Simultaneous Estimation of Elliptic Flow Coefficient and Impact Parameter in Heavy-Ion Collisions using CNN
Abstract
A deep learning based method with Convolutional Neural Network (CNN) algorithm is developed for simultaneous determination of the Elliptic Flow coefficient () and the Impact Parameter in Heavy-Ion Collisions at relativistic energies. The proposed CNN is trained on PbPb collisions at = 5.02 TeV with minimum biased events simulated with the AMPT event generator. A total of twelve models were built on different input and output combinations and their performances were evaluated. The predictions of the CNN models were compared to the estimations of the simulated and experimental data. The deep learning model seems to preserve the centrality and dependence of at the LHC energy together with predicting successfully the impact parameter with low margins of error. This is the first time a CNN is built to predict both and the impact parameter simultaneously in heavy-ion system.
I Introduction
The ultra-relativistic nucleus-nucleus collisions act as a unique tool to produce and probe the hot and dense matter created in laboratories at RHIC and LHC energies under controlled conditions 1, 2, 3. The size of the dense and deconfined matter produced in such collisions depends on the impact parameter of the collision. This can be viewed from a simple picture of geometrical overlap of ions 4. However, the impact parameter which characterizes the initial state of the collisions is not directly measurable in experiments. It is generally estimated using experimentally measurable observables like charged particle multiplicity, transverse energy etc. which are strongly correlated with the impact parameter 5. Flow is an experimentally relevant observable that provides information on the initial conditions of the collision, the equation of state, and the transport properties of the matter created in heavy-ion collisions 6, 7, 8. The initial asymmetry in the geometrical overlap of the colliding nuclei as well as the presence of interaction between the constituents of the created matter causes the azimuthal anisotropy in the particle production. This anisotropy is one of the cleanest signatures of the collective flow in heavy-ion collisions. The widely measured flow coefficient is the elliptic flow coefficient (), defined as the second Fourier coefficient of the azimuthal anisotropy of the produced particles.
Recently, deep learning methods have been used in various scientific research challenges due to their ability to perceive unique features and patterns and to solve unconventional problems such as classification, regression, and clustering 9. There are even attempts to implement various machine learning algorithms to estimate , impact parameter () etc. as well 11, 12, 13. The present work aims to estimate the impact parameter and elliptic flow coefficient simultaneously in PbPb collisions at = 5.02 TeV using the multi-transport AMPT model 14. A CNN-based regression model has been used to study the centrality as well as the dependence of the elliptic flow coefficient. The impact parameter has also been successfully estimated simultaneously using the same model.
II The AMPT Model
A multi-phase transport model (AMPT) is a hybrid Monte Carlo model to study pA and AA collisions at relativistic energies. It consists of four major components namely, the initial conditions, partonic interactions, hadronization, and subsequent interactions among the produced hadrons. The spatial and momentum distributions of the mini-jet partons and soft string excitations defining the initial state is obtained from the HIJING model 15. The partonic scatterings which include two-body scatterings only is described by the Zhang’s parton cascade model 16. The default mode of AMPT uses the Lund string fragmentation model for hadronization while the string melting mode uses the quark coalescence model of recombining the quarks to form hadrons. The hadronization is followed by the interactions among the hadrons defined by a hadron cascade using a relativistic transport model(ART) 17. The hadronic interactions are stopped after a certain cut-off time and events are fetched subsequently.
III Target Observables
In this section, the two observables, namely the elliptic flow coefficient, and the impact parameter, are discussed.
III.1 Elliptic Flow ()
In heavy-ion collisions, elliptic flow is an experimental observable which quantifies the azimuthal asymmetry of the momentum distribution of produced particles in the transverse plane. The phenomenon is observed due to the anisotropic pressure gradient in initial stages as a result of spatial asymmetry of the nuclear overlap region in non-central collisions. It can be expressed conveniently as the Fourier decomposition of the differential momentum distribution of particles in an event as the following,
| (1) |
Here, is the order harmonic flow coefficient, is the azimuthal angle and is the harmonic symmetry plane angle. As more interactions lead the system to thermalize, the values also probe the degree of thermalization in the system. By construction, requires the information of the reaction plane angle on an event-by-event basis, whose measurement is non-trivial in experiments. There are a couple of methods that offer the solution such as the the cumulant method 18 and the usage of principal component analysis 19.
III.2 Impact Parameter ()
Heavy-ions, unlike protons are extended objects and therefore, the properties of the created system as a function of the degree of overlap of the colliding nuclei are quite different. To study the properties of the created system, the collisions are classified into different centrality classes defined by the impact parameter of the collision. However, the impact parameter cannot be directly measured experimentally. The collision centrality is therefore estimated from the measured particle multiplicities, with the fair assumption of the multiplicity being linearly related to . Phenomenologically, the total particle production was found to scale with the number of participating nucleons and the number of binary collisions. A realistic description of the nuclear geometry in a Glauber calculation could be used to relate these number of participating nucleons and binary collisions to the impact parameter, 4.
IV Deep Learning with Convolutional Neural Network (CNN)
IV.1 Concept
The computing machines require a specific algorithm to perform a task in which the solution to the problem is written in a top-to-down approach and the control flows accordingly resulting in an outcome. Yet, most of the problems come with no standard predefined set of rules to develop the algorithm that can solve them. Another direction is the high-complexity non-linear problems, where linear-based numerical methods usually fail. In such cases, Machine Learning (ML) with smart algorithms such as the Boosted Decision Trees (BDT)20, Deep Neural Network (DNN) 9, Generative Adversarial Networks (GAN) 21 etc. could help the machine learn from the data through a process called training. ML is the branch of Artificial Intelligence (AI) that gives the ability to the computers to learn correlations from data components. Recently, DNN models have been used to map complex non-linear functions by using simulated data in the field of astronomy 22. This ability could be exploited to train machine learning models to look for the hidden physics laws that govern particle production, anisotropic flow, spectra, impact parameter etc. in heavy-ion collisions. CNN, in general, have the following components,
-
1.
Convolution operation - A kernel-matrix is slid across the input map to produce a lower (or same) dimensional representation of the features. It is these kernels that get updated during training. Since the same kernel convolves all the pixels of the image, the CNN picks up spatial correlations inherent in the input image.
-
2.
Max/Average Pooling - The main purpose of using a Pooling layer is to reduce the dimension of the input image. The input image is divided into windows, where the largest (or average) value is chosen and taken to the next step. In general, a input image becomes after one pooling step
-
3.
Flattening - All the pixels of the input features are flattened to form one long vector as it is easier to manipulate to get the desired output shape.
V Analysis Method
The AMPT event generator was used to generate 50K minimum bias PbPb events at TeV. The string melting version of AMPT ISOFT mode was used. All charged particles with transverse momentum (), GeV/c and a pseudorapidity acceptance of were considered for the estimation of elliptic flow coefficient using the event plane method. In AMPT simulation, the reaction plane angle () was set to zero, although it is non-trivial in experiments. One can therefore, obtain the elliptic flow coefficients as . The average was taken over all the selected charged particles in an event. 80% (40K) of the total event sample was used for training and validation while 20% was used for testing and evaluation. The analysis was performed using Keras v2.11.0 Deep Learning API 23 with Tensorflow v2.11.0 24.
V.1 Input and Output
In this study, a CNN-based regression model was trained for the target observables and . The binned coordinate space for all charged particles in an event was considered for the primary input space. Here, and . The bin settings, (16, 16) and (32, 32) was considered for this procedure. This selection was chosen because anything below 16 offered very little number of features for the CNN to work with and anything above 32 allowed large sparse inputs where most of the features were absent. It is always a good practice to work with powers of two to make it easy for the machine to compute. Additional kinematic information was included as two secondary layers to the space. These two layers were simply weighted by the and the mass of the charged particles. From these two input layers, a third layer, containing the information of and mass, was constructed. This layer was weighted by the transverse mass () of the particles defined by . Figure 1 shows the three layers of the weighted space with (32, 32) bins for a single event. The space was directly read as images in the CNN.
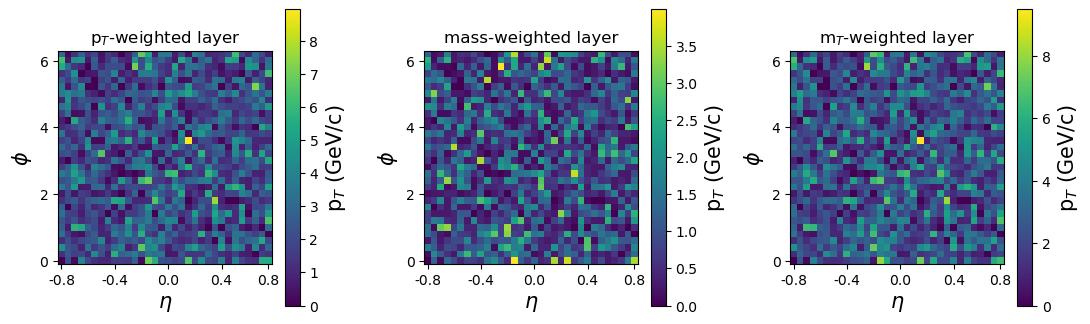
A total of four different options for input, (only , only , both ( and ), and ), and three different options for output, (only , only , and both ( and )) were considered. All these different combinations were addressed by considering twelve (4 inputs x 3 outputs) separate models. A single CNN architecture with variable input and output neurons was used. The impact parameter values were normalized such that in order to make the estimations more machine-friendly. Such a normalization step was not required for since . None of the inputs were normalized considering that this model could be directly implemented to data measured at LHC experiments.
V.2 CNN Architecture
For the present study, the input was either -weighted, mass-weighted or -weighted or both and mass-weighted distribution. Hence, the shape of the input layer was (16, 16, 1) for (16, 16) bins weighted by or mass or , (16, 16, 2) for (16, 16) bins weighted by both and mass, (32, 32, 1) for (32, 32) bins weighted by or mass or and (32, 32, 2) for (32, 32) bins weighted by both and mass. All the twelve models were constructed with the same architecture to ensure uniformity while comparing the performance of these models.
The first and the second convolutional(Conv) layer had 16 filters. The third and the fourth convolutional layer had 32 filters. Furthermore, the output of the fourth convolutional layer was flattened to a multi-layer perceptron (MLP). This MLP led to two dense layers with 64 and 32 neurons, respectively. Finally, the neural network ended with the output neuron(s). The output was either only or only or both ( and ).
The activation used for every Conv and Dense layer was linear. The padding of each Conv layer was kept to be same to avoid over-complicating the shape of the layers. To avoid over-fitting and generalization of the learned pattern mapping, the following three techniques were used.
-
1.
Each Conv layer was followed by a Group Normalization technique with the number of groups set to four.
-
2.
Conv layer 2 and 4 were followed by a dropout layer with a dropout rate of 0.1.
-
3.
Every Conv and Dense layer had an L1L2 kernel regularizer.
The model was compiled with a Mean-Squared Error loss function and the Adam algorithm was used to update the kernel weights. The Mean-Absolute Error (MAE) was also tracked while training to evaluate the learning. The model trained with a batch size of 256 for 70 epochs showed a good convergence with no over-fitting.
VI Results and Discussion
VI.0.1 General Performance
Table 1 shows the performances of all the 24 models that were built and trained for the 2 bin settings, (16 16) and (32 32). The MAE column shows the error obtained while testing the models. The percentage indicates the magnitude of the error but not the relative error. It can be observed that all 24 models performed well with maximum error being less than 6%. However, a detailed discussion predominantly focusing on the bin setting (32, 32) is given in the following section as bin (32, 32) outperformed (16, 16) in several cases.
| Input | Output | MAE | MAE |
| (16 16) | (32 32) | ||
| pT | v2 | 5.30% | 4.93% |
| pT | b | 4.12% | 3.83% |
| pT | both | 4.73% | 4.43% |
| mass | v2 | 5.63% | 5.46% |
| mass | b | 4.47% | 3.39% |
| mass | both | 4.99% | 4.48% |
| v2 | 5.38% | 5.28% | |
| b | 3.84% | 3.90% | |
| both | 4.50% | 4.48% | |
| both | v2 | 5.52% | 4.77% |
| both | b | 3.86% | 4.43% |
| both | both | 4.67% | 4.37% |
VI.0.2 Mean Absolute Error
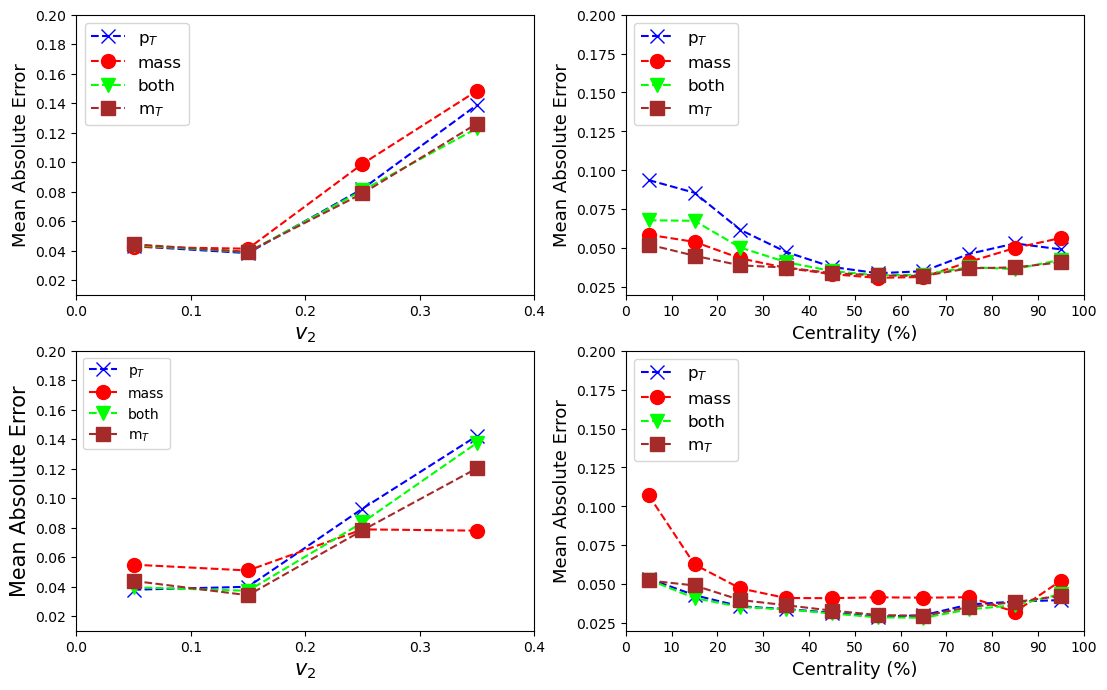
Figure 2 shows the variation of MAE for different values of target observables and therefore compares the performance of all the 12 models under the bin setting of (32, 32). The top left panel describes the model where the output is while the top right one describes the model where the output is . The bottom two panels describe the model with both outputs, and plotted separately. In each figure, the blue curve describes the model where the input was a -weighted image, the red curve describes the model where the input was a mass-weighted image, the orange curve describes the model where the input was weighted image and the green curve describes the model where the inputs were both and mass-weighted images.
As evident from the figure, in predicting , the CNN models performed well for . The MAE only increased beyond the mentioned value and can be attributed to fewer statistics in this region. But the interesting point is that despite low statistics, the CNN models could learn the pattern within a relative error (), of 5%. Models with different inputs performed very similarly.
The prediction of is slightly different. The models seemed to perform well for mid-central regions ( (30 - 70 )%) in comparison to central and peripheral collisions. Again, this behavior could be attributed to less number of samples in these regions, thereby affecting the learning. Moreover, the worst performing class, (0-10)% centrality, only deviated by 0.25 fm with a relative error, , of 7.1%. In the best scenario, the relative error is as low as 0.5% which is impressive.
When it comes to inputs, the CNN models have a preference. In the case where the output was only , the model with only -weighted image input performed poorly while the model with only -weighted input performed best. In the case where the output was both and , the model with only mass-weighted image input performed poorly while the rest of the models performed more or less equally well. However, the differences in the performance was due to the contribution from low statistics regions and yet they were not significant in terms of relative error.
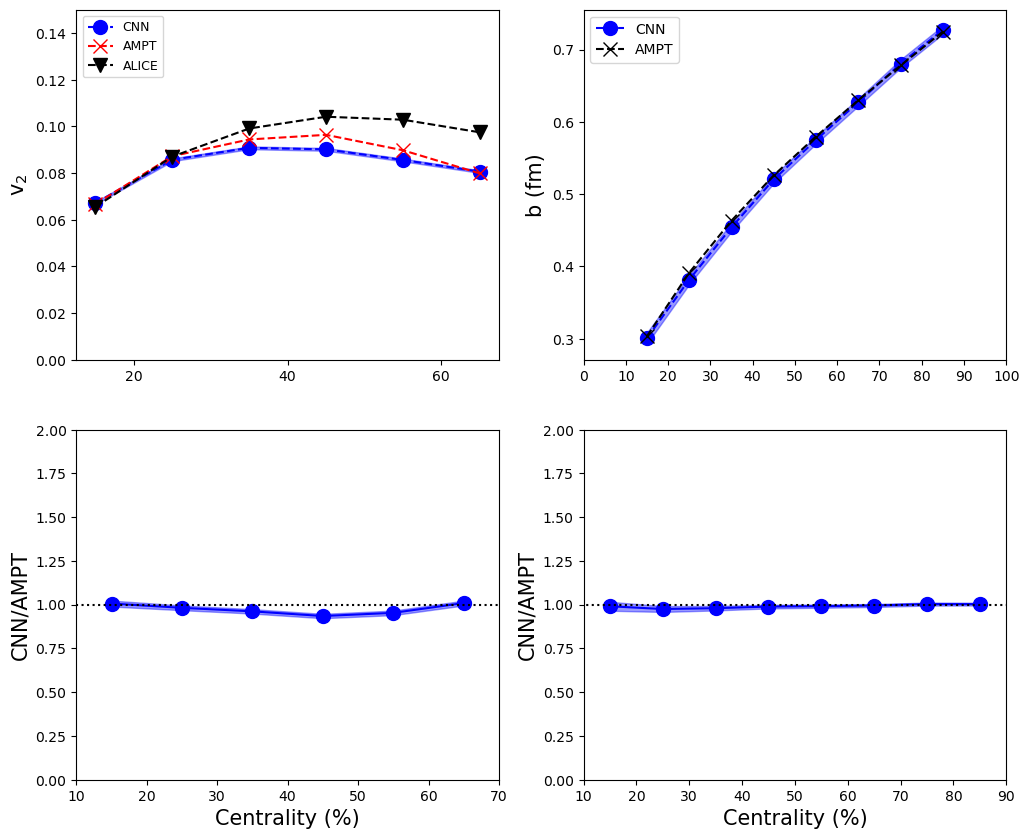
Figure 3 shows the centrality dependence of the target observables predicted with the model with and mass-weighted distribution as inputs. The top figure of the left panel shows the centrality dependence of and is compared with the experimental data 10 while the figure on the right shows the centrality dependence of . The bottom panels show the ratio of CNN and AMPT predictions quantifying the agreement between the model and the CNN prediction.
As can be seen, the predictions of the CNN model has good agreement with the simulation data for all centrality classes. The ratio is close to one in both the cases. When compared to different (input, output) combinations, this model seems to perform well. This can be attributed to input having two layers giving maximum kinematic information. By training the CNN model with minimum bias PbPb collisions at TeV, one allows the machine to learn physics for a larger and more complex system. This model can be directly implemented in heavy-ion collision systems tuned to LHC energies.
However, there are some discrepancies in the peripheral regions. It is to be noted that the estimation of in ALICE using has some level of non-flow contributions. In addition, different methods of flow estimation could also introduce a degree of uncertainty. This is the first time a single model is employed to estimate both and .
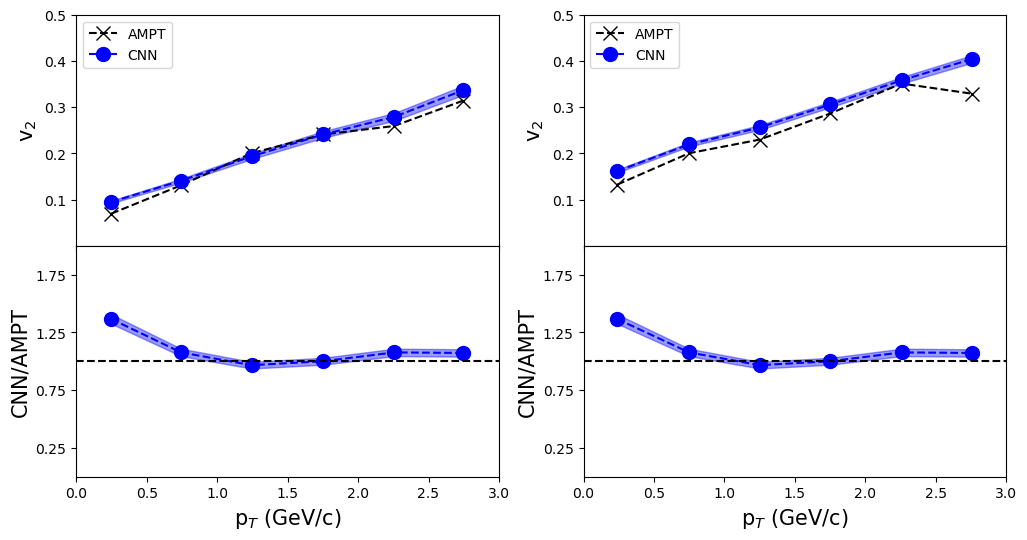
VI.0.3 dependence of
Figure 4 shows the variation of with for different centrality classes. The best model for each, (16,16) and (32,32), bin is shown. Usually, fewer particles are detected for high , suggesting that the input regions for high would be very sparse. Despite this constraint, all twelve models have predicted the relation in both bin settings. This feature along with the centrality dependence make these models even more robust and versatile.
VI.0.4 Activation Maps
In the case of convolutional neural networks (CNNs), commonly used in visual recognition tasks, various methods have been developed to visualize their behavior. One such method is class activation mapping (CAM) 25, which involves global average pooling and calculating the importance of neurons within a CNN. This technique allows for the localization of crucial regions in two dimensional matrices that contribute to the model’s success in classification tasks. Building on the CAM method, Selvaraju et al. introduced a more generalized approach called gradient-weighted class activation mapping (Grad-CAM) 26. Grad-CAM can be applied to a wider range of CNN architectures and provides deeper insights into the learned features of the neural network.
In the CAM method, the class activation map for
class c (in the present case, c is trivial and can be suppressed because we have a regression problem instead of a classification problem) is defined as .
| (2) |
Here, represents the activation of the feature k in the final convolutional layer at spatial location of input data , and is the weight measuring the importance of unit k for class c. In Grad-CAM, is defined as the result of performing global average pooling on the gradient of the score for class c for activations :
| (3) |
where is the operation of global average pooling. Subsequently, the gradient-weighted class activation map is given as
| (4) |
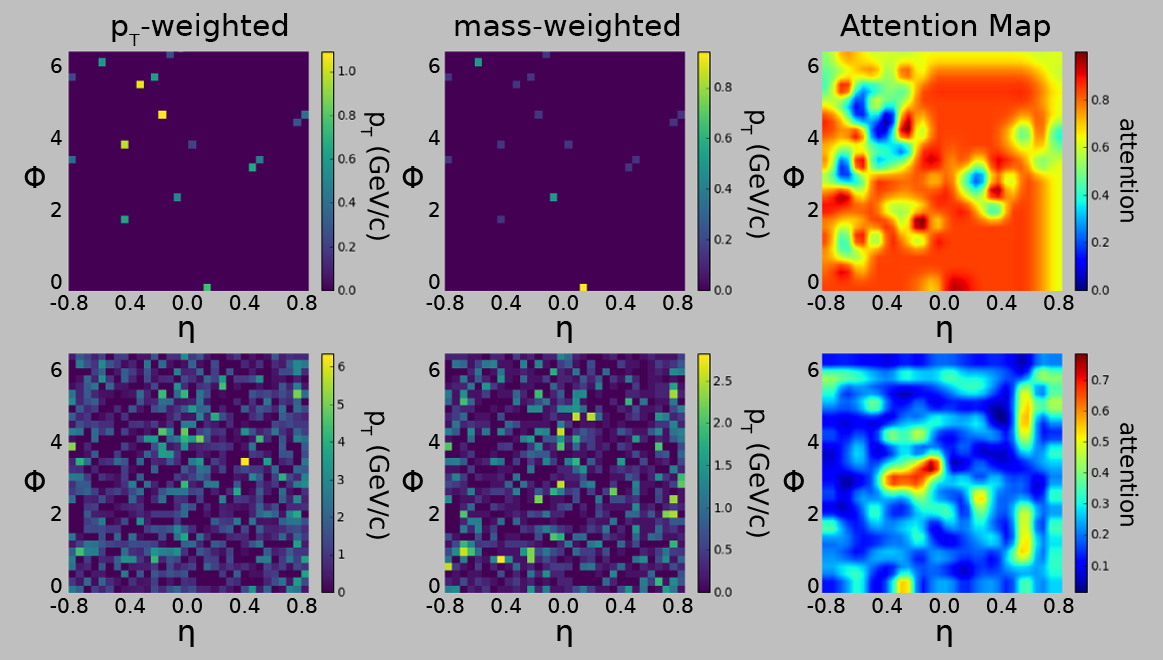
The Attention Maps for the best-performing model was obtained. Figure 5 shows the Attention Maps for two samples with different input distributions. It can be observed that the region of the input space where very little information is available, demands maximum attention from the CNN. The top figure with sparsely distributed information has a bright red (high attention) heat map while the bottom plot with uniformly distributed information has a blue (low attention) heat map.
This may be surprising since CNN, or any neural networks for that matter, naturally tend to map regions of information to target variables. However, the attention maps point towards a different story. Figure 6 shows the distribution of pixel values for -weighted layers across all the events. It is seen that the overwhelming majority of the pixel values lie very close to zero. This directly shows that most of the data are sparsely distributed inputs. The y-axis is log-scaled to show the sheer difference in magnitude of the number of pixels with values close to zero from those that are non-zero. The shape of the distribution is the same for all pixels. Similar kind of behavior was also seen for mass-weighted layers. This indicates that the CNN is predominantly trained on samples with highly localized regions of information. Inputs that are uniformly distributed are essentially rare and the CNN sees fewer of them while training. So, it does make sense for the CNN to effectively rely on regions of less information to extract target variables.
VI.0.5 Quality over Quantity
Neural nets usually rely on a large dataset to effectively extract mappings between input and output neurons. A sophisticated network like the one built in this work, performs well in regions of fewer statistics like for and highly central ( or peripheral) collisions. However, one can always train these models with newer datasets to further improve their accuracy. Since these models are already performing efficiently, newer datasets must exhibit good quality rather than a large quantity. Quality is subjective but it can be defined precisely for a given ML problem. In the case of weighted distribution as input, the quality of a dataset can be defined as the degree to which the distribution of the new dataset agrees with the one that was used for training. Any dataset that has a pixel distribution that is similar to Figure 6 is good. The CNN, when trained on such datasets, will certainly learn new patterns and will improve its performance. Deviations from the distributions of pixel values shown in Figure 6 will result in a dip in the performance of the CNN.
However, datasets from other event generators which incorporated inbuilt flow like HYDJET++ 27 can also be used for training but for those datasets, the quality matters over quantity. In fact, to test the robustness of the models built in this work, one can generate data from different event generators and analyze the performance of the predictions. The distributions from the experimental data can be directly used. Since these distributions would have to most realistic distribution of pixel values, even a small dataset of 10K events should give a good understanding of how inputs must be distributed for the CNN to learn best. Such comparison would also provide some room for improvement in these Monte Carlo based event generators.
VII Conclusion
In conclusion, the implementation of a novel CNN technique to include the kinematic properties of charged particles produced in heavy-ion collisions is carried out to estimate the elliptic flow coefficient and the impact parameter simultaneously. The proposed CNN model uses the two-dimensional distribution of charged particles weighted with , mass and as model input under two different bin settings, (16, 16), (32, 32). A total of 12 different combinations were built, trained and tested with minimum-bias PbPb collision events simulated at TeV utilizing the AMPT event generator. The CNN models show a good agreement between the predictions and the simulated values. The best performing combination was obtained for both and mass-weighted input distribution with outputs as and under the bin setting of (32, 32). This particular combination utilized the maximum available information to predict the quantities with the best precision. Furthermore, all the models seem to preserve the -dependence of across all centrality classes.
VIII Acknowledgement
S.D would like to acknowledge the SERB Power Fellowship, SPF/2022/000014 for the support in this work.
References
- [1] S. Acharya et al., ALICE Collaboration, Eur. Phys. J. C 84 (2024) 813.
- [2] G. F. Chapline, M. H. Johnson, E. Teller, and M. S. Weiss. Phys. Rev. D8:4302–4308 (1973).
- [3] T. D. Lee and G. C. Wick. Phys. Rev. D9:2291, 1974.
- [4] Michael L. Miller, Klaus Reygers, Stephen J. Sanders, Peter Steinberg, Ann. Rev. Nucl. Part. Sci. 57, 205-243 (2007).
- [5] K. Aamodt et al.[The ALICE Collaboration], Phys. Rev. Lett. 105, 252302 (2010).
- [6] A. M. Poskanzer and S.A. Voloshin, Phys. Rev. C58, 1671 (1998).
- [7] K. Aamodt et al.[ALICE Collaboration], Phys. Rev. Lett., 105, 252302 (2010).
- [8] K. Aamodt et al.,ALICE Collaboration, Phys. Rev. Lett., 107,032301 (2011).
- [9] J. Schmidhuber, Neural Networks, 61, 85–117 (2015).
- [10] J. Adam et al., ALICE Collaboration, Phys. Rev. Lett. 116, 132302(2016).
- [11] Mallick et al. , Phys. Rev. D105, 114022 (2022).
- [12] X.Zhang et al.,Phys. Rev. C105, 034611 (2022).
- [13] Pei Xiang, Yuan-Sheng Zhao, Xu-Guang Huang, arXiv:2112.03824 (2021).
- [14] Zi-Wei Lin, Che Ming Ko, Bao-An Li, Bin Zhang, Subrata Pal, Phys.Rev.C 72,064901 (2005).
- [15] M. Gyulassy and X. N. Wang, Comput. Phys. Commun. 83, 307 (1994).
- [16] B. Zhang, Comput. Phys. Commun. 109, 193 (1998).
- [17] B. Li, A. T. Sustich, B. Zhang, and C. M. Ko, Int. J. Mod. Phys. E 10, 267 (2001)
- [18] N. Borghini, P. M. Dinhand J. Y. Ollitrault, Phys. Rev. C63, 054906 (2001).
- [19] R. S. Bhalerao, J. Y. Ollitrault, S.Pal and D. Teaney, Phys. Rev. Lett. 114, 152301 (2015).
- [20] Y. Coadou, arXiv:2206.09645 (2022)
- [21] Ian J. Goodfellow et al., arXiv:1406.2661 (2014)
- [22] Dalya Baron, arXiv:1904.07248 (2019)
- [23] Jeff Heaton, arXiv:2009.05673,(2020)
- [24] Martín Abadi et al., arXiv:1605.08695, (2016)
- [25] Pham Thi Minh Anh, arXiv:2309.14304 (2013)
- [26] Selvaraju, Ramprasaath R. et al. , International Journal of Computer Vision, 128, 2, 336–359 (2019).
- [27] I.P. Lokhtin, L.V. Malinina, S.V. Petrushanko, A.M. Snigirev, I. Arsene, K. Tywoniuk, Comput. Phys. Commun. 180,779-799 (2009).