4541 | 0.5340 | 0.5295 |
With these considerations, we experimented with the following fusion conditions in Table 4: (6a) document translation combining BM25 and SPLADE; (6b) query translation combining BM25 and SPLADE; (6c) combining document and query translation with BM25; (6d) combining SPLADE document and query translation; (6e) combining all lexical approaches; (6f) combining both dense approaches; (6g) combining everything. The top block of Table 4 repeats the effectiveness of the first-stage retrievers for convenience. In the bottom block of the table, cases in which the fusion results are worse than the best input are shown in red. In these cases, fusion provides no value over just selecting the best individual run.
From these results, it appears that for Persian and Russian, the best effectiveness can be achieved by fusing both document translation and query translation SPLADE models, row (6d), although for Chinese, the same fusion is a bit worse than just document translation SPLADE. Fusing all the lexical runs, row (6e), is a bit worse than fusing just SPLADE runs in Persian and Russian, but it improves Chinese. Finally, incorporating evidence from the language-independent dense retrieval techniques appears to provide value over simply fusing the lexical results, as we see comparing (6g) and (6e). This is surprising given that by themselves, the dense retrieval runs are quite poor.
Overall, we were somewhat surprised by the finding that fusion did not improve effectiveness as robustly as we had hoped. In Table 4, the figures in red represent all the cases in which fusion actually hurt effectiveness, i.e., fusion performed worse than the best single input run. We attribute this finding to the large differences in effectiveness between the runs, in that RRF does not work as well if one of the fusion inputs is much better than the others.
To more rigorously test this observation, we performed significance testing comparing the document translation SPLADE model, row (2a) in Table 4, against fusion of SPLADE models, row (6d), fusion of all lexical models, row (6e), and fusion of all lexical and dense models, row (6g). These comparisons answer the following questions, starting from the single best first-stage retriever: Does SPLADE fusion provide any additional value? What about BM25? Dense retrieval?
The conclusion, reported in Table 4 with the symbol †, is that most of the fusion combinations are not statistically significantly better than document translation with SPLADE, the single best first-stage retriever. For nDCG@20, the largest ensemble is significantly better than DT–SPLADE only on Russian; for recall@1000 we see more significant improvements, but only on Persian and Chinese. Notably, combining evidence from both document and query translation with SPLADE, row (6d), is not significantly better than DT–SPLADE alone.
In our final set of experiments, we compared the effectiveness between early and late fusion for a subset of the conditions in Table 4. These results are reported in Table 5. In this case, we use QT–SPLADE as the point of comparison, which appears to provide the best single-stage retriever and reranking combination. For Persian, late fusion appears to be either about the same or slightly better, with the exception of (6f); this appears to be the case for Russian also, although the late fusion margin of improvement seems to be smaller. Chinese results are a bit more mixed, with early beating late in some cases. To more rigorously compare early vs. late fusion, we performed significance tests comparing all pairs. Only a few of these differences are significant, and they only happen for cases where early fusion is better than late fusion. Two of the three cases, however, occurred for the dense models, which are less effective to begin with. Overall, these experiments are inconclusive with respect to the question of which fusion strategy is better.
To provide additional context, the best runs from the NeuCLIR 2022 evaluation were from members of our group, but were generated under the time pressure of deadlines and thus it was not possible to carefully consider all configurations as we did in Table 5. The best runs were (nDCG@20 scores): (i) Persian: p2.fa.rerank, 0.588; (ii) Russian: p3.ru.mono, 0.567; (iii) Chinese: p2.zh.rerank, 0.516. Comparing those runs to the best conditions reported here, we verify that just by carefully studying the various effects of different system components, improvements are possible across all languages, achieving new state-of-the-art effectiveness with (i) Persian: 6d late-fusion 0.612 (0.024); (ii) Russian: 6d late-fusion 0.592 (0.025); (iii) Chinese: 6e early-fusion 0.539 (0.023).
6. Conclusions
The NeuCLIR evaluation at TREC 2022 represents a “revival” of interest in the cross-lingual information retrieval challenge in the “neural era”. As a high-level summary, this work captures a collaboration between two teams that submitted the most effective runs and a research group that is experienced in building retrieval toolkits to support research. Together, we take a more principled approach to the panoply of methods that were deployed in the evaluation and provide an organizing conceptual framework based on mono-lingual retrieval.
What are the high-level takeaways? It appears that query translation and document translation, general approaches dating back decades, adapt well to the neural age. In particular, SPLADE appears to be highly effective, demonstrating the promise of sparse learned representations. Although language-independent representations do not appear to be as effective as either query or document translation, we have only begun to scratch the surface of this class of techniques, as xDPR can only be considered a baseline. But if one considers that the same xDPR model works for all three languages, we can see tremendous potential.
Across the NLP and IR communities, we have only begun to explore the application of large pretrained transformer models. We find future prospects very exciting, and believe that our conceptual framework, experimental results, and software infrastructure offer a solid foundation for further exploration.
Acknowledgements
This research was supported in part by the Natural Sciences and Engineering Research Council (NSERC) of Canada.
References
- (1)
- Asai et al. (2021) Akari Asai, Jungo Kasai, Jonathan Clark, Kenton Lee, Eunsol Choi, and Hannaneh Hajishirzi. 2021. XOR QA: Cross-lingual Open-Retrieval Question Answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Online, 547–564.
- Bajaj et al. (2018) Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. 2018. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. arXiv:1611.09268v3 (2018).
- Bartell et al. (1994) Brian T. Bartell, Garrison W. Cottrell, and Richard K. Belew. 1994. Automatic Combination of Multiple Ranked Retrieval Systems. In Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 1994). Dublin, Ireland, 173–181.
- Bonifacio et al. (2021) Luiz Bonifacio, Vitor Jeronymo, Hugo Queiroz Abonizio, Israel Campiotti, Marzieh Fadaee, Roberto Lotufo, and Rodrigo Nogueira. 2021. mMARCO: A Multilingual Version of the MS MARCO Passage Ranking Dataset. arXiv:2108.13897 (2021).
- Burges et al. (2005) Christopher J. C. Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Greg Hullender. 2005. Learning to Rank Using Gradient Descent. In Proceedings of the 22nd International Conference on Machine Learning (ICML 2005). Bonn, Germany, 89–96.
- Conneau et al. (2020) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 8440–8451.
- Cormack et al. (2009) Gordon V. Cormack, Charles L. A. Clarke, and Stefan Büttcher. 2009. Reciprocal Rank Fusion Outperforms Condorcet and Individual Rank Learning Methods. In Proceedings of the 32nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2009). Boston, Massachusetts, 758–759.
- Craswell et al. (2020) Nick Craswell, Bhaskar Mitra, Emine Yilmaz, and Daniel Campos. 2020. Overview of the TREC 2020 Deep Learning Track. In Proceedings of the Twenty-Ninth Text REtrieval Conference Proceedings (TREC 2020). Gaithersburg, Maryland.
- Craswell et al. (2019) Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, and Ellen M. Voorhees. 2019. Overview of the TREC 2019 Deep Learning Track. In Proceedings of the Twenty-Eighth Text REtrieval Conference Proceedings (TREC 2019). Gaithersburg, Maryland.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, 4171–4186.
- Federico and Bertoldi (2002) Marcello Federico and Nicola Bertoldi. 2002. Statistical Cross-Language Information Retrieval using N-Best Query Translations. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2002). Tampere, Finland, 49–56.
- Formal et al. (2022) Thibault Formal, Carlos Lassance, Benjamin Piwowarski, and Stéphane Clinchant. 2022. From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. Madrid, Spain, 2353–2359.
- Galus̆c̆áková et al. (2021) Petra Galus̆c̆áková, Douglas W. Oard, and Suraj Nair. 2021. Cross-language Information Retrieval. arXiv:2111.05988 (2021).
- Gao et al. (2021) Luyu Gao, Zhuyun Dai, Tongfei Chen, Zhen Fan, Benjamin Van Durme, and Jamie Callan. 2021. Complementing Lexical Retrieval with Semantic Residual Embedding. In Proceedings of the 43rd European Conference on Information Retrieval (ECIR 2021), Part I. 146–160.
- Harman (2011) Donna Harman. 2011. Information Retrieval Evaluation. Morgan & Claypool Publishers.
- Hull and Grefenstette (1996) David A. Hull and Gregory Grefenstette. 1996. Querying Across Languages: A Dictionary-Based Approach to Multilingual Information Retrieval. In Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 1996). Zürich, Switzerland, 49–57.
- Jeronymo et al. (2023) Vitor Jeronymo, Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, Roberto Lotufo, Jakub Zavrel, and Rodrigo Nogueira. 2023. InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval. arXiv preprint arXiv:2301.01820 (2023).
- Johnson et al. (2019) Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data 7, 3 (2019), 535–547.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online, 6769–6781.
- Lassance et al. (2023) Carlos Lassance, Hervé Déjean, and Stéphane Clinchant. 2023. An Experimental Study on Pretraining Transformers from Scratch for IR. arXiv:2301.10444 (2023).
- Li et al. (2021) Hang Li, Ahmed Mourad, Shengyao Zhuang, Bevan Koopman, and Guido Zuccon. 2021. Pseudo Relevance Feedback with Deep Language Models and Dense Retrievers: Successes and Pitfalls. arXiv:2108.11044 (2021).
- Li et al. (2022) Hang Li, Shuai Wang, Shengyao Zhuang, Ahmed Mourad, Xueguang Ma, Jimmy Lin, and Guido Zuccon. 2022. To Interpolate or not to Interpolate: PRF, Dense and Sparse Retrievers. In Proceedings of the 45th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2022). Madrid, Spain, 2495–2500.
- Lin (2021) Jimmy Lin. 2021. A Proposed Conceptual Framework for a Representational Approach to Information Retrieval. SIGIR Forum 55, 2 (2021), 4:1–29.
- Lin and Ma (2021) Jimmy Lin and Xueguang Ma. 2021. A Few Brief Notes on DeepImpact, COIL, and a Conceptual Framework for Information Retrieval Techniques. arXiv:2106.14807 (2021).
- Lin et al. (2021) Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. 2021. Pyserini: A Python Toolkit for Reproducible Information Retrieval Research with Sparse and Dense Representations. In Proceedings of the 44th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2021). 2356–2362.
- Liu (2022) Yuqi Liu. 2022. Simple Yet Effective Pseudo Relevance Feedback with Rocchio’s Technique and Text Classification. Master’s thesis. University of Waterloo.
- Ma et al. (2022) Xueguang Ma, Kai Sun, Ronak Pradeep, Minghan Li, and Jimmy Lin. 2022. Another Look at DPR: Reproduction of Training and Replication of Retrieval. In Proceedings of the 44th European Conference on Information Retrieval (ECIR 2022), Part I. Stavanger, Norway, 613–626.
- Mackenzie et al. (2021) Joel Mackenzie, Andrew Trotman, and Jimmy Lin. 2021. Wacky Weights in Learned Sparse Representations and the Revenge of Score-at-a-Time Query Evaluation. arXiv:2110.11540 (2021).
- Mallia et al. (2021) Antonio Mallia, Omar Khattab, Torsten Suel, and Nicola Tonellotto. 2021. Learning Passage Impacts for Inverted Indexes. In Proceedings of the 44th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2021). 1723–1727.
- Matveeva et al. (2006) Irina Matveeva, Chris Burges, Timo Burkard, Andy Laucius, and Leon Wong. 2006. High Accuracy Retrieval with Multiple Nested Ranker. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2006). Seattle, Washington, 437–444.
- Nie (2010) Jian-Yun Nie. 2010. Cross-Language Information Retrieval. Morgan & Claypool Publishers.
- Nogueira and Cho (2019) Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT. arXiv:1901.04085 (2019).
- Nogueira et al. (2020) Rodrigo Nogueira, Zhiying Jiang, Ronak Pradeep, and Jimmy Lin. 2020. Document Ranking with a Pretrained Sequence-to-Sequence Model. In Findings of the Association for Computational Linguistics: EMNLP 2020. 708–718.
- Nogueira et al. (2019a) Rodrigo Nogueira, Wei Yang, Kyunghyun Cho, and Jimmy Lin. 2019a. Multi-Stage Document Ranking with BERT. arXiv:1910.14424 (2019).
- Nogueira et al. (2019b) Rodrigo Nogueira, Wei Yang, Jimmy Lin, and Kyunghyun Cho. 2019b. Document Expansion by Query Prediction. arXiv:1904.08375 (2019).
- Pradeep et al. (2022) Ronak Pradeep, Yuqi Liu, Xinyu Zhang, Yilin Li, Andrew Yates, and Jimmy Lin. 2022. Squeezing Water from a Stone: A Bag of Tricks for Further Improving Cross-Encoder Effectiveness for Reranking. In Proceedings of the 44th European Conference on Information Retrieval (ECIR 2022), Part I. Stavanger, Norway, 655–670.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research 21, 140 (2020), 1–67.
- Roberts et al. (2019) Kirk Roberts, Dina Demner-Fushman, Ellen M. Voorhees, William R. Hersh, Steven Bedrick, Alexander J. Lazar, Shubham Pant, and Funda Meric-Bernstam. 2019. Overview of the TREC 2019 Precision Medicine Track. In Proceedings of the Twenty-Eighth Text REtrieval Conference (TREC 2019). Gaithersburg, Maryland.
- Rosa et al. (2022) Guilherme Moraes Rosa, Luiz Bonifacio, Vitor Jeronymo, Hugo Abonizio, Roberto Lotufo, and Rodrigo Nogueira. 2022. Billions of Parameters Are Worth More Than In-domain Training Data: A case study in the Legal Case Entailment Task. arXiv:2205.15172 (2022).
- Rosa et al. (2021) Guilherme Moraes Rosa, Ruan Chaves Rodrigues, Roberto de Alencar Lotufo, and Rodrigo Nogueira. 2021. To Tune or Not To Tune? Zero-shot Models for Legal Case Entailment. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law. 295–300.
- Vogt and Cottrell (1999) Christopher C. Vogt and Garrison W. Cottrell. 1999. Fusion Via a Linear Combination of Scores. Information Retrieval 1, 3 (1999), 151–173.
- Voorhees (2002) Ellen M. Voorhees. 2002. The Philosophy of Information Retrieval Evaluation. In Evaluation of Cross-Language Information Retrieval Systems: Second Workshop of the Cross-Language Evaluation Forum, Lecture Notes in Computer Science Volume 2406. 355–370.
- Wang and Oard (2006) Jianqiang Wang and Douglas W. Oard. 2006. Combining Bidirectional Translation and Synonymy for Cross-Language Information Retrieval. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2006). Seattle, Washington, 202–209.
- Wang et al. (2010) Lidan Wang, Jimmy Lin, and Donald Metzler. 2010. Learning to Efficiently Rank. In Proceedings of the 33rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2010). Geneva, Switzerland, 138–145.
- Xiong et al. (2021) Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N. Bennett, Junaid Ahmed, and Arnold Overwijk. 2021. Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021).
- Xue et al. (2021) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Online, 483–498.
- Yang et al. (2018) Peilin Yang, Hui Fang, and Jimmy Lin. 2018. Anserini: Reproducible Ranking Baselines Using Lucene. Journal of Data and Information Quality 10, 4 (2018), Article 16.
- Yang et al. (2019) Wei Yang, Kuang Lu, Peilin Yang, and Jimmy Lin. 2019. Critically Examining the “Neural Hype”: Weak Baselines and the Additivity of Effectiveness Gains from Neural Ranking Models. In Proceedings of the 42nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2019). Paris, France, 1129–1132.
- Yu and Allan (2020) Puxuan Yu and James Allan. 2020. A Study of Neural Matching Models for Cross-lingual IR. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2020). 1637–1640.
- Zhang et al. (2020) Edwin Zhang, Nikhil Gupta, Rodrigo Nogueira, and Jimmy Lin Kyunghyun Cho. 2020. Rapidly Deploying a Neural Search Engine for the COVID-19 Open Research Dataset. In Proceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020.
- Zhang et al. (2021) Xinyu Zhang, Xueguang Ma, Peng Shi, and Jimmy Lin. 2021. Mr. TyDi: A Multi-lingual Benchmark for Dense Retrieval. In Proceedings of 1st Workshop on Multilingual Representation Learning. Punta Cana, Dominican Republic, 127–137.
- Zhang et al. (2022) Xinyu Zhang, Kelechi Ogueji, Xueguang Ma, and Jimmy Lin. 2022. Towards Best Practices for Training Multilingual Dense Retrieval Models. arXiv:2204.02363 (2022).
- Zhuang and Zuccon (2021) Shengyao Zhuang and Guido Zuccon. 2021. Fast Passage Re-ranking with Contextualized Exact Term Matching and Efficient Passage Expansion. arXiv:2108.08513 (2021).