Simulating the spread of COVID-19 with cellular automata: A new approach
Abstract
Between the years 2020 to 2022, the world was hit by the pandemic of COVID-19 giving rise to an extremely grave situation. Many people suffered and died from this disease. Also the global economy was badly hurt due to the consequences of various intervention strategies (like social distancing, lockdown) which were applied by different countries to control this pandemic. There are multiple speculations that humanity will again face such pandemics in the future. Thus it is very important to learn and gain knowledge about the spread of such infectious diseases and the various factors which are responsible for it. In this study, we have extended our previous work (Chowdhury et.al., 2022) on the probabilistic cellular automata (CA) model to reproduce the spread of COVID-19 in several countries by modifying its earlier used neighbourhood criteria. This modification gives us the liberty to adopt the effect of different restrictions like lockdown and social distancing in our model. We have done some theoretical analysis for initial infection and simulations to gain insights into our model. We have also studied the data from eight countries for COVID-19 in a window of 876 days and compared it with our model. We have developed a proper framework to fit our model on the data for confirmed cases of COVID-19 and have also re-checked the goodness of the fit with the data of the deceased cases for this pandemic. Our model is compared with other well known CA models and the ODE based SEIR model. This model fits well with different peaks of COVID-19 data for all the eight countries and can be possibly generalized for a global prediction. Our study shows that the rate of disease spread depends both on infectivity of a disease and social restrictions. Also, it shows an overall decrement in mortality rate with time due to COVID-19 as more and more people get infected as well as vaccinated. Our minimal model with modified neighbourhood condition can easily quantify the degree of social restrictions. It is statistically concluded that the overall degree of social restrictions is above the mean when we considered all eight countries. Finally to conclude, this study has given us various important insights about this pandemic which can help in preparing for combating epidemics in future situations.
1 Introduction
Epidemics and pandemics have been hampering human civilizations from centuries. In recent times, the COVID-19 disease had infected people of almost all countries globally. There are some claims that world will face a pandemic again in the near future [1, 2]. Thus it is very important to study and understand their nature. Mathematical models help us to simulate their behaviour and can give us many hidden details.
COVID-19 is caused by SARS-COV-2 virus. Globally, the number of infected cases and deaths from this disease is extremely high [3]. In India, this pandemic left a very serious toll on human life and economy. Due to rapid mutations, many variants of SARS-COV-2 have been found worldwide. Delta and Omicron are some commonly known mutations [4]. Recently, many reports have been published about the worrying situation of COVID-19 in China [5, 6].
Epidemics and pandemics have been modeled through different mathematical and computational techniques. In the year 1927, Kermack and McKendrick established a dynamical model for epidemics known as the SIR model, which is a backbone for many current models [7]. This model consists of nonlinear differential equations. Many variants of this model like SEIR, SIRS and SEIAR have been developed throughout the year [8, 9, 10, 11, 12, 13, 14]. These nonlinear differential equations based models have been extensively used to study COVID-19 pandemic [15, 16, 17, 18, 19, 20, 21, 22]. Cellular automata is a spatio-temporal model which is represented with a collection of colored cells. The shape of these cells can be of any type like square and triangular [23]. Each of the color of the cells represent a state of the system. All the cells of the CA model evolve simultaneously and each cell evolves according to a predefined algorithm. This algorithm not only governs the interaction of a cell with neighbourhood cells but also controls evolution of the whole system. The states of the model and the neighbourhood condition depends on the system. In modeling epidemics, the four main states which have been considered are susceptible, exposed, infectious and recovered (or removed). Also, the Moore’s and the Neumann’s neighbourhood conditions are examples of trivial interaction methods which are used for CA to model epidemics. [24, 25, 26, 27]
CA has not only been used for diseases which spread by contact like influenza but also has been used in many vector-borne diseases like chikungunya, dengue [23, 28, 29, 30, 31, 32, 24, 33]. Mostly in literature a disease spread is modeled in a square lattice where each lattice cell represents a person or a fraction of the population. However, there are some studies where a disease spread is modeled in a triangular or in a hexagonal lattice. In these models, the total population is divided into many sub-populations like Susceptible, Exposed, Infectious and Removed (SEIR) or various successors of it. In CA models, a neighbourhood condition is used to represent spatial interactions between cells. To study epidemics and pandemics, Moore’s neighbourhood condition and Neumann’s neighbourhood condition are the most widely used spatial interaction criteria. However these neighbourhood conditions lead to a serious issue which is called neighbourhood saturation [34]. This issue can be eliminated by taking a modified neighbourhood condition for example, Mikler et. al. proposed a global neighbourhood criteria to eliminate this issue [34, 35].
Recently, cellular automata (CA) models have been used by many authors to study COVID-19 pandemic [36, 37, 38, 39, 40, 41, 42, 43]. In these studies CA has been mostly used to predict the future behaviour of the spread COVID-19 by studying its past behaviour. There are studies which also suggest various intervention and vaccination strategies to control this pandemic. Some advanced studies which have used the Genetic Algorithm (GA) and proposed various methods to optimize the CA model to fit the COVID-19 data [38, 44, 40]. In these studies, different types of neighbourhood condition have been used. A particular neighbourhood condition called the -neighbourhood condition is used widely in literature [37, 38]. In this model a person can interact upto the th neighbours with equal probabilities and thus increasing the range of disease spread beyond nearest neighbours.
In this study, we have defined a generalized neighbourhood condition. We have analyzed and studied this neighbourhood condition in detail to get a clear picture of its behaviour. We have applied this condition in our CA model and have done some analytical estimates. Various simulations have been done on this system after defining a suitable algorithm. We have also compared our model with other current models used in literature. Finally, we have studied COVID-19 data from eight different countries in relevance to our model and analyzed the concurrence between the two.
This paper is organized as follows: In Sec. 2, we have defined our neighbourhood condition. An initial analysis on this neighbourhood condition has been done in Sec. 2.2. In Sec. 3 and Sec. 4, probability of infection has been calculated and theoretical analysis of our CA model is described respectively. In Sec. 5, we have defined an algorithm for this CA model and shown different results of our simulations. Our model is compared to other models in Sec. 6 and 7. The detailed study on COVID-19 data using our CA model is described in Sec. 8. Finally we have listed the concluding remarks in Sec. 9.
2 Model description
In this article, we have studied the SEIR model by cellular automata with a modified neighbourhood condition. In this section, we mainly discuss our neighbourhood condition in detail and also its features which will affect a real situation. All the other important assumptions for this model are similar to Chowdhury et. al (2022) [40] where the choice of periodic boundary condition is of special importance in this study.
2.1 Neighbourhood condition
Suppose the lattice size for this CA model is . Then with respect to any cell, the lattice can be divided into several layers (by considering periodic boundary condition) as shown in Fig. 1.
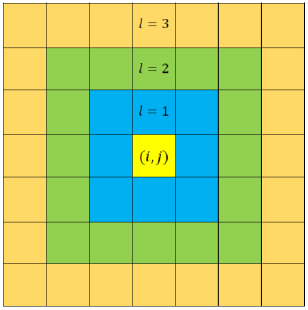
Here represents the layer number. Any layer of number has number of cells. With respect to any cell, indexed by , of a lattice, the total number of layers can be calculated by
| (1) |
when is odd. If, is even and then Eq.1 is approximately true. The main assumptions for this modified neighbourhood condition, similar to Chowdhury et. al (2022) and references there in [40] are
-
•
The distance between any two cells is proportional to the layer number of any one cell with respect to the other cell. Hence, . For, simplicity we can assume .
-
•
Probability of interaction () between two cells is inversely proportional to the th power of the distance. Thus, . Here = degree exponent and it can have any positive or negative values.
Thus probability of interaction () can be written as,
| (2) |
where, .
2.2 Average distance of interaction ()
In modeling disease spread, the interaction between people is very important. In real world, interaction between two persons will depend on the distance between them. As distance increases, chance of interaction between two persons decrease [45, 46]. Also at the time of COVID-19 pandemic, interactions between people were controlled by various restrictions like lockdown and social distancing. These facts motivate us to assume the power law form of the interaction probability as shown in Eq. 2. Here degree exponent can tune the interaction probability as per the requirements of different strictness of restrictions on social interactions and models.
In this section, we have defined the average distance of interaction and discuss its dependence on the degree exponent . The average distance of interaction () and the variance of the interaction distance () can be deduced from Eq.2 as,
| (3) |
| (4) |
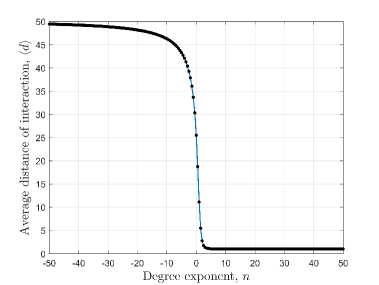
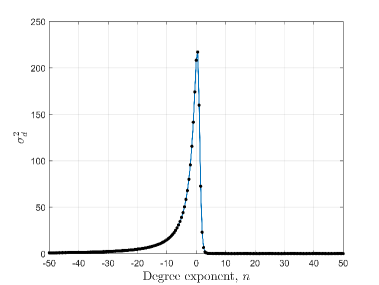
Fig. 2(a) shows that the average distance of interaction () falls very rapidly when degree exponent () changes from negative to positive. Also, Fig. 2(b) shows that variance () has a very sharp peak for which have slightly higher value than zero. Numerically it is found that has a peak at for . So, the values around 0.0 are very significant because of the high values of . When is positive then quickly saturates to one and for negative values of , quickly saturates to maximum layer number (). Variance of the interaction distance, rapidly saturates to zero for both positive and negative values of . As, decreases with increase in , can be defined as ‘social confinement’ [40]. Also, we want to mention that a high negative value incorporates that a person will mainly interact with the distant persons which is physically not possible. Thus very high positive or negative values of the degree exponent is physically irrelevant.
3 Probability of infection
Probability of infection of any susceptible cell at () states the total probability of infection of this susceptible cell due to the infectious cells around it. To calculate it is needed to define some probabilities which are given below:
-
•
Probability of infection per contact (): This defines the probability of infection when a susceptible cell interacts with an infectious cell. This probability depends on the infectivity of the virus of a disease and the immunity of a person. If a virus is more infectious than its previous mutations, the probability of infection per contact will increase. Also, if a population gains immunity from a disease, then the probability of infection per contact will decrease. For COVID-19, the immunity is mainly achieved by vaccination.
-
•
Probability that an infectious person is at a distance is given by (): can be represented as,
(5)
Hence from these probabilities the probability of infection () of any susceptible cell at can be derived as,
| (6) |
| (7) |
So, it is noted that the probability of infection () is highly depended on the degree exponent . If then probability of infection of any susceptible cell depends on the number nearest infectious cells only.
4 Dependence of initial infection growth on various free parameters
In this section, we have tried to find the initial infection growth of our model and its dependence on various free parameters. Here we have assumed that initially there are no removed persons in the region, which means .
4.1 Initial infection growth with one initial infection
Let, the total size of the lattice is . Also, assuming that at time, there is only one infectious person in the region. This infectious person has number of susceptible neighbours at a distance , which can be understood from Fig. 1. In other words, there are susceptible persons who are placed at a distance from the infectious person. Thus the probability of infection for each of these susceptible persons is
| (8) |
Hence, on average, the number of newly infected cases between these susceptible persons at is,
| (9) |
Thus considering all distances, the average number of newly infected cases at are,
| (10) |
So, with one initial infectious case, the average number of newly infected cases at is a constant and have a value equal to , which is the probability of infection per contact and is independent of .
4.2 New infected cases with multiple initial infections
Let at , there are number of infectious cells and which are represented by and the distance between any two infectious cells and is represented by . To estimate the new infections, we will consider each infectious person one by one. An infectious person can infect everyone except the already infected person. Thus, the average number of susceptible persons who can only be infected by is,
| (11) |
As an infectious person cannot infect another infectious person, we have subtracted those probabilities from . Considering all infectious cases, we can write,
| . |
| . |
| . |
As , every term in the summation repeats twice. Hence the new infected cases at time are,
| (12) |
The summation of Eq. 12 consists of number of terms. If , number of relative terms in Eq. 12 are negligible. Thus we can write,
| (13) |
Next we will look at another method of estimating average number of newly infected cases with randomly distributed initial infections. We note that the relative terms in Eq. 12 are difficult to estimate as they can have different values for different simulation as a function of relative distances. However, we can adopt an average approach to this. Thus from Eq. 11, the average new infected cases for can be written as,
| (14) |
Probability that an infectious person will be randomly placed in layer with respect to is . Here, we take instead of as one place is occupied by . Hence,
| (15) |
All terms in the sum given in Eq. 14 have the same average as given in Eq. 15. Hence, from Eq. 14 we can write,
| (16) |
Hence, for all infectious cases,
| (17) |
4.3 Interpreting the basic reproduction number
Let, represent the mean infectious period. If initial infectious cases, , the new infected cases, (Eq. 13) after unit time steps. So, one infectious person will spread approximately number of infections. As the infectious period is one infectious person will spread number of infections in this period. This quantity is equivalent to the basic reproduction number ().
5 Algorithm and simulation of the CA model
In this section, we have discussed about the algorithm of our CA model and shown multiple simulation results.
5.1 Algorithm
This CA model consists of four sub-populations: susceptible (), exposed (), infectious () and removed () (recovered+dead). At any time , each cell of the lattice belongs to any one of these sub-populations. For simulations, these sub-populations are represented with values 0, 1, 2 and 3 respectively. The algorithm for the CA model is same as described in Chowdhury et. al (2022) [40].
Suppose, the lattice size is and at time the number of cells belonging to different sub-populations like exposed, infectious and removed are , , and respectively. Thus the number of cells belonging to the susceptible sub-population at time is . Any susceptible cell at position can be infected with a probability as described in Eq. 7. These newly infected cells at time will be moved to the exposed sub-population at . Also, the exposed and infectious cells will move to the infectious and removed sub-populations respectively after the latency period () and infectious period () for the disease. Therefore at time , if a cell is exposed (or infectious), it will move to the infectious (or removed) sub-population at time (or ).
5.2 Simulated results
In this section, we have discussed various simulations and results of our model. To start with, all the free parameters of our simulation are lattice size (), sample size (), probability of infection per contact (), degree exponent (), mean latency period of the disease (), and mean infectious period of the disease ().
For our simulations, we have assumed the values of and as and . Also we have assumed that the initially there is only one infectious cell in the whole lattice and all other cells are susceptible. Hence, the initial condition for the CA model with a lattice is , , , .
At first, we have checked the dependence of the model on the two free parameters, sample size () and lattice size (). We have checked this through the time evolution of the fraction of the infectious cases (). The results are shown in the Fig. 3.
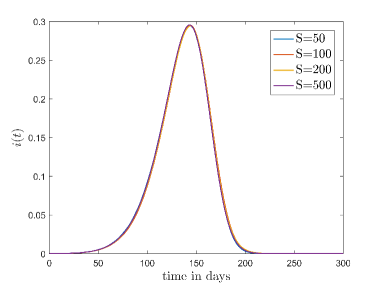
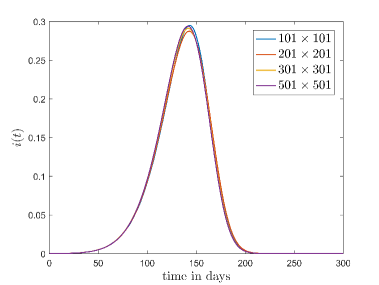
Fig. 3(a) shows the variation of which is averaged out for different sample sizes when , and lattice size is fixed at . It is found that there is no major deviation happens in by changing sample size.
Fig. 3(b) shows the variation of for different lattice sizes. Here, we have again considered , and also the sample size as . It is found that if the initial fraction of the infection cases () is same then the evolution of is approximately independent of the lattice size. Here we have checked the results with different combinations of the parameters for both of these cases. Thus we can conclude, the model is approximately sample and size independent. For future simulations we have fixed the lattice size at and sample size at .
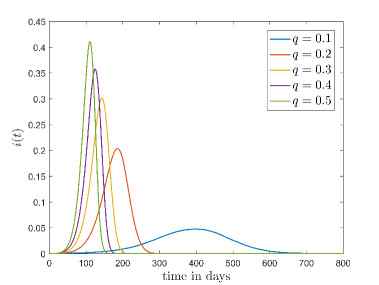
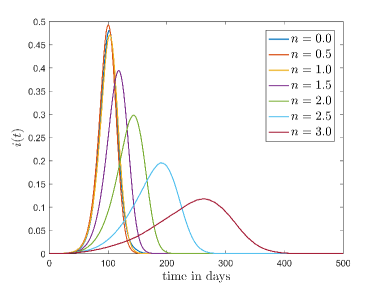
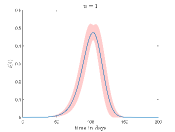
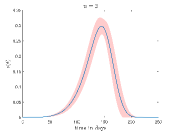
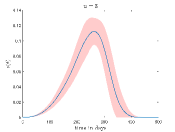
Fig. 4 shows how the the fraction of the infectious cases () varies with time for different values and values. In Fig.4(a) it is shown how varies for different when . Here, we can see that growth of is very fast for high values. This is reasonable because high means when a susceptible people cell with an infectious cell then there is a very high chance that the susceptible people will be infected. Thus the disease spread is faster for high values than the low values.
To simulate Fig. 4(b) we have fixed at . It can be seen from this figure that when increases the peak of the fraction of the infectious cases () falls significantly and disease spread become slower.
 |
 |
 |
 |
 |
 |
 |
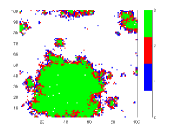 |
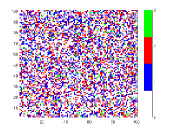
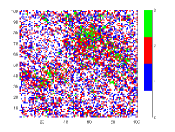
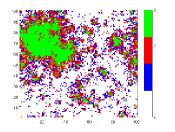
To understand the reason behind the slower disease spread for higher we have plotted the time variation of with the spatial distribution of the disease spread at a intermediate time for different values of (Fig. 5). Here, the spatial distribution for a particular is chosen randomly from 50 samples. It is shown that the disease spread is more clustered for higher values of . This is the reason for slower disease spread. Also, Fig. 4(b) shows that for the peak of is lower than the . The reason behind this is the variance . For this figure, have the highest value amongst all values which have been used for this plot (Fig. 4(b)).
6 Comparison with the continuous SEIR model
In this section, we have compared our model with the continuous SEIR model. The model is described by the following equations:
| (18) |
| (19) |
| (20) |
| (21) |
= Infection rate.
= Latency period.
= Infectious period.
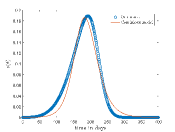
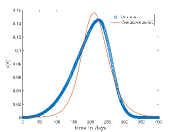
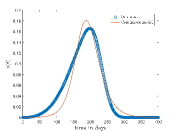
In this model, , and are the free parameters. By definition we have assumed and . We have generated various simulated data from the stochastic model for different values with = 0.0, 0.5, 1.0, 1.5, 2.0, 2.5 and 3.0. Now for a particular value, we have fitted the continuous model on the simulated data corresponding to these values to find the best fit result for this particular . To achieve this, the sum of squared errors () of has been minimized by varying the free parameter using an optimization algorithm, pattern search (PS).
| (22) |
= Fraction of the infectious cases of the simulated data from our model.
= Fraction of the infectious cases from the continuous SEIR model.
 |
 |
 |
 |
| 0.2 | 2.0 | 0.1554 | 3.90E-02 |
| 0.3 | 2.5 | 0.1544 | 5.73E-02 |
| 0.4 | 3.0 | 0.1367 | 7.94E-02 |
| 0.5 | 3.0 | 0.1512 | 8.48E-02 |
| 0.6 | 3.0 | 0.1677 | 9.11E-02 |
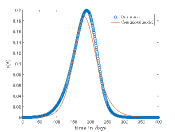
Tab. 1 shows different values and corresponding values for which continuous model fit well on our CA model data. Also, this table shows the optimized values of the continuous model and values of the respective cases. In Fig.6 shows the best fit results which are given in Tab. 1. From these results we can say that continuous model fits better on our model for higher .
7 Comparison with other neighbourhood conditions
In our model, we have introduced a different neighbourhood condition (refer to Sec. 2 for a detailed discussion) than those favored in the current literature. In this context, we discuss and compare our neighbourhood condition with other neighbourhood conditions in this section.
7.1 Moore’s neighbourhood condition
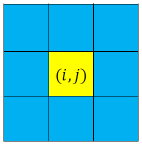
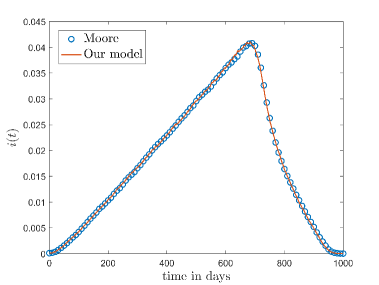
In Moore’s neighbourhood condition any cell can interact only with those neighbours which belongs to the first layer [25]. In our model when , and decreases with increasing . Thus our model with degree exponent will give a similar result like a model with Moore’s neighbourhood condition. Fig.8 shows the comparison between Moore’s neighbourhood condition and our model for .
7.2 -neighbourhood
Another one of the most popular neighbourhood conditions, which has been used in many CA models to study with the COVID-19 pandemic, is the -neighbourhood condition [36, 37, 38]. In this neighbourhood condition, a cell can interact any other cell in a radius of . Thus the probability of interaction of a cell with any other cells upto the th layer is assumed to be equal. Fig. 9 shows this neighbourhood condition for .
Thus the interaction probability of a cell to another cell of layer , where is
| (23) |
Here, is the total number of cells in layer and is the total number of cells at one side of the th layer which have value . Thus for a -neighbourhood model, the probability of interaction varies linearly with layer number () when and goes to zero for . Hence if we take the value of the degree exponent as, for and when in our model (referred to Eq. 2) then it gives the similar result as for the -neighbourhood model.
Thus in our neighbourhood condition, we have introduced a discontinuity at the layer for defining our probability of interaction to reproduce the results of the -neighbourhood condition. Thus, () is mathematically expressed as,
| (24) |
| (25) |
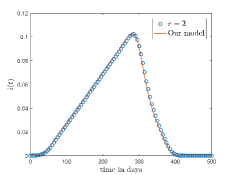
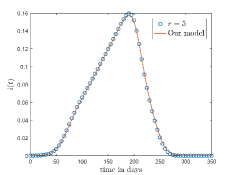
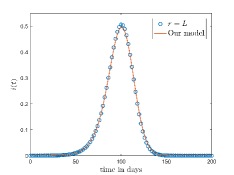
Fig. 10(a) and 10(b) shows the comparison between the -neighbourhood model and our model for and respectively. Also for a lattice, if we choose , where denotes the total number of layers in the lattice and given by Eq. 1 then one cell can interact with any other cell of the lattice. The comparison of the results for -neighbourhood model with and our model is shown in Fig. 10(c).
8 COVID-19 data and our model
Here, we have discussed the results obtained from fitting of our model on multiple peaks of COVID-19 data for different countries. Here, we have considered a total of eight countries: Italy, France, Germany, Brazil, US, India, South Africa and Japan. The arrangement and number of peaks in daily data of new cases varies with respect to different countries. Also, the size of the peaks differ for different countries. Thus to fit the model in COVID-19 data we have made following assumptions:
-
1.
We have explored only those part of COVID-19 data where there has been a sharp increase of daily new cases and have ignored those parts where daily data for new cases remains low for a long time.
-
2.
Every peak of this disease spread was considered separately for fitting. When a particular peak other than the first peak is modeled, the effective susceptible population that has been considered includes both new susceptible people and the people who had been infected but have again become susceptible due to lack of sustainable immunity against COVID-19.
-
3.
Each peak is considered as a new disease spread in a population. It is like a fresh start. So, it does not have any relation with the disease spread previous to it. The peaks of COVID-19 for a particular country have different features and reasons of occurrence. The number of infected persons as well as the time span for these peaks are different. Also, there could be multiple reasons for their incidence like mutation in the SARS-COV-2 virus or decrement of social restrictions. CA models have been made with finite lattices and we need to fix its size throughout the study. However, the number of effective susceptible people (susceptible persons who take part in the disease dynamics) in these peaks are different due to the variation of the total number of infections between peaks. Thus it will be difficult to model all the peaks together by a single CA model.
We have taken data from the COVID-19 data repository of Johns Hopkins University Center for Systems Science and Engineering (JHU CSSE) [47]. This repository contains time series data of confirmed cases and deaths for different countries. However, the time series data for recovered cases is discontinued at a very early stage. Our model needs removed cases (Recovered and dead both) data, which was not available in this database. Thus we have made further assumptions which are enlisted below:
-
1.
Number of deaths () and removed cases () at any time is related by,
(26) Here is a function of time and has a value between 0 and 1.
-
2.
Number of deaths during the COVID-19 pandemic not only depended on the fatality of the virus but also on the condition of the medical infrastructure. New variants of SARS-COV-2 virus appeared at different times as well as the medical supplies and the healthcare facilities were not always the same during this entire COVID period. Thus it is a better proposal to keep dynamic with time. However, to preserve the simplicity of our model, we have assumed that during a particular peak in a country, is constant.
Here the model is fitted to the confirmed cases data. Since we have considered the peaks separately, the confirmed cases data for a particular peak required proper scaling before fitting. We suppose that any one chosen peak starts at time and ends at . Thus to scale the confirmed cases data in the range to , we have to subtract the confirmed cases data in this range with the confirmed cases at time . So the scaled confirmed cases for a particular peak can be written as,
| (27) |
Also the confirmed cases for peak () has been normalized as,
| (28) |
The time scale of has also been changed from to .
These scaled and normalized confirmed cases, in (omitting the superscript and assuming ) is fitted with the normalized total infected cases, in the same timescale. Here the total infected cases (from our model) is normalized as,
| (29) |
We have used Genetic Algorithm (GA) to optimize the following Sum of Squared Errors (SSE) as given in Eq. 30 to fit our model to the data.
| (30) |
Here,
= Fraction of confirmed cases for a particular peak.
= Fraction of total cases for that peak simulated from the model.
For fitting, we have assumed a squared lattice of size . Our model has four free parameters () and needs three initial conditions (). We have assumed that, , and taken as a free parameter. Thus, Eq. 30 is optimized with five free parameters and .
To compare the model results with the data representing the number of deaths, we need a slightly different scaling than the one which is described in Eq. 27. According to our model, an infectious person will be moved to the removed compartment after days.Thus, for , the removed cases, as well as deaths, is zero. Suppose denotes the number of deaths at any time for a particular peak which is ranged from . We have assumed each peak separately, however the number of deaths will not be zero in the range . Number of deaths in this range depends on the number of infectious cases (or, active cases, both are same in our model) at , which are not zero generally. Thus to compare our model to the data representing deaths, we have to omit number of deaths in the range . Thus the proper scaling for the deceased cases is,
| (31) |
If we re-scale the time axis, then the above relation will have a form,
| (32) |
Thus, in this paper, we have fitted our model to the data by considering each peak separately by minimizing Eq. 30. We have used GA to optimize Eq. 30. We have run GA multiple times to get best fit parameter values. Then we have re-checked these parameters values by comparing the variation of deaths (simulated) with the deceased cases data.
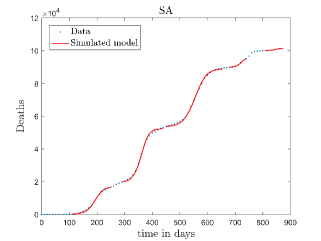
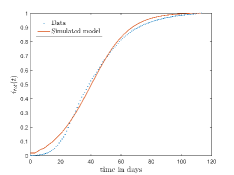
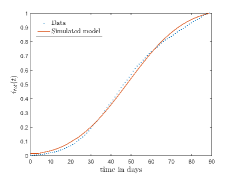
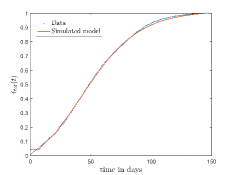
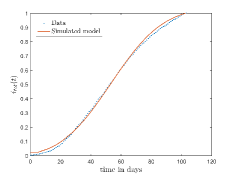
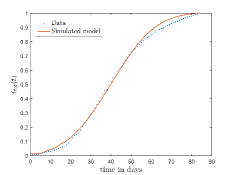
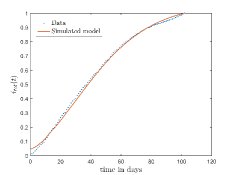
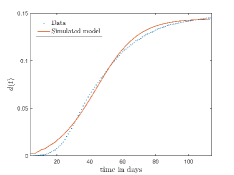
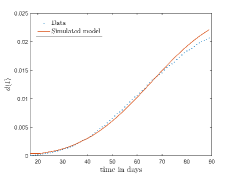
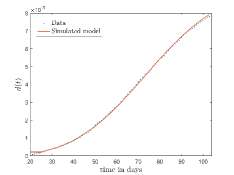
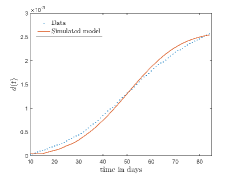
In Fig. 13, we show our model is fitted to the confirmed cases data of six peaks (with proper scaling) of Italy. Also, we have used best fit values of the parameters to simulate the variations of the fraction of death cases for these peaks and have compared them with the scaled deceased cases data of Italy in Fig. 14.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/050f3c34-5f83-4ea1-8e5c-e785ba048f6b/x28.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/050f3c34-5f83-4ea1-8e5c-e785ba048f6b/x29.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/050f3c34-5f83-4ea1-8e5c-e785ba048f6b/x30.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/050f3c34-5f83-4ea1-8e5c-e785ba048f6b/x31.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/050f3c34-5f83-4ea1-8e5c-e785ba048f6b/x32.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/050f3c34-5f83-4ea1-8e5c-e785ba048f6b/x33.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/050f3c34-5f83-4ea1-8e5c-e785ba048f6b/x34.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/050f3c34-5f83-4ea1-8e5c-e785ba048f6b/x35.png) |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
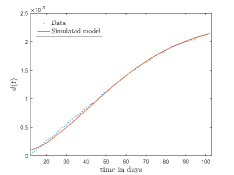 |
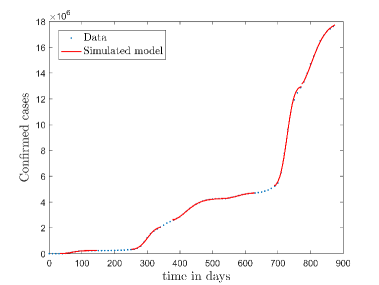
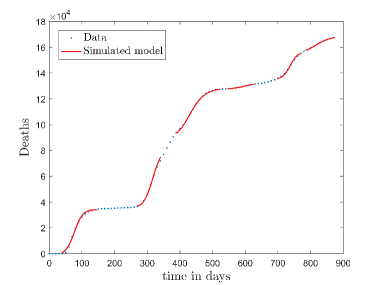
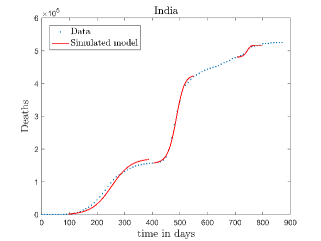
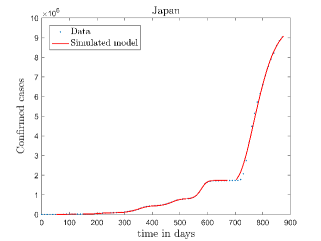
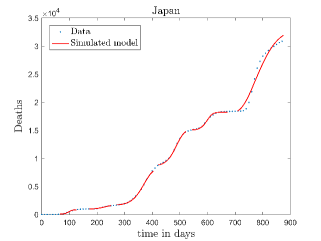
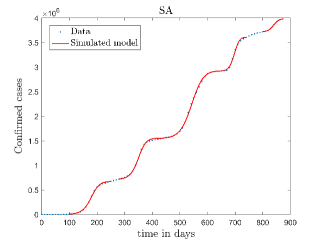
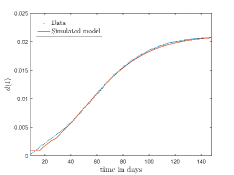
In Fig. 11, we have combined all the fitted plots and re-scaled them to plot against the whole data of Italy from 22/01/2020 to 15/06/2022. Fig. 11(a) represents the plot for confirmed cases data as well as our model. Fig. 11(b) represents the same for number of deaths.
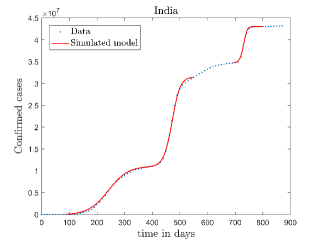
In Fig. 12, we have shown variations of confirmed cases as well as deaths with time for different countries. In confirmed cases plots, there are some intermediate parts which are not fitted. These regions in-between the peaks, the daily number of new cases are very low and tending to almost zero in comparison to the earlier days. This leads to an almost flat region in the curve for the cumulative number of infected people. Our fit incorporates this behaviour as an end to the falling part of each of the peaks. We have judiciously chosen not to fit small regions only when the number of infected people reach the base level. Also, in death plots, there are some more parts which are not under the simulated regions. This is because of the delay () in death cases, as mentioned earlier. Thus for each peak initial number of points are omitted for simulation, as described in Eq. 32.
| Country | Parameters | Peak number | |||||
|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | 6th | ||
| Italy | 0.36985 | 0.21206 | 0.24585 | 0.16389 | 0.35715 | 0.13025 | |
| 1.06260 | 2.82571 | 2.95011 | 2.79717 | 2.73188 | 2.21768 | ||
| 3 | 4 | 7 | 5 | 5 | 1 | ||
| 4 | 17 | 9 | 20 | 10 | 12 | ||
| 111 | 151 | 362 | 227 | 162 | 254 | ||
| Germany | 0.20273 | 0.10106 | 0.16616 | 0.17170 | 0.18498 | 0.11204 | |
| 1.09335 | 2.81062 | 1.12124 | 2.79799 | 1.59799 | 2.31692 | ||
| 3 | 7 | 9 | 4 | 2 | 5 | ||
| 14 | 36 | 14 | 20 | 10 | 20 | ||
| 96 | 228 | 397 | 144 | 99 | 203 | ||
| France | 0.37132 | 0.16421 | 0.11439 | 0.17635 | 0.25612 | 0.14976 | |
| 1.57481 | 0.45996 | 0.93457 | 2.79593 | 2.65914 | 2.85849 | ||
| 4 | 9 | 8 | 4 | 3 | 1 | ||
| 7 | 18 | 12 | 18 | 12 | 17 | ||
| 114 | 176 | 170 | 196 | 218 | 481 | ||
| US | 0.19558 | 0.11801 | 0.17678 | 0.17359 | – | – | |
| 2.86244 | 2.60631 | 2.92009 | 2.17452 | – | – | ||
| 5 | 5 | 5 | 2 | – | – | ||
| 11 | 18 | 21 | 19 | – | – | ||
| 156 | 97 | 92 | 166 | – | – | ||
| Brazil | 0.15814 | 0.10295 | 0.27827 | – | – | – | |
| 0.15893 | 2.17049 | 2.36806 | – | – | – | ||
| 3 | 8 | 5 | – | – | – | ||
| 8 | 16 | 11 | – | – | – | ||
| 11 | 62 | 135 | – | – | – | ||
| India | 0.13576 | 0.12967 | 0.30007 | – | – | – | |
| 1.15718 | 0.93383 | 1.84286 | – | – | – | ||
| 8 | 3 | 2 | – | – | – | ||
| 11 | 15 | 12 | – | – | – | ||
| 29 | 26 | 45 | – | – | – | ||
| Japan | 0.19671 | 0.17511 | 0.12692 | 0.14812 | 0.23149 | 0.28547 | |
| 1.44642 | 2.76158 | 1.58285 | 1.19748 | 2.09850 | 2.69654 | ||
| 1 | 4 | 8 | 8 | 6 | 2 | ||
| 13 | 23 | 19 | 16 | 21 | 6 | ||
| 123 | 132 | 73 | 200 | 96 | 42 | ||
| SA | 0.17435 | 0.21300 | 0.15079 | 0.22935 | 0.29409 | – | |
| 1.15340 | 1.29217 | 1.60608 | 2.43431 | 1.63147 | – | ||
| 8 | 7 | 4 | 2 | 3 | – | ||
| 14 | 11 | 12 | 24 | 7 | – | ||
| 64 | 67 | 22 | 71 | 118 | – | ||
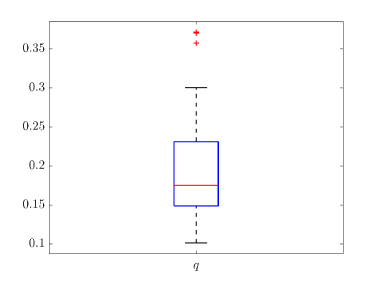
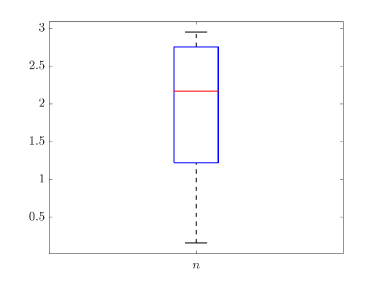
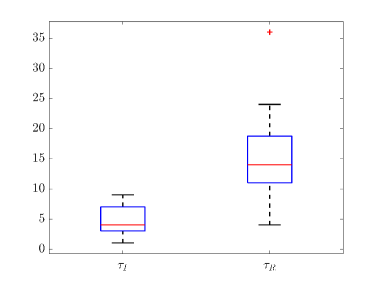
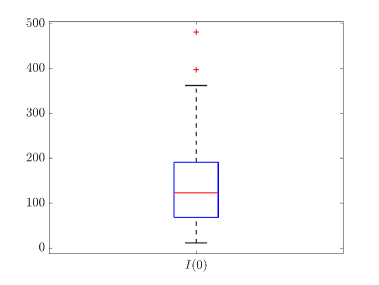
Tab. 2 shows all the best fit parameter values to the confirmed cases data (scaled) of different peaks for various countries. The fitted values of a particular parameter are not only varied for different countries but also varied between peaks. The distribution of the best-fit values of the parameters are represented with box plots and shown in Fig. 15. In the box plot, the middle red line represents the median value of the distribution. Upper and lower edge of the box represents third and first quartile values of the distribution respectively, whereas the length of the box represents inter-quartile range (IQR). Also the upper and lower whiskers represent the values which are lain above and below the third and first quartile values respectively and have a length of 1.5*IQR. Outliers are represented with red cross. The median values of , , , and are 0.17511, 2.1705, 4, 14 and 123 respectively. From fig. 15(b), we can see that the values of is closely distributed to 3.0.
| Country | Peak number | |||||
| 1st | 2nd | 3rd | 4th | 5th | 6th | |
| Italy | 0.14365 | 0.02494 | 0.02080 | 0.00890 | 0.00259 | 0.00223 |
| Germany | 0.04838 | 0.03428 | 0.01427 | 0.00614 | 0.00654 | 0.00128 |
| France | 0.15821 | 0.01343 | 0.01644 | 0.00392 | 0.00114 | 0.00112 |
| US | 0.01831 | 0.01463 | 0.01314 | 0.00502 | – | – |
| Brazil | 0.03332 | 0.02784 | 0.00550 | – | – | – |
| India | 0.01540 | 0.01307 | 0.00431 | – | – | – |
| Japan | 0.05050 | 0.01076 | 0.01883 | 0.01773 | 0.00338 | 0.00187 |
| SA | 0.02473 | 0.03896 | 0.02562 | 0.00831 | 0.00538 | – |
The values of (as described in equation. 26) which are estimated to compare our model to the deceased cases data for different peaks of various countries are shown in Tab. 3. This table shows an overall decrement of values as peak number increases for a country. This means, the death rate due to COVID-19 is decreased with time and it is true for all countries.
9 Conclusions
To conclude, we summarize the main results and features of this work with a short discussion. Our main aim, as stated earlier, is to build a generalized probabilistic cellular automata model with the help of basic SEIR model to study the spread of epidemics, with reference to COVID-19. In this study, our main motive is to show that merging a simple model like SEIR model with a CA model with modified neighbourhood condition can produced very good results for a pandemic which is versatile in many different fronts. We have tried to show that a simple model like the one that we have adopted has been able to take into account the effects produce by the different factors of this pandemic like infectivity of the virus, social restrictions, immunity due to vaccination, re-infection and mortality rate to a large extent. Here we have described a method to fit the COVID-19 data for different peaks with different intensities and time periods. We have compared our model with some general models and tried to understand their differences. We have also fitted our model to the data for total infected cases of eight countries and tried to understand the relevance of this model in the spread of infection of COVID-19 in the different countries widely. To achieve this, we have taken the following steps:
-
•
A square lattice of the size is considered for our study. We have chosen different values of like 101, 201, 301.
-
•
We have built a neighbourhood criteria and made some assumptions which are described in Sec. 2. According to this neighbourhood criteria, the distance between any two cells () is proportional to the number of layers () between them. Also, the probability of interaction between two cells, separated by distance , , where is power law exponent.
-
•
The average distance of interaction () is calculated by considering the above mentioned neighbourhood condition (described in Sec. 2.2). average distance of interaction falls very rapidly to one for positive values of and saturates to a value equal to the maximum layer number () for negative values of . Also, in this section we have reasoned about the irrelevance of large positive and negative values of .
-
•
In Sec. 3 and 4, , which is the probability of infection for any cell , has been defined and a mathematical analysis based on this quantity has been undertaken. We find that initially, if there are number of initial infectious cases, the newly infected cases will be , where represents infectivity of the disease. Also, we have defined an equivalent quantity for the basic reproduction number () as, , where represents infectious period of the disease.
-
•
A suitable epidemic algorithm is defined for our model which is described in Sec. 5.1.
We have run model simulations and compared our results with various other models, which are listed below:
-
•
We have simulated our model with different lattice and sample sizes (discussed in Sec. 5.2). However, we could not find any significant variations in the results by changing lattice and sample sizes. Thus throughout our study, we have considered lattice size and sample size .
-
•
There are two parameters of our model which mainly control the rate of the disease spread or in other words sharpness of the infectious cases (or active cases) curve. These two parameters are: , which is referred as infectivity of the disease and , which is defined as ‘social confinement’. Thus if decrease or increase, the rate of the disease spread will decrease and the curves of the infectious cases will be flatten out. These results are portrayed in Fig. 4 of Sec. 5.2.
-
•
In Sec. 5.2, we have shown the effect of on the spatial distribution of disease spread. As increases that is the parameter controls ‘social confinement’, the disease spreads in small pockets in clustered form.
-
•
We have seen that our model has been able to reproduce the basic features of the SEIR model quite well with some discrepancies as shown in Fig. 6.
-
•
We have also compared our model with other CA models having different neighbourhood conditions. We have shown that for our model behaves exactly similar to the models with Moore’s neighbourhood condition. If we assume as a step function of layer number () instead of choosing is a constant, our model exhibits similar results as the CA models consisting different -neighbourhood conditions. (detailed discussion in Sec. 7)
Finally, our model is used to study the time variation of COVID-19 cases in different countries for understanding this pandemic properly. We have used data of COVID-19 from eight countries, namely Italy, Germany, France, US, Brazil, India, Japan and South Africa, to obtain a fit of our model. Procedures and results of this study are described below:
-
•
We have fitted each of the peaks in the COVID-19 data separately to get the best fit parameters for our model.
-
•
The data of COVID-19 for different countries is obtained from JHU CSSE data repository. Before analyzing, a proper scaling has been done on this data. Our model is fitted with the data of confirmed cases for COVID-19. To get the best fit parameters, we have minimized the sum of squared error (SSE) between the CA model and data by applying a genetic algorithm (GA), as discussed in Sec. 8.
-
•
The parameter values obtained from the fitting is then re-checked with the data for deceased cases. Our model can generate the data for removed cases ( recovered+dead). However, the data for recovered cases is not fully available in JHU CSSE data repository. We have assumed that for a particular peak, deceased cases vary linearly with removed cases, where is the proportionality constant and have values between 0 and 1. This assumption help us to generate the data for deceased cases from our model and compare with the real data (detailed discussion in Sec. 8).
- •
-
•
These plots and the table show that the rate of the spread of COVID-19 mainly depends on two parameters and .
-
•
The data for deceased cases and simulated results show deviations in some situations, as seen in Fig. 12. The main reason behind this is the assumption of the linear relationship between the deceased cases and the removed cases for a particular peak. This zeroth order model with a linear relationship can be seen to be valid for most situations.
-
•
We have drawn box plots (Fig. 15) for fitting parameters to show their distribution. An important thing to note that the median value of is at 2.1705, which is above the central value, of our chosen range. Thus theoretically we can say that the degree of ‘social confinement’ in different countries are above average. Effect of various restrictions like social-distancing, and lockdown may be causes of this.
-
•
Also Tab. 3 shows that the value of decreases (not always monotonically) as COVID-19 pandemic proceeds. This means the death rate decreases with time
In this work, we have analyzed COVID-19 data from a different perspective. In future, we aim to compare and validate this stochastic model with physically motivated models. We hope our work will help to understand and forecast future pandemic situations.
10 Acknowledgment
One of the authors (S. C.) would like to acknowledge the financial support lent by the University Grant Commission (UGC), Government of India, in the form of CSIR-UGC NET-JRF stipend. Another author (S. R. C.) would like to thank St. Xavier’s College (Autonomous), Kolkata for providing financial support in the form of ‘Intramural Research Grant for R&D Projects’. S. C. would also like to thank Mr. Saswata Das and Mr. Bappaditya Manna for providing support during this work. Finally, all the authors would like to acknowledge St. Xavier’s College (Autonomous), Kolkata as their host institution.
References
- [1] Marco Marani, Gabriel G. Katul, William K. Pan, and Anthony J. Parolari. Intensity and frequency of extreme novel epidemics. Proceedings of the National Academy of Sciences, 118(35):e2105482118, 2021. DOI: 10.1073/pnas.2105482118.
- [2] Camilo Mora, Tristan McKenzie, Isabella M Gaw, Jacqueline M Dean, Hannah von Hammerstein, Tabatha A Knudson, Renee O Setter, Charlotte Z Smith, Kira M Webster, Jonathan A Patz, et al. Over half of known human pathogenic diseases can be aggravated by climate change. Nature climate change, 12(9):869–875, 2022. DOI: 10.1038/s41558-022-01426-1.
- [3] Live update of COVID-19 situation in different countries- Worldometers. https://www.worldometers.info/coronavirus/.
- [4] Tracking SARS-CoV-2 variants (WHO). https://www.who.int/en/activities/tracking-SARS-CoV-2-variants/.
- [5] Hannah Ritchie, Nectar Gan, Simone McCarthy, Selina Wang, and Mengchen Zhang. Leaked notes from chinese health officials estimate 250 million covid-19 infections in december: reports. CNN International, Dec, 23, 2022.
- [6] James Glanz, Mara Hvistendahl, and Agnes Chang. How deadly was china’s covid wave? The New York Times, Feb, 15, 2023.
- [7] William Ogilvy Kermack, A. G. McKendrick, and Gilbert Thomas Walker. A contribution to the mathematical theory of epidemics. Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character, 115(772):700, 1927. DOI: 10.1098/rspa.1927.0118.
- [8] Syafruddin Side and Mohd Salmi Md Noorani. A sir model for spread of dengue fever disease (simulation for south sulawesi, indonesia and selangor, malaysia). World Journal of Modelling and Simulation, 9(2):96–105, 2013.
- [9] Mevin B. Hooten, Jessica Anderson, and Lance A. Waller. Assessing north american influenza dynamics with a statistical sirs model. Spatial and Spatio-temporal Epidemiology, 1(2):177–185, 2010. DOI: 10.1016/j.sste.2010.03.003.
- [10] Daisuke Furushima, Shoko Kawano, Yuko Ohno, and Masayuki Kakehashi. Estimation of the basic reproduction number of novel influenza a (h1n1) pdm09 in elementary schools using the sir model. The Open Nursing Journal, 11:64, 2017. DOI: 10.2174/1874434601711010064.
- [11] Tianmu Chen, Yuanxiu Huang, Ruchun Liu, Zhi Xie, Shuilian Chen, and Guoqing Hu. Evaluating the effects of common control measures for influenza a (h1n1) outbreak at school in china: A modeling study. PLOS ONE, 12(5):1–20, 2017. DOI: 10.1371/journal.pone.0177672.
- [12] Christian L Althaus. Estimating the reproduction number of ebola virus (ebov) during the 2014 outbreak in west africa. PLoS currents, 6:ecurrents.outbreaks.91afb5e0f279e7f29e7056095255b288, 2014. DOI: 10.1371/currents.outbreaks.91afb5e0f279e7f29e7056095255b288.
- [13] T. Berge, J.M.-S. Lubuma, G.M. Moremedi, N. Morris, and R. Kondera-Shava. A simple mathematical model for ebola in africa. Journal of Biological Dynamics, 11(1):42–74, 2017. DOI: 10.1080/17513758.2016.1229817.
- [14] K. Glass, Y. Xia, and B.T. Grenfell. Interpreting time-series analyses for continuous-time biological models measles as a case study. Journal of Theoretical Biology, 223(1):19 – 25, 2003. DOI: 10.1016/s0022-5193(03)00031-6.
- [15] Brody H. Foy, Brian Wahl, Kayur Mehta, Anita Shet, Gautam I. Menon, and Carl Britto. Comparing covid-19 vaccine allocation strategies in india: A mathematical modelling study. International Journal of Infectious Diseases, 103:431, 2021. DOI: 10.1016/j.ijid.2020.12.075.
- [16] Namrata Soni, Jyoti Bhola, Ashutosh Yadav, Ishita Srivastva, and Utcarsh Mathur. A mathematical reflection of covid-19 and vaccination acceptance in india. 8:150, 2021. DOI: 10.21276/apjhs.2021.8.3.27.
- [17] Ting-Yu Lin, Sih-Han Liao, Chao-Chih Lai, Eugenio Paci, and Shao-Yuan Chuang. Effectiveness of non-pharmaceutical interventions and vaccine for containing the spread of covid-19: Three illustrations before and after vaccination periods. Journal of the Formosan Medical Association, 120:S46, 2021. DOI: 10.1016/j.jfma.2021.05.015.
- [18] Simon A Rella, Yuliya A Kulikova, Emmanouil T Dermitzakis, and Fyodor A Kondrashov. Rates of sars-cov-2 transmission and vaccination impact the fate of vaccine-resistant strains. Scientific Reports, 11(1):15729, 2021. DOI: 10.1038/s41598-021-95025-3.
- [19] Sourav Chowdhury, Suparna Roychowdhury, and Indranath Chaudhuri. Universality and herd immunity threshold: Revisiting the sir model for covid-19. International Journal of Modern Physics C, 32(10):2150128, 2021. DOI: 10.1142/S012918312150128X.
- [20] Sourav Chowdhury, Suparna Roychowdhury, and Indranath Chaudhuri. A robust prediction from a minimal model of covid-19–can we avoid the third wave? arXiv preprint arXiv:2112.08794, 2021.
- [21] André F. Steklain, Ahmed Al-Ghamdi, and Euaggelos E. Zotos. Using chaos indicators to determine vaccine influence on epidemic stabilization. Phys. Rev. E, 103:032212, Mar 2021. DOI: 10.1103/PhysRevE.103.032212.
- [22] Jorge Duarte, Cristina Januário, Nuno Martins, Jesús Seoane, and Miguel AF Sanjuán. Controlling infectious diseases: the decisive phase effect on a seasonal vaccination strategy. arXiv preprint arXiv:2102.08284, 2021.
- [23] Gerardo Ortigoza, Fred Brauer, and Iris Neri. Modelling and simulating chikungunya spread with an unstructured triangular cellular automata. Infectious Disease Modelling, 5:197–220, 2020. DOI: 10.1016/j.idm.2019.12.005.
- [24] Puspa Eosina, Taufik Djatna, and Helda Khusun. A cellular automata modeling for visualizing and predicting spreading patterns of dengue fever. TELKOMNIKA, 14(1):228, 2016. DOI: 10.12928/TELKOMNIKA.v14i1.2404.
- [25] S. Hoya White, A. Martín del Rey, and G. Rodríguez Sánchez. Modeling epidemics using cellular automata. Applied Mathematics and Computation, 186(1):193–202, 2007. DOI: 10.1016/j.amc.2006.06.126.
- [26] Gui-Quan Sun, Zhen Jin, Li-Peng Song, Amit Chakraborty, and Bai-Lian Li. Phase transition in spatial epidemics using cellular automata with noise. Ecological research, 26:333–340, 2011. 10.1007/s11284-010-0789-9.
- [27] B. Cissé, S. El Yacoubi, and A. Tridane. Impact of neighborhood structure on epidemic spreading by means of cellular automata approach. Procedia Computer Science, 18:2603–2606, 2013. 2013 International Conference on Computational Science.
- [28] A. Holko, M. Medrek, Z. Pastuszak, and K. Phusavat. Epidemiological modeling with a population density map-based cellular automata simulation system. Expert Systems with Applications, 48:1–8, 2016. DOI: 10.1016/j.eswa.2015.08.018.
- [29] Khaled M Khalil, M Abdel-Aziz, Taymour T Nazmy, and Abdel-Badeeh M Salem. An agent-based modeling for pandemic influenza in egypt. In Handbook on Decision Making, volume 33, pages 205–218. Springer, 2012. DOI: 10.1007/978-3-642-25755-1_11.
- [30] Senthil Athithan, Vidya Prasad Shukla, and Sangappa Ramachandra Biradar. Epidemic spread modeling with time variant infective population using pushdown cellular automata. Journal of Computational Environmental Sciences, 2014:769064, 2014. DOI: 10.1155/2014/769064.
- [31] Sheng Bin, Gengxin Sun, and Chih-Cheng Chen. Spread of infectious disease modeling and analysis of different factors on spread of infectious disease based on cellular automata. International Journal of Environmental Research and Public Health, 16(23), 2019. DOI: 10.3390/ijerph16234683.
- [32] Murali Krishna Enduri and Shivakumar Jolad. Dynamics of dengue disease with human and vector mobility. Spatial and Spatio-temporal Epidemiology, 25:57–66, 2018. DOI: 10.1016/j.sste.2018.03.001.
- [33] Emily Burkhead and Jane Hawkins. A cellular automata model of ebola virus dynamics. Physica A: Statistical Mechanics and its Applications, 438:424–435, 2015. DOI: 10.1016/j.physa.2015.06.049.
- [34] Armin R. Mikler, Sangeeta Venkatachalam, and Kaja Abbas. Modeling infectious diseases using global stochastic cellular automata. Journal of Biological Systems, 13(04):421–439, 2005. DOI: 10.1142/S0218339005001604.
- [35] Henrique Fabricio Gagliardi and Domingos Alves. Small-world effect in epidemics using cellular automata. Mathematical Population Studies, 17(2):79–90, 2010. DOI: 10.1080/08898481003689486.
- [36] P.H.T. Schimit. A model based on cellular automata to estimate the social isolation impact on covid-19 spreading in brazil. Computer Methods and Programs in Biomedicine, 200:105832, 2021. DOI: 10.1016/j.cmpb.2020.105832.
- [37] P.K. Jithesh. A model based on cellular automata for investigating the impact of lockdown, migration and vaccination on covid-19 dynamics. Computer Methods and Programs in Biomedicine, 211:106402, 2021. DOI: 10.1016/j.cmpb.2021.106402.
- [38] Sayantari Ghosh and Saumik Bhattacharya. A data-driven understanding of covid-19 dynamics using sequential genetic algorithm based probabilistic cellular automata. Applied Soft Computing, 96:106692, 2020. DOI: 10.1016/j.asoc.2020.106692.
- [39] L. L. Lima and A. P. F. Atman. Impact of mobility restriction in covid-19 superspreading events using agent-based model. PLOS ONE, 16(3):1–17, 03 2021. DOI: 10.1371/journal.pone.0248708.
- [40] Sourav Chowdhury, Suparna Roychowdhury, and Indranath Chaudhuri. Cellular automata in the light of covid-19. The European Physical Journal Special Topics, 231(18-20):3619–3628, 2022. DOI: 10.1140/epjs/s11734-022-00619-1.
- [41] Yusra Bibi Ruhomally, Maheshsingh Mungur, Abdel Anwar Hossen Khoodaruth, Vishwamitra Oree, and Muhammad Zaid Dauhoo. Assessing the impact of contact tracing, quarantine and red zone on the dynamical evolution of the covid-19 pandemic using the cellular automata approach and the resulting mean field system: A case study in mauritius. Applied Mathematical Modelling, 111:567–589, 2022. DOI: 10.1016/j.apm.2022.07.008.
- [42] Ihor Kosovych, Igor Cherevko, Denys Nevinskyi, and Yaroslav Vyklyuk. Simulation of various distribution restrictions of covid-19 using cellular automata. In 2022 12th International Conference on Advanced Computer Information Technologies (ACIT), pages 58–61, 2022. DOI: 10.1109/ACIT54803.2022.9913172.
- [43] Puspa Eosina, Aniati Murni Arymurthy, and Adila Alfa Krisnadhi. A non-uniform continuous cellular automata for analyzing and predicting the spreading patterns of covid-19. Big Data and Cognitive Computing, 6(2), 2022. DOI: 10.3390/bdcc6020046.
- [44] Larissa M. Fraga, Gina M. B. de Oliveira, and Luiz G. A. Martins. Multistage evolutionary strategies for adjusting a cellular automata-based epidemiological model. In 2021 IEEE Congress on Evolutionary Computation (CEC), pages 466–473, 2021. DOI: 10.1109/CEC45853.2021.9504738.
- [45] George Grekousis. Spatial analysis methods and practice: describe–explore–explain through GIS. Cambridge University Press, 2020.
- [46] A. Stewart Fotheringham. Spatial structure and distance-decay parameters. Annals of the Association of American Geographers, 71(3):425–436, 1981.
- [47] Ensheng Dong, Hongru Du, and Lauren Gardner. An interactive web-based dashboard to track covid-19 in real time. The Lancet infectious diseases, 20(5):533–534, 2020. DOI: 10.1016/S1473-3099(20)30120-1.